Современный этап развития технологий, в том числе и вычислительной техники, показывает нам рост объёмов данных и потребностей во все более мощных вычислителях. В основе развития центральных процессоров всегда лежала технология увеличения числа транзисторов на кристалле микропроцессора. Известный закон Мура гласит: «при сохранении этой тенденции мощность вычислительных устройств за относительно короткий промежуток времени (24 месяца) может вырасти экспоненциально»
Однако, тот же Мур в 2003 году опубликовал работу «No Exponential is Forever: But „Forever“ Can Be Delayed!», в которой признал, что экспоненциальный рост физических величин в течение длительного времени невозможен. Лишь эволюция транзисторов и технологий их изготовления позволяла продлить действие закона ещё на несколько поколений.
В 2007 году Мур заявил, что закон, очевидно, скоро перестанет действовать из-за атомарной природы вещества и ограничения скорости света. На текущий момент предельный размер транзистора в процессоре составляет 5 нанометров. Имеются также пробные образцы трёхнанометрового процессора, но его выпуск начнётся не раньше 2021 года. Это говорит о том, что в скором времени дальнейшее увеличение количества транзисторов на кристалле прекратится (пока не будет открыт новый материал или кардинально обновлен технологический процесс).
Одним из решений данной проблемы являются параллельные вычисления. Под этим термином понимается такой способ организации компьютерных вычислений, при котором программы разрабатываются как набор взаимодействующих вычислительных процессов, работающих параллельно (одновременно).
Параллельные вычисления по способу синхронизации делятся на два вида.
В первом варианте взаимодействие процессов происходит через разделяемую память: на каждом процессоре мультипроцессорной системы запускается отдельный поток исполнения. Все потоки принадлежат одному процессу. Потоки обмениваются данными через общий для данного процесса участок памяти. Количество потоков соответствует количеству процессоров. Потоки создаются либо средствами языка программирования (например, Java, C#, C++ начиная с C++11, C начиная с C11), либо с помощью библиотек. При этом возможно создавать потоки явно (например, в С/C++ с помощью PThreads), декларативно (например, с помощью библиотеки OpenMP), либо автоматически – встроенными средствами компилятора (например, High Performance Fortran). Описанный вариант параллельного программирования обычно требует какой-то формы захвата управления (мьютексы, семафоры, мониторы) для координации потоков между собой.
Во втором варианте взаимодействие осуществляется при помощи передачи сообщений. На каждом процессоре многопроцессорной системы запускается однопоточный процесс, который обменивается данными с другими процессами, работающими на других процессорах, с помощью сообщений. Процессы создаются явно, путём вызова соответствующей функции операционной системы, а обмен сообщениями производится с помощью специальной библиотеки (например, реализация протокола MPI), или с помощью средств языка (например, High Performance Fortran, Erlang или occam).
Кроме двух вышеописанных, применяется также и гибридный вариант: на многопроцессорных системах с распределённой памятью (DM-MIMD), где каждый узел системы представляет собой мультипроцессор с общей памятью (SM-MIMD), можно использовать следующий подход. На каждом узле системы запускается многопоточный процесс, который распределяет потоки между процессорами данного узла. Обмен данными между потоками на узле осуществляется через общую память, а обмен данными между узлами — через передачу сообщений. В этом случае количество процессов определяется количеством узлов, а количество потоков — количеством процессоров на каждом узле. Гибридный способ параллельного программирования более сложен (требуется особым образом переписывать параллельную программу), но наиболее эффективен в использовании аппаратных ресурсов каждого узла многопроцессорной системы.
В данной статье я предлагаю адаптировать такой гибридный подход для распараллеливания вычислений на языке Python. Ключевой особенностью работы является использование технологии docker-контейнеров. Разрабатываемый фреймворк будет иметь клиент-серверную архитектуру, включающую следующие элементы.
На стороне клиента:
На стороне сервера:
Общая архитектура разрабатываемой системы представлена на рисунке.
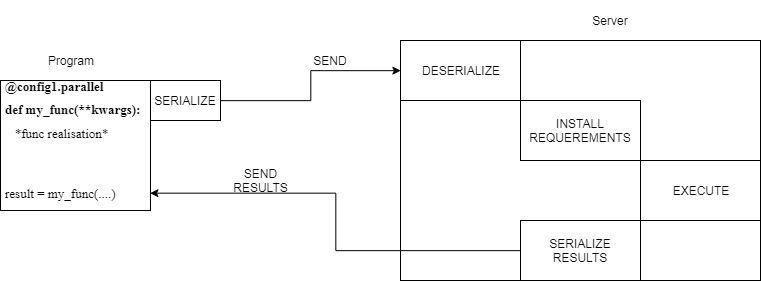
Для связи между клиентом и сервером могут использоваться сокеты либо фреймворк twisted, взаимодействие с которыми будет выполняться посредством разработанного API.
Реализация данной системы предполагает использование технологии docker. Это позволяет обеспечить удобство и высокую скорость настройки ПО для начала работы: достаточно запустить кластер docker-swarm, развернуть docker-образ на выбранном сервере и выставить количество репликаций.
Другими важными плюсами применения технологии docker являются создание однородной вычислительной среды путем виртуализации UNIX-подобной системы(Ubuntu – облегченная Alpine Linux), а также наличие swarm-режима, который позволяет запускать множества контейнеров на разных серверах и оперативно балансировать нагрузку, перебрасывая задания на свободные контейнеры.
