
Приветствую всех! Меня зовут Георгий. Я работаю в компании servers.com. Я пришел рассказать про Ansible: про хороший Ansible и про плохой Ansible в основном, т. е. про то, как люди могут плохо делать на Ansible.
Для начала я хочу задать вопрос. Кто знает, о чем вот это?

Зал отвечает: "Это про боль"
Я увидел три руки. Я не верю, что в зале три человека, которые работают с Ansible. Видимо, не самая приличная картинка.

Несколько слов про нашу компанию. Мы специализируемся на хостинге. На хороших серверах с очень хорошим качеством сервиса с глобальной приватной сетью между континентами.
Я работаю в R&D отделе, который занимается исследованием технологий.
Во многих компаниях, когда адаптируется новая технология, принцип адаптации технологии выглядит так: есть проблема, кто-то где-то прочитал статью о новой технологии, примерно похожей на решение проблемы, и появляется предложение ее использовать. Или приходит человек, который говорит: «Я эту вещь люблю, давайте ее использовать». Или: «Я эту вещь не люблю, давайте не будем ее использовать».
Вместо этого у нас используется другой подход. Когда формулируется какая-то задача, исследуются все доступные решения. Исследуются до уровня, когда мы можем сказать о применимости и не применимости в нашем случае, а также про достоинства и недостатки при решении проблемы. И в рамках этой вещи мы активно используем Ansible.

Почему Ansible? Это нетривиальный вопрос, потому что R&D отдел занимается немножко деплоем, но между мной и production достаточно большое расстояние. И классическая цепочка CI/CD нас касается, но в самом зародыше, еще до того, как попала в руки программиста. При этом Ansible используется очень активно.
В компании у нас используется не только Ansible. Используется еще и Chef. В одном из подразделений компаний использовался CFengine.
И вопрос: «Почему Ansible?» внутри компании иногда звучит, потому что есть фанаты других систем конфигураций.
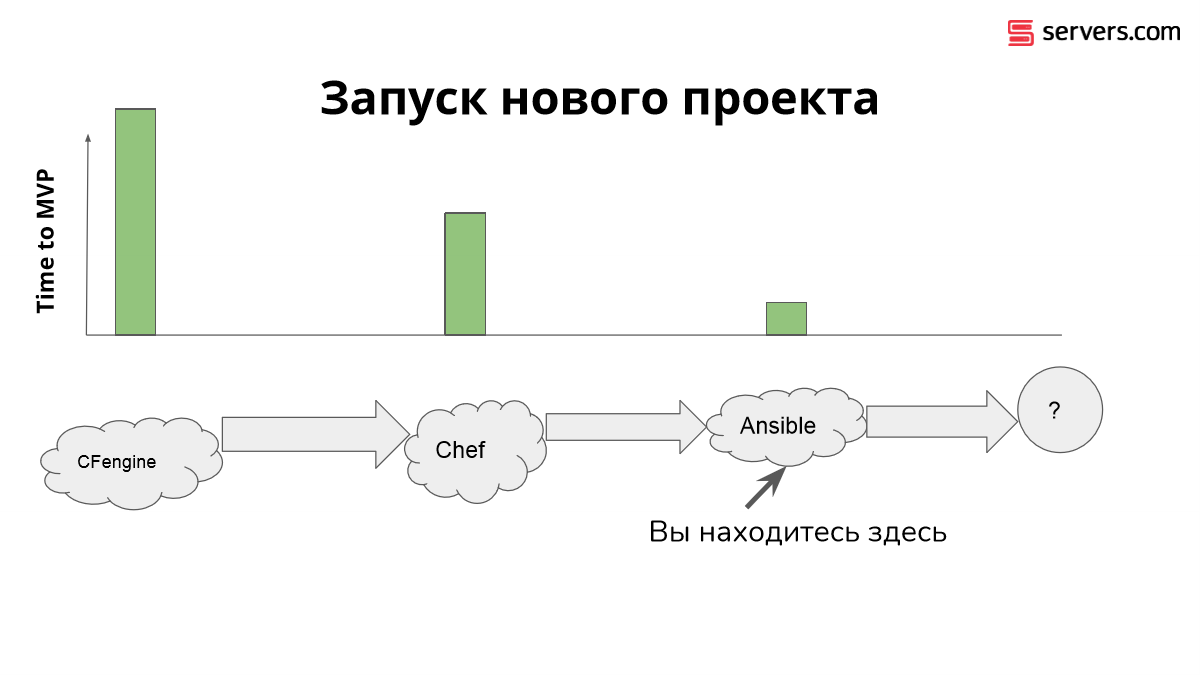
Основная причина состоит в том, сколько времени уходит на создание нового проекта.
Представьте себе, что у вас есть 20 минут на то, чтобы поднять небольшую веб-компанию, оставляя в стороне юридические вопросы. Через какое время у вас будет готов минимальный продукт обслуживания клиентов в режиме автоматизации, т. е. воспроизводимый?
Для Ansible вы начинаете писать playbook, который делает то, что нужно. Для Chef вам нужна какая-то начальная инфраструктура, т. е. сервер, а также вам надо обеспечить появление chef-клиента. И получается так, что на Ansible начать намного проще.
Однако после того, как вы начали, возникает следующая проблема.

