Часто бывает так, что большую часть приложения составляют различные списки и таблицы. Чтобы каждый раз не изобретать велосипед, я как и многие, чаще использовал таблицы Angular Material.
Позже эти таблицы разрастались, в ячейки помещались как текстовые данные, так и вложенные элементы. Все это растет и становится неплохой нагрузкой на машину пользователя. И понятное дело это никому не нравится.
В моем последнем домашнем проекте была таблица, ячейки которой в основном были заполнены различными полями (можно даже сказать, что это была одна большая форма).
И рендеринг её занимал около 8 секунд (таблица 40 x 40).
Так как можно оптимизировать MatTable для больших списков?

Для того, чтобы помочь остальным разобраться с этой проблемой я написал небольшое тестовое приложение. Все та же таблица MatTable, с пятью колонками (первая — id элемента, остальные — обычные текстовые поля MatFormField).

Казалось бы, простая таблица, однако даже рендеринг 100 сток такой таблицы занимает ни много, ни мало 2 секунды (Ох уж этот материал и его «топовая» производительность).

Сам рендеринг в данном случае занял только (860 мс), однако на все 2.2 секунды страница зависла и пользователь расстроился.
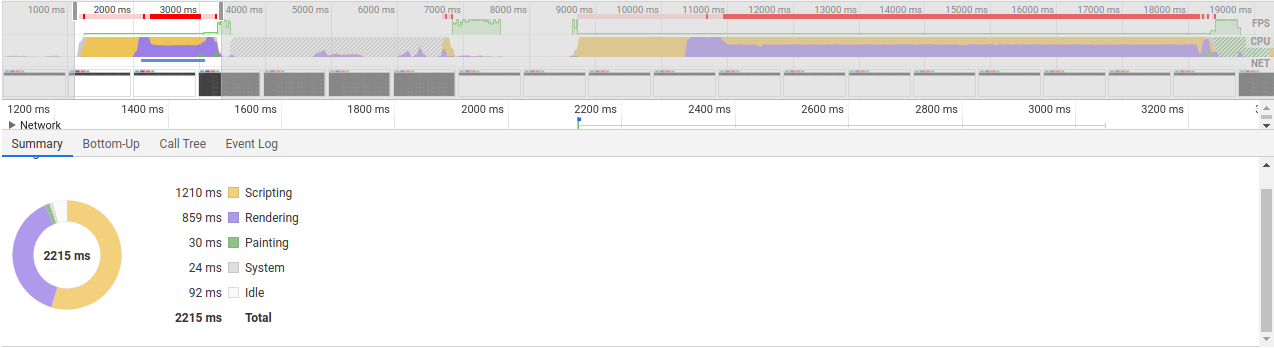
Что же, давайте попробуем, отрендерить таблицу в которой будет 300 строк. И барабанная дробь, немного ждем и видим, что на скриптинг и рендеринг в сумме было потрачено почти 10 секунд. То-есть в случае, когда пользователь захочет вывести такую таблицу в 300 строк, его страница зависнет на 10 секунд. Это очень страшно и удивительно (на самом деле нет).
На самом деле я ещё пытался сделать замер времени, которое потребуется для отрисовки 1000 элементов, однако мой жалкий i7 не выдерживал и страница постоянно отваливалась.
Попытаемся сделать это позже с уже примененным решением.
И так, делать замеры с помощью браузерных утилит может каждый, а вот решить эту проблему нет.
К этому решению меня привело рассуждение над самой сутью проблемы.
Проблема найдена. Теперь остается придумать, как ее решить. Самым первым на ум приходит самое простое решение. Если проблема в обработке всех данных сразу, то нужно заставить таблицу обрабатывать данные частями.
Но как это сделать?
Давайте подумаем, что у нас для этого есть из-под коробки. Первым на ум приходит Track By функция. При изменение датасоурса не будет перерендивариватья всю таблица, а только ее изменения.
Давайте добавим эту функцию в нашу таблицу:
Хорошо, но ведь у нас нет такого условия, что данные таблицы как-то изменяются, да и вообще не об этом сейчас разговор. Но что, если написать Pipe, который при инициализции data source будет разбивать данные и отдавать их таблице порционно. В свою очередь функция trackBy поможет избежать полного ререндера.
Вот такой небольшой кусок кода, поможет вашему железу рендерить такие большие таблицы.
Применим этот pipe к нашему data source.
Теперь попробуем провести замеры. Рендерим 100, 300 и 1000 элементов.

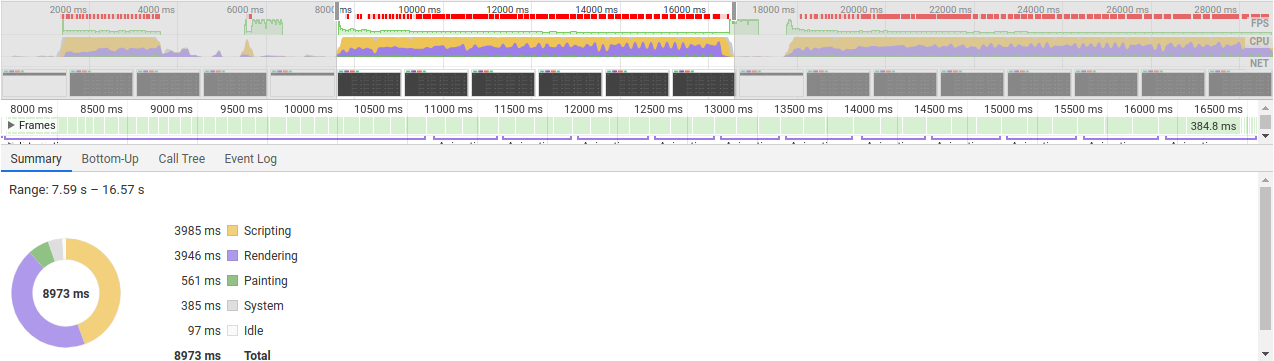
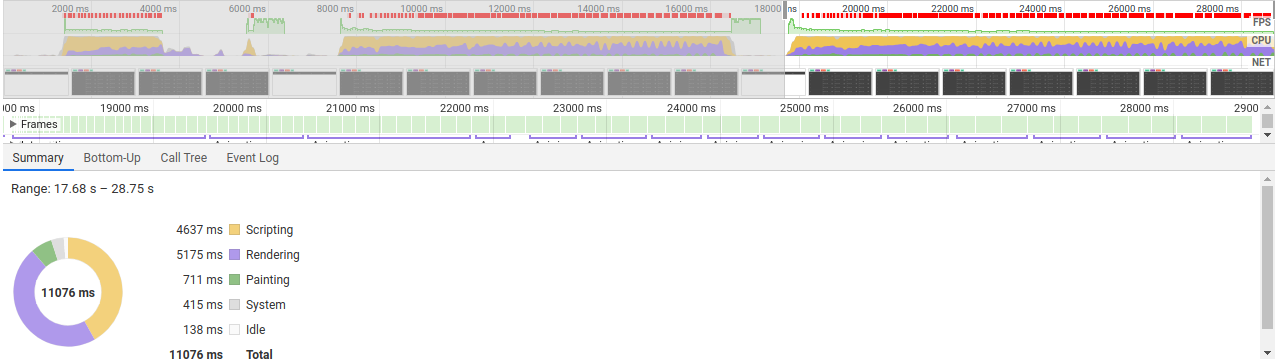
И что мы видим? Что на самом успех не такой как мы ожидали:
Но не спешите делать выводы, давайте для начала посмотрим на поведение страницы в обоих случаях.


Как видно, в обычном случае страница зависает на несколько секунд и пользователь ничего не может сделать в этот момент, тогда как использование нашей пайпы с связке с trackBy дает пользователю практически мгновенную инициализацию таблицы и не вызывает никакого дискомфорта во время использования приложения.
Надеюсь кому-нибудь поможет эта статья.
Исходники тестового приложения есть на Stack Blitz.
Позже эти таблицы разрастались, в ячейки помещались как текстовые данные, так и вложенные элементы. Все это растет и становится неплохой нагрузкой на машину пользователя. И понятное дело это никому не нравится.
В моем последнем домашнем проекте была таблица, ячейки которой в основном были заполнены различными полями (можно даже сказать, что это была одна большая форма).
И рендеринг её занимал около 8 секунд (таблица 40 x 40).
Так как можно оптимизировать MatTable для больших списков?

Тестовый пример
Для того, чтобы помочь остальным разобраться с этой проблемой я написал небольшое тестовое приложение. Все та же таблица MatTable, с пятью колонками (первая — id элемента, остальные — обычные текстовые поля MatFormField).

Казалось бы, простая таблица, однако даже рендеринг 100 сток такой таблицы занимает ни много, ни мало 2 секунды (Ох уж этот материал и его «топовая» производительность).

Сам рендеринг в данном случае занял только (860 мс), однако на все 2.2 секунды страница зависла и пользователь расстроился.
Что же, давайте попробуем, отрендерить таблицу в которой будет 300 строк. И барабанная дробь, немного ждем и видим, что на скриптинг и рендеринг в сумме было потрачено почти 10 секунд. То-есть в случае, когда пользователь захочет вывести такую таблицу в 300 строк, его страница зависнет на 10 секунд. Это очень страшно и удивительно (на самом деле нет).

На самом деле я ещё пытался сделать замер времени, которое потребуется для отрисовки 1000 элементов, однако мой жалкий i7 не выдерживал и страница постоянно отваливалась.
Попытаемся сделать это позже с уже примененным решением.
Решение проблемы
И так, делать замеры с помощью браузерных утилит может каждый, а вот решить эту проблему нет.
К этому решению меня привело рассуждение над самой сутью проблемы.
правильное понимание проблемы, это уже как минимум половина ее решения.Я думаю каждому понятно, что это происходит потому что данные таблицы сначала обрабатываются скриптами, а потом выплёвываются одним куском. В свою очередь именно поэтому мы и видим характерное подвисание.
Проблема найдена. Теперь остается придумать, как ее решить. Самым первым на ум приходит самое простое решение. Если проблема в обработке всех данных сразу, то нужно заставить таблицу обрабатывать данные частями.
Но как это сделать?
Давайте подумаем, что у нас для этого есть из-под коробки. Первым на ум приходит Track By функция. При изменение датасоурса не будет перерендивариватья всю таблица, а только ее изменения.
Давайте добавим эту функцию в нашу таблицу:
<mat-table [trackBy]="trackByFn" [dataSource]="commonDataSource">Хорошо, но ведь у нас нет такого условия, что данные таблицы как-то изменяются, да и вообще не об этом сейчас разговор. Но что, если написать Pipe, который при инициализции data source будет разбивать данные и отдавать их таблице порционно. В свою очередь функция trackBy поможет избежать полного ререндера.
@Pipe({
name: 'splitSchedule'
})
export class SplitPipe implements PipeTransform {
public transform(value: any, takeBy: number = 4, throttleTime: number = 40): Observable<Array<any>> {
return Array.isArray(value)
? this.getSplittedThread(value, takeBy, throttleTime)
: of(value);
}
private getSplittedThread(data: Array<any>, takeBy: number, throttleTime: number): Observable<Array<any>> {
const repeatNumber = Math.ceil(data.length / takeBy);
return timer(0, throttleTime).pipe(
map((current) => data.slice(0, takeBy * ++current)),
take(repeatNumber)
);
}
}
Вот такой небольшой кусок кода, поможет вашему железу рендерить такие большие таблицы.
Применим этот pipe к нашему data source.
<mat-table [trackBy]="trackByFn"
[dataSource]="commonDataSource | splitSchedule | async">
Теперь попробуем провести замеры. Рендерим 100, 300 и 1000 элементов.



И что мы видим? Что на самом успех не такой как мы ожидали:
- 300 элементов рендерились на 1 секунду быстрее
- 1000 отрендерерилось за 11 секунд, и вкладка не умерла
- а 100 элементов вообще рендерелись на 150 мс дольше
Но не спешите делать выводы, давайте для начала посмотрим на поведение страницы в обоих случаях.
Как видно, в обычном случае страница зависает на несколько секунд и пользователь ничего не может сделать в этот момент, тогда как использование нашей пайпы с связке с trackBy дает пользователю практически мгновенную инициализацию таблицы и не вызывает никакого дискомфорта во время использования приложения.
Надеюсь кому-нибудь поможет эта статья.
Исходники тестового приложения есть на Stack Blitz.







