В интересное время живем, что ни день – то новость, как нейросети помогают делать нашу жизнь проще и удобнее. Мне давно хотелось поэкспериментировать с алгоритмами машинного обучения на базе нейронок, и вот подвернулась нетривиальная задача.

C переходом на самоизоляцию в марте этого года, мы, как и многие компании, перевели в онлайн все наши продуктовые мероприятия. Ну, вы помните эту замечательную картинку про вебинары с обезъянками. За прошедшие полгода только по тематике датацентров, за которую отвечает моя команда, у нас накопилось около 25-ти 2х-часовых записанных вебинаров, 50 часов видео суммарно. Проблема, которая встала в полный рост – как понять, в каком видео искать ответы на те или иные вопросы. Каталог, теги, краткое описание — это хорошо, ну вот нашли мы в итоге, что по теме есть 4 двухчасовых ролика, а дальше что? Смотреть на перемотке? А можно как-то по-другому? А если выступить по-модному и попробовать прикрутить ИИ?
Для нетерпеливых спойлер: законченную чудо-систему ни найти, ни собрать на коленке у меня не получилось, да и не было бы тогда смысла в этой статье. Но по итогам нескольких дней (а точнее вечеров), изысканий, получился рабочий MVP, про который я хочу рассказать. Цель статьи – посмотреть на уровень интереса к этому вопросу, получить советы от знающих людей и, возможно, найти кого-то еще, у кого есть такая же проблема.
На первый взгляд, все выглядело просто — берешь видео, прогоняешь через нейросеть, получаешь текст, дальше ищешь в тексте фрагмент, где описана интересующая тема. Еще удобнее было бы искать сразу по всем видео в каталоге. Вообще-то, выкладывать расшифровки текста вместе с роликами придумали уже давно, это умеют делать Youtube и большинство образовательных платформ, хотя понятно, что там эти тексты редактируют люди. Текст можно быстро пробежать глазами и понять, есть ли там ответ на нужный вопрос. Наверное, из удобного функционала не помешала бы возможность ткнуть в интересующее место текста и послушать, что там говорит и показывает лектор, это тоже несложно, если есть разметка слов по времени, где они находятся в тексте. Ну это я замечтался – о возможных направлениях развития давайте поговорим в конце, а сейчас попробуем просто максимально качественно реализовать цепочку
видеофайл –> текстовый фрагмент –> нечеткий поиск по тексту.
Сначала я подумал, раз все так просто, и про этот кейс уже года 4 говорят на всех конференциях по ИИ, такие системы должны существовать готовые. Пару часов поиска и чтения статей показали, что это не так. По видео, в-основном, ищут лица, машины и другие визуальные объекты (маски/каски), а по аудио – песни, треки, а также тон/интонации говорящего, как часть решений для call-центров. Удалось найти лишь это упоминание про систему Deepgram. Но у нее, к сожалению, нет поддержки русского языка. Также очень похожая функциональность есть у Microsoft в Streams, но нигде не нашел упоминания про поддержку русского языка, судя по всему, ее тоже нет.
Хорошо, давайте изобретать. Я не профессиональный программист (и, кстати, с удовольствием приму конструктивную критику по коду), но периодически пишу что-то «для себя». Нейросети, которые могут преобразовывать речь в текст называются (сюрприз-сюрприз), speech-to-text. Если получится найти публичный сервис speech-to-text, то его можно использовать, чтобы «оцифровать» речь во всех вебинарах, а сделать потом нечеткий поиск по тексту – более простая задача. Признаюсь, я поначалу не думал «лезть в облако», хотел собрать все локально, но, после прочтения этой статьи на Хабре, решил, что распознавание речи действительно лучше делать в облаке.
Поиск сервисов, способных делать speech-to-text показал, что таких систем масса, в том числе и разработанных в России, есть среди них также глобальные облачные провайдеры вроде Google, Amazon, MS Azure. Описание нескольких сервисов, включая русскоязычные есть вот тут. Вообще, первые 20 строчек в выдаче поисковика будут уникальными. Но тут есть еще одна загвоздка – мне хотелось бы в будущем запустить эту систему в продакшн, это затраты, а я работаю в Cisco, которая глобально имеет контракты с ведущими облаками. Так что из всего списка я решил пока рассматривать только их.
Итак, мой список сократился до Google, Amazon, Azure, IBM Watson (ссылки на названиях — такие же, как в таблице ниже). Все сервисы имеют API, через которые их можно использовать. Проанализировав остальные возможности, я составил небольшую таблицу:

IBM Watson сошел с дистанции на этом этапе, так как все записи у меня на руссском, остальных провайдеров решено было испытать на небольшом отрывке вебинара. В AWS и Azure завел аккаунты. Забегая вперед, скажу, что майкрософт в плане заведения аккаунта оказался крепким орешком. Работал я из корпоративной сети, которая «приземляется» в Интернет где-то в Амстердаме, в процессе регистрации меня дважды спросили, уверен ли я, что мой адрес – Россия, после чего система высветила сообщение, что аккаунт на административной блокировке «до выяснения». Спустя 5 дней, пока я писал эту статью, ситуация не поменялась, так что протестировать Azure пока не удалось, а жаль! Я понимаю – безопасность, но это пока не позволило мне попробовать сервис. Попробую сделать это позже, когда ситуация решится.
Отдельно хотелось бы протестировать такую функцию у Яндекс.Облака, распознавание русской речи у них, по-идее, должно быть лучше всех. Но, к сожалению, на странице тестового доступа сервиса есть только возможность «наговорить» текст, загрузка файла не предусмотрена. Значит, отложим вместе с Azure во вторую очередь.
Итак, остались Google и Amazon, давайте же скорее тестировать! Прежде, чем писать какой-то код, можно все проверить и сравнить руками, у обоих провайдеров кроме API есть административный интерфейс. Для теста я сначала подготовил фрагмент длиной 10 минут, общего характера, по возможности, с минимумом специальной терминологии. Но потом оказалось, что Google поддерживает в тестовом режиме фрагмент до 1 минуты, поэтому для сравнения сервисов я использовал вот этот отрывок длиной 57 секунд.
По итогам работы оба сервиса выдают распознанный текст, можно сравнить результаты их работы на минутном отрезке.

Результат, прямо скажу, не такой как ожидалось, но ведь не зря в моделях предусмотрены разные варианты их настройки. Как мы видим, движок Google «из коробки» чище распознал бОльшую часть текста, также ему удалось увидеть названия некоторых продуктов, хотя и не все. Это говорит о том, что их модель допускает мультиязычный текст. У Amazon (в дальнейшем это подтвердилось) такая возможность отсутствует — сказали русский, значит, будем петь: «Кинь бабе лом» и точка!
Но возможность получить размеченный JSON, которую предоставляет Amazon, мне показалась очень интересной. Ведь это позволит в будущем реализовать прямой переход в ту часть, файла, где встретился искомый фрагмент. Возможно, у Google такая функция тоже есть, ведь все распознающие речь нейросети так работают, но беглым поиском по документации найти эту фичу не удалось.

Если посмотреть на этот JSON, видно, что он состоит из трех разделов: переведенного текста (transcript), массива слов (items), и набора сегментов (segments). Для массива слов и сегментов для каждого элемента указано его время начала и окончания, а также уверенность нейросети (confidence), что она его правильно распознала.
Итак, по итогам этого этапа я решил выбрать Amazon Transcribe для дальнейших экспериментов и попробовать настроить модель обучения. А уж, если не получится добиться устойчивого распознавания – разбираться с Google. Дальнейшие тесты проводились на фрагменте длиной 10 минут.
В AWS Transcribe есть две возможности тюнить то, что распознает нейросеть, и еще пара фич для последующей обработки текста:
Итак, я решил сделать свой словать для текста. Очевидно, что в него попадут такие слова, как «сеть, серверы, профили, датацентр, устройство, контроллер, инфраструктура». У меня после 2-3 тестов словарь вырос до 60 слов. Словарь этот нужно создавать в обычном текстовом файле, по одному слову на строчку, все прописными буквами. Есть и более сложный вариант (описан вот тут) с возможностью указать, как слово произносится, но на начальном этапе я решил обойтись простым списком.
Перед тем, как использовать словарь, необходимо его создать. На закладке Custom vocabulary в Amazon Transcribe жмем Create Vocabulary, загружаем текст нашего файла, указываем язык русский, отвечаем на остальные вопросы, и начинается процесс создания словаря. Как только он из Processing станет Ready – словарем можно будет пользоваться.
Остался вопрос – как распознавать «англоязычные» термины? Напомню, словарь поддерживает только один язык. Сначала я подумал создать отдельно словарь с английскими терминами, и прогонять тот же текст через него. При обнаружении терминов типа Cisco, VLAN, UCS и т.д. c probability rate 100% — брать их для данного временного фрагмента. Но сразу скажу – получилось никак, анализатор английского языка не распознал больше половины терминов в тексте. Подумав, я решил, что это логично, так как мы произносим все эти термины с «русским акцентом», нас даже англо-американцы не с первого раза понимают. Это натолкнуло на мысль просто добавить эти термины в русский словарь по принципу «как слышится, так и пишется». Циско, юсиэс, эйсиай, вилан, виикслан – ведь мы же, положа руку на сердце, так и говорим, когда общаемся между собой. Это увеличило словарь еще на пару десятков слов, но, забегая вперед, на порядок улучшило качество распознавания!
Как говорится «хорошая мысля приходит опосля», первый словарь уже создан, поэтому решил создать еще один, добавив в него все аббревиатуры, и сравнить, что получится.
Запустить распознавание со словарем так же просто, в сервисе Transcribe на закладке Transcription job выбираем Create job, указываем русский язык, и не забываем указать нужный нам словарь. Еще одно полезное действие – можно попросить нейросеть давать нам несколько альтернативных результатов поиска, пункт Alternative results – Yes, я задал 3 альтернативных варианта. Позже, когда я буду делать нечеткий поиск по тексту, это сильно пригодится.
Трансляция 10-ти минутного фрагмента текста идет 4-5 минут, чтобы не терять время, я решил написать небольшой инструмент, который облегчит процесс сравнения результатов. Я буду выводить итоговый текст из JSON-файла в браузере, попутно подсвечивая цветом «надежность» обнаружения отдельных слов нейросетью (тот самый параметр confidence). У меня три варианта результирующего текста – трансляция по-умолчанию, словарь без терминов и словарь с терминами. Пусть все три текста отображаются одновременно в трех столбцах. Слова с надежностью выше 95% подсвечиваю зеленым, от 95% до 70% — желтым, ниже 70% — красным. Наскоро собранный код получившейся HTML-страницы ниже, файлы JSON должны лежать в той же директории, где находится файл. Названия файлов задаются в переменных FILENAME1 и т.д.
Скачиваю файлы asrOutput.json по всем трем задачам, переименовываю, как написано в HTML-скрипте, и вот что получается.

Четко видно, что добавление русскоязычных терминов позволило нейросети более точно распознавать специфические термины — «сервисный профиль» и т.д. А добавление русской транскрипции на втором шаге – превратило “ЦСКА” в «циско». Текст все еще довольно «грязный», но для моей задачи контекстного поиска должен уже подходить. По мере добавления и вычитывания новых вебинаров словарь постепенно будет расширяться, это процесс поддержки такой системы, про который не нужно забывать.
Существует, наверное, десяток подходов к решению задачи нечеткого поиска, по большей части они базируются на небольшом наборе математических алгоритмов, таких как, например, расстояние Левенштейна. хорошая статья про это, еще одна и еще одна. Но мне хотелось найти что-то готовое, типа запустил и работает.
Из готовых решений для локального поиска по документам, после небольшого ресерча нашел относительно давний проект SPHINX, также возможность полнотекстового поиска, вроде бы, есть в PostgreSQL, об этом написано ТУТ. Но больше всего материалов, в том числе на русском, удалось найти про Elasticsearch. После чтения хороших руководств по запуску и настройке, например, этого поста или этого урока, вот еще, а также документации и руководства по API для Python, мной принято решение использовать его.
Для всех локальных экспериментов я давно использую Docker, и очень рекомендую всем, кто почему-то с ним еще не разобрался, это сделать. По факту, я стараюсь ничего, кроме сред разработки, браузеров и «вьюверов» в локальной операционке не запускать. Кроме отсутствия проблем с совместимостью и т.д. это позволяет быстро попробовать новый продукт и понять, хорошо ли он работает.
Контейнер с Elasticsearch выкачиваем и запускаем двумя командами:
После запуска контейнера, по адресу
Вот как выглядит окно этого плагина с описанным в одном из руководств выше примером про веселых котят.
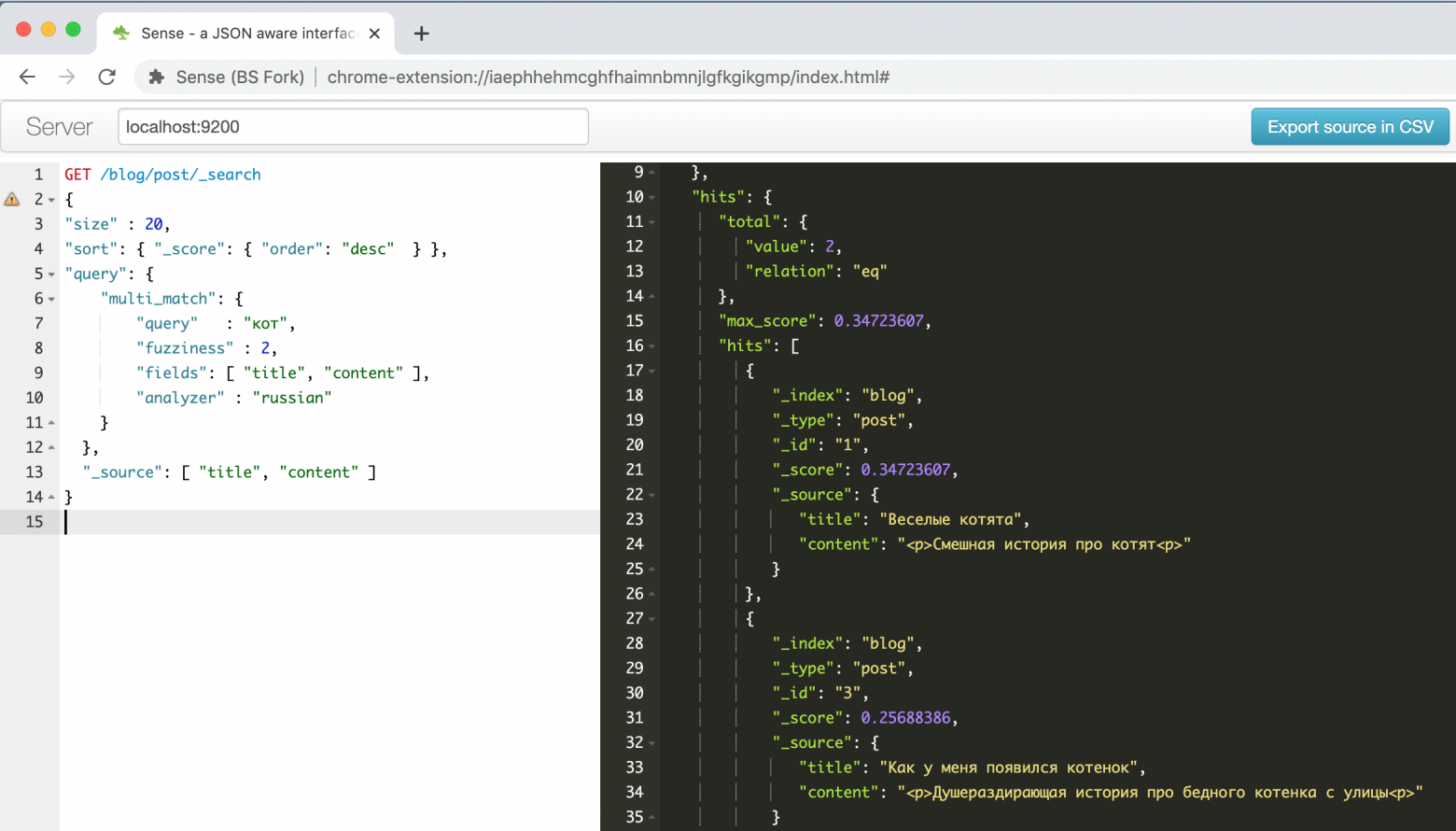
Слева запрос – справа ответ, автозаполнение, подсветка синтаксиса, автоформатирование – что еще нужно для продуктивной работы! Кроме того, этот плагин умеет распознавать во вставляемом из буфера тексте формат командной строки CURL и правильно его форматировать, например, попробуйте вставить строку
«curl -X GET $ES_URL» и посмотрите, что получится. Удобная штука, в-общем.
Что и как я буду хранить и искать? Elasticsearch принимает все документы в формате JSON и хранит их в структурах, которые называются индексы. Разных индексов может быть сколько угодно, но в одном индексе могут лежать однородные данные и документы, с похожей структурой полей и одинаковым подходом к поиску.
Для исследования возможностей нечеткого поиска я решил сделать загрузку и поиск по разделу фраз (segments) файла транскрипции, полученного на предыдущем шаге. В разделе segments JSON-файла данные хранятся в следующем формате:
Я хочу увеличить вероятность успешного поиска, поэтому буду загружать в базу для поиска все альтернативные варианты, а потом уже из найденных фрагментов выбирать тот, у которого суммарный confidence выше.
Для переформатирования и загрузки JSON документа в Elasticsearch использую небольшой скрипт на Python, логика скрипта следующая:
Если у вас нет Python-а, не расстраивайтесь, нам опять поможет Docker. Я обычно использую контейнер с Jupyter notebook — к нему можно подключаться обычным браузером и делать все что нужно, единственное, нужно подумать о сохранении результатов, так как при уничтожении контейнера вся информация теряется. Если вы ранее с этим инструментом не работали, то вот хорошая статья для начинающих, кстати, раздел про инсталляцию вы уже можете смело пропустить
Запускаем контейнер с Python notebook командой:
И подключаемся к нему любым браузером по адресу, который видим на экране после успешного запуска скрипта, это
Создаем новый блокнот, в первой ячейке пишем:
Запускаем, ждем пока установится пакет для работы с ES через API, во вторую ячейку копируем наш скрипт и запускаем. После его работы, если все успешно, мы можем проверить в консоли Elasticsearch, что наши данные успешно загружены. Вводим команду

Настало время попробовать нечеткий поиск – то ради чего все и затевалось. Например, для поиска по фразе «ядро сети датацентра», для этого нужно дать такую команду:
Получаем аж 47 результатов!
Неудивительно, тем так как бОльшая часть из них – разные вариации одного и того же фрагмента. Напишем еще один скрипт, чтобы выбрать из каждого сегмента одну запись с наибольшим значением confidence.
Пример вывода:
Мы видим, что результатов стало гораздо меньше, и теперь мы можем просмотреть их и выбрать тот, который нас интересует больше всего.
Также, поскольку у нас есть время начала и окончания видеофрагмента, мы можем сделать страничку с видеоплеером и программным путем «перематывать» его к интересующему фрагменту.
Но эту задачу я вынесу в отдельную статью, если будет интерес к дальнейшим публикациям по этой теме.
Итак, в рамках этой статьи я показал, как решал задачу построения системы текстового поиска по видеорахиву с записями вебинаров на техническую тематику. В итоге получилось то, что принято называть MVP, т.е. минимально работающий алгоритм, позволяющий получить результат и доказывающий, что результат в принципе достижим на имеющихся технологиях.
До конечного продукта предстоит еще долгий путь, из идей, которые можно реализовать в ближайшем будущем:
Если у вас есть вопросы/комментарии, буду рад на них ответить, также рад буду услышать любые предложения по улучшению или упрощению процесса в целом. Это моя первая техническая статья для Хабр-а, очень надеюсь, что получилось полезно и интересно.
Удачи всем в творческих поисках, и да прибудет с вами Сила!

C переходом на самоизоляцию в марте этого года, мы, как и многие компании, перевели в онлайн все наши продуктовые мероприятия. Ну, вы помните эту замечательную картинку про вебинары с обезъянками. За прошедшие полгода только по тематике датацентров, за которую отвечает моя команда, у нас накопилось около 25-ти 2х-часовых записанных вебинаров, 50 часов видео суммарно. Проблема, которая встала в полный рост – как понять, в каком видео искать ответы на те или иные вопросы. Каталог, теги, краткое описание — это хорошо, ну вот нашли мы в итоге, что по теме есть 4 двухчасовых ролика, а дальше что? Смотреть на перемотке? А можно как-то по-другому? А если выступить по-модному и попробовать прикрутить ИИ?
Для нетерпеливых спойлер: законченную чудо-систему ни найти, ни собрать на коленке у меня не получилось, да и не было бы тогда смысла в этой статье. Но по итогам нескольких дней (а точнее вечеров), изысканий, получился рабочий MVP, про который я хочу рассказать. Цель статьи – посмотреть на уровень интереса к этому вопросу, получить советы от знающих людей и, возможно, найти кого-то еще, у кого есть такая же проблема.
Что я хочу сделать
На первый взгляд, все выглядело просто — берешь видео, прогоняешь через нейросеть, получаешь текст, дальше ищешь в тексте фрагмент, где описана интересующая тема. Еще удобнее было бы искать сразу по всем видео в каталоге. Вообще-то, выкладывать расшифровки текста вместе с роликами придумали уже давно, это умеют делать Youtube и большинство образовательных платформ, хотя понятно, что там эти тексты редактируют люди. Текст можно быстро пробежать глазами и понять, есть ли там ответ на нужный вопрос. Наверное, из удобного функционала не помешала бы возможность ткнуть в интересующее место текста и послушать, что там говорит и показывает лектор, это тоже несложно, если есть разметка слов по времени, где они находятся в тексте. Ну это я замечтался – о возможных направлениях развития давайте поговорим в конце, а сейчас попробуем просто максимально качественно реализовать цепочку
видеофайл –> текстовый фрагмент –> нечеткий поиск по тексту.
Сначала я подумал, раз все так просто, и про этот кейс уже года 4 говорят на всех конференциях по ИИ, такие системы должны существовать готовые. Пару часов поиска и чтения статей показали, что это не так. По видео, в-основном, ищут лица, машины и другие визуальные объекты (маски/каски), а по аудио – песни, треки, а также тон/интонации говорящего, как часть решений для call-центров. Удалось найти лишь это упоминание про систему Deepgram. Но у нее, к сожалению, нет поддержки русского языка. Также очень похожая функциональность есть у Microsoft в Streams, но нигде не нашел упоминания про поддержку русского языка, судя по всему, ее тоже нет.
Хорошо, давайте изобретать. Я не профессиональный программист (и, кстати, с удовольствием приму конструктивную критику по коду), но периодически пишу что-то «для себя». Нейросети, которые могут преобразовывать речь в текст называются (сюрприз-сюрприз), speech-to-text. Если получится найти публичный сервис speech-to-text, то его можно использовать, чтобы «оцифровать» речь во всех вебинарах, а сделать потом нечеткий поиск по тексту – более простая задача. Признаюсь, я поначалу не думал «лезть в облако», хотел собрать все локально, но, после прочтения этой статьи на Хабре, решил, что распознавание речи действительно лучше делать в облаке.
Ищем облачные сервисы для speech-to-text
Поиск сервисов, способных делать speech-to-text показал, что таких систем масса, в том числе и разработанных в России, есть среди них также глобальные облачные провайдеры вроде Google, Amazon, MS Azure. Описание нескольких сервисов, включая русскоязычные есть вот тут. Вообще, первые 20 строчек в выдаче поисковика будут уникальными. Но тут есть еще одна загвоздка – мне хотелось бы в будущем запустить эту систему в продакшн, это затраты, а я работаю в Cisco, которая глобально имеет контракты с ведущими облаками. Так что из всего списка я решил пока рассматривать только их.
Итак, мой список сократился до Google, Amazon, Azure, IBM Watson (ссылки на названиях — такие же, как в таблице ниже). Все сервисы имеют API, через которые их можно использовать. Проанализировав остальные возможности, я составил небольшую таблицу:

IBM Watson сошел с дистанции на этом этапе, так как все записи у меня на руссском, остальных провайдеров решено было испытать на небольшом отрывке вебинара. В AWS и Azure завел аккаунты. Забегая вперед, скажу, что майкрософт в плане заведения аккаунта оказался крепким орешком. Работал я из корпоративной сети, которая «приземляется» в Интернет где-то в Амстердаме, в процессе регистрации меня дважды спросили, уверен ли я, что мой адрес – Россия, после чего система высветила сообщение, что аккаунт на административной блокировке «до выяснения». Спустя 5 дней, пока я писал эту статью, ситуация не поменялась, так что протестировать Azure пока не удалось, а жаль! Я понимаю – безопасность, но это пока не позволило мне попробовать сервис. Попробую сделать это позже, когда ситуация решится.
Отдельно хотелось бы протестировать такую функцию у Яндекс.Облака, распознавание русской речи у них, по-идее, должно быть лучше всех. Но, к сожалению, на странице тестового доступа сервиса есть только возможность «наговорить» текст, загрузка файла не предусмотрена. Значит, отложим вместе с Azure во вторую очередь.
Итак, остались Google и Amazon, давайте же скорее тестировать! Прежде, чем писать какой-то код, можно все проверить и сравнить руками, у обоих провайдеров кроме API есть административный интерфейс. Для теста я сначала подготовил фрагмент длиной 10 минут, общего характера, по возможности, с минимумом специальной терминологии. Но потом оказалось, что Google поддерживает в тестовом режиме фрагмент до 1 минуты, поэтому для сравнения сервисов я использовал вот этот отрывок длиной 57 секунд.
- Для тестов в Google нужно перейти по ссылке выше, залогиниться и можно загружать тестовый фрагмент файла.
- Для тестов в AWS Transcribe нужно завести учетную запись AWS, первый год они позволяют часть сервисов использовать бесплатно в определенных лимитах. На сервис AWS Transcribe дается 1 бесплатный час работы в месяц. Для того, чтобы запустить распознавание, нужно сначала загрузить файл в объектное хранилище AWS S3. Не буду здесь приводить выдержки из документации, там все неплохо описано
По итогам работы оба сервиса выдают распознанный текст, можно сравнить результаты их работы на минутном отрезке.
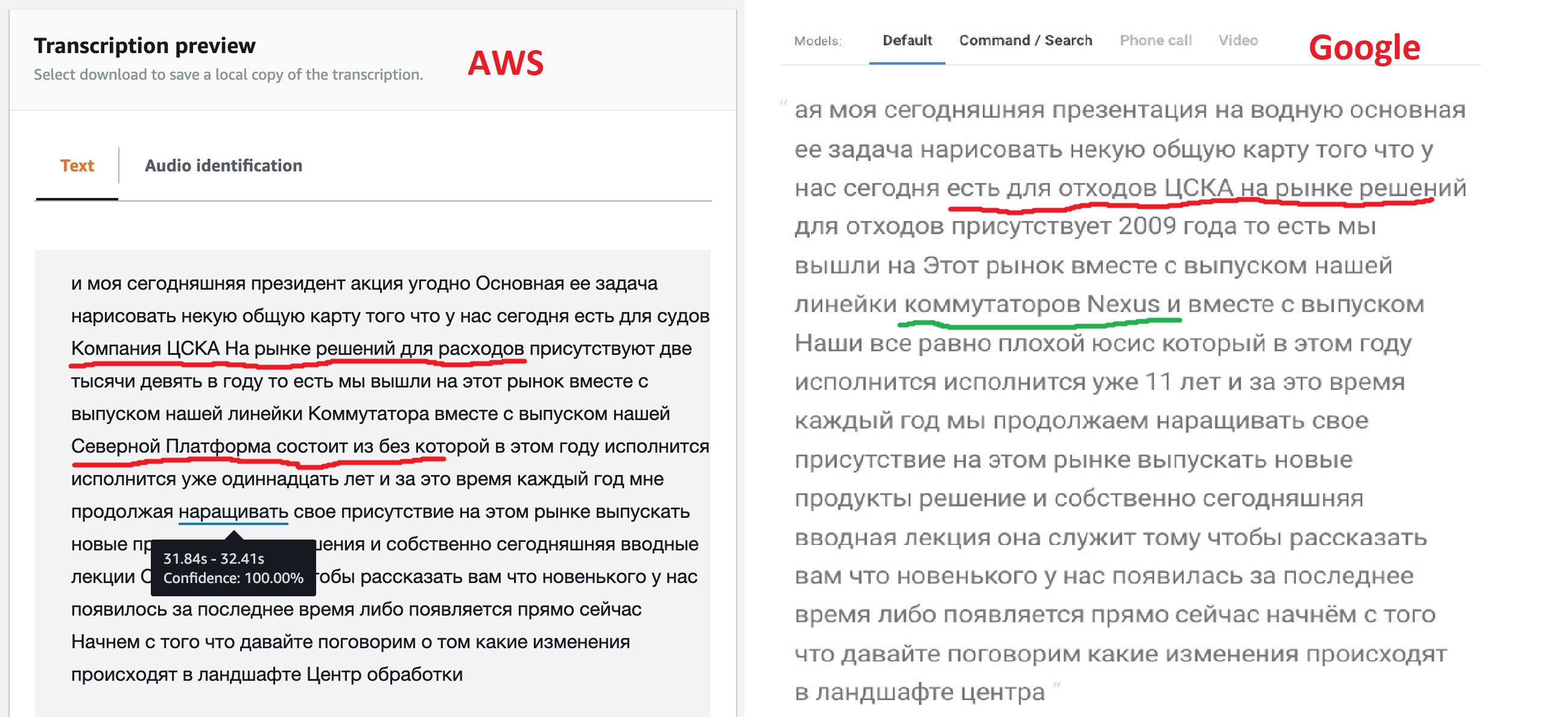
Результат, прямо скажу, не такой как ожидалось, но ведь не зря в моделях предусмотрены разные варианты их настройки. Как мы видим, движок Google «из коробки» чище распознал бОльшую часть текста, также ему удалось увидеть названия некоторых продуктов, хотя и не все. Это говорит о том, что их модель допускает мультиязычный текст. У Amazon (в дальнейшем это подтвердилось) такая возможность отсутствует — сказали русский, значит, будем петь: «Кинь бабе лом» и точка!
Но возможность получить размеченный JSON, которую предоставляет Amazon, мне показалась очень интересной. Ведь это позволит в будущем реализовать прямой переход в ту часть, файла, где встретился искомый фрагмент. Возможно, у Google такая функция тоже есть, ведь все распознающие речь нейросети так работают, но беглым поиском по документации найти эту фичу не удалось.

Если посмотреть на этот JSON, видно, что он состоит из трех разделов: переведенного текста (transcript), массива слов (items), и набора сегментов (segments). Для массива слов и сегментов для каждого элемента указано его время начала и окончания, а также уверенность нейросети (confidence), что она его правильно распознала.
Учим нейросеть разбираться в датацентрах
Итак, по итогам этого этапа я решил выбрать Amazon Transcribe для дальнейших экспериментов и попробовать настроить модель обучения. А уж, если не получится добиться устойчивого распознавания – разбираться с Google. Дальнейшие тесты проводились на фрагменте длиной 10 минут.
В AWS Transcribe есть две возможности тюнить то, что распознает нейросеть, и еще пара фич для последующей обработки текста:
- Custom Vocabularies – позволяет создать «словарь» из тех, слов, которые должна «выучить» нейросеть перед тем, как приступить к распознаванию. В словарь можно внести все специальные термины: «ЦОДы, интеграция, мультиканальный» чтобы нейросеть не пыталась действовать как корректироващик ошибок Word в далеком 97-м году. Отдельно нужно отметить, что в настоящий момент все слова в словаре должны быть из одного языка, т.е. нельзя смешивать русские и английские термины в рамках одного распознавания.
- Custom Language Models – интересная возможность «загрузить» в распознаватель собственный корпус текстов начиная от 10 тыс. слов, на котором нейросеть обучается распознавать специфическую терминологию. К, сожалению, данная опция не поддерживает русский язык, так что ее на данном этапе использовать не получится.
- После распознавания из текста можно убрать слова по словарю, например, обсценную лексику или слова-паразиты. Также, есть специальный фильтр для чувствительной информации – номеров кредитных карт, персданных и т.д. Полезная фича для колл-центров, наверное.
Итак, я решил сделать свой словать для текста. Очевидно, что в него попадут такие слова, как «сеть, серверы, профили, датацентр, устройство, контроллер, инфраструктура». У меня после 2-3 тестов словарь вырос до 60 слов. Словарь этот нужно создавать в обычном текстовом файле, по одному слову на строчку, все прописными буквами. Есть и более сложный вариант (описан вот тут) с возможностью указать, как слово произносится, но на начальном этапе я решил обойтись простым списком.
Перед тем, как использовать словарь, необходимо его создать. На закладке Custom vocabulary в Amazon Transcribe жмем Create Vocabulary, загружаем текст нашего файла, указываем язык русский, отвечаем на остальные вопросы, и начинается процесс создания словаря. Как только он из Processing станет Ready – словарем можно будет пользоваться.
Остался вопрос – как распознавать «англоязычные» термины? Напомню, словарь поддерживает только один язык. Сначала я подумал создать отдельно словарь с английскими терминами, и прогонять тот же текст через него. При обнаружении терминов типа Cisco, VLAN, UCS и т.д. c probability rate 100% — брать их для данного временного фрагмента. Но сразу скажу – получилось никак, анализатор английского языка не распознал больше половины терминов в тексте. Подумав, я решил, что это логично, так как мы произносим все эти термины с «русским акцентом», нас даже англо-американцы не с первого раза понимают. Это натолкнуло на мысль просто добавить эти термины в русский словарь по принципу «как слышится, так и пишется». Циско, юсиэс, эйсиай, вилан, виикслан – ведь мы же, положа руку на сердце, так и говорим, когда общаемся между собой. Это увеличило словарь еще на пару десятков слов, но, забегая вперед, на порядок улучшило качество распознавания!
Как говорится «хорошая мысля приходит опосля», первый словарь уже создан, поэтому решил создать еще один, добавив в него все аббревиатуры, и сравнить, что получится.
Запустить распознавание со словарем так же просто, в сервисе Transcribe на закладке Transcription job выбираем Create job, указываем русский язык, и не забываем указать нужный нам словарь. Еще одно полезное действие – можно попросить нейросеть давать нам несколько альтернативных результатов поиска, пункт Alternative results – Yes, я задал 3 альтернативных варианта. Позже, когда я буду делать нечеткий поиск по тексту, это сильно пригодится.
Трансляция 10-ти минутного фрагмента текста идет 4-5 минут, чтобы не терять время, я решил написать небольшой инструмент, который облегчит процесс сравнения результатов. Я буду выводить итоговый текст из JSON-файла в браузере, попутно подсвечивая цветом «надежность» обнаружения отдельных слов нейросетью (тот самый параметр confidence). У меня три варианта результирующего текста – трансляция по-умолчанию, словарь без терминов и словарь с терминами. Пусть все три текста отображаются одновременно в трех столбцах. Слова с надежностью выше 95% подсвечиваю зеленым, от 95% до 70% — желтым, ниже 70% — красным. Наскоро собранный код получившейся HTML-страницы ниже, файлы JSON должны лежать в той же директории, где находится файл. Названия файлов задаются в переменных FILENAME1 и т.д.
код HTML-страницы для просмотра результатов
<!DOCTYPE html>
<html lang="en">
<head> <meta charset="UTF-8"> <title>Title</title> </head>
<body onload="initText()">
<hr> <table> <tr valign="top">
<td width="400"> <h2 >По-умолчанию </h2><div id="text-area-1"></div></td>
<td width="400"> <h2 >Фильтр 1: только русский/яз </h2><div id="text-area-2"></div></td>
<td width="400"> <h2 >Фильтр 2: русский/яз и термины </h2><div id="text-area-3"></div></td>
</tr> </table> <hr>
<style>
.known { background-image: linear-gradient(90deg, #f1fff4, #c4ffdb, #f1fff4); }
.unknown { background-image: linear-gradient(90deg, #ffffff, #ffe5f1, #ffffff); }
.badknown { background-image: linear-gradient(90deg, #feffeb, #ffffc2, #feffeb); }
</style>
<script>
// File names
const FILENAME1 = "1-My_CiscoClub_transcription_10min-1-default.json";
const FILENAME2 = '2-My_CiscoClub_transcription_10min-2-Russian_only.json';
const FILENAME3 = '3-My_CiscoClub_transcription_10min-v3_Russian_terminilogy.json';
// Read file from disk and call callback if success
function readTextFile(file, textBlockName, callback) {
let rawFile = new XMLHttpRequest();
rawFile.overrideMimeType("application/json");
rawFile.open("GET", file, true);
rawFile.onreadystatechange = function() {
if (rawFile.readyState === 4 && rawFile.status == "200") {
callback(textBlockName, rawFile.responseText);
}
};
rawFile.send(null);
}
// Insert text to text block and color words confidence level
function updateTextBlock(textBlockName, text) {
var data = JSON.parse(text);
let translatedTextList = data['results']['items'];
const listLen = translatedTextList.length;
const textBlock = document.getElementById(textBlockName);
for (let i=0; i<listLen; i++) {
let addWord = translatedTextList[i]['alternatives'][0];
// load word probability and setup color depends on it
let wordProbability = parseFloat(addWord['confidence']);
let wordClass = 'unknown';
// setup the color
if (wordProbability > 0.95) {
wordClass = 'known';
} else if (wordProbability > 0.7) {
wordClass = 'badknown';
}
// insert colored word to the end of block
let insText = '<span class="' + wordClass+ '">' + addWord['content'] + ' </span>';
textBlock.insertAdjacentHTML('beforeEnd', insText)
}
}
function initText() {
// read three files each to it's area
readTextFile(FILENAME1, "text-area-1", function(textBlockName, text){
updateTextBlock(textBlockName, text);
});
readTextFile(FILENAME2, "text-area-2", function(textBlockName, text) {
updateTextBlock(textBlockName, text);
});
readTextFile(FILENAME3, "text-area-3", function(textBlockName, text) {
updateTextBlock(textBlockName, text);
});
}
</script>
</body></html>
Скачиваю файлы asrOutput.json по всем трем задачам, переименовываю, как написано в HTML-скрипте, и вот что получается.

Четко видно, что добавление русскоязычных терминов позволило нейросети более точно распознавать специфические термины — «сервисный профиль» и т.д. А добавление русской транскрипции на втором шаге – превратило “ЦСКА” в «циско». Текст все еще довольно «грязный», но для моей задачи контекстного поиска должен уже подходить. По мере добавления и вычитывания новых вебинаров словарь постепенно будет расширяться, это процесс поддержки такой системы, про который не нужно забывать.
Нечеткий поиск по распознанному тексту
Существует, наверное, десяток подходов к решению задачи нечеткого поиска, по большей части они базируются на небольшом наборе математических алгоритмов, таких как, например, расстояние Левенштейна. хорошая статья про это, еще одна и еще одна. Но мне хотелось найти что-то готовое, типа запустил и работает.
Из готовых решений для локального поиска по документам, после небольшого ресерча нашел относительно давний проект SPHINX, также возможность полнотекстового поиска, вроде бы, есть в PostgreSQL, об этом написано ТУТ. Но больше всего материалов, в том числе на русском, удалось найти про Elasticsearch. После чтения хороших руководств по запуску и настройке, например, этого поста или этого урока, вот еще, а также документации и руководства по API для Python, мной принято решение использовать его.
