Заранее хочу отметить, что тот кто знает как обучается персептрон — в этой статье вряд ли найдет что-то новое. Вы можете смело пропускать ее. Почему я решил это написать — я хотел бы написать цикл статей, связанных с нейронными сетями и применением TensorFlow.js, ввиду этого я не мог опустить общие теоретические выдержки. Поэтому прошу отнестись с большим терпением и пониманием к конечной задумке.
При классическом программировании разработчик описывает на конкретном языке программирования определённый жестко заданный набор правил, который был определен на основании его знаний в конкретной предметной области и который в первом приближении описывает процессы, происходящие в человеческом мозге при решении аналогичной задачи.
Например, может быть запрограммирована стратегия игры в крестики-нолики, шахмат и другое (рисунок 1).

Рисунок 1 – Классический подход решения задач
В то время как алгоритмы машинного обучения могут определять набор правил для решения задач без участия разработчика, а только на базе наличия тренировочного набора данных.
Тренировочный набор — это какой-то набор входных данных ассоциированный с набором ожидаемых результатов (ответами, выходными данными). На каждом шаге обучения, модель за счет изменения внутреннего состояния, будет оптимизировать и уменьшать ошибку между фактическим выходным результатом модели и ожидаемым результатом (рисунок 2).

Рисунок 2 – Машинное обучение
Долгое время учёные, вдохновляясь процессами происходящими в нашем мозге, пытались сделать реверс-инжиниринг центральной нервной системы и попробовать сымитировать работу человеческого мозга. Благодаря этому родилось целое направление в машинном обучении — нейронные сети.
На рисунке 3 вы можете увидеть сходство между устройством биологического нейрона и математическим представлением нейрона, используемого в машинном обучении.

Рисунок 3 – Математическое представление нейрона
В биологическом нейроне, нейрон получает электрические сигналы от дендритов, модулирующих электрические сигналы с разной силой, которые могут возбуждать нейрон при достижении некоторого порогового значения, что в свою очередь приведёт к передаче электрического сигнала другим нейронам через синапсы.
Математическая модель нейронной сети, состоящего из одного нейрона, который выполняет две последовательные операции (рисунок 4):
Рисунок 4 – Математическая модель персептрона
В качестве активационной функции может использоваться любая дифференцируемая функция, наиболее часто используемые приведены в таблице 1. Выбор активационной функции ложиться на плечи инженера, и обычно этот выбор основан или на уже имеющемся опыте решения похожих задач, ну или просто методом подбора.
Процесс обучения состоит из несколько шагов. Для большей наглядности, рассмотрим некую вымышленную задачу, которую мы будем решать нейронной сетью, состоящей из одного нейрона с линейной активационной функции (это по сути персептрон без активационной функции вовсе), также для упрощения задачи – исключим в нейроне узел смещения b (рисунок 5).

Рисунок 5 – Обучающий набор данных и состояние нейронной сети на предыдущем шаге обучения
На данном этапе мы имеем нейронную сеть в некотором состоянии с определенными весами соединений, которые были вычислены на предыдущем этапе обучения модели или если это первая итерация обучения – то значения весов соединений выбраны в произвольном порядке.
Итак, представим, что мы имеем некоторый набор тренировочных данных, значения каждого элемента из набора представлены вектором входных данных (input data), содержащих 2 параметра (feature) . Под в модели в зависимости от рассматриваемой предметной области может подразумеваться все что угодно: количество комнат в доме, расстояние дома от моря, ну или мы просто пытаемся обучить нейронную сеть логической операции И, или ИЛИ.
. Под в модели в зависимости от рассматриваемой предметной области может подразумеваться все что угодно: количество комнат в доме, расстояние дома от моря, ну или мы просто пытаемся обучить нейронную сеть логической операции И, или ИЛИ.
Каждый вектор входных данных в тренировочном наборе сопоставлен с вектором ожидаемого результата (expected output). В данном случае вектор выходных данных содержит только один параметр, которые опять же в зависимости от выбранной предметной области может означать все что угодно – цена дома, результат выполнения логической операции И или ИЛИ.
ШАГ 1 — Прямое распространение ошибки (feedforward process)
На данном шаге мы вычисляем сумму входных сигналов с учетом веса каждой связи и применяем активационную функцию (в нашем случае активационной функции нет). Сделаем вычисления для первого элемента в обучающем наборе:

Рисунок 6 – Прямое распространение ошибки
Обратите внимание, что написанная формула выше – это упрощенное математическое уравнение для частного случая операций над тензорами.
Тензор – это по сути контейнер данных, который может иметь N осей и произвольное число элементов вдоль каждой из осей. Большинство с тензорами знакомы с математики – векторы (тензор с одной осью), матрицы (тензор с двумя осями – строки, колонки).
Формулу можно написать в следующем виде, где вы увидите знакомые матрицы (тензоры) и их перемножение, а также поймете о каком упрощении шла речь выше:
ШАГ 2 — Расчет функции ошибки
Функция ошибка – это метрика, отражающая расхождение между ожидаемыми и полученными выходными данными. Обычно используют следующие функции ошибки:
— среднеквадратичная ошибка (Mean Squared Error, MSE) – данная функция ошибки особенно чувствительна к выбросам в тренировочном наборе, так как используется квадрат от разности фактического и ожидаемого значений (выброс — значение, которое сильно удалено от других значений в наборе данных, которые могут иногда появляться в следствии ошибок данных, таких как смешивание данных с разными единицами измерения или плохие показания датчиков):
— среднеквадратичное отклонение (Root MSE) – по сути это тоже самое что, среднеквадратичная ошибка в контексте нейронных сетей, но может отражать реальную физическую единицу измерения, например, если в нейронной сети выходным параметров нейронной сети является цена дома выраженной в долларах, то единица измерения среднеквадратичной ошибки будет доллар квадратный ( ), а для среднеквадратичного отклонения это доллар ($), что естественно немного упрощает задачу анализа человеком:
), а для среднеквадратичного отклонения это доллар ($), что естественно немного упрощает задачу анализа человеком:
— среднее отклонение (Mean Absolute Error, MAE) -в отличии от двух выше указанных значений, является не столь чувствительной к выбросам:
— перекрестная энтропия (Cross entropy) – использует для задач классификации:
где
 – число экземпляров в тренировочном наборе
– число экземпляров в тренировочном наборе
 – число классов при решении задач классификации
– число классов при решении задач классификации
 — ожидаемое выходное значение
— ожидаемое выходное значение
 – фактическое выходное значение обучаемой модели
– фактическое выходное значение обучаемой модели
Для нашего конкретного случая воспользуемся MSE:
ШАГ 3 — Обратное распространение ошибки (backpropagation)
Цель обучения нейронной сети проста – это минимизация функции ошибки:
Одним способом найти минимум функции – это на каждом очередном шаге обучения модифицировать веса соединений в направлении противоположным вектору-градиенту – метод градиентного спуска, и это математически выглядит так:
где – k -ая итерация обучения нейронной сети;
– k -ая итерация обучения нейронной сети;
 – шаг обучения (learning rate) и задается инженером, обычно это может быть 0.1; 0.01 (о том как шаг обучения влияет на процесс сходимости обучения отметить чуть позже)
– шаг обучения (learning rate) и задается инженером, обычно это может быть 0.1; 0.01 (о том как шаг обучения влияет на процесс сходимости обучения отметить чуть позже)
 – градиент функции-ошибки
– градиент функции-ошибки
Для нахождения градиента, используем частные производные по настраиваемым аргументам :
:
В нашем конкретном случае с учетом всех упрощений, функция ошибки принимает вид:
Найдем следующие частные производные:
Тогда процесс обратного распространения ошибки – движение по модели от выхода по направлению к входу с модификацией весов модели в направлении обратном вектору градиента. Задавая обучающий шаг 0.1 (learning rate) имеем (рисунок 7):

Рисунок 7 – Обратное распространение ошибки
Таким образом мы завершили k+1 шаг обучения, чтобы убедиться, что ошибка снизилась, а выход от модели с новыми весами стал ближе к ожидаемому выполним процесс прямого распространения ошибки по модели с новыми весами (см. ШАГ 1):
Как видим, выходное значение увеличилось на 0.2 единица в верном направлении к ожидаемому результату – единице (1). Ошибка тогда составит:
Как видим, на предыдущем шаге обучения ошибка составила 0.64, а с новыми весами – 0.36, следовательно мы настроили модель в верном направлении.
Следующая часть статьи:
Машинное обучение. Нейронные сети (часть 2): Моделирование OR; XOR с помощью TensorFlow.js
Машинное обучение. Нейронные сети (часть 3) — Convolutional Network под микроскопом. Изучение АПИ Tensorflow.js
При классическом программировании разработчик описывает на конкретном языке программирования определённый жестко заданный набор правил, который был определен на основании его знаний в конкретной предметной области и который в первом приближении описывает процессы, происходящие в человеческом мозге при решении аналогичной задачи.
Например, может быть запрограммирована стратегия игры в крестики-нолики, шахмат и другое (рисунок 1).

Рисунок 1 – Классический подход решения задач
В то время как алгоритмы машинного обучения могут определять набор правил для решения задач без участия разработчика, а только на базе наличия тренировочного набора данных.
Тренировочный набор — это какой-то набор входных данных ассоциированный с набором ожидаемых результатов (ответами, выходными данными). На каждом шаге обучения, модель за счет изменения внутреннего состояния, будет оптимизировать и уменьшать ошибку между фактическим выходным результатом модели и ожидаемым результатом (рисунок 2).

Рисунок 2 – Машинное обучение
Нейронные сети
Долгое время учёные, вдохновляясь процессами происходящими в нашем мозге, пытались сделать реверс-инжиниринг центральной нервной системы и попробовать сымитировать работу человеческого мозга. Благодаря этому родилось целое направление в машинном обучении — нейронные сети.
На рисунке 3 вы можете увидеть сходство между устройством биологического нейрона и математическим представлением нейрона, используемого в машинном обучении.

Рисунок 3 – Математическое представление нейрона
В биологическом нейроне, нейрон получает электрические сигналы от дендритов, модулирующих электрические сигналы с разной силой, которые могут возбуждать нейрон при достижении некоторого порогового значения, что в свою очередь приведёт к передаче электрического сигнала другим нейронам через синапсы.
Персептрон
Математическая модель нейронной сети, состоящего из одного нейрона, который выполняет две последовательные операции (рисунок 4):
- вычисляет сумму входных сигналов с учетом их весов (проводимости или сопротивления) связи

- применяет активационную функцию к общей сумме воздействия входных сигналов.

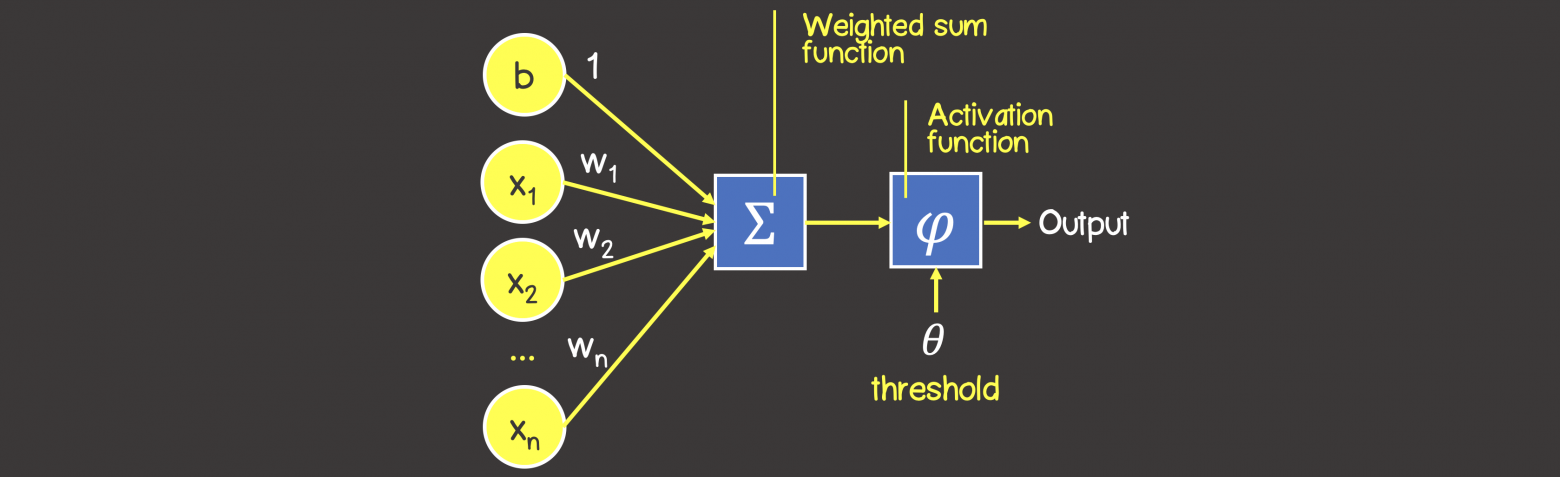

Рисунок 4 – Математическая модель персептрона
В качестве активационной функции может использоваться любая дифференцируемая функция, наиболее часто используемые приведены в таблице 1. Выбор активационной функции ложиться на плечи инженера, и обычно этот выбор основан или на уже имеющемся опыте решения похожих задач, ну или просто методом подбора.
Заметка
Однако есть рекомендация – что если нужна нелинейность в нейронной сети, то в качестве активационной функции лучше всего подходит ReLU функция, которая имеет лучшие показатели сходимости модели во время процесса обучения.
Таблица 1 - Распространенные активационные функции
| Имя | Формула | График |
| Linear function |
|
 . . |
| Sigmoid function |
|
 |
| Softmax function |
|
Используется для задач классификации (где количество классов более 2) |
| Hyperbolic Tangent function |
|
 Сжимает входной сигнал в интервале [-1, 1]. Применяется в скрытых слоях нейронной сети, так как центрирует выходной сигнал относительно нуля, что ускоряет процесс обучения |
| Rectified Linear Unit (ReLU) |
|
 Используется в скрытых слоях нейронной сети, имеет лучшую сходимость, чем sigmoid и tanh функции |
| Leaky ReLU |
|
 Лишен недостаток ReLU функции в интервале отрицательных выходных сигналов, где частичная производная равна 0 |







Процесс обучения персептрона
Процесс обучения состоит из несколько шагов. Для большей наглядности, рассмотрим некую вымышленную задачу, которую мы будем решать нейронной сетью, состоящей из одного нейрона с линейной активационной функции (это по сути персептрон без активационной функции вовсе), также для упрощения задачи – исключим в нейроне узел смещения b (рисунок 5).

Рисунок 5 – Обучающий набор данных и состояние нейронной сети на предыдущем шаге обучения
На данном этапе мы имеем нейронную сеть в некотором состоянии с определенными весами соединений, которые были вычислены на предыдущем этапе обучения модели или если это первая итерация обучения – то значения весов соединений выбраны в произвольном порядке.
Итак, представим, что мы имеем некоторый набор тренировочных данных, значения каждого элемента из набора представлены вектором входных данных (input data), содержащих 2 параметра (feature)
. Под в модели в зависимости от рассматриваемой предметной области может подразумеваться все что угодно: количество комнат в доме, расстояние дома от моря, ну или мы просто пытаемся обучить нейронную сеть логической операции И, или ИЛИ. Каждый вектор входных данных в тренировочном наборе сопоставлен с вектором ожидаемого результата (expected output). В данном случае вектор выходных данных содержит только один параметр, которые опять же в зависимости от выбранной предметной области может означать все что угодно – цена дома, результат выполнения логической операции И или ИЛИ.
ШАГ 1 — Прямое распространение ошибки (feedforward process)
На данном шаге мы вычисляем сумму входных сигналов с учетом веса каждой связи и применяем активационную функцию (в нашем случае активационной функции нет). Сделаем вычисления для первого элемента в обучающем наборе:


Рисунок 6 – Прямое распространение ошибки
Обратите внимание, что написанная формула выше – это упрощенное математическое уравнение для частного случая операций над тензорами.
Тензор – это по сути контейнер данных, который может иметь N осей и произвольное число элементов вдоль каждой из осей. Большинство с тензорами знакомы с математики – векторы (тензор с одной осью), матрицы (тензор с двумя осями – строки, колонки).
Формулу можно написать в следующем виде, где вы увидите знакомые матрицы (тензоры) и их перемножение, а также поймете о каком упрощении шла речь выше:
![${\vec{Y}}_{predicted}=\ {\vec{X}}^T\vec{W}=\left[\begin{matrix}x_1\\x_2\\\end{matrix}\right]^T\cdot \left [ \begin{matrix} w_1\\ w_2 \end{matrix} \right ]=\left [ \begin{matrix} x_1 & x_2 \end{matrix} \right ] \cdot \left [ \begin{matrix} w_1\\ w_2 \end{matrix} \right ] =\left [ x_1w_1+x_2w_2 \right ]$](https://habrastorage.org/getpro/habr/formulas/a36/9d4/929/a369d49299583d08cbd19bea1e116daf.svg)
ШАГ 2 — Расчет функции ошибки
Функция ошибка – это метрика, отражающая расхождение между ожидаемыми и полученными выходными данными. Обычно используют следующие функции ошибки:
— среднеквадратичная ошибка (Mean Squared Error, MSE) – данная функция ошибки особенно чувствительна к выбросам в тренировочном наборе, так как используется квадрат от разности фактического и ожидаемого значений (выброс — значение, которое сильно удалено от других значений в наборе данных, которые могут иногда появляться в следствии ошибок данных, таких как смешивание данных с разными единицами измерения или плохие показания датчиков):

