Комментарии 21
Overhead меряли? Что с другими архитектурами?
Эксперименты показали, что malloc работает не так уж медленно:
Windows x64:

Linux x64:
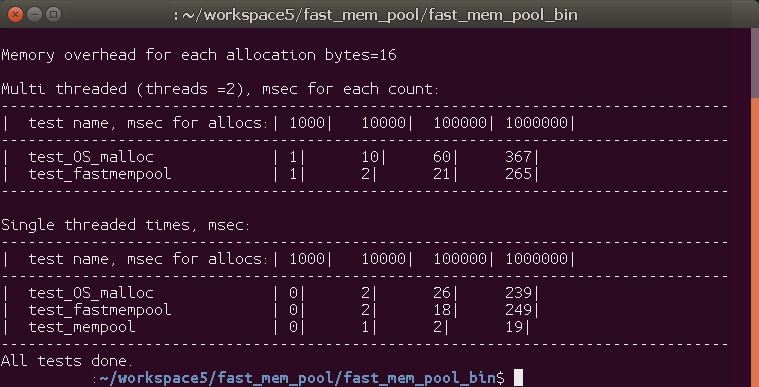
Всех быстрее однопоточный MemPool (это тот же FastMemPool в котором убрал atomic операции). В многопоточной работе FastMemPool позволил добиться кратного роста производительности + в нём же ещё есть фишки для контроля выхода за пределы аллокации… некая польза есть…
Сам тест тут test_overhead.cpp
Windows x64:

Linux x64:

Всех быстрее однопоточный MemPool (это тот же FastMemPool в котором убрал atomic операции). В многопоточной работе FastMemPool позволил добиться кратного роста производительности + в нём же ещё есть фишки для контроля выхода за пределы аллокации… некая польза есть…
Сам тест тут test_overhead.cpp
«Что с другими архитектурами?» — у меня была возможность на ARM померить:

Исходник теста тут: FastMemPool on Android

Исходник теста тут: FastMemPool on Android
Если я не ошибаюсь, то стандарт не регламентирует реализацию std::atomic.
В случае если CPU не предоставляет специальных атомарных инструкций, то std::atomic может быть реализован при помощи std::mutex.
Так что технически Ваша реализация может на 99% lock-free, но не на 100%.
В случае если CPU не предоставляет специальных атомарных инструкций, то std::atomic может быть реализован при помощи std::mutex.
Так что технически Ваша реализация может на 99% lock-free, но не на 100%.
Для гарантии можно использовать static_assert на std::atomic::is_always_lock_free.
https://en.cppreference.com/w/cpp/atomic/atomic/is_always_lock_free
В общем — не плохо.
А если конкретную задачу решать — 16 потоков, кадры с камер(ы?),
то я бы ограничился контролем за счетчиком выделенной памяти в каждом потоке, например, так:
Выделение-освобождение памяти это ведь операция, над которой хотелось бы не задумываться (в идеале), поэтому… из преимуществ остается только первое, но его можно добиться и проще (и то стоит заморачиваться, только если это действительно нужно).
А если конкретную задачу решать — 16 потоков, кадры с камер(ы?),
то я бы ограничился контролем за счетчиком выделенной памяти в каждом потоке, например, так:
const size_t BUFF_SZ = 10000;
vector<byte> buffer(BUFF_SZ);
size_t bufCPos = 0; // в каждом потоке свой буфер, поэтому без atomic
byte* popMem(size_t frameSz){
if (bufCPos + frameSz > BUFF_SZ){
return nullptr; // памяти не хватает - пропускаем кадр
}
bufCPos += frameSz;
return buffer.data() + (bufCPos - frameSz);
}
void pushMem(size_t frameSz){
bufCPos -= frameSz;
}
Выделение-освобождение памяти это ведь операция, над которой хотелось бы не задумываться (в идеале), поэтому… из преимуществ остается только первое, но его можно добиться и проще (и то стоит заморачиваться, только если это действительно нужно).
камера отдаёт кадры в своём потоке, кадры аллоцированны в потоке камеры из буфера камеры который тормозит камеру от того чтобы съесть всю RAM на компьютере — как потокам_обработчикам вернуть память кадров обратно в буфер камеры после того как они закончат обработку?
Как то так бы делал:
Память пусть в потоке камеры остается.
Камера в своем потоке циклически записывает кадры в свой буфер (состоит из структур типа — {frame, flag}) и пишет флаг для каждой позиции — «кадр обновлен».
В рабочем потоке (одном из) бежать по буферу камеры, искать обновленный кадр, его брать себе — копируя в свою память, флаг менять — «кадр взят в работу».
Камера может обновить кадр, только если в этой позиции стоит флаг «взят в работу». Если нет таких, то есть все потоки заняты, то пропускает этот кадр.
Память пусть в потоке камеры остается.
Камера в своем потоке циклически записывает кадры в свой буфер (состоит из структур типа — {frame, flag}) и пишет флаг для каждой позиции — «кадр обновлен».
В рабочем потоке (одном из) бежать по буферу камеры, искать обновленный кадр, его брать себе — копируя в свою память, флаг менять — «кадр взят в работу».
Камера может обновить кадр, только если в этой позиции стоит флаг «взят в работу». Если нет таких, то есть все потоки заняты, то пропускает этот кадр.
Насколько реальным считаете выполнение аналогичной задачи с помощью нескольких камер и мультистерео? При том, что освещение листов было бы идеально настроено.
опыт показывает что идеального освещения не бывает — для каждого вида детектора приходится колдовать с освещением… мультистерео — это для съёмки спецэффектов в кино?
Но ведь освещение проще поставить, если уж собираются данные с помощью лазерного сканера?
Мультистерео — восстановление картинки с нескольких камер.
Например, по двум изображеням восстановить карту глубины и по ней Z-координату, например. Можно использовать и 3 картинки с разных камер, а можно и еще больше.
Можно и одну камеру, а сдвигать только лист. Тем самым можно получить объемное изображение листа. Но точность будет относительная.
Кстати, а можно примеры изображений листа и той модели, что получаете по итогу?
Мультистерео — восстановление картинки с нескольких камер.
Например, по двум изображеням восстановить карту глубины и по ней Z-координату, например. Можно использовать и 3 картинки с разных камер, а можно и еще больше.
Можно и одну камеру, а сдвигать только лист. Тем самым можно получить объемное изображение листа. Но точность будет относительная.
Кстати, а можно примеры изображений листа и той модели, что получаете по итогу?
Получаем карту из uint16_t где каждое значение коррелирует с высотой = карта высот. Визуализировать можно по разному — основная сложность в том что градаций серого/цвета на экране всего 256 => либо идёшь окном визуализации по диапазону высот, либо всё ужимаешь в 256 делением теряя детали. Для Детектора это не имеет значения так как он работает с raw uint16_t (т.е. какая картинка в RGB\BGR ему не важно). Видим все изломы/вмятины/неровности поверхности — это и является результатом детекции. Конкурентные иностранные подобные решения работают с очень небольшой площадью и стоят очень дорого.
В этом куске кода
Что будет, если после compare_exchange_strong поток «зависнет» (планировщик потоков ос например отдаст ядро комуто другому) и в этот момент другие потоки продолжат пользоваться этим листом, забирая и возвращая куски памяти?
if (deallocated == (Leaf_Size_Bytes - available))
{ // everything that was allocated is now returned, we will try, carefully, reset the Leaf
if (leaf_array[head->leaf_id].available.compare_exchange_strong(available, Leaf_Size_Bytes))
{
leaf_array[head->leaf_id].deallocated -= deallocated;
}
}Что будет, если после compare_exchange_strong поток «зависнет» (планировщик потоков ос например отдаст ядро комуто другому) и в этот момент другие потоки продолжат пользоваться этим листом, забирая и возвращая куски памяти?
Ничего страшного:
все возможности для неадекватного поведения закрыты согласно en.cppreference.com/w/cpp/atomic/memory_order
// тут все синхронизировались и узнают что было вычитание:
