Продолжаем наши исследования по выбору рациональных планов (здесь к месту использование термина каркасов, ибо на этом этапе от конкретных технологий параллельного программирования будем абстрагироваться) выполнения параллельных программ (ПВПП) по графовому описанию алгоритмов. Приоритетом при этом будем считать получение ПВПП с максимальным использованием вычислительных ресурсов (собственно параллельных вычислителей), такая цель соответствует представлению о плотности кода (об этом понятии подробнее ниже).
Естественным перед началом анализа будет указание ограничений на ширину и глубину исследований. Принимаем, что многозадачность в рассматриваемых параллельных системах осуществляется простейшим путём - перегрузкой всего блока (связки) выполняющихся операторов (одновременное выполнение операторов разных программ не предполагается) или же система работает в однозадачном режиме; в противном случае высказанное в предыдущей фразе утверждение может быть неверным. Минимизация объёма устройств временного хранения данных (описано здесь) проводиться не будет. На этом этапе исследований также не учитываются задержки времени на обработку операторов и пересылку данных между ними (для системы SPF@home формально эти параметры могут быть заданы в файлах с расширениями med и mvr).
В предыдущей публикации была описана технология получения ПВПП на основе модели потокового (Data-Flow) вычислителя. Обычно считают, что правила выбора операторов для выполнения в такой машине подчиняются логике действия некоторых сущностей, совместно выполняющих определённые действия – “актёров” (actors); при этом естественным образом моделируются связанные с характеристиками времени параметры обработки операторов. В общем случае при этом отдельные операторы выполняются асинхронно. В публикации показано, что описанный принцип получения ПВПП приемлем (при выполнении несложных условий) и для машин архитектуры VLIW (Very Long Instruction Word, сверхдлинное машинное слово), отличающихся требованием одновременности начала выполнения всех операторов в связке. В расчётах использовали модель ILP (Instruction-Level Parallelism, параллелизм уровня машинных команд).
В рассматриваемый программный комплекс включен модуль SPF@home, позволяющей работать с гранулами параллелизма любого размера (“оператор” любой сложности). Основным инструментом этого модуля является метод получения ярусно-параллельной формы (ЯПФ) графа алгоритма (здесь используется информационный граф, в котором вершинами являются узлы преобразования информации, а дугами – её передачи).
Реформирование ЯПФ может дать результат, идентичный полученному моделированием выполнения программы на Data-Flow -машине, но в некоторых случаях результаты расходятся. В самом деле, это во многом различные подходы. Не столь сложно представить себе рой самостоятельных, взаимодействующих программ-“актёров”, выполняющих действия по поиску готовых к выполнению операторов, свободных в данный момент отдельных вычислителей и назначающих обработку выбранных операторов конкретному вычислителю etc etc, но действия эти логично производятся в RunTime и именно на границе (“линии фронта”) между уже выполненными и ещё не выполненными операторами (метафора “поиска в ширину”, а не “в глубину” в теории графов). При этом естественным образом создаётся очень подробный план выполнения параллельной программы с точными временными метками начала и конца выполнения операторов с привязкой их к конкретным вычислителям. Такой план хорош (с точностью до математической модели, которая в конечном счёте всегда в чём-то ограничена), однако автор сомневается в степени “достаточной безумности” практического использования полученного т.о. ПВПП…
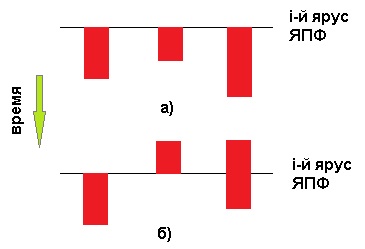
Метод обработки ЯПФ в целом более теоретичен и от многих особенностей абстрагирован, однако он может ещё до выполнения программы (DesignTime) показать ПВПП “сверху” (учитывая не только параллельный фронт выполнения операторов, но и всю “карту боевых действий”). Следствием большего абстрагирования ЯПФ-метода является субъективность интерпретации связи моментов обработки операторов с собственно ярусом ЯПФ. В самом деле, можно рассмотреть несколько укрупнённых подходов к таким интерпретациям; см. рис. ниже слева варианты a) и б) соответственно. На этом рисунке операторы показаны красными прямоугольниками, а яруса (в целях большей выразительности сказанного) - горизонтальными линиями:
выполнение всех принадлежащих конкретному ярусу операторов начинается одновременно (тогда это фактически VLIW-идеологема и ПВПП изначально обладает ограниченностью, связанной с потерями времени на ожидание выполнения наиболее длительного оператора на ярусе; точное решение получается лишь при одинаковости времён выполнения всех операторов на ярусе);
промежуток времени выполнения операторов может “плавать” относительно связанного с ярусом момента времени (возможна даже ограниченная асинхронность выполнения операторов).
