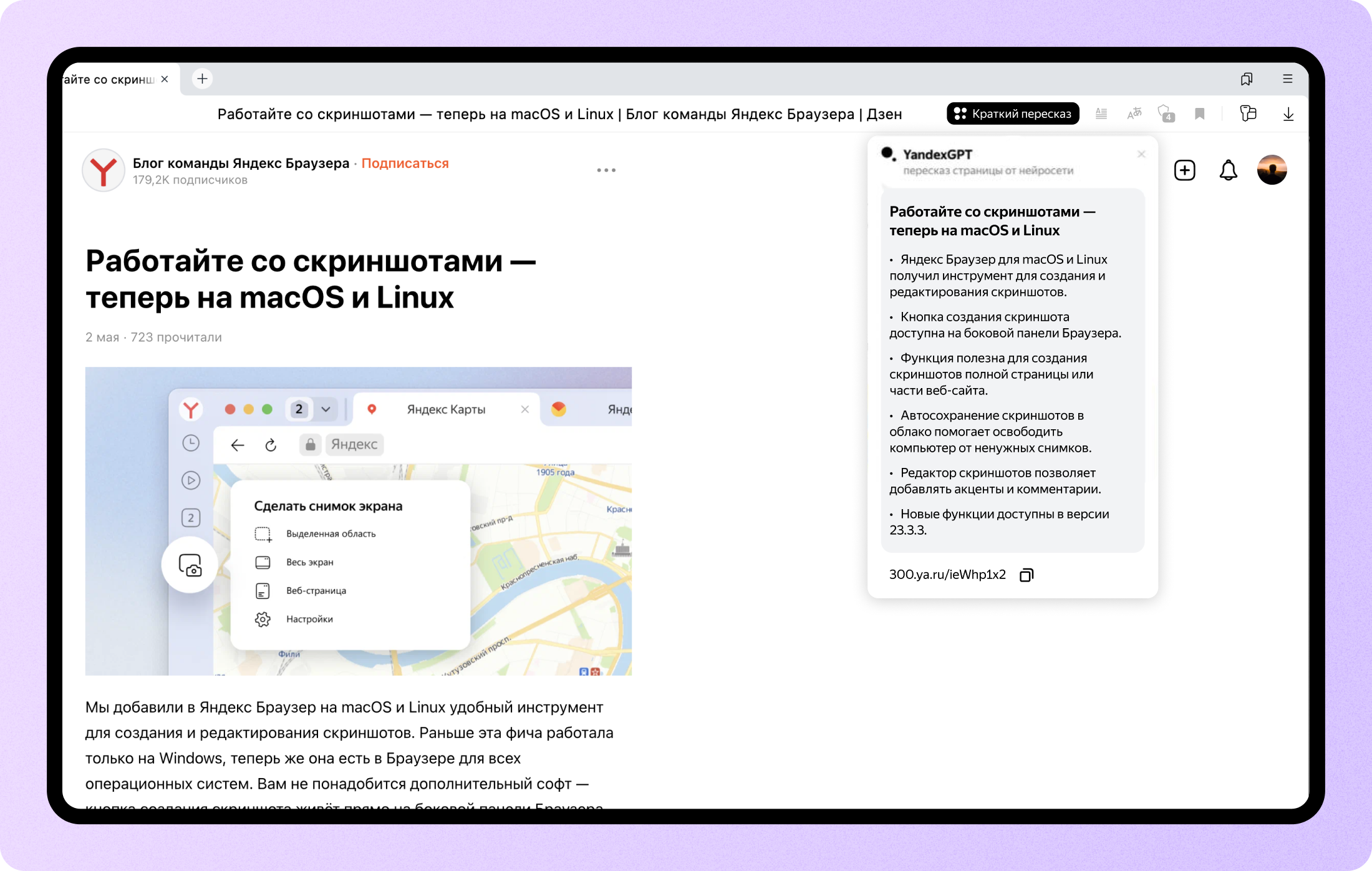
Эта статья посвящена основным современным моделям для генерирующего реферирования и генерации текста в целом: BertSumAbs, GPT, BART, T5 и PEGASUS, и их использованию для русского языка.
В отличие от извлекающих моделей, которые рассмотрены в предыдущих двух статьях, эти модели создают новые тексты, а не только выделяют предложения из оригинального документа. Из-за этого они могут нетривиально изменять исходный текст: удалять слова или заменять их на синонимы, сливать и упрощать предложения, а значит делать ровно то, что делают люди при составлении рефератов.
Ещё десять лет назад методы из этой категории казались фантастикой. Развитие систем нейросетевого машинного перевода сделало генерирующее автоматическое реферирование намного более лёгкой задачей.
Серьёзные методы оценки качества реферирования будут в следующих частях цикла. Сейчас же для наглядности мы испытаем алгоритмы на одной конкретной новости про секвенирование РНК клеток коры головного мозга. Это свежая новость, то есть модели заведомо не могли её видеть. К тому же она довольно сложная: 5.7 баллов по шкале N+1.
Кстати говоря, заголовок к этой статье написан одной из описываемых моделей.