От переводчика: все началось с топика на форуме D.
После оценки скорости компиляции D по сравнению с другими языками мне было интересно, существует ли какой-нибудь язык, который компилируется в нативный код почти так же быстро или быстрее, чем D, за исключением C?
Если да, то скорее всего, он должен использовать бэкэнд, отличный от LLVM.
Я думаю, что Jai способен на это, но он еще не вышел в релиз.
Бенчмарки скорости компиляции различных комбинаций языков и компиляторов. Поддерживаемые языки:
Компиляторы в нативный код
- C (gcc, clang и cproc),
- C++ (g++ и clang++),
- D (dmd ldmd2, и gdc),
- Go (go и gccgo),
- Swift (swiftc),
- Rust (rustc),
- Julia (julia).
- Ada (gnatgcc),
- Zig (zig),
- V (v),
- Vox (vox),
- C3 (c3c),
Компиляторы в байт-код
Сколько-то из них может быть установлено на Ubuntu (проверено на 20.04) скриптом ./install-compilers-on-ubuntu-20.04.sh из этого репозитория.
Как это сделано
Бенчмарк запускается так
./benchmark \
--function-count=$FUNCTION_COUNT \
--function-depth=$FUNCTION_DEPTH \
--run-count=5для подходящих значений $FUNCTION_COUNT и $FUNCTION_DEPTH или просто
./benchmarkдля значений по умолчанию.
Можно указать тесты выборочно, например
./benchmark --languages=C++,D,RustЭто сгенерирует код в каталог generated и затем для каждой комбинации языка, типа операции и компилятора запустит поддерживаемые бенчмарки. В итоге на стандартный вывод выдается таблица в формате Markdown, показывающая результаты бенчмарка. Обратите внимание, что время компиляции в этой таблице в столбце Time [us/#fn] является нормализацией микросекунд к количеству сгенерированных тестовых функций, т.е делится на (args.function_count * args.function_depth).
GCC и Clang не выполняют все семантические проверки для C++ (потому что это слишком дорого). Это контрастирует с компиляторами D и Rust, которые выполняют все из них.
Пример сгенерированного кода
Чтобы понять, как работает генерация кода, мы можем, например, сделать следующее
./benchmark --function-count=3 --function-depth=2 --run-count=5Это для C, сгенерирует файл generated/c/main.c содержащий
long add_long_n0_h0(long x) { return x + 15440; }
long add_long_n0(long x) { return x + add_long_n0_h0(x) + 95485; }
long add_long_n1_h0(long x) { return x + 37523; }
long add_long_n1(long x) { return x + add_long_n1_h0(x) + 92492; }
long add_long_n2_h0(long x) { return x + 39239; }
long add_long_n2(long x) { return x + add_long_n2_h0(x) + 12248; }
int main(__attribute__((unused)) int argc, __attribute__((unused)) char* argv[]) {
long long_sum = 0;
long_sum += add_long_n0(0);
long_sum += add_long_n1(1);
long_sum += add_long_n2(2);
return long_sum;
}Кэширование компиляторами
Числовые константы рандомизируются при каждом вызове. Это делает невозможным для любого компилятора использовать какой-либо механизм кэширования при последовательных вызовах с одними и теми же опциями компиляции. Это делается для того, чтобы сделать более справедливым сравнение между компиляторами с различными уровнями кэширования.
Например, механизм кэширования эталонного компилятора Go больше не может быть отключен опциями.
Дженерики
Для каждого языка $LANG, поддерживающего дженерики, наряду с main.$LANG будет сгенерирован дополнительный шаблонный исходный файл main_t.$LANG, эквивалентный содержимому main.$LANG, за исключением того, что все функции (кроме main) являются шаблонами. Этот шаблонный исходный файл также будет пробенчмаркан. Колонка Templated в таблице ниже показывает, использует ли компиляция шаблонированные функции или нет.
Прим.пер. Здесь не различаются дженерики и шаблоны, что есть большая разница, как справедливо заметили на форуме. Но пользователю языка это неважно — обычно в языке присутствует единственный механизм.
Выводы (из приведенного ниже проведенного бенчмарка)
Проверка и сборка Vox, по большому счёту, самая быстрая. В 3-4 раза быстрее своего ближайшего конкурента, dmd. Обратите внимание, что Vox, однако, является высокоэкспериментальным языком, не имеющим статуса официального релиза, с бэкэндом только для Windows и обладающим меньшим количеством языковых возможностей, чем большинство других языков, прошедших бенчмаркинг.
На втором месте находятся эталонный компилятор D dmd и cproc. Однако, обратите внимание, что cproc — это высокоэкспериментальный компилятор Си без встроенной поддержки препроцессора Си.
