Комментарии 592
Радоваться или бояться? А то Майкрософт, помнится, любила java и Интернет...
А с джавой или интернетом разве что-то случилось?
С джавой случился C#. И, кажется, это даже неплохо.
В этом смысле даже котлин воспринимается, как позитивная тенденция мира джавы.
Именно благодаря C# с джавой всё хорошо. Всё дело в том, что Java очень неповоротлива в плане добавления нового функционала, а C# её расшевелил. Конкуренция всегда идёт на пользу обеим сторонам.
Так этот цикл и ускорение выпусков и пришло в Java благодаря наличию конкуренции в лице C#.
В общем-то именно, что да, потому что они как бы сверху приделываются бантиком, поэтому они получаются слишком частными и хрупкими.
Вот например records. Пришлось аж целое новое ключевое слово вводить, в то время как в Rust это просто частный случай обычной структуры, на которую просто добавили некоторые дополнительные derive'ы.
Sealed классы без smart cast-ов будут выглядеть уродско. Новый instanceOf тут не замена, имхо, получается ужасный код.
Лямбды имеют уродский синтаксис, да ещё и _ запрещено. И похерили проверяемые исключения.
switch-expression сделали «чтобы был», добавив отдельный кусок синтаксиса для него.
Я не вижу проблемы в большом количестве сахара и не вижу большой проблемы в том, что код может стать короче. Разумеется, что иногда это ведёт к удару по производительности, но никто не заставляет использовать сахар. На том же шарпе, условно, можно писать как на си даже без вызовов (практически) к ГК. Главное, чтобы вы понимали, как этот сахар работает.
Более того. Если вы мего-зануда и не хотите чтобы кто-то использовал в вашем коде определённые вещи — уделите полчаса и напишите анализатор (имеется в виду выбросить ошибку или ворнинг).
Правда, для тех кто начинает сейчас только изучать шарп… это наверное катастрофа. Куча всего. Почему это можно сделать 10 разными способами?
С Интернетом случился Internet Explorer.
P.S.Кроме MS JVM еще был J#.
Кто сказал, что здесь история не повторится?Подвижки уже есть.
И проект «Verona» о котором вы нам по секрету поведали, то о нем Левик говорит в своем видео, которое указано. И там он говорит, что не знает статуса и планов этого эксперимента. Но Verona лежит на гитхаб-е — да.
С java случился эпичный батл в суде, после чего Sun запретило MS делать свою JVM (которая отличалась от задаваемых Sun стандартов)… собственно тогда Sun вообще задалась вопросом более жёсткого контроля выпускаемых JVM. Впрочем я бы сказал что в данном случае это успех, а вот если бы Sun потупило ещё пару лет, то проблем в Java было бы столько же, сколько было в вебе с ie6 в эпоху chrome-ff-ie8. А так поимело проблем ограниченное количество java-девелоперов + некоторая часть кода внезапно превратилась в тыкву.
Если большая корпорация с кучей лишних денег сейчас использует технологию X — это ещё не значит, что завтра эту технологию не закопают, а команду промоутеров — не переведут на другие проекты, или что эту технологию вообще используют для реальных проектов, а не для того, чтобы насолить конкурентам.
Жалко наивных людей, которые «хотят быть как Microsoft» и ведутся на этот промоушен, а потом остаются без реального опыта в востребованных технологиях.
Срочно все забываем C#!
C# был официально выпущен Microsoft в комплекте со средствами разработки и фреймворками. Что выпущено ими по Rust? Предлагаете считать заявление какого-то подметайла официальной позицией Microsoft? Тогда что за язык Verona? Я запутался: что мне выбирать для проекта следующего космического корабля: Rust или Verona?
Наверное пишете с компьютера под Singularity? Когда собираетесь переходить с IronRuby на Rust?
Но зато это прекрасно поможет самому расту еще больше утвирдиться а мире
их статистика CVE соответствует показателям другихА где можно посмотреть это статистику «других»?
А то обсасывается одна цифра из одного источника, как я вижу.
гугл (хром) www.techspot.com/news/85368-google-70-percent-serious-security-bugs-memory-safety.html
эпл langui.sh/2019/07/23/apple-memory-safety
Точно помню похожую статистику про адоб
Думаю, если покопаться в базе CVE, то можно и самому собрать такие данные по кому угодно.
Однако, как Вы верно заметили — ошибок «удаление файлов пользователя» и «бесконечного цикла перезагрузок» ни один язык программирования (по кр.мере, из известных мне) устранить не может.
Это если знать плюсы. А если не знать ни плюсов ни раста, то один и тот же не очень сложный код пишется на расте в разы быстрее, чем на плюсах. Эргономичнее он.
в которых можно доказать отсутствие такого поведения
Погодите-погодите! Вы не приведете пример, как доказать отсутствие бесконечных перезагрузок и удаления лишних файлов, случаем?
Тут, знаете ли, «поля этой книги слишком узки»…
Не то, что это невозможно доказать в принципе… но для формализации всех требований потребуется столько всего формально описать — что даже у Microsoft столько разработчиков нету.
Но какие-то более простые вещи — вполне возможно.
Отсутствие «бесконечного цикла перезагрузок» надо доказывать не для каждой отдельной программы, а для совокупности программ, запускающихся при загрузке. А это уже на порядок сложнее.
Хуже того: нигде нет гарантии, что набор программ, запускающихся при загрузке, будет нужным: м.б. так, что часть программ от новой версии, а часть от старой; или вообще каким-то образом туда влезло что-то постороннее. Как Вы понимаете, количество вариантов растёт экспоненциально, сложность доказательства становится непомерной.
Частично помогает строгая изоляция программ — когда каждая программа имеет строго свою функцию и не может сделать ничего за её пределами. Но разделение функций — это вопрос не к языку программирования, а к архитектуре. В Windows — архитектура такова, что доказать можно лишь отсутствие изоляции. Хуже того — архитектура PC-совместимого компьютера такова, что до момента загрузки ядра операционки изоляция в принципе невозможна; а реально — изоляция становится возможной существенно позже загрузки и инициализации ядра. Так что доказуемая надёжность системы на ранних этапах старта — на данный момент в принципе недостижима.
Ну и до кучи: строгая изоляция программ обязательно понижает эффективность работы.
Я бы начал с того, что пользовательская программа не должна приводить к перезагрузке компьютера (в самом деле, зачем?).
А halt и shutdown это пользовательские программы? А когда кнопочка в «меню пуск» посылает сигнал системе о перезагрузке, это пользовательская программа? Я думаю да. Как без них то перезагрузить, питание дернуть?
Впрочем это всё — разговоры «в пользу бедных». Почему ваш телефон, с вероятностью 99%, поддерживает вывод данных на консоль через serial port? Потому что когда-то давно к компьютерам присоеденили телетайп, а потом… эта — работает не трогай…
Никакой язык это не изменит…
А уже кнопочка выключения могла бы посылать «запрос на перезагрузку» привилигерованной части
картошка — картофель
как не назови, сигнал или непосредственный вызов кода, а пользовательский софт инициализирует перезагрузку.
чтобы написать спецификацию ОС которая не будет косячить, надо придумать все возможные косяки.
Возьмем
superCoolDelete: (path: FilePath) -> Not (UserFile path) -> Eff [Delete] ()
*Интересное наблюдение, недавно 0xd34df00d'у скинули кусок кода, так он прокоментировал типа «я не совсем понимаю, потомучто не знаю язык», зато сам как не кусок кода, идрис, который никто не знает.
Вернемся к коду. Немножко изменим задачу, «защитить от случайного удаления файлов». Вспомним нвидиа и их скрипт который вместо
rm -rf /var/bla/bla/bla сделал
rm -rf /var /bla/bla/bla.От такого можно защитить? Например как? создать специальную rm1, которая примет только 1 аргумент? Больше вариантов не знаю. Но ведь чтобы это создать, надо сначала натолкнуться на такую проблему и понять что она имеет место быть.
Если сигнатура функции удаления выглядит как что-то в духеНу а кто сказал, что невозможно удалить файлы иным способом? Например, какая-то программа Икс создаёт текстовый файл; а программа Игрек запускает shell и передаёт ему этот файл в качестве скрипта. Теперь надо доказать, что в скрипте не м.б. команды удаления файла с путём юзерского каталога. Я боюсь, тут мы попадаем на нереальную задачу, ибо shell явно не входит в число языков, комплментарных к доказующим системам.
superCoolDelete : (path : FilePath) -> Not (UserFile path) -> Eff [Delete] ()
то её не получится вызвать без аргумента, доказывающего, что по указанному пути не лежит пользовательский файл.
Я бы начал с того, что пользовательская программа не должна приводить к перезагрузке компьютера (в самом деле, зачем?).Вообще-то, программа shutdown — вполне пользовательская.
Или вот вариант, практиковавшийся в старых Windows (в W'XP точно, в остальных я не уверен; может, и сейчас есть): В ходе загрузки было обнаружено повреждение файловой системы. После исправления сбоев — система перезагружается, загрузка стартует заново.
Аналогично — система установки обновлений в Windows после установки некоторых обновлений (видимо, тех, которые затрагивают ядро и системные процессы) перезагружает систему.
Вопрос в том, сколько из этих вариантов на самом деле достаточно уникальны.Если у нас стоит вопрос о доказательстве — то запросто уникальными м.б. все варианты.
Так-то и количество вариантов чисел для утвержденияНу, я с радостью посмотрю доказательство. Я-то всегда считал, что это — базовая аксиома алгебры., гм, большое, но доказать это свойство можно парой строк.(a + b) + c = a + (b + c)
Описанное Вами утверждение — достаточно простое в силу простоты составляющих его элементов и малого числа элементов в утверждении. Тогда как типичные программы содержат огромное количество простых элементов.
Посмотрел на биографию Ryan Levick:
I’m a developer advocate working in Berlin, Germany. I joined Microsoft via the acquisition of Wunderlist. I’ve spent my career building apps on the server and client side and exploring a wide range of open source technologies with a particular focus on functional programming.
Skills:
* Rust, JavaScript/TypeScript, Elm, Elixir
* Functional programming
* Software architecture
* Software Education
И меня смутило несколько аспектов:
- Он инженер, разработчик, который был включен в микрософт поглощением другой компании заявляет от лица всей микрософт что будут использовать Раст?
- В его профиле кроме раст JavaScript/TypeScript, Elm, Elixir больше ничего нет, он действительно может что-то с чем то сравнивать?
Я понимаю, что молодому языку нужно пробивать себе дорогу в жизни, но тоньше работать надо, если людей долбить по голове будет просто секта. Если люди реально увидят пользу и захотят — будет новый С.
Например — хочу я микроконтроллер на Риск5 и раст, все что у меня есть это россыпь GitHub репозиториев, бол-во устаревший, а другие как конструкторы. Код который будет генерировать компилятор должен быть надежный, я не могу потратить время отлаживая еще и генерируемый ассемблер.
В общем что я хочу сказать текущему тренду на «вдалбливание, что раст могуч» — чтоб он действительно таковым стал уйдут годы и годы, мы состаримся, а потом он либо тихо умрет, либо так же тихо станет стандартом де-факто, но ни в 1 сценарии он не станет стандартом только потому что пользователей активно убеждают.
Я понимаю, что молодому языку нужно пробивать себе дорогу в жизни, но тоньше работать надо, если людей долбить по голове будет просто секта.
Что у нас там с сектой любителей картофеля? Картофель в России внедрялся давлением сверху, без особой тонкости, если что.
Впрочем, картофельные бунты были, да.
К чему может привести ставка на один картофель на все случаи жизни, вам могут рассказать ирландцы середины 19 века :) А вообще согласен с предыдущим оратором насчёт попыток агрессивного вдалбливания.
Здесь аналогия работает скорее не в пользу C (и классическое: картошка не при чём, это неправильные ирландцы). Но я имел в виду то, что к сектантству такие ситуации имеют мало отношения, хотя многим почему-то хочется видеть это именно так.
Ну не знаю. Если один инструмент позволяет совершить 10 ошибок на N строк кода, а другой — только 1, то очевидно нужно выбирать второй. При этом никто не говорит, что вот совсем никаких ошибок не будет, это скорее всего невозможно. Но значительно уменьшить их количество вполне реально.
Насчет тенденциозно — ну извините, если в каждой фразе делать оговорки, что вот в этих случаях может быть это, а в этих то, то вместо живой речи получим юридическо-бирократический язык. Парень правильно делает, что говорит о плюсах раста там, где у C/C++ традиционно все плохо — с безопасностью памяти и агитирует за переход на те инструменты, где с этим получше. Подробности вы всегда можете узнать сами — чай github еще не стал платным, хотя многие после покупки его Майкрософтом и ударились в панику.
Ну и давайте до абсурда не доводить. У нас с одной стороны есть C/C++, которые вообще ничего не дают в плане безопасности. С другой у нас есть rust, который даже без формальной верификации чисто технически способен предотвращать кучу ошибок. Мы же не требуем формальной верификации о статических анализаторов, виртуальных машин со сборщиками мусора и прочими штуками, которые мы считаем безопасным. Умозрительно нам понятно, что они достаточно безопасны. Как бы, это уже огромный шаг вперед и этого достаточно, чтобы задуматься о переходе. Формальная верификация я даже не знаю кому реально нужна, если даже ядро ОС пишут без всяких верификаций и строгих стандартов кодирования. Отрасли, где на кону жизни людей, может быть повременят, хотя даже там используются все теже С/С++, обложенные кучей костылей, чтобы сделать их безопаснее.
Этого типа достаточно, чтобы исчезло подавляющее большинство CVE, которые обычно приводят или прямо к RCE, или повышению привилегий.
Гонки данных, как недавно было продемонстрировано — не предотвращает. Ну или точнее, может и предотвращает для хелловорлдов, но не на реальных применениях (где мешает дизайн Раста).
1. Pin держит для текущего потока указатель (ссылку), чтобы OB его не переместил (move, consume) или не удалил по концу лайфтайма
2. Pin через unsafe отдает сырой указатель (ссылку) другому потоку или кому угодно, что тот с ним работал. Но ОВ второго потока ни сном ни духом про соперника.
Итого это не заслуга языка, а простой костыль, аналогичный Memory.Pin в C#
1. Pin держит для текущего потока указатель (ссылку), чтобы OB его не переместил (move, consume) или не удалил по концу лайфтайма
Нет же. Pin оборачивает некий указатель на объект. Сам Pin можно перемещать, он требуется для того, чтобы через указатель нельзя было вытащить данные за указателем (при помощи, например, std::mem::swap). Это позволяет сохранять стабильный адрес объекта в памяти и, как следствие, хранить в объекте ссылки на себя.
Для неудаления в конце времени жизни тоже есть тип, но это другой тип, ManuallyDrop, и он нужен совсем для других вещей.
2. Pin через unsafe отдает сырой указатель (ссылку) другому потоку или кому угодно, что тот с ним работал. Но ОВ второго потока ни сном ни духом про соперника.
Потоки тут не при чём. Pin может отдавать мутабельную ссылку на внутренности, и эта операция unsafe из-за того, что при этом можно вытащить объект из-за ссылки и потенциально инвалидировать самоссылающиеся объекты. Временем жизни Pin никак не управляет.
С тем, что Pin — это костыль, никто и не спорит. Но это — естественное следствие того, что Rust разрабатывался как язык, в котором любое значение тривиально перемещаемо. Я не уверен, что это можно было бы сделать как-то получше, не сломав при этом обратную совместимость.
Но вопрос был в том, что Раст предотвращает Датарейс, но если используем Pin — то нет.
И я про то. Pin обходит OB для содержащегося указателя (кроме умеющих в Unpin, как я понял).
Pin обходит правила владения не больше чем Box. Вы же не будите, что из-за Box в расте возникают датарейсы?
Из документации этого не видно — но по факу Pin(&T) не умеет в as_mut().
В итоге, читая доку, я был обманут.
Итоговый результат в этом треде — Раст предотвращает гонку данных между потоками. Но цена этого — вы не можете использовать общие данные между потоками в safe Rust. Никак!
Вообще-то видно:
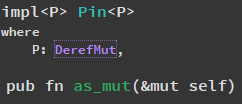
P: DerefMut означает, что можно получить мутабельную ссылку на содержимое P, что неверно, если P=&T. В этом можно убедиться, посмотрев реализации трейта DerefMut. DerefMut для &T там явно запрещён:
impl<'_, T> !DerefMut for &'_ T
Я то в исходниках потом нашел.
https://doc.rust-lang.org/std/pin/struct.Pin.html#method.as_mut
Условие со скрина написано строчкой выше.
Без синхронизации — действительно не можете и это хорошо. А если у вас данные Sync — шарьте сколько угодно.
Из документации этого не видно
Как же это не видно. Видите, какое ограничение на параметр P? Что-то, что может дать мутабельную ссылку. Просто для новичка возможно это не слишком очевидно, так ведь и Pin не новичкам нужен.
В документации это прекрасно видно, метод as_mut присутствует только в impl-блоке для тех P, которые реализуют DerefMut: https://doc.rust-lang.org/std/pin/struct.Pin.html#method.as_mut
Но цена этого — вы не можете использовать общие данные между потоками в safe Rust.
Это совершенно не верно. Как минимум можно использовать безопасные примитивы синхронизации. Также и без них можно шарить между потоками объект по статической ссылке.
Ну а если вы подразумеваете, что в конечном итоге все равно где-то "под капотом" будет вызываться unsafe — то да, без этого не обойдется ни одна сколь-либо значимая операция. Я не могу взять объект из Vec по индексу или проитерироваться по массиву с тем, чтобы не стриггерить какой-нибудь unsafe-код. Ну и что с того?
Это совершенно не верно. Как минимум можно использовать безопасные примитивы синхронизации. Также и без них можно шарить между потоками объект по статической ссылке.Можно пример?
2. Pin через unsafe отдает сырой указатель (ссылку) другому потоку или кому угодно, что тот с ним работал. Но ОВ второго потока ни сном ни духом про соперника.
Ну вот опять вы придумываете.
Pin, как и другие смарт-поинтеры раста, не нарушает гарантии, которые предоставляет раст для своего safe подмножества и не передает никакие указатели в другие потоки сам по себе.
pub fn as_mut(&mut self) -> Pin<&mut P::Target> {
// SAFETY: see documentation on this function
unsafe { Pin::new_unchecked(&mut *self.pointer) }
}Кек. Если у вас на руках есть &mut-ссылка, то у вас уже заведомо доступ к Pin есть только из одного потока. Это на этапе компиляции проверяется.
For correctness, Pinrelies on the implementations of Deref and DerefMut not to move out of their self parameter, and only ever to return a pointer to pinned data when they are called on a pinned pointer.
Тем не менее, получается, что "благодаря" Pin сочетание safe Rust + standard library может приводить к BC. И это закрыли без фикса: https://github.com/rust-lang/rust/issues/66544
Это точно полный и окончательный фикс? Я не вижу как он может предовратить имплементацию DerefMut, перемещающую self куда-нибудь. Или, например, меняющую местами две части self, которые отдаются в норме только через Pin (structured pinning это называется, кажется).
Я не вижу как он может предовратить имплементацию DerefMut
Как-то так
Вообще, вопросы, связанные с Unsoundness для Pin действительно не простые. Если вы не согласны с фиксом, то думаю, гораздо продуктивнее будет написать сразу в указанную вами issue.
Кстати, на моей [длинной] памяти это первый язык, нарушающий правило — хороший код — самодокументированный.
В Расте комментарии документирования превышают код втрое
Из того, что в std Rust хорошо все задокументировано, как вы делаете вывод, что код там не самодокументированный? По-вашему в дополнении к самодокументированному коду невозможно написать хорошую документацию?
А вот комментарии к Pin, которых я вдоволь начитался вчера, доставляют
- Notice that this guarantee does *not* mean that memory does not leak!
- The following implementations aren't derived in order to avoid soundness issues..
- this method is safe because..(много повторений)
- This constructor is unsafe because we cannot guarantee that...
- This function is unsafe. You must guarantee...(несколько шт)
- we just need to take care not to allow such impls to land in std
Но главное, что работает :troll:
Отрасли, где на кону жизни людей, может быть повременят, хотя даже там используются все теже С/С++, обложенные кучей костылей, чтобы сделать их безопаснее.Нет. В ядерной энергетике и авиации используют Ada, Ravenscar profile, SPARK. С программами на С/С++ предпочитают дела не иметь.
Также, например, safety-critical ПО на недавно отшумевшем Crew Dragon написано на С++. Так что, мне кажется, вы слишком категоричны.
С/С++ это индустриальный стандарт сейчас и уже давно.
www.cvedetails.com/vulnerability-list/vendor_id-26/Microsoft.html
и список CVE в The RustSec Advisory Database
rustsec.org/advisories
как бы намекает, и на данный момент не идет ни в какое сравнение.
Ошибок «не может не быть», но если кому-то хочется их много, то это дело «хозяйское», насильно мил не будешь…
P.S. Тезис «Rust выбирают „любимой женой“ ПЯТЫЙ год подряд» тоже как бы… такой. Я, например, ни разу не голосовал там ни за какой язык, мне есть, чем заняться кроме этого, а представители пресловутой Rust Evangelism Strike Force просто более организованны и активны в этом плане, ходят строго в ногу, долбят одни и те же сомнительные тезисы из статьи в статью пополам с маркетинговым булшитом в стиле «a fundamental break in the history of technology», и что с того? Да ничего.
Ладно, не интересно, все это уже жевано-пережевано уже много раз, принимать участие в дальнейшей дискуссии на эту тему никакого желания у меня нет, я уже наперед знаю все аргументы всех сторон :)
ограниченность дизайна safe Rust
Для обеспечения доказуемой корректности программы можно или ограничить возможности языка или обязать программиста писать доказательства вручную. В Rust выбрали первый вариант. Вряд ли это можно назвать ограничением дизайна языка.
Есть ограничения текущей реализации borrow checker, которая не пропускает некоторые корректные программы, это — да.
Вот тут не то что передергивание, а откровенное вранье — кто ж там вас проверит как было в 90-х?? В 1995 — FIDO net был еще вполне живой и бодрый, я то помню, а инет могли позволить себе далеко не везде.
Так что зря тут была написана откровенная ложь, относительно «рекламирования» и аппелирование о «какой то там не доказательности».
… просто потенциальные места их возникновения пытаются обозначить флажками..
Еще одно ложное утверждение.
Эти агрессивные сторонники Rust дошли до того, что ПЯТЫЙ год подряд на StackOverflow выбирают его в «любимые языки». Вот где источник максимальной агрессии! Тут уже никак не поспорить…
Плюс картофель свою нишу действительно завоевал и не только в России, не будь он выгодным для людей на деле, он бы тихо скончался на обочине истории.
Я вам приведу пример — еще года 3 назад когда меня стали со всех сторон бомбардировать статьями какой прекрасный язык Раст, я честно пошел и изучил предмет.
Но в изучаемом материале было больше паблик-релэйшиншип и рекламы нежели инженирии.
Одно заявление, что Мозилла доверяет расту, но тихо умалчивая, что в ее же недрах его и сделали — стоит многого и показывает какими приемами готовы пользоваться люди продвигающие Раст в массы.
Я желаю Расту удачи, но чем больше вижу нечистоплотной рекламы, тем меньше шансов, что лично я к нему обращу свой взор. Потому что если меня пытаются дурить вот здесь — то где еще и сколько мне это будет стоить когда мой микроконтроллер в поле перестанет работать?
Но в изучаемом материале было больше паблик-релэйшиншип и рекламы нежели инженирии.
О каких материале речь? В своё время, изучал язык по раст-буку, rust by example и растономикону. В первом ещё можно найти признаки рекламы, но с другой стороны, мало какая книга о языке обойдётся без хвалебных эпитетов. Растономикон так вообще состоит чисто из технических подробностей.
Одно заявление что Мозилла доверяет расту, но тихо умалчивая что в ее же недрах его и сделали стоит многого и показывает какими приемами готовы пользоваться люди.
Ну, вообще-то изначально Rust был проектом Грейдона Хоара, и разрабатывался несколько лет перед тем, как его разработку начала спонсировать Mozilla.
В общем, по тем временам всё выглядело настолько убого, что пользоваться этим дерьмом мог либо мазохист, либо сумасшедший.
Но как же её пиарили! Java представлялась чуть ли не как новый виток развития ни много ни мало человеческой цивилизации! Пиар настолько зашкаливал, что за свою жизнь я потом всего однажды встречал нечто подобное (и это был момент выхода первой книги про Гарри Поттера). Право же, реклама Rust и рядом не стоит с тем уровнем упоротости и агрессивности, с которым продвигалась Java в середине 90-х.
