Всем привет! Сегодня мы с Вами познакомимся с новым сервисом из линейки Microsoft 365, который называется SharePoint Syntex. Данный сервис входит в ряд технологий Microsoft под названием Project Cortex. Технологии Project Cortex направлены на применение искусственного интеллекта для обработки и получения информации из контента, с целью последующей категоризации и распределения данных. SharePoint Syntex является первым продуктом Project Cortex и он позволяет использовать машинное обучение для извлечения ключевых данных из контента библиотек SharePoint. Все это происходит без каких-либо сложных настроек и программирования. Плюс ко всему, сервис SharePoint Syntex официально доступен начиная с 1 октября 2020 года и уже сейчас можно установить его к себе в Microsoft 365. Так для чего же можно использовать SharePoint Syntex?

К примеру, у Вас есть библиотека документов SharePoint. При добавлении файла в эту библиотеку, зачастую, вы дополнительно снабжаете этот файл определенными метаданными. Создаете несколько полей и пишете в них некую информацию для того, чтобы классифицировать файлы, находящиеся в этой библиотеке. Но это делается вручную и для каждого файла необходимо вводить данные каждый раз снова и снова. SharePoint Syntex призван автоматизировать этот процесс, путем извлечения ключевых данных из файла, согласно настроенной модели, и сохранения этих данных в поля библиотеки. Звучит неплохо. Давайте посмотрим, как это работает?
Так как SharePoint Syntex идет в рамках отдельной лицензии, то нам необходимо данную лицензию получить. Идем на сайт Microsoft, находим продукт SharePoint Syntex и нажимаем «Free Trial».

После ввода учетной записи Вашего Microsoft 365 и подтверждения активации триальной лицензии, переходим в центр администрирования Microsoft 365. Далее заходим в левом меню в раздел «Установка» («Setup») и выбираем пункт Automate Content Understanding. В случае русской локали, как у меня, это будет звучать «Автоматизация осмысления контента».
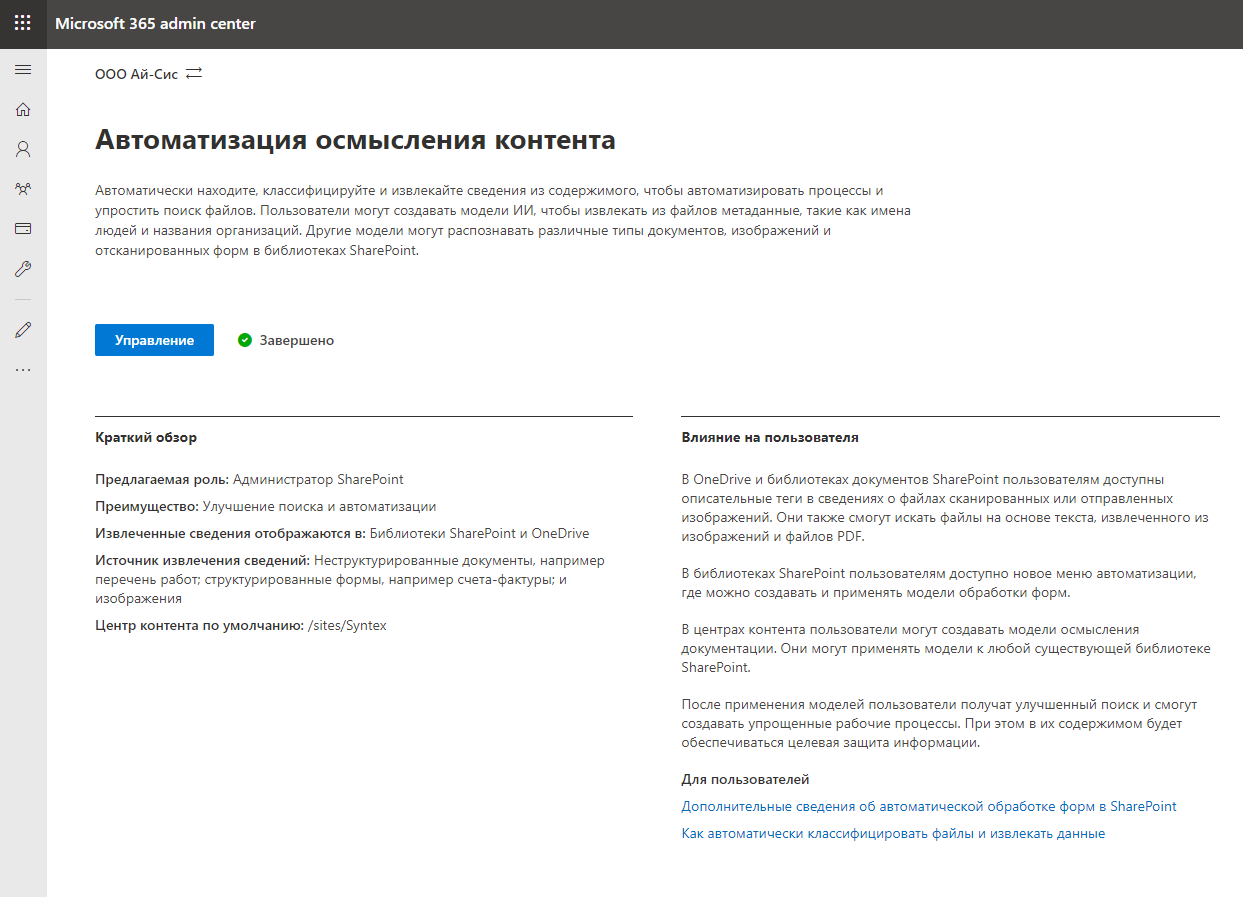
Заходим в «Управление» и приступаем к настройке службы. В первую очередь необходимо указать какие библиотеки будут поддерживать возможности SharePoint Syntex. Можно выбрать конкретные библиотеки или разрешить для всех библиотек. Идем ва-банк.
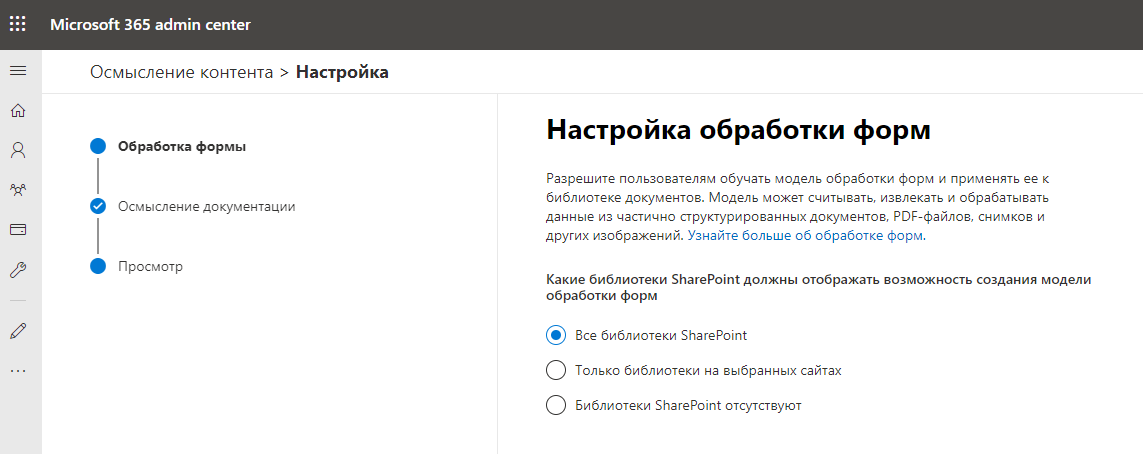
Далее указываем имя и адрес сайта, который будет являться центром контента и хранить обученные модели данных. Всё выглядит так, как будто создается новая сайт-коллекция SharePoint Online. Впрочем, именно это и происходит.