Для всех локальных экспериментов я давно использую Docker, и очень рекомендую всем, кто почему-то с ним еще не разобрался, это сделать. По факту, я стараюсь ничего, кроме сред разработки, браузеров и «вьюверов» в локальной операционке не запускать. Кроме отсутствия проблем с совместимостью и т.д. это позволяет быстро попробовать новый продукт и понять, хорошо ли он работает.
Контейнер с Elasticsearch выкачиваем и запускаем двумя командами:
$ docker pull elasticsearch:7.9.1
$ docker run -d --name elasticsearch -p 9200:9200 -e "discovery.type=single-node" elasticsearch:7.9.1
После запуска контейнера, по адресу
http://localhost:9200 появляется интерфейс эластика, к нему можно обращаться с помощью браузера или REST API инструмента типа POSTMAN. Но я нашел удобный плагин для Chrome. Вот как выглядит окно этого плагина с описанным в одном из руководств выше примером про веселых котят.
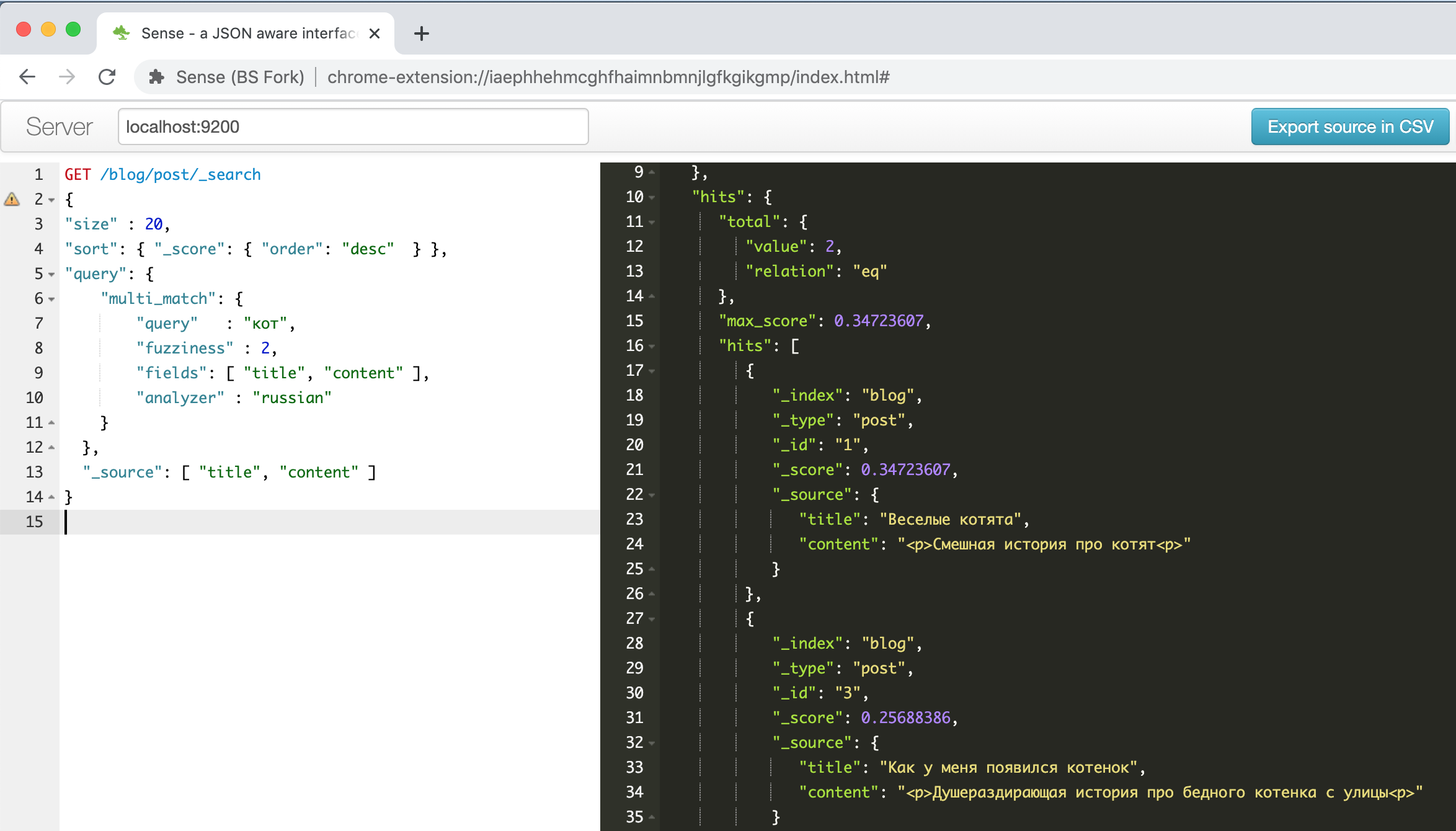
Слева запрос – справа ответ, автозаполнение, подсветка синтаксиса, автоформатирование – что еще нужно для продуктивной работы! Кроме того, этот плагин умеет распознавать во вставляемом из буфера тексте формат командной строки CURL и правильно его форматировать, например, попробуйте вставить строку
«curl -X GET $ES_URL» и посмотрите, что получится. Удобная штука, в-общем.
Что и как я буду хранить и искать? Elasticsearch принимает все документы в формате JSON и хранит их в структурах, которые называются индексы. Разных индексов может быть сколько угодно, но в одном индексе могут лежать однородные данные и документы, с похожей структурой полей и одинаковым подходом к поиску.
Для исследования возможностей нечеткого поиска я решил сделать загрузку и поиск по разделу фраз (segments) файла транскрипции, полученного на предыдущем шаге. В разделе segments JSON-файла данные хранятся в следующем формате:
- Фрагмент 1 (segment)
-> Время начала / время окончания
-> Альтернативные варианты распознавания
--> Альтернатива 1
----> Распознанный вариант фразы
----> Список слов, для каждого указан коэффициент надежности (confidence) распознавания
--> Альтернатива 2
----> Распознанный вариант фразы
----> Список слов, для каждого указан коэффициент надежности (confidence) распознавания
Я хочу увеличить вероятность успешного поиска, поэтому буду загружать в базу для поиска все альтернативные варианты, а потом уже из найденных фрагментов выбирать тот, у которого суммарный confidence выше.