Разрабатываемый фреймворк может найти применение в различных областях, где требуется выполнять большие объёмы вычислений на языке Python, в том числе для задач машинного обучения и глубокого анализа данных, а также для более простых задач – например, для распределённой проверки решений при проведении олимпиад по программированию.
Однако, тот же Мур в 2003 году опубликовал работу «No Exponential is Forever: But „Forever“ Can Be Delayed!», в которой признал, что экспоненциальный рост физических величин в течение длительного времени невозможен. Лишь эволюция транзисторов и технологий их изготовления позволяла продлить действие закона ещё на несколько поколений.
В 2007 году Мур заявил, что закон, очевидно, скоро перестанет действовать из-за атомарной природы вещества и ограничения скорости света. На текущий момент предельный размер транзистора в процессоре составляет 5 нанометров. Имеются также пробные образцы трёхнанометрового процессора, но его выпуск начнётся не раньше 2021 года. Это говорит о том, что в скором времени дальнейшее увеличение количества транзисторов на кристалле прекратится (пока не будет открыт новый материал или кардинально обновлен технологический процесс).
Одним из решений данной проблемы являются параллельные вычисления. Под этим термином понимается такой способ организации компьютерных вычислений, при котором программы разрабатываются как набор взаимодействующих вычислительных процессов, работающих параллельно (одновременно).
Параллельные вычисления по способу синхронизации делятся на два вида.
В первом варианте взаимодействие процессов происходит через разделяемую память: на каждом процессоре мультипроцессорной системы запускается отдельный поток исполнения. Все потоки принадлежат одному процессу. Потоки обмениваются данными через общий для данного процесса участок памяти. Количество потоков соответствует количеству процессоров. Потоки создаются либо средствами языка программирования (например, Java, C#, C++ начиная с C++11, C начиная с C11), либо с помощью библиотек. При этом возможно создавать потоки явно (например, в С/C++ с помощью PThreads), декларативно (например, с помощью библиотеки OpenMP), либо автоматически – встроенными средствами компилятора (например, High Performance Fortran). Описанный вариант параллельного программирования обычно требует какой-то формы захвата управления (мьютексы, семафоры, мониторы) для координации потоков между собой.
Во втором варианте взаимодействие осуществляется при помощи передачи сообщений. На каждом процессоре многопроцессорной системы запускается однопоточный процесс, который обменивается данными с другими процессами, работающими на других процессорах, с помощью сообщений. Процессы создаются явно, путём вызова соответствующей функции операционной системы, а обмен сообщениями производится с помощью специальной библиотеки (например, реализация протокола MPI), или с помощью средств языка (например, High Performance Fortran, Erlang или occam).
Кроме двух вышеописанных, применяется также и гибридный вариант: на многопроцессорных системах с распределённой памятью (DM-MIMD), где каждый узел системы представляет собой мультипроцессор с общей памятью (SM-MIMD), можно использовать следующий подход. На каждом узле системы запускается многопоточный процесс, который распределяет потоки между процессорами данного узла. Обмен данными между потоками на узле осуществляется через общую память, а обмен данными между узлами — через передачу сообщений. В этом случае количество процессов определяется количеством узлов, а количество потоков — количеством процессоров на каждом узле. Гибридный способ параллельного программирования более сложен (требуется особым образом переписывать параллельную программу), но наиболее эффективен в использовании аппаратных ресурсов каждого узла многопроцессорной системы.
В данной статье я предлагаю адаптировать такой гибридный подход для распараллеливания вычислений на языке Python. Ключевой особенностью работы является использование технологии docker-контейнеров. Разрабатываемый фреймворк будет иметь клиент-серверную архитектуру, включающую следующие элементы.
На стороне клиента:
- Сериализатор: в соответствии с названием, сериализует функции и их переменные (то есть позволяет сохранять их на внешнее устройство или сеть с последующей загрузкой в память на этом же или другом узле). Также стоит выделить декоратор parallel, который представляет собой функцию-обертку, позволяющую применять сериализатор для функций различного вида.
- Классы для конфигурации подключения к серверу/кластеру
- Дополнительные языковые средства, позволяющие отмечать функции, подлежащие распараллеливанию.
На стороне сервера:
- Десериализатор – соответственно, десериализует полученные данные (см. выше).
- Executor – класс, обрабатывающий десериализованные данные (функции и их аргументы), а также устанавливающий необходимые библиотеки в виртуальное окружение интерпретатора Python.
Общая архитектура разрабатываемой системы представлена на рисунке.

Для связи между клиентом и сервером могут использоваться сокеты либо фреймворк twisted, взаимодействие с которыми будет выполняться посредством разработанного API.
Реализация данной системы предполагает использование технологии docker. Это позволяет обеспечить удобство и высокую скорость настройки ПО для начала работы: достаточно запустить кластер docker-swarm, развернуть docker-образ на выбранном сервере и выставить количество репликаций.
Другими важными плюсами применения технологии docker являются создание однородной вычислительной среды путем виртуализации UNIX-подобной системы(Ubuntu – облегченная Alpine Linux), а также наличие swarm-режима, который позволяет запускать множества контейнеров на разных серверах и оперативно балансировать нагрузку, перебрасывая задания на свободные контейнеры.
Разрабатываемый фреймворк может найти применение в различных областях, где требуется выполнять большие объёмы вычислений на языке Python, в том числе для задач машинного обучения и глубокого анализа данных, а также для более простых задач – например, для распределённой проверки решений при проведении олимпиад по программированию.









