ONTAP Select это логическое развитие линейки Data ONTAP-v, т.е. Software Defined Storage. Софт ONTAP (Операционную систему или прошивку по-народному, если хотите) можно использовать на специализированной аппаратной плтформе FAS или в виде виртуальной машины: в публичных облаках или на комодити оборудовании.
Два последних варината называют ONTAP for Cloud и ONTAP Select соответственно.
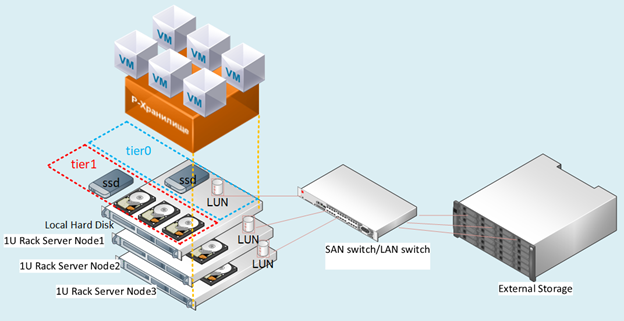
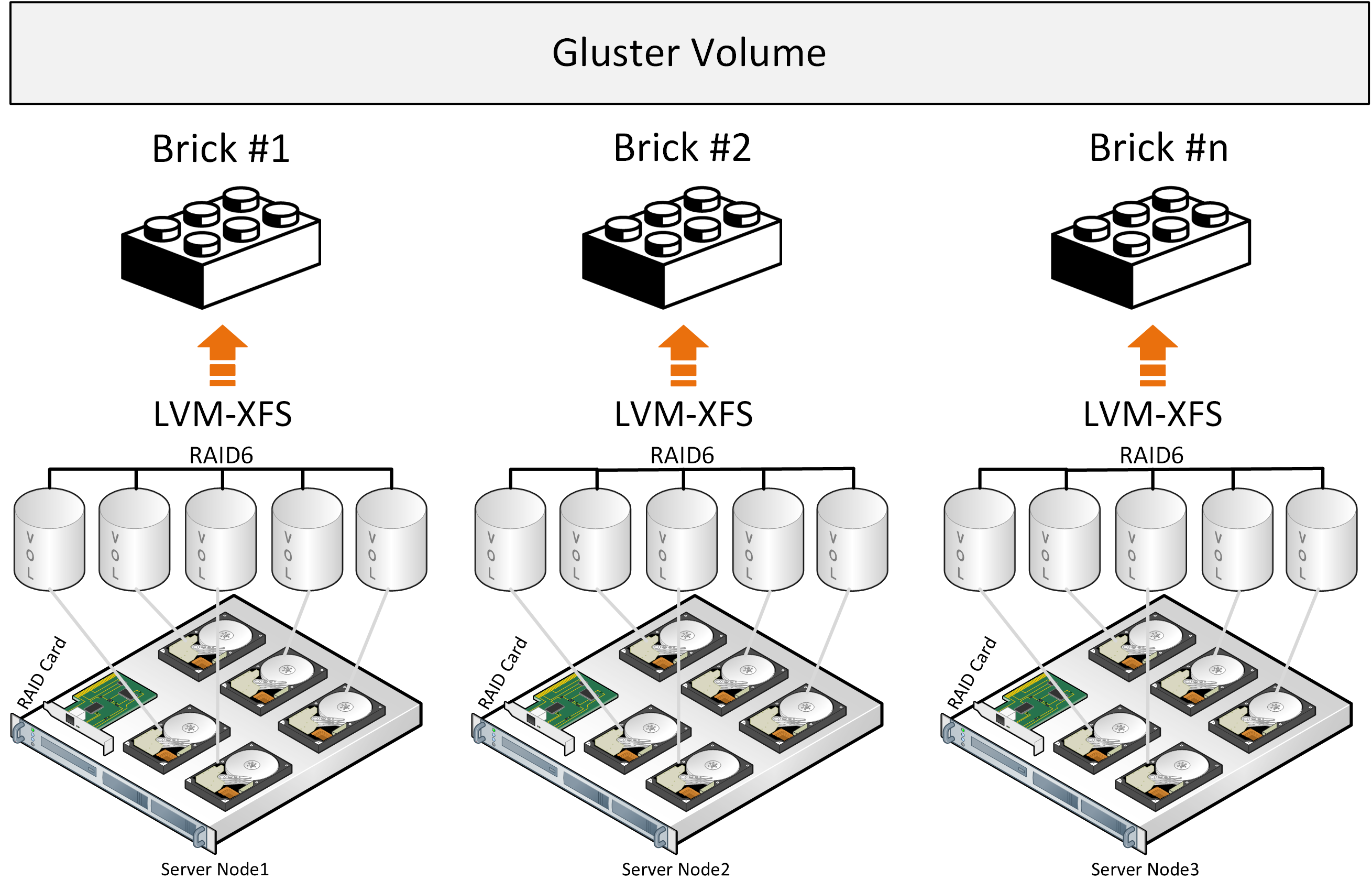
Как и предшественник ONTAP Select, этот продукт, который живёт в виде виртуальной машины и полностью опирается на традиционный RAID контроллер, установленный в вашем сервере. Поддерживаются NAS (CIFS, NFS) и IP SAN (iSCSI) протоколы и отсутствует поддержка FCP. В документах NetApp можно встретить внутренее название ONTAP Select — sDOT, это одно и тоже.
