Оригинал статьи находится по адресу
В этой статье мы попытаемся найти ответ на вопрос, обозначений в заголовке. А также порассуждаем на тему возможности универсального решения на все случае жизни.
Три типовых решения при работе с бизнес-логикой по Фаулеру
С одной стороны сложно писать об организации бизнес-логики в приложении. Получается очень абстрактная статья. Благо есть книги, где затронута эта тема и даже есть примеры кода. Мартин Фаулер в книге "Шаблоны корпоративных приложений" выделял три основных типовых решения. Сценарий транзакции (Transaction Script), модуль таблицы (Table Module) и модель предметной области (Domain Model). Самый элементарный из них - это сценарий транзакции. Не будем их здесь обсуждать подробно - они очень хорошо описаны в первоисточнике с примерами. Приведем для дальнейших рассуждений лишь схему все из той же книги:
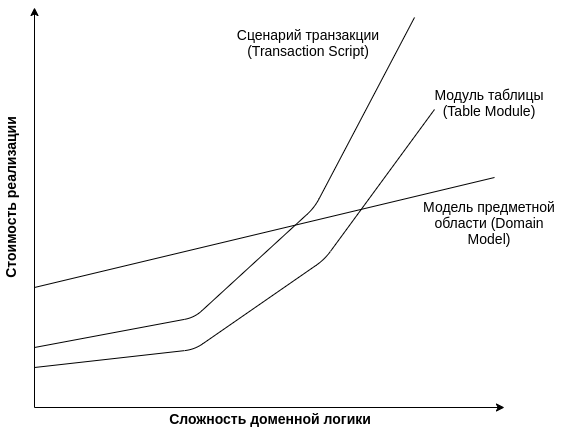
На этом графике показана _приблизительная_ зависимость между сложностью доменной логики и стоимостью реализации для трех видов типовых решений. Сразу бросается в глаза очевидная схожесть между тем, как ведет себя сценарий транзакции и модуль таблицы. И совсем особняком стоит модель предметной области, которую применяют для сложной бизнес-логики. Как выбирать решение для вашего проекта? Очень просто, вы оцениваете, насколько сложная будет бизнес-логика. Например, расчет скидочной программы для клиентов. Какое типовое решение выбрать? Обычно при расчете скидок пользователи могут быть в разных категориях скидочной программы, в зависимости от категории можно получать скидки на разные группы товаров, причем товары могут входить в иерархические группы. Категории скидок распространяются на категории товаров. А еще есть число посещений заведения за заданный период. Периоды с разными характеристиками, заведения в сети заведений - различаются и т.д. и т.п. Если представить код - это приложение, в котором большое число классов с разнообразными свойствами и большое число связей между этими классами. А также разнообразные стратегии, которые оперируют всеми этими сущностями. В таком случае ответ очевиден - проектирование с использованием модели предметной области позволит вам совладать со всеми сложностями. Другой пример - у вас простое приложение, которое хранит свои данные в 3-х таблицах и никаких особенных операций с ними не делает. Рассылка сообщений по почте - список почтовых ящиков и список отправленных писем. Здесь нет смысла тащить какой-то сложный фреймворк. Простое приложение должно оставаться простым, и тут лучше выбрать модуль таблицы или даже сценарий транзакции. В зависимости от того на какой платформе вы собираетесь разрабатывать.
Сколько типовых решений на самом деле?
Похожесть двух кривых объясняется очень просто. Сценарий транзакции и модуль таблицы реализуются преимущественно с использованием процедурной парадигмы программирования. В то время как модель предметной области — с использованием объектно-ориентированной парадигмы программирования. Если посмотреть на проблему под этим углом - все становится на свои места.
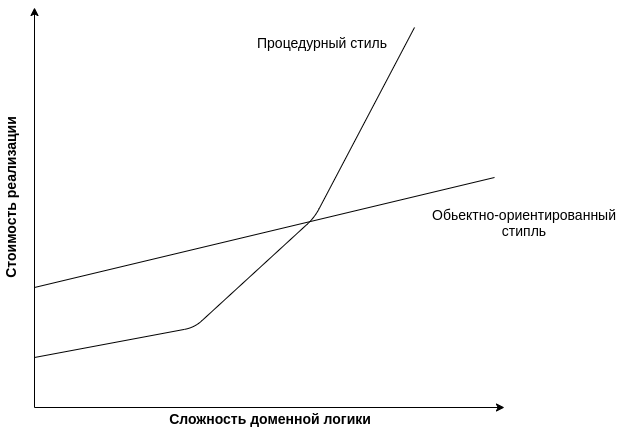
Понятно, что речь не идет о чистой реализации той или иной парадигмы. Всегда есть компромиссы, вызванные ограничениями используемых технологий. Если вы пишете на C# или Java, объектно-ориентированных языках по своей природе, то это совсем не значит, что ваш код автоматически становится объектно-ориентированным. Всю программу вполне могут поместить в один единственный класс, объявить все методы статическими и использовать их из любого фрагмента кода. Таким образом, в каждом конкретном приложении будет своя кривая. Нужно лишь понять, к какой из этих двух категорий она ближе.