And don’t even remind me of the fertilizer George Gilder spread about Java:
A fundamental break in the history of technology…
That’s one sure tip-off to the fact that you’re being assaulted by an Architecture Astronaut: the incredible amount of bombast; the heroic, utopian grandiloquence; the boastfulness; the complete lack of reality. And people buy it! The business press goes wild!
Говоря по правде, Java в своё время была действительно прорывом. Особенно, когда вышел Hotspot, тогда и произошла смена парадигм, C++ начал стремительно вытесняться из бизнес-сектора.
JavaStation ведь в Sun на полном серьёзе разрабатывали.
И, потом, не в HotSpot дело. Что там у нас было актально, когда вокруг Java хайп начался? Pentium на 120MHz да MicroSPARC на 100Mhz?
Ну с эмулятором MicroSPARC я не знаю, но точный эмулятор Pentium на 120Mhz найти не проблема.
Можете взять любые свои HotSpot'ы и убедиться что на том железе, вокруг которого разводили хайп — Java, по прежнему, практически невозможно использовать.
То есть в конечном итоге Java — так и осталась тормозным, прожорливым чудом-юдом, однако, на счастье её продвигателей, производители железа смогли-таки сотворить процессоры на которых её можно использовать. И даже почти без отвращения.
P.S. Правда по итогу компания, которая это всё затеяла в надежде, что ей удастся сделать самые быстрые процы и заработать за счёт Java-тормозов кучу денег — сделать этого не смогла и, в конечном итоге, сгинула… но то такое: карма — страшная вещь…
Дело было именно в Hotspot, и в удобстве разработки для серверов. Я в соседнем сообщении писал, что тот факт, что разрабатывать можно было на относительно слабых машинках (как правило Win 95 и позже 2k), а запускать на самых настоящих серверах, при этом не тормозя эти самые сервера -- вот это и обеспечило стремительное вытеснение C++.
Даже сейчас писать кроссплатформенный C++ трудновато, а тогда у тебя максимум была ACE, wxWidgets и крутись как хочешь, никаких бустов. Ошибки, связанные с различием между разработческим и прод окружениями были нормой, и они зачастую были весьма нетривиальны.
А я не зря упомянул Hotspot, до него к Java относились с большим пренебрежением, видя насколько сильно падала производительность. А с ним у многих сразу многие увидели, что на этом можно делать проекты.
Да, и GC, и JIT компиляция, и VM были известны до этого, но предоставить всё это в одной удобной упаковке, с хорошей стандартной библиотекой, при этом разрабатывать можно было на относительно слабых машинках (как правило тогда сидели под виндой), а запускать на самых настоящих серверах — вот это всё впервые дала Java.
То есть затея Sun, в принципе, удалась, просто к 10м годам большие сервера тупо «выдохлись»: люди научились в распределённые системы, стала важна не просто максимальная скорость, а «скорость на доллар» — а по этому показателю «настоящие сервера» никогда и близко не приближались к x86…
Честно говоря, не вижу проблем с "пиаром". Если об языке не говорить, то о нём никто и не узнает. В своё время, заинтересовался как раз из-за срачей на одном форуме. Ну и да, это часть продвижения. Языков нынче много, конкуренция большая: приходится и доступные учебные материалы предоставлять и над качеством документации работать. Ну и да, рекламироваться — как с любым другим продуктом.
Кстати, забавный момент: не будет ведь кто-то предполагать, что мозилла проплатила майкрософту за рекламу? А если контора, которая сама может создавать языки (и успешно это делает), хвалит чью-то стороннюю разработку, то это очень даже положительная характеристика, как по мне.
"Стандартом де-факто" стать не так просто и далеко не всегда на это влияют чисто технические причины. Возьмём, к примеру, swift — язык неплохой, но если бы он не был официальным языком для яблочных платформ, то какая у него была бы доля? Или тот же С#. Или даже котлин — за ним не стоит мега-корпорация со своей платформой, но когда к языку сразу прилагается отличная ИДЕ, то это тоже намного облегчает порог входа.
Опять же, если вместо "болтовни" майкрософт (или кто угодно) начал "насильно" внедрять раст, то недовольных было бы не меньше, хотя казалось бы.
который был включен в микрософт поглощением другой компании заявляет от лица всей микрософт что будут использовать Раст?
Подозреваю, что кому попало делать заявления от лица компании не разрешают.
Подозреваю, что кому попало делать заявления от лица компании не разрешают.
В рамках грустного юмора: зато кто попало считает себя вправе делать заявления от лица компании.
Кажется, в статье описан не такой случай, просто грустное наблюдение.
Но спустя несколько месяцев и пару книжек я понимаю что у этого заявления А должен был быть мелкий шрифт о котором забыли (не просто напечатали мелким, но нарочно забыли — мы же не будем на каждом углу об этом говорить как заявили выше), то у меня появляется чувство что что-то пошло не так и доверие которое было вначале падает до отрицательных величин.
А далее происходит еще интереснее трансформации — инженеры которые говорят о прогрессивности раста мной начинают восприниматься как продажники, а не как инженеры, а чем больше повторяется тезис А, тем больше напоминает секту.
Сколько было этих статей про безопасность, о скорости, о красоте и прочем. Там ведь даже мелкого шрифта не было, а ведь это не рекламные брошюры это материалы для инженеров.
В видео с которого была написана оригинальная статья — там все сказано Левиком.
И в свете этого ваши крайне надуманные глупости выглядять слегка убого, видно что вы не пытались и не будете его слушать. Более того, Левик в конце отвечает на задаваемые в чате вопросы.
Ей богу, ваши потуги выглядят совсем «не в тему».
Небезопасный код в Rust почти всегда является подмножеством большего объема безопасного кода.
В исходнике:
Unsafe Rust code is almost always a subset of a larger body of safe code.
Видимо, Левик пытался сказать, что небезопасный (ну т.е. просто — опасный) код составляет малую долю от всего кода.
А получилось противоречивое высказывание.
Ему бы теорию множеств подучить.
Correctness в переводе — безошибочность, правильность.
Они быстрые, только с ассемблером между кодом и самой машиной.
It is fast, with the only assembly between the code and the machine itself.Совсем плохой перевод.
А тут масса народу развела «песню АНЫКАНА про агрессивную рекламу» — у таких все в порядке с логикой или видят только «заговор» ??? :)))
А можно озвучить эти самые "принципы инженерного подхода"? Как вообще связаны эти две штуки: "инженерный подход" и "агрессивное продвижение"?
Инженерную команду Rust сложно назвать зависимой от хайпа, пиара и т. д. Они заворачивают любые RFC, идеи и реализации, которые могут вызывать хоть малейшие проблемы в дизайне языка и совместимости с другими вещами. Они просто планомерно делают своё дело, развивают язык так как считают нужным.
То, что у языка есть продвижение и он на слуху, это разве плохо? Может это только моё видение, но мне кажется, что основной хайп вокруг Rust создаётся сарафанным радио, то есть самими пользователями, которые устали от проблем в широкоиспользуемых языках программирования, они попробовали или перешли на Rust и теперь хотят рассказать об этом всему миру.
unwrap и unsafe… какой же это, нафиг, безопасный язык?).Понять, что безопасность — это, простите, не
bool и даже не скаляр, что у безопасности — много измерений… они, почему-то, не в состоянии.Ну вот так же, как и фанаты OpenBSD, на самом деле. Если что-то повышает безопасность и этого у вас в операционке нету — то там «не безопасность, а дерьмо».
А тот факт, что операционка, кроме того, чтобы быть безопасной, должна быть полезной… и то же самое — с языком… этого они, почему-то, понять не в состоянии.
Что-то вы в каком то другом мире живете, основное припекание я видел от людей с Си++ головного мозга. Хаскелисты вообще выше всего этого, как мне кажется.
А как раз людей, умеющих в C++, типа 0xd34df00d а Rust особо и не напрягает…
Ну вообще в плане безопасности Rust тут весьма узкую проблему решает, хотя и очень популярную. Количество сегфолтов, когда я перешел на раст, действительно серьезно упало по сравнению с плюсами, причем оставшиеся почти все оказались связаны с FFI, а остальные с моими кривыми руками при написании unsafe блоков кода, которых я не так уж и много настрочил.
Но те, кто хвалят раст за безопасность забывают, что у него есть еще и другие хорошие стороны, система трейтов, АТД, дерайв макросы. Я уж не говорю про удобный тулинг в виде cargo или про систему документации.
То есть он в целом оставляет ощущение заботы о том, чтобы программисту было удобно жить из коробки, за этого его и любят на Stackoverflow.
Файловая и именная иерархия Явы и прочих более удобна.
Предлагаю засечь время чтобы найти описание (повторить мой пусть)
heapless::consts::U9
Один клик в IDE? (:
IDE открывать было лень, поэтому пользовался гитхабом и кликами. Заняло с минуту. Зашёл в heapless/lib.rs увидел, что consts — это реимпорт из typenum/consts.
И прямо в доке typenum/consts второй строкой написано, что эти константы генерятся во время билда, так что в исходниках их нет, есть только кодогенерация. Ну и в целом описание этих констант там прямо в доке.
В расте я новичок, если что — опыта на 2 kloc + активное чтение статей и чужого кода.
В общем, не знаю, к чему именно у вас претензии — если к кодогенерации, то смысла не вижу. А если к тому, что для typenum она вообще нужна, то тут да, проблема молодости языка присутствует. Const generics в разработке, и с ними весь этот бойлерплейт вроде можно будет выкинуть.
Если говорить чуть глобальнее касательно вашего вопроса "непонятно что где искать", то я в целом могу согласиться, мне тоже порой непривычно что операция A над B может быть реализована за счёт импорта трейта C, потому что там дженерик хитрый. Мне кажется, это дело привычки, и то что раст не очень дружелюбен к новичку — довольно известная тема.
Однако у этого подхода есть и плюс — довольно сильные возможности композиции, которые неплохо так заменяют отсутствие привычного ООП (не в прямом смысле, но гибкость при проектировании архитектуры дают сильную). Думаю, это хорошая компенсация за порог входа
и это не кодогенерация
Наверное, я не очень понимаю, что значит "найти". Найти вот это https://docs.rs/heapless/0.5.5/heapless/consts/type.U9.html или вот это https://docs.rs/typenum/1.12.0/typenum/consts/type.U9.html (что в общем-то одно и тоже)? Или найти как с этим работать (т.е. почитать доку к typenum)? Или что-то ещё?
А какую Вам информацию дало найденное описание? =)
typenum тут ни при делах
Боюсь, я не согласен с тем, что это не кодогенерация (т.к. противоположное написано прямо в документации), да и вот та самая строка файла генератора, где создаётся определение типа https://github.com/paholg/typenum/blob/master/build/main.rs#L168
С другой стороны я также не понимаю, что не так с моим ответом, т.к. определение типа я вам нашёл прямо в doc.rs (а куда ещё идти за этим если не туда?)
type U9 = UInt<UInt<UInt<UInt<UTerm, B1>, B0>, B0>, B1>;Собирать локально heapless и делать скриншот из сгенерированного файла мне пожалуй не хочется.
Возможно мы с вами просто говорим на разных языках, но я искренне не понимаю ваших выводов.
И раз: https://github.com/japaric/heapless/blob/master/src/lib.rs#L79
pub use generic_array::typenum::{consts, PowerOfTwo};И два: https://github.com/fizyk20/generic-array/blob/master/src/lib.rs#L78
pub extern crate typenum;Так что там "совсем другое", если это реэкспорт? Секундомер не запускал, но по ощущениям — загрузить гитхаб потребовалось больше времени, чем найти нужные строки.
В общем искать надо мне было не U9, а String<U9>. и с большим трудом обнаружил, что это формируется макросом.
Но это же не макрос.
macro_rules! impl_from_num {
($num:ty, $size:ty) => {
impl<N> From<$num> for String<N>
Этот макрос в самой heapless раскрывается в такую конструкцию:
impl<N> From<u8> for String<N>
where
N: ArrayLength<u8> + IsGreaterOrEqual<U4, Output = True>,
{
fn from(s: u8) -> Self {
let mut new = String::new();
write!(&mut new, "{}", s).unwrap();
new
}
}(и аналогично для других пар, перечисленных ниже). Далее, при наличии реализации From for U, автоматически генерируется реализация Into в обратную сторону. Как следствие, в Вашем коде можно написать:
let num: u8 = ... // как-то получили число
let string: String<N> = num.into();P.S. Кстрати предложенное вам решение: ткнуть в IDE и посмотреть — отлично работает и в C++ и в Rust. Да, оно приведёт вас куда-то в недра сгенерированного файла, но займёт это меньше секунды в обоих случаях.
Нет, build-скрипт — это именно кодогенерация, а не макрос.
Я так понимаю, утро вечера мудренее, надо переносить.
Еще один. heapless::
Вы читать когда научитесь?
Заняло с минуту. Зашёл в heapless/lib.rs увидел, что consts — это реимпорт из typenum/consts.
Вот вам пруф: https://github.com/japaric/heapless/blob/ab9f2515a71baeab86055a1560ee7f5ce1bb4836/src/lib.rs#L79
Сгенерированная документация у Rust тоже кликабельная. Часто проще посмотреть в документацию, потому что там для каждого типа приводится полный набор реализованных трейтов, все в одном месте.
У Раста много хороших сторон, но вот макросы — непонятно зачем второй язык, и с модульностью я, например, что то не понимаю — в каком, ска файле искать тот или иной трейт для типа!? Теряю много времени просто на поиск исходника.
Если код расположен локально, то можно локально сбилдить документацию при помощи rustdoc и в списке реализаций трейтов для типа перейти по ссылке к месту, где написан impl. Если документация уже готовая, то можно её онлайн открыть и точно так же ткнуть ссылку на исходник.
Файловая и именная иерархия Явы и прочих более удобна.
Не уверен. Собственно, главное, что нужно понять в системе модулей Rust — это то, что объявление модуля располагается не в самом модуле, а в родительском модуле. Это позволяет построить всё дерево DAG модулей, имея доступ только к корневому модулю, вне зависимости от того, как они реально располагаются в файловой структуре. И не надо по файлу на модуль делать.
а прямо сейчас у меня есть и риск5 контроллеры разных моделей и пишу нативный код для них на расте. инструментов для разработки уже достаточно.
бывает, что подглядываю в исходники на Си, но это касается только переписывания драйверов подключаемых устройств и пробелов в их документации.
Он инженер, разработчик, который был включен в микрософт поглощением другой компании заявляет от лица всей микрософт что будут использовать Раст?Да, представьте себе. Иногда бывает полезно смотреть не только вглубь, но и, собственно, на поверхность предмета тоже.
Вы тут покопали и установили, что, исходя из опыта человека, он однозначно пропогандировал бы Rust — независимо от того, где он работал бы. И это — полезна информация.
Однако же покупка Wunderlist случилась пять лет назад. Все сроки, которые могли быть по типичным контрактам — давно вышли.
А этого человека не только не уволили, но поставили на должность «developer advocate» (да-да, представьте себе — это оффициальное название должности).
Что это говорит нам о позиции Microsoft в отношении Rust?
В его профиле кроме раст JavaScript/TypeScript, Elm, Elixir больше ничего нет, он действительно может что-то с чем то сравнивать?А почему он дожен что-то с чем-то сравнивать? Задача «developer advocate» — не сравнивать что-то с чем-то объективно. Задача developer advocate — продвигать ту технологию, которую скажут (как правило он должен в эту технологию ещё и сам верить, иначе продвигать плохо получается, но это, строго говоря, не обязательно). А вот продвигать только те технологии, в которые верит нанявшая тебя компания — это обязательно.
Тут как с рекламным агенством: если рекламный агент говорит «наши кроссовки — самые лучшие в мире», то он лично, может быть, так и не склонен считать… но компания, которая его наняла — так считает точно (ну или, как минимум, хочет, чтобы вы так считали). И даже неважно — где он до этого работал и что он рекламировал.
В общем что я хочу сказать текущему тренду на «вдалбливание, что раст могуч» — чтоб он действительно таковым стал уйдут годы и годы, мы состаримся, а потом он либо тихо умрет, либо так же тихо станет стандартом де-факто, но ни в 1 сценарии он не станет стандартом только потому что пользователей активно убеждают.Действительно — активное убеждение не может быть единственным фактором. Очевидно что будут применены и другие.
Вот поэтому я и говорю о том что евангелисты раста не ведут себя как инженеры, а ведут себя как рекламщики-продажники
While researching Rust, we found some issues that gave and continue to give us pause. Some of these concerns include how to regulate the usage of the “unsafe” superset of Rust at scale, lack of first-class interoperability with C++, and interoperability with existing Microsoft tooling. We’ll be blogging about many of these in the future as they do pose challenges for adoption at the scale of Microsoft, and we want to involve the Rust and wider software communities in helping us find solutions that work for everyone.
msrc-blog.microsoft.com/2019/07/22/why-rust-for-safe-systems-programming
Это было меньше года назад, не думаю что вдруг все описанные проблемы исчезли.
stackoverflow.blog/2020/06/05/why-the-developers-who-use-rust-love-it-so-much
While some languages just add polish and ease to existing concepts, several users feel that Rust is actually doing new things with a programming language. And it’s not doing new things just to be showy; they feel these design choices solve hard problems with modern programming.
Поймите, эта технология может стать мэйнстримом, но будет это через годы и годы, если вообще будет. Те войны что ведете вы сейчас вообще бессмысленны.
Мы технари, хотим фактов, открытости и без передергивания, пожалуйста если вы один из нас — уважайте это.
Статья написана по видео? В нем все высказано…
И вот сегодня я потратил еще 44 минуты своей жизни на очередной пиар.
В этом видео (ОТ ИНЖЕНЕРА) единственные цифры это сколько денег стоит то и то и красивые графики которые можно рисовать пачками при продаже чего угодно нового, будь то процессор или машина, убеждая наивных покупателей почему им стоит потратить свои деньги.
Расчет Раст сообщества прост — пока он сообразит у него уже весь тулчейн на нем, уже часть кода переписано и жалко все это бросать и вот новый боец в строю.
Вы апеллируете к видео — я его посмотрел, это очередная рекламная брошюра занимающая 44 минуты!!! Карл, 44 минуты рекламы!
Я больше ни 1 материала в своей жизни по расту не прочитаю, вот никогда. Когда станет стандартом де факто — тогда и приходите. До тех пор ни секунды своего времени.
Я больше ни 1 материала в своей жизни по расту не прочитаю, вот никогда. Когда станет стандартом де факто — тогда и приходите. До тех пор ни секунды своего времени.Знаете вы мне напоминаете одного моего знакомого — бывшего Delphi-программиста. Он вот так же выступал, когда в конце прошлого века начала «активно насаждаться» Java (а до того — C++). Так и остался со своим Pascal (а потом, соответственно — Delphi).
Когда он обратился ко мне лет 5 назад за советом «что теперь-то делать, когда его знания Delphi 7 больше не ценят»… я ответил, что, как бы, решать нужно было в 90е годы, в крайнем случае в нулевые… а сейчас — поезд ушёл.
Он страшно на меня за что-то обиделся… до сих пор не знаю за что. Программировать он, насколько я знаю, бросил, сейчас на рынке чем-то торгует… но причём тут я? Я, что ли, заставлял его «вставать в позу» и отказываться от предложений работы на Java или C++ (когда ему ещё предлагали).
Да, Rust дошёл до той стадии, когда важны (и нужны) не только технические статьи и видео, но и вот такие вот тоже.
Потому что 90% программистов вообще пофигу на чём и как программировать — они не умеют программировать ни на каком. Но и те 10%, кому не всё равно, и тот 1%, который реально крутые вещи создают — они оттуда же вырастают.
Расчет Раст сообщества прост — пока он сообразит у него уже весь тулчейн на нем, уже часть кода переписано и жалко все это бросать и вот новый боец в строю.Только это не «расчет Раст сообщества» — все популярные языки становятся популярными по этой вот схеме. Техническое совершенство вас в Top10 не выведет. Можете у фанатов Haskell спросить…
Чаще всего языки через какую то нишу выстреливают, вот как пример котлин и андроид или свифт и ios.
Да даже python и data science.
Когда он обратился ко мне лет 5 назад за советом «что теперь-то делать, когда его знания Delphi 7 больше не ценят»… я ответил, что, как бы, решать нужно было в 90е годы, в крайнем случае в нулевые… а сейчас — поезд ушёл.
Да почему ушел, была бы мотивация, выучил бы спокойно любой новый ЯП, фундаментально, их когнитивная сложность не особо выросла. Просто он не захотел ни в какой поезд садиться.
Просто он не захотел ни в какой поезд садиться.Дык это и есть типичная проблема с людьми, требующими «инженерной честности»: они, как правило, способны понять что новое — это не сильно переделанное старое, но вот понять что этого вполне может быть достаточно для вытеснения и замены — почему-то неспособны.
Ну вот почему «столбовая линия» ALGOL 58 ⇒ ALGOL 60 ⇒ ALGOL 60 ⇒
Там же нет ничего вот принципиально, радикально нового!
Когда за плечами уже много всяких технологий, уже видел как одни поднимались, другие умирали — не очень страшно. И да, когда то тоже была делфи, потом были другие языки, это всего лишь технологии.
Прочитайте внимательно мои комментарии — я уже изучил технологию, разочаровался. И да, меня не пугает изучение нового даже если я проморгал и это мэйнстрим :) За всеми белками не угонишься.
Я больше ни 1 материала в своей жизни по расту не прочитаю, вот никогда. Когда станет стандартом де факто — тогда и приходите.
Вот это прям "инженерный подход" во всей красе. Я-то думал, что инженер — это тот, кто изучит матчасть и сделает выбор руководствуясь плюсами и минусами инструмента, а не тот, кто "обидевшись на некрасивый пиар" будет игнорировать и всё остальное.
Ну и я хоть и относительно доволен растом, но по сторонам посматриваю. И даже не потому, что боюсь пропустить становление "нового стандарта", а потому что интересно же! И про свежие стандарты плюсов читаю по той же причине.
И про свежие стандарты плюсов читаю по той же причине.Со свежими стандартами… странно. Ну вот появилась новая интересная фишка… Microsoft даже в свой блог о ней написала.
А компилятор до ума — Пушкин будет доводить?
Самое смешное, что clang 9 генерит нормальный код, а потом вы свой clang апгрейдите, и всё.Почему «всё»? Векторизация началась. Там где этот код вы потом в цикл засунете — всё хорошо будет. А вот в отдельной стоящей функции — да, беда. Можно
-fno-slp-vectorize поиспользовать… но тогда он совсем всё в скалярах оставит…Ну тут, хотя бы, можно говорить что новый подход у
clang обычно (когда всё инлайнится) будет лучше…Ещё если добавить alignas(16), то gcc тоже генерит нормальный код, но я не понимаю, почему для x86_64 это важно.Ну 16-то сразу зачем? Достаточно
alignas(8). Тоже, я думаю, та же фигня. Хотя вот после этого как-то уже всё это даже не смешно. Пять лет они в gcc эту проблему починяют… Самое смешное — что что -O1 отлично работает. Вот как так-то?Что вообще векторизовать в сравнении 8-байтного куска памяти с другими 8 байтами?Ну нет. Нету у вас там «сравнении 8-байтного куска памяти с другими 8 байтами». Там у вас сравнение двух кусков по 4 байта, однако. Без векторизации (и в Rust, кстати) — вы ровно это и получите.
Оно ж влезает в один 8-байтовый кусок, и код, который сгенерил clang 9, для этого конкретного случая оптимален.Потому что там, скорее всего, была отдельная обработка подобного случая. А в clang 10 понадеялись на векторизацию. Бывает.
Но я ожидаю, что компилятор поймёт, что у меня здесь нет паддинга, и можно относится к экземпляру структуры как к одному большому 8-байтному куску.А за счёт чего он это сделает, извините? У вас две, совершенно независимые операции, потом вы как-то вот это всё комбинируете — да ещё и весьма нетривиально.
Гляньте-ка вот сюда: это крошечная модификация вашего примера.
Причём гарантированно дающая тот же результат, что и раньше. Однако обратите внимание: clang 10 всё отработал так же успешно, как и раньше — а в clang 9 всё «поехало». Заметьте, кстати, что во всех компиляторах, кроме, собственно, clng 9 — результат (как и должно) стал лучше (в clang 10 — «не хуже») чем раньше.
