VictoriaMetrics, TimescaleDB и InfluxDB были сравнены в предыдущей статье по набору данных с миллиардом точек данных, принадлежащих 40K уникальным временным рядам.
Несколько лет назад была эпоха Zabbix. Каждый bare metal сервер имел не более нескольких показателей – использование процессора, использование оперативной памяти, использование диска и использование сети. Таким образом метрики с тысяч серверов могут поместиться в 40 тысяч уникальных временных рядов, а Zabbix может использовать MySQL в качестве бэкенда для данных временных рядов :)
В настоящее время один node_exporter с конфигурациями по умолчанию предоставляет более 500 метрик на среднем хосте. Существует множество экспортеров для различных баз данных, веб-серверов, аппаратных систем и т. д. Все они предоставляют множество полезных показателей. Все больше и больше приложений начинают выставлять различные показатели на себя. Существует Kubernetes с кластерами и pod-ами, раскрывающими множество метрик. Это приводит к тому, что серверы выставляют тысячи уникальных метрик на хост. Таким образом, уникальный временной ряд 40K больше не является высокой мощностью. Он становится мейнстримом, который должен быть легко обработан любой современной TSDB на одном сервере.
Что такое большое количество уникальных временных рядов на данный момент? Наверное, 400К или 4М? Или 40м? Давайте сравним современные TSDBs с этими цифрами.
Установка бенчмарка
TSBS – это отличный инструмент бенчмаркинга для TSDBs. Он позволяет генерировать произвольное количество метрик, передавая необходимое количество временных рядов, разделенных на 10 — флаг -scale (бывший -scale-var). 10 – это количество измерений (метрик), генерируемых на каждом хосте, сервере. Следующие наборы данных были созданы с помощью TSBS для бенчмарка:
- 400K уникальный временной ряд, 60 секунд интервал между точками данных, данные охватывают полные 3 дня, ~1.7B общее количество точек данных.
- 4M уникальный временной ряд, интервал 600 секунд, данные охватывают полные 3 дня, ~1.7B общее количество точек данных.
- 40M уникальный временной ряд, интервал 1 час, данные охватывают полные 3 дня, ~2.8 B общее количество точек данных.
Клиент и сервер были запущены на выделенных экземплярах n1-standard-16 в облаке Google. Эти экземпляры имели следующие конфигурации:
- vCPUs: 16
- ОЗУ: 60 ГБ
- Хранение: стандартный жесткий диск емкостью 1 ТБ. Он обеспечивает пропускную способность чтения/записи 120 Мбит/с, 750 операций чтения в секунду и 1,5К операций записи в секунду.
TSDBs были извлечены из официальных образов docker и запущены в docker со следующими конфигурациями:
VictoriaMetrics:
docker run -it --rm -v /mnt/disks/storage/vmetrics-data:/victoria-metrics-data -p 8080:8080 valyala/victoria-metrics
Значения InfluxDB (- e необходимы для поддержки высокой мощности. Подробности смотрите в документации):
docker run -it --rm -p 8086:8086 \ -e INFLUXDB_DATA_MAX_VALUES_PER_TAG=4000000 \ -e INFLUXDB_DATA_CACHE_MAX_MEMORY_SIZE=100g \ -e INFLUXDB_DATA_MAX_SERIES_PER_DATABASE=0 \ -v /mnt/disks/storage/influx-data:/var/lib/influxdb influxdb
TimescaleDB (конфигурация была принята из этого файла):
MEM=`free -m | grep "Mem" | awk ‘{print $7}’`
let "SHARED=$MEM/4"
let "CACHE=2*$MEM/3"
let "WORK=($MEM-$SHARED)/30"
let "MAINT=$MEM/16"
let "WAL=$MEM/16"
docker run -it — rm -p 5432:5432 \
--shm-size=${SHARED}MB \
-v /mnt/disks/storage/timescaledb-data:/var/lib/postgresql/data \
timescale/timescaledb:latest-pg10 postgres \
-cmax_wal_size=${WAL}MB \
-clog_line_prefix="%m [%p]: [%x] %u@%d" \
-clogging_collector=off \
-csynchronous_commit=off \
-cshared_buffers=${SHARED}MB \
-ceffective_cache_size=${CACHE}MB \
-cwork_mem=${WORK}MB \
-cmaintenance_work_mem=${MAINT}MB \
-cmax_files_per_process=100Загрузчик данных был запущен с 16 параллельными потоками.
Эта статья содержит только результаты для контрольных показателей вставки. Результаты выборочного бенчмарка будут опубликованы в отдельной статье.
400К уникальных временных рядов
Давайте начнем с простых элементов — 400К. Результаты бенчмарка:
- VictoriaMetrics: 2,6М точек данных в секунду; использование оперативной памяти: 3 ГБ; окончательный размер данных на диске: 965 МБ
- InfluxDB: 1.2M точек данных в секунду; использование оперативной памяти: 8.5 GB; окончательный размер данных на диске: 1.6 GB
- Timescale: 849K точек данных в секунду; использование оперативной памяти: 2,5 ГБ; окончательный размер данных на диске: 50 ГБ
Как вы можете видеть из приведенных выше результатов, VictoriaMetrics выигрывает в производительности вставки и степени сжатия. Временная шкала выигрывает в использовании оперативной памяти, но она использует много дискового пространства — 29 байт на точку данных.
Ниже приведены графики использования процессора (CPU) для каждого из TSDBs во время бенчмарка:

Выше скриншот: VictoriaMetrics — Загрузка CPU при тесте вставки для уникальной метрики 400K.

Выше скриншот: InfluxDB — Загрузка CPU при тесте вставки для уникальной метрики 400K.
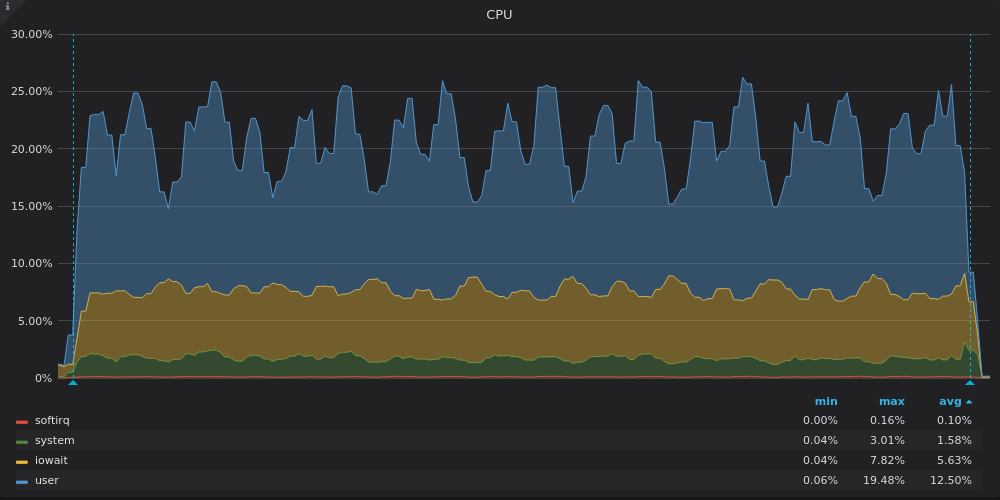
Выше скриншот: TimescaleDB — Загрузка CPU при тесте вставки для уникальной метрики 400K.
VictoriaMetrics использует все доступные vCPUs, в то время как InfluxDB недостаточно использует ~2 из 16 vCPUs.
Timescale использует только 3-4 из 16 vCPUs. Высокие доли iowait и system на TimescaleDB графике временных масштабов указывают на узкое место в подсистеме ввода-вывода (I/O). Давайте посмотрим на графики использования пропускной способности диска:
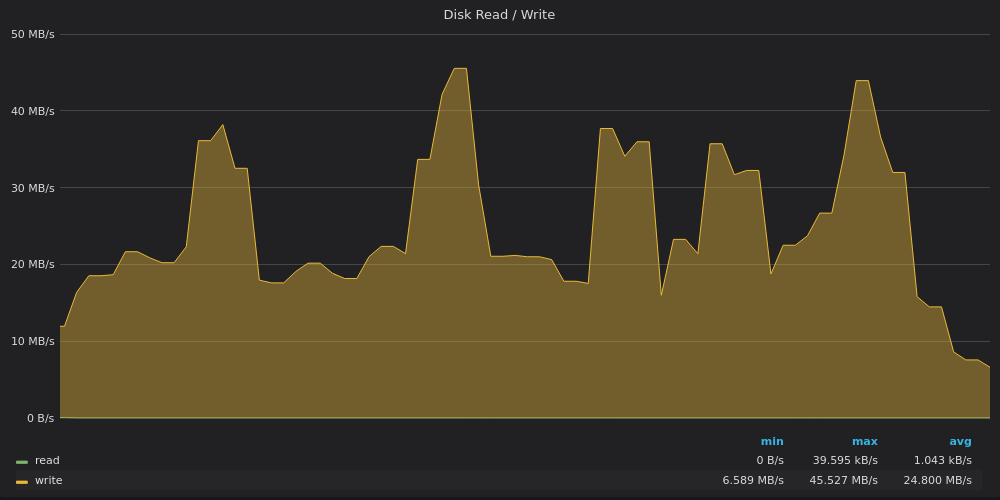
Выше скриншот: VictoriaMetrics — Использование пропускной способности диска при тесте вставки для уникальных показателей 400K.

Выше скриншот: InfluxDB — Использование пропускной способности диска при тесте вставки для уникальных показателей 400K.

Выше скриншот: TimescaleDB — Использование пропускной способности диска при тесте вставки для уникальных показателей 400K.
VictoriaMetrics записывает данные со скоростью 20 Мбит/с с пиками до 45 Мбит/с. Пики соответствуют большим частичным слияниям в дереве LSM.
InfluxDB записывает данные со скоростью 160 МБ/с, в то время как 1 ТБ диск должен быть ограничен пропускной способностью записи 120 МБ/с.
TimescaleDB ограничена пропускной способностью записи 120 Мбит/с, но иногда она нарушает этот предел и достигает 220 Мбит/с в пиковых значениях. Эти пики соответствуют провалам недостаточной загрузки процессора на предыдущем графике.
Давайте посмотрим на графики использования ввода-вывода (I/O):
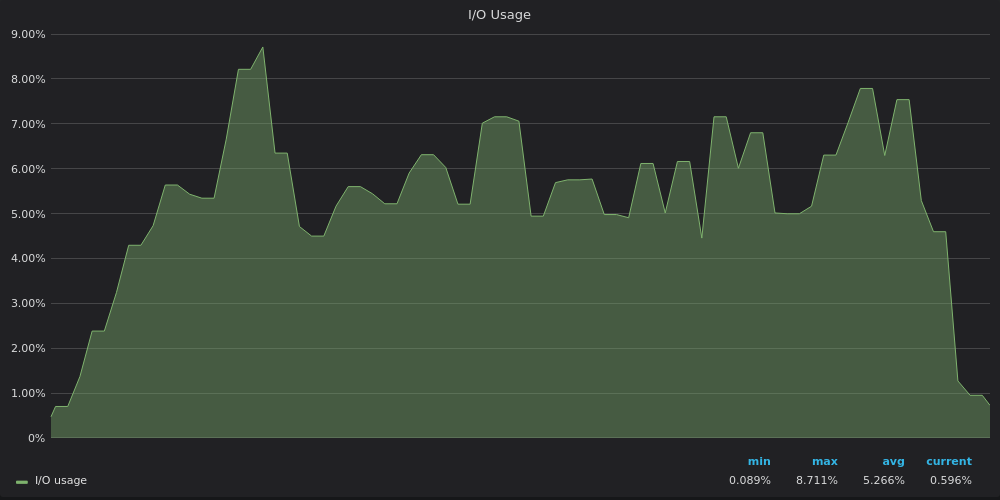
Выше скриншот: VictoriaMetrics — Использование ввода-вывода при тесте вставки для 400K уникальных метрик.