Как влияют фреймворки и инструменты разработки на кривую стоимости?
Сразу обозначим, что в качестве хранилища данных может выступать не только реляционная СУБД, но и NoSQL хранилище, NewSQL и даже обычные файлы, сериализованные в json, бинарный формат и т.п. Мы смотрим на ситуацию в комплексе. Если говорить про работу с обычными SQL хранилищами, здесь также огромный выбор. Вы можете писать простые запросы, писать хранимые процедуры, можете использовать ORM, использовать Code First, либо DB First подходы - все это в конечном счете сказывается на стиле, в котором написана бизнес логика. В большей степени процедурном, либо в большей степени объектно-ориентированном. Ниже я примерно обозначил свое мнение о популярных схемах работы с БД.
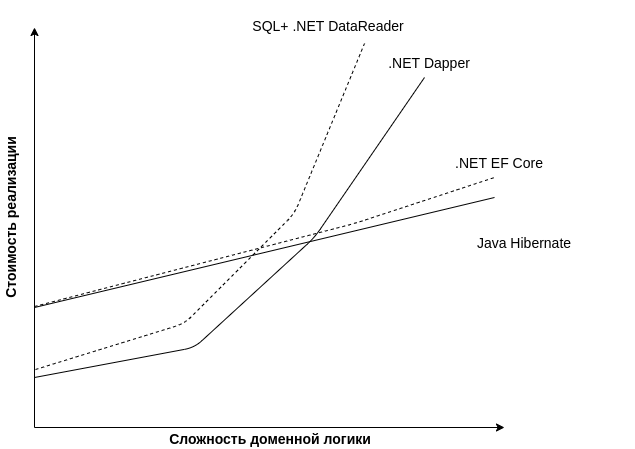
Проблема в том, что используемые средства накладывают ограничения, которые не позволят вам реализовать тот или иной подход в полной мере. Например, с помощью Dapper не удобно работать со сложными ассоциациями внутри доменных сущностей. А при использовании ORM уровня Entity Framework вы добавляете код для отображения сущностей на таблицы. Если говорить о NoSQL СУБД, для примера Neo4j, то там очень выразительный и мощный для своих задач язык. Но опять же это приведет к использованию процедурной парадигмы.
Насколько легко сменить выбранное решение?
Давайте попробуем представить ситуацию, где мы решили кардинально изменить схему работы с хранилищем данных. С чем мы можем в таком случае столкнуться? До этого мы обсудили два важнейших аспекта - сложность кода и стоимость его сопровождения. Но на практике этого оказывается мало. Есть еще как минимум вопрос производительности - создаваемое приложение должно быть быстрым. И это сказывается на стиле написания кода. Чем жестче требования производительности, тем более процедурный код мы получаем на выходе. В каком-то экстремальном случае это может быть сервис или приложение, написанное с использованием полностью SQL, где вся логика скрыта в хитрообразных джойнах, оконных функция и обобщенных табличных выражениях. Работает быстро, но перевести его на ORM уже не так просто - все равно, что переписать с нуля. Развитие такого продукта также может столкнуться с сложностями, учитывая график выше и процедурный стиль. Еще один вопрос - консистентность данных. Например, реляционные СУБД предоставляют очень богатые возможности по работе с транзакциями. Разобравшись с ними один раз - можно легко писать код, где вы точно знаете, какие данные увидит пользователь, какие сможет изменить. С другой стороны, если вы пользуетесь ORM и выносите всю вашу бизнес-логику в классы, работать в терминах транзакций становится сложнее. Обычно происходит реорганизация структуры таблиц и даже бизнес-сценариев таким образом, что они начинают работать в стиле согласованности данных в конечном счете (eventual consistency). Очевидно, что это также затрудняет перевод с одной схемы на другую, если вы заранее не заложили такую возможность. Компетенцию команды также не следует сбрасывать со счетов. Часто разработчики знают хорошо либо SQL, либо ORM, и при переходе можно неожиданно столкнуться с проблемами.
Выводы
Из всего, что мы обсудили, можно сделать выводы:
При проектировании сервиса с нуля лучше сразу прогнозировать дальнейшее развитие этого сервиса и выбирать наиболее подходящее типовое решение.
Если дальнейшее развитие для сервиса не очевидно, то лучше сразу позаботиться о возможной смене парадигмы. Например, предпочитая eventual consistency. При добавлении нового функционала всегда держать в уме возможность смены решения.
Для доставшегося в "наследство" программного кода одно из первых действий - это оценка степени соответствия выбранного типового решения и объема уже реализованной логики. Как показывает практика - это наиболее частая причина технического долга.
Какие еще выводы вы могли бы предложить? Оставляйте ваши комментарии, давайте обсудим.