Так clang 9 спокойно это и генерит без всякой векторизации, сравнивая по 8 байт.Зуб не дам, но выглядит так, что в clang 9 был какой-то peephole, а в clang 10, поскольку векторизатор стал достаточно умным, его убрали…
Интересно каким был реальный код, который к этому расследованию вас привёл…
Это на уровне того, что я могу выразить средствами языкаНу здравствуйте, я ваша тётя. Работа «с двумя кусками по 8 байт», разумеется, в C++ тоже выражается — и, внезапно, отлично работает и во всех версиях gcc и в clang. Правда не в MSVC… ну тут уже «горбатого могила исправит», я извиняюсь. От MSVC мне никогда не удаётся получить хоть сколько-нибудь близкий к оптимальному код…
int128 в C++ вроде как пока не завезли.Старые песни о главном: как стандартным образом, но при этом эффективно сравнивать структуры данных на равенство.Ну так в лоб — вполне себе ничего: там где вы этот оператор будете вызывать вне простейшей функции — там всё может быть далеко не так красиво на старых версиях clang.
Peephole — они такие. Шаг вправо, шаг влево — и оптимизация рассыпалась.
Ну и вполне можно себе представить правило, которое преобразует набор сравнений последовательных кусков памяти в одно сравнение всего куска целиком.Представить-то можно… вот реализовать — это сложнее. Вот рассмотрите эти два варианта: с векторизацией (кстати заметьте, что векторизовали тут это две версии компилятора уже одинаково и без (и тут — тоже одинаково).
Какая будет быстрее? А вот фиг знает: не имея информации о том как часто ваши структуры отличаются в первом
intе и как часто — не отличаются вообще вы этого просто не скажите.А вот если сравнивать, как вы завещали, 8-байтовые куски… тогда уже места для выпендрёжа не остаётся.
Но в любом случае я бы этим стал заниматься, только если бы уже было ясно — что именно там у нас затык. Слишком, на самом деле, много неизвестных даже в такой простой задаче.
Который лишь подчёркивает, что писать код, которому требуется быть производительным, на плюсах (да и на сях, думаю, тоже) нельзя.Можно конечно. Нельзя писать код, которому требуется быть максимально производительным.
А просто производительный код — вполне себе получается. Вот то поделие, которое clang 10 устроил — оно, на самом деле не так и медленно (по сравнению с просто ценой вызова функции это всё не так страшно, а после встраивания результат может уже далеко не так сильно отличаться).
Да и не конструктивно это: C++ — медленный… а что тогда быстрое? Не знаю ни одного языка, где без бенчмарков и аккуратного просматривания получается код стабильно более быстрый, чем на C++, а если один язык (там Haskell или Rust) мы бенчмаркаем и правим, а на другом (C или C++) просто «пишем идеоматично» — то это ж не совсем честное сравнение получается.
Причём про многие из этих вещей люди знают и «работают над этим». Скажем в современном C++ идеоматично передавать объект через передачу std::unqiue_ptr. Но это генерит лишний код. Чтобы от этого избавиться у нас есть trivial_abi — но он всё равно не делает тип trivial for the purposes of call! Знают разработчики об этом? Знают. Может лет через 10 и починят…
И вот в этом — весь C++: от момента, когда некая «теоретически zero-cost» идиома рождается до момента, когда она реально становится zero-cost — проходит лет 10-20… но ведь в других языках всё примерно так же…
Абсолютно верно. Поэтому никакой язык не быстрый.А вот есть C--, который нужен для этих ваших GHC IR.
А можно я немножечко встряну? Тут вот аналогичный код на Rust компилируется в хороший ассемблер вне зависимости от уровня компиляции (кроме нулевого, конечно), причём на всех версиях, начиная от 1.27.0, выпущенной 21 июня 2018.
Возьмите что-нибудь, что прявляется в Clang — и в Rust оно у вас тоже отличненько проявится. Код, мягко так скажем, недотягивает и до уровня C++ в clang 10…
А время потраченное на такие срачи — не считается? (:
Есть такая полезная штука — рефлексия, говорят помогает взглянуть на вещи под другим углом.
А в сраче, если посмотреть статистически, мои жалкие 10 коментариев (этот 11ый) капля в море.
Жаль, вы стольких людей таким стилем подачи материала отвратили… молодо, зелено.
Вы заметели что на хабре регулярно при упоминании Раста тред разрастается до немыслимых масштабов? Интересно почему…
Благодаря усилием обеих сторон, естественно. Даже "самые упоротые расто-фанатики" самостоятельно сотки комментариев не напишут. Новости о релизах тому примером — там и 20 комментариев редко бывает.
А в сраче, если посмотреть статистически, мои жалкие 10 коментариев (этот 11ый) капля в море.
И на чтение чужих комментариев время тоже не тратится? Да на эту тему можно больше чем на обсуждаемое видео потратить.
Жаль, вы стольких людей таким стилем подачи материала отвратили…
Кто мы? Лично я? Лично мне — пофиг. Мне за код на расте деньги платят, а не за евангелизм.
И на чтение чужих комментариев время тоже не тратится? Да на эту тему можно больше чем на обсуждаемое видео потратить.
Хм, думаю час где то суммарного времени.
Раз пошел отсчет времени и придирки к мелочам :)) (это ирония если что)
Кто мы? Лично я? Лично мне — пофиг. Мне за код на расте деньги платят, а не за евангелизм.
Походу платят Вам за евангелизм, т.е. не хотят, а платят. Рабочее же время :)
И если пофиг, чтож вы со мной переписываетесь пассивно-агрессивно.
Ладно, это риторический вопрос :) Удачи Вам и пусть действительно Раст вам помогает в работе.
Жаль, вы стольких людей таким стилем подачи материала отвратили… молодо, зелено.Почему вы так уверены? И почему вы считаете, что те, кого таким образом удалось отвратить — более полезные для экосистемы, чем те, кого этим удалось привлечь?
Это «агрессивное продвижение» — это просто фаза. Обозначающая что на язык обратили внимание «серьёзные дяди» — и продвигают его по всем правилам маркетинга.
Значит ли это, что в результате язык завоюет популярность и вытеснит другие? Ну… само по себе — скорее нет: вокруг Ада хайпа тоже хватало, а ничего особо популярного так и не выросло.
Но вот что можно сказать точно: без хайпа и агрессивного продвижения популярности не достичь.
Даже Python через эту фазу прошёл, несмотря на мягкость и аккуратность самого Гвидо.
Почему вы так уверены? И почему вы считаете, что те, кого таким образом удалось отвратить — более полезные для экосистемы, чем те, кого этим удалось привлечь?
Вам не нужны инженеры с стажем в 10-20 лет? Люди которые делают реальное железо, спокойные, которым ничего не нужно уже доказывать, но они будут реальными драйвером роста? :)
Около 10 моих коллег ранее были впечатлены марекетинговыми заявлениями по расту в плане безопасности, скорости разработки и все в итоге разочаровались, это те люди которых вы потеряли.
Это «агрессивное продвижение» — это просто фаза.
Да все что мы говорим просто буковки и слова со знаками препинания.
Фанатизм и евангелизм это как раз то состояние в котором способность слышать отключается и появляется уверенность.
Надеюсь мы с вами не в этой реальности находимся?
Даже Python через эту фазу прошёл, несмотря на мягкость и аккуратность самого Гвидо.
Питон поднимался на моих глазах и там даже близко не было тех обещаний который раздает сообщество Раста.
Питон ругали — он улучшался, но было отличие — способность слышать.
Люди отворачиваются т.к. эта способность с самого начала была задавлена агрессивным маркетингом, апологетом которого видимо являетесь и Вы.
Ладно, как заметил мой предыдущий собеседник комментов уже настрочили много, сказали все что хотели, тот кто хочет — услышит.
Удачи вам.
Вам не нужны инженеры с стажем в 10-20 лет? Люди которые делают реальное железо, спокойные, которым ничего не нужно уже доказывать, но они будут реальными драйвером роста? :)Нет. Они не будут «драйвером роста». Они скорее тормозом будут. «Драйвером роста» станут новички — со временем. Ровно как у Планка.
Потому, разумеется, описанные вами люди нужны — но только в том случае, если они не будут отталкивать новичков. Молодость — это единственный недостаток, который сам по себе проходит со временем.
Около 10 моих коллег ранее были впечатлены марекетинговыми заявлениями по расту в плане безопасности, скорости разработки и все в итоге разочаровались, это те люди которых вы потеряли.Что значит «потеряли»? Если бы не было «марекетинговыми заявлений» — они вообще пришли бы к расту? Если нет — то нельзя сказать, что их кто-то «потерял». Вот они — да, они что-то потеряли. Время. А раст — нет, он просто не приобрёл ещё десяток сторонников. Если, вместо этого, он получил 100 новичков — это приемлемый компромисс.
Питон поднимался на моих глазах и там даже близко не было тех обещаний который раздает сообщество Раста.Там другие были. Тот же принцип должен существовать один и, желательно, только один очевидный способ сделать это как-то не очень согласуется с тремя парсерами командной строки: getopt, optparse, argparse. А явное лучше, чем неявное — как это вообще согласуется с динамической типизацией?
В Python тоже полно «невыполненных обещаний» — просто, возможно, вы не так близко к сердцу их принимали, потому их невыполнение вами не так остро переживается…
Питон ругали — он улучшался, но было отличие — способность слышать.Серьёзно? Не видел. Это я скорее у разработчиков PHP наблюдаю. Когда в python 3 сломали, к чертям собачьим, строки — то на все жалобы ответ был «вы просто не понимаете, как нужно работать со строками». «Наступить на горло собственной песне и сделать то, что сделали разработчики PHP с PHP6 — так и не смогли.
Чем это отличается от поведения разработчиков в Rust, которые некоторые вещи действительно отвергают с подобными же оправданиями?
При этом Rust, хотя бы, не ломал язык чтобы поддержать негодную парадигму…
Обычно новые научные истины побеждают не так, что их противников убеждают и они признают свою неправоту, а большей частью так, что противники эти постепенно вымирают, а подрастающее поколение усваивает истину сразу.
Нет. Они не будут «драйвером роста». Они скорее тормозом будут. «Драйвером роста» станут новички — со временем. Ровно как у Планка.
Вам видимо виднее… скажу коллегам, что их время вышло.
Заодно закопаем С/С++ с его базой инженеров.
В Python тоже полно «невыполненных обещаний» — просто, возможно, вы не так близко к сердцу их принимали, потому их невыполнение вами не так остро переживается…
Возможно, не буду спорить. Это субеъективная зона в которую мы вступаем.
Чем это отличается от поведения разработчиков в Rust, которые некоторые вещи действительно отвергают с подобными же оправданиями?
Было разделение коммерческих обещаний и реакции и комментариев сообщества и инженеров.
У Раста полное взаимопонимание, коммерческие материалы распространяются как инженерные самими инженерами.
А при выявлении несогласных начинается подавление.
Далее вступает в силу обратная связь когда здравомыслие это порок и люди с опытом по вашим заявлениям должны отмереть… по таким критерями формируется сообщество, какой итог будет у такого отбора вопрос открытый.
Удачи вам.
Нет. Они не будут «драйвером роста». Они скорее тормозом будут.Надо просто не забывать, кто кого принимает на работу =)
Ну и еще — наверху собираются сливки,… и пена (с)
Ооочень жёлтая статья. Ничего не говорю о раст(я его не знаю), но вкратце в статье следующие аргументы:
Статический анализ не используется по умолчанию
C++ не могут быть исправлены потому что нет доказательств что обучение разработчиков поможет
Трудно понять используются ли контракты (видимо речь о контрактах из c++20, не понимаю в чем трудность, но теоритически допуская что это чрезвычайно трудно вполне возможно это дешевле чем развивать ещё один язык)
Мягко говоря аргументы крайне сомнительны, а то и вовсе содержат явную логическую ошибку.
А аргументы предельно ясны. Они опираются на десятилетия опыта и статистику по уязвимостям. Людям, которые воспринимают С++ просто как инструмент, а не какой-то объект поклонения, давно понятно, что проблема именно в нем и решить ее невозможно в рамках этого языка. Раст как бы не случайно был придуман, а как следствие этого всего.
C++ и rust разделяет 27 летЭто между какими событиями? Просто интересно…
Сколько лет различает вас и вашего отца? Вот между этими событиями.Проблема в том, что у нас с отцом есть сертификаты рождения. А у языков их нет. Потому непонятно — то ли вы говорите о самом начале (но тогда C++ начинается как «C с классами» в 1982м, а Rust — соотвественно в 2006м… это 24 года разницы), то ли разница между первым релизом C++ и первым релизом Rust… (но это всего 17 лет, не 27), то ли ещё что…
Вот и возникает вопрос: что вы вы взяли за реперную точку, что разница в 27 лет получилась?
но ни в 1 сценарии он не станет стандартом только потому что пользователей активно убеждаютНаоборот — ни в одном сценарии он не станет стандартом, если не будет агрессивного убеждения пользователей.
комитет по стандартизации Rust
Спасибо, но лучше не надо. Развитие с референсным компилятором мне пока нравится гораздо больше.
Проблема с референсным компилятором в том, что непонятно, относительно чего он верифицируется, то есть как определяется, что вот такой вот выхлоп для такого исходника — правильный, а вот такой для такого исходника — неправильный, и нужно фиксить компилятор. В идеале должна быть спека, но её нет.
В идеале должна быть спека, но её нет.Спека тоже ничего принципиально не меняет, так как в ней тоже могут быть ошибки.
С одной стороны это конечно хорошо когда стандарт и всё такое. С другой стороны у трёх основных компиляторов до сих пор несовместимые расширения, не говоря о том, что MSVC до версии 19 (2017я студия) вообще весьма вольно относился к стандарту.
Но что меня больше всего удручает — как фичи вносятся в стандарт. Возьмём к примеру модули в С++ и async-await в Rust. Просто для примера. Модули до внесения в стандарт были в экспериментальном (и, насколько я знаю, отличающемся от стандарта) виде только в MSVC. CLang поддерживал гораздо более старую версию, если не вообще другой драфт. Ситуация с async-await же была совершенно иная. Последняя редакция фичи, которую внесли в стабильную ветку простым удалением гейта, была доступна на нестабильной ветке что-то около полугода, и все желающие могли её общупать по полной. Более того, все фичи перед стабилизацией сидят в анстэйбле, и их можно общупать не только по одной, но и в комбинациях.
Ну и у раста также нет альтернативных компиляторов, так что сравнение не совсем корректное. Неизвестно как в этом случае были бы дела у раста, вероятно не лучше чем в сишных компиляторах.
А если бы оно было не лучше — то и зачем тогда этот стандарт с зоопарком компиляторов? Просто потому, что у сишников и плюсовиков так принято?
У них так сложилось исторически. Сейчас же наступает эпоха корпоративных языков, ожидать каких либо стандартов или альтернативных компиляторов нет смысла. Насколько это в целом жизнеспособно в доглосрочной перспективе по сравнению с классической моделью разработки языков — время покажет.
Сейчас же наступает эпоха корпоративных языков, ожидать каких либо стандартов или альтернативных компиляторов нет смысла.Вообще-то это то, с чего начинались языки программирования в 50е. Оттуда выросли не только COBOL и FORTRAN (из сохранившихся в наше время), но REXX, MATLAB и куча других (большинство умерло… хотя одно время были популярны — вские FOCAL и прочие… ну так и вообще, в принципе, большинство языков программирования умерло).
Насколько это в целом жизнеспособно в доглосрочной перспективе по сравнению с классической моделью разработки языков — время покажет.Это не классическая модель, а изобретение «академиков» в 60е. Когда было принято описывать языки вообще не думая (или очень мало думая) о том, можно ли их реализовать и как. Lisp, ALGOL так появились.
А Rust разрабатывается по не менее классической модели кооперации вокруг одной реализации: так были созданы Java, C#, PHP, Swift, Go, Ruby, Perl… это только из Top20. И ни один из этих языков не собирается помирать, что характерно…
Это не классическая модель, а изобретение «академиков» в 60е.
60-ые годы уже не классика)? Да и к тому же си появился и вырос не в академической среде, хотя в итоге был стандартизован.
60-ые годы уже не классика)?Если искодить чисто из возраста, то все эти модели сегодня классика, так как одом из XX века.
Да и к тому же си появился и вырос не в академической среде, хотя в итоге был стандартизован.Ну C как раз появился так же, как и Rust: Ритчи где-то описывал, что там был цикл: новые фичи языка требовали увеличивать размер компилятора (что логично), что приближало его к границам «железа», но зато позволяли в следующей версии уменьшить размер компилятора и освободить место для следующих фич…
А стандартизация — это уже конец 80х (первый стандарт — C89 он же C90… 17-18 лет после появления языка).
Но там это потребовалось, чтобы «подружить» множество несовместимых диалектов… а у Rust (как и вообще у всех языков «нового поколения») этой проблемы нет: распространяется бесплатно, новую версию может скачать кто угодно и почти мгновенно… откуда, внезапно, взяться кучам несовместимых реализаций?
Очевидно же, что не сработает
While Microsoft is bulish on Rust, Levick admits that Microsoft core developers won’t stop using C/C++ anytime soon.
“We have a lot of C++ at Microsoft and that code is not going anywhere,” he said. “In fact, Microsoft c++ continues to be written and will continue to be written for a while.”
исходя из написанной на русском статеечки сверху — следует именно то, что я написал
приведённый вами кусок английского текста — взять непонятно откуда — скорее всего с зарубежных серверов которыми владеет цру, поэтому строить на нём свои умозаключения — я не буду
Хотя Microsoft оптимистично настроена на Rust, Левик признает, что разработчики ядра Microsoft не прекратят использовать C/C++ в ближайшее время.
«У нас в Microsoft много C++ и этот код никуда не денется» — сказал он. «Фактически, Microsoft продолжает писать c++ и будет писать некоторое время».
А вот анализатор не поможет, потому что в самом языке нет нужной для его работы информации. Не просто так в расте есть синтаксис лайфтаймов.
Вот возьмем, например, главный козырь и киллер фичу Раста — безопасность по памяти, которую обычно противопоставляют отсутствию оной в C/C++. Но в связи с этим вопрос: а чем хуже C++ в связке с хорошим статическим анализатором, чем Раст? Ответ: ничем. Очередная статья очередного апологета Раста, который не имеет опыта разработки на C/C++, выдвигает по этому поводу следующий тезис:
Статический анализ упоминается, как еще одно возможное решение. Но статический анализ требует слишком много времени: его необходимо подключить к системе сборки. «Так что есть большой стимул не использовать статический анализ» — сказал Левик. «Если он не включен по умолчанию, он не поможет».То есть человек всерьез утверждает, что внедрение статического анализа в CI и в повсведневную разработку слишком дорого по сравнению с обучением сотрудников новому языку.
Кстати об обучению новому языку: синтаксис Раста — это просто треш имхо. За 10 лет программирования на 5+ языках я такого не встречал ни разу. Пусть это субъективное мнение, но я готов поспорить, что ни одному программисту с мало мальски серьезным опытом промышленной разработки такой синтаксис не будет привычен. В этом, очевидно, стоит винить создателей языка. Но оставим в стороне синтаксис — в языке нет ООП. Даже с учетом критики ООП (вполне обоснованной, кстати) эта парадигма на сегодняшний день является де-факто стандартом в индустрии. Создавать в 21xx году язык, в котором наследование заменено костылем в виде трейтов — у меня этому нет объяснения.
Стоит отдать должное Расту — это хороший нишевый язык, который лучше, чем C, подходит для разработки систем, в которых на первом месте стоит формальная корректность. Но зачем писать на Расте микросервисы и тому подобное, да еще и агрессивно продвигать его в качестве 10/10 языка для таких задач? Ответа нет.
Это лишь малый список недостатков Раста, который позволяет поставить под сомнения главный тезис статьи. В общем резюме: с моей точки зрения, Раст конкретно пиарят, не совсем ясно только, кто за это платят. По факту это просто yet another programming language с претензиями. Кто сомневается в искусственно созданном ажиотаже вокруг языка, рекомендую к ознакомлению любопытную статью «Why the developers who use Rust love it so much». При внимательном прочтении можно увидеть все то же, чем грешит данная статья, да и вообще все статьи типа «раст — крута»: о преимуществах Раста перед C/C++, скорой смерти C/C++ и безопасности по памяти обычно громче всех кричат те, кто раньше писал фронтенд на Джаваскрипте (я утрирую, конечно, но суть ясна). Чего стоит только этот пассаж:
When I think of a “statically typed language”, I think of Java, or C#, or something like TypeScript.
и где очень важно не падать и торговать корректно
М-м-м. Перспектива словить в произвольном месте unwrap() (и соответствующий краш) вместо исключения не смущает? :)
Если уж совсем боль, то unwrap можно перехватить.
Что неприятно: просмотреть только код, помеченный
unsafe — недостаточно.Более того: писанных правил о том куда можно экспортировать небезопасность — я вообще не нашём. Что ешё более неприятно.
Кто-то подкрадётся и вставит unwrap в произвольное место? Кроме того есть крейт no_panic, который может проверить отсутствие паник во время компиляции.
Смущает не больше, чем возможность "словить" exit или abort.
Кстати, unwrap — это не краш.
То есть они, конечно, большая проблема — но меньшая, чем убытки от того, что программа на Idris будет банально медленнее.
А что такого? Они достаточно детерменированы, в отличии от сегфолтов, можно еще и логическую ошибу пропустить с такими же последствиями.
Вы же не пишете «C/C#»?Можно ещё C#/F#/J# писать.
Хотя с C и C++ странно: они довольно-таки сильно перемешаны — хотя формально являются разными языками. Может быть потому что на Windows C++ так и соблагоизволил получить стабильный ABI и потому много C библиотек на самом деле «внутри» на C++ написаны.
Каким конкретно анализатором и какими конкретно настройками этого анализатора мне добиться той же безопасности, которую даёт раст?Выпишите, пожалуйста, список гарантий, подберем вам анализатор.
У меня
Может, я
у меня есть
Я писалПропускаем, не интересно. Не считаю нужным тратить время на спор насчет личных предпочтений.
Даже тут не соглашусь. Для систем, где важна формальная корректность, раст слишком слаб.Согласен, я не совсем корректно употребил термин. Я видел ваши публикации про развлечения с Идрисом, и, честно говоря, я не считаю, что формальная корректность в таком виде нужна хоть кому-нибудь в индустрии. Я имел в виду больше что-то вроде бортовых систем, где главный показатель корректности — отсутствие гонок. Хотя вроде Раст в этом случае тоже ничего не гарантирует, но это все-таки лучше, чем словить UB из-за алиасинга.
Это два разных языка с двумя разными философиями и идиомами. Писать их через слешс странно. Вы же не пишете «C/C#»?Не очень уместная придирка. Очевидно, что в этом контексте C и C++ идут в тандеме, так как Раст противопоставляется им обоим с одинаковой аргументацией.
Не знаю, на чем там пишется софт для кардиостимуляторов, но то, на чем он пишется, явно не смогло защитить продукцию Medtronic и Abbott. Пару-тройку лет назад был большой скандал на тему того, что их кардиостимуляторы принимали команды управления по беспроводной связи без аутентификации, а медицинские данные отсылали наружу без применения шифрования. Вспоминается старая шутка, что баран с пистолетом или даже автоматом становится отнюдь не волком, но просто вооружённым бараном.
Но в связи с этим вопрос: а чем хуже C++ в связке с хорошим статическим анализатором, чем Раст? Ответ: ничем.
Сразу мимо… Даже в том же обсуждении -wlifetime для clang предлагали помечать код специальными аннотациями чтобы анализатор мог правильно исследовать время жизни.
Без подсказок со стороны программиста провести исчерпывающий анализ времен жизни невозможно — там существуют неоднозначности, которые должен как раз программист разрешать, расставляя атрибуты. В случае Rust это как раз привело к созданию lifetime синтаксиса.
Создавать в 21xx году язык, в котором наследование заменено костылем в виде трейтов — у меня этому нет объяснения.
Вообще-то этот "костыль" намного более выразителен, чем наследование. Может объясните мне его костыльность? Как по мне это еще более сильное разделение между данными и алгоритмами работы с ними, чем это есть в наследовании.
Это лишь малый список недостатков Раста, который позволяет поставить под сомнения главный тезис статьи
Список из субьективного восприятия синтаксиса и крайне спорный момент насчет ООП это прямо таки список недостатков. Сильная аргументация, ничего не скажешь.
Но зачем писать на Расте микросервисы и тому подобное, да еще и агрессивно продвигать его в качестве 10/10 языка для таких задач? Ответа нет.
Может потому, что их получается писать легко и они при этом еще и работают хорошо?
Сразу мимо… Даже в том же обсуждении -wlifetime для clang предлагали помечать код специальными аннотациями чтобы анализатор мог правильно исследовать время жизни.Дело не в анализаторе, а в ограничениях языка — потому статический анализатор Раста (встроенный в язык) имеет априори преимущество перед [внешними ]Линтерами С++.
Вообще-то этот «костыль» намного более выразителен, чем наследование. Может объясните мне его костыльностьТрейты с 9ю параметрами конечно более выразительные, но нихрена не читаемые.
Трейты с 9ю параметрами конечно более выразительные, но нихрена не читаемые.
Это как? Ты их не путаешь с char_traits?
Но вот проблема большого кол-ва параметров на практике наблюдается.
А можно пример, я не очень понимаю что за параметры
Но кажется, это я не в тему (ООП с помощью трейтов) заехал…
Дело не в анализаторе, а в ограничениях языка — потому статический анализатор Раста (встроенный в язык) имеет априори преимущество перед [внешними ]Линтерами С++.
Ну, как минимум потому, что в Rust подобным образом проверяется весь код, включая std и зависимости. В C++ такую роскошь себе позволить не получается.
Сразу мимо… Даже в том же обсуждении -wlifetime для clang предлагали помечать код специальными аннотациями чтобы анализатор мог правильно исследовать время жизни.Мне кажется или этот пассаж как раз таки равняет Раст и C++ с аннотациями?
Без подсказок со стороны программиста провести исчерпывающий анализ времен жизни невозможно — там существуют неоднозначности, которые должен как раз программист разрешать, расставляя атрибуты. В случае Rust это как раз привело к созданию lifetime синтаксиса.
Вообще-то этот «костыль» намного более выразителен, чем наследование. Может объясните мне его костыльность? Как по мне это еще более сильное разделение между данными и алгоритмами работы с ними, чем это есть в наследовании.Не знаю насчет выразительности, но код читать тяжелее имхо. Вполне возможно, что у меня ООП головного мозга, но все-таки сознательно делать язык, который не следует общепринятым концепциям, просто так — это как минимум странно. Или быть может есть конкретная причина, почему Раст не реализует ООП?
Список из субьективного восприятия синтаксиса и крайне спорный момент насчет ООП это прямо таки список недостатков. Сильная аргументация, ничего не скажешь.Я склонен считать, что эти моменты имеют место не только для меня. Кроме того, в вашем ответе объективности не больше. Самое объективное, конечно, это:
Может потому, что их получается писать легко и они при этом еще и работают хорошо?Диссертация на тему «легко» и «хорошо» как метрики оценки трудоемкости разработки и качества ПО.
но все-таки сознательно делать язык, который не следует общепринятым концепциям, просто так — это как минимум странноТак зачем делать «как было», если можно сделать лучше?
Или быть может есть конкретная причина, почему Раст не реализует ООП?Он реализует ООП. Прекрасно. Он не реализует то, что продают под видом ООП разработчикам C++ и Java.
И да, тому есть вполне понятная и совершенно очевидная причина: наследование реализации — штука небезопасная и потому всовывать её в язык, который пытается что-то предоставить в области безопасности… несколько странно.
Можно было бы, наверное, сделать что-нибудь в духе Go (без наследования реализации, но с интерфейсами), но, боюсь, это вызвало бы ничуть не меньше стонов — а с точки зрения эффективности этот подход проигрывает.
Он реализует ООП. Прекрасно.Полиморфизм ручками?
"Что-нибудь в духе Go" в Rust как раз сделано, добавление ключевого слова dyn к имени трейта даёт интерфейс.
В Rust, насколько я знаю, так делать нельзя.
Если делать ООП по SOLID, то все случайные реализации интерфейсов структурами так и останутся случайностями, а все отличия Go от Rust в этом плане сведутся к наличию impl и dyn в последнем.
Увы и ах — «все отличия Go от Rust в этом плане сводятся к наличию impl и dyn в последнем» только в тех случах когда подобные вещи разработчики предвидят в 100% случаев.
На практике же ситуация, когда из какого-то интерфейса выделяется какой-то полезный подинтерфейс — редкостью не является.
И решить эту проблему в Rust можно только одним способом: не объявлять
trait с более, чем одним методом, а если нужны более сложные — то обявлять каждый метод отдельным trait и потом, поверх этого уже — собирать более сложные trait.Слава богу так никто не делает.
И нет, я не говорю, что нужно «ООП в стиле Go» привнести в Rust — он там явно не к месту. Я просто говорю о том, что они таки разные — и да, эта разница практически заметна тоже.
Вау! Круто-то как. То есть в вашей вселенной разработчики Haskell не ломали совместимость, чтобы сделать монаду аппликативом, а моноид — полугруппой?
А как от этого помогут интерфейсы в стиле Go?
Кстати, именно в Rust это можно было бы сделать (при наличии HKT, разумеется) без особых проблем, потому что язык более лояльно относится к перекрывающимся реализациям.
Всего-то вместо требования базовой реализации trait Monad : Applicative надо предоставить реализацию по умолчанию: impl<T> Applicative for T where T: Monad.
И то же самый принцип работает для любых "полезных подинтерфейсов".
PS не смотря на то, что лично я знаю про историю с Applicative, для случайного собеседника в интернете вполне допустимо про нее не знать. Так что сбавьте тон и не обвиняйте оппонентов в том, что они живут в каких-то там "отдельных вселенных".
Но в связи с этим вопрос: а чем хуже C++ в связке с хорошим статическим анализатором, чем Раст? Ответ: ничем.
Серьёзно? То есть у microsoft столько проблем с безопасностью, связанных с ошибками работы с памятью, потому что они не прогнали свои исходники через статический анализатор? Или посыл в том, что раст на самом деле не помогает от ошибок работы с памятью?
я готов поспорить, что ни одному программисту с мало мальски серьезным опытом промышленной разработки такой синтаксис не будет привычен
12 лет продакшена на С++ вас устроят?
Плюс эпизодически Java, C#, Python. Всякую мелочёвку не берём.
Угадайте у каких языков я считаю синтаксис наиболее вырвиглазным? С++ с его кучей контекстно-чувствительных вещей. И Perl.
EDIT: Убрал огрызки редактирования
Я, кстати, откровенно не понимаю, почему такому количеству людей кажется, что спец. символов там больше — когда их уж никак не больше по количеству и явно меньше по разнообразию. Можно прикинуть хотя бы по количеству операторов вообще и перегружаемых в частности. У меня только две идеи на этот счёт.
Первая — ключевые слова короче, их тоже меньше. В результате визуальная плотность спецсимволов растёт.
Вторая — в С++ "утиные шаблоны", а в Rust ограничения на типы надо прописывать явно. Из-за этого сигнатуры визуально распухают. В ту же копилку — лайфтаймы.
Почему в Rust не выбрали модель управления памяти с помощью ARC как например в Objective C/Swift? Borrowing не решает всех проблем, всё равно нужны смарт-пойнтеры, так не проще ли было сделать единообразное решение на все случаи, к тому же ARC того типа что в Swift — это не Garbage collector и работает пооптимальнее.
Потому что это сужает область применения. И потом, с ARC у нас уже есть Swift.
Потому что использование обычных ссылок за которыми следит Borrow Checker не накладывает рантайм оверхед который есть у ARC. А также вообще не предполагает что ваш процессор поддерживает atomic операции. По сути раст ссылки это некий аналог смарт пойнтеров которые существуют на этапе компиляции, но в рантайме представляют собой просто сырые указатели
если бы бы объект управляемый ARC, в конце блока счетчик ссылок достиг бы нуля и произошло освобождение. Получается что оверхед по сравнению с борровингом только несколько операций — увеличение ссылки, уменьшение, проверка ссылки. Операцию освобождения не учитываем — она есть там и там.
Насчет атомарности — да, вот не знаю как работает ARC с потоками, может какраз использует атомарные счетчики. Но по идее атомарные операции должны происходить быстро если нет конкуренции.
Атомарные операции происходят быстро, но тем не менее имеют определенный оверхед (например на синхронизацию кешей разных процессоров). Поэтому в том же Rust есть Rc (не потокобезопасный смарт пойнтер) и Arc (потокобезопасный). В том и прелесть что вы можете использовать ровно тот тип управления памятью который нужен для вашей задачи. И для 80-90% задач достаточно использовать обычные ссылки
А еще Rc и Arc и прочее ARC это история про память в хипе, что тоже плохо иногда.
Атомарные операции происходят быстро, но тем не менее имеют определенный оверхед (например на синхронизацию кешей разных процессоров).Там даже без какой-либо синхронизации и вообще участия двух ядер скорость такая, что прикручивать это к структурке из двух-трёх
int-ов — идея плохая. Откройте табличку и посмотрите. Даже если забыть про Bulldozer с его «вроде как 55ю тактами» (ну не смог Агнер придумать как такие тормоза точно промерить), то даже и 18 тиков у Skylake и 17 у Ryzen — это не бог весть как быстро…А давая выбор Arc или Rc — тут появляется возможность ошибки, так? Если программист ошибся и выбрал Rc где нужен был Arc, не съест ли такая ошибка оптимизации, да и просто неприятная ошибка логики. Это ведь нижний слой обслуживания технологии, и неприятно что даже на этом уровне можно сделать ошибку.
UPD: интересная ссылка на табличку, спасибо
а нельзя как-то оптимизировать работу со ссылкой пока счетчик равен 1?
А если этот флаг выставляют два потока одновременно?
А давая выбор Arc или Rc — тут появляется возможность ошибки, так? Если программист ошибся и выбрал Rc где нужен был Arc, не съест ли такая ошибка оптимизации, да и просто неприятная ошибка логики.
Ничего не съест, потому что такой код попросту не скомпилируется. Вот от обратной ошибки уже, действительно, не поможет.
А если этот флаг выставляют два потока одновременно?
мм, не соображу — как такое может быть? У каждого потока свой стэк выполнения, и если они доступаются к общему объекту, то как они могут одновременно выполнять его конструирование? Флаг ведь менялся бы на этапе создания объекта.
т.е. если оба потока вызвают
User ref = new User(); // не знаю как в растето ref будет у каждого свой. Если же они доступаются к уже созданному — то флаг будет уже поднят
а нельзя как-то оптимизировать работу со ссылкой пока счетчик равен 1?Можно, но не нужно. Дело в том, что если вы говорите программисту: «одна ссылка — это очень-очень дёшево, а за две — будем хлестать розгами»… то он чешет репу, долго думает — и изобретает таки структуру данных, в которой почти все обращения идут через единственную ссылку (которую можно, впрочем, кому-то на время отдавать).
Внезапно: так устроенных языков у нас не один, а два — Rust и современный C++. С его std::unique_ptr и std::move.
И потому, оп-ля, современный идеоматичный код на C++ часто можно переписать на достаточно идеоматичный Rust.
А вот если этого не сделать… то думать об этом никто не будет и «живых ссылок» — будет масса.
Отсюда, на самом деле, «растут ноги» у странного феномена: на всех бенчмарках — C++ и C#/Java показывают близкие результаты. А вот в реальных программах — почему-то разница на порядок, а то и на два.
Это не потому, что GC такой медленный. Это потому что если людям разрешить не думать о памяти — то они этого делать и не будут… а потом — уже никакой оптимизатор вас не спасёт.
Если остальных случаев когда нужны Rc, Arc и тд. всего 10% то потеря производительности должна быть небольшой, а семантика одна и та же, и не надо фиксить какие-то проблемы лайфтаймами. Если я верно понимаю, в некоторых случаях когда переменные имеют разную область определения, нужно использовать лайфтаймы скажем при передаче аргументов в функцию.
Это потому что если людям разрешить не думать о памяти — то они этого делать и не будут… а потом — уже никакой оптимизатор вас не спасёт.
а как, кстати, решается проблема фрагментации кучи в Rust? Или такой проблемы нет?
А когда появляется 2-я — тогда и создавать атомарный счетчик.
Чтобы во время исполнения программы определить когда появляется вторая ссылка, нужно где-то держать информацию о том, что этой второй ссылки ещё нет. Никакой экономии не получится.
Какие-то частные случаи можно отлавливать во время компиляции (escape analysis), но программист теряет контроль над поведением ссылок, что неприемлемо для системного языка.
а как, кстати, решается проблема фрагментации кучи в Rust? Или такой проблемы нет?
В этом плане Rust ничем не отличается от C или С++, которые тоже не рассчитаны на использование компактифицирующих менеджеров памяти. То есть стратегией выделения памяти занимается менеджер памяти, а не язык.
Чтобы во время исполнения программы определить когда появляется вторая ссылка, нужно где-то держать информацию о том, что этой второй ссылки ещё нет. Никакой экономии не получится.
я давненько кодил на с++, но кажется там была такая точка — оператор присваивания. Если же нет — флага на true-false хватило бы, это 1 байт. Я думаю что способ должен быть, ведь имплементация раста почти не открывает сырых указателей, т.е. всё это хозяйство под её контролем.
но программист теряет контроль над поведением ссылок, что неприемлемо для системного языка.
сейчас начнут минусить, но мне это аксиомой не кажется ) Это верно лишь до поры пока не придумают хороший способ с минимальным оверхэдом. Когда-то когда поставили паровой двигатель на поезд, некоторые ученые считали что человеческий организм не выдержит скорости выше 30 км/час.
Имплементация раста потому и почти не открывает сырых указателей, что лайфтаймы позволяют так делать.
флага на true-false хватило бы, это 1 байт
Есть такие вещи как выравнивание полей структуры, оверхед на вспомогательные структуры данных менеджера памяти и гранулярность выделения памяти. Из-за них этот 1 байт и дополнительная аллокация атомарного счетчика требуют больше памяти чем 1+размер счётчика.
мне это аксиомой не кажется
На микроконтроллерах кучи вообще может не быть.
На микроконтроллерах кучи вообще может не быть.
и как с этим живут?
и как с этим живут?
Без динамического выделения памяти. Объем необходимой памяти определяется функциональными требованиями к контроллеру и она выделяется один раз при начале работы системы. Рекурсивные вызовы не используются, так что максимальный нужный объем стека тоже известен.
и как с этим живут?Вы бы ещё спросили как с этим живут в Java. Из JavaCard, к примеру, просто взяли и тупо выкинули сборщик мусора (ну и кой-чего ещё… по мелочи).
И ничего — работают люди. Жить захочешь — ещё не так раскорячишься…
Это верно лишь до поры пока не придумают хороший способ с минимальным оверхэдом.Подобные фразы, к сожалению, переносят спор из конструктивного обсуждения ЯП в область ненаучной фантастики.
А если придумают как перемещаться на Марс телепортацией? Нужны ли нам всё ещё будут счётчики ссылок?
Когда-то когда поставили паровой двигатель на поезд, некоторые ученые считали что человеческий организм не выдержит скорости выше 30 км/час.И вот когда это не случилось — начали разрабатывать скоростные поезда. А космические станции — после полёта Гагарина, который нормально так слетал — и с ума не сошёл.
Вы же ставите телегу впереди лошади: если вдруг кто-то что-то такое придумает с минимальным оверхедом… тогда и будем обсуждать.
Вы же ставите телегу впереди лошади: если вдруг кто-то что-то такое придумает с минимальным оверхедом… тогда и будем обсуждать.
а как можно придумать что-то новое, если считать это заведомо невозможным?
в область ненаучной фантастики.
ну так езду на поезде со скоростью 30 км/час и считали фантастикой ))
а как можно придумать что-то новое, если считать это заведомо невозможным?Никак, очевидно. И?
ну так езду на поезде со скоростью 30 км/час и считали фантастикой ))И, в те времена, оная езда и являлась фантастикой!
Понимаете — я не то, чтобы против фантастики. Я против того, чтобы на неё тратились ресурсы, которые выделены на инженерию.
Вот в каком-нибудь фантастическом романе гиперпространственный двигатель — самое оно. А где-нибудь в НАСА отдел, разрабатывающий ракету для колонизации Марса из рассчёта того, что кто-то когда-то создаст-таки оный двигатель — это, извините, «нецелевое расходование средств».
То же самое и здесь: хотите изобретать
А до тех пор… что-то выстраивать поверх несуществующей у вас концепции — не стоит. Вот и всё.
Если вы так любите поезда: представьте себе, что основатели какий-нибудь Ост-Индской компании вложились бы не в строительство парусников, а в строительство инфораструктуры вокруг трансконтинетальной железной дороги… вспомнал бы кто-нибудь о ней сегодня? Нет, конечно: Транссиб постоили через 300 лет после основания этой компании и за 30 — после того, как она уже закончила свою работу.
Даже при солидных усилиях на продвижение этот язык может не выстрелить.
И, в те времена, оная езда и являлась фантастикой!
так говорили те, кто противился попыткам установки парового двигателя на поезд, и если бы их послушали, то как минимум получили бы паровоз позже.
Форд тоже как-то сказал: «Если бы я спросил людей, чего они хотят, они бы попросили более быструю лошадь».
то есть сделать что-то лучше чем Rust — это нецелевое расходование средств?Нет. Заявлять что мы, возможно, придумаем в будущем — как дёшево считать ссылки (хотя пока этого не знаем) и стоить на этой базе «что-то лучшее» сегодня, сейчаc — это нецелевое использование средств.
Вот после того, как вы придумаете как это эффективно делать — можно будет что-то обсуждать.
Форд тоже как-то сказал: «Если бы я спросил людей, чего они хотят, они бы попросили более быструю лошадь».Совершенно верно — но он продавал-таки автомобиль, а не коробку с надписью «тут должен быть эффективный двигатель… но у меня пока его ещё нет».
так говорили те, кто противился попыткам установки парового двигателя на поезд, и если бы их послушали, то как минимум получили бы паровоз позже.Но получили бы, ведь так? А вот если бы вместо того, чтобы стоить железные дороги с тем, что у них в начале XIX века было (лошадьми, да) — люди бы начали строить всё сразу под паровозы… то могли бы и не получить вообще ничего.
Вот и с языками то же самое: пока у вас нет реализованной и протестированной вашей схемы быстого учёта счётчиков — будем использовать то, что есть. Как реализуете — посмотрим, стоит ли её использовать или нет.
Совершенно верно — но он продавал-таки автомобиль, а не коробку с надписью «тут должен быть эффективный двигатель… но у меня пока его ещё нет».
автомобиль у него появился точно не сразу, и на тот момент когда он решился на эту затея, наверняка это считалось авантюрой.
Но получили бы, ведь так?
что значит «ну получили бы?». Если бы слушали консервативных людей — нет, не получили бы. Дороги тут не при чем, речь о паровозе.
Вот и с языками то же самое: пока у вас нет реализованной и протестированной вашей схемы быстого учёта счётчиков — будем использовать то, что есть. Как реализуете — посмотрим, стоит ли её использовать или нет.
у меня нет ни времени, ни денег чтобы делать это. Я выступаю сейчас скорее как потенциальный пользователь Rust, и сейчас больше прицениваюсь. И это плохо когда на сложности языка просто отвечают «а ты попробуй сделать лучше». Взаимный упрёк никого не сделает лучше. Я спрашивал — возможно ли принципиально упростить это управление памяти ещё больше чем это сделали в Rust? Мне ответили что нельзя, потому что «ручное управление должно быть, иное неприемлимо». Я спросил — почему это неприемлимо? Потому что микроконтроллеры и тд. Но это тоже — вопрос оверхэда или ограничений. Опять таки, не всё вокруг — микроконтроллеры.
18 тиков промаха, или +1 байт — это мало о чем мне говорит. Какова просадка на уровне приложения? Какая просадка была бы если написать ОС с таким подходом? 20% или 200% Если 20-30 — по мне это приемлимая потеря если ПО будет стабильнее. Насколько язык проще если управление памяти не ручное? По моему опыту — намного. Проще — меньше ошибок.
Покажи контрпример — это не доказательство. Если бы я не смог в 10-м веке показать черного лебедя, это не доказало бы что их не существует или они невозможны.
автомобиль у него появился точно не сразу,То есть истории мы не знаем и знать не хотим? Автомобиль он построил в 1896м году. А потом — у него ушло куча времени и денег на то, чтобы разработать технологию массового производства.
и на тот момент когда он решился на эту затея, наверняка это считалось авантюрой.Да, конечно. Много народу не верило, что на этом можно заработать денег. Однако вот конкретно техническая возможность — сомнению не подлежала. Путешествие в Пфорцхайм случилось за восемь лет до того, как Форд построил свой первый автомобиль и за двадцать лет, до того, как Форд Т сошёл с конвеера.
Дороги тут не при чем, речь о паровозе.А куда и зачем ездил бы ваш паровоз? Без железных-то дорог, извините? И без угля? Не припомните что случилось с паровозом Черепановых?
18 тиков промаха, или +1 байт — это мало о чем мне говорит.Если вам это ни о чём не говорит — то используйте Python или PHP, в чём вопрос-то?
Какая просадка была бы если написать ОС с таким подходом?А какая, в сущности, разница? Если делать этого никто не будет?
Проще — меньше ошибок.Нет. Это распространённое заблуждение. Посмотрите на современный Web-сайт. На машинке, которая его поддерживает крутятся десятки мегабайт кода. Это, соотвественно, десятки миллионов строк. Тем не менее дыры там обнаруживаются, как правило, не в этих самых десятках миллионов строк «опасного» C и C++ кода — а в буквально сотне тысяч строк кода бизнес-приложения на «безопасных» яыках с GC. Разница в плотности ошибок — в разы… и не в пользу «простого» кода.
Если бы я не смог в 10-м веке показать черного лебедя, это не доказало бы что их не существует или они невозможны.Но доказало бы, что закладываться на определённое потребление мяса чёрного лебедя в рационе — глупо и бессмысленно.
То есть истории мы не знаем и знать не хотим? Автомобиль он построил в 1896м году. А потом — у него ушло куча времени и денег на то, чтобы разработать технологию массового производства.
это не важно в контексте того что он не сел молиться на коня
Нет. Это распространённое заблуждение. Посмотрите на современный Web-сайт. На машинке, которая его поддерживает крутятся десятки мегабайт кода. Это, соотвественно, десятки миллионов строк. Тем не менее дыры там обнаруживаются, как правило, не в этих самых десятках миллионов строк «опасного» C и C++ кода — а в буквально сотне тысяч строк кода бизнес-приложения на «безопасных» яыках с GC. Разница в плотности ошибок — в разы… и не в пользу «простого» кода.
откуда такая инфа?
А какая, в сущности, разница? Если делать этого никто не будет?
тогда зачем эти все данные про тики и байты, если «какая разница?»
это не важно в контексте того что он не сел молиться на коняЭто важно в том смысле, что они ни в какой момент не пытался сравнивать предмет, который у него был с тем, чего у него не было.
тогда зачем эти все данные про тики и байты, если «какая разница?»Этих данных — достаточно для человека, который знает всем известные числа, чтобы понять — чего стоит делать в операционке, а чего — не стоит.
Ну не будет никто делать операционку, превращая функцию, которая исполняется 3 такта в функцию, которая исполняется 33 такта. Просто не будет. Даже если итоговое замедление будет не 10кратным, а «всего лишь» двукратным.
И если вам это неочевидно и вы этого на основании пары чисел не осознаёте — то значит вам это не так и принципиально. Можно использовать Go или Swift с их 3-5 кратным замедлением или вообще Python с его 20-50 кратным замедлением.
Зачем вам тогда Rust вообще?
Если же вы целитесь-таки в latency-critical код и можете придумать что-то типа Swift, но с ценой вызова не 30 тактов на типичную функцию, а 2-3 — ну вот тогда будет о чём говорить.
Но, извините, представить себе что что-то подобное сможет изобрести человек, не представляющий себе что такое 17 тактов — я не могу. И паровозы и автомобили в реальности создавались-таки инжинерами, а не писателями-фантастами…
Это важно в том смысле, что они ни в какой момент не пытался сравнивать предмет, который у него был с тем, чего у него не было.
это не важно, сравнивал или нет. Он сделал хороший шаг вперёд, а мог бы решить: «лошади — это идеально, ничего лучше и быть не может». Да и как вообще можно доподлинно знать что у него в голове происходило? Обычно когда хотят сделать новое, то представляют в общих чертах что хотят, и чем это будет лучше чем то что есть. Или по вашему он представлял себе коня, а у него получился автомобиль?