Выше скриншот: InfluxDB — Использование ввода-вывода при тесте вставки для 400K уникальных метрик.
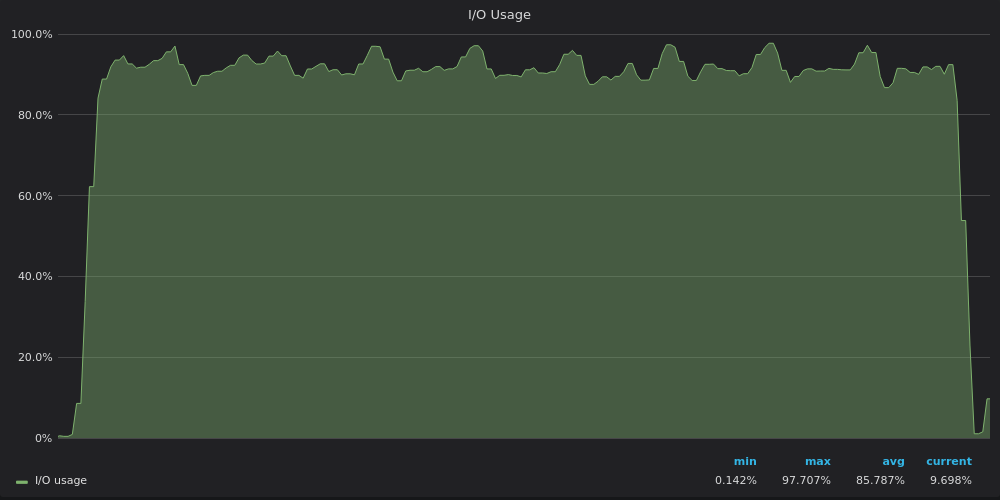
Выше скриншот: TimescaleDB — Использование ввода-вывода при тесте вставки для 400K уникальных метрик.
Теперь ясно, что TimescaleDB достигает предела ввода-вывода, поэтому он не может использовать оставшиеся 12 vCPUs.
4M уникальные временные ряды
4M временные ряды выглядят немного вызывающе. Но наши конкуренты успешно сдают этот экзамен. Результаты бенчмарка:
- VictoriaMetrics: 2,2М точек данных в секунду; использование оперативной памяти: 6 ГБ; окончательный размер данных на диске: 3 ГБ.
- InfluxDB: 330К точек данных в секунду; использование оперативной памяти: 20,5 ГБ; окончательный размер данных на диске: 18,4 ГБ.
- TimescaleDB: 480K точек данных в секунду; использование оперативной памяти: 2,5 ГБ; окончательный размер данных на диске: 52 ГБ.
Производительность InfluxDB упала с 1,2 млн точек данных в секунду для 400К временного ряда до 330 тыс. точек данных в секунду для 4M временного ряда. Это значительная потеря производительности по сравнению с другими конкурентами. Давайте посмотрим на графики использования процессора, чтобы понять первопричину этой потери:
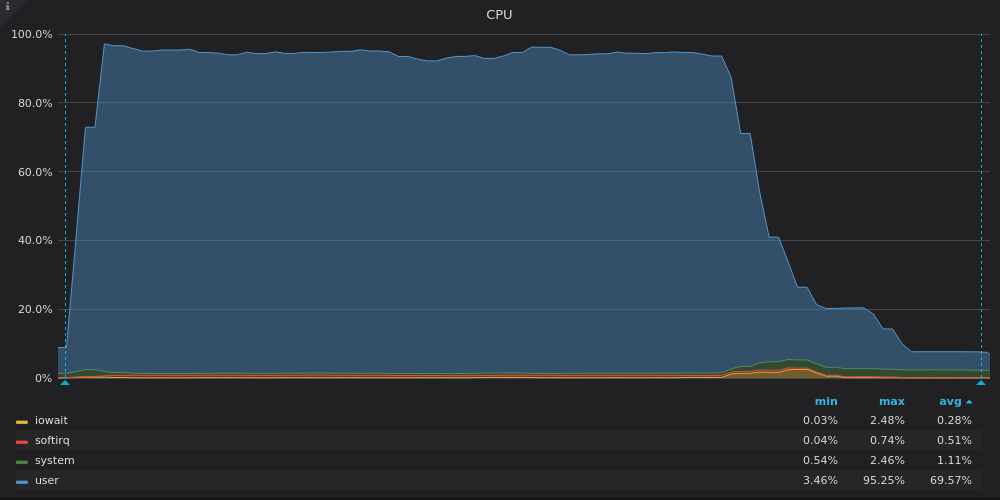
Выше скриншот: VictoriaMetrics — Использование CPU при тесте вставки для уникального временного ряда 4M.
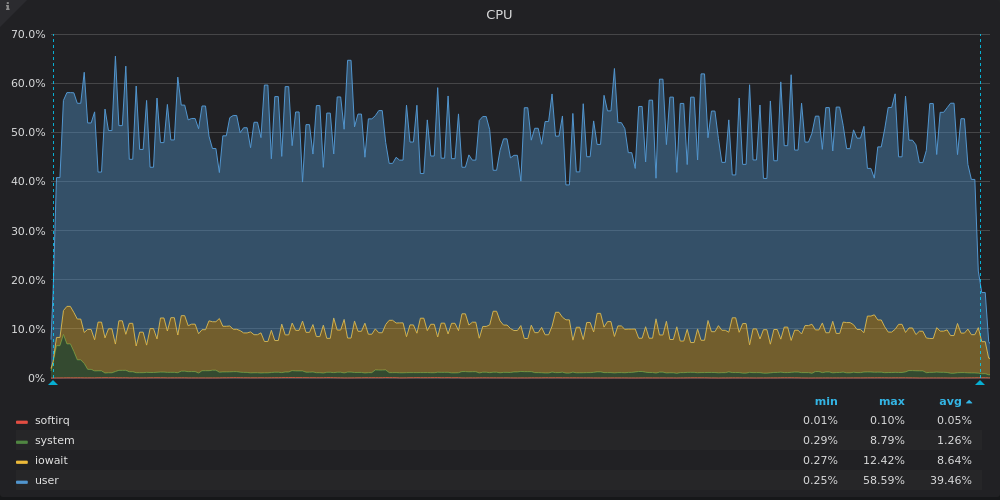
Выше скриншот: InfluxDB — Использование CPU при тесте вставки для уникального временного ряда 4M.

Выше скриншот: TimescaleDB — Использование CPU при тесте вставки для уникального временного ряда 4M.
VictoriaMetrics использует почти всю мощность процессора (CPU). Снижение в конце соответствует оставшимся LSM слияниям после вставки всех данных.
InfluxDB использует только 8 из 16 vCPUs, в то время как TimsecaleDB использует 4 из 16 vCPUs. Что общего у их графиков? Высокая доля iowait, что, опять же, указывает на узкое место ввода-вывода.
TimescaleDB имеет высокую долю system. Полагаем, что высокая мощность привела ко многим системным вызовам или ко многим minor page faults.
Давайте посмотрим на графики пропускной способности диска:
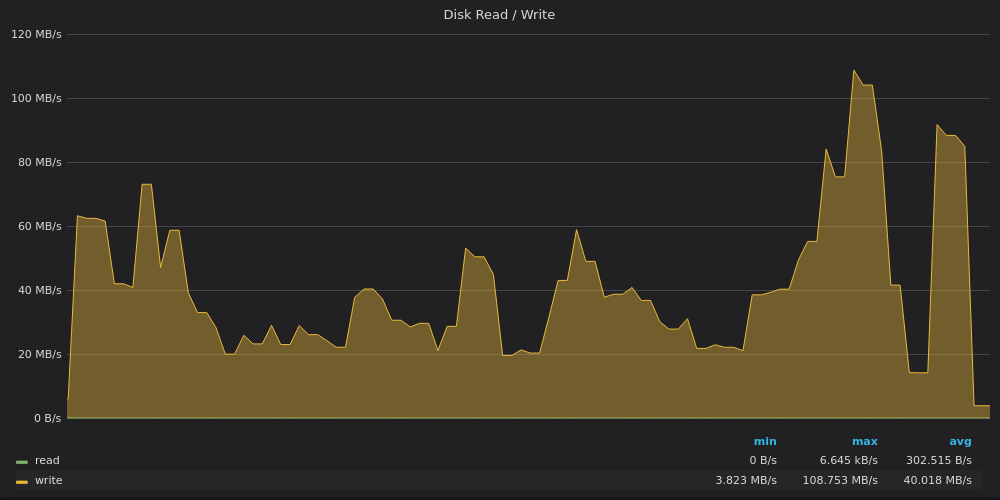
Выше скриншот: VictoriaMetrics — Использование полосы пропускания диска для вставки 4M уникальных метрик.
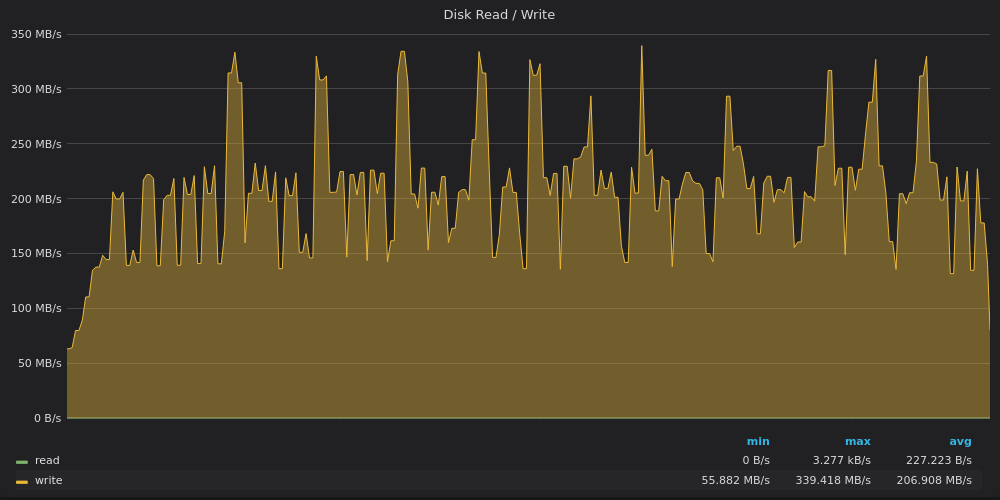
Выше скриншот: InfluxDB — Использование полосы пропускания диска для вставки 4M уникальных метрик.