После того, как вы написали приличного размера проект, дописать что-то новое в проект на Ansible оказывается тяжело. При том, что Ansible выглядит простым, писать на нем большие вещи оказывается очень-очень сложно.
На Chef тоже сложно, но не настолько сложно, как на Ansible.
 Когда я делал слайды, я решил выписать слоганы всех систем автоматизаций на рынке. И, как видите, у Ansible наиболее удачное рыночное позиционирование, потому что это единственный слоган, который можно хорошо прочитать.
Когда я делал слайды, я решил выписать слоганы всех систем автоматизаций на рынке. И, как видите, у Ansible наиболее удачное рыночное позиционирование, потому что это единственный слоган, который можно хорошо прочитать.
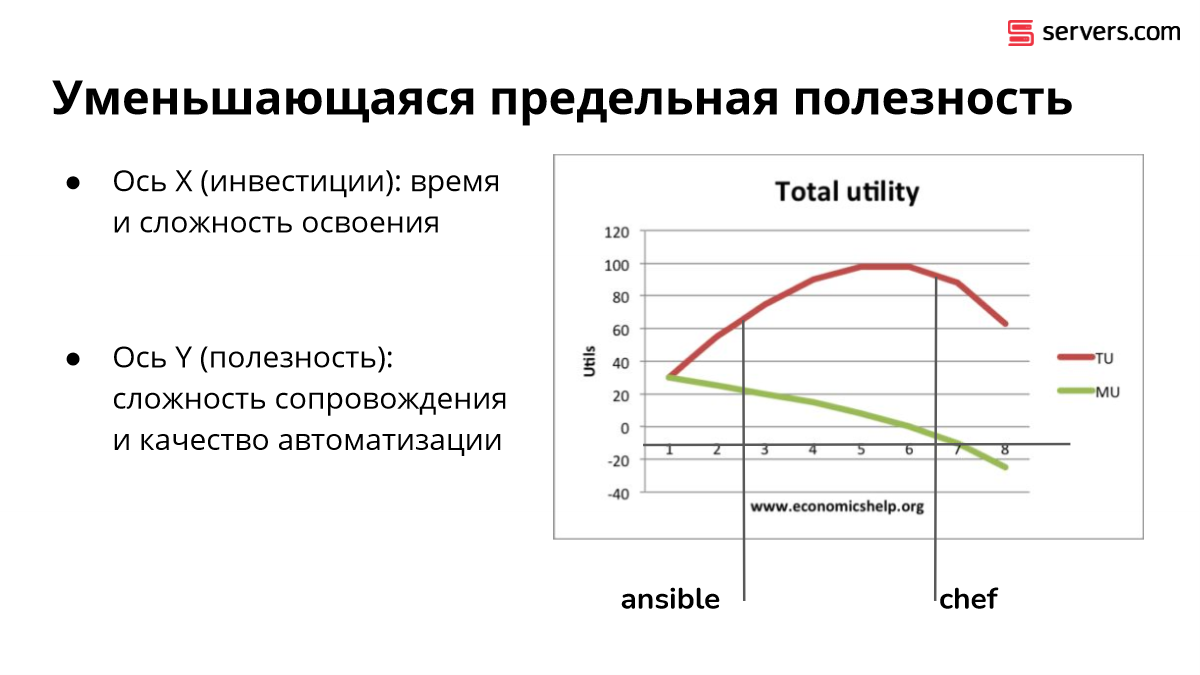
Есть второй аргумент, говорящий, почему Ansible оказался таким популярным. Существует экономическая теория про предельные полезности. Она говорит о том, что третье мороженое куда менее радостное, чем первое мороженое, которое получил.
Соответственно, чем больше усилий вкладывается, тем больше результат, но сам результат радует меньше. То есть появление автоматизации значит в компании больше, чем офигенная автоматизация. И если сравнить компанию, в которой так себе автоматизация и с очень хорошей автоматизацией, то они примерно похожи. Если сравнить компанию, у которой вообще нет автоматизации и компанию, в которой она есть, то между ними большая разница.
Моя личное мнение, что Chef слегка переусложнен. И если бы его сделали чуть-чуть попроще, то с меньшим количеством усилий был бы такой же результат.
Ansible находится в начале кривой. Это означает, что вот этот уровень качества на Ansible просто не достижим.
Повторю, что это касается больших проектов. Официально можно сказать, что у вас большой проект, когда в вашем проекте нет ни одного человека, который бы знал все аспекты проекта, т. е. проект командный, его пишут много человек. И каждый отвечает за свою область. В тот момент, когда у вас появляется ситуация, что какие-то углы вашего проекта вы не знаете, то у вас большой проект. Именно в этом месте Ansible не выдерживает.

Еще одна причина популярности Ansible – это сетевые устройства. Оказалось, что модель работы Ansible идеально ложится на конфигурирование сетевых и любых других устройств с API, потому что у Ansible отсутствует понятие агента, клиента, какого-то кода, исполнявшегося со стороны конфигурируемого устройства. Вместо этого Ansible приходит на сервер, на сетевое устройство и вносит туда изменение.

