Комментарии 31
Честно говоря пару раз пробовал переписать сишную функцию на ассемблере. Как я не старался прироста в производительности не получил.
Так то Intel, там и компилятор нормальный. А я вот как не напишу функцию на ассемблере для своего VLIW DSP — все раз в 10 быстрее чем на Си.
НЛО прилетело и опубликовало эту надпись здесь
Ну и откуда взять это понимание?
Я помню времена, когда просто посчитав количество инструкций в функции можно было бы примерно оценить ее производительность. Но сейчас такое не работает. Глядя на количество строк кода невозможно в уме прикинуть быстр этот код или нет.
А вот компилятор скорее всего все это знает.
Я помню времена, когда просто посчитав количество инструкций в функции можно было бы примерно оценить ее производительность. Но сейчас такое не работает. Глядя на количество строк кода невозможно в уме прикинуть быстр этот код или нет.
А вот компилятор скорее всего все это знает.
НЛО прилетело и опубликовало эту надпись здесь
Вот, например, отреверсенная программа после С-компилятора, архитектура со стеком и всеми делами:
Так вот, задача функцыи простая: взять свой агрумент из стека в виде байта, в соответсвии с каждым битом из байта устарновить лог «0» или «1» на выходе микроконтроллера.
Имеем после компилятора: используется косвенная адресацыя, установили указатель на аргумент (6 команд, т.к. архитектура 8 бит, а указатели — слово), поместили в аккумулятор, наложыли маску в соответствии с целевым битом (2 команды), в зависимости от значения установили лог «0» или «1» (4 команды). И так 8 раз — для каждого бита, итого 12х8=96 команд (192 байта памяти).
Как бы это выглядело на ассемблере: установили указатель на агрумент (6 команд, но можно упростить до 3х, если учесть что старшая часть адреса неизменна), поместили аргумент в память (2 команды), потом 8 раз: сдвиг на 1 бит (1 команда) и установка «0»/«1» по результатам (4 команды, но можно и в 3 соптимизировать). Итого 6+8*(1+4) = 46 команд или даже 39 после простой оптимизацыи. Или 92 и 78 байт памяти соответственно.
В итоге в отреверсенном коде из 11 кБ половина — это всякие прыжки указателями вокруг стека в т.ч проверка в каждой функцыи по завершению, не вышли ли указатели за границы стека и их коррекцыя. И таким образом программу можно уменьшыть по размеру в 2 раза!
Конечно, есть подозрения, что это сделано бесплатной версией компилятора, не умеющей оптимизацыю, но в итоге этот код в продакшене.
Извиняюсь за форматирование, у меня не работает кнопка исходный код, а хабр не умеет выравнивать ни табами, ни пробелами
Штуки КАПСОМ на всю строку без команд — это метки.
LCD_WC_DB0
;FSR0 to Arg1
movf FSR2L, W, ACCESS
addlw 0xFE
movwf FSR0L, ACCESS
movlw 0xFF
addwfc FSR2H, W, ACCESS
movwf FSR0H, ACCESS
;W = Arg1
movf INDF0, W, ACCESS
andlw b'00000001'
bnz LCD_WC_DB0ON
LCD_WC_DB0OFF
bcf LCD_DB0 ;DB0 = 0
bra LCD_WC_DB1
LCD_WC_DB0ON
bsf LCD_DB0 ;DB0 = 1
LCD_WC_DB1
;FSR0 to Arg1
movf FSR2L, W, ACCESS
addlw 0xFE
movwf FSR0L, ACCESS
movlw 0xFF
addwfc FSR2H, W, ACCESS
movwf FSR0H, ACCESS
;W = Arg1
movf INDF0, W, ACCESS
andlw b'00000010'
bnz LCD_WC_DB1ON
LCD_WC_DB1OFF
bcf LCD_DB1 ;DB1 = 0
bra LCD_WC_DB2
LCD_WC_DB1ON
bsf LCD_DB1 ;DB1 = 1
Штуки КАПСОМ на всю строку без команд — это метки.
