Бытует мнение, что накладные расходы на вызов методов и организацию процесса выполнения не должны превышать 15% времени выполнения приложения, иначе стоит серьезно задуматься над вопросом рефакторинга приложения и оптимизации его логики. Вооружившись такими мыслями я наткнулся на метод
Интересным моментом здесь является сравнение элементов — для обеспечения гибкости его вынеслив отдельный класс реализующий интерфейс
Итак у нас есть стандартная реализация быстрой сортировки Хоара, которая для сравнения элементов массива использует метод
Поскольку исследовать мы будем исключительно вызов операции сравенния, то все изменения этой функции будут делаться только в строках 1, 12, 16, 53 и 61, которые помечены в листинге опознавательными комментариями.
Для начала оценим вклад накладных расходов на вызов операции сравнения двух чисел в длительность выполнения процесса сортировки. Для этого в приведенной функции меняем вызовы «
Что же могло так сильно замедлить работу? Очевидно что дело в излишней сложности процесса сравнения (и это при том, что сама операция сводится к вычитанию двух чисел!):
При этом первые два пункта являются отличием CIL-инструкции
Ну а четвертый пункт вызван стандартной реализацией comparer-а (все проверки на
Будем убирать слои по одному, начнем с вызова
Замеры показывают выиграш 15% по времени. И это при том, что мы рассматриваем массив целых чисел и вызов
Благодаря передаче фактического типа в функцию сортировки, при разворачивании параметров генерика будет учтен реальный тип comparer'а и для вызова операции сравнения задействуется более эффективная инструкция
На заметку: В библиотеке STL из C++ все предикаты передаются именно таким образом — тип идет через параметр шаблона. Дополнительно, благодаря этому трюку, компилятор C++ получает полную информацию о типах и как правило производит разворачивание (inlining) кода предиката, тем самым полностью исключая затраты на вызов метода. Мои опыты с дизассемблированием результатов работы .Net JIT показали, что вопреки всем ухищрениям, здесь никакого разворачивания не происходит. Судя по всему это либо связано с генериками, либо работает оно исключительно для статических методов.
На заметку #2: Сэкономить на передаче comparer'а при помомщи пустой структуры не удалось — размер (
Если свести данные в единую диаграмму, получим следующее распределение времени выполнения сортировки стандартным методом:

Напрашивающийся очевидный вывод — при разработке тяжелых в вычислительном плане библитек есть смысл частовызываемые предикаты делать структурами и их тип передавать через параметры генерика.
Но не числами едиными живут наши приложения :) Возник вопрос влияния в контексте работы с массивами объектов, проверим? Легко! В качестве опытного образца берем вот такой простенький класс:
И проводим аналогичные нехитрые опыты но уже с массивом объектов, в итоге получаем чуть другую ситуацию:
И если соотношение между частями процесса сравнения остались неизменными, то их вклад в общее время заметно уменьшился. Взникает вполне везонный вопрос: а в чем же дело, что замедляется? Беглого взгляда на код функции сортировки достаточно чтоб понять: замедлилась работа единственного отличающегося куска кода — обмена значений между элементами массива. Но ведь мы работает со ссылочным типом, переставляются только указатели, а они «в душе» числа! Раз интересно, значит будем смотреть что там так замедляется, чтение CIL пользы особо не дает — код обмена асболютно идентичный за исключением использования инструкций
Раз не помог CIL, значит дело в выходе из JIT, значит будем смотреть ассемблер :) Здесь нас ждет весялая неприятность — независимо от крнфигурации (Debug/Release), JIT-компилятор смотрик на свое окружение и, в зависимости от наличия присоединенного к процессу отладчика, генерирует разный код. Поэтому для доступа к реальному коду через окно Disassembly мы будем запускать приложение без отладки а точки останова поставим в виде вызовов
В листингах сразу же бросается в глаза вызов некоторой функции для записи в массив объектов, причем вызов этот отсутствовал пока мы смотрели CIL. Очевидно, что эта функция делает нечто большее чем просто копирование адреса и помимо затрат на органицазию этого вызова мы получаем еще что-то, а значит детали лежат в реализации CLR. Действительно, почитав исходники публичной версии CLR 2.0 (пакет SSCLI 2.0), находим следующий код:
Как видно отсюда, при записи элемента в массив объектов, помимо стандартной проверки границ массива, также проверяется совместимость типов и при необходимости производятся соответствующие конвертации. Стоит заметить, что будучи строко типизированным, сам C# также содержит контроль типов, но поскольку в CIL инструкцию информация уже приходит в виде
Какие из этого всего можно сделать выводы? Хардкорные оптимизации предлагать не буду, но есть смысл избегать виртуальных вызовов внутри больших циклов, особенно в миниатюрных функциях-предикатах. На практике это например:
Конечно, это не единственные возможные выводы, но ведь надо же оставить читателю простор для мыслей :)
QuickSort из стандартного класса ArraySortHelper<T> использующийся для сортировки массивов в .Net.Интересным моментом здесь является сравнение элементов — для обеспечения гибкости его вынеслив отдельный класс реализующий интерфейс
IComparer<T>. Вооружившись разнообразными мыслями и студией было решено оценить сколько же такая гибкость стоит и что с этим можно было бы сделать — под катом анализ затрат на сравнение элементов во временя работы QuickSort.Итак у нас есть стандартная реализация быстрой сортировки Хоара, которая для сравнения элементов массива использует метод
Compare(T x, T y) из объекта реализующего интерфейс IComparer<T>. Для наших опытов, при помощи рефлектора, получаем код метода сортировки в следующем виде:Copy Source | Copy HTML
- static public void Sort<T, TValue>(T[] keys, TValue[] values, int left, int right, IComparer<T> comparer)
- {
- do
- {
- int index = left;
- int num2 = right;
- T y = keys[index + ((num2 - index) >> 1)];
- do
- {
- try
- {
- /* Cmp 1 */ while (comparer.Compare(keys[index], y) < 0)
- {
- index++;
- }
- /* Cmp 2 */ while (comparer.Compare(y, keys[num2]) < 0)
- {
- num2--;
- }
- }
- catch (IndexOutOfRangeException)
- {
- throw new ArgumentException(null, "keys");
- }
- catch (Exception)
- {
- throw new InvalidOperationException();
- }
- if (index > num2)
- {
- break;
- }
- if (index < num2)
- {
- T local2 = keys[index];
- keys[index] = keys[num2];
- keys[num2] = local2;
- if (values != null)
- {
- TValue local3 = values[index];
- values[index] = values[num2];
- values[num2] = local3;
- }
- }
- index++;
- num2--;
- }
- while (index <= num2);
- if ((num2 - left) <= (right - index))
- {
- if (left < num2)
- {
- /* Call 1 */ Sort<T, TValue>(keys, values, left, num2, comparer);
- }
- left = index;
- }
- else
- {
- if (index < right)
- {
- /* Call 2 */ Sort<T, TValue>(keys, values, index, right, comparer);
- }
- right = num2;
- }
- }
- while (left < right);
- }
Поскольку исследовать мы будем исключительно вызов операции сравенния, то все изменения этой функции будут делаться только в строках 1, 12, 16, 53 и 61, которые помечены в листинге опознавательными комментариями.
Часть первая. Опыты с массивами чисел (int)
Для начала оценим вклад накладных расходов на вызов операции сравнения двух чисел в длительность выполнения процесса сортировки. Для этого в приведенной функции меняем вызовы «
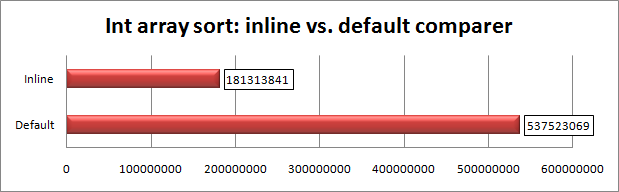
comparer.Compare(a, b)» на выражения вида «a - b». Замеряем время работы обеих версий и видим… Видим ужасную картину — практически две трети времени тратится на организацию вызова предиката сравниващего числа:
Что же могло так сильно замедлить работу? Очевидно что дело в излишней сложности процесса сравнения (и это при том, что сама операция сводится к вычитанию двух чисел!):
- Проверка объекта
comparerнаnull - Поиск метода
Compareв виртуальной таблице объекта - Вызов метода
Compareдля объектаcomparer - Вызов метода
CompareTo - Собственно сравнение чисел
При этом первые два пункта являются отличием CIL-инструкции
callvirt от call. Напомню, что callvirt, из-за наличия проверки на null, генерируется для вызова всех нестатических методов классов независимо от их виртуальности.Ну а четвертый пункт вызван стандартной реализацией comparer-а (все проверки на
null естественным образом убираются JIT-компилятором при подстановке int вместо T):Copy Source | Copy HTML
- class GenericComparer<T> : IComparer<T> where T : IComparable<T>
- {
- public int Compare(T x, T y)
- {
- if (x != null)
- {
- if (y != null)
- {
- return x.CompareTo(y);
- }
- return 1;
- }
- if (y != null)
- {
- return -1;
- }
- return 0;
- }
- }
Будем убирать слои по одному, начнем с вызова
CompareTo, благо это делается элементарно — написанием своего comparer'а следующего вида:Copy Source | Copy HTML
- class IntComparer : IComparer<int>
- {
- public int Compare(int x, int y)
- {
- return x - y;
- }
- }
Замеры показывают выиграш 15% по времени. И это при том, что мы рассматриваем массив целых чисел и вызов
CompareTo для них, как и для всех методов для всех структур является невиртуальным. Следующий слой, отличие между callvirt и call при вызове, проверить сложнее, особенно в рамках тех же требований к гибкости функции сортировки. Впрочем нет ничего невозможного — при работе через инстанцию структуры, все методы всех структур вызываются при помощи операции call, в том числе реализации методов унаследованных от интерфейсов. Благодаря этому мы можем сделать следующую оптимизацию:Copy Source | Copy HTML
- static public void SortNoVirt<T, TValue, TCmp>(T[] keys, TValue[] values, int left, int right, TCmp comparer) where TCmp : IComparer<T>
- {
- // ...
