Введение
Эта статья является компиляцией другой статьи. В ней я намерен сконцентрироваться на инструментах для работы с Big data, ориентированных на анализ данных.
Итак, предположим, вы приняли необработанные данные, обработали их, и теперь они готовы к дальнейшему использованию.
Существует множество инструментов, используемых для работы с данными, каждый из которых имеет свои преимущества и недостатки. Большинство из них ориентировано на OLAP, но некоторые также оптимизированы для OLTP. Часть из них использует стандартные форматы и сосредоточена только на выполнении запросов, другие используют свой собственный формат или хранилище для передачи обработанных данных в источник в целях повышения производительности. Некоторые из них оптимизированы для хранения данных с использованием определенных схем, например «звезда» или «снежинка», но есть и более гибкие. Подводя итог, имеем следующие противопоставления:
- Хранилище данных против Озера
- Hadoop против Автономного хранилища
- OLAP против OLTP
- Движок запросов против OLAP механизмов
Мы также рассмотрим инструменты для обработки данных с возможностью выполнения запросов.
Инструменты для обработки данных
Большинство упомянутых инструментов могут подключаться к серверу метаданных, например Hive, и выполнять запросы, создавать представления и т.п. Это часто используется для создания дополнительных (улучшенных) уровней отчетности.
Spark SQL предоставляет способ беспрепятственно смешивать запросы SQL с программами Spark, поэтому вы можете смешивать API DataFrame с SQL. Он имеет интеграцию с Hive и стандартное подключение через JDBC или ODBC, так что вы можете подключить Tableau, Looker или любой инструмент бизнес-аналитики к своим данным через Spark.

Apache Flink также предоставляет SQL API. Поддержка SQL в Flink основана на Apache Calcite, который реализует стандарт SQL. Он также интегрируется с Hive через HiveCatalog. Например, пользователи могут хранить свои таблицы Kafka или ElasticSearch в Hive Metastore с помощью HiveCatalog и повторно использовать их позже в запросах SQL.
Kafka тоже предоставляет возможности SQL. В целом большинство инструментов обработки данных предоставляют SQL интерфейсы.
Инструменты выполнения запросов
Этот тип инструментов ориентирован на унифицированный запрос к различным источникам данных в разных форматах. Идея состоит в том, чтобы направлять запросы к вашему озеру данных с помощью SQL, как если бы это была обычная реляционная база данных, хотя у нее есть некоторые ограничения. Некоторые из этих инструментов могут также выполнять запросы к NoSQL базам и многое другое. Эти инструменты предоставляют интерфейс JDBC для внешних инструментов, таких как Tableau или Looker, для безопасного подключения к вашему озеру данных. Инструменты запросов — самый медленный вариант, но обеспечивают максимальную гибкость.
Apache Pig: один из первых инструментов наряду с Hive. Имеет собственный язык, отличный от SQL. Отличительным свойством программ созданных Pig является то, что их структура поддается существенному распараллеливанию, что, в свою очередь, позволяет им обрабатывать очень большие наборы данных. Благодаря этому он все еще не устарел в сравнении с современными системами на базе SQL.
Presto: платформа от Facebook с открытым исходным кодом. Это распределенный механизм SQL-запросов для выполнения интерактивных аналитических запросов к источникам данных любого размера. Presto позволяет запрашивать данные там, где они находятся, включая Hive, Cassandra, реляционные базы данных и файловые системы. Она может выполнять запросы к большим наборам данных за секунды. Presto не зависит от Hadoop, но интегрируется с большинством его инструментов, особенно с Hive, для выполнения SQL-запросов.
Apache Drill: предоставляет механизм SQL запросов без схем для Hadoop, NoSQL и даже облачного хранилища. Он не зависит от Hadoop, но имеет множество интеграций с инструментами экосистемы, такими как Hive. Один запрос может объединять данные из нескольких хранилищ, выполняя оптимизацию, специфичную для каждого из них. Это очень хорошо, т.к. позволяет аналитикам обрабатывать любые данные как таблицу, даже если фактически они читают файл. Drill полностью поддерживает стандартный SQL. Бизнес-пользователи, аналитики и специалисты по обработке данных могут использовать стандартные инструменты бизнес-аналитики, такие как Tableau, Qlik и Excel, для взаимодействия с нереляционными хранилищами данных, используя драйверы Drill JDBC и ODBC. Кроме того, разработчики могут использовать простой REST API Drill в своих пользовательских приложениях для создания красивых визуализаций.
OLTP базы данных
Хотя Hadoop оптимизирован для OLAP, все же бывают ситуации, когда вы хотите выполнять запросы OLTP для интерактивного приложения.
HBase имеет очень ограниченные свойства ACID по дизайну, поскольку он был построен для масштабирования и не предоставляет возможностей ACID из коробки, но его можно использовать для некоторых сценариев OLTP.