Из ожидаемых новшеств:
На ряду с High Availability и кластеризацией по-прежнему поддерживаются однонодовые конфигурации.
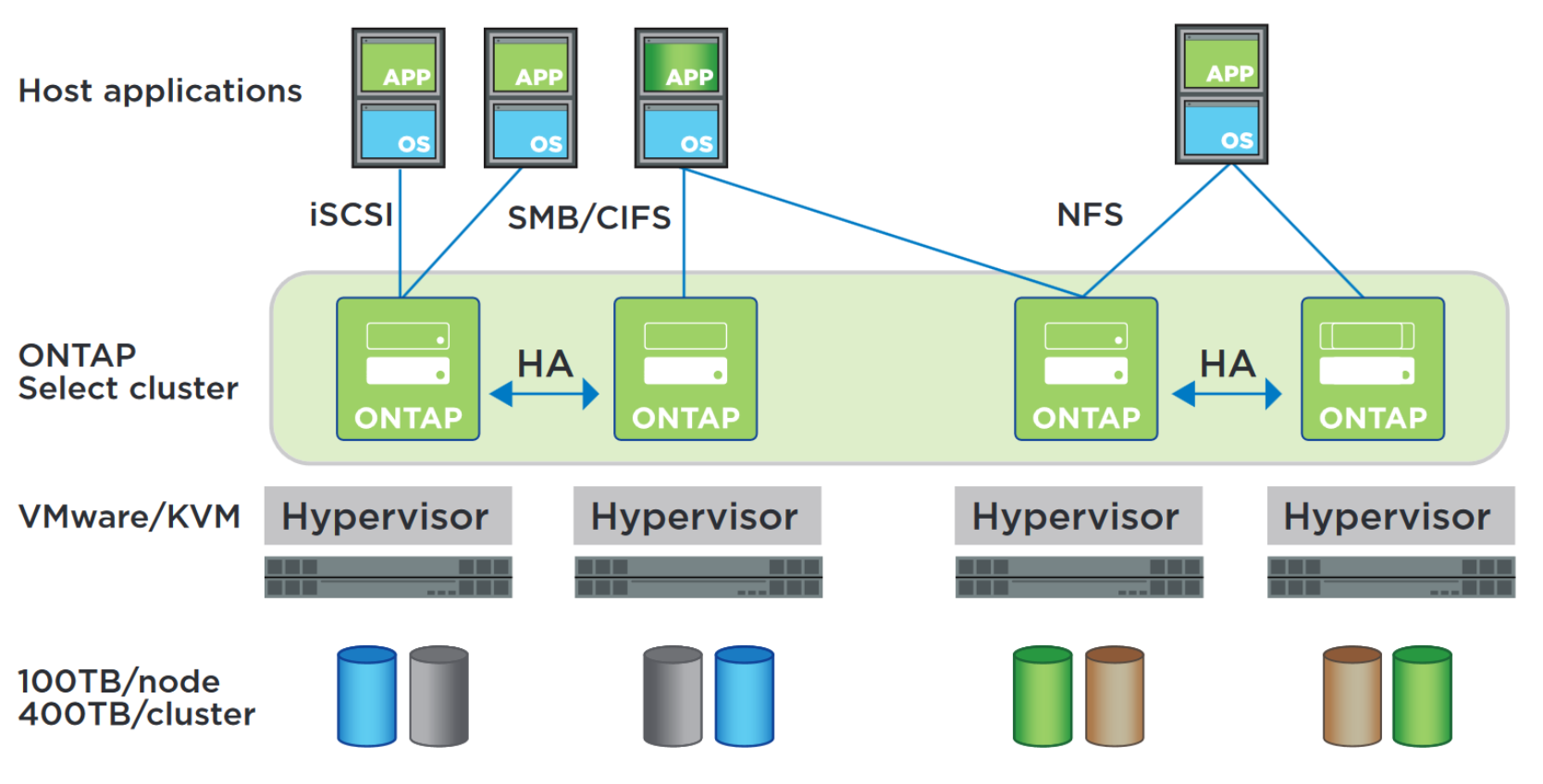
Два последних варината называют ONTAP for Cloud и ONTAP Select соответственно.