- }
-
- struct IntComparerNoVirt : IComparer<int>
- {
- public int Compare(int x, int y)
- {
- return x - y;
- }
- }
Благодаря передаче фактического типа в функцию сортировки, при разворачивании параметров генерика будет учтен реальный тип comparer'а и для вызова операции сравнения задействуется более эффективная инструкция
call. Замеры времени показывают прирост произодительности около 35% от времени выполнения «стандартного» вызова, при этом прирост от последующей замены вызова Compare на отнимание составляет 18%.На заметку: В библиотеке STL из C++ все предикаты передаются именно таким образом — тип идет через параметр шаблона. Дополнительно, благодаря этому трюку, компилятор C++ получает полную информацию о типах и как правило производит разворачивание (inlining) кода предиката, тем самым полностью исключая затраты на вызов метода. Мои опыты с дизассемблированием результатов работы .Net JIT показали, что вопреки всем ухищрениям, здесь никакого разворачивания не происходит. Судя по всему это либо связано с генериками, либо работает оно исключительно для статических методов.
На заметку #2: Сэкономить на передаче comparer'а при помомщи пустой структуры не удалось — размер (
sizeof) структуры без полей в C# оказался равным единице (а не нулю, как хотелось). В VC++ размер пустой структуры также равен единице, при этом в стандарте говорится, что размер пустого класса (структуры) должен быть больше нуля. Сделано это из-за популярной конструкции для вычисления длины массива «sizeof(array) / sizeof(array[0])». В C#/.Net это видимо сделано для бинарной совместимости при взаимодействии с кодом написаным на C++.Если свести данные в единую диаграмму, получим следующее распределение времени выполнения сортировки стандартным методом:
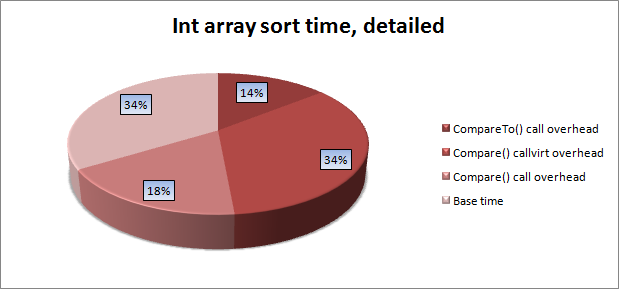
Напрашивающийся очевидный вывод — при разработке тяжелых в вычислительном плане библитек есть смысл частовызываемые предикаты делать структурами и их тип передавать через параметры генерика.
Часть вторая. А что с будет объектами?
Но не числами едиными живут наши приложения :) Возник вопрос влияния в контексте работы с массивами объектов, проверим? Легко! В качестве опытного образца берем вот такой простенький класс:
Copy Source | Copy HTML
- class IntObj : IComparable<IntObj>
- {
- public int value;
-
- public int CompareTo(IntObj other)
- {
- return value - other.value;
- }
- }
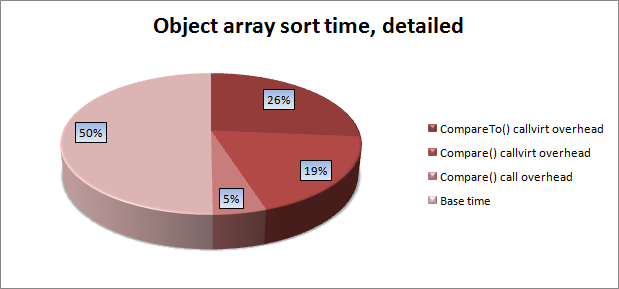
И проводим аналогичные нехитрые опыты но уже с массивом объектов, в итоге получаем чуть другую ситуацию:

И если соотношение между частями процесса сравнения остались неизменными, то их вклад в общее время заметно уменьшился. Взникает вполне везонный вопрос: а в чем же дело, что замедляется? Беглого взгляда на код функции сортировки достаточно чтоб понять: замедлилась работа единственного отличающегося куска кода — обмена значений между элементами массива. Но ведь мы работает со ссылочным типом, переставляются только указатели, а они «в душе» числа! Раз интересно, значит будем смотреть что там так замедляется, чтение CIL пользы особо не дает — код обмена асболютно идентичный за исключением использования инструкций
*.i4 для чисел и *.ref для объектов.Раз не помог CIL, значит дело в выходе из JIT, значит будем смотреть ассемблер :) Здесь нас ждет весялая неприятность — независимо от крнфигурации (Debug/Release), JIT-компилятор смотрик на свое окружение и, в зависимости от наличия присоединенного к процессу отладчика, генерирует разный код. Поэтому для доступа к реальному коду через окно Disassembly мы будем запускать приложение без отладки а точки останова поставим в виде вызовов
