Несколько статей назад мы рассмотрели методику работы с USB-устройством при помощи библиотеки libusb. Данные в устройстве у нас формировались по таймеру, поэтому мы были не просто уверены, что рано или поздно они придут к нам, но даже могли предсказать, через какой срок это произойдёт. Однако в анализаторе (который является конечной целью разработки) данные идут непредсказуемо. Будут данные или нет – зависит от поведения объекта контроля.
Поэтому, во-первых, было бы полезно видеть, какой их объём уже прошёл в буфер, чтобы представлять, работает система или нет. Ну, и во-вторых, если данных не предвидится, а всё интересное уже попало к нам в память, надо иметь возможность прекратить приём и начать разбор того, что уже накопилось. Ни то, ни другое невозможно при использовании функций, которые были рассмотрены в той статье. По крайней мере, со стороны PC. Без читов, добавленных в «прошивку» ПЛИС.
Сегодня мы научимся обращаться к библиотеке libusb асинхронным методом. Это позволит и грубо отслеживать объём уже пришедших данных, и прерывать работу в любой момент, и даже повысить общую производительность системы. Причём всё это будет сделано только за счёт вызова штатных функций libusb. Код для FX3 и ПЛИС мы для этого дорабатывать не будем. Итак, приступаем.

Предыдущие статьи цикла:
Напомню, что в предыдущей статье про libusb я читал данные из FX3 так:
И всё. До истечения таймаута (а для анализатора он может быть огромным) текущий поток будет исполняться внутри данной функции. Управления мне никто не вернёт. Мы будем ждать, ждать и ждать, как бедняга на вступительном рисунке, отмеченном крестиком.
В противовес такой работе (её ещё называют синхронной), в любой уважающей себя USB-библиотеке должна быть ещё и асинхронная. Там мы вызываем функцию чтения, и управление немедленно возвращается нам. Что будет дальше, зависит от конкретной библиотеки. Где-то в нужный момент будет переведён в активное состояние объект «Событие». В libusb будет вызвана Callback-функция. Короче, нам поступит сообщение о том, что наш запрос выполнен, как на вступительном рисунке с галочкой.
И никто не запрещает нам в любой момент вызвать функцию, отменяющую процесс обмена. При этом, если часть данных уже прошла по каналу, они будут нам всё равно выданы. Ничего не пропадёт.
Скоро мы рассмотрим, как это работает, но сначала я объясню, почему не стал рассказывать об асинхронной работе немедленно после синхронной. Дело в том, что при проверке асинхронной работы, мы должны провоцировать ситуации с таймаутами. А значит, наш таймер должен не молотить от начала жизни и до бесконечности, а выдавать строго дозированные порции данных. Чтобы это делать, мы должны управлять им. Собственно, в предыдущих двух статьях мы и осваивали этот процесс. Теперь мы вполне можем посылать запросы на шину AVALON_MM. Поэтому, подключив таймер к этой шине, мы сможем управлять и им. Приступаем.
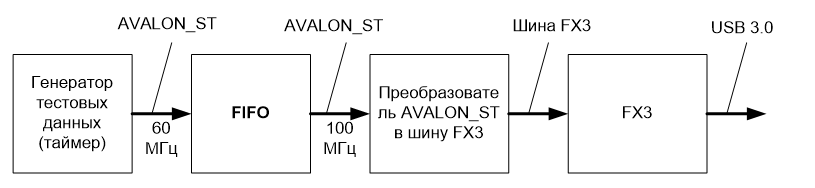
Да, я обещал, что мы будем работать только средствами libusb. Но этот раздел ничему не противоречит. Он показывает не работу, а доработку средств тестирования. Итак, верилоговский модуль таймера, формирующего воздействия, несколько изменился. В него была добавлена шина AVALON_MM. Из самого счётчика убраны все особенности поведения. Раньше после переполнения приёмника он стартовал не сразу. Теперь — всё просто. При старте он стоит. По шине AVALON_MM попросили сделать N тиков – перешлёт ровно столько слов, сколько попросили. Переслал – снова стоит.
Таким образом, наша программа сможет вырабатывать строго заданное количество 16-разрядных слов, которые уйдут в шину AVALON_ST, дальше – в FIFO, а из него – в FX3 и USB 3.0.
Под катом – получившийся Verilog код таймера.
Сегодня мы будем черпать вдохновение на соответствующей странице документации библиотеки libusb.
Чтобы сделать простейший асинхронный запрос, надо проделать следующий путь:
Собственно, после вызова функции libusb_submit_transfer() хост начнёт попытку инициировать обмен с устройством. Когда процесс завершится (либо возникнет таймаут или ещё какая нештатная ситуация вплоть до вытаскивания устройства из разъёма), будет вызвана функция обратного вызова.
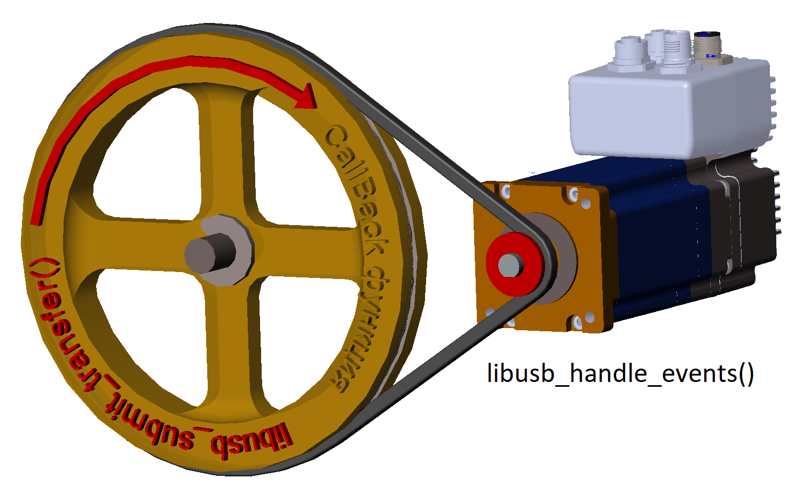
Если транзакция была не последняя, после завершения работы обработки текущей можно, прямо находясь в функции обратного вызова, снова обратиться к функции libusb_submit_transfer(), чтобы инициировать новую транзакцию. Поэтому получаем такое рабочее колесо (фраза «функция обратного вызова» заняла бы на нём много места, поэтому она заменена на «CallBack-функция»):
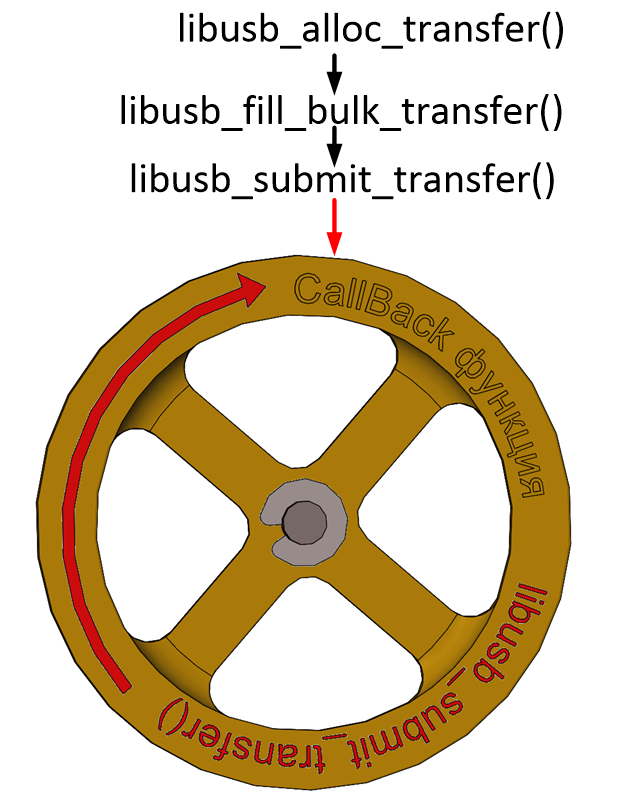
То есть, после отработки libusb_submit_transfer(), Callback-функция, получив управление, под конец своей работы снова вызывает libusb_submit_transfer() и завершается. Через некоторое время она снова получает управление, снова вызывает libusb_submit_transfer() и т.д.
При этом функция libusb_submit_transfer() возвращает управление немедленно, а следующий вызов CallBаck-функции произойдёт через существенный промежуток времени. Таким образом, всё это время основная программа может продолжать своё выполнение. Мало того, CallBack-функция по своей сути похожа на обработчик прерывания микроконтроллера. Она совершенно не изменяет ход работы основной программы. Появились данные – функция была вызвана. Функция отработала – управление вернулось в то место, где программа была в момент прихода данных. А как эта функция взаимодействует с основной программой – всё в руках программиста.
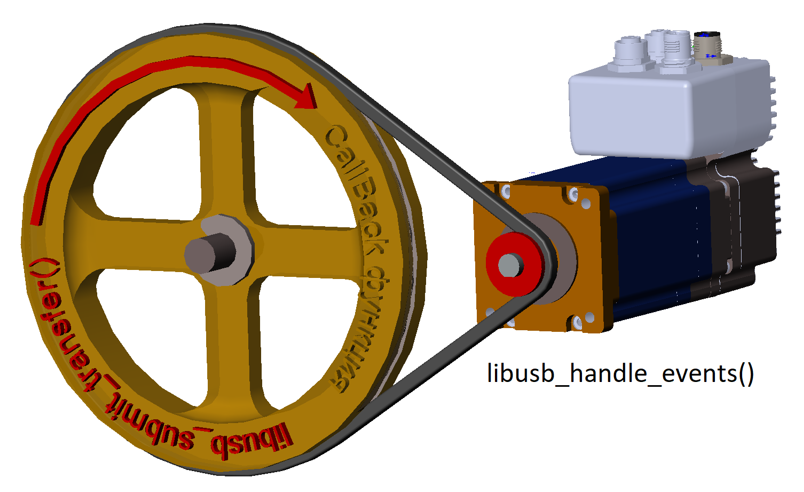
Когда я написал первое тестовое приложение и попробовал его отлаживать, оказалось, что создать описанное выше колесо необходимо, но недостаточно. Надо ещё добавить мотор, который будет его вращать. Для этого надо постоянно вызывать функцию libusb_handle_events(). Причём сама по себе функция вполне себе блокирующая. Правда, если углубиться в документацию, то выяснится, что на самом деле, это всего лишь обёртка. Из неё вызывается libusb_handle_events_timeout() с таймаутом 60 секунд. Так что блокировка будет максимум на минуту. При желании, можно вызывать libusb_handle_events_timeout() с любым своим таймаутом, зависящем от желаемой скорости реакции на возможное прерывание процесса.
Вызывать эту функцию можно и в текущем потоке, но можно создать для этого отдельный поток.
В общем, рисунок изменяется так:
По окончании работы надо остановить все незавершённые передачи при помощи функции libusb_cancel_transfer(), дождаться фактического завершения их активности (будет вызвана функция обратного вызова) и освободить выделенную память при помощи libusb_free_transfer() (вариант, когда эта функция будет вызвана автоматически рассматривается в документации на libusb, но нами не используется).