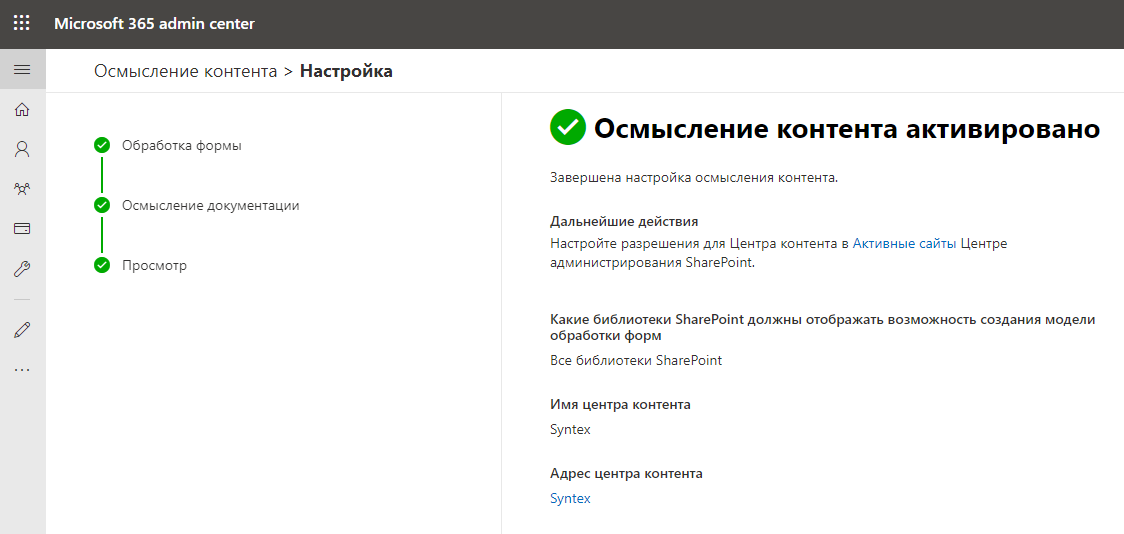
Создание сайта центра контента занимает несколько минут. У меня он создался где-то минут за 5, я как раз успел налить себе чай. Прихожу, а тут уже активировано осмысление контента, ну ничего себе.
Переходим на сайт SharePoint Syntex. Внешне он выглядит как обычный сайт SharePoint Online, но это только на первый взгляд. На данном сайте мы будем настраивать и обучать модели обработки и анализа данных.
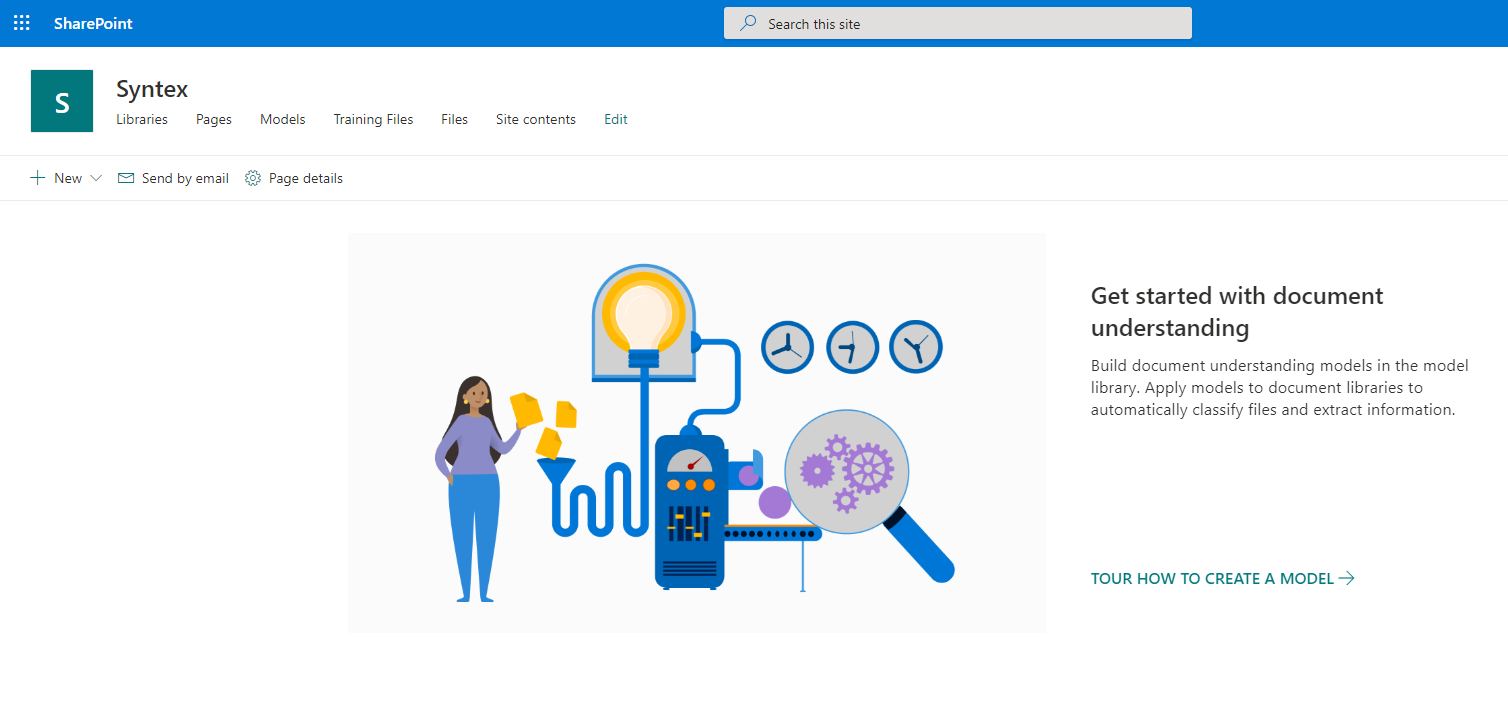
Пора бы и приступить к настройке модели. Нажимаем «New» и выбираем пункт «Document Understanding Model».
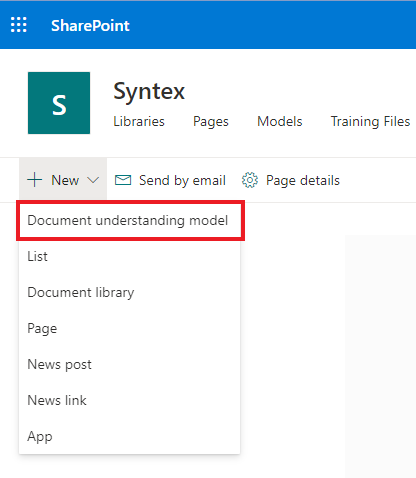
Пишем имя нашей будущей модели и указываем необходимость создания нового типа контента для нее. Я выбрал уже, возможно, знакомый Вам по прошлым статьям кейс с подачей заявки на техническую поддержку. Не пропадать же множеству шаблонов подобных обращений.

Далее нас встречает страница со Step-By-Step инструкцией, описывающей что нам необходимо сделать, чтобы заставить будущую модель работать, а в идеале работать правильно. Итак, сначала необходимо загрузить несколько (рекомендуется не меньше 5) файлов, помочь SharePoint Syntex их классифицировать нужным образом и настроить так называемые «Extractors» — шаблоны извлечения данных из файлов. После того как весь путь будет пройден, можно применить данную модель для требуемых библиотек SharePoint.

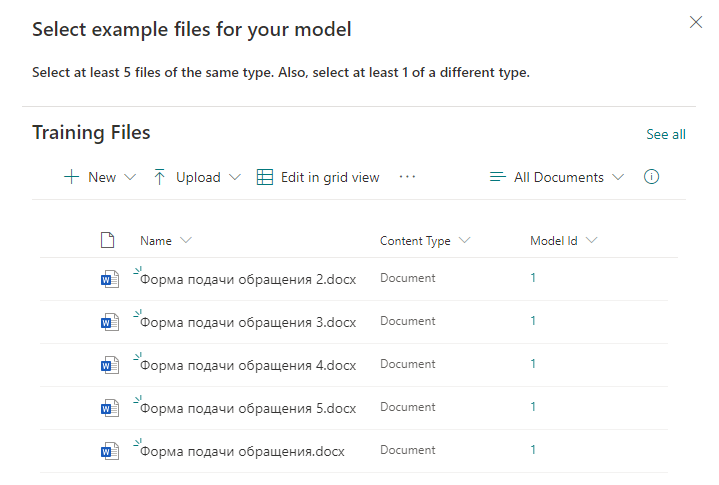
Добавляем заготовленные файлы шаблонов, которые будут использоваться для классификации будущих реальных файлов.
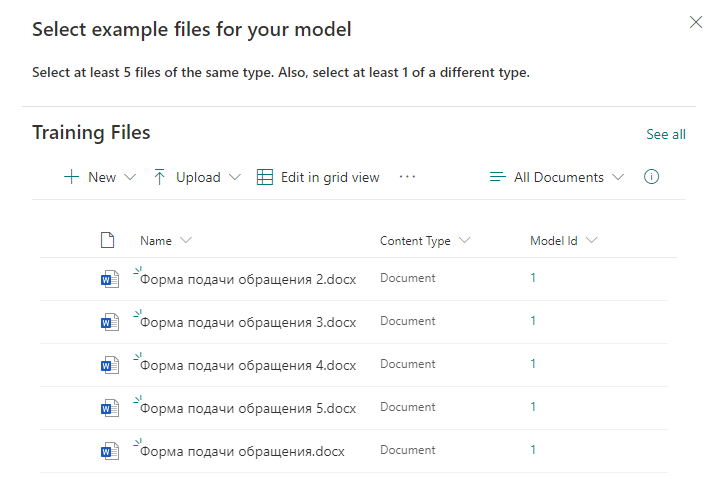
Затем указываем ключевые слова, по которым будет осуществляться поиск информации в документе. В каждой строке указываем новое слово или фразу, которая будет использоваться для поиска.
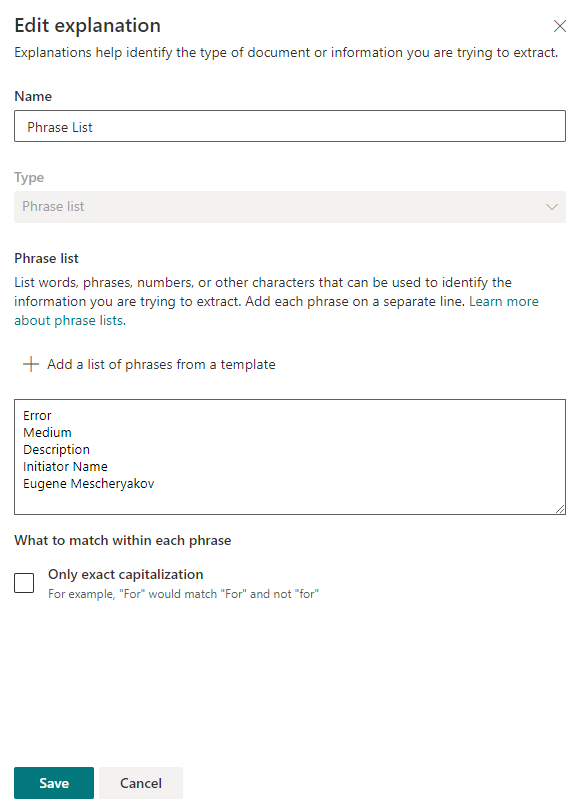
После сохранения настроек можно попробовать просканировать имеющиеся файлы на предмет поиска ключевых фраз. Если совпадение найдено, то напротив файла будет стоять «Match».
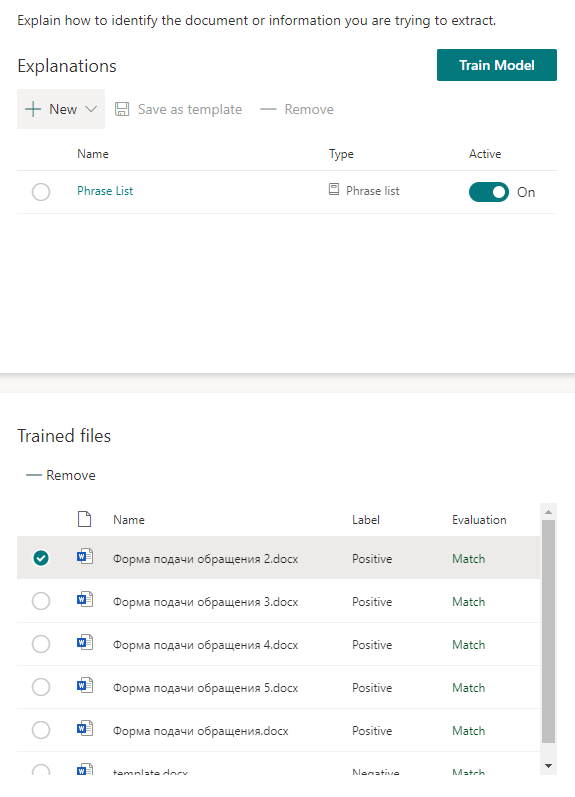
Запускаем обучение модели и идем наливать чай. Потребуется некоторое время.
После того как модель обучена необходимо настроить «Extractors» – модели извлечения данных. Каждый экстрактор — это, по сути, поле SharePoint определенного типа, которое автоматически будет создано в целевой библиотеке. После добавления файла в эту библиотеку, в данное поле будет записана информация, извлеченная из файла.