— среднеквадратичное отклонение (Root MSE) – по сути это тоже самое что, среднеквадратичная ошибка в контексте нейронных сетей, но может отражать реальную физическую единицу измерения, например, если в нейронной сети выходным параметров нейронной сети является цена дома выраженной в долларах, то единица измерения среднеквадратичной ошибки будет доллар квадратный (
), а для среднеквадратичного отклонения это доллар ($), что естественно немного упрощает задачу анализа человеком:
— среднее отклонение (Mean Absolute Error, MAE) -в отличии от двух выше указанных значений, является не столь чувствительной к выбросам:

— перекрестная энтропия (Cross entropy) – использует для задач классификации:

где
– число экземпляров в тренировочном наборе – число классов при решении задач классификации — ожидаемое выходное значение – фактическое выходное значение обучаемой моделиДля нашего конкретного случая воспользуемся MSE:

ШАГ 3 — Обратное распространение ошибки (backpropagation)
Цель обучения нейронной сети проста – это минимизация функции ошибки:

Одним способом найти минимум функции – это на каждом очередном шаге обучения модифицировать веса соединений в направлении противоположным вектору-градиенту – метод градиентного спуска, и это математически выглядит так:

где
– k -ая итерация обучения нейронной сети; – шаг обучения (learning rate) и задается инженером, обычно это может быть 0.1; 0.01 (о том как шаг обучения влияет на процесс сходимости обучения отметить чуть позже) – градиент функции-ошибкиДля нахождения градиента, используем частные производные по настраиваемым аргументам
:![$\nabla L\left(\vec{w}\right)=\left[\begin{matrix}\frac{\partial L}{\partial w_1}\\\vdots\\\frac{\partial L}{\partial w_N}\\\end{matrix}\right]$](https://habrastorage.org/getpro/habr/formulas/d25/bb0/a13/d25bb0a13bb5593a7c26f98f0ed48352.svg)
В нашем конкретном случае с учетом всех упрощений, функция ошибки принимает вид:


Памятка формул производных
Напомним некоторые формулы производных, которые пригодятся для вычисления частных производных

![$\frac{d}{dx}\left[cf\left(x\right)\right]=cf^\prime\left(x\right);\ c=const$](https://habrastorage.org/getpro/habr/formulas/57e/054/a5f/57e054a5f25bedee72173a87243d0f2c.svg)

![$\frac{d}{dx}\left[f\left(x\right)\pm g(x)\right]=f^\prime\left(x\right)\pm g^\prime(x)$](https://habrastorage.org/getpro/habr/formulas/8c4/ee1/b1e/8c4ee1b1e4fa1c726492439ccf9a4742.svg)
![$\frac{d}{dx}\left[f\left(x\right)g\left(x\right)\right]=f^\prime\left(x\right)g\left(x\right)+g^\prime\left(x\right)f\left(x\right)$](https://habrastorage.org/getpro/habr/formulas/991/671/90b/99167190b2483305b32d72b8d4c479b7.svg)

Найдем следующие частные производные:




Тогда процесс обратного распространения ошибки – движение по модели от выхода по направлению к входу с модификацией весов модели в направлении обратном вектору градиента. Задавая обучающий шаг 0.1 (learning rate) имеем (рисунок 7):



Рисунок 7 – Обратное распространение ошибки
Таким образом мы завершили k+1 шаг обучения, чтобы убедиться, что ошибка снизилась, а выход от модели с новыми весами стал ближе к ожидаемому выполним процесс прямого распространения ошибки по модели с новыми весами (см. ШАГ 1):

Как видим, выходное значение увеличилось на 0.2 единица в верном направлении к ожидаемому результату – единице (1). Ошибка тогда составит:

Как видим, на предыдущем шаге обучения ошибка составила 0.64, а с новыми весами – 0.36, следовательно мы настроили модель в верном направлении.
Следующая часть статьи:
Машинное обучение. Нейронные сети (часть 2): Моделирование OR; XOR с помощью TensorFlow.js
Машинное обучение. Нейронные сети (часть 3) — Convolutional Network под микроскопом. Изучение АПИ Tensorflow.js







