
Привет, Хабр!
Однажды, штудируя очередную книгу по пресловутой Data Science, я пришел к мысли, что пора бы применить накопленные знания на практике и увидеть жизнь отдела аналитики своими глазами. К моему счастью, Яндекс запустил отбор на полугодичную стажировку по соответствующему направлению, и я не мог пройти мимо. Приём заявок 2020 уже закончился, поэтому в этой статье я с чистой совестью разберу задачи, которые Яндекс предлагал решить соискателям на первом этапе. Будет и код на Python. Спойлер: сложно, но интересно.
Задача 1. Дедлайн
Условие задачи
Начинающий аналитик пытается решить задачу. Если задачу решить не удалось, то он теряет мотивацию, и вероятность успеха на следующей попытке падает. На одну попытку требуется день, а дедлайн по задаче — 90 дней. Вероятность, что аналитик решит задачу с i-ой попытки, составляет:

С какой вероятностью аналитик успеет решить задачу до дедлайна?
Решение
Вы, возможно, уже потянулись печатать: "@nice_one, ты же говорил, будет сложно, а это что?" Терпение, друзья, это простенькая задачка для разогрева, но и здесь есть, что упустить, если не вдуматься в условие. Разберём на примере первого пункта. Необходимо подсчитать суммарную вероятность того, что аналитик решит задачу в какой-либо из имеющихся в запасе 90 дней, при этом дана вероятность успеха в каждый i-ый день. Заманчивым вариантом может показаться подставить в выражение числа от 1 до 90 вместо i и сложить, однако это неверно. Данное выражение говорит о вероятности успеха в конкретный i-ый день, но для того, чтобы до этого i-го дня добраться, аналитик обязательно должен провалиться в прошлые (i — 1) дней. Если вероятность успеха в i-ый день равна
 , то вероятность провала в этот день, следовательно, равна
, то вероятность провала в этот день, следовательно, равна  . Как известно, чтобы найти вероятность одновременного наступления нескольких событий, необходимо перемножить вероятности наступления каждого. Таким образом, вероятность того, что аналитик справится ровно за n дней равна
. Как известно, чтобы найти вероятность одновременного наступления нескольких событий, необходимо перемножить вероятности наступления каждого. Таким образом, вероятность того, что аналитик справится ровно за n дней равна  .
. Стоящие под знаком произведения члены отвечают за провал в каждый из первых
 дней, затем необходимо домножить произведение на вероятность успеха в n-ый день.
дней, затем необходимо домножить произведение на вероятность успеха в n-ый день.Итак, для любого количества дней знаем вероятность успеха ровно за этот срок. Нас интересует суммарная вероятность успеха за каждый возможный срок до 90 дней включительно. Вот теперь можно подставлять числа от 1 до 90, но уже в полученную формулу. Проще всего написать цикл в каком-нибудь питоне, который будет вычислять и складывать вероятности, что я и сделал.
Код
import numpy as np
n = 90
probs = []
for i in range(1, n+1): # Для каждого дня
prob_now = 1/(i+1) # вычисляем вероятность успеха в этот день
prob_not_before = []
for k in range(1, i): # И вероятность провала во все прошлые
prob_not_before.append(k/(k+1))
prob_not_before = np.array(prob_not_before).prod() # Перемножаем
probs.append(prob_not_before * prob_now)
s = sum(probs) # Считаем суммарную вероятность
print(s)
Решение второго пункта полностью аналогично первому, отличается лишь формула. Я оставлю код, решающий второй пункт — думаю, все будет понятно.
Пункт 2
import numpy as np
n = 90
probs = []
for i in range(1, n+1): # Для каждого дня
prob_now = 1/((i+1)**2) # вычисляем вероятность успеха в этот день
prob_not_before = []
for k in range(1, i): # И вероятность провала во все прошлые
prob_not_before.append(1 - (1/((k+1)**2)))
prob_not_before = np.array(prob_not_before).prod()
probs.append(prob_not_before * prob_now)
s = sum(probs) # Считаем суммарную вероятность
print(s)
Задача 2. Судьба хомяка
Условие задачи
Чтобы выжить зимой, жадный голодный хомяк решил ограбить ореховый заводик, находящийся в 1000 м от его норы. На заводике осталось 3000 орехов. В щеки хомяка помещается максимум 1000 орехов. Куда и с чем бы ни шел хомяк, каждый метр ему необходимо подкрепляться 1 орехом. Хомяк уже на заводике и опасен. Какое максимальное число орехов он сможет запасти? Ответ необходимо округлить до целого числа.
