Всем привет! Не так давно, после очень плотного изучения аллокаторов и алгоритмов распределения памяти, а также в последующем применении их на практике мне в голову пришла идея написать статью, в которой будет максимально подробно рассказано о них. Считаю, что данная тема будет достаточно востребованной, так как в сети, особенно в русскоязычной части, на данный момент существует очень мало источников, посвященных этому вопросу.
Для начала, хотелось бы сразу отметить, что если кто-то впервые слышит термины «аллокатор», «алгоритмы распределения памяти» и не понимает, для чего это все нужно, то тогда, прежде чем читать данную статью, я рекомендую ознакомиться с данным источником. В данной статье достаточно хорошо рассказывается, какие существуют проблемы в стандартных аллокаторах памяти, и для каких целей стоит использовать другие способы распределения памяти, помимо стандартных. Здесь же я буду рассказывать только о самих алгоритмах распределения, ну и, конечно же, в конце приведу реализацию одного из аллокаторов, которая может быть без проблем использована в стандартных контейнерах С++.
Концептуально выделяется пять основных операции, которые можно осуществить над аллокатором (хочется отметить, что не все аллокаторы могут явно соответствовать этому интерфейсу):
Linear Allocator, он же «линейный» — это самый простой вид аллокаторов. Идея состоит в том, чтобы сохранить указатель на начало блока памяти выделенному аллокатору, а также использовать другой указатель или числовое представление, которое необходимо будет перемещать каждый раз, когда выделение из аллокатора завершено. В этом аллокаторе внутренняя фрагментация сведена к минимуму, потому что все элементы вставляются последовательно (пространственная локальность), и единственная фрагментация между ними — выравнивание.
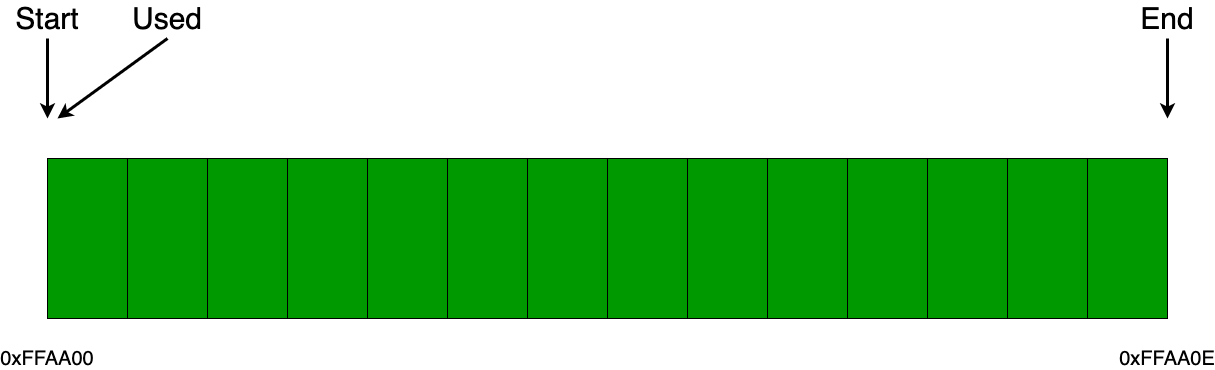
Дальше предлагаю рассмотреть несколько примеров, в которых будет наглядно показано в деталях, как работает данный аллокатор. Возьмем некоторый блок памяти равный 14 байтам и отдадим его в управление аллокатору. Как видно из картинки ниже, мы сохраняем указатель на начало памяти (start), а также храним два указателя, либо два числовых представления, которые содержат информацию об общем (end) и используемом (used) размерах памяти.
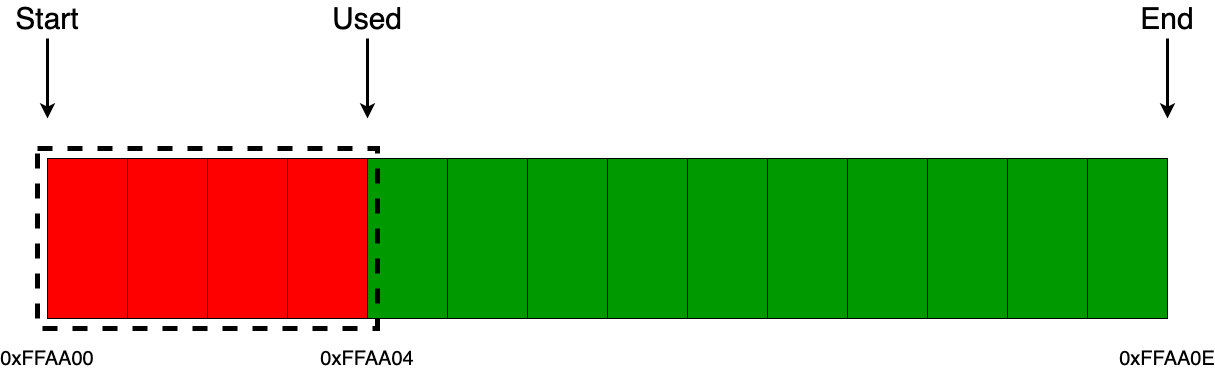
Представим, что в аллокатор поступил запрос на выделение 4 байт памяти. Действия аллокатора на исполнения этого запроса будут следующие:

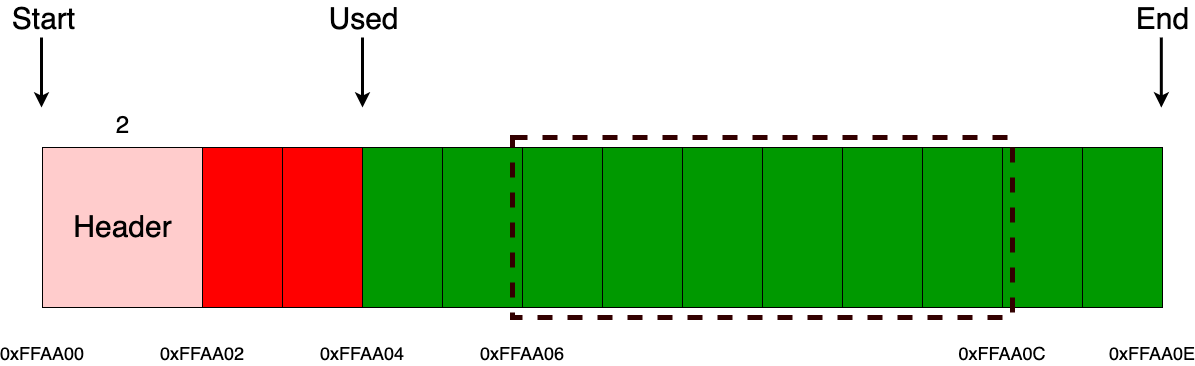
Дальше, например, приходит запрос на выделение 8 байт и, соответственно, действия аллокатора будут точно такими же вне зависимости от размера выделяемого блока памяти.
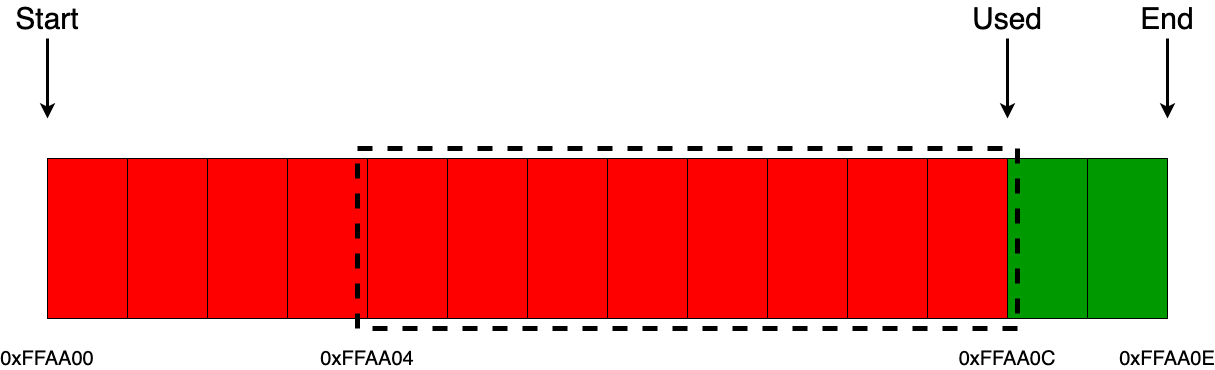
А вот здесь уже будет немного интереснее, например, если приходит запрос на выделение только 1 байта, и если мы не хотим выравнивать блоки в памяти (например адреса кратные 2, 4, …), то действия аллокатора останутся точно такими же.

Но, если нам нужно выделять блоки памяти с определенным выравниванием (например выравнивание адресов кратных 2), то здесь действие аллокатора немного меняется. Меняется оно не в плане реализации, а в том, что помимо самих данных равных объему одного байта, мы еще забираем и один дополнительный байт из памяти аллокатора для выравнивания, который не несет никакой смысловой нагрузки. Как раз-таки это и есть та самая возможная минимальная фрагментация памяти внутри линейного аллокатора.

Отлично, теперь самое время поговорить об освобождении памяти. Как уже отмечалось ранее, данный вид аллокоторов не поддерживает выборочное освобождение определенных блоков памяти. То есть, если провести тонкую аналогию с malloc/free, имея указатель, скажем, на 0xFFAA00, мы могли бы освободить этот блок памяти, но вот линейный аллокатор нам этого позволить не может.
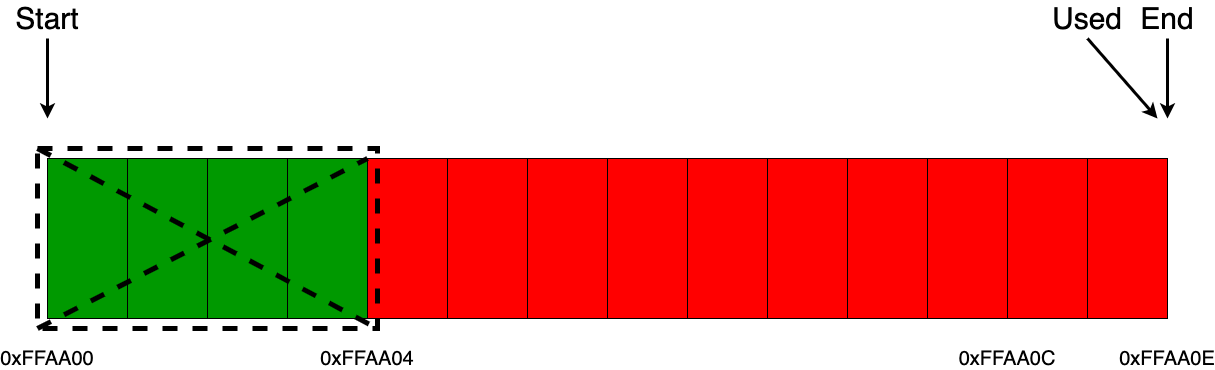
Все, что мы можем сделать, это освободить всю занятую память целиком внутри аллокатора и продолжить работать с ним, как с совершенно пустым.
Идея блочного аллокатора заключается в том, что он разделяет некоторый большой участок памяти на более мелкие участки одинакового размера. По своей сути он также является очень простым аллокатором, так как, когда запрашивается выделение, он просто возвращает один из свободных участков памяти фиксированного размера, а когда запрашивается освобождение то, он просто сохраняет этот участок памяти для дальнейшего использования. Таким образом, распределение работает очень быстро, а фрагментация все еще очень мала.
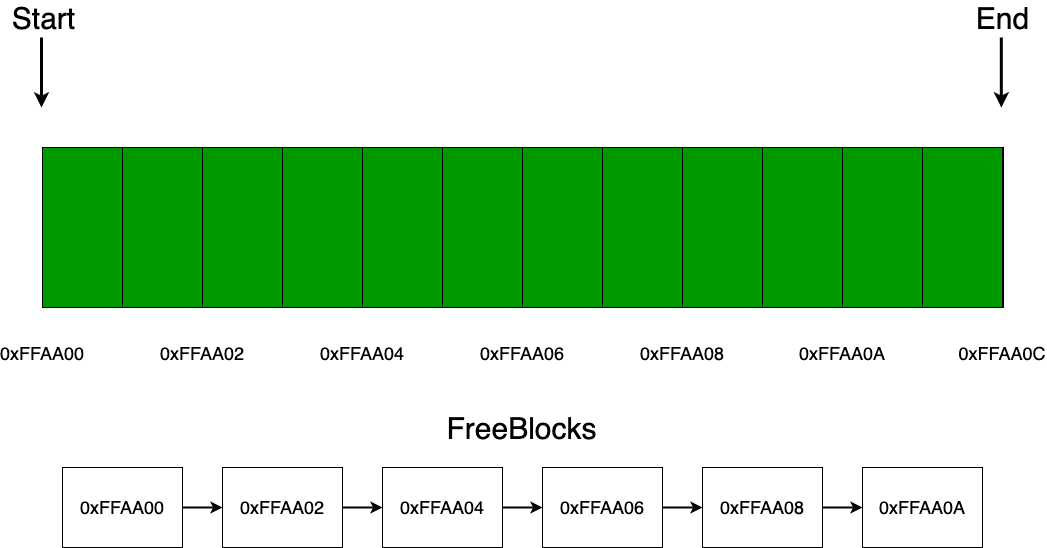
Дальше, также, как и с линейным аллокатором, предлагаю рассмотреть все на примере, чтобы детальнее понять, как он работает, поэтому возьмем некоторый блок памяти равный 12 байт и отдадим его в управление аллокатору. Как видно из картинки ниже, мы сохраняем указатель на начало (start) и конец (end) памяти, которой управляет аллокатор, а также список (freeblocks) из адресов свободных блоков в аллокаторе. В качестве средства для хранения данных о том, что блок занят или свободен, можно использовать много средств, например массив из булевых значений, но я именно решил остановиться на выборе односвязного списка, так как он наиболее просто и наглядно характеризует данную концепцию (кстати, сами звенья списка можно хранить в свободных блоках памяти, тем самым убрав дополнительные расходы с памятью).
Если приходит запрос на выделение одного блока памяти, то действия аллокатора очень примитивные. Сначала он проверяет, есть ли звенья в списке свободных блоков, если их там нет, то не трудно догадаться, что память в аллокаторе уже закончилась. Если же там есть хотя бы одно звено, то он просто достает корневое или хвостовое (в данной реализации отдаются хвостовые звенья) звено списка и отдает его адрес пользователю.
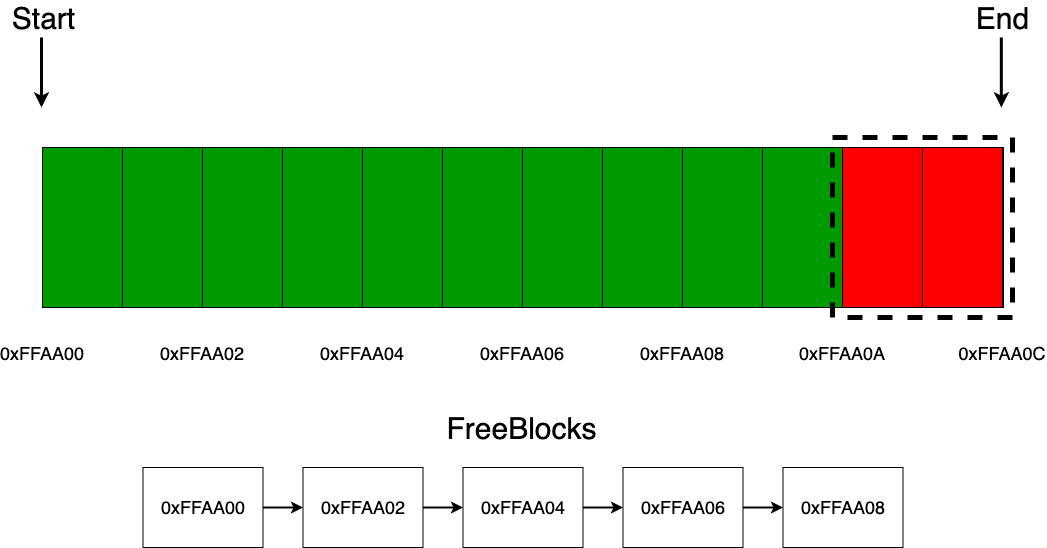
Если приходит запрос на выделение нескольких блоков памяти, то аллокатор точно так же по очереди проделывает те же действия, описанные на предыдущем шаге.