Поговорим о проблемах Ansible, которые приводят к ситуации появления плохого кода. Конечно, в плохом коде всегда виноваты люди, но инструментарии могут либо этому активно мешать, либо пассивно способствовать.
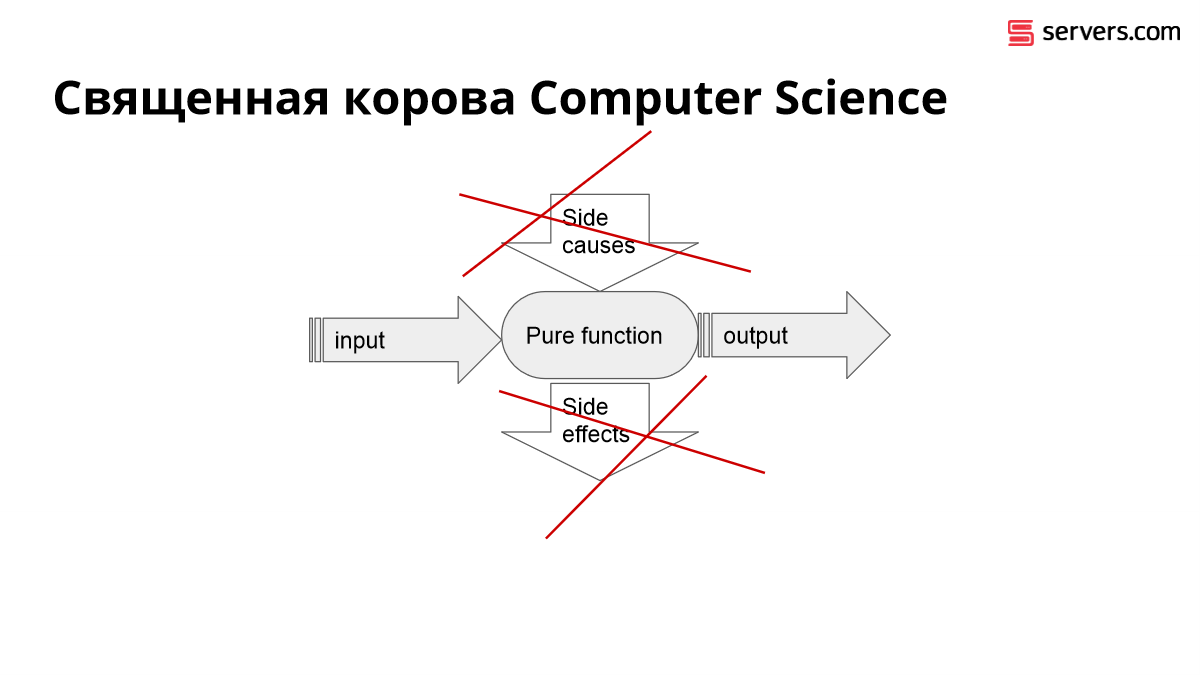
Священная корова Computer Science – это чистые функции.
Чистая функция принимает на входе аргументы и выдает результат. Каждый раз получая те же самые аргументы, она выдает тот же самый результат, ничего не меняет в системе.
- Такую функцию удобно тестировать.
- Такую функцию удобно рефакторить.
- Такую функцию удобно масштабировать.
- Такую функцию удобно анализировать на наличие или отсутствие ошибок, на сохранение инвариантов.
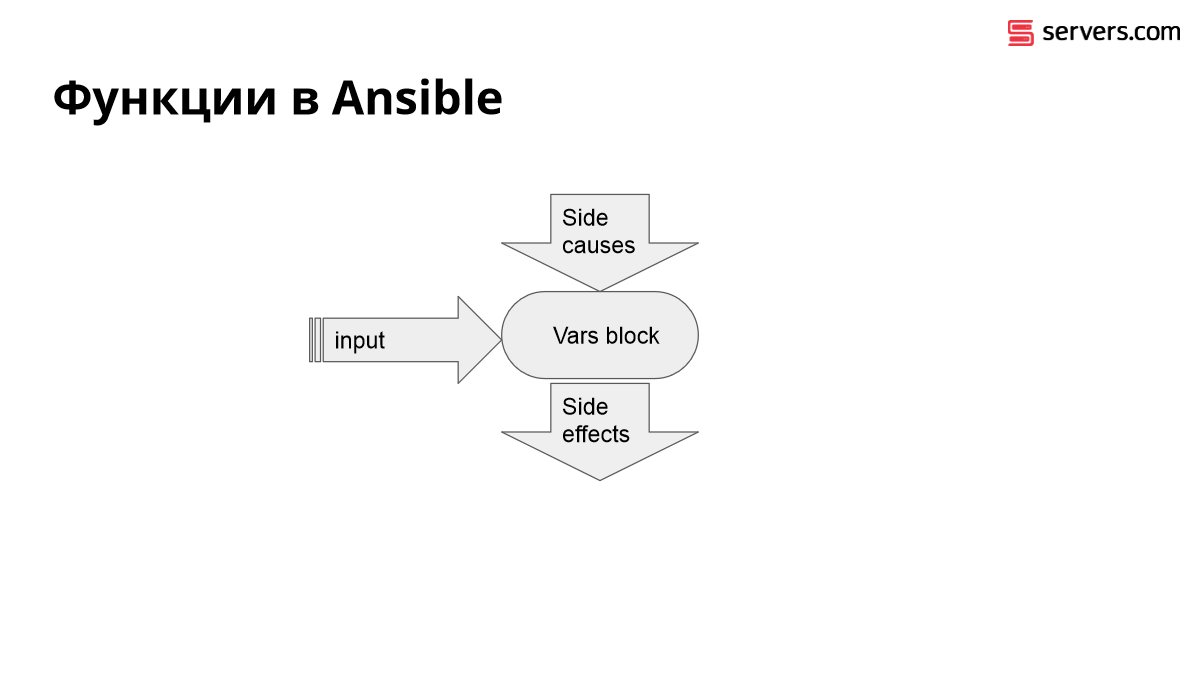
Вот так выглядит функция в Ansible. Вы не можете иметь output из функции Ansible. В Ansible нет функций. Ближайший его аналог – это выражение Jinja в блоке Vars, позволяющий осуществить вычисление.
У вас есть входное значение, на которое влияют side effects снаружи. И все, что он может сделать, это осуществить свои эффекты, поменяв один из слоев оверлеев переменных в глобальных переменных Ansible.
Вот так выглядят ожидания от Ansible у начинающих пользователей. Опытные пользователи знают, что выглядит это вот так:
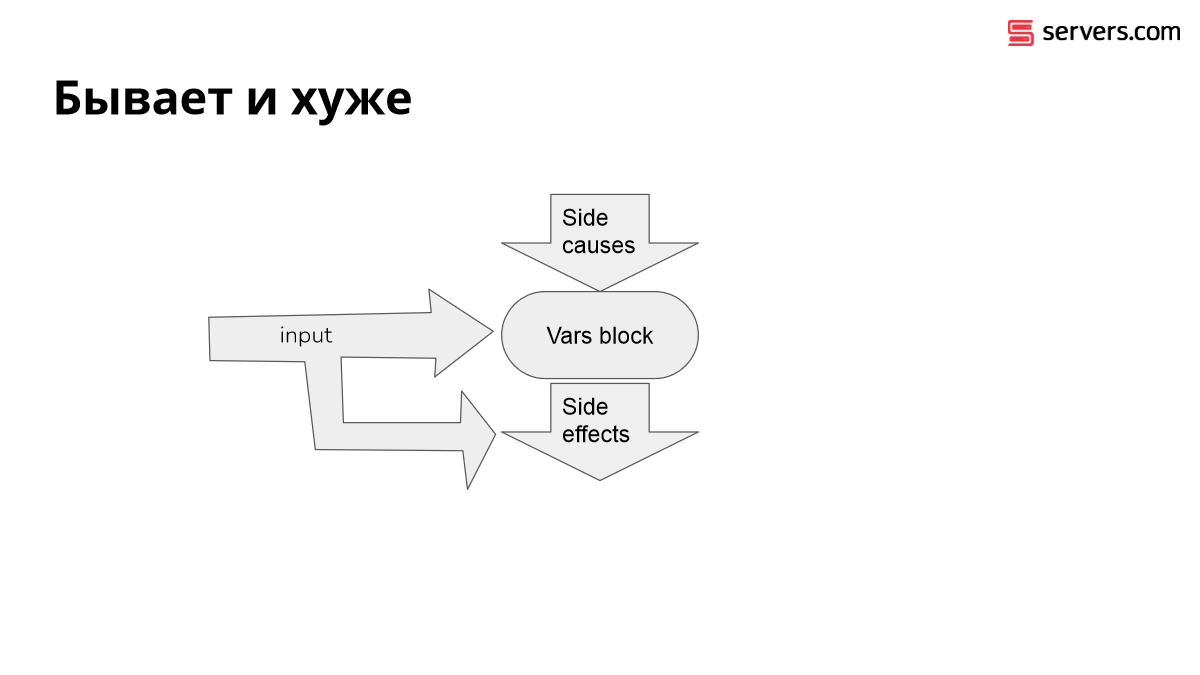
У вас есть входное значение, которое внутри себя может содержать, а может и не содержать side effects. И вы, будучи системным администратором, пишущим Ansible, не можете никаким образом запретить появление этого side effect.

Второй неприятный момент в Ansible – это модель переменной Jinja, которая запрещает вот такие простые вещи. Вы можете взять переменную X и записать в нее значение x. Для чего это нужно? Например, чтобы сказать, что внутри шаблона используется переменная вот с таким названием.
Аналогично мы не можем изменить композитные объекты. Мы не можем никаким образом кратко изменить словари и списки.
Существует несколько хаков, как можно все-таки сделать, но все они обладают одним из двух свойств: либо они невероятно большие и сложные, либо они обладают непереносимостью, т. е. то, что работает в одном месте, в другом месте вызывает неожиданное поведение.
И всем, кто хотел мне сказать про дефолтные значения, отвечу, что все это сломается в тот момент, когда вы будете это использовать внутри цикла.