Так вот, задача функцыи простая: взять свой агрумент из стека в виде байта, в соответсвии с каждым битом из байта устарновить лог «0» или «1» на выходе микроконтроллера.
Имеем после компилятора: используется косвенная адресацыя, установили указатель на аргумент (6 команд, т.к. архитектура 8 бит, а указатели — слово), поместили в аккумулятор, наложыли маску в соответствии с целевым битом (2 команды), в зависимости от значения установили лог «0» или «1» (4 команды). И так 8 раз — для каждого бита, итого 12х8=96 команд (192 байта памяти).
Как бы это выглядело на ассемблере: установили указатель на агрумент (6 команд, но можно упростить до 3х, если учесть что старшая часть адреса неизменна), поместили аргумент в память (2 команды), потом 8 раз: сдвиг на 1 бит (1 команда) и установка «0»/«1» по результатам (4 команды, но можно и в 3 соптимизировать). Итого 6+8*(1+4) = 46 команд или даже 39 после простой оптимизацыи. Или 92 и 78 байт памяти соответственно.
В итоге в отреверсенном коде из 11 кБ половина — это всякие прыжки указателями вокруг стека в т.ч проверка в каждой функцыи по завершению, не вышли ли указатели за границы стека и их коррекцыя. И таким образом программу можно уменьшыть по размеру в 2 раза!
Конечно, есть подозрения, что это сделано бесплатной версией компилятора, не умеющей оптимизацыю, но в итоге этот код в продакшене.
НЛО прилетело и опубликовало эту надпись здесь
Просто переписать недостаточно. Нужно сделать это лучше компилятора. Нужно иметь хитрый план по оптимизации. Нужно знать то, что не знает компилятор, и учесть это (например, если размер циклического буфера кратен степени двойки — можно использовать and вместо остатка для деления, если выровнен по 32 байта — можно использовать vmovapd вместо vmovupd, если размер массива ограничен сверху небольшим значением — можно развернуть его полностью и использовать динамически сформированные адреса для перехода, и т.д. и т.п.). Нужно решить оптимизационную задачу — как минимизировать количество обращений к памяти и промахи кеша, используя регистры по максимуму. В частности, используя интрисики AVX в с++ коде ускорения в 4 раза обычно не получается только потому, что компилятор один фиг хранит их (ymm регистры) в памяти и полностью все 16 штук сразу не будет использовать никогда.
Конечно, многие оптимизационные стратегии можно применить непосредственно на си. Но опять же, есть нюанс — для этого нужно уметь мыслить на ассемблере. А чтобы уметь мыслить на ассемблере, нужно уметь программировать на ассемблере и иметь соответствующий опыт.
Конечно, многие оптимизационные стратегии можно применить непосредственно на си. Но опять же, есть нюанс — для этого нужно уметь мыслить на ассемблере. А чтобы уметь мыслить на ассемблере, нужно уметь программировать на ассемблере и иметь соответствующий опыт.
Вы сравниваете теплое с мягким — очевидно, что тривиальная программа при прочих равных медленнее/менее точна чем программа с итеративным вычислением тригонометрии. Так что непонятно, на что списывать разницу в результатах — на ассемблер или на алгоритм. Нужно реализовать итеративную тригонометрию на C# и сравнить ассемблер с ней.
Ну и странно, что fsincos вызывается n раз — можно посчитать функции только для phi, а дальше все по формулам.
Ну и странно, что fsincos вызывается n раз — можно посчитать функции только для phi, а дальше все по формулам.
