
ClickHouse — open-source DBMS от Яндекса — традиционно используется для аналитики различного рода логов или потоков событий от онлайн-систем. Однако, гибкость ClickHouse позволяет применять его для более широкого класса задач.
Видео:
Здравствуйте! У меня будет несколько специфический доклад про то, как мы забиваем ClickHouse гвозди. Обычно говорят, что микроскопом гвозди забивают, но ClickHouse – это все-таки штука, которая смотрит вдаль и работает с большими объемами, поэтому микро к нему не подходит. Я назвал это телескопом. Почему? Я, надеюсь, вы сейчас поймете.

Я – выпускник МГУ и работаю в компании LifeStreet уже больше 10 лет. Занимаюсь там аналитической инфраструктурой. Мы одними из первых задеплоили у себя ClickHouse после Яндекса. И это нам так понравилось, и в частности мне так понравилось, что я вместе с коллегами соосновал компанию Altinity, которая пытается ClickHouse продвигать по всему миру вместе с Яндексом.

Все вы знаете, что ClickHouse очень быстрый, очень удобный. Все об этом всегда рассказывают. Рассказывают, что он замечательно подходит для разного рода аналитики. Но не совсем понятно для чего он еще подходит. Про это еще я и поговорю.

Доклад будет про то, как использовать ClickHouse НЕ для аналитики.

Традиционные примеры использования ClickHouse обычно укладываются в какие-то такие вещи, т. е. это:
- Аналитика веб-приложений. Это то, с чего начал Яндекс. И большое количество компаний идут в ту же сторону.
- Это различные AdTech-компании, которые занимаются рекламной оптимизацией. У них немножко другой сценарий. У них другой трафик, у них другие задачи. Может быть больше машинных алгоритмов и меньше запросов пользователей.
- Кроме того, очень много похожих сценариев, когда анализируются логи. Это могут логи операционные. Это могут быть логи безопасности.
- Это может быть то, что делают DNS, http-запросы. Это не совсем логи, но они идут с каких-то устройств.
- Это различные системы мониторинга. Хотя ClickHouse не идеально подходит для мониторинга, но лучше, чем многое другое.
- Используется даже для мониторинга производственных процессов.

Что общего у этих всех сценариев?
- То, что в этих сценариях всегда в ClickHouse загружается очень много данных. Это обычно пакеты разного размера. Это может быть пакет на загрузку, либо через Kafka, но смысл один.
- А потом гоняют OLAP-запросы. Что такое OLAP? Обычно это range scan по таблице и какая-то агрегация. И комбинация этих запросов, а иногда, может быть, объединение этих запросов, составляет 99,99 % того, что с ClickHouse делают клиенты, алгоритмы и т. д.

И считается, что ClickHouse не надо использовать для:
- Транзакционных систем. В ClickHouse транзакций нет.
- Key-value.
- Хранилищ документов.
И что здесь общего? То, что они все предполагают point queries, т. е. запросы, которые получают одну или небольшое количество записей. И понятно, что это в ClickHouse антипаттерн, но он предназначен для того, чтобы сразу много чего читать и много всего делать.

Но ClickHouse очень гибкий. Когда я рисовал этот слайд, я так подумал, что его можно интерпретировать немножко двояко, т. е. можно подумать, что ClickHouse гибкий, а можно подумать, что он стоит на месте, а вам вокруг него надо изогнуться узлом, чтобы что-то сделать.
Обе точки зрения имеют право на существование, т. е. ClickHouse действительно очень гибкий. А если еще дополнительно вокруг него завязаться узлом, то можно получить совершенно потрясающие результаты.

Поговорка про забивание гвоздей пошла от фантастического романа А. Н. Толстого "Гиперболоид инженера Гарина". ClickHouse – это такая замечательная штука. И мы собираемся ею забивать гвозди, например, делать point queries.
Хорошая это задача или нет? Это одна из задач, о которой я расскажу. Вторая задача будет совсем другой, но тоже с виду для ClickHouse совершенно не подходящей. И тем не менее на ClickHouse ее можно достаточно эффективно решить.

Какая у нас задача? На самом деле задача очень обычная и простая. Это как раз то, с чего началось использование в LifeStreet. И я рассказывал подробно на HighLoad два года назад, что есть много-много серверов, которые пишут логи. И логи большие. Когда я рассказывал два года назад, я говорил, что 2 килобайта записи на одну запись. Где-то в начале этого года запись была – 4-5 килобайт. А сейчас, когда я готовился к этому выступлению, я посмотрел, что 15-20 килобайт – это одна запись в логе. Они, конечно, упакованы, но тем не менее это достаточно большие записи и их достаточно много.
Почему так? Я сейчас покажу запись в логе.

Это одна запись в логе. Почему она так выросла? Можно пытаться прочитать, что там написано, можно не пытаться. Когда система пытается что-то на RTB выиграть, она принимает очень много решений: когда, что и на какой трафик надо делать ставку. И когда она приняла эти решения, они пишутся в лог, чтобы можно было потом проанализировать во время отладки и т. д. Но лог совершенно непотребный.
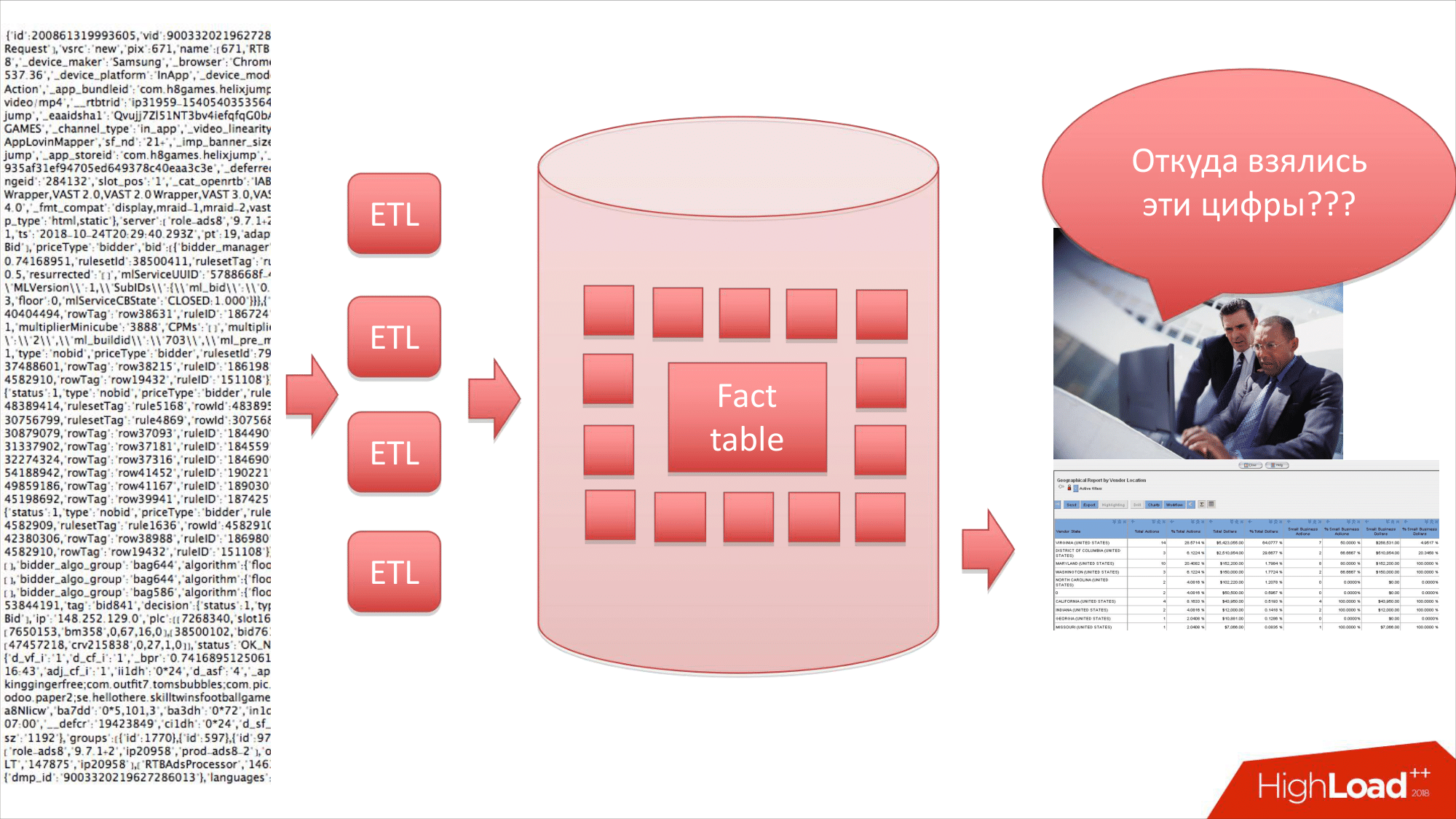
Естественно, этот лог мы пропускаем через ETL. Можно загрузить в Data Warehouse, который ClickHouse. И после этого получить какой-то отчет. Это то, что делают все. И LifeStreet это тоже прекрасно делает. Это паттерн.
Дальше какие-то люди, например, бизнес-аналитики смотрят в эти данные. И иногда им что-то не нравится. Они видят, что там какие-то неправильные цифры. И они часто задают вопрос: «Откуда взялись эти цифры?». И вы начинаете разбираться в системе, чтобы понять, где. Смотрите и видите, что вот здесь вроде правильно, ETL вроде правильно написан, в схеме лежит тоже вроде все правильно, отчет сгенерирован тоже правильно. А где же ошибка?

Чтобы найти ее, надо вернутся обратно в лог, т. е. нужно найти транзакцию в этом огромном логе с пятисот серверов, причем эта транзакция может быть не за сегодня. Она может быть за вчера или за несколько дней назад. Но сильно-сильно в прошлом – это редко. И, во-первых, все логи надо сохранить где-то. И, во-вторых, сделать способ, чтобы достаточно быстро в этих логах эту транзакцию найти. Это хороший антипаттерн для ClickHouse.

Еще до начала использования ClickHouse мы пробовали разные подходы.
Например:
- Можно сделать распределенный grep каким-то образом. Что здесь немножко помогает? То, что обычно мы знаем, в каком файле надо искать. Поскольку это наша система, то мы можем узнать из какого файла пришла транзакция. И тогда можно попытаться найти этот файл среди миллионов файлов. Найти распаковать его, грепнуть. Это все можно, но это не очень быстро работает.
- Можно использовать Spark. Он по идее для таких задач хорошо приспособлен. Он ускоряет, не делает лишнее.
- Или Elastic Search.
Но мы решили попробовать ClickHouse. Т. е. сначала у нас было какое-то решение на grep и Spark. Они были не очень хорошие. Решили попробовать ClickHouse.

Какая здесь может быть структура данных? Структура записи, которая описывает лог, может быть примерно такой. Здесь data-файлы, timestamp, сервер, с которого это пришло и название файла. И вот эта странная штука, которая называется tx. Это как раз ID транзакции. И с default он видит ParamExtractInt. Что это такое? Это может быть одной из самых интересных тут вещей. Партиционируем по дате, делаем индекс по имени файла и по транзакции.
В принципе, можно было сделать индекс и по транзакции, если нам нужно было бы искать только транзакции. Но иногда хочется найти целиком все, что находится в файле. Например, ETL-процесс, загружая эти логи, иногда ругается и падает. Выдает, что не может обработать файл, у него там что-то не так. И вам нужно найти этот файл, а он может уже куда-то ушел, удалился. И проще в одно место идти, а не искать, где этот файл находится сейчас. И можно тогда найти, и посмотреть прямо на log storage.
И последний здесь написан index_granularity. Об этом мы поговорим подробнее. Это уже не DEFAULT. DEFAULT = 8192 в ClickHouse. Мы уже его поменяли. А что это и зачем мы поменяли, и надо ли менять дальше – это мы сейчас увидим.

Что такое DEFAULT visitParamExtractInt? ClickHouse позволяет вам делать вычисления в момент INSERT и SELECT на колонках. Как делаются вычисления во время INSERT? Я могу делать INSERT в таблицу и не указывать это поле «tx». И мне посчитает ClickHouse как выражение на другой колонке. И в данном случае я взял из row, который у меня JSON, вытащил параметр ID, т. е. ClickHouse может парсить JSON не очень хорошо. Он может это делать очень быстро, но не очень правильно. Но для наших целей это подходит. Вытащили ID и положили его в транзакцию сразу. А когда говорю, что это может работать во время SELECT, я имею в виду, что мы можем эту схему дальше расширять.

Я сначала решил, что мне нужна транзакция. А потом решил, что в этой транзакции есть еще очень много полезных вещей, которые хорошо бы иметь сразу на записи.
И что я могу сделать? Я могу сделать ALTER TABLE и добавить колонку с DEFAULT. Причем ClickHouse, естественно, не будет это считать сразу, потому что это было бы неразумно с точки зрения Алексея Миловидова. Поэтому ALTER у нас работает мгновенно. У нас колонка добавится. Она будет пустой, но если вы сделаете в нее SELECT, то ClickHouse начнет делать сложное регулярное выражение. Это будет медленно.
Но и это еще не все. Когда ClickHouse начнет мержить, он это все-таки вычислит, запишет в базу. И через некоторое время, даже если вы добавили колонку, у вас в базе данных будет правильное значение, которое быстро можно вычислить. Т. е. не нужно уже разбирать регулярное выражение, оно уже там есть.

И когда мы это сделали, что у нас получается? У нас получилась какая-то таблица, в которой мы вставляем только две колонки. Это имя файла и сама строчка лога, а все остальное вычисляется. ClickHouse делает там 2/3 работы за нас. И он это делает очень эффективно, потому что мы знаем, что ClickHouse написан на C++ и все функции хорошо оптимизированы. И сделать лучше, быстрее на Java совершенно точно нельзя.

Теперь посмотрим, как это все работает или может работать. Сначала посмотрим, какой объем логов. Вот это объем логов из той статистики, которая их там загружает. Это не то, что лежит реально в сервере. Это то, что мы думаем, что лежит в сервере. Логи за 10 дней с почти 500 серверов – это 1,3 миллионов файлов, в которых 64 миллиарда записей. И это занимало на диске, упакованное в brotli, 61 терабайт.

Когда это загрузилось в ClickHouse, то здесь получился почти петабайт сырых распакованных данных. Я их не мог посчитать во время загрузки, но их можно посчитать в ClickHouse. И почти петабайт данных сжался в 84 терабайта. Упакованные в brotli они занимали 61 терабайт, в ClickHouse – 84 терабайта. Немножко хуже, но это тоже неплохо. Это 5 серверов достаточно средненьких, у них просто достаточно большой RAID-массив у каждого сервера. По-моему, там 60 терабайт диска в RAID-10. Т. е. примерно на данные у нас есть чуть меньше 30 терабайт. Соответственно, на каждом сервере здесь примерно 17 терабайт данных. А если в сырых числах посчитать, то примерно 200 терабайт на сервер.
Очень консервативная система. Почему? Потому что ходить в логи надо редко.

Прежде чем я покажу, как это может работать быстро или медленно, маленькое замечание, если вы хотите что-то измерять в ClickHouse. Алексей рассказывал про page cache, что ClickHouse пытается кэшировать, но с логами это сделать обычно не получается. Можно предположить, что если у вас огромные терабайты логов и спрашивают произвольные транзакции, то, скорее всего, в кэш не попадете почти никогда. Тем более, что у нас сервера не очень большие, диски гораздо больше.
И если вы хотите перед тем, как деплоить, проверить, как это работает, то нужно всегда сбрасывать кэши файловой системы, прежде чем выполнять какой-нибудь запрос. Иначе они будут выполняться очень быстро.

Вот идеальный случай, когда мы используем полный индекс, т. е. ищем там лог-запись какую-то четко по имени файла и по транзакции. Я ее здесь обрезал, чтобы не забивать экран. Работает полторы секунды. Достаточно неплохо. 
Случай похуже, когда у нас есть только частичный индекс, т. е. мы не знаем, какая транзакция и только предполагаем в каком типе файла она находится. Тогда это работает уже 17 секунд. И уже нам это немножко не нравится. Это кажется долгим, чтобы найти транзакцию.
Это интересная тема для дискуссий. Я постараюсь ее чуть-чуть ее коснуться.
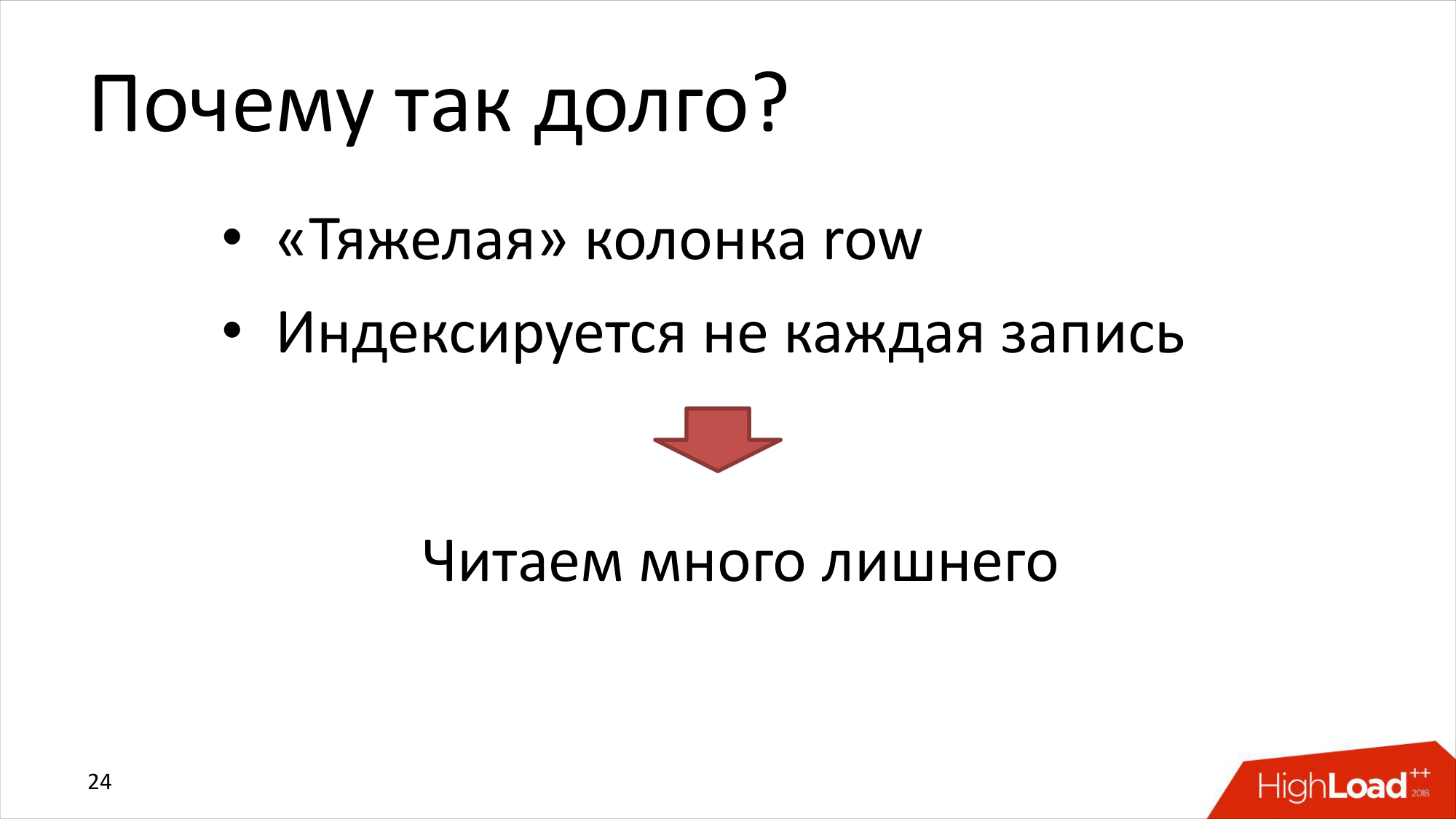
Во-первых, эта колонка с записью очень тяжелая. Она занимает 15-20 килобайт. А ClickHouse пытается читать сразу помногу. И в частности он пытается считать помногу, потому что он индексирует не каждую запись, а только каждую N-запись. И когда мы делаем запрос, который должен вернуть одну запись, ClickHouse все равно приходится прочитать много. Это распаковать, что тоже много. Это достаточно большие накладные расходы.
В случае полного индекса оно не так очевидно. В случае частичного индекса ClickHouse приходится в любом случае считать что-то лишнее. И это лишнее накапливается, накапливается. И в результате мы прочитали тут миллион с лишним строчек и, может быть, из разных мест.
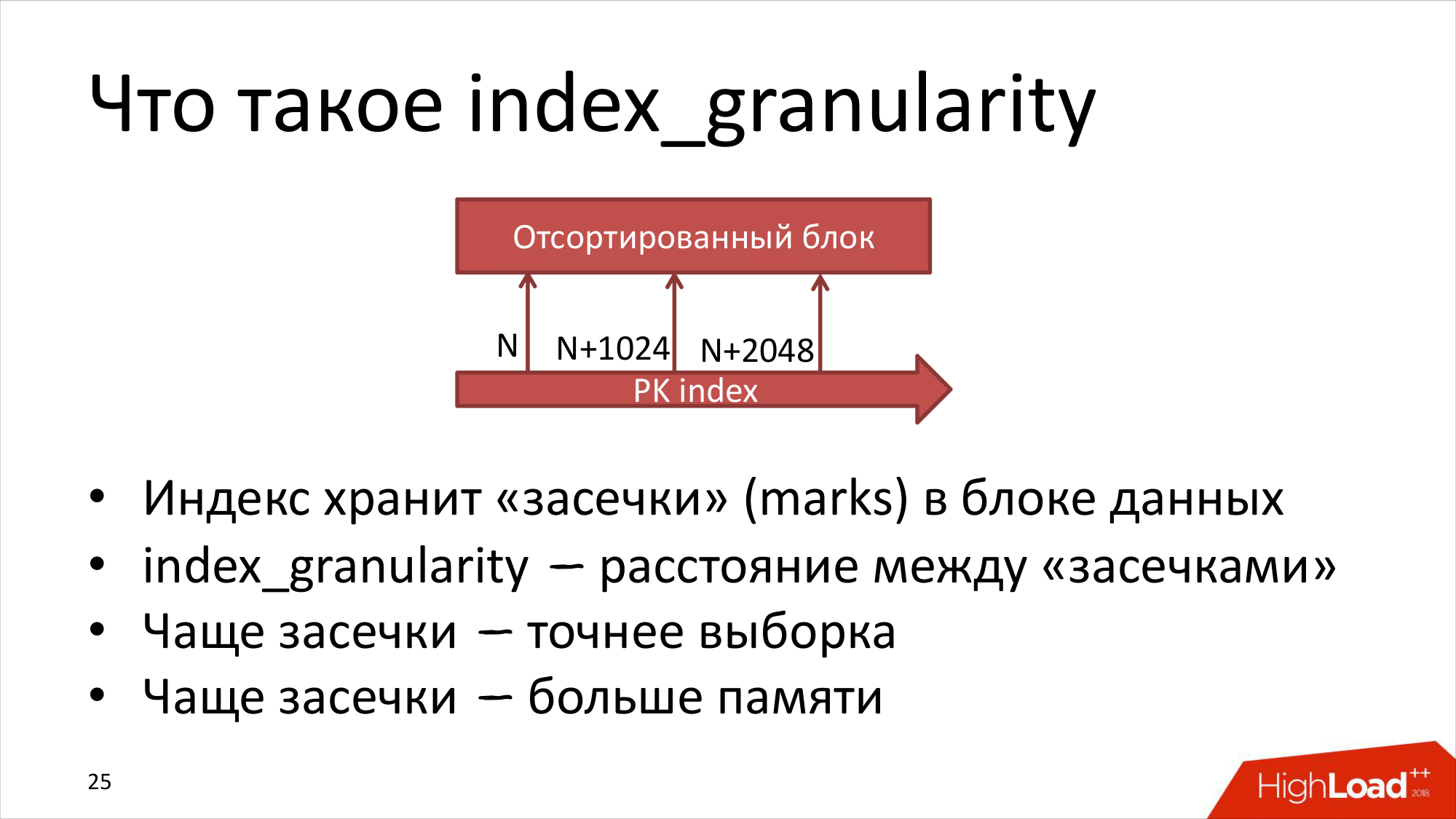
Что такое index_granularity, который мы уже уменьшили на 1024 и, может быть, надо его уменьшать еще? ClickHouse хранит отсортированные данные на диске. Он хранит индекс и на диске, и в памяти, который индексирует каждую N-запись.
По дефолту N = 8192. Мы уже немножко уменьшили. Сейчас попробуем уменьшить еще.
Что это значит? Это значит, что в файле есть засечка, т. е. когда мы хотим найти что-то по индексу, ClickHouse может найти только примерно. Т. е. не точно эту запись, а эту запись + сколько-то записей. Это окно может быть сдвинуто в ту или в другую сторону. Он прочитает в любом случае больше. Плюс дополнительно к этому сами данные могут быть разбиты на другие блоки другим образом в файлах данных, т. е. он может еще чуть-чуть больше прочитать.
Хотелось бы, наверное, сделать index-granularity поменьше и индексировать, может быть, почти каждую запись, но тогда нам потребуется существенно больше памяти, ее не хватит. Если сейчас индекс может занимать где-то гигабайт памяти, и если мы увеличим в 8 раз, то это будет 8 гигабайт памяти на сервер. Если еще в 8 раз уменьшим granularity, то еще в 8 раз больше памяти потребуется. Все время будет больше и больше. И это не очень хорошо. Здесь нужен разумный баланс.

Давайте проверим. Сейчас попробуем уменьшить немножко индекс, уменьшить granularity и посмотрим – будет ли какой-то эффект.
На полной записи, т. е. в первом случае, когда мы используем две колонки индекса, эффект почти в 3 раза. И видно, что количество строк уменьшилось ровно в 8 раз. Количество данных, которые ClickHouse обработал и прочитал, уменьшилось не в 8 раз. Уменьшилось всего в 2,5 раза. Эффект есть, но не в 8 раз.

А по частичному индексу эффект еще меньше. Т. е. у нас было 17 секунд. Мы уменьшили, стало 12 секунд. Все-таки ClickHouse для point queries предназначен не идеально, но тем не менее это уже хорошие результаты. Я считаю, что если иногда, например, несколько раз в день надо найти транзакцию, то мы можем это использовать. И 12 секунд – это совсем немного.
 Эту идею можно развивать. Это некоторая инфраструктура, с которой можно что-то начинать. И что можно здесь начинать?
Эту идею можно развивать. Это некоторая инфраструктура, с которой можно что-то начинать. И что можно здесь начинать?
- Можно искать все транзакции пользователя.
- Можно искать последнюю транзакцию пользователя. И об этом я чуть-чуть попозже расскажу.
Предположим, что вы занимаетесь атрибуцией в рекламной сети и вам нужно привязать некоторый ивент к последней транзакции пользователя. И до этого последнюю транзакцию нужно найти.
Идея в том, что можно использовать in-memory storage, хранить там все транзакции. Когда приходит request, туда сходить, вытащить транзакции пользователя и найти последнюю, которая подходит под эту атрибуцию. Далее связать и записать обратно. Но это хорошо, пока данных не очень много.
Если использовать атрибуцию по показу и иметь достаточно большое окно, то в рекламе, особенно, в брендовой рекламе считается, что все, что человек видел аж 30 дней назад по конкретному продукту, у него это где-то там откладывается. И когда он что-то купил, надо все это дело проанализировать, просчитать. И, может быть, даже заплатить тому, кто дней 30 назад показал рекламу конкретно этого продукта. И получается огромный объем данных, который надо держать в памяти. Поэтому можно использовать не память, а ClickHouse.

И в ClickHouse выстроить вот такую хитрую структуру. Во-первых, мы начинаем с того, что вытаскиваем user ID как отдельную колонку. А после этого строим AggregatingMergeTree.
AggregatingMergeTree – это очень классная штука в ClickHouse, которая позволяет строить частичные агрегации для тех вещей, которые обычно не агрегируются. Например, юники. Вы можете построить агрегацию для юников. Хотя считается, что юники складывать нельзя.
Или то, что я здесь использую. Это агрегация argMax. Понятно, что максимум можно агрегировать легко. Максимум от максимума – это всегда будет максимум. А argMax уже не получится. Нужно хранить что-то дополнительно.
И для этого используется AggregatingMergeTree в ClickHouse, который хранит state агрегации, т. е. какую-то дополнительную информацию, чтобы можно было потом это все объединить.
И используя все данные, которые мы собрали по логам, мы можем выстроить снапшот. И он будет хранить последнюю транзакцию для пользователя. Или будет хранить последнее состояние транзакции по пользователю. В этом примере – это последнее состояние.

Если вы хотите что-то получить из этого снапшота, то просто выполняйте вот такой запрос. И работает это достаточно хорошо. Почему? Потому что мы user id поставили на первое место в индексе. Здесь у нас четко заточенный под бизнес-задачу случай.
Кроме того, мы можем сразу выполнять этот запрос для многих user ID, а не для одного. И если так сделать, то получается эффективное по цене решение, не требующее большого количества железа. Т. е. вместо того, чтобы разворачивать in-memory-систему, можно обойтись маленьким классным ClickHouse.

Подводя тут некоторый промежуточный подытог, я хочу отметить, что:
ClickHouse неплохо работает с сырым JSON. И это иногда очень сильно упрощает жизнь, если у вас какие-то данные в JSON.
Point-queries – если очень хочется, то можно. Т. е. это не эффективно в ClickHouse, особенно, если это делать часто, но тем не менее для редких случаев, когда надо достать что-то достаточно редко, это работает вполне неплохо.
И обратите внимание, что это был антипаттерн в том смысле, что мы не использовали колоночную структуру практически. Вместо того, чтобы наделать много-много колонок, которые хорошо оптимизированы под разные наши структуры данных, у нас все лежит в одном JSON. И если хочется поискать по этому JSON что-то функциями работы с JSON или регулярными выражениями, то это будет, конечно, очень медленно. Запрос вернется, но он там может проработать несколько десятков минут. Все-таки перелопатить 80 терабайт данных придется ClickHouse. Если мы в один день смотрим, то меньше. Но придется это все загрузить, распаковать, выполнить поисковую операцию и продолжить дальше. Физику не обманешь, это все будет очень долго. Поэтому если хочется делать point-queries, надо очень внимательно подходить к тому, как именно вы ищете вещи.
И если обычно говорят, что для ClickHouse не так важно, какой у вас индекс, главное, чтобы он был не самый плохой, то для Point-queries без хорошего индекса ничего не получится.
AggregatingMergeTree позволяет получить последнее состояние, что тоже очень удобная и полезная технология, которую далеко не все используют.

Теперь совершенно другая задача. Она совершенно из другой области и совершенно по-другому используется ClickHouse.
Предположим, что у вас есть некоторые данные по времени. Например, какие-то финансовые или нефинансовые. И эти данные приходят в нерегулярные моменты времени. И есть какая-то фиксированная временная сетка. И у вас стоит задача – аппроксимировать существующие данные на эту сетку, либо же их сдвинуть на эту сетку.
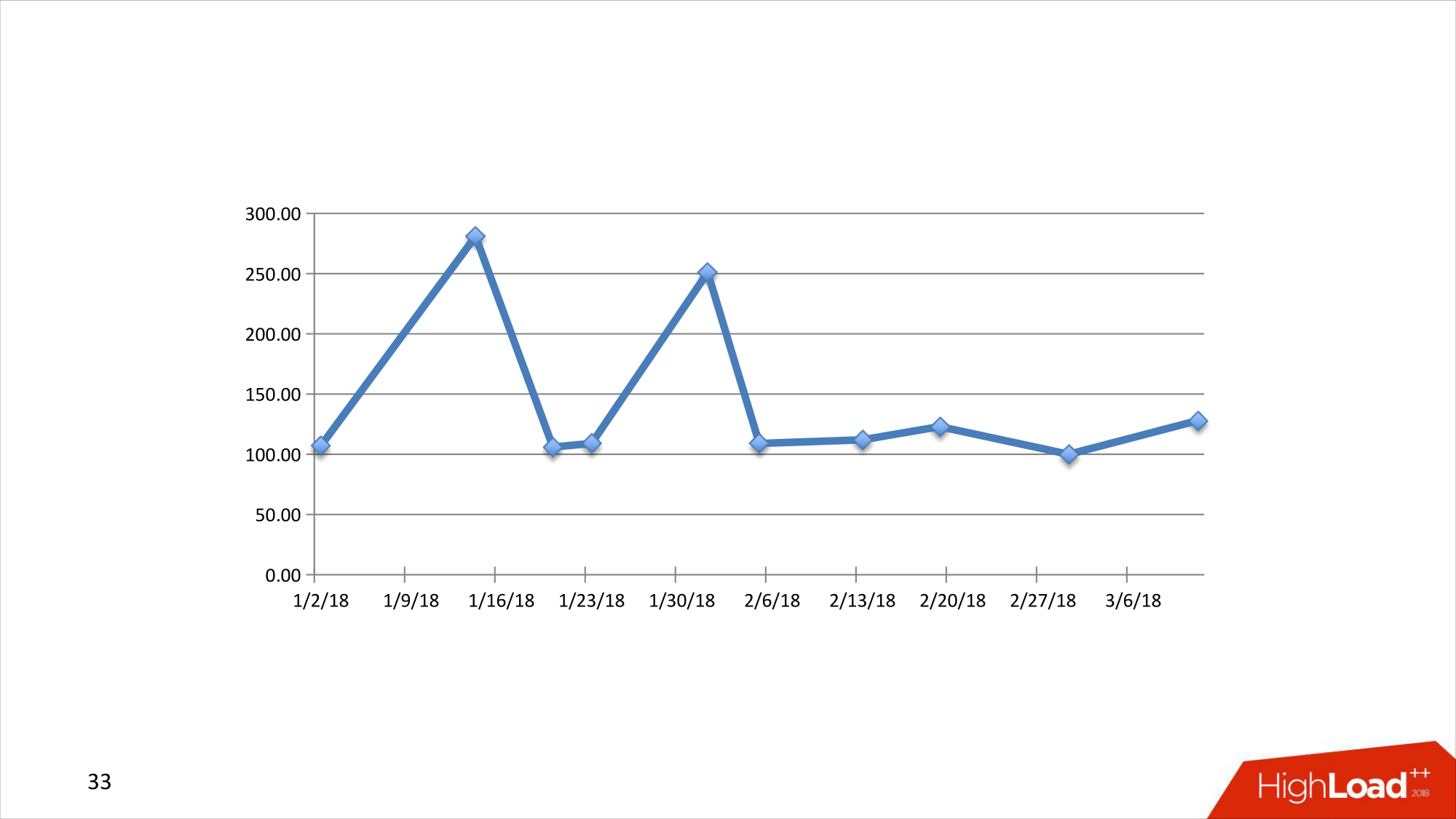
Т. е. какой-то есть график непонятный. Здесь в качестве времени использованы даты, какие-то случайные числа. И видно, что временные промежутки разные. А для многих видов анализа, например, финансового и т. д., вам нужно, чтобы у вас данные были пронумерованы одинаковым образом с точки зрения временных промежутков. И некоторые люди захотели это аппроксимировать, либо хотя бы до этой сетки фиксированной сдвинуть. Т. е. оставить то же количество data points, но уже привязанных к сетке.
И как это сделать на ClickHouse? Можно ли вообще это сделать или нет?

Начнем со структуры данных. У нас структура данных очень простая. У нас есть таблица Т, где есть номер серии, т. е. много серий лежит в таблице. Есть дата и есть значение. И есть таблица с сеткой. Там другие даты другим образом построены.
И я здесь специально написал «Engine = Memory». Предполагается, что сетку мы можем использовать разную. Это временная структура. Нам она нужна только иногда.

И какой алгоритм примерно можно предположить? У нас темным выделены точки, которые отходят к исходным данным – K, K+1. И мы считаем линейную интерполяцию. В левой части вторая подзадача – мы сдвигаем до сетки. Вот так захотелось.

Как это сделать на ClickHouse? Какую технологию можно использовать?
Для этого надо использовать массивы. Обычно массивы используются в ClickHouse не для этого. Или не только для этого.
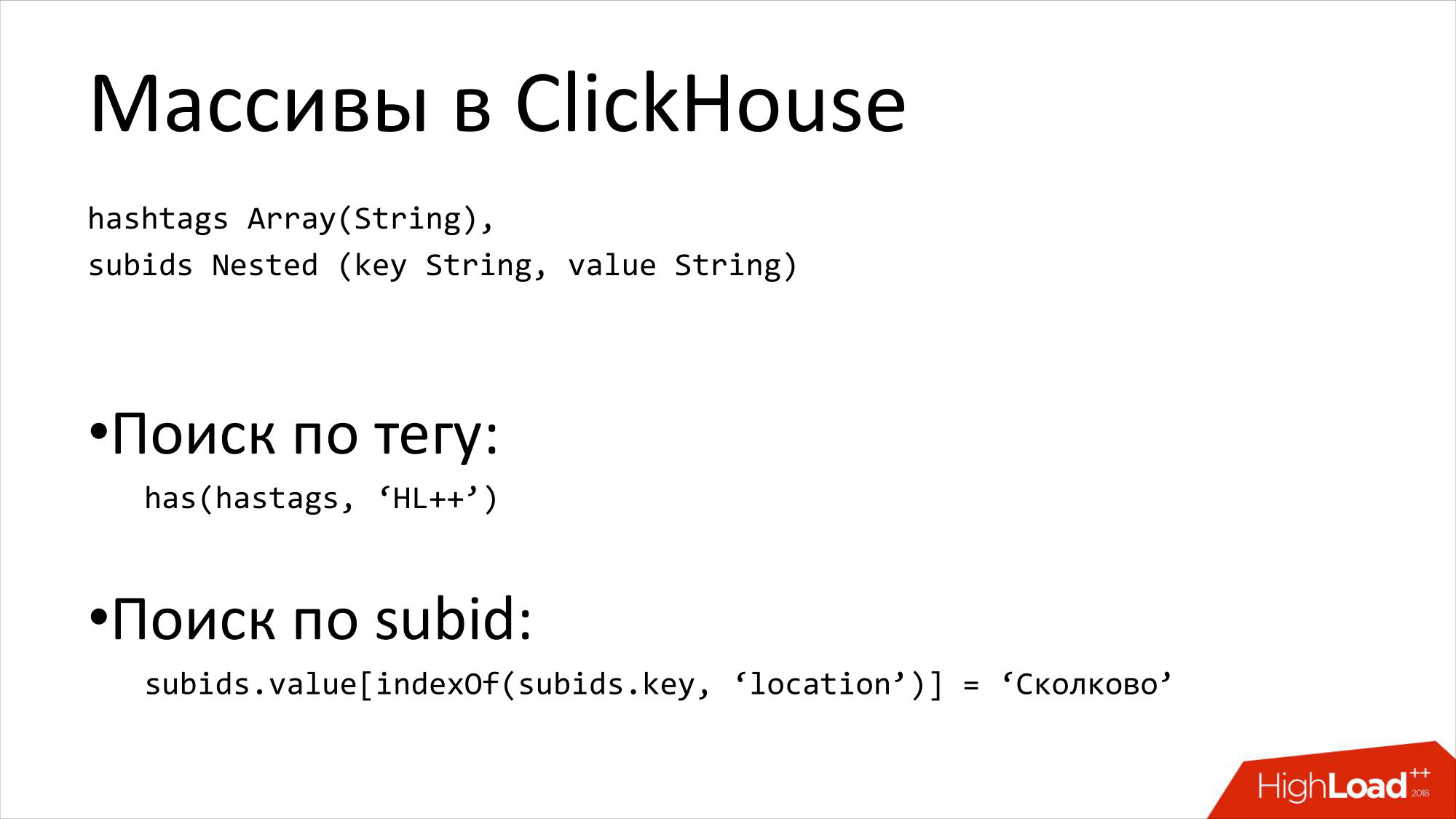
Массивы – это очень классная штука, чтобы хранить хештеги. Можно очень быстро найти все хештеги, например, HighLoad. Или это очень классная штука, чтобы хранить какие-нибудь subids. Например, name-value pairs. Там вы храните два массива. И можно по ним легко искать.
Вот такие случаи позволяют существенно упростить схему по сравнению с другой базой данных.
Как массивы относятся к нашей задаче? Вот так относятся. Сейчас попробую сделать еще один тест. Один раз я делал его в одной аудитории, он прошел на половину. Сейчас проверим в вашей аудитории.

Что написано на экране? Это программа на языке, которая называется A Programming Language, т. е. APL. Это язык 1960-го года. Очень интересный и необычный. В частности, чтобы на нем программировать, для него выпускалась специальная клавиатура со всеми этими буковками.

Давайте посмотрим еще одну программу. Вот это на каком языке написано? Ушли все греческие буквы здесь. Она делает то же самое, что и предыдущая программа. Это эквивалентная программа. Это опопсованная версия APL, которая называется язык J. Создатели этого языка считали, что у них слишком короткая жизнь, чтобы писать длинные программы. И они придумали язык J, на котором периодически выигрывают соревнования по программированию, где программируют нетривиальные вещи.
Это тоже достаточно старый язык. Он, по-моему, с середины или с конца 70-ых годов. И до сих пор на нем разрабатывают. Возможно, вы слышали про базу данных KDB+. Она используется в банках, это супербыстрая in-memory база данных. Она написана на следующем развитии языка J, который называется язык K. Так что эти идеи живы.

Следующий вопрос: «А что вот это такое?». А это уже ClickHouse. Это уже программа, которую надо написать. Я ее специально здесь написал самым непонятным образом, хотя оставил несколько лишних пробелов.

Я скопировал этот код в ClickHouse, выполнил. Он как-то отформатировался чуть-чуть по-другому и выполнился. Но, конечно, в таком виде никто программу не пишет. Я его специально портил, чтобы сделать непонятным.

Программа написана вот так на ClickHouse, где уже все более понятно выглядит, во-первых. И, во-вторых, она имеет дополнительную информацию, которую удобно отлаживать. Сначала мы из сетки создаем массив. Потом заворачиваем в массивы и время, и данные, причем там группировка осуществляете по ID. Для каждой серии это мы все делаем отдельно.
После этого идет шаг 1. Мы мапируем C в некоторые множество индексов К, получаем множество индексов. После этого мы делаем интерполяцию, т. е. переводим пару. И arrayMap может работать не только с одним массивом, а может работать с несколькими массивами. Мы передаем ему два массива: C и K. И переводим пару уже в интерполированное значение.
И вторая часть задачи: мы уже мапируем S в другое какое-то множество индексов. И округляем это до сетки. Вот такая получается программа на ClickHouse.