Вместе с этим можно попытаться понять, какой Ansible будет хороший.
Хороший Ansible – это тот, который идет и делает то, что сказали. Он не думает, он не пытается принимать какие-то решения за пределами специфики конфигурации сервера.
И если вы ставите своей целью за минимальные усилия получить просто автоматизацию, то вы можете использовать Ansible.

А вот так Ansible нельзя использовать, т. е. получить максимальные результаты и приложить героические усилия. Усилия будут очень героические, а результаты будут еще хуже, чем, когда вы начали.

Когда я знакомился с Ansible, мне достался очень-очень сложный проект с программистами, которые не хотели думать про определенные аспекты работы сетевых устройств. И мне пришлось его реализовать на Ansible.
Вот это находится в третьем цикле вложенности. Вот это является переменной из цикла выше.
Когда я это написал, и оно заработало, я был собой очень горд. Когда я это рефакторил через пару лет, у меня было глубокое чувство неполноценности, потому что я не понимал, как это работает.
Ansible мне в этом очень сильно "помог", потому что на тот момент, когда я рефакторил, здесь чуть-чуть поменялась логика работы includes. И код работал, но не так.

Я много рефакторил, я много писал на Ansible. Я видел чужой код и я могу показать ошибки. Ошибки есть нескольких видов.

Сначала простые ошибки:
- Это нарушение идемпотентности.
- Попытка применения функциональной декомпозиции.
- Попытка программирования.
- И еще несколько вещей, про которые я расскажу.

Сначала простые ошибки.

Вот это типовая ошибка человека, который не понимает, как писать на Ansible. Он думает, что чем больше у него переменных, тем лучше. Он думает: «Почему у меня будет имя константа? Пускай у меня будут переменные в двух ролях». И это касается всего.
Признак такого синдрома, когда вы читаете код на Ansible, вы постоянно вынуждены прыгать по различным файлам. Так делать не надо.

Нарушение идемпотентности первого вида. Идемпотентность на входе означает, что вы можете снова и снова исполнять один и тот же play. Вот эта команда не может быть выполнена во второй раз. Во второй раз она сломается, потому что файла /etc/foo больше нет.
Тоже самое во втором примере. Просто сломается.

Нарушение идемпотентности на выходе позволяет Ansible работать, но ломает или ухудшает ситуацию в системе.
Например, если мы сделаем себе файл и попытаемся его перезаписать еще раз, то мы можем обнаружить, что, когда следующей задачей в него что-то записали, она его стерла.
Аналогично вот здесь. Мы будем по каждому прогону добавлять новые-новые строчки.

Еще одна ошибка – это сломанные теги. Теги нужны в Ansible для того, чтобы оператор мог выполнить кусок playbook и только. Они не используются ни для аннотации, они не используются ни для каких магических операций.
Вот здесь пример тега, который не работает, потому что мы зависим от предыдущей задачи, в которой тега нет.

Аналогичная проблема возникает вот здесь, когда мы в процессе письма начинаем использовать синонимы в тегах.
Не существует никакого метода выполнить эти две роли с помощью одного тега.
В больших проектах наблюдается часто разбегание знака подчеркивания, без знака подчеркивания, тега с префиксом, тега без префикса, тега на всякий случай, авось кому-то пригодится. Ничего этого не должно быть.
Теги расставляются операторами для того, чтобы контролировать какие куски кода исполняются.
Отдельные таски могут иметь свои собственные персональные теги для удобства отладки, но раскидывать теги просто так не стоит.

Следующая ошибка – это ошибка в расположении переменных. И это одна из самых фатальных ошибок, которую можно сделать в проекте.
Когда люди обнаруживают, что им нужно сконфигурировать несколько несвязанных сервисов на нескольких несвязанных серверах с использованием одной некой магической переменной, которую не хочется отдавать в inventory, они начинают думать, куда разместить эту переменную.
Существует много неправильных методов размещения этой переменной. Существует одно правильное место, где эта переменная должна быть – в playbook, который объединяет конфигурацию этих двух серверов.
Если вы положите в групповые переменные, если вы положите в дефолтные предварительно подключающиеся роли, то это все ухудшит ситуацию.

Последний паттерн в разработке характерен для Ansible больше, чем для языков программирования, точнее это антипаттерн.
Сводится он к тому, что люди начинают писать на Ansible. Пишут довольно большой кусок кода. И понимают, что они могут написать лучше. Придумывают, как писать лучше. Продолжают писать лучше. К тому времени, как заканчивают писать лучше, они пишут еще лучше. И следующие роли они пишут еще лучше. И весь проект состоит из бесконечных слоев все больше хорошего кода, при этом старый код остается в том виде, в каком он был, полагаясь на ошибочные предположения, неправильное расположение переменных и т. д.
Каждый последующий еще более умный прием делает ситуацию все хуже и хуже, и хуже.
Бороться с таким паттерном можно только одним образом – не умничать с применением новых решений. Лучше держаться одного стиля в течение одного проекта, чем постоянно экспериментировать с новыми стилями.

Последняя ошибка, которую я встречал довольно много. Она касается больше пользователей Kubernetes. Это шаблонизация YAML и шаблонизация JSON.
Jinja и YAML не совместимы в том смысле, что вы никогда не сможете сгенерировать хороший YAML с помощью циклов в подстановке переменных и других ужасов Jinja. Вместо этого нужно взять структуру данных, которую вы хотите записать в JSON или в YAML и записать с помощью фильтра to_nice_yaml.
Это кажется ерундой до тех пор, пока вы не обнаруживаете гигантский проект, в котором несколько тысяч строк кода посвящено подготовке данных для того, чтобы записать с помощью Jinja в YAML-файл.
Это была простая часть. Это вещи, которые практически любой пользователь Ansible начинает чувствовать довольно быстро.

А сейчас я хочу рассказать про главную вещь. Я с этой мыслью бегаю уже, наверное, месяц. Это мысль о проблеме связанности внутри проекта.

У coupling есть определение. Это из очень умного стандарта. Нас интересует вот это. Ситуация, когда один кусок программного обеспечения полагается на детали реализации внутри другого куска программного обеспечения.
Ansible не предоставляет возможности уменьшать coupling. Не существует инструмента внутри, с помощью которого вы можете уменьшить степень связанности в вашем проекте.
Единственный метод – поддерживание дисциплину в голове.