Сравнение конечно же несправедливое. Компилятор использует новейший набор инструкций AVX2, а я — устаревшую технологию, медленную по определению. Никто же этим фактом не возмутился. Сравниваются же подходы к оптимизации в первую очередь — машинное против человеческого. Итеративное вычисление ко/синусов компилятору вполне доступно (как минимум в теории) — ведь это же по сути просто комплексное умножение.
fsincos вызывается n раз во внешнем цикле — потому что регистров сопроцессора не хватило бы, чтобы их все там держать. Пришлось бы сохранять их во внешних переменных — а это слегка бы нарушило чистоту эксперимента. А так мы получаем повышение точности вычислений без явного определений переменных расширенной точности.
fsincos вызывается n раз во внешнем цикле — потому что регистров сопроцессора не хватило бы, чтобы их все там держать. Пришлось бы сохранять их во внешних переменных — а это слегка бы нарушило чистоту эксперимента. А так мы получаем повышение точности вычислений без явного определений переменных расширенной точности.
Вот сравнение с исправленным вариантом от teology (cpp2 и csharp2) также на 10000 элементах:
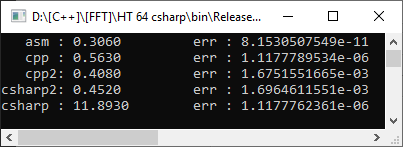
Результат стал получше, но не в разы — причём с си-шарпом практически сравнялись. А вот падение точности — катастрофическое, 3 значащих цифры только осталось.

Результат стал получше, но не в разы — причём с си-шарпом практически сравнялись. А вот падение точности — катастрофическое, 3 значащих цифры только осталось.
kovserg увидел ошибку в моем коде, надо ввести временную переменную tmp, в которой сохранить предыдущее значение cos_w и cos_dw и использовать tmp при вычислении sin_w, sin_dw.
Оптимизатор настраиваете при компиляции на максимум -O3?
Странные у Вас тайминги. Я не смог запустить Ваш ассемблер, но сварганил сравнение изначального C++ с оптимизированным — так у меня оптимизированный в 9 быстрее. Но точность — да, проседает, причем я даже не знаю почему, вроде бы вычисление тригонометрии должно быть менее точным чем сложения/умножения.
Вот код:
Вот код:
Тест
#include <stdio.h>
#include <stdlib.h>
#define _USE_MATH_DEFINES
#include <math.h>
#include <chrono>
void ht_cpp0(double* data, double* result, int n)
{
double phi = 2.0 * M_PI / n;
for (int i = 0; i < n; ++i)
{
double sum = 0.0;
for (int j = 0; j < n; ++j)
{
double w = phi * i * j;
sum += data[j] * (cos(w) + sin(w));
}
result[i] = sum / sqrt(n);
}
}
void ht_cpp1(double* data, double* result, int n)
{
double phi = 2.0 * M_PI / n;
double cos_phi = cos(phi);
double sin_phi = sin(phi);
double sqrtn = 1 / sqrt(n);
double sin_dw = 0.0;
double cos_dw = 1.0;
for (int i = 0; i < n; ++i)
{
double sin_w = 0.0;
double cos_w = 1.0;
double sum = 0.0;
for (int j = 0; j < n; ++j)
{
sum += data[j] * (cos_w + sin_w);
double new_cos_w = cos_w * cos_dw - sin_w * sin_dw;
double new_sin_w = sin_w * cos_dw + cos_w * sin_dw;
cos_w = new_cos_w;
sin_w = new_sin_w;
}
result[i] = sum * sqrtn;
double new_cos_dw = cos_dw * cos_phi - sin_dw * sin_phi;
double new_sin_dw = sin_dw * cos_phi + cos_dw * sin_phi;
cos_dw = new_cos_dw;
sin_dw = new_sin_dw;
}
}
double MeanSquaredError(double* data1, double* data2, int n)
{
double sum = 0;
for (int i = 0; i < n; i++)
{
double df = data1[i] - data2[i];
sum += df * df;
}
return sqrt(sum);
}
int main()
{
enum : int { data_length = 10000 };
double data_src[data_length];
for (int i = 0; i < data_length; i++)
data_src[i] = i + 1;
double data_in[data_length];
double data_out[data_length];
{
auto t0 = std::chrono::high_resolution_clock::now();
ht_cpp0(data_src, data_in, data_length);
ht_cpp0(data_in, data_out, data_length);
auto t1 = std::chrono::high_resolution_clock::now();
std::chrono::duration<double> ms_double = t1 - t0;
double err = MeanSquaredError(data_src, data_out, data_length);
printf("cpp0 : %lf\terr : %1.10lf\n", ms_double, err);
}
{
auto t0 = std::chrono::high_resolution_clock::now();
ht_cpp1(data_src, data_in, data_length);
ht_cpp1(data_in, data_out, data_length);
auto t1 = std::chrono::high_resolution_clock::now();
std::chrono::duration<double> ms_double = t1 - t0;
double err = MeanSquaredError(data_src, data_out, data_length);
printf("cpp1 : %lf\terr : %1.10lf\n", ms_double, err);
}
system("pause");
}Тайминги в секундах. Мерил и из шарпа, и из плюсов — почти совпадают. А где, кстати, ваши? У вас же, я так понимаю, другой компилятор и возможно даже другая платформа.