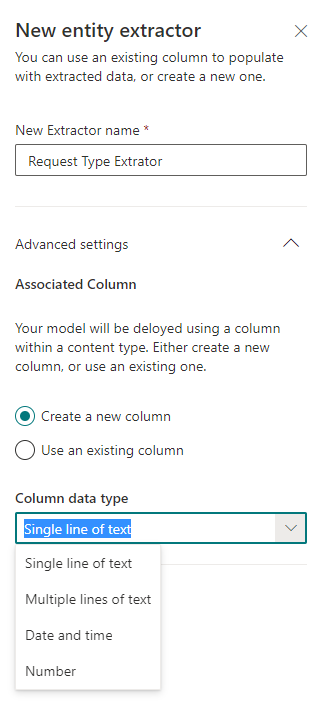
При создании экстрактора нужно указать его имя и тип. На текущий момент поддерживается 4 типа:
Можно использовать и существующие поля библиотеки SharePoint.
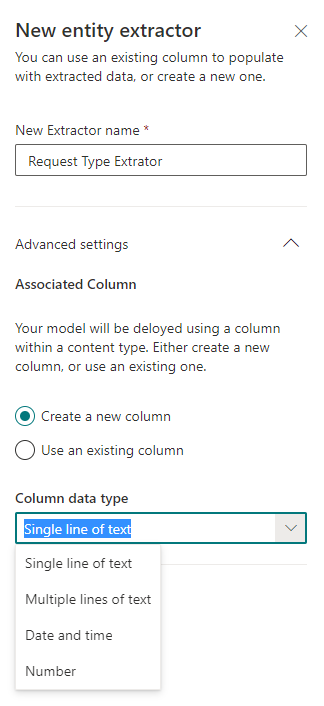
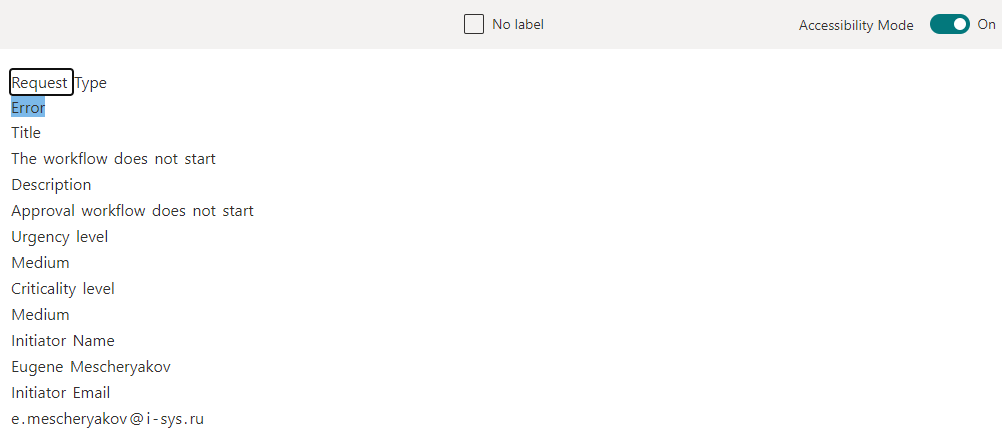
При настройке экстрактора в шаблоне загруженного файла отмечаем двойным кликом мыши какую информацию, распознанную на предыдущем шаге, мы хотим извлечь.

Создаем несколько таких экстракторов, отмечаем нужные данные и, после этого, переходим к финальной части – применению обученной модели к библиотеке SharePoint и проверке того работает ли это всё вообще.
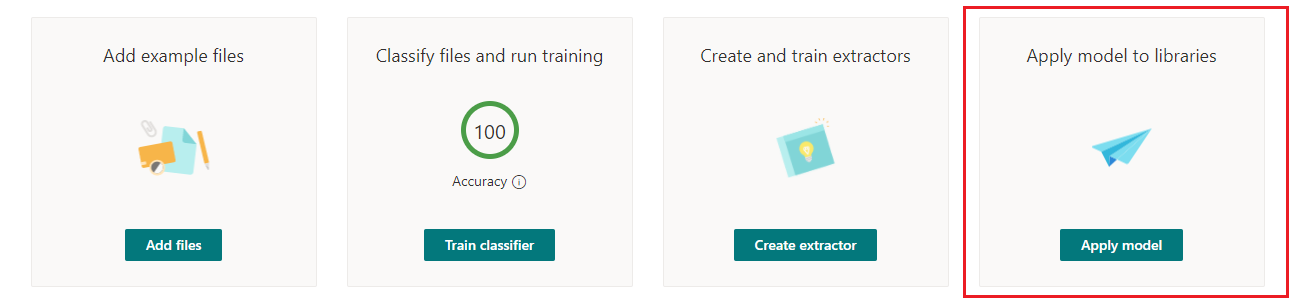
Выбираем требуемый сайт SharePoint и указываем целевую библиотеку. Я заранее создал библиотеку HelpDesk Requests и не производил никаких изменений в ней, оставив ее в исходном виде. Сохраняем настройки и идем в библиотеку. После сохранения настроек SharePoint Syntex в библиотеке появляются новые поля SharePoint соответствующие по имени и типу созданным экстракторам.
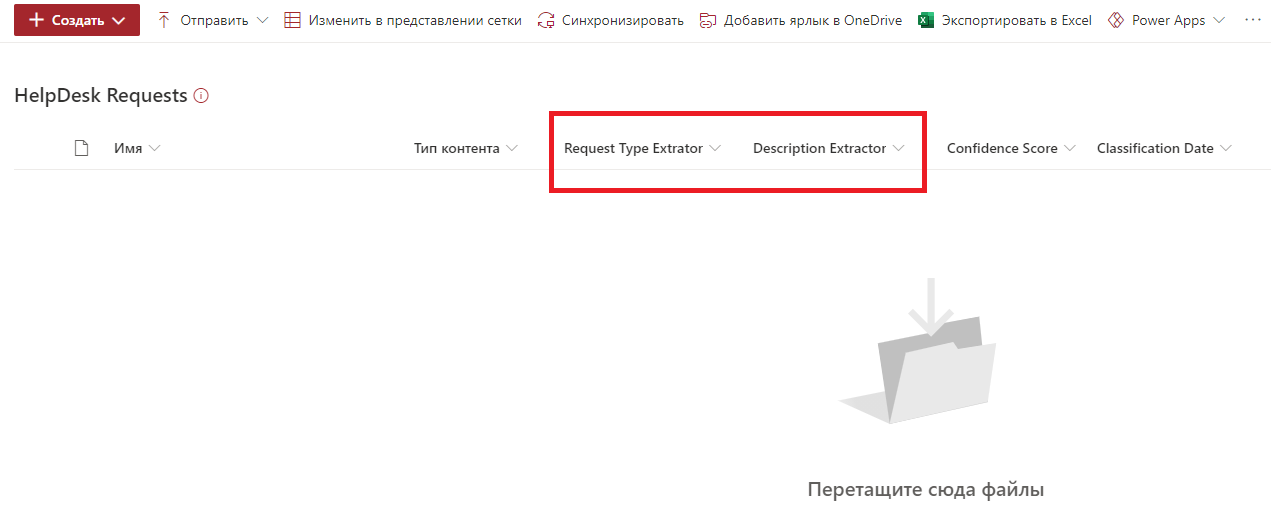
Осталось добавить файл в библиотеку и проверить. Добавляем очередной файл шаблона обращения.