Вот примеры ошибок.
Этот пример мне очень понравился, потому что я его увидел на код ревью. Я не знал, что так можно, но это было очень ошибочно. В корне проекта лежал общий YAML-файл, который включался из двух разных ролей.
Эта относительно невинная ошибка создает зависимости роли 1 от роли 2 и наоборот, потому что роль 2 не знает, кто будет использовать этот файл. И в момент рефакторинга роли 2, если мы вот сюда внесем изменения, мы сломаем роли. Не существует механизма, с помощью которого, глядя вот сюда, можно понять, что мы ломаем роль 2.
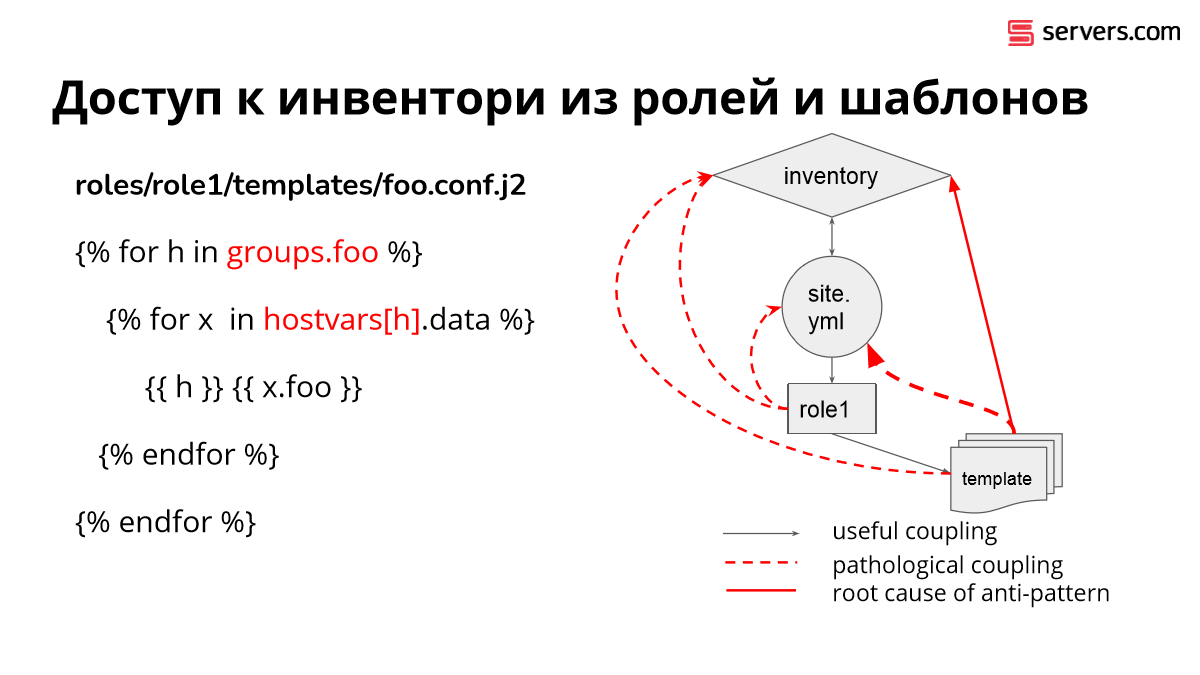
Вот это шаблон, который присутствует в 80 % всех проектов на Ansible, когда мы берем шаблон и начинаем шариться в группах и в переменных соседних хостов. Это почти фатальная ошибка. Проект, в котором такое появляется, обречен на тяжелый рефакторинг.
Основная причина в том, что у нас самый нижний уровень иерархии внезапно лезет вот сюда. Человек, который это пишет, абсолютно не может себе представить, что в какой-то второстепенной роли есть шаблон, внутри которого кто-то ожидает, что у него будет такая-то роль.
Более того, он не может себе представить, что там кто-то ожидает переменную на хостах, к которым эта роль не имеет отношение.
Несколько таких вещей создают спагетти в коде. И этого следует избегать любой ценой. Благо, в отличии от многих других случаев, Ansible предоставляет простой способ этого избежать. Надо сбор этих переменных вынести вот сюда. Playbook апеллирует понятием host. В нем написано: host:, т. е. связь между inventory и playbook не является патологической. Это то, что все ожидают.
Если вы в этом месте соберете все нужные данные и поместите их в переменную, то роль, получив переменные из playbook и передав в template, не создаст патологической связи.
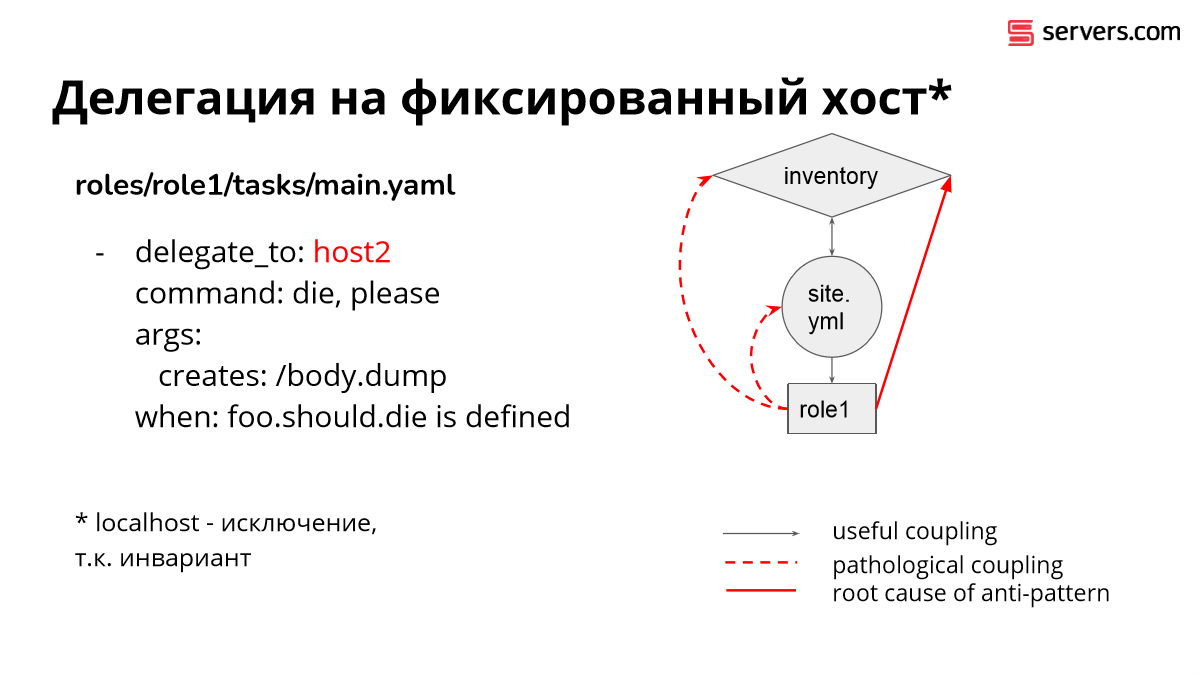
Следующая практически эквивалентная вещь происходит очень часто. Это делегация на константное имя хоста. Абсолютно эквивалентная проблема – роль полезла в inventory.
Роль никогда не должна трогать объекты из inventory, которые не относятся к переменным, которые доступны сами по себе. Как только мы лезем в hostvars из роли, мы делаем что-то не так. Как только мы упоминаем имя хоста, мы делаем что-то не так.
Как эту проблему решать? Абсолютно эквивалентным образом. Укажите имя хоста, куда надо делегировать в виде переменной на уровне play.