Как и предшественник ONTAP Select, этот продукт, который живёт в виде виртуальной машины и полностью опирается на традиционный RAID контроллер, установленный в вашем сервере. Поддерживаются NAS (CIFS, NFS) и IP SAN (iSCSI) протоколы и отсутствует поддержка FCP. В документах NetApp можно встретить внутренее название ONTAP Select — sDOT, это одно и тоже.
Из ожидаемых новшеств:
- Поддержка High Avalability
- Поддержка кластеризации до 4 нод
- Максимальный полезный объем 400 ТБ (по 100ТБ на ноду в 4х нодовом кластере)
На ряду с High Availability и кластеризацией по-прежнему поддерживаются однонодовые конфигурации.
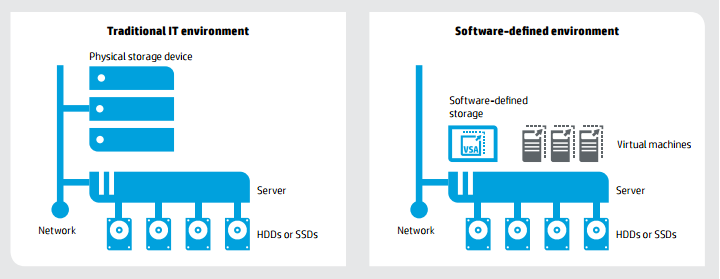
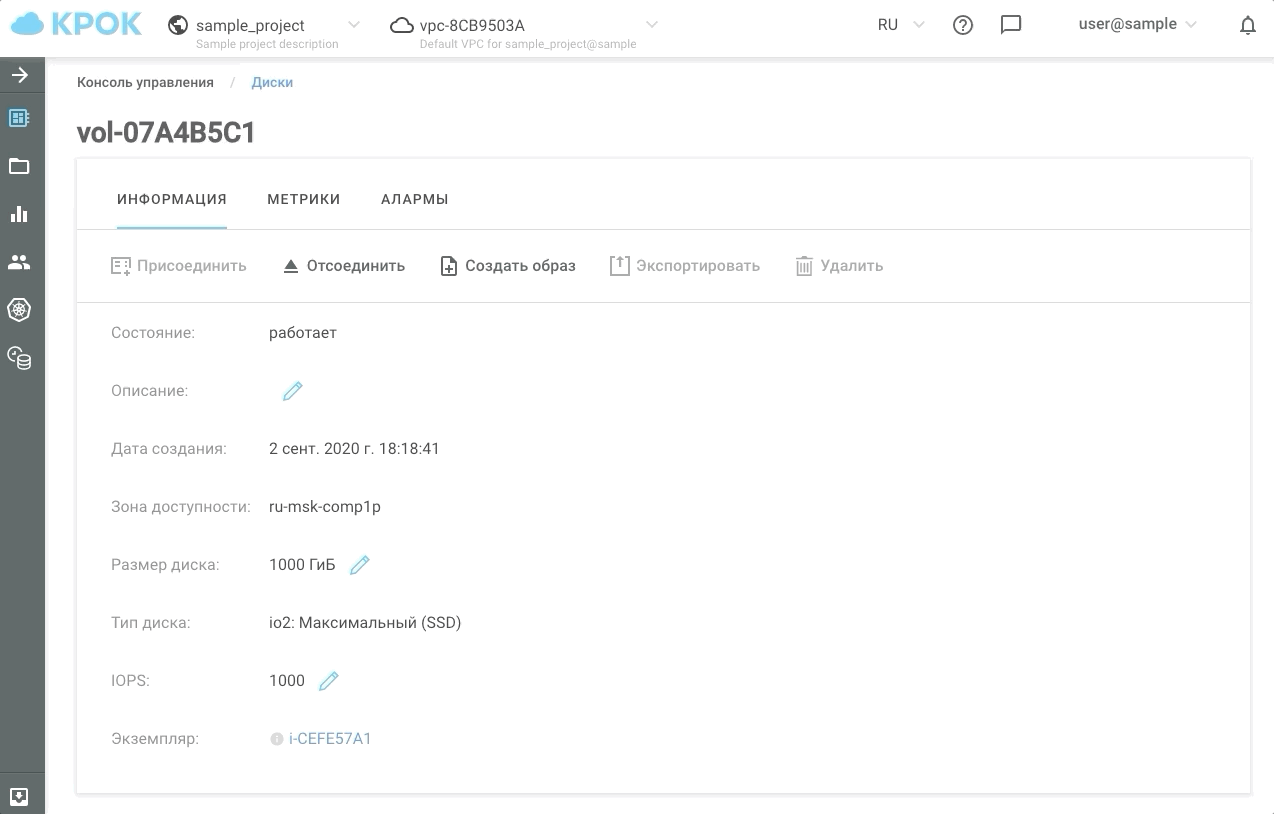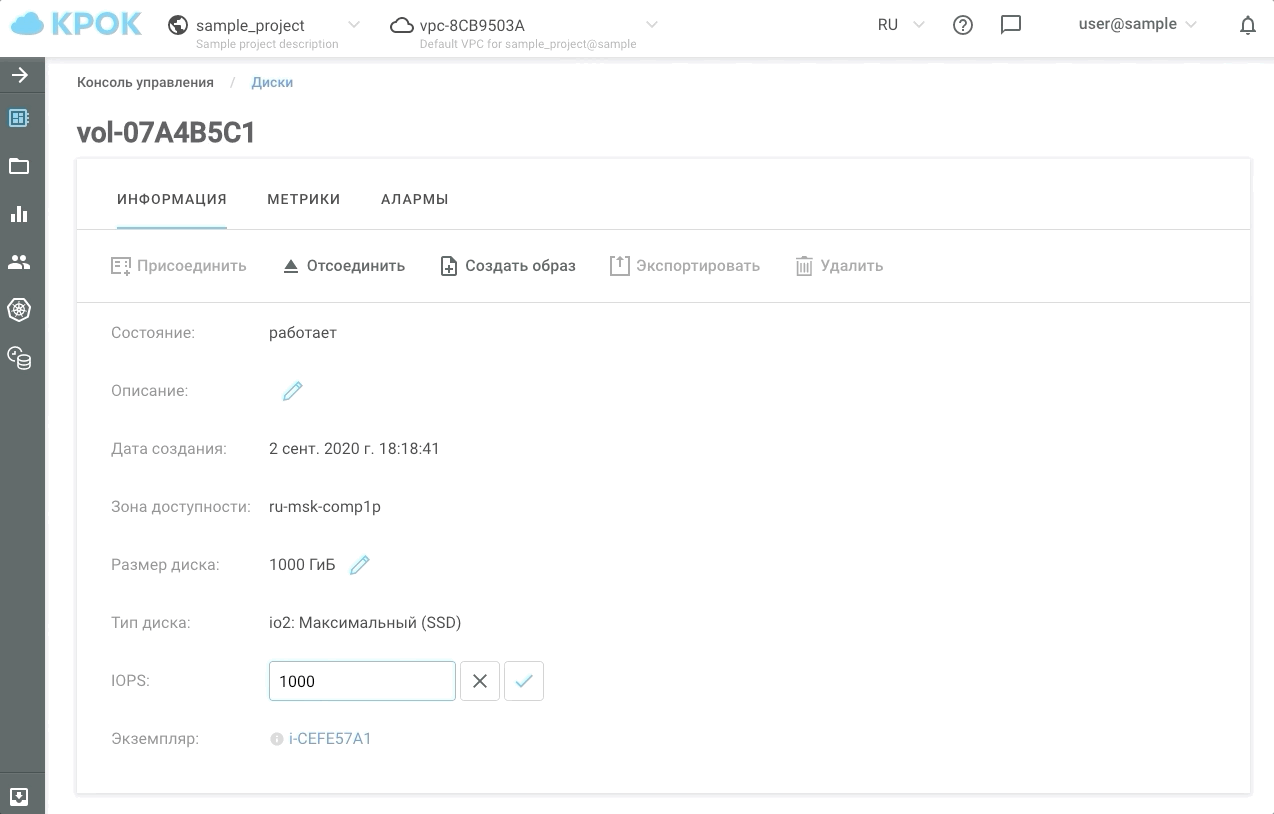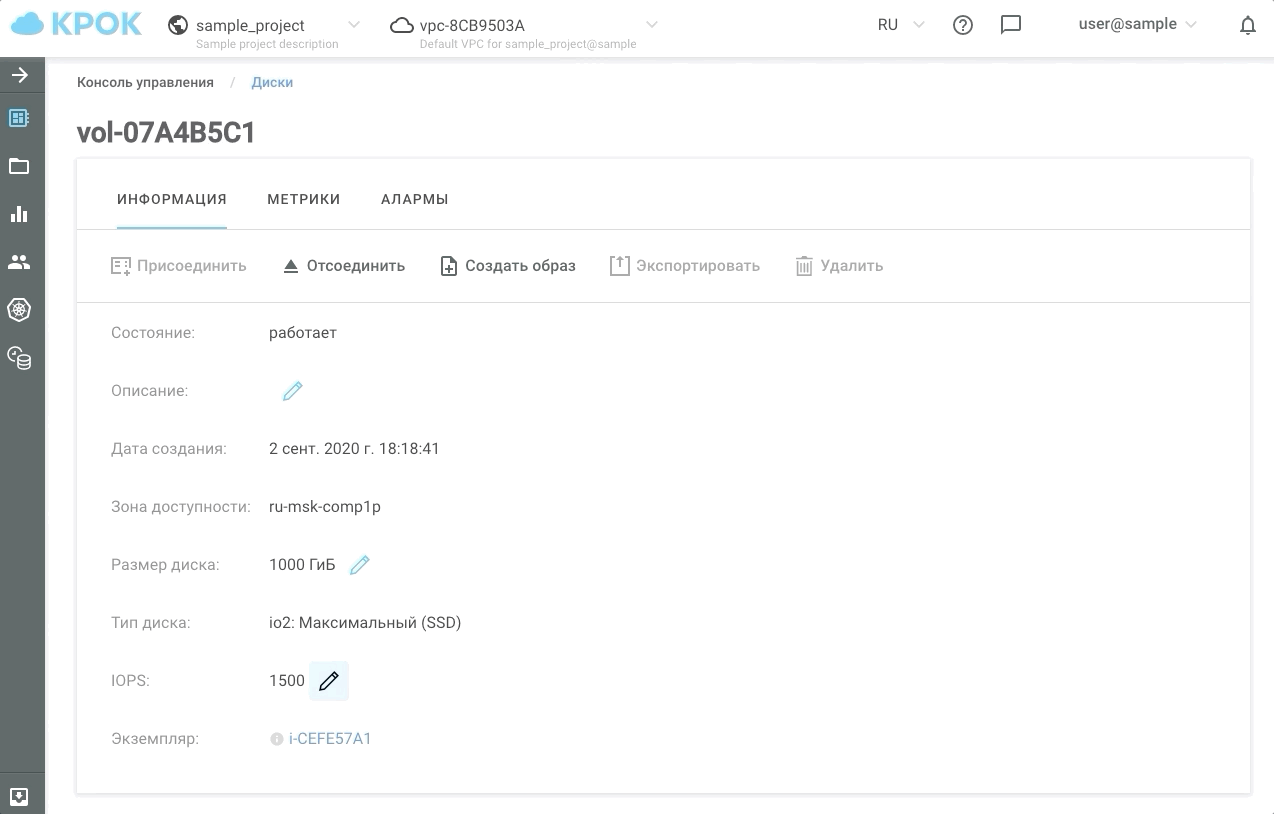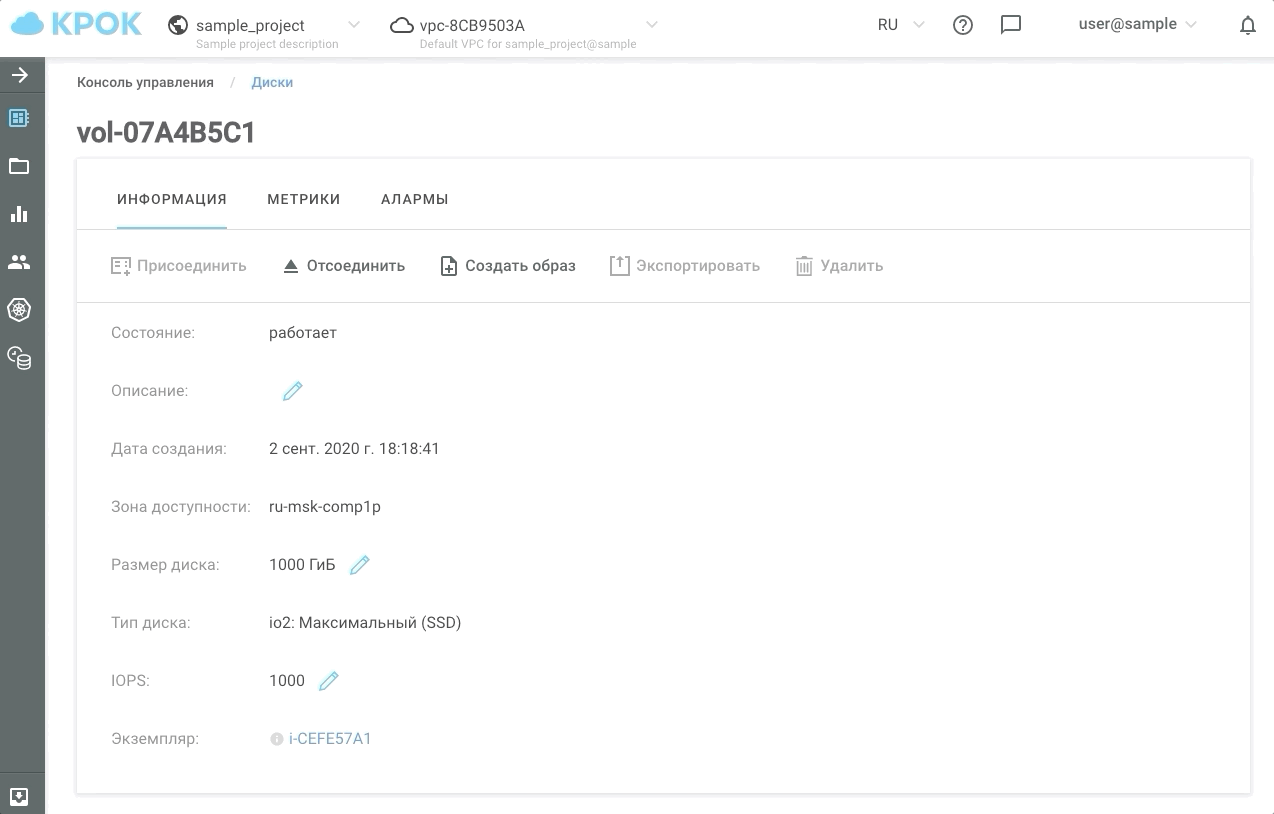
 Проект любой сложности, как ни крути, сталкивается с задачей хранения данных. Таким хранилищем могут быть разные системы: Block storage, File storage, Object storage и Key-value storage. В любом вменяемом проекте перед покупкой того или иного storage-решения проводятся тесты для проверки определённых параметров в определённых условиях. Вспомнив, сколько хороших, сделанных правильно растущими руками проектов прокололись на том, что забыли про масштабируемость, мы решили разобраться:
Проект любой сложности, как ни крути, сталкивается с задачей хранения данных. Таким хранилищем могут быть разные системы: Block storage, File storage, Object storage и Key-value storage. В любом вменяемом проекте перед покупкой того или иного storage-решения проводятся тесты для проверки определённых параметров в определённых условиях. Вспомнив, сколько хороших, сделанных правильно растущими руками проектов прокололись на том, что забыли про масштабируемость, мы решили разобраться: