Расшифровка доклада/tutorial "Управление высокодоступными PostgreSQL кластерами с помощью Patroni". А.Клюкин, А.Кукушкин
Patroni — это Python-приложение для создания высокодоступных PostgreSQL кластеров на основе потоковой репликации. Оно используется такими компаниями как Red Hat, IBM Compose, Zalando и многими другими. С его помощью можно преобразовать систему из ведущего и ведомых узлов (primary — replica) в высокодоступный кластер с поддержкой автоматического контролируемого (switchover) и аварийного (failover) переключения. Patroni позволяет легко добавлять новые реплики в существующий кластер, поддерживает динамическое изменение конфигурации PostgreSQL одновременно на всех узлах кластера и множество других возможностей, таких как синхронная репликация, настраиваемые действия при переключении узлов, REST API, возможность запуска пользовательских команд для создания реплики вместо pg_basebackup, взаимодействие с Kubernetes и т.д.
Слушатели мастер-класса подробно узнают, как работает Patroni, получат практические навыки настройки высокодоступных кластеров на его основе, познакомятся с различными дополнительными возможностями и поучаствуют в диагностике проблем. Будут рассмотрены следующие темы:
- область применения: какие задачи HA успешно решаются Patroni
- обзор архитектуры
- создание тестового кластера
- утилита patronictl
- изменение конфигурации PostgreSQL для кластера, управляемого Patroni
- мониторинг с помощью API
- подходы к переключению клиентов
- дополнительные возможности: ручное переключение, перезагрузка по расписанию, режим паузы
- настройка синхронной репликации
- расширяемость и универсальность
- частые ошибки и их диагностика

В конце есть опрос: "На сколько постов разделить tutorial? Прошу проголосовать."
(Алексей Клюкин) Здравствуйте! Большое спасибо, что вы пришли на этот tutorial о Patroni. Меня зовут Алексей. Мой коллега – Александр. Мы работаем в Zalando разработчиками по базам данных. И мы является также разработчиками Patroni. И мы очень рады использовать эту возможность для того, чтобы поделиться с вами нашими знаниями. И, может быть, поспособствовать тому, чтобы больше людей спало спокойно, используя автоматический failover и используя при этом Patroni. И мы хотим также рассказать о каких-то дополнительных возможностях, которые, возможно, мы еще не освещали в наших докладах.
# Для полного участия в мастер-классе вам понадобится ноутбук с установленным git, vagrant и virtual box.
# Vagrant можно загрузить со страницы https://www.vagrantup.com или установить с помощью пакетов в вашем дистрибутиве. Virtualbox: https://www.vagrantup.com
# После установки Vagrant и Virtualbox нужно выполнить:
$ git clone https://github.com/alexeyklyukin/patroni-training
$ cd patroni-training
$ vagrant up
$ vagrant ssh
$ sudo -iu postgres
$ cd patroni
$ ls
postgres0.yml postgres1.yml postgres2.yml На экране слайд с инструкциями для vagrant’а. Если у вас есть ноутбук и вы хотите следовать за нами, и выполнять команды, которые мы говорить (мы будем останавливать и говорить, что эти команды можно выполнить на своем ноутбуке и получить требуемый результат), то вы можете скачать vagrant или вы можете по адресу на GitHub, который здесь указан, скачать vagrantfile. После чего сделать vagrant up и vagrant ssh. И вы получите виртуальную машину, в которую уже установлен etcd, в которую установлен Postgres и в которую установлен Patroni. И эту виртуальную машину мы использовали для того, чтобы сделать слайды.
Если у вас нет ноутбука или вы не хотите за нами следовать, это не проблема. У нас также есть слайды, на которых будет написан результат всех тех действий, которые нужно предпринять и, соответственно, сами действия тоже. Поэтому вы можете просто смотреть на слайды. Мы слайды эти сделаем доступными после презентации, поэтому вы можете всегда использовать их, как справочный материал, когда вы будете работать с Patroni.
Patroni не требует от вас, чтобы у вас было слишком много postgres-кластеров. Вы можете использовать его для одного кластера и снова спать спокойно, и делать failover. А в Zalando у нас сотни кластеров. Мы доверяем Patroni каждый день, чтобы он переключал роль мастера на нужный нам postgres-кластер. Но вы можете использовать его на значительном меньшем количестве кластеров.

(Алексей Клюкин) Давайте начнем. Начнем мы с того, что я расскажу, чем мы будем заниматься. В начале мы расскажем про автоматический failover. Мы расскажем, как неправильно его делать, потому что очень много возможностей сделать его неправильно. Мы покажем, как не надо делать.
Мы расскажем про архитектуру Patroni, потому что очень важно понимать, как работает то решение, которому вы решили доверить свою базу данных.
После этого мы покажем, как создать кластер с помощью Patroni. Мы углубимся в детали, как менять конфигурацию рабочего кластера без перезагрузок. Если требуются перезагрузки, то Patroni поможет понять, когда их делать.
Мы расскажем про мониторинг, про те возможности, которые встроены в Patroni для того, чтобы мониторить ваши кластера.
Мы расскажем про возможности расширить функциональность Patroni с помощью пользовательских скриптов, которые выполняются при определенных действиях. В таких, как failover, как callback скрипты.
Мы также не обойдем вниманием вопрос, как перенаправлять клиентов на мастер-узел.
Мы расскажем про дополнительные возможности Patroni. В таких, как перезагрузка или failover по расписанию. Мы затронем теги, которые используются для модификации в репликации в Patroni. Расскажем подробнее про синхронную репликацию.
И в конце концов мы остановимся на различных способах создания реплик, которые есть в Patroni. А также на том, как Patroni решает такие задачи, как, например, склонировать существующий кластер или сделать point in time recovery существующего кластера на другом кластере.
И в самом конце мы рассмотрим типичные ошибки, с которыми мы встречались, когда поддерживали Patroni на GitHub. Мы рассмотрим, какие возникают ошибки и какие есть способы для решения этих ошибок.
Я теперь передаю слово Александру. Он вам расскажет про архитектуру в Patroni и вообще про автоматический failover.

(Александр Кукушкин) Здравствуйте! Для начала мы не будем рассматривать архитектуру в Patroni, а сделаем широкий взгляд сверху на High Availability, на высокодоступные решения, чтобы делать Postgres высокодоступным.
Давным-давно уже существует решение какого-то разделяемого хранилища. Это может быть какое-то сетевое хранилище, когда вы выделяете раздел и монтируете его на сервер. И при падении мастера, это хранилище перемонтируется на другой сервер, и там запускается Postgres. Как правило, такие решения достаточно дорогие, поэтому люди предпочтительно используют DRDB и LVM.
Для того, чтобы в таком случае переключать мастер, как правило, используют Corosync, PaceMaker. Это тоже очень сложная система. И люди очень часто делают ошибки в настройках. Основная проблема PaceMaker в том, что большую часть времени он работает. И ты постепенно забываешь, как с ним управляться, как он настраивается. И в какой-то момент что-то идет не так. И в этот момент, вы понимаете, что все знания утеряны, забыты и непонятно, что делать.
Логическая репликация или репликация, основанная на триггерах – это примерно одно и то же. Конечно, логическая репликация появилась в Postgres в 10-ой версии. Но никакой большой разницы между trigger-based репликацией или логической репликацией, по сути, нет.
У них есть свои плюсы и минусы. Но главный минус в том, что, как правило, при использовании такой логической репликации, вы реплицируете только данные. У вас не реплицируются какие-то служебные объекты, такие, как роли, юзеры. Реплицируются только какие-то отдельные базы, таблицы, т. е. не реплицируется кластер(сервер) целиком.
К счастью, в 2009-ом году появился Postgres 9.0, в котором появилась потоковая физическая репликация. Она позволяет кластер реплицировать один в один. И, как правило, все решения по High Availability строятся на физической репликации.
Многие думают, что с появлением multi-master’а у них эта проблема отпадет, потому что у вас будет много нод. Каждая нода сможет принимать данные на запись. В данный момент это можно реализовать с помощью BDR или bucardo. Но это обычно не то, что люди хотят. Поскольку и BDR, и bucardo также реплицируют исключительно данные. Они не реплицируют никаких служебных объектов в базе. И вам при таких решениях необходимо каким-то образом настраивать разрешение конфликтов. Потому что две ноды могут затрагивать один и тот же объект. И не всегда понятно, каким образом и в каком порядке эти изменения должны быть применены. Конечно, там можно настраивать эту стратегию. Но никакой стратегии по умолчанию невозможно придумать, которая бы удовлетворила всех. Поэтому большинство решений по High Availability строятся на потоковой репликации.
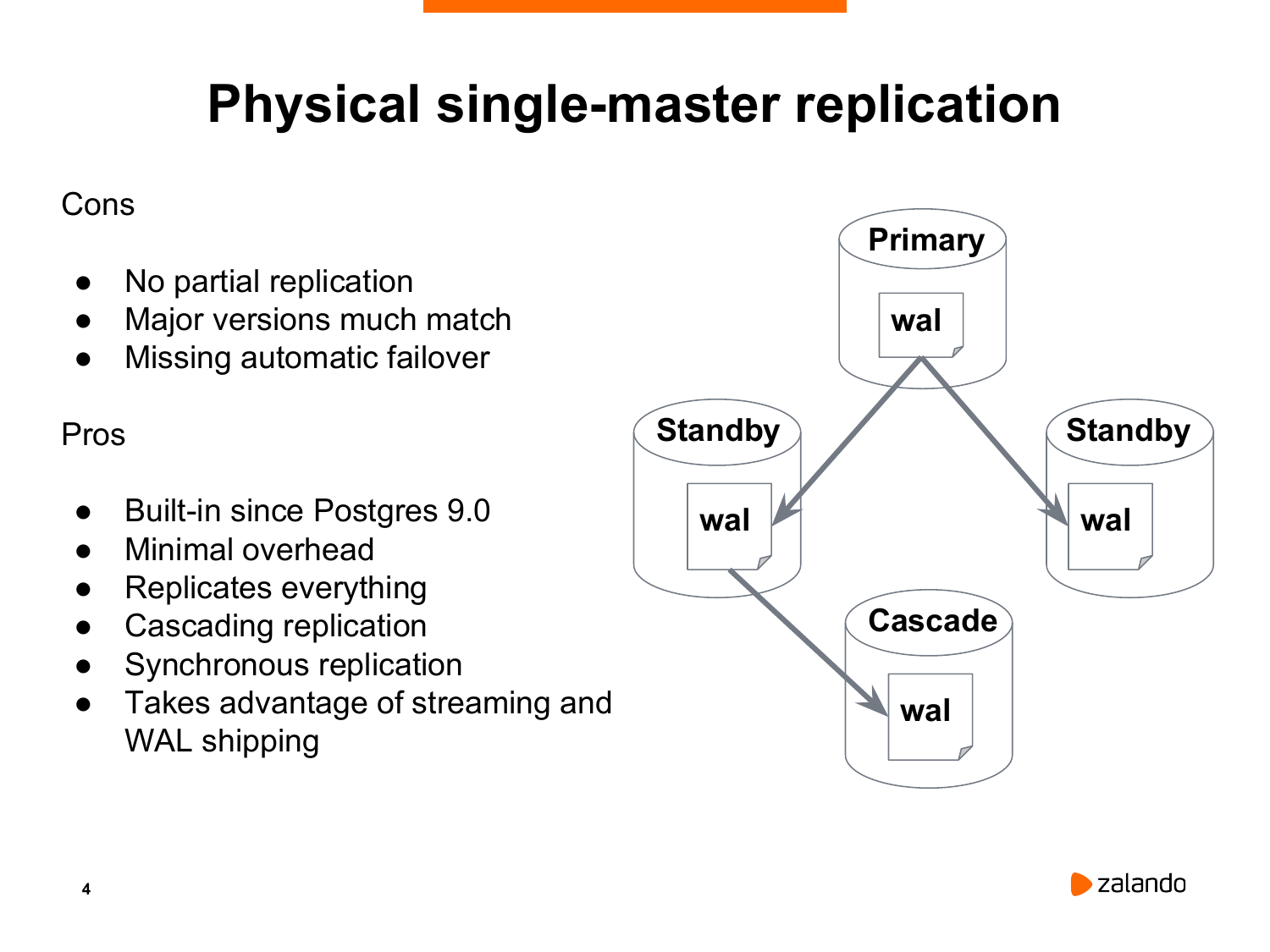
Какая в этом есть проблема? Сама по себе потоковая репликация не является полным решением высокой доступности. Потому что нет никакого встроенного решения, которое бы позволило перевести standby в режим нового мастера, если что-то произошло со старым мастером.
У этого решения есть очень глобальный недостаток в том, что потоковая репликация работает только на той же самой major versions.
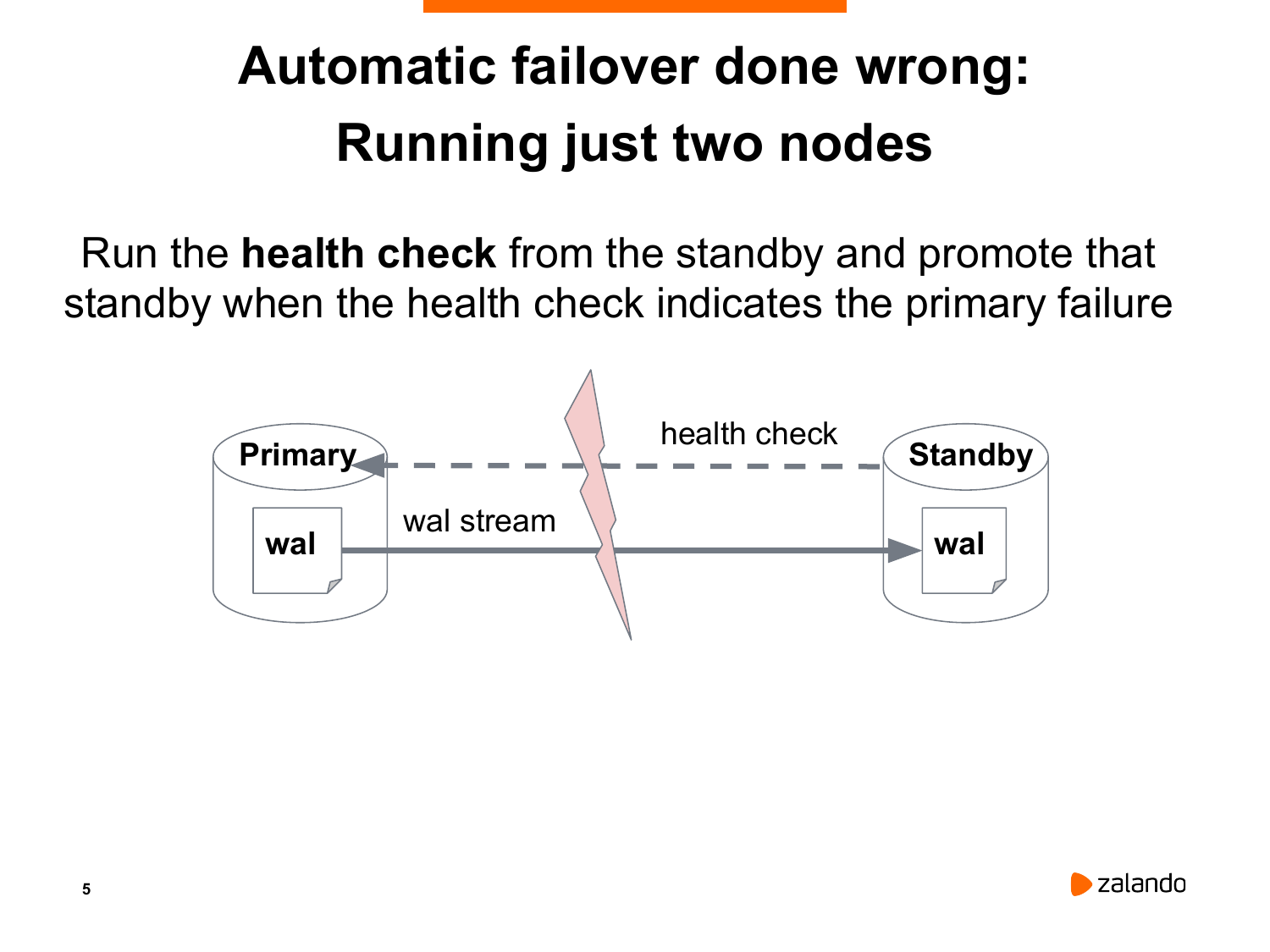
Что люди пытаются сделать: Мы построим базу, которая является мастером primary. Мы сделаем standby базу, которая будет через потоковую репликацию получать данные. Напишем какой-нибудь скрипт, который будет периодически запрашивать состояние мастера. И при условии, если мастер недоступен, мы будем превращать standby в новый мастер.
Мы живем в реальном мире. И поэтому сеть тоже неидеальная. Могут быть какие-то короткие всплески недоступности. Т. е. по факту с мастером ничего не случилось, он до сих пор работает. Он обслуживает соединения клиентские, все хорошо, но standby каким-то образом оказался, например, изолированным. И что происходит?

У нас получаются два мастера. Так называемая split-brain ситуация.
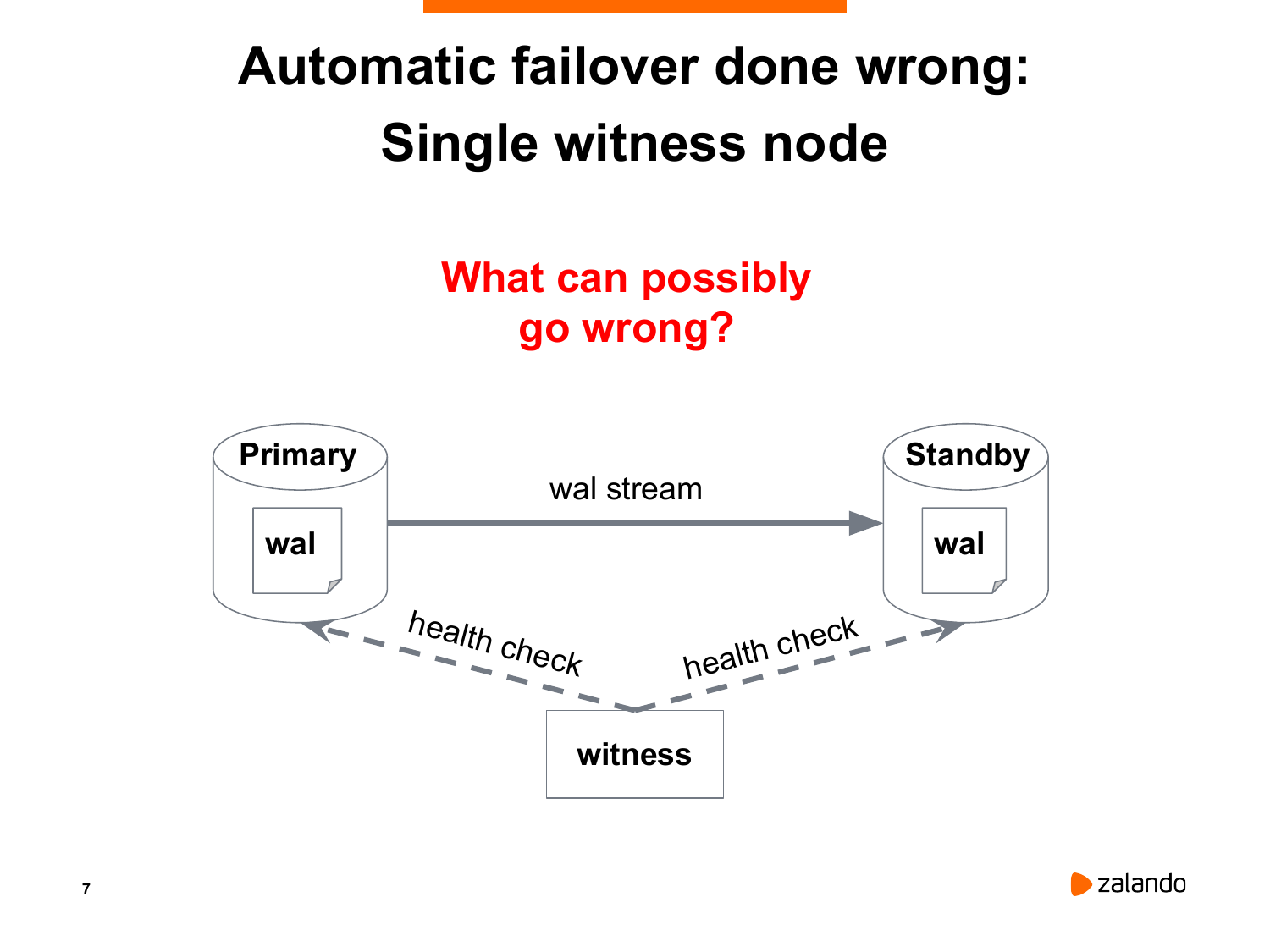
Поэтому есть другой подход к решению данной проблемы. Мы будем принимать решения о переводе standby в новый мастер с помощью какого-то третьего сервера.
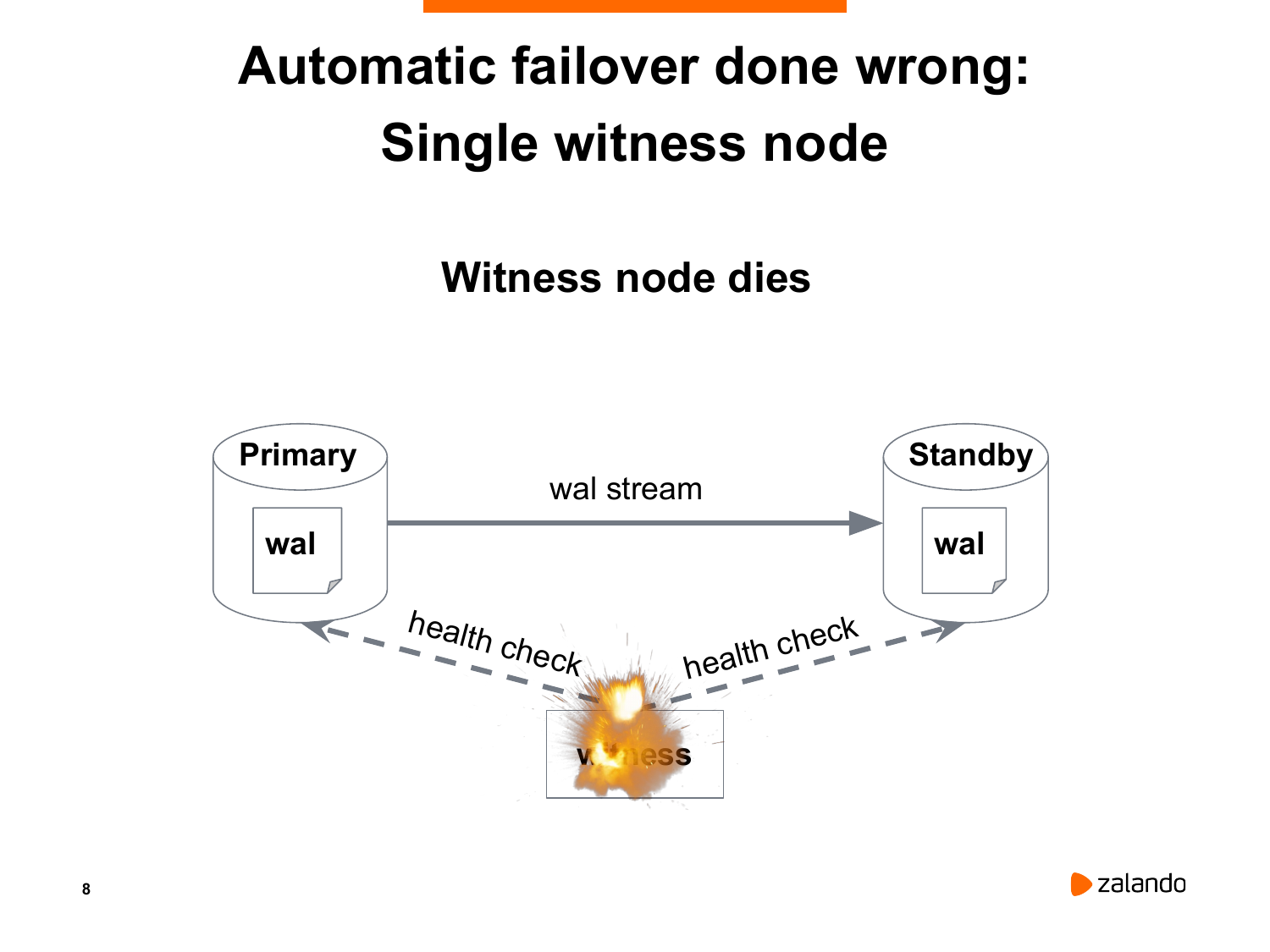
И, как вы думаете, что здесь может пойти не так? Во-первых, этот сервис тоже может сам по себе исчезнуть. Мы живем в реальном мире. И железки имеют обыкновение иногда сгорать, умирать, глючить. В этом случае мы теряем автоматический failover. С одной стороны, ничего критичного, мы можем поднять. Но с другой стороны, что может произойти в тот момент, когда нода, которая принимает решение, недоступна? У нас тоже может мастер отказать. И никто его не переключит. Никто не даст команду реплике переключиться.
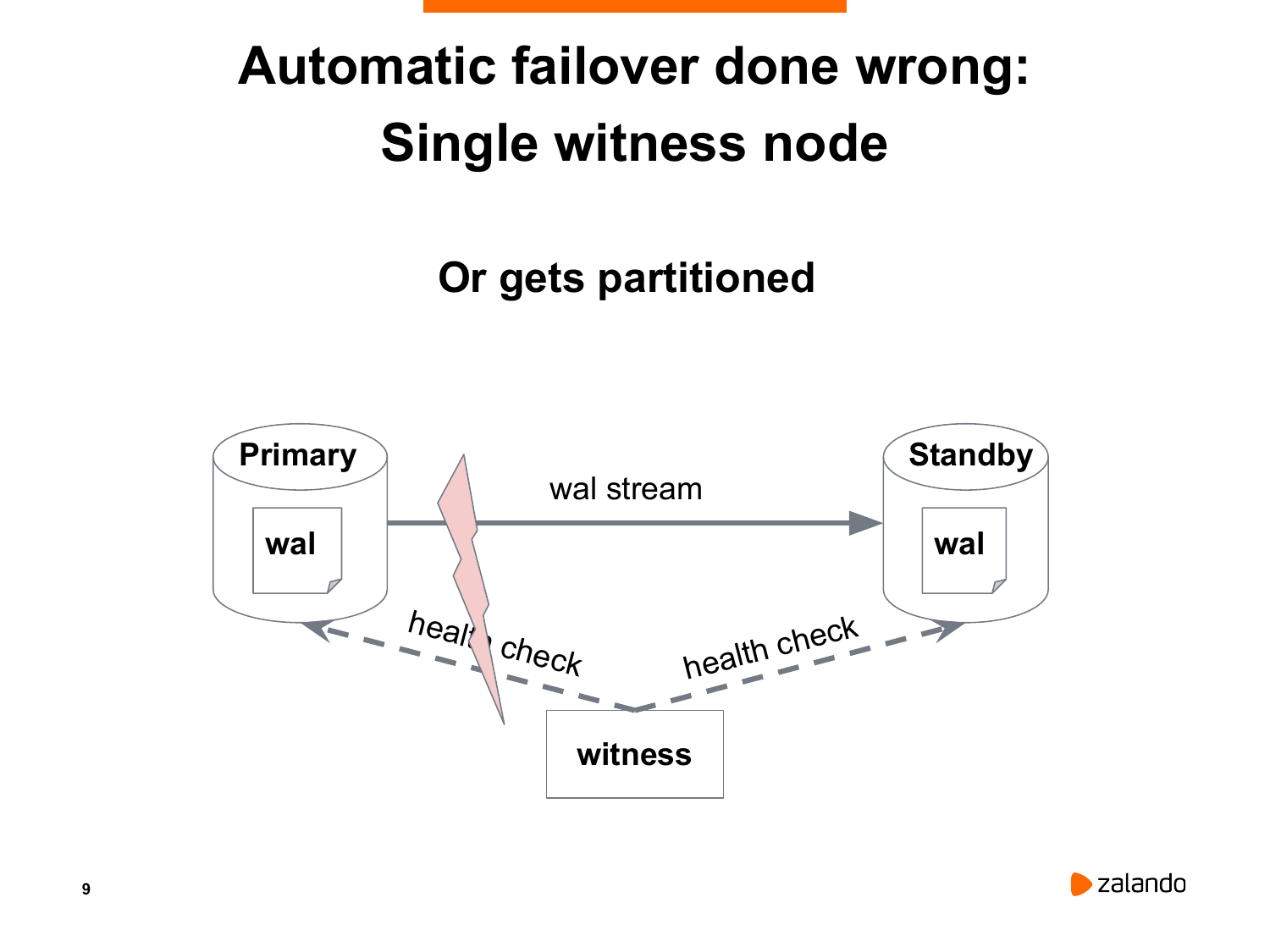
Есть еще одна ситуация. Может так оказаться, что мастер и standby оказались в разных сегментах сети. И нода, которая принимает решение, она может оказаться в том сегменте, где у нас находится standby. Нода понимает, что мастер недоступен, хотя мастер живой и обслуживает соединения. И нода принимает решение перевести standby в новый мастер. И мы снова получаем тот же самый split-brained.
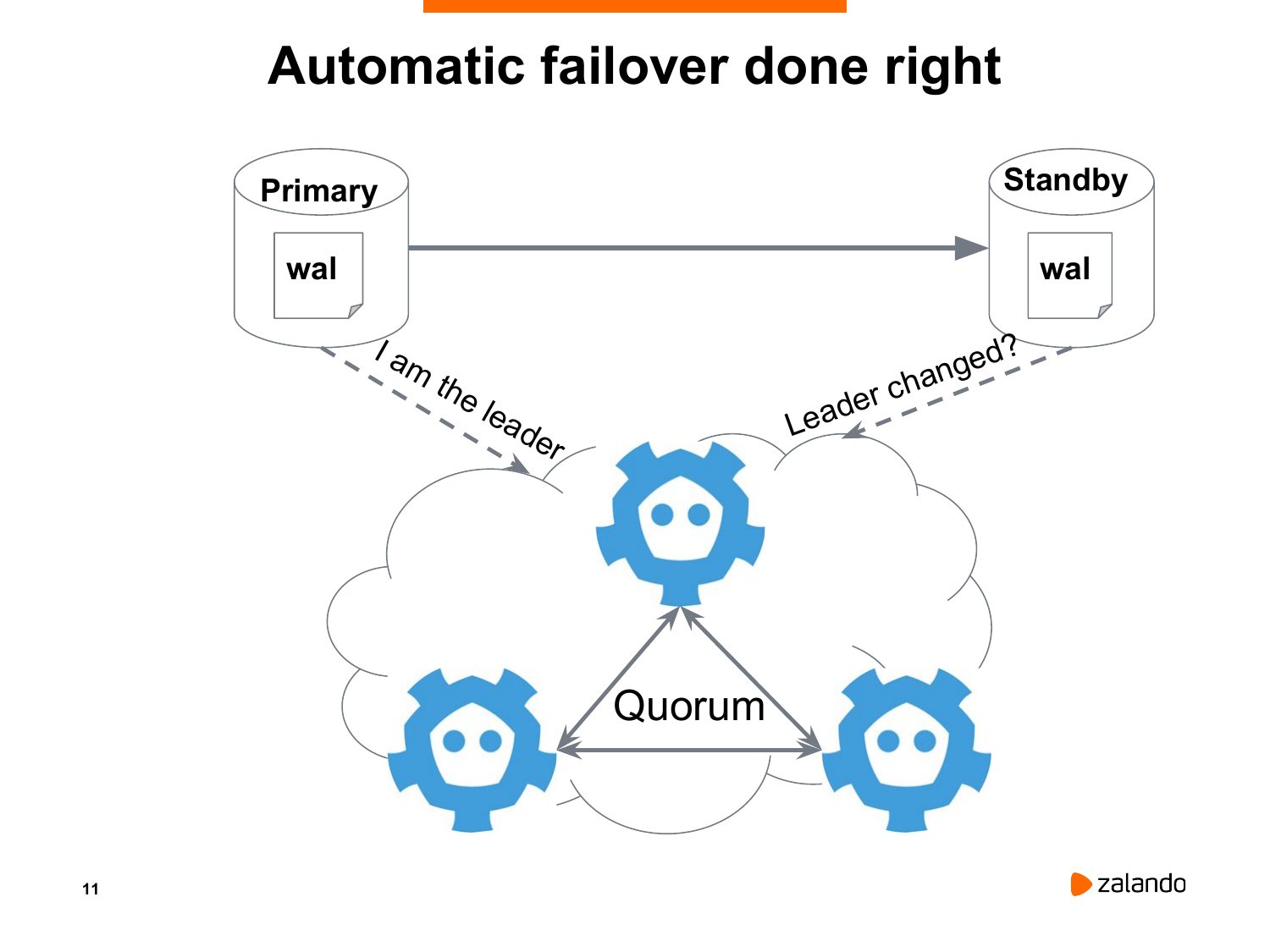
И потихоньку мы подходим к современному и правильному способу определения является ли мастер и реплика живыми. Это можно сделать только при условии, что у нас есть нечетное количество нод, которые проводят голосование.
В данном случае у нас есть три ноды. Если две ноды соглашаются о том, что у нас primary недоступен, то у этих двух нод есть большинство голосов. Два из трех – это большинство. Почему не рекомендуется использовать четное количество? В принципе, в этом нет ничего страшного, но для того, чтобы получить большинство голосов из четырех нод, должны три согласиться с результатами выборов.
(Уточнение: этого слайда я не нашел)
Конечно, очень важно убить старые соединения к мастеру. Для этого, как правило, выполняется STONITH. По-русски – это будет «пристрелить другую ноду в голову».
Quorum позволяет нам решать сложные задачи разрешения партицирования сети. Когда какой-то сегмент сети недоступен, то несколько других сегментов могут принимать решения. А изолированный сегмент в этом случае должен остановить старого мастера.
И очень хорошо иметь Watchdog. Это либо аппаратный, либо программный комплекс, который позволяет перезагрузить ноду при условии, что наш сервис не отвечает. Например, если что-то произошло в Patroni, то Watchdog не будет получать периодических сигналов и просто перезагрузит ноду. Это тоже способ закрытия сервера, потому что мы не должны оставлять Postgres работать самого по себе.
 И потихоньку мы приходим к подходу бота, который был придуман ребятами из компании «Compose». Compose был куплен IBM. Это достаточно большая компания. Идея в том, что мы рядом с каждым Postgres на каждой ноде запустим специального daemon`a, который будет управлять нашим instance Postgres. В случае если все хорошо и у нас есть доступ к какому-то распределенному хранилищу, где мы можем периодически обновлять lock, то данная нода может работать как мастер. Либо если у нас lock'а нет, то нода будет работать как реплика.
И потихоньку мы приходим к подходу бота, который был придуман ребятами из компании «Compose». Compose был куплен IBM. Это достаточно большая компания. Идея в том, что мы рядом с каждым Postgres на каждой ноде запустим специального daemon`a, который будет управлять нашим instance Postgres. В случае если все хорошо и у нас есть доступ к какому-то распределенному хранилищу, где мы можем периодически обновлять lock, то данная нода может работать как мастер. Либо если у нас lock'а нет, то нода будет работать как реплика.
И Bot занимается многими вещами. Но основная его задача следить за тем, что у нас Postgres работает либо в режиме мастера, когда он обязан быть один и только один, либо в режиме реплики.
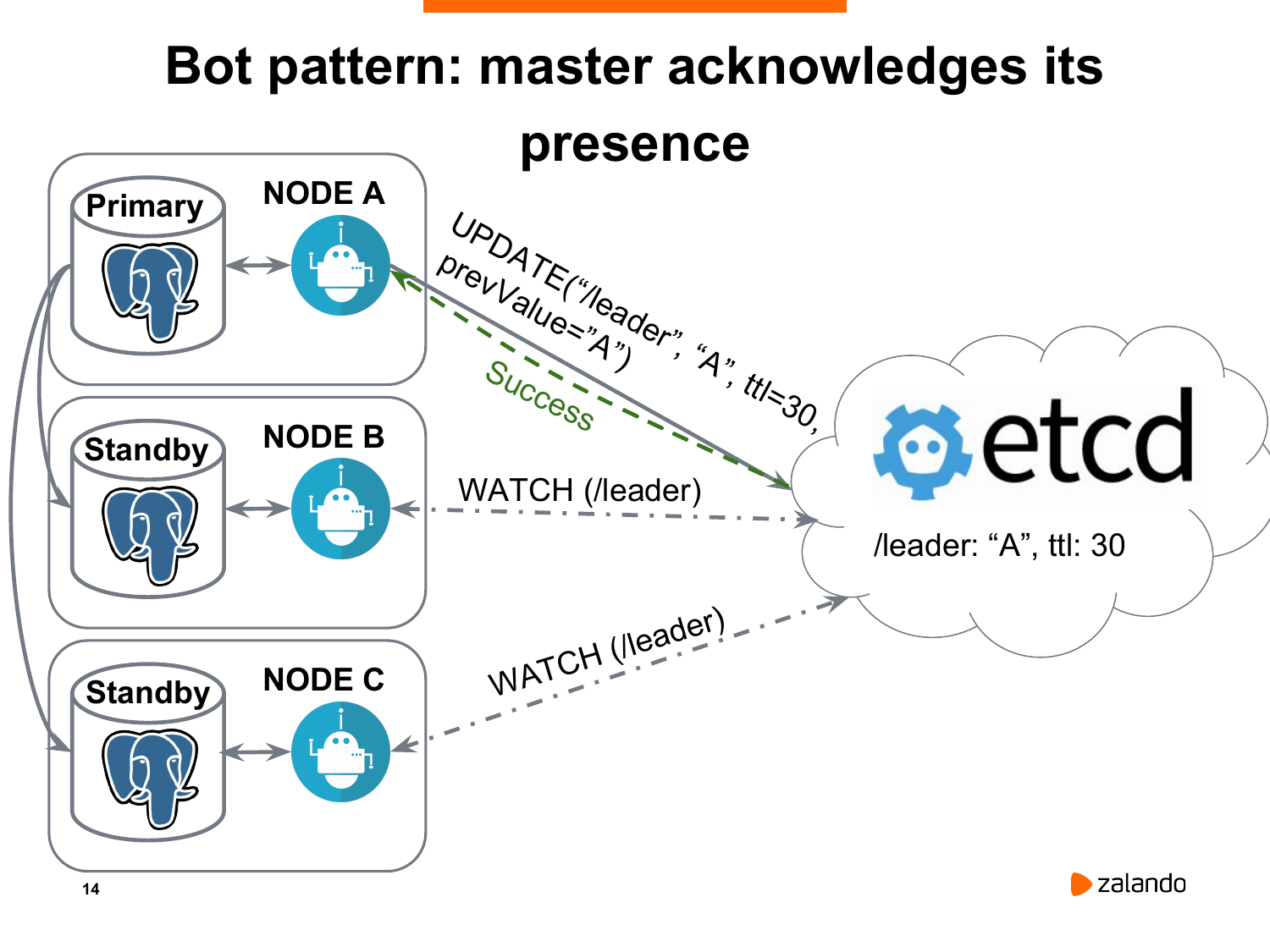
И вот, как все у нас происходит. На картинке у нас есть нода А, которая является текущим мастером. И она периодически отправляет в etcd запрос на обновление ключа лидера. Она это делает по умолчанию с периодичностью раз в 30 секунд. И важно, что у ключа лидера есть ttl. Это время в секундах, по истечению которого ключ пропадет.
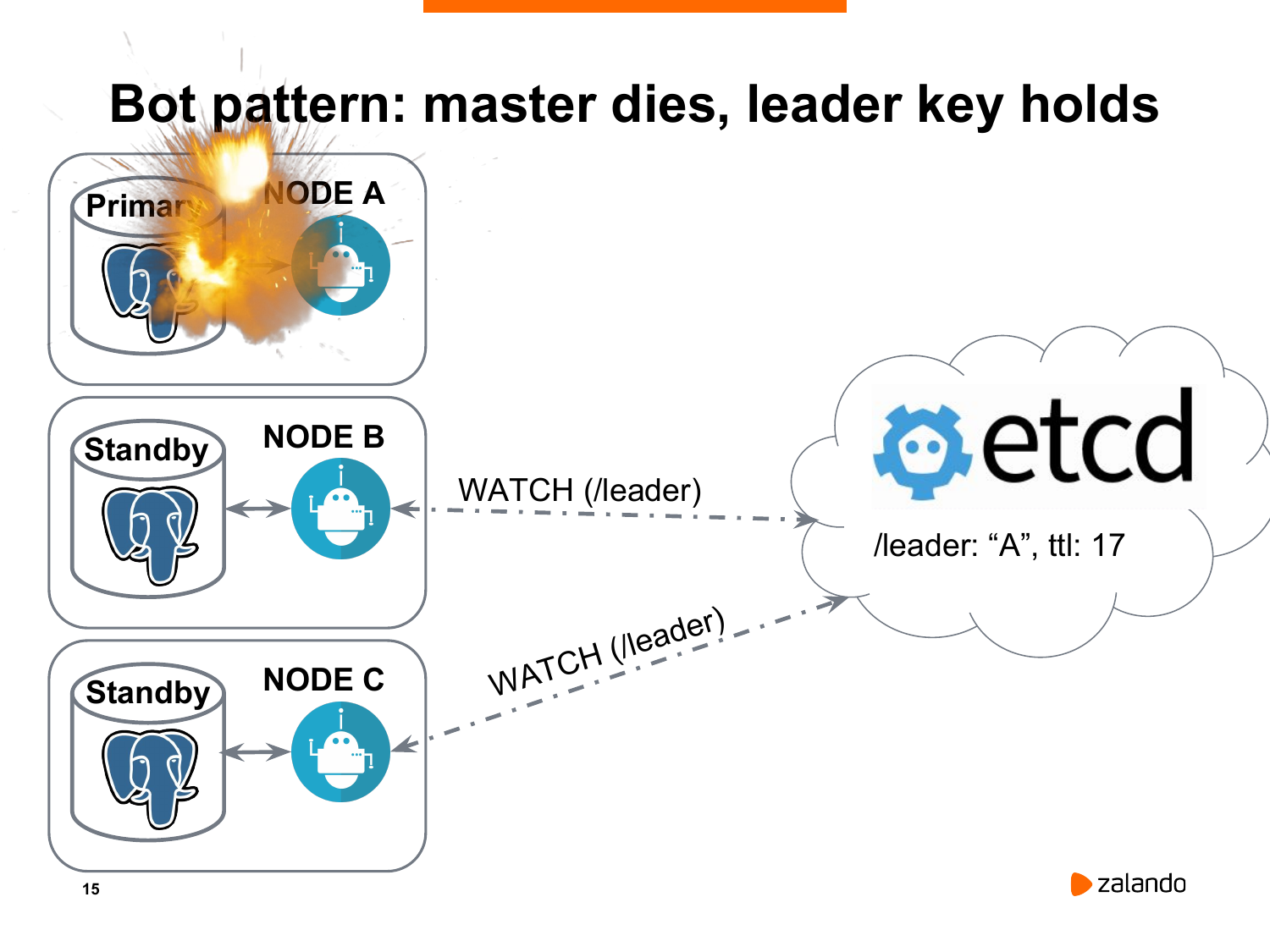
Если у нас что-то случилось с нашей нодой, она не будет обновлять ключ лидера. И потихоньку мы придем к ситуации, когда ключ лидера исчезнет.
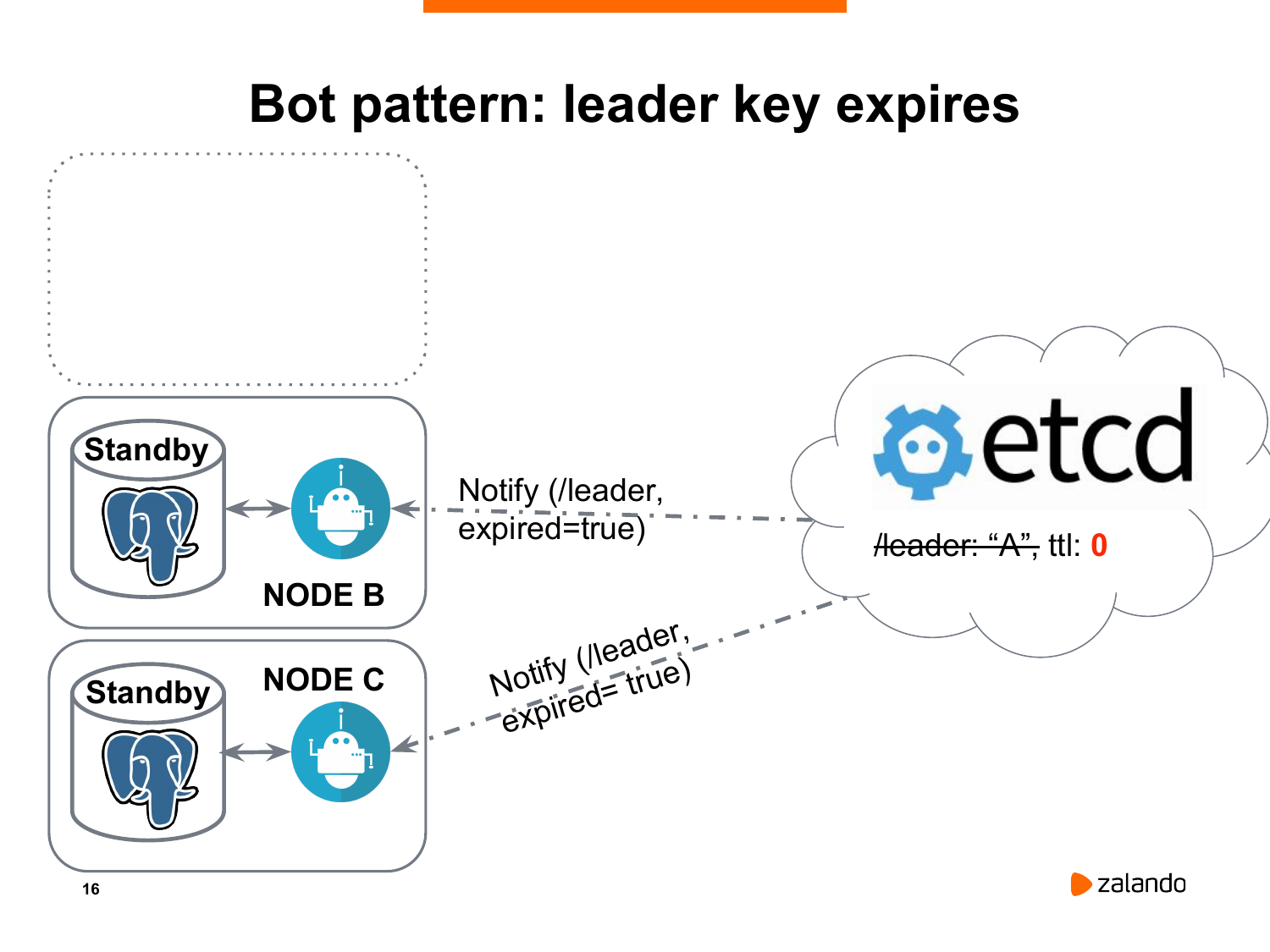
И оставшиеся ноды получат оповещение о том, что лидера нет, согласно etcd. И мы должны провести новые выборы.
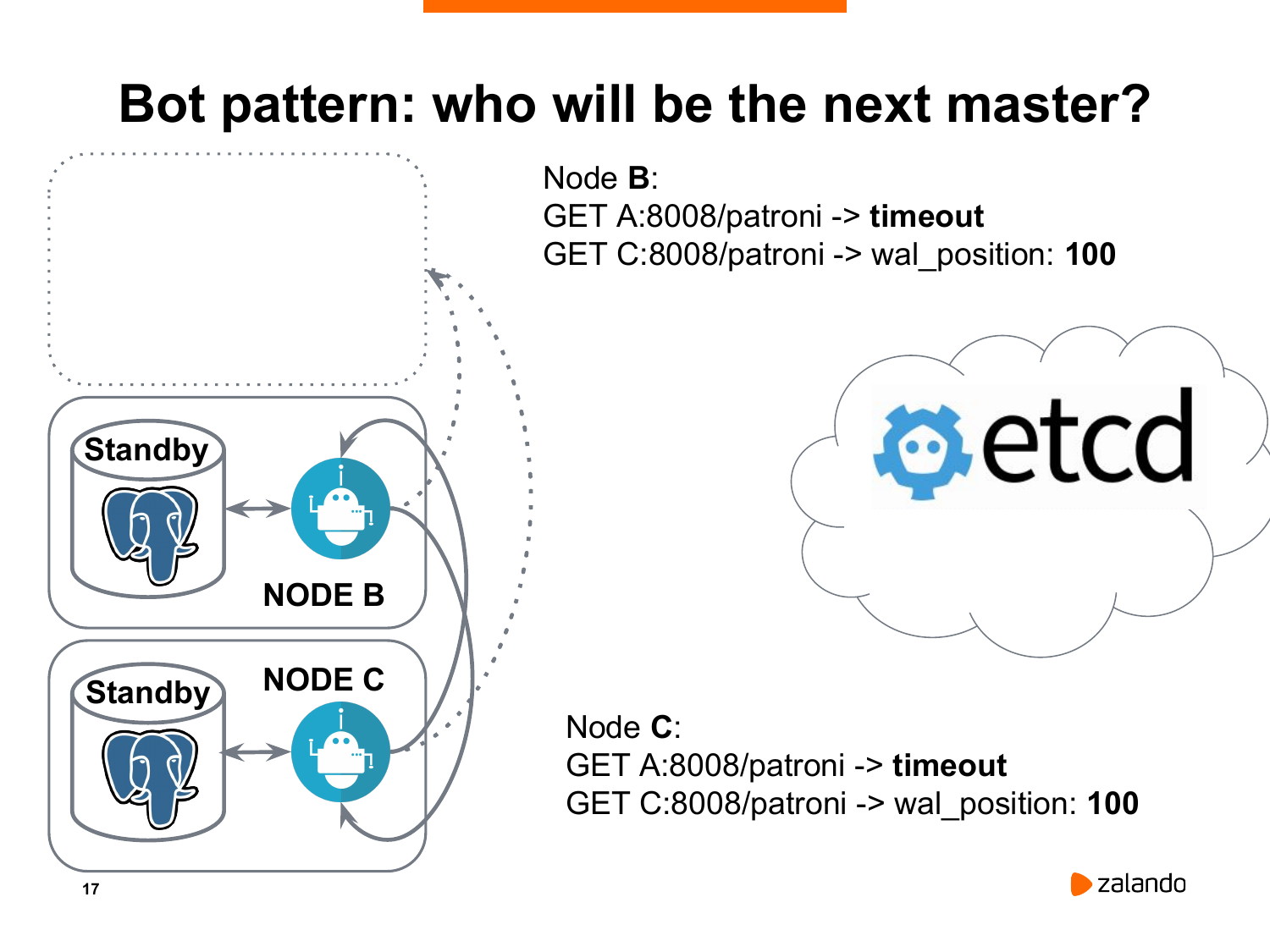
Как они это делают? Каждая нода обращается ко всем другим нодам, включая старый исчезнувший мастер. Потому что вдруг это были какие-то временные проблемы, и вдруг он до сих пор жив. Нам в этом надо убедиться. И каждая нода сравнивает позицию WAL со своей. При условии, если нода является впереди всех остальных или хотя бы не отстает, как в данном случае, когда у обоих реплик оказался wal_position равный 100, то они начинают гонку за лидером. Т. е. они отправляют запрос на создание нового ключа лидера в etcd.
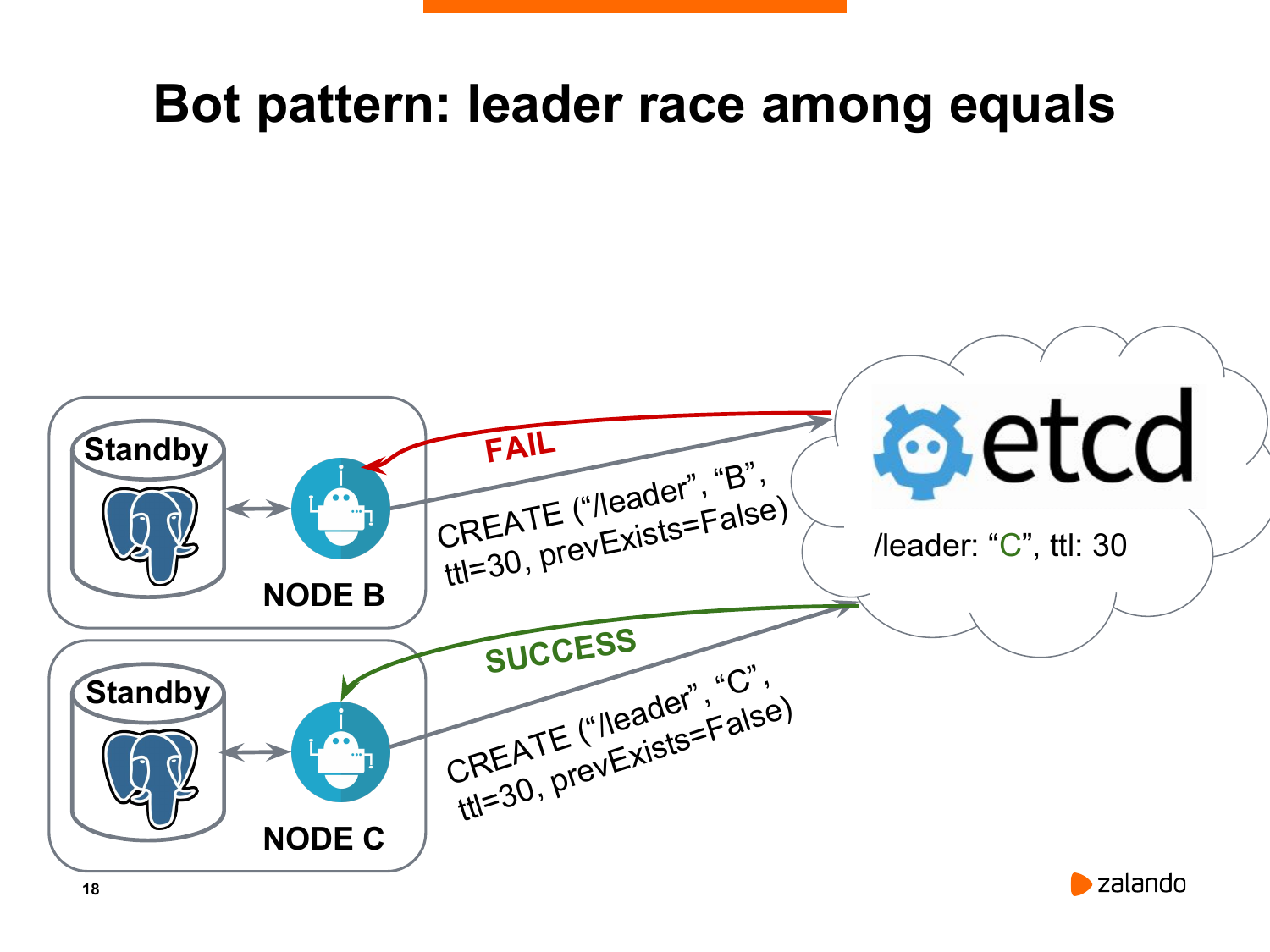
В чем прелесть etcd? В том, что он позволяет такие вещи делать атомарно. Т. е. когда одна нода создала ключ, то вторая нода, при условии, что мы запрещаем перезаписывать уже существующий ключ, его создать не сможет.
И на этом слайде мы видим, что нода C выиграла, она успела создать ключ лидера, а нода B не смогла.
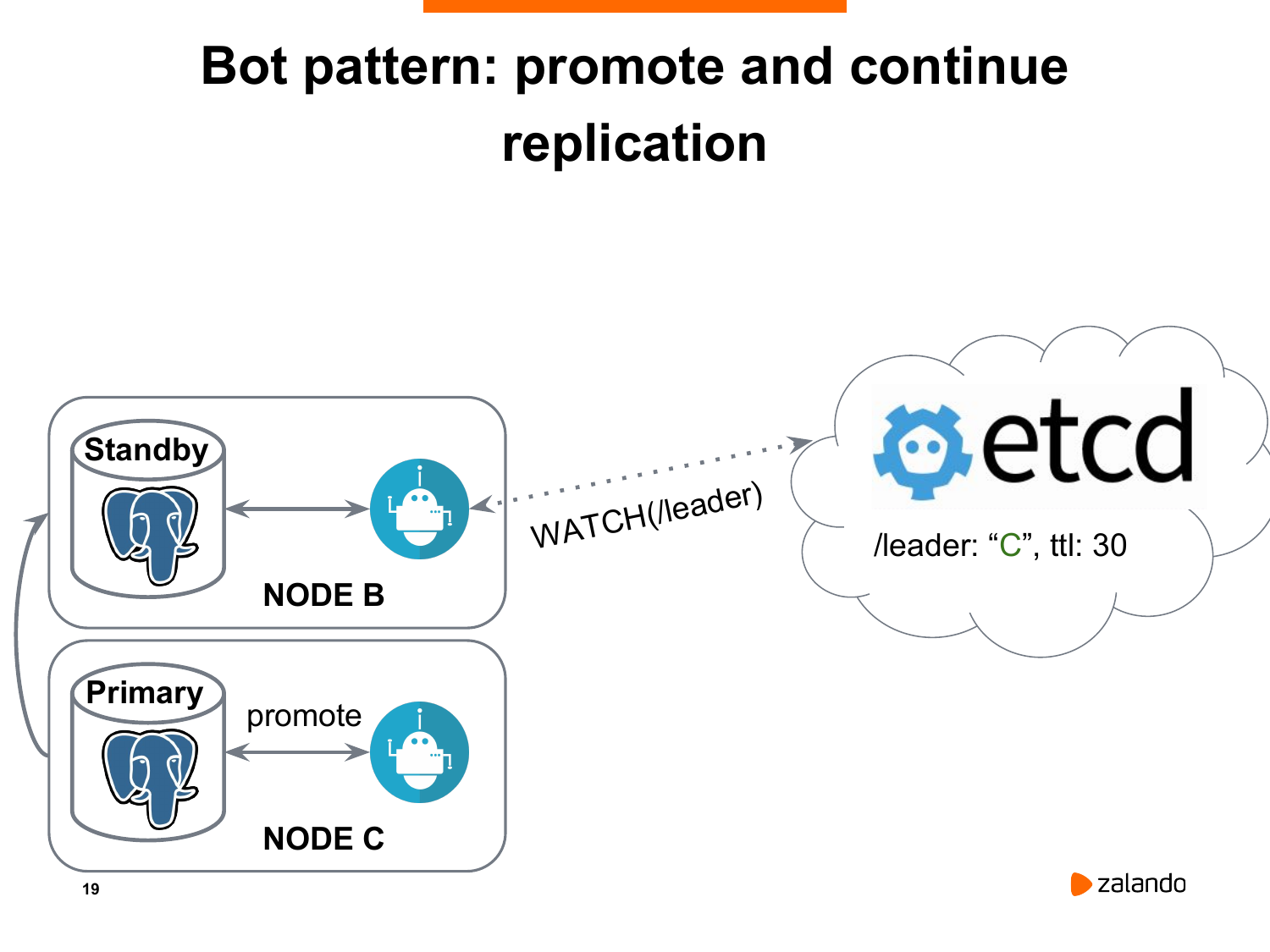
И в результате мы получаем, что нода C становится новым мастером, она выполняет promote для Postgres. А нода B становится новой репликой, которая будет уже реплицировать не с ноды A, которая недоступна, а с ноды C.
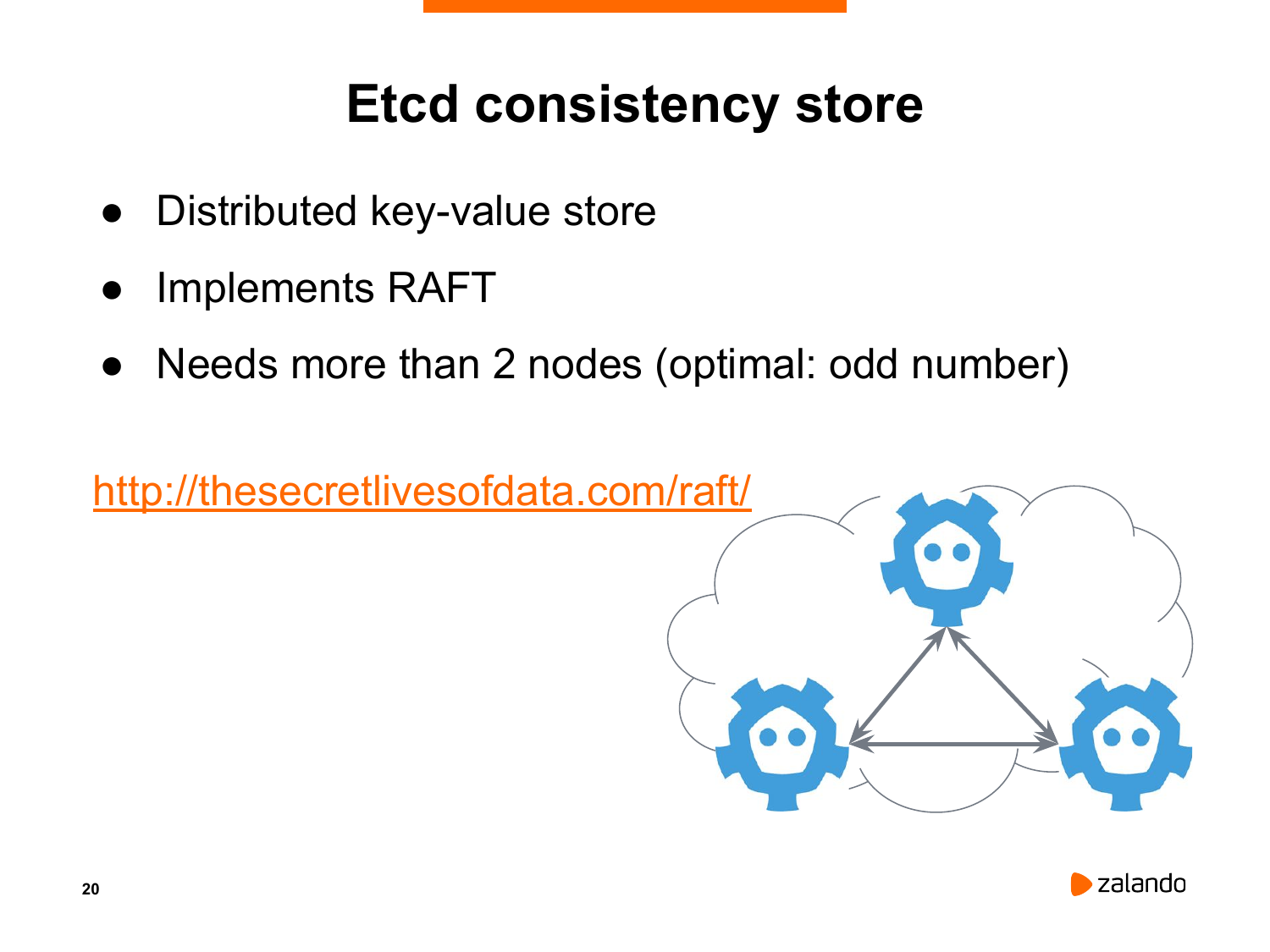
И немного про etcd. Это, конечно, не является главной темой нашего мастер-класса, но Patroni очень сильно зависит от таких distributed consistency store, от таких, как Etcd, Consul, Zookeeper. В том числе мы можем использовать Kubernetes API.
Etcd построен на алгоритме RAFT. И для его функционирования мы должны иметь больше двух нод, лучше три или пять.
И по этой замечательной ссылке вы можете поиграть с тем, как etcd внутри себя выполняет leader election, каким образом он определяет, какая из нод является ведущей, какие ноды являются репликой и позволяет разрешать в том числе любые проблемы сети, когда у нас одна сеть становится недоступна по отношению к другим.

Patroni имплементирует такой шаблон бота. Patroni написан на Python. И в основном разработкой занимаемся мы в Zalando, но в том числе у нас очень много других разработчиков. В основном это мелкие патчи, исправление проблем. Иногда документация. И помощь нам оказывает один из сотрудников Cybertec. Это очень известная компания, которая занимается консалтингом Postages. И они в том числе используют Patroni для своих клиентов.

(Алексей Клюкин) Мы сейчас перейдем к тому, что создадим наш первый Patroni кластер. Возможно, для некоторых людей он будет не первым, но в любом случае мы покажем, что достаточно просто создать High Availability кластер.

Для этого требуется выполнить всего несколько команд. И это тот слайд, который был изначально. И если вы хотите следовать за нами, то на вашем компьютере должен быть поставлен vagrant. У вас должна быть виртуальная машина. И вы можете сделать vagrant ssh туда, и выполнить команды sudo -iu postgres и там будет конфигурация Patroni.
И мы попробуем вместе получить наш первый High Availability Patroni кластер.
Запуск Patroni – это очень просто. В нашей машине vagrant’а уже запущен etcd. Поскольку это локальная виртуальная машина, то там запущен всего один instance etcd. На production кластерах, естественно, вы запускаете, три и больше instance etcd, потому что вся идея etcd в том, чтобы хранить информацию о состоянии кластера и ключ лидер. И это та система, которая должна быть постоянно доступной. Поэтому, пожалуйста, не запускайте один etcd на production. Если он упадет, никакого High Availability не будет, Patroni перейдет в режим только чтение.
И когда мы стали пользоваться Postgres, мы перешли в каталог Patroni. У нас там есть три yml-файла. Откуда мы взяли эти yml-файлы? Мы их взяли из GitHub, поскольку Patroni – это open source проект, то на GitHub выложены его исходные коды и в том числе тут есть эти yml-файлы. Мы их не придумывали из головы, мы просто взяли, как они есть здесь. Т. е. если вы сделаете git clone https://github.com/zalando/patroni.git, то вы можете это повторить на локальной машине, если у вас есть Python и все зависимости. Просто на виртуальной машине эти все зависимости уже установлены.

C 26:33 начинается demо.
Вот моя машина. Есть два Postgres. Я перехожу в каталог Patroni. Я уже здесь. И запускаю patroni postgres0.yml. Нам нужно перейти в каталог Patroni. Отлично, я запустил первый узел Patroni.
Первый узел Patroni увидел, что кластера у нас еще нет. И инициализировал мастер-узел, он запустил initdb. Initdb отработал. Вот есть вывод initdb. И он нам показал, что мы инициализировали новый кластер. У узла, на котором мы это запустили, есть lock, т. е. у него есть индикация, что он лидер. И он об этом говорит: «lock owner: postgresql0; I om postgresql0», т. е. говорит, что все хорошо, он работает как мастер.
Теперь давайте сделаем тоже самое со вторым узлом. Мы запустим patroni postgres1.yml. Что произошло со вторым узлом? Второй узел нашел etcd-сервер. Нашел, что кластер уже создан. У него уже есть лидер. И в etcd уже есть информация про то, что кластер создали. Поэтому вместо того, чтобы запускать initdb и стать мастером, он запустил pg_basebackup. Это утилита Postgres, которая позволяет вам создавать реплики. И создал себя в качестве реплики.
Вот он себя создал. И после этого попытался стартовать Postgres. Он ждет пока Postgres стартует. Это может занять некоторое время. После чего он сказал, что он не может получить WAL-файлы. Он сказал, что не может получить файлы с мастера.
Почему это происходит? Мы сделали реплику, все хорошо, Patroni ее настроил. Дело в том, что Patroni создает слот репликации для каждой реплики. В Postgres для потоковой репликации есть возможность сохранять те изменения, которые должны быть переданы на реплику. В нормальном случае, если вы не создадите слот и ваша реплика будет погашена по каким-то причинам, то через определенное время мастер возьмет все wal-файлы, которые у него накопились и отротирует их. Если реплика после этого подключится к кластеру, то она запросит wal-файлы, которых на мастере уже нет. И репликация будет невозможна. Вам для этого придется переинициализировать реплику.
Слоты репликации были созданы в Postgres как раз для того, чтобы решить эту проблему. Т. е. когда у вас есть слот репликации, то этот слот накапливает в себе изменения и не дает Postgres эти wal-файлы отротировать. И как только вы подключаете реплику, она подключается к этому слоту и все файлы передаются.
У этого способа также есть недостаток, потому что если ваша реплика потушена, а слот создан, то никто эти wal-файлы не проигрывает. Они накапливаются на мастере. И они будут накапливаться, пока у мастера не закончится место. Поэтому в Patroni есть возможность выключить слоты репликации. Но мы настоятельно рекомендуем ими пользоваться, потому что это избавляет вас от проблем, когда вам нужно будет на короткое время потушить реплику и после этого включить ее обратно.
Что здесь происходит? Он сказал, что не может включить репликацию, потому что Patroni еще не создал слот. На мастере Patroni смотрит на список реплик, которые подключились. И для каждой реплики создает слот через некоторое время.
Мы сейчас немного подождали. И вы видите, что эти ошибки прекратились. Эти ошибки выдаются не Patroni, эти ошибки выдаются Postgres. Он попытался подключиться к слоту под названием «postgres1», а postgres1 – это имя нашей реплики. И у него не получалось до определенного момента, пока Patroni все-таки не создал слот. И после этого репликация пошла нормально. Вот это сообщение показывается на реплике. Она говорит, что мастер lock завладел postgresql0, а я potstresql1, т. е. я – не мастер, я – реплика, у меня нет lock, я не предпринимаю никаких действий. А действием в данном случае может быть promote, потому что она следует за мастером, у которого есть lock. И дальше Patroni будет показывать это периодически. В данном случае достаточно часто и на мастере, и на реплике, т. е. он будет подтверждать, что здесь он показывает, что он мастер, а здесь Patroni показывает, что он реплика.
У кого получилось довести это до конца? У двоих. У остальных какие проблемы? Нет python-etcd. Я покажу эту команду. Для этого я создам новую консоль. Вам нужно зайти в patroni-training, зайти в ваш vagrant. И сказать pip install python-etcd. Вот эта команда установит etcd для Patroni. После чего те команды, которые я сделал для запуска Patroni, они увенчаются успехом. Patroni найдет etcd и сделает кластер.

Что мы сделаем дальше? Мы возьмем утилиту, которая называется Patronictl. Patronictl предназначена для контроля Patroni. В данном случае мы посмотрим на состояние нашего кластера.
Как мы это сделаем? Мы откроем еще одну консоль. Захожу в Patroni и говорю «patronictl», указываю конфигурацию одного из узлов. Из этой конфигурации он достанет имя кластера. Можно альтернативно указать ему имя кластера. И указываю команду, которую я хочу выполнить, т. е. «list».
И что я получаю? Я получаю вот такую табличку. В этой табличке указано название кластера, указано название узла «postgresql0» или «postgresql1», указан хост, на котором находятся. И очень важно, что указаны роли. Мы видим, что у нас кластер живой. Все хорошо, у нас один лидер. И указано также состояние Postgres, т. е. Postgres запущен на обоих узлах. Последняя колонка (Lag) – это если у нас есть реплика, то она может отставать от мастера по разным причинам. Потому что реплика медленная, потому что сеть, потому что на мастер большая нагрузка. Если у нас есть отставания, то Patroni эти отставания измеряет и показывает вам через утилиту Patronictl в отдельной колонке. Сейчас мы видим, что у нас никакого отставания нет, потому что на кластер никакой нагрузки нет.
То, что я вам показал, это ни разу не автоматический failover. Это просто как инициализировать кластер с точки зрения Patroni.

Что я вам хочу показать? Я хочу показать, как Patroni реализует автоматический failover. Есть терминалогия. Есть switchover, есть failover. Switchover – это переключение узлов, когда вы сами решаете переключить мастер на какой-нибудь другой узел. В то время, как failover (или на русском – аварийное переключение) – это когда от вас ничего не зависит, у вас сервер сгорел или с ним что-то случилось нехорошее. И вы хотите, чтобы Patroni переключился.
И мы покажем вам именно failover. Что мы для этого сделаем? Мы возьмем и оставим Patroni на мастере. Мы остановим Patroni специальным образом. Мы не сделаем «kill Patroni», потому что если я сделаю «kill Patroni», то он также остановит Postgres. Вместо я сделаю ctrl+Z, т. е. я переведу Patroni в background режим, и он остановится.
Давайте попробуем это сделать. Вот мой лидер. Я нажимаю «ctrl+Z» и я его остановил. Вот моя реплика.
Что происходит с репликой? Пока с ней ничего не происходит. Почему с ней ничего не происходит? Потому что пока еще у Patroni есть режим лидера. Пока еще в etcd находится ключ лидера. Должно пройти некоторое время. В данном случае при дефолтной конфигурации – это до 30 секунд. Это контролируется специальным параметром «ttl». Это все настраивается. Я об этом расскажу чуть позже. Там есть некое соотношение между разными параметрами Patroni. Вы можете поставить и 8 секунд, и 10 секунд, и меньше. Вам нужно соблюдать баланс между тем, как ваша сеть падает, поднимается и тем, насколько надежно вы хотите сделать failover. Но я бы не рекомендовал делать этот параметр сильно меньше, чем 30 секунд.
Что мы видим? Вот это последние сообщения. Что случилось дальше? Дальше случился вот такой warning в логах. Patroni сказал «request failed», т. е. не получилось сделать GET request. Что это такое? Patroni увидел, что lock’a в etcd больше нет. И попытался постучаться на мастер. Когда lock теряется, Patroni стучится на все известные узлы в кластере. И спрашивает у этого узла: «Ты – мастер?». А если он не мастер, то Patroni спрашивает позицию wal’а, т. е. насколько этот узел ближе к мастеру.

И вот то, что мы видим. У нас было два узла. И он попытался спросить у мастера: «Доступен ли ты?». И мастер ему ничего не ответил, потому что мы потушили Patroni на мастере. И после того, как это случилось, он принял решение сделать себе promotion, т. е. стать после этого лидером. Вот видите: promoted self to leader by acquiring session lock.
Вопрос: как долго Patroni опрашивает ноды?
Ответ: Он порядка две секунды тратит для каждой ноды, чтобы получить оттуда ответ. Все ноды он опрашивает параллельно.
Да, некоторое время он ждет, пока не ответит мастер. После этого делает себе promotion.
Вопрос: Можно ли держать etcd на тех же нодах что и Patroni?
Ответ: Как правило, лучше иметь отдельный кластер. У Etcd основное требование – ни большое количество памяти, ни большое количество процессоров, ему нужны только быстрые диски, чтобы он писал данные. В данной конфигурации – это демо. У нас здесь всего одна etcd нода, т. е. только для того, чтобы Patroni работал. В принципе, это вы сами можете решать. Вы можете иметь две ноды, на которых будет работать Postgres, плюс на каждой из них будет работать etcd. И иметь какой-нибудь третий сервер, на котором будет исключительно одна нода etcd.
Сейчас по факту в этой машине у нас работает и etcd, и два Patroni, и два Postgres, потому что это проще для демо.
Если один etcd упадет, то в некотором смысле – это является точкой отказа, если вы его не восстановите. Если у вас etcd будет работать независимо от Postgres, то два etcd сервера по-прежнему выполняют свою функцию. И если один из etcd серверов отказал, надо быстро его поднять.
Вопрос: Что произойдет с etcd, если network partition, т. е. если один из узлов оказывается изолированным?
Ответ: Произойдет network partition. У etcd тоже есть лидер, он сам выбирает лидера. Если в этой части сети, которая оказалась изолированной был лидер, то два оставшиеся сервера выбирают нового лидера. И, соответственно, новый лидер будет находиться в одной из двух оставшихся сетей. А старый лидер начнет перевыборы, потому что он поймет, что две другие ноды недоступны. Но при этом никакая запись через старого лидера не будет возможна.
И вот этот узел, который мы только что оставили, он сделает себе promotion. И дальше он работает как лидер. Он говорит, что он лидер, что у него есть lock, что он postgres1 и все хорошо.
Теперь мы сделаем одну очень интересную вещь. Вы помните, что на postgres0 узле, мы остановили Patroni? Мы остановили Patroni, но Postgres там еще работает. И Postgres там сейчас работает в режиме мастера.
Это мы сделали специально, потому что в реальной жизни, как правило, могут быть какие-то данные не реплицированы. Мы этот Postgres оставили только для того, чтобы сделать небольшой split-brain, т. е. только в целях демо.
Да. У нас есть бывшая реплика, которая сделала promotion и стала мастером. И у нас есть бывший мастер, который так и остался работать мастером, потому что мы потушили на нем Patroni.
Сейчас мы возьмем бывший мастер и запишем какие-то данные. Таким образом, сделав искусственный split-brain. А потом мы посмотрим, как Patroni будет бороться с этим split-brain.

Что мне для этого нужно? Мне нужно создать таблицу. Я создаю таблицу, которая называется «split-brain». И есть интересная возможность в Postgres. Можно создавать таблицу с нулем колонок. И этого достаточно.
Теперь я создал таблицу. И теперь самое интересное. Я возьму тот Patroni, который у меня сейчас остановлен. И скажу ему – продолжать свою работу. Мы поставили Patroni, чтобы он запускался, как основной процесс. И вот, что получилось.
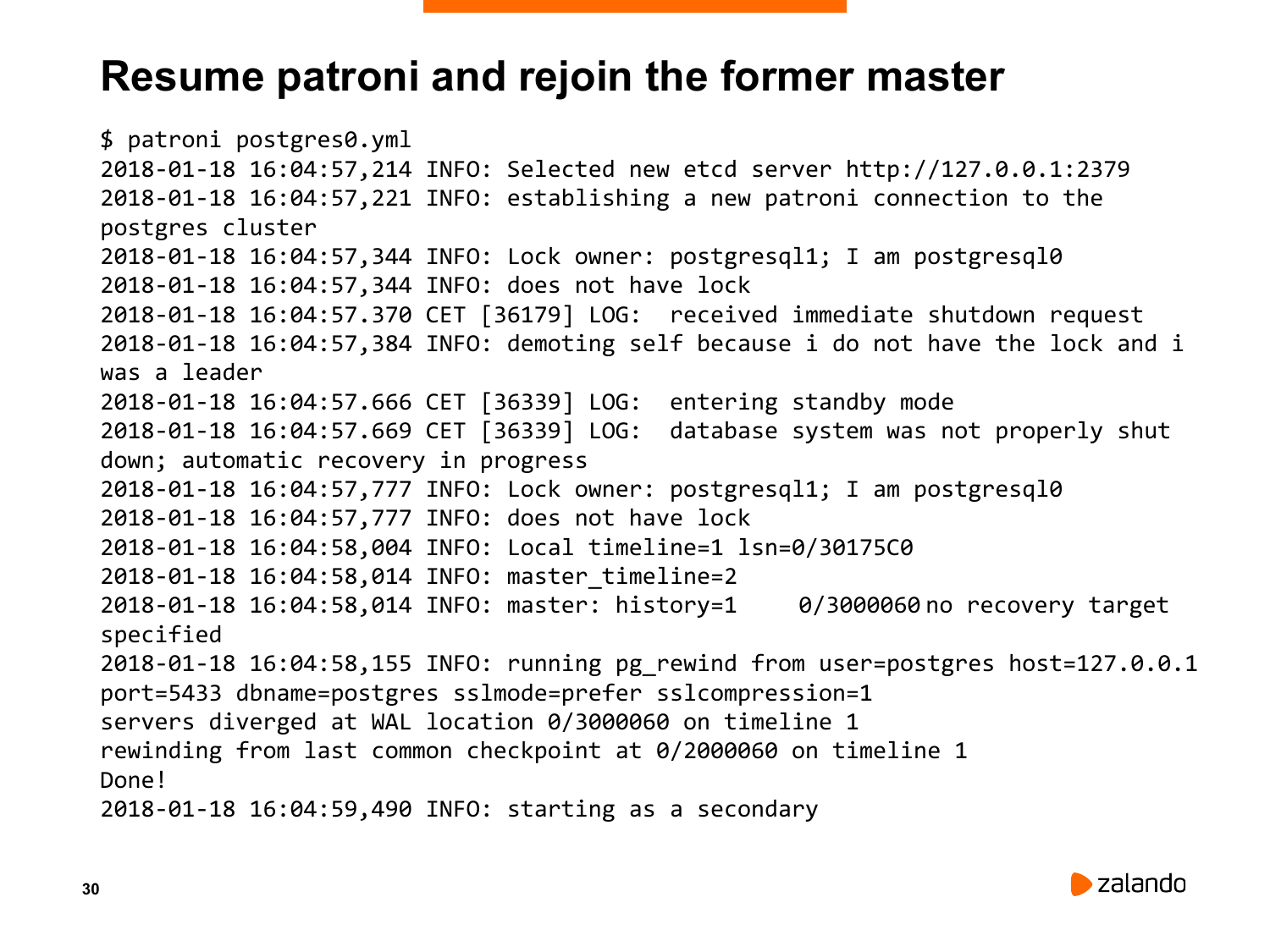
Внезапно он увидел, что он – мастер и то, что уже существует мастер. И что он сделал? Он сделал demoting Postgres настолько быстро, насколько возможно. Т. е. он сказал Postgres – сделай immediate shutdown прямо сейчас без всяких прелюдий. И Postgres сделал immediate shutdown. Это вот такой полупанический shutdown, т. е. он просто убивает все процессы, которые у вас есть. И мы это как раз сейчас видим. Он остановил базу данных и потом он сказал, что сделаю demoting, т. е. действие обратное promotion, потому что у меня нет lock’а. И после этого он стартовал Postgres.
Он делал crash recovery, потому что immediate shutdown – это не является чистой остановкой базы. И он препятствует pg_rewind. Pg_rewind откажется работать с кластером, у которого не было чистой остановки. Поэтому мы запускаем crash recovery mode в single user. Ничего не делаем, он просто запускает в single user и останавливает. После этого запускает pg_rewind, потому что Patroni знает, что там старый мастер был немного впереди нового мастера, когда произошел promotion.
Т. е. мы запустились в crash recovery. Когда он запустился, он проверил свою позицию в wal-сегменте. И он проверил wal-сегмент мастера. И он нашел, что произошел split-brain, потому что он – реплика, но он ушел вперед от мастера, потому что мы сделали create table split-brain. И он принял решение запустить pg_rewind.
Что такое pg_rewind? Это утилита в Postgres, которая позволяет предыдущему мастеру подключиться как реплика и перемотать обратно все те изменения, которые не попали на текущий мастер. Он перематывает до того момента, когда произошел разрыв между мастером и репликой, когда существующий мастер сделал promotion.
И мы это здесь увидим. Вот он написал «running pg_rewind from postgresql1». Pg_rewind написал, что был split-brain, что мастер и реплика разделились вот в такой позиции. Сказал, что мы сделали rewind, написал – done. И теперь мы можем увидеть, что старый мастер подключился как реплика. Он говорит, что мастер – postgresql1, а он – postgresql0. Т. е. в данном случае мы увидели, что, несмотря на то, что произошел split-brain (split-brain произошел, потому что мы остановили Patroni, если бы мы не останавливали Patroni, то никакого split-brain не было бы), мы все равно смогли разрешить эту ситуацию автоматически. Т. е. Patroni смог найти второго мастера, быстро его остановить. После этого он смог запустить его как реплику, сделать ему pg_rewind и включить его в кластер.
 Теперь мы можем посмотреть снова на результат работы утилиты Patronictl. И здесь мы теперь увидим картину, которая похожа на предыдущую, только лидер у нас переключился на postgreslq1. Раньше он был postgresql0, сейчас он postgresql1. И, соответственно, postgresql0 у нас тоже есть, он работает нормально, он является репликой. И он совершенно не отстает. Таким образом мы симулировали failover и показали, что Patroni может успешно разрешать такие ситуации.
Теперь мы можем посмотреть снова на результат работы утилиты Patronictl. И здесь мы теперь увидим картину, которая похожа на предыдущую, только лидер у нас переключился на postgreslq1. Раньше он был postgresql0, сейчас он postgresql1. И, соответственно, postgresql0 у нас тоже есть, он работает нормально, он является репликой. И он совершенно не отстает. Таким образом мы симулировали failover и показали, что Patroni может успешно разрешать такие ситуации.
Вопрос: Что случилось с таблицей, в которую я вставил?
Ответ: Этой таблицы уже нет. Т. е. если я сейчас пойду на мастер, то я не найду этой таблицы, потому что данные со старого мастера отмотались назад. И мы не сможем получить эти данные. Произошел split-brain, эти данные потерялись. И задача Patroni – не допускать split-brains, чтобы не терять данные.
Мир у нас реальный. И иногда репликации происходят с задержками. Т. е. какое-то количество транзакций при аварийных ситуациях могут быть потеряны. Чтобы избежать потерь, необходимо использовать синхронную репликацию. Синхронная репликация поддерживается в Patroni. Мы к этому подойдем немножко попозже. Но по большей части люди используют асинхронную репликацию, потому что синхронная репликация очень сильно бьет по производительности.
Что я хочу вам показать теперь? Это содержимое etcd. То содержимое, в котором хранится информация про наш кластер. Сделаем мы это с помощью утилиты etcdctl. И я могу показать, что мы храним внутри etcd. Это может быть также Consul, ZooKeeper или Kubernetes. Структура одинакова.
Etcd – это система ключ-значение. У нас есть какие-то ключи. И у этих ключей есть какое-то значение. Вы можете увидеть, что у нас есть ключ лидера, у нас есть ключ для каждого из участников кластера, т. е. для postgresql0 и для porsgresql1. У нас есть ключ initialize, который говорит о том, что кластер инициализирован и внутри хранится идентификатор кластера, который позволяет подключиться только тем узлам, которые являются частью этого кластера. Т. е. если вы подключите узел, который является частью какого-то другого кластера, он не сможет подключиться. Потому что в этом ключе initialize хранится как раз индификатор и ключ, связанный с конфигурацией кластера.

Давайте я покажу это на слайде, потому что там немножко лучше выделено. Вот тот же самый результат. После этого я смотрю на то, что хранится в узле members/postgresql1. Это json, в котором хранятся несколько важных параметров.
В частности, здесь хранится url, по которому можно подключиться к базе данных Postgres. Здесь хранится api_url, т. е. url, по которому Patroni, когда он делает promotion, может спросить у другого узла Patroni – мастер он или нет. Здесь хранится состояние базы данных. У нас может быть Patroni запущен на узле, но база данных еще не запущена. У нас хранится роль. И у нас хранится текущая позиция xlog’а или wal’а для данного узла, т. е. в какой позиции он восстанавливает или создает wal-сегменты. И также у нас здесь хранится timeline.
У нас есть несколько других ключей. Есть history. Если вы знаете, что такое timeline history, то вы знаете, что это история promotion данного кластера, история того, как кластер становился из реплики мастером. Здесь хранится эта история. И также хранится время, когда случился promotion. Т. е. по этому ключу вы можете узнать, когда произошел последний failover.

У нас есть кластер, он работает. Я хочу показать, как можно динамически менять конфигурацию вашего Postgres.

Почему это важно и почему это нужно? Потому что у вас есть кластер. Там есть несколько узлов. Вы можете, конечно, пойти на каждый из этих узлов и поменять там postgresql.conf или сделать autosystem для того, чтобы изменить параметры конфигурации, но это изменение будет применено только к одному узлу. А в реальной ситуации, если вы запускаете кластер с мастером и с несколькими репликами, то вам очень-очень хочется, чтобы конфигурация на этих узлах была аутентичная. Потому что любая из ваших реплик может стать мастером и вы не хотите, чтобы у нового мастера параметры shared_buffers и max_connections сильно отличались. Потому что это повлияет на функционирование кластера.
Что я хочу показать? Хочу показать, как отредактировать параметр, который называется maintenance_work_mem или work_mem, который делает подсказку планировщику Postgres о том, сколько у нас памяти доступно для вакуума и для создания индексов.
Для этого я возьму Patronictl. Укажу конфигурацию. Скажу – edit-config. И укажу название кластера. Вот команда и вот результат.
И что я хочу сделать? Я хочу поставить этот параметр «maintenance_work_mem» или work_mem. Я иду в Postgres, в parameters. И выставляю его. И говорю ему – 128 MB.
После этого я сохраняю. И Patroni мне говорит, что вот изменения, которые произошли, хотите ли вы применить эти изменения? Я говорю, что хочу применить эти изменения.

И теперь мы смотрим на то, что случилось с нашими кластерами. Посмотрим на лидера. Лидер говорит, что он получил SIGHUP. Это сигнал, который используется Postgres для перезагрузки конфигурации. Я получил SIGHUP и параметр maintenance_work_memory поменял свое значение, теперь он равен 128 MB.
Теперь я пойду на реплику и я увижу тоже самое. Я получил SIGHUP и этот параметр тоже стал равен 128 MB.
Т. е. мы сделали одно действие на одном узле и результат этого действия применился ко всему кластеру. Более того, Patroni сделал reloading за вас. Т. е. вам нужно поменять конфигурацию в одном месте и все. Patroni сделает все остальные действия за вас.
Patronictl можно запускать с вашего ноутбука. Это необязательно делать на сервере.
Теперь мы сделаем более интересное действие. Потому что maintenance_work_mem можно менять, не перезагружая кластер.

Теперь мы посмотрим, что произойдет, если мы поменяем параметр, для которого нужна перезагрузка кластера. Для этого мы также запустим edit-config. Только вместо maintenance_work_memory мы поменяем параметр «max_connections». На что влияет этот параметр? Это максимальное количество соединений, которое может получить ваш postgres-кластер. Если вы направите на него больше клиентов, чем max_connections, то ваши клиенты получат сообщение о том, что у кластера слишком много соединений.
Max_connection нельзя поставить на реплике меньше, чем на мастере.
В max_connection мы сейчас поставим значение – 101. И посмотрим, что произойдет. Вот тот же самый вывод. Max_connection поменялся, стало 101. Я говорю, чтобы изменения применились. И давайте посмотрим, что у нас с мастером. Будет ли на нем что-то показываться? Он продолжает работать и ничего не показывает, как будто ничего не произошло.
Почему? Для того чтобы изменить этот параметр, нужна перезагрузка Postgres. Patroni не будет за вас перезагружать ваш кластер. Потому что, если вы перезагрузите мастер, то клиенты, которые соединяются с мастером, отвалятся. И вам позвонят разработчики и спросят: «Что вы делаете посередине production и зачем вы это делаете?». Поэтому это решение Patroni оставляет пользователю.

Каким образом мы можем узнать о том, что нам нужно перезагрузить кластер? Мы можем спросить у самого Patroni. Мы можем использовать REST API. У Patroni есть REST API, который позволяет узнать очень много информации про кластер, в частности ту информацию, которая есть в etcd.
Мы сейчас выполним эту команду. И что мы здесь видим? Мы видим, что – это реплика. Но это не так важно. Что еще мы здесь видим, кроме того, что это реплика? Мы видим, что у нас вот такой флаг «pending_restart» включился и стал «true». Т. е. pending_restart – это требуется перезагрузка. Раньше этого флага не было. Сейчас он стал «true». И по значению этого флага мы можем знать, что для того, чтобы изменения, которые были сделаны в конфигурации, вступили в силу, необходимо перезагрузить кластер.

Если мы пойдем на мастер, то мы увидим тоже самое. Все узлы ждут, пока мы перезагрузим кластер. И на том, и на том узле у нас есть этот флаг. Теперь нам нужно перезагрузить этот кластер. Что мы сделаем?
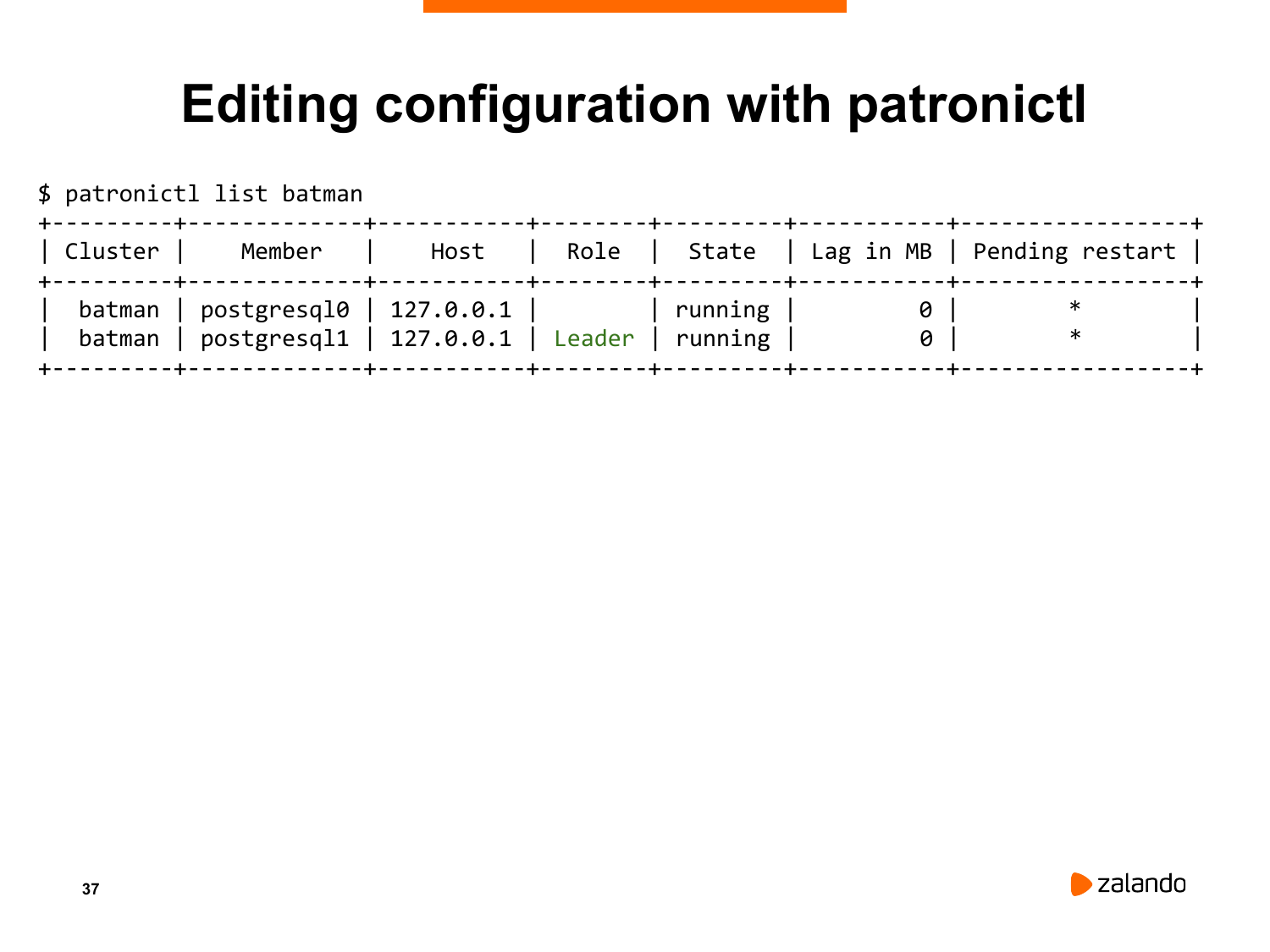
Мы можем запустить Patronictl list для того, чтобы увидеть тоже самое. Patronictl показывает вам, что оба узла нуждаются в перезагрузке. Что мы можем сделать?

Мы можем взять и перезагрузить Patronictl, т. е. перезагрузить Patroni с помощью команды «patronictl restart». Здесь у нас есть два узла, он спрашивает, какой узел я хочу перезагрузить. Он сейчас спрашивает подтверждение. Я скажу ему, что я хочу перезагрузить все узлы кластера, т. е. и postgresql1 и postgresql2. В production ситуации я могу сначала перезагрузить реплики, потом сделать на них failover, потом перезагрузить мастер.
Или просто перезагрузить мастер.
Дальше тут есть различные опции у рестарта, на которых я сейчас заострять внимание не буду. И что у нас получилось? Мы перезагрузили реплику, мы перезагрузили мастер. При этом мастер не потерял свой ключ, т. е. он остался мастером. И реплика осталась репликой, реплицирует с мастера.

Теперь давайте посмотрим – получилась ли наша затея с изменением max_connections или нет. Для этого мы подключимся к любому из этих узлов и скажем «show max_connections». Видите – 101. Давайте проверим другой узел. Тоже 101. (Уточнение: Если бы перезагрузили только мастер, то на реплике было бы max_connections равно 100) Т. е. мы изменили max_connections. С помощью Patroni мы перезагрузили весь кластер. И изменения применились.
Если бы мы это делали вручную, нам нужно было быть очень аккуратными. Потому что max_connections на реплике должен быть не меньше, чем max_connections на мастере. Если бы вначале увеличили max_connections на мастере, оставили реплику неизменной, то реплика не смогла реплицировать данные с мастера, если бы мы все это делали вручную. В случае Patroni нам не нужно об этом задумываться. Patroni все сделает сам.
Т. е. в крайнем случае, если реплика поймет то, что max_connections на мастере был увеличен, она остановится. Patroni увидит, что Postgres не работает и запустит его с новым max_connections.
Рестарт требует указать имя кластера и имя одной ноды. Вы можете выбрать какую ноду вы хотите зарестартить. Batman – это имя кластера. Если никаких нод не указывать, то он сделает рестарт для всех нод кластера. Но вы можете указать какую-то конкретную ноду.

Patroni работал хорошо, теперь я хочу показать экстремальную ситуацию, когда что-то пойдет не так.
Для этого я хочу остановиться на конфигурации самого Patroni. Т. е. мы сейчас меняли конфигурацию Postgres, но у Patroni тоже есть конфигурация, записанная в yml. И в частности до этого у нас был вопрос: «Насколько быстро может реплика определить, что мастера уже нет и после этого сделать promotion?».
Это поведение регулируется параметром ttl, т. е. время жизни ключа лидера в etcd или в другой системе. И есть определенная зависимость между этим параметром ttl и некоторыми другими параметрами.
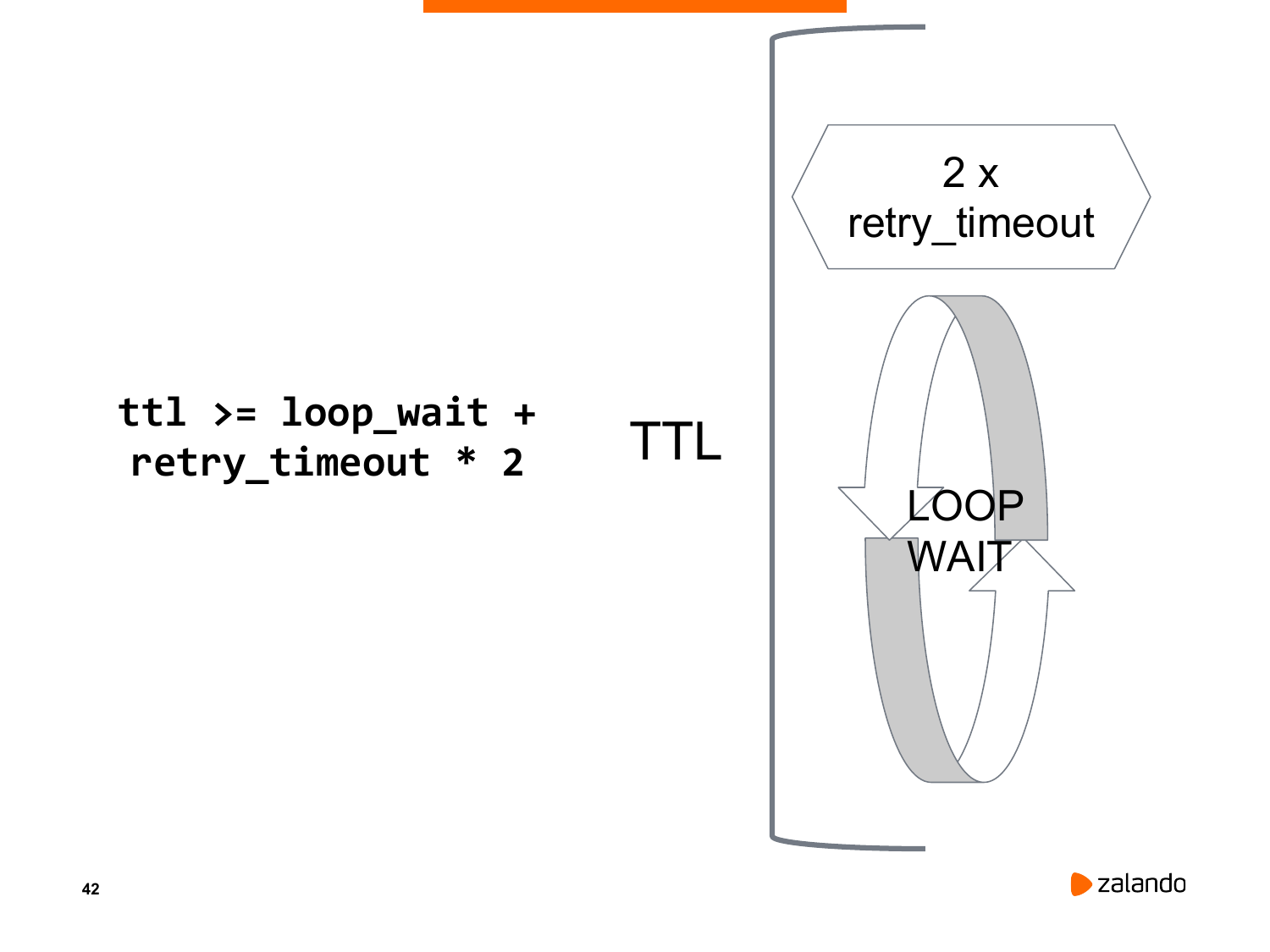
Нужно немножко остановиться на том, как работает Patroni. У Patroni есть цикл обработки событий, когда он смотрит на свою роль, он смотрит на какие-то действия, которые ему, возможно, необходимо выполнить. Например, сделать рестарт, сделать failover.

Если никаких действий не надо делать, он засыпает. И после этого снова просыпается. Параметр, насколько он засыпает, это параметр «loop_wait». Т. е. сколько он ждет перед тем, как начать новую итерацию цикла.
Что будет, если поставить loop_wait больше, чем ttl? Patroni заснет. Во время того, как он спит, он потеряет ключ, если он мастер. И пройдет promotion какого-то другого узла. У этого другого узла ситуация повториться ровно зеркально. Т. е. этот узел заснет, он потеряет свой ключ лидера.
Поэтому есть фундаментальная зависимость, что ttl должен быть больше, чем loop_wait. Но есть еще одно слагаемое в этой формуле, потому что когда Patroni не видит etcd, он не мгновенно говорит «demoting», а пытается несколько раз соединиться с etcd для того, чтобы действительно убедиться, что ее нет. Вот это время соединения регулируется параметром retry_timeout.
Соответственно, формула такая: ttl ключа лидера должен быть больше, чем loop_wait + 2 значения retry_timeout. И на схеме видно, что есть loop_wait, есть retry_timeout и вот это ttl.
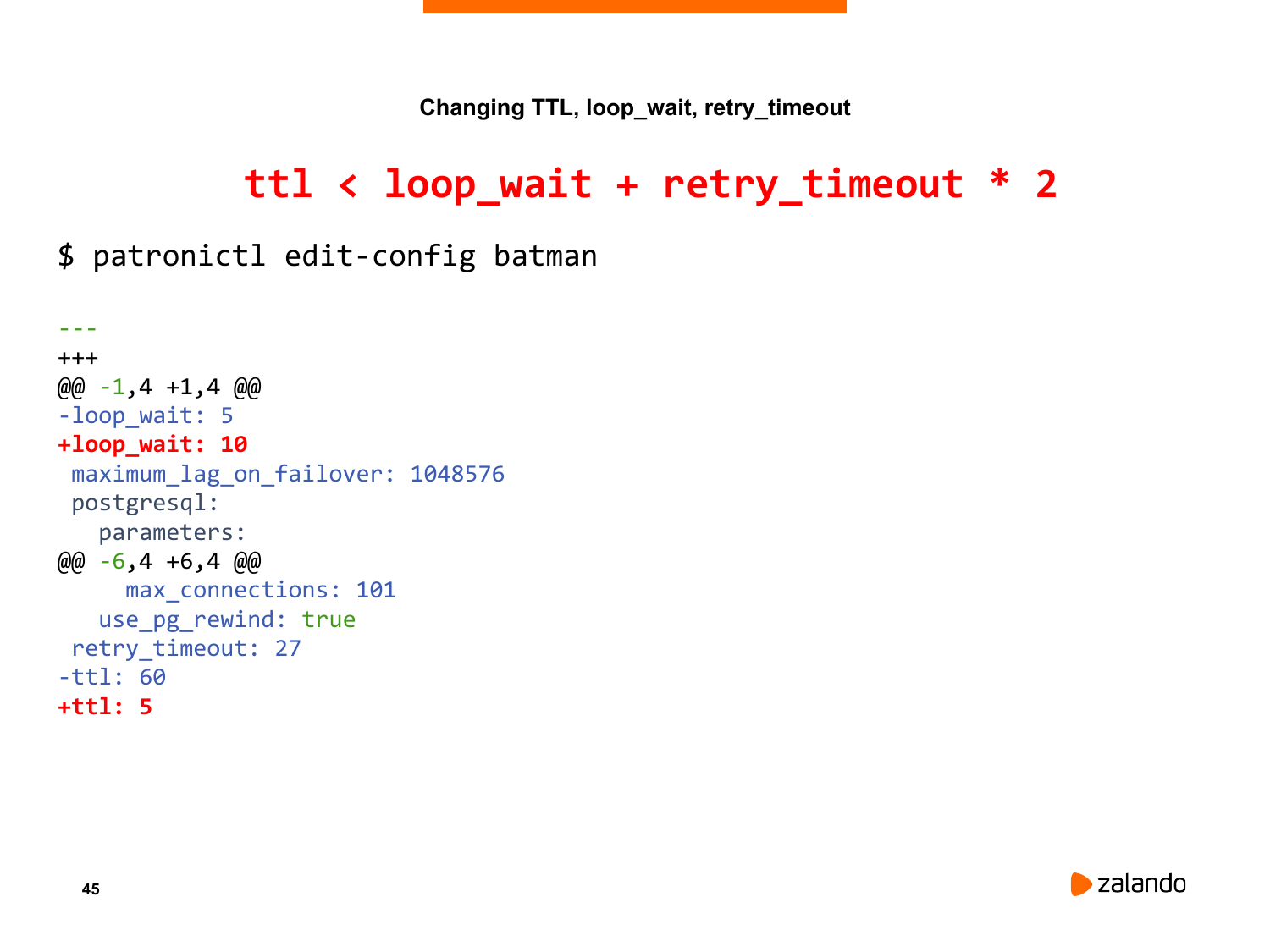
Что мы сейчас попробуем сделать? Мы попробуем эту зависимость нарушить. Т. е. мы поставить loop_wait очень маленьким, ttl поставим очень большим. Мы поставим loop_wait в 10 секунд, а ttl в 5. Таким образом ключ лидера заэкспайрится в то время, когда Patroni будет спать. Посмотрим, что будет.
Я делаю «patronictl edit-config» и ставлю ttl в 5 секунд, loop_wait в 10 секунд. Что произойдет в данном случае, мы сейчас увидим.

Мы применили изменения. И сразу же мы видим, что поддержка watchdog’а, которая есть в Patroni, сказала, что есть ошибка. Если бы мы включили watchdog, то он бы просто убил этот кластер, потому что у нас нет ключа лидера. Что мы еще здесь видим? Мы видим, что наш лидер потерял ключ лидера и после этого получил этот ключ лидера заново.
Postgres работает как мастер. Он пишет «acquired session lock as a leader». Что произошло? Пока наш Patroni спал, ключ лидера заэкспайрился, Patroni все еще был мастером. Он после этого увидел, что он мастер и у него нет ключа лидера. Ему нужно получить этот ключ лидера. Он получил ключ лидера, заснул. После этого ключ лидера снова заэкспайрился, потому что мы спим больше, чем время экспирации ключа. И это поведение у нас повторяется все время. Он все время перезабирает ключ лидера. И сам же его теряет после этого.

Гораздо интереснее посмотреть, что на реплике происходит. На реплике происходит полный хаос, потому что у нас нет больше ключа лидера и она пытается себя избрать новым лидером. И получает ответ от текущего лидера. Т. е. когда она пытается избрать себя новым лидером, она опрашивает бывшего лидера через REST API и получает ответ, что он жив, что у него роль мастера. И она говорит, что не может сделать себе promotion. И это все повторяется.
В данном случае в etcd ничего не записано. Там пусто, поэтому она никому не следует. Да, она говорит «following a different leader», т. е. следую другому лидеру. Но поскольку ключа etcd у нас нет, то она остается в режиме только чтение, т. е. она не реплицирует ниоткуда. И эта ситуация повторяется. Т. е. у нас есть мастер, который переполучает свой ключ. И есть реплика, которая остановилась и ничего не делает.

Это то, как делать не надо, поэтому мы сейчас поменяем конфигурацию в обратную сторону и убедимся, что все у нас работает. В данном случае я поменял конфигурацию обратно. И вы можете видеть, что лидер перестал переполучать свой ключ, т. е. лидер начал стабильно работать как лидер отныне. И мы можем видеть, что реплика подключилась к этому лидеру и начала нормальную репликацию. Это была иллюстрация на тему того, почему вот это важно, т. е. почему важно это соотношение, когда ttl был больше, чем loop_wait + retry_timeout *2.
Вывод из этого такой: если вы хотите определять, что ваш мастер исчез и делать это быстро, то вам нужно уменьшить ttl. Но когда вы уменьшаете ttl, вы должны также следить за тем, чтобы это соотношение выполнялось, т. е. уменьшать и loop_wait тоже. Иначе вы получите ту проблему, которую мы только что продемонстрировали.
И, скорее всего, retry_timeout придется сделать поменьше. Но при этом не забывайте, что иногда сеть может лагать. И если в retry_timeout не удается выполнить какое-то действие в etcd, то Patroni сделает demoting текущему мастеру. В обычном дата-центре, где у нас работают обычные сервера, мы, наоборот, увеличили ttl до 60 секунд, потому что у нас один раз была проблема, когда switches перезагружались. В течение 30 секунд не было никакой связи. И когда мастер прыгает туда-сюда, то это не самая лучшая ситуация.

И я бы хотел показать саму конфигурацию Patroni. Давайте посмотрим, как это выглядит. Вот это типичная конфигурация Patroni. И в этой конфигурации есть bootstrap секция. В этой bootstrap секции мы можем увидеть эти параметры ttl и loop_wait, а также retry_timeout, которые мы указали. И можем увидеть некоторые другие, в том числе параметры Postgres.
Для чего служит bootstrap секция? Когда вы инициализируете абсолютно новый кластер в etcd, то параметры из этой bootstrap секции записываются в etcd. И после этого применяются на других узлах этого кластера. В частности, ttl, loop_wait. Они записываются изначально. И после этого новый узел, который стартует, он получает эти параметры из etcd и продолжает работать с этими параметрами.
В частности, в PostgreSQL у нас есть параметр «use_pg_rewind», который говорит о том, что мы хотим использовать pg_rewind. Это параметр Patroni, это не параметр Postgres. Мы также можем указать параметры Postgres. В данном случае у нас тут нет ничего, т. е. все параметры закомментированы. Но мы можем указать любой из параметров. И он будет применен на всех узлах кластера изначально, когда кластер стартует.
Но если после того, как кластер был создан, вы поменяли секцию bootstrap и перезагрузили Patroni, то ничего не произойдет. Вся дальнейшая работа с такой конфигурацией должна выполняться при помощи Patronictl, т. е. вы должны менять ее в etcd. Patronictl предоставляет удобный интерфейс для этого.
Т. е. как только кластер был создан, а именно, когда информация в etcd была создана и когда первая нода была инициализирована успешно, то с этого момента как бы вы не меняли параметры в этой секции bootstrap, эти изменения никаким образом не войдут силу, потому что эти параметры записываются при изначальном создании кластера. И после этого они игнорируются.
Что же делать? Как же нам менять параметры у Postgres? Для этого у нас есть несколько путей.
Один из путей – это поменять их в patroni.yaml. У нас есть секция bootstrap. Но также, если мы промотаем чуть ниже, у нас есть просто секция PostgreSQL. И в секции PostgreSQL те параметры, которые мы укажем, они локальны для данного кластера. Т. е. с помощью параметров в Patroni мы можем поставить какие-то параметры на этом узле кластера. И эти параметры не применятся к другим узлам. Например, если у нас узлы кластера неравнозначные с точки зрения конфигурации железа, например, на одном узле у нас 16 ГB памяти, а на другом всего Г MB, то мы можем поставить на одном 4 ГB shared buffers, на другом всего 1 ГB. И таким образом у нас будет сохраняться баланс между размером памяти и размером shared buffers. Т. е. один из способов – это изменение конфигурации Patroni в локальной секции. Не в секции bootstrap, а в секции локальной конфигурации.

Есть другие способы. Мы можем эту конфигурацию поменять в etcd. В etcd у нас есть ключ config. Мы можем посмотреть это.
etcdctl ls / service/batman/config
У нас конфигурация собирается из разных источников. В первую очередь мы смотрим, что у нас в etcd хранится. Потом в Patroni.yaml, т. е. в конфигурационном файле для данной конкретной ноды можно какие-то параметры переопределить. Мы у себя в production, как правило, это не делаем, потому что все сервера более-менее одинаковые.
Третьим вариантом может быть изменение в каком-то конфигурационном файле Postgres. И четвертым вариантом может быть alter system или еще что-то.
Мы сейчас к этому подойдем. Я хотел показать, что у нас хранится в etcd конфигурации. Вот у нас есть конфигурация, которая инициализировалась в момент bootstrap, в момент создания кластера. Вот она здесь, в том числе и retry_timeout, и в том числе параметры Postgres. Таким же образом можно в etcd что-то записать в postgresql parameters. И то, что мы там запишем, применится Patroni на узлах кластера, когда мы скажем Patroni, чтобы он перезагрузил конфигурацию.
И patronictl показывает данную конфигурацию, когда мы ее редактируем. Только единственная разница в том, что хранится в json, а patronictl использует yml, который более человекочитаемый и самое главное – человекозаписываемый. Потому что редактировать json вручную – это непростое занятие.
В первую очередь он берет из etcd. Если тот же самый параметр указан в patroni.yaml, то он будет переопределять то, что в etcd записано. Т. е. work_mem в etcd был 16 MB, в patroni.yaml он стал 12 MB. Patroni.yaml будет иметь приоритет. И как это работает? Patroni сгенерирует postgres’овый конфигурационный файл, куда записывает 12 MB. Дальше вы еще можете использовать Alter System, но это необязательно, т. е. patroni.yaml имеет приоритет над etcd.
Т. е. вот, например, postgresql.conf, который записывает Patroni для кластера, который он инициализировал. Это просто postgresql.conf. Я покажу команду, которую я выполнил. Я хочу посмотреть содержимое этого файла. И самые первые две строчки говорят о том, что не надо редактировать этот файл вручную. Этот файл создал Patroni.
И следующая строчка у нас include ‘postgresql.base.conf’. Мы можем посмотреть на него.
Вот этот base файл вы можете редактировать. Либо можно в конфигурации Patroni сказать – пожалуйста, используй не base файл, а какой-нибудь другой, т. е. файл, который вы можете деплоить из Git, например, и сами менеджить его.
Что взял Patroni? Он взял оригинальный postgresql.conf и переименовал его postgresql.base.conf. Мы видим, что это первозданный postgres файл. И после этого создал свой postgresql.conf, в который он непосредственно записывает те параметры, которые он получает из etcd и других источников. И включил в него также postgresql.base.conf.
Что это нам дает? Это нам дает возможность редактировать конфигурацию с помощью команды alter system. Эти параметры будет применены, эти параметры будут записаны в base.conf и эти параметры будут использоваться. Но если вы сделаете alter system на каком-то узле, то эти параметры, которые вы изменили, будут применены только на одном узле. Если вы хотите поменять параметры везде, глобально во всем кластере, то используйте Patronictl edit-config также, как я вам показал на примере maintenance_woke_mem или shared_buffers. Они в таком случае применяются на всех узлах кластера.

Здесь показана как раз последовательность, о которой мы уже сказали. Т. е. сначала берутся параметры из узла ключа config. Параметры могут также переопределяться в patroni.yaml. Если они переопределены в patroni.yaml для конкретного узла, то эти параметры будут более приоритетные, чем из config, если один параметр указан и там, и там. Или есть параметры alter system, которые еще более приоритетные для данного узла. Но если вы поменяете что-то с помощью alter system, что требует перезагрузки кластера, например, max_connections, то Patroni вам об этом не скажет с помощью pending_restart.
Через alter system не получится max_connections поменять.
Да, хорошо. Плохой пример. Shares_buffers.
Есть также список зависимых параметров, т. е. зависимые параметры на мастере и на реплике. В частности, значение на реплике должно быть не меньше значения на мастере. Это те же самые max_connections, max_locks_per_transaction, wal_level. Wal_revel регулирует каким образом wal будет создаваться на мастере. Если вы поставите минимум, то у вас реплики не будет никакой. Она не сможет эти wal’ы проигрывать.
И Patroni не разрешит поставить его минимум. Он должен быть либо реплика, либо logical.
Что происходит с Patroni? Когда он запускает Postgres он передает эти параметры в командной строке. Поэтому вы не сможете переопределить их локально для данного кластера. Потому что ваши переопределения будут перезаписаны Patroni. Вы сможете переопределить их только с помощью Patronictl edit-config глобально для всего кластера. Это то, что вы хотите, потому что это позволит вам избежать ошибок и избежать случая, когда реплика не может стартовать, потому что этот параметр установлен в неправильное значение.

Теперь мы поговорим про Patroni в основном и про REST API, который он предоставляет. Поговорим о том, как его можно использовать и поговорим для чего он нужен.

С самого начала проекта Patroni предоставлял два или три endpoints в REST API. Один из них – это мастер или просто слэш, он принимает только GET requests. В принципе, еще options принимает, но это не так важно.
Для чего он нужен? Мастер вернет статус 200 ОK, только при условии, что данная нода работает как мастер. PostgreSQL у нас не работает в recovery и у нас есть ключ лидера.
Реплика вернет статут 200 OK только в случае, если данная нода работает как реплика, если она не исключена из балансирования read-only нагрузки и при условии, что у нас там Postgres работает. Т. е. если Postgres там стартует или сломался, или еще что-то, то реплика вернет 503.
Соответственно, с мастером тоже самое. Если нода не работает как мастер, то такой endpoint /master будет возвращать статус 503.
Есть у нас еще Patroni. В принципе, он возвращает такой же ответ как мастер или реплика. Т. е. помимо статуса они возвращают json-документ, в котором будут указаны позиция xlog’а, состояние Postgres и какая-нибудь другая дополнительная информация. Например, требует ли данный узел рестарта и тому подобное. Но отличие в том, что Patroni всегда возвращает статус 200.
Есть у нас еще отдельный endpoint для изменений и просмотра конфигурации /config. В принципе, он сейчас не очень нужен, потому что все делается очень удобно через Patronicrl. Но раньше это был единственный способ управления глобальной конфигурацией.
Patroni умеет делать /switchover и /failover. Switchover, как мы уже знаем, это штатная операция переключения. Т. е. у нас был мастер, который был в работоспособном состоянии, но по какой-то причине мы решили, что мастер у нас теперь должен жить на каком-то другом сервере, потому что на старом сервере, например, мы хотим провести какие-то работы регламентные. Например, заменить жесткий диск или блок питания, или один из блоков питания сбоит.
Patroni также через REST API умеет рестартовать Postgres. Для этого есть у нас /restart endpoint.
И Patroni умеет реинициализировать кластер. Т. е. может возникнуть такая ситуация, что не получается стартовать реплику и pg_rewind тоже не работает. Реплика очень сильно запаздывает по отношению к мастеру. Может быть, wal’ы были потеряны, может быть, еще что-то. И единственный вариант – это сделать полный /reinitialize, т. е. остановить Postgres, удалить дата-директорию и взять base_backup.
И большинство из этих endpoints используются в Patronictl и вам необязательно их дергать.

Как выглядит ответ Patroni endpoint на мастере? Это json-документ. Он показывает нам database_system_identifier. Это такой уникальный ключ, который генерируется только тогда, когда мы создаем новый кластер. Он говорит о том, что это за кластер, какое у него имя. Это batman. Говорит о том, когда у нас Postgres стартовал.
На мастере мы еще видим состояние репликации. Он говорит, что мы работаем как мастер.
И в server_version он говорит версию Postgres. В данном случае – это у нас 10.0. Вы можете мониторить, что у вас Postgres последней версии.

На реплике выглядит это примерно так же. Она говорит, что я – реплика, я работаю, у меня timeline – 2.
И xlog выглядит немножко по-другому, потому что у реплики есть информация о том, какая позиция xlog’а была получена от мастера, сколько было его применено.
Последний timestamp – null. Почему replayed_timestamp – null? Потому что у нас не было никакой активности, когда мы этот скриншот делали. Соответственно, если на мастере никаких транзакций не происходит, то ничего не известно о том, какой timestamp был у последней транзакции.
И у нас replayed_location каким-то образом получился больше, чем received на 300 байт. Почему? Как такое может быть? Вот эти две функции, которые возвращают данные позиции, они не транзакционные. Просто запрос составлен таким образом, что received_timestamp запрашивается раньше, чем replayed_timestamp. Мы, конечно, это исправим, поменяем их местами.

И вот эти endpoints можно использовать для мониторинга состояния Postgres, для мониторинга состояния Patroni.

Мы можем использовать в том числе эти endpoints для того, чтобы перенаправлять клиентские соединения на мастер, либо делать какую-то балансировку между репликами.
HAProxy умеет посылать активные запросы о состоянии. HAProxy периодически посылает на все ноды, которые описаны в его конфигурации, запрос – работаешь ли ты как мастер? Мастер скажет статус 200, реплики скажут 503. И с репликами, наоборот. И на основе этого HAProxy может отправлять клиентские запросы, которые предназначены для мастера, исключительно на мастер. И он делает такую балансировку между репликами.
Как еще можно клиентские коннекты перенаправлять? Например, вы работаете внутри одного дата-центра или у вас есть возможность назначать IP между разными дата-центрами, но один и тот же IP. Либо можете менять DNS, то в этом случае не требуется перекидывать IP из одного дата-центра на другой.
У Patroni есть возможность выполнить какой-нибудь исполняемый файл. Обычно это shell script. Patroni дернет такой файл при некоторых событиях. Например, когда он стартует Postgres, он выполнит скрипт, который описан в on _start, при остановке Postgres он выполнит скрипт, который описан в on_stop. При on_reload, on_restart – все тоже самое.
On_role_change – это немного хитрее. Допустим, у нас была реплика, которая стала мастером. Т. е. Patroni выполнил pg_ctl promote. И сразу же после этого Patroni выполнит скрипт, который описан в on_role_change. Вы можете, например, назначить новый виртуальный IP на этот сервер, где мастер работает.
Какие у нас еще есть возможности? Поскольку топология кластера может меняться, мы можем перенести ноду с одной машины на другую. Там может IP поменяться. И поддерживать конфигурацию HAProxy – это задача малоприятная. Мы не хотим каждый раз брать и идти в HAProxy и удалять старую ноду оттуда, добавить новую. Для этого есть замечательная утилита. Называется confd. Она позволяет с помощью информации, которая хранится либо в etcd, либо в ZooKeeper строить конфигурационный файл по шаблону. Пример https://github.com/zalando/patroni/blob/master/extras/confd/conf.d/haproxy.toml
И для этой утилиты у нас есть файл с настройками, что мы должны делать, когда у нас в etcd что-то поменялось. Т. е. если новый конфигурационный файл получается измененным, то в первую очередь этот confd может проверить корректность нового файла. И если все выполнено успешно, он сможет записать новый файл и сделать reload, т. е. перезапустить или перечитать новую конфигурацию HAProxy.
И можем посмотреть, как выглядит template для HAProxy. Мы описываем здесь max_connections, описываем тайм-ауты и описываем два сервера. Один будет перенаправлять трафик на матер, а другой будет балансировать трафик между репликами.
Что здесь важно? Мы обязаны применить такую опцию «on-marked-down shutdown-sessions». Что это означает? Если вдруг нода, которая раньше была мастером и отвечала статусом 200, вдруг стала отвечать статусом 503 или вообще перестала быть доступной, то HAProxy возьмет и отрубит все эти соединения. Он не будет больше отправлять наши запросы с клиента на сервер, который мастером был, но теперь перестал им быть. Потому что может быть ситуация, что Postgres до сих пор работает и выполняет какие-то транзакции. И этого мы обязаны избежать. И HAProxy позволяет это решить. И с помощью такой конструкции генерируется список узлов, между которыми HAProxy будет выполнять health checks и балансировать.
И какой у нас еще есть вариант? Мы можем адаптировать такой же подход для confd, чтобы он генерировал config для PgBouncer. Это может быть даже лучше, потому что PgBouncer умеет ставить наши соединения на паузу. И если вдруг происходит ситуация, когда мастер перемещается на другую ноду, потому что failover произошел, то клиент может этого даже не заметить. PgBouncer позволит разрешить данную ситуацию.
И начиная с Postgres 10-ой версии мы можем указать несколько хостов в connection string. Мы можем запросить режим read-write и libpq попытается подсоединиться ко всем указанным хостам. И в случае, если это у нас мастер, то он на нем остановится. Можно указать read only или еще что-нибудь.

Давайте посмотрим более подробно на callbacks. Это пример конфигурации, которую мы используем в нашем классическом дата-центре.

У нас есть callbacks скрипт, который либо добавляет service_ip (виртуальный ip), либо убирает его при определенных ситуациях.
Если мы стартуем как мастер или вдруг наша нода была promotion до мастера, то мы должны добавить service_ip. Во всех остальных ситуациях мы должны удалить его с данной ноды. Этот скрипт исполняется только на одной ноде. Другая нода, если она имеет этот скрипт, она его будет исполнять независимо от этого.
И этот скрипт как параметр получает, во-первых, имя callback и, во-вторых, роль, которую имеет этот узел. Т. е. если этот узел стал мастером, то скрипт будет вызван как on_role_change. Мастер и scope – это кластерное имя.

Что важно звать про callbacks? Они исполняются асинхронно по отношению ко всем остальным действиям в кластере. И может возникнуть такая ситуация, что мастер прыгает туда-сюда. И callback на одном из узлов, на котором он был запущен раньше, он завершится позже по времени, чем callback, запущенный на другом узле. И, соответственно, если у нас мастер вдруг станет прыгать туда-сюда, то может оказаться неприятной ситуацией то, что этот виртуальный IP вдруг окажется назначен на какую-то неправильную ноду, поэтому тут надо быть осторожным. У нас есть issue, где вы можете почитать подробности.

Как мы можем управлять поведением нод? Что мы можем сделать, если у нас есть нода в каком-то удаленном дата-центре и мы не хотим, чтобы она стала мастером в результате таких выборов?
Для этого у нас есть механизм tags. Эти теги прописываются в конфигурации Patroni в отдельной секции. Их можно прописать только в конфигурации. Если вы пропишите эти теги глобально в etcd, то никакого значения они не будут иметь на нодах. Исключительно нужно писать в конфигурационном файле.
Если вы хотите, чтобы нода никогда не стала мастером, то вы можете установить тег nofailover в true. По умолчанию он false.
Еще у нас есть тег noloadbalance. Если мы делаем read only, то noloadbalance при помощи HAProxy даже, когда нода действительно как реплика, она все равно будет выдавать статус 503, при условии, что у нас тег установлен в true.
Есть еще интересный тег. Он называется clonefrom. Это говорит о том, что нода разрешает с нее взять basebackup. Как мы знаем, pg_basebackup умеет делать бэкап не только с мастера, но и с любой реплики. И если вы создаете какие-то новые ноды, то вы, как правило, не хотите загружать мастер бесполезной нагрузкой. Например, вам надо скопировать один терабайт данных, но мастеру и так есть чем заняться, он транзакцию выполняет. Если какая-то из существующих других нод имеет выставленный тег clonefrom, то Patroni basebackup с этой ноды. Если у нас несколько таких нод, то он возьмет и в случайном порядке выберет какую-то из них.
Также есть возможность контролировать синхронную репликацию на таком уровне для каждой ноды. Может быть ситуация, когда есть какая-то нода на удаленном дата-центре. И пинг достаточно большой. И мы не хотим, чтобы эта нода становилась синхронной, даже если она осталась единственной. В этом случае мы можем ее пометить с помощью nosync.
И Patroni предоставляет возможность строить каскадные решения. Мы можем реплицироваться не напрямую с мастера, а с какой-то из существующих нод. Когда это может быть полезно? Если у вас есть два или три дата-центра. И один из этих дата-центров удаленный. И вы настраиваете одну из нод в этом дата-центре на то, что он реплицировал с матера, а все остальные ноды будут реплицировать с данной ноды. Т. е. вы будете гнать трафик из одного дата центра в другой – всего лишь один раз. Это выгодно, когда канал узкий или трафик дорогой.
Replicatefrom говорит о том, с какой конкретной ноды мы хотим реплицировать данные. Почему нельзя сделать наоборот? Потому что Patroni создает replication-слоты. И нода не может создать replication-слоты для каких-то других нод, если она не знает, что с нее хотят реплицировать. Т. е. мастер создает слоты для всех нод, которые хотят реплицировать с мастера, а какая-то нода, с которой ведется каскадная репликация, она создаст слоты для нод, которые хотят с нее реплицировать.
Для чего нужны replication-слоты? Они нужны для того, чтобы избежать удаления wal-сегментов, которые вдруг не были среплицированы, пока Postgres был на какой-то реплике недоступен или запаздывал.
И я уже сказал, что вы можете сконфигурировать теги только внутри Patroni конфигурационного файла и бесполезно их писать в etcd.

Вы можете поиграть с каскадной репликацией. Для этого у нас есть postges2.yml файл. Насколько я помню там прописано то, что она должна реплицироваться с postgres1. Соответственно, postgres1 создаст replication-слот и postgres2 будет реплицировать с нее.

В чем разница между switchover и failover? И всегда ли failover может быть автоматический?
Switchover – это плановые работы. Т. е. мы берем и переключаем мастера с одной ноды на другую.
Failover – это когда возникают внештатные ситуации, когда у нас мастер отказал.

Но с failover могут быть такие проблемы. Можно ли использовать данную реплику для того, чтобы она стала новым мастером? И может возникнуть ситуация, когда реплика очень сильно запаздывает. А мастер периодически записывал в etcd свою последнюю позицию xlog’а. И этот параметр настраиваемый. По умолчанию, по-моему, он равен нулю. Может быть 10 MB, но это не важно, поскольку вы его можете настроить в зависимости от ваших требований. И если нода замечает, что lag был больше, чем 10 MB и принимает решение, что она не может стать новым мастером. И звезды на небе могут сойтись таким образом, что ноды понимают, что они очень сильно запаздывали. И в этом случае нам придет на помощь manual failover. Мы можем выбрать какую-то конкретную ноду, которая была ближе всего к мастеру, т. е. можем вручную сказать ей, что ты будешь новым мастером.
Switchover можно сделать в данный момент времени или его можно сделать отложенным, т. е. дать задание Patroni. Но самое важно, что switchover можно сделать только, если у нас есть мастер и он в данный момент работает. И что особенно важно, так это то, что Patroni позаботится о том, чтобы определить – может ли какая-нибудь из других нод стать новым мастером. Т.е. прежде чем остановить Postgres, Patroni подконнектится к оставшимся нодам для того, чтобы понять – если ли среди них хороший кандидат. Если кандидата нет, то switchover просто откажется делать. Это и защита от дурака, и не дает себе выстрелить в ногу.

Давайте теперь попробуем сделать switchover.
Т. е. я хочу показать вам сейчас switchover. И мы покажем синхронную репликацию в интерактивном режиме. А все остальное я вам буду показывать на экране, поэтому что эти слайды очень похожи.
Эти команды есть на слайде. Эти слайды будут доступны, вы можете их посмотреть. И вы сможете повторить то, что мы сейчас показываем, в интерактивном режиме у себя на виртуальной машине.
Давайте посмотрим на switchover. Я запущу ту же самую команду, которая у нас есть: patronictl switchover batman. Имя кластера у нас batman. Нам нужно указывать параметр конфигурации, потому что Patronictl должен найти, где находится etcd.
Он спрашивал мастер postgres1. Я нажимаю – enter, т. е. я с ним согласен. Он предлагает кандидата на выбор. Я могу указать конкретного кандидата. Или я могу сказать, что мне все равно. И он переключится на любую реплику, которая будет удовлетворять условиям переключения, т. е. которая будет достаточно близко к мастеру и на которой будет работать Postgres.
Switchover гарантирует отсутствие потери данных. Все реплики, которые реплицируют с мастера при switchover, они гарантировано получат все данные с прошлого мастера.
И теперь самое интересное. У нас есть возможность переключиться по расписанию. Т. е. мы можем сказать, что переключиться нужно не сейчас, а через некоторое время. Это было сделано для того, чтобы можно было обновить, например, все реплики на новую версию Postgres. А после этого где-нибудь в 4 часа ночи сказать – сделайте нам switchover, чтобы нам не просыпаться и не делать это вручную, а доверить эту задачу Patroni. Мы это много раз делали на AWS. И мы очень рады, что у нас такая возможность есть, потому что это позволяет нам спать спокойно ночью, а не заниматься поддержкой кластера.
Да, переключение 150 кластеров за одну ночь – это не самое приятное занятие. Но с Patroni мы спим спокойно.
Давайте я скажу «сейчас», чтобы показать, как он работает. И Patronictl показывает последнее подтверждение. Он спрашивает – действительно ли я это хочу? Вот у нас есть реплика postgresql0 и вот у нас есть мастер postresql1. Он спрашивает: «Сейчас?». Мы говорим, что да. И смотрим, что произойдет.

Сейчас мы сделаем patronictl list batman. И на данный момент у нас лидер поменялся. Т. е. когда он сказал «switchover», он сказал «Successfully failed over to "postgresql0"», т. е. успешно переключились на postgresql0. И вы можете увидеть, что postgresql0 – это лидер. А предыдущий мастер был остановлен. Т. е. мы его остановили, потом перевели его в режим real only. Он соединился и после этого стал следовать текущему мастеру.
И вы можете увидеть, что через некоторое время состояние stopped поменялось на состояние running. И сейчас он запущен и работает.
Мы можем посмотреть это на примере логов в Patroni. Что в данном случае произошло? Давайте возьмем реплику. У реплики не было lock’а. Мастер остановился и удалил ключ лидера. Это важно, потому что в данном случаи у нас не будет ситуации, когда у нас одновременно два мастера работают.
После этого реплика нашла, что ключа лидера нет. Сделала promote себя. И после этого продолжила работать как мастер. А мастер, соответственно, в какой-то момент сказал, что он получил запрос на то, чтобы сделать switchover с параметрами. Т. е. он подтвердил, что он лидер. Мы указываем лидера в switchover, потому что вы можете сделать switchover, а потом лидер поменяется. И тогда мы switchover делать не будем, потому что состояние кластера уже изменилось.
И мастер здесь спросил у реплики ее состояние, чтобы убедиться в том, что у нас есть реплика и в том, что она в состоянии стать новым мастером. Он убедился, что реплика действительно работает, что с ней все нормально и она может стать мастером. И после этого остановился и отдал ключ лидера. Вот manual failover: demoting myself.
Там даже два запроса производилось. В первую очередь Patroni API или Patronictl делал такой запрос. И после уже сам switchover происходил внутри цикла High Availability, т. е. Patroni потом еще раз убедился перед тем, как сделать demoting, в том, что у нас есть реплика и она готова. Т. е. двойная защита. Потому если мы делаем отложенный switchover, то вначале не имеет смысла убеждаться в том, что там есть реплика, которая готова стать новым мастером. Но в 4 часа ночи Patroni перед тем, как остановиться, все-таки убедится, что у нас есть реплика, которая готова для данного действия.
И вы видите, что мастер сделал demoting. После этого остановился, после этого стартанул. Здесь он посмотрел – нужно ли ему сделать pg_rewind. Он решил не делать pg_rewind потому что у нас был clean shutdown.

Что мы можем еще сделать здесь? Я не буду это показывать вживую. Я просто покажу на слайдах. Мы можем указать время, когда мы хотим сделать switchover. В данном случае указали его с точностью до минуты. И после этого вместо того, чтобы прямо сейчас сделать switchover, Patroni его внесет в свое расписание. И после этого, когда наступит искомое время, Patroni сделает switchover. А до этого момента Patronictl вам покажет, что есть switchover, который запланирован на вот такую-то дату для этого узла. Этот узел будет мастером. И дальше, когда эта дата наступит, он выберет реплику и сделает switchover.

Также у нас есть возможность перезагрузить узел Postgres. Зачем нам это нужно? Вы можете перезагрузить узел с помощью pg_ctl –d data directory restart.
У этого способа есть один недостаток. Если этот узел – мастер, то он может потерять ключ мастера и сделать promote. Я думаю, что это не то, что вы хотели, когда вы хотели перезагрузить Postgres.
Самая частая причина для чего нужно перезагружать Postgres – это либо изменить параметр, который требует перезагрузки, либо поставить новую версию Postgres.
Т. е. таким способом мы можем это сделать, не теряя ключ лидера, а просто сказать «restart». В restart’е можно указать конкретный узел. Он сделает перезагрузку этого узла. В restart’е также можно указать, что нужно перезагрузить все узлы, тогда он перезагрузит все узлы.
И также у нас есть возможность сделать scheduled restart. Это очень полезно, если вы обновили Postgres и хотите, чтобы эти изменения применились не в то время, когда у вас пиковая нагрузка, а в тот момент, когда у вас почти нет клиентов. Он работает так же, как scheduled failover. По сути, вы говорите, что хотите сделать restart в такое-то время. И после этого Patroni в это время делает restart. И если вы сделаете patronictl list, то он вам также укажет, что запланирована перезагрузка кластера.

Здесь есть вывод того, что Patroni вам показывает. По сути, это похоже на Patronictl failover, т. е. пока restart не произойдет, он вам будет говорит, что ждем рестарта. И будет говорить, когда этот restart произойдет. И когда restart произойдет, он напишет вам, что есть restart, который был запланирован. И после того, как restart произойдет, мы видим, что Patroni, который раньше был мастером, он продолжает быть мастером. Он не потерял lock и это главная причина, почему мы можем делать restart.
Но если вы решите схитрить и все-таки зарестартить Postgres вручную с помощью pg_ctrl, то Patroni это заметит. И в следующий раз больше рестартить не будет.

Кто из вас читал статью в GitLab о разборе полетов после того, как в GitLab произошла большая проблема с базами данных?
Есть ссылка на статью, если будете потом смотреть на слайды. Это хорошее чтение для того, чтобы понять, что может пойти не так в большой организации с не нулевым бардаком с точки зрения инфраструктуры.
Идея была такая, что у них начала запаздывать реплика. Они решили ее переинициализировать. Pg_basebackup у них не отработал до конца из-за каких-то проблем. Они решили дата-директорию удалить. И по ошибке удалили дата-директорию на мастере. И все, game over. Поэтому, мы считаем, что удаление даты-директории вручную на реплике – это не очень хороший способ, чтобы эту реплику реинициализировать, потому что можно ошибиться.
Поэтому в Patroni есть команда «reinit», которая позволяет вам реинициализировать узел, который вы указали. Т. е. мы говорим «reinit», а также название кластера, имя узла. Patroni попросит подтверждение о том, действительно ли вы хотите реинициализировать узел. Вы скажете, что да. Он этот узел реинициализирует. И когда он будет его реинициализировать, статус Postgres, что Postgres работает, поменяется на статус, который будет говорить о создании реплики до того момента, пока реплика не создастся. А после этого он снова будет running.
Что будет, если вы скажете «patronictl reinit cluster» и укажете имя узла мастера? Reinit просто откажется работать. Reinit скажет, что мы не можем реинициализировать мастер и если вы действительно хотите реинициализировать Postgres на этом узле, то вам сначала нужно сделать switchover куда-нибудь еще, а потом уже реинициализировать этот узел как реплику. По понятным причинам мы не хотим случайно затереть наш мастер.

И есть режим паузы. Для чего мы этот режим изначально придумали? У нас есть Patroni, который управляет postgres-кластером. Делает автоматический failover. И стартует узлы, которые были остановлены по каким-то причинам.
В некоторых случаях мы этого не хотим. В некоторых случаях мы не хотим, чтобы Patroni делал автоматический failover, потому что мы что-то делаем с нашим postgres-кластером, например, выполняем какие-то ручные операции. Мы знаем, что это – мы и мы не хотим, чтобы Patroni вмешивался. Мы говорим ему, чтобы он убрал руки от нашего кластера.
И этот режим называет режим паузы. Этот режим включается также в Patronictl имя кластера. И этот режим глобальный для всего кластера. Т. е. и мастер, и реплики перейдут в этот режим. Они перейдут не сразу, а тогда, когда увидят ключ паузы в etcd через некоторое время. Это время пропорционально loop_wait.
При этом не будет происходить автоматический failover. Если у вас мастер станет недоступным, то так кластер и будет продолжать работать, т. е. он не выберет какой-нибудь из узлов в качестве нового мастера и не сделает ему promote.
Полезная функция этого режима – это если у вас недоступен etcd, потому что вы etcd потушили для апгрейда или еще для чего-то. Кластер продолжит работать так же, как и работал.
Но самое главное – включить режим паузы до того, как вы делаете что-то с etcd.
Вы включается сначала режим паузы. Кластер переходит в режим паузы. После этого вы тушите etcd. Ваш кластер не уходит в read-only режим и не начинает показывать тысячу сообщений об ошибках, о том, что etcd не доступен. Вместо этого он продолжает работать так, как и работал, пока режим паузы у вас сохраняется.
В нормальной ситуации, если вы останавливаете Patroni, то Patroni останавливает Postgres, чтобы не было такого, что вы остановили Patroni и после этого сделали promote вашей реплики и у вас включился multi-мастер. В режиме паузы Patroni этого делать не будет.
В режиме паузы, если вы остановите Patroni, то postgres-кластер продолжит работать как ни в чем не бывало.
Также если вы остановите Postgres и Patroni будет в режиме паузы, то Patroni не попытается его запустить. В нормальном режиме он попытается это сделать. Он подумает, что что-то случилось с Postgres, надо это исправить, надо его запустить. В режиме паузы вы можете остановить Postgres, сделать что-то с ним, что вы хотите сделать. И после этого запустить Postgres обратно. Patroni не будет вмешиваться.
Однако, если у нас работает мастер и работают реплики, то мастер будет продолжать обновлять свой ключ лидера в etcd, если etcd, конечно, доступен.
Кроме того, вы в этом режиме все равно можете создавать новые реплики. Т. е. если вы подключите новый узел к этому кластеру, то этот узел в режиме паузы и будет инициализирован, и получит basebackup с мастера.
И также в этом режиме вы можете делать ручной failover. Т. е. если вы явно скажете, что я хочу, чтобы этот узел стал мастером, то Patroni это учтет и поменяет роль мастера на тот узел, который вы скажете. Т. е. switchover работает, если мастер умрет, работать в этом режиме не будет.

Вот такой у нас режим. Он включает командой «pause». Есть ключ b, который не возвратит вам управление, пока режим паузы не будет включен на всех узлах. По умолчанию он просто скажет, что он учел, что вы хотите режим паузы. И режим паузы будет включен через какой-то интервал. В режиме wait он будет ждать, пока он не включен. И в этом режиме, когда вы говорите «list» для кластера, когда вы говорите «покажите нам все узлы», он также укажет, что режим паузы включен.
И в логе Patroni каждый узел будет сообщать о том, что помимо того, что он лидер или реплика, также включен режим паузы.
Вот такой режим для различных операций с кластерами. И если вы хотите, чтобы Patroni ничего не делал, то поставьте режим паузы.
 В режиме паузы можно сделать promote одному из узлов, который является репликой. Т. е. у вас есть кластер с мастером и у вас есть реплика в этом кластере. Вы приходите вручную к реплике, соединяетесь с ней и говорите этой реплике «pg_ctl posgresql1 promote».
В режиме паузы можно сделать promote одному из узлов, который является репликой. Т. е. у вас есть кластер с мастером и у вас есть реплика в этом кластере. Вы приходите вручную к реплике, соединяетесь с ней и говорите этой реплике «pg_ctl posgresql1 promote».
И что получается? Patroni вам никаким образом не препятствует. Он не меняет состояние этого кластера. У вас в кластере становятся два мастера. Естественно, это не multi-мастер, они между собой общаться не могут. И у вас становится split-brain. Но этот split-brain вы сами сделали. Поэтому Patroni в этом не виноват. Вы сами выставили режим паузы и после этого сделали promote.
Что интересно в этом случае? Patroni вам скажет, что он продолжает работать как мастер, но lock’а у него нет. Т. е. у него нет индикации в etcd о том, что он мастер, потому что в etcd есть ключ лидера, который указывает на другого мастера. А он мастер, потому что мы его запромоутили, но он работает как мастер без lock’а.

И если вы пойдете на такой мастер без lock’а, который вы сами запромоутили и спросите у него через REST API о том, мастер он или нет, то он даст ответ статусом 503. А нормальный мастер с lock’ом даст ответ 200. Почему 503? Если вы посылаете клиентов на мастер и даже если вы запромоутите один из узлов вручную, все равно клиенты пойдут на настоящий мастер, если вы используете REST API для этого. Фейковый мастер не будет сообщать о себе через REST API как о мастере, он будет показывать статус 503. И, кстати, для реплики, наверное, тоже будет говорить 503. И на него, скорее всего, вообще никто не может прийти.

Что произойдет, когда мы сделали split-brain мастера, у которого нет lock’а, а потом выключили в кластере режим паузы? Вот этот мастер сразу получит immediate shutdown, т. е. Patroni сразу скажет, что мы не можем быть мастером, у нас уже есть мастер. Сделает immediate shutdown. Postgres после этого остановится. И когда он запустится, Patroni попробует сделать pg_rewind для того, чтобы этот мастер, который вы сделали, смог снова присоединиться к кластеру.
В нашей ситуации он смог сделать pg_rewind. И после этого стартовал как standby, как secondary. И после этого присоединился к кластеру как ни в чем не было. Т. е. Patroni починил проблему split-brain, который мы сами сделали.

Есть еще поддержка синхронной репликации. И она работает в двух режимах. И в конфигурации Patroni вам нужно указать режим синхронной репликации. Это true или false.
Этот параметр применится для всего кластера. И что произойдет? Patroni найдет реплику, которая хороша для синхронной репликации, которая не отстает. И добавит на мастере параметр «synchronous standby name». Это параметр Postgres. И он добавит эту реплику в synchronous standby name, т. е. он сделает обычную синхронную репликацию.
Но кроме этого Patroni не будет делать failover ни на какую реплику, кроме синхронной. Раз вы сказали, что вы хотите синхронную реплику для того, чтобы она была постоянной и имела те же самые данные, что и мастер, то Patroni вам не даст сделать failover на какую-нибудь другую реплику, кроме синхронной.
Что в данном случае еще важно? Предложим, что у вас синхронной реплики нет. Она каким-то образом исчезла, она упала, с ней что-то случилось. Что в этом случае сделает Patroni? В этом случае Patroni предпочтет доступность над возможностью принимать запись от клиента. И выключит синхронный режим. И у вас будет мастер и асинхронные реплики.
Либо реплики, которые не могут быть синхронными, потому что кто-то их пометил nosync, либо у вас остался только мастер и для того, чтобы не терять возможность записи, Patroni переведет в обычный не синхронный режим.
В некоторых случаях мы этого не хотим. Мы поставили синхронный режим. И мы рассчитываем, что у нас всегда должно быть две копии данных. Т. е. если у нас синхронная реплика исчезает, то правило, что у нас есть две копии данных, может не соблюдаться.
И в этом случае, если нам всегда нужно, чтобы всегда была синхронная реплика, то если синхронной реплики нет, то мы не принимаем записи на мастер. В этом случае Patroni может вам помочь. Вы можете поставить режим synchronous_mode_strict, т. е. строгий режим синхронной репликации.
Он работает так же, как и обычный синхронный режим за одним исключением. Если у вас синхронная реплика исчезает, то синхронный режим остается, и мастер перестает принимать соединения до момента, когда у вас синхронная реплика появится снова.
Однако есть возможность выключить синхронный режим для каждого запроса. Немногие об этом знают, но в Postgres есть замечательная функция, которая есть не во всех базах данных. Для каждой транзакции вы можете сказать – хотите ли вы ее передавать синхронно или хотите ее сделать асинхронной. Т. е. даже если у вас сконфигурирована синхронная реплика, вы можете сделать транзакцию асинхронной. И тогда она не будет ждать, пока транзакция передастся на реплику и от реплики придет ответ.
Это делается с помощью параметра «synchronous commit», который вы можете указать прямо в транзакции, т. е. setting synchronous_commit to local, т. е. сделать его локальным на мастере. И в этом случае он не будет ждать, пока данные не передадутся на реплику. И даже если вы установили строгий синхронный режим, то в этом случае вы потенциально можете транзакцию потерять, если во время этой транзакции все упадет. Но это уже ваш личный выбор.
Поддерживаем ли мы более, чем одну синхронную реплику? Нет, мы пока не поддерживаем. У нас есть обсуждение на GitHub, вы можете присоединиться к нему. Мы вместе решим, как осуществлять поддержку более одной синхронной реплики. И, скорее всего, Quorum мы начнем поддерживать, начиная с 10-ки.

Я хочу показать, как это включается. Еще раз повторю команду. Т. е. я редактирую конфигурацию кластера. И после этого говорю – включить синхронный режим. Пишу здесь synchronous_mode: true. До этого он стоял в false по умолчанию. И говорю – применить эти изменения.

И давайте посмотрим, что случится в этом случае. У нас есть лидер, у которого есть lock. У нас есть реплика. И как только эти изменения применились, он нашел реплику. У нас единственная реплика, которая не отстает, поэтому очень логично, что он сделал эту реплику синхронной. И Patroni показывает, что параметр «synchronous_standby_names». Это тот самый параметр в Postgres, который позволяет вам задать реплики, был установлен в postgresql1. И Postgres говорит, что postgresql1 является сейчас синхронным standby.
На реплике у нас ничего не поменялось. Но мы можем посмотреть на patronictl list. И в данном случае у нас будет кластер лидер, как и раньше. А эта реплика будет synchronous standby. И таким образом мы можем увидеть, что в кластере есть синхронные реплики.

И в добавок к этому у нас есть специальный endpoint, который возвращает 200 только тогда, когда вы обращаетесь к синхронной реплике. Давайте попробуем это сделать. Вот видите, этот endpoint нам возвратил 200. Зачем это нужно? У ваших клиентов может быть необходимость читать данные сразу после того, как данные были изменены. Т. е. вы запустили апдейт. И вы после этого запустили select на ту же страничку. И вы хотите, чтобы этот select возвратил уже данные, которые были обновлены.
Если бы не было этого endpoint, то вы могли попасть на какую-нибудь другую реплику, у которые эти данные еще не пришли, потому что репликация асинхронная. В нашем случае мы можем использовать этот endpoint для того, чтобы прийти на синхронную реплику и быть уверенным, что вы получаете самые свежие данные.
У нас есть еще async endpoint, который возвращает 200 только, если реплика является асинхронной. В данном случае мы сделали async на синхронную реплику. И, понятное дело, что он нам возвратил 503, потому что реплика не синхронная.
Давайте ее выключим таким же самым образом. Мы можем сказать synchronous_mode: false. И можем убрать его из конфигурации. В данном случае пройдет некоторое время, и мастер выключит синхронный режим. И если мы сейчас сделаем list, то мы увидим, что реплика стала асинхронной. Если мы попробуем к async endpoint, то он возвратит 200. Если мы обратимся к sync endpoint, то он возвратит 503. Т. е. мы доказали, что реплика асинхронная.
Дальше Саша вам расскажет, как можно расширить функциональность Patroni.
Тут есть вопрос: «Что произойдет, если перезагрузить синхронный standby?». Например, есть один мастер и одна реплика, которая является синхронной. У нас есть два режима: один synchronous_mode, а другой synchronous_mode_strict. Strict запретит любые транзакции на мастере, если у нас нет реплики вообще. А обычный синхронный режим, если у нас реплики нет, то он отключит вот этот синхронный режим. И мастер будет применять все транзакции, т. е. это то, что вам надо. После того, как вы обратно включите реплику и в тот момент, когда она догонит мастера, Patroni ее сделает синхронной автоматически.

Patroni нам позволяет делать очень интересные вещи. Он позволяет кастомизировать очень много разных вещей таких, как создание новых реплик или создание новых кластеров, или позволит выполнить какие-то действия после того, как мы создали новый кластер. Для чего все это надо?

К примеру, мы хотим создавать новые реплики, не используя basebackup, а используя https://github.com/wal-e/wal-e (или wal-g). Потому что у нас есть всего один мастер, у нас есть бэкап, который где-то лежит, сделанный с помощью wal-e.
И мы хотим создать новую реплику, не нагружая мастер. В принципе, Patroni позволяет описать конфигурацию и указать какие-то скрипты, которые Patroni должен выполнить для того, чтобы инициализировать реплику из какого-то внешнего источника. В данном случае мы описываем create_replica_method. Это список.
Соответственно, Patroni попробует выполнить несколько методов из этого списка в том порядке, как они описаны. Первым в списке у нас идет wal_e. И для wal_e у нас есть своя конфигурация. В конфигурации мы обязаны написать команду, которую мы должны выполнить, и мы можем передать некоторые параметры. Эти параметры, которые описаны в yml, они будут сконвертированы особым образом в аргументы командной строки.

Как это все происходит? Некоторые параметры имеют двойное значение. Например, у нас есть такой параметр, как no_master. Это означает, что данный метод создания реплики будет работать даже, если у нас мастера нет.
Для чего это надо? Может произойти какая-то внештатная ситуация, когда у вас кластер полностью недоступен. Вы потеряли все машины. У вас есть бэкап и вы хотите восстановить все из бэкапа. Для этого достаточно запустить Patroni. Patroni выполнит команду, которая возьмет этот бэкап и развернет новый кластер.

Я уточню, что речь идет о физическом бэкапе. Это wal-сегменты и basebackup, это не pg_dump.
Это не логический бэкап. Логический бэкап в общем случае – это не бэкап. Это снапшот данных в определенный момент времени. И вот каким образом все это конвертируется в команду. Т. е. у нас есть wale_restore. Соответственно, Patroni начинает строить эту команду. Это wale_restrore. Он передаст ему имя кластера, передаст дату директорию, куда мы должны положить наши файлы. передаст зачем-то роль, хотя большого смысла в этом нет. Передаст connstring, по которому он может достучаться до мастера. Для чего это надо? Вы можете обратиться к мастеру и понять, как ситуация изменилась и посчитать, например, сколько WAL было нагенерировано. Если там нагенерировано терабайт логов, то может быть восстановление с помощью такого метода не самый эффективный и лучше сделать basebackup. Т. е., в принципе, вы можете все заскриптовать.
И вот он передает no_master. Envdir — это директория, которая содержит некоторые конфигурационные параметры для wal_e. Например, retries. Сам скрипт обязан обрабатывать большинство из этих параметров.

И, соответственно, если при исполнении команды у нас код возврата 0, значит команда была исполнена успешно, и мы можем попробовать стартовать этот кластер. Если команда была не успешной, то Patroni попробует следующую команду в списке. Если следующей команды нет, то он ничего пробовать не будет. Но на следующей итерации он сделает еще попытку.

По умолчанию, когда мы создаем абсолютно новый кластер, Patroni его инициализирует с помощью initdb.

Но может возникнуть ситуация, когда вы хотите сделать полный клон какого-то существующего кластера. Вот у вас есть кластер в production и вы хотите попробовать накатить какие-то изменения. Вы хотите его просто склонировать как есть.

Для этого мы поддерживаем метод custom bootstrap. Он работает примерно так же, как custom replica, как create method, т. е. вы описываете метод и описываете какие-то параметры для этого метода. Т. е. обязательно надо писать command. В данном случае – это склонировать кластер s3.
В этом примере мы будем делать point in time recovery. Т. е. мы знаем, что у нас здесь произошел какой-то несчастный случай. И какие-то данные были удалены. И мы знаем, когда это случилось. Соответственно, мы описываем такую команду, которая возьмет из s3 какой-то бэкап, который попадает в данный recovery target timeline.
После того, как у нас бэкап был развернут из s3, Patroni создаст recovery.conf с некоторыми параметрами. Мы говорим, что, пожалуйста, возьми последний актуальный timeline и сделай promote в тот момент, когда ты достигнешь данный recovery target timeline, но сделай promote за миллисекунду и микросекунду, т. е. не включая именно этот target timeline, т. е. чуть-чуть раньше.

И после того, как все удалось, Patroni запустит Postgres. Postgres начнет устанавливать wal’ы из какого-то внешнего хранилища, из s3 в данном случае. И в какой-то момент произойдет promote. После этого Patroni запустит post_bootstrap script. Для чего это надо? В этом скрипте вы можете создать каких-то пользователей, какие-то служебные таблицы. Это все конфигурировано, вы сами должны знать, что вам нужно.
С initdb происходит примерно то же самое. Т. е. мы имеем возможность задать какие-то параметры для initdb. Например, выключить trust аутентификацию, которая по умолчанию включена для localhost.
Но это все происходит только после того, как один из instance Patroni взял ключ инициализации. Т. е. вот этот bootstrap будет происходить исключительно на одной ноде. Это примерно такая же ситуация, как с лидером. Но если у нас какой-то из шагов bootstrap оказался неуспешным, то Patroni удалит initialize ключ и даст другим нодам шанс попытаться. Если других нод нет, то он сам будет пытаться дальше.
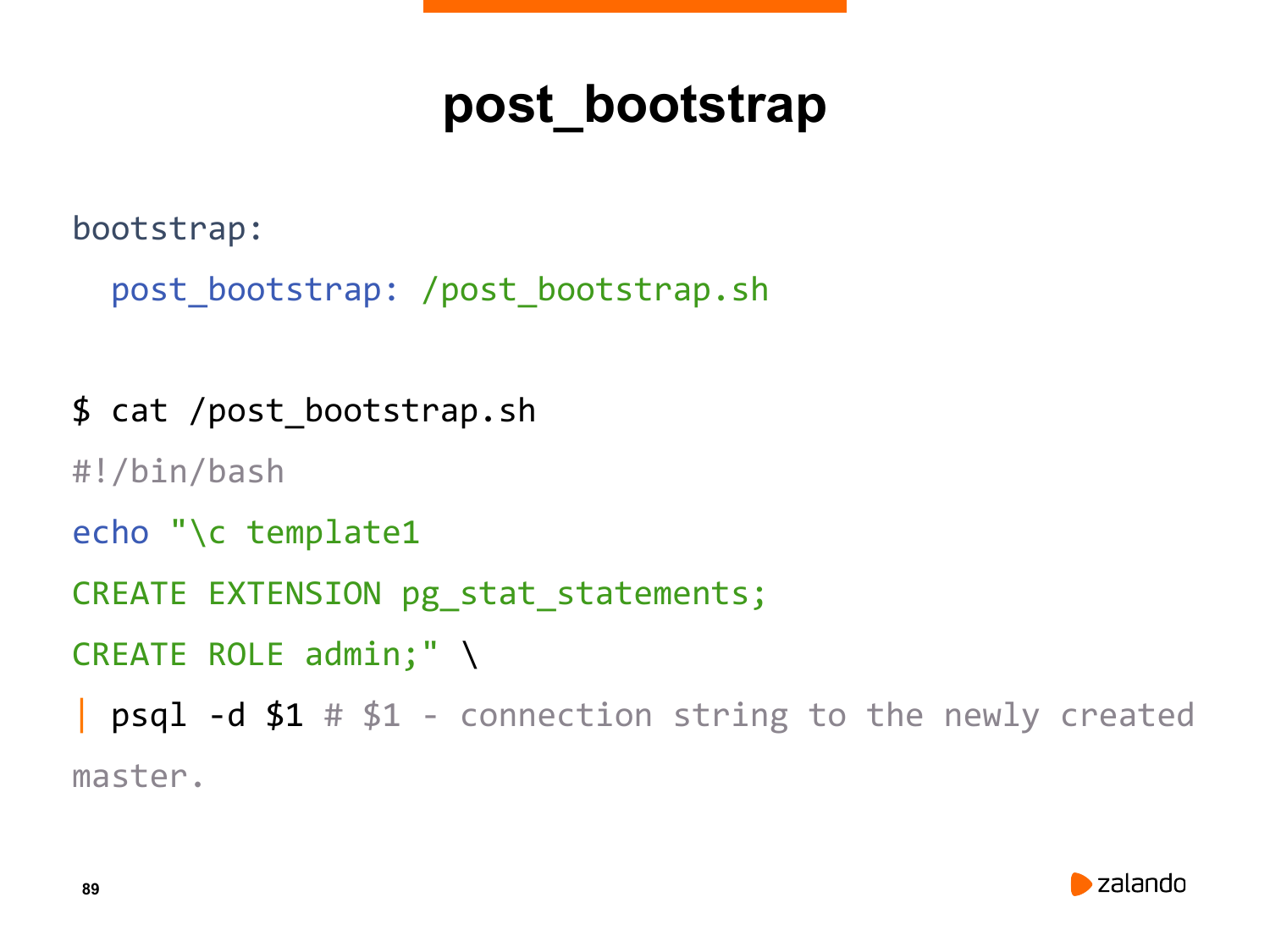
Вот пример, как мы можем post_bootstrap использовать. Например, мы создадим pg_stat_statements extension внутри базы данных temlate1. Для чего это надо? Пользователь дальше создаст какую-то другую база и у него там сразу будет pg_stat_statements. Это достаточно удобно. Потому что просто так extension создавать нельзя, это может делать только superuser, а обычным пользователям не стоит давать роль superuser’а. В данном случае мы решили проблему одним махом.

Давайте посмотрим на конфигурационный файл Patroni. Тут есть несколько секций. Во-первых, мы должны описать, что у нас за кластер, т. е. во всех нодах, которые относятся к данному кластеру scope должен совпадать. Мы тут используем batman.
Namespace – этот параметр говорит о том, что где внутри etcd мы будем держать информацию о нашем кластере. По умолчанию – это сервис, но вы можете переопределить. Вы можете использовать Patroni, вы можете использовать еще что-то. Но самое важное, чтобы namespace совпадал среди всех узлов у данного кластера.
Дальше мы можем каким-то образом сконфигурировать REST API в Patroni на данной конкретной ноде. А также указать каким образом Patroni будет общаться с etcd, как мы будем делать bootstrap, какие мы хотим конфигурационные параметры применить Postgres, watchdog и tags.

С restapi все просто, мы говорим на каком API мы будем слушать и каким образом другие ноды к нам могут обратиться. Опционально вы можете включить SSL и можете включить authentication.

Поскольку мы поддерживаем разные DCS такие, как etcd, Consul, то тоже самое. Вы должны описать хост, вы должны описать, какой протокол использовать. Может быть, требуется авторизация, может быть, требуются какие-то сертификаты и ключи. Все это конфигурируемо.

С ZooKeeper такая же ситуация, только там нет авторизации, если я не ошибаюсь. Но для ZooKeeper обязаны перечислить все хосты в кластере. Exhibitor позволяет это немного упросить, но, как правило, люди его не очень часто используют.

На Bootstrap мы уже смотрели и уже о нем говорили. Соответственно, все, что написано в Bootstrap будет использовано всего один раз, когда мы создаем кластер.

На bootstrap_method мы тоже уже смотрели.

Здесь два важных момента. Мы должны определить listen_address и connect_address. Listen_address – это где Postgres будет слушать. И Connect_address – это для того, чтобы в etcd опубликовать, как к нам можно обратиться. Это исключительно для реплик.
И второй важный момент – это authentication. Соответственно, Patroni при инициализации кластера создать superuser и создать пользователя для репликации. На репликах эти параметры должны быть абсолютно такими же, как и на мастере.
И плюс опционально вы можете какие-то конфигурационные параметры для Postgres здесь настроить.

Про callback и replica_method тоже говорили.

Если вы работаете на железе, то очень важно его правильно настроить. Тут ручек, которые можно покрутить совсем немного. Есть такой параметр как safety_margin. Он говорит: «Пожалуйста, за 5 секунд до того, как у нас истечет ключ лидера, перезагрузи весь сервер». Т. е. это для того, чтобы обезопаситься от всего-всего.
И про tags мы уже говорили достаточно подробно.

Очень многие параметры можно сконфигурировать не только через yml-файл. Можно использовать environment. По ссылке все это подробно описано.
И есть возможность целиком конфигурационный файл передать через environment variables. Она называется Patroni configuration. Но при этом важно, что никакие другие environment variables просто не будет использованы. И даже, если вы где-то передадите config в командной строке, то он тоже будет игнорирован.

Про troubleshooting – это будет для вас как домашнее задание, видимо.
Мы можем быстренько пробежаться по нему, потому что о нем очень много всего. И это любимый раздел, потому что все эти ошибки я делаю сам.

Т. е. если у вас есть etcd, но etcd перестает быть доступной для какого-то узлов, то этот узел вам начнет выдавать ошибки о том, что он пытается общаться с etcd, но у него не получается. И после этого покажет вам сообщение о том, что он ждет, пока etcd не станет доступным. Это относится к другим системам тоже.

Вот это довольно частая проблема. Вы установили Debian. У вас пути до бинарных файлов postgres, pg_ctl и других не находятся в переменной path. После этого вы запускаете Patroni. Patroni у вас отваливается именно с такой ошибкой. Он говорит subprocess. call, т. е. не возвратил успешный результат. И говорит, что нет файла pg_ctl. И, соответственно, никакого мастера после этого быть не может, потому что у вас нет бинарных файлов Postgres.
И есть достаточно простое решение. Нужно пойти в конфигурацию и прописать такой параметр, как bindir. Он должен указывать на путь, где ваши бинарные файлы находятся. Или альтернативно указать в переменной path путь, где находятся бинарные файлы Postgres.

Вот эту ошибку я уже показывал вживую, когда Patroni создает репликационные слоты для реплики. Он создает их не сразу, а когда он обнаруживает, что реплика появилась. Поэтому первые несколько секунд (до 10 секунд) показывается вот это сообщение, что нельзя стартовать репликацию, потому что слота нет. Это сообщение исчезнет само по себе.

Вы можете указать конфигурацию initdb внутри Patronictl.yml. В некоторых случаях люди указывали конфигурацию неправильно. Например, у нас есть параметр «data-checksums», который позволяет включить checksums, включить контрольные суммы на кластер, которые вы инициализируете. Этот параметр в самом initdb показывается, как --data-checksums. Не --data-checksums: true, а - data-checksums. Patroni, соответственно, требует его в таком же виде. И если вы укажете - data-checksums: true, то вы получите ошибку, которая говорит, что опция data-checksums не предусматривает аргументов. И initdb не сработает, и вам придется поменять конфигурацию Patroni перед тем, как продолжать работать с этим кластером.
И моя любимая ошибка. Yaml – называют форматом, который доступен для записи обычным людям. Т. е. обычные люди должны уметь писать yaml, так разрабатывался yaml. Но форматирование в yaml имеет значение, т. е. индентация в yaml так же, как и в Python, она значима. Если вы забудете указать пробел, то yaml вместо подчиненного списка решит, что это эти параметры находятся на одном и том же уровне.
В данном случае, что он попытался сделать? Он подумал, что это строка. Он попытался все это преобразовать в строку, разбил ее на отдельные символы. И получилась чепуха.
Поэтому, если вы видите что-то подобное, то валидируйте ваш yaml перед тем, как запускаете его в production.

Вот это интересная проблема. Когда вы в Debian или в Ubuntu ставите Postgres, он у вас по умолчанию делает initdb для кластера. И, по-моему, даже его запускает.
Что произойдет, если вы попытаетесь после этого этот узел, в котором произошел initdb, подключить к существующему кластеру как реплику? У нас есть мастер, есть initdb, который произошел независимо от того мастера. У каждого postgres-кластера есть такая штука как системный идентификатор, который одинаков на всех узлах мастера и реплики, и другой на других кластерах, которые сделаны с помощью initdb отдельно.
И когда вы пытаетесь в Patroni подключить такой кластер, то Patroni вам скажет «критическая ошибка». Системный идентификатор текущего узла, который инициализировал этот кластер, не совпадает с системным идентификатором той реплики, которую вы попытались подключить. Поэтому эта реплика подключиться не сможет. И я не могу продолжать. Это сделано специально для того, чтобы вы не потеряли данные, попытавшись подключить совершенно не относящиеся к этому кластеру узел. И потом увидев, что он не подключился, не сделали reinit этому узлу и не потеряли данные.
И решение такое. Если это Debian, если у вас уже есть дата-директория, то вам нужно дата-директорию удалить и подключить ее как реплику.

Есть полезные ссылки.
Есть Patroni. Он находится на GitHub. Это open source проект. Вы можете прийти и открыть issue. Или прийти туда и посмотреть на другие issue. Или просто прийти туда, скопировать и запустить его.
Есть документация о Patroni. Она находится по отдельному адресу: https://patroni.readthedocs.io. Это документация поддерживает поиск. Если вы ищите какой-то параметр, вы можете найти. Там подробно описываются все параметры. Подробно описывается, как работает Patroni в разных режимах. В том числе описана синхронная репликация. Описано, как работает Kubernetes, о котором мы сегодня не говорили, потому что у нас не хватило для этого времени.
И есть docker-образ, который включает в себя Postgres и Patroni и многое другое. Он называется Spilo. Он также находится на GitHub в open source, и мы его используем внутри Zalando для того, чтобы запускать Postgres. И вы его можете использовать для той же самой цели.
Вопросы:
(Сами вопросы не в микрофон, их не слышно)
Вопрос: Как вы запускаете patroni в kubernetes?
Ответ: В Kubernetes мы запускаем Patroni в Spilo. И управляем с помощью postgres-оператора. Это отдельный open source проект.
Вопрос: Будет ли поддержка OpenShift?
Ответ: Хороший вопрос. Надеемся, что да, потому что Red Hat в этом тоже заинтересован. У нас нет OpenShift, поэтому поддержкой OpenShift занимаются люди, которые в этом заинтересованы, в частности Red Hat. Я думаю, что будет.
Вопрос: Уже есть мастер, есть standby. И можно ли подцепить Patroni к существующему standby, не переинициализируя его?
Ответ: Да, это возможно. В первую очередь, вы должны запустить Patroni на мастере, чтобы ничего не предвиденного не произошло. И уже только потом запустить его на хосте, где работает standby. Но это операция не очень хорошо документированная. И прежде чем выполнять на production, вы лучше потренируйтесь где-нибудь, например, на laptop’е, например.
Но, в принципе, мы это проделывали. У нас именно такая ситуация. В классическом дата-центре у нас есть мастер, у нас есть standby. Мы сначала запустили Patroni на хосте, где у нас мастер. Он записал все, что нужно в ZooKeeper в нашем случае. Потом мы запустили Patroni на реплике. Соответственно, Patroni понял, что у нас есть мастер. И весь этот кластер стал работать под управлением Patroni. Никакой переинициализации делать не пришлось.
Вопрос: Можно ли сделать bootstrap не в S3, а из локальных файлов?
Ответ: Для этого вы можете использовать не wal-e, а что-нибудь другое. Т. е. это все кастомизируется. Вы можете написать любые скрипты, которые будут выполнять бэкапы.
Если ваш вопрос был о том, можете ли вы использовать S3 не из Amazon, а из локальной машины, то – да, вы можете это сделать тоже. Вы можете бэкапиться на S3, даже не находясь в Amazon, если в этом есть смысл.
Вопрос: Если вы Postgres запускаете не с помощью pg_ctl, а с помощью какой-то своей специальной команды?
Ответ: Patroni управляет Postgres на данном конкретном узле. Соответственно, для каждого узла Patroni запускает Postgres. Вы не можете взять и сделать так, чтобы Patroni запустил несколько Postgres’ов, т. е. один Patroni на разных узлах.
Вопрос: «Кастамизируется ли строка запуска Postgres в Patroni?».
Ответ: Нет, она не кастомизируется. Но зачем?
Вопрос: Как через Patroni запустить Postgres на определенных процессорах?
Ответ: Думаю, что для этого вам нужно запустить Patroni на этих процессорах. Поскольку Patroni потом запустит Postgres. Вопрос о том, наследуется ли все это. Я, честно говоря, не знаю. Вероятно, да, потому что вы запускаете postmaster, который после этого запускает Postgres. И поэтому, если это работает в случае просто Postgres, то это сработает и с Patroni тоже. Но в вашем случае я бы экспериментировал. Ответ на ваш вопрос – это примените эти параметры к Patroni.
Вопрос: Что будет с асинхронной репликой, если упадет синхронная реплика?
Ответ: Если что-то произошло с синхронной репликой, то Patroni какую-нибудь из существующих асинхронных реплик, которые удовлетворяют определенным условиям, просто выберет следующей синхронной.
Вопрос: Что он будет делать в этот момент, пока у него нет синхронной реплики?
Ответ: Patroni может либо перейти в асинхронный режим совсем, либо продолжать считать себя в синхронном режиме и не принимать соединения, пока у него не будет действующей синхронной реплики. Но имейте в виду, что все эти операции не происходят мгновенно. Т. е. требуется некоторое время, чтобы понять, что синхронная реплика отвалилась.
Вопрос: Возможно ли использовать Patroni на физическом сервере вместо облака?
Ответ: Да, возможно. Patroni не связан с каким-либо контейнером. Вы можете запустить его на местном сервере. Это то, чем мы занимаемся здесь. У нас была виртуальная машина. И мы запустили Patroni виртуальной машиной, и все прекрасно сработало. Мы использовали его на физическом сервисе, т. е. он не привязан к контейнеру. Есть docker-контейнер, есть spilo, но у spilo есть Postgres Patroni. А Patroni – это программа, которая может работать везде.
Вопрос: Какая цель у Haproxy?
Ответ: Прокси – это балансировщик нагрузки. И его первичная цель направлять трафик от клиента мастеру. У вас может быть более одного узла в кластере. Например, если три узла, то HAProxy отвечает за то, чтобы определить, где работает мастер. И когда клиент подсоединяется к HAProxy, то автоматически HAProxy направит это на правильный узел. Это запрос из Postgres. Oн работает, как обычный TCP proxy. Он не использует postgres-протокол, но направляет трафик от клиента в Postgres.