Если честно, то без доработок описанный выше механизм неприемлем для USB3.0. По этой шине данные летят широким потоком, а мы надолго прерываем приём. Пока мы войдём в функцию обратного вызова, пока она отработает, пока запустит приём новых данных… Медленно всё это! Поэтому практический пример я покажу не для USB3, а для изохронных передач USB2. Вдохновение я черпал в файле \libusb-1.0.23\examples\sam3u_benchmark.c, который шёл в комплекте с библиотекой. Тот код можно считать эталонным, но я покажу свою перепевку (которая может что-то не учитывать).
Вот такую я сделал функцию обратного вызова. Она не выполняет никаких полезных действий, я просто ставил там точки останова и изучал в отладчике структуры пришедших данных. Ну, и статистику она мне строит. Тест мне был нужен, чтобы убедиться, что я понимаю принципы работы. В конце, как я уже и говорил, вызывается libusb_submit_transfer() для запуска приёма новой посылки. Объёмы изохронного трафика от микрофона (а ловил я именно их) таковы, что заботиться о скорости мне не требовалось. Там буквально килобайты в секунду идут.
Вот я создаю собственный буфер данных (можно его создать и средствами библиотеки, но я предпочитаю выделять память так, чтобы она самоосвободилась в деструкторе класса), после чего – заполняю ранее созданную структуру, передав ей указатели на буфер и функцию обратного вызова:
где
Дальше я запускаю процесс ожидания и приёма посылки:
И не забываю запустить отдельный поток, который выполняет роль мотора:
сам поток прост, так как я просто изучал принципы работы и совершенно не задумывался о функциональности, так что он совершенно не обрабатывает ошибочные ситуации:
Как решить главную проблему, описанную выше (большой временной участок, когда не идёт приём), мне подсказал VelocidadAbsurda в комментариях к этой статье. Надо просто создать несколько структур типа libusb_transfer и запустить много операций обмена. Они встанут в очередь. Как только выполнится одна – в игру вступит следующая. Пока мы находимся в обработчике, система не будет простаивать. Во время экспериментов я запускал 16 передач одновременно. Эту работу я рассмотрю уже на реальном примере для целевой шины USB3.
Опишу кратко, какую стратегию работы с буфером я выбрал для данного конкретного проекта. Можно было бы сопоставить каждой структуре libusb_transfer собственный буфер памяти, а по факту прихода данных, копировать их в мой огромный буфер:
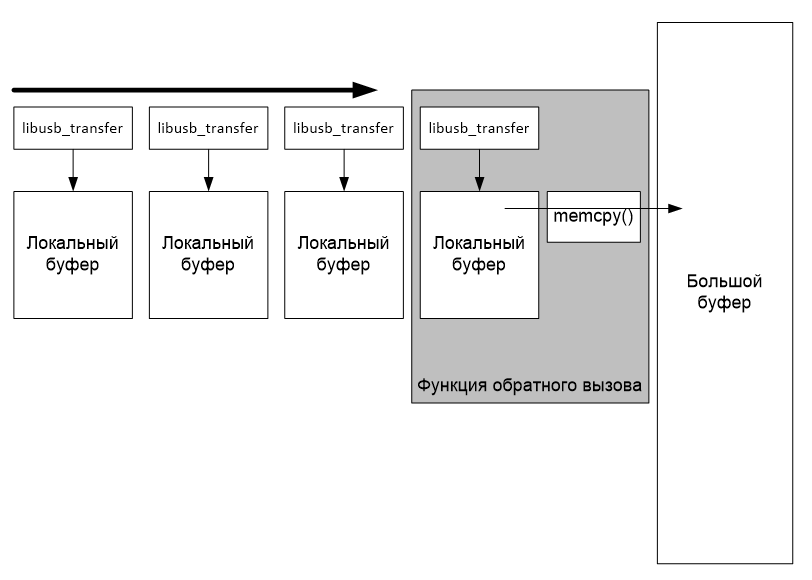
Но мой опыт говорит, что при скоростной работе с огромными объёмами данных функции копирования памяти отнимают большой процент времени. Поэтому я пошёл другим путём. Я нарезаю буфер на маленькие кусочки (размером с одну транзакцию) и настраиваю структуру libusb_transfer на приём сразу туда, куда нужно мне. Поэтому дополнительные копирования уже не требуются. Функция обратного вызова просто перенаправляет указатель на очередной участок буфера и снова ставит его в очередь.
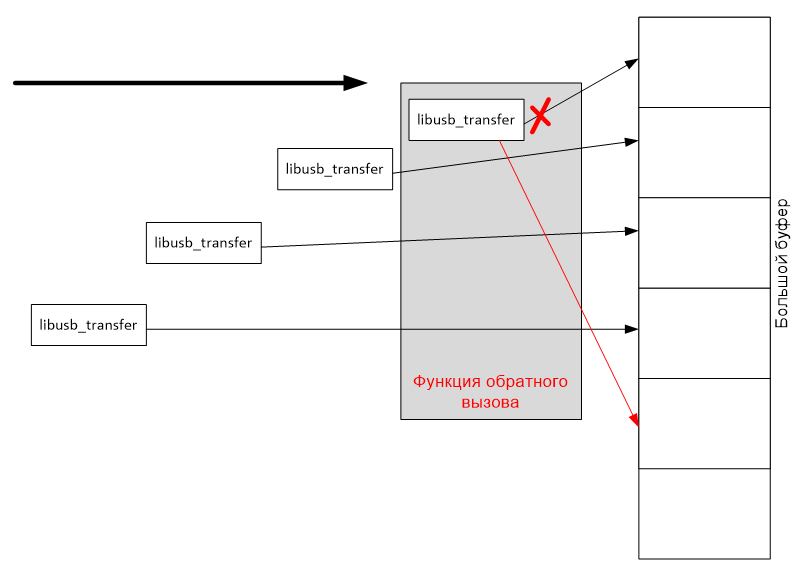
Снова начнём обсуждение кода с функции обратного вызова. Давайте пока не будем обсуждать ветку LIBUSB_TRANSFER_CANCELLED в ней. Она нас отвлечёт. Разберём основной ход.
Как я уже говорил, эта функция как-то должна взаимодействовать с основной программой. Для этого нужна кучка переменных. Я предпочёл объединить их в единую структуру:
И функция, пользующаяся этой структурой, выглядит так:
Она простая. Есть буфер, вдоль которого мы скользим, принимая фрагменты потока данных. Например, буфер 120 мегабайт, а фрагменты – по 64 килобайта. У нас есть указатель головы буфера. И задача функции просто посмотреть, не достигла ли голова конца буфера. Нет – тогда установили новый указатель в структуре libusb_transfer. Прочие её поля не трогаем, они же уже заполнены в основной программе. Затем – сдвигаем голову и проворачиваем колесо, вызвав libusb_submit_transfer(). Всё!
В этом тесте я решил не выносить моторную часть в отдельный поток. Поэтому запуск теста и моторная часть у меня располагаются в одной и той же функции. Эта функция вызывается из многих других.
Собственно, в ней мы видим почти то же самое, что и в изохронном примере, только структуры libusb_transfer создаются и обрабатываются оптом.
Сначала я заполняю поля структуры, которая используется для связи с функцией обратного вызова:
Теперь создаём нужное количество структур libusb_transfer, которые указывают на функцию обратного вызова и на участок буфера. При этом не забываем сдвигать указатель на буфер:
Отмечу также, что в коде выше, я задаю параметр «таймаут» равным 60 секунд. При работе с данными, вырабатываемыми таймером, этого более, чем достаточно. В следующем разделе я отдельно рассмотрю, почему иногда это значение надо существенно увеличить.
Дальше я активирую все передачи, ставя их в очередь (которая существует где-то в недрах библиотеки). Я вынес это в отдельный цикл не столько для наглядности, сколько из-за того, что я измеряю производительность теста при помощи таймера, и здесь он уже тикает. А время инициализации этим таймером не учитывалось.
Теперь возникает следующая ситуация. По мере прихода данных будет проворачиваться рабочее колесо. И функция обратного вызова всё время будет увеличивать поле m_asyncParams.actualTranfered. Когда все данные придут, оно станет равно m_asyncParams.dataSizeInBytes. Поэтому моторная часть у меня выглядит так:
Я по-прежнему игнорирую ошибки. Это – тестовый пример. А так – ошибка возникнет, даже если устройство выдернут из разъёма. Но обработчики ошибок сильно усложнят понимание статьи, так что я просто ещё раз напоминаю тем, кто захочет работать на практике, что мои примеры надо рассматривать творчески.
Дальше я вычисляю и вывожу скорость (код можно посмотреть в полном варианте функции), а затем – начинаю освобождать ресурсы.
Собственно, всё!
Тестовая функция завязана исключительно на библиотеку libusb. Вся подготовка аппаратуры и выделение буферов вынесены из неё. Давайте рассмотрим один пример, как эта функция вызывается. Так я тестирую зависимость скорости передачи от числа передач, поставленных в очередь.
При прогоне этого теста я получил очень интересный результат. При некоторых прогонах я вижу ошибки в принятых буферах:

Собственно, все ошибки происходят на малой скорости передачи, так что это вполне логично. Правда, раньше никогда не было просадок, если скорость начиналась на «120», но при снятии скриншотов, возник такой эффект. Тем не менее, всё равно там скорость была ниже, чем при других опытах. Судя по тому, что значение счётчика круто изменилось, пауза в получении данных была существенной.
Как можно спровоцировать просадки скорости. Просто уводим курсор «мыши» в область панели задач и начинаем водить по ней. При этом возникают уменьшенные окошки

Вот их формирование часто и приводит к задержкам. Причём машина у меня – не самая слабая:

Но вот что вижу, то вижу. Получается, что очень критичные к производительности системы (напомню, у меня конечная цель – анализатор без собственной буферной памяти, только с небольшой очередью FIFO, выдающий данные со скоростью 120 миллионов байт в секунду) можно делать только для себя. С собой договориться всегда можно. А для внешних Заказчиков – не получится. Есть у меня знакомый, который любит, чтобы на одной машине работала и технологическая программа, и редактор текстов, и игрушка, причём всё одновременно, и на не самой мощной машине…
Однако, когда количество одновременно запрошенных передач близко к шестнадцати, всё более-менее хорошо. Так что повторю, с собой лично договориться о том, что при измерениях не двигать особо «мышку», я смогу. Но анализатор и измеряемая программа явно должны быть запущены на разных машинах. Ну, или всё-таки надо будет ставить в ПЛИСовую часть большое буферное ОЗУ…
В далёком 2009-м году участвовал я в разработке программатора ПЗУ на базе FX2LP. Там требовалось выжать из скорости максимум. И вот тогда, после ряда опытов, я выяснил, что хоть физически по шине USB2 бегают пакеты, не больше, чем 512 байт, всё равно надо запрашивать сразу большие объёмы данных. Это связано с тем, что кроме размера пакета, есть ещё разбиение временной оси на кадры. В пределах одного кадра устройство может обменяться более, чем одним пакетом, если это запланировано хостом. Но если запрос пришёл слишком поздно, он может быть вписан в планына следующую пятилетку следующий кадр. Чтобы избежать этого, надо сразу просить много. Тогда планы будут свёрстаны с учётом наших потребностей.
С тех пор я упоминаю об этом к месту и не к месту. Соответствующий график для USB2, реализованной средствами ПЛИС, я публиковал в своей статье про логические ограничения производительности шин. Сегодня я просто обязан построить такой же график для шины USB3, работающей через FX3.