При использовании ЯПФ в своих изысканиях Исследователь должен сам выбрать определённую модель и далее ей следовать. В рамках системы SPF@home, например, имеется возможность целевой реорганизации ЯПФ с конечной целью собрать на ярусах операторы с наиболее близкими длительностями обработки. Именно использование ЯПФ как нельзя лучше отвечает идеологеме EPIC (Explicitly Parallel Instruction Computing, явный параллелизм выполнения команд), позволяющей параллельной вычислительной системе выполнять инструкции согласно плану, заранее сформированному компилятором. Не следует игнорировать и субъективный фактор - бесспорным преимуществом ЯПФ является возможность простой и недвусмысленной визуализации собственно ПВПП.
Исходными данными для модуля SPF@home служат описания информационных графов алгоритма (программы) в стандартной DOT-форме (расширения файлов gv, могущие быть полученными импортом из модуля Data-Flow или иными путями). Допустимые (не нарушающие информационные связи в алгоритме) преобразования ЯПФ управляются программой на языке Lua, реализующей разработанные методы реструктуризации ЯПФ (дополнительная информация приведена в публикации). Эти методы неизбежно будут являться эвристическими вследствие невозможности прямого решения поставленных (относящихся к классу NP-полных) задач.
Т.о. вся ценность исследования сосредотачивается в разработке эвристических методов (“эвристик”) создания ПВПП при заданных целях и определённых ограничениях (напр., c учётом заданного поля параллельных вычислителей, максимума скорости выполнения, минимизации или ограничения размеров временного хранения данных и др.). Конечная цель работы – встраивание этих алгоритмов в состав распараллеливающих компиляторов новых поколений.
В действительности эвристический подход предполагает метод итераций по постепенному приближению к наилучшему решению сформулированной задачи (ибо точное оной решение априори неизвестно). Поэтому тут же встаёт вопрос определения “качества работы” этих эвристик и их вычислительной сложности с многокритериальной оптимизацией по этим (определённым количественно, конечно же!) параметрам. Учитывая сложность обсуждаемых эвристических алгоритмов данную область знания можно обоснованно отнести к наиболее сложным случаям “Науки о данных” (Data Science).
В качестве “пациентов” использовались имеющиеся в наличии информационные графы алгоритмов, в основном класса линейной алгебры (как одни из наиболее часто встречающиеся в современных задачах обработки данных). По понятным причинам исследования проводились на данных небольшого объёма в предположении сохранения корректности полученных результатов при обработке данных большего размера. Описанные в данной публикации исследования имеют цель продемонстрировать возможности имеющегося инструментария при решении поставленных задач. При желании возможно исследовать произвольный алгоритм, описав и отладив его в модуле Data-Flow (https://habr.com/ru/post/535926/) с последующим импортом в форме информационного графа в модуль SPF@home.
Как было сказано, основной целью исследования выбрано получение плана выполнения параллельной программы с максимальной плотностью кода. В данном случае плотность кода определяем через степень использования ресурсов вычислительной системы – чем больше из имеющихся параллельных вычислителей занято процессом обработки данных на каждом этапе выполнения программы, тем плотность кода выше. Т.к. имеем дело с ярусно-параллельной формой графа алгоритма, логично в качестве количественной характеристики целевой функции использовать величину неравномерности распределения ширин ярусов ЯПФ (формально идеалом является равенство числа операторов по всем ярусам).
В данной работе исследования проводились над программами, каждая из которых представляет собой один из часто встречающихся алгоритмов обработки данных. Автор отдаёт отчёт в том, что реально исполняемые программы обладают существенно большей сложностью структуры (включая множество алгоритмов, процедуры обработки прерываний и др.), но считает, что на этапе моделирования процессов трудно подобрать в качестве объекта исследований более подходящий материал, чем распространённые алгоритмы обработки данных. Практичность такого выбора подтверждается известным фактом - обычно основная вычислительная трудоёмкость программ сосредоточена именно в отдельных алгоритмах (знаменитый “закон 90/10”), поэтому рационально оптимизировать (в вышеуказанном смысле) именно эти блоки; для реализации такого подхода в библиотеках полезно определить специальные метки, несущие информацию о типе алгоритма и эффективных методах его оптимизации.
