История знает много примеров преждевременных открытий и изобретений. Хочу рассказать об одном из них.
Речь пойдет о визуальном поисковике, получившим первые западные венчурные инвестиции в области ИТ в России, построенном на основе активных семантических нейронных сетях. Под катом мы расскажем об его основных принципах работы и архитектуре.
Мне крупно повезло в жизни – я учился у Николая Михайловича Амосова, выдающегося человека, кардиохирурга и кибернетика. Учился заочно — развал СССР не дал мне возможности встретиться лично.

О Николае Михайловиче можно говорить много, родился в крестьянской семье в деревеньке под Череповцом и при этом получил второе место в проекте «Великие украинцы» уступив первое место Ярославу Мудрому. Выдающийся кардиохирург и инженер-кибернетик, самостоятельно разработавший первый в СССР искусственный клапан. Его именем названы улицы, медицинское училище, колледж, курсирующий в Иваньковском водохранилище катер.
Об этом много написано и в Википедии, и на других сайтах.
Хочу затронуть не так широко освещенную сторону Амосова. Широкий кругозор, два образования (медицинское и инженерное) позволило ему разработать теорию активных семантических нейронных сетей (М-сетей), в рамках которой более 50-ти лет назад были реализованы вещи, которые и на сегодняшний день поражают своей уникальностью.
И если бы в то время были достаточные вычислительные мощности, возможно, сегодня бы уже был реализован сильный ИИ.
В своих работах Амосов сумел выдержать баланс между нейрофизиологией и математикой, изучая и описывая информационные процессы интеллекта. Результаты его работ представлены в нескольких трудах, заключительной была монография «Алгоритмы разума», изданная в 1979 году.
Приведу краткую цитату из нее об одной из моделей:
«…(нами) проводилось исследование, цель которого состояла в том, чтобы изучить возможности М-сетей в области нейрофизиологии и нейропсихологии, а также оценить практическую и познавательную важность таких моделей. Был разработан и исследован М-автомат, моделирующий механизмы речи. В модели представлены такие аспекты устной речи, как восприятие, осмысливание, словесное выражение.
Модель предназначена для воспроизведения относительно простых речевых функций (!!!) — ответов на вопросы ограниченного типа, повторения, называния. Она содержит следующие блоки: слуховых восприятий, сенсорный речевой, проприоцептивный речевой, понятийный, эмоций, мотивационный, двигательный речевой, артикуляторный и блок СУТ. Блоки модели соотнесены с определенными мозговыми образованиями…
… На вход модели подавались буквы русского алфавита, объединенные в слова и фразы, а также специальные объекты, соответствующие образам предметов. На выходе модели, в зависимости от режима ее работы, наблюдались последовательности букв русского алфавита, которые были либо ответами на входные вопросы, либо повторением входных слов, либо названиями предметов.
То обстоятельство, что при создании модели широко использовались данные нейрофизиологии, позволило в экспериментах имитировать ряд поражений мозга органического и функционального характера, приводящих к нарушениям функций речи».
И это лишь одна из работ.
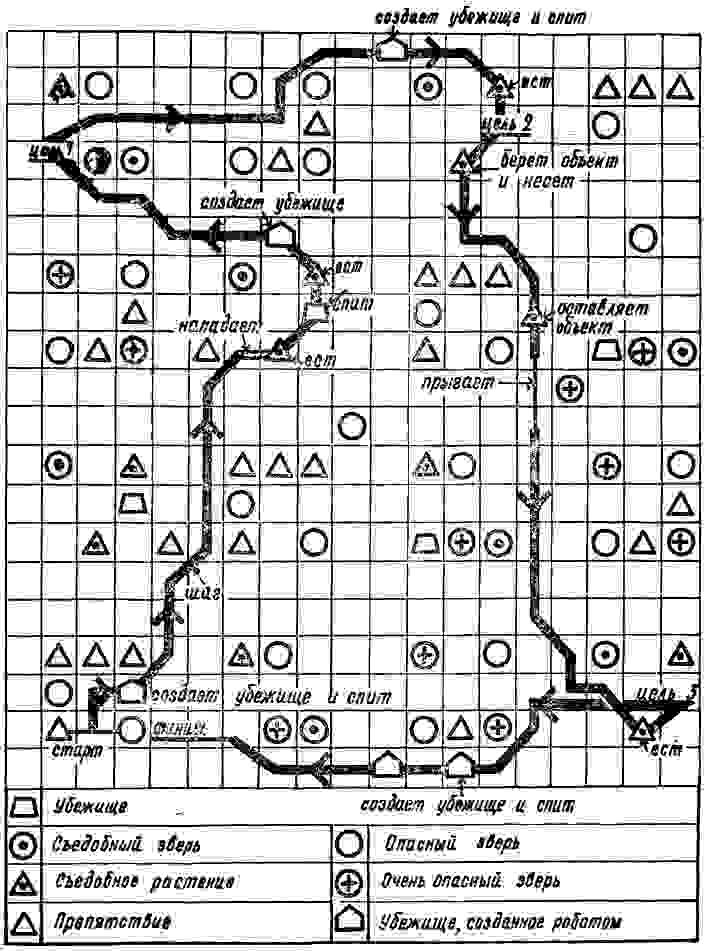
Другая — управление мобильным роботом. “… система управления роботом предполагает осуществление целенаправленного движения с обеспечением собственной безопасности (объезд препятствий, избегание опасных мест, поддержание внутренних параметров в заданных пределах) и минимизацию временных и энергетических затрат”.

