Комментарии 89
Ведь ни один из существующих сервисов не позволяет быстро понять насколько подходит тебе кандидат, нельзя создать сложные фильтры именно по конкретным навыкам, проектам и позициям или исключающие определенные навыки, позиции и проекты.
Почему никто не предоставляет такие возможности? Да потому, очевидно, что ни у кого нет таких данных. И взять их в общем-то негде. Единственный их источник — кандидат. А его никто не может обязать давать всю эту информацию, а тем более — давать полную и точную.
А если пойти чуть дальше, и попробовать понять, что такое скажем позиция — то мы быстро придем к выводу, что искать по этому критерию вообще не имеет смысла, потому что позиция (в ее конкретном виде, с названием и т.п.) имеет смысл только в рамках одной компании (а то и проекта), а сравнивать ее с другой нет никакой возможности и смысла.
То есть, получается что и у кандидата этой информации тоже нет?
Тоже самое и с навыками. Что это такое, навык? Откуда мы знаем, что у кандидата А навык Б сопоставим с тем же навыком у кандидата В? В чем мы этот навык измеряем? Откуда мы узнаем, что величина этого навыка вот такая?
Благодарю за содержательное замечание, с которым сложно поспорить.
В таком ракурсе да, сложно сравнивать бананы с грушами.
Но систему постоянно улучшают в плане понимания как можно сравнить несравнимое и выделить нужные критерии для сравнения, наблюдая и собирая данные.
Несомненно, но мы всегда ограничены данными, их качеством и временем.
Потому со временем система будет развиваться и дальше.
Однако, чем больше экспертизы в данной предметной области, тем можно точнее спроектировать базу данных.
Спасибо за статью. Поясните, пожалуйста, зачем в связи 1-1 в примере человек-паспорт нужны foreign key constraint в обе стороны?
Это один из способов гарантировать отношение 1:1, когда сущность разделяют на две сущности. Например, человек и его документы, чтобы не делать очень большую таблицу.
И потому в конце сказано, что все типы отношений существуют в жизни между субъектами и между субъектами и объектами, и важно в системе зафиксировать нужные для работы формальные связи.
В данном случае, имелось в виду гражданство РФ для поиска работы в России.
Т е если подразумевается гражданство одно, то связь будет 1:1, а если гражданств может быть несколько, то многие ко многим, т к одно и тоже гражданство может быть у разных людей.
У человека могут быть два и более российских паспорта, другое дело, что действующий должен быть только один.
Интересный кейс)
Но в любом случае принимают на работу по одному паспорту, а не по нескольким.
Принимать могут по одному, а Увольнять нужно будет по другому. При этом, желательно, не потеряв информации о том, по какому принимали.
Сервис по найму, не по увольнению.
Если паспорт меняется, то меняются и соответствующие поля в таблице.
В данном случае историю изменений паспорта или его замены хранить не требовалось в отличии от истории работ (т е резюме).
Вопрос скорее к тому, почему бы обе таблицы не повешать на один общий суррогатный ключ, например CitizenID?
Тоже можно, но тогда нужно следить за целостностью данных.
Если можете, приведите схему для примера картинкой.
Как понимаю, именно в случае с 2 ключами нужно следить за непротиворечивостью, чтобы все пары ключей совпадали а обоих таблицах.
Пример с общим ключом
create table citizen (
id integer primary key,
...)
create table personal_data (
citizen_id integer primary key,
foreign key citizen_id references citizen(id),
...)
Благодарю за пример. Однако, это пример 1:1 с необязательной связью, т к в таком случае нет гарантий, что для каждой записи из первой таблицы найдется соответствующая ей запись во второй таблице.
Конечно можно в первую таблицу также добавить foreign key id references personal_data(citizen_id), но придётся один из fk сделать отложенным, чтобы проверялся в конце транзакции. Но и в исходном примере невозможно добавить данные сразу в обе таблицы, одну из них нужно будет ещё и update.
Вы совершенно правы, но схема-это одно, а реализация-другое. Т е по схеме важно, чтобы отношение было таким, каким надо его зафиксировать (в нашем случае 1:1 с обязательной связью).