Видно, что во время опытов я экспериментировал с размерами, так как каждый замер идёт долго, но хотелось снять разные варианты.
Самый интересный из полученных графиков, выглядит так (первый столбец – размер транзакции в байтах, второй – получившаяся скорость передачи в байтах в секунду):

В общем, не стоит работать блоками меньше, чем 8 килобайт. Правда, я меньше 64 килобайт обычно и не использую.
Вот здесь я попробовал разное число транзакций в очереди (одну, две и четыре). Если честно, то в таблице видно, что чем больше транзакций, тем лучше, но на графике разница особенно и не видна. То есть, она несущественна. И мы уже знаем, что меньше восьми лучше не запускать. Я обычно меньше шестнадцати не запускаю.
Отдельно хочется отметить, что скорость передачи возросла по сравнению с аналогичной, полученной при синхронной работе. То, что скорость чуть превышает 120 миллионов байт в секунду, не является признаком ошибки измерений. Я отмечал в предыдущих статьях, что по осциллографу видно, что ULPI выдаёт тактовую частоту чуть выше, чем 60 МГц.
Коротко покажу, как я провоцировал остановки шины для постскриптума к этой статье. Чтобы их спровоцировать, просто необходимы как управление таймером, так и возможность подкинуть тактов таймера, когда передача данных уже началась. В общем, без асинхронности – никак. Вот так выглядел тестовый код. Я сначала генерил набор тактов, а затем – ещё чуть-чуть. Но мы помним, что проход запроса через программную шину SPI крайне медленный. Поэтому однозначно результаты предыдущей работы таймера ушли, и шина остановилась. Возникла большая пауза в передаче. И тут-то я досылал финальные байтики, которые приходили при уже упавшем флаге flagb. Подробнее о теории – в той статье (см. выше).
Для этой функции я впервые вынес «моторную» функциональность в обособленное место:
И ключевой участок тестового кода выглядит так:
Как этот тест изменил Verilog код преобразователя AVALON_ST в FX3, я уже рассказывал. Собственно, практически полностью изменил.
Теперь рассмотрим самый полный, но и самый сложный пример. Попросим тестовую аппаратуру в ПЛИС сформировать данные так, чтобы процесс не смог завершиться. При этом программа будет отображать нам текущее заполнение буфера и давать возможность прервать процесс.
Функцию обратного вызова я оставил ту же самую. Но так как сейчас у нас всё должно быть весьма асинхронно, я добавил в класс виртуальную функцию обработки таймера. В Qt это делается именно так. Собственно, функция проста, а её логика нам знакома. Мы анализируем поле, в котором функция обратного вызова сохраняет объём фактически прокачанных данных. Если ещё не 100% — отображаем значение и выходим. Если 100% — останавливаем процесс.
Так как остановка процесса возможна не только автоматически, но ещё и по кнопке Cancel, она вынесена в отдельную функцию, чтобы её могли вызывать обе ветки. Там мы посылаем запрос на остановку моторного потока, дожидаемся фактической остановки, удаляем все структуры libusb_transfer и останавливаем таймер. Всё!
Раз уж зашла речь о моторном потоке, то рассмотрим его подробнее. Здесь нужен поток и только поток. Реализуем его, согласно правилам Qt. Каждые 500 миллисекунд (если точнее, то 500 000 микросекунд) библиотека возвращает нам управление, чтобы мы могли проверить, не пора ли завершить работу с устройством. Я по-прежнему не обрабатываю критические ошибки в угоду читаемости:
Кнопка Cancel, согласно теории, должна завершить незавершённые передачи. Звучит красиво, но на практике, мне пришлось посидеть. Я гарантирую, что всё сработает в Windows, но не удивлюсь, если в других ОС поведение будет чуть иным. Дело в том, что в любой момент времени, все передачи имеют состояние «Успешно завершена». Идёт ожидание, не идёт… Завершена и всё тут. Поэтому я просто пытаюсь загасить все передачи. Если передача действительно завершена, функция вернёт ошибку. Если же она в процессе работы – функция отмены завершится успешно. И вот тогда я увеличиваю счётчик активных транзакций на единицу:
Этот счётчик не простой. Он атомарно доступный. Я объявил его так:
Помните, в функции обратного вызова я предлагал отложить рассмотрение участка на потом? Пришло время сделать это!
Когда мы запросили отмену транзакции – нам всё равно вызовут соответствующую ей Callback-функцию. И, согласно документации на библиотеку, мы должны дождаться фактического завершения всех транзакций. Тут мы уже всего дождались и отмечаем это. А вот как основной поток ждёт того, что все транзакции успешно завершились:
Ну, а потом завершаем работу, вызвав уже рассмотренную ранее функцию:
Уффф. С инфраструктурой разобрались. Теперь – запуск. Я сделал возможность задавать, сколько слов недосылать таймеру, чтобы можно было провоцировать различные ситуации. Например, висим с одной недокачанной передачей, висим, когда все передачи недокачаны и т.п.
С учётом этого старт работы выглядит так.
Уже известное нам заполнение параметров и выделение буфера:
Уже приевшееся выделение памяти для структур libusb_transfer. Но в нём кое-что поменялось. Я заменил значение таймаута. Давайте сначала посмотрим на код, а потом я порассуждаю про эти таймауты.
Почему я установил таймауты на максимальное значение? Во всём виноват выбранный мной способ задания адреса. Если бы у каждой транзакции был бы свой буфер, при срабатывании таймаута функция обратного вызова просто проигнорировала бы содержимое буфера и отправила бы транзакцию вновь в очередь.
Но что будет в нашем случае? Допустим, случился таймаут. Транзакция была вытолкнута библиотекой из очереди. В ход пошла следующая, которая указывает на другой участок буфера. Всё! Текущий участок пропал! Вновь пришедшие данные лягут куда-то дальше. А на этот участок указывать бесполезно. Если в него что-то и ляжет, то совсем из другой точки временной оси!
Поэтому когда я заполняю буфер выбранным мною способом, транзакция не может отвалиться по таймауту. Она должна ждать фактического поступления данных, и всё тут! Вот я и установил значение таймаута на максимально возможное значение, на всякий случай, не трогая старший бит. Вдруг число рассматривается со знаком?
Возвращаемся к коду. Классический запуск передач:
Запускаем «моторный» поток. Ради интереса, я задал ему высокий приоритет:
Запуск таймера, отображающего процесс:
И только сейчас – запуск ПЛИСового таймера, который формирует нам данные. С учётом того, что он нам недошлёт:
На самом деле, в целом, всё достаточно скучно. Если задать «недосылать 0», то всё отработает и автоматически остановится. Мы просто увидим, как бежит прогресс.
Если оставить значение недосланных слов, какое вписано по умолчанию (800 – числа здесь шестнадцатеричные), то остановка произойдёт на девяноста девяти процентах. При этом, как я уже говорил, у всех структур libusb_transfer будет состояние «завершено». Это можно проверить, поставив точку останова в обработчике таймера.

Но давайте я поставлю точку останова вот сюда:
и нажму на Cancel. О-па! Одна структура перешла в состояние CANCELLED:

И я проверял, один раз будет вызвана CallBack-функция. Причём часть данных будет отмечена, как переданная:
Так что всё в порядке. Выбранный вариант поведения работает. Но я проверял только в Windows.
А теперь мы недошлём существенно больше. Не 0x800, а 0x800800 слов. Теперь всё остановится на отметке 93%.

И в точке останова получим такую картинку:
Все транзакции были активны, но так и не дождались своего завершения.
CallBAck-функция будет вызвана 16 раз, но только при одном из вызовов поле с актуальной длиной будет иметь ненулевое значение. Но при выбранной схеме передачи данных, это не так и интересно. Данные же уже легли в буфер. Вот если бы они пришли в маленький буфер, связанный с транзакцией, их бы потребовалось скопировать.
В статье было показано, как можно работать с библиотекой libusb 1.0 через асинхронные запросы. Показаны основные моменты, без которых ничего не заработает. Раскрыта работа множеством транзакций, помещённых в очередь.
Показано, что в некоторых случаях, фактическая скорость передачи по шине всё-таки проседает. Поэтому выбранная автором стратегия перекачки больших объёмов данных без сохранения в буферном ОЗУ для ЭВМ общего использования с произвольным пользователем, неприемлема. Либо пользователь должен отдавать себе отчёт и не выполнять опасных действий во время работы, либо должна использоваться ЭВМ, не дающая выполнить эти действия (на ней должна запускаться только программа, обслуживающая оборудование).
Рассмотрен также типовой метод отображения процесса приёма данных и его прерывания в произвольный момент.
Материалы, получившиеся при написании данной статьи, можно скачать тут.
P.S. Собственно, это – вся теория, которую я хотел рассказать про работу с USB через FX3. Само собой, это всё – только верхушка айсберга, но повторяю вновь и вновь: я не собираюсь становиться гуру в работе с этим контроллером. Я хотел взять типовой пример и сделать мост – я сделал это. Всё! Остальное мне пока не нужно.
Но само собой, надо раскрыть интригу сезона: получился анализатор или нет. Получился! Мелочи, которые позволили собрать все прежние наработки в кучу и итоговые файлы, я оформлю в следующей статье. Она и станет заключительной в цикле. Но выйдет она через одну публикацию. А следующей будет выложена статья, где я расскажу не о своих, а о чужих наработках. Побуду корреспондентом в среде разработчиков, делающих сервис All Hardware. Перескажу с их слов, как можно пробрасывать UART из Линукса по сети (правда, примеры я там написал свои, так как все слова предпочитаю перепроверять).
Та статья написана ещё в прошлом году, но было желание пустить её уже после цикла про FX3. Но ситуация изменилась. Компания-разработчик сервиса All-hardware, который предоставляет бесплатный доступ к отладочным платам, объявила конкурс на разработку прошивок для плат, размещенных в сервисе, поэтому сейчас – самое лучшее время для публикации статьи про сервис, возможно она будет полезна участникам. Конкурс продлится до 9 апреля. Но лучше не затягивать со стартом, вот она и вклинится «вне очереди».
Поэтому, во-первых, было бы полезно видеть, какой их объём уже прошёл в буфер, чтобы представлять, работает система или нет. Ну, и во-вторых, если данных не предвидится, а всё интересное уже попало к нам в память, надо иметь возможность прекратить приём и начать разбор того, что уже накопилось. Ни то, ни другое невозможно при использовании функций, которые были рассмотрены в той статье. По крайней мере, со стороны PC. Без читов, добавленных в «прошивку» ПЛИС.
Сегодня мы научимся обращаться к библиотеке libusb асинхронным методом. Это позволит и грубо отслеживать объём уже пришедших данных, и прерывать работу в любой момент, и даже повысить общую производительность системы. Причём всё это будет сделано только за счёт вызова штатных функций libusb. Код для FX3 и ПЛИС мы для этого дорабатывать не будем. Итак, приступаем.

Предыдущие статьи цикла:
- Начинаем опыты с интерфейсом USB 3.0 через контроллер семейства FX3 фирмы Cypress
- Дорабатываем прошивку USB 3.0, используя анализатор SignalTap, встроенный в среду разработки Quartus
- Учимся работать с USB-устройством и испытываем систему, сделанную на базе контроллера FX3
- Боремся с таймаутами при использовании USB 3.0 через контроллер FX3, возникающими при определенных условиях
- Добавляем поддержку Vendor-команд к USB3.0 устройству на базе FX3
- Делаем блок SPI to AVALON_MM для USB-устройства на базе FX3
1 Зачем всё это
Напомню, что в предыдущей статье про libusb я читал данные из FX3 так:
int res = libusb_bulk_transfer(tester.m_hUsb,0x81,(uint8_t*)pData,bytesCnt,&actualLength,10000);
И всё. До истечения таймаута (а для анализатора он может быть огромным) текущий поток будет исполняться внутри данной функции. Управления мне никто не вернёт. Мы будем ждать, ждать и ждать, как бедняга на вступительном рисунке, отмеченном крестиком.
В противовес такой работе (её ещё называют синхронной), в любой уважающей себя USB-библиотеке должна быть ещё и асинхронная. Там мы вызываем функцию чтения, и управление немедленно возвращается нам. Что будет дальше, зависит от конкретной библиотеки. Где-то в нужный момент будет переведён в активное состояние объект «Событие». В libusb будет вызвана Callback-функция. Короче, нам поступит сообщение о том, что наш запрос выполнен, как на вступительном рисунке с галочкой.
И никто не запрещает нам в любой момент вызвать функцию, отменяющую процесс обмена. При этом, если часть данных уже прошла по каналу, они будут нам всё равно выданы. Ничего не пропадёт.
Скоро мы рассмотрим, как это работает, но сначала я объясню, почему не стал рассказывать об асинхронной работе немедленно после синхронной. Дело в том, что при проверке асинхронной работы, мы должны провоцировать ситуации с таймаутами. А значит, наш таймер должен не молотить от начала жизни и до бесконечности, а выдавать строго дозированные порции данных. Чтобы это делать, мы должны управлять им. Собственно, в предыдущих двух статьях мы и осваивали этот процесс. Теперь мы вполне можем посылать запросы на шину AVALON_MM. Поэтому, подключив таймер к этой шине, мы сможем управлять и им. Приступаем.
2 Дорабатываем таймер
Да, я обещал, что мы будем работать только средствами libusb. Но этот раздел ничему не противоречит. Он показывает не работу, а доработку средств тестирования. Итак, верилоговский модуль таймера, формирующего воздействия, несколько изменился. В него была добавлена шина AVALON_MM. Из самого счётчика убраны все особенности поведения. Раньше после переполнения приёмника он стартовал не сразу. Теперь — всё просто. При старте он стоит. По шине AVALON_MM попросили сделать N тиков – перешлёт ровно столько слов, сколько попросили. Переслал – снова стоит.
Таким образом, наша программа сможет вырабатывать строго заданное количество 16-разрядных слов, которые уйдут в шину AVALON_ST, дальше – в FIFO, а из него – в FX3 и USB 3.0.
Под катом – получившийся Verilog код таймера.
Смотреть код таймера.
module Timer_ST (
input clk,
input reset,
input [2:0] avalon_mm_address,
input [31:0] avalon_mm_data_in,
input avalon_mm_wr,
input logic source_ready,
output logic source_valid,
output logic[15:0] source_data
);
logic [31:0] cnt = 0;
logic [31:0] counter = 0;
always @ (posedge clk)
begin
// На том конце очередь переполнена
// Значит, когда она освободится - начнём
// слать данные не сразу...
if (reset == 1)
begin
counter <= 0;
cnt <= 0;
end else
begin
if (avalon_mm_wr)
begin
cnt <= avalon_mm_data_in;
counter <= 0;
end else
begin
counter <= counter + 1;
if ((source_ready==1)&&(cnt != 0))
begin
cnt <= cnt - 1;
end
end
end
end
assign source_valid = (source_ready!=0) && (cnt != 0);
assign source_data [15:0] = counter [15:0];
endmodule
3 Первый эксперимент
3.1 Подготовка
Сегодня мы будем черпать вдохновение на соответствующей странице документации библиотеки libusb.
Чтобы сделать простейший асинхронный запрос, надо проделать следующий путь:
- Выделить память для структуры libusb_transfer, для чего имеется функция libusb_alloc_transfer();
- Заполнить поля созданной структуры. Причём не надо мучиться с ручным заполнением. В зависимости от типа транзакции мы можем использовать функции libusb_fill_control_setup(), libusb_fill_control_transfer(), libusb_fill_bulk_transfer(), libusb_fill_interrupt_transfer() или libusb_fill_iso_transfer(). Есть ещё заполнение потоковой структуры, но врать не буду, я с нею не разобрался.
- На шаге 2 заполняется указатель на функцию обратного вызова. Эту функцию надо написать.
- Запустить передачу в работу, вызвав libusb_submit_transfer().
3.2 Работа
Собственно, после вызова функции libusb_submit_transfer() хост начнёт попытку инициировать обмен с устройством. Когда процесс завершится (либо возникнет таймаут или ещё какая нештатная ситуация вплоть до вытаскивания устройства из разъёма), будет вызвана функция обратного вызова.
Если транзакция была не последняя, после завершения работы обработки текущей можно, прямо находясь в функции обратного вызова, снова обратиться к функции libusb_submit_transfer(), чтобы инициировать новую транзакцию. Поэтому получаем такое рабочее колесо (фраза «функция обратного вызова» заняла бы на нём много места, поэтому она заменена на «CallBack-функция»):
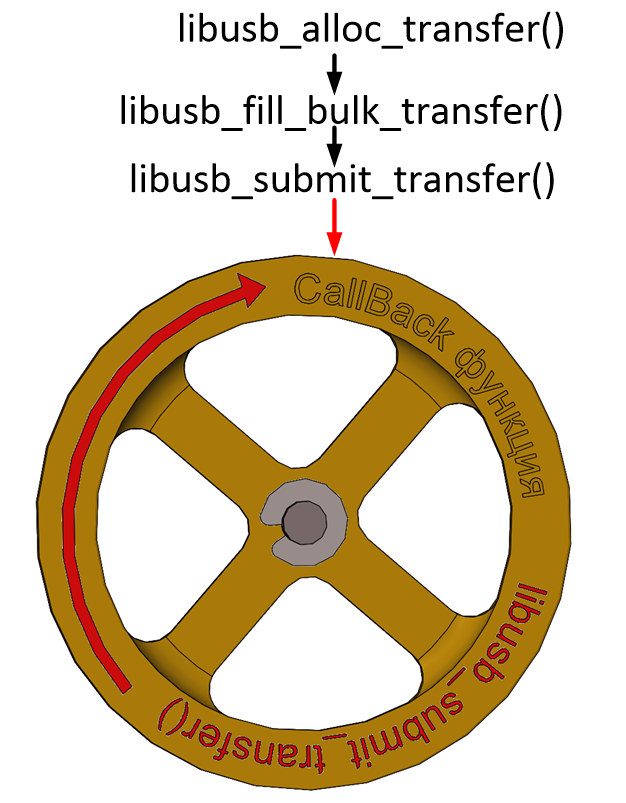
То есть, после отработки libusb_submit_transfer(), Callback-функция, получив управление, под конец своей работы снова вызывает libusb_submit_transfer() и завершается. Через некоторое время она снова получает управление, снова вызывает libusb_submit_transfer() и т.д.
При этом функция libusb_submit_transfer() возвращает управление немедленно, а следующий вызов CallBаck-функции произойдёт через существенный промежуток времени. Таким образом, всё это время основная программа может продолжать своё выполнение. Мало того, CallBack-функция по своей сути похожа на обработчик прерывания микроконтроллера. Она совершенно не изменяет ход работы основной программы. Появились данные – функция была вызвана. Функция отработала – управление вернулось в то место, где программа была в момент прихода данных. А как эта функция взаимодействует с основной программой – всё в руках программиста.
3.3 Очень важный момент
Когда я написал первое тестовое приложение и попробовал его отлаживать, оказалось, что создать описанное выше колесо необходимо, но недостаточно. Надо ещё добавить мотор, который будет его вращать. Для этого надо постоянно вызывать функцию libusb_handle_events(). Причём сама по себе функция вполне себе блокирующая. Правда, если углубиться в документацию, то выяснится, что на самом деле, это всего лишь обёртка. Из неё вызывается libusb_handle_events_timeout() с таймаутом 60 секунд. Так что блокировка будет максимум на минуту. При желании, можно вызывать libusb_handle_events_timeout() с любым своим таймаутом, зависящем от желаемой скорости реакции на возможное прерывание процесса.
Вызывать эту функцию можно и в текущем потоке, но можно создать для этого отдельный поток.
В общем, рисунок изменяется так:
3.4 Окончание работы
По окончании работы надо остановить все незавершённые передачи при помощи функции libusb_cancel_transfer(), дождаться фактического завершения их активности (будет вызвана функция обратного вызова) и освободить выделенную память при помощи libusb_free_transfer() (вариант, когда эта функция будет вызвана автоматически рассматривается в документации на libusb, но нами не используется).
3.5 Практический пример
Если честно, то без доработок описанный выше механизм неприемлем для USB3.0. По этой шине данные летят широким потоком, а мы надолго прерываем приём. Пока мы войдём в функцию обратного вызова, пока она отработает, пока запустит приём новых данных… Медленно всё это! Поэтому практический пример я покажу не для USB3, а для изохронных передач USB2. Вдохновение я черпал в файле \libusb-1.0.23\examples\sam3u_benchmark.c, который шёл в комплекте с библиотекой. Тот код можно считать эталонным, но я покажу свою перепевку (которая может что-то не учитывать).
Вот такую я сделал функцию обратного вызова. Она не выполняет никаких полезных действий, я просто ставил там точки останова и изучал в отладчике структуры пришедших данных. Ну, и статистику она мне строит. Тест мне был нужен, чтобы убедиться, что я понимаю принципы работы. В конце, как я уже и говорил, вызывается libusb_submit_transfer() для запуска приёма новой посылки. Объёмы изохронного трафика от микрофона (а ловил я именно их) таковы, что заботиться о скорости мне не требовалось. Там буквально килобайты в секунду идут.
Смотреть код.
Теперь, как запускается процесс. Вот я создаю структуру:
void LIBUSB_CALL CIsoWriteTest::cb_xfr(struct libusb_transfer *xfr)
{
CIsoWriteTest* pForm = (CIsoWriteTest*) xfr->user_data;
if (xfr->status == LIBUSB_TRANSFER_COMPLETED)
{
uint minBlockSize = 100000;
uint maxBlockSize = 0;
uint total = 0;
int nBlocks = 0;
for (int i=0;i<xfr->num_iso_packets;i++)
{
if (xfr->iso_packet_desc[i].status == LIBUSB_TRANSFER_COMPLETED)
{
if (xfr->iso_packet_desc[i].actual_length > maxBlockSize)
{
maxBlockSize = xfr->iso_packet_desc[i].actual_length;
}
if (xfr->iso_packet_desc[i].actual_length < minBlockSize)
{
minBlockSize = xfr->iso_packet_desc[i].actual_length;
}
nBlocks += 1;
total += xfr->iso_packet_desc[i].actual_length;
}
}
pForm->ui->m_lblSize->setText(QString ("%1 Byttes transfered in %2 blocks").arg(total).arg(nBlocks));
pForm->ui->m_lblMinBlockSize->setText(QString ("Min Block Size = %1 bytes").arg(minBlockSize));
pForm->ui->m_lblMaxBlockSize->setText(QString ("Max Block Size = %1 bytes").arg(maxBlockSize));
pForm->ui->m_lblBytesPerSec->setText("***");
} else
{
pForm->ui->m_lblSize->setText(DecodeTransferStatus(xfr->status));
pForm->ui->m_lblMinBlockSize->setText("***");
pForm->ui->m_lblMaxBlockSize->setText("***");
pForm->ui->m_lblBytesPerSec->setText("***");
}
if (libusb_submit_transfer(xfr) < 0)
{
// todo Catch Errors
}
}
Теперь, как запускается процесс. Вот я создаю структуру:
// Allocate transfer
m_xfr = libusb_alloc_transfer(TEST_NUM_PACKETS);
if (m_xfr == 0)
{
QMessageBox::critical (this,"Error","Cannot Allocate Transfer");
return;
}
Вот я создаю собственный буфер данных (можно его создать и средствами библиотеки, но я предпочитаю выделять память так, чтобы она самоосвободилась в деструкторе класса), после чего – заполняю ранее созданную структуру, передав ей указатели на буфер и функцию обратного вызова:
m_buffer.resize(m_epParams.epMmaxPacketSize * TEST_NUM_PACKETS);
libusb_fill_iso_transfer(m_xfr, m_epParams.hDev, m_epParams.nEndPoint,(unsigned char*) m_buffer.constData(),
m_buffer.size(), TEST_NUM_PACKETS, cb_xfr, this, 1000);
libusb_set_iso_packet_lengths(m_xfr, m_epParams.epMmaxPacketSize);
где
#define TEST_NUM_PACKETS 128
Дальше я запускаю процесс ожидания и приёма посылки:
int res = libusb_submit_transfer(m_xfr);
if (res != 0)
{
QMessageBox::critical(this,"Error",libusb_error_name(res));
}
И не забываю запустить отдельный поток, который выполняет роль мотора:
m_thread.start();
сам поток прост, так как я просто изучал принципы работы и совершенно не задумывался о функциональности, так что он совершенно не обрабатывает ошибочные ситуации:
void CMonitorIsoTransactionThread::run()
{
while (!isInterruptionRequested())
{
libusb_handle_events(NULL);
}
}
4 Пользуемся очередью запросов
Как решить главную проблему, описанную выше (большой временной участок, когда не идёт приём), мне подсказал VelocidadAbsurda в комментариях к этой статье. Надо просто создать несколько структур типа libusb_transfer и запустить много операций обмена. Они встанут в очередь. Как только выполнится одна – в игру вступит следующая. Пока мы находимся в обработчике, система не будет простаивать. Во время экспериментов я запускал 16 передач одновременно. Эту работу я рассмотрю уже на реальном примере для целевой шины USB3.
4.1 Работа с буфером
Опишу кратко, какую стратегию работы с буфером я выбрал для данного конкретного проекта. Можно было бы сопоставить каждой структуре libusb_transfer собственный буфер памяти, а по факту прихода данных, копировать их в мой огромный буфер:
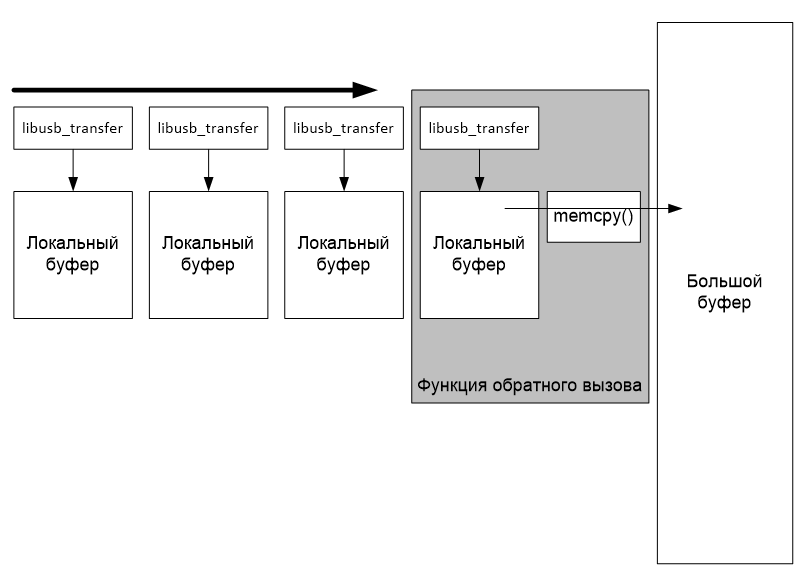
Но мой опыт говорит, что при скоростной работе с огромными объёмами данных функции копирования памяти отнимают большой процент времени. Поэтому я пошёл другим путём. Я нарезаю буфер на маленькие кусочки (размером с одну транзакцию) и настраиваю структуру libusb_transfer на приём сразу туда, куда нужно мне. Поэтому дополнительные копирования уже не требуются. Функция обратного вызова просто перенаправляет указатель на очередной участок буфера и снова ставит его в очередь.
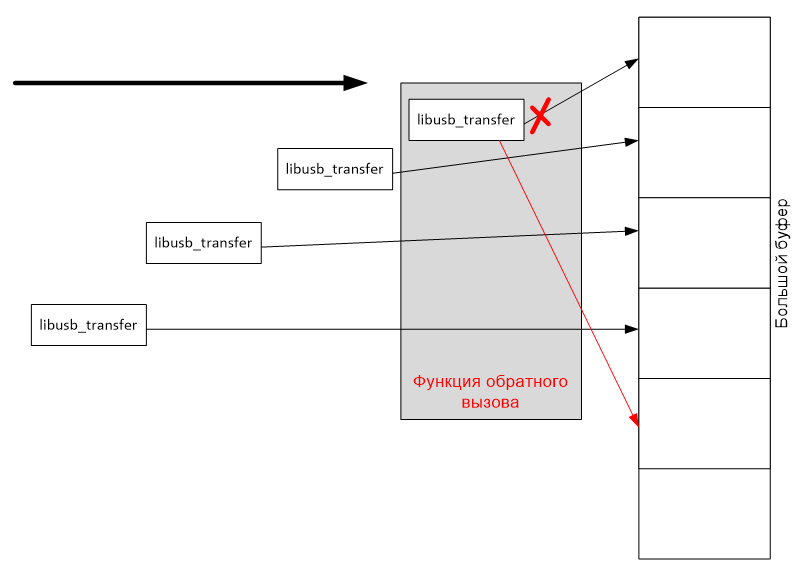
4.2 Функция обратного вызова
Снова начнём обсуждение кода с функции обратного вызова. Давайте пока не будем обсуждать ветку LIBUSB_TRANSFER_CANCELLED в ней. Она нас отвлечёт. Разберём основной ход.
Как я уже говорил, эта функция как-то должна взаимодействовать с основной программой. Для этого нужна кучка переменных. Я предпочёл объединить их в единую структуру:
struct asyncParams
{
// Указатель на большой буфер, в который
// мы принимаем массив. Он может быть размером
// в сотни мегабайт
uint8_t* pData;
// Каждая транзакция принимает маленький кусочек.
// Например, 64 килобайта. В этой переменной лежит
// текущее смещение. Поставили транзакцию в очередь -
// сдвинулись в буфере. Короче, это указатель
// запрошенной части буфера.
int dataOffset;
// Размер буфера в байтах. Полезен, чтобы знать,
// когда следует прекращать работу. Если смещение
// дошло до этой величины - функция обратного вызова
// перестанет создавать новые запросы на передачу
int dataSizeInBytes;
// Размер одной передачи
int transferLen;
// Используется для отображения заполненности буфера,
// увеличивается по факту прихода новой порции данных.
// То есть, это указатель фактически заполненного буфера
int actualTranfered;
};
И функция, пользующаяся этой структурой, выглядит так:
void SpiToAvalonDemo::ReadDataTranfserCallback(libusb_transfer *transfer)
{
SpiToAvalonDemo* pClass = (SpiToAvalonDemo*) transfer->user_data;
switch (transfer->status )
{
case LIBUSB_TRANSFER_COMPLETED:
// Отметили, что принят очередной блок данных
pClass->m_asyncParams.actualTranfered += transfer->length;
// Если буфер принят ещё не весь
if (pClass->m_asyncParams.dataOffset < pClass->m_asyncParams.dataSizeInBytes)
{
// Новая пачка ляжет вот сюда
transfer->buffer = pClass->m_asyncParams.pData+pClass->m_asyncParams.dataOffset;
// Сдвигаем указатель на следующий блок в буфере
pClass->m_asyncParams.dataOffset += pClass->m_asyncParams.transferLen;
// Запустили передачу
libusb_submit_transfer(transfer);
}
break;
case LIBUSB_TRANSFER_CANCELLED:
{
pClass->m_cancelCnt -= 1;
}
break;
default:
break;
}
}
Она простая. Есть буфер, вдоль которого мы скользим, принимая фрагменты потока данных. Например, буфер 120 мегабайт, а фрагменты – по 64 килобайта. У нас есть указатель головы буфера. И задача функции просто посмотреть, не достигла ли голова конца буфера. Нет – тогда установили новый указатель в структуре libusb_transfer. Прочие её поля не трогаем, они же уже заполнены в основной программе. Затем – сдвигаем голову и проворачиваем колесо, вызвав libusb_submit_transfer(). Всё!
4.3 Запуск процесса и моторная часть
В этом тесте я решил не выносить моторную часть в отдельный поток. Поэтому запуск теста и моторная часть у меня располагаются в одной и той же функции. Эта функция вызывается из многих других.
Собственно, в ней мы видим почти то же самое, что и в изохронном примере, только структуры libusb_transfer создаются и обрабатываются оптом.
Сначала я заполняю поля структуры, которая используется для связи с функцией обратного вызова:
m_asyncParams.pData = (uint8_t*) pData;
m_asyncParams.dataOffset = 0;
m_asyncParams.dataSizeInBytes = bytesCnt;
m_asyncParams.transferLen = transferSize;
m_asyncParams.actualTranfered = 0;
Теперь создаём нужное количество структур libusb_transfer, которые указывают на функцию обратного вызова и на участок буфера. При этом не забываем сдвигать указатель на буфер:
for (int i=0;i<nTransfersInParallel;i++)
{
m_transfers[i] = libusb_alloc_transfer(0);
libusb_fill_bulk_transfer (m_transfers[i],m_tester.m_hUsb,0x81,
m_asyncParams.pData+m_asyncParams.dataOffset,transferSize,ReadDataTranfserCallback,
this,60000);
m_asyncParams.dataOffset += transferSize;
}
Отмечу также, что в коде выше, я задаю параметр «таймаут» равным 60 секунд. При работе с данными, вырабатываемыми таймером, этого более, чем достаточно. В следующем разделе я отдельно рассмотрю, почему иногда это значение надо существенно увеличить.
Дальше я активирую все передачи, ставя их в очередь (которая существует где-то в недрах библиотеки). Я вынес это в отдельный цикл не столько для наглядности, сколько из-за того, что я измеряю производительность теста при помощи таймера, и здесь он уже тикает. А время инициализации этим таймером не учитывалось.
QElapsedTimer timer;
timer.start();
// Separated loop for more careful time checking
for (int i=0;i<nTransfersInParallel;i++)
{
libusb_submit_transfer(m_transfers[i]);
}
Теперь возникает следующая ситуация. По мере прихода данных будет проворачиваться рабочее колесо. И функция обратного вызова всё время будет увеличивать поле m_asyncParams.actualTranfered. Когда все данные придут, оно станет равно m_asyncParams.dataSizeInBytes. Поэтому моторная часть у меня выглядит так:
while (m_asyncParams.actualTranfered<m_asyncParams.dataSizeInBytes)
{
libusb_handle_events(m_tester.m_ctx);
}
Я по-прежнему игнорирую ошибки. Это – тестовый пример. А так – ошибка возникнет, даже если устройство выдернут из разъёма. Но обработчики ошибок сильно усложнят понимание статьи, так что я просто ещё раз напоминаю тем, кто захочет работать на практике, что мои примеры надо рассматривать творчески.
Дальше я вычисляю и вывожу скорость (код можно посмотреть в полном варианте функции), а затем – начинаю освобождать ресурсы.
for (int i=0;i<nTransfersInParallel;i++)
{
libusb_free_transfer(m_transfers[i]);
}
Собственно, всё!
Для справки, полный текст функции под катом.
bool SpiToAvalonDemo::AsyncStep(uint16_t *pData, const int bytesCnt, const int transferSize, const int nTransfersInParallel)
{
QElapsedTimer timer;
m_asyncParams.pData = (uint8_t*) pData;
m_asyncParams.dataOffset = 0;
m_asyncParams.dataSizeInBytes = bytesCnt;
m_asyncParams.transferLen = transferSize;
m_asyncParams.actualTranfered = 0;
// Allocate Transfers
for (int i=0;i<nTransfersInParallel;i++)
{
m_transfers[i] = libusb_alloc_transfer(0);
libusb_fill_bulk_transfer (m_transfers[i],m_tester.m_hUsb,0x81,
m_asyncParams.pData+m_asyncParams.dataOffset,transferSize,ReadDataTranfserCallback,
this,60000);
m_asyncParams.dataOffset += transferSize;
}
timer.start();
// Separated loop for more careful time checking
for (int i=0;i<nTransfersInParallel;i++)
{
libusb_submit_transfer(m_transfers[i]);
}
while (m_asyncParams.actualTranfered<m_asyncParams.dataSizeInBytes)
{
libusb_handle_events(m_tester.m_ctx);
}
quint64 after = timer.nsecsElapsed();
quint64 size = bytesCnt;
size *= 1000000000;
quint64 speed = size/after;
qDebug() << nTransfersInParallel << "," << transferSize << "," << speed;
int from = 0xc001;
uint16_t prevData = pData[from];
for (int i=from+1;i<bytesCnt/2;i++)
{
if (pData[i] != ((prevData + 1)&0xffff))
{
qDebug() << Qt::hex << i << " : " << prevData << ", " << pData[i];
}
prevData = pData[i];
}
// Release Resources
for (int i=0;i<nTransfersInParallel;i++)
{
libusb_free_transfer(m_transfers[i]);
}
return true;
}
4.4 Пример вызова тестовой функции
Тестовая функция завязана исключительно на библиотеку libusb. Вся подготовка аппаратуры и выделение буферов вынесены из неё. Давайте рассмотрим один пример, как эта функция вызывается. Так я тестирую зависимость скорости передачи от числа передач, поставленных в очередь.
void SpiToAvalonDemo::on_m_btnAsync128M_clicked()
{
static const int len = 128 * 1024 * 1024;
// Set Up Timer to 128 megabytes
QByteArray ar1;
ar1.resize(len);
// Заполнили буфера FX3, иначе подвиснет
m_tester.WriteDword(0,0x10000);
for (int i=1;i<16;i++)
{
// Set Transfer Size for timer
m_tester.WriteDword(0,len/2);
AsyncStep ((uint16_t*)ar1.constData(),len,65536,i);
}
}
При прогоне этого теста я получил очень интересный результат. При некоторых прогонах я вижу ошибки в принятых буферах:
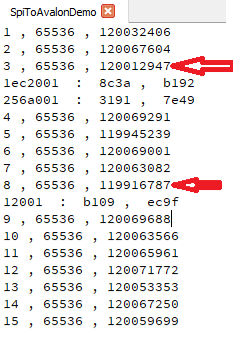
Собственно, все ошибки происходят на малой скорости передачи, так что это вполне логично. Правда, раньше никогда не было просадок, если скорость начиналась на «120», но при снятии скриншотов, возник такой эффект. Тем не менее, всё равно там скорость была ниже, чем при других опытах. Судя по тому, что значение счётчика круто изменилось, пауза в получении данных была существенной.
Как можно спровоцировать просадки скорости. Просто уводим курсор «мыши» в область панели задач и начинаем водить по ней. При этом возникают уменьшенные окошки
Вот их формирование часто и приводит к задержкам. Причём машина у меня – не самая слабая:
Но вот что вижу, то вижу. Получается, что очень критичные к производительности системы (напомню, у меня конечная цель – анализатор без собственной буферной памяти, только с небольшой очередью FIFO, выдающий данные со скоростью 120 миллионов байт в секунду) можно делать только для себя. С собой договориться всегда можно. А для внешних Заказчиков – не получится. Есть у меня знакомый, который любит, чтобы на одной машине работала и технологическая программа, и редактор текстов, и игрушка, причём всё одновременно, и на не самой мощной машине…
Однако, когда количество одновременно запрошенных передач близко к шестнадцати, всё более-менее хорошо. Так что повторю, с собой лично договориться о том, что при измерениях не двигать особо «мышку», я смогу. Но анализатор и измеряемая программа явно должны быть запущены на разных машинах. Ну, или всё-таки надо будет ставить в ПЛИСовую часть большое буферное ОЗУ…
5 Лирическое отступление о размере одной посылки
В далёком 2009-м году участвовал я в разработке программатора ПЗУ на базе FX2LP. Там требовалось выжать из скорости максимум. И вот тогда, после ряда опытов, я выяснил, что хоть физически по шине USB2 бегают пакеты, не больше, чем 512 байт, всё равно надо запрашивать сразу большие объёмы данных. Это связано с тем, что кроме размера пакета, есть ещё разбиение временной оси на кадры. В пределах одного кадра устройство может обменяться более, чем одним пакетом, если это запланировано хостом. Но если запрос пришёл слишком поздно, он может быть вписан в планы
С тех пор я упоминаю об этом к месту и не к месту. Соответствующий график для USB2, реализованной средствами ПЛИС, я публиковал в своей статье про логические ограничения производительности шин. Сегодня я просто обязан построить такой же график для шины USB3, работающей через FX3.
Графики строил я примерно так.
void SpiToAvalonDemo::on_m_btnAsync128M_clicked()
{
static const int len = 128 * 1024 * 1024;
// Set Up Timer to 128 megabytes
QByteArray ar1;
ar1.resize(len);
// Заполнили буфера FX3, иначе подвиснет
m_tester.WriteDword(0,0x10000);
qDebug()<<"";
qDebug()<<"";
qDebug()<<"";
// for (int i=1024;i<512*1024;i*=2)
for (int i=1024;i<32*1024;i+=1024)
{
// Set Transfer Size for timer
m_tester.WriteDword(0,len);
AsyncStep ((uint16_t*)ar1.constData(),len-128*1024,i,1);
}
qDebug()<<"";
qDebug()<<"";
qDebug()<<"";
// for (int i=1024;i<512*1024;i*=2)
for (int i=1024;i<32*1024;i+=1024)
{
// Set Transfer Size for timer
m_tester.WriteDword(0,len);
AsyncStep ((uint16_t*)ar1.constData(),len-128*1024,i,2);
}
qDebug()<<"";
qDebug()<<"";
qDebug()<<"";
// for (int i=1024;i<512*1024;i*=2)
for (int i=1024;i<32*1024;i+=1024)
{
// Set Transfer Size for timer
m_tester.WriteDword(0,len);
AsyncStep ((uint16_t*)ar1.constData(),len-128*1024,i,4);
}
}
Видно, что во время опытов я экспериментировал с размерами, так как каждый замер идёт долго, но хотелось снять разные варианты.
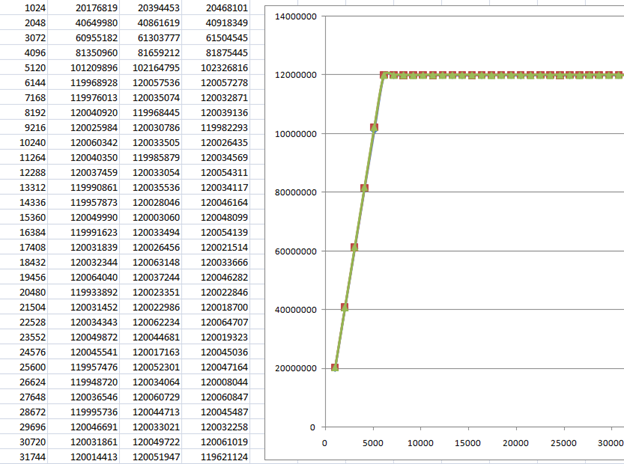
Самый интересный из полученных графиков, выглядит так (первый столбец – размер транзакции в байтах, второй – получившаяся скорость передачи в байтах в секунду):
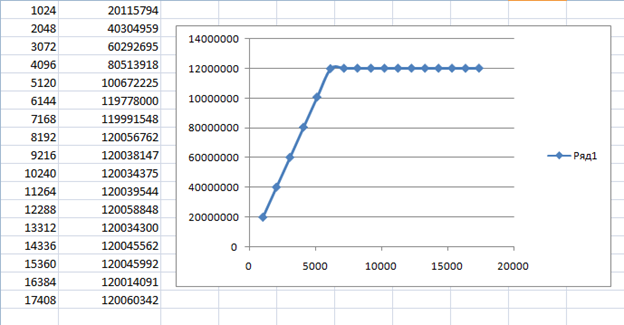
В общем, не стоит работать блоками меньше, чем 8 килобайт. Правда, я меньше 64 килобайт обычно и не использую.
Вот здесь я попробовал разное число транзакций в очереди (одну, две и четыре). Если честно, то в таблице видно, что чем больше транзакций, тем лучше, но на графике разница особенно и не видна. То есть, она несущественна. И мы уже знаем, что меньше восьми лучше не запускать. Я обычно меньше шестнадцати не запускаю.
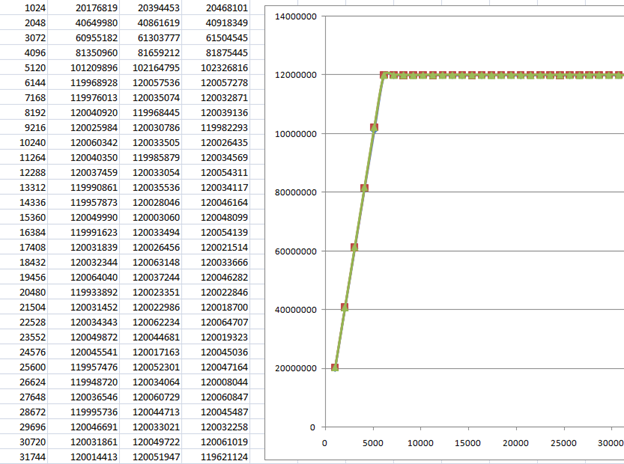
Отдельно хочется отметить, что скорость передачи возросла по сравнению с аналогичной, полученной при синхронной работе. То, что скорость чуть превышает 120 миллионов байт в секунду, не является признаком ошибки измерений. Я отмечал в предыдущих статьях, что по осциллографу видно, что ULPI выдаёт тактовую частоту чуть выше, чем 60 МГц.
6 Как я провоцировал остановки шины
Коротко покажу, как я провоцировал остановки шины для постскриптума к этой статье. Чтобы их спровоцировать, просто необходимы как управление таймером, так и возможность подкинуть тактов таймера, когда передача данных уже началась. В общем, без асинхронности – никак. Вот так выглядел тестовый код. Я сначала генерил набор тактов, а затем – ещё чуть-чуть. Но мы помним, что проход запроса через программную шину SPI крайне медленный. Поэтому однозначно результаты предыдущей работы таймера ушли, и шина остановилась. Возникла большая пауза в передаче. И тут-то я досылал финальные байтики, которые приходили при уже упавшем флаге flagb. Подробнее о теории – в той статье (см. выше).
Для этой функции я впервые вынес «моторную» функциональность в обособленное место:
void SpiToAvalonDemo::UsbLoop(uint32_t timeIn_ms)
{
timeval tv;
tv.tv_sec = 0;
tv.tv_usec = 500000;
QElapsedTimer timer;
timer.start();
while (timer.elapsed()<timeIn_ms)
{
libusb_handle_events_timeout(m_tester.m_ctx,&tv);
}
}
И ключевой участок тестового кода выглядит так:
UsbLoop (500);
m_tester.WriteDword(0,len/4);
UsbLoop (500);
m_tester.WriteDword(0,(len/4)-2);
UsbLoop (1500);
m_tester.WriteDword(0,2);
А вся функция – так.
void SpiToAvalonDemo::on_m_btnWithLatencyProblem_clicked()
{
static const int len = 0x10000;
// Set Up Timer to 128 megabytes
QByteArray ar1;
ar1.resize(0x100000);
m_asyncParams.pData = (uint8_t*)ar1.constData();
m_asyncParams.dataOffset = 0;
m_asyncParams.dataSizeInBytes = len;
m_asyncParams.transferLen = len;
m_asyncParams.actualTranfered = 0;
libusb_transfer* transfer = libusb_alloc_transfer(0);
libusb_fill_bulk_transfer (transfer,m_tester.m_hUsb,0x81,
m_asyncParams.pData+m_asyncParams.dataOffset,len,ReadDataTranfserCallback,
this,60000);
m_asyncParams.dataOffset += len;
libusb_submit_transfer(transfer);
UsbLoop (500);
m_tester.WriteDword(0,len/4);
UsbLoop (500);
m_tester.WriteDword(0,(len/4)-2);
UsbLoop (1500);
m_tester.WriteDword(0,2);
while (m_asyncParams.actualTranfered<m_asyncParams.dataSizeInBytes)
{
libusb_handle_events(m_tester.m_ctx);
}
libusb_free_transfer(transfer);
}
Как этот тест изменил Verilog код преобразователя AVALON_ST в FX3, я уже рассказывал. Собственно, практически полностью изменил.
7 Отображаем текущее состояние и добавляем остановку процесса
Теперь рассмотрим самый полный, но и самый сложный пример. Попросим тестовую аппаратуру в ПЛИС сформировать данные так, чтобы процесс не смог завершиться. При этом программа будет отображать нам текущее заполнение буфера и давать возможность прервать процесс.
7.1 Таймер, отображающий текущий процент и отлавливающий факт успешного завершения работы
Функцию обратного вызова я оставил ту же самую. Но так как сейчас у нас всё должно быть весьма асинхронно, я добавил в класс виртуальную функцию обработки таймера. В Qt это делается именно так. Собственно, функция проста, а её логика нам знакома. Мы анализируем поле, в котором функция обратного вызова сохраняет объём фактически прокачанных данных. Если ещё не 100% — отображаем значение и выходим. Если 100% — останавливаем процесс.
void SpiToAvalonDemo::timerEvent(QTimerEvent *event)
{
Q_UNUSED(event)
static int prevPercent = 0;
int percent = (int)(((int64_t)m_asyncParams.actualTranfered * 100LL)/(int64_t)m_asyncParams.dataSizeInBytes);
if (prevPercent != percent)
{
ui->m_progressForCancel->setValue(percent);
prevPercent = percent;
}
if (percent == 100)
{
StopProcess();
}
}
7.2 Функция завершения работы
Так как остановка процесса возможна не только автоматически, но ещё и по кнопке Cancel, она вынесена в отдельную функцию, чтобы её могли вызывать обе ветки. Там мы посылаем запрос на остановку моторного потока, дожидаемся фактической остановки, удаляем все структуры libusb_transfer и останавливаем таймер. Всё!
void SpiToAvalonDemo::StopProcess()
{
// Всё, больше мотор не нужен! Глушим его!
m_transactionsThread.requestInterruption();
while (m_transactionsThread.isRunning())
{
QThread::msleep(10);
}
// Освободили память
for (int i=0;i<m_dataTranfersInParallel;i++)
{
libusb_free_transfer(m_transfers[i]);
}
ui->m_progressForCancel->setValue(0);
// Таймер, собственно, тоже стал не нужен
killTimer(m_timeId);
}
7.3 Моторный поток
Раз уж зашла речь о моторном потоке, то рассмотрим его подробнее. Здесь нужен поток и только поток. Реализуем его, согласно правилам Qt. Каждые 500 миллисекунд (если точнее, то 500 000 микросекунд) библиотека возвращает нам управление, чтобы мы могли проверить, не пора ли завершить работу с устройством. Я по-прежнему не обрабатываю критические ошибки в угоду читаемости:
void CTransactionThread::run()
{
timeval tv;
tv.tv_sec = 0;
tv.tv_usec = 500000;
while (!isInterruptionRequested())
{
libusb_handle_events_timeout(m_libusb_ctx,&tv);
}
}
7.4 Кнопка Cancel
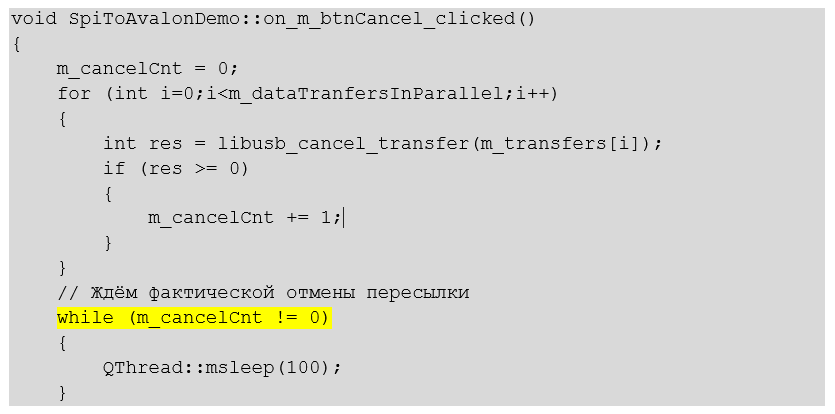
Кнопка Cancel, согласно теории, должна завершить незавершённые передачи. Звучит красиво, но на практике, мне пришлось посидеть. Я гарантирую, что всё сработает в Windows, но не удивлюсь, если в других ОС поведение будет чуть иным. Дело в том, что в любой момент времени, все передачи имеют состояние «Успешно завершена». Идёт ожидание, не идёт… Завершена и всё тут. Поэтому я просто пытаюсь загасить все передачи. Если передача действительно завершена, функция вернёт ошибку. Если же она в процессе работы – функция отмены завершится успешно. И вот тогда я увеличиваю счётчик активных транзакций на единицу:
m_cancelCnt = 0;
for (int i=0;i<m_dataTranfersInParallel;i++)
{
int res = libusb_cancel_transfer(m_transfers[i]);
if (res >= 0)
{
m_cancelCnt += 1;
}
}
Этот счётчик не простой. Он атомарно доступный. Я объявил его так:
QAtomicInt m_cancelCnt;
Напомню, что атомарные операции нужны для обеспечения потокобезопасности. Реальная строчка на языке высокого уровня
data += 1;
обычно распадается минимум на три ассемблерные команды:
- загрузка из памяти в регистр,
- увеличение регистра,
- выгрузка регистра в память («обычно» — потому что на PDP-11 можно было обойтись одной ассемблерной командой, но её времена уже прошли).
В теории поток может быть прерван в любой момент. И возможна ситуация, когда в регистр попало некое значение, после чего работа потока была прервана. Другой поток изменил значение в памяти. Управление вернулось. Но у нас в регистре по-прежнему лежит нечто, и наш поток понятия не имеет о том, что произошло в другом. Поэтому мы завершим инкремент старого значения и положим в память его результат. Данные в памяти станут неверными. Вот чтобы этого избежать, и используются атомарные операции. Они гарантированно завершатся перед прерыванием потока. Так как переменная m_cancelCnt модифицируется в функции обратного вызова, правила активации которой нам неизвестны, я и применил атомарный тип библиотеки Qt для этой переменной.
Помните, в функции обратного вызова я предлагал отложить рассмотрение участка на потом? Пришло время сделать это!
case LIBUSB_TRANSFER_CANCELLED:
{
pClass->m_cancelCnt -= 1;
}
Когда мы запросили отмену транзакции – нам всё равно вызовут соответствующую ей Callback-функцию. И, согласно документации на библиотеку, мы должны дождаться фактического завершения всех транзакций. Тут мы уже всего дождались и отмечаем это. А вот как основной поток ждёт того, что все транзакции успешно завершились:
// Ждём фактической отмены пересылки
while (m_cancelCnt != 0)
{
QThread::msleep(100);
}
Ну, а потом завершаем работу, вызвав уже рассмотренную ранее функцию:
// Остановили работу.
StopProcess();
Для справки, полный текст функции, обрабатывающей нажатие кнопки Cancel.
void SpiToAvalonDemo::on_m_btnCancel_clicked()
{
m_cancelCnt = 0;
for (int i=0;i<m_dataTranfersInParallel;i++)
{
int res = libusb_cancel_transfer(m_transfers[i]);
if (res >= 0)
{
m_cancelCnt += 1;
}
}
// Ждём фактической отмены пересылки
while (m_cancelCnt != 0)
{
QThread::msleep(100);
}
// Остановили работу.
StopProcess();
}
7.5 Запускаем процесс
Уффф. С инфраструктурой разобрались. Теперь – запуск. Я сделал возможность задавать, сколько слов недосылать таймеру, чтобы можно было провоцировать различные ситуации. Например, висим с одной недокачанной передачей, висим, когда все передачи недокачаны и т.п.
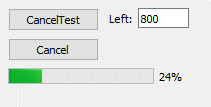
С учётом этого старт работы выглядит так.