Решение
Сильно напоминает задачу о джипе, не правда ли? Так и есть, перед нами очередная её разновидность. В общем случае, в задаче о джипе фигурирует некое транспортное средство (в данном случае хомяк), которому необходимо пройти определенное расстояние в условиях ограниченной вместимости топливного контейнера (щечки хомяка). Идея, лежащая в основе решения любой задачи такого класса — по ходу пути можно оставлять запасы топлива, а также возвращаться назад за новым. В остальном, единого алгоритма решения не существует, так как начальные условия и цели могут быть самыми разными. Предложенный здесь вариант интересен тем, что необходимо не просто пройти расстояние от заводика до норы (что элементарно, ведь хомяк может вместить ровно 1000 орехов, чего хватит на 1000 метров), но перенести в нее как можно больше орехов. Лучше всего нарисовать схему, изобразив отрезок в 1000 м и запас орехов на заводике, и подумать, как действовать хомяку, если он хочет переправить в нору 3000 орехов, съев как можно меньше, т. е. пройдя как можно меньшее суммарное расстояние. Попробуем перемещаться самыми малыми шагами, по 1 м, перенося все 3000 орехов с собой в несколько походов.
Очевидно, что для того, чтобы перенести 3000 орехов в какую-нибудь точку, хомяку понадобится как минимум 3 раза возвращаться в предыдущую. Когда орехов останется 2000, а остальные будут съедены в пути, хомяку потребуется 2 похода в предыдущую точку, чтобы переместить их в новую. Когда же топлива будет меньше 1000 единиц, назад возвращаться не придется, оно все поместится в щечках хомяка. Таким образом, процесс переноса орехов можно разделить на три соответствующих этапа. Посмотрим, какой у хомяка будет «расход топлива» на каждом. Когда орехов будет больше 2000, для перемещения на 1 м хомяку придется:
- Набрать полные щеки орехов и пройти 1 м
- Выгрузить 998 орехов (1 съел в пути, 1 оставил, чтобы вернуться назад)
- Снова пройти 1 м назад, к запасам орехов
- Повторить пункты 1-3 для второй тысячи орехов
- Взять последнюю тысячу и пройти с ней 1 м вперед
Таким образом, 1 м перемещения со всей добычей стоит хомяку 5 орехов. Когда же орехов станет < 2000, а это произойдет после 200 м перемещения, алгоритм будет следующий:
- Набрать полные щеки орехов и пройти 1 м
- Выгрузить 998 орехов (1 съел в пути, 1 оставил, чтобы вернуться назад)
- Снова пройти 1 м назад, к запасам орехов
- Взять последнюю тысячу и пройти с ней 1 м вперед
1 м перемещения стоит хомяку 3 ореха. Когда же он достигнет точки 534 м, будет съеден суммарно 2001 орех, и хомяку останется взять последние 999 орехов и спокойно идти оставшиеся 466 метров в свою нору. Когда он доберется, в щечках останется 533 ореха — это и будет ответом к задаче.
Хочу отметить, что задачи такого класса довольно популярны в теории алгоритмов, а также на собеседованиях в крупных компаниях. Лучший способ научиться их решать — практика. Единого механизма решения нет (ну или он проплыл мимо меня), но вот набить на них руку и развить творческое мышление вполне реально.
Задача 3. Аналитическое распределение
Условие задачи
Яндекс хочет создать
 команд аналитиков. При найме каждый аналитик случайно выбирает себе группу, где будет работать. Руководитель группы хочет посчитать, какое минимальное количество тысяч аналитиков достаточно нанять, чтобы в его группе с вероятностью выше
команд аналитиков. При найме каждый аналитик случайно выбирает себе группу, где будет работать. Руководитель группы хочет посчитать, какое минимальное количество тысяч аналитиков достаточно нанять, чтобы в его группе с вероятностью выше  было не меньше
было не меньше  человек?
человек?Необходимо написать программу на Python, которая принимает на вход
, и в одной строке, а на выходе даёт количество тысяч аналитиков.  ,
,  ,
, 
Решение
Ну вот нам и пригодились знания статистики, а именно биномиального распределения. Обозначим нанимаемое Яндексом количество аналитиков за
 . Каждый из нанятых аналитиков выбирает команду. С точки зрения нашего руководителя группы, прием аналитика на работу есть эксперимент с двумя исходами: либо новичок попадает в нашу команду, либо нет. Вероятность попадания равна
. Каждый из нанятых аналитиков выбирает команду. С точки зрения нашего руководителя группы, прием аналитика на работу есть эксперимент с двумя исходами: либо новичок попадает в нашу команду, либо нет. Вероятность попадания равна  , вероятность выбора аналитиком иной группы, соответственно, равна
, вероятность выбора аналитиком иной группы, соответственно, равна  . Всего таких экспериментов с выбором команды будет . Количество попаданий в нашу команду
. Всего таких экспериментов с выбором команды будет . Количество попаданий в нашу команду  из выборов аналитиков распределено биномиально, функция распределения равна:
из выборов аналитиков распределено биномиально, функция распределения равна: 
. Нас же интересует вероятность того, что количество попаданий будет больше или равно заданному, поэтому задача выглядит так:
То есть требуется найти количество нанятых аналитиков
, при котором в команду попадет как минимум человек для заданной вероятности . Хорошо, с математикой разобрались — как теперь найти
? Перебором. Можно написать цикл, который будет перебирать число нанятых аналитиков, увеличивая его до тех пор, пока вероятность получить как минимум аналитиков не станет удовлетворительной.
Код
def c(n, k): # Подсчёт числа сочетаний, быстрый алгоритм без факториалов
if 0 <= k <= n:
nn = 1
kk = 1
for t in range(1, min(k, n - k) + 1):
nn *= n
kk *= t
n -= 1
return nn // kk
else:
return 0
def bin_prob(trials, k, m): # Формула Бернулли для подсчета функции распределения
return c(trials, k) * ((1/m)**k) * ((1 - 1/m)**(trials - k))
def cdf(maximum, trials, m): # Функция распределения
value = 0
for i in range(maximum + 1):
value += bin_prob(trials, i, m)
return value
n, m, p = [(float(i)) for i in input().split()] # Ввод данных в одну строчку по условию
n = int(n)
m = int(m)
x = 1000
while (1 - cdf(n, x, m)) < p: # Пока вероятность не станет удовлетворительной
x += 1000 # Накидываем ещё аналитиков
print(int(x / 1000)) # Печатаем результат
Задача 4. Исследование подарков
Условие задачи
Дед мороз принёс Анастасии 100 подарков и разместил их под ёлкой. Ёлка разлапистая и пушистая, поэтому Анастасии сложно под ней ориентироваться. Анастасия исследует подарки так: случайно протягивает руку со случайной стороны ёлки на случайную дальность, берёт подарок, рассматривает его и кладёт обратно. Получается, что каждый раз Анастасия может равновероятно взять любой подарок из лежащих под ёлкой. Найдите матожидание доли подарков, которые Анастасия рассмотрит за 100 случайных протягиваний?
Решение
На первый взгляд задача кажется очень простой, даже появляется уверенность, что решение можно найти какой-нибудь элементарной формулой, однако не все так просто. Далеко не так просто. Я потратил на эту задачу неприлично много времени, пытаясь расписать варианты и вывести формулу, но у меня не получилось. Тогда я пошел в Google и мне, к моему же удивлению, пришлось знатно покопаться в форумах, прежде чем я нашел решение для общего случая. Итак, если мы случайно с возвратом отбираем элементы из множества, вероятность за
отборов из  элементов множества вытащить ровно
элементов множества вытащить ровно  различных равна:
различных равна:
Где
 есть число Стирлинга второго рода — количество неупорядоченных разбиений множества из элементов на непустых подмножеств. Ну а чтобы найти матожидание, необходимо сложить подсчитанные по этой формуле вероятности для каждой возможной доли уникальных рассмотренных подарков — от одной сотой до одной целой. Сделать это можно с помощью цикла в Python.
есть число Стирлинга второго рода — количество неупорядоченных разбиений множества из элементов на непустых подмножеств. Ну а чтобы найти матожидание, необходимо сложить подсчитанные по этой формуле вероятности для каждой возможной доли уникальных рассмотренных подарков — от одной сотой до одной целой. Сделать это можно с помощью цикла в Python.
Код
import math
import numpy as np
import sys
import sympy # Библиотека с числами Стирлинга - и такое есть
sys.setrecursionlimit(10**9)
def c(n, k): # Cочетания
return (math.factorial(n))/(math.factorial(k) * math.factorial(n-k))
def s(n, k): # Псевдоним для числа Стирлинга второго рода
return sympy.functions.combinatorial.numbers.stirling(n, k)
def p(m, k, n): # Вероятность рассмотреть ровно k
return c(m, k) * math.factorial(k) * s(n, k) / (m**n)
pr = []
# Тут я считаю не для долей, а для количества подарков...
for j in range(1, 101):
pr.append(p(100, j, 100))
pr = np.array(pr)
#...поэтому потом делю на 100
frac = np.array([i for i in range(1, 101)]) / 100
print(sum(pr*frac)) # Печатаем результат
Задача 5. Равновероятный путник
Условие задачи
Путник начинает движение по рёбрам двумерной сетки с целыми узлами строго вправо или вверх. Он движется из точки
 в точку
в точку  . С какой вероятностью он пересечёт реку, проходящую по прямой, соединяющей начальную и конечную точку, если считать, что все возможные маршруты равновероятны? Считается, что путник пересёк реку, если он в одном и том же маршруте оказался строго выше и ниже реки. Заход на реку не считается пересечением.
. С какой вероятностью он пересечёт реку, проходящую по прямой, соединяющей начальную и конечную точку, если считать, что все возможные маршруты равновероятны? Считается, что путник пересёк реку, если он в одном и том же маршруте оказался строго выше и ниже реки. Заход на реку не считается пересечением.Решение
Найдём вероятность пересечения классическим подходом — поделим число маршрутов с пересечением на общее число возможных маршрутов. Пусть
— длина ребра квадратной сетки. Тогда общее число возможных маршрутов:
Вывод формулы описан здесь. А вот как узнать число маршрутов с пересечением реки для каждого
? Озадачившись этим вопросом, я решил взять несколько длин сетки поменьше, нарисовать поля и вручную подсчитать, сколько маршрутов пересекают реку, надеясь проследить зависимость (Очень рекомендую вам также сейчас взять листочек и ручку и поэкспериментировать с рисованием маленьких сеток и путей).Пусть имеется сетка размером 3 на 3 клетки. Побочная диагональ сетки занята рекой, путник стоит в левом нижнем углу.
Картинка
Рисунок не идеальный, но я пытался, честно
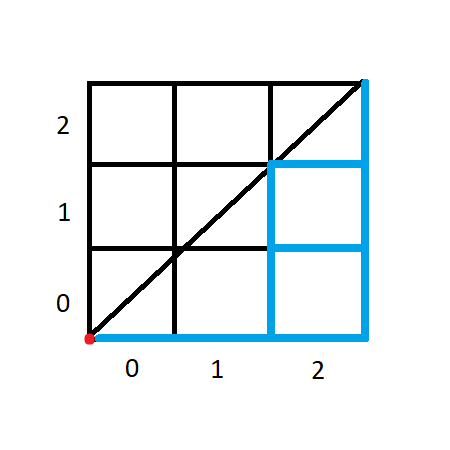

Как только я сделал рисунок, понял, что намного проще будет отследить маршруты, реку не пересекающие, а именно маршруты ниже реки. Затем можно будет умножить их число на 2, учтя таким образом и зеркальные маршруты выше реки. Так как мы знаем вдобавок и общее число маршрутов, найдём и количество пересекающих реку. Но вернёмся к главной задаче — нам нужна зависимость между
и числом путей с переходом реки.На рисунке выше для случая 3x3 я отметил синим некоторые «сухопутные» маршруты, доступные путнику: отмеченные маршруты проходят по рёбрам клеток с горизонтальной координатой 2, на левые и верхние рёбра клеток раньше путник не заступает. Таких маршрутов 3, т. е.
. Теперь разберёмся с маршрутами, что проходят через клетку столбца 1.
Картинка


Новые пути я отметил красным. Итак, понятно, что если путник свернёт на левое и затем верхнее ребро клетки (1, 0), ему далее будут доступны лишь 2 из трёх путей через клетки с горизонтальной координатой 2, ведь двигаться можно лишь вверх и вправо — третий же путь лежит ниже. Таким образом, добавив в маршрут новую клетку из столбца 1, мы увеличили общее число путей на то количество маршрутов, которое проходит через клетки столбца 2, находящиеся не ниже нашей новой клетки.
Возьмём сетку 4 на 4 и продолжим распутывать клубок. Стало понятно, что добавление новой клетки какого-либо столбца увеличивает число путей на то количество маршрутов, которое проходит через следующий столбец не ниже верхнего ребра добавленной клетки. Не буду отмечать маршруты цветом, ограничусь текстовым описанием, но если считаете необходимым, рисуйте — в процессе решения я нарисовал добрый десяток разных сеток, прежде чем сумел уверенно прочувствовать зависимость.
Картинка


Крайний правый столбец вновь даёт нам
маршрутов. Верхнее ребро клетки (2, 0) добавит нам  маршрут. Верхнее ребро клетки (2, 1) добавит
маршрут. Верхнее ребро клетки (2, 1) добавит  маршрута. Верхнее ребро клетки (1, 0) добавит столько маршрутов, сколько добавили клетки (2, 0) и (2, 1) вместе. При желании можно нарисовать сетку побольше и продолжить считать маршруты тем же алгоритмом. Наша задача — подсчитать маршруты для сетки 100x100. Для этого можно написать программку, которая примет на вход и построит матрицу
маршрута. Верхнее ребро клетки (1, 0) добавит столько маршрутов, сколько добавили клетки (2, 0) и (2, 1) вместе. При желании можно нарисовать сетку побольше и продолжить считать маршруты тем же алгоритмом. Наша задача — подсчитать маршруты для сетки 100x100. Для этого можно написать программку, которая примет на вход и построит матрицу  , начиная со столбца и далее для каждой клетки предыдущих столбцов подсчитывая число добавленных клеткой путей, основываясь на данных предыдущего столбца. Таким образом, количество не пересекающих реку путей будет найдено.
, начиная со столбца и далее для каждой клетки предыдущих столбцов подсчитывая число добавленных клеткой путей, основываясь на данных предыдущего столбца. Таким образом, количество не пересекающих реку путей будет найдено.
Код
import numpy as np
import math
def routes_total(n): # Общее число путей
return math.factorial(2*n) / (math.factorial(n)**2)
def fill_matrix(n): # Число путей, не пересекающих реку с одной стороны реки
net = np.zeros((n, n))
net[0, 0] = n # Крайний столбец даёт n путей
for i in range(n-2):
net[1, i] = n - i - 1
for i in range(2, n):
for j in range(n - i - 1):
net[i, j] = 0
for g in range(j, n - i + 1):
net[i, j] += net[i - 1, g]
# Сумму полученных чисел умножаем на 2, чтобы учесть другую сторону реки
return (2 * sum(sum(net)))
# Хотим долю пересекающих реку путей - вычитаем результат из 1
print(1 - fill_matrix(100) / routes_total(100))
Задача 6. Государство Линейного Распределения
Условие задачи
Государство Линейного Распределения представляет собой множество городов, некоторые из которых соединены дорогами.
