Комментарии 438
А почему bash-completion так лагает при выводе подсказок по systemd? Это и на нескольких последних версиях Убунты, и на других дистрибутивах, судя по аналогичным вопросам на stackoverflow. Лечения так и не нашел.
По правда говоря, это пост не о войнах systemd. Если хотите почитать ещё, но лень копаться в списках рассылки, то держите чей-то материал, который отчасти вдохновил меня на этот пост
в этом "чьем-то материале" есть не только описания войн systemd, но и техническая критика. Мягко говоря, разгромная. Не обычная вода про "не юниксвей", а подробное описание архитектуры, в частности того ада которым там являются зависимости. Я думал, тут будет перевод именно этой, самой важной части статьи.
Я думал, тут будет перевод именно этой, самой важной части статьи.
Ну… Если вы захотите перевести эту часть поста и опубликовать самостоятельно, то я только за!
Представьте, что вам нужен понятный и легко читаемый rc-script который:
- запускает некий процесс, при этом:
— гарантирует наличие сети к моменту его запуска
— гарантирует наличие определенных mount-points к моменту запуска - перезапускает его если он вылетает при определенных кодах возврата
- не даёт запустить больше чем один процесс (при повторных вызовах)
- адекватно завершает процесс при shutdown но до того как отключатся сеть и некоторые другие процессы
- всё вышеперечисленное должно работать одинаково (и надёжно) в debian/arch/centos
Сколько строчек получилось? И насколько понятно-читаемых?
запускает некий процесс, при этом:
— гарантирует наличие сети к моменту его запуска
— гарантирует наличие определенных mount-points к моменту запуска
Такого не должно быть в правильном софте. Софт должен самостоятельно проверять необходимые ему зависимости, а не полагаться на третьи в общем виде недоваренные сервисы.
перезапускает его если он вылетает при определенных кодах возврата
Такие вещи нельзя отдавать на сторонний софт. А что будет, если успешное условие запуска так и не произойдёт? Вы получите постоянно перезапускающийся сервис.
не даёт запустить больше чем один процесс (при повторных вызовах)
Десятки лет это решалось наличием файлика daemon.pid в run директории.
адекватно завершает процесс при shutdown но до того как отключатся сеть и некоторые другие процессы
Опять же это должен делать сам софт, а не внешняя система запуска.
всё вышеперечисленное должно работать одинаково (и надёжно) в debian/arch/centos
Как раз с этим проблем не было.
Такого не должно быть в правильном софте.
Вместо того чтобы сделать инструмент который удовлетворяет большому количеству сценариев, говорить что ваши сценарии неправильные — это путь в никуда.
У нас в городе адепты вашей логики, вместо удобной среды для всех, строят один неудобный пешеходный переход — в итоге люди бегают через дорогу там где удобно, создают аварии. Архитектор не виноват, это люди неправильные да?
Такого не должно быть в правильном софте.
По такой логике правильного софта не существует.
Вы получите постоянно перезапускающийся сервис.
Поэтому systemd позволяет ограничить частоту и количество перезапусков.
Десятки лет это решалось наличием файлика daemon.pid в run директории.
Который можно случайно (не) удалить или случайно не создать. Или вообще устроить race condition. Это очень ненадёжно.
Опять же это должен делать сам софт, а не внешняя система запуска.
Зачем переусложнять софт тоннами проверок, если всё это может делать система инициализации? В чём смысл?
Софт должен самостоятельно проверять необходимые ему зависимости, а не полагаться на третьи в общем виде недоваренные сервисы.
Во-первых, софт может и не знать, что у него есть какая-та там зависимость. Во-вторых, что делать когда этой зависимости нет? Если активно ждать зависимость — то это лишние паузы в процессе запуска системы плюс напрасная трата процессорного времени.
Такие вещи нельзя отдавать на сторонний софт. А что будет, если успешное условие запуска так и не произойдёт? Вы получите постоянно перезапускающийся сервис.
Постоянно перезапускающийся сервис вы получите если будете делать защиту от падений "на коленке". А systemd умеет останавливаться при повторяющейся ошибке.
Десятки лет это решалось наличием файлика daemon.pid в run директории.
Ага, и с гонками вокруг того файла.
Софт должен самостоятельно проверять необходимые ему зависимости, а не полагаться на третьи в общем виде недоваренные сервисы.
То есть каждый софт который работает с сетью должен сам эту самую сеть настроить и запустить? А если ему нужен доступ к какому-то NFS то ещё и его подмонтировать?
Вы фактически предлагаете любое приложение превращать в отдельную OS.
А что будет, если успешное условие запуска так и не произойдёт? Вы получите постоянно перезапускающийся сервис.
Если условия для запуска не наступают — то логично что сервис не запустится вообще и "запускатель" будет ждать (с минимальным оверхедом) наступления условий (что делает systemd — и отлично делает). В случае с rc-script всё зависит от кривизны рук его писателя (обычно они кривые).
Вообще отслеживание зависимостей запуска должно быть сделано вне самого приложения — потому что приложение (сервис) может банально не иметь прав/знаний чтобы эти самые зависимости запустить/реализовать, всё что оно должно "мочь" — это сказать что ему нужно, а не как и где.
Десятки лет это решалось наличием файлика daemon.pid в run директории.
Угу… как уже упомянули выше — с этим связаны массы race conditions, не говоря уже о том что pid-file — это только поллинг, со всеми вытекающими.
Опять же это должен делать сам софт, а не внешняя система запуска.
Да без проблем — сервису для работы с (допустим) почтой доверим shutdown системы и корректное завершение работы БД, чтобы он успел всё что нужно сделать. Примерно так?
Десятки лет это решалось наличием файлика daemon.pid в run директории.
лол, как будто не может быть гоночек в системе и этот pid будет кому-то другому назначен (я такое хватал). Проверка по pid — это, к сожалению, не самое надежное, что есть в этом мире.
> Это дает такие и такие удобства
> Удобства нинужны!
Десятки лет это решалось наличием файлика daemon.pid в run директории.
Я добавлю, что дело не в файлике. systemd вполне мог бы и файлик создавать и проверять его.
Но зачем это делать в КАЖДОМ rc скрипте? Для адекватной проверки это лишних 5-10 строк вместо одной легкочитаемой.
Представьте, что вам нужен понятный и легко читаемый rc-script который:.....
Захожу по SSH в FreeBSD и вижу там скрипты которые делают все это и многое другое.
Причем написать свой не представляется большой трудностью даже без частых подглядываний в интернет только на основе того, что уже есть в базовой системе.
Как говорил Жванецкий: «Может нужно что-то в консерватории подправить?»
Могу только съязвить, что линуксы между собой могут отличаться больше, чем Линукс (произвольный) отличается от бсд.
Ну, и, конечно, брать бсд как пример. Такое себе. Система хорошая, но больно узкоспециализированная по нынешним временам
Захожу по SSH в FreeBSD и вижу там скрипты которые делают все это и многое другое.А статью не напишите? Про то, как всё устроено. И как система поднимается, ждёт получения имени по DHCP, после чего решает откуда понтировать (через NFS) Web-сайтик и только после этого запустить Web-сервер. А FTP-сервер (монтирующийся с другого NFS-сервера) дожен, разумеется, работать даже если Web-сервер не поднялся.
Банальная такая задачка — будет интересно посмотреть как именно FreeBSD это всё разрулила. Кроме шуток.
Как говорил Жванецкий: «Может нужно что-то в консерватории подправить?»Может быть. Статью реально жду. Потому что количество костылей, которые требовалось забить, чтобы что-то подобное сделать на бездисковых станциях под Linux у нас в школе… вызывало некоторую оторопь.
Бездисковые станции ушли в прошлое, но теперь те же самые задачи возникают на серверах. Если FreeBSD это успешно и надёжно решает скриптами — то будет интересно на это посмотреть.
А статью не напишите? Про то, как всё устроено. И как система поднимается...
На хабре много блогов, где коммерсы выкупили посты, а несчастные сотрудники потом занимаются переводом англоязычных статей и документации. Для них как раз идея подойдет. Остальным я бы посоветовал просто читать документацию, а не мои опусы.
по DHCP, после чего решает откуда понтировать (через NFS) Web-сайтик и только после этого запустить Web-сервер. А FTP-сервер (монтирующийся с другого NFS-сервера) дожен, разумеется, работать даже если Web-сервер не поднялся.
Здесь все просто:

Я думаю, все от того, что на той же самой машине не пытаются одновременно запустить Tensorflow, PyTorch, майнер и еще IP-телефония для жилого квартала куда-то пропала.
Представьте, что вам нужен понятный и легко читаемый rc-script который:
Давайте лучше не rc, с ними всё понятно, а лучше рассмотрим run-скрипт для Runit.
• запускает некий процесс, при этом:
— гарантирует наличие сети к моменту его запуска
— гарантирует наличие определенных mount-points к моменту запуска
Сеть и монтирования в Runit выполняются на 1-м (синхронном) этапе загрузки, до начала запуска (асинхронного) всех сервисов. Выглядит это примерно так:
mount -at noproc,nofuse
swapon -a
ip link set lo up
iptables-restore </etc/iptables
ip link set eno1 up
ip addr add 1.2.3.4/24 dev eno1
ip route add default via 4.3.2.1 dev eno1• перезапускает его если он вылетает при определенных кодах возврата
Runit это супервизор, который контролирует сервисы по SIGCHLD — иными словами сервис не должен демонизироваться, но зато нет никаких pid-файлов и race, сервис будет гарантированно автоматически перезапущен (1 раз в секунду если он непрерывно падает).
Можно добавить (однострочный) finish-скрипт, который выключит сервис если он завершился с определённым кодом возврата (чтобы он перестал перезапускаться).
• не даёт запустить больше чем один процесс (при повторных вызовах)
Не даёт, разумеется. Попытка запустить уже запущенный сервис успешно завершается ничего не сделав.
• адекватно завершает процесс при shutdown но до того как отключатся сеть и некоторые другие процессы
Отключение сети и маунтов выполняется на третьем (тоже синхронном) этапе, после того как был инициирован shutdown/reboot и второй этап (запустивший все сервисы) был завершён (сервисы были остановлены).
• всё вышеперечисленное должно работать одинаково (и надёжно) в debian/arch/centos
Так и работает, достаточно поставить и запустить runit.
Сколько строчек получилось? И насколько понятно-читаемых?
Ну, как сказать. Приведу несколько примеров. Начнём с простого: sshd.
$ cat /etc/sv/ssh/run
#!/bin/sh
exec &>/var/log/all/.log
exec /usr/sbin/sshd -DНо это скучно. Давайте что-то по-сложнее, dbus:
$ cat /etc/sv/dbus/run
#!/bin/sh
exec 2>&1
mkdir -p /var/run/dbus
rm /var/run/dbus.pid
dbus-uuidgen --ensure=/etc/machine-id
exec dbus-daemon --nofork --systemНу или давайте что-то с зависимостями от других сервисов, напр. postfix:
$ cat /etc/sv/postfix/run
#!/bin/bash
exec 2>&1
sv start /etc/service/postsrs &>/dev/null || exit
sv start /etc/service/postgrey &>/dev/null || exit
sv start /etc/service/opendkim &>/dev/null || exit
sv start /etc/service/opendmarc &>/dev/null || exit
exec postfix start-fgНу и на закуску X-ы:
$ cat /etc/sv/x/run
#!/bin/bash
exec &>/var/log/all/.log
sv start /etc/service/*tty* &>/dev/null || exit
sv start /etc/service/dbus &>/dev/null || exit
sv start /etc/service/elogin &>/dev/null || exit
. /etc/profile
exec slim -nodaemonКак Вам количество строчек и их читаемость?
P.S. Забавный факт: официально в runit вообще нет поддержки зависимостей между сервисами, считается, что если сервис при запуске не нашёл чего-то необходимого, то он просто упадёт и будет перезапущен 1-2 раза (а в тому моменту сервисы, от которых зависит этот уже будут готовы к работе). Так что вышеупомянутая "реализация" зависимостей между сервисами — это по большей части моё баловство, не всегда обязательное. Полноценная поддержка зависимостей есть в S6, так что кому не хватает функционала Runit просто берёт S6, там намного больше фич.
Выглядит круто, но есть куча вопросов
- что с параллельностью запусков сервисов? То что здесь я вижу — скорее последовательный запуск. То что я увидел у Вас — это не зависимости, а чертизнаетчто.
- в systemd основная фишечка — это расширяемость и переопределение. Вот, скажем, постфикс — он притаскивает свой системный юнит. Меня он не устраивает. Что я делаю? Я закидываю переписанный юнит на /etc/systemd/system или дроп-ины туда и я уверен, что при обновлении пакета постфикса мои изменения не будут перезаписаны. Это на самом деле очень важно.
- Что делать если нужны дополнительные возможности — вроде засовывания целых поддеревьев процессов в це-группы, лимитирование по памяти, процессору и прочие продвинутые штуки?
И многое другое. Я так понимаю, что в рамках примера "runit — простой до безобразия" Вам это не удалось сделать. В ключе же, что "соберу свой дистрибутив с нуля" — да, это возможно альтернативный, возможный подход. Но точно не в production, чтобы все было унифицированно, понятно, исправляемо любым квалифицированным инженером (=поддерживаемо) и относительно дешево.
Сервисы запускаются параллельно всегда. Где Вы там увидели последовательный запуск — я без понятия. Ещё раз, у runit 3 стадии работы:
- На первой выполняется один скрипт, который инициализирует систему синхронно (mount, udev, fsck, sysctl, net — вот это вот всё). Тут нет особо долгих или блокирующих операций, поэтому выполняется он за 3-5 секунд, что не имеет никакого значения, учитывая как часто перегружаются машины.
- На второй одновременно запускаются все сервисы, без учёта каких-либо зависимостей. Если каким-то сервисам чего-то нехватило — они падают и автоматически перезапускаются через 1 секунду.
- Третья запускается в момент shutdown/reboot, это тоже один синхронный скрипт как на 1-й стадии, он сначала останавливает все сервисы, а потом выполняет необходимые операции перед отключением (hwclock, alsactl, random, net, umount). Он так же отрабатывает за пару секунд.
В целом, такое разделение операций на синхронные (1,3) и асинхронные (2) позволило сильно упростить всё — и реализацию самого runit, и понимание мной как админом что и как происходит при загрузке и отключении системы.
Вот, скажем, постфикс — он притаскивает свой системный юнит. Меня он не устраивает.
Ну, в Runit с этим всё хорошо. В смысле, postfix ничего про runit не знает, и своих юнитов не притаскивает. Вышеупомянутый мной run-файл пишется ручками, под нужды текущей системы. Напр. у моего папы на компе postfix нужен чисто для отправки почты (можно было какой-нить ssmtp поставить, наверное), поэтому у него run-файл postfix выглядит вот так:
#!/bin/sh
exec postfix start-fg 2>&1И да, представляете, написать такое руками займёт примерно столько же времени, сколько установить этот файл каким-нибудь apt install postfix-runit.
По сути, я именно это и пытаюсь Вам всё это время объяснить: загрузка системы и запуск сервисов может (и должен) быть намного-намного проще, чем это сделано в sysvinit и systemd.
засовывания целых поддеревьев процессов в це-группы, лимитирование по памяти, процессору и прочие продвинутые штуки?
Ну, тут такое дело. Если Вам реально необходимы все те продвинутые фишки systemd — значит надо использовать systemd и платить запрошенную им цену (сложность), потому что в этой ситуации данная цена является приемлемой.
Но лично из моего опыта — в этих фичах просто нет необходимости… для типовых системных сервисов. Они слишком давно существуют, написаны и отлажены достаточно хорошо, и не замечены в безудержном пожирании системных ресурсов. Иными словами, изолированы они по cgroups или нет — на работе системы это никак не сказывается. А сервисы не системные, наши собственные, реализующие работу нашего проекта, под который этот сервер, собственно, и был запущен — это совсем другое дело, и для них ограничивать ресурсы действительно необходимо… только вот это уже отлично делает докер/куб. (Иными словами, systemd в этом месте опять успешно решил не существующую на практике проблему.)
P.S. Впрочем, если речь не о cgroups, а о более традиционных ограничениях (chroot, uid/gid, env, ulimit, …) то для этого существует куча мелких утилит (идущих в комплекте и с daemontools, и с runit, и с s6 — напр. вот chpst из runit), которые обычно вызываются из run-файла цепочкой. Например, запуск внутри chroot под юзером nobody (плюс обновление бинарников и so-библиотек внутри chroot-каталога):
$ cat /etc/sv/3proxy/run
#!/bin/sh
exec 2>&1
# update binaries and libraries
for f in $(find root/ -type f -perm /001 | sed s,^root,,); do
cp "$f" "root$f"
done
exec chpst -/ root/ -u nobody /usr/bin/3proxy /etc/3proxy.cfgвыполняется он за 3-5 секунд
У меня через 5 секунд уже графическая форма логина отображается, при том что ещё даже не все USB-устройства проинициализированы на тот момент.
они падают и автоматически перезапускаются через 1 секунду.
Бессмысленное засирание логов тоннами ошибок, systemd в этом плане явно лучше.
Ну, насколько я понимаю, львиную часть этих 3-5 секунд съедает как раз блокирующая инициализация udev (т.е. по сути код Вашего любимчика Поттеринга). Впрочем, это не важно. Если кому-то экономия 2-3 секунд на перезагрузке компа компенсирует сложность systemd — значит он понимает, зачем ему нужен systemd и всё в порядке. Я лично комп перегружаю примерно раз в месяц для обновления ядра, и мне эта экономия сложность systemd точно не компенсирует. (Кстати, на соседнем компе Debian 10 с systemd, и я что-то не замечал, чтобы он грузился быстрее моего, а точнее он грузится заметно медленнее, хотя в автозапуске у него меньше всего и нет браузера, в отличие от моего компа.)
Бессмысленное засирание логов тоннами ошибок
Ну вот откуда вы все это берёте… Между сервисами не так много зависимостей (особенно если не считать "сервисами" вещи вроде fsck/mount/net — которые в Runit делаются до запуска всех сервисов), они не так часто умудряются запуститься настолько неудачно, чтобы это сломало зависимости и кто-то из них упал, плюс вышеупомянутый мной пример проверки зависимостей прямо в run-файле позволяет просто не запускать сервис (и не писать ничего в лог) пока зависимости не готовы. В результате в логах если и бывают ошибки на эту тему, то буквально одна на все сервисы, и то не при каждом перезапуске. (Иными словами systemd опять решил несуществующую проблему.)
Ну вот откуда вы все это берёте…
Из практики. Какой-нибудь danted зависит от сетевых интерфейсов, какой-нибудь Django-сайт зависит от запущенного MySQL и насыпет ошибок в лог при его отсутствии, и так далее
вышеупомянутый мной пример проверки зависимостей прямо в run-файле
И это всё вместо того, чтобы написать одну строчку?
After=opendkim.service opendmarc.service mysqld.service
Ваш пример является отличной антирекламой runit. Я предпочту написать одну строчку декларативного конфига, чем десяток строчек мутных скриптов с кучей ручных проверок.
Публичный или корпоративный веб-сервер, который поднимется, не ожидая запуска базы, может логи очень сильно забить 500-ми.
Ну, как сказать "забить". Если юзеры честно получали эти 500-е — я бы хотел видеть их в логах, это поможет саппорту разбирать жалобы юзеров.
Но в общем случае всё, что я тут пишу про runit — это про системные сервисы. Я не принимаю во внимание запуск самописных и прочих "enterprise" сервисов на java и нужных им БД, потому что всё это обычно запускается в докере/кубе, и проблемы эти разруливаются (или нет) средствами докера/куба. Нет, серьёзно, когда-то действительно выкатывать их ансиблом в systemd было разумным, но в 2020-то зачем так делать?
в 2020-то зачем так делать?
Затем, что почему бы и нет? Выкатываю ансиблом в systemd все свои серверы и радуюсь жизни. Зачем тратить драгоценные ресурсы вдсок на жирнющий докер и возиться с его настройкой и написанием обмазанных костылями докерфайлов — не знаю. (У ансибла, впрочем, есть свои недостатки, но systemd тут уже ни при чём)
Вопрос "зачем нужен докер для собственных сервисов" несколько выходит за рамки обсуждения systemd. Но в ответе на него обычно звучат слова "тесты/CI, контроль внешнего окружения, простота запуска проекта на машине разработчиков, лёгкая переносимость между серверами, …".
Насчёт жирнющий и настроек — первый раз слышу такие претензии в отношении докера, особенно в контексте enterprise-java-сервисов, на фоне которых демон докера теряется по определению. А настройка обычно сводится к перенаправлению логов в более подходящее место и запуску docker swarm init|join.
особенно в контексте enterprise-java-сервисов
К счастью, судьба меня бережёт от кровавого тяжёлого ынтырпрайза, и я верчусь в небольших проектах, котором и самой нищебродской вдски более чем достаточно и которым докер ни к чему.
А слова "тесты/CI, контроль внешнего окружения, простота запуска проекта на машине разработчиков, лёгкая переносимость между серверами, …" легко реализуются и без докера, если руки из правильного места растут.
лёгкая переносимость между серверами
да-да-да, это пока не выясняется одно из нескольких:
- версия докера не та (были проблемы, если образы собранные последним докером запускать на более старом)
- нужны какие-то специфичные sysctl (напр., для запуска эластика)
- пока архитектура процессора та же — если скомпилировали код с оптимизациями под xeon, то он запросто может не запуститься на amd — тупо illegal instruction и все. Это как бы не собственно проблема докера, а ложь об обещаниях переносимости (она сама внезапно не появляется, но современному поколению это неизвестно)
- пока не нужно засунуть systemd внутрь докера — там целая эпопея с приключениями
- пока не нужен специфичный драйвер оборудования
- пока не нужен privileged режим
…
где-то тут еще могут стрельнуть особенности работы сети с докером (привет, телефония и прочие штуки) или особенности работы с диском
и масса другого. Т.е. отрицать то, что докер отрыл новую страницу в истории и популяризировал контейнеризацию нельзя. Но натянуть на него все возможные юзкейсы… попросту нормально не получается. Да и не нужно.
docker swarm init|join.
swarm мертв, закопайте его труп и забудьте его уже.
напр., для запуска эластика
Это какие? Разве что число дескрипторов, но такие вещи делаются на самом хосте.
Разве что число дескрипторов, но такие вещи делаются на самом хосте.
так об этом и речь! Переносимости нет (контейнер стартанет и упадет) — пока не настроишь хост. В общем-то возможно пример не особо честный, но просто надо иметь в виду, что абстракции текут. И это надо уметь учитывать.
Не всегда это возможно.
managed сервер или кластер. Нам только докер/кубер ендпоинты открыты.
swarm мертв, закопайте его труп и забудьте его уже.
Standalone swarm — да. Встроенный в докер — живее всех живых, и отлично заменяет намного более сложный куб в большинстве мелких/средних проектов.
жирнющий докер
Чего? Он вообще не тратит никаких ресурсов, оверхед докера давно развеянный миф для подавляющего большинства приложений. Плюс полно других рантаймов, которые легче, но это сказывается только на скорости запуска контейнера.
подавляющего большинства приложений.
все так, но иногда оверхед от докера вылезает :-/
100-150МБ оперативы на демон докера — раз.
Гигабайт-другой на скачивание образов ubuntu/debian/alpine, причём в разных контейнерах разные их версии — два.
Оверхед на сеть, на что жалуются примерно все пользователи докера — три.
И всё это пихать на вдску с 1ГБ оперативы и 10ГБ HDD? Спасибо, не надо.
Плюс полно других рантаймов, которые легче
В любом случае мне и без докера хорошо.
Гигабайт-другой на скачивание образов ubuntu/debian/alpine, причём в разных контейнерах разные их версии — два.
Алпайн весит 3МБ, убунта 30МБ. О чем вы?
Оверхед на сеть, на что жалуются примерно все пользователи докера — три.
На подобной вдске? Смешно. А что до жалоб — я не встречал подобных жалоб за года работы с докером (что скорее означает, что проблемы либо нет, либо она вызвана не докером, либо встречается в очень специфичных кейсах), а исследование IBM показывает ничтожную разницу, которую чтобы разглядеть в продакшене я не знаю что надо делать. А уж когда работаешь на таком уровне, то как правило есть железо, чтобы было пофиг на этот оверхед.
Что до оперативки, если 100мб это настолько дорого, то это уж совсем какой-то странный кейс. Но ладно, кому-то может надо экономить даже настолько.
Алпайн весит 3МБ, убунта 30МБ.
В реальном использовании на многочисленных разных образах набегает несколько гигабайт.
это уж совсем какой-то странный кейс.
Рад за вас, если у вас завались денег и вы можете скупать дедики целыми стойками, не задумываясь об оперативке. К сожалению, я не из таких. Запустится с десяток служб по 100МБ — и всё, оперативка кончилась, привет swap и OOM Killer.
В реальном использовании на многочисленных разных образах набегает несколько гигабайт.
Это уже проблема конкретных приложений, которые поверх образа убунты накатывают хренову тучу юзерспейс фигни. Сами базовые образы весят ничтожно мало.
Запустится с десяток служб по 100МБ
Откуда десяток уже взялся, когда докер один?
Откуда десяток уже взялся, когда докер один?
для меня до сих открытый вопрос — насколько хорошо докер шарит страницы памяти между одинаковыми инстансами одного приложения в нескольких репликах ( суть — в разных контейнерах, можно даже из разных, но бинарно идентичных образов).
Откуда десяток уже взялся, когда докер один?
Вы же понимаете, что на сервере докер будет далеко не единственным процессом?
будто тут докер виноват в этих сервисах
Ну так докер один из сервисов. Если у меня есть возможность не занимать лишние 100МБ — зачем мне их занимать? Я их лучше мускулю выдам, чтобы он чуточку быстрее запросы выполнял.
А ситуации, когда я буду готов пожертвовать 100МБ памяти, гигабайты образов и денежку на более мощный сервер ради какого-нибудь фатального преимущества докера, у меня пока не возникало.
Вот как раз у докера таких средств нет, у докер-композ почти нет, а у кубера опять нет.
Да! :) Но делать-то нечего, запускается всё это всё-равно в докере… так что наличие этих средств у systemd ничем не поможет.
На самом деле не знаю, как насчёт вырожденного кейса с подключением единственного сервиса-вебсайта к БД, может в этом случае разработчики ленятся нормально написать код (пере)подключения. Но обычно в мире микросервисов ситуация, когда внезапно отвалился какой-то сервис из тех, от которых зависит текущий сервис — штатная. Поэтому код всегда пишется так, чтобы это не создавало проблем, и (пере)подключение происходит в фоне, как на старте сервиса так и в процессе его работы. И в этом случае нет никакой необходимости отслеживать зависимости между сервисами на уровне их супервизора.
База, обычно, часть сервиса. И вот тут какой-нибудь сервис дискавери видит, что сервис есть, 80-й порт слушает, а по факту у него один ответ — 500 с каким-нибудь mysql has gone
У вас за скромные несколько постов здесь уже набралась пачка «зачем так делать».Угу. И при этом ещё усиленное педалирование количества
Issues.Конечно если все баги закрывать с
WONTFIX или NOTERROR — то ни одного бага в таком софте не будет.Но захотите ли вы им пользоваться?
Антиреклама Runit получилась знатная, надо сказать…
Если каким-то сервисам чего-то нехватило — они падают и автоматически перезапускаются через 1 секунду
Потрясающий ход, конечно.
Таки да! Простой, очевидный, и надёжный. Из потенциальных недостатков разве что "засирание логов", но я про это ответил выше — на практике этой проблемы нет.
Да, трата. Но во-первых это количество ресурсов пренебрежимо мало, и во-вторых вовсе не бесполезная: её польза в возможности использовать значительно более простой и надёжный инструмент — runit.
Пренебрежимо мало, пока вас в энтерпрайзе не просят запустить какую-нибудь джава или вебсферу.
Если каким-то сервисам чего-то нехватило — они падают и автоматически перезапускаются через 1 секунду.
Фактически, это busy wait. Ничего хорошего в нём не вижу.
И не факт, что они потом перезапустятся.
Вот ситуация в моём случае: имеется сервер OpenVPN, серверу требуется сетевой мост. Так вот иногда случается, что при старте системе он запускается слишком быстро — раньше, чем поднимется мост, из-за чего сервис не упадёт, а будет просто работать некорректно. То есть придётся сначала зайти по ssh и перезапустить сервис.