Windows/VS 2019. Но я понял, в чем было дело — я не включил поддержку AVX2. С ней происходит векторизация внутреннего цикла изначального варианта, вызываются функции "__vdecl_sin4"/"__vdecl_cos4", которые видимо обрабатывают по 4 аргумента за раз, и тогда соотношение времени выполнения двух алгоритмов у меня примерно совпадает с Вашим. Но тут стоит заметить, что для оптимизированного алгоритма компилятор векторизацию не сделал (хотя unroll на 10 итераций сделать смог), если доделать ее — результат должен улучшиться.
Но точность — да, проседает, причем я даже не знаю почему, вроде бы вычисление тригонометрии должно быть менее точным чем сложения/умножения.
Все просто объяснимо. Синус-косинус считается каждый раз заново и погрешность там возникает при вычислении 10-20 слагаемых и эта ошибка более-менее постоянна в течение всего алгоритма. А алгоритм с рекурсивной формулой накапливает ошибку при n^2 пересчетах. Проделайте вычисления самой первой итерации большого цикла вручную и поймете.
Шарп то тут при чем? Давайте бульдозером картофель копать… ;) Кроме того, если уж такая проблема и возникает, ничего не мешает шарпом подгрузить dll.
Попробуйте:
1. Вместо умножений использовать инкремент.
2. Вместо вычислений sin/cos углов вычислять sin/cos суммы углов (текущий угол = предыдущий угол + инкремент).
3. На всякий случай закэшировать вычисление 1/sqrt(n), вдруг компилятор слабо оптимизирует.
Можете еще выбросить вычисление углов w и dw, но компилятор должен это сам сделать.
Итого: в циклах нет ни одного вычисления синуса и косинуса. Ускорение должно составить 40 крат?
1. Вместо умножений использовать инкремент.
2. Вместо вычислений sin/cos углов вычислять sin/cos суммы углов (текущий угол = предыдущий угол + инкремент).
3. На всякий случай закэшировать вычисление 1/sqrt(n), вдруг компилятор слабо оптимизирует.
static void ht_csharp(double[] data, double[] result)
{
int n = data.Length;
double phi = 2.0 * Math.PI / n;
double cos_phi = Math.Cos(phi); // кэшируем
double sin_phi = Math.Sin(phi); // кэшируем
double sqrtn = 1 / Math.Sqrt(n); // кэшируем
double dw = 0.0; // угол приращения
double sin_dw = 0.0;
double cos_dw = 1.0;
for (int i = 0; i < n; ++i)
{
double w = 0.0;
double sin_w = 0.0; // начальный синус
double cos_w = 1.0; // начальный косинус
double sum = 0.0;
for (int j = 0; j < n; ++j)
{
sum += data[j] * (cos_w + sin_w);
w += dw;
cos_w = cos_w * cos_dw - sin_w * sin_dw; // пересчитываем косинус по формуле косинуса суммы
sin_w = sin_w * cos_dw + cos_w * sin_dw; // пересчитываем синус по формуле синуса суммы
}
result[i] = sum * sqrtn;
dw += phi;
cos_dw = cos_dw * cos_phi - sin_dw * sin_phi; // пересчитываем косинус по формуле косинуса суммы
sin_dw = sin_dw * cos_phi + cos_dw * sin_phi; // пересчитываем синус по формуле синуса суммы
}
}
Можете еще выбросить вычисление углов w и dw, но компилятор должен это сам сделать.