SharePoint Syntex распознал тип обращения и описание. Данные сохранены в поля. Кажется всё в порядке.
Настройка модели данных SharePoint Syntex заняла у меня совсем немного времени, всё достаточно интуитивно понятно и легко настраивается и применяется. Из плюсов я вижу действительно полезную возможность автоматически вытягивать из содержимого файлов ключевую информацию и записывать ее в поля SharePoint. Данная возможность может существенно ускорить работу и убрать лишние этапы работы пользователей, когда после добавления файла необходимо еще вручную заполнять ряд реквизитов в библиотеке. Из минусов – хотелось бы больше типов полей для экстракторов и более тесную интеграцию с Microsoft Power Platform. Но я уверен, что это в скором времени добавят в рамках ближайших обновлений.
Также SharePoint Syntex требует отдельной лицензии (5 долларов на пользователя в месяц) и, в настоящий момент, не идет в составе Enterprise лицензий Microsoft 365. Но в будущем может всё измениться и возможно SharePoint Syntex станет частью базовых сервисов Microsoft 365. Попробуйте активировать триальную версию на месяц и посмотреть возможности данного сервиса. Хорошего всем дня!

К примеру, у Вас есть библиотека документов SharePoint. При добавлении файла в эту библиотеку, зачастую, вы дополнительно снабжаете этот файл определенными метаданными. Создаете несколько полей и пишете в них некую информацию для того, чтобы классифицировать файлы, находящиеся в этой библиотеке. Но это делается вручную и для каждого файла необходимо вводить данные каждый раз снова и снова. SharePoint Syntex призван автоматизировать этот процесс, путем извлечения ключевых данных из файла, согласно настроенной модели, и сохранения этих данных в поля библиотеки. Звучит неплохо. Давайте посмотрим, как это работает?
Как активировать SharePoint Syntex?
Так как SharePoint Syntex идет в рамках отдельной лицензии, то нам необходимо данную лицензию получить. Идем на сайт Microsoft, находим продукт SharePoint Syntex и нажимаем «Free Trial».

После ввода учетной записи Вашего Microsoft 365 и подтверждения активации триальной лицензии, переходим в центр администрирования Microsoft 365. Далее заходим в левом меню в раздел «Установка» («Setup») и выбираем пункт Automate Content Understanding. В случае русской локали, как у меня, это будет звучать «Автоматизация осмысления контента».
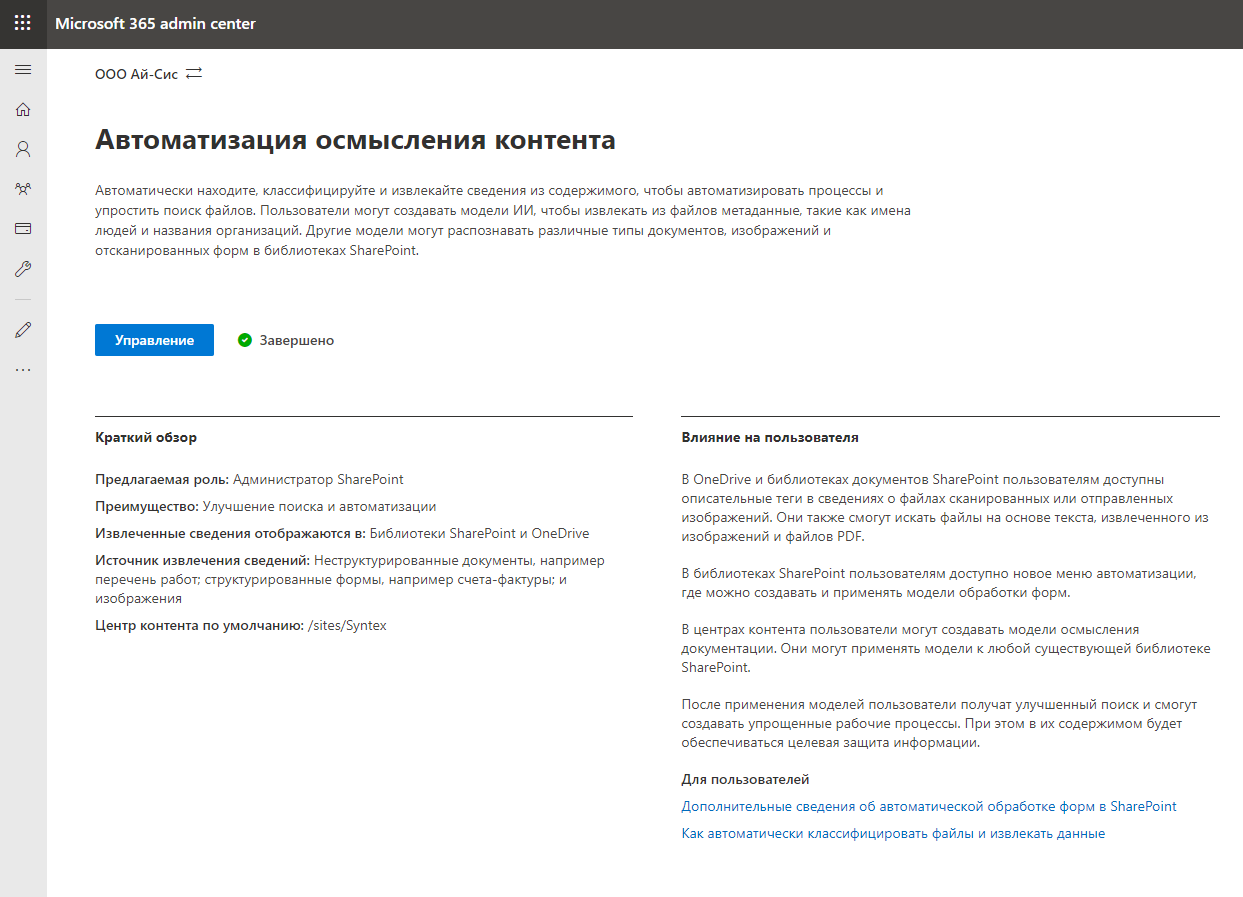
Заходим в «Управление» и приступаем к настройке службы. В первую очередь необходимо указать какие библиотеки будут поддерживать возможности SharePoint Syntex. Можно выбрать конкретные библиотеки или разрешить для всех библиотек. Идем ва-банк.