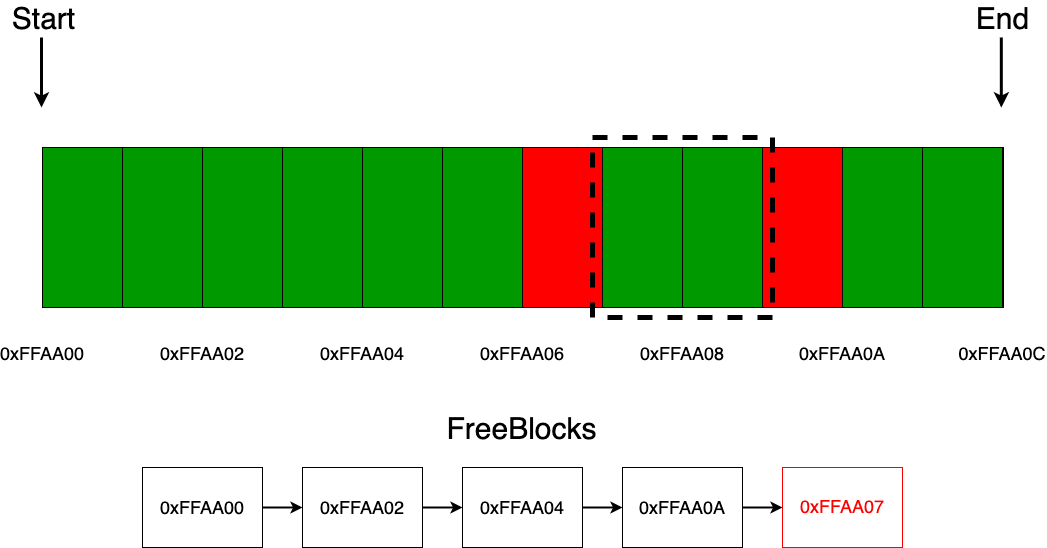
Что касается освобождения блока, если приходит запрос на освобождение, то тогда аллокатор просто добавляет этот адрес в один из концов односвязного списка. Стоит отметить такой момент, что в качестве адреса блока для освобождения может прийти, например адрес, несоответствующий адресу памяти аллокатора, например 0xEFAB12, и тогда будет возможна такая ситуация, что мы в дальнейшем отдадим пользователю тот участок памяти, который нам не принадлежит (конечно же, это приведет к undefined behavior или если очень сильно повезет, то просто к краху программы). Для избегания этой возможной проблемы как раз-таки и используются begin и end, которые позволяют проверить, не ошибся ли пользователь адресом во время запроса на операцию освобождения.

Помимо выхода за пределы памяти, которой не управляет аллокатор, есть еще одна возможная проблема. Пользователь может прийти с запросом освободить совершенно любой адрес, находящийся в области памяти аллокатора, но не равный адресу начала какого-либо из блоков, допустим блока с адресом 0xFFAA07. Эта операция, конечно же, приведет к undefined behavior. Если есть необходимость дополнительно проверять, все ли правильно делает пользователь, то есть возможность это отслеживать. Для отслеживания этого существует множество решений, например хранить также адреса и занятых блоков или вообще проверять адрес на кратность размеру блоков в аллокаторе (все зависит от фантазии и от конкертной ситуации, в которой используется аллокатор).
На самом деле, это умная эволюция линейного распределителя, которая позволяет управлять памятью, как стеком. Все так же, как и раньше, мы сохраняем указатель вместе с «header» блоком (в дальнейшем будет употребляться, как заголовок) на текущий адрес памяти и перемещаем его вперед для каждого выделения. В отличие от линейного аллокатора, мы также можем переместить его назад, то есть выполнить операцию deallocate, которая линейным аллокатором не поддерживается. Как и прежде, сохраняется принцип пространственной локальности, а фрагментация все еще минимальная.
Предлагаю рассмотреть несколько примеров все с тем же блоком памяти в 14 байт. Как и с линейным аллокатором, мы точно также сохраняем указатели на начало памяти (start) и конец (end), а также указатель на конец используемой памяти (used).

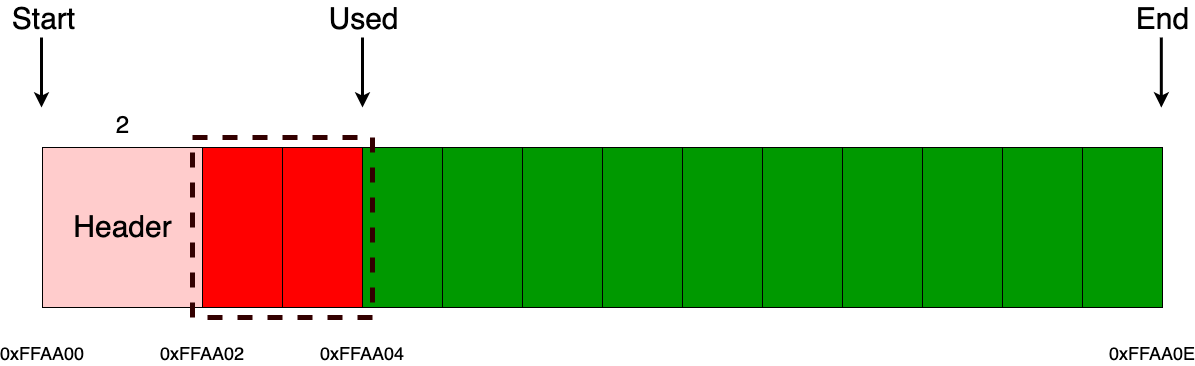
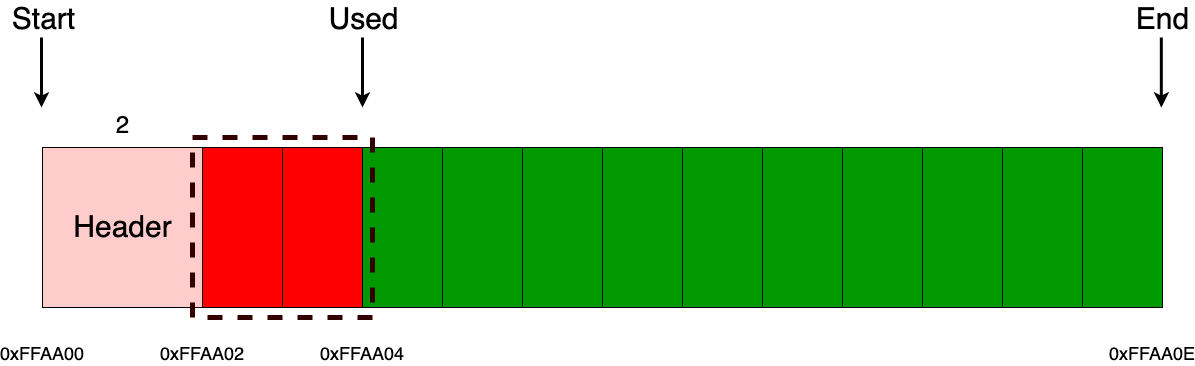
Когда приходит запрос на выделение памяти, помимо выделения некоего ее объема памяти, запрашиваемого пользователем, мы еще дополнительно выделяем заголовок (пользователь с ним никак не будет взаимодействовать), в котором храним сведения о том, сколько было выделено байт (в данном примере размер заголовка составляет 2 байта). Например, если пришел запрос на выделение 2 байт, то состояние аллокатора будет точно таким же, как на рисунке ниже. Важно отметить то, что пользователю будет отдан указатель не на заголовок, а на блок, следующий сразу за заголовком, то есть в данном примере это блок с адресом 0xFFAA02.
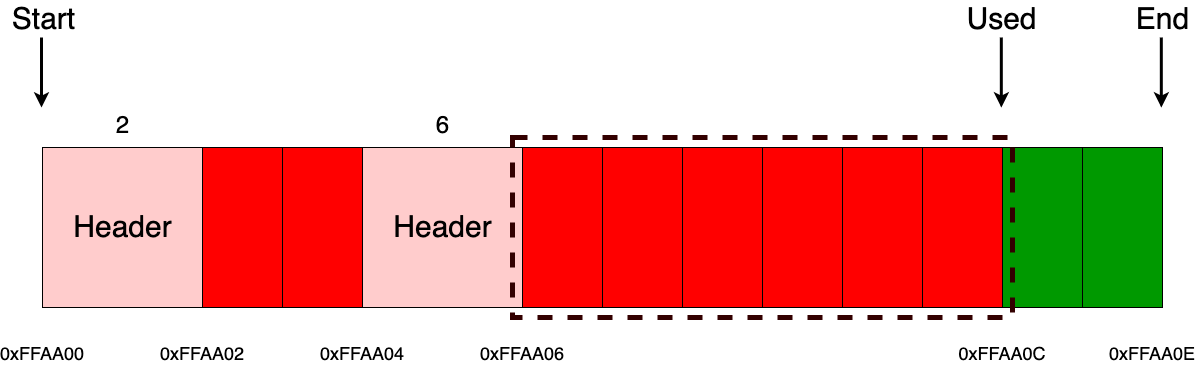
Аналогичная ситуация будет и, например с выделением 6 байт.
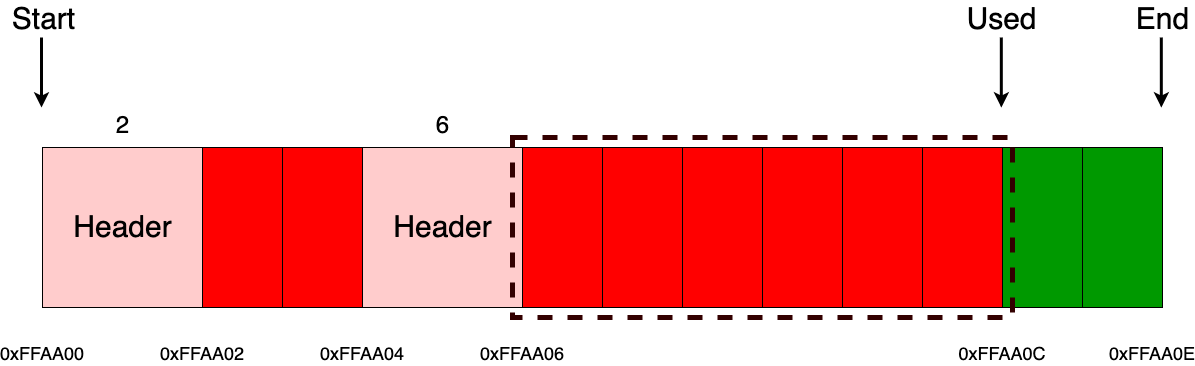
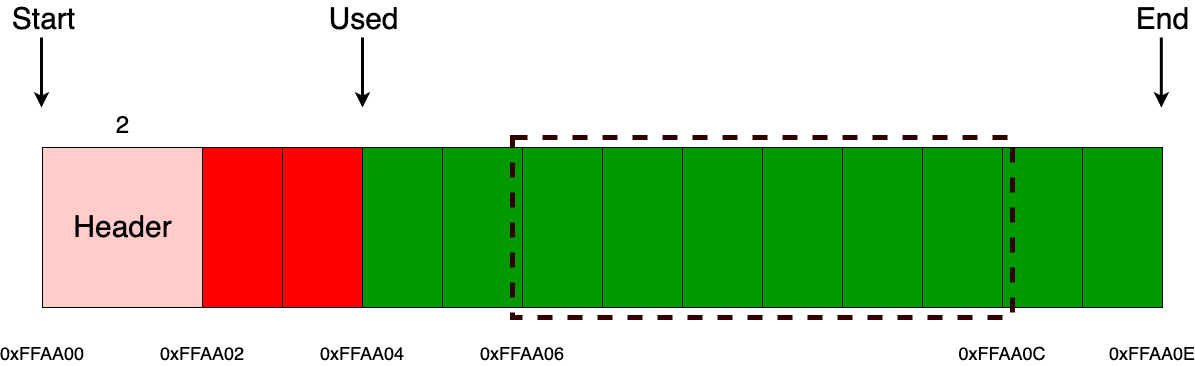
А вот с освобождением все немного поинтереснее (как уже обсуждалось ранее, выделять и освобождать память мы можем только с использованием алгоритма LIFO). Для начала от указателя, который пользователь просит освободить, нужно отнять размер заголовка, после чего разыменовать значение и уже только после этого сдвинуть указатель used на размер заголовка вместе с размером блока, полученного из заголовка. Здесь так же, как и с блочным аллокатором, возможна ситуация освобождения «рандомных» блоков памяти, которая также приведет к undefined behavior. Дополнять аллокаторы дополнительными проверками или нет – дело каждого. Самое главное — не забывать об этом моменте.
Теперь, разобравшись в основах, самое время освоить что-то более серьезное.
Дальше будет представлена реализация аллокатора, который можно будет без проблем использовать с STL. Алгоритм распределения памяти в этом аллокаторе будет схож с алгоритмом, который используется стандартным аллокатором. Хочу сразу отметить, что не претендую на полноту реализации malloc, мною были взяты лишь основные концепции из него c добавлением в некоторых местах своей логики. Все его тонкости и нюансы, конечно же, не были учтены в этой реализации…
В основе алгоритма лежит взаимодействие с «chunks» (дальше будет употреблено, как участок, в данной реализации их размер статичен и должен быть кратен четырем, а также все выделения памяти из памяти аллоктора выравниваются на размер, кратный четырем), о которых дальше и пойдет речь. В качестве примера возьмем участок c размером 16 байт. Внутри себя он будет содержать указатели на начало (start) и конец (end) памяти, указатель на максимальный блок памяти (maxblock) и множество (freeblocks), в котором будут храниться заголовки свободных блоков. Размер заголовка в данной реализации занимает 4 байта, но он может без проблем варьироваться в размере для нужных вам целей. Например, если вы точно знаете, что размер выделяемых блоков памяти будет не больше, чем максимальное числовое значение, которое можно представить в одно или двухбайтной переменной, то можно будет использовать заголовок в размере 1 или 2 байт.

При операции выделения памяти из участка, прежде всего нужно проверить, достаточно ли памяти (в данной реализации, это константная операция, мы просто сравниваем с maxblock заголовком и, если размер аллоцируемой памяти меньше, чем максимальный блок, то значит у нас достаточно памяти для этого выделения). Если памяти достаточно, то мы просто отдаем адрес памяти, следующий за заголовком, как и в стековом аллокаторе, а также удаляем прошлый заголовок из множества свободных блоков и уже только после этого добавляем туда новый заголовок, только что выделенного блока памяти. Важно отметить, что если мы аллоцировали память из максимального блока, то нам нужно будет обновить значение максимального блока.
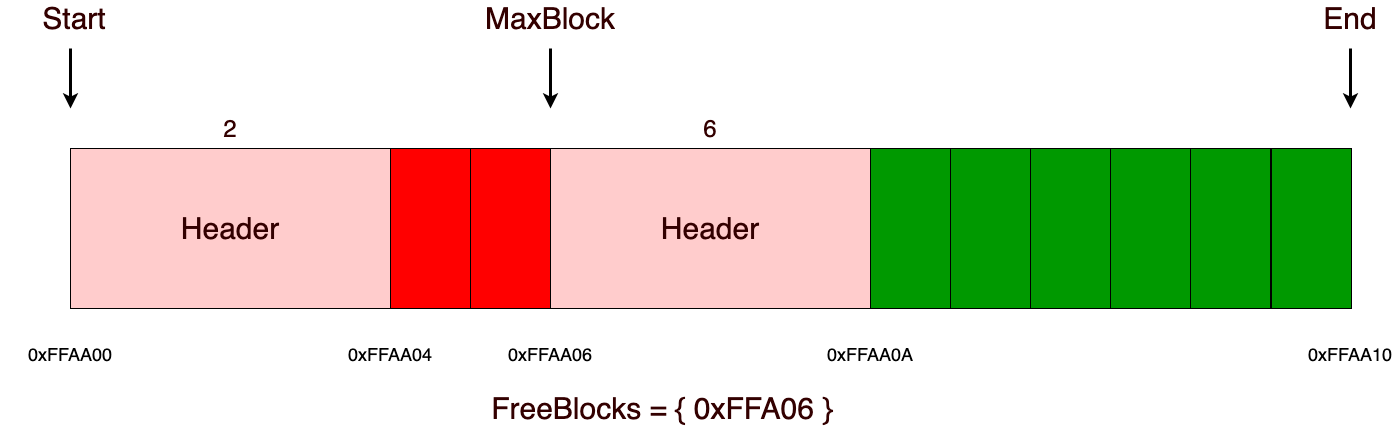
При последующих выделениях все происходит точно также, как и на предыдущем шаге.

Но вот как только память в участке закончилась, аллокатор берет и просто создает еще один участок того же или большего размера (в данной реализации все участки одинакового размера). Стоит также следить за тем, чтобы размер возможного блока для выделения не превышал размер участка с вычетом размера заголовка.

Дальше уже в новом участке можно без проблем выделять нужные блоки памяти. Выделение памяти будет происходить по точно такому же сценарию, как и в предыдущем участке.

Теперь немного о том, почему именно в данной реализации размер участка должен быть кратен четырем. Ответ очень просто – это делается для простоты реализации и восприятия алгоритма. Так как возможна такая ситуация, что в конце участка может остаться некоторая область памяти, в которой просто на просто не поместится заголовок (пример этого продемонстрирован на следующем рисунке). Чтобы решить эту проблему, можно будет заполнять эту память дополнительным выравниваем, либо делать размер заголовка меньшим или же использовать дополнительные средства для отслеживания этой возможной проблемы, иначе эта память будет потеряна и самая главное, что в дальнейшем потерянная память сможет накапливаться!

Прежде, чем освободить память, нужно определить, в каком участке находится блок (в текущей реализации эта операция с линейной сложностью относительно общего количества участков, если подразумевается, что будет большое количество участков, то ее можно будет сделать константной, добавив в заголовок индекс участка, в котором была выделена память). В последующем операция освобождения идентична со стековым аллокатором, за исключением того, что нужно будет добавить адрес заголовка освобожденного блока во множество свободных блоков, а также обновить maxblock, если размер только что освобожденного блока больше, чем maxblock.

Важно отметить, что в данной реализации, при каждом последующем освобождении памяти происходит попытка дефрагментации в том участке из которого была освобождена память. Дефрагментация нужна для того, чтобы объединять свободные блоки в большие по размеру. Например, в данной ситуации, как на рисунке ниже, мы не сможем выделить 6 байт, пусть даже размер свободной памяти нам и позволяет это сделать, но зато фрагментация говорит нам твердое и решительное «нет»!

Операция дефрагментации очень примитивная. Суть ее заключается в том, что после операции освобождения памяти идет проверка, не свободны ли два соседних блока слева и справа от освобожденного. Если два соседствующих блока свободны, то они объединяются в один единый.

Еще хотелось бы отметить, что данная реализация будет катастрофически ужасно работать с выделением маленьких блоков памяти, например равных 1 байту. В такой ситуации мы получаем +7 лишних байт на выделение всего лишь одно байта памяти из-за того, что размер заголовка равен 4 байтам и еще плюс 3 байта для вырывания адресов, которые должны быть кратны четырем. Этим я хочу сказать, что не стоит слепо использовать какой-либо алгоритм распределения памяти, так как вместо долгожданной оптимизации иногда можно получить только лишь дополнительные затраты.

Думаю, теории будет достаточно и поэтому, как сказал Линус Торвальдс: «Болтовня ничего не стоит. Покажите мне код». Ну что ж, приступаем…
Требования к аллокаторам приведены в стадарте С++ в главе "Allocator requirements [allocator.requirements]". Исходя из тех требований самый примитивный интерфейс аллокатора, который может использоваться в STL, должен выглядеть примерно вот так:
Предполагается, что STL контейнеры обращаются к аллокатору не напрямую, а через шаблон std::allocator_traits, который предоставляет значения, такие как:
Отлично, с требованиями разобрались, теперь наконец приступаем к написанию аллокатора. Для начала напишем некоторый интерфейс или адаптер, на самом деле это трудно назвать и тем, и другим, поэтому пусть это будет некая «прослойка», в которой при помощи стратегий мы сможем без проблем менять алгоритм аллоцирования памяти для определенных целей:
Благодаря стратегии для распределения памяти, мы сможем делать примерно вот так:
То есть мы можем гибко менять алгоритмы распределения для необходимых целей в той или иной ситуации. Единственное требование к AllocationStrategy — у них должны быть операции allocate и deallocate.
Здесь и дальше используются стандартные контейнеры. Согласен, что будет очень много выделений из кучи. Думаю, что для тех, кто будет писать свои аллокаторы, это будет неприемлемо. В качестве альтернативы, конечно же, можно писать свои контейнеры или использовать чужие, заточенные под определенные нужды, но в данной реализации я старался как можно проще преподнести материал, поэтому мой выбор лег именно на стандартные контейнеры.
Теперь немного о том, как можно украсить использование аллокаторов вместе со стандартными контейнерами:
Можно также использовать аллокаторы и с умными указателями, но для этого придется написать небольшую прослойку:
Ну и теперь, наконец, пример использования всего этого:
Хотелось бы заострить внимание на том, что данная реализация является самой примитивной, но она может быть без проблем расширена в ту сторону, которая вам необходима, поэтому все в ваших руках!
Спасибо за внимание, очень надеюсь, что данная статья оказалась кому-то полезной. Также желаю всем успехов в тесном взаимодействии с памятью, и самое главное, не забывать очень важные слова Дональда Кнута: «Преждевременная оптимизация — корень всех зол».
Ссылка на репозиторий с полной реализацией аллокатора.
Предисловие
Для начала, хотелось бы сразу отметить, что если кто-то впервые слышит термины «аллокатор», «алгоритмы распределения памяти» и не понимает, для чего это все нужно, то тогда, прежде чем читать данную статью, я рекомендую ознакомиться с данным источником. В данной статье достаточно хорошо рассказывается, какие существуют проблемы в стандартных аллокаторах памяти, и для каких целей стоит использовать другие способы распределения памяти, помимо стандартных. Здесь же я буду рассказывать только о самих алгоритмах распределения, ну и, конечно же, в конце приведу реализацию одного из аллокаторов, которая может быть без проблем использована в стандартных контейнерах С++.
Основы
Концептуально выделяется пять основных операции, которые можно осуществить над аллокатором (хочется отметить, что не все аллокаторы могут явно соответствовать этому интерфейсу):
- create – создает аллокатор и отдает ему в распоряжение некоторый объем памяти;
- allocate – выделяет блок определенного размера из области памяти, которым распоряжается аллокатор;
- deallocate – освобождает определенный блок;
- free – освобождает все выделенные блоки из памяти аллокатора (память, выделенная аллокатору, не освобождается);
- destroy – уничтожает аллокатор с последующим освобождением памяти, выделенной аллокатору.
Linear Allocator
Linear Allocator, он же «линейный» — это самый простой вид аллокаторов. Идея состоит в том, чтобы сохранить указатель на начало блока памяти выделенному аллокатору, а также использовать другой указатель или числовое представление, которое необходимо будет перемещать каждый раз, когда выделение из аллокатора завершено. В этом аллокаторе внутренняя фрагментация сведена к минимуму, потому что все элементы вставляются последовательно (пространственная локальность), и единственная фрагментация между ними — выравнивание.
Дальше предлагаю рассмотреть несколько примеров, в которых будет наглядно показано в деталях, как работает данный аллокатор. Возьмем некоторый блок памяти равный 14 байтам и отдадим его в управление аллокатору. Как видно из картинки ниже, мы сохраняем указатель на начало памяти (start), а также храним два указателя, либо два числовых представления, которые содержат информацию об общем (end) и используемом (used) размерах памяти.

Представим, что в аллокатор поступил запрос на выделение 4 байт памяти. Действия аллокатора на исполнения этого запроса будут следующие:
- проверить достаточно ли памяти для выделения;
- сохранить текущий указатель used, который в дальнейшем будет отдан пользователю, как указатель на блок выделенной памяти из аллокатора;
- сместить указатель used на величину равную объему выделенного блока памяти, т.е. на 4 байта.
Дальше, например, приходит запрос на выделение 8 байт и, соответственно, действия аллокатора будут точно такими же вне зависимости от размера выделяемого блока памяти.
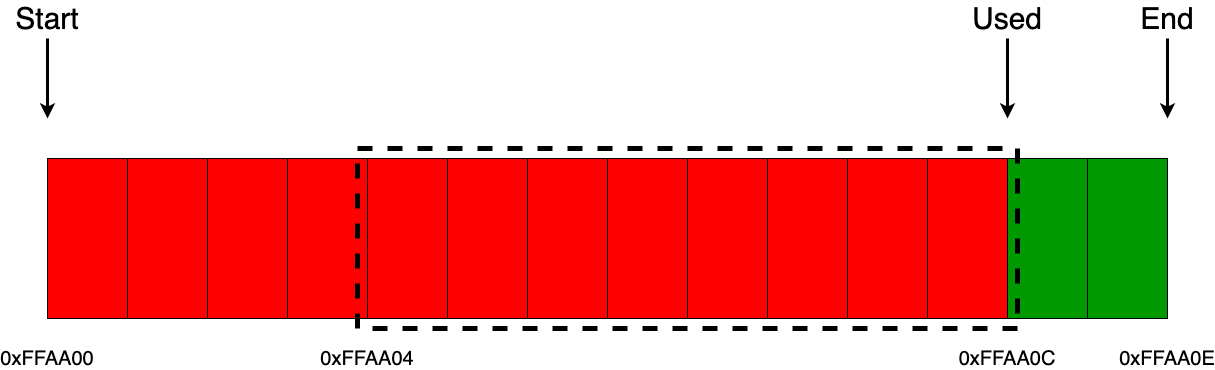
А вот здесь уже будет немного интереснее, например, если приходит запрос на выделение только 1 байта, и если мы не хотим выравнивать блоки в памяти (например адреса кратные 2, 4, …), то действия аллокатора останутся точно такими же.
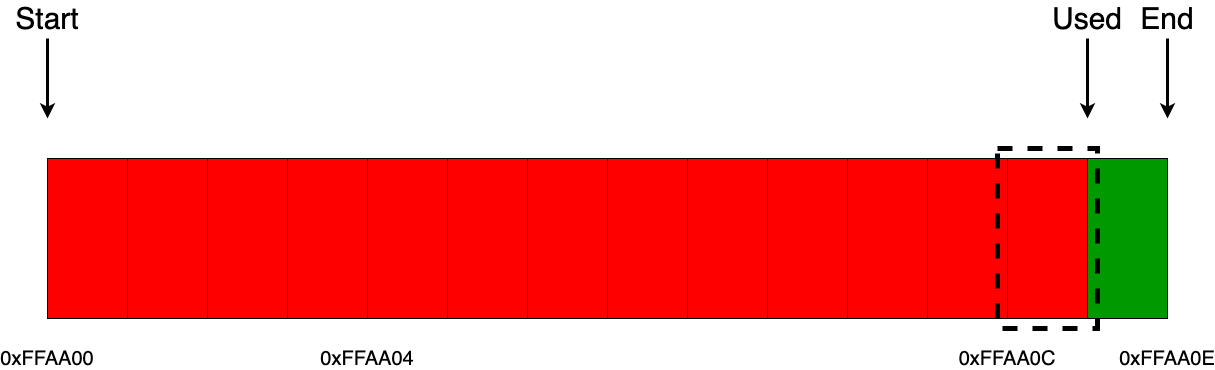
Но, если нам нужно выделять блоки памяти с определенным выравниванием (например выравнивание адресов кратных 2), то здесь действие аллокатора немного меняется. Меняется оно не в плане реализации, а в том, что помимо самих данных равных объему одного байта, мы еще забираем и один дополнительный байт из памяти аллокатора для выравнивания, который не несет никакой смысловой нагрузки. Как раз-таки это и есть та самая возможная минимальная фрагментация памяти внутри линейного аллокатора.
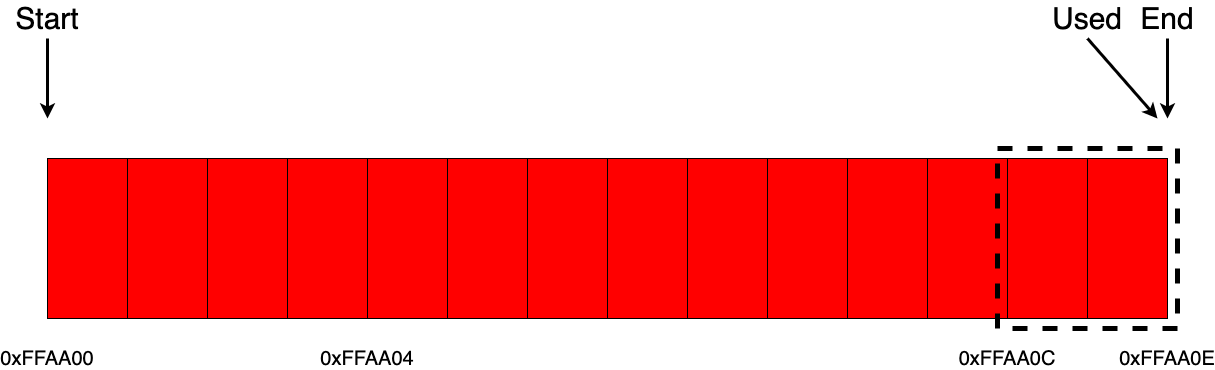
Отлично, теперь самое время поговорить об освобождении памяти. Как уже отмечалось ранее, данный вид аллокоторов не поддерживает выборочное освобождение определенных блоков памяти. То есть, если провести тонкую аналогию с malloc/free, имея указатель, скажем, на 0xFFAA00, мы могли бы освободить этот блок памяти, но вот линейный аллокатор нам этого позволить не может.

Все, что мы можем сделать, это освободить всю занятую память целиком внутри аллокатора и продолжить работать с ним, как с совершенно пустым.
Pool Allocator
Идея блочного аллокатора заключается в том, что он разделяет некоторый большой участок памяти на более мелкие участки одинакового размера. По своей сути он также является очень простым аллокатором, так как, когда запрашивается выделение, он просто возвращает один из свободных участков памяти фиксированного размера, а когда запрашивается освобождение то, он просто сохраняет этот участок памяти для дальнейшего использования. Таким образом, распределение работает очень быстро, а фрагментация все еще очень мала.
Дальше, также, как и с линейным аллокатором, предлагаю рассмотреть все на примере, чтобы детальнее понять, как он работает, поэтому возьмем некоторый блок памяти равный 12 байт и отдадим его в управление аллокатору. Как видно из картинки ниже, мы сохраняем указатель на начало (start) и конец (end) памяти, которой управляет аллокатор, а также список (freeblocks) из адресов свободных блоков в аллокаторе. В качестве средства для хранения данных о том, что блок занят или свободен, можно использовать много средств, например массив из булевых значений, но я именно решил остановиться на выборе односвязного списка, так как он наиболее просто и наглядно характеризует данную концепцию (кстати, сами звенья списка можно хранить в свободных блоках памяти, тем самым убрав дополнительные расходы с памятью).

Если приходит запрос на выделение одного блока памяти, то действия аллокатора очень примитивные. Сначала он проверяет, есть ли звенья в списке свободных блоков, если их там нет, то не трудно догадаться, что память в аллокаторе уже закончилась. Если же там есть хотя бы одно звено, то он просто достает корневое или хвостовое (в данной реализации отдаются хвостовые звенья) звено списка и отдает его адрес пользователю.
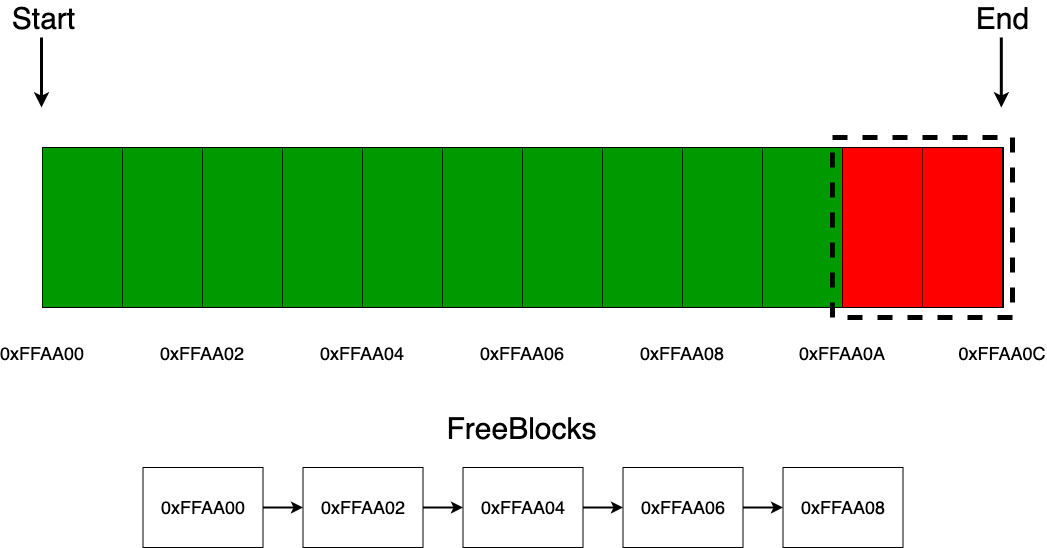
Если приходит запрос на выделение нескольких блоков памяти, то аллокатор точно так же по очереди проделывает те же действия, описанные на предыдущем шаге.
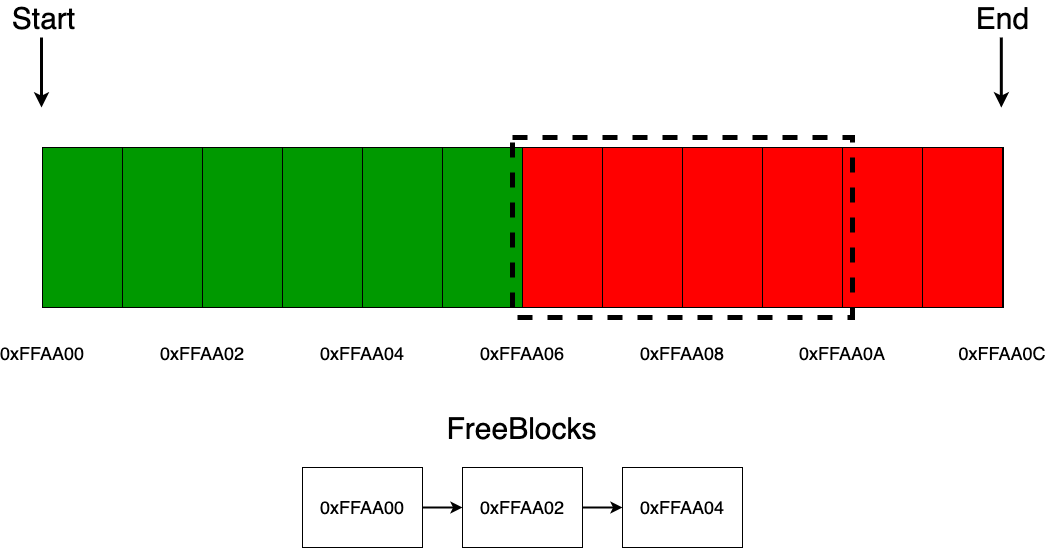
Что касается освобождения блока, если приходит запрос на освобождение, то тогда аллокатор просто добавляет этот адрес в один из концов односвязного списка. Стоит отметить такой момент, что в качестве адреса блока для освобождения может прийти, например адрес, несоответствующий адресу памяти аллокатора, например 0xEFAB12, и тогда будет возможна такая ситуация, что мы в дальнейшем отдадим пользователю тот участок памяти, который нам не принадлежит (конечно же, это приведет к undefined behavior или если очень сильно повезет, то просто к краху программы). Для избегания этой возможной проблемы как раз-таки и используются begin и end, которые позволяют проверить, не ошибся ли пользователь адресом во время запроса на операцию освобождения.

Помимо выхода за пределы памяти, которой не управляет аллокатор, есть еще одна возможная проблема. Пользователь может прийти с запросом освободить совершенно любой адрес, находящийся в области памяти аллокатора, но не равный адресу начала какого-либо из блоков, допустим блока с адресом 0xFFAA07. Эта операция, конечно же, приведет к undefined behavior. Если есть необходимость дополнительно проверять, все ли правильно делает пользователь, то есть возможность это отслеживать. Для отслеживания этого существует множество решений, например хранить также адреса и занятых блоков или вообще проверять адрес на кратность размеру блоков в аллокаторе (все зависит от фантазии и от конкертной ситуации, в которой используется аллокатор).

Stack Allocator
На самом деле, это умная эволюция линейного распределителя, которая позволяет управлять памятью, как стеком. Все так же, как и раньше, мы сохраняем указатель вместе с «header» блоком (в дальнейшем будет употребляться, как заголовок) на текущий адрес памяти и перемещаем его вперед для каждого выделения. В отличие от линейного аллокатора, мы также можем переместить его назад, то есть выполнить операцию deallocate, которая линейным аллокатором не поддерживается. Как и прежде, сохраняется принцип пространственной локальности, а фрагментация все еще минимальная.
Предлагаю рассмотреть несколько примеров все с тем же блоком памяти в 14 байт. Как и с линейным аллокатором, мы точно также сохраняем указатели на начало памяти (start) и конец (end), а также указатель на конец используемой памяти (used).
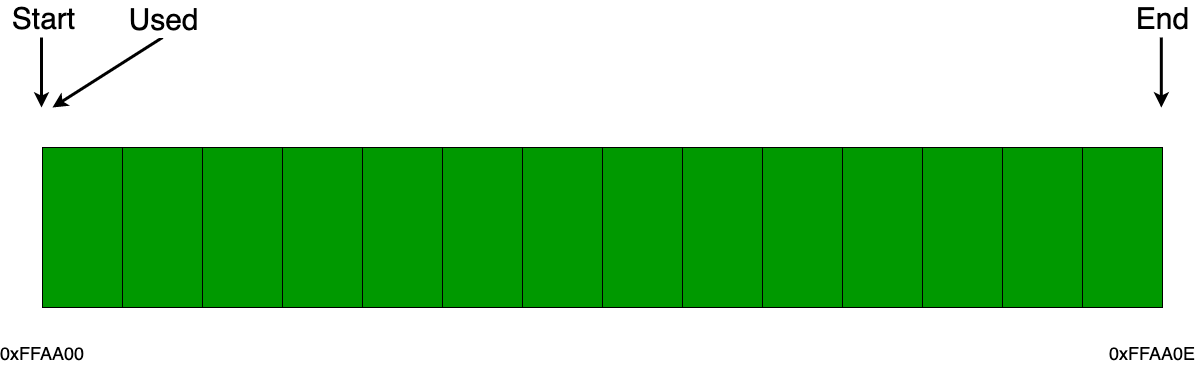
Когда приходит запрос на выделение памяти, помимо выделения некоего ее объема памяти, запрашиваемого пользователем, мы еще дополнительно выделяем заголовок (пользователь с ним никак не будет взаимодействовать), в котором храним сведения о том, сколько было выделено байт (в данном примере размер заголовка составляет 2 байта). Например, если пришел запрос на выделение 2 байт, то состояние аллокатора будет точно таким же, как на рисунке ниже. Важно отметить то, что пользователю будет отдан указатель не на заголовок, а на блок, следующий сразу за заголовком, то есть в данном примере это блок с адресом 0xFFAA02.
Аналогичная ситуация будет и, например с выделением 6 байт.
А вот с освобождением все немного поинтереснее (как уже обсуждалось ранее, выделять и освобождать память мы можем только с использованием алгоритма LIFO). Для начала от указателя, который пользователь просит освободить, нужно отнять размер заголовка, после чего разыменовать значение и уже только после этого сдвинуть указатель used на размер заголовка вместе с размером блока, полученного из заголовка. Здесь так же, как и с блочным аллокатором, возможна ситуация освобождения «рандомных» блоков памяти, которая также приведет к undefined behavior. Дополнять аллокаторы дополнительными проверками или нет – дело каждого. Самое главное — не забывать об этом моменте.
Теперь, разобравшись в основах, самое время освоить что-то более серьезное.
«Примитивный стандартный аллокатор»
Дальше будет представлена реализация аллокатора, который можно будет без проблем использовать с STL. Алгоритм распределения памяти в этом аллокаторе будет схож с алгоритмом, который используется стандартным аллокатором. Хочу сразу отметить, что не претендую на полноту реализации malloc, мною были взяты лишь основные концепции из него c добавлением в некоторых местах своей логики. Все его тонкости и нюансы, конечно же, не были учтены в этой реализации…
