Последние примерно полгода я занимался созданием системы борьбы с фродом (fraudulent activity, fraud, etc.) без какой-либо начальной инфраструктуры для этого. Сегодняшние идеи, которые мы нашли и реализовали в нашей системе, помогают нам обнаруживать множество мошеннических действий и анализировать их. В этой статье я хотел бы рассказать о принципах, которым мы следовали, и о том, что мы сделали для достижения текущего состояния нашей системы, не углубляясь в техническую часть.
Когда вы слышите такие термины, как «automatic» и «fraud», вы, скорее всего, начинаете думать о машинном обучении, Apache Spark, Hadoop, Python, Airflow и других технологиях экосистемы Apache Foundation и области Data Science. Я думаю, что есть один аспект использования этих инструментов, который, обычно, не упоминается: они требуют наличия определенных предварительных условий в вашей корпоративной системе, прежде чем начать их использовать. Короче говоря, вам нужна корпоративная платформа данных, которая включает озеро данных и хранилище. Но что, если у вас нет такой платформы, и вам все еще нужно развивать эту практику? Следующие принципы, о которых я рассказываю ниже, помогли нам достичь момента, когда мы можем сосредоточиться на улучшении наших идей, а не на поиске работающей. Тем не менее, это не «плато» проекта. В плане еще много вещей с технологической и продуктовой точек зрения.
Во главе всех наших усилий мы поставили «ценность для бизнеса». В целом, любая система автоматического анализа относится к группе сложных систем с высоким уровнем автоматизации и технической сложностью. Создание законченного решения займет уйму времени, если вы создадите его с нуля. Мы решили поставить на первое место ценность бизнеса, а на второе — технологическую завершенность. В реальной жизни это означает, что мы не принимаем передовые технологии, как догму. Мы выбираем технологию, которая лучше всего работает для нас на данный момент. Со временем может показаться, что нам придется заново реализовать некоторые модули. Этот компромисс, который мы приняли.
Бьюсь об заклад, большинство людей, которые не вовлечены глубоко в разработку решений машинного обучения, могут подумать, что замена людей — это цель. На самом деле, решения машинного обучения далеки от совершенства и только в определенных областях возможна замена. Мы отказались от этой идеи с самого начала по нескольким причинам: несбалансированные данные о мошеннической деятельности и невозможность предоставить исчерпывающий список функций для моделей машинного обучения. В отличие от этого, мы выбрали вариант с расширенным интеллектом. Это альтернативная концепция искусственного интеллекта, которая фокусируется на вспомогательной роли ИИ, подчеркивая тот факт, что когнитивные технологии предназначены для улучшения человеческого интеллекта, а не для его замены. [1]
Учитывая это, разработка полного решения машинного обучения с самого начала потребовала бы огромных усилий, которые задержали бы создание ценности для нашего бизнеса. Мы решили построить систему с итеративно растущим аспектом машинного обучения под руководством наших экспертов в предметной области. Сложная часть разработки такой системы состоит в том, что она должна предоставлять нашим аналитикам кейсы не только с точки зрения того, является ли это мошеннической деятельностью или нет. В общем, любая аномалия в поведении клиентов — это подозрительный случай, который специалистам необходимо расследовать и как-то реагировать. Лишь некоторая часть этих зафиксированных случаев действительно может быть отнесена к категории мошенничества.
Самая сложная часть нашей системы — это сквозная проверка рабочего процесса системы. Аналитики и разработчики должны легко получать наборы данных за прошлые периоды со всеми метриками, которые использовались для анализа. Кроме того, платформа данных должна предоставлять простой способ дополнить существующий набор показателей новым. Процессы, которые мы создаем, а это не только программные процессы, должны позволять легко пересчитывать предыдущие периоды, добавлять новые метрики и изменять прогноз данных. Мы могли бы добиться этого, накапливая все данные, которые генерирует наша производственная система. В таком случае данные постепенно стали бы помехой. Нам нужно было бы хранить растущий объем данных, которые мы не используем, и защищать их. В таком сценарии со временем данные будут становиться все более и более нерелевантными, но по-прежнему требуют наших усилий для управления ими. Для нас накопление данных (data hoarding) не имело смысла, и мы решили использовать другой подход. Мы решили организовать хранилища данных в реальном времени вокруг целевых сущностей, которые мы хотим классифицировать, и хранить только те данные, которые позволяют проверять самые последние и актуальные периоды. Сложность этих усилий заключается в том, что наша система является неоднородной с несколькими хранилищами данных и программными модулями, которые требуют тщательного планирования для согласованной работы.
У нас есть четыре основных компонента в нашей системе: система приема (ingestion system), вычисления (computational), анализ (BI analysis) и система отслеживания (tracking system). Они служат для конкретных изолированных целей, и мы держим их изолированными, следуя определенным подходам в разработке.