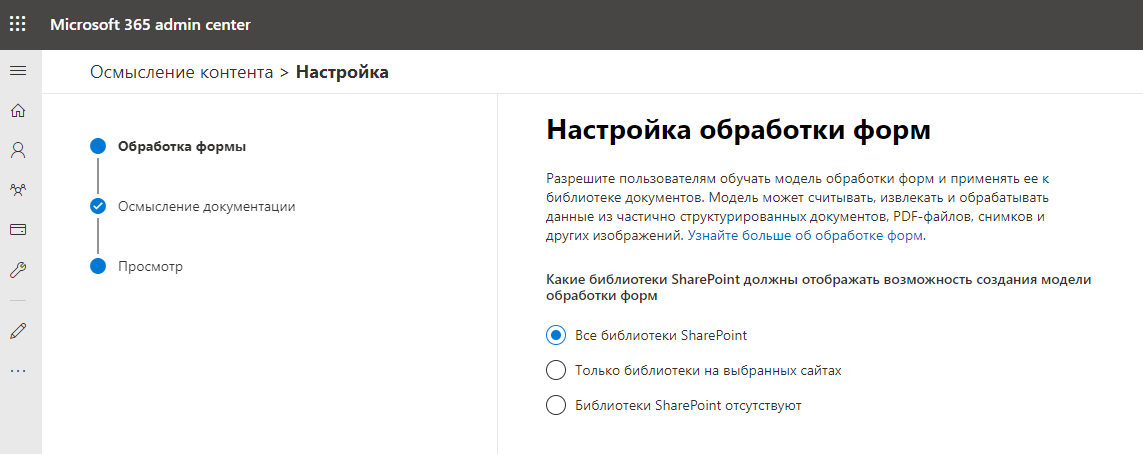
Далее указываем имя и адрес сайта, который будет являться центром контента и хранить обученные модели данных. Всё выглядит так, как будто создается новая сайт-коллекция SharePoint Online. Впрочем, именно это и происходит.
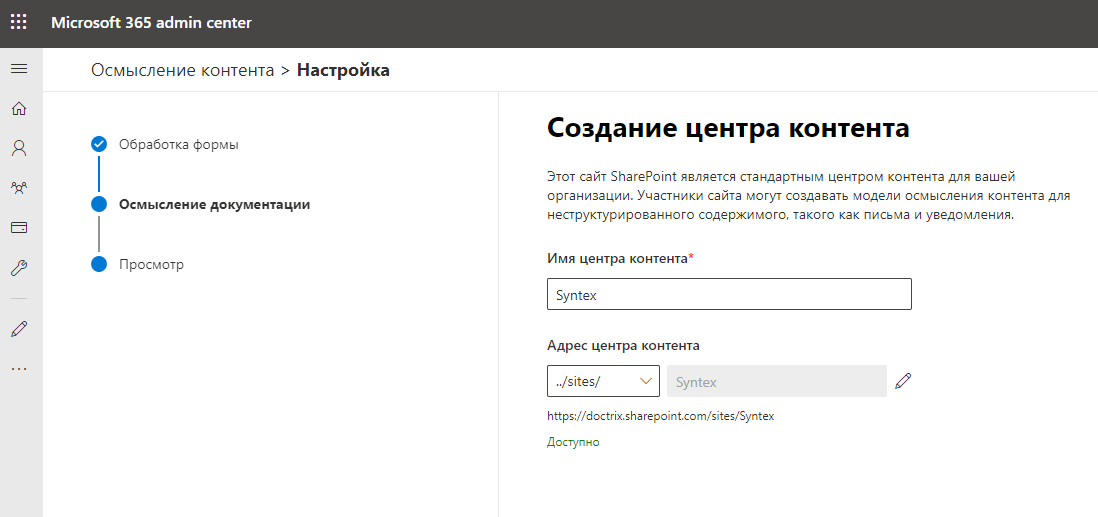
Создание сайта центра контента занимает несколько минут. У меня он создался где-то минут за 5, я как раз успел налить себе чай. Прихожу, а тут уже активировано осмысление контента, ну ничего себе.
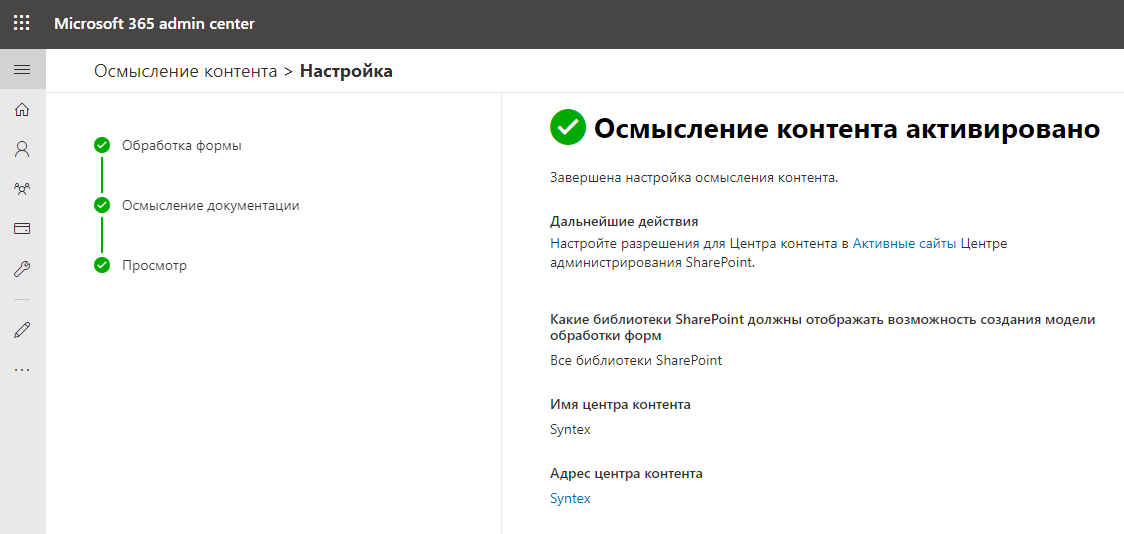
Настройка SharePoint Syntex
Переходим на сайт SharePoint Syntex. Внешне он выглядит как обычный сайт SharePoint Online, но это только на первый взгляд. На данном сайте мы будем настраивать и обучать модели обработки и анализа данных.