Также, в монографии описаны результаты моделирования свободного поведения “некоего субъекта в среде, которая содержала полезные и опасные для него объекты. Мотивы поведения субъекта определялись ощущениями усталости, голода и стремлением к самосохранению. Субъект изучал среду, выбирал цель движения, строил план достижения этой цели и затем реализовал его, выполняя действия-шаги, сравнивая результаты, получаемые в ходе движения, с запланированными, дополняя и корректируя план в зависимости от складывающихся ситуаций”.
В своих работах Амосов предпринял попытку создать информационно/алгоритмическую модель как мы сейчас говорим “сильного интеллекта” и на мой взгляд, его теория наиболее близко описывает то, что реально происходит в мозге млекопитающих.
Основными особенностями М-сетей, кардинально отличающие их от других нейросетевых парадигм является строгая семантическая нагрузка каждого нейрона и наличие системы внутренней оценки своего состояния. Есть нейроны-рецепторы, нейроны-объекты, нейроны-чувства, нейроны-действия.
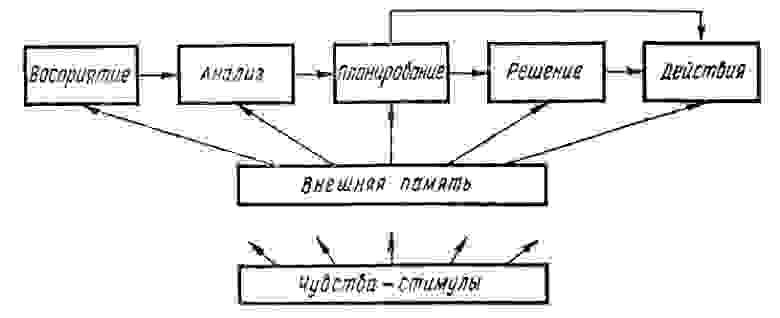
Обучение происходит по модифицированному правилу Хебба с учетом своего внутреннего состояния. Соответственно и принятие решения происходит на основе понятного распространения активности семантически обозначенных нейронов.
Сеть обучается «на лету», без многократного повторения. Одни и те же механизмы работают с различными видами информации будь то речь или восприятие визуальных данных, двигательная активность. Данная парадигма моделирует как работу сознания, так и подсознания.
Желающие смогут найти книги Амосова с более подробным описанием теории и практических реализаций различных аспектов интеллекта, я же расскажу про наш опыт построения визуальной поисковой системы Quintura Search.

Компания Quintura была создана в 2005-м году. На собственные деньги был реализован прототип десктопного приложения, демонстрирующего наш подход. На ангельские деньги Ратмира Тимашева и Андрея Баронова (позже фонд ABRT) была произведена доработка прототипа, проведены переговоры и получены инвестиции от люксембургского фонда Mangrove Capital Partners. Это была первая западная инвестиция в России в области ИТ. Все три партнера фонда приехали в Сергиев Посад посмотреть нам в глаза и принять решение об инвестировании.
На полученные средства за шесть лет был разработан полный функционал веб-поисковика — сбор информации, индексирование, обработка запросов и выдача результатов. Ядром была М-сеть, точнее множество М-сетей (одна понятийная сеть и сети для каждого документа). Сеть обучалась за один проход по документу. За пару-тройку тактов пересчета выделялись ключевые слова, находились документы совпадающие с запросом по смыслу, строились их аннотации. Сеть понимала контекст запроса, точнее позволяла пользователю уточнить его, добавляя нужные смыслы для поиска и удаляя из выдачи документы, имеющие нерелевантные контексты.
Как было отмечено выше, каждый нейрон сети имеет свою смысловую нагрузку. Для иллюстрации патентов, нами была предложена визуальная картинка (прошу извинить за качество – оригиналы картинок не сохранились, здесь и далее использованы картинки со сканов наших патентов и из статей о нас с различных сайтов):
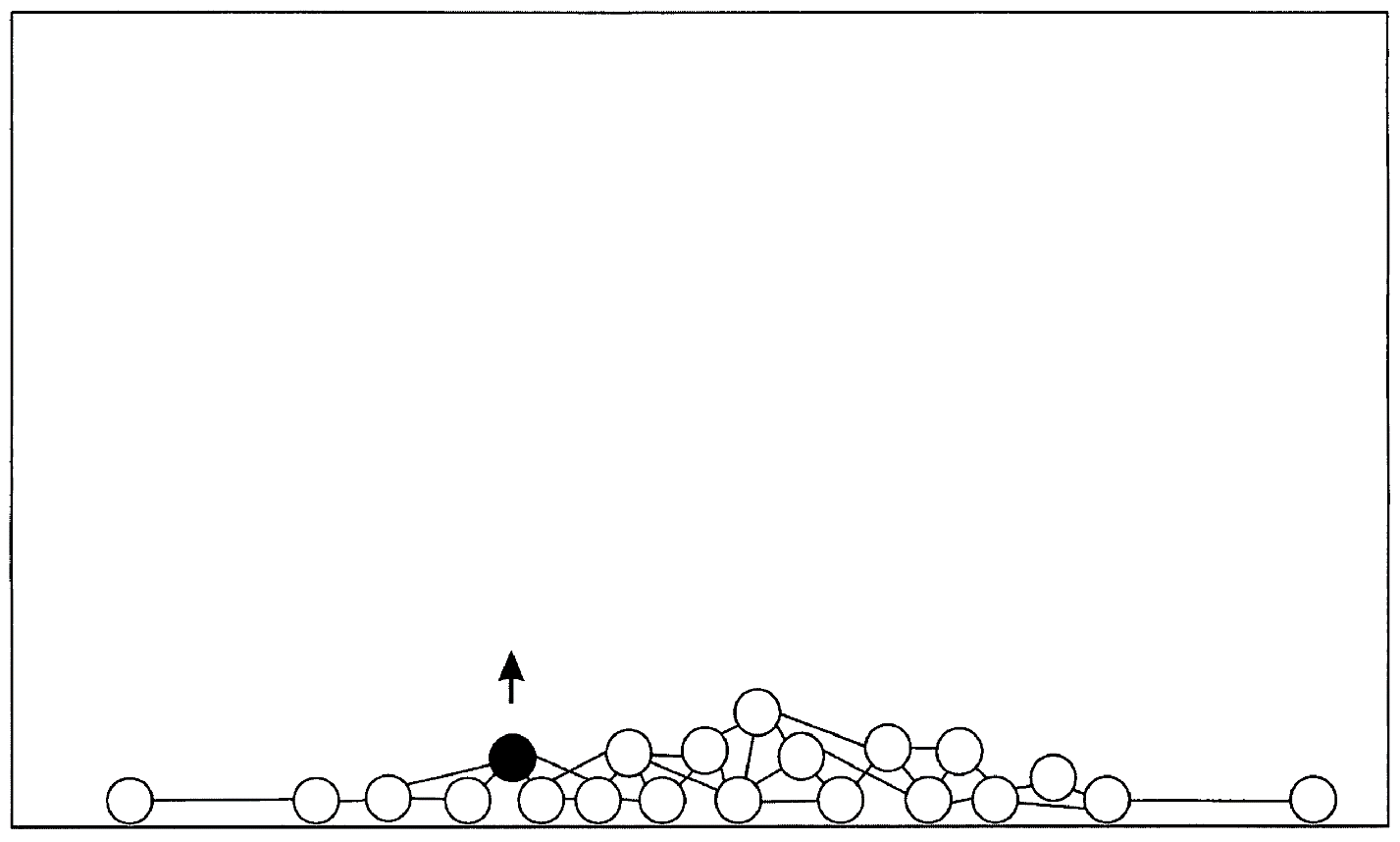
Упрощенно, понятийная сеть представляет собой набор нейронов-понятий связанных друг с другом связями, пропорционально частоте встречаемости их друг с другом. Когда пользователь вводит слово запроса, мы «вытягиваем» нейрон(нейроны) этого слова, а он, в свою очередь, тянет за собой связанные с ним. И чем сильнее связь, тем ближе будут к нейрону запроса другие нейроны.

