Ранее мы уже научились перехватывать блокировки из лога сервера PostgreSQL. Давайте теперь положим их в БД и разберем, какие фактические ошибки и проблемы производительности можно допустить на примере их простейшего анализа.
В логах у нас отражается всего 3 вида событий, которые могут происходить с блокировкой:
deadlock'и исключим из анализа — это просто ошибки, и попробуем выяснить, сколько всего времени мы потеряли из-за блокировок за конкретный день на определенном хосте.
Для начала нам понадобится таблица, куда мы будем собирать все такие записи:
Попробуем ответить на вопрос, вынесенный в начало статьи, простейшим способом.
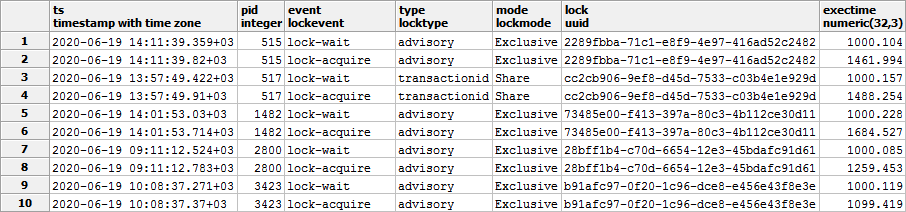
Что такое время ожидания блокировки? Ну, очевидно же, — это время ее получения для каждого случая ее ожидания:
Тип блокировки (
Дальше останется только просуммировать полученные результаты.
Все просто и ясно! А что нам покажет
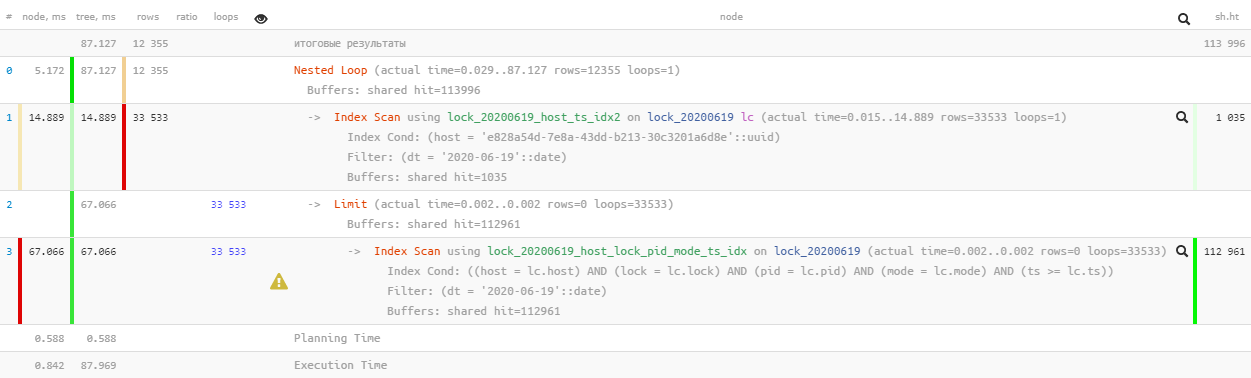
Оу… пришлось прочитать почти 900MB данных, причем почти все — из-за поиска связанной записи для каждой блокировки, не очень красиво.
Но является ли этот запрос вообще корректным для нашей задачи? Нет! Посмотрим внимательно в собранные данные:

Ой… Оказывается, сервер «жалуется» в логи на одну и ту же неполученную блокировку иногда много-много раз. А это означает, что мы учли время ее ожидания кратно количеству таких записей в логе, что совсем не соответствует желаемому.
Собственно, а зачем мы вообще для каждой записи ожидания ищем связанную? Мы же хотим узнать, сколько заняло ожидание, а оно прямо записано в
Почти, да не совсем. Дело в том, что под нагрузкой лог-процесс может пропускать любые из записей — хоть о начале ожидания блокировке, хоть о факте ее получения:

Так неужели нет способа за одно чтение сразу получить все нужные нам данные?
На помощь нам придут оконные функции.