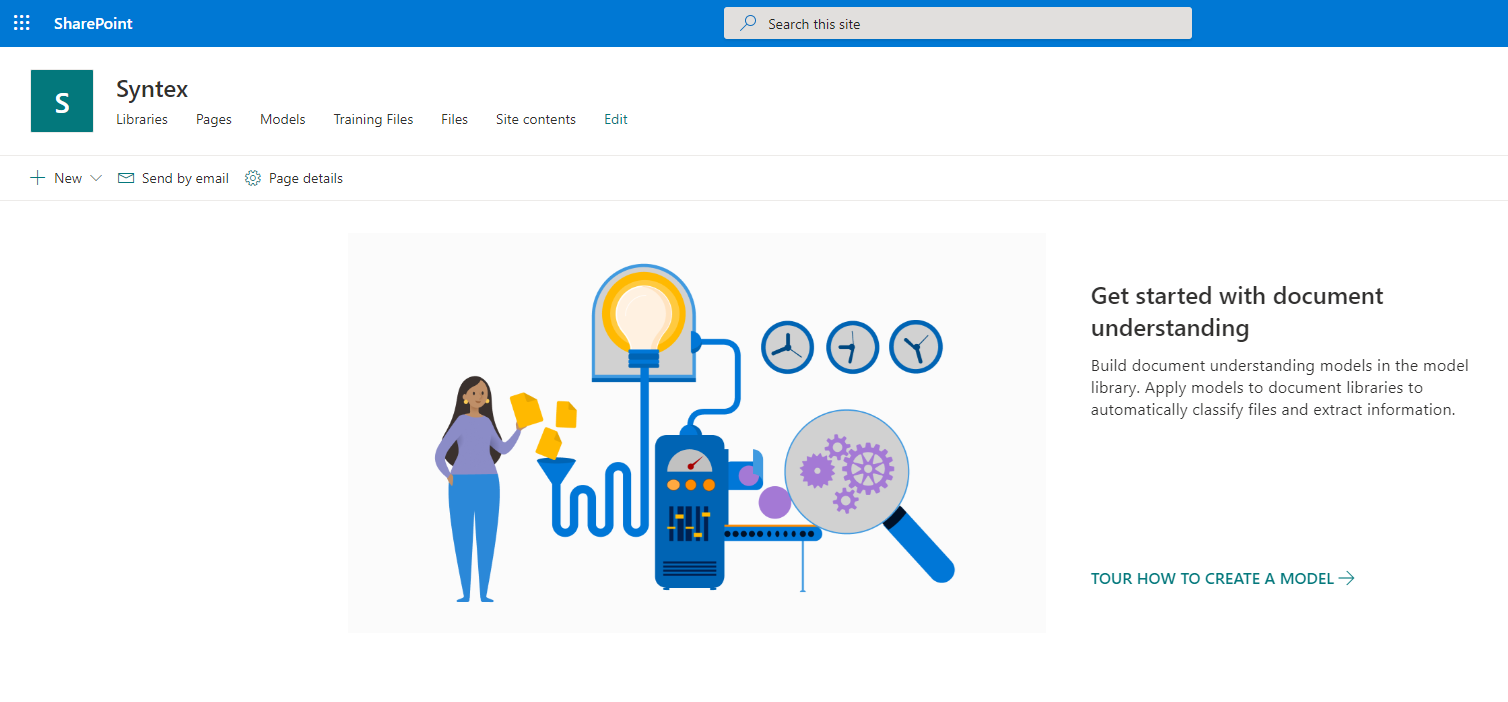
Пора бы и приступить к настройке модели. Нажимаем «New» и выбираем пункт «Document Understanding Model».
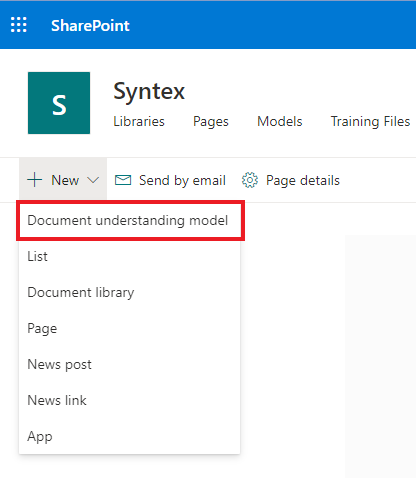
Пишем имя нашей будущей модели и указываем необходимость создания нового типа контента для нее. Я выбрал уже, возможно, знакомый Вам по прошлым статьям кейс с подачей заявки на техническую поддержку. Не пропадать же множеству шаблонов подобных обращений.
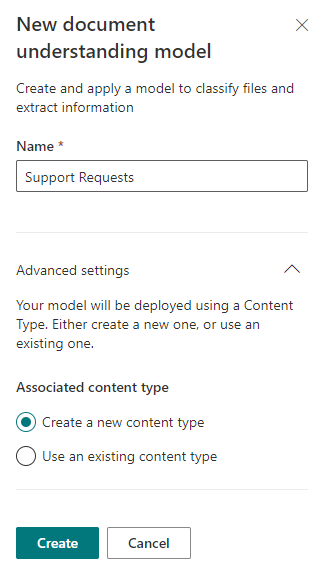
Далее нас встречает страница со Step-By-Step инструкцией, описывающей что нам необходимо сделать, чтобы заставить будущую модель работать, а в идеале работать правильно. Итак, сначала необходимо загрузить несколько (рекомендуется не меньше 5) файлов, помочь SharePoint Syntex их классифицировать нужным образом и настроить так называемые «Extractors» — шаблоны извлечения данных из файлов. После того как весь путь будет пройден, можно применить данную модель для требуемых библиотек SharePoint.
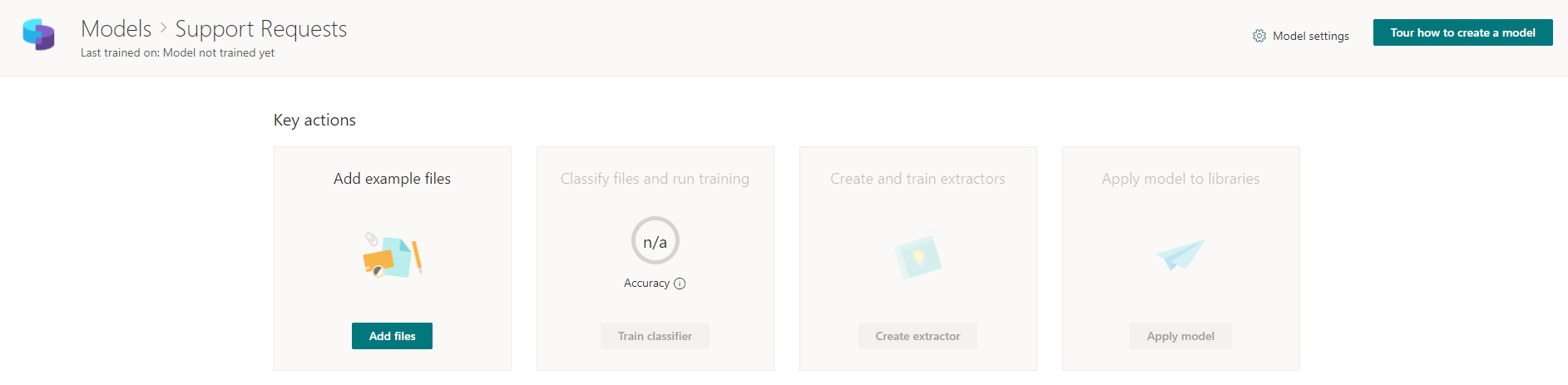
Добавляем заготовленные файлы шаблонов, которые будут использоваться для классификации будущих реальных файлов.
Затем указываем ключевые слова, по которым будет осуществляться поиск информации в документе. В каждой строке указываем новое слово или фразу, которая будет использоваться для поиска.