Ниже приведены результаты моделирования трёх наиболее часто встречающихся типов задач (в реальном случае обычно требуется выполнение нескольких из них одновременно):
1. Расписание выполнения программ на минимальном числе параллельных вычислителей при сохранении высоты ЯПФ
Фактически задача заключается в “балансировке” числа операторов по всем
ярусам ЯПФ (здесь “балансировка” – стремление к достижению одинакового числа), причём идеалом является число операторов по уровням, равное средне-арифметическому (с округлением до целого вверх). Такая организация ЯПФ фактически позволяет увеличить плотность кода, недостатком которой часто страдают вычислители VLIW-архитектуры. Надо понимать, что данная постановка задачи имеет в большей степени методологическую ценность, ибо число физических параллельных вычислителей обычно много меньше ширины ЯПФ реальных задач.
Далее приведены результаты вычислительных экспериментов с двумя разнящимися методами (с общим символическим названием “Bulldozer”, возникшим по аналогии с отвалом бульдозера, перемещающим грунт с “возвышенностей” во “впадины” (причём границу между последними на первый взгляд кажется естественным провести на уровне средне-арифметического ширин всех ярусов ЯПФ). В реальности качестве границы принималась величина, на единицу меньшую ширины яруса, с которого оператор “уходит” (этот приём более эффективен по сравнению с вариантом средне-арифметического значения). Впрочем, это тонкости разработки эмпирических методов, всю прелесть создания которых каждый разработчик должен ознакомиться лично…
Эмпирический метод “1-01_bulldozer” имеет целью получение наиболее равномерного распределения операторов по ярусам ЯПФ без возрастания её высоты (сохранение времени выполнения программы); операторы переносятся только “вниз” (первоначально ЯПФ строится в “верхнем” варианте). Для этого метод старается перенести операторы с ярусов шириной выше среднего на яруса с наименьшей шириной. На каждом ярусе операторы перебираются в порядке очередности слева направо.
Метод “1-02_bulldozer” является модификацией предыдущего с адаптацией. Для оператора с максимумом вариативности (назовём так диапазон возможного размещения операторов по ярусам ЯПФ без изменения информационных связей в графе алгоритма) в пределах яруса вычисляются верхний и нижний пределы его возможного расположения по ярусам.
В результирующей табл.1 рассматриваются: mnk_N – программа аппроксимации методом наименьших квадратов N точек прямой, mnk_2_N – то же, но квадратичной функцией, korr_N – вычисление коэффициента парной корреляции по N точкам, slau_N – решение системы линейных алгебраических уравнений порядка N прямым (не итерационным) методом Гаусса, m_matr_N - программа умножения квадратных матриц порядка N традиционным способом, m_matr_vec_N – умножение квадратной матрицы на вектор, squa_equ_2 – решение полного квадратного уравнения в вещественных числах, squa_equ_2.pred – то же, но с возможностью получения вещественных и мнимых корней при использовании метода предикатов для реализации условного выполнения операторов, e17_o11_t6, e313_o206_t32, e2367_o1397_t137, e451_o271_t30, e916_o624_t89, e17039_o9853_t199 – сгенерированные специальной программой по заданным параметрам информационного графа. Вычислительную трудность преобразования будем характеризовать числом перемещений операторов с яруса на ярус. Неравномерность распределения числа операторов по ярусам ЯПФ характеризуется коэффициентом неравномерности (отношение числа операторов на наиболее и наименее “нагруженных” ярусов соответственно).
Для удобства анализа в таблице цветом выделены ячейки, соответствующие случаю достижению снижения ширины без возрастания высоты ЯПФ, а жирным начертанием цифр – величины для сравнения.

Как видно из табл.1, во многих случаях удается значительно (до 1,5-2 раз) снизить ширину ЯПФ, но почти никогда до минимальной величины (средне-арифметическое значение ширин ярусов). В целом эвристика “1-02_bulldozer” несколько более эффективна, но проигрывает по вычислительной сложности. В большинстве случаев увеличение размера обрабатываемых данных повышает эффективность “балансировки” (очевидно, это связано с повышением числа “степеней свободы” ЯПФ).
Интересно, что для некоторых алгоритмов (напр., slau_N) ни один из предложенных методов не дал результата. Сложность “балансировки” ЯПФ связана с естественным стремлением разработчиков алгоритмов создавать максимально “плотные” записи последовательности действий.