В основе алгоритма лежит взаимодействие с «chunks» (дальше будет употреблено, как участок, в данной реализации их размер статичен и должен быть кратен четырем, а также все выделения памяти из памяти аллоктора выравниваются на размер, кратный четырем), о которых дальше и пойдет речь. В качестве примера возьмем участок c размером 16 байт. Внутри себя он будет содержать указатели на начало (start) и конец (end) памяти, указатель на максимальный блок памяти (maxblock) и множество (freeblocks), в котором будут храниться заголовки свободных блоков. Размер заголовка в данной реализации занимает 4 байта, но он может без проблем варьироваться в размере для нужных вам целей. Например, если вы точно знаете, что размер выделяемых блоков памяти будет не больше, чем максимальное числовое значение, которое можно представить в одно или двухбайтной переменной, то можно будет использовать заголовок в размере 1 или 2 байт.
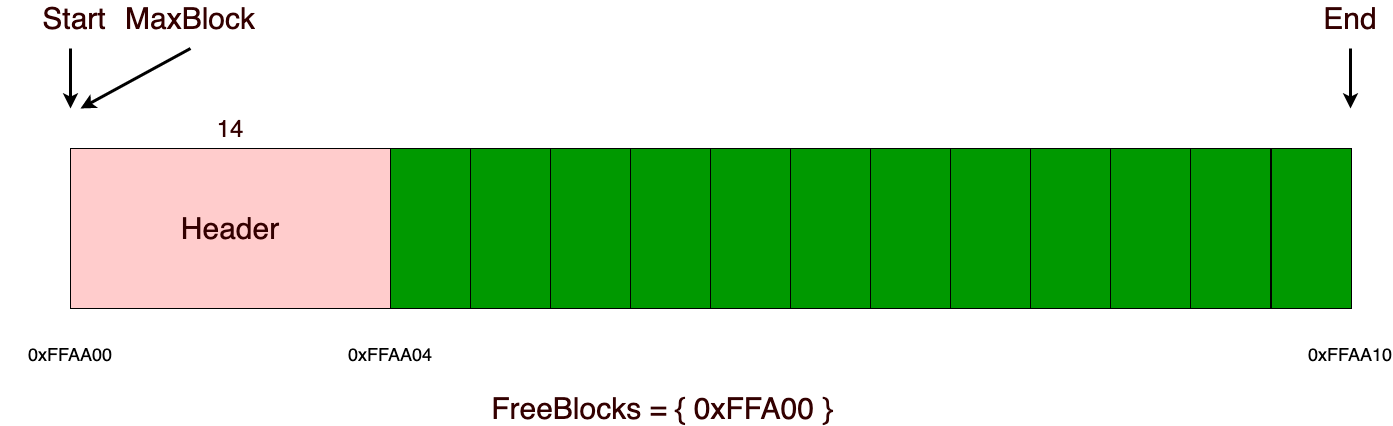
При операции выделения памяти из участка, прежде всего нужно проверить, достаточно ли памяти (в данной реализации, это константная операция, мы просто сравниваем с maxblock заголовком и, если размер аллоцируемой памяти меньше, чем максимальный блок, то значит у нас достаточно памяти для этого выделения). Если памяти достаточно, то мы просто отдаем адрес памяти, следующий за заголовком, как и в стековом аллокаторе, а также удаляем прошлый заголовок из множества свободных блоков и уже только после этого добавляем туда новый заголовок, только что выделенного блока памяти. Важно отметить, что если мы аллоцировали память из максимального блока, то нам нужно будет обновить значение максимального блока.
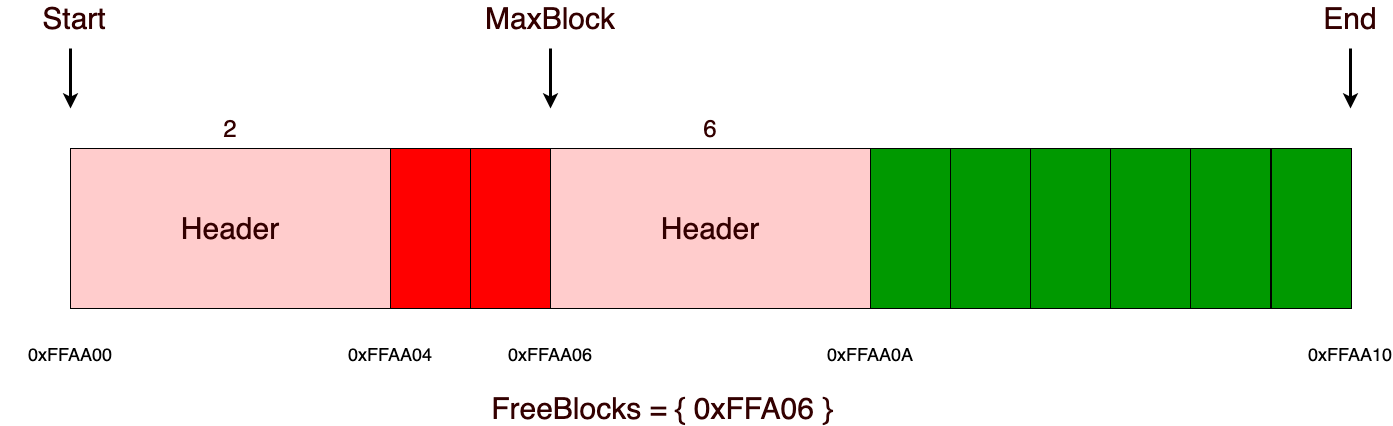
При последующих выделениях все происходит точно также, как и на предыдущем шаге.
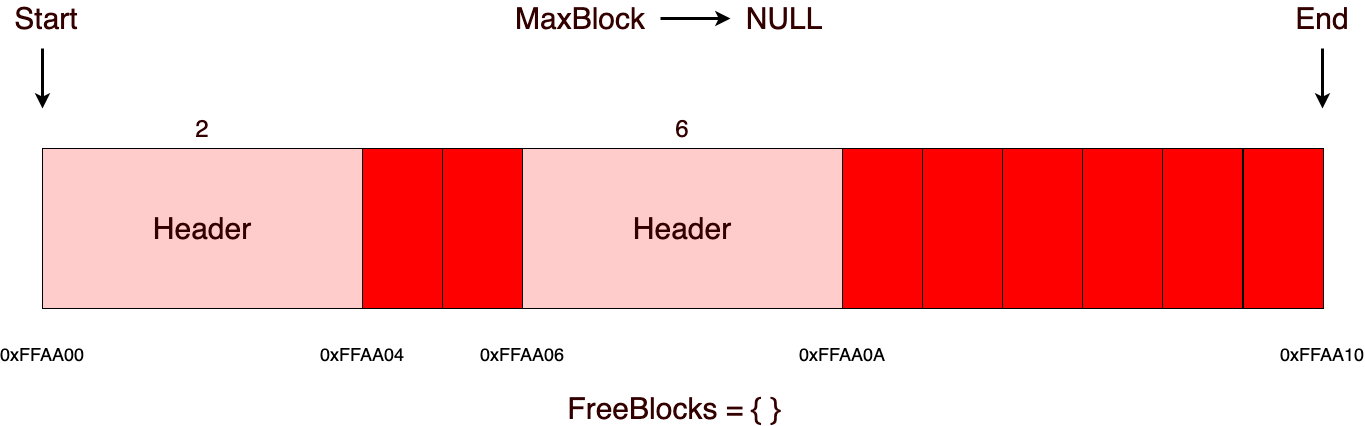
Но вот как только память в участке закончилась, аллокатор берет и просто создает еще один участок того же или большего размера (в данной реализации все участки одинакового размера). Стоит также следить за тем, чтобы размер возможного блока для выделения не превышал размер участка с вычетом размера заголовка.
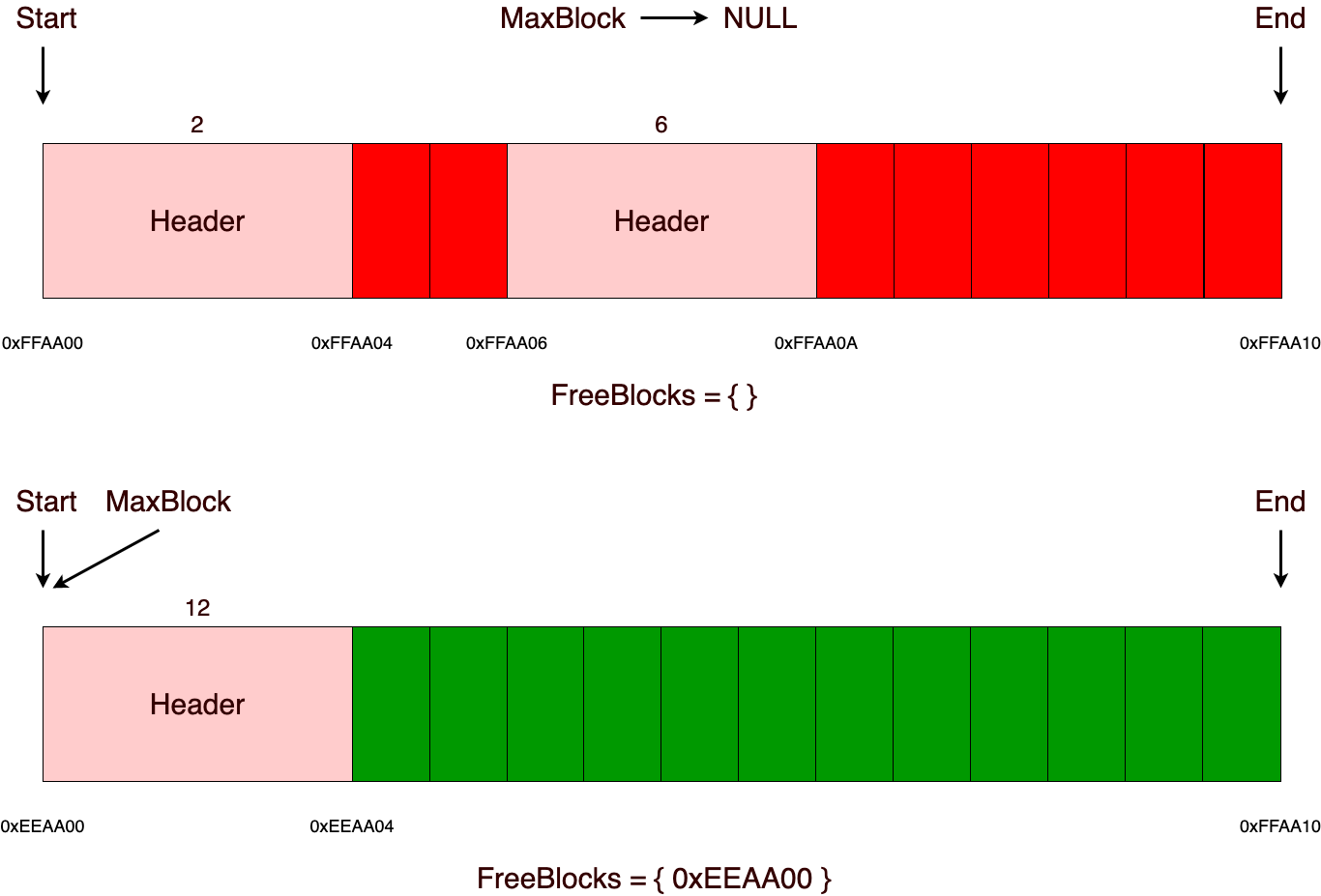
Дальше уже в новом участке можно без проблем выделять нужные блоки памяти. Выделение памяти будет происходить по точно такому же сценарию, как и в предыдущем участке.
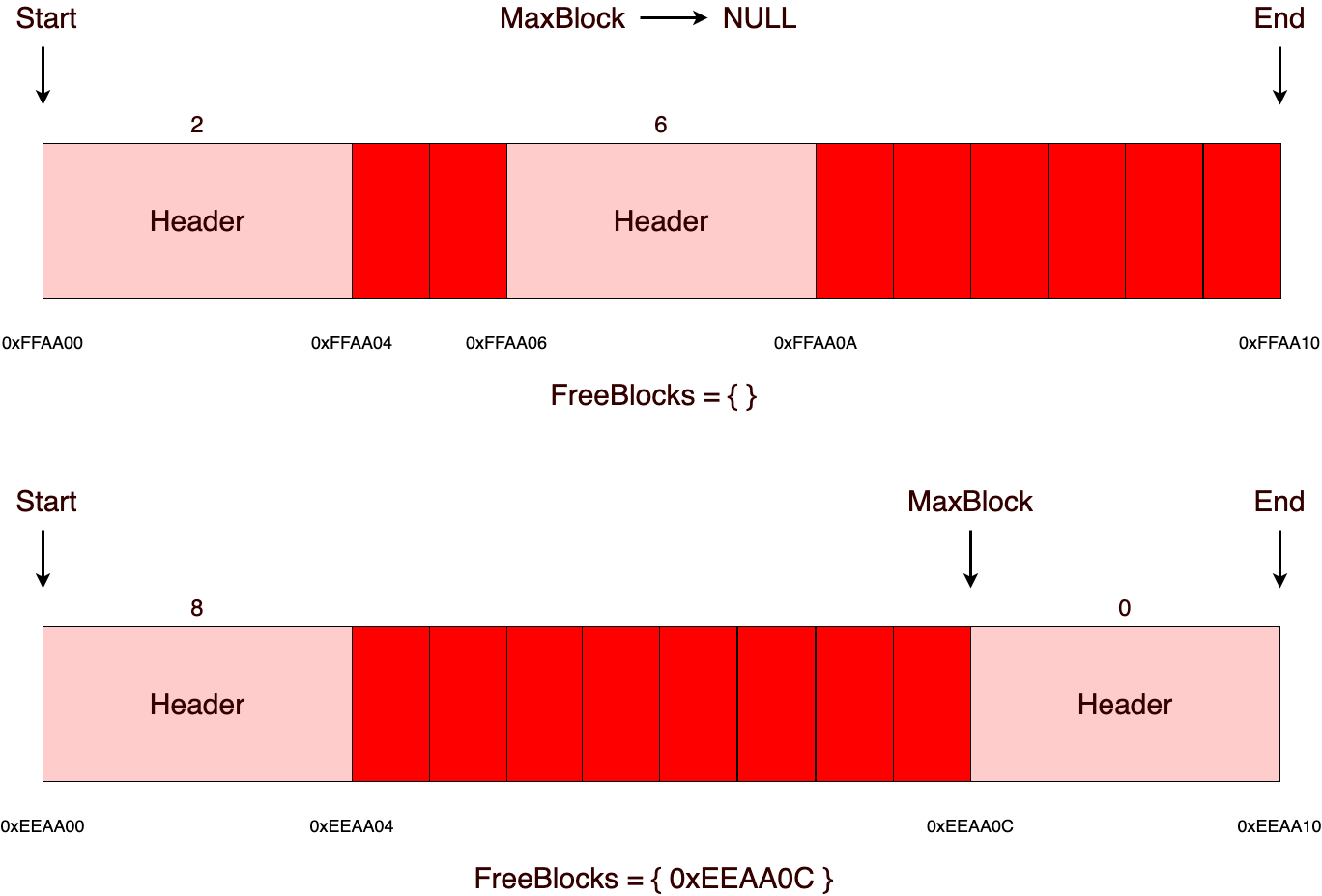
