Представляю читателям статистику, собранную во время создания простейшего робота-генератора русских фраз
Приведу сначала некоторые цифры.
На 12.5Мб русского текста (в основном классическая литература разных авторов), на 142114 разных слов в нём, чаще всего встречается союз «и» — 83575 раз (слова берутся во всех словоформах). И это больше, чем половина!
Вторым по частоте встречаемости оказывается предлог «в» — 52124 раз, на третьем месте — частица «не»: 36268 раз.
Глагол «сказал» (ед.ч., 3л.) встречается 6566 раз и находится на 28-м месте.
А вот слово «да» находится на 36-м месте и встречается 5039 раз, тогда как «нет» — встречается 2948 раз и находится на 53 месте.
Остальные слова выбраны достаточно случайно, исходя из предпочтений автора.
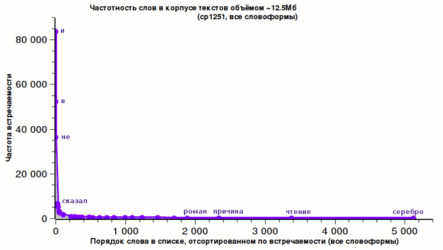

Частотность слов на корпусе текстов изучалась со времён открытия закона Ципфа для английского языка (т.е., уже более 60-ти лет), публиковались различные словари и обзоры по этой теме, но мы посмотрим на русскую речь немного внимательнее и нагляднее.
Подробные графики и примеры с выводами
Распределение слов
Приведу сначала некоторые цифры.
На 12.5Мб русского текста (в основном классическая литература разных авторов), на 142114 разных слов в нём, чаще всего встречается союз «и» — 83575 раз (слова берутся во всех словоформах). И это больше, чем половина!
Вторым по частоте встречаемости оказывается предлог «в» — 52124 раз, на третьем месте — частица «не»: 36268 раз.
Глагол «сказал» (ед.ч., 3л.) встречается 6566 раз и находится на 28-м месте.
А вот слово «да» находится на 36-м месте и встречается 5039 раз, тогда как «нет» — встречается 2948 раз и находится на 53 месте.
Остальные слова выбраны достаточно случайно, исходя из предпочтений автора.
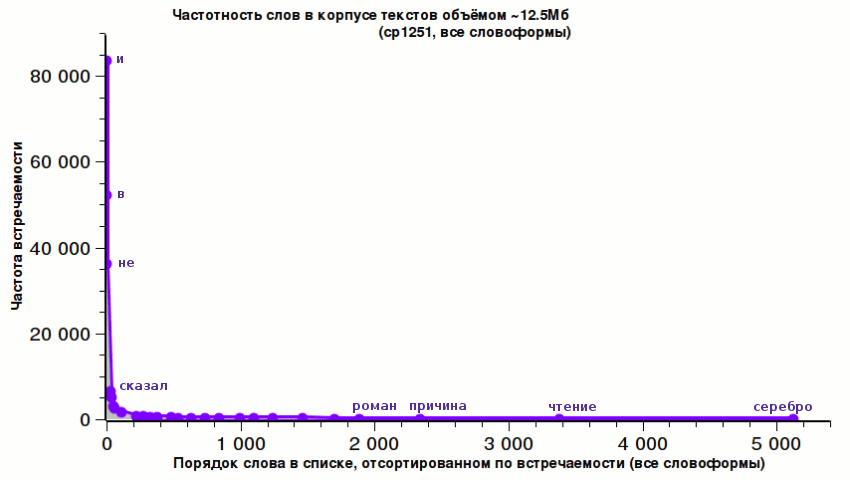
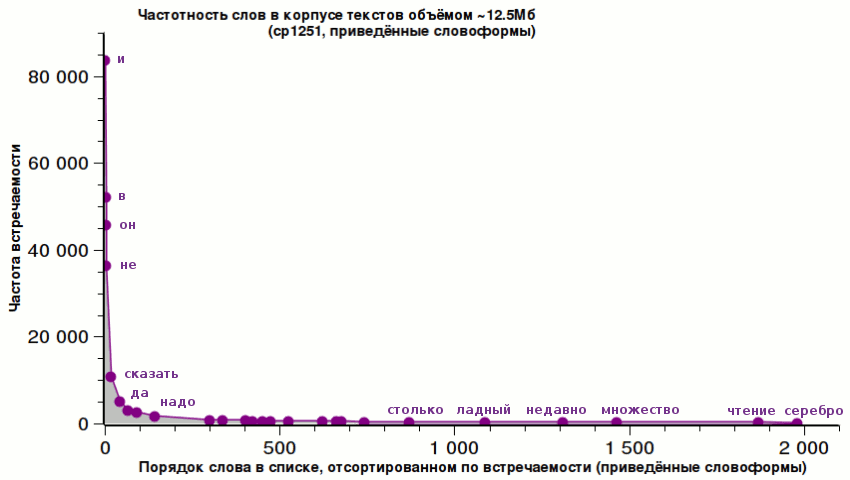
Частотность слов на корпусе текстов изучалась со времён открытия закона Ципфа для английского языка (т.е., уже более 60-ти лет), публиковались различные словари и обзоры по этой теме, но мы посмотрим на русскую речь немного внимательнее и нагляднее.
Подробные графики и примеры с выводами