Прежде всего, мы договорились, что компоненты должны полагаться только на определенные структуры данных (контракты), которые передаются между ними. Это позволяет легко интегрировать между ними и не навязывать конкретный состав (и порядок) компонентов. Например, в некоторых случаях это позволяет нам напрямую интегрировать систему приема с системой отслеживания предупреждений. В таком случае это будет сделано в соответствии с согласованным контрактом на оповещения. Это означает, что оба компонента будут интегрированы с использованием контракта, который может использовать любой другой компонент. Мы не будем добавлять дополнительный контракт на добавление предупреждений в систему отслеживания из системы ввода. Такой подход требует использования заранее определенного минимального количества контрактов и упрощает систему и коммуникации. По сути, мы используем подход, который называется «Contract First Design», и применяем его к контрактам потоковой передачи данных. [2]
Сохранение и управление состоянием в системе неизбежно приведет к усложнениям в ее реализации. В общем случае, состояние должно быть доступным из любого компонента, оно должно быть согласованным и предоставлять наиболее актуальное значение для всех компонентов, и оно должно быть надежным с правильными значениями. Кроме того, наличие вызовов к постоянному хранилищу для получения последнего состояния увеличит количество операций ввода-вывода и сложность алгоритмов, использующихся в наших конвейерах реального времени. Из-за этого мы решили убраться хранение состояния, по возможности, полностью из нашей системы. Этот подход требует включения всех необходимых данных в передаваемый блок данных (сообщение). Например, если нам нужно вычислить общее количество некоторых наблюдений (количество операций или случаев с определенными характеристиками), мы вычисляем его в памяти и генерируем поток таких значений. Зависимые модули будут использовать разбиение (partition) и пакетирование (batch) для дробления потока по сущностям и оперирования последними значениями. Этот подход устранил необходимость иметь постоянное дисковое хранилище для таких данных. Наша система использует Kafka в качестве брокера сообщений, и его можно использовать как базу данных с KSQL. [3] Но его использование сильно связало бы наше решение с Kafka, и мы решили не использовать его. Выбранный нами подход позволяет заменить Kafka другим брокером сообщений без серьезных внутренних изменений системы.
Эта концепция не означает, что мы не используем дисковые хранилищя и базы данных. Для проверки и анализа производительности системы нам необходимо хранить на диске значительную часть данных, которые представляют различные показатели и состояния. Важным моментом здесь является то, что алгоритмы реального времени не зависят от таких данных. В большинстве случаев мы используем сохраненные данные для автономного анализа, отладки и отслеживания конкретных случаев и результатов, которые выдаёт система.
Есть определенные проблемы, которые мы решили до определённого уровня, но они требуют более продуманных решений. Сейчас я просто хотел бы упомянуть их здесь, потому что каждый пункт стоит отдельной статьи.
Принципы нашей системы
Когда вы слышите такие термины, как «automatic» и «fraud», вы, скорее всего, начинаете думать о машинном обучении, Apache Spark, Hadoop, Python, Airflow и других технологиях экосистемы Apache Foundation и области Data Science. Я думаю, что есть один аспект использования этих инструментов, который, обычно, не упоминается: они требуют наличия определенных предварительных условий в вашей корпоративной системе, прежде чем начать их использовать. Короче говоря, вам нужна корпоративная платформа данных, которая включает озеро данных и хранилище. Но что, если у вас нет такой платформы, и вам все еще нужно развивать эту практику? Следующие принципы, о которых я рассказываю ниже, помогли нам достичь момента, когда мы можем сосредоточиться на улучшении наших идей, а не на поиске работающей. Тем не менее, это не «плато» проекта. В плане еще много вещей с технологической и продуктовой точек зрения.
Принцип 1: ценность для бизнеса в первую очередь
Во главе всех наших усилий мы поставили «ценность для бизнеса». В целом, любая система автоматического анализа относится к группе сложных систем с высоким уровнем автоматизации и технической сложностью. Создание законченного решения займет уйму времени, если вы создадите его с нуля. Мы решили поставить на первое место ценность бизнеса, а на второе — технологическую завершенность. В реальной жизни это означает, что мы не принимаем передовые технологии, как догму. Мы выбираем технологию, которая лучше всего работает для нас на данный момент. Со временем может показаться, что нам придется заново реализовать некоторые модули. Этот компромисс, который мы приняли.