Теперь немного о том, почему именно в данной реализации размер участка должен быть кратен четырем. Ответ очень просто – это делается для простоты реализации и восприятия алгоритма. Так как возможна такая ситуация, что в конце участка может остаться некоторая область памяти, в которой просто на просто не поместится заголовок (пример этого продемонстрирован на следующем рисунке). Чтобы решить эту проблему, можно будет заполнять эту память дополнительным выравниваем, либо делать размер заголовка меньшим или же использовать дополнительные средства для отслеживания этой возможной проблемы, иначе эта память будет потеряна и самая главное, что в дальнейшем потерянная память сможет накапливаться!
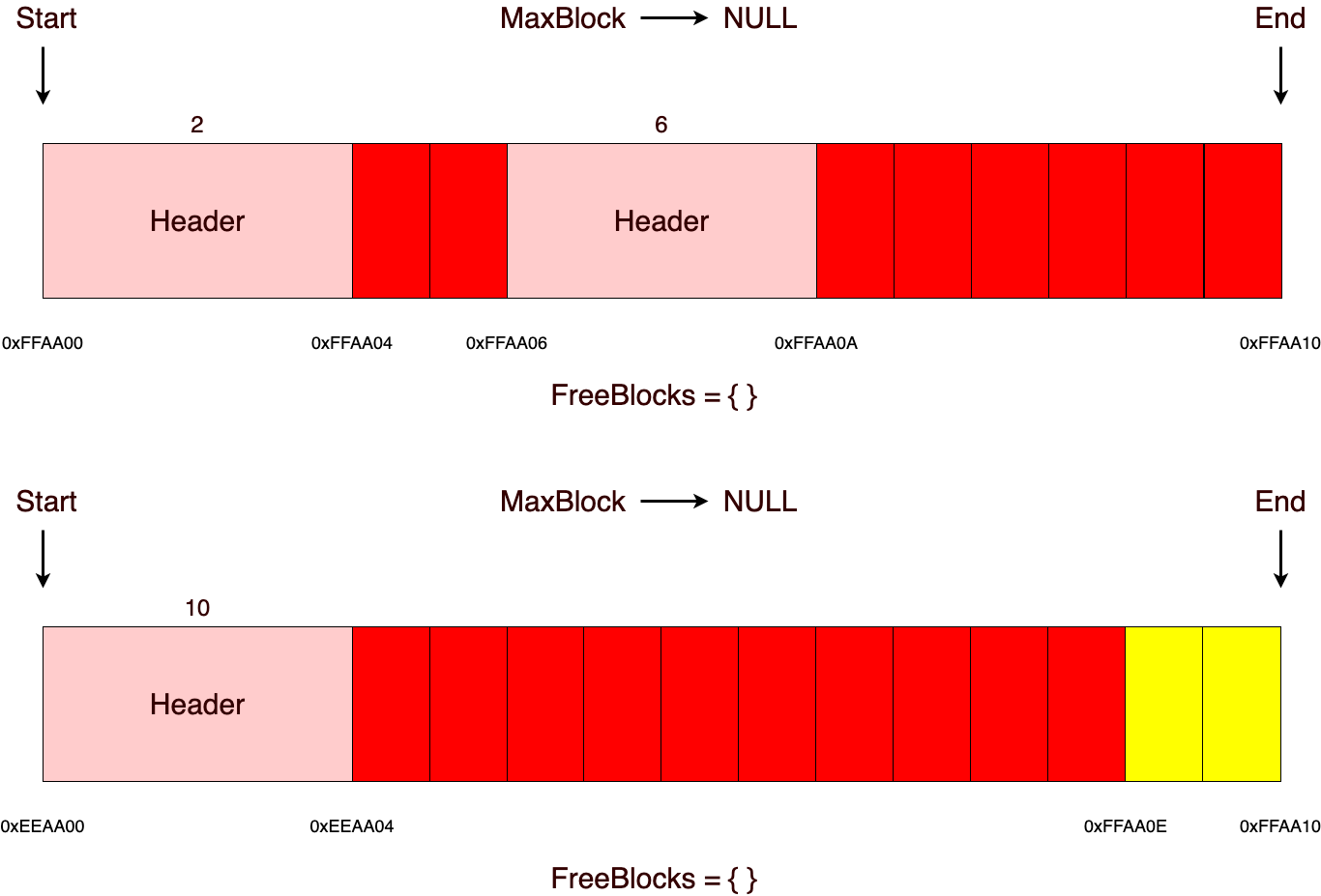
Прежде, чем освободить память, нужно определить, в каком участке находится блок (в текущей реализации эта операция с линейной сложностью относительно общего количества участков, если подразумевается, что будет большое количество участков, то ее можно будет сделать константной, добавив в заголовок индекс участка, в котором была выделена память). В последующем операция освобождения идентична со стековым аллокатором, за исключением того, что нужно будет добавить адрес заголовка освобожденного блока во множество свободных блоков, а также обновить maxblock, если размер только что освобожденного блока больше, чем maxblock.
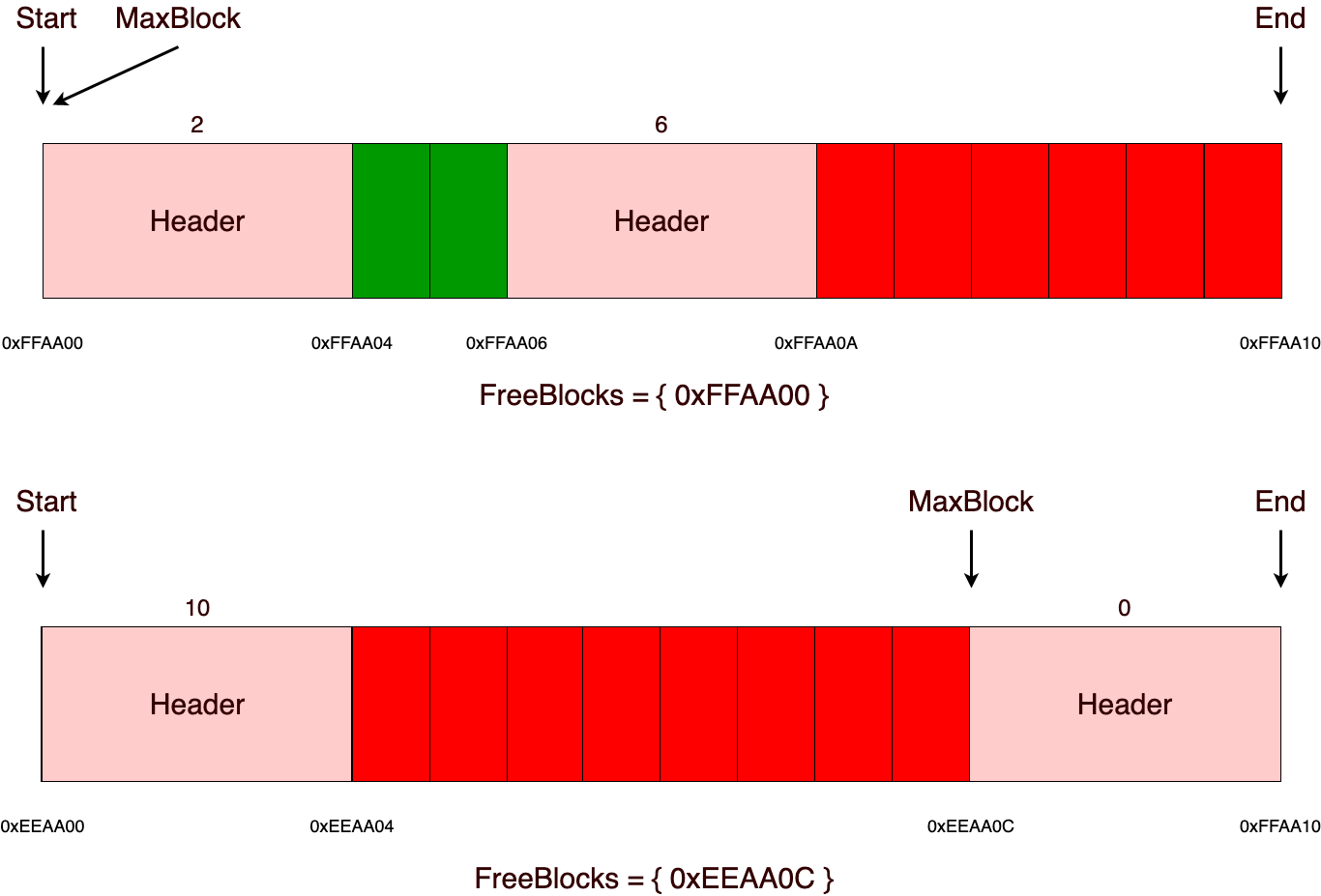
Важно отметить, что в данной реализации, при каждом последующем освобождении памяти происходит попытка дефрагментации в том участке из которого была освобождена память. Дефрагментация нужна для того, чтобы объединять свободные блоки в большие по размеру. Например, в данной ситуации, как на рисунке ниже, мы не сможем выделить 6 байт, пусть даже размер свободной памяти нам и позволяет это сделать, но зато фрагментация говорит нам твердое и решительное «нет»!
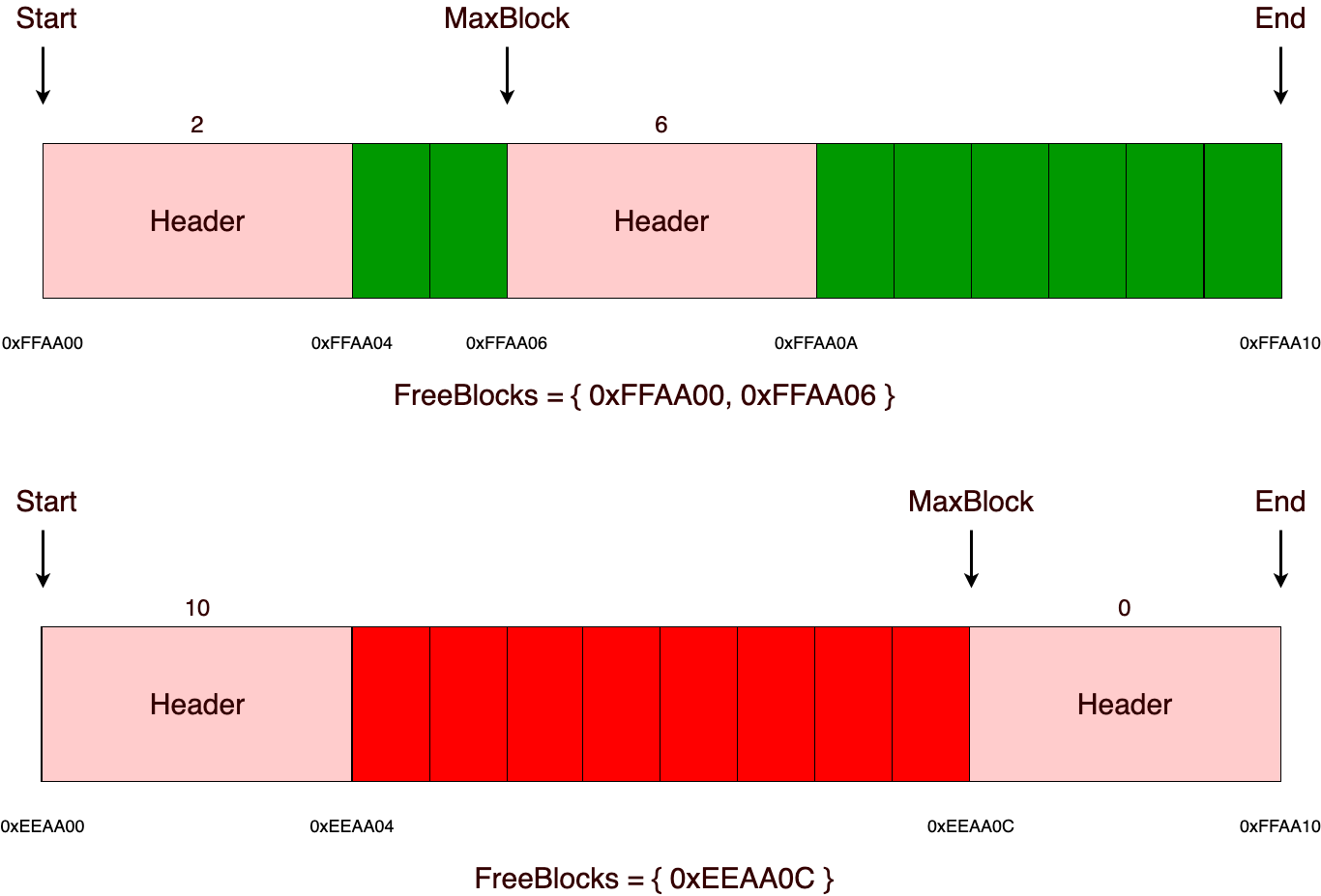
Операция дефрагментации очень примитивная. Суть ее заключается в том, что после операции освобождения памяти идет проверка, не свободны ли два соседних блока слева и справа от освобожденного. Если два соседствующих блока свободны, то они объединяются в один единый.
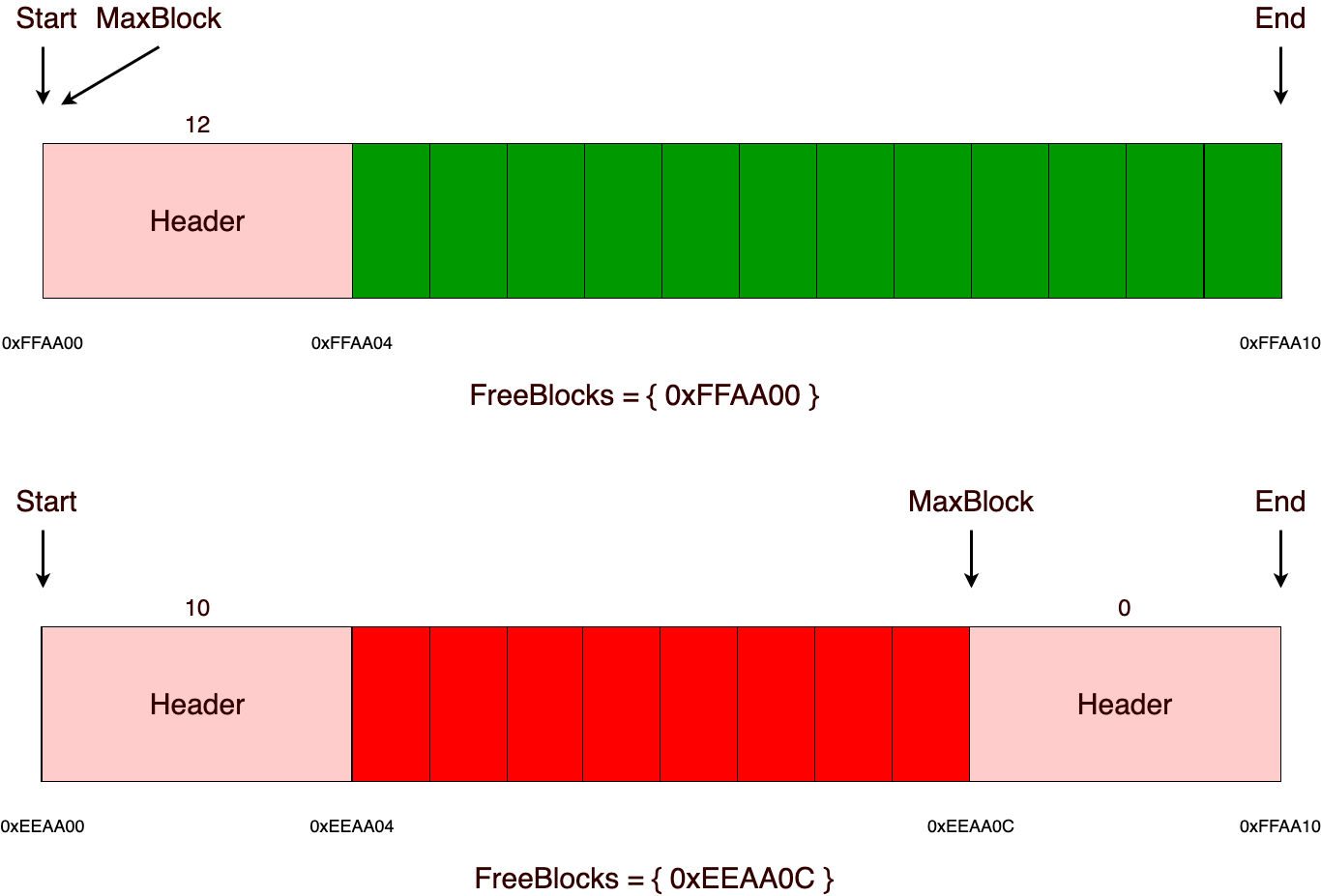
Еще хотелось бы отметить, что данная реализация будет катастрофически ужасно работать с выделением маленьких блоков памяти, например равных 1 байту. В такой ситуации мы получаем +7 лишних байт на выделение всего лишь одно байта памяти из-за того, что размер заголовка равен 4 байтам и еще плюс 3 байта для вырывания адресов, которые должны быть кратны четырем. Этим я хочу сказать, что не стоит слепо использовать какой-либо алгоритм распределения памяти, так как вместо долгожданной оптимизации иногда можно получить только лишь дополнительные затраты.