В runit сеть настраивается до запуска всех сервисов.
Иными словами, описанная Вами проблема сначала была искусственно создана (кто-то решил, что абсолютно всё-всё надо сделать "сервисами" и запускать асинхронно), а потом потребовалось героически и с кучей лишних сложностей её решать.
У вас очень opinionated view. Сеть и ее настройки — это не монолит. Как пример, ВПН запускается только тогда, когда есть активный интерфейс. Или на фрилансим регулярно вижу — напишите скрипт, который ВПН внутри впна, который внутри третьего впна. На системди не без боли, но сделаешь. На runit?
Честно говоря, мне такое делать пока не приходилось. Насколько я понимаю, при использовании wireguard это всё заработает автоматически, достаточно просто запустить все три. При использовании OpenVPN, вероятно, придётся добавить в run-файл VPN2 зависимость от наличия нужного интерфейса VPN1 (предположим, VPN1 поднимает tun1, VPN2 поднимает tun2, …):
### в начале /etc/sv/openvpn2/run:
ip link show tun1 &>/dev/null || exitно вот что случится если/когда этот интерфейс временно отвалится — вопрос любопытный. Если само не заработает, то придётся в finish-скрипт первого openvpn добавить перезапуск зависящего от него второго:
### в /etc/sv/openvpn1/finish:
sv t openvpn2Ага, а теперь добавлю пикантную подробность: изначально всё настраивалось в Ubuntu 14 (без systemd).
В runit сеть настраивается до запуска всех сервисов.Гениальность просто зашкаливает. Напоминает историю с мой прошлой работе, когда экскаватор перерубил оптику и ни один комп нельзя было перезагрузить пока сеть не восстановится, так как они все банально висли на этапе «достучаться к NFS-серверу из соседнего офиса».
Притом что этот NFS-сервер нужен, чтобы можно было выложить изменения в документацию без которых можно прекрасно обойтись.
Иными словами, описанная Вами проблема сначала была искусственно создана (кто-то решил, что абсолютно всё-всё надо сделать «сервисами» и запускать асинхронно), а потом потребовалось героически и с кучей лишних сложностей её решать.Отчасти согласен. С тем только лишь замечанием, что вот как раз «поднятие сети» и «монтирование файловых систем» — точно нужно делать асинхронно.
Да, в некоторых ситуациях поднятие некоторых сетевых интерфейсов (OpenVPN, например) и монтирование некоторых сетевых файловых систем (не критичных для основного функционала сервера) действительно надо делать асинхронно (и это без проблем делается в runit).
Тем не менее, тот факт, что вся остальная сеть и маунты делаются синхронно до сервисов — крайне облегчает жизнь и сильно уменьшает необходимость в и сложность управления зависимостями между сервисами.
Сеть и монтирования в Runit выполняются на 1-м (синхронном) этапе загрузкиОтлично. У нас упал NFS-сервер отвечающий за
/home/build (без него система вполне работоспособна, только не работает распределённая сборка… она не всем и не всегда нужна).Как Runit разрулит эту проблему, когда я смогу войти в свою любимый GNOME (KDE, XFCE, нужное подчеркнуть) и, главное, что будет с теми сервисами, которым нужен-таки
/home/build?Полноценная поддержка зависимостей есть в S6, так что кому не хватает функционала Runit просто берёт S6, там намного больше фич.Как именно происходит переход?
Потому что главная претензия к systemd — это то, что «если мне это всё нинужна, то я не хочу всё это изучать». Два системы, от одной из которых можно плавно и безболезненно перейти к другой и обратно — это решение… но вот насколько прост как раз этот переход?
Не знаю, мне пока хватало возможностей runit. Но если/когда понадобится что-то, чего runit не умеет — буду переходить на s6.
Немного напрягает то, что runit вообще не развивается много лет — автор считает его "законченным". В каком-то смысле так и есть, он делает всё необходимое (из поставленных перед ним изначально задач) и делает это хорошо — багов нет, всё работает. Но опыт показывает, что в long term эта стратегия с софтом, к сожалению, не работает — окружающий мир меняется, и достаточно сильно, поэтому софт, который этот факт игнорирует и не развивается вместе с миром — умирает. Пока что изменения мира никаких проблем с runit не создали, но первый "звоночек" уже прозвучал — поддержка cgroups выглядит интересной, хоть и не особо нужной (для системных сервисов) фичей… только вот уже появился сервис elogind (вытащенный logind из systemd) которому для работы нужны предоставленные менеджером сервисов cgroups (к счастью, в нём есть возможность реализовать этот функционал в нём самом, а не ждать его от менеджера сервисов, так что пока обошлось). А вот S6 активно развивается, так что "путь отхода" с runit доступен, если он вообще понадобится, конечно.
А почему однотипный код в программах выносят в функции, а не дублируют его?
Понятных? Не соглашусь. Мне понадобилось написать самому первые такие скрипты незадолго до того, как в arch пришел systemd. Так что я точно могу сказать, что без опыта разобраться в systemd'шных сервисах оказалось проще и быстрее (а я смотрел, как решить мою задачу на убунте, центоси и когда я отчаялся — полез гуглить, узнал про systemd, попробовал его), и я просто поставил на тот сервер arch и решил задачу. И до сих пор рад, systemd + ansible это прям удобно.
Потому что systemd позволяет сделать запуск маленького читаемого скриптика И ЕЩЁ КУЧУ ВСЕГО, при этом оставаясь читаемым. Если кроме скриптика ничего больше не нужно, ничего не мешает сделать systemd-юнит, который будет только запускать этот скриптик и больше ничего.
Для меня знакомство с init и systemd случилось одновременно ("перепиши", говорит, "вот эти скриптики, ну ты разберёшься"), и честно скажу, systemd гораздо, гораздо понятнее и, эм, документированнее.
Да, поддержу, что как система инициализации systemd на порядки превосходит sysvinit.
Помню, было прямо откровение, когда в первый раз здоровенная и не очень надежная баш портянка инициализации превратилась в надежный, простой и понятный systemd юнит.
А вот с journald не сложилось. Бинарный формат — печаль, т.к. не пригоден для легкого просмотра.
journald прекрасен, т.к. Вам логи глазами все равно напрямую смотреть не нужно — почти наверняка Вы логи фильтруете (стандартные текстовые) grep'ом или чем угодно, чтобы выбрать нужное. Ну, так пользуйтесь journalctl — делов-то. Это раз. Два — логи на машине это в целом ненадежная вещь — их можно сливать в некое централизованная хранилище, а там уже гуй, поиск, дашборды и все такое. Третья история, что по сути написав приложение по 12 factor app, что сейчас и не только модно, но и является необходимостью, просто пакетируете его для установки на сервер с systemd unit'ом и вуаля! Все логи собираются, красота.
По-моему journald это один из тех компонентов который тянет systemd вниз.
Например, разумно ведь в desktop системе все логи писать на HDD, а SSD использовать для более интересных задач, на самом деле нет:
time sudo journalctl -n 10 --no-pager
real 0m8,817s
user 0m0,020s
sys 0m0,059sв то время как с того же диска и точно так же с "холодным" дисковым кэшем:
time tail -n 10 /var/log/pacman.log
real 0m0,022s
user 0m0,004s
sys 0m0,000sВсе бы ничего, но systemctl status использует journald и поэтому тоже дико тормозит: https://github.com/systemd/systemd/issues/2460
Или захочется использовать центрилизованный сбор логов и можно поиметь кучу проблем: https://habr.com/ru/company/southbridge/blog/317182/, некоторые не решаются годами: https://github.com/systemd/systemd/issues/1387
Спасибо за комментарий по существу.
https://habr.com/ru/company/southbridge/blog/317182/
Знаю такую историю. И я бы тоже не стал журналом передавать журнал на удаленную машину. У меня есть достаточные опасения (как и у Вас), что это не будет нормально работать. Но с внешним решением — будь то rsyslog или fluent-bit — все прекрасно передается по удаленному протоколу.
Еще добавлю, что была прекрасная вводная статья от Селектел по вопросу journald.
Например, разумно ведь в desktop системе все логи писать на HDD, а SSD использовать для более интересных задач, на самом деле нет:
Разрешите вопрос? А что мешает Вам в Вашей личной конфигурации подмонтировать раздел под логи с HDD-накопителя? Или вы думаете, что дефолты в конкретном дистрибутиве говно? А зачастую это так. Но тогда причем тут системди?
Например, разумно ведь в desktop системе все логи писать на HDD, а SSD использовать для более интересных задачв 2020 году стало сложновато найти десктоп с hdd, тенденция к «hdd где-то там далеко в облаках/на серверах», а в рабочих станциях и домашних компах одни только ssd. Гибриды ssd + hdd в одной машине — издержки переходного периода, который потихоньку заканчивается.
Ну и — ничто не мешает же смонтировать hdd в /var/log.
разумно ведь в desktop системе все логи писать на HDD
У вас в 2020 году HDD на десктопе? Даже без bcache? А что-за диск, кстати, не какой-нибудь пыльный Seagate 15-летней давности или люто тормозной WD Green случайно?
но systemctl status использует journald и поэтому тоже дико тормозит
Это никому не нужно. Большинство на SSD живут. Поэтому Поттеринг разумно выжидает, пока все оставшиеся некроманты не перейдут на SSD.
Или захочется использовать центрилизованный сбор логов
Ну опять же — если очень надо, то делайте PR на гитхаб. Очевидно, что этот функционал не особо востребован, поэтому тикет висит несколько лет, а решить его некому.
Для сбора логов есть другие, более подходящие средства.
У вас в 2020 году HDD на десктопе?
Это никому не нужно. Большинство на SSD живут.А что тут такого сверхъестественного? В тех же самых ноутбуках есть выбор, условно либо HDD на 1 Тб, либо SSD на 256 Гб за сравнимые цены.
У меня 9-летней давности ноут с 500Гб SSD. Что я делаю не так?
Цены? Ну вроде как в IT индустрии на зарплаты люди не жалуются?
(сразу добавлю, что ноут — это ThinkPad x220 и он старый не потому, что денег нету на новый :)
Цены? Ну вроде как в IT индустрии на зарплаты люди не жалуются?Разумеется все остальные, не айтишники, а так же те, кто только начал работу и всё ещё не получает условные 1000 в месяц тоже могут купить объёмный ssd. И именно по этой причине для windows 10 рекомендуют ssd.
Лично я для себя преимуществ ssd не вижу. Ускорение загрузки раз в месяц не стоит тех денег.
Есть хорошие по железу/цене ноутбуки с комбинациями типа SSD 512Gb + HDD 2Tb
Ну и не только айтишники ноутбуками пользуются.
Ну, вообще я долго пользовался линуксами на ноутбуках — где-то с поколения thinkpad t4x. И в целом складывается впечатление, что это костыли и велосипеды. Чего только стоит, что постоянно что-то приходится вручную доконфигурировать. Есть постоянно маленькие досаждающие баги (из серии "блютуз не включается"). Танцы с установкой — uefi/legacy/secureboot. Но в целом обычно работоспособная конфигурация получается. И все относительно ровно. Но вот время работы от АКБ прям расстраивает. По сравнению с ним же под виндой. Для меня это особой проблемой не было — розетка обычно есть. Но кто-то другой может расстроиться.
В ноутбуках используется довольно специфичное железо с закрытым API и ограниченной поддержкой производителями операционных систем.
Мое мнение после 10 лет эксплуатации линукса на ноутах(thinkpad x серии и vaio) — для мобильного рабочего места линукс не подходит, будет какая-то фигня вылазить постоянно, вот для сервера или десктопа очень даже неплохо.
Поэтому перешел на мак потому что в нем в отличии от thinkpad, нормальное охлаждение(кулеры+алюминиевый корпус), нормальный корпус(пластик скрепит, царапается, затирается), нормальная ось(режим сна работает). При этом и мак и thinkpad x серии в одну цену. И это уже не тот старый добрый thinkpad от ibm в котором корпус был титановом-магниевый.
Все именно так, поэтому сижу на macbook pro 13
В теории можно возродить историю с thinkpad на новом уровне, но очевидно, что это будет гик продукт. И поэтому стоимость будет ого-го, а проблем надо решить массу. С другой стороны, у этих же ребят что-то получилось https://system76.com/laptops/lemur ?
И скажу прямо, когда Торвальдс начнет использовать ноут как мобильное рабочее место — эти все проблемы решаться.
Поклонником thinkpad являлся до последнего, но терпение вышло, да и сидеть на старом «трушном» железе уже проблематично, хотя и таких знаю, кто до сих пор покупает старые ibm thinkpad для работы, но это очень специфичная работа, в основном в консоли + хfce на минималках. И если до этого я всеми силами пытался избегать мака, то сейчас производители не оставили альтернативы.
Кастомные решения всегда были, но это еще хуже чем стоковые, рынок сильно узкий, бренд неизвестный, и бабла в r&d вливают сильно меньше чем apple, dell, hp и прочие крупные производители ноутов.
бабла в r&d вливают сильно меньше чем apple, dell, hp и прочие крупные производители ноутов.
не ради холивара, но что толку от вливаний в R&D, если ноуты получаются посредственные? Я уже у второго работодателя вижу патологическую любовь к корпоративным HP. И могу сказать, что это обусловлено совершенно не техническими причинами, а скорее тем, что раз заказываешь сервера HP, то вот тебе и ноутбуки в нагрузку. Это раз. Два — я не могу сказать, что те же хапэ ужасные ноутбуки — десктопный сегмент еще хуже, но эффективность работы на них по разным причинам сильно ниже, чем на аналогичных dell или маках. И это серьезно. Потому что ноутбук должен быть не только напичкан всякими крутыми r&d штуками и нести на себе крутой логотип крутого бренда, но и вообще быть нормальной, сбалансированной железкой. А крупным вендорам… пофиг. Они не этим берут. С другой стороны — да, есть поддержка, вероятность проблем минимальна, в отличие от безымянного Китая, ну, и всегда есть гарантия — вот была история, что у XPSок батарейка вспухает — но приходится вендору идти на попятную и менять или чинить несчастным владельцам устройство.
Так что, повторюсь, по совокупности — я тоже перешел с thinkpad'ов на мак. (((( и пока альтернатив не вижу.
В целом маки имеют кучу проблем, но количество этих проблем стабильно в каждой версии и не больше двух проблем за раз. Другие же производители улучшают много чего и сразу, и в целом решение хуже чем предыдущее, вот и страдает качество.
С «не эппл» — это как раз хорошо показывает линукс, я до этого постоянно пользуясь только одной x серией thinkpad-ов, при покупке нового сначала смотрел в инете что с поддержкой. И где-то первые пол года — год было печально и больно с поддержкой. И это в пределах одной серии одного производителя, а что говорить про переход между производителями и разными сериями.
r&d наверное важнее больше в мобильном сегменте и только потом эти разработки должны попадать в ноуты.
Linux нормально маки поддерживает? Или вместе с железом и софт сменили?
В смысле нормально? Я не понимаю Вашего комментария? ОКей. Давайте с самого простого — нафига на мак ставить линукс? Если очень надо — докер есть, виртуалбокс тоже нормально работает. Предположу, что Вы бескомпромиссны, мак ось вообще не переносите и хотите полностью тюнить систему сами. Ну, окей — ставьте линукс, кто запрещает-то? Оборудование у маков вполне стандартное. Ну, может какие-то специфические возможности потеряете вроде шифрования дисков. Ну, и ладно.
Речь шла о том, что железо у эппл хорошее, качественное, корпуса не скрипят и т. п.
А почему его не поставить? Если я его покупаю как просто хороший ноутбук и с радостью бы купил без ОС, если бы он стоил заметно дешевле чем с ОС. Зачем мне переучиваться на новую ОС?
Если я его покупаю как просто хороший ноутбук и с радостью бы купил без ОС, если бы он стоил заметно дешевле чем с ОС.
В случае маков такого нет и никогда не будет
Речь шла о том, что железо у эппл хорошее, качественное, корпуса не скрипят и т.
Не хуже, чем у остальных. Но есть и серийные проблемы, о которых все знают.
У меня на старом ноуте была точно такая же ситация, но с виндой. Там в итоге ещё и SSD отваливался из-за перегрева.
Сейчас новый ноут — тьфу-тьфу, не включается.
Мак точно для разработчиков?
вполне. Опять же — не предполагается, что что-то сверх-тяжелое будет выполняться на ноутбуке, но какие-нибудь легкие тесты и отладка — почему нет. У DS'ов больше бомбит от того, что у им своим GPU-оптимизированные (CUDA) приложения локально не позапускать. Этот кусок рынка яблоко реально откровенно просрало, но, к справедливости, у всех DS'ов есть мощные самосборные машинки с 3+ видеокартами для того, чтобы датасеты с kaggle обсчитывать, куда они ходят удаленно по ssh — и тут опять встает вопрос — а действительно ли локально нужно иметь мощную машину.
Ну, и еще один момент — надо понимать — мы пишем код под POSIX (ну, типа переносимый между lin/win/mac) и тогда все ок, либо надо расчехлять докер или виртуалку, т.к. мак все-таки другая операционная система.
Только вот почему-то гуглохром под макосью при заходе на соответствующую страницу браузер наглухо вис (до перезагрузки, впрочем), так что пришлось звонить с мобильника.
активно пользуюсь — google chrome, meet, hangouts, zoom, skype, telegram и пр — проблем никаких нет
Есть хорошие по железу/цене ноутбуки с комбинациями типа SSD 512Gb + HDD 2TbЯ не отрицаю их наличие. Просто среднестатистический человек не может их купить, не больше ни меньше.
Среднестатистический человек не может или не будет в Линукс, и ?
Поэтому Поттеринг разумно выжидает, пока все оставшиеся некроманты не перейдут на SSD.Вот уж действительно некромантия, прогресс ради прогресса. Вот интересно, а использование x86 приложений, это некромания в какой степени?
Я себе недавно взял себе ноутбук — так в нём вообще нет возможности поставить HDD, только два M.2 SSD. В итоге поставил SSD на терабайт — обошлось мне это в 8 тысяч рублей, ни о каких $500 речи больше нет.
48 — ноутбук, 8 — ssd, 2.5 — модуль памяти.
Ух-ты, я как-то пропустил момент когда терабайтники SSD начали стоить чуть больше $100! Да, теперь для HDD реально осталось только одно применение — хранить видео-файлы и бэкапы.
Я так понимаю, это qlc. Там вопросы к скорости за пределами кэша и к надежности. Tlc всё-таки две сотни стоит.
Нет, там TLC, стоят они сейчас порядка $120-130 за обычные модели, а $200 и выше — это уже топовые модели типа Samsung 970 PRO.
На самом деле, всё зависит от сценария использования. Мне не нужно копировать за раз несколько десятков гигабайт данных, поэтому на скорость за пределами кэша мне пофигу. Основной критерий был — энергопотребление, нагрев при достаточных скоростных характеристиках.
SMR-то выдержит, а механика?
Стрессовая нагрузка (запуск) в разделившемся на фракции гидроподшипнике может передать привет. Особенно, если на нем тоже сэкономят.
Только вот винт на полке не попадает ни в одну из этих категорий.
И это прекрасно.
Но вы же не можете не понимать, что о совершенно другом диске этот опыт не говорит ровным счетом ничего.
Особенно если учесть, что в предполагаемом новом smr-диске начали экономить, ради чего, собственно, smr-то и завезли, и стали втихую пропихивать.
Собственно, этот-то чего сказать хотел… Спорить о надежности двух продуктов, сделанных с целью максимального удешевления… ну, то такое.
Да и гарантия у WD 5 лет на эти железки. Так что всё не так страшно. А данные можно и на самом надежной модели диска потерять — там как с динозавром вероятность.
Так что всё не так страшно, если в десктоп/ноутбук втыкать. В серверах может и быстро умрет.
Но да, TLC, а тем более дешевые — наименее надежные по тестам, это не новость. Хочется надежных — либо платите скоростью доступа, либо платите интелу, давно известный факт.
А в серверах надо использовать диски для серверов, у которых резервные области большие, алгоритмы работы нормальные и скорость не падает в ноль, когда внезапно кто-то флашит каждую запись на диск.
У меня OCZ отлично работает с 2011 года. Осталось ещё 98% ресурса. А от багованного контроллера умер купленный чуть раньше Corsair x128.
Но в целом надо понимать, что SSD — это штука не столько для надёжного хранения данных, сколько для ускорения работы с данными. Необходимость бэкапов никто не отменял.
400 TBW для террабайтника — не самый плохой вариант, в общем-то. Особенно, когда не хочется нести интелу 18+ тысяч за десктопный ssd.
А все остальные — те же сорта дерьмеца, про которые можно сказать, что когда-то там в каком-то году они или сыпались, или тормозили.
> А в серверах надо использовать диски для серверов
В серверах используют то, что на данный момент в конкретном данном сервере оправдано. И у террабайтных консумерских ssd на 1TB область применения в серверах сейчас есть, как была и у 512GiB, которыми забиты все бюджетные хостеры — и никто не жалуется.
400 TBW для террабайтника — не самый плохой вариант
По нынешним меркам плохой, если диск умирает ровно на этих 400. По тестам 250Гб версия сдохла после 82тбайт записи из 100 заявленных. Это позорный результат.
А все остальные — те же сорта дерьмеца
Все остальные имеют совершенно разные контроллеры и память. На рынке есть признанный лидер в лице самсунга, который петабайт записи выдерживает и не светится в заголовках о массово дохнущих дисках. Но они и стоят несколько дороже. Похуже, но недалеко идет интел.
В серверах используют то, что на данный момент в конкретном данном сервере оправдано.
Естественно сервера разные бывают, только как правило под этим подразумевают что-то серверное по нагрузкам, для чего консьюмеровские диски никак не катят. Базы на них крутить себе дороже. Они свои скорости в таких областях не могут обеспечить, ибо контроллеры у них для других целей.
Так пусть в гарантию отнесут, у 256 гарантия до 150 TBW, у террабайтника до 400 распространяется, в чём проблема?
У них SunDisk ultra 3D, который является тем же диском с другой наклейкой, 500+ надолбил. А у 3dnews WD blue 700+ отмотал тот же.
Бестолку судить по одному тесту на единственном сайте, тем более, когда есть совершенно противоположные мнения.
А самсунг привез 256Gb-платы в корпусе от террабайтника с серийником от террабайтника. Их тоже не покупать из-за одного случая?
> только как правило под этим подразумевают что-то серверное по нагрузкам
Не знаю, что у вас там за «правила», но серверов, которые обслуживают высоконагруженные БД в мире — единицы процентов (если не десятые процента). Девелоперских/тестовых серверов, хомячков с лампой на сотню тысяч запросов в день и файлопомоек — в разы больше (буквально). И там дешманские ssd отлично прижились. Потому что через 5 лет ты их тупо выкидываешь и меняешь на х4 по объёму. А помирать? Да нет, не помирают массово, иначе всякие hetzner-ы и OVH уже давно разорились бы.
Понятное дело, что есть задачи, в которых десктопным ssd не обойдешься — но их количество не позволяет даже близко заявлять, что чему-то там где-то там не место.
Просто выбираете подходящий по цене диск от известных производителей — OCZ, WD, Corsair, Samsung, подставить_своё. Главное, чтобы была российская гарантия и возможность достучаться до неё.
Если задача более сложная и есть деньги — всегда покупаю Intel (впрочем, единственное место, где я купил intel лично себе — домашний сервер, ssd под систему).
У любого производителя бывают неудачные партии с браком, так что вероятность потерять данные — всегда 50%, если диск один. А даже самая минимальная тысяча циклов перезаписи для личного ПК — огромный ресурс, пара десятков лет минимум с учетом TRIM-а. По сути самые первые SSD из условно «современных» (2008-2010) ещё не начали массово умирать из-за израсходования ресурса перезаписи, если речь про ПК с обычными задачами.
Ну у меня за 73290 часов работы по данным контроллера суммарно записано порядка 22 ТБ данных. SSD не жалел совсем: и своп на нём, и торренты. Так что 400 TBW для меня — это достаточная величина.
Есть и попроще модели, типа 128+512. Я к тому, что HDD на домашних или рабочих компах ещё не редкость.
И там уже была вполне вменяемая система запуска сервисов и довольно функциональный ServiceControlManager.
Неужели было настолько сложно взять это удачное решение (SCM API) за основу?
У него уже тогда было довольно много очевидных преимуществ над той системой, что тогда была в линуксе, расширенный контроль системы над состоянием сервисов и т.д.
И по сей день отдельные виндовые сервисы (mdt monitor, например) при фейле зависимостей возвращаются с кодом 0 и не перезапускаются вне зависимости от настроек SCM.
Ну а чтобы собственный сервис добавить в SCM нужно либо перекомпилять всё, либо врапперы использовать. В общем, оно тоже не сахар, это ваше SCM API.
Сервис в винде — это отдельно-хитрый бинарник со своим энтрипоинтом и прочим. В линуксах демоны просто детачатся от терминала, в остальном это точно такие же бинарники, как и везде. SCM полагается на то, что логику управления сервисом будет реализовывать сама бинарь, sysvinit возлагает эту обязанность на инитскрипты, так как внутри бинари это будет привязано к определенной инит-системе, что противоречит духу платформы.
внутри бинари это будет привязано к определенной инит-системе, что противоречит духу платформы.
Это генерирует много ненужных костылей вокруг запуска этих скриптов.
И потом использование SCM вполне может быть опциональным — есть же виндовые программы, которые могут запускаться и как сервис, и как обычная программа.
Ну и да, совершенно необязательно повторять все косяки Win SCM. Я говорю о самой структуре управления сервисами, когда часть, отвечающую за репорт состояния сервиса, берёт на себя сам сервис.
репорт состояния сервиса
Не в курсе чё там в SCM, но в systemd какой-то репорт таки есть через функцию sd_notify (впрочем, это таки требует линковки с libsystemd)
Так а нет понятия «сервис» в этих ваших линуксах. У демонов детачим консоль, а сервисы — это демоны с каким-то дополнительным функционалом для работы с инит системой (какой именно?) И через что взаимодействовать будем — dbus, али ещё что? (upd: чуть выше зашла речь про сокеты, и это действительно был вариант)
В 90-х всего этого попросту не существовало, вероятно поэтому и ограничились скриптами.
Решился в итоге на обновления виртуалок с debian 7 только спустя год после выхода 8ки jessie, и в принципе не пожалел. И следом обновил совсем уж старые centos6 до centos7. Разницы конечно глобально не заметил, upstart на центоси и runit на дебиане функции свои выполняли исправно, единственное, что стало плюсом, одинаковый конфиг сервисов на любой ОС. Хотя понравилось что ушли от своеобразной системы логирования у runit, всё стало логироваться в syslog.
Но как я понимаю, что это до поры до времени, journalctl пока не повсеместно используется, пока в 10м дебиане и центос8 логи пишутся по старинке, но вот в домашней федоре уже просто грепом по файликам не пройтись, и это не очень нравится. Конечно, дело привычки, но всё же.
По стабильности, за 4 года столкнулся всего два раза что сервисы переставали отвечать на команды, не запускались, не останавливались. Оба раза помогло systemctl daemon-reexec, без дорогостоящей перезагрузки всей системы.
Из мелочей — не работает опция CapabilityBoundingSet, например CapabilityBoundingSet=CAP_NET_ADMIN CAP_IPC_LOCK CAP_SYS_NICE не выдаёт нужные права, решилось установкой через setcap непосредственно на бинарник.
И в итоге — по моему опыту использования как раз основная претензия к journalctl, если остальные компоненты systemd занимаются ровно тем, чем должны по идеологии PID1, на мой взгляд как раз логирование выходит за эти рамки.
в домашней федоре уже просто грепом по файликам не пройтись
Это как раз просто — journalctl --since today | grep ... — ничем не хуже, даже в чём-то лучше (с учётом других опций).
Проблема с journald (одна из) совсем в другом, на самом-то деле — он пишет всё что есть, нет возможности фильтрации до записи (кроме как по уровням), со всеми неудобствами (очень много мусора), но редиска Поттеринг сопротивляется этому всеми фибрами, утверждая что писать нужно всё без исключений (даже тонны мусора), а фильтровать исключительно при просмотре.
Ну вот, собственно, это и причиняет неудобства. Я не совсем корректно выразился, что хотел сказать. С этим разобрался, конечно, с флагами, но то что пишется всё в одну кучу, не айс. Смешались в кучу, люди, кони, и всё другое. Это нехорошо. И всё равно, даже есть такая возможность, на основной процесс, который рулит всей системой, вешать логирование неправильно, причём без права разделения.
И всё равно, даже есть такая возможность, на основной процесс, который рулит всей системой, вешать логирование неправильно, причём без права разделения.
на самом деле правильно. Вот, предположим, запись в лог у вас блокирующая. Место на диске кончилось. Ваши действия? Ждать пока логротейт придет?
Кстати, в убунтах этих ваших — выхлоп journald бережно rsyslog'ом режется на файлы и складывается в текстовом виде в /var/log/*.log (auth, syslog etc.). Т.с. для легаси админов, которые умеют только в текстовые файлики. Все для Вашего удобства, т.с.
на основной процесс, который рулит всей системой, вешать логирование
Никто там ничего не вешает.
root 46465 0.0 0.7 133572 64680 ? Ss May28 0:16 /lib/systemd/systemd-journaldЭто отдельный процесс вообще-то.
Запустите systemd-cgls — увидите много интересного.
но редиска Поттеринг сопротивляется этому всеми фибрами, утверждая что писать нужно всё без исключений (даже тонны мусора), а фильтровать исключительно при просмотре.
если подумать, то он прав...
Подумайте об устройствах типа RPi с SD-картами, где какой-то сервис пишет неотключаемый дебаг в журнал минимум раз в секунду, причём на уровне info вместе с иногда (и очень редко) нужными сообщениями.
Или о системе где сотня сервисов и каждый (ре)стартует посредством таймеров раз в несколько секунд — зачем мне знать что они start/stop, если мне гораздо важнее знать как раз наоборот — что кто-то этого вовремя не сделал?
Или о сервисе который вдруг выдал сотню тысяч строк дебага, ушедшего в журнал и убившего (за счёт ротации) всё остальное что там было?
Или… в общем, масса ситуаций когда логи забиты мусором (потому что авторы сервисов не подумали) и никакого способа от него избавится, но вот почему-то Поттеринг решает за вас, оператора и владельца системы, как и сколько писать на диск, вместо того чтобы дать возможность фильтрации на входе, которая будет полезна сразу массе людей.
Ну и наконец… Есть всё-таки разница, фильтровать вывод с чего-то размером в 100 мегабайт или 10 гигабайт, особенно если в последнем случае полезной информации не более чем 100 мегабайт, но вам нужен диск побольше просто ради мусора (и хорошо если это не SSD/SD).
Что примечательно — на гитхабе несколько многолетних веток на эту тему, ясно что фича нужная и полезная, но позиция Поттеринга — "я не убежден что это нужно". Ушли буквально годы чтобы в сервисах можно стало перенаправлять вывод в файлы или сокеты (вместо journald), на фильтрацию, наверное, вообще уйдут десятки лет… И проблема совсем не в том чтобы это сделать (pull requests были) — проблема в позиции "это неправильно, нужно писать всё и не давать никому выбора". Чем-то напоминает djb с его errno...
Если почитать его мнения на этот счёт — да, в идеальном мире это должно делаться на стороне сервиса — и фильтрация, и прочее, journald не может знать что важно а что нет, но увы, мы живём в реальном мире и некоторые (особенно очень древние) сервисы не переписать и ненужные логи не отфильтровать, разве что посредством внешнего приложения типа multilog, что вносит другие проблемы.
PS: Извините, наболело. По факту, это единственная насущная проблема связанная с systemd… всё остальное, при всех недостатках, всё же сильно перебивается достоинствами.
А повесить свой фильтр на свой сокет, писать в него, а он уже после фильтрации будет в журнал?
Если вы не желаете чтобы ВСЁ писалось на диск/флешку — можно легко отключить запись бинарных логов journald на non-volatile storage и хранить логи только в оперативной памяти. Мне мнится, что на типичном десктопе с или raspberry pi почти всегда логами с прошлых запусков системы можно пренебречь. Опционально можно копировать логи из journald в какой-нибудь классический syslog демон, его силами фильтровать ненужное, а потом писать что хочется, куда хочется и как хочется. Я лично, к примеру, на серверах локально пишу таким образом нужные кусочки логов. И доволен аки слон.
Кстати, у journald эта опция по дефолту выставлена в "Auto", при этом значении на диск логи пишутся в случае существования пути /var/log/journal/. Если пути нет — пишутся только в память. Поэтому на всяческих rpi можно просто сразу сделать rm -rf /var/log/journal и забыть о проблеме.
Ну и напоследок хочу заметить: мне кажется крайне неправильно считать journald этакой плохо спроектированной и недостаточно фичастой заменой классическим syslog демонам или специализированным решениям для сборки и консолидации логов на отдельной хранилке. Воспринимайте journald как нечто, что собирает в одном месте выхлоп от всего, что его в принципе производит, заодно авторитетно добавляя поля типа pid/name источника. А дальше это нечто позволяет делать с собранным то, что вам нужно + даёт возможность посмотреть все логи единым полотном, что нередко очень и очень удобно.
CapabilityBoundingSet=CAP_NET_ADMIN CAP_IPC_LOCK CAP_SYS_NICE не выдаёт нужные права
Он не для выдачи прав, а для ограничения возможностей. Например, указанная строка сделает так, что процесс и его дети не смогут делать, всё остальное (что через capabilities рулится), даже если от рута работают.
Для выдачи прав есть AmbientCapabilities=, например:
AmbientCapabilities=CAP_NET_BIND_SERVICEЭто не в systemd дело, просто подсистема capabilities так работает.
Из всего сказанного понятно, что главным недостатком BSD like скриптов, sysvinit,…, является то, что они написаны не Поттерингом.
Оно и верно, зачем изучать разумное и совершенствовать его? Ведь надо создавать новое, отрицать старое, мешать в одну кучу udev и system start/stop, нарушать принципы, вести народ в будущее.
У нас нет авторитетов! Мы делаем новую жизнь, нам понятен формат winini файлов.
Ура, товарищи!
У меня стойкое впечатление, что об удобстве и разумности rc скриптов пишут в основном те, кому не приходилось в вопрос запуска сервисов дальше выставления автозапуска у установленного из репозитория софта лезть. rc скрипты по запуску типичного сервиса типа nginx или mysql, выполняющие всё то, что реально хотелось бы от них, — это чудовищного размера абоминации, причём каждый второй со своей логикой.
Те полотнища, которые в принципе занимались подготовкой всего юзерспейса после старта ядра, я даже не стану упоминать.
Однако сообщество, вместо того, чтобы написать автору какой-либо библиотеки предложение по улучшению в их скриптов, решило что лучше отдать все на откуп pkgconfig (который, кстати тоже глючит немерянно).
Так вот, когда мне приходится работать со сторонними демонами, я либо отлаживаю поставляемые в их составе rc скрипты, либо создаю для них новые. Всегда стараюсь написать автору и предложить решение существующих или потенциальных проблем.
И это нормально, это же OSS сообщество, где люди помогают друг другу, а не враждуют.
Однако сейчас о такой кооперации остается только мечтать. Общество становится все более токсичным и люди скорее склонны отрицать старое разумное, ввиду невозможности понять, и создавать альтернативы, которые кстати зачастую убивают лучшее и привносят новые ошибки. Так было во время введения pkgconfig, так было во время создание systemd, так же будут поступать с Autoconf, Automake путем их замены на CMake, ninja+meson,…
Но я надеюсь на то, что OSS сообщество не превратится в террариум.
Full disclosure: я терпеть не могу systemd. Но статья понравилась, хоть и написана очевидно предвзято, но автор и не скрывает. Поэтому просто немного прокомментирую статью.
начиналось как просто PID 1 и стала тем, что я бы назвал middleware современного дистрибутива Linux
И это плохо само по себе. Тем более, что опыт показывает, что в этом нет реальной необходимости: у меня Gentoo, причем даже не на OpenRC а на Runit, и при этом много лет используется udev (точнее eudev) и вот на днях перешёл на logind (точнее на elogind). Как видите, нет большой проблемы выделить полезные и нужные компоненты из systemd — или, говоря иначе, нет и небыло реальной технической (в отличие от политической!) необходимости изначально слеплять их в одно целое.
В атмосфере беспорядочного хаоса было предприняты несколько попыток решить проблемы sysvinit:
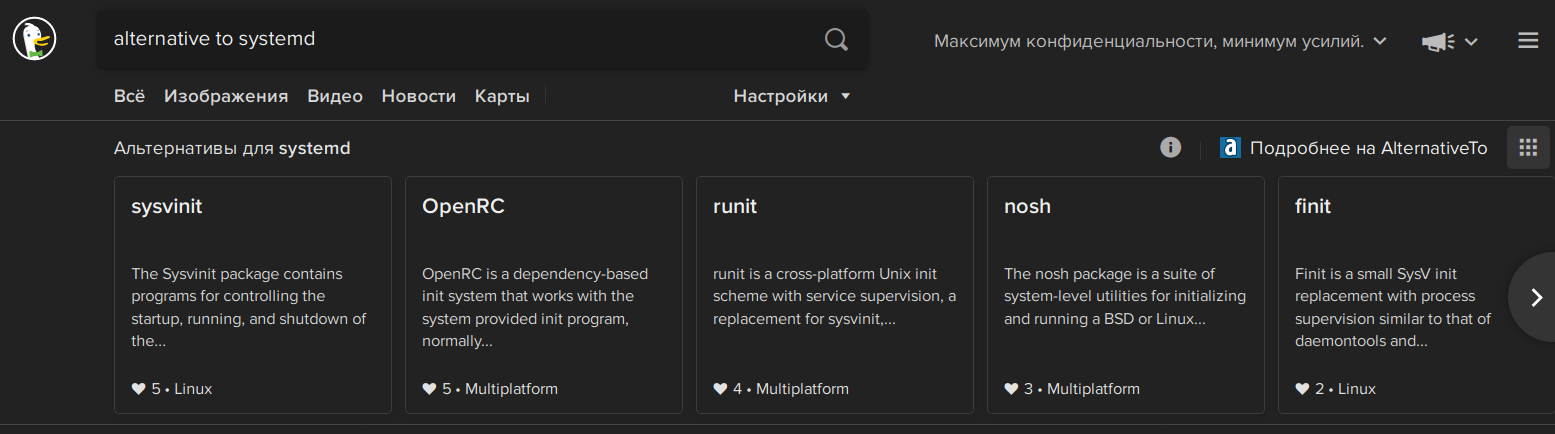
Вы забыли упомянуть некоторые более достойные альтернативы, вроде того же OpenRC, Runit и S6 — а без этого обзор, мягко говоря, не даёт реальной картины.