Уже известное нам заполнение параметров и выделение буфера:
m_analyzerData.resize(120*1024*1024);
m_asyncParams.pData = (uint8_t*)m_analyzerData.constData();
m_asyncParams.dataOffset = 0;
m_asyncParams.dataSizeInBytes = m_analyzerData.size()*sizeof(uint16_t);
m_asyncParams.transferLen = 0x20000;
m_asyncParams.actualTranfered = 0;
for (int i=0;i<m_dataTranfersInParallel;i++)
{
m_transfers[i] = libusb_alloc_transfer(0);
}
Уже приевшееся выделение памяти для структур libusb_transfer. Но в нём кое-что поменялось. Я заменил значение таймаута. Давайте сначала посмотрим на код, а потом я порассуждаю про эти таймауты.
for (int i=0;i<m_dataTranfersInParallel;i++)
{
libusb_fill_bulk_transfer (m_transfers[i],m_tester.m_hUsb,0x81,
m_asyncParams.pData+m_asyncParams.dataOffset,m_asyncParams.transferLen,
ReadDataTranfserCallback,this,0x7fffffff);
m_asyncParams.dataOffset += m_asyncParams.transferLen;
}
Почему я установил таймауты на максимальное значение? Во всём виноват выбранный мной способ задания адреса. Если бы у каждой транзакции был бы свой буфер, при срабатывании таймаута функция обратного вызова просто проигнорировала бы содержимое буфера и отправила бы транзакцию вновь в очередь.
Но что будет в нашем случае? Допустим, случился таймаут. Транзакция была вытолкнута библиотекой из очереди. В ход пошла следующая, которая указывает на другой участок буфера. Всё! Текущий участок пропал! Вновь пришедшие данные лягут куда-то дальше. А на этот участок указывать бесполезно. Если в него что-то и ляжет, то совсем из другой точки временной оси!
Поэтому когда я заполняю буфер выбранным мною способом, транзакция не может отвалиться по таймауту. Она должна ждать фактического поступления данных, и всё тут! Вот я и установил значение таймаута на максимально возможное значение, на всякий случай, не трогая старший бит. Вдруг число рассматривается со знаком?
Возвращаемся к коду. Классический запуск передач:
for (int i=0;i<m_dataTranfersInParallel;i++)
{
libusb_submit_transfer(m_transfers[i]);
}
Запускаем «моторный» поток. Ради интереса, я задал ему высокий приоритет:
m_transactionsThread.m_libusb_ctx = m_tester.m_ctx;
m_transactionsThread.start(QThread::HighestPriority);
Запуск таймера, отображающего процесс:
m_timeId = startTimer(100);
И только сейчас – запуск ПЛИСового таймера, который формирует нам данные. С учётом того, что он нам недошлёт:
uint64_t left = ui->m_txtWordsLeft->text().toInt(0,16);
m_tester.WriteDword(0,m_analyzerData.size()-left);
Для справки, полная функция.
void SpiToAvalonDemo::on_m_btnCancelTest_clicked()
{
m_analyzerData.resize(120*1024*1024);
m_asyncParams.pData = (uint8_t*)m_analyzerData.constData();
m_asyncParams.dataOffset = 0;
m_asyncParams.dataSizeInBytes = m_analyzerData.size()*sizeof(uint16_t);
m_asyncParams.transferLen = 0x20000;
m_asyncParams.actualTranfered = 0;
for (int i=0;i<m_dataTranfersInParallel;i++)
{
m_transfers[i] = libusb_alloc_transfer(0);
}
for (int i=0;i<m_dataTranfersInParallel;i++)
{
libusb_fill_bulk_transfer (m_transfers[i],m_tester.m_hUsb,0x81,
m_asyncParams.pData+m_asyncParams.dataOffset,m_asyncParams.transferLen,
ReadDataTranfserCallback,this,0x7fffffff);
m_asyncParams.dataOffset += m_asyncParams.transferLen;
}
for (int i=0;i<m_dataTranfersInParallel;i++)
{
libusb_submit_transfer(m_transfers[i]);
}
m_transactionsThread.m_libusb_ctx = m_tester.m_ctx;
m_transactionsThread.start(QThread::HighestPriority);
m_timeId = startTimer(100);
uint64_t left = ui->m_txtWordsLeft->text().toInt(0,16);
m_tester.WriteDword(0,m_analyzerData.size()-left);
}
7.6 Практические опыты
На самом деле, в целом, всё достаточно скучно. Если задать «недосылать 0», то всё отработает и автоматически остановится. Мы просто увидим, как бежит прогресс.
Если оставить значение недосланных слов, какое вписано по умолчанию (800 – числа здесь шестнадцатеричные), то остановка произойдёт на девяноста девяти процентах. При этом, как я уже говорил, у всех структур libusb_transfer будет состояние «завершено». Это можно проверить, поставив точку останова в обработчике таймера.
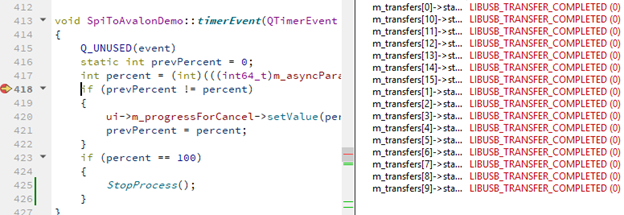
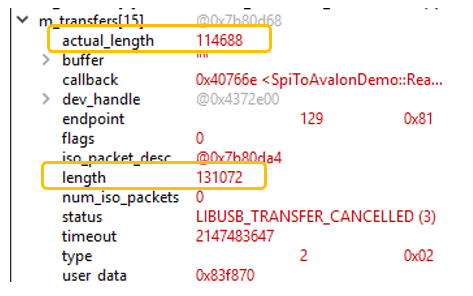
Но давайте я поставлю точку останова вот сюда:
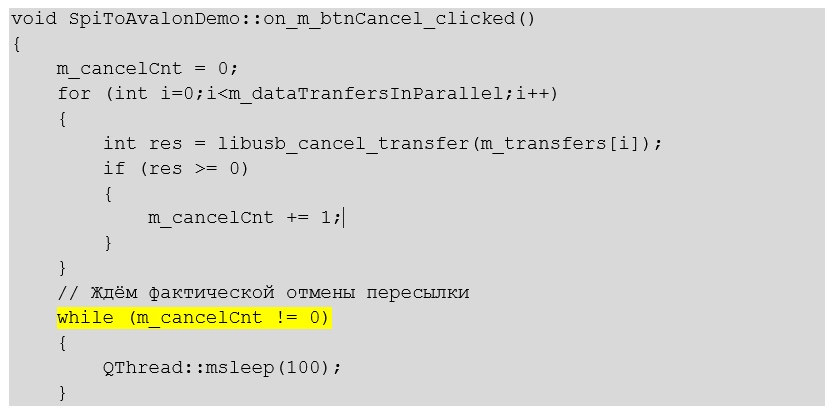
То же самое текстом.
void SpiToAvalonDemo::on_m_btnCancel_clicked()
{
m_cancelCnt = 0;
for (int i=0;i<m_dataTranfersInParallel;i++)
{
int res = libusb_cancel_transfer(m_transfers[i]);
if (res >= 0)
{
m_cancelCnt += 1;
}
}
// Ждём фактической отмены пересылки
while (m_cancelCnt != 0)
{
QThread::msleep(100);
}
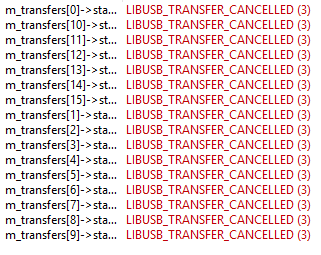
и нажму на Cancel. О-па! Одна структура перешла в состояние CANCELLED:
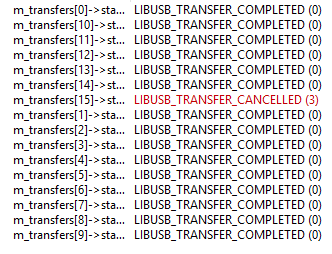
И я проверял, один раз будет вызвана CallBack-функция. Причём часть данных будет отмечена, как переданная:
Так что всё в порядке. Выбранный вариант поведения работает. Но я проверял только в Windows.
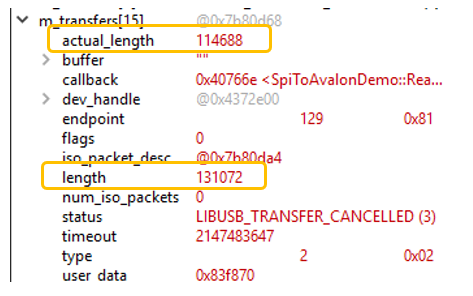
А теперь мы недошлём существенно больше. Не 0x800, а 0x800800 слов. Теперь всё остановится на отметке 93%.
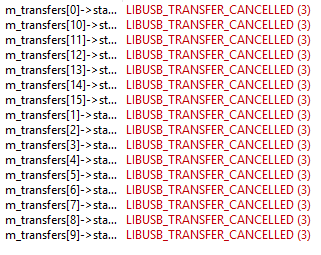
И в точке останова получим такую картинку:
Все транзакции были активны, но так и не дождались своего завершения.
CallBAck-функция будет вызвана 16 раз, но только при одном из вызовов поле с актуальной длиной будет иметь ненулевое значение. Но при выбранной схеме передачи данных, это не так и интересно. Данные же уже легли в буфер. Вот если бы они пришли в маленький буфер, связанный с транзакцией, их бы потребовалось скопировать.
8 Заключение
В статье было показано, как можно работать с библиотекой libusb 1.0 через асинхронные запросы. Показаны основные моменты, без которых ничего не заработает. Раскрыта работа множеством транзакций, помещённых в очередь.
Показано, что в некоторых случаях, фактическая скорость передачи по шине всё-таки проседает. Поэтому выбранная автором стратегия перекачки больших объёмов данных без сохранения в буферном ОЗУ для ЭВМ общего использования с произвольным пользователем, неприемлема. Либо пользователь должен отдавать себе отчёт и не выполнять опасных действий во время работы, либо должна использоваться ЭВМ, не дающая выполнить эти действия (на ней должна запускаться только программа, обслуживающая оборудование).
Рассмотрен также типовой метод отображения процесса приёма данных и его прерывания в произвольный момент.
Материалы, получившиеся при написании данной статьи, можно скачать тут.
P.S. Собственно, это – вся теория, которую я хотел рассказать про работу с USB через FX3. Само собой, это всё – только верхушка айсберга, но повторяю вновь и вновь: я не собираюсь становиться гуру в работе с этим контроллером. Я хотел взять типовой пример и сделать мост – я сделал это. Всё! Остальное мне пока не нужно.
Но само собой, надо раскрыть интригу сезона: получился анализатор или нет. Получился! Мелочи, которые позволили собрать все прежние наработки в кучу и итоговые файлы, я оформлю в следующей статье. Она и станет заключительной в цикле. Но выйдет она через одну публикацию. А следующей будет выложена статья, где я расскажу не о своих, а о чужих наработках. Побуду корреспондентом в среде разработчиков, делающих сервис All Hardware. Перескажу с их слов, как можно пробрасывать UART из Линукса по сети (правда, примеры я там написал свои, так как все слова предпочитаю перепроверять).
Та статья написана ещё в прошлом году, но было желание пустить её уже после цикла про FX3. Но ситуация изменилась. Компания-разработчик сервиса All-hardware, который предоставляет бесплатный доступ к отладочным платам, объявила конкурс на разработку прошивок для плат, размещенных в сервисе, поэтому сейчас – самое лучшее время для публикации статьи про сервис, возможно она будет полезна участникам. Конкурс продлится до 9 апреля. Но лучше не затягивать со стартом, вот она и вклинится «вне очереди».







