
Этот перевод является продолжением серии статей про тестирование:
На очереди практические советы по построению тестопригодного кода и примеры применения изложенных знаний на реальных проектах.
P. S. Отдельное спасибо taxigy за корректуру русского перевода.
Я думаю, что баги можно разделить на три базовые категории:
- Логические. Логические баги наиболее популярны и часто встречающиеся. Это ваши if'ы, циклы и другая подобная логика в коде. (Мысли: это работает неверно).
- Баги взаимодействия. Баг взаимодействия — когда два разных объекта неправильно взаимодействуют между собой. Например, выход одного объекта является не тем, что ожидает следующий объект в цепочке. (Мысли: данные к месту назначения пришли испорченными).
- Баги отображения. Баг отображения — когда вывод (обычно некоторый пользовательский интерфейс, UI) отображается некорректно. Ключевой момент — в том, что это человек определяет, что есть правильно, а что — нет. (Мысли: это «выглядит» неправильно)
ПРЕДУПРЕЖДЕНИЕ: Некоторые разработчики считают что, когда они строят пользовательский интерфейс, то все баги — это баги отображения! Под багами отображения понимаются ошибки, подобные ошибке выхода текста за границу кнопки. Но случай, когда вы кликаете на кнопку, и происходят неправильные вещи, — это скорее из-за ошибок взаимодействия (баги взаимодействия), или что-то неверно в логике (логические баги). Баги отображения очень редки.
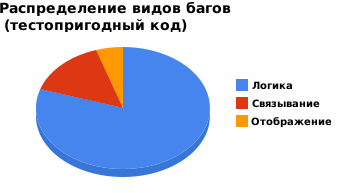
Типичное распределение видов багов в программе
Первая вещь, которую я подметил с тремя типами багов, — это то, что вероятность встретить каждый из них неравномерна. Кроме вероятности различны еще сложность их поиска и исправления в коде (я уверен, что вы так же помните это по своему опыту). Мой опыт построения веб-приложений говорит о том, что больше всех распространены логические баги, за ними следуют баги связывания, и в конце — баги отображения.
Сложность обнаружения Бага
Логические баги обнаружить сложнее всего. Одна из причин состоит в том, что они проявляются только при определенных входных условиях, и поиск этих загадочных наборов или их воспроизведение сопровождается большим напряжением извилин. Баги связывания проще обнаружить, поскольку они легко воспроизводимы на большинстве независимых входных условиях. А баги отображения вы можете просто увидеть своими глазами и быстро показать, что выглядит не так.
Сложность исправления Бага
Практический опыт может показать нам, насколько сложно исправлять ошибки. Логический баг починить довольно сложно, поскольку для поиска решения вы должны понимать все пути выполнения кода. После внесения правок, мы так же должны быть уверены, что исправления не сломают уже существующую функциональность. Проблемы связывания попрвить легче, поскольку они проявляют себя с помощью exсeption'а или неверным местонахождением данных. Баги отображения сами наглядно показывают, что пошло не так, и вы сразу знаете как это исправить. Мы изначально проектируем нашу программу, учитывая частые изменения пользовательского интерфейса, и поэтому нам легче вносить подобные правки.
| Логические | Связывания | Отображения | |
|---|---|---|---|
| Вероятность появления | Высокая | Средняя | Низкая |
| Сложность обнаружения | Сложно | Легко | Тривиально |
| Сложность исправления | Высокая | Средняя | Низкая |
Как тестопригодность меняет распределение видов багов?
Так получается, что написание тестопригодного кода влияет на распределение видов багов в программе. Для тестопригодности код должен:
- Иметь явное разделение ответственности классов. Это уменьшает вероятность появления багов связывания. К тому же, меньшее количество кода на класс приводит и к меньшему количеству логических багов.
- Использовать инъекции зависимостей (dependency injection) — это делает связывание явным, в отличие от одиночек (singletons), глобальных объектов или локаторов сервисов.
- Содержать явное разделение логики и связывания — связывание легче тестировать, если в нем не намешано логики.
Следование этим правилам ведет к существенному сокращению багов связывания. В процентном отношении количество логических багов выросло, но общее количество всех багов сократилось.
Интересно отметить, что можно получить пользу от тестопригодного кода, не написав при этом ни строчки самих тестов. Подобный код — лучший код! (Когда я слышу, как люди приносят в жертву «хороший код» ради тестопригодности, то понимаю, что они совершенно не осознают, что такое на самом деле тестопригодный код)
Мы любим писать модульные тесты (unit tests)
Модульные тесты дают нам в руки очень мощное оружие. Данные тесты предназначены для обнаружения наиболее распространенных багов, сложных для обнаружения и исправления. Модульные тесты также способствуют написанию тестопригодного кода, который неявно помогает с багами связывания. В итоге, при написании автоматических тестов мы должны большей частью сосредоточиться на модульных тестах. Каждый подобный тест фокусируется только на логике одного класса/метода.
Модульные тесты сфокусированы на логических багах. Они проверяют ваши i'ы и циклы, но не проверяют связывание напрямую (и конечно, не проверяют отображение)
Модульные тесты сфокусированы на КПТ (класс-под-тестом, CUT, class-under-test). Это важно, поскольку вы должны быть уверены, что эти тесты не встанут на пути будущего рефакторинга. Модульные тесты должны ПОМОГАТЬ рефакторингу, а не МЕШАТЬ ему. (Повторюсь: когда я слышу, как кто-то говорит, что тесты мешают рефакторингу, то полагаю, что этот человек не понимает, что такое модульный тест).
Модульные тесты напрямую не скажут, что все OK со связыванием. Они делают это неявно, путем принуждения вас к написанию тестопригодного кода.
Функциональные тесты проверяют связанность, однако это не все. Вы можете долго делать рефакторинг, если у вас много функциональных тестов ИЛИ если вы смешиваете функциональные и логические тесты.
Управление Багами
Я люблю думать о тестировании как об управлении багами (с целью от них избавится). Не все виды ошибок одинаковы, поэтому я выбираю тесты, на которых нужно сконцентрироваться. Я понял, что люблю модульные тесты. Но они должны быть хорошо сфокусированы! Если тест проверяет много классов за один проход, то я могу быть рад хорошему покрытию тестами, но на самом деле после этого сложно найти то место, которое зажгло «красный» тест. Это также может затруднить рефакторинг. Я стараюсь облегчить себе жизнь при функциональном тестировании: для меня достаточно одного теста, который доказывает правильность связывания.
Я слышу, как многие заявляют, что они пишут модульные тесты, но при ближайшем рассмотрении это оказывается смесь функциональных (проверка связывания) и модульных (логика) тестов. Это происходит, когда тесты пишутся после того, как написан код, и из-за этого он получается нетестопригодным. Нетестопригодный код ведет к появлению мокеров (от англ. «mock» — заглушка) — это тест, для которого необходимо много заглушек, а эти заглушки, в свою очередь, используют другие заглушки. Используя тесты с мокерами, вы будете мало в чем уверены. Подобные тесты работают на слишком высоком уровне абстракции, нужном для того, чтобы что-то утверждать на уровне методов. Эти тесты глубоко завязаны на реализации (это видно по наличию большого количества связей между заглушками), вследствие чего любой рефакторинг будет очень болезненным.
---------------------------
translated.by/you/my-unified-theory-of-bugs/into-ru/trans
Оригинал (английский): My Unified Theory of Bugs (http://misko.hevery.com/2008/11/17/unified-theory-of-bugs/)
Перевод: © Alexander MAZUROV, taxigy
translated.by переведено толпой