Думаю, теории будет достаточно и поэтому, как сказал Линус Торвальдс: «Болтовня ничего не стоит. Покажите мне код». Ну что ж, приступаем…
Реализация
Требования к аллокаторам приведены в стадарте С++ в главе "Allocator requirements [allocator.requirements]". Исходя из тех требований самый примитивный интерфейс аллокатора, который может использоваться в STL, должен выглядеть примерно вот так:
template<class T>
class Allocator
{
typedef T value_type;
Allocator(аргументы конструктора);
template <class T>
Allocator(const <T>& other);
T* allocate(std::size_t count_objects);
void deallocate(T* ptr, std::size_t count_objects);
};
template<class T, class U>
bool operator==(const Allocator<T>&, const Allocator<U>&);
template<class T, class U>
bool operator!=(const Allocator<T>&, const Allocator<U>&);
Предполагается, что STL контейнеры обращаются к аллокатору не напрямую, а через шаблон std::allocator_traits, который предоставляет значения, такие как:
typedef T* pointer;
typedef const T* const_pointer;
…
Отлично, с требованиями разобрались, теперь наконец приступаем к написанию аллокатора. Для начала напишем некоторый интерфейс или адаптер, на самом деле это трудно назвать и тем, и другим, поэтому пусть это будет некая «прослойка», в которой при помощи стратегий мы сможем без проблем менять алгоритм аллоцирования памяти для определенных целей:
// Common interface for interaction with STL
// containers and algorithms. You can manually change
// allocation algorithm with different 'AllocationStrategy'
//
// In this implementation was not implented 'adress' and 'max_size'
// unnecessary functions for.
template<typename T, class AllocationStrategy>
class Allocator
{
static_assert(!std::is_same_v<T, void>, "Type of the allocator can not be void");
public:
using value_type = T;
template<typename U, class AllocStrategy>
friend class Allocator;
template<typename U>
struct rebind
{
using other = Allocator<U, AllocationStrategy>;
};
public:
Allocator() = default;
explicit Allocator(AllocationStrategy& strategy) noexcept
: m_allocation_strategy(&strategy) {}
Allocator(const Allocator& other) noexcept
: m_allocation_strategy(other.m_allocation_strategy) {}
template<typename U>
Allocator(const Allocator<U, AllocationStrategy>& other) noexcept
: m_allocation_strategy(other.m_allocation_strategy) {}
T* allocate(std::size_t count_objects)
{
assert(m_allocation_strategy && "Not initialized allocation strategy");
return static_cast<T*>(m_allocation_strategy->allocate(count_objects * sizeof(T)));
}
void deallocate(void* memory_ptr, std::size_t count_objects)
{
assert(m_allocation_strategy && "Not initialized allocation strategy");
m_allocation_strategy->deallocate(memory_ptr, count_objects * sizeof(T));
}
template<typename U, typename... Args>
void construct(U* ptr, Args&&... args)
{
new (reinterpret_cast<void*>(ptr)) U { std::forward<Args>(args)... };
}
template<typename U>
void destroy(U* ptr)
{
ptr->~U();
}
private:
AllocationStrategy* m_allocation_strategy = nullptr;
};
template<typename T, typename U, class AllocationStrategy>
bool operator==(const Allocator<T, AllocationStrategy>& lhs, const Allocator<U, AllocationStrategy>& rhs)
{
return lhs.m_allocation_strategy == rhs.m_allocation_strategy;
}
template<typename T, typename U, class AllocationStrategy>
bool operator!=(const Allocator<T, AllocationStrategy>& lhs, const Allocator<U, AllocationStrategy>& rhs)
{
return !(lhs == rhs);
}
Благодаря стратегии для распределения памяти, мы сможем делать примерно вот так:
template<typename T>
using AllocatorForSmallObjects = Allocator<T, StrategyForSmallObjects>;
template<typename T>
using AllocatorForBigObjects = Allocator<T, StrategyForBigObjects>;
То есть мы можем гибко менять алгоритмы распределения для необходимых целей в той или иной ситуации. Единственное требование к AllocationStrategy — у них должны быть операции allocate и deallocate.
// Strategy for manipulation memory chunks, like
// a primitive malloc allocator.
//
// Warning: if you try to deallocate some random block
// of the memory, most of all it will be an undefined behavior,
// because current implementation doesn't check this possible situation.
template<std::size_t CHUNK_SIZE = 16'384u>
class CustomAllocationStrategy
{
static_assert(CHUNK_SIZE != 0u, "Chunk size must be more, than zero");
static_assert(CHUNK_SIZE <= std::numeric_limits<std::uint32_t>::max(),
"Chunk size must be less or equal max value of the uint32_t");
public:
void* allocate(std::size_t size)
{
assert(size < CHUNK_SIZE && "Incorrect chunk size for future usage");
if (size == 0u)
{
return nullptr;
}
for (auto& chunk : m_chunks)
{
void* allocated_block = chunk.tryReserveBlock(size);
if (allocated_block) //if the block was not reserved, then memory in the chunk has run out
{
return allocated_block;
}
}
m_chunks.push_back(details::Chunk<CHUNK_SIZE>{});
auto& chunk = m_chunks.back();
std::uint8_t* allocated_block = chunk.tryReserveBlock(size);
return allocated_block;
}
void deallocate(void* memory_ptr, std::size_t size)
{
if ( (!memory_ptr) || (size == 0u) )
{
return;
}
std::uint8_t* deallocation_ptr = static_cast<std::uint8_t*>(memory_ptr);
for (auto& chunk : m_chunks)
{
if (chunk.isInside(deallocation_ptr))
{
chunk.releaseBlock(deallocation_ptr);
}
}
}
private:
std::deque<details::Chunk<CHUNK_SIZE>> m_chunks{ 1u };
};
Здесь и дальше используются стандартные контейнеры. Согласен, что будет очень много выделений из кучи. Думаю, что для тех, кто будет писать свои аллокаторы, это будет неприемлемо. В качестве альтернативы, конечно же, можно писать свои контейнеры или использовать чужие, заточенные под определенные нужды, но в данной реализации я старался как можно проще преподнести материал, поэтому мой выбор лег именно на стандартные контейнеры.
namespace details
{
std::size_t getAlignmentPadding(std::size_t not_aligned_address, std::size_t alignment)
{
if ( (alignment != 0u) && (not_aligned_address % alignment != 0u) )
{
const std::size_t multiplier = (not_aligned_address / alignment) + 1u;
const std::size_t aligned_address = multiplier * alignment;
return aligned_address - not_aligned_address;
}
return 0u;
}
// Current chunk implementation works only with size
// aligned by 4 bytes, because HEADER_SIZE now also 4 bytes.
// You can modify it with HEADER_SIZE without problems for your purposes.
template<std::size_t CHUNK_SIZE>
class Chunk
{
static constexpr std::size_t HEADER_SIZE = 4u;
static_assert(CHUNK_SIZE % HEADER_SIZE == 0, "CHUNK_SIZE must be multiple of the four");
static_assert(CHUNK_SIZE > HEADER_SIZE, "CHUNK_SIZE must be more than HEADER_SIZE");
public:
Chunk()
{
m_blocks.resize(CHUNK_SIZE);
std::uint32_t* init_header = reinterpret_cast<std::uint32_t*>(m_blocks.data());
*init_header = CHUNK_SIZE - HEADER_SIZE;
m_max_block = init_header;
m_free_blocks.insert(init_header);
}
bool isInside(const std::uint8_t* address) const noexcept
{
const std::uint8_t* start_chunk_address = reinterpret_cast<const std::uint8_t*>(m_blocks.data());
const std::uint8_t* end_chunk_address = start_chunk_address + CHUNK_SIZE;
return (start_chunk_address <= address) && (address <= end_chunk_address);
}
std::uint8_t* tryReserveBlock(std::size_t allocation_size)
{
const std::size_t not_aligned_address = reinterpret_cast<std::size_t>(m_max_block) + allocation_size;
const std::size_t alignment_padding = getAlignmentPadding(not_aligned_address, HEADER_SIZE);
const std::uint32_t allocation_size_with_alignment = static_cast<std::uint32_t>(allocation_size + alignment_padding);
if ( (!m_max_block) || (allocation_size_with_alignment > *m_max_block) ) // Check on enaught memory for allocation
{
return nullptr;
}
// Find min available by size memory block
const auto min_it = std::min_element(m_free_blocks.cbegin(), m_free_blocks.cend(), [allocation_size_with_alignment] (const std::uint32_t* lhs, const std::uint32_t* rhs)
{
if (*rhs < allocation_size_with_alignment)
{
return true;
}
return (*lhs < *rhs) && (*lhs >= allocation_size_with_alignment);
});
assert(min_it != m_free_blocks.cend() && "Internal logic error with reserve block, something wrong in implementation...");
assert(**min_it >= allocation_size_with_alignment && "Internal logic error with reserve block, something wrong in implementation...");
std::uint32_t* header_address = *min_it;
std::uint32_t* new_header_address =
reinterpret_cast<std::uint32_t*>(reinterpret_cast<std::uint8_t*>(header_address) + HEADER_SIZE + allocation_size_with_alignment);
if (m_free_blocks.find(new_header_address) == m_free_blocks.cend()) // check if there is free memory in the current block
{
const std::uint32_t old_block_size = *header_address;
const std::uint32_t difference = old_block_size - HEADER_SIZE;
if (difference >= allocation_size_with_alignment) // check if there is enough space for another block
{
const std::uint32_t new_block_size = difference - allocation_size_with_alignment;
*new_header_address = new_block_size;
m_free_blocks.insert(new_header_address);
}
}
m_free_blocks.erase(header_address);
*header_address = static_cast<std::uint32_t>(allocation_size);
if (header_address == m_max_block) // if the maximum block were changed, then need to find the maximum block again
{
// Find max block by size
const auto max_it = std::max_element(m_free_blocks.cbegin(), m_free_blocks.cend(), [] (const std::uint32_t* lhs, const std::uint32_t* rhs)
{
return (*lhs) < (*rhs);
});
// If there are no free blocks, therefore the memory in this chunk is over
m_max_block = (max_it != m_free_blocks.cend()) ? (*max_it) : (nullptr);
}
return reinterpret_cast<std::uint8_t*>(header_address) + HEADER_SIZE;
}
void releaseBlock(std::uint8_t* block_ptr)
{
std::uint8_t* header_address = block_ptr - HEADER_SIZE;
const std::uint32_t size_relized_block = *header_address;
if ( (!m_max_block) || (size_relized_block > *m_max_block) ) // if the relized block is greater than the maximum, then need to replace it
{
m_max_block = reinterpret_cast<std::uint32_t*>(header_address);
}
m_free_blocks.insert(reinterpret_cast<std::uint32_t*>(header_address));
auto forward_it = m_free_blocks.find(reinterpret_cast<std::uint32_t*>(header_address));
auto backward_it = tryDefragment(forward_it, m_free_blocks.end());
tryDefragment(std::make_reverse_iterator(backward_it), m_free_blocks.rend());
}
private:
template<typename DstIterator, typename SrcIterator>
constexpr DstIterator getIterator(SrcIterator it) const
{
using iterator = std::set<std::uint32_t*>::iterator;
using reverse_iterator = std::set<std::uint32_t*>::reverse_iterator;
if constexpr ( (std::is_same_v<SrcIterator, iterator>) && (std::is_same_v<DstIterator, reverse_iterator>) )
{
return std::make_reverse_iterator(it);
}
else if constexpr ( (std::is_same_v<SrcIterator, reverse_iterator>) && (std::is_same_v<DstIterator, iterator>) )
{
return it.base();
}
else
{
return it;
}
}
template<typename Iterator>
Iterator tryDefragment(Iterator start_it, Iterator end_it)
{
// primitive defragmentation algorithm - connects two neighboring
// free blocks into one with linear complexity
auto current_it = start_it++;
auto next_it = start_it;
std::uint32_t* current_header_address = *current_it;
if ( (current_it != end_it) && (next_it != end_it) )
{
std::uint32_t* next_header_address = *next_it;
const std::uint32_t current_block_size = *current_header_address;
const std::uint32_t* available_current_block_address =
reinterpret_cast<std::uint32_t*>(reinterpret_cast<std::uint8_t*>(current_header_address) + HEADER_SIZE + current_block_size);
if (available_current_block_address == next_header_address)
{
const std::uint32_t next_block_size = *next_header_address;
const std::uint32_t new_current_block_size = current_block_size + HEADER_SIZE + next_block_size;
*current_header_address = new_current_block_size;
if (new_current_block_size > *m_max_block)
{
m_max_block = reinterpret_cast<std::uint32_t*>(current_header_address);
}
auto delete_it = getIterator<std::set<std::uint32_t*>::iterator>(next_it);
return getIterator<Iterator>(m_free_blocks.erase(delete_it));
}
}
return current_it;
}
public:
std::vector<std::uint8_t*> m_blocks;
std::set<std::uint32_t*> m_free_blocks;
std::uint32_t* m_max_block;
};
}
Теперь немного о том, как можно украсить использование аллокаторов вместе со стандартными контейнерами:
template<typename T, std::size_t CHUNK_SIZE = 16'384u>
using CustomAllocator = Allocator<T, CustomAllocationStrategy<CHUNK_SIZE>>;
template<typename T>
using CustomAllocatorWithStackChunks = Allocator<T, CustomAllocationStrategy<1'024u>>;
template<typename T>
using CustomAllocatorWithHeapChunks = Allocator<T, CustomAllocationStrategy<16'384u>>;
template<typename T>
using custom_vector = std::vector<T, CustomAllocator<T>>;
template<typename T>
using custom_list = std::list<T, CustomAllocator<T>>;
template<typename T>
using custom_set = std::set<T, std::less<T>, CustomAllocator<T>>;
template<typename T>
using custom_unordered_set = std::unordered_set<T, std::hash<T>, std::equal_to<T>, CustomAllocator<T>>;
template<typename K, typename V>
using custom_map = std::map<K, V, std::less<K>, CustomAllocator<std::pair<const K, V>>>;
template<typename K, typename V>
using custom_unordered_map = std::unordered_map<K, std::hash<K>, std::equal_to<K>, CustomAllocator<std::pair<const K, V>>>;
using custom_string = std::basic_string<char, std::char_traits<char>, CustomAllocator<char>>;
Можно также использовать аллокаторы и с умными указателями, но для этого придется написать небольшую прослойку:
template<typename T>
using custom_unique_ptr = std::unique_ptr<T, std::function<void(T*)>>;
template<class Allocator, typename T = typename Allocator::value_type, typename... Args>
custom_unique_ptr<T> make_custom_unique(Allocator allocator, Args&&... args)
{
const auto custom_deleter = [allocator](T* ptr) mutable
{
allocator.destroy(ptr);
allocator.deallocate(ptr, 1u);
};
void* memory_block = allocator.allocate(1u);
if (memory_block)
{
T* object_block = static_cast<T*>(memory_block);
allocator.construct(object_block, std::forward<Args>(args)...);
return custom_unique_ptr<T>{ object_block, custom_deleter };
}
return nullptr;
}
Ну и теперь, наконец, пример использования всего этого:
int main(int argc, char** argv)
{
CustomAllocationStrategy allocation_area{};
CustomAllocator<int> custom_int_allocator{ allocation_area };
custom_vector<int> vector{ custom_int_allocator };
for (int i = 0u; i < 100; ++i)
{
vector.push_back(i);
std::cout << vector.at(i) << " ";
}
vector.resize(16u);
for (int val : vector)
{
std::cout << val << " ";
}
CustomAllocator<int> custom_int_allocator_copy = vector.get_allocator();
custom_unique_ptr<int> ptr1 = make_custom_unique<CustomAllocator<int>>(custom_int_allocator_copy, 100);
custom_unique_ptr<int> ptr2 = make_custom_unique<CustomAllocator<int>>(custom_int_allocator_copy, 500);
custom_unique_ptr<int> ptr3 = make_custom_unique<CustomAllocator<int>>(custom_int_allocator_copy, 1000);
custom_unique_ptr<int> ptr4 = make_custom_unique<CustomAllocator<int>>(custom_int_allocator_copy, 1500);
std::cout << *ptr1 << " " << *ptr2 << " " << *ptr3 << " " << *ptr4 << " ";
CustomAllocator<float> custom_float_allocator { custom_int_allocator };
custom_list<float> list{ { 10.0f, 11.0f, 12.0f, 13.0f, 14.0f, 15.0f }, custom_float_allocator };
for (float val : list)
{
std::cout << val << " ";
}
CustomAllocator<std::pair<double, double>> custom_pair_allocator{ allocation_area };
custom_map<double, double> map{ { { 1.0, 100.0 }, { 2.0, 200.0 } }, custom_pair_allocator };
for (const auto& it : map)
{
std::cout << "{" << it.first << " : " << it.second << "} ";
}
CustomAllocator<double> custom_double_allocator{ allocation_area };
custom_set<double> set{ { 1000.0, 2000.0, 3000.0 }, custom_double_allocator };
for (double val : set)
{
std::cout << val << " ";
}
CustomAllocator<char> custom_char_allocator{ allocation_area };
custom_string string1{ "First allocated string without SBO ", custom_char_allocator };
custom_string string2{ "Second allocated string without SBO ", custom_char_allocator };
custom_string string3{ "Third allocated string without SBO ", custom_char_allocator };
custom_string result_string = string1 + string2 + string3;
std::cout << result_string;
return EXIT_SUCCESS;
}
Хотелось бы заострить внимание на том, что данная реализация является самой примитивной, но она может быть без проблем расширена в ту сторону, которая вам необходима, поэтому все в ваших руках!
Заключение
Спасибо за внимание, очень надеюсь, что данная статья оказалась кому-то полезной. Также желаю всем успехов в тесном взаимодействии с памятью, и самое главное, не забывать очень важные слова Дональда Кнута: «Преждевременная оптимизация — корень всех зол».
Ссылка на репозиторий с полной реализацией аллокатора.