Если слов в запросе несколько, то и «вытягивать» за собой будет все нейроны, соответствующие словам запроса.
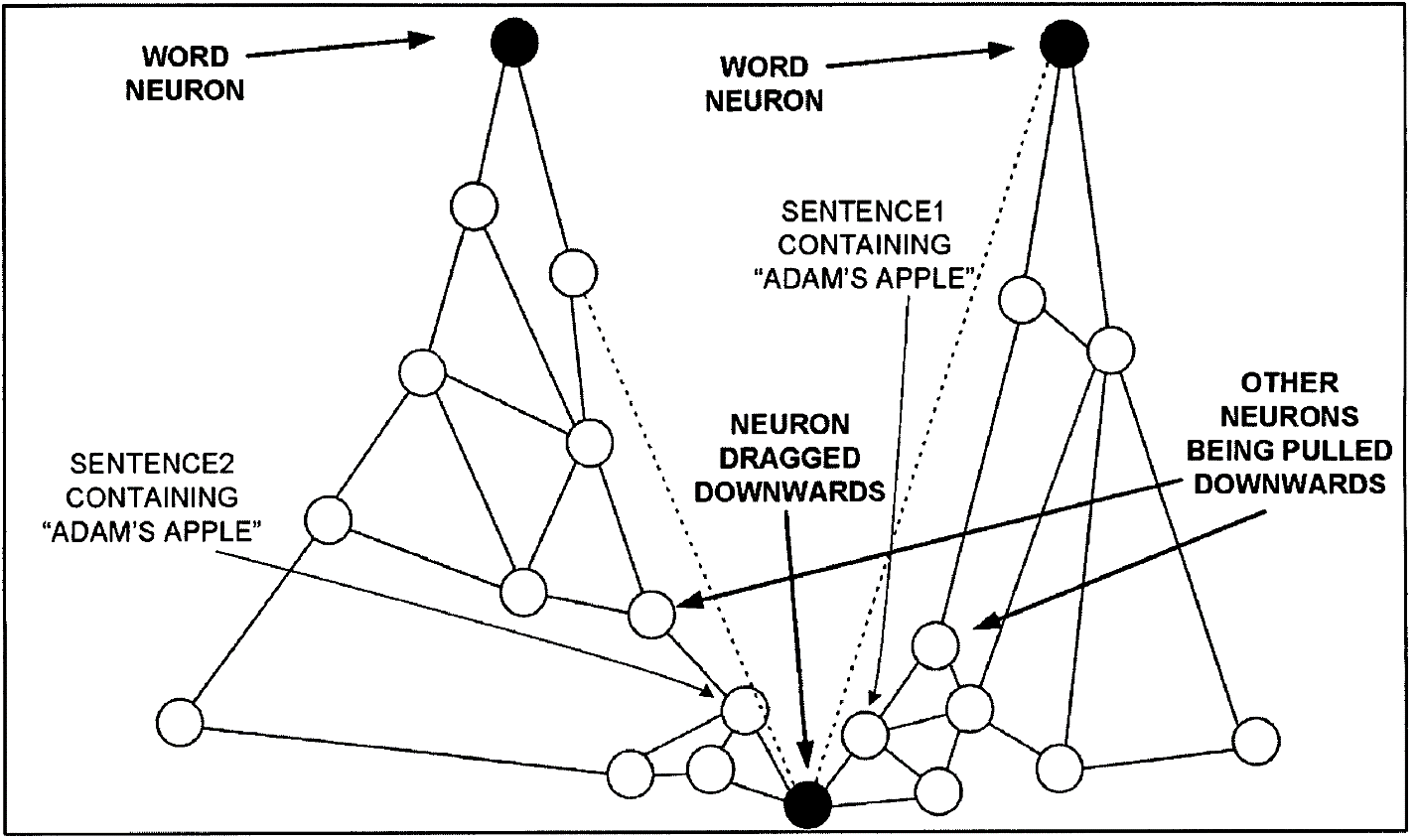
Если же мы решим удалить нерелевантное слово, мы как бы вешаем на него груз, тянущий вниз как удаляемое понятие, так и связанные с ним.
В результате мы получаем облако тегов, где слова запроса находятся наверху (самый крупный шрифт), а связанные понятия располагаются рядом, чем больше связь, тем крупнее шрифт.
Ниже смысловая карта документов, найденных по запросу «beauty».

При наведении мыши на слово «fashion» карта перестраивается:

Если перевести указатель мыши на слово «travel», получим другую карту:

Таким образом, мы можем уточнять запрос указывая нужное нам направление, формировать нужный нам контекст.
Одновременно с перестраиванием карты мы получаем и документы, которые наиболее релевантны заданному контексту, а ненужные ветки мы исключаем, удаляя нерелевантные слова.
Индекс документов мы строим по следующему принципу:
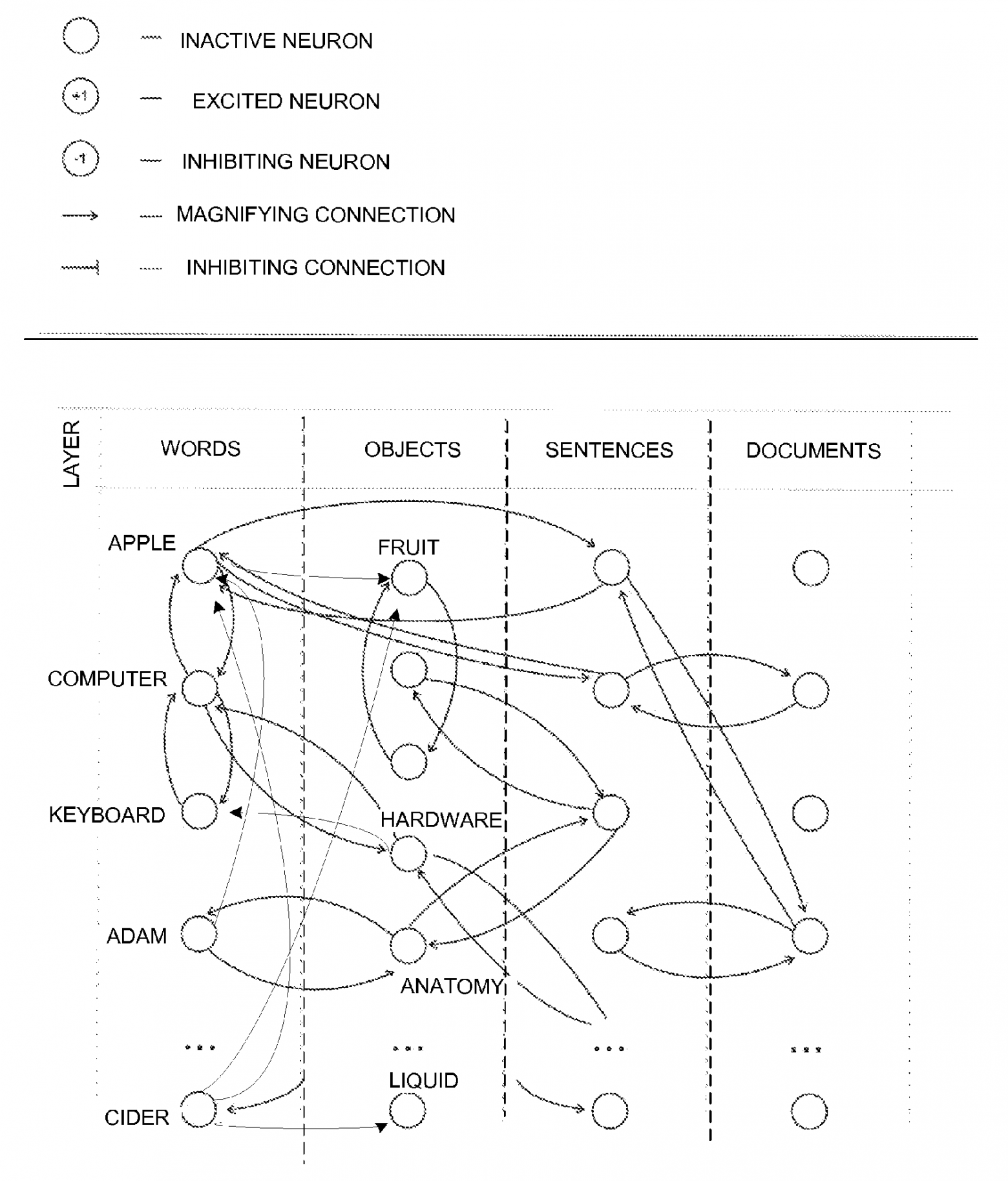
Существует 4 слоя нейронов. Слой слов, слой понятий (их можно объединить в один слой), слой предложений, слой документов.
Нейроны могут быть связаны между собой двумя типами связей – усиливающими и тормозными. Соответственно каждый нейрон может быть в трех типах состояний активном, нейтральном и подавленном. По усиливающим связям нейроны передают активность по сети, тормозными «якорят». Слой понятий полезен для работы с синонимами, а также выделения «сильных» или значимых понятий над остальными, определения категорий документа.
Например, слово Apple в слое слов будет связано с понятиями фрукта, анатомического термина и компании. Oil – с нефтью и маслом. Русское слово “коса” с прической, орудием труда, оружием, рельефом. И т.п.
Связи мы устанавливаем двунаправленные – как прямые, так и обратные. Обучение (изменения связей) происходит за один проход по документу на основе правила Хебба – мы увеличиваем связи между словами, располагающимися близко друг к другу, также, дополнительно связываем меньшими связями слова, находящиеся в одном предложении, абзаце, документе. Чем чаще слова встречаются рядом как в пределах одного документа, так и группы документов, тем больше становится связь между ними.
Данная архитектура позволяет эффективно решать следующие задачи:
Рассмотрим реализацию каждой задачи.
Этот кейс был проиллюстрирован ранее. Пользователь вводит слова запроса, эти слова возбуждают все связанные с ними, далее, мы можем либо выделить ближайшие понятия (имеющие максимальное возбуждение), либо и дальше передаем возбуждение по сети уже от всех возбужденных на предыдущем шаге нейронов и так далее – в этом случае начинают работать ассоциации. На карту выводятся некоторое количество самых возбужденных слов/понятий (также можно выбирать что показывать – слой слов, понятий, либо оба). При необходимости нерелевантные слова удаляются (удаляя с карты связанные с ними понятиями), тем самым производится точное описание требуемого поискового контекста.
Состояние первых двух слоев сети на этом шаге передают свое возбуждение на следующие слои, нейроны которых ранжируются по возбужденности и мы получаем список документов, ранжированных по релевантности не просто словам запроса, а сформированному контексту.
Таким образом, в выдачу попадут не только документы содержащие слова запроса но и связанные с ними по смыслу. Полученные документы можно использовать для изменения поискового контекста либо усиливая понятия, содержащиеся в «нужных» нам документах, либо понижая вес понятий, связанных с нерелевантными документам. Так можно легко и интуитивно уточнять запрос и управлять поисковой выдачей.
Передача возбуждения в обратную сторону, от нейронов-документов к нейронам понятиям/словам позволяет получить наглядную карту того, какие смысловые контексты присутствуют в наборе документов. Это альтернативный способ получения смысловой карты тегов и навигации в пространстве смыслов. Данный процесс можно выполнять итеративно меняя направление возбуждения – получая документы по поисковым контекстам, либо изменяя поисковый контекст по активным документам.
Обычно, сценарий работы поисковика следующий – начальная карта формируется либо на основе последних новостей, популярных статей, запросов или их комбинации. Далее пользователь может либо начать формировать запрос кликая на слова с карты, либо создав новый запрос введя интересующие его слова в поле ввода.
В нашем детском сервисе Quintura Kids могли работать и искать нужную информацию даже не умеющие писать дети (или имеющие затруднения с этим).
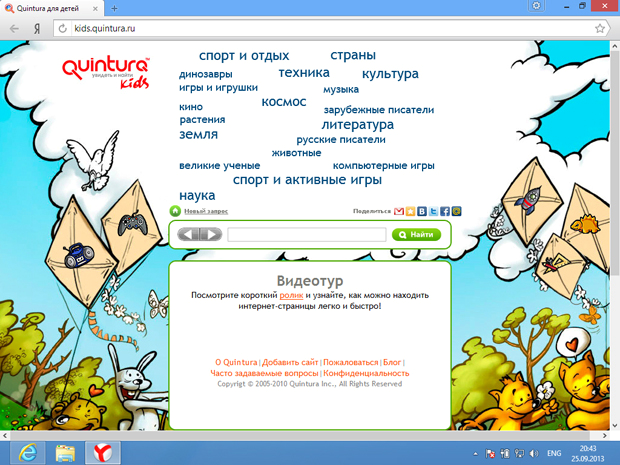
Так выглядела начальная карта
А это пользователь видел после клика на слово «Космос».
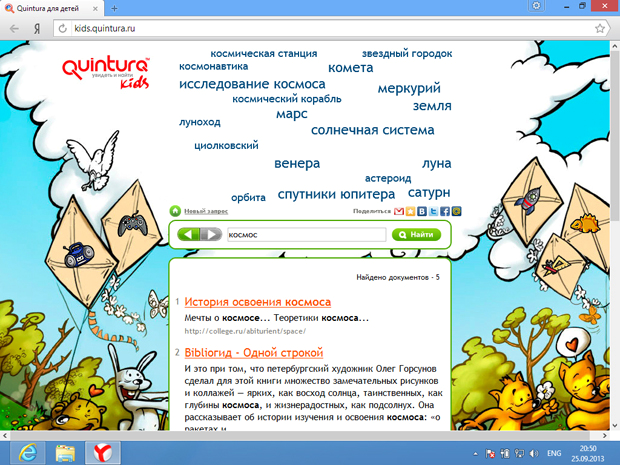
Детский сервис был построен на вручную отобранных и допущенных сайтах, поэтому ничего взрослого ребенок увидеть не мог. Этим объясняется и небольшое количество найденных документов. Англоязычная версия содержала в разы большее количество документов — спасибо детскому каталогу Yahoo.
Собственно те слова и понятия, которые становятся активными при передачи возбуждения от слоя документов или слоя предложений и являются ключевыми словами. Они также ранжируются по активности, далее от них отрезается определенное количество, которое и отображается.
Тут мы применили еще одно решение. Считаем, что суммарное возбуждение всех слов или понятий равно 100%. Тогда мы можем легко управлять количеством слов, которые будем считать ключевыми задавая процент активности в качестве порога.

Например, представим, что есть документ, в котором рассматривается контракт с хедлайнером Боинга. При передаче возбуждения от нейрона этого документа к слою слов/понятий возбудились слова, представленные на этом рисунке. Взвешенное суммарное возбуждение, приведенное к 100%, дало нам индивидуальный вес каждому слову. И если мы хотим получить 75% «смысла» ключевых слов, то мы увидим слова «BOEING», «787», «DREAMLINER», а если захотим увидеть 85% «смысла», то к этим словам добавиться еще и «SALES».
Этот способ позволяет автоматически ограничивать количество отображаемых ключевых слов и предложений/документов.
Получение сниппетов также осуществлялось вышеописанным способом. Сначала мы получаем ключевые слова документа, после чего прямым распространением возбуждения от ключевых слов получаем список предложений, приводим веса этих предложений к 100% и обрезаем требуемое количество «смысла», после чего отображаем эти предложения в той последовательности, в которой они встретились в тексте документа.
Передача возбуждения от нейрона, соответствующего документу для которого мы ищем похожие по смыслу к слою слов/понятий и после этого в обратную сторону к слою документов позволяет нам находить документы, похожие первоначальному по контексту или смыслу. Если мы сделаем несколько тактов передачи возбуждения в слое слов/понятий, мы можем расширить первоначальный контекст. В данном случае мы можем найти документы, которые не содержат точного совпадения по всем словам, но совпадают по теме.
На самом деле, данный механизм можно использовать для определения похожести чего угодно, например, добавив к сети слой где нейронам будет соответствовать идентификатор пользователя, мы можем находить людей, имеющих схожие интересы. Заменив слой предложений и документов на индексы музыкальных или видео произведений получим поиск музыки/видео.
В данной статье раскрыты лишь базовые принципы визуальной поисковой системы Quintura. За шесть лет жизни Компании было решено множество сложных задач, как связанных с архитектурой активных семантических нейросетей, так и в построении отказоустойчивого, расширяемого кластера. Поисковый индекс состоял из множества нейросетей, работающих параллельно, результат работы этих сетей объединялся, строилась индивидуальная карта интересов пользователя.
В рамках проекта был реализован сервис поиска по сайту, детский поисковик, инструмент для анализа текстов, начаты работы по формированию информационной онтологии мира, построению нейросетевой морфологии, получены 9 патентов США.
Однако, мы так и не смогли монетизировать нашу систему. На тот момент бума нейросетей еще не было, договориться с крупными поисковиками нам не удалось (как нам сказал архитектор одного из них – “у нас слишком разные парадигмы и мы не понимаем как их объединить”).
Проект пришлось закрыть.
Лично у меня так и осталась «недосказанность» — есть огромное желание дать вторую жизнь данному проекту. Информация о том, что бывший глава рекламы Google создает поисковик без рекламы, где пользователи смогут «вырваться из пузыря фильтров персонализации контента и инструментов слежения», лишь укрепляет мою уверенность в актуальности наших разработок.
Еще раз перечислю особенности активных нейронных сетей, построенных на основе теории Николая Амосова:
Надеюсь, данная статья станет первым шагом в открытии реализованных технологий для широкой общественности разработчиков и послужит началом opensource проекта активных семантических нейросетей Амосова.
Речь пойдет о визуальном поисковике, получившим первые западные венчурные инвестиции в области ИТ в России, построенном на основе активных семантических нейронных сетях. Под катом мы расскажем об его основных принципах работы и архитектуре.
Истоки
Мне крупно повезло в жизни – я учился у Николая Михайловича Амосова, выдающегося человека, кардиохирурга и кибернетика. Учился заочно — развал СССР не дал мне возможности встретиться лично.

О Николае Михайловиче можно говорить много, родился в крестьянской семье в деревеньке под Череповцом и при этом получил второе место в проекте «Великие украинцы» уступив первое место Ярославу Мудрому. Выдающийся кардиохирург и инженер-кибернетик, самостоятельно разработавший первый в СССР искусственный клапан. Его именем названы улицы, медицинское училище, колледж, курсирующий в Иваньковском водохранилище катер.
Об этом много написано и в Википедии, и на других сайтах.
Хочу затронуть не так широко освещенную сторону Амосова. Широкий кругозор, два образования (медицинское и инженерное) позволило ему разработать теорию активных семантических нейронных сетей (М-сетей), в рамках которой более 50-ти лет назад были реализованы вещи, которые и на сегодняшний день поражают своей уникальностью.
И если бы в то время были достаточные вычислительные мощности, возможно, сегодня бы уже был реализован сильный ИИ.
В своих работах Амосов сумел выдержать баланс между нейрофизиологией и математикой, изучая и описывая информационные процессы интеллекта. Результаты его работ представлены в нескольких трудах, заключительной была монография «Алгоритмы разума», изданная в 1979 году.
Приведу краткую цитату из нее об одной из моделей:
«…(нами) проводилось исследование, цель которого состояла в том, чтобы изучить возможности М-сетей в области нейрофизиологии и нейропсихологии, а также оценить практическую и познавательную важность таких моделей. Был разработан и исследован М-автомат, моделирующий механизмы речи. В модели представлены такие аспекты устной речи, как восприятие, осмысливание, словесное выражение.
Модель предназначена для воспроизведения относительно простых речевых функций (!!!) — ответов на вопросы ограниченного типа, повторения, называния. Она содержит следующие блоки: слуховых восприятий, сенсорный речевой, проприоцептивный речевой, понятийный, эмоций, мотивационный, двигательный речевой, артикуляторный и блок СУТ. Блоки модели соотнесены с определенными мозговыми образованиями…
… На вход модели подавались буквы русского алфавита, объединенные в слова и фразы, а также специальные объекты, соответствующие образам предметов. На выходе модели, в зависимости от режима ее работы, наблюдались последовательности букв русского алфавита, которые были либо ответами на входные вопросы, либо повторением входных слов, либо названиями предметов.
То обстоятельство, что при создании модели широко использовались данные нейрофизиологии, позволило в экспериментах имитировать ряд поражений мозга органического и функционального характера, приводящих к нарушениям функций речи».
И это лишь одна из работ.
Другая — управление мобильным роботом. “… система управления роботом предполагает осуществление целенаправленного движения с обеспечением собственной безопасности (объезд препятствий, избегание опасных мест, поддержание внутренних параметров в заданных пределах) и минимизацию временных и энергетических затрат”.

Также, в монографии описаны результаты моделирования свободного поведения “некоего субъекта в среде, которая содержала полезные и опасные для него объекты. Мотивы поведения субъекта определялись ощущениями усталости, голода и стремлением к самосохранению. Субъект изучал среду, выбирал цель движения, строил план достижения этой цели и затем реализовал его, выполняя действия-шаги, сравнивая результаты, получаемые в ходе движения, с запланированными, дополняя и корректируя план в зависимости от складывающихся ситуаций”.

Особенности теории
В своих работах Амосов предпринял попытку создать информационно/алгоритмическую модель как мы сейчас говорим “сильного интеллекта” и на мой взгляд, его теория наиболее близко описывает то, что реально происходит в мозге млекопитающих.
Основными особенностями М-сетей, кардинально отличающие их от других нейросетевых парадигм является строгая семантическая нагрузка каждого нейрона и наличие системы внутренней оценки своего состояния. Есть нейроны-рецепторы, нейроны-объекты, нейроны-чувства, нейроны-действия.

Обучение происходит по модифицированному правилу Хебба с учетом своего внутреннего состояния. Соответственно и принятие решения происходит на основе понятного распространения активности семантически обозначенных нейронов.
Сеть обучается «на лету», без многократного повторения. Одни и те же механизмы работают с различными видами информации будь то речь или восприятие визуальных данных, двигательная активность. Данная парадигма моделирует как работу сознания, так и подсознания.
Желающие смогут найти книги Амосова с более подробным описанием теории и практических реализаций различных аспектов интеллекта, я же расскажу про наш опыт построения визуальной поисковой системы Quintura Search.
Quintura

Компания Quintura была создана в 2005-м году. На собственные деньги был реализован прототип десктопного приложения, демонстрирующего наш подход. На ангельские деньги Ратмира Тимашева и Андрея Баронова (позже фонд ABRT) была произведена доработка прототипа, проведены переговоры и получены инвестиции от люксембургского фонда Mangrove Capital Partners. Это была первая западная инвестиция в России в области ИТ. Все три партнера фонда приехали в Сергиев Посад посмотреть нам в глаза и принять решение об инвестировании.
На полученные средства за шесть лет был разработан полный функционал веб-поисковика — сбор информации, индексирование, обработка запросов и выдача результатов. Ядром была М-сеть, точнее множество М-сетей (одна понятийная сеть и сети для каждого документа). Сеть обучалась за один проход по документу. За пару-тройку тактов пересчета выделялись ключевые слова, находились документы совпадающие с запросом по смыслу, строились их аннотации. Сеть понимала контекст запроса, точнее позволяла пользователю уточнить его, добавляя нужные смыслы для поиска и удаляя из выдачи документы, имеющие нерелевантные контексты.
Основные принципы и подходы
Как было отмечено выше, каждый нейрон сети имеет свою смысловую нагрузку. Для иллюстрации патентов, нами была предложена визуальная картинка (прошу извинить за качество – оригиналы картинок не сохранились, здесь и далее использованы картинки со сканов наших патентов и из статей о нас с различных сайтов):

Упрощенно, понятийная сеть представляет собой набор нейронов-понятий связанных друг с другом связями, пропорционально частоте встречаемости их друг с другом. Когда пользователь вводит слово запроса, мы «вытягиваем» нейрон(нейроны) этого слова, а он, в свою очередь, тянет за собой связанные с ним. И чем сильнее связь, тем ближе будут к нейрону запроса другие нейроны.

Если слов в запросе несколько, то и «вытягивать» за собой будет все нейроны, соответствующие словам запроса.

Если же мы решим удалить нерелевантное слово, мы как бы вешаем на него груз, тянущий вниз как удаляемое понятие, так и связанные с ним.
В результате мы получаем облако тегов, где слова запроса находятся наверху (самый крупный шрифт), а связанные понятия располагаются рядом, чем больше связь, тем крупнее шрифт.
Ниже смысловая карта документов, найденных по запросу «beauty».

При наведении мыши на слово «fashion» карта перестраивается:

Если перевести указатель мыши на слово «travel», получим другую карту:

Таким образом, мы можем уточнять запрос указывая нужное нам направление, формировать нужный нам контекст.
Одновременно с перестраиванием карты мы получаем и документы, которые наиболее релевантны заданному контексту, а ненужные ветки мы исключаем, удаляя нерелевантные слова.
Индекс документов мы строим по следующему принципу:

Существует 4 слоя нейронов. Слой слов, слой понятий (их можно объединить в один слой), слой предложений, слой документов.
Нейроны могут быть связаны между собой двумя типами связей – усиливающими и тормозными. Соответственно каждый нейрон может быть в трех типах состояний активном, нейтральном и подавленном. По усиливающим связям нейроны передают активность по сети, тормозными «якорят». Слой понятий полезен для работы с синонимами, а также выделения «сильных» или значимых понятий над остальными, определения категорий документа.
Например, слово Apple в слое слов будет связано с понятиями фрукта, анатомического термина и компании. Oil – с нефтью и маслом. Русское слово “коса” с прической, орудием труда, оружием, рельефом. И т.п.
Связи мы устанавливаем двунаправленные – как прямые, так и обратные. Обучение (изменения связей) происходит за один проход по документу на основе правила Хебба – мы увеличиваем связи между словами, располагающимися близко друг к другу, также, дополнительно связываем меньшими связями слова, находящиеся в одном предложении, абзаце, документе. Чем чаще слова встречаются рядом как в пределах одного документа, так и группы документов, тем больше становится связь между ними.
Данная архитектура позволяет эффективно решать следующие задачи:
- задание и управление поисковым контекстом;
- поиск документов, соответствующих поисковому контексту (не только содержащих слов запроса);
- отображение смысловые контексты набора документов (какие ассоциации у поисковика со словами запроса);
- выделение ключевых слов документа/документов;
- аннотирование документа;
- поиск похожих по смыслам документов.
Рассмотрим реализацию каждой задачи.
Задание и управление поисковым контекстом
Этот кейс был проиллюстрирован ранее. Пользователь вводит слова запроса, эти слова возбуждают все связанные с ними, далее, мы можем либо выделить ближайшие понятия (имеющие максимальное возбуждение), либо и дальше передаем возбуждение по сети уже от всех возбужденных на предыдущем шаге нейронов и так далее – в этом случае начинают работать ассоциации. На карту выводятся некоторое количество самых возбужденных слов/понятий (также можно выбирать что показывать – слой слов, понятий, либо оба). При необходимости нерелевантные слова удаляются (удаляя с карты связанные с ними понятиями), тем самым производится точное описание требуемого поискового контекста.
Поиск документов, соответствующих поисковому контексту
Состояние первых двух слоев сети на этом шаге передают свое возбуждение на следующие слои, нейроны которых ранжируются по возбужденности и мы получаем список документов, ранжированных по релевантности не просто словам запроса, а сформированному контексту.
Таким образом, в выдачу попадут не только документы содержащие слова запроса но и связанные с ними по смыслу. Полученные документы можно использовать для изменения поискового контекста либо усиливая понятия, содержащиеся в «нужных» нам документах, либо понижая вес понятий, связанных с нерелевантными документам. Так можно легко и интуитивно уточнять запрос и управлять поисковой выдачей.
Отображение смысловых контекстов набора документов
Передача возбуждения в обратную сторону, от нейронов-документов к нейронам понятиям/словам позволяет получить наглядную карту того, какие смысловые контексты присутствуют в наборе документов. Это альтернативный способ получения смысловой карты тегов и навигации в пространстве смыслов. Данный процесс можно выполнять итеративно меняя направление возбуждения – получая документы по поисковым контекстам, либо изменяя поисковый контекст по активным документам.
Обычно, сценарий работы поисковика следующий – начальная карта формируется либо на основе последних новостей, популярных статей, запросов или их комбинации. Далее пользователь может либо начать формировать запрос кликая на слова с карты, либо создав новый запрос введя интересующие его слова в поле ввода.
В нашем детском сервисе Quintura Kids могли работать и искать нужную информацию даже не умеющие писать дети (или имеющие затруднения с этим).