Из-за невозможности одновременно поддержать два внешних ключа при добавлении записи, идут сначала односторонним путем, описанным Вами выше, а затем либо добиваются двусторонней целостности в том числе подходом, описанным Вами выше, либо проверку этой целостности выносят в другой слой-не на уровне БД.
Но при этом работать должно как нарисовано на схеме вне зависимости от деталей ее реализации.
Вспомнил ещё интересный пример, когда можно вставить данные, когда обе таблицы ссылаются друг на друга и не принимают NULL в своих связях.
Добавляются в обе эти таблицы нулевые строки с нулевыми идентификаторами, т е 0 при целочисленном типе и все нули — при GUID.
Далее сначала ссылаются на нулевую строку, затем меняют поле на нужный идентификатор.
Такой подход также позволяет в ряде случаев избавиться от внешних соединений и делать только внутренние.
Я думаю, что скиллы неправильно так привязывать к проекту. Потому что, например, в одном и том же проекте могут работать специалисты по фронтенду, бэкэнду, и, например, девопсу. Это не говоря уже о тестировщиках и аналитиках. И скиллы у всех этих групп будут разные.
Да, для того есть позиции-т е кем работал специалист-фронт, бэк, девопс и т д
Ну я к тому, что если хочется нормализации, то можно ввести сущность «роль на проекте», и к ней уже прилинковать скиллы.
А если есть желание автоматически раскладывать из какого-нибудь hh.ru по табличкам, то там будет прямо набор скиллов у человека. Или набор скиллов у человека на конкретном проекте. То есть схема в обоих случаях будет другая.
спасибо за попытку систематизировать.
2.1 отношение один ко многим с обязательной связью
2.2 отношение один ко многим с необязательной связью
я бы не стал делить, рассматривал только случай 2.2, потом отдельно написал про NULL/NOT NULL/FOREIGN KEY/CONSTRAINT (может быть даже отдельная статья).
1.1.2 отношение один к одному с обязательной связью в одной сущности (таблице)
не вижу ни одной причины в реальной жизни использовать это (и сходу не могу вспомнить когда встречал/использовал).
и иллюстрации с паспортами/жёнами/… очень удачные, только выводы из них не сделаны.
если БД хранит реальные данные, то нужно учитывать, что "к одному" может меняться со временем (человек может поменять паспорт, сотрудник может перевестись в другой отдел, etc), и такие отношения нужно хранить в привязке к моменту времени.
На самом деле это было систематизировано уже достаточно давно и много раз
да кто же спорит. но иногда пытаться объяснить «на пальцах» стоит, такие объяснения не заменяют «академические», а дополняют их, облегчая новичкам погружение в тему.
насколько удачна именно эта попытка — сходу не скажу.
Полностью соглашусь, в данном случае было интерпретировано просто о сложном со своими плюсами и минусами как это обычно бывает при подобных дополнениях.
Ожидание: есть принципы проектирования БД, позволяющие изначально правильно выстроить ее архитектуру, чтобы и гибко было, и работало быстро, сейчас мне про них доступно и коротенечко расскажут.
Реальность: есть несколько способов размещать сущности в таблицах БД. Если вы вдруг облажались, решив, что номер паспорта это свойство, а не отдельная сущность, и через некоторое время выяснилось, что связь человек-паспорт это один-ко-многим, то вы можете переделать схему БД, чтобы стало правильно. А потом еще раз переделать, когда вскроется следующая проблема. И еще раз.
Спасибо, кэп, но так я и сам умею.
Потому важно заранее определить как будет жить ваша информационная система и как правильно для этого формализовать сущности и их отношения.
Это как зафиксировать картину мира на холсте, только в цифровом виде.
Весь мир формализовать не нужно, только то, что нужно с учётом будущего развития.
Есть ли подобные программы сейчас, модифицированы ли они под новомодные схемы хранения XML/JSON и прочего No-SQL (потому что тогда они строили схему БД в 3-й нормальной форме реляционной модели) — я даже не знаю.
Но это хорошо, что древнее знание не забывается (хотя, может быть — и переоткрывается).
Ну вообще по-другому особо и не бывает. Большинство систем изменяются и развиваются. Вы конечно можете все с первого раза угадать, но гарантировать что нигде потом ничего не изменится — не можете все равно. Потому что не обязательно вскроется проблема — появится изменение постановки задачи.
То есть, нет таких принципов. Если вдруг постановка изменилась, и некая связь стала из 1:M вдруг M:M, вам придется перепроектировать минимум эту часть схемы. И еще раз, и еще.
Был рассмотрен сферический конь в вакууме и получено соответствующее решение.
Например, скилы:
- Таблица должна быть расширяема. Кандидат должен иметь возможность вводить новые навыки. Потому, что всех навыков ты в системе не предусмотришь.
- Навыки должны иметь связь на себя же, т.к. есть навыки — синонимы.
- Навыки должны иметь иерархическую связь, т.е. есть навыки общего характера (программист), а есть частного (C++).
- Навыки должны иметь связь совместимости, для отображения саджестов. В какой-то степени, может помочь иерархия, но не всегда. Иногда в саджестах программисту нужно отобразить, например, scrum.
И тут ключевой вопрос — поддержание консистентности данных. И вот… расширяемость таблицы становится нетривиальной задачей.
И это только поверхность айсберга.
П.1 предусмотрен-через добавление
П.2 необязателен
П.3- не нужно смешивать должности (позиции) и навыки
П.4 для этого навыки связываются с проектом, а проект с резюме
П1 обозначен как требование, котрое в итоге выдрержать становится затруднительно. А в вашей схеме — невозможно. Приведите пример как ваша схема противодействует дублированию скилов.
П2 С чего вы взяли, что не обязателен? Вам так видится? Он обязателен. В рельной системе. Более того, еще и релевантность такой связи нужно определить.
П3 должности тут не при делах. Аналитик и бизнес-аналитик. Что тут должность а что навык? Еще? Юрист и юрисконсульт. Scrum-мастер и scrum. Людям свойственно указывать свой навык точно, а вот искать обобщенно.
П4 это не решает проблему. Привидите пример, почему в новой анкете программисту Java будет в топе предложен скил scrum или jira, а не photoshop или 1С.
Поиск работы это не простой матчинг требований и данных. Это всегда некоторые люфты. Разработчик PHP при желании может найти работу Go. Сантехник может пойти продавцом сантехники и т.д. Поэтому, при подборе даже косвенно связанные скилы должны позволять найти кандидата. Естественно, в приоритете по релевантности.
Все зависит от того, что нужно от системы.
В данном примере приведена упрощенная модель реальной базы данных.
Предлагаю рассмотреть еще потребность в шардировании данных. А также, в разделение сущностей по изолированным БД. Например ПД должны находится в отдельном контуре и принадлежать профилю пользователя. В то время как анкета индексироваться и участвовать в поиске.
И тут такая штука как master key как int становится неприемлемой. Нужны GUID. Желательно с указанием класса сущности в нем.
Благодарю за замечания, не хотелось перегружать материал.
В реальной системе используются последовательные GUID по возможности (но увы не всегда, т е попадаются GUID непоследовательные).
identity можно использовать, если знать как разделить диапазоны идентификаторов при РСУБД (это не всегда возможно).
Строго говоря паспорт может быть не один, его может и не быть, мало того это даже может быть не паспорт, а «документ, удостоверяющий личность».
Такое ощущение, что Вы плохо понимаете нотацию crow foot. Есть куча мест, где по тексту связь обязательна, а на схеме — необязательна.
Пример: п.2.1, цитирую: "У каждого родителя есть как минимум один ребенок.". При этом на схеме у таблицы Child значок "от 0 до N", т.е. детей у родителя может и не быть.
В п.2.2, где наличие детей становится необязательным, Вы почему-то сделали необязательным наличие родителя — со стороны таблицы Person изображена мощность "0 или 1".
Ещё пример — 1.1.2. По Вашей схеме у гражданина наличие паспорта необязательно, как и наличие у паспорта гражданина.
И т.д.
Пересмотрел картинки-все верно, т е если необязательная связь, то поле становится возможным принимать NULL, иначе-нет.
Предлагаю привести в комментариях исправленные версии схем по Вашему мнению.
Нет, не правильно.
Если, как у Вас написано, "У каждого родителя есть как минимум один ребенок.", то связь должна выглядеть вот так:
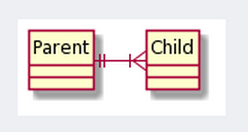
Вы только что повторили схемы 2.1.2 и 2.2.2
В том-то и дело, что у Вас схема 2.1.2 выглядит так:

Именно это я и пытаюсь до Вас донести.
На всякий случай подытожу — вдруг в будущем эту статью будут читать студенты, надо их предостеречь :) — и больше уже возвращаться не буду.
В нотации crow foot значки  и
и  имеют разный смысл, так же, как и
имеют разный смысл, так же, как и  и
и  , и в статье много неверных схем в том смысле, что они не соответствуют тексту, например, в тексте речь идёт про обязательность, а на схеме этот конец связи с "ноликом".
, и в статье много неверных схем в том смысле, что они не соответствуют тексту, например, в тексте речь идёт про обязательность, а на схеме этот конец связи с "ноликом".
Несомненно это верно, но в концептуальной модели, а не в логической модели базы данных, где есть просто связь и указывается обязательная она или нет.
Детально про ER-диаграммы можно почитать здесь.
Если Вы мне советуете это почитать, то зря — я как раз-таки понимаю разницу между концептуальной, логической и физической моделями базы данных.
И не могут при переходе между уровнями модели внезапно изменяться свойства связи — мощность, обязательность и т.д.
Поэтому если Вы на концептуальном уровне указали, что на данном конце связи должно быть "ноль или один" — в таком виде это у Вас и доедет до физической модели.
Так что тут Вы опять ошиблись.
И всё равно всё вышесказанное Вами не отменяет того факта, что у Вас в статье схемы не соответствуют тексту. Заканчивайте уже выискивать какие-то странные оправдания в виде размытых фраз.
Не хочу задеть, но у меня сложилось впечатление, что Вы теоретик и оперируете академическими понятиями из ВУЗа, где так много уделялось видам стрелок с кружком и без.
Я практик, и представленные схемы есть мой опыт, а также наблюдаемый опыт коллег, с которыми я работал. В совокупности опыт составил более 10 лет.
При этом были созданы:
1) 20+ информационных систем с нуля (принимал участие в проектировании и в разработке)
2) 60+ информационных систем с нуля или оптимизированы/изменены (в качестве консультанта и иногда разработчика).
Важно не что Вы знаете, а как применяете и понимаете.
За весь свой опыт ни разу не увидел, чтобы база данных была хотя бы в первой нормальной форме. Ни разу в успешных системах!
А на многих курсах выдалбливают эти нормальные формы.
Важнее понять просто суть нормализации и денормализации, а также научиться формализовать сущности и их связи, поняв 7 формальных правил.
Все-и вперёд проектировать быстро и четко.
Не хочу задеть, но у меня сложилось впечатление, что Вы теоретик и оперируете академическими понятиями из ВУЗа, где так много уделялось видам стрелок с кружком и без.
Ошибаетесь, я — практик. И если уж мы тут начали пиписками меряться, то моя нынешняя должность называется "Эксперт по разработке". (А вообще Ваша тирада выглядит странно — наличие большого опыта исключает возможность делать ошибки или заблуждаться?)
И как практик я знаю, что всевозможные схемы (в т.ч. различные схемы БД) служат, в первую очередь, для передачи знаний между членами команды. И если Вы в голове держите "1 или N", а на схеме нарисовали "0 или N", то другой разработчик при имплементации какой вариант реализует, как думаете?
Конечно все ошибаются.
Я про то, что Ваши вопросы задайте разработчикам этой диаграммы, что рисует именно так, когда спроектировано верно.
А также тогда Вам как практику должно быть известно, что Бобер и SSMS рисуют просто связи, не разделяя из кружком.
Тогда что? Тоже критиковать разработчиков бобра и SSMS?
Или просто понять, что на логическом уровне эти связи так не выделяют.
Ещё вопрос: в SSMS в диаграмме тоже верно с кружком и без рисует связи?
В SSMS диаграмма выглядит так:
 .
.
Где кружки?
Создаётся впечатление, что Вы не увидели сути в публикации и критикуете инструмент по визуализации диаграмм баз данных.
Даже инструменты на логическом уровне не рисуют Ваших кружков. Тот же Бобер тоже-проверил только что.
Не путайте модели и тем более не путайте инструменты для визуализации конкретного типа модели базы данных.
Я не в PowerDesigner это делал, а в простых инструментах, доступных каждому.
Вау, Вы меня впечатлили! )))))
Я, вообще-то, говорил о нотации crow foot (которую Вы использовали в статье).
А то, что SSMS использует какую-то свою, совсем другую — это все знают. Ну, или не все… =D
Создаётся впечатление, что Вы не увидели сути в публикации и критикуете инструмент по визуализации диаграмм баз данных
Я даже не знаю, каким Вы инструментом пользовались, и в данном контексте это вообще не важно.
Услыште меня, я уже устал повторять одно и тоже — Вы неправильно используете нотацию crow foot, в тексте у Вас связь обозначена как обязательная, а на схеме — как необязательная. И эта ошибка повторена неоднократно.
И это может сбить с толку неопытных читателей Вашей статьи (джунов, студентов и т.п.), только поэтому я за этот момент и зацепился. Детей жалко :)
А Вы можете сколько угодно оставаться в мире своих заблуждений. Я бы порекомендовал Вам поразбираться с этой нотацией, но что-то мне подсказывает, что Вы этого делать не захотите.
За сим всё-таки окончательно откланиваюсь, ничего конструктивного Вы так и не сказали (но за SSMS отдельное спасибо, хорошее настроение у меня на весь день обеспечено :)).
"Я даже не знаю, каким Вы инструментом пользовались, и в данном контексте это вообще не важно"-на этом и остановимся, спасибо.
Также советую не путать концептуальную и логическую модели базы данных.
А то по Вашим словам получается, что такие ПО как Бобер и SSMS неверно рисуют диаграммы, что конечно неправда.
Практик отличается от теоретика тем, что проектирует систему сразу в логической модели, т е в том инструменте, где сразу и будет создавать базу данных, если напр такие инструменты как PowerDesigner недоступны.
И в конце концов напишите свою публикацию, чем критиковать причем не созданные мною инструменты в адрес данной публикации.
Задавать связь мощности "1:1" через две связи между таблицами нельзя. Тем самым Вы открываете дорогу для возникновения неконсистентного состояния системы.
Пример:
- В таблице Citizen есть запись с CitizenID == 42 и PassportID == 999 (пусть это будет некто Иванов).
- В таблице PassportData есть запись с PassportID == 999 и CitizenID == 123 (это айдишник Петрова).
Вопрос: кому принадлежит паспорт с айдишником 999 — Иванову или Петрову?
Можно, и более того такие подходы работают в реальных системах.
Делают это для того, чтобы не раздувать таблицу, а также когда например хотят разделить те поля, которые не у всех заполняются (напр, детали сущности).
Однако, консистентность поддерживать в таком случае будет естественно сложнее.
Это как пример, когда выносят большие файлы из базы данных на внешние носители-очень удобно. Но нужно соблюсти версионирование синхронно с базой данных-сложно, но можно.
Делают это для того, чтобы не раздувать таблицу, а также когда например хотят разделить те поля, которые не у всех заполняются (напр, детали сущности).
Как раз при правильной структуре будет меньше полей за счёт того, что связь будет одна.
сложно, но можно.
Если что-то может пойти не так — оно обязательно пойдёт не так.
На предыдущем проекте наелись вот этого самого. В структуре БД не был предусмотрен (нашими предками) контроль консистентности, в результате багов (и ещё неправильных подходов к разработке) накопилось такое огромное количество "мусорных" данных, что решение этой проблемы заняло сотни человеко-часов.
Отчасти соглашусь с Вами, также периодически встречаются такие проблемы в исторических системах.
Однако, есть и другой сценарий-не собирали какие-то данные, т к их не обрабатывали (типа мусора), а потом понадобилось их обрабатывать в том числе задним числом. Но данных нет, а значит задним числом нельзя и нужно подождать пока данные накопятся в нужном объеме для последующего анализа. В результате бизнес упустил возможную выгоду ровно на столь долгий период, пока будут копиться данные для анализа.