Рассмотренная ситуация возникает в случаях, когда ширина ЯПФ сравнима с числом вычислителей в параллельной системе (а точнее, не превышает их числа). В действительности (при реальных размерах обрабатываемых данных) ширина ЯПФ оказывается много больше числа параллельных вычислителей, поэтому основной практический интерес представляет следующий раздел исследований. Здесь основной функцией цели является получение ЯПФ наименьшей высоты (что соответствует скорейшему выполнению программы) за минимальное число перемещений операторов между ярусами; плотность кода (в вышеописанном понимании) при этом будет максимальной.
2. Расписания выполнения программ на фиксированном числе параллельных вычислителей при возможности увеличения высоты ЯПФ
Практический интерес представляют методы с увеличением высоты ЯПФ (см. табл.2, в которой дано сравнение двух методов с метафорическими названиями “Dichotomy” и “WidthByWidth”); при этом приходится смириться с увеличение времени выполнения программы. В ходе вычислительных экспериментов задавалась конечная ширина преобразованной ЯПФ (отдельные столбцы в правой части табл.2). Количественные параметры преобразований выдавались в форме частного, где числитель и знаменатель показывают число перемещений (первая строка), высоту ЯПФ (вторая) и коэффициент вариации CV (третья строка) для каждого исследованного графа. Характеризующий неравномерность распределения ширин ярусов коэффициент вариации рассчитывался как CV=σ/W̅, где σ - среднеквадратичное отклонение числа операторов по всем ярусам ЯПФ, W̅ - среднеарифметическое числа операторов по ярусам.
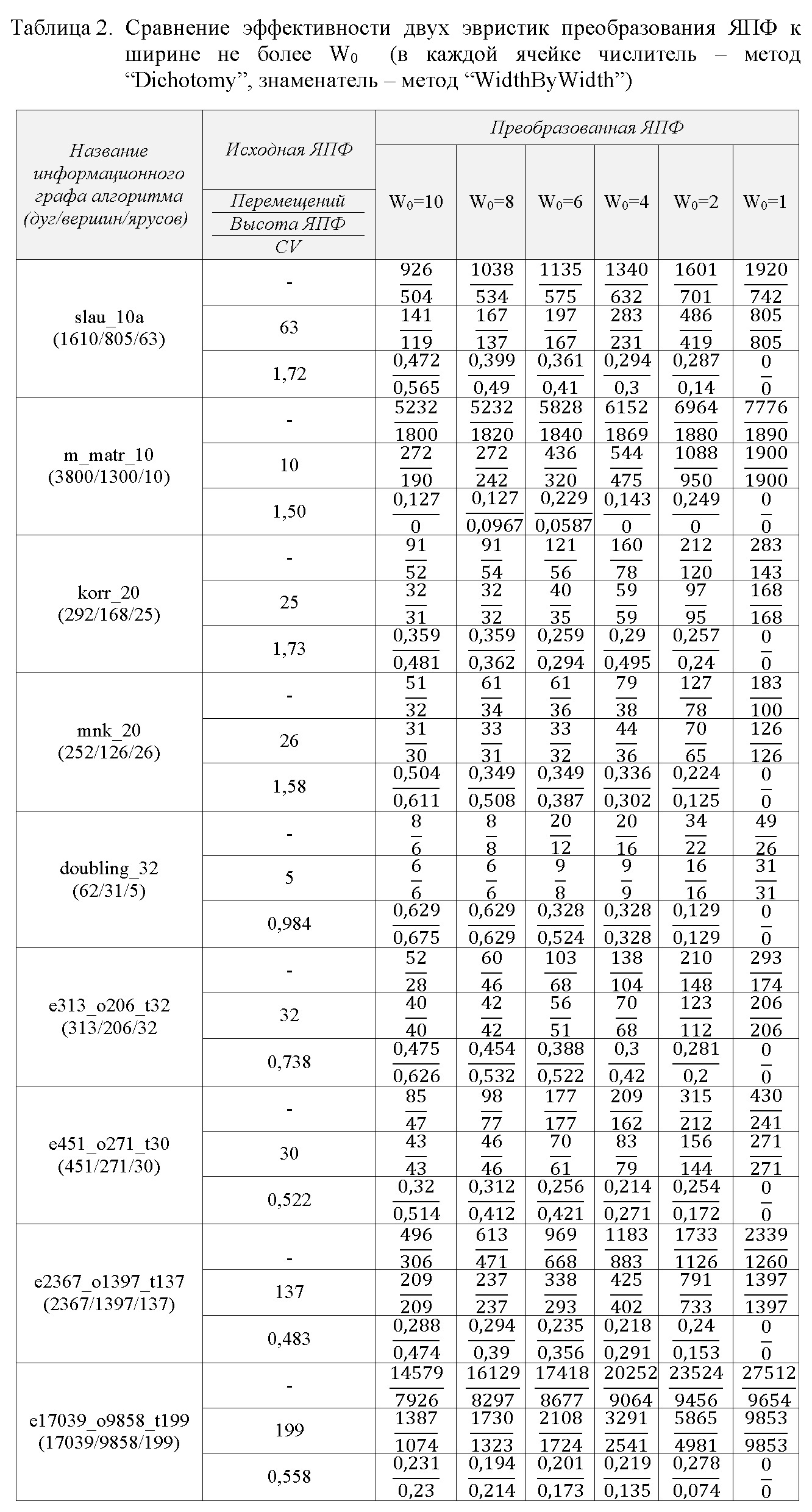
Эвристика “Dichotomy” предполагает для “разгрузки” излишне широких ярусов перенос половины операторов на вновь созданный ярус под текущим, эвристика “WidthByWidth” реализует постепенный перенос операторов на вновь создаваемые яруса ЯПФ. Из табл.2 видно, что метод “WidthByWidth” в большинстве случаев приводит к лучшим результатам, нежели “Dichotomy” (например, высота преобразованной ЯПФ существенно меньше – что соответствует снижению времени выполнения параллельной программы – притом за меньшее число перемещений операторов).
3. Расписание выполнения программ на фиксированном числе гетерогенных параллельных вычислителей