похоже что вы просто поклонник этого языка. Интересно, а если Microsoft сделает клон Rust, но только лучше, за какой из этих вариантов вы будете?
Нет. Это распространённое заблуждение. Посмотрите на современный Web-сайт. На машинке, которая его поддерживает крутятся десятки мегабайт кода. Это, соотвественно, десятки миллионов строк. Тем не менее дыры там обнаруживаются, как правило, не в этих самых десятках миллионов строк «опасного» C и C++ кода — а в буквально сотне тысяч строк кода бизнес-приложения на «безопасных» яыках с GC. Разница в плотности ошибок — в разы… и не в пользу «простого» кода.
так что, есть какие-то данные которые это подтверждают? И которые бы сравнивали не user код и код библиотек, а код библиотек или user код для обоих случаев. И что, значит никакой проблемы с си/с++ нет? ))
Получается что когда надо порекламировать Rust — с++ имеет проблемы с управлением памятью и небезопасен, а когда отказаться от ручного управления — тогда хоба и оно уже не такое уж и проблемное )
Выходит по типу «что в Rust есть — то нужно, а чего нет — то не нужно», т.е. предвзятость подтверждения заранее готового ответа.
Зачем вам тогда Rust вообще?
похоже что незачем. Если бы D не помер — я бы его предпочел. Либо надо просто подождать пока кто-то из гигантов не сделает что-то съедобное, а не свалку из закорючек.
Обычно когда хотят сделать новое, то представляют в общих чертах что хотят, и чем это будет лучше чем то что есть.Совершенно верно — вот только Форд ничего нового не изобрёл. В этом вся фишка. Чем Квадроцикл Форда лучше, чем автомобиль Бенца? Да ничем, в сущности.
Или по вашему он представлял себе коня, а у него получился автомобиль?Он хотел (и сделал) такой же автомобиль, как уже существовавшие в то время — а уже потом начал думать как его улучшать.
Он сделал хороший шаг вперёд, а мог бы решить: «лошади — это идеально, ничего лучше и быть не может».Мог бы. И тогда автомобильный завод построил бы кто-то другой. Но принципиально — это ничего не изменило бы. Потому что когда Форд начал всем этим заниматься автомобиль был новинкой, но ни в коем случае не мечтой!
Разницу видите или нет?
похоже что вы просто поклонник этого языка.С чего вы взяли? Я поклонник идеи: безопасность, за которую мы не платим в рантайм. Ни GC, ни каких-то там дурацких счётчиков ссылок, ничего. После компиляции — всё стирается.
Rust первый такой язык, «первый автомобиль», в некотором смысле. Но будут и другие, почти наверняка. Вот только не факт, что им удастся достичь хоть сколько-нибудь заметной популярности…
Интересно, а если Microsoft сделает клон Rust, но только лучше, за какой из этих вариантов вы будете?Rust, скорее всего. Просто не люблю языки, находящиеся под контролем одной фирмы. Тем более такой, как Microsoft. Посмотрите что они сделали с FoxPro или с Visual Basic…
так что, есть какие-то данные которые это подтверждают?А самому факт-чекинг не приходило в голову сделать? Думалка того, атрофировалась за ненадобностью? Важны только авторитеты и ссылки, всё остальное неважно? Ну вот хотя бы на CVE гляньте. У Linux — их порядка 6000 тысяч строк, у Drupal — порядка 1000, у WordPress — где-то 2500.
Вы, хотя бы примерно, представляете разницу между количеством кода в Drupal и Linux? Или вам для этого тоже ссылки нужны?
И что, значит никакой проблемы с си/с++ нет? ))Нет, проблема есть. 6000 ошибок — это много. Даже если учесть что это на почти 30 миллионов строк кода — всё равно много. Хочется сделать лучше. Но если сравнить это с языками, на которых кодят не думая «потому что они ж безопасны»…
Получается что когда надо порекламировать Rust — с++ имеет проблемы с управлением памятью и небезопасен, а когда отказаться от ручного управления — тогда хоба и оно уже не такое уж и проблемное )Получается, что нужно думать. Я понимаю что жить ни о чём не думая и ничего не помня — проще. Но зачем тогда вообще регистрироваться на Хабре и что-то тут писать?
Если бы D не помер — я бы его предпочел.А зачем вам D? Он, в общем-то, тоже для думающих людей позиционировался…
Либо надо просто подождать пока кто-то из гигантов не сделает что-то съедобное, а не свалку из закорючек.А зачем они будут это делать? Я наблюдаю появление Rust в Android, в Fuchsia, вот из статьи узнал, что его теперь Microsoft тоже поддерживает… похоже заниматься «изобретением велосипеда» они не хотят… так что пора учить Rust…
«Свалка из закорчек» мне самому не нравится (и мне на Хабре за это регулярно высказывают)… ну так и у C/C++ синтаксис не ахти. Вот это вот, что — не «свалка из закорючек»:
void (*signal(int signum, void (*handler)(int)))(int signum);?Но это не помешало C/C++ выдавить Pascal, Ada и 100500 Oberon'ов, которые мне, если честно, нравятся, с точки зрения синтаксиса, гораздо больше.
Но если сравнить это с языками, на которых кодят не думая «потому что они ж безопасны»…
ну да, эти высокоуровневые языки придумали чтобы делать побольше ошибок. Ага
А самому факт-чекинг не приходило в голову сделать? Думалка того, атрофировалась за ненадобностью?
А зачем вам D? Он, в общем-то, тоже для думающих людей позиционировался…
Получается, что нужно думать. Я понимаю что жить ни о чём не думая и ничего не помня — проще. Но зачем тогда вообще регистрироваться на Хабре и что-то тут писать?
дальше нет смысла общаться, это хамство и низко
Смешной у вас спор. Вы хотите на Марс, общаетесь с разработчиком ракет, он вам объясняет: "мол вот тут первая ступень она выводит ракету туда-то, вот вторая...". На что вы отвечаете: "нее ракеты и ступени это слишком сложно, две ступени это вообще в два раза ошибок больше! Я вот вчера кино смотрел и там главный герой пользовался автомобилем, который умел телепортироваться. Давайте поедем в космос на на авто! ..." :)
и что-то я не вижу тут «разработчиков ракет». Как-то больше агрессивных пропагандистов. Разработчики ракет разрабатывают ракеты и думаю у них нет времени на срачи в каментах ))
"ручное управление ДОЛЖНО быть" Его сложно назвать действительно ручным (скорее полуавтоматическим), т.к. не нужно в явном виде расставлять free(..) в коде. Но управление таки должно быть если вы хотите добиться максимальной производительности от своего кода. ИМХО вы несколько неправильно воспринимаете Rust. Вы смотрите на него с со стороны какого нибудь высокоуровневого языка типа Python,Go,C#,etc. и поэтому он вам кажется переусложненным, т.к. Ваш язык прячет от вас все те детали которые тут торчат наружу. Вместо этого ИМХО надо на Rust смотреть со стороны того же C и видеть что, не уступая в точности управления памятью и ресурсами программам на С, Rust при этом дает вам возможности близкие к тем что есть в высокоуровневых языках. Т.е. надо его воспринимать не как недо-Python. а как следующее поколение С (не будем упоминать С++ чтоб не вызвать новый холивар от батхерта отдельных товарищей)
Но управление таки должно быть если вы хотите добиться максимальной производительности от своего кода.
что значит «должно быть»? И 100 и 200 лет спустя и вообще? Я полагаю что «оно» никому и ничего не должно ))
Вы смотрите на него с со стороны какого нибудь высокоуровневого языка типа Python,Go,C#,etc. и поэтому он вам кажется переусложненным, т.к. Ваш язык прячет от вас все те детали которые тут торчат наружу
а что если не кажется а он и есть переусложнённый? Выбор странного синтаксиса, непохожего ни на что, куча закорючек от которых кровь в глазах идёт. Синтаксис будто никогда не проектировался, а формировался по типу «о, давайте добавим того, этого». У Go в основе синтаксиса лежит цельная идеология. Да, у него есть недостатки, но он хотя бы создаётся с последовательной философией. У Python тоже самое, Гвидо имеет фантастическую интуицию что стоит добавлять а что нет.
И ведь Rust — это язык относительно молодой, и дальше он будет ещё расширяться, и через какое-то время хоба — и ещё один «с++-20» со 100500 особенностей которые надо помнить.
Язык D нормально воспринимается. Так что это снова безосновательное утверждение что якобы недостатки языка обусловленны системным уровнем.
Касательно ручного управления, как минимум не все так считают
lang D Garbage Collection
что значит «должно быть»? И 100 и 200 лет спустя и вообще? Я полагаю что «оно» никому и ничего не должно ))
Как минимум до тех пор пока ИИ не научится писать системные драйвера и прочие низкоуровневые приложения.
У Go в основе синтаксиса лежит цельная идеология. Да, у него есть недостатки, но он хотя бы создаётся с последовательной философией.
философия у Go конечно есть хотя на мой взгляд она и ущербная. В том же Go есть ряд сложно решаемых проблем которых априори нет в Rust. В свежей версии вон вставили очередной костыль в планировщик (вытеснение корутин) который нужен для устранения последствий предидущего костыля (корутин без возможности их остановить). В этом плане если вы поймете философию Rust вы увидите что она гораздо более строгая и красивая и содержит меньше противоречий чем в том же Go.
У Python тоже самое, Гвидо имеет фантастическую интуицию что стоит добавлять а что нет.
Python отличный язык и я сам большую часть времени на нем пишу, но это не отменяет того что в нем есть фундаментальный костыль GIL, да и вообще производительность приложений на чистом питоне оставляет желать лучшего. Так что здесь просто надо понимать что вам важнее — внешняя простота или все же возможности которые вам даны через эти закорючки.
Скажу из своего опыта — прежде всего стоит начать с прочтения Rust book для того чтобы без привязки к закорючкам понять именно философию языка. А уже осознав основные идеи и зачем они нужны смотреть на то какими закорючками это выражается. Как показывает моя практика простая программа на Rust выглядит почти также как простая программа на Python. Необходимость в закорючках возникает тогда когда вы делаете вещи которые принципиально невозможно реализовать в Python. А если писать на Rust сложные вещи то поначалу бывает сложно перестроить способ мышления для того чтобы выражать те или иные вещи в понятиях Rust. Но проблема не в закорючках, а все таки в необходимости по другому организовать работу с данными для того чтобы эффективно использовать ресурсы железа
поначалу бывает сложно перестроить способ мышления для того чтобы выражать те или иные вещи в понятиях Rust. Но проблема не в закорючках, а все таки в необходимости по другому организовать работу с данными для того чтобы эффективно использовать ресурсы железа
это звучит как «поначалу воняет, но потом принюхиваешься»
по-моему, Rust-идеологи не понимают одну простую вещь — при том что безопасность таки важный фактор, на memory-safety программирование не заканчивается, и задача не становится выполненной.
Я поставил Gnome3 и он жутко тормозит, Firefox запускается прилично так секунд на хорошем железе. Gnome3 строится на с++ подложке, тогда почему он такой тормозной? Ведь вызовы с++ дешевые, всё занимает мало тиков, мало байтов и тд. Что ж такое, почему чуда не происходит?
Тики и байты — это не итоговая производительность, и в этом мало смыла если выигрыш на тиках и байтах съедают ошибки обусловленные error-prone языком. А язык способствует ошибкам тем больше чем он сложнее, синтаксис вырвиглазнее, особенностей побольше. С каждой новой особенностью языка растёт когнитивная нагрузка на программиста, количество того что надо держать в уме и всё это ослабляет барьёр прохождения ошибки.
Миллионы строк кода в линукс и код Drupal — не показатель. В конце концов Drupal может быть просто плохим продуктом, а 20 строк кода на с++ могут быть равны 5 строкам на Python. Можно конечно затариться иллюзией что якобы программисты на Rust просто элита и намного умнее всех прочих, но это лишь иллюзия, т.к. «закалённость ручным управлением памяти» никак не поможет от всех других ошибок.
Для меня совсем не очевидно что Gnome написанный на Rust был бы непременно быстрее написанного на Go.
это звучит как «поначалу воняет, но потом принюхиваешься»
Имхо больше похоже на то: раньше (на Python) можно было создавать сотни мусорных обьектов и все кое как работало (правда медленно и с повышенным расходом памяти), а теперь приходится думать о концепции владения и продумывать моменты когда эти обьекты перестают быть нужны и выражать это в понятиях Rust.
Для меня совсем не очевидно что Gnome написанный на Rust был бы непременно быстрее написанного на Go.
Конечно это не гаринтировано, тут более интересно послушать примеры из того же Firefox — они долго пытались переделать расчет и рендер CSS написанный на С++, но так и не осилили переписать его для корректной паралельной работы. В итоге переписали на Rust и оказалось что средствами языка можно гарантировать корректность многопоточного решения.
Имхо больше похоже на то: раньше (на Python) можно было создавать сотни мусорных обьектов и все кое как работало (правда медленно и с повышенным расходом памяти), а теперь приходится думать о концепции владения и продумывать моменты когда эти обьекты перестают быть нужны и выражать это в понятиях Rust.
ну а где идут основные потери в памяти? Я так понимаю в основном в создании ненужных копий, в алгоритмах не in-place? Во всех прочих случаях особо не сэкономишь, т.к. невозможно не создать нужный объект в принципе, для этого нужно менять алгоритм, и тут языки уже не при чем
из моего опыта основные потери связаны с большой фрагментацией памяти. Любые выделения памяти происходят на куче и типичный паттерн поведения это:
1) создается 1000-10К короткоживущих обьектов
2) создается относительно небольшое количество долгоживущих обьектов которые в памяти расположены после обьектов из пункта 1.
3) короткоживущие обьекты освобождаются
4) обьекты созданные в пункте 2. фрагментируют память и не дают вернуть большие блоки памяти в ОС
Т.е. с точки зрения Python все корректно но можно было бы написать сервис гораздо лучше, если бы было больше контроля за тем где именно располагаются обьекты.
Какое-нибудь банальное
for i in range(10):
...
порождает в куче
StopIteration и кидает исключение! Хорошо хоть не порождает сходу (как в Python2) все числа в заданном диапазоне…насколько я понимаю, в языках с GC эти вещи может на себя взять менеджер памяти хотя бы.
Т.е. с точки зрения Python все корректно но можно было бы написать сервис гораздо лучше, если бы было больше контроля за тем где именно располагаются обьекты.
вот тут не понял. Память выделяет система, как тут сказать какой кусок давать и где он расположен?
Поможет в том плане что можно создание 90% временных обьектов перенести в стек. Понятно это не решает полностью проблемы фрагментации, но условно меняет ситуацию с "сервис надо рестартить раз в день" на "сервис надо рестартить раз в год"
Как тут помогут лайфтаймы, борровинг если создавать много мелких объектов входит в потребности программы?А это как раз наш случай. У нас от этого программа страдала очень. Arena allocator — и без проблем.
Интересно, кстати, есть ли оно в Rust «из коробки». На C++ пришлось руками писать 200 строк…
Память выделяет система, как тут сказать какой кусок давать и где он расположен?В C++ этим заведует параметр шаблона с говорящим названием Allocator.
Firefox запускается прилично так секунд на хорошем железе.А чего вы ещё хотите от программы с UI на JavaScript?
Gnome3 строится на с++ подложке, тогда почему он такой тормозной?Потому что кому-то пришла в голову «гениальная идея» сделать всё на JavaScript. Gnome2, в котором всё было на C и C++ — как раз не тормозил. А в Gnome3 написано ядро, а уже весь UI — на JavaScript. Ради «гибкости».
После чего мы и наблюдаем тормоза? Случайность? Ну да, конечно.
Заметьте: даже вы сами не рискнули написать про Gnome3 что он на C++ написан. Так как знаете что это неправда. Написали про «подложку».
Но забыли, при этом, что скорость — таки зависит не от «подложки», но от всего стека. Достаточно одного тормозного компонента — и вы получите, в целом, тормоза. Уже независимо от скорости всех остальных компонент.
Что ж такое, почему чуда не происходит?А вот потому и не происходит, что вы не там его ищите.
Для меня совсем не очевидно что Gnome написанный на Rust был бы непременно быстрее написанного на Go.Если и тот и другой будут всего лишь подложкой для JavaScript-кода? Скорее всего разницы особой не будет…
Синтаксис будто никогда не проектировался, а формировался по типу «о, давайте добавим того, этого». У Go в основе синтаксиса лежит цельная идеология. Да, у него есть недостатки, но он хотя бы создаётся с последовательной философией. У Python тоже самое, Гвидо имеет фантастическую интуицию что стоит добавлять а что нет.
Т. е. вы пока еще не понимаете идеологии раста. Видимо, вам стоит просто получше разобраться с языком. Могу на этот счет посоветовать rust book.
Для меня качество языка выражается не набором возможностей, а соотношением возможностей к неудобствам и сложностям. У Rust это соотношение посредственное. Качество языка — это многогранный показатель, а не просто «смотрите, ухты-ухты, а тут можно вот так!»
Кстати весьма показательный пример в этом плане — Scala. Язык мегатехнологичный, реально мощный и тд и тп. И какой итог? Scala постепенно умирает. Весьма вероятно что скоро на рынке «better java» она будет вытеснена Kotlin.
А всё почему? Потому что все деньги в Java, и потому что при своей сложности Scala не могла стать рядовым инструментом программиста, несмотря на свою технологичность и теоретико-концептуальную мощь.
Та же участь может ждать и Rust — это просто хорошая попытка, пока кто-то не придёт, не возьмём основные удачные концепции Rust и не сварит из этого что-то более удобоваримое в использовании.
Поэтому, было бы крайне хорошо если бы новый системный язык предлагал не просто альтернативную систему закорючек, но и какие-то новые удобства. Memory safety — это важный параметр, но всё же это не относится к категории удобств.
Вам Rust не дает никаких "новых удобств"? Чем же вы таким занимаетесь, что вам ни контроль времени жизни ссылок, ни единообразная работа с ресурсами с автоматическим их освобождением, ни мощная система типов с нулевым оверхедом, ни подконтрольная компилятору многопоточность, ни развитые средства метапрограммирования, ни прекрсный тулинг не дают никаких удобств?
Scala тоже имеет over9000 фич и мощна как господь бог, но похоже весьма скоро до этого никому не будет дела.
Может если бы там были эти защитные штуки + минимум необходимого — я бы и пользовался. Но есть же просто вагон всего — тут тебе и паттерн матчинг, и алгебраические типы, и тд и тп.
Лихо вы выкинули из необходимого фичу (паттерн-матчинг и АТД — это две стороны одной фичи), которая
а) является безопасным заменителем union, а последние в каком-то виде однозначно необходимы,
б) органично соответвует идеологии: АТД позволяют гибко управлять мощностью типа данных и, тем самым, избавляться от представимых но невалидных значений,
в) является тем, что всё равно так или иначе приходится эмулировать там, где её нет (C#, C++),
г) является основой для всей стандартной библиотеки.
б) органично соответвует идеологии: АТД позволяют гибко управлять мощностью типа данных и, тем самым, избавляться от представимых но невалидных значений,
это в теории. На практике есть давление сроков, разношерстная команда, легаси-код, и «оценить проект но сделать до 10-го». Кто будет сидеть и проектировать эти АТД если надо сделать побыстрее и вообще на вчера? Там хоть бы методы поместили в правильный класс, а класс в уместный пакет, да тестов чуток написали.
Зачем в этой мастерской набор разных ключей, шуруповерт, дрель, тиски?.. То ли дело молоток! Им и гвозди, и шурупы прекрасно забиваются. Он предельно простой и его нужно держать всегда только в одной руке. Все эти переусложнения — ни к чему.
Все эти переусложнения — ни к чему.
конечно )) Это системный язык, ему незачем становиться всецелевым и соревноваться с другими языками в их нишах. Молоток хотя бы хорошо умеет что-то одно
Лихо вы выкинули из необходимого фичу (паттерн-матчинг и АТД — это две стороны одной фичи), которая
разумеется! Всё важно, и без всего жить нельзя, надо всё добавлять, чтобы удовлетворить всех возможных хипстеров.
вряд ли именно так получаются хорошие дизайны ЯП
Ну может вы всё таки приведёте конкретный пример "лишней фичи" в Rust? АТД не годится — помимо уже сказанного, это ещё и база для Option, а на Option работает null-safety.
en.wikipedia.org/wiki/Safe_navigation_operator#:~:text=In%20object%2Doriented%20programming%2C%20the,the%20second%20argument%20(typically%20an
Кто будет сидеть и проектировать эти АТД если надо сделать побыстрее и вообще на вчера?
Хотелось бы увидеть развёрнуто, как АДТ тормозят разработку и мешают сделать побыстрее. Наоборот, когда они есть — их пишешь и не задумываешься, а когда нет — каждый раз когда нужен АТД, приходится что-то изобретать, писать бойлерплэйт, терять время.
Null-safety можно сделать без АТД, но принципиально иной подход. Надо взвешивать плюсы и минусы и выбирать, и это было сделано, и был выбран подход на основе АТД. И при этом подходе АТД — элемент совершенно необходимый, и мановением руки его выкинуть ну никак не получится.
Хотелось бы увидеть развёрнуто, как АДТ тормозят разработку и мешают сделать побыстрее.
я думаю у вас будет такая возможность на работе, когда сроки подожмут.
я со своей стороны не понимаю что там экономит АТД. Если вы пришли из Хаскеля, то в системной языке неприменимы многие подходы ФП. Цепочки вычислений в духе ФП с постоянным копированием иммутабл результатов это неэффективно если то же можно сделать in-place. Задавать таким образом дерево — это тоже неэффективно.
Есть вообще много людей каждому из которых нравится какая-то фича, и все точно уверены что без этой штуки точно нельзя никак, это святое, без этого и кофе не заварится и даже снег идти не будет. Так что, нужно впилить их ВСЕ?
Гвидо ван Россум в этом отношении правильно поступил что тормозил пылкость ФП-фанатов, которые точно так же пытались просунуть эти фичи. Нормальные авторы и дизайнеры языков умеют говорить «Нет» сиюминутным веяниям и исходить из здравого смысла. И правильно делают
Теперь я понимаю почему у Rust такие ярые поклонник — т.к. в язык всунули буквально всё возможное.
Я знаю на примере с++ как работает такая универсальность и мультипарадигменность — ею все довольны, до тех пор пока не наталкиваются на код написанный в диаметрально противоположном стиле
Так что, нужно впилить их ВСЕ?
Все не надо. Но мы, блин, говорим, о фиче, на которой построено в соответствующей экосиситеме всё. И всерьёз ставите вопрос о её необходимости. Ну это вообще как?
на которой построено в соответствующей экосиситеме всё.
в Go нормально живут без этого. Целый linux написали тоже без паттерн матчинга и алгебраческих типов. Что они такого добавляют? Null safety можно и без них сделать.
Я бы не сказал, что в Go живут без этого нормально. Как-то живут, но не нормально. Например, эмулируют тип-сумму с помощью типа-произведения для возврата результата либо ошибки. В Rust из-за политики строгой типизации в сочетании с минимальным оверхэдом такой трюк просто невозможен.
Linux на Си, а в Си есть юнионы, то есть те же АТД, но без строгой типизации, без безопасности и с undefined behavior, который Линус отказывается исправлять.
в Go нормально живут без этого.
В Go не живут, а выживают.
В Go не живут, а выживают.
откуда инфа? ))
В отличие от Rust, в Go ещё могут сделать новые штуки, просто они не спешат, и это разумно по-своему. Многие ругались на пакеты — это уже решили. Ругаются на обработку ошибок — думаю тоже решат со временем. У них ещё есть выбор
У Rust такого выбора уже почти нет. Добавлена масса всего. И небось ещё будут добавлять
Rust puts safe, precise memory management front and center of everything. Unfortunately, that's seldom the problem domain, which means a large fraction of the thinking and coding are dedicated to essentially a clerical job (which GC languages actually automate out of sight). Safe, deterministic memory reclamation is a hard problem, but is not the only problem or even the most important problem in a program. Therefore Rust ends up expending a disproportionately large language design real estate on this one matter. It will be interesting to see how Rust starts bulking up other aspects of the language; the only solution is to grow the language, but then the question remains whether abstraction can help the pesky necessity to deal with resources at all levels.