Если посмотреть, что она выводит, то сначала у нас идет отладочная информация. Можно увидеть, что C(i) через каждые два дня идет. S – это наши исходные данные, в которых совершенно произвольные временные промежутки. V – это наши значения, которые были. Дальше идет множество индексов, которые мы определяем, куда надо сдвигать. Интерполяция. И второй множественный индекс, и сдвиг по сетке.
Вот такая штука на массивах. Одним SQL-запросом мы сделали для всего большого датасета, сразу для всех серий его можно выполнить: положить в другую таблицу или туда, куда нам нужно. И это будет работать быстро, потому что это ClickHouse.

- Массивы и функции работы над массивами.
- Немного воображения, либо иметь опыт функционального программирования.
- Расширяемость. Наверное, многие операции можно было сделать более эффективно, если они были бы написаны на C++. Но поскольку ClickHouse расширяется не самым тривиальным образом, то мы их написали на ClickHouse.

Но тем не менее ClickHouse можно расширять. И вот реальный пример, который был показан некоторое время назад. Была задача у одного человека, что ему нужно было считать arrayDifference по массиву.
И он делал вот так. Т. е. можно с помощью функции работы с массивами посчитать arrayDifference. Это не единственный способ, там можно было сделать несколькими способами.
Ему показалось, что это неудобно, ему захотелось сделать лучше, поэтому он взял и написал свою функцию в ClickHouse. arrayDifference, сделал pool request. Леша Миловидов посмотрел, вмержил. И теперь в ClickHouse есть функция «arrayDifference». А также есть много других новых функций работы с массивами. Все гораздо удобнее и эффективнее.

- ClickHouse – это не только OLAP-система. Не надо думать, что ClickHouse – это только аналитика, только многомерные кубы и т. д.
- ClickHouse – это очень гибкая система. И ее очень часто называют DBMS для программистов, потому что она написана программистами для программистов. На самом деле она написана программистами для всех, но программисты могут получить гораздо больше удовольствия от ее использования, чем, может быть, те, кто пытаются написать сложные JOIN.
- Все вещи, о которых я рассказал, есть в документации, просто ее надо внимательно читать. Там есть достаточно много примеров.
- Но только читать документацию, конечно, недостаточно, нужно экспериментировать. ClickHouse – это такая система, которая любит, чтобы с ней экспериментировали, чтобы смотрели, как там все выполняется, как работает схема и т. д. Алексей два часа назад прекрасно рассказал, как можно профилировать различные вещи выполнения запросов и понимать, какие структуры работают эффективно, а какие нет.
- И спрашивайте. Спрашивайте в Телеграме — https://t.me/clickhouse_ru.

Вот такой набор юного слесаря из ClickHouse я вам сегодня попытался продемонстрировать. Спасибо!

Вопросы.
Здравствуйте! В примере, который с массивами, есть какое максимальное ограничение на количество элементов в массиве? Например, по байтам или по количеству элементов?
В данном случае были даты. И поэтому дат не очень много. Проблемы такой не стояло. Если временной ряд очень длинный, надо бить на куски. Массивы – это не панацея, если нужно миллионы обработать. Но я другого способа в ClickHouse, как сделать это без массивов, не знаю. Если бы был Oracle или Postgres, то можно было бы написать процедуру. И она, скорее всего, работала бы медленнее, чем таким образом написанный запрос.
И еще вопрос по поводу max state. Получается, что здесь атрибуция происходит только, если один ивент у одного пользователя и надо заатрибутить последнюю транзакцию. А что если таких транзакций было несколько у пользователя? Получается, что, если вчера была транзакция, сегодня была транзакция, то вчерашние ивенты должны уйти. Есть справочник run hash, но там только с точности до даты поддерживает, да?
Этот справочник не подходит, если у вас несколько сотен миллионов транзакций лежит в поиске. И предполагается, что атрибуция происходит не задним числом. Например, у нас сейчас есть какой-то набор ивентов. Например, пакетами по 5 минут. И для каждого ивента находится для человека последняя транзакция. Или последние несколько, потому что иногда есть логика, какая из этих последних транзакций должна быть использована.
Александр, спасибо за доклад! Зачем кейс с логами? И альтернативы какие были? Чего добились?
Для того чтобы хранить логи, большого ума не надо. Можно просто выкинуть на storage, и они там будут лежать. Проблема с тем, что надо искать. Найти транзакцию в петабайте данных, хоть они и упакованы в 80 терабайт, и сделать это быстро, т. е. в течение нескольких секунд, — это задача, на мой взгляд, далеко не тривиальная. Особенно, если на нее не хочется тратить много серверов. Это то, что требуется сделать, может быть, несколько раз в день. Конечно, можно поставить ферму из 100 Elastic, и они будут очень быстро это делать, но это будет очень дорого. А тут стоит 5 серверов. Они стоят около 1 000 долларов в месяц в хостинге. Почему нет?
Спасибо!
По тому же вопросу, т. е. по поводу логов. Я правильно понимаю, что в эти 12-17 секунд, за которые мы вытаскивали запись по ID, туда не включалось время расчета, мы выставляли, что это парсится JSON?
Это данные, которые уже лежат в ClickHouse. Они уже подготовлены. И чтобы проверить, как это работает, мы всегда дропаем все кэши. Это сколько времени ClickHouse потребовалось. И это с учетом того, что мы используем не лучший индекс. А JSON парсится на INSERT. Т. е. ClickHouse будет парсит JSON на INSERT и заполнять DEFAULT.
До этого я услышал, что при INSERT парсится не всегда, а есть некий умный подход, что только при том, когда мы трогаем эти данные, они вычисляются.
Это если сделать ALTER TABLE, тогда он не будет их считать сразу. А если таблица уже есть, то любой INSERT приведет к тому, что все, что здесь показано, посчитается.
Понял. Спасибо!
Вы рассказывали про функцию «argMaxState». Она выбирает максимальное по дате, например. Если у меня транзакция произошла за одну секунду, например, изменился статус дважды, то как вот здесь выбирать? У меня получается две одинаковые транзакции с разными значениями. Как мне выбрать?
Здесь TS – это не DateTime. Вы правильно сказали, что если с точностью до секунды, то может возникнуть неоднозначность, поэтому там TS надо хранить либо как строку, либо дополнительные миллисекунды еще добавить.
Т. е. выбора нет?
В DateTime – секунда, да. Либо хранить миллисекунды отдельным полем, либо хранить что-то другое. Например, как бэкенд, но просто с точностью до миллисекунды отдельную колонку.