Apache Phoenix построен на основе HBase и обеспечивает способ выполнения запросов OTLP в экосистеме Hadoop. Apache Phoenix полностью интегрирован с другими продуктами Hadoop, такими как Spark, Hive, Pig, Flume и Map Reduce. Он также может хранить метаданные, поддерживает создание таблиц и добавочные изменения с управлением версиями при помощи команд DDL. Это работает довольно быстро, быстрее, чем при использовании Drill или другого
механизма запросов.
Вы можете использовать любую крупномасштабную базу данных за пределами экосистемы Hadoop, такую как Cassandra, YugaByteDB, ScyllaDB для OTLP.
Наконец, очень часто бывает, что в быстрых базах данных любого типа, таких как MongoDB или MySQL, есть более медленное подмножество данных, обычно самые свежие. Упомянутые выше механизмы запросов могут объединять данные между медленным и быстрым хранилищами за один запрос.
Распределенное индексирование
Эти инструменты обеспечивают способы хранения и поиска неструктурированных текстовых данных, и они живут за пределами экосистемы Hadoop, поскольку им требуются специальные структуры для хранения данных. Идея состоит в том, чтобы использовать инвертированный индекс для выполнения быстрого поиска. Помимо текстового поиска, эту технологию можно использовать для самых разных целей, таких как хранение журналов, событий и т.п. Есть два основных варианта:
Solr: это популярная, очень быстрая платформа корпоративного поиска с открытым исходным кодом, построенная на Apache Lucene. Solr является надежным, масштабируемым и отказоустойчивым инструментом, обеспечивая распределенное индексирование, репликацию и запросы с балансировкой нагрузки, автоматическое переключение при отказе и восстановление, централизованную настройку и многое другое. Он отлично подходит для текстового поиска, но его варианты использования ограничены по сравнению с ElasticSearch.
ElasticSearch: это также очень популярный распределенный индекс, но он превратился в собственную экосистему, которая охватывает множество вариантов использования, таких как APM, поиск, хранение текста, аналитика, информационные панели, машинное обучение и многое другое. Это определенно инструмент, который нужно иметь в своем наборе инструментов либо для DevOps, либо для конвейера данных, поскольку он очень универсален. Он также может хранить и искать видео и изображения.
ElasticSearch можно использовать в качестве слоя быстрого хранения для вашего озера данных для расширенных функций поиска. Если вы храните свои данные в большой базе данных типа «ключ-значение», такой как HBase или Cassandra, которые предоставляют очень ограниченные возможности поиска из-за отсутствия соединений, вы можете поставить ElasticSearch перед ними, чтобы выполнять запросы, возвращать идентификаторы, а затем выполнять быстрый поиск в своей базе данных.
Его также можно использовать для аналитики. Вы можете экспортировать свои данные, индексировать их, а затем запрашивать их с помощью Kibana, создавая информационные панели, отчеты и многое другое, вы можете добавлять гистограммы, сложные агрегации и даже запускать алгоритмы машинного обучения поверх ваших данных. Экосистема ElasticSearch огромна, и ее стоит изучить.
OLAP базы данных
Тут мы рассмотрим базы данных, которые также могут предоставлять хранилище метаданных для схем запросов. Если сравнивать эти инструменты с системами выполнения запросов, эти инструменты также предоставляют хранилище данных и могут применяться для конкретных схем хранения данных (звездообразная схема). Эти инструменты используют синтаксис SQL. Spark, либо другие платформы могут с ними взаимодействовать.
Apache Hive: мы уже обсуждали Hive, как центральный репозиторий схем для Spark и других инструментов, чтобы они могли использовать SQL, но Hive также может хранить данные, так что вы можете использовать его в качестве хранилища. Он может получить доступ к HDFS или HBase. При запросе Hive он использует Apache Tez, Apache Spark или MapReduce, будучи намного быстрее Tez или Spark. Он также имеет процедурный язык под названием HPL-SQL. Hive — это чрезвычайно популярное хранилище мета-данных для Spark SQL.
Apache Impala: это собственная аналитическая база данных для Hadoop, которую вы можете использовать для хранения данных и эффективных запросов к ним. Она может подключаться к Hive для получения метаданных с помощью Hcatalog. Impala обеспечивает низкую задержку и высокий уровень параллелизма для запросов бизнес-аналитики и аналитики в Hadoop (что не предоставляется пакетными платформами, такими как Apache Hive). Impala также масштабируется линейно, даже в многопользовательских средах, что является лучшей альтернативой для запросов, чем Hive. Impala интегрирована с собственной системой безопасности Hadoop и Kerberos для аутентификации, поэтому вы можете безопасно управлять доступом к данным. Она использует HBase и HDFS для хранения данных.