Принцип 2: Расширенный интеллект человека (augmented intelligence)
Бьюсь об заклад, большинство людей, которые не вовлечены глубоко в разработку решений машинного обучения, могут подумать, что замена людей — это цель. На самом деле, решения машинного обучения далеки от совершенства и только в определенных областях возможна замена. Мы отказались от этой идеи с самого начала по нескольким причинам: несбалансированные данные о мошеннической деятельности и невозможность предоставить исчерпывающий список функций для моделей машинного обучения. В отличие от этого, мы выбрали вариант с расширенным интеллектом. Это альтернативная концепция искусственного интеллекта, которая фокусируется на вспомогательной роли ИИ, подчеркивая тот факт, что когнитивные технологии предназначены для улучшения человеческого интеллекта, а не для его замены. [1]
Учитывая это, разработка полного решения машинного обучения с самого начала потребовала бы огромных усилий, которые задержали бы создание ценности для нашего бизнеса. Мы решили построить систему с итеративно растущим аспектом машинного обучения под руководством наших экспертов в предметной области. Сложная часть разработки такой системы состоит в том, что она должна предоставлять нашим аналитикам кейсы не только с точки зрения того, является ли это мошеннической деятельностью или нет. В общем, любая аномалия в поведении клиентов — это подозрительный случай, который специалистам необходимо расследовать и как-то реагировать. Лишь некоторая часть этих зафиксированных случаев действительно может быть отнесена к категории мошенничества.
Принцип 3: платформа обширных аналитических данных
Самая сложная часть нашей системы — это сквозная проверка рабочего процесса системы. Аналитики и разработчики должны легко получать наборы данных за прошлые периоды со всеми метриками, которые использовались для анализа. Кроме того, платформа данных должна предоставлять простой способ дополнить существующий набор показателей новым. Процессы, которые мы создаем, а это не только программные процессы, должны позволять легко пересчитывать предыдущие периоды, добавлять новые метрики и изменять прогноз данных. Мы могли бы добиться этого, накапливая все данные, которые генерирует наша производственная система. В таком случае данные постепенно стали бы помехой. Нам нужно было бы хранить растущий объем данных, которые мы не используем, и защищать их. В таком сценарии со временем данные будут становиться все более и более нерелевантными, но по-прежнему требуют наших усилий для управления ими. Для нас накопление данных (data hoarding) не имело смысла, и мы решили использовать другой подход. Мы решили организовать хранилища данных в реальном времени вокруг целевых сущностей, которые мы хотим классифицировать, и хранить только те данные, которые позволяют проверять самые последние и актуальные периоды. Сложность этих усилий заключается в том, что наша система является неоднородной с несколькими хранилищами данных и программными модулями, которые требуют тщательного планирования для согласованной работы.
Конструктивные концепции нашей системы
У нас есть четыре основных компонента в нашей системе: система приема (ingestion system), вычисления (computational), анализ (BI analysis) и система отслеживания (tracking system). Они служат для конкретных изолированных целей, и мы держим их изолированными, следуя определенным подходам в разработке.
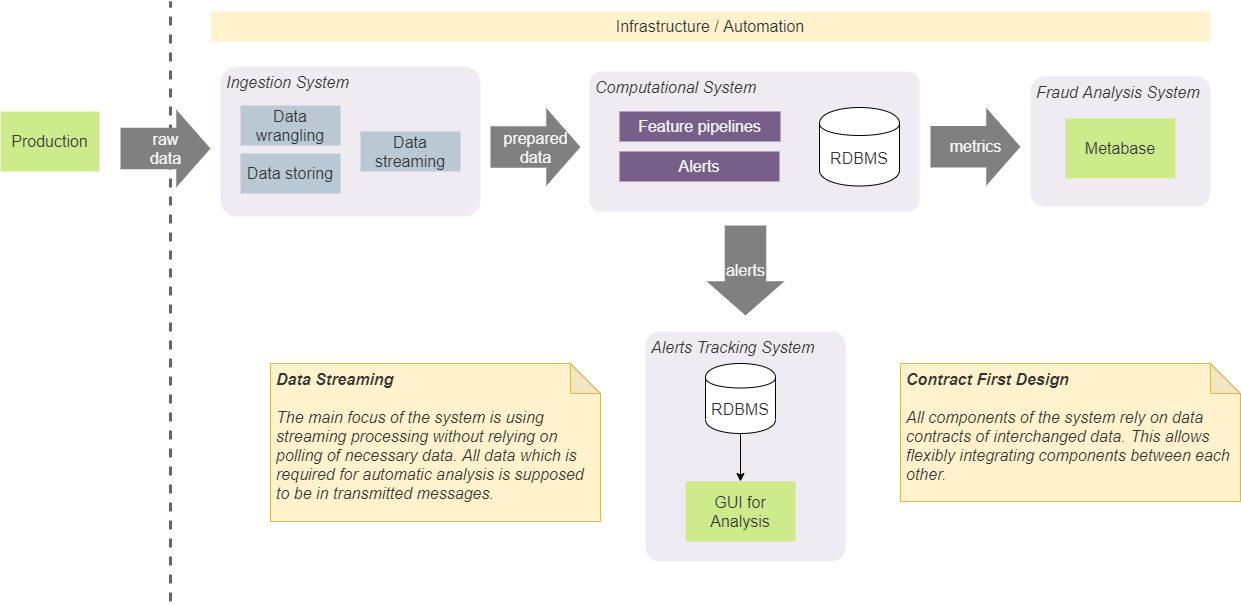
Дизайн на основе контрактов
Прежде всего, мы договорились, что компоненты должны полагаться только на определенные структуры данных (контракты), которые передаются между ними. Это позволяет легко интегрировать между ними и не навязывать конкретный состав (и порядок) компонентов. Например, в некоторых случаях это позволяет нам напрямую интегрировать систему приема с системой отслеживания предупреждений. В таком случае это будет сделано в соответствии с согласованным контрактом на оповещения. Это означает, что оба компонента будут интегрированы с использованием контракта, который может использовать любой другой компонент. Мы не будем добавлять дополнительный контракт на добавление предупреждений в систему отслеживания из системы ввода. Такой подход требует использования заранее определенного минимального количества контрактов и упрощает систему и коммуникации. По сути, мы используем подход, который называется «Contract First Design», и применяем его к контрактам потоковой передачи данных. [2]