Однажды королю Государства стало известно, что в его границы собирается вторгнуться Народ Точек Разрыва. Так как Государство не было готово к обороне, король принял нелёгкое решение — разделить Государство на много маленьких, каждое из которых будет самостоятельно защищать свои границы.
Было решено, что два города можно и нужно оставить в одном государстве, если из одного города можно будет добраться во второй, даже если Народ Точек Разрыва захватит одну дорогу между двумя любыми городами Государства Линейного Распределения. Во всех остальных случаях — города должны оказаться в разных государствах.
На каждой дороге, которая будет пересекать границу каких-либо двух новых государств, необходимо поставить бастион. Это нужно на случай, если одно из этих государств будет захвачено Народом Точек Разрыва. Тогда второе сможет продолжать оборонять свои границы. Иными словами, бастион будет поставлен на дороге, которая соединяет города из разных государств.
Король попросил вас дать ему список дорог, на которых необходимо поставить бастионы.
Формат ввода и вывода в программе
Первая строка входного файла содержит два натуральных числа и — количества городов и дорог в Государстве Линейного Распределения соответственно.  . Следующие m строк содержат описание дорог по одной строке. Дорога номер i описывается двумя натуральными числами
. Следующие m строк содержат описание дорог по одной строке. Дорога номер i описывается двумя натуральными числами  — номерами городов, которые эта дорога соединяет
— номерами городов, которые эта дорога соединяет 
Первая строка выходного файла должна содержать одно натуральное число b — количество дорог, на которых необходимо поставить бастионы. На следующей строке выводится b целых чисел — номера дорог, на которых будут установлены бастионы, по возрастанию. Дороги нумеруются с единицы в том порядке, в котором они заданы во входном файле.
Такие условия были даны изначально, в коде решения, который я приведу ниже, ввод производится с клавиатуры, а вывод — в консоль.
Формат ввода
Первая строка входного файла содержит два натуральных числа
и — количества городов и дорог в Государстве Линейного Распределения соответственно. . Следующие m строк содержат описание дорог по одной строке. Дорога номер i описывается двумя натуральными числами — номерами городов, которые эта дорога соединяет Формат вывода
Первая строка выходного файла должна содержать одно натуральное число b — количество дорог, на которых необходимо поставить бастионы. На следующей строке выводится b целых чисел — номера дорог, на которых будут установлены бастионы, по возрастанию. Дороги нумеруются с единицы в том порядке, в котором они заданы во входном файле.
Такие условия были даны изначально, в коде решения, который я приведу ниже, ввод производится с клавиатуры, а вывод — в консоль.
Решение
А вот и задачка на теорию графов. За долгими рассказами о судьбе Государства Линейного Распределения составители скрыли довольно интересную задачу поиска мостов в графе, узлами которого являются города, а ребрами — дороги. Если кратко, мост — такое ребра графа, удаление которого отрежет некую часть этого графа от других вершин. В этом и заключается идея захвата дороги — если будет захвачен мост, сообщение между некоторыми городами будет нарушено, в противном случае между городами всегда будет альтернативная дорога, поэтому именно мосты разделяют государства, на мостах необходимо поставить бастионы.
Алгоритм поиска мостов базируется на поиске в глубину (Depth-first search, DFS) — методе обхода графа, при котором рассматриваются все рёбра, исходящие из начальной вершины, и если ребро ведет в вершину, еще не рассмотренную, алгоритм тут же рекурсивно запускается из этой вершины. В поиске мостов поможет следующий факт:
Пусть мы находимся в поиске в глубину, просматривая сейчас все рёбра из вершины V. Тогда если текущее ребро (V, U) таково, что из вершины U и из любого его потомка в дереве обхода в глубину нет обратного пути в вершину V или какого-либо её предка, рассматриваемое ребро является мостом.
Для того, чтобы научиться проверять этот факт для вершины V, введём время вхождения в вершину disc[V] (от англ. discovered). В этой переменной будет записываться шаг алгоритма, на котором вершина была обработана. Также, с каждой вершиной V будет связана переменная lowest[V], в которую запишем время вхождения самой ранней вершины U, в которую можно попасть из вершины V. При первичной обработке вершины lowest[V] = disc[V] (В вершину раньше самой себя не попасть), однако впоследствии в процессе поиска в глубину мы можем найти какого-нибудь сына V, одно из ребер которого ведет в предка V (Назовём его S). В таком случае, мы обновим lowest[V]: lowest[V] = disc[S]. А когда же мы сможем выцепить мост? Тогда, когда поиском в глубину дойдем до вершины, у которой нет еще не рассмотренных сыновей (Опять назовём её U). В этом случае мы проверим, в какую самую раннюю вершину можно попасть из U, и если эта самая ранняя вершина встречается позже, чем непосредственный родитель U (Это возможно, например, когда у U нет сыновей, тогда lowest[U] = disc[U]), то связь U с родителем является мостом.
Ниже прикреплён код реализованного алгоритма с комментариями. Удобно не создавать отдельные переменные для disc и lowest каждой вершины, а завести под каждую величину массивы, где индексом является номер вершины, к которой относится значение.
Код
import sys
from collections import Counter
import numpy as np
sys.setrecursionlimit(10**6)
n, m = [int(i) for i in input().split()]
roads = [None] # Сохраним список дорог - понадобится для исключения дубликатов
graph = {} # Граф будем хранить как словарь дорог, ведущих из каждого города
for i in range(1, n+1):
graph[i] = []
for i in range(1, m+1):
twns = [int(j) for j in input().split()]
graph[twns[0]].append(twns[1])
graph[twns[1]].append(twns[0])
roads.append(frozenset([j for j in twns]))
disc = [0] * (n+1) # Массив discovered
lowest = disc.copy() # Массив lowest
used = disc.copy() # Массив used. Показывает, обрабатывалась ли вершина ранее
c = Counter(roads)
timer = 0 # Счётчик шагов алгоритма
nbridges = 0 # Счётчик мостов
bridges = [] # Список мостов
def dfs(v, parent): # Алгоритм поиска в глубину, модифицирован для нахождения мостов
global timer
global nbridges
global bridges
timer += 1 # Увеличиваем счётчик шагов
disc[v] = timer
lowest[v] = timer
used[v] = True # Отмечаем текущую вершину как обработанную
for u in graph[v]: # Перебираем все ребра из текущей вершины
if u == parent:
continue # Ребро в непосредственного родителя не рассматриваем, это не имеет смысла, мы из него пришли
if used[u]: # Если вершину, в которую ведет ребро, рассматривали ранее
lowest[v] = min(lowest[v], disc[u]) # Смотрим, не является ли она предком текущей вершины; обновляем lowest текущей
else: # Если не рассматривали
dfs(u, v) # Запускаем из неё поиск в глубину
# Когда поиск в глубину дошел до вершины без еще не раccмотренных сыновей U:
lowest[v] = min(lowest[v], lowest[u])
if lowest[u] > disc[v]: # Если из u не попасть в v или её предка, мы поймали мост
twns = [] # Города, соединённые мостом
twns.append(u)
twns.append(v)
if c[frozenset(twns)] > 1: # Если ребро уже отмечено мостом, пропускаем его, чтобы не было дубликатов
continue
nbridges += 1
bridges.append(roads.index(set(twns)))
dfs(1, 0) # Начинаем поиск с первой вершины графа
print(nbridges)
bridges = np.sort(bridges)
for bridge in bridges:
print(bridge)
Во многом разобраться с задачей мне помог следующий источник, поэтому считаю необходимым оставить на него ссылку. Стоит посмотреть и вот это видео — там есть хорошая анимация работы алгоритма.
Заключение
Вот такие задачи должен уверенно решать претендующий на стажировку в Яндексе специалист. На приведённый выше набор заданий давалось 5 часов — довольно небольшой, по моему мнению, срок, но каждый работает в своём темпе.
Мои решения были проверены, и они дают корректные ответы, однако я не сомневаюсь, что есть и более эффективные способы справиться с предложенными задачами. Если вы готовы предложить более быстрое или более понятное решение или же нашли у меня ошибку — не стесняйтесь об этом написать.
Всем желаю найти себе позицию по душе!