происходит какраз то о чем говорил Александреску. Разбухание языка.
7 лет прошло, а разработка компилятора и ЯП идет вполне нормально. Где то «разбухание раст» и где D?
Где то «разбухание раст» и где D?
типа выживает то что лучше? Не обязательно )
Вы пишите на D, являетесь архитектором какого-то языка/компилятора? — если нет, то почему мне стоит доверять вашему мнению? :)
А я заставляю мне доверять?
я процитировал мнение архитектора D. Rust сообщество воспринимает только похвалы а критику отбрасывает
Не важно кто и что скажет о Rust, итог всегда один
Почему тогда мне стоит доверять автору доклада из MS? Он тоже не архитектор а «адвокат»(=пропагандист)
У них ещё есть выборНет у них выбора. В C++ были запланированы исключения более-менее с самого начала (в ARM они уже есть). Тем не менее тот факт, что в момент, когда C++ начал получать распространение были доступны только SJLJ-exceptions обусловило тот факт, что куда народу до сих пор их не использует.
Переход на STL с «рукописных» контейнеров — занял десятилетия и до сих пор не окончен.
Python для того, чтобы строки поменять (причём с нормальных на идиотские — но это другой вопрос) потребовалось 10 лет — и процесс нифига не окончен.
Оссификация ЯП происходит невероятно быстро… что-то «легко и просто» менять могут только языки, которыми никто не пользуется.
происходит какраз то о чем говорил Александреску. Разбухание языка.Нет. Происходит то, о чём говорил Stroustrup: There are only two kinds of languages: the ones people complain about and the ones nobody uses.
Так вот D, чтобы не попасть в первую категорию, решил попасть во вторую. Ну… это их выбор. И об этом их выборе, собственно, говорит и Александреску тоже: Overall it could be said that D has the downsides of GC but doesn't enjoy its benefits.
Вот этим всё кончатеся, когда вы начинаете безкопромиссно бороться с разбуханием языка.
В случае цепочек вычислений никто не мешает оптимизатору свернуть промежуточные результаты и сгенерировать мутирующий код. Более того, линейные типы (которые с функциональщиной отлично сочетаются) помогают вам дать понять оптимизатору, что и сколько раз вы пользуете.
это значит усложнение компилятора, так что тоже не бесплатно
это значит усложнение компилятора, так что тоже не бесплатноЭту точку бифуркации проехали ещё в прошлом веке. C++ построен на базе подхода «если чего компилятор может выкинуть при компиляции — то это бесплатно». И Rust его подход перенял. А никаких других «языков, озабоченных скоростью» в двадцатке и нету (есть ещё Assembler, но это не «язык, озабоченный скоростью», а «язык, прибитый гвоздями к железу» — это немножко о другом).
Любой язык с простой семантикой может быть одновременно быстрым и в компиляции и в исполнении.
Любой язык с простой семантикой может быть одновременно быстрым и в компиляции и в исполнении.Нет, не может. Потому что то, что вы не вычислили во время компиляции вам придётся вычислять во время исполнения.
И тут уже даже неважно — какая у вашего языка семантика, тут чистый Ломоносов: ежели где убудет несколько, то умножится в другом месте.
Возможно, моя информация устарела — я не настолько слежу за компиляторами, но мне кажется, что не каждая оптимизация требует отдельного полного прохода.
И я знаю точно, что шаблоны в этом очень дорогие, что твой пример не учитывает.
И я знаю точно, что шаблоны в этом очень дорогие, что твой пример не учитывает.Мой пример был в достаточной степени патологичным, просто чтобы показать «как оно бывает».
А шаблоны дорогие, внезапно, за счёт того, что много времени уходит на последующие оптимизации, которые должны как раз поудалять zero-cost asbtractions из кода. Компиляция шаблонов с -O0 — часто на порядок (а иногда и на два) быстрее, чем -O2… но и скорость работы полученного кода — тоже на порядок медленнее оказывается.
А вот в старых компиляторах отпимизация была, действительно, очень дешёвой… но все ведь знают во что это выливалось.
С точки зрения современных компиляторов тогдашние просто не умели нифига оптимизировать — вот и всё.
Только насколько выразительным и безопасным он будет?Это уже даже неважно. Даже если вы пожертвуете выразительностью и безопасностью, то получится, как у нас, что-нибудь в это дуже:
$ time as gen_x86_64_ref.S real 0m15.313s user 0m15.064s sys 0m0.257s $ wc gen_x86_64_ref.S 20049609 63657313 583298678 gen_x86_64_ref.SДа, это не руками писанный код, а генерённый (если это непонятно из названия). Если же что-то подобное ещё и руками кого-то заставить писать, то это всё, кроме долгой компиляции — вам ещё в зарплате встанет в какие-то нехилые суммы.
Только насколько выразительным и безопасным он будет?Оберон тут образцом.
Оптимизировать его можно до идеала. Безопасным — не хуже Раста, выразительность конечно на уровне дат разработки — 2013 макс.
А теперь возьмем Safe C. Время компиляции — на уровне С (Раст тормоз, если кто не в курсе), за счет толстых указателей — безопасность памяти вполне (в Расте это заимствовано в виде &str — слайсов, не в обиде за идею).
Безопасным — не хуже Раста
Вы это сейчас серьёзно говорите? Про язык с нуллабельными указателями без проверки времён жизни?
unwrap без проверок? Вот как раз в этом месте Rust ничем не отличается от Java.В случае чего — вылетает «паника» и ошарашенный пользователь видит длинную портянку. Если её не спрячут, конечно, за «цивильным» сообщением «Наши сервера испытывают большую нагрузку, попробуйте, пожалуйста, позже».
А чем это, в принципе, отличается от бесконечных unwrap без проверок?Тем, что можно из Option вытащить значение и потом его уверенно использовать, не держа в голове его нуллабельность. С указателями (а не примитивные типы в Java по факту ими и являются) это так не работает. Вы, конечно, можете проверить, что какой-то конкретный указатель не null, но в системе типов это не выражается.
А ещё вы пишите так, чтобы специально создать впечатление, что программы на Rust усыпаны unwrap, а это не так.
А чем это, в принципе, отличается от бесконечных unwrap без проверок?
Тем, что бесконечные unwrap без проверок — это вопрос дисциплины кода, а нуллабельные указатели — элемент языка?
Безусловно. И использование ссылок вместо указателей в C++ (там, где это имеет смысл) — это тоже часть дисциплины кода. Кроме того, важно, какие будут последствия от использования null-ссылки: в C++, насколько я помню, это UB, в Java — NPE, который ведёт себя предсказуемо и который, в крайнем случае, можно просто явно ловить.
Тем, что бесконечные unwrap без проверок — это вопрос дисциплины кода, а нуллабельные указатели — элемент языка?Проверка на нуль это тоже дисциплина кода.
Не спорю. Разница только в том, что проверку на null можно просто не сделать, и дисциплина состоит в том, чтобы, грубо говоря, про неё не забыть. А с Option в любом случае придётся что-то сделать, прежде чем получить само значение, и дисциплина состоит в том, чтобы обработать ошибочное значение корректно; кроме того, при желании можно тупо грепнуть исходники по unwrap и проверить, какие из них обоснованы, а какие лучше заменить хотя бы на expect. На мой взгляд — разница заметная, но я здесь по понятным причинам не авторитет.
А с Option в любом случае придётся что-то сделать, прежде чем получить само значениеНапоминаю про недавний пример, где игнорирование Result приводит к ошибке.
Аналогично берем и пишем Option.unwrap()
где игнорирование Result приводит к ошибке
А ворнинги компилятора вам на что даны? Компилируйте с
RUSTFLAGS="-D warnings" cargo buildИ будут вам ошибки компиляции, вместо ворнингов. В таком случае проигнорировать Result не получится.
Не надо полумер, советуйте сразу писать без ошибок!
Option.unwrap варнинга, кстати, не генерирует.
Option.unwrap варнинга, кстати, не генерирует
А почему должен? Этот метод достает из Option значение или приводит к панике, если там оказался None. Если вы в своем коде позвали этот метод, то наверное вы сознательно это сделали? О чем тут компилятор должен предупреждать? Если бы вызов unwrap считался ошибкой, то такого бы метода просто не было.
Вы это сейчас серьёзно говорите? Про язык с нуллабельными указателями без проверки времён жизни?И чем же Option безопаснее нуллабельного указателя??? Паникой вместо GPF/segfault?
То есть ответ типа "паникой в том месте, которое можно найти, просто грепнув код, а не при произвольной операции с указателем", равно как и "детерминированным действием вместо UB", Вас не устраивает? Они оба уже здесь были высказаны, насколько я помню.
Тем что
Optionможно не использовать. То есть, хотя в некоторых случаях у вас будет написан.unwrap()вместо разыменования нулевого указателя, но в остальных-то случаях у вас просто не будет никакогоOption, никакого.unwrap()и никакой возможности получить панику.
Тем, что все потенциально некорректные места явно обозначены программистом.
И чем же Option безопаснее нуллабельного указателя??? Паникой вместо GPF/segfault?
Если уж на то пошло, то разыменовывание нулевого указателя в C и C++ — это неопределённое поведение, вы не можете в принципе рассчитывать на какой-то определённое поведение от скомпилированной программы. В частности, если компилятор может доказать, что в какой-то ветке кода гарантированно происходит разыменовывание нулевого указателя, то он может эту ветку кода удалить вообще, включая бизнес-логику, которая там содержится.
По существу: да, unwrap безопаснее. Во-первых, потому что у unwrap совершенно чёткое, гарантированное, детерминированное поведение, и, в крайнем случае, если паника реализована через раскрутку стека, то её можно перехватить. Во-вторых, в языках с нуллабельными указателями зачастую нет гарантированно валидных указателей (как в Java, например), поэтому там проблематично реализовать на практике подход parse, don't validate. В Rust таких проблем нет. Более того, в силу того, что Option является точно таким же типом, как и любой другой, обработать случай отсутствующего значения можно при помощи одно из многочисленных комбинаторов, и unwrap — это только один из них. Если логика предполагает, что вместо отсутствующего значения можно использовать некоторое значение по умолчанию, то можно использовать unwrap_or (или unwrap_or_else, если создание экземпляра типа — дорогая операция). Если нужно использовать нужное значение сейчас, а обработать случай отсутствующего значения потом, то можно использовать map (или and_then, если сама операция также может зафейлиться). Ну и, в конце концов, если на текущем уровне иерархии у кода недостаточно информации, чтобы обработать случай отсутствующего значения, то программист может воспользоваться самой ленивой опцией: дописать после значения ?, чтобы вызывающий код сам разбирался с ситуацией (перед этим, возможно преобразовав Option в Result, чтобы уточнить ошибку).
Впрочем, легко поправимое и без ломающих последствий.
Собственно, по мне писать на Расте — это как плавать со связанными руками. Неудивителен рост на Тиобе — без гугла ни строки. (
Не, ну так-то можно было бы к методу добавить атрибут #[must_use]. Другое дело, что структуры данных, подобные тем, что есть в heapless, обычно используются, когда у нас есть некоторые соображения, позволяющие доказать, что размера буфера хватит для всех данных, которыми мы оперируем, поэтому тот факт, что по умолчанию ошибки игнорируются, не столь страшен.
Вот как раз в этом месте Rust ничем не отличается от Java.
В случае чего — вылетает «паника» и ошарашенный пользователь видит длинную портянку
Вот вы нашли к чему придраться, просто фантастический хедшот! Дебажить же без стек-трейса так забавно, правда?
Дебажить же без стек-трейса так забавно, правда?Проблема не в стек-трейсе. Проблема в том, что ты его получаешь вместо осмысленного сообщения об ошибка.
А так-то да, если «случилось страшное», то, конечно, стек-трейс необходим. Просто, в идеале, вот это вот «страшное» не должно случаться «на ровном месте», когда кто-то поле «Фамилия» не заполнил…
Да, поэтому писать unwrap() вместо обработки ошибок считается запашком в коде.
Впрочем Rust тут не один такой. Та же самая ситуация у какого-нибудь Haskell и функции head.
Тут мы уже подходим к феномену, который Страуструп метко описал как There are only two kinds of languages: the ones people complain about and the ones nobody uses.
Это уже тот уровень «бардака», который может меня заставить жаловаться на неидельность где-нибудь на форуме, но не тот, который может меня отважить от языка в принципе.
Из двух, критически важных для меня проблем, одну — наконец решили.
Осталась только полная невозможность создания хоть каких-то разделяемых библиотек со стабильным высокоуровневым API.
Ну не через protobuf же два компонента в одном процессе должны общаться!.. хотя это, кстати, интересная идея. Надо будет обдумать.
Осталась только полная невозможность создания хоть каких-то разделяемых библиотек со стабильным высокоуровневым API.Кроме extern C еще изобрели CORBA и DCOM. Все благополучно издохли.
Жениться вам барин надо (с)
Кроме extern C еще изобрели CORBA и DCOM. Все благополучно издохли.Ну дык, а чего вы хотите от нарушителей пятого правила: It is always possible to aglutenate multiple separate problems into a single complex interdependent solution. In most cases this is a bad idea.
Потом: и CORBA и даже DCOM, всё-таки, в основном для общения с компонентами в других процессах существуют (а ещё параллельно они решают 100500 других задач). Мне же всего лишь нужен интерфейс для плагинов в том же процессе.
Проблема в том, что какой-то мудак:
- не проверил данные на null и словил NPE
- потребил неприличное количество памяти и словил OoME
- обернул checked exception в unchecked или тупо скинул наверх по стеку.
Все эти ситуации — это тот самый code smell, нарушение политик и прочее. В общем при нормальных процессах при разработке пользователь никогда не увидит стектрейс в сообщениях (они кидаются только в лог-файлы). Ну а если говнокодить, то да — всякое случается.
Но этот риск (для говнокодеров, ага) намного лучше непонятной ошибки на языках где его нет.
Если вам нужен молоток — и только — то зачем вам Rust? Используйте C, его для ваших потребностей судя по всему должно хватить. А вот определение того, зачем в Rust такой широкий инструментарий и почему его следует применять в прикладной разработке, оставьте тем, кому он реально нужен в таком качестве.
Это системный язык, ему незачем становиться всецелевым и соревноваться с другими языками в их нишах.Вот с этим согласен. Все-таки ручная работа с памятью и работа с бизнес-процессами — разные вещи. Целиться в: betterC + nativeJava опасно превращением в новый супер-громоздкий (или просто переусложненный) ЯП.
И история с С++ тому пример.
А я не согласен: Что делает Rust универсальным языком программирования
А я не согласен: Что делает Rust универсальным языком программирования
мне кажется что этот сниппет какраз говорит о том почему Rust-у не нужно пытаться соперничать с языками из несистемной ниши. Этот кусок мог бы выглядеть получше почти на любом из веб-ориентированных языков.
Да и в чем цель-то? Чтобы девелопер на Rust мог при случае написать веб-сервис? Зачем если для этого есть инструменты получше?
use std::io;
use actix_web::{get, web, App, HttpServer, Responder};
#[allow(non_camel_case_types, missing_docs)]
pub struct index;
impl actix_web::dev::HttpServiceFactory for index {
fn register(self, __config: &mut actix_web::dev::AppService) {
async fn index(info: web::Path<(u32, String)>) -> impl Responder {
{
let res = ::alloc::fmt::format(::core::fmt::Arguments::new_v1(
&["Hello ", "! id:"],
&match (&info.1, &info.0) {
(arg0, arg1) => [
::core::fmt::ArgumentV1::new(arg0, ::core::fmt::Display::fmt),
::core::fmt::ArgumentV1::new(arg1, ::core::fmt::Display::fmt),
],
},
));
res
}
}
let __resource = actix_web::Resource::new("/{id}/{name}/index.html")
.name("index")
.guard(actix_web::guard::Get())
.to(index);
actix_web::dev::HttpServiceFactory::register(__resource, __config)
}
}
А зачем код после его развёртки макросом приводить? Что это должно демонстрировать?
Вот как это выглядит для программиста:
use std::io;
use actix_web::{get, web, App, HttpServer, Responder};
#[get("/{id}/{name}/index.html")]
async fn index(info: web::Path<(u32, String)>) -> impl Responder {
format!("Hello {}! id:{}", info.1, info.0)
}
#[actix_rt::main]
async fn main() -> io::Result<()> {
HttpServer::new(|| App::new().service(index))
.bind("127.0.0.1:8080")?
.run()
.await
}А то, что вы привели — результат кодогенерации.
да и вообще — зачем пытаться писать веб на Rust? Понимаю что можно в теории, но это должен быть исключительный случай и в 99% случаев тупо не имеет смысла.
макрос пишут один раз. Возьмите фласк в своем любимом питончике там похожая фигня с аттрибутами функций обработчиков.
Давайте, только не забудьте типизацию из python3 расставить
А иероглифы каким-то образом улучшают статический (да хотя бы и динамический) анализ кода транслятором и средой разработки?
А зачем в питоне тогда типы если вы не хотите их использовать, получается и там куча всего "ненужного".
Ну а если серьёзно то я не вижу никаких иероглифов в примере на расте.
::;
_::{, , , , };
#[(___, _)]
;
_:::: {
(, __: & _::::) {
(: ::<(, )>) -> {
{
= ::::::(::::::::_(
&[" ", "! :"],
& (&., &.) {
(, ) => [
::::::::(, ::::::::),
::::::::(, ::::::::),
],
},
));
}
}
__ = _::::("/{}/{}/.")
.("")
.(_::::())
.();
_::::::(__, __)
}
}оставил с того сниппета чисто спец. символы. Какой .py файл мне проанализировать чтобы в нём было столько же требухи из каракулей?
P.S. Вообще не понимаю, зачем в Расте есть ещё какие-то буквы, символы? Почему бы не писать ВСЁ на апострофах, скобках, двоеточиях, амперсандах? Нормально же выглядит ))
все эти литеры, читабельность — это для изнеженных слабаков. Жизнь настоящего кодера должна быть сложной!
В pyo файле тоже малочитаемый текст. Зачем вы мне опять приводите пример кодогенерации, вы бы еще асм скопировали.
Зачем вы мне опять приводите пример кодогенерации, вы бы еще асм скопировали.
.pyo и макросы это не одно и то же. Макросы должен писать человек. Это не какая-то полупереваренная фигня, это вполне Rust-код, с Rust синтаксисом. И будто бы никто не сможет написать такого же говна не в макросе, да?
т.е. на самом деле в коде Rust нет ни апострофов, ни скобок, не двоеточий, ни амперсандов? Или их мало «на самом деле»?
«это не тот пример» — это просто попытка отрицать неудобную правду. Вариация отмазки ну это просто был не настоящий шотландец
Писать макросы и смотреть на результат того во что они раскрываются это же разные вещи. Особенно смотреть на результат того во что раскрываются несколько вложенных макросов вообще смысла нету, т.к. нас интересует в каждый момент времени максимум один.
И будто бы никто не сможет написать такого же говна не в макросе, да?
Написать говна можно везде.
Из особенностей раста тут только спец симовол &. Ещё куча ::, но они не нужны в таком количестве в нормальном коде. Все остальные закорючки есть в любом языке.
Написать говна можно везде.
это не довод, т.к. вопрос степени. Иначе по аналогии можно сказать «ошибок можно везде наделать, так что к черту безопасность раста». Разные языки по-разному способствуют написанию кода тарабарщиной. Раст в этом плане плох
Тот код в который раскрылся макрос он ничем не плох с точки зрения кода. Просто он излишне подробный, особенно часть в format, которую вообще никогда нету смысла трогать т.к. это часть core либы. Мне не известен язык которы защищает от плохих названий переменных, или там от импортов длинных. Какая притензия конкретно к расту в этом месте? Я бы поверил если бы вы хотя бы жаловлись на код с лайфтаймами или сложными trait bounds. Но в этом конкретном куске вообще ничего нету кроме двоеточий.
Кстати как раз наоборот, в раст компилятор не даст ничего плохого написать и ещё и ошибки отловит. А вот в джава-скрипте там закорючек мало, но навортить можно говна любой степени.
Вот поддержу. Как-то надо было разобраться, как работает некоторая часть большого js-проекта — пришлось перелопатить чуть ли не половину проекта, чтобы понять, что конкретно делает и с какими данными работает одна функция. В Rust, конечно, сигнатуры обобщенных функция выглядят сильно перегруженнее и трудночитаемее js-овских, но время на осознание того, что делает код в этом месте они сокращают кардинально.
Кстати, есть ещё такое когнитивное искажение, когда непривычное, новое воспринимается как объективно плохое. Его преодоление требует определённых усилий. Я бы поставил на то, что вы, phtaran, находитесь под влиянием этого психологического эффекта.
когда непривычное, новое воспринимается как объективно плохое
так можно обо всем сказать. «Есть какашки не то что невкусно — просто непривычно»
А можно изучить теорию музыки (гармония, полифония, музыкальная форма, сольфеджио, инструментоведение, ритмику, ...) и та же самая музыка которую слушал раньше будет восприниматься совсем по другому. Вкусы изменятся.
Тоже самое и с языками.
Я не так сказал.
Я бы дождался решения от Микрософт.
А если серьёзно, то как бы вы изменили синтаксис раста, чтобы сохранить ту же выразительную силу?
не знаю, но я бы выбрал большую читабельность, возможно пожертвовав выразительностью. Rust помешан на безопасности, выразительности… но это вылазит боком в других местах (это, конечно, можно отрицать). Для меня «что черезчур — то нездраво».
В одних местах язык типа помогает отфильтровать ошибки, но программист просто допустит их в других местах — ошибки логики ведь никто не отменял, а читабельность и незахламлённость кода имеет на это самое прямое влияние.
Я вряд ли буду использовать Rust при надобности, т.к. не хочу себя уговаривать «ну чо там, не так уж и много закорючек». Мне перед собой притворяться нет смысла )
Пока, конечно, рано судить насколько оправдана эта выразительность, будем посмотреть когда он получит массовое распространение. «Любой алмаз кажется большим, пока его не огранят»(с)
Ну а в остальном, кажется стало даже понятнее! :troll:
Но в данном примере явно нехватает лайфтамов, это которые `
Если вы все будете писать словами — получится литературный текст, его как программу тоже будет тяжело читать. Будет также, как при расписывании математических теорем текстом.
Задача как-раз в том, чтобы найти баланс использования спецсимволов, ключевых слов и пользовательских идентификаторов (которые обычно всегда слова) с тем, чтобы улучшить восприятие кода и сократить его набор. То есть, если у вас написано:
New tuple equals begin first and second end.То далеко не факт, что это лучше читается, чем
let tuple = (first, second);Потому что программа — это не литературное произведение, это не текст, имитирующий последовательность звучащих слов речи, это — структурированные данные, отражающие работу некоторого алгоритма. И так уж получается, что спецсимволы зачастую предпочтительнее в качестве структурных разделителей и на их фоне пользовательские имена воспринимаются быстрее и вернее, если, конечно, они не однобуквенные.
ADD a, b TO c
ON SIZE ERROR
DISPLAY "Error"
END-ADD
Однако, я скорее согласен с критикой Дейкстры и считаю, что язык программирования не должен быть близким к естественному языку — у него другая задача.
А то, что COBOL до сих пор так широко используется… Тут нужно отдельно исследовать этот феномен, но видится мне, что просто синтаксис в распространении ЯП играет далеко не самую главную роль, как бы ни казалось обратное при поверхностном взгляде.
И так уж получается, что спецсимволы зачастую предпочтительнее в качестве структурных разделителей
ну так я и говорю — почему бы не писать чисто на спец. символах?
а если серьёзно, этот нормально до какой-то границы.
Если что-то выглядит коряво, то оно и будет выглядеть коряво, какие доводы не выдумывай. Можно конечно сказать что «а знаете, а мне нравится тарабарщина!» типа как в анекдоте «Раньше я писался в штаны, но теперь я это преодолел — я этим горжусь».
ну так я и говорю — почему бы не писать чисто на спец. символах?
Потому что язык не состоит только из структурных разделителей. Если это не Lisp, конечно )
Если использовать только спецсимволы — то что они будут разделять? В таком языке легко будут отделяться только пользовательские имена, заданные в виде слов, от остальных спецсимволов. Использовать ключевые слова для различных встроенных команд — это прекрасно, но не надо требовать писать словами разделители и границы структурных блоков, воспринимать такой код будет труднее и медленнее.
Задача как-раз в том, чтобы найти баланс использования спецсимволов, ключевых слов и пользовательских идентификаторов (которые обычно всегда слова) с тем, чтобы улучшить восприятие кода и сократить его набор.