А конкретнее — модель выделения «цепочек» в готовой выборке из статьи «SQL HowTo: собираем «цепочки» с помощью window functions».
Сначала поймем, что условием окончания «цепочки» — то есть сегмента подряд идущих по ключу
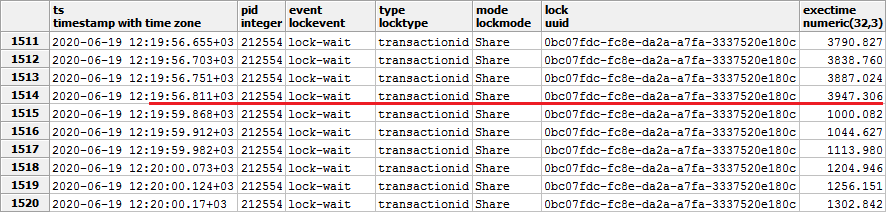
Также надо учесть тот факт, что время может совпадать для нескольких записей лога даже с одного PID. В этом случае надо дополнительно сортировать по

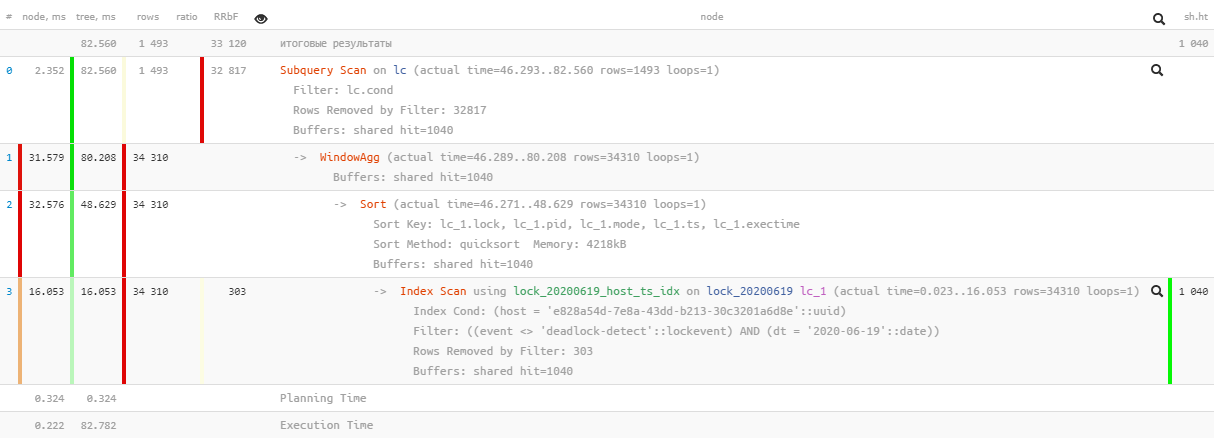
Теперь мы прочитали всего 8MB данных (в 100 раз меньше!), чуть-чуть уменьшив итоговое время выполнения.
Его можно уменьшить еще, если создать индекс, идеально подходящий под
В логах у нас отражается всего 3 вида событий, которые могут происходить с блокировкой:
- ожидание блокировки
LOG: process 38162 still waiting for ExclusiveLock on advisory lock [225382138,225386226,141586103,2] after 100.047 ms - получение блокировки
LOG: process 38162 acquired ExclusiveLock on advisory lock [225382138,225386226,141586103,2] after 150.741 ms - взаимоблокировка
ERROR: deadlock detected
deadlock'и исключим из анализа — это просто ошибки, и попробуем выяснить, сколько всего времени мы потеряли из-за блокировок за конкретный день на определенном хосте.
Для начала нам понадобится таблица, куда мы будем собирать все такие записи:
CREATE TABLE lock(
dt -- ключ хронологического секционирования
date
, host -- сервер, на котором возникла блокировка
uuid
, pid -- PID процесса из строки лога
integer
, ts -- момент события
timestamp
, event -- { lock-wait | lock-acquire | deadlock-detect }
lockevent
, type -- { relation | extend | ... }
locktype
, mode -- { AccessShare | RowShare | ... }
lockmode
, lock -- объект блокировки
uuid
, exectime -- продолжительность
numeric(32,2)
);Более подробно про организацию секционирования в нашей системе мониторинга можно прочитать в статье «Пишем в PostgreSQL на субсветовой: 1 host, 1 day, 1TB», а про различные типы и режимы блокировок — в «DBA: кто скрывается за блокировкой».
Как слышится, так и пишется
Попробуем ответить на вопрос, вынесенный в начало статьи, простейшим способом.
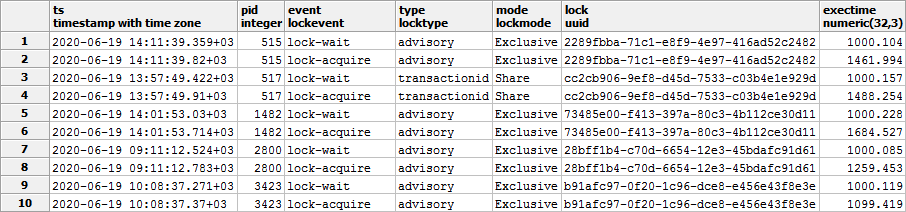
Что такое время ожидания блокировки? Ну, очевидно же, — это время ее получения для каждого случая ее ожидания:
- берем каждый случай ожидания (
lock-wait) - для него находим ближайшую «снизу» по времени запись получения (
lock-acquire) «этой же»(lock, pid, mode)блокировки — то есть на тот же объект, в том же процессе, с тем же режимом
Тип блокировки (
type) в нашем случае можно опустить, поскольку он однозначно определяется самим объектом (lock).Дальше останется только просуммировать полученные результаты.
SELECT
ts
, pid
, event
, type
, mode
, lock
, exectime
, T.*
FROM
lock lc
, LATERAL (
SELECT
exectime waittime
FROM
lock
WHERE
(
dt
, host
, lock
, pid
, mode
, event
) = (
'2020-06-19'::date
, lc.host
, lc.lock
, lc.pid
, lc.mode
, 'lock-acquire'
) AND
ts >= lc.ts
ORDER BY
ts
LIMIT 1
) T
WHERE
(
lc.dt
, lc.host
, lc.event
) = (
'2020-06-19'::date
, 'e828a54d-7e8a-43dd-b213-30c3201a6d8e'::uuid
, 'lock-wait'::lockevent
);Все просто и ясно! А что нам покажет
EXPLAIN?..
Оу… пришлось прочитать почти 900MB данных, причем почти все — из-за поиска связанной записи для каждой блокировки, не очень красиво.
Но является ли этот запрос вообще корректным для нашей задачи? Нет! Посмотрим внимательно в собранные данные:

Ой… Оказывается, сервер «жалуется» в логи на одну и ту же неполученную блокировку иногда много-много раз. А это означает, что мы учли время ее ожидания кратно количеству таких записей в логе, что совсем не соответствует желаемому.
Помни о цели!
Собственно, а зачем мы вообще для каждой записи ожидания ищем связанную? Мы же хотим узнать, сколько заняло ожидание, а оно прямо записано в
lock-acquire. Так давайте сразу отбирать только их, тогда будет всего лишь один Index Scan — правильно?Почти, да не совсем. Дело в том, что под нагрузкой лог-процесс может пропускать любые из записей — хоть о начале ожидания блокировке, хоть о факте ее получения:

Так неужели нет способа за одно чтение сразу получить все нужные нам данные?
Window Functions: семерых одним ударом
На помощь нам придут оконные функции.
А конкретнее — модель выделения «цепочек» в готовой выборке из статьи «SQL HowTo: собираем «цепочки» с помощью window functions».
Сначала поймем, что условием окончания «цепочки» — то есть сегмента подряд идущих по ключу
(host, lock, pid, mode) записей блокировки — для нас является или явное возникновение event = 'lock-acquire' или (что очень редко, но бывает) начало нового сегмента блокировки того же объекта, чья длительность (exectime) начала считаться заново.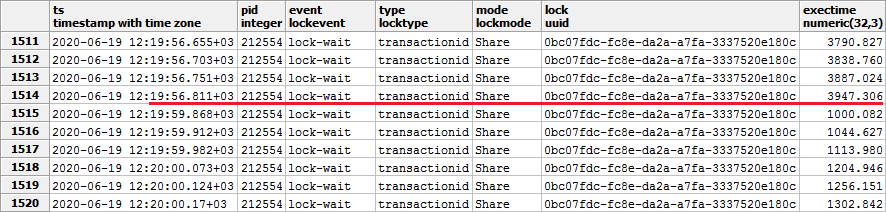
Также надо учесть тот факт, что время может совпадать для нескольких записей лога даже с одного PID. В этом случае надо дополнительно сортировать по
exectime, чтобы получить правильную последовательность:
-- формируем условие окончания блокировки
WITH lc AS (
SELECT
*
, CASE
WHEN event = 'lock-wait' THEN
exectime > coalesce(lead(exectime) OVER(PARTITION BY lock, pid, mode ORDER BY ts, exectime), 0) -- "перелом" времени ожидания
ELSE TRUE -- 'lock-acquire' - блокировка получена
END cond -- условие окончания "цепочки"
FROM
lock lc
WHERE
event <> 'deadlock-detect' AND -- исключаем все deadlock
(
lc.dt
, lc.host
) = (
'2020-06-19'::date
, 'e828a54d-7e8a-43dd-b213-30c3201a6d8e'::uuid
)
)
-- оставляем только "последние" записи - их exectime и есть время ожидания "всей" блокировки
SELECT
ts
, pid
, event
, type
, mode
, lock
, exectime
FROM
lc
WHERE
cond;
Теперь мы прочитали всего 8MB данных (в 100 раз меньше!), чуть-чуть уменьшив итоговое время выполнения.
Его можно уменьшить еще, если создать индекс, идеально подходящий под
OVER (то есть включающий lock, pid, mode, ts, exectime), избавившись от Sort-узла. Но обычно поле в индексе «за timestamp» делать не стоит.