Но на сегодня самой известной альтернативой (кроме systemd) является, пожалуй, Upstart.
Да неужели?!
Это и произошло. Debian Jessie вышла с systemd в качестве менеджера системы, и вслед за Debian …
… появился Devuan, который "Debian без systemd". Википедия говорит, что есть 53 дистрибутива без systemd. Я это к тому, что из Вашего описания складывается впечатление, что последние бастионы сопротивления пали на дебиане, и везде воцарился systemd… так вот, это не так.
С целью решить эти проблемы и был представлен journald:
Честно говоря, даже не хотел это комментировать — его не пнул только ленивый, и даже фанаты systemd на него плюются. Впрочем, чего молчать-то: большая часть "решённых" проблем не является реальными проблемами на практике (или уже имеют отличные решения в runit/s6), зато те новые проблемы, которые он создал взамен старых — весьма реальны.
К примеру, systemd спроектирован со вниманием к безопасности, поэтому каждый из компонентов запускается с минимальными требуемыми правами и делает лишь свою задачу.
Это просто слова. А факты можно увидеть в базе CVE: 56 записей.
Платформа systemd, на самом деле, гораздо проще традиционного Linux, потому что она объединяет системные объекты и их зависимости в юнитах с простым синтаксисом конфигурационных файлов.
Это бред, уж простите меня за прямоту. Юнит-файлы systemd проще rc-скриптов sysvinit — безусловно. Но сам systemd крайне сложен, и ограничить его изучение синтаксисом unit-файлов можно ровно до первой проблемы… а потом придётся разбираться с самим systemd, и это будет намного сложнее отладки rc-скриптов sysvinit, OpenRC и тем более run-файлов Runit.
В целом, systemd, возможно, настолько прост, насколько системный менеджер может быть простым.
Посмотрите на Runit или S6, чтобы не было потом стыдно за такие заявления.
число багов довольно мало для такого ключевого компонента ОС
1200+ issues, из них 89 открытых багов… для такого ключевого компонента ОС — это просто неприемлемо!
Для сравнения, у OpenRC 61 issue, из них поиск по слову bug выдаёт 14 (и не факт, что всё это реальные баги OpenRC, а 89 вышеупомянутых багов systemd имеют метку баг поставленную разработчиками systemd, т.е. это признанные баги). Про Runit сказать сложнее за отсутствием его на гитхабе, но насколько мне известно багов в нём нет. У S6 сейчас открыт 1 issue, и да, это баг — но баг сборки.
В целом, Ваши слова являются типичным проявлением Стокгольмского синдрома.
это новая эпоха в истории экосистемы Linux
Ага. Позднее её назовут "тёмные века". :)
Нормально он себя ведёт. Если его просто запустить и больше средствами systemd не трогать.
Вообще, забавная складывается ситуация в наши дни — у меня на кучке серверов водится systemd, но я про это почти ничего не знаю… потому что всё, что он делает — это запускает докер, а всё остальное на этом сервере запускается внутри докера. Так что есть там systemd, нет там systemd — мне без разницы, ни одной systemd-специфичной команды за всё время существования этих серверов я так и не запустил.
Что забавно, по сути это означает, что на этих серверах systemd так и не стал упомянутой в статье миддварью для всей системы, а используется ровно в том же качестве, что и простейший init-скрипт для одного сервиса.
потому что всё, что он делает — это запускает докер, а всё остальное на этом сервере запускается внутри докера.
это потому что у Вас нет специфических задач. Скажем, такой пример. Лежат файлы на NFS. Вы можете его подмонтировать как systemd mount — это правильно (либо сделать как-то иначе, но лучше не стоит). Далее выясняется, что докер контейнеры не умеют в зависимости. Вы их оборачиваете в системди юниты и выстраиваете цепочку перезапуска. Либо тащить nfs клиента в каждый докер образ (фу). Если же цепочку не выстроить — будет очень простая история, что протекут какие-нибудь дескрипторы, где-то внутри что-нибудь отвалится и вероятно, что Вы даже про это не узнаете, разве что по каким-то косвенным признакам.
Вы берёте сложный инструмент и пытаетесь решить простую проблему сложным способом, раз уж инструмент даёт такую возможность. А в реальности всё намного проще: сетевые диски нужно монтировать до запуска всех сервисов, включая докер. И, разумеется, их не нужно отмонтировать в процессе работы. Всё, проблема зависимостей решена, точнее её просто нет. Просто представьте себе, что этот сетевой диск — это volume на AWS. Да, он сетевой. Нет, он есть всегда, доступен сразу при загрузке, и отключать его в процессе работы никто не будет — потому что он притворяется локальным диском, как и должно быть. (А если будет — то он знает, что делает и какие будут последствия.)
Только вот, во-первых, у вас не aws, во-вторых, я и не предлагаю его отмонтировать на ходу. Я ещё в здравом уме. Но вот залипнуть клиент nfs вполне может. Сетевые проблемы, скажем. И тогда придется перемонтировать. Дальше — по моему сообщению.
Т.е. по существу — вопрос в том как разбита система на уровни и кто за них отвечает.
Если он залип в процессе работы — это уже никакого отношения к зависимостям между сервисами не имеет, потому что в этот момент зависящие от NFS сервисы уже давно запущены (и тоже залипли на попытке I/O). Перемонтирование в этих условиях не должно приводить к перезапуску зависимых сервисов, они просто штатно получат ошибку от ядра и обработают её как для них это правильно — повторив операцию I/O, например.
Но вот залипнуть клиент nfs
ЕМНИП, 20+ лет назад эту проблему эффективно решал amd и всё такое.
Вот не факт, что всё надо монтировать на этапе загрузки по сути. Не все сервисы должны стартовать автоматом, а держать маунт удалённой ФС на всякий случай — чревато
Вы правы. Всегда можно усложнить постановку задачи до такой степени, что без сложного инструмента с ней не справиться. Но, если честно, как часто лично у Вас на практике возникала такая ситуация — есть сервис, который не должен запускаться при загрузке сервера, сервису нужен NFS, который так же не должен монтироваться при загрузке сервера, и при этом есть реальная необходимость автоматически подмонтировать NFS в момент, когда админ ручками запустит сервис? Мне вот ни разу.
Вас, как и меня будут дизлайкать. Это нормально. Если вы не в секте, то будет так.
Проблема не в том, что кто-то в секте, а кто-то нет. Г-н powerman выказывает свое личное мнение, через призму своего личного искажения реальности.
а потом придётся разбираться с самим systemd, и это будет намного сложнее отладки rc-скриптов sysvinit
ну, например. Вот обожаю такой пример драматизации, чтобы перетянуть неспециалиста на свою сторону. А ничего, что
- как правило с systemd проблем нет? Вот пускай г-н powerman приведет хотя бы несколько проблем, когда проблема была в systemd. Тогда и подумаем насколько это сложно отлаживать
- уже рассказали как init скрипты (классические) не умеют отрабатывать исключительные ситуации. Ой, а они у нас отсутствуют, просто потому что случаются 1 раз в 1000 лет? Ну, мы же знаем — рвется, там где тонко, и попросту можно проблему не заметить, а данные, например, уже в кашу
- разбираться со спецификой init скриптов — то еще удовольствие. Это примерно как восстанавливать работу "макаронного кода" с непонятными зависимостями. Не говоря уже о том, что у каждого мейтейнера, у каждого софтодела и каждого дистрибутива свой взгляд на то, как должен выглядеть инит скрипт. Да, вроде бы на старте нужно только знание баша, но это примерно то же самое, что и утверждать, что в машинных кодах можно писать сложные современные многокомпонентные системы (спойлер — нет)
Позднее её назовут "тёмные века".
вообще пять. Апплодирую стоя.
Спасибо за высокую оценку. Но Вы снова противопоставляете systemd init-скриптам, а я говорил о Runit и S6 в первую очередь. Почему, Вы думаете, я упомянул, что использую Runit вместо OpenRC в Gentoo — при том, что это не является поддерживаемым подходом в Gentoo и поддерживать его мне приходится самостоятельно? Именно потому, что sysvinit — это однозначно неприемлемо. OpenRC всё-таки решил многие проблемы sysvinit, но лично я предпочту сам поддерживать загрузку системы на runit чем иметь дело с init-скриптами, пусть даже OpenRC.
Что касается "проблем с systemd" — их на данную секунду примерно 589 (открытых issues не являющихся фиче-реквестами). На самом деле меньше, конечно, часть из них не звучат как проблемы, но всё-равно их порядка полтыщи… и это спустя 10