Вы же это прочитали? Так зачем опять сводите ситуацию к абсурду и продолжаете демагогию?
так а макрос писать не нужно? Или разбираться в том что сгенерировано как оно работает?
Достаточно это сделать один раз при изучении того, как работает макрос. И то, это в сложных случаях, когда нет документации и если по контексту вызовов не понятно, как он работает.
Или точку останова поставить (если такое возможно).
Мне в своей более чем трехлетней практике использования Rust в разработке приходилось пользоваться отладчиком ровно один раз, и то для того, чтобы понять, как работает внешняя С-библиотека. Ни разу ни мне, ни моим знакомым и коллегам не приходилось отладчиком смотреть внутрь макроса.
Или если бы этот код написать без макроса — стал бы он намного лучше?
Почти всегда есть обходной путь. Не нравятся макросы — не используйте. Тот же actix-web имеет и API без макросов. Другое дело, что без них придется больше писать шаблонного кода, который в целом сильнее затрудняет чтение программы, чем декларативные атрибуты, например.
да и вообще — зачем пытаться писать веб на Rust? Понимаю что можно в теории, но это должен быть исключительный случай и в 99% случаев тупо не имеет смысла.
Но ведь web на Rust многие пишут! Я лично знаю несколько компаний, разрабатывающих свои веб-приложения на Rust.
Rust быстрый, абстракции у него либо бесплатные, либо очень дешевые. Для систем, работающих под нагрузкой — это важное качество. Далее, в Rust очень мощная система типов для в целом императивного языка. Она позволяет избежать массы проблем, всегда возникающих в больших проектах. Также дает возможность переложить на компилятор больше проверок логики, выраженной в системе типов. Опять же, из-за правил владения и системы типов очень просто писать многопоточный и асинхронный код. Инструментарий отлично развит, легко создавать модули и управлять зависимостями, простая и эффективная встроенная поддержка тестов, настраиваемый автоформаттер и много, много чего еще.
Эти преимущества настолько очевидны и столько раз уже были озвучены, что мне как-то странно, что у кого-то, кто следит за этой темой, еще возникают вопросы на этот счет.
Для систем, работающих под нагрузкой — это важное качество. Далее, в Rust очень мощная система типов для в целом императивного языка. Она позволяет избежать массы проблем, всегда возникающих в больших проектах.
По части нагрузок. Go проигрывает в среднем в 2-3 раза, java примерно так же, может в 3-4 раза. Это должен быть исключительный случай какой-то mission-critical системы чтобы разница в 2-3 раза имела такое важное значение. Примером может быть nginx или reverse proxy
И то — Go проигрывает в 2-3 раза — это в среднем. Сколько он будет проигрывать в качестве веб-сервиса по нагрузке — неизвестно, вполне возможно что меньше.
Что касается обычных веб-сервисов, если нагрузка на веб-сервис высокая, то сервис обычно масштабируют горизонтально. Или вы думаете что раз Rust быстрее, то всё можно экономненько запхнуть на один инстанс? А если этот инстанс упадёт, что тогда? Это даунтайм который стоит денег для бизнеса. Redundancy почти неизбежно, и тут разница в 2-3 раза уже не играет такой роли, т.к. масштабироваться нужно в любом случае.
Какое бизнесу дело до тикив, байтов и мощной системы типов? Нужно выкатить побыстрее в продакшн, и эти деньги на на доп. инстансы компенсируются скоростью разработки на мейнстрим инструментах. Я знаю компании которые имеют сотни инстансов EC2 на каждом энве, и пишут веб-сервисы на расходных с вашей точки зрения языках. Пока это работает, никто и не подумает переводить свой стэк ни на какие расты.
Rust быстрый, абстракции у него либо бесплатные, либо очень дешевые.
java сейчас где-то 25 лет. C# может чуть поменьше. Вы хоть представляете какой там объём наработанных готовых решений для веба и интерпрайза? Нормальный архитектор вряд ли станет делать ставку на бедную экосистему в которой сделал пару шагов от простого — rest controller'а из примера и окажется что дальше ничерта нет — ни внедрения зависимостей, ни IOC контейнеров, ни фреймворков для аутентификации, ни service discavery, ни интеграции с субд, ни интеграции с клауд сервисами, ни всего того на чем строится enterprise обычно. Только не надо сейчас по-быстрому гуглить и говорить «вот есть на Rust библиотечка для json». На java/c# есть проверенные и работающие решения, и даже если не устроило одно — можно найти альтернативы, и объёмы, разнообразие и стабильность этих решений ни идут ни в какой сравнение с вашим Rust-ом )
И этот проигрыш в 3 раза по скорости, да хоть бы даже в 10, никак не покроет бешеную стоимость разработки подобных решений на Rust. Разработка не состоит из одних только красивых концепций, это вообще-то бизнес.
Достоинства Раста по управлениею памяти — эта «священная корова» Rust, тут ничего не дает, потому что эта проблема в языках с GC ОТСУТСТВУЕТ КАК КЛАСС и все те усилия по управлению памятью идут на реализацию прикладной задачи. Можно сколько угодно хейтить расход памяти в java или c# но решение на них будет разработано и выведено в продакшн, причем в разы быстрее чем на Раст, а это и есть деньги. Программисты стоят не дешевле чем расходы на сервера, и каждый день отсрочки выхода на рынок — это потерянные деньги.
И код на этих языках таки не выглядит как свалка с закорючками (апострофами, амперсандами, скобками, двоеточиями — слава богу хоть китайских иероглифов нет). А значит это решение ещё будет стоить меньше из-за стоимости поддержки, т.к. код пишут 1-2-3-4 раза, а потом читают, дорабатывают и отлаживают много раз.
Или вы думаете что раз Rust быстрее, то всё можно экономненько запхнуть на один инстанс?
Можно запихнуть на три инстанса, каждый в своем ДЦ и не переживать, что оставшиеся после отвала ДЦ инстансы не справляются с нагрузкой.
Программисты стоят не дешевле чем расходы на сервера, и каждый день отсрочки выхода на рынок — это потерянные деньги.
Иногда дешевле потратить больше человекочасов и написать экономичный и быстрый код. И развернуть его не на 15 тысячах серверов, а всего лишь на 5 тысячах. Правда это очень редкий кейс, как в плане необходимости, так и в плане такого серьезного выигрыша производительности.
Можно запихнуть на три инстанса, каждый в своем ДЦ и не переживать, что оставшиеся после отвала ДЦ инстансы не справляются с нагрузкой.
если сервис на Go/java проскейлен на больше 5-6 инстансов, то при всей скорости Rust, в 1 инстанс его не вопхнуть. Во-вторых, если нагрузка на инстансы составляла больше 70%, то после падения 1-го из 3-х инстансов будет каскадный сбой всех троих.
Т.е. Rust врядли может повлиять на вопрос масштабирования в виде «Yes/No»
К тому же есть ещё один фактор. Производительность Rust будет в значительной степени нивелирована, потому что веб-сервис это не числодробилка. Надо запросить другой сервис, надо запросить базу, всё такое. Так что тут Rust вряд ли даст выигрыш в 2-3 раза по сравнению с Go. Улучшения latency и throughput скорее всего не произойдёт. Разве что по утилизации памяти, но и то не факт что намного.
Это должен быть исключительный случай какой-то mission-critical системы чтобы разница в 2-3 раза имела такое важное значение.Никаких mission-critical. Разница в 2-3 раз в скорости обозначает ровно такую же разницу в оплате железа.
Вы, может быть, не поверите — но компании для которых это важная статья расходов — таки существуют. И это далеко не только Гугл.
Я знаю компании которые имеют сотни инстансов EC2 на каждом энве, и пишут веб-сервисы на расходных с вашей точки зрения языках. Пока это работает, никто и не подумает переводить свой стэк ни на какие расты.Не. Не «пока это работает», а «пока под это дают кредиты». А кредиты дают, пока работает «принтер, печатающий доллары».
То, что он остановится — достаточно очевидно. Хотя есть две возможности — либо американцы «рванут стоп-кран» и жёстко его тормознут. Либо США станет соседом СССР на страницах учебников истории. В первом случае — всё может случиться буквально в следующие год-два. Во втором — могут и лет 10-20 ещё протянуть.
Но в какой-то момент возможности заливать всё это баблом иссякнут.
Разработка не состоит из одних только красивых концепций, это вообще-то бизнес.Если бы это был бизнес, то ни C#, ни Java не получили бы распространения никогда. Нет, сегодня это, в основном, «развод инвесторов на деньги».
Но ведь не все ещё занимаются подобным «бизнесом». Есть и люди, производящие реальную продукцию.
Можно сколько угодно хейтить расход памяти в java или c# но решение на них будет разработано и выведено в продакшн, причем в разы быстрее чем на Раст, а это и есть деньги.Не. Это не деньги. Это лапша на ушах инвесторов. Если бы это были «деньги», то всё сильно по другому бы развивалось. И ФРС не пришлось бы печатать по триллиону долларов в месяц (а ведь десять лет назад печаталось всего лишь по триллиону в год и это считалось «много»).
Если бы это был бизнес, то ни C#, ни Java не получили бы распространения никогда. Нет, сегодня это, в основном, «развод инвесторов на деньги».
запахло теорией заговора. Видимо всемирные евреи посещают каждого архитектора и науськивают его использовать джаву и сишарп
P.S. дальше обсуждать нет смысла
Так вроде бы никто не заставляет писать на раст то что можно написать на ноде. Если нужно написать что-то массовое (в смысле то что делается пачками в разных конторах) то самый простой способ это действительно облажится фреймворками про которые вы написали и готово. Но ведь слава богу на этом задачи не заканчиваются.
Как вы думаете, почему в одной большой и в нашей стране хорошо известной компании почти половина всей кодовой базы — это C++, хотя основной язык — Java? Подумайте над этим, а то окажется, что ваши представления о стоимости производительных решений на Java не вполне адекватны, а вы и не знаете.
Теперь, вы пробовали писать многопоточный код на Java? А управлять ресурсами в многопоточном коде? В Rust компилятор защищает от большинства проблем многопоточности, чего хватает в 90% случаев. Управление ресурсами — элементарное, точно такое же, как и общее управление памятью. Вот посмотрите неплохой доклад о некоторых проблемах управления ресурсами в Java: https://youtu.be/K5IctLPem0c В Rust таких проблем нет.
Что касается типизации — я вообще не понимаю, как человек, имеющий хоть какой-то опыт enterprise-разработки может сомневаться в ее полезности? Ну да, давайте сэкономим на проектировании абстракций, слабаем императивную лапшу и остаток жизни будем чинить вечные баги, так что ли? К слову, и на Rust можно писать лапшу, только делать это труднее.
Опять же, чем лучше контроль типов — тем проще код дорабатывать и рефакторить. Потому что компилятор больше проверок делает за вас, читаемость кода тут вообще не причем (хотя я не вижу проблем и с читаемостью: у меня были претензии к синтаксису Rust только до тех пор, пока я его не изучил в достаточной мере и не приобрел опыт работы с кодом на Rust).
Единственный реальный недостаток — это молодая, пока недостаточно развитая экосистема. Но, к счастью, не все компании желают только пользоваться свободными компонентами, но есть и те, кто готов вносить и свой вклад в их развитие.
Ну да, давайте сэкономим на проектировании абстракций, слабаем императивную лапшу и остаток жизни будем чинить вечные баги, так что ли?
вы думаете что программистам мешает разрабатывать хорошие абстракции какой-то конкретный язык? )
Как вы думаете, почему в одной большой и в нашей стране хорошо известной компании почти половина всей кодовой базы — это C++, хотя основной язык — Java?
Google использует Go, java, Python, c++. Из них хорошо перформит только с++, сносно — Go.
вы думаете что программистам мешает разрабатывать хорошие абстракции какой-то конкретный язык?
Конечно. Попробуйте-ка вместо примитивных типов в Java использовать на каждый чих классы — и вы сами это поймете.
Конечно. Попробуйте-ка вместо примитивных типов в Java использовать на каждый чих классы — и вы сами это поймете.
как это относится к делу?
Вы повторяете как мантру что Раст быстрый, всё в нём бесплатно и очевидно что он самый лучший.
инструменты выбирают исходя из целесообразности. А на абстракции и хороший код обычно влияет больше факторов чем просто язык. На хороший код нужно время, хорошо поставленные процессы, проработанные требования, квалифицированные специалисты. Язык в этом всём играет далеко не первую роль, это всего лишь инструмент, а компилятор — просто помощник, а не бог способный решить все проблемы.
Вы рассуждаете как наивный идеалист, который никогда не работал под давлением.
Хорош тот язык, который позволяет быстро писать код среднего качества в ближайшее десятилетие будет скорее всего в фаворе, по сравнению с языком на котором писать хорошо но долго (Rust). К тому же что будет с этим канцелярским языком при давлении сроков (а это обычное дело)? Я скажу что — будет резкая деградация качества и срезание углов. Причем более резкая чем на языке который позволяет писать быстро но средне.
Можно и дальше говорить что java/с# плохие, но на них выведено в прод куча софта, они проверены реальными боевыми условиями, в отличие от.
как это относится к делу?
Уже писал тут: https://habr.com/ru/post/504622/
в разделе "Бесплатные абстракции".
Вы рассуждаете как наивный идеалист
Нет, просто у вас предельно консервативная позиция, вы не видите и не хотите видеть реальных перспектив, которые дают новые языки. Они, кстати говоря, не на ровном месте появились, а в процессе решения тех или иных проблем старых языков. Вы же — просто закостенели, вы боитесь, что скоро придется значительную часть своего опыта просто выкинуть — а ведь так хорошо живется "старым жиром"! Я это говорю без осуждения, знаю по себе, как неприятно расставаться со своим "багажом" и снова "садиться за парту". Но еще хуже — постоянно мучиться проблемами C++ и Java (которые я использовал для своих проектов и от "особенностей" которых я просто устал). Так что теперь совсем не жалею, что проделел эту процедуру — это пошло на пользу и делу, и мне, как разработчику.
Единственный серьезный недостаток у Rust сегодня — это некоторая сырость самого языка и его экосистемы. Но эта проблема решается популярностью и временем.
Rust — это очень передовой язык по многим технологическим аспектам инженерии ПО. Да, у него есть недостатки, да — он не идеален. Но пока — это лучшее, что есть для разработки больших, требовательных к производительности программных систем. Вам этого не надо? Не используйте Rust. Вы хотите что-то проверенное временем? Берите тот же COBOL. Но не надо очернять новый язык ни написав на нем ни одной сколь-либо значимой строчки: как бы вы не боролись с прогрессом, рано или поздно такая борьба приведет вас к неудачам.
Уже писал тут: habr.com/ru/post/504622
в разделе «Бесплатные абстракции».
на хабре мало реальных продакшн историй Rust. Я что-то видел считанные разы (кроме Discord ничего не помню). Почти нет реальных историй, почему выбрали, сколько времени писали, с какими проблемами сталкивались, как решали.
Но еще хуже — постоянно мучиться проблемами C++ и Java
какие проблемы java вас утомили?
Слишком сложная многопоточность, вечные NPE, необходимость иметь под рукой эксперта по тюнингу JVM, если не хочешь принудительно перезапускаться раз в месяц, непредсказуемые моменты сборки мусора и освобождения ресурсов, нарастающие тормоза при попытке писать выразительный высокоуровневый код.
Ну и сам язык развивается путем накручивания костылей сверху, яркий пример — система модулей. Появляется куча нюансов, которые нужно знать и учитывать, как только ты чуть сворачиваешь в сторону от написания типового шаблонного кода. Простой и лаконичной Java я бы не назвал, во многих аспектах она сложнее, чем Rust.
нарастающие тормоза при попытке писать выразительный высокоуровневый код
можно подробнее, о чем речь?
Самое элементарное: оберните инты в классы, чтобы добиться контроля типов со стороны компилятора, и посмотрите, что произойдет с производительностью вашей программы. В моем случае она падала почти на порядок.
Кстати, как с этим в Rust вообще? Можно новый, несовместимый
int, как в старом добром Паскале сделать?type Kilograms = i32;
type Ampere = i32;
fn main() {
let kg: Kilograms = 5;
let amp: Ampere = 10;
kg_ampere(amp, kg)
}
fn kg_ampere(a: Kilograms, b: Ampere) {
println!("ampere + kilo {}", a + b);
}Взять библиотеку, например, такую.
Только выяснилось, что специализации трейтов еще не сделали, и перегрузки операторов неудобные в реализации и в использовании, например в моем примере нельзя сделать
let sum_kg = kg + kgок, а что нужно чтоб работало как надо? Это работает чисто как с++ typedef и всё
Нужно создать новые типы, а не просто добавить алиасы имен. Вот в этой статье хорошо написано, что нужно делать: Передача намерений.
Не на уровне языка, но да, можно, а потом ещё и добавить все арифметические операции.
В Rust компилятор защищает от большинства проблем многопоточностиЭто бред. Раст просто запрещает разделение ресурсов. Это не решает проблем многопоточности.
Конечно, ваша девственность защищена на 100% поясом, только использовать вы не можете НИЧЕГО.
Я уже приводил вам пример, как в Rust шарить неизменяемую ссылку на статический объект между потоками. А если ваш ресурс изменяемый — то логично, что в 90% случаев он должен быть защищен примитивом синхронизации. Остальное — это unsafe, оно такое в расте и есть.
Так что сдается мне, что бредите тут все-таки вы.
Rust шарить неизменяемую ссылку на статический объект между потокамиЭто в общем то и всё, что он может. Это могут все. Смешно.
Я зря надеялся на большее (
А чего вы ожидали? Встроенную синхронизацию в сам язык, а не спец. типы в стандартной библиотеке? Я вот не пойму, в чем проблема-то? Свою задачу предотвращения гонок и защиты от пересылки не шарящихся между потоками объектов — Rust решает, и в практике многопоточного программирования это серьезно помогает.
И какое-же решение существует для предотвращения data races на разделяемых мутируемых данных без примитивов синхронизации (явных или под капотом)?
Да, понятно, что планов громадье (и я только «за»), но важно понимать, что такой ЯП должен быть также удобен для большого количества разработчиков. Иначе будет как
Впрочем, мне в следующем году тоже будет 30, приятно ощущать, что я всё ещё буду в категории молодёжи.Вы вообще младенцем себя должны ощущать, если «модно-молодёжные» идеи имеют тот же возраст, что и вы.
Обычно новые идеи всё-таки бывают помладше, чем их носители, так как мало кто может придумать что-то кардинально новое в детском саду…
Но дело, вероятно, не только в синтаксисе.
ситуации Rust и Scala похожи. Оба языка позиционируются как «замена» в своей нише. Оба очень мощные, оба языка взяли себе набор максим в каркас, стремящихся сделать язык масштабируемым на произвольные случаи.
Различается возможно предпосылки создания, хотя я особо не интересовался кто авторы Rust — прямо забавно, Go спроектировали серьёзные ветераны индустрии, Java — тоже, си — тоже, а про создателей Rust я никогда ничего не слышал. Ну да ладно.
Я вижу ситуацию так. Mozilla проиграла войну браузеров, и ей пришлось менять её «вижн», они решили позиционироваться как браузер с приватностью. Rust стали активно наполнять фичами, и выглядит так что Mozilla стала решать проблемы проектов с помощью языка. Заманчиво вместо решения проблем проектов просто добавить ещё одну удобную фичу в язык.
Оба языка, и Scala и Rust стали тяжеловесами по набору возможностей и синтаксису.
у Rust синтаксис — трэш, «тушите свет, выносите окна». Это такой же важный фактор как и безопасность, просто его недооценивают.
0xd34df00d: попытки скрестить ООП и ФП в таком виде — непонятно, зачем это надоПросто Scala это неудачный пример такого скрещивания. А так-то как-раз надо! Ну и «много-стильность» Скалы тоже в ей минусы записалось. И там непривычный синтаксис — это уже просто вишенька на торте.
phtaran: у Rust синтаксис — трэш, «тушите свет, выносите окна». Это такой же важный фактор как и безопасность, просто его недооцениваютИ это единственная трудность у Раста (возможно оправданная), с остальным у него все в порядке (в отличии от той-же Scala).
В любом случае, для успеха ЯП нужна массовость его использования, а здесь порог входа (в том числе синтаксис) для новых ЯП все-таки важен. Ну что-ж, будем посмотреть…
В любом случае, для успеха ЯП нужна массовость его использованияХайп нужен, прежде всего.
А тут у Rust всё прекрасно: тут тебе и Microsoft (обсуждаемая статья) и Intel и Google, все дружно, в унисон… почти как Java, в своё время (до развода между Sun и Microsoft).
А хорош ли при этом сам язык — почти неважно: ранние версии Java были, если честно, редкостным убожеством — даже для того времени.
Но при наличии достаточного количества ресурсов кашу, как известно, можно сварить и из топора…
Зачем? Я этого не понимаю ни как плюсовщик, ни как хаскелист.То есть вне функциональной архитектуры кода (не архитектуры ПО, как полезного механизма, а самого кода) элементы ФП бесполезны? О-о… Недавно вот на Хабре была статья про простое ФП, где как раз идею о полезности даже элементов функционального подхода всегда и везде автор и пытался доказать (см. Заключение).
То есть вне функциональной архитектуры кода (не архитектуры ПО, как полезного механизма, а самого кода) элементы ФП бесполезны?Немножко всё строго наоборот: ООП, в том виде, в каком он пропагандируется в C++ или Java, в достаточно развитом языке ФП попросту не нужен. Все задачи решаются (и гораздо «красивее» решаются) без него.
О-о…Почитайте про CLOS — это 1980е, время когда C++ только появлялся, а Java ещё и в проекте не было. AMOP, хотя бы. Там даже никаких монад не было ещё — но выразительность уже была. Причём такая, что когда после этого снова смотришь на C++ или Java, то вопрос: «и вот это вот — они реально хотят обозвать ООП?» возникает автоматически.
Например «вечный» вопрос «кому принадлежит метод» получает ответ столько естественный, сколь и неожиданный: никому, разумеется. Если у вас есть принтер/экран и текстовый документ/электронная таблица, то почему, вообще метод «изобразить» должен кому-то из них принадлежать? У вас же очевидным образом четыре варианта, которые образуют один метод… и в ФП — так и будет.
Половина книжки «банды четырёх» является, на самом деле, объяснением того, какие костыли нужно нагородить, чтобы в современных языках как-то симитировать что-то подобное.
Ну и… зачем вам всё это? Зачем вам «костыли», если у вас нормальные ноги есть?
Недавно вот на Хабре была статья про простое ФП, где как раз идею о полезности даже элементов функционального подхода всегда и везде автор и пытался доказать (см. Заключение).Ну это всё можно обсуждать, но если вы взглянете на современный C++ (Eigen — хороший пример), то обнаружите, может быть с удивлением, что ФП там используется «и в хвост и в гриву», а слово
virtual нужно ещё-таки поискать.Отказаться от него, если мы уже всё равно меняем язык… по-моему нормально.
Отказаться от него (ООП), если мы уже всё равно меняем язык… по-моему нормально.Да не вопрос, если при этом удастся обеспечить большой пул доступных программистов ©
В Rust язык потихоньку расширяется и даже переход от Rust 2015 к Rust 2018 вроде как достаточно плавный… а уже освоенные знания в тыкву превращаются небыстро.
В Rust язык потихоньку расширяется и даже переход от Rust 2015 к Rust 2018 вроде как достаточно плавный… а уже освоенные знания в тыкву превращаются небыстро.Нет ли у вас ощущения, что для развития Rust было бы выгодно сделать как в истории с Python2->Python3? Пока еще он не сильно распространен…
Ну ничего такого, чтобы прям переучиваться нужно было, не меняли.Каждая версия компилятора перечисляет изменения, которые что-нибудь ломают. Да, в C++ тоже есть Caveats, но там они касаются расширений, которые, внимание, можно не использовать (причём реально, это не просто декларация). А стандарт — так и вообще «священен». В Haskell же мало того, что меняют язык так, что он не соотвествует стандарту, так ещё и на любой вопрос слышишь в ответ «включи расширение X» или «включи расширение Y».
Rust, в этом смысле, мне нравится куда больше: есть куча фенечек, которые есть «в ночных сборках» (и, соотвественно, иногда меняются несовместимым образом), но если уже что-то объявили стабильным — так оно таки, того, стабильно.