Так выглядела начальная карта
А это пользователь видел после клика на слово «Космос».

Детский сервис был построен на вручную отобранных и допущенных сайтах, поэтому ничего взрослого ребенок увидеть не мог. Этим объясняется и небольшое количество найденных документов. Англоязычная версия содержала в разы большее количество документов — спасибо детскому каталогу Yahoo.
Выделение ключевых слов документа/документов
Собственно те слова и понятия, которые становятся активными при передачи возбуждения от слоя документов или слоя предложений и являются ключевыми словами. Они также ранжируются по активности, далее от них отрезается определенное количество, которое и отображается.
Тут мы применили еще одно решение. Считаем, что суммарное возбуждение всех слов или понятий равно 100%. Тогда мы можем легко управлять количеством слов, которые будем считать ключевыми задавая процент активности в качестве порога.

Например, представим, что есть документ, в котором рассматривается контракт с хедлайнером Боинга. При передаче возбуждения от нейрона этого документа к слою слов/понятий возбудились слова, представленные на этом рисунке. Взвешенное суммарное возбуждение, приведенное к 100%, дало нам индивидуальный вес каждому слову. И если мы хотим получить 75% «смысла» ключевых слов, то мы увидим слова «BOEING», «787», «DREAMLINER», а если захотим увидеть 85% «смысла», то к этим словам добавиться еще и «SALES».
Этот способ позволяет автоматически ограничивать количество отображаемых ключевых слов и предложений/документов.
Аннотирование документа.
Получение сниппетов также осуществлялось вышеописанным способом. Сначала мы получаем ключевые слова документа, после чего прямым распространением возбуждения от ключевых слов получаем список предложений, приводим веса этих предложений к 100% и обрезаем требуемое количество «смысла», после чего отображаем эти предложения в той последовательности, в которой они встретились в тексте документа.
Поиск похожих по смыслу документов
Передача возбуждения от нейрона, соответствующего документу для которого мы ищем похожие по смыслу к слою слов/понятий и после этого в обратную сторону к слою документов позволяет нам находить документы, похожие первоначальному по контексту или смыслу. Если мы сделаем несколько тактов передачи возбуждения в слое слов/понятий, мы можем расширить первоначальный контекст. В данном случае мы можем найти документы, которые не содержат точного совпадения по всем словам, но совпадают по теме.
На самом деле, данный механизм можно использовать для определения похожести чего угодно, например, добавив к сети слой где нейронам будет соответствовать идентификатор пользователя, мы можем находить людей, имеющих схожие интересы. Заменив слой предложений и документов на индексы музыкальных или видео произведений получим поиск музыки/видео.
Продолжение следует
В данной статье раскрыты лишь базовые принципы визуальной поисковой системы Quintura. За шесть лет жизни Компании было решено множество сложных задач, как связанных с архитектурой активных семантических нейросетей, так и в построении отказоустойчивого, расширяемого кластера. Поисковый индекс состоял из множества нейросетей, работающих параллельно, результат работы этих сетей объединялся, строилась индивидуальная карта интересов пользователя.
В рамках проекта был реализован сервис поиска по сайту, детский поисковик, инструмент для анализа текстов, начаты работы по формированию информационной онтологии мира, построению нейросетевой морфологии, получены 9 патентов США.
Однако, мы так и не смогли монетизировать нашу систему. На тот момент бума нейросетей еще не было, договориться с крупными поисковиками нам не удалось (как нам сказал архитектор одного из них – “у нас слишком разные парадигмы и мы не понимаем как их объединить”).
Проект пришлось закрыть.
Лично у меня так и осталась «недосказанность» — есть огромное желание дать вторую жизнь данному проекту. Информация о том, что бывший глава рекламы Google создает поисковик без рекламы, где пользователи смогут «вырваться из пузыря фильтров персонализации контента и инструментов слежения», лишь укрепляет мою уверенность в актуальности наших разработок.
Еще раз перечислю особенности активных нейронных сетей, построенных на основе теории Николая Амосова:
- обучение на лету;
- добавление новых сущностей без необходимости переобучения всей сети;
- четкая семантика – понятно почему сеть приняла то или иное решение;
- единая архитектура сети для различных областей применения;
- простая архитектура, как следствие — высокое быстродействие.
Надеюсь, данная статья станет первым шагом в открытии реализованных технологий для широкой общественности разработчиков и послужит началом opensource проекта активных семантических нейросетей Амосова.