Современные многоядерные процессоры все чаще разрабатываются с вычислительными ядрами различных возможностей. Поэтому практически полезно уметь строить расписание выполнения параллельных программ для подобных систем (с гетерогенным полем параллельных вычислителей).
Модуль SPF@home поддерживает эту возможность путём сопоставления информации из двух файлов – для операторов и вычислителей (*.ops и *.cls соответственно). Имеется возможность задавать совпадение по множеству свободно назначаемых признаков для любого диапазона операторов/вычислителей. Условием выполнимости данного оператора на заданном вычислителе является minVal_1≤Val_1≤maxVal_1 для одинакового параметра (Val_1, minVal_1, maxVal_1 – числовые значения данного параметра для оператора и вычислителя соответственно).
Разработка расписания для выполнения программы на гетерогенном поле параллельных вычислителей является более сложной процедурой относительно вышеописанных и здесь упор делается на программирование на Lua (API-функции системы SPF@home обеспечивают минимально необходимую поддержку). Т.к. на одном ярусе ЯПФ могут находиться операторы, требующие для выполнения различных вычислителей, полезным может служить концепция расцепления ярусов ЯПФ на семейства подъярусов, каждое из которых соответствует блоку вычислителей c определёнными возможностями (т.к. все данного операторы яруса обладают ГКВ-свойством, последовательность выполнения их в пределах яруса/подъяруса в первом приближении произвольна). На схеме ниже слева показано расщепление операторов на одном из ярусов ЯПФ в случае наличия 6 параллельных вычислителей 3-х типов.

Пример плана выполнения программы на поле из 3-х типов параллельно работающих вычислителей (c количествоv 5,3,4 штук соответственно и номерами 1-5, 6-8, 9-12 по типам, всего 12 штук) приведён в табл.3. При расчёте в качестве исходной использовался конкретный алгоритм, характеризующийся ЯПФ с числом операторов 206 и дуг 323, ярусов 32 (после расчета подъярусов получилось 48). Первый столбец таблицы показывает (разделитель – символ прямого слеша) номер яруса/подъяруса; в ячейках таблицы приведены номера операторов, сумма их числа по подъярусам равно числу операторов на соответствующем ярусе ЯПФ.