Запомнить, что Semigroup теперь суперкласс Monoid, или что Applicative — суперкласс Monad, не столь сложно, чтобы это было переучиванием.Проблема в том, что человек в это въезжает, с размаху, когда он ещё даже учебник не закончил читать и что, куда и как — понимает не слишком уверенно.
В C++, кстати, такое тоже есть. Немножко. Учебники, основанные на Turbo C++ 3.1 до сих пор учат, что
main возвращает void и, разумеется, говорят что включать нужно iostream.h.Ну тут… такое: кто мог подумать что в 2020м году кто-то будет учить язык используя компилятор, вышедший за шесть лет до выхода первого стандарта? Я когда этот проект обнаружил… немножко прифигел. Но для Индии — это нормально.
P.S. А кто-то тут на Windows XP баллоны катит. Куда там этому новоделу по сравнению с неумирающей классикой!
Почему-то оказалось, что это никому толком неинтересно, и люди, готовые вложить свои силы, вкладывают их во что-то другое.Это как раз нормально. Попытки превратить Java в ISO стандарт тоже провалились. И даже ECMA-334 никого, насколько я знаю, не интересует.
Увы, наиболее правильным решением будет признать, что попытки стандартизации современного хаскеля провалились.И вот это — самая большая беда. Страусиная политика. Haskell — не первых язык, который не удалось стандартизовать. Жизнь же на этом не заканчивается.
Но при этом — делается вид, что «всё на мази», «подождите чуток и Haskell-2020 будет с вами».
Вас история Perl, который из-за того, что все ждали Perl6, а те, кому надоедало, уходили с Perl5 на другие языки, ничему не научила?
Впрочем, тот же real world haskell (имхо лучшая книжка) вроде кто-то начал допиливать до современного состояния экосистемы.Ну и почему на эту «допиленную» версии нет ссылок из соответствующего раздела Haskell.org?
Сравните с тем, что происходит с Rust.
Вот что в Rust сделано грамотно и правильно — это
rust-lang.org (да и вообще вся экосистема поддерживается в неплохом состоянии).Ну, про последнее уже даже самые большиеПотому что смотреть нужно со стороны. Эффект Осборна, потому что. Это Perl на себе очень хорошо прочуствовал, когда люди отказываются смотреть на язык, потому что последняя версия (Perl 6) не готова… а она так никогда и не появляются. Хотя по ней уже и книги есть и всё такое.фанатикиоптимисты не говорят, кажется.
Короче, я запутался и не понял, почему это засовывание головы в песок.
Через это прошло много технологий: кроме Perl, из известных, ещё и HTML и PHP. Решение — всегда одинаково: «перескочить через версию», назвать то, что у тебя есть «новинкой сезона» и дать людям что-то «более новое». HTML 3.0 с поддержкой таблиц, математики и кучи других «плюшек» был выкинут и вместо него выкатили HTML 3.2, включавший плюс-минус список фич MS IE. Про PHP6 забыли, выпустили взамен PHP7. Теперь вот Perl туда же.
В Rust всё было вообще сделано идеально: объявнение о следующей версии объединено с возможностью её «потрогать».
Можно как угодно относиться к тому, что в современном мире люди покупаются на рекламу… но игнорировать этот факт нельзя.
А висящий аннос Haskel 2020 посреди 2020го года… притом что над ним ещё и никто, в реальности, не работает… это скорее антиреклама.
Какая разница? Повесьте красную плашку сверху в предупреждениями.Ну и почему на эту «допиленную» версии нет ссылок из соответствующего раздела Haskell.org?Потому что она ещё не допилена.
Для PR не требуется готовый, законченный, продукт, для PR нужна «движуха».
А ещё нужна, как ни странно, «генеральная линия партии». Да, у Haskell есть и Cabal и Stack и много ещё чего… но разница между ними хоть в каком-нибудь тьюториале объясняется?
Детский сад какой-то, честное слово: вам мало того, что большинство программистов не знакомы с функциональным программированием, им и так его освоить сложно — вы ещё 100500 преград у них на пути выставить решили?
Вот что у Rust сделано правильно — так это пресловутое «community». После объявления Rust 2018 учебник сразу был заменён на обновлённую версию, хотя в ней половины глав не хватало. Ну а то, что недописали — там ссылка на старую версию. С извинениями… и объяснениями как эту старую версию всё-таки использовать. Все нужные для начала работы вещи — «пристёгнуты» к тьюториалу и регулярно обновляются. Сделано всё, для того, чтобы повичок мог в этот «чудный новый мир» въехать с минимальным напряжением сил. Ему и без того, блин, тяжело со всеми этими
mut и borrow-checker'ом! И люди, занимающиеся Rust это понимают. А люди, занимающиеся Haskell — нет. Или, ещё хуже, понимают и не хотят менять: «мы-то через все эти буераки прорвались, мы элита, а эти что — по стобовой дороге пройдут?.. нет, так нельзя».Я так понимаю эта беда, в основном, из-за того, что очень много людей в Haskell-community — это ресёрчеры, не практические программисты. Им главное — статью в журнал написать, а там — хоть трава не расти. Вопрос «а как люди будут с этим на практике жить» их волнует примерно в промежутке от «нам это это не волнует» до «вообче пофигу».
Но в результате — очень мало как программистов, так и предложений работы (работодателям, в очень большом количестве случаев, неинтересно знать как быстро вы напишите код, им интересно знать сколько будет стоить его поддердка, если вы уволитесь).
А потом понял, что у меня просто кривая архитектура (я уж не помню, что там у меня было) — в итоге все эти лайфтаймы, борроу чекер — они загоняют в такие рамки, когда ты и проектировать код должен правильно и он выходит логичней и безопасней сам по себе.
Все таки вы это не просто набор закорючек, а очень стройный набор правил и принципов, которые определяют сам стиль программирования. Просто надо его как следует разжевать
Главная фишка, которую в IT индустрию привнёс Rust — это понимание того, что с подобными ограничениями можно реально написать 90% (а то и 99%) практически полезного кода.
Вот что было самым главным прорывом. А не закорючки и даже не изобретение самих принципов.
И вот это вот — нифига ни из каких теоретических выкладок не следует. Это просто эмпирический факт.
А раз так — можно вокруг этого соорудить язык и в нём эти правила «жёстко прибить гвоздями».
не будем упоминать С++ чтоб не вызвать новый холивар от батхерта отдельных товарищейА как раз с C++ всё просто и понятно:
Rust ни в коем разе нельзя рассматривать как «следующее поколение C++». Они находятся примерно в том же соотношении, как, собственно, сам C по отношению к PL/1. Гораздо более простой и менее выразительный язык, который, тем не менее, достаточно выразителен на практике — и потому имеющий шанс заменить C++.Реализуется ли это на практике… увидим.
Принципиальная невозможность телепорта тоже не доказана.
похоже что незачем. Если бы D не помер — я бы его предпочел.Он то не помер, но в вашей аналогии — у него 4 коробки передач и несколько 5х колес =)
Так что тоже всё непросто
а как можно придумать что-то новое, если считать это заведомо невозможным?
Попытаться доказать что это «что-то» действительно невозможно и прийти к противоречию.
Проблема в том, что даже если некоторое изобретение ничему не противоречит и, теоретически, может быть сделано — пока вы его не совершите… вы не знаете сколько времени это займёт.
Вот когда вы уже знаете как и что делать — да, можно начинать что-то делать не имея на руках полностью работоспособной реализации.
В конце-концов знаменитую железную дорогу Ливерпуль — Манчестер Стефенсон начал строить, не имея ещё, на руках, работавшего паровоза… но он уже знал, примерно, как он будет устроен. Ибо конструировал паровозы и раньше.
Кхе-кхе. Тут товарищи померили производительность сетевых драйверов на разных ЯП-ах, и Swift показал себя довольно фигово, причём что в плане troughput, что в плане latency. В частности, как написано в папире (раздел 6.2.7):
Swift increments a reference counter for eachobject passed into a function and decreases it when leaving the function. This is done for every single packet as they are wrapped in Swift-native wrappers for bounds checks. There is no good way to disable this behavior for the wrapper objects while maintaining an idiomatic API for applications using the driver. A total of 76% of the CPU time is spent incrementing and decrementing reference counters. This is the only language runtime evaluated here that incurs a largecost even for objects that are never free’d.
Use the unsafe, Swift © =)
Там не просто инкремент/декремент, а атомарный инкремент/декремент. То есть требуется синхронизация содержимого кэш линии разных ядер и вполне можем получить cache line contention.
Да даже и на одном ядре скорость снижается из-за взаимодействия атомарных read-modify-write с out-of-order execution.
Тогда каждая функция должна быть по типу «сложили два инта»Не совсем, но близко. Пара атомарных инкрементов — это 30-40 тиков на современном процессоре. Если аргументов 3-5 — то это выливается в 100-200 тиков. А это уже — довольно-таки дофига, с учётом того, что современный процессор может исполнять до 4 иструкций за тик, а одна в среднем — это типичный вполне код.
Получается что оверхед по сравнению с борровингом только несколько операций — увеличение ссылки, уменьшение, проверка ссылки.Во-первых вам эти счётчики нужно где-то хранить. Во-вторых — вы же добавляете эти «несколько операций» не только к каким-то «тяжёлым» операциям типа пересылки пакета по сети или записи блока на SSD, но и к простейшим, самым элементарным операциям, где вся «бизнес-логика», зачастую — пара инструкций процессора.
Но по идее атомарные операции должны происходить быстро если нет конкуренции.Да, они быстрые. На Ryzen, к примеру, LOCK ADD занимает всего 17 тиков. И, опять-таки, если сравнить это с пересылкой пакета по сети — то это мгновенно, а если, скажем, с VMOVDQA (один такт при чтении, два при записи), то это значит что вы за это время сможете скопировать из одного участка в памяти 160 байт… что довольно-таки дофига (и объясняет почему, кстати, в C++11 перешли от COW-строк к SSO-строкам).
Rust, появившийся позже, решил на эти грабли не наступать… что достаточно логично…
А в расте sso нету из коробки, а cow как раз есть. Это хорошо или плохо я не понял?
В расте SSO просто не нужен, там строки-литералы и так обладают богатым API. Это в C++ при создании std::string память всегда на куче выделяется, а литеральная строка никакого API не имеет. Поэтому там нужен костыль в виде SSO, чтобы маленькие литеральные строки оборачивать в std::string, иметь нормальный API и не платить за это выделениями в куче
Потому везде и всюду передаются просто строки и нужен COW или SSO.
В Rust слайсы были с самого начала, потому этой проблемы просто нет.
Это вы сами придумали? Можно ссылку на документацию которая утверждает что Borrowing это тот же самый ARC? ARC подразумевает некий рантайм оверхед на управление пойнтером чего нет в случае использования обычных ссылок.
Как раз преимущество Rust в том что если вам не нужны смарт пойнтеры то вам хватит и обычных ссылок за которыми следит Borrow Checker. Если вам не хватает стандартных ссылок то в стандартной библиотеке есть полный набор из смарт пойнтеров на все возможные ситуации
У нас ОДИН указатель => потому оверхеда нет.
Почему ОДИН? если вы используете неизменяемую ссылку то у вас может быть множество указателей на один и тот же участок памяти, а оверхеда все еще нет :)
Как нужно структурировать свои программы, чтобы все или большинство структур данных были изменяемы и менять их нужно было из разных, не связанных между собой скоупов?
Это что за лапша?
Например, я хочу одну изменяемую ссылку на запись, и несколько неизменяемых — на чтение. Возможно из разных потоков, актор-модель.
Ссылки — это readers-writer lock времени компиляции. Хотеть уникальную ссылку на значение одновременно с неуникальными — это как хотеть одновременно взять writer и reader лок. Хотеть можно, но сделать придётся что-то другое.
Ну так берите Mutex<Cell<...>>. А вообще, для актор-модели нужна актор-бибилиотека.
Единообразное решение на все случаи вряд ли возможно. Как отличить ссылки, время жизни которых не больше времени жизни объекта на которые они указывают от тех, что предполагают продление времени жизни? Если вы возвращаете ссылку из функции, то это так и задумано и просто нужно продлить время жизни объекта или это ошибка?
Можно, конечно, навязать силой одну единственную схему управления памятью, но тогда язык перестанет быть универсальным. А если позволять пользоваться разными, то предстоит решить, какую лучше сделать по-умолчанию. Как часто в реальном коде вам действительно требуются Arc, Rc, Mutex и Box? В моем опыте прикладной разработки на Rust — они требуются намного реже, чем обычные & и &mut.
Даже скорее, не столько.
unsafe в Rust'e чаще используется для обхода своих собственных ограничений, потому иначе он совершенно нежизнеспособен. Потому в любом поголовно проекте есть куча ансейфов — только в хороших меньше.
Их удобнее отслеживать, но не более — зависимости 3-4го уровня уже проглядишь.
unsafe в Rust'e чаще используется для обхода своих собственных ограничений, потому иначе он совершенно нежизнеспособен. Потому в любом поголовно проекте есть куча ансейфов — только в хороших меньше.
Может, вы всё-таки не будете настолько нагло врать? По грубым оценкам (с использованием этого инструмента), чуть больше 70% крейтов содержат только safe код, и порядка 95% кода на crates.io в целом является safe. Даже с учётом ошибок, внесённых методологией измерений, на "поголовно" ну никак не тянет.
Их удобнее отслеживать, но не более — зависимости 3-4го уровня уже проглядишь.
cargo geiger для отслеживания unsafe в своём коде и во всех зависимостях, cargo crev для ревью кода в экосистеме.
Дело не в нахождении ансейфов, а в оценке их [вероятно негативного] влияния в нижележащих на 3-4 уровня библиотек на вашу личную программу.
Дело не в нахождении ансейфов, а в оценке их [вероятно негативного] влияния в нижележащих на 3-4 уровня библиотек на вашу личную программу.Почему вы не оцениваете «вероятно негативное» влияние C++-рантайма C# или Java на эти языки и не мылите верёвку?
Мне лично кажется что
unsafe нужно относиться как к ассемблеру: во всех наших прогреммах есть куски, написанные на ассемблере (хотя бы потому что API, который используется чтобы передать данные от ядра к программе не описывается на языках высокого уровня никак, в принципе), но это не значит, что по этому поводу нужно обо всех языках забыть и начать программировать в машинных кодах…Более того, я только сейчас начал задумываться всерьёз о замене C++ на Rust — после прочтения вот этого.
Потому что, по моему мнению, никакой язык не может претендовать на звание «годящегося для низкоуровневой разработки», пока в нем нет поддержки ассемблера.
Поддержка ассемблера есть во всех системных языках, в том или ином виде. Достижение уровня 1.
Ну вот, к примеру, либа miniz_oxide. Вполне жизнеспособная, быстрее оригинала на C. unsafe не содержит.
Её зависимость crc32fast содержит чуток unsafeов, но не потому что "язык нежизнеспособен", ибо без unsafe там всё так же будет работать хорошо, а всего лишь потому что хочется "чуточку сладких интринсинков":
Due to the use of SIMD intrinsics for the optimized implementations, this crate contains some amount of unsafe code.
Другая её зависимость libc — это FFI, который по определению unsafe (никакой язык не может гарантировать что будет происходить внутри кода другого языка). Опять же, причина не в ограниченой выразительности.
Всё. По сути, средствами выразительности только safe Rust реализована либа, ничуть не хуже эталонного оригинала на С.
Так что "потому иначе он совершенно нежизнеспособен" — это явно перегиб с Вашей стороны, из-за недостаточной подкованности в теме.
Перекладывание байтиков в массиве (zip/unzip) возможно без ансейфа, браво!
Или таки с «неважными» ансейфами… Несущественно, исключения подтверждают правила, и я согласен снизить свою оценку до 99%, чего мелочиться — даже до 96%!
Но не это ссуть — а проблема наблюдается таки системная — без ансейфа раста практически нет. Сравним с C# или Go?
Но не это ссуть — а проблема наблюдается таки системная — без ансейфа раста практически нет. Сравним с C# или Go?
Ну давайте сравним коробку-механику и коробку-автомат, нет? Странно слышать претензии к механике, что она не умеет автоматически переключать передачи, ещё и сцепление, такую гадость, выжимать нужно, чтобы переключиться.
Rust, в сравнении с Go и C#, не ограничивает в управлении и даёт возможность настолько ювелирно настроить процессы руками, насколько нужно. Потому "сцепление выжимать" будут неизбежно чаще. В самых низкоуровневых абстракциях, будь то std, FFI, либо аля-std фундаментальные крейты (tokio и т.п.) unsafe необходим, и это именно то, что в Go/C# в основном поставляется рантаймом и std. Но почему-то там мы считаем, что всего этого нет, а в Rust говорим, что "всё, капец, без ансейва нет ни одной программы, только перекладывание байтиков в массивы!!!!11". При этом почему-то игнорируется что с каждым новым слоем абстракции градус unsafe падает, и когда доходит до прикладного юзер-кода, юзающего все эти абстракции, unsafe применять смысла уже нету и туча высокоуровневых крейтов с #![forbid(unsafe)] (могу дать примеров). Они точно так же опираются на safe абстракции своих зависимостей, как и в C#/Go, просто что у последних основная масса unsafe абстрагирована уже в рантайме и std, в то время как у Rust это дело больше вынесено в зависимости.
С таким подходом можно сказать что без ансейва — вообще ничего нет. Потому что любой язык и его экосистема в своём фундаменте опирается на тщательно абстрагированные небезопасные операции.
И, к слову, за 2 года использования Rust я не словил ни одного сегфолта от низлежащих зависимостей. Но зато когда я работал с PHP, я их ловил достаточно часто, просто переходя на новую версию всеми используемого PHP-расширения. И как же так? Получается PHP — это не safe язык ведь, верно? Ведь в нём небезопасная операция просочилась в safe код, который гарантированно должен был быть safe.
Понимаете абсурдность претензии?
Можете не распинаться так, этот товарищ — давно известный любитель самодокументирующегося ассемблера с двумя крестами для защиты от бесов, который постоянно объявляется в растосрачах чисто с целью попопугаить одни и те же аргументы и обозвать всех вокруг растаманами.
Даже страшно представить, что привело к такой болезненной реакции — не то завернул всю программу в unsafe и нечаянно уронил прод в субботу, не то просто глаза застилает страх потерять работу в перспективе через 10-15 лет :-)
опирается на тщательно абстрагированные небезопасные операцииКак в Актиксе — обмазанный ансейфом сырой указатель наружу?
Или как тут обходятся лайфтаймы?
#[inline(always)]
pub unsafe fn change_lifetime_const<'a, 'b, T>(x: &'a T) -> &'b T {
&*(x as *const T)
}
/// # Safety
///
/// Requires that you ensure the reference does not become invalid.
/// The object has to outlive the reference.
#[inline(always)]
pub unsafe fn change_lifetime_mut<'a, 'b, T>(x: &'a mut T) -> &'b mut T {
&mut *(x as *mut T)
}
Нет, в юзеркоде и прикладных библиотеках ансейфу не место. Либо поправят дизайн языка, принуждающий костылить такое, либо у Раста так и останется дутая рекламная надежность.
11 обнаруженных сегфолтов на весь PHP7 — хороший результат. Сколько там в Расте? o_O
Ну, от "протекающего" unsafe никто не застрахован, поэтому сообщество всегда внимательно следит за тем, как небезопасный код в той или иной реализации перетекает в safe Rust. unsafe означает, что гарантии безопасности перекладываются с компилятора на программиста.
Внимание, еще раз: unsafe не означает отсутствие гарантий, он означает, что эти гарантии должен предоставить программист в отношении внешнего API, который внутри использует unsafe.
И пример с Actix тут скорее с положительной стороны характеризует подход Раста, так как сообщество добилось того, чтобы в популярной и важной для экоситемы библиотеке не было неправильного unsafe.
Rust нигде не скрывает такого своего подхода к безопасности, какие тут к нему претензии? Ах, компилятор не может полностью гарантировать безопасность кода, где происходит разыменование сырых указателей. А компилятор какого языка это может?
Сколько там в Расте? o_O
Так это только в Расте или еще в LLVM и сишных библиотеках, которые использует rustc?
Rust нигде не скрывает такого своего подхода к безопасности, какие тут к нему претензии?Слишком запрещающий дизайн приводит к «срезанию углов» через ансейфы.
Так это только в Расте или еще в LLVM и сишных библиотеках, которые использует rustc?Это был только php-memcached, вот верная ссылка на php. Запрос одинаковый
Слишком запрещающий дизайн
Что именно слишком запрещающее? Невозможность иметь несколько мутабельных ссылок на объект? Если разрешим, то получим data races. Чтобы избавиться от data races придётся запрещать передачу мутабельных ссылок в другой поток. В одном потоке получим проблемы с инвалидацией итераторов, для избавления от которых придётся вводить какие-то другие ограничения.
Ну. справедливости ради, эффективный двухсвязный список на safe Rust написать таки проблематично.
Стоит анализировать причины — почему авторы библиотек в том или ином случае на это идут, и можно ли без.
Впрочем вроде как ни на одной платформе, где Rust сегодня поддерживается неразрешимых проблем с вызовом функций не возникает — но всё это выглядит как-то ну очень странно. Это вам, чтобы какой-нибудь барьер вставить нужно целую функцию в другом файле вызывать? Выглядит несколько дико…
Впрочем, толку от fine-grained-барьера на уровне инлайн-асма всё равно мало, если компилятор про него не знает (и, соответственно, не знает, что и куда он может переупорядочивать).Ну как раз в Rust сделано разумно: по умолчанию компилятор считает, что ничего никуда переупорядочивать нельзя, все флаги клобберятся… а если всё-таки можно — то приписки
pure и/или preserves_flags нужно делать явно.Возможно это не так оптимально (в Clang/GCC всё сделано наоборот), но с точки зрения языка «заточенного» под безопасность — это естественное решение…
хотя бы потому что API, который используется чтобы передать данные от ядра к программе не описывается на языках высокого уровня никак, в принципеЧего? Приведите пример, пожалуйста.
Чего? Приведите пример, пожалуйста.Вот тут подробно описано что лежит в стеке, когда процесс стартует. Оно не соотвествует ничему вообще.
В принципе, зная как устроен ABI C, наверное можно состряпать описание, которое позволить это распарсить (на x86-64 нужно будет описать 6 фиктивных аргументов, на arm — 4 и так далее). Но если мы уже всё равно делаем разные вещи на разных платформах — можно и немножко ассемблера добавить…
Но да, был неправ: формально, на большинстве платформ, в C это можно распарсить. Вроде как только на IA-64 нельзя, но это не платформа, а исторический курьёз…
Вот тут подробно описано
Ссылка не потерялась ли?
Потому в любом поголовно проекте есть куча ансейфов — только в хороших меньше.
Могу не глядя назвать автора )
Как вам удается так изящно сочетать адекватную риторику(иногда) и лютейшую дичь?
А после выхода — их стараются использовать по-минимуму.
Так что когда язык не угрожает сделать Windows ненужной — Microsoft вполне с ним может «дружить». Вон даже UTF-8 начали нормально поддерживать.
Странно что про go не сказано ни слова.
Странно что про go не сказано ни слова.А чего сказать? Скудный язык с невыразительной системой типов (+), вряд ли можно назвать безопасным, ну и rust более низкоуровневый.
Поздравляю, никогда такого не было, и вот опять (С)…
Фактически, Rust может обеспечить более чем 10-кратное улучшение, что делает его полезным для инвестиций.
По поводу радости Левика про Rust — ну еще бы кулик свое болото не хвалил. Но по факту, радости там вообще немного и от кривых ручек защиты все еще нет.
от кривых ручек защиты все еще нет
И никогда не будет. Язык не может подкорректировать неправильное понимание задачи программистом, например. Перестаём пытаться что-то сделать? Раст, по крайней мере, обязывает ставить флажок "вот тут я могу всё сломать" (unsafe).
Если язык начнет разбираться в предметной области, то ему и программист не нужен будет :)
Сейчас по словам Левика, 70% CVE созданных в Microsoft, являются проблемами безопасности памяти.
Другой пример — в Java есть такая конская ошибка, как NPE. Средствами языка вполне ее можно было бы решить для большинства случаев. Вообще Java — идеальный пример, как создатели языка клали болт на разработчиков и по максимуму раскладывали возможности стрельнуть себе в ногу.
Так что да — в его конференции, нет «радостного оптимизма», имхо.
Microsoft: Rust является 'лучшим шансом' в отрасли программирования безопасных систем