const int deallocated = leaf_array[head->leaf_id].deallocated.fetch_add(real_size, std::memory_order_acq_rel) + real_size;
int available = leaf_array[head->leaf_id].available.load(std::memory_order_acquire);
if (deallocated == (Leaf_Size_Bytes - available))
{ // everything that was allocated is now returned, we will try, carefully, reset the Leaf
if (leaf_array[head->leaf_id].available.compare_exchange_strong(available, Leaf_Size_Bytes))
{
// Это самая жёсткая синхронизация потому как "The default behavior of all atomic operations in the library provides for sequentially consistent ordering":
leaf_array[head->leaf_id].deallocated -= deallocated;
}
}
все возможности для неадекватного поведения закрыты согласно en.cppreference.com/w/cpp/atomic/memory_order
Нет, дело не в memory order, а в простой логике.
Например (это только один из примеров, думаю можно найти больше)
1) Мы дошли до последней строчки этого кода, не успев ее выполнить и «зависли»
2) При этом available у нас уже сброшено в Leaf_size
3) Какойто поток приходит, видит что в available чтото есть, берет память и отдает.
4) Потом опять берет много-много (всю память) и всю ее отдает обратно. В результате available == 0, а в deallocated 2 * Leaf_Size_Bytes, мы не проходим проверку if (deallocated == (Leaf_Size_Bytes — available)) и выходим из этого куска кода
5) Просыпается наш зависший поток, и производит уменьшение. В результате deallocated == Leaf_Size_Bytes
6) Никто не может взять новый кусок памяти, так как available == 0
7) Никто не может войти в этот кусок кода, так как для того чтобы сюда войти, нужно выполнить освобождение, а освобождать нечего, так как никто ничего не может взять
Например (это только один из примеров, думаю можно найти больше)
1) Мы дошли до последней строчки этого кода, не успев ее выполнить и «зависли»
2) При этом available у нас уже сброшено в Leaf_size
3) Какойто поток приходит, видит что в available чтото есть, берет память и отдает.
4) Потом опять берет много-много (всю память) и всю ее отдает обратно. В результате available == 0, а в deallocated 2 * Leaf_Size_Bytes, мы не проходим проверку if (deallocated == (Leaf_Size_Bytes — available)) и выходим из этого куска кода
5) Просыпается наш зависший поток, и производит уменьшение. В результате deallocated == Leaf_Size_Bytes
6) Никто не может взять новый кусок памяти, так как available == 0
7) Никто не может войти в этот кусок кода, так как для того чтобы сюда войти, нужно выполнить освобождение, а освобождать нечего, так как никто ничего не может взять
Вот я и пишу, что ничего страшного: никто не начал работать с деаллоцированными страницами — просто из пула выбыл один лист. Кроме этого вероятность описанной Вами драмы крайне мала:
Кто-то должен суметь успеть между compare_exchange_strong и следующей операцией sequentially consistent ordering(которая всех тормозит и выравнивает) сделать следующее:
1) Получить кусок памяти и зафиксироваться в available сделав минимум 2 atomic операции
2) Не совершая никакой полезной работы сразу пойти возвращать полученную память (добавление вызова в call stack, проверки аллокации всякой математикой)
3) Сделать ещё 2 atomic вызова получив текущие deallocated и available,
и при этом обогнать того кто ещё до пп1) стоит всё ждёт со своим sequentially consistent ordering (на deallocated -= deallocated; )
Конечно в бесконечной вселенной на бесконечном отрезке времени любую ненулевую вероятность если умножить на бесконечность — то мы получим гарантированное событие, но на этой же бесконечности ещё столько других багов — что потеря одного листа памяти из пула это самое безобидное что может произойти в этой жизни…
Кто-то должен суметь успеть между compare_exchange_strong и следующей операцией sequentially consistent ordering(которая всех тормозит и выравнивает) сделать следующее:
1) Получить кусок памяти и зафиксироваться в available сделав минимум 2 atomic операции
2) Не совершая никакой полезной работы сразу пойти возвращать полученную память (добавление вызова в call stack, проверки аллокации всякой математикой)
3) Сделать ещё 2 atomic вызова получив текущие deallocated и available,
и при этом обогнать того кто ещё до пп1) стоит всё ждёт со своим sequentially consistent ordering (на deallocated -= deallocated; )
Конечно в бесконечной вселенной на бесконечном отрезке времени любую ненулевую вероятность если умножить на бесконечность — то мы получим гарантированное событие, но на этой же бесконечности ещё столько других багов — что потеря одного листа памяти из пула это самое безобидное что может произойти в этой жизни…
...
template<class T, class FAllocator = FastMemPoolNull >
struct FastMemPoolAllocator : public std::allocator<T>
...
std::unordered_map<int, int> umap2(1024, std::hash<int>(), std::equal_to<int>(), FastMemPoolAllocator<std::pair<const int, int>>());
так лучше не делать, в c++17 не просто так задеприкейтили половину функций в std::allocator
в конструкторе unordered_map происхоит усечение до std::allocator, в котором нет ни одной виртуальной функции
см.
en.cppreference.com/w/cpp/memory/allocator_traits
если уж хочется от чего-то унаследоваться см.
en.cppreference.com/w/cpp/memory/memory_resource
en.cppreference.com/w/cpp/memory/polymorphic_allocator
Спасибо за комментарий.
Шаблоны в работе использую достаточно редко, когда реально какой-то код типовой… пробелы есть.
Почитал про std::pmr::polymorphic_allocator, кажется штука полезная если есть проблемы с сопоставлением типов разных контейнеров…
Можете привести пример из жизни — как (и какие) изменения в шаблоне FastMemPoolAllocator
могли бы решить решить какую-то реальную задачу?
Шаблоны в работе использую достаточно редко, когда реально какой-то код типовой… пробелы есть.
Почитал про std::pmr::polymorphic_allocator, кажется штука полезная если есть проблемы с сопоставлением типов разных контейнеров…
Можете привести пример из жизни — как (и какие) изменения в шаблоне FastMemPoolAllocator
могли бы решить решить какую-то реальную задачу?
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
C++ template аллокатора с потокобезопасным циклическим буфером