Комментарии 6
Попытка интересная, но очень много смеси тёплого с мягким.
Например, посмотрим на модель данных. «Data warehouse» – это что за модель? В большинстве случаев хранилище данных – это реляционная СУБД.
«Решаемая проблема» в классификации по модели данных – тоже несколько надумана. Очевидно, что реляционная модель лучшая, а другие модели – плата за какие-то дополнительные возможности. Та же Cassandra не реляционная не потому, что её модель удобнее, а потому, что сделать такую же распределённую БД реляционной не так-то просто.
«Scale» – это хорошо, но правильнее делить БД на монолитные и распределённые. Из этого следуют все принципиальные отличия.
Вот как-то так примерно:

Например, посмотрим на модель данных. «Data warehouse» – это что за модель? В большинстве случаев хранилище данных – это реляционная СУБД.
«Решаемая проблема» в классификации по модели данных – тоже несколько надумана. Очевидно, что реляционная модель лучшая, а другие модели – плата за какие-то дополнительные возможности. Та же Cassandra не реляционная не потому, что её модель удобнее, а потому, что сделать такую же распределённую БД реляционной не так-то просто.
«Scale» – это хорошо, но правильнее делить БД на монолитные и распределённые. Из этого следуют все принципиальные отличия.
Вот как-то так примерно:
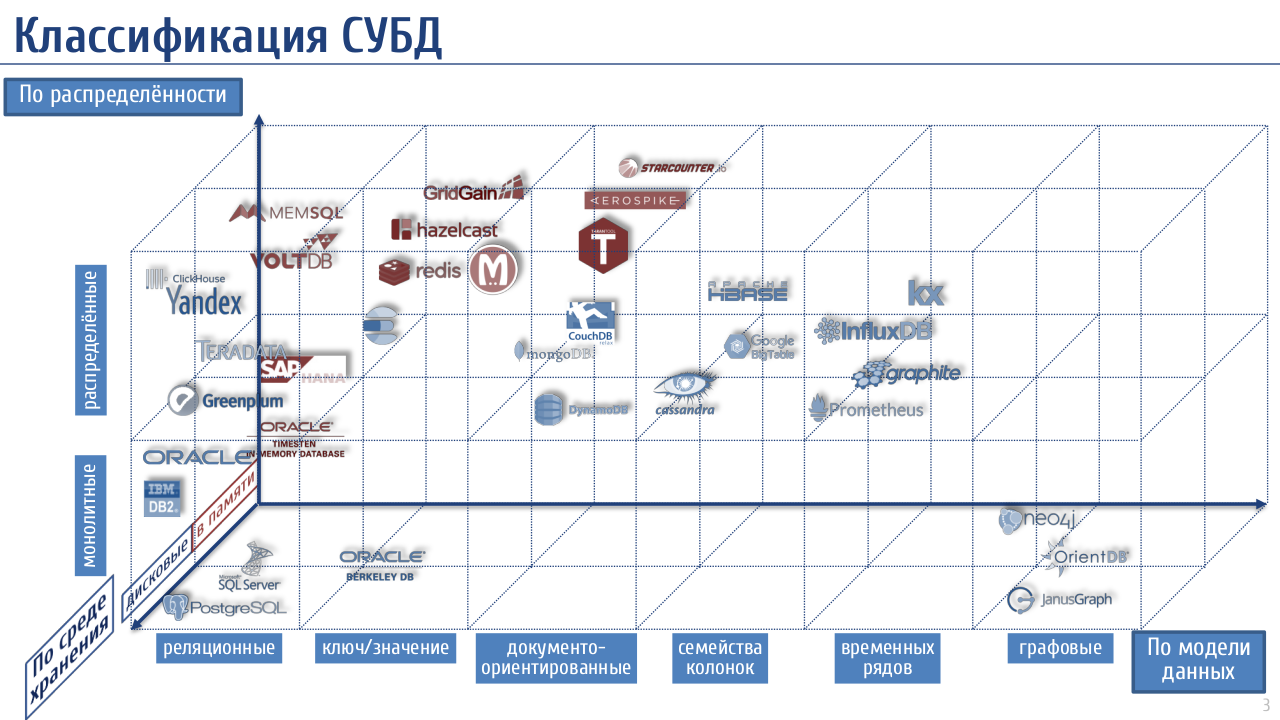
Приятно изучать такую эффектно выглядящую и профессионально составленную диаграмму! Я так и вижу, как можно успешно продать российскому бизнесу внедрение какого-либо решения с помощью ее презентации.
Ваша классификация подробная и понятная, даже если исключить конкретные реализации (которые, развиваясь, со временем могут перемещаться по диаграмме), можно проводить по ней сессии обмена знаниями в коллективе…
Интересно, с какой практической целью Вы составили эту диаграмму? Как Вы ее используете?
Ваша классификация подробная и понятная, даже если исключить конкретные реализации (которые, развиваясь, со временем могут перемещаться по диаграмме), можно проводить по ней сессии обмена знаниями в коллективе…
Интересно, с какой практической целью Вы составили эту диаграмму? Как Вы ее используете?
Полезная штука, спасибо!
Вы не планируете написать обзор на базе этого сборника?
Вы не планируете написать обзор на базе этого сборника?
Я бы Persistence сегментировал так:
— In Memory
— WAL
— Snapshot
— Disk Based
А уже поддерживаться DBMS может комбинация из этих вариантов.
— In Memory
— WAL
— Snapshot
— Disk Based
А уже поддерживаться DBMS может комбинация из этих вариантов.
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
Сборник диаграмм классификаций баз данных