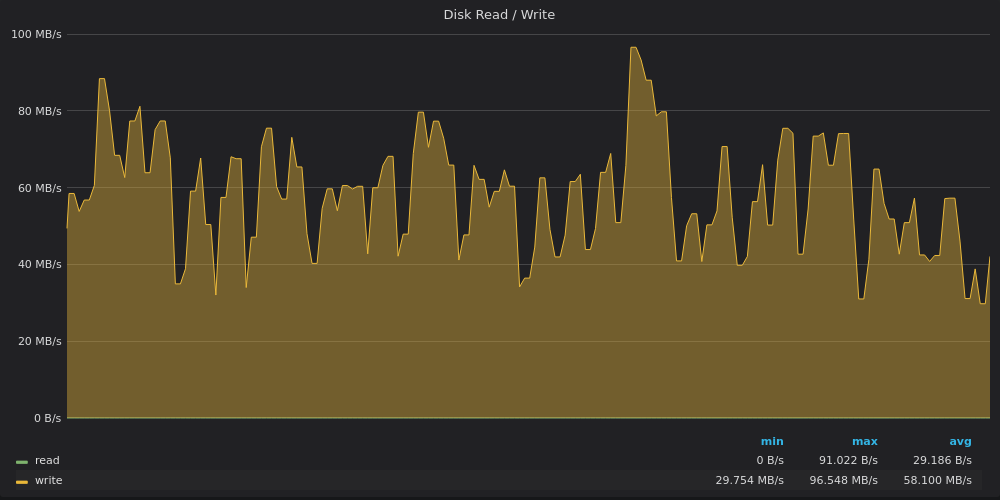
Выше скриншот: TimescaleDB — Использование полосы пропускания диска для вставки 4M уникальных метрик.
VictoriaMetrics достигали предела 120 МБ/с в пик, в то время как средняя скорость записи составляла 40 МБ/с. Вероятно, во время пика было выполнено несколько тяжелых слияний LSM.
InfluxDB снова выжимает среднюю пропускную способность записи 200 МБ/с с пиками до 340 МБ/с на диске с ограничением записи 120 МБ/с :)
TimescaleDB больше не ограничена диском. Похоже, что он ограничен чем-то еще, связанным с высокой долей системной загрузки CPU.
Давайте посмотрим на графики использования IO:

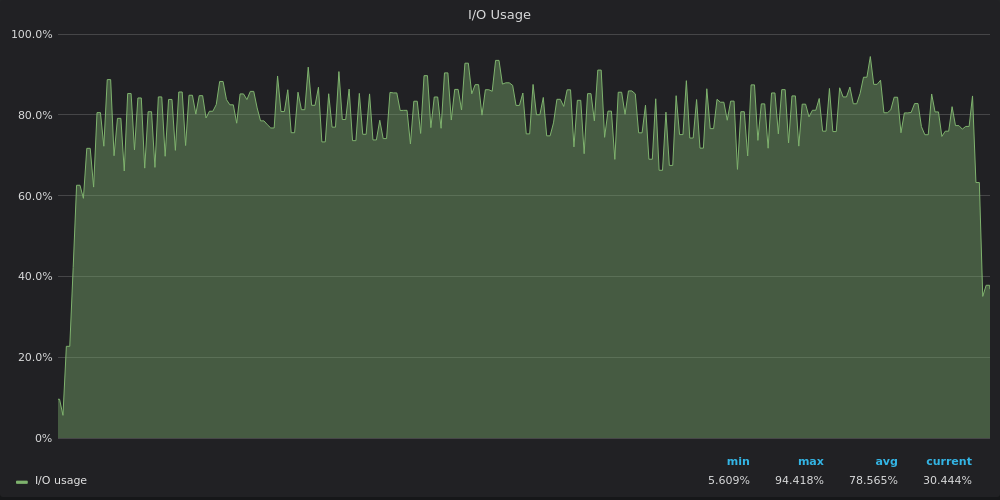
Выше скриншот: VictoriaMetrics — Использование ввода-вывода во время теста вставки для уникального временного ряда 4M.
Выше скриншот: InfluxDB — Использование ввода-вывода во время теста вставки для уникального временного ряда 4M.