Причем в одном реальном случае потери были подсчитаны более, чем семизначным числом правда в рублях для небольшой компании.
Не совсем понимаю, как проблема с несобираемыми данными связана с неправильной в данном конкретно случае структурой БД.
Структура БД является правильной в зависимости от потребностей.
В публикации были приведены несколько вариантов.
В зависимости от потребностей можно выбирать один из правильных вариантов, например, при связи "1:1" хранить всё в одной таблице или в двух связанных.
Какие потребности могут заставить выбрать неправильный вариант, я не представляю.
В схеме, где 2 таблицы приводятся, описывается как должно работать без технических деталей как и в какой степени будет поддерживаться консистентность. Но в идеале должна полностью поддерживаться. В реалии не всегда представляется возможным поддержать консистентность, когда таблицу дробят на куски в отношении 1:1.
Вспомнил ещё интересный пример, когда можно вставить данные, когда обе таблицы ссылаются друг на друга и не принимают NULL в своих связях.
Добавляются в обе эти таблицы нулевые строки с нулевыми идентификаторами, т е 0 при целочисленном типе и все нули — при GUID.
Далее сначала ссылаются на нулевую строку, затем меняют поле на нужный идентификатор.
Такой подход также позволяет в ряде случаев избавиться от внешних соединений и делать только внутренние.
Когда была полная семья и было несколько детей, то отношение между родителем имело вид один ко многим с обязательной связью. Однако, если рассматривать любую семью, где может и не быть детей, то отношение будет такое же, но уже с необязательной связью.
Я так понимаю имелось ввиду отношение между родителем и детьми?
Когда же появились попечители у детей, то связь между ними стала как многие ко многим, т к у каждого попечителя могут быть другие подопечные дети, а у каждого ребенка могут быть другие попечители (родители).
Может я как-то не внимательно прочитал ваш пост, можете пожалуйста объяснить, почему изначально, когда в постановке у нас полная семья с несколькими детьми, то связь не была многие-ко-многим, а стала таковой только поле появления попечителей (родителей)? Ведь изначально оба ребенка имеют двух родителей, и оба родителя имеют двух детей
Правила описывают в том числе и неполно-структурированные данные, т е NoSQL.
Потому неверно называть публикацию только для реляционной модели.
На счёт нормализации-ни одна встречающаяся мне база данных не находится даже в первой нормальной форме.
Нормализация и формальные связи никак не связаны, т к первая решает вопрос уменьшения возникновения аномалий в данных за счёт уменьшения зависимостей и повторяемости в данных, а вторые (формальные связи) были формализованы из жизни, т к эти связи были и есть всегда причем не только в ИТ, а ИТ их заимствовала.
Т е нормальные формы придумал человек, а формальные связи существуют и без человека. Достаточно понимать суть нормализации и денормализации, но не стремиться к ней. Важнее построить систему, которая будет отвечать всем требованиям предметной области и бизнеса, а также быстродействия и т д и т п.
Напр, оглянитесь вокруг: посмотрите как субъекты относятся друг к другу или к объектам, и Вы увидите все виды связей сразу. Вопрос в том, что для Вашей информационной системы нужно-что из этих сущностей из жизни Вы формализуете, какие из свойства и какие именно связи возьмёте.
2. есть еще такое понятие как денормализация, применяется для оптимизации доступа к данным, соотвественно приведение к 1й нормальной форме не имеет смысла кроме как в академических целях. Но без этих основных понятий не понять зачем вводить связи и самое главное как правильно это делать
- Не путайне неполно-структурировпнные данных со словарем, а ключ-значение, это по сути словарь, а не модель и не база данных.
Неполно-структурированные данные бывают документоориентированными (XML, JSON и т д) и графовыми, на документоориентиоованный тип примеры даны в формальных связях. Графовый также дан, где таблица ссылается на саму себя. - Связи существуют вне зависимости есть нормальная форма или нет.
Достаточно просто понимать смысл нормализации и денормализации.
Нужно использовать единую колонку для обоих таблиц и в обоих таблицах уникальный индекс по колонке.
Основы правил проектирования базы данных