Debugger.Break();. Далее приведены листинги с кодом который генерируется для обмена местами значений в двух ячейках массива:В листингах сразу же бросается в глаза вызов некоторой функции для записи в массив объектов, причем вызов этот отсутствовал пока мы смотрели CIL. Очевидно, что эта функция делает нечто большее чем просто копирование адреса и помимо затрат на органицазию этого вызова мы получаем еще что-то, а значит детали лежат в реализации CLR. Действительно, почитав исходники публичной версии CLR 2.0 (пакет SSCLI 2.0), находим следующий код:
Copy Source | Copy HTML
- /****************************************************************************/
- /* assigns 'val to 'array[idx], after doing all the proper checks */
-
- HCIMPL3(void, JIT_Stelem_Ref_Portable, PtrArray* array, unsigned idx, Object *val)
- {
- if (!array)
- {
- FCThrowVoid(kNullReferenceException);
- }
- if (idx >= array->GetNumComponents())
- {
- FCThrowVoid(kIndexOutOfRangeException);
- }
-
- if (val)
- {
- MethodTable *valMT = val->GetMethodTable();
- TypeHandle arrayElemTH = array->GetArrayElementTypeHandle();
-
- if (arrayElemTH != TypeHandle(valMT) && arrayElemTH != TypeHandle(g_pObjectClass))
- {
- TypeHandle::CastResult result = ObjIsInstanceOfNoGC(val, arrayElemTH);
- if (result != TypeHandle::CanCast)
- {
- HELPER_METHOD_FRAME_BEGIN_2(val, array);
-
- // This is equivalent to ArrayStoreCheck(&val, &array);
- #ifdef STRESS_HEAP
- // Force a GC on every jit if the stress level is high enough
- if (g_pConfig->GetGCStressLevel() != 0
- #ifdef _DEBUG
- && !g_pConfig->FastGCStressLevel()
- #endif
- )
- GCHeap::GetGCHeap()->StressHeap();
- #endif
-
- #if CHECK_APP_DOMAIN_LEAKS
- // If the instance is agile or check agile
- if (!arrayElemTH.IsAppDomainAgile() && !arrayElemTH.IsCheckAppDomainAgile() && g_pConfig->AppDomainLeaks())
- {
- val->AssignAppDomain(array->GetAppDomain());
- }
- #endif
- if (!ObjIsInstanceOf(val, arrayElemTH))
- {
- COMPlusThrow(kArrayTypeMismatchException);
- }
-
- HELPER_METHOD_FRAME_END();
- }
- }
-
- // The performance gain of the optimized JIT_Stelem_Ref in
- // jitinterfacex86.cpp is mainly due to calling JIT_WriteBarrierReg_Buf.
- // By calling write barrier directly here,
- // we can avoid translating in-line assembly from MSVC to gcc
- // while keeping most of the performance gain.
- HCCALL2(JIT_WriteBarrier, (Object **)&array->m_Array[idx], val);
-
- }
- else
- {
- // no need to go through write-barrier for NULL
- ClearObjectReference(&array->m_Array[idx]);
- }
- }
- HCIMPLEND
Как видно отсюда, при записи элемента в массив объектов, помимо стандартной проверки границ массива, также проверяется совместимость типов и при необходимости производятся соответствующие конвертации. Стоит заметить, что будучи строко типизированным, сам C# также содержит контроль типов, но поскольку в CIL инструкцию информация уже приходит в виде
System.Object, то CLR, для надежности, проверяет еще раз.Часть третья. Подобие выводов
Какие из этого всего можно сделать выводы? Хардкорные оптимизации предлагать не буду, но есть смысл избегать виртуальных вызовов внутри больших циклов, особенно в миниатюрных функциях-предикатах. На практике это например:
- реализаця предикатов в виде структур, а не классов с последующей предачей информации о типе через параметры генерика
- замена мелких утилитарных методов классов на статические методы-расширения, которые из-за своей статичности будут вызваны в обход виртуальной таблицы
Конечно, это не единственные возможные выводы, но ведь надо же оставить читателю простор для мыслей :)







