TL;DR Пожалуйста, выносите код миграции данных в Rake-задачи или пользуйтесь полноценными гемами в стиле миграций схемы. Покрывайте тестами эту логику.
Я работаю бэкенд-разработчиком в FunBox. В ряде проектов мы пишем бэкенд на Ruby On Rails. Мы стремимся выстраивать адекватные процессы разработки, поэтому, столкнувшись с проблемой, стараемся её осмыслить и выработать методические рекомендации. Так произошло и с проблемой миграции данных. Однажды я сделал миграцию данных в отдельной Rake-задаче, покрытой тестами, и у команды возник вопрос: «Почему не в миграции схемы?» Я спросил во внутреннем чате разработчиков, и, к моему большому удивлению, мнения разделились. Стало понятно, что вопрос неоднозначный и достоин вдумчивого анализа и статьи. Программа-максимум по целям на статью для меня будет выполнена, когда ссылку на этот текст кто-нибудь приведёт на ревью кода в ответ на вопрос, зачем конкретная миграция данных вынесена или, наоборот, не вынесена из миграции схемы.
Лирическое отступление
Я взялся писать эту статью, чтобы снизить боль и увеличить продуктивность командной работы. В начале я надеялся отыскать жёсткие доказательные доводы о вреде злоупотребления миграциями схемы для миграций данных. Параллельно с этим я читал книгу Николая Бердяева «Смысл творчества. Опыт оправдания человека». Из неё я почерпнул понятие «соборный дух».
В мире программирования и IT преимущественно царит желание людей придать всей деятельности наукообразность с подведением подо всё доказательной базы. Когда я приобщился к миру Ruby, я почувствовал что-то совсем другое. Юкихиро Матсумото создал язык, чтобы облегчить общение людей через код, и это породило особое сообщество человеколюбивых людей. Мне кажется, что в этом сообществе ощущается именно соборный дух: все разделяют похожие ценности, имеют схожие интуиции и относятся друг к другу с любовью в евангельском смысле слова, а значит, не нуждаются в доказательствах, так как, по Бердяеву, доказательства нужны при разных враждебных интуициях.
Открытие понятия соборного духа воодушевило меня на написание статьи, когда я уже понял, что доказательные доводы вряд ли возможны. Я поставил себе цель собрать аргументы, которые найдут отклик в сердцах разработчиков и породят интуицию, подсказывающую, что смешивать миграции схемы и миграции данных неэффективно, ибо это может приводить к проблемам в эксплуатации и сопровождении.
Смешивание миграций данных и схемы
Схема данных — совокупность таблиц с их столбцами, представлений (views), индексов и хранимых процедур, используемых для хранения и манипуляции с данными бизнес сущностей. Является существенной частью бизнес логики.
Миграция схемы данных — логика изменения схемы данных (добавление, удаление таблиц, столбцов, индексов и пр.) необходимая для добавления новой фукциональной возможности в продукт. Качественная миграция предполагает определение обратных действий для возможности отката к предыдущей версии продукта. Совокупность миграций схемы не является неотъемлемой частью бизнес логики и может быть теоретически заменена на одну миграцию, которая будет включать логику всех миграций. На CI, где всегда БД создаётся с нуля, можно (и нужно) структуру загружать целиком SQL скриптом, который генерируется при прогоне миграций.
Миграция данных — логика изменения самих данных в таблицах. То есть всё, что делается через DML-операцию UPDATE языка SQL. Главный предмет статьи. Не является неотъемлемой частью бизнес логики.
Непрерывная доставка (Continuous Delivery) — качество процесса разработки, позволяющее автоматически развернуть любую версию продукта одной командой.
В официальной документации Rails говорится, что миграции предназначены для миграции схемы данных, то есть ограничиваются DDL-запросами. Но отсутствие готового решения для миграций данных, приводит к злоупотреблению миграциями схемы для преобразования данных. Кажется, что проблема эта специфична именно для Rails и подобных ему omakase-фреймворков бэкенд разработки. Когда для миграций схемы нет решения из коробки, то и злоупотреблять нечем.
Положительные аспекты смешивания миграций данных и схемы
Есть положительный аспект в том, чтобы преобразования данных делать по тому же принципу, что и преобразования схемы. То есть создавать инкременты изменений между версиями, которые можно выполнить в прямом и обратном направлении. С точки зрения непрерывная доставка, должна быть возможность развернуть любую версию системы таким образом, чтобы схема и состояние данных было корректным и целостным. Так же удобно видеть все инкременты единым списком в файловой системе и единообразно с ними поступать при эксплуатации системы.
Проблемы смешивания миграций данных и схемы
Миграции данных имеют отличную от миграций схемы природу и создают другой профиль нагрузки при выполнении. Это создаёт проблемы, о которых много говорится в англоязычной блогосфере. Я собрал наиболее частые (возможно, все) доводы и выделил проблемы эксплуатации, сопровождения и сомнительные проблемы.
Проблемы эксплуатации
Миграции данных занимают больше времени, чем миграции схемы. Это увеличивает время простоя при развертываниях. При больших объёмах время простоя может превысить время тайм-аута, установленного для миграций, и понадобится ручное вмешательство.
Длинные транзакции по миграции данных повышают вероятность возникновения deadlocks в БД.
Для предотвращения обозначенных проблем эксплуатации, на этапе разработки можно использовать инструменты статического анализа кода, например, гемы Zero Downtime Migrations и Strong Migrations.
Проблемы сопровождения
Нарушение принципа единой ответственности
Миграции схемы — это DSL (Domain Specific Language) на Ruby для DDL-конструкций языка SQL и обвязки над ними. Пока мы пользуемся DSL, разумное качество гарантируется ручной проверкой того, что миграция успешно выполняется в прямом и обратном направлении. Если мы ошибёмся в смысле миграции, то не сможем продолжить разработку и сразу исправим её.
Как только мы выходим за рамки DSL, чтобы произвести манипуляцию с данными, мы нарушаем принцип единой ответственности SRP. Последствием этого нарушения для нас является повышенный риск ошибок. Если мы захотим его устранить, то нам захочется покрывать миграции тестами, но…
Нет тестов (по крайней мере адекватных, дешевых)
Автор статьи Ruby On Rails Data Migration ради тестирования миграций данных накатывает предыдущие миграции и проверяет, что целевая миграция выполнит нужные изменения данных. В большом приложении, это будет выполняться чудовищно долго и повысит когнитивную нагрузку на команду необходимостью читать и писать подобные тесты. Нежелательно иметь логику миграции данных внутри кода Rails-миграции, где её так сложно протестировать. Где эту логику расположить я расскажу в разделе о решениях.
Проблемы сопровождения при использовании классов моделей в миграции
Для логики миграции данных очень удобно вместо SQL использовать код моделей и средства языка ORM ActiveRecord.
Но это может приводить к следующим проблемам:
- Класс модели может быть переименован или удалён. Тогда будет получена ошибка несуществующей константы.
- В модели могут быть добавлены валидации, которые не позволят выполнить изменения.
- В модели могут присутствовать callbacks с побочными эффектами, на которые автор кода миграции не рассчитывает.
Для этих ситуаций придуман «костыль» с переопределением класса модели прямо в миграции. Это дублирование знания, и не может считаться образцовым решением.
Процитирую пример такого «костыля» из официального руководства Rails (до версии 4.2):
# db/migrate/20100513121110_add_flag_to_product.rb
class AddFlagToProduct < ActiveRecord::Migration
class Product < ActiveRecord::Base
end
def change
add_column :products, :flag, :boolean
Product.reset_column_information
Product.all.each do |product|
product.update_attributes!(:flag => false)
end
end
endЛично мне не хочется иметь в кодовой базе подобное.
Кстати, вместо each стоит использовать find_each c batch-обработкой.
Любопытно было заметить, что, начиная с версии 4.2 этот пример из руководства совсем убрали.
Проблемы сопровождения при использовании SQL в миграции
Если, стремясь уйти от использования моделей в миграциях, мы хотим использовать напрямую команды SQL, то мы сталкиваемся со следующими недостатками такого подхода:
- Логика выражается сложнее, чем через код модели. Сложнее, ибо менее лаконично, на более низком уровне абстракции, на другом языке (SQL), которым мы пользуемся сравнительно редко.
- Если есть JOIN-ы, это уже серьёзное дублирование знаний, выраженных в связях моделей.
- При длительной обработке невозможно отслеживать прогресс и невозможно понять, идёт ли ещё обработка или уже случился deadlock.
Сомнительные проблемы
В статье Thoughtbot приводится такое соображение: миграции схемы данных не являются бизнес-логикой, поэтому должна быть возможность в любой момент их выбросить и загружать схему целиком через DDL. Это позволит быстрее готовить окружение и прогонять тесты на CI. При удалении миграций из проекта содержащаяся в них логика миграции данных теряется.
Я не вижу здесь проблемы. Логика миграции данных точно так же, как и схемы, не является бизнес-логикой и потенциально может выбрасываться из проекта. А именно, когда эта логика применена и маловероятны откаты до состояния, предшествующего миграции. Если загружать готовую схему данных, то нас не интересуют никакие промежуточные преобразования существующих данных.
Например, в миграции данных могут устанавливаться значения полям, которые раньше были пустыми и стали обязательными. Но если нет никаких данных, то значения не для чего указывать.
Допустим, данные есть и мы выбрасываем старые миграции. Но старые миграции данных уже привели базу в нужное состояние, и они всё равно нерелевантны.
Вынашивая замысел статьи, на этот довод я возлагал большие надежды, но увы. Напишите, пожалуйста, в комментариях, что я могу здесь упускать.
Исключения, когда допустимо делать миграции данных в миграциях схемы
Миграцию данных допустимо включить в миграцию схемы в том случае, если без этого откатываемая миграция невозможна.
Например, превращение nullable-поля в поле со значением по умолчанию или наоборот.
Так как миграции должны быть откатываемыми, мы должны обеспечить обратное преобразование и без обновления значения никак не обойтись.
Запрос будет тривиальным, вида:
UPDATE table SET field = 'f' WHERE field IS NULLВся миграция может выглядеть так:
class ClientDemandsMakeApprovedNullable < ActiveRecord::Migration
def up
change_column_null :client_demands, :approved, true
change_column_default :client_demands, :approved, nil
end
def down
execute("UPDATE client_demands SET approved = 'f' WHERE approved IS NULL")
change_column_null :client_demands, :approved, false
change_column_default :client_demands, :approved, false
end
endВообще говоря, при большом объёме данных в таблице так делать не стоит и нужно прибегать к более изощренным приёмам. Например, не выполнять миграцию на проде, а делать все изменения руками и потом подменять файл миграции и версию в БД. Подробно этот приём описан в статье Dan Mayer Managing DB Schema & Data Changes в разделе Modifying Large Tables.
Возможные решения
Отказ от решения ввиду мизерного объёма приложения или данных
До определённого момента роста можно закрывать глаза на проблемы смешиванния. Эти старые «грехи», никак вам не навредят. Бросить можно в любой момент и даже поступать по ситуации. Подскажите мне, пожалуйста, в комментариях, если я заблуждаюсь.
Использование единого механизма миграций схемы и данных, при условии написания качественных откатываемых миграций обеспечит возможность непрерывной доставки.
Но если приложение, база или команда разрастаются, то лучше прийти к более строгой дисциплине ради снижения потерь.
Вынос миграций данных из кодовой базы в тикет систему
Так как наибольшее беспокойство вызывает наличие миграций данных внутри миграций схемы, то вынос их оттуда является первостепенной задачей. Можно условиться не считать миграции данных частью кодовой базы. Их можно отладить в REPL на сервере стейджинга и сохранить в тикете для ручного применения на продакшне.
Это будет улучшением, но есть существенные недостатки такого подхода:
- Код миграций данных не находится при поиске по названию модели;
- Не происходит мыслительного процесса разработки через тест;
- Нет непрерывной доставки.
Прагматичная философия призывает никому не доверять и себе в особенности. Нельзя доверять скрипту, который отлаживался на стейджинговых данных. Данные эти могут быть не полными. Проектирование кода через тест даёт наиболее качественные результаты из известных мне способов.
Допускаю, что могут быть такие проекты, где этот подход будет оправдан, но не могу рекомендовать его для проектов, в которых участвую сам.
Вынос миграций данных в Rake-задачи
Более надёжное, доступное и действенное средство — создавать для миграций данных Rake-задачи. Вот их удобно покрывать тестами непосредственно. У меня в процессе написания теста миграции данных часто случаются озарения по поводу требований и удаётся решить потенциальные бизнес-проблемы.
Недавно на проекте была не покрытая тестом Rake-задача миграции данных. На ревью кода никто не заметил, что вместо добавления элемента в массив производилась перезапись всего массива. Опечатка привела к повреждению данных и необходимости восстановления данных из бэкапа в ручном выборочном режиме. В процессе написания теста такая логическая опечатка не могла бы быть допущена. Так что тесты — наши великие помощники в мыслительном процессе.
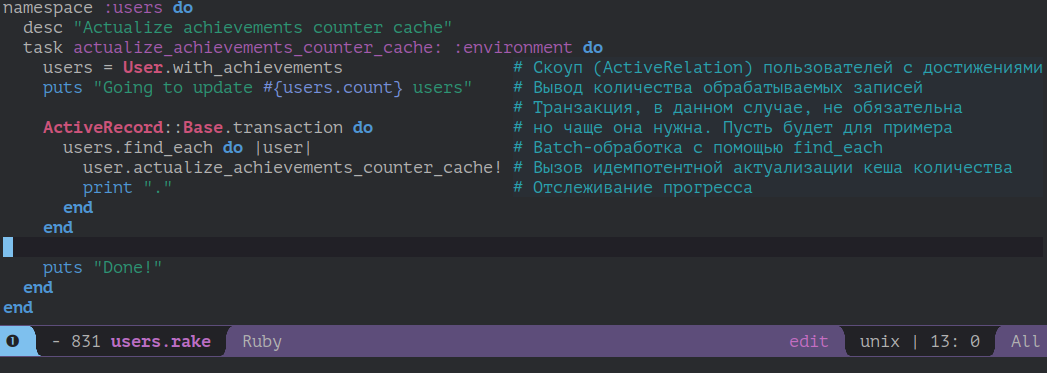
Процитирую пример, использующий все удобства, которые даёт Rake, из статьи Thoughtbot:
# lib/tasks/temporary/users.rake
namespace :users do
desc "Actualize achievements counter cache"
task actualize_achievements_counter_cache: :environment do
# Cкоуп (ActiveRelation) пользователей с достижениями
users = User.with_achievements
# Вывод количества обрабатываемых записей
puts "Going to update #{users.count} users"
# Транзакция, в данном случае, не обязательна
# но чаще она нужна. Пусть будет для примера
ActiveRecord::Base.transaction do
# Batch-обработка с помощью find_each
users.find_each do |user|
# Вызов идемпотентной актуализации кеша количества
user.actualize_achievements_counter_cache!
# Отслеживание прогресса
print "."
end
end
puts "Done!"
end
endЯ заменил each на find_each, чтобы обработка шла порциями и не загружала в память всю выборку. Это обязательная практика для обработки больших выборок без memory bloats. Подробнее в статье от Akshay Mohite.
Важно следить за идемпотентностью таких преобразований. Крайне вероятно, что Rake-задача будет выполнена на проде более одного раза.
При всей простоте и привлекательности этого решения, у него остаётся существенный недостаток. Он не позволяет автоматически развернуть любую версию продукта одной командой. Он пригоден в ситуации, когда развитие продукта происходит не частыми инкрементами, редко откатывается и удаётся сделить за выполнением ручных действий при развертываниях. Но для непрерывной доставки этот способ не годится.
Вынос миграций данных в отдельные внутренние классы внутри миграции
Mark Qualie предлагает внутри кода миграций схемы добавлять определение вложенного класса с методом up, определяющим логику миграции данных. Таким образом достигается «локальность» знаний об изменении схемы и связанных изменениях в данных. Вот пример кода из статьи:
class AddLastSmiledAtColumnToUsers < ActiveRecord::Migration[5.1]
def change
add_column :users, :last_smiled_at, :datetime
add_index :users, :last_smiled_at
end
class Data
def up
User.all.find_in_batches(batch_size: 250).each do |group|
ActiveRecord::Base.transaction do
group.each do |user|
user.last_smiled_at = user.smiles.last.created_at
user.save if user.changed?
end
end
end
end
end
endВыполнять эту логику автор предлагает вот таким образом:
Dir.glob("#{Rails.root}/db/migrate/*.rb").each { |file| require file }
AddLastSmiledAtColumnToUsers::Data.new.upПричём данный код автор предлагает поместить в асинхронный Job, добавив логирование и отслеживание выполненных миграций наподобие хранения в БД версии миграций схемы.
Использование полноценных гемов для миграций данных в стиле миграций схемы
Когда команда большая, приложение большое или миграции данных возникают в каждом втором-третьем релизе, может окупиться использование готового полнофункционального гема для миграций данных в стиле миграций схемы.
Это решение уже удовлетворяет требованиям непрерывной доставки, ибо отслеживание версии миграций данных делается так же, как и для миграций схемы.
Подобных гемов оказалось достаточно много, но суперпопулярных среди них нет. Видимо, потому что масштаб проблемы мало у кого доходит до нужного размера.
У гема data-migrate наибольшее количество звездочек (> 670), ссылок из статей, а также самый ухоженный Readme. Он работает только с Rails 5+.
Ещё два гема с подобным опытом, но поддержкой Rails 4+:
rails-data-migrations(> 93 звездочек)
nonschema_migrations(> 53 звездочек)
Название последнего особенно примечательно. Оно кричит о противопоставлении миграций схемы и миграций НЕ схемы.
Аудит кода всех этих гемов я не проводил, ибо на проекте моего масштаба хватает подхода с Rake-задачами. Но их обнаружение было для меня одним из стимулов написать эту статью. Для меня они являются признаком серьёзности проблемы, с которой можно столкнуться при росте приложения.
Все они позволяют сгенерировать класс миграции данных в папке проекта db/data, которая находится рядом с традиционной db/migrate c миграциями схемы:
rails g data_migration add_this_to_thatА потом запускать и проверять статус командами вроде таких:
rake data:migrate
rake db:migrate:with_data
rake db:rollback:with_data
rake db:migrate:status:with_dataХорошей идеей для упрощения тестирования будет выделение логики миграции во вложенный класс внутри миграции, как в предыдущем примере.
Сравнительная характеристика решений
| Миграция схемы Rails | Скрипт в тикете | Rake | Внутренний класс в миграции схемы | Гем миграций данных | |
|---|---|---|---|---|---|
| Смешивание | + | - | - | - | - |
| Zero Downtime Deployment | - | + | + | + | + |
| Test First | - | - | + | + | По желанию |
| Непрерывноя доставка | + | - | - | Нужно разрабатывать руками механизм отслеживания версий | + |
| Принадлежность к кодобазе | + | - | + | + | + |
| Локальность | + | - | - | + | + |
По горизонтали расположены решения о размещении логики миграции данных.
По вертикали — качества, а именно:
- Смешивание — факт использования единого механизма миграций схемы для миграции данных;
- Zero Downtime Deployment — возможность минимизации времени прогона миграций, за счет использования только самых необходимых и быстрых операций по изменению схемы при развертывании;
- Test First — удобство разработки логики миграции данных через написание теста адекватной сложности;
- Непрерываная доставка — возможность выкатывания продукта любой версии одним действием;
- Принадлежность к кодобазе — размещение кода миграций данных внутри кодовой базы, в отличие от одноразовых скриптов в системе тикетов;
- Локальность — нахождение миграций данных в стандартизованном месте кодовой базы, которое можно найти навигацией по проекту, а не поиском по ключевым словам.
Заключение
Когда миграции данных возникают раз в несколько месяцев, то запускаемые вручную Rake-задачи — прагматичное решение.
Но когда это происходит чаще, то стоит присмотреться к полномасштабным автоматизированным решениям через готовый гем в стиле миграций схемы. Это обеспечит требования непрерывной доставки.
Таким образом, проблему миграции данных стоит решать по мере роста масштаба проекта — в архитектурном стиле, соответствующем этому масштабу. Кажется, такой подход имеет все шансы сделать процесс разработки адекватным.
Источники
- Rails Guides.
- Thoughtbot. Data Migrations in Rails.
- AtomicObject. Testing Data Migrations in Rails.
- Marcqualie. Rails Data Migrations.
- Ombulabs. Three Useful Data Migration Patterns for Rails.
- Статическй анализатор проблем в миграциях Strong Migrations.
- Ещё один статический анализатор Zero Downtime Migrations.
- Dan Mayer. Managing DB Schema & Data Change.
Akshay Mohite Статья о предпочтении find_eachвместоeach.- Николай Бердяев. «Смысл творчества. Опыт оправдания человека». Глава 1, 8 абзац. Противопоставление наукообразности философии, требующей доказательств, и соборного духа философии людей со сходными интуициями.
UPD 2020-08-06: Благодаря комментарию Extrapolator добавил ещё одно решение «Вынос миграций данных из кодовой базы в тикет систему».
Мне оно в голову не пришло при написании статьи из-за моей установки на прагматичную философию, призывающую всё держать в кодовой базе и разрабатывать через Test First подход.
Но для полноты картины этот способ должен быть в статье.
UPD 2020-08-07: Благодаря обратной связи в комментариях и в соц. сетях стало понятно, что в статье не хватает определений ключевых понятий статьи. Это приводит к существенному недопониманию. Добавил определения для схемы данных, миграции схемы и миграции данных.
UPD 2020-08-08: Благодаря обратной связи в Твиттере, добавил новый ключевой аспект в статью. Оказалось, что я совсем не уделил внимание положительным аспектам смешивания миграций схемы и данных. Речь о непрерывной доставке, которое требует автоматизации всех действий, в том числе миграций данных. Я добавил раздел «Положительные аспекты смешивания миграций данных и схемы», а в разделы решений добавил упоминание о том, какие из них пригодны к непрерывной доставке. Так же добавил сводную таблицу качеств предложенных решений. Это неоценимое вознаграждение за написание статьи, когда люди с другим опытом раскрывают глаза на новые измерения в рассматриваемой проблеме.