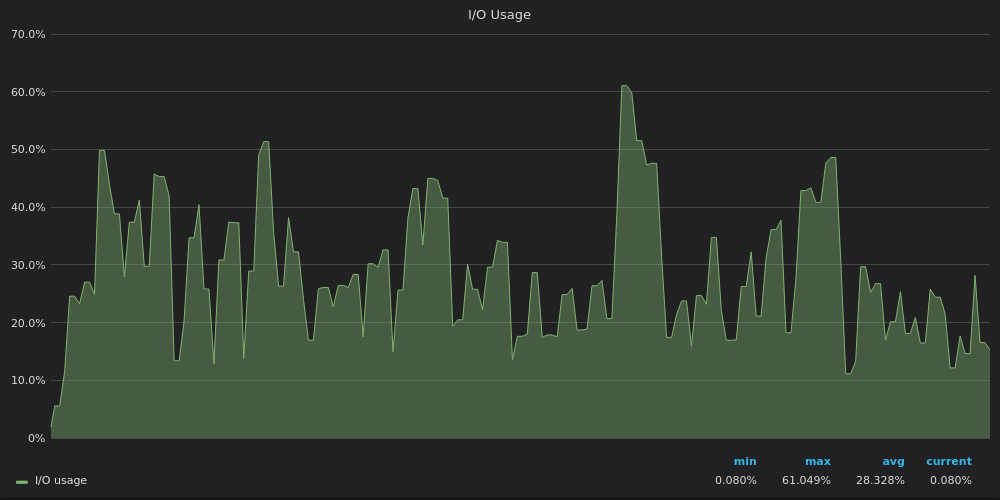
Выше скриншот: TimescaleDB — Использование ввода-вывода во время теста вставки для уникального временного ряда 4M.
Графики использования IO повторяют графики использования полосы пропускания диска — InfluxDB ограничен IO, в то время как VictoriaMetrics и TimescaleDB имеют запасные ресурсы ввода-вывода IO.
40М уникальные тайм серии
40М уникальные временные ряды были слишком большими для InfluxDB :(
Результаты бечмарка:
- VictoriaMetrics: 1,7М точек данных в секунду; использование оперативной памяти: 29 ГБ; использование дискового пространства: 17 ГБ.
- InfluxDB: не закончил, потому что для этого требовалось более 60 ГБ оперативной памяти.
- TimescaleDB: 330К точек данных в секунду, использование оперативной памяти: 2,5 ГБ; использование дискового пространства: 84GB.
TimescaleDB показывает исключительно низкое и стабильное использование оперативной памяти – 2,5 ГБ — столько же, сколько и для уникальных метрик 4M и 400K.
VictoriaMetrics медленно увеличивались со скоростью 100 тысяч точек данных в секунду, пока не были обработаны все 40М метрических имен с метками. Затем он достиг устойчивой скорости вставки 1,5-2,0М точек данных в секунду, так что конечный результат составил 1,7М точек данных в секунду.
Графики для 40М уникальных временных рядов аналогичны графикам для 4М уникальных временных рядов, поэтому давайте их пропустим.
Выводы
- Современные TSDBs способны обрабатывать вставки для миллионов уникальных временных рядов на одном сервере. В следующей статье мы проверим, насколько хорошо TSDBs выполняет выбор по миллионам уникальных временных рядов.
- Недостаточная загрузка процессора обычно указывает на узкое место ввода-вывода. Кроме того, это может указывать на слишком грубую блокировку, когда одновременно может работать только несколько потоков.
- Узкое место ввода-вывода действительно существует, особенно в хранилищах без SSD, таких как виртуализированные блочные устройства облачных провайдеров.
- VictoriaMetrics обеспечивает наилучшую оптимизацию для медленных хранилищ с низким уровнем ввода-вывода. Он обеспечивает наилучшую скорость и наилучшую степень сжатия.
Загрузите односерверный образ VictoriaMetrics и попробуйте его на своих данных. Соответствующий статический двоичный файл доступен на GitHub.
Подробнее о VictoriaMetrics читайте в этой статье.
Обновление: опубликована статья, сравнивающая производительность вставки VictoriaMetrics с InfluxDB с воспроизводимыми результатами.
Обновление#2: Читайте также статью о вертикальной масштабируемости VictoriaMetrics vs InfluxDB vs TimescaleDB.
Обновление #3: VictoriaMetrics теперь с открытым исходным кодом!
Телеграм чат: https://t.me/VictoriaMetrics_ru1