Итого: в циклах нет ни одного вычисления синуса и косинуса. Ускорение должно составить 40 крат?
В ассемблере так и сделано, но только для внутреннего цикла, во внешнем считаются sin/cos каждую итерацию.
cos_w = cos_w * cos_dw - sin_w * sin_dw;
sin_w = sin_w * cos_dw + cos_w * sin_dw;
...
cos_dw = cos_dw * cos_phi - sin_dw * sin_phi;
sin_dw = sin_dw * cos_phi + cos_dw * sin_phi;
1. Вам понадобиться временная переменная иначе, результат будет немного странный.
2. При больших n можно огрести проблемы с численной неустойчивостью.
3. Зачем w и dw если не используются
ps: БПФ ускорит гораздо лучше особенно при больших n
Ваш код даёт некорректный результат, в нём где-то ошибка. Даже если на это закрыть глаза — то он работает всего лишь в 2 раза быстрее (с компилятором c#) наивной реализации.
Тогда этот код C# может оказаться быстрее ассемблера.
P.S. Я проверил, код эквивалентно работает, ошибок нет.
P.S. Я проверил, код эквивалентно работает, ошибок нет.
По мне лучше интринсиками пользоваться, чем асм вставками. Или весь проект писать на асме, ну или dll-ку на асме. Тем более писать на высокоуровневом ассемблере не слишком сложно.
Вот пример.
Вот пример.
UASM
Библиотеки макросы свои.;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; Quick sort v1.01
;; http://rosettacode.org/wiki/Sorting_algorithms/
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
.386
.model flat, stdcall
option casemap:none
include msvcrt.inc
include macros.asm
.code
align_proc
quicksort proc uses esi edi ebx pBegin:ptr sdword, pEnd:ptr sdword
ASSUME edi:ptr sdword, esi:ptr sdword
mov edi, pBegin ;указатель на первый элемент массива
mov esi, pEnd ;указатель на последний элемент массива
.if (edi!=esi)
;pivot = pBegin[(pEnd - pBegin + 1)/2];//ecx
lea edx, [esi+1*4]
.for (edx-=edi, edx>>=3, ecx=[edi+edx*4]: : edi+=4, esi-=4)
.for (: sdword ptr [edi] < ecx: edi+=4)
.endfor
.for (: sdword ptr [esi] > ecx: esi-=4)
.endfor
.break .if (edi >= esi)
swap [edi], [esi]
.endfor
quicksort(pBegin, &[edi-1*4])
quicksort(edi, pEnd)
.endif
ASSUME edi:nothing, esi:nothing
ret
quicksort endp
createSpisok(spisok, sdword, 4, 65, 2, -31, 0, 99, 2, 83, 782, 1)
main proc C argc:sdword, argv:ptr ptr, envp:ptr
printf("Quick sort.\n")
.for (esi = spisok.pFirst: esi <= spisok.pLast: esi+=4)
printf("%d ", dword ptr [esi])
.endfor
printf("\n")
quicksort(spisok.pFirst, spisok.pLast)
.for (esi = spisok.pFirst: esi <= spisok.pLast: esi+=4)
printf("%d ", dword ptr [esi])
.endfor
printf("\n")
xor eax, eax
ret
main endp
main_startup3_ENDЗарегистрируйтесь на Хабре, чтобы оставить комментарий
Как писать на ассемблере в 2021 году