Производительность как GCC, так и Clang значительно ухудшается с каждым новым релизом (в настоящее время 8, 9, 10 в таблице ниже).
Шаблонный (дженерик) исходный код C++ проверяется примерно в 3 раза медленнее, чем не-шаблонный при использовании gcc-8, и примерно в 2.3 раза медленнее для gcc-10. Для clang++-10 замедление составляет примерно 1.6. Соответствующее замедление для шаблонов D (dmd) примерно в 2.5 раза. С другой стороны, интересно, что версию с дженериками Rust обрабатывает в 2-3 раза быстрее, чем не-дженерик версия.
JIT-компилятор Джулии (в настоящее время) очень нуждается в памяти. Максимально рекомендуемое произведение function-count и function-depth для Julia — 5000. Таким образом, при достижении этого максимума Джулия будет исключена из бенчмарка.
Оптимизирующий нативный компилятор OCaml ocamlopt очень медленный для больших входных файлов и поэтому отключается, когда произведение function-count и function-depth превышает 10000.
Пример запуска бенчмарка
Вывод на моем Intel Core i7-4710HQ CPU @ 2.50GHz × 8 с 16 GB памяти под Ubuntu 20.04 для вызова
./benchmark --function-count=200 --function-depth=450 --run-count=3или же, используя для более быстрой генерации кода Pypy 3
pypy3 ./benchmark --function-count=200 --function-depth=450 --run-count=3Результаты вывода в таблице
От переводчика. Таблица, где свалено все подряд, показалась мне малочитаемой — пришлось даже порыть исходники, чтобы понять смысл. Потому я рассортировал и сделал графики различных сущностей — время полной сборки с генерацией объектных файлов отдельно от проверки синтаксиса против шаблонного/дженерик кода отдельно от нешаблонного. Итого 4 графика.
Посередине графика строка с коэффициентом относительно лидера. Этот коэффициент приведен отдельно среди всех проверок синтаксиса (с и без дженериков), и аналогично среди всех полных компиляций в бинарник.


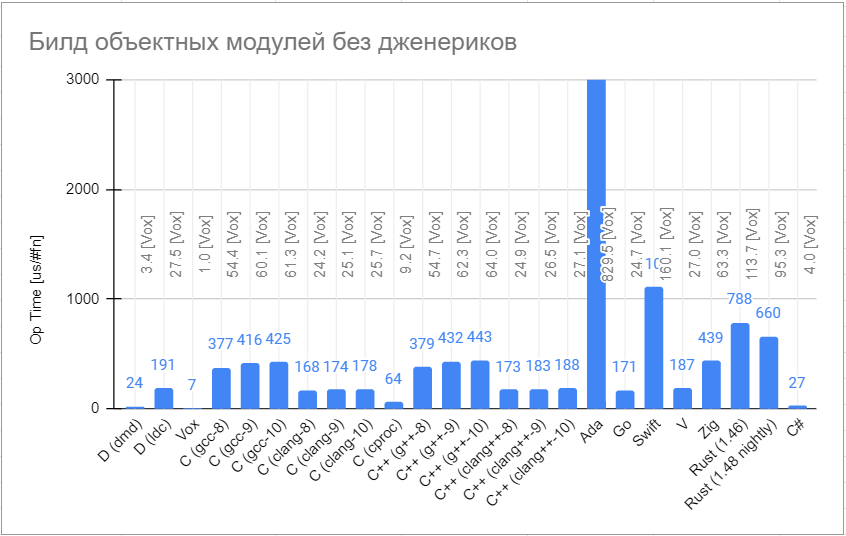
Значение для Ады — 5746,1

Шкала логарифмическая
Доделать
- поддержку языка C3
- время полной сборки и проверки синтаксиса собрать в одну строку в разные столбцы
- добавить измерение потребляемой памяти с помощью Питоновского Subprocess
- распараллелить вызовы проверки и сборки
- добавить Fortran
- добавить Pony
Ссылки
Мнение от переводчика
Данный бенчмарк показывает только синтетический результат, бесконечно далекий от реальности. К примеру в том же D стандартная библиотека Phobos абсолютно шаблонизирована, что замедляет компиляцию даже простых программ, и чем больше кода — тем медленнее, притом нелинейно.
С другой стороны — не учитывается медлительность систем сборки при перепроверках билда, и кроме того — я переводил пример, где одна и та же программа потребовала 12 пакетов зависимостей для D и около 230 для Rust, что делает сравнение времени в общем случае невозможным.
По ссылке же из соответствующего раздела можно увидеть не только сравнение с другими языками, отсутствующими тут, но и то, как далеко шагнуло компиляторостроение за 4 года в плане сборки огромных программ.