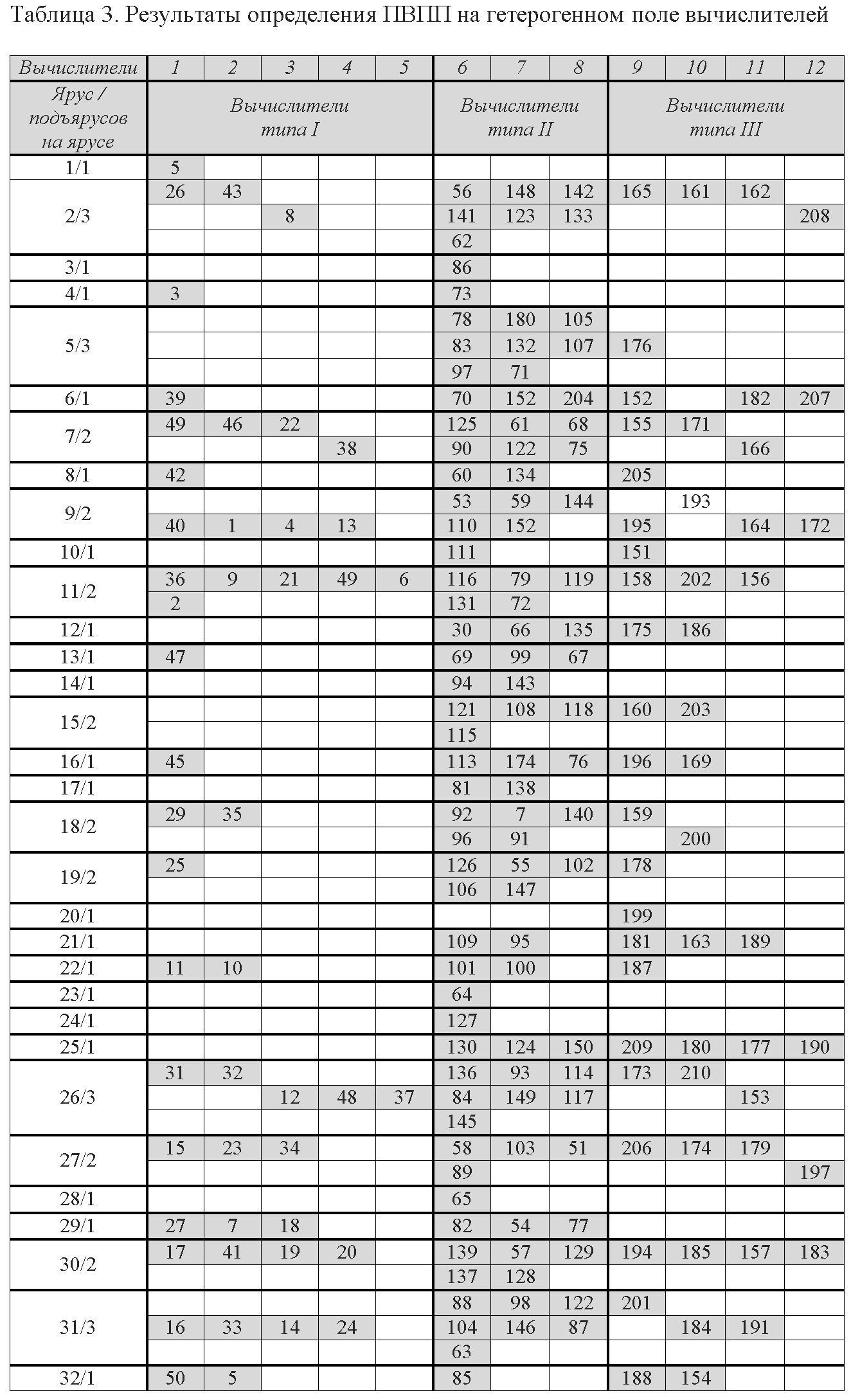
Моделирование, результат которого приведён в табл.3, может быть использовано в форме решения обратной задачи при определении оптимального числа параллельных вычислителей различного типа для выполнения заданных алгоритмов (групп алгоритмов).
В самом деле, в рассматриваемом случае общее время T решения задачи определяется суммой по всем ярусам максимальных значений времён выполнения операторов на подъярусах данного яруса, т.к. группы операторов на подъярусах выполняются последовательно (первая сумма берётся по j, вторая – по i, максимум – по kj):
T=⅀(max⅀tik),
где j - число ярусов ЯПФ, i - число подъярусов на данном ярусе, kj - типы вычислителей на j-том ярусе, tik - время выполнения оператора типа i на вычислителе типа k. Если ставится задача достижения максимальной производительности, вполне возможно определить число вычислителей конкретного типа, минимизирующее T (напр., для показанного табл.3 случая количество вычислителей типа II полезно увеличить в пику вычислителяv типа I).
Задача минимизации общего времени решения T усложняется в случае возможности выполнения каждого оператора на нескольких вычислителях вследствие неоднозначности tik в вышеприведённом выражении; здесь необходима дополнительная “балансировка” по подъярусам.