Следующая проблема, к сожалению, не имеет решения в Ansible. И это является лимитом Ansible по сложности. Это случайные коллизии между именами переменных.
Если роль в одной части проекта выставила значение переменной, в силу перекрытия (shadowing) переменных вот это значение может прилететь в другую роль.
Случайное выставление vars в одном месте может поменять значение для другой роли.
Тоже самое касается set_facts, которые могут случайно затереть чужой default. В Ansible нет механизмов, которые позволяют такие вещи обнаружить.
Единственный метод с этим бороться – это дисциплина в проекте, именование переменных и все.

Плохой проект на Ansible выглядит вот так, причем это довольно маленький проект. 5 ролей, 3 playbooks, 1 inventory.
Для того чтобы это исправлять, нужно идти и резать линки с патологическими связями.
Как только вы убираете патологические связи в проекте, как только вы перестаете полагаться на поведение соседних ролей, как только вы перестаете лазить в чужие объекты, в этот момент у вас появляется свобода рефакторинга.
Роль должна сохранять свой функционал, если открыть inventory и переименовать все группы. Например, взять и каждой группе дописать единичку, запустить проект. Проект должен показать 0 changing. Если что-то сломалось, значит вы сделали что-то не так.

Я нахожусь в смешанных чувствах относительно Ansible, потому что на Ansible быстро сделать, но вот эти проблемы являются ограничителем роста. Если честно, то я жду от индустрии лучшего Ansible, т. е. с более хорошей типизацией, с локальными переменными и с возможностью масштабироваться без оглядки на соседние элементы в проекте.
Мои личные советы по поводу, что делать в Ansible.

Не нужно бороться за компактность кода. Куда лучше написать 200 строк копи-пастом с небольшими изменениями, чем пытаться быть очень умным и использовать несколько includes. Как только вы используете несколько includes, вы вступаете в сложную область видимости переменных.
Существует несколько ошеломительных случаев, когда роль может быть доступна из одного слоя, а значения будут уходить в другой слой. Т. е. роль получает на входе переменную значением 2, говорит: «Я эту переменную выставляю в 3», роль продолжает видеть значение 2. И далее роль заканчивается, следующая за этой ролью получает значение 3. Это выглядит абсолютным абсурдом, когда разработчики Ansible говорят: «Все правильно», а окружающие люди говорят: «Не делайте так».
Проблема с любыми includes, import состоит в том, что вы никогда не знаете, как не надо делать. Вы об этом узнаете потом, после специального тест-кейса.

Никаких чистых функций. Соответственно, если у вас нет чистых функций, вы не можете реализовать бизнес-логику. Чем меньше вы принимаете решений в коде, тем лучше.
В Ansible есть единственная вещь, на которую можно всерьез положиться и ожидать, что она будет исполняться хорошо, это порядок исполнения тасок.
Как только вы пытаетесь это изменить с помощью дополнительных условий, циклов, импортов, includes вы обнаруживаете, что проект становится менее устойчивым, потому что Ansible хорошо делает линейное исполнение кода.

Как я уже сказал, механизмов уменьшения связностей нет никаких.
Единственный метод уменьшить связностей в проекте Ansible – разделить его на 2 playbooks и запускать в 2 раздельных запуска Ansible. Потому что в любой момент любая самая маленькая роль где-то в углу может пойти и поменять критически важную переменную для другого участка кода. Соответственно, это требует особой дисциплины.
У меня есть внутренние убеждение, что Ansible сильно напоминает C. У вас очень много undefine behavior, у вас очень простой язык с очень сложными последствиями.

Последний вопрос, который я хочу поднять, это написание своих модулей и плагинов для Ansible.
Тут есть два разных случая, каждый из которых надо разобрать отдельно.
Первый случай – вы пишете бизнес-логику на Ansible. пишете, пишете, пишете. В какой-то момент вы понимаете, что вы больше не можете писать бизнес-логику на Ansible. Говорите: «Ок, я пойду писать плагин». И пишете плагин, который реализует самую сложную часть бизнес-логики.
То, что вы получаете при этом в проекте: у вас бизнес-логика на Ansible; самая сложная часть переключается с одного языка на другой язык программирования.
А дальше, когда вы сопровождаете проект, вы обнаружите, что бизнес-логика обладает свойством чуть-чуть меняться, потому что бизнес адаптируется к реальности. И в те моменты, когда нужно сделать маленькие изменения, их обычно делают в Ansible. Получается, что через некоторое время код Ansible не совсем соответствует python’ному коду. Еще через несколько изменений вы обнаруживаете, что python’ный код активно мешает Ansible. И вы начинаете бороться со своим собственным кодом. И обычно это заканчивается победой Ansible – код либо переписывают, либо убирают.
Ключевая проблема здесь состояла в том, что вы начали делать бизнес-логику на Ansible, а плагином вы усугубили последствия.
Второй случай программирования – это когда вы обнаруживаете, что вы снова и снова пишете одну и ту же конструкцию тасок, чтобы получить список адресов на интерфейсе и проверить есть ли мой адрес в списке интерфейса. Если нет, то повесить его на интерфейс. В этой ситуации абсолютно разумно пойти и написать модуль на Ansible.
В отличие от плагинов, которые глубоко завязаны на внутренности самого Ansible, модули автономные. Они могут быть написаны на любом языке программирования. Python более любим, но если вы хотите, то вы можете писать модули на Go, на Ryby, на чем хотите.
Модуль получает на stdin параметры, выводит на stdout JSON результат – поменялось или нет. Ansible копирует модуль на сервер, запускает, берет результат.
Соответственно, написав модуль, вы получаете стабильный интерфейс, который не ломается от версии к версии Ansible и получаете более компактный код роли или playbook.
Очень важно понимать разницу: когда вы пишете модуль, вы просто пишите код, который просто что-то делает; когда вы пишете lookup-плагин с целью облегчить себе работу со строчной структурой, то пишете бизнес-логику. В Ansible не надо писать бизнес-логику.