Стриминг везде
Сохранение и управление состоянием в системе неизбежно приведет к усложнениям в ее реализации. В общем случае, состояние должно быть доступным из любого компонента, оно должно быть согласованным и предоставлять наиболее актуальное значение для всех компонентов, и оно должно быть надежным с правильными значениями. Кроме того, наличие вызовов к постоянному хранилищу для получения последнего состояния увеличит количество операций ввода-вывода и сложность алгоритмов, использующихся в наших конвейерах реального времени. Из-за этого мы решили убраться хранение состояния, по возможности, полностью из нашей системы. Этот подход требует включения всех необходимых данных в передаваемый блок данных (сообщение). Например, если нам нужно вычислить общее количество некоторых наблюдений (количество операций или случаев с определенными характеристиками), мы вычисляем его в памяти и генерируем поток таких значений. Зависимые модули будут использовать разбиение (partition) и пакетирование (batch) для дробления потока по сущностям и оперирования последними значениями. Этот подход устранил необходимость иметь постоянное дисковое хранилище для таких данных. Наша система использует Kafka в качестве брокера сообщений, и его можно использовать как базу данных с KSQL. [3] Но его использование сильно связало бы наше решение с Kafka, и мы решили не использовать его. Выбранный нами подход позволяет заменить Kafka другим брокером сообщений без серьезных внутренних изменений системы.
Эта концепция не означает, что мы не используем дисковые хранилищя и базы данных. Для проверки и анализа производительности системы нам необходимо хранить на диске значительную часть данных, которые представляют различные показатели и состояния. Важным моментом здесь является то, что алгоритмы реального времени не зависят от таких данных. В большинстве случаев мы используем сохраненные данные для автономного анализа, отладки и отслеживания конкретных случаев и результатов, которые выдаёт система.
Проблемы нашей системы
Есть определенные проблемы, которые мы решили до определённого уровня, но они требуют более продуманных решений. Сейчас я просто хотел бы упомянуть их здесь, потому что каждый пункт стоит отдельной статьи.
- Нам все еще необходимо определить процессы и политики, которые способствуют накоплению значимых и актуальных данных для нашего автоматического анализа, обнаружения и исследования данных.
- Внедрение результатов анализа человеком в процесс автоматической настройки системы для её обновления на последних данных. Это не только обновление нашей модели, но также обновление процессов и улучшение понимания наших данных.
- Нахождение баланса между детерминированным подходом IF-ELSE и ML. Кто-то сказал: «ML — это инструмент для отчаявшихся». Это означает, что вы захотите использовать ML, когда больше не понимаете, как оптимизировать и улучшить свои алгоритмы. С другой стороны, детерминированный подход не позволяет обнаружение аномалий, которые не были предвидены.
- Нам нужен простой способ проверить наши гипотезы или коореляции между метриками в данных.
- Система должна иметь несколько уровней истинно положительных (true positive) результатов. Случаи мошенничества — это лишь часть всех случаев, которые можно считать положительными для системы. Например, аналитики хотят получать все подозрительные случаи для проверки, и лишь небольшая часть из них — мошенничество. Система должна эффективно предоставлять аналитикам все случаи, независимо от того, является ли это реальным мошенничеством или просто подозрительным поведением.
- Платформа данных должна позволять получать наборы данных за прошлые периоды с вычислениями, созданными и рассчитанными на лету.
- Простое и автоматическое развертывание любого из компонентов системы как минимум в трех различных средах: производственной, экспериментальной (бета) и для разработчиков.
- И последнее, но не менее важное. Нам необходимо создать обширную платформу проверки производительности, на которой мы сможем анализировать наши модели. [4]