Описание параметров операторов располагается в файлах с расширением ops, параметров вычислителей – cls; соответствующая API-функция (обёрнутая Lua-вызовом) возвращает значение, разрешающее или запрещающее выполнение данного оператора на заданном вычислителе. Описанные файлы являются текстовыми (формат данных определён в документации), что даёт возможность разработки внешних программ для генерации требуемого плана эксперимента с использованием модуля SPF@home в режиме командной строки.
В порядке обсуждения небезынтересно будет рассмотреть вариант ЯПФ в “нижней” форме (при этом все операторы перемещены максимально в сторону окончания выполнения программы). Такая ЯПФ может быть получена из “верхней” перемещениями операторов по ярусам “как можно ниже” или проще – построением ЯПФ в направлении от конца программы к её началу. Ниже проиллюстрировано сравнение распределения ширин ЯПФ в “верхней” и “нижней” формах (изображения в строке слева и справа соответственно в 4-х рядах) для алгоритма умножения матриц традиционным способом при порядках матриц N=3,5,7,10. Здесь H, W и W̅ – высота, ширина и среднеарифметическая ширина ЯПФ (последняя показана на рисунках пунктиром; символ прямого слеша разделяет параметры для “верхней” и “нижней” ЯПФ (фиолетовый цвет – ярус максимальной ширины, красный – минимальной).

Соответствующие иллюстрации для процедуры решения систем линейных алгебраических уравнения порядков N=3,5,7,10 безытерационным методом Гаусса представлены ниже.

Последние представленные иллюстрации интересны возможностью существенной “балансировки” ЯПФ без применения сложных эвристических алгоритмов реорганизации ЯПФ (ср. данными табл.1). Фактически все возможные решения при реорганизации ЯПФ находятся в диапазоне между “верхней” и “нижней” формами, но при выборе в качестве исходной “нижней” формы приоритетным перемещением операторов является движение “вверх”. Последнее высказывание фактически ставит очередной вопрос – а нет ли среди двух пограничных (“верхней” и “нижней”) форм состояний с ещё лучшим показателем балансировки?

Для ответа на этот вопрос был проведён эксперимент по пошаговому преобразованию ЯПФ из “верхней” формы в “нижнюю” (на рис. вверху оцифровка осей абсцисс соответствует числу перемещений операторов с яруса на ярус). На этом рис. a) и b) – ранее рассмотренные алгоритмы умножения матриц и решение систем линейных алгебраических уравнений; красные, зелёные и синие линии – размерности 10, 7 и 5 задачи; сплошные и пунктирные линии – значения коэффициента вариации CV (левые шкалы ординат) и неравномерности (отношение самого широкого яруса к самому узкому) ширин ярусов (правые шкалы ординат) соответственно. При этом собственно метод преобразования ЯПФ из “верхней” формы в “нижнюю” использовался самый простой – операторы с использованием Lua-скрипта в гнезде из двух вложенных циклов (по ярусам и по операторам) последовательно перемещались как можно “ниже” без нарушения информационных зависимостей в графе.
Эксперименты показали (рис. вверху), что целевые величины обладают свойством невозрастания в диапазоне существования и минимальны именно в “нижней” ЯПФ. Указанный случай характерен для алгоритмов, характеризующихся большим объёмом входных данных - форма кривой интенсивности вычислений интенсивности вычислений при достаточном количестве параллельных вычислителей близка к показанной на рис.2 в публикации “Динамика потокового вычислителя”. Соответственно эту же форму имеет начальное (до возможного реформирования) распределение ширин “верхней” ЯПФ данного алгоритма.
Будем считать алгоритмы, начальная (нереформированная) форма распределения ширин которых в “верхней” ЯПФ соответствует вышеописанной, принадлежащими к П-классу. Для алгоритмов П-класса в большинстве случаев удаётся перераспределить находящийся в начале ЯПФ “горб” (образованный интенсивной обработкой большого количества входных данных) на оставшуюся длину ЯПФ (даже без возрастания высоты оной).
Пример показывает важность изучения свойств (включая классификацию) алгоритмов (со стороны их сущностной грани, представляющей собой внутренний параллелизм) с целью наилучшего этих свойств практического использования.
Читатели могут поучаствовать в экспериментах и тем самым помочь в понимании проблемы, установив систему SPF@home (Win’32, GUI) c дистрибутива http://vbakanov.ru/spf@home/content/install_spf.exe и проведя соответствующие вычислительные эксперименты (имеющийся набор gv-файлов входит в инсталляционный комплект, их описание в read_me.txt, для получения ЯПФ достаточно манипулировать клавишами F5 и Ctrl-F5).