Apache Tajo: это еще одно хранилище данных для Hadoop. Tajo разработан для выполнения специальных запросов с малыми задержкой и масштабируемостью, онлайн-агрегирования и ETL для больших наборов данных, хранящихся в HDFS и других источниках данных. Он поддерживает интеграцию с Hive Metastore для доступа к общим схемам. Он также имеет множество оптимизаций запросов, он масштабируемый, отказоустойчивый и предоставляет интерфейс JDBC.
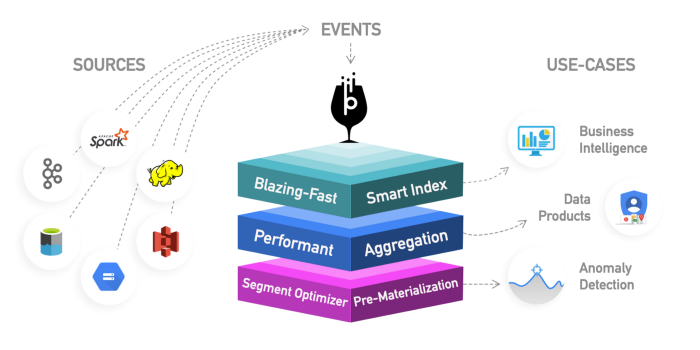
Apache Kylin: это новое распределенное хранилище аналитических данных. Kylin чрезвычайно быстр, поэтому его можно использовать для дополнения некоторых других баз данных, таких как Hive, для случаев использования, где важна производительность, таких как панели мониторинга или интерактивные отчеты. Это, вероятно, лучшее хранилище данных OLAP, но его сложно использовать. Другая проблема заключается в том, что из-за большой растягиваемости требуется больше места для хранения. Идея состоит в том, что если механизмы запросов или Hive недостаточно быстры, вы можете создать «Куб» в Kylin, который представляет собой многомерную таблицу, оптимизированную для OLAP, с предварительно вычисленными
значениями, которые вы можете запрашивать из панелей мониторинга или интерактивных отчетов. Он может создавать «кубики» прямо из Spark и даже почти в реальном времени из Kafka.
Инструменты OLAP
В эту категорию я включаю более новые механизмы, которые представляют собой эволюцию предыдущих баз данных OLAP, которые предоставляют больше функций, создавая комплексную аналитическую платформу. Фактически, они представляют собой гибрид двух предыдущих категорий, добавляющих индексацию в ваши базы данных OLAP. Они живут за пределами платформы Hadoop, но тесно интегрированы. В этом случае вы обычно пропускаете этап обработки и непосредственно используете эти инструменты.
Они пытаются решить проблему запросов к данным в реальном времени и к историческим данным единообразно, поэтому вы можете немедленно запрашивать данные в реальном времени, как только они становятся доступными, вместе с историческими данными с низкой задержкой, чтобы вы могли создавать интерактивные приложения и информационные панели. Эти инструменты позволяют во многих случаях запрашивать необработанные данные практически без преобразования в стиле ELT, но с высокой производительностью, лучше, чем у обычных баз данных OLAP.
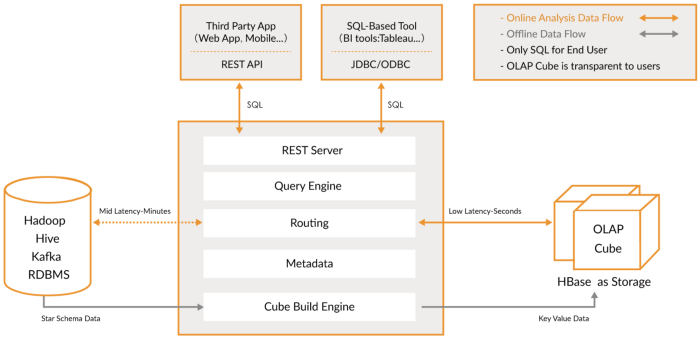
Их объединяет то, что они обеспечивают унифицированное представление данных, прием данных в реальном времени и пакетных данных, распределенную индексацию, собственный формат данных, поддержку SQL, интерфейс JDBC, поддержку горячих и холодных данных, множественные интеграции и хранилище метаданных.
Apache Druid: это самый известный движок OLAP в реальном времени. Он ориентирован на данные временных рядов, но может использоваться для любых данных. Он использует свой собственный столбчатый формат, который может сильно сжимать данные, и он имеет множество встроенных оптимизаций, таких как инвертированные индексы, кодирование текста, автоматическое сворачивание данных и многое другое. Данные загружаются в реальном времени с использованием Tranquility или Kafka, которые имеют очень низкую задержку, хранятся в памяти в формате строки, оптимизированном для записи, но как только они поступают, они становятся доступными для запроса, как и предыдущие загруженные данные. Фоновая процесс отвечает за асинхронное перемещение данных в систему глубокого хранения, такую как HDFS. Когда данные перемещаются в глубокое хранилище, они разделяются на более мелкие фрагменты, сегрегированные по времени, называемые сегментами, которые хорошо оптимизированы для запросов с низкой задержкой. У такого сегмента есть отметка времени для нескольких измерений, которые вы можете использовать для фильтрации и агрегирования, и метрики, которые представляют собой предварительно вычисленные состояния. При пакетном приеме данные сохраняются непосредственно в сегменты. Apache Druid поддерживает проглатывание по принципу push и pull, имеет интеграцию с Hive, Spark и даже NiFi. Он может использовать хранилище метаданных Hive и поддерживает запросы Hive SQL, которые затем преобразуются в запросы JSON, используемые Druid. Интеграция Hive поддерживает JDBC, поэтому вы можете подключить любой инструмент бизнес-аналитики. Он также имеет собственное хранилище метаданных, обычно для этого используется MySQL. Он может принимать огромные объемы данных и очень хорошо масштабируется. Основная проблема в том, что в нем много компонентов, и им сложно управлять и развертывать.
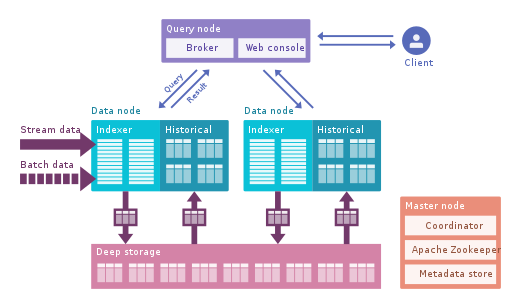
Apache Pinot: это более новая альтернатива Druid с открытым исходным кодом от LinkedIn. По сравнению с Druid, он предлагает меньшую задержку благодаря индексу Startree, который выполняет частичное предварительное вычисление, поэтому его можно использовать для приложений, ориентированных на пользователя (он использовался для получения лент LinkedIn). Он использует отсортированный индекс вместо инвертированного, который работает быстрее. Он имеет расширяемую архитектуру плагинов, а также имеет множество интеграций, но не поддерживает Hive. Он также объединяет пакетную обработку и режим реального времени, обеспечивает быструю загрузку, интеллектуальный индекс и сохраняет данные в сегментах. Его легче и быстрее развернуть по сравнению с Druid, но на данный момент он выглядит немного недозрелым.
ClickHouse: будучи написанным на C++, этот движок обеспечивает невероятную производительность для запросов OLAP, особенно для агрегатов. Это похоже на реляционную базу данных, поэтому вы можете легко моделировать данные. Он очень прост в настройке и имеет множество интеграций.
Прочитайте эту статью, которая сравнивает 3 движка детально.
Начните с малого, изучив свои данные, прежде чем принимать решение. Эти новые механизмы очень мощные, но их сложно использовать. Если вы можете ждать по несколько часов, используйте пакетную обработку и базу данных, такую как Hive или Tajo; затем используйте Kylin, чтобы ускорить запросы OLAP и сделать их более интерактивными. Если этого недостаточно и вам нужно еще меньше задержки и данные в реальном времени, подумайте о механизмах OLAP. Druid больше подходит для анализа в реальном времени. Кайлин больше ориентирован на дела OLAP. Druid имеет хорошую интеграцию с Kafka в качестве потоковой передачи в реальном времени. Kylin получает данные из Hive или Kafka партиями, хотя планируется прием в реальном времени.
Наконец, Greenplum — еще один механизм OLAP, больше ориентированный на искусственный интеллект.
Визуализация данных
Для визуализации есть несколько коммерческих инструментов, таких как Qlik, Looker или Tableau.
Если вы предпочитаете Open Source, посмотрите в сторону SuperSet. Это замечательный инструмент, который поддерживает все упомянутые нами инструменты, имеет отличный редактор и действительно быстрый, он использует SQLAlchemy, что обеспечивает поддержку многих баз данных.
Другие интересные инструменты: Metabase или Falcon.
Заключение
Есть широкий спектр инструментов, которые можно использовать для обработки данных, от гибких механизмов запросов, таких как Presto, до высокопроизводительных хранилищ, таких как Kylin. Единого решения не существует, я советую изучить имеющиеся данные и начать с малого. Механизмы запросов — хорошая отправная точка из-за их гибкости. Затем для различных случаев использования вам может потребоваться добавить дополнительные инструменты чтобы достигнуть необходимого вам уровня обслуживания.
Обратите особое внимание на новые инструменты, такие как Druid или Pinot, которые обеспечивают простой способ анализа огромных объемов данных с очень низкой задержкой, сокращая разрыв между OLTP и OLAP с точки зрения производительности. У вас может возникнуть соблазн подумать об обработке, предварительном вычислении агрегатов и т.п., но подумайте об этих инструментах, если вы хотите упростить свою работу.








