Комментарии 24
совет сохранять хэши перебранных ранее вариантов…
Вызывает удивление как этот факт, так и выбранные структуры данных. Два new List и new Element на каждый чих (т.е. примерно 20*20*8^4 раз) вводят меня в ступор, честно говоря (надеюсь, компилятор их соптимизирует)
Искал оптимизацию полного перебора, хотя бы тупое отсечение по нехватке миллиона на умножение текущего элемента для превышения текущего максимума. Так как все числа меньше 100, если текущий максимум превышает 50 00 00 00, или 50 миллионов, пропускать элементы со значением 50 или ниже.
Ещё — ваш метод GetFactorCombinations не позволяет цепочки в форме ромба, т.е. перебор ещё и неполон. Цепочка в форме ромба — от стартового элемента вниз-вправо, вниз-влево, вверх-влево.
Так как все числа меньше 100, если текущий максимум превышает 50 00 00 00, или 50 миллионов, пропускать элементы со значением 50 или ниже.
И это действительно дельный совет. То есть, максимально возможный результат произведения это 100*100*100*100 = 100 000 000. Если комбинация со значением произведения уже равна 80 000 000 можно игнорировать все числа меньше 80. Возьму на вооружение
На счет цепочки в форме ромба. Только что проверил, их он тоже учитывает.
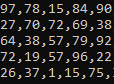
гляньте на число 78 нулевая строка, первый столбец.

Хмм, рекурсивный, кажется, полный, а вот итеративный — нет. Разве что у меня глазной дебаггер заглючил :)
А когда ищете четвёртого соседа, то можно не всех найденных добавлять, а максимального из соседей, чтобы не делать лишние умножения потом, по всем найденным комбинациям.
PS — идея абсолютно не протестирована ).
Нули там встречаются, хотя идея вполне здравая, просто вместо логарифма нуля пихать логарифм от одной стомиллионной, чтобы заведомо не вошел никуда. А ядра conv2d — видимо, варианты расположения цепочки при фиксированном первом элементе, правильно?
О-ох, забыл я уже высшую математику. По мне, тут тензор будет перебором, тут хватит пиксельного шейдера, суммирующего текущий элемент матрицы с элементами цепочки, начинающейся в нем, конкретной формы. Форм ограниченное количество, и шейдеров таких можно сгенерировать по одному на форму, потом только выбирай максимум. Перебор все равно будет по факту полным, зато массивно-параллельным.
Если оптимизировать для длины 4, то можно было бы вычислить в отдельный массив результат умножения пары чисел (4 варианта для каждой ячейки — вправо, вниз, вниз-влево, вниз-вправо), и затем перебирать уже пары для этого нового массива. Причем перебирать не все пары "пар", а только те, которые дают цепочку, подходящую под задание (скажем, "вниз" от текущей ячейки умножить на "вправо" от ячейки вниз-вправо), и без дублирования "фигур". Есть необоснованное подозрение, что в таком случае получим оптимальное число операций умножения. Кроме того, необязательно вычислять весь массив пар сразу — достаточно вычислить 3 строки массива для 4 строк исходных данных, поискать фигуры в них, и потом для каждой строки данных отбрасывать верхнюю строку массива и вычислять одну новую.
UPD: я подумал еще раз и понял, что сильно быстрее не станет, извиняюсь.
Я применил некоторые оптимизации, результат ускоряется очень сильно. Понятно, что 20x20 будет работать быстро и без опnимизаций, поэтому я мерил производительность на двух случаях: 1) матрица 10,000x10,000, заполненная случайными значениями, и 2) матрица 1,000x1,000, заполненная «наихудшими» значениями так, чтобы максимальное произведение четырех соседних элементов было в самом конце.
Без оптимизаций первый вариант я не дождался, когда закончит вычисления, а второй вариант — 30 секунд.
Оптимизация, которую нашел vesper-bot, — пропускать числа, умножение которых на 99*99*99 будет меньше уже найденного результата, улучшает сильнее всего — «случайный» вариант ускоряется до 8 секунд, наихудший — никак не ускоряется (так как я специально подбирал для него значения!)
Кроме этого, если текущее значение = 99*99*99*99, то можно дальше не искать, так как это максимально возможный результат. Это ускоряет случайный вариант до 6 секунд.
Далее, так как перебирать всех соседей всех клеток на каждом шаге дорого, то до начала работы можно вычислить уникальные пути из четырех клеток. Их оказалось всего 102. Это ускоряет случайный вариант до 3 секунд, а наихудший — с 30 до 2 секунд.
При этом в случайном варианте заполнение матрицы случайными значениями занимает больше времени, чем решение задачи. Поэтому последня оптимизация — не создавать всю матрицу с нуля, а создать первые 4 строчки, а потом сдвигать их вверх, вычисляя четвертую строчку на каждом шаге. Также, на данном этапе проверка выхода за границу матрицы уже дает ощутимый вклад, поэтому еще одна оптимизация — расширить матрицу на три клетки во все стороны, заполненные нулями. Это ускоряет случайный вариант до 0.2 секунд, а наихудший — до 1 секунды, больше я ускорить не смог. Еще я проверил идею заменить произведение суммой логарифмов, но особо результат не ускорился (но и не замедлился).
Интересно, что хотя сложность задачи совершенно явно O(n*n), но для случайной матрицы, если она достаточно большая, рано или поздно найдется максимальное произведение (99*99*99*99), и дальше можно будет не искать. Учитывая, что оптимизированная версия создает матрицу построчно, скорость работы в среднем случае для случайной матрицы, похоже, будет O(n). Именно поэтому «случайный» вариант работает в 10 раз быстрее на большей матрице.
Найти комбинацию соседних чисел, имеющих самое большое произведение