Общей тенденцией формы начальной “верхней” (до целенаправленной реорганизации) ЯПФ является интенсивный рост в начале выполнения программы с относительно плавным снижением к концу выполнения. Логично предположить, что повышение степени этой неравномерности является одной из важных причин возрастания вычислительная сложность преобразования ЯПФ. В связи с этим целесообразно иметь методику численной оценки такой неравномерности (полезно для классификации ЯПФ алгоритмов по этому признаку).
Выше использованные количественные характеристики неравномерности не дают информации о форме кривой, обладающей этой неравномерностью. В качестве дополнительной оценки неравномерности распределения операторов по ярусам ЯПФ может быть признан известный графо-аналитического метод определения дифференциации доходов населения, заключающегося в расчёте численных параметров расслоения (кривая Лоренца и коэффициент Джини), несмотря на зеркально-противоположную форму анализируемых кривых. Удобство сравнения ЯПФ различных алгоритмов достигается нормированием обоих осей графиков на общую величину (единицу или 100%).
На рисунке слева внизу приведены частичные результаты начала подобного анализа (на примере ЯПФ алгоритма решения полного квадратного уравнения в вещественных числах), равномерность распределения операторов по ярусам ЯПФ характеризуется близостью кривых к прямой равномерного распределения (диагональный штрих-пунктир).

На рисунке сплошная линия – исходная “верхняя” ЯПФ, пунктир – результат применения эвристики “балансировки” ЯПФ без увеличения её высоты, точечная линия – “нижняя” ЯПФ. Степень “балансировки” численно определяется отношением площади между соответствующей кривой и прямой равномерного распределения к полуплощади прямоугольного графика (при этом также несёт информацию знак, показывающий, с верхней или нижней стороны прямой равномерного распределения находится анализируемая площадь).
Итак, программная система SPF@home выполняет практическую задачу по составлению расписаний выполнения заданных алгоритмов (программ) на заданном поле параллельных вычислителей и дает возможность проводить различного типа исследования свойств алгоритмов (в данном случае – оценивать вычислительную сложность методов составления расписаний). Система нацелена в основном на анализ программ, созданных с использованием языков программирования высокого уровня без явного указания распараллеливания и в системах c концепцией ILP (Instruction-Level Parallelism, параллелизм на уровне команд), хотя возможности модуля SPF@home позволяют использовать в качестве неделимых блоков последовательности команд любого размера.
В целом с помощью предложенной системы можно численно оценивать способность алгоритмов, представленных информационными графами в ярусно-параллельной форме (ЯПФ), к реорганизации с заданными целями (“балансировка” ЯПФ без возрастания её высоты, получение ЯПФ заданной ширины при возможном увеличении высоты, повышение плотности кода) путём применения эвристических методов.
Анализ приведенных данных позволяет для конкретного случая выбрать отвечающий текущим требованиям алгоритм построения расписания выполнения параллельной программы (“быстрый, но менее качественный” или “медленный, но более качественный”).
Вышеприведенное исследование по моделированию и определению рациональных параметров процессов обработки данных является необходимым этапом в реализации блоков компиляторов для заданной системы команд процессора (на практике придётся учесть немало особенностей конкретной системы команд, однако без наличия общего подхода конкретная реализация практически всегда оказывается малоэффективной).
Предыдущие публикации на тему исследования параметров функционирования вычислительных систем методами математического моделирования:
Есть ли параллелизм в произвольном алгоритме и как его использовать лучшим образом (https://habr.com/ru/post/530078/, 26.11.2020)
Такие важные короткоживущие данные (https://habr.com/ru/post/534722/, 24.12.2020)
Это непростое условное выполнение (https://habr.com/ru/post/535926/, 03.01.2021)
Динамика потокового вычислителя (https://habr.com/ru/post/540122/, 01.02.2021)
Параллелизм и плотность кода (https://habr.com/ru/post/545498/, 05.03.2021) - текущая
Сколько стоит расписание (https://habr.com/ru/post/551688/, 10.04.2021)
Параллелизм в алгоритмах - выявле́ние и рациональное его использование. Возможности компьютерного моделирования (https://habr.com/ru/articles/688196/, 14.09.2022)
Построение планов параллельного выполнения программ для процессоров со сверхдлинным машинным словом (проект) (https://habr.com/ru/articles/792744/, 10.02.2024)