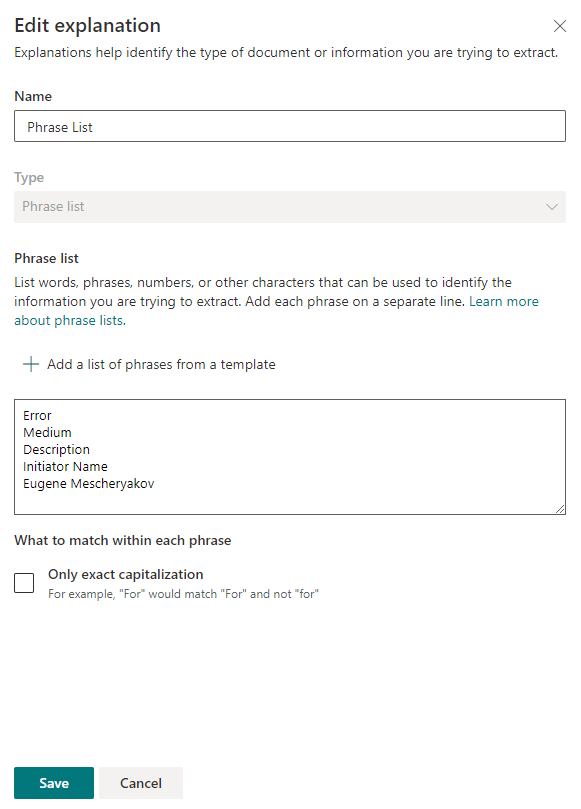
После сохранения настроек можно попробовать просканировать имеющиеся файлы на предмет поиска ключевых фраз. Если совпадение найдено, то напротив файла будет стоять «Match».
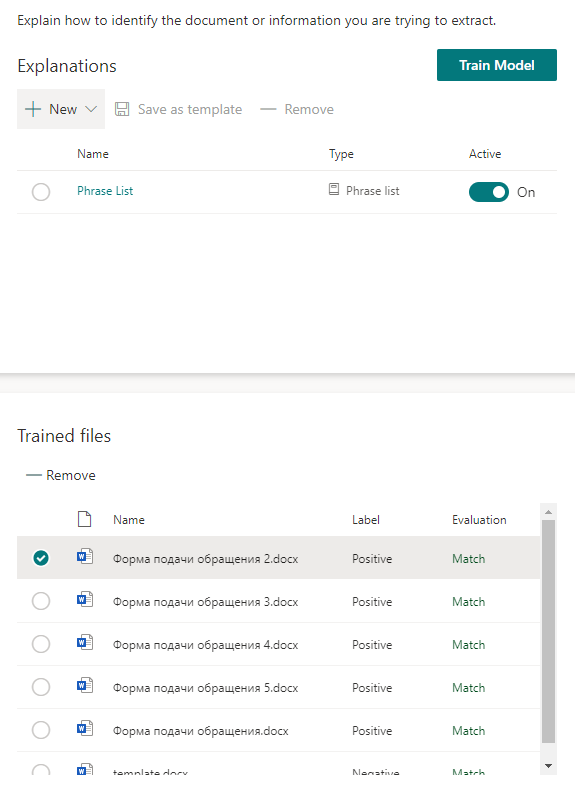
Запускаем обучение модели и идем наливать чай. Потребуется некоторое время.
После того как модель обучена необходимо настроить «Extractors» – модели извлечения данных. Каждый экстрактор — это, по сути, поле SharePoint определенного типа, которое автоматически будет создано в целевой библиотеке. После добавления файла в эту библиотеку, в данное поле будет записана информация, извлеченная из файла.
При создании экстрактора нужно указать его имя и тип. На текущий момент поддерживается 4 типа:
- Однострочный текст
- Многострочный текст
- Дата и время
- Число
Можно использовать и существующие поля библиотеки SharePoint.
При настройке экстрактора в шаблоне загруженного файла отмечаем двойным кликом мыши какую информацию, распознанную на предыдущем шаге, мы хотим извлечь.
Создаем несколько таких экстракторов, отмечаем нужные данные и, после этого, переходим к финальной части – применению обученной модели к библиотеке SharePoint и проверке того работает ли это всё вообще.

Выбираем требуемый сайт SharePoint и указываем целевую библиотеку. Я заранее создал библиотеку HelpDesk Requests и не производил никаких изменений в ней, оставив ее в исходном виде. Сохраняем настройки и идем в библиотеку. После сохранения настроек SharePoint Syntex в библиотеке появляются новые поля SharePoint соответствующие по имени и типу созданным экстракторам.
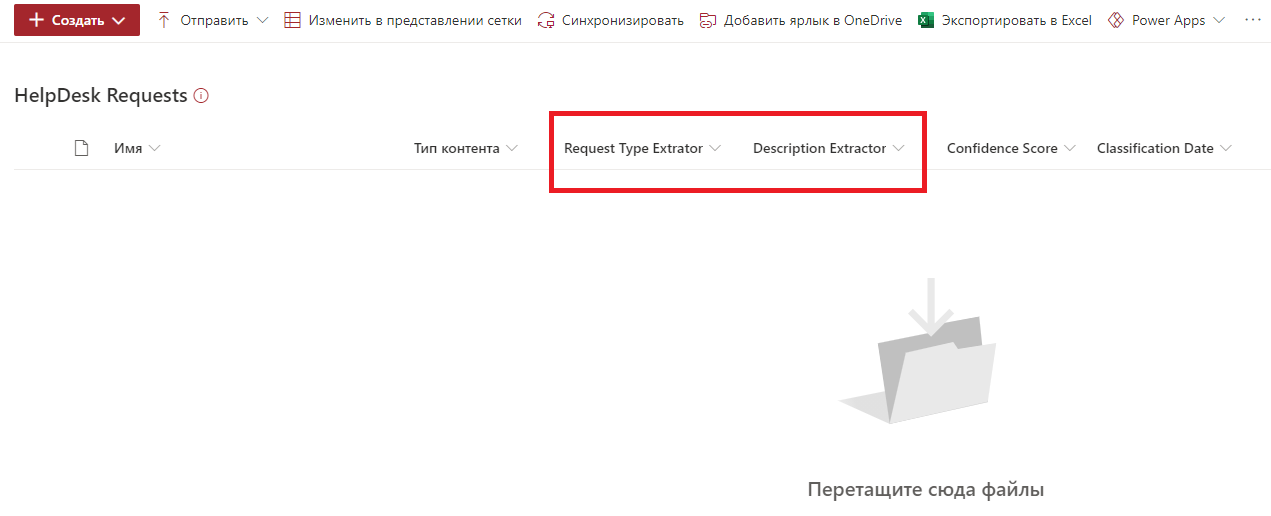
Осталось добавить файл в библиотеку и проверить. Добавляем очередной файл шаблона обращения.

SharePoint Syntex распознал тип обращения и описание. Данные сохранены в поля. Кажется всё в порядке.
Итого
Настройка модели данных SharePoint Syntex заняла у меня совсем немного времени, всё достаточно интуитивно понятно и легко настраивается и применяется. Из плюсов я вижу действительно полезную возможность автоматически вытягивать из содержимого файлов ключевую информацию и записывать ее в поля SharePoint. Данная возможность может существенно ускорить работу и убрать лишние этапы работы пользователей, когда после добавления файла необходимо еще вручную заполнять ряд реквизитов в библиотеке. Из минусов – хотелось бы больше типов полей для экстракторов и более тесную интеграцию с Microsoft Power Platform. Но я уверен, что это в скором времени добавят в рамках ближайших обновлений.
Также SharePoint Syntex требует отдельной лицензии (5 долларов на пользователя в месяц) и, в настоящий момент, не идет в составе Enterprise лицензий Microsoft 365. Но в будущем может всё измениться и возможно SharePoint Syntex станет частью базовых сервисов Microsoft 365. Попробуйте активировать триальную версию на месяц и посмотреть возможности данного сервиса. Хорошего всем дня!