Но, что делать, если вы оказались в ситуации, когда в вашем проекте бизнес-логика требуется, потому что это бизнес-проект? Ответ – использовать внешние инструментарии.
Внешние инструментарии можно использовать двумя разными образами:
- Внешний инструментарий может подготовить все для запуска Ansible, принять за него решение и записать, что нужно сделать.
- Ansible может прийти к внешнему проекту и попросить принять решение.
Издалека кажется, что это практически одно и то же, но на самом деле есть большая разница.
Когда кто-то подготовил данные для Ansible и запустил его, то у вас есть эти данные, вы можете повторить попытку, если что-то пошло не так.
Если же Ansible пошел за данными в реальном времени по http, то вы не можете воспроизвести эту ситуацию, потому что вы оказываетесь завязаны на логику внешнего сервиса, который вы не можете воспроизвести на своей машине.
В то же самое время, если у вас есть сгенерированные файлы, с которыми Ansible запускается, то вы можете повторить снова и снова до тех пор, пока не найдете место, где ошибка.

Спасибо большое за этот доклад! Это огромная боль. У меня дополнение. В магическом квадранте Gartner систем управления конфигураций есть уже лидеры индустрии и есть те, кто только подбирается. Ansible из тех, кто только подбирается, а Chef и Puppet в лидерах. Они у большинства стоят и по всем характеристикам для масштабирования больше подходят.
Тут есть классическая проблема. У меня есть мысль о том, что на рынке побеждает наиболее плохой из достаточно работающих продуктов.
CFEngine не смог победить, поскольку он слишком плохой, а Ansible достаточно хороший, чтобы его можно было терпеть. И он самый плохой из всех существующих.
На самом деле это «плохо» имеет под собой оборотную сторону, потому что хорошо написанный код на Ansible вызывает вопрос: «А что тут было писать?». У вас таска, таска, таска. Поставились, записали шаблон, перезапустили, поставили, перезаписали, запустили.
Написать такой код иногда сложно, потому что нужно каким-то образом догадаться, как бизнес-логику влить в этот простой процесс. Но, если вы хорошо написали код на Ansible, он ни у кого не вызывает вопросов. Он читается линейно, он простой, понятный. Чем меньше там условий, handlers, сложных трюков, циклов, тем он лучше.
Хорошо написанный код должен по второму запуску показывать 0 changes, не ломать ничего при втором запуске, представлять из себя линейный список тасок, возможно, с подключением ролей, которые что-то конфигурируют. Каждая роль может быть перевешана на другой сервер и не ломаться от этого. Не должно быть зависимостей от странных эффектов в Ansible. Например, можно в handler на notify посылать следующему handler. А если handler написать с when, то вы получаете замечательную event-машину, которую можно писать неограниченно долго.
Но есть одна маленькая проблема. Handlers срабатывают по какому-то начальному событию. Поэтому, если у вас эта цепочка сломается, допустим, изначального события не будет, и ничего не случится, и система останется не сконфигурированной. Поэтому хорошо написанный Ansible выглядит тривиально.
Вопрос. Писать свои роли или использовать сторонние? Свои – понятней, поэтому максимально хорошо получится, а сторонние…
Все очень просто. Вы открываете роль, ее таск. И если она вам также понятна, как то, что вы написали, это хорошая роль. Если вы смотрите на Debops и думаете, что тут какая-то странная зависимость, они что-то от меня странное ожидают, то задумайтесь использовать или нет. Эта роль решает чью-то бизнес-задачу. И на вас пытаются повесить чужое бизнес-решение, которое нельзя делать.
Я из проекта в проект таскаю роль, давно взятую с Galaxy. Она мне нравится тем, что я ее открываю, она тривиальна. Да, не сэкономили 2 экрана текста. Я сам сяду и за 15-20 минут напишу те же 2 экрана. Поэтому переиспользование ролей – это не работа с Knife. Если кто понимает, то в Chef – это система управления cookbooks. Это не Knife, это не сложная система зависимостей с рецептами, интерфейсами, провайдерами.
Как раз из проекта, из которого я показывал черный скриншот, он живее всех живей. В нем несколько десятков тысяч строк. И я постепенно его вывожу из этой бездны. И в процессе выведения мне все еще приходится делать двойной цикл.
Спасибо за доклад! Вся эта боль очень знакома. Как вы относитесь к Tower или AWX в данном случае? Может ли он исправить какую-то боль? Точнее может ли он уменьшить какую-то боль?
И второй вопрос. Если более безболезненно переходить, то это Chef или что-то другое?
Я не зря на первом слайде нарисовал вопросительный знак после стрелочки. Потому что у меня значительно меньше опыта на Chef. И, если честно, то мне не нравится в Chef попытка описать infrastructure as code. Это подразумевает, что у вас такой же уровень контроля над infrastructure, какой есть у программиста над моделью памяти. Но это не так. В системном администрировании нам кто-то когда-то пообещал, что есть такое понятие и оно работает вот так. Потом мы приходим и обнаруживаем, что у нас висит процесс в состоянии D+. И все, что нам рассказывали про то, что kill -9 гарантированно убьет процесс, это не так.
И это происходит в каждом моменте. Это не только в ядре. Системное администрирование значительным куском состоит из устного предания о том, где разложены грабли, а где мины. По граблям не так больно.
И попытка описать это как код наталкивается на то, что компьютер, для которого мы пишем, противоречив. Поэтому попытка описать инфраструктуру как код наталкивается на необходимость выполнения большого количества defense-приемов в программе, которые все равно не дают гарантий успеха. Вы все равно будете зависеть от нюансов.
Есть священный Грааль, что мы описываем инфраструктуру как код и она работает как код. Но мы знаем, что просьба программистам написать без багов вызывает недоумение. И то же самое в инфраструктуре.
А еще проблема состоит в том, что на это требуются огромные усилия. Если средняя компания может себе позволить, например, 50 разработчиков, которые пишут продукт, которые приносят компании деньги, и если начальник сопровождения придет и скажет, что мне нужно 50 администраторов для того, чтобы все те же сервера делали тоже самое, но у нас все было описано как код, то обычно это "нет". Потому что если у вас есть 50 администраторов, то у вас обычно задачи такого уровня, которые для описания как код потребуют 500 человек, а, может, 1 000 человек. А, может, это вообще будет невозможно сделать, потому что это противоречиво.
Задача у Tower – это аудит, кто и что запускал. Вся система доступа к Ansible на самом деле прекрасно заменяется любой job’ой Jenkins, Gitlab-CI и т. д.
Это приятно видеть, но на самом деле .gitlab-ci.yml заменяет собой примерно половину Tower.
Я понимаю бизнес-модель Ansible до покупки компанией Red Hat. Модель была – продать красиво интерфейс и дать иллюзию контроля за тем, что мы контролируем, что будет происходить на серверах.
Во-первых, это иллюзия, потому что Ansible не контролирует, что происходит на серверах. А, во-вторых, существующие инструментарии, на мой взгляд, заменяют его в полном объеме.
Если честно, модель RBAC к серверам где-то на уровне контроля доступа к исполнению playbook – слишком далекая от production. И даже Netflix, который использует хитрейшую систему с ssh-сертификатами для доступа на production-сервера, использует более близкий к production метод. И можно увидеть, что человек сделал.
Не решило бы много проблем внедрение тестирования?
Я 4 раза пытался начать использовать Молекулу. Я 4 раза заканчивал это делать. В последний раз я обнаружил, что Молекула копирует файл, связанный с выбором провайдеров в tmp. Использует этот файл и больше не читает файл, который я пишу. Т. е. если я меняю провайдера, то Молекула это игнорирует до перезагрузки моего компьютера. И где-то на этом месте я ее закрыл.
Потом человек, который использует Молекулу, сказал, что в основном ее используют для того, что запустить linter и проверить, что роль ничего не меняет во второй раз. Обе эти задачи прекрасно решаются двумя jobs в ci без особых затруднений.
Я бы очень хотел увидеть хорошее фреймворковое тестирование Ansible, но проблема в том, что нужно исправлять интерфейс между Ansible и Jinja. Потому что: Ansible – внутри Python, а Jinja – внутри YAML. И там происходит самая страшная вещь, которая может произойти. Нет другого языка программирования (если считать Ansible языком программирования) в существующей индустрии с настолько плохой типизацией.
Например, есть выражения в Jinja. Ansible приходит и дописывает выражение Jinja: if что-то true else false. А потом запускает Jinja. Получает строку. И эту строку пытается прочитать как YAML или JSON. И если у вас в этом месте проскакивает лишний пробел, какие-то вещи, которые смущают парсер YAML, то вы можете обнаружить, что у вас вместо словаря, например, строка. Ни в одном языке программировании такого ужаса нет: ни в Javascript, ни в PHP.
Если известна проблема, что с Ansible такие вещи происходят, то существуют ли какие-то инструменты, которые могут эти вещи подсветить, автоматизировать?
Во-первых, Ansible-lint – лучше, чем кажется. Некоторые вещи, которые он требует сделать в коде, ловят часть проблем Ansible. Ansible-lint ловит все, что можно поймать статическим анализом. Но так как у Ansible отсутствует модель переменных в том виде, какая она есть во всех языках программирования, поэтому невозможно сделать статический анализ.
Я примерно описываю модель того, что происходит с переменными, но я не до конца уверен, что я делаю правильно. В Ansible массив глобальных переменных. Каждая переменная всегда глобальная. Но в некоторых моментах времени на него накладывается overleaf. Тот самый presage, который описан в переменных, т. е., что переменные в set_facts важнее, чем переменные в default. Этот происходит не в тот момент, когда значение записывается. Это не вопрос: «Какой из вариантов выбрать?». Это определяют некие прозрачные, трудноуловимые в самом Ansible слои, пока эта переменная действует. Слой закончился, переменная возвращается к своему старому значению.
Любой человек, который делал include c set_fact, импорты ролей с переменными, передаваемыми в импорт, наверное, рано или поздно на эту проблему натыкается. Поскольку границы не формализованы, нет в двух предложениях описания, что это такое. А ещё в Ansible их постоянно подкручивают, пытаясь придать им подобие полезности. А на выходе мы имеем, что в 2.6, 2.7, 2.8 и 2.9 каждый раз includes, импорты ломают странным образом чуть-чуть. Тут поломали, тут поломали.
Самый красивый баг, который я знаю, был в тот момент, когда выполнение то ли импорт-роли, толи include-роли перестало уважать delegate. Мы говорили, что импорт-роль delegate, такой-то хост. А потом оно перестало уважать. И все, что было написано, сломалось молча на другом хосте. И обнаружилось это не в тот момент, когда мы исполняли, а в самом конце. Приложение ожидает, что эти файлы есть, а вдруг выясняется, что они на другом сервере. Меня это задержало на миграцию на 2.6, пока не написал минимальный тест-кейс. Потом тоже самое сделали на 2.7, 2.8, и сейчас на 2.9.
Как я уже сказал, в последний раз я обнаружил следующую вещь. Пишется простой playbook. Import role vars x=1. Внутри роли написано: set_facts x=2, debug var=x. и после импорта роли мы снова говорим: debug var=x. Т. е. мы передаем переменную в роль, меняем ее там, выводим, завершаем роль, выводим.
Нормальные люди ожидают, что, если мы в роли написали 2, то мы увидим 2. Роль закончилась, но мы либо ничего не увидим, либо увидим последнее значение. То, что мы видим в реальности, совершенно противоположно. Роль видит ту переменную, которую ей передали 1, она говорит: set_fact x=2. Чему равно х? 1. Роль заканчивается, слой убирается, set_fact выставил х в 2. И несмотря на то, что там написано х 1, нам выводят, что это 2. Т. е. полная противоположность от ожиданий.
Импорт-роль, include-роль находятся в превью все эти годы. Их постоянно меняют.
Еще вопрос возник. Во всей этой истории есть ли место Terraform? Что вы об этом думаете?
У Terraform есть второй фатальный недостаток. Первый – не я его писал, а второй фатальный недостаток состоит в том, что внутри Terraform заложена коммерческая бомба.
Коммерческая бомба состоит в том, что Terraform не может использоваться командой без общего state. Terraform генерирует файл в states. Он важен для n+1 provisioning. И для open source версии Terraform говорит: «Делайте, что хотите. Git, locks, синхронизации – изобретайте сами». Коммерческим пользователям мы делаем хорошо.
Соответственно, для меня продукт, в котором ключевую вещь для коллаборации закрывают от пользователей, опасен. Посмотрите на docker. Должен быть open source проект, а на самом деле нет.
Ansible и Terraform не являются конкурентами вообще нигде, потому что вы не можете сделать то, что делает Terraform с помощью Ansible и обратно тоже. Вы не можете нормально конфигурировать сервера внутри с помощью Terraform.
Terraform – это фактически декларативный метод заказа услуг. Они это называют provisioning, а на самом деле вы либо сами себе эти услуги предоставляете, либо предоставляют сторонние провайдеры. Terraform – это стандартизированный метод заказа услуг у сторонних поставщиков через машинобогатый интерфейс. Они находятся очень рядом друг с другом, но Terraform работает, грубо говоря, до прихода Ansible.