Для переформатирования и загрузки JSON документа в Elasticsearch использую небольшой скрипт на Python, логика скрипта следующая:
- Сначала проходим по по всем элементам раздела segments и всем альтернативным вариантам транскрипции
- Для каждого варианта транскрипции считаем его суммарный confidence распознавания, я просто беру среднее арифметическое для отдельных слов, хотя, наверное, в будущем к этому нужно подойти внимательнее
- Для каждого альтернативного варианта транскрипции загружаем в Elasticsearch запись вида
{ "recording_id" : <ссылка на исходную запись>, "seg_id" : <id сегмента>, "alt_id" : <id альтернативного варинта транскрипции>, "start_time" : <время начала сегмента в файле>, "end_time" : <время окончания сегмента в файле>, "transcribe_score" : <надежность (confidence) распознавания>, "transcript" : <распознанный текст> }
Скрипт на Python, который загружает записи из JSON-файла в Elasticsearch
from elasticsearch import Elasticsearch
import json
from statistics import mean
# Не забудьте поменять на имя вашего файла
TRANCRIBE_FILE_NAME = "3-My_CiscoClub_transcription_10min-v3_Russian_terminilogy.json"
LOCAL_IP = "192.168.2.35"
INDEX_NAME = 'ciscorecords'
# Setup Elasticsearch connection
es = Elasticsearch([{'host': LOCAL_IP, 'port': 9200}])
if not es.ping():
print ("ES connection error, check IP and port")
es.indices.create(index=INDEX_NAME) # Create index for our recordings
# Open and load file
res = None
with open(TRANCRIBE_FILE_NAME) as json_file:
data = json.load(json_file)
res = data['results']
# Загружаем результат анализа файла
index = 1
for idx, seq in enumerate(res['segments']):
# enumerate fragments
for jdx, alt in enumerate(seq['alternatives']):
# enumerate alternatives for each segments
score_list = []
for item in alt['items']:
score_list.append( float(item['confidence']))
score = mean(score_list)
obj = {
"recording_id" : "rec_1",
"seg_id" : idx,
"alt_id" : jdx,
"start_time" : seq["start_time"],
"end_time" : seq ["end_time"],
"transcribe_score" : score,
"transcript" : alt["transcript"]
}
es.index( index=INDEX_NAME, id = index, body = obj )
index += 1
Если у вас нет Python-а, не расстраивайтесь, нам опять поможет Docker. Я обычно использую контейнер с Jupyter notebook — к нему можно подключаться обычным браузером и делать все что нужно, единственное, нужно подумать о сохранении результатов, так как при уничтожении контейнера вся информация теряется. Если вы ранее с этим инструментом не работали, то вот хорошая статья для начинающих, кстати, раздел про инсталляцию вы уже можете смело пропустить
Запускаем контейнер с Python notebook командой:
$ docker run -p 8888:8888 jupyter/base-notebook sh -c 'jupyter notebook --allow-root --no-browser --ip=0.0.0.0 --port=8888'
И подключаемся к нему любым браузером по адресу, который видим на экране после успешного запуска скрипта, это
http://127.0.0.1:8888 с указанным ключом безопасности.Создаем новый блокнот, в первой ячейке пишем:
!pip install elasticsearchЗапускаем, ждем пока установится пакет для работы с ES через API, во вторую ячейку копируем наш скрипт и запускаем. После его работы, если все успешно, мы можем проверить в консоли Elasticsearch, что наши данные успешно загружены. Вводим команду
GET /ciscorecords/_search и видим в окошке ответа наши загруженные записи, всего 173 штуки, как говорит нам поле hits.total.value.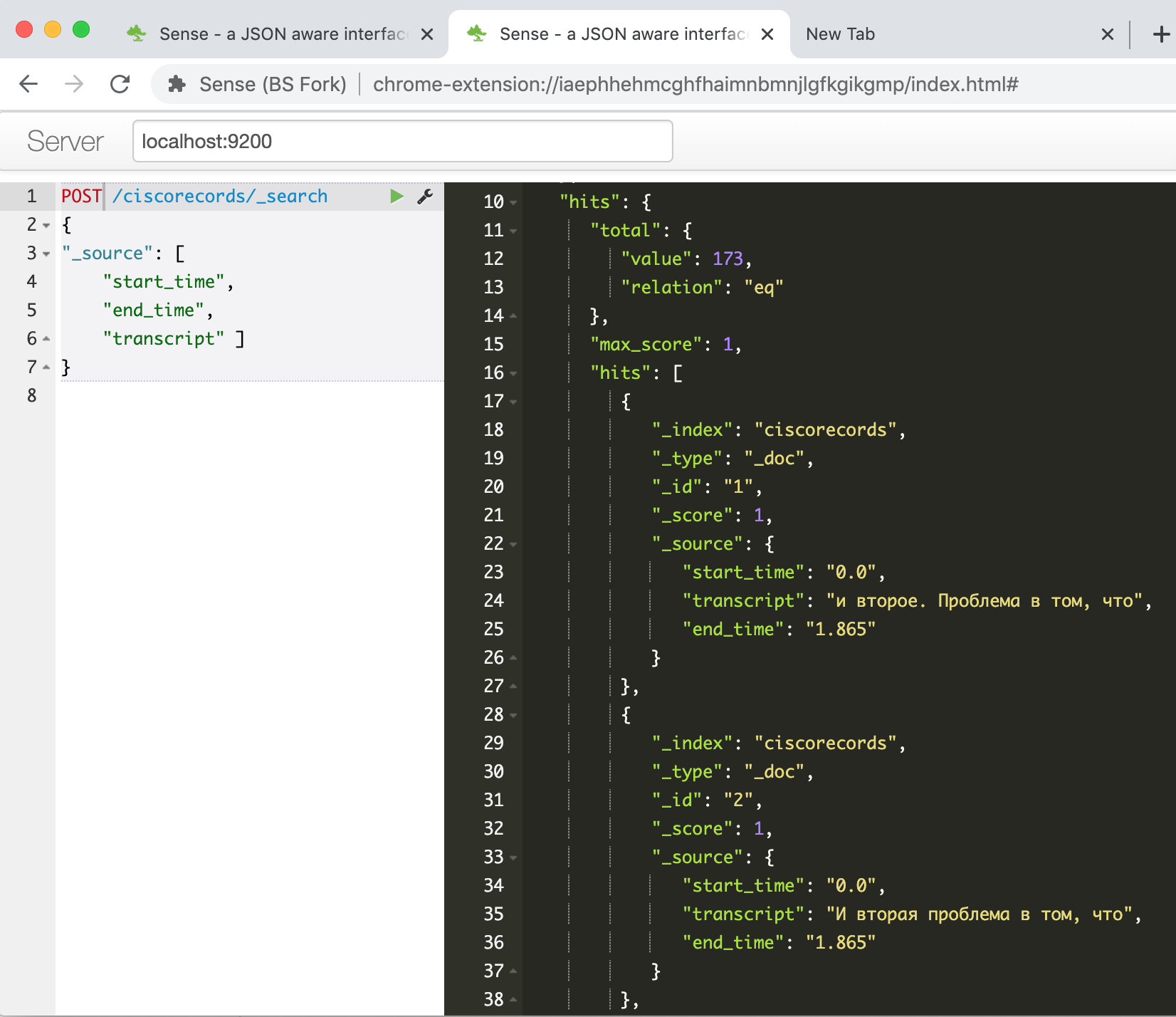
Настало время попробовать нечеткий поиск – то ради чего все и затевалось. Например, для поиска по фразе «ядро сети датацентра», для этого нужно дать такую команду:
POST /ciscorecords/_search
{
"size" : 20,
"min_score" : 1,
"sort": { "_score": { "order": "desc" } },
"query": {
"multi_match": {
"query" : "ядро сети датацентра",
"fuzziness" : 2,
"fields": [ "transcript" ],
"analyzer" : "russian"
}
},
"_source": [ "transcript", "transcribe_score" ]
}
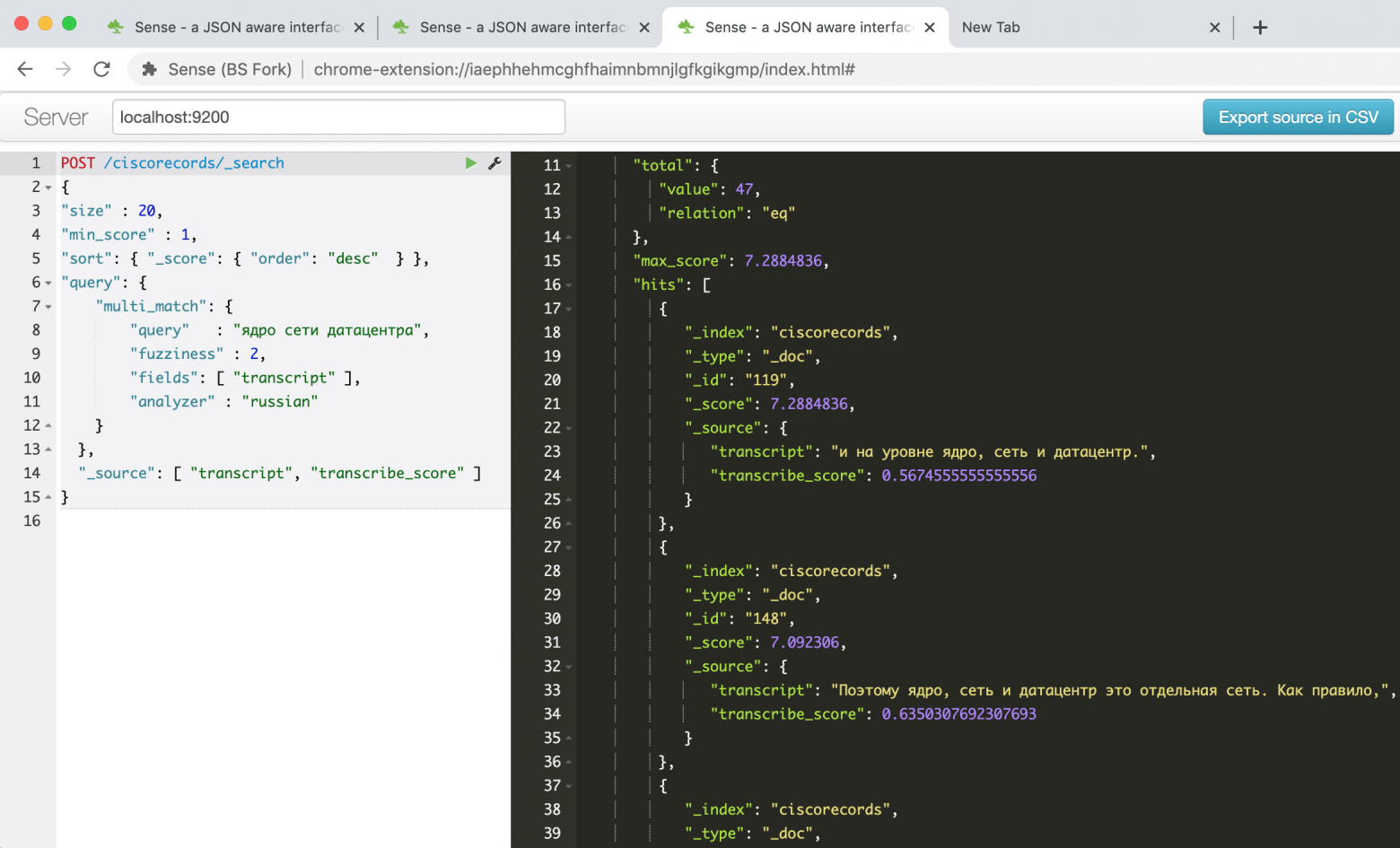
Получаем аж 47 результатов!

Неудивительно, тем так как бОльшая часть из них – разные вариации одного и того же фрагмента. Напишем еще один скрипт, чтобы выбрать из каждого сегмента одну запись с наибольшим значением confidence.
Скрипт на Python для запроса к базе Elasticsearch
##### Выбираем только уникальные фрагменты по запросу
# фраза для поиска
# PHRASE = "платформы контейнерной виртуализации"
# PHRASE = "управление через профили"
PHRASE = "ядро сети датацентра"
LOCAL_IP = "192.168.2.35"
INDEX_NAME = 'ciscorecords'
# Составляем запрос
elastic_queary = {
"size" : 40,
"min_score" : 1,
"sort": { "_score": { "order": "desc" } },
"query": {
"multi_match": {
"query" : PHRASE,
"fuzziness" : 2,
"fields": [ "transcript" ],
"analyzer" : "russian"
}
},
}
# Setup Elasticsearch connection
es = Elasticsearch([{'host': LOCAL_IP, 'port': 9200}])
if not es.ping():
print ("ES connection error, check IP and port")
# Отправляем запрос и печатаем сколько получили записей
res = es.search(index=INDEX_NAME, body = elastic_queary)
print ("Got %d Hits:" % res['hits']['total']['value'])
# Выбираем по одному альтернативному варианту на сегмент
search_results = {}
for hit in res['hits']['hits']:
seg_id = hit["_source"]['seg_id']
if seg_id not in search_results or search_results[seg_id]['score'] < hit["_score"]:
_res = hit["_source"]
_res["score"] = hit["_score"]
search_results[seg_id] = _res
print ("%s unique results \n-----" % len(search_results))
for rec in search_results:
print ("seg %(seg_id)s: %(score).4f : start(%(start_time)s)-end(%(end_time)s) -- %(transcript)s" % \
(search_results[rec]))
Пример вывода:
Got 47 Hits:
16 unique results
-----
seg 39: 7.2885 : start(374.24)-end(377.165) -- и на уровне ядро, сеть и датацентр..
seg 49: 7.0923 : start(464.44)-end(468.065) -- Поэтому ядро, сеть и датацентр это отдельная сеть...
seg 41: 4.5401 : start(385.14)-end(405.065) -- и как забросить этот трафик из датацентр наружу наружу. Это означает либо в корпоративных, в сети Интернет, или какой то вилан канал, то есть куда то туда, опять же уже десять лет сети центров обработки данных и сети там, где у нас работает пользователи...
seg 30: 4.3556 : start(292.74)-end(298.265) -- Мы понимаем, что датацентр у нас есть вычислительная платформа, то есть то там, где работают
seg 44: 2.1968 : start(415.34)-end(426.765) -- Если интернет процесс сетевой нас профиль, трафик в основном вертикально, то есть профили пользоваться очень мало, общаются друг с другом. Они в основном шли вопросы куда интернет датацентр еще куда-то
seg 48: 2.0587 : start(449.64)-end(464.065) -- У нас очень много бегает именно между оборудованием датацентр и там абсолютно другие задачи, как с точки зрения связанности, так и с точки зрения тех сервисный, которые нам нужны, и того, как этим управляет.
seg 26: 1.8621 : start(243.24)-end(259.065) -- вот эта история в целом. Управление через профили. Соответственно, для вычислительную платформа. То есть система циско юсиэс серверная платформа циско юсиэс...
Мы видим, что результатов стало гораздо меньше, и теперь мы можем просмотреть их и выбрать тот, который нас интересует больше всего.
Также, поскольку у нас есть время начала и окончания видеофрагмента, мы можем сделать страничку с видеоплеером и программным путем «перематывать» его к интересующему фрагменту.
Но эту задачу я вынесу в отдельную статью, если будет интерес к дальнейшим публикациям по этой теме.
Вместо заключения
Итак, в рамках этой статьи я показал, как решал задачу построения системы текстового поиска по видеорахиву с записями вебинаров на техническую тематику. В итоге получилось то, что принято называть MVP, т.е. минимально работающий алгоритм, позволяющий получить результат и доказывающий, что результат в принципе достижим на имеющихся технологиях.
До конечного продукта предстоит еще долгий путь, из идей, которые можно реализовать в ближайшем будущем:
- Прикрутить видеоплеер, чтобы можно было прослушивать, просматривать найденный фрагмент
- Подумать над возможностью редактирования текста, при этом можно оставлять привязку к тексту слов, распознанных на 100%, редактировать только фрагменты, где качество распознавания «провисает»
- Нужно более внимательно настроить поиск в elasticsearch, почему-то у меня не все релевантные фрагменты обнаруживаются
- Нужно попробовать другие движки speech-to-text, Google, Yandex, Azure. Если у большого количества участников будет интерес к данной теме – напишу отдельную статью
- Анализ корпуса технологических статей на русском языке, чтобы из них «вытащить» больше специальных терминов для словаря
- Можно попробовать прикрутить к итоговому набору текстов алгоритм BERT (Bi-directional Encoder Representation from Transformer), описание есть тут. Это позволит получать от системы ответы на специфические вопросы – «сколько xx поддерживает yy». Должно быть удобно
- Возможно, было бы удобно искать фрагменты видео текстовым вопросом через чат-бот и получать в ответ ссылку на фрагменты на каком-то видеохостинге. Найти видеоуроки по многим вопросам не Youtube не сложно, но часто приходится прослушивать 15-20 мин видео, чтобы узнать, что лектор ничего не сказал по конкретному интересующему вопросу
- Еще интересно сделать поиск по слайдам в презентации – показываешь системе слайд, она просматривает видео и ищет, где про этот или похожий слайд рассказывают, такая система лично мне бы съэкономила кучу времени
Если у вас есть вопросы/комментарии, буду рад на них ответить, также рад буду услышать любые предложения по улучшению или упрощению процесса в целом. Это моя первая техническая статья для Хабр-а, очень надеюсь, что получилось полезно и интересно.
Удачи всем в творческих поисках, и да прибудет с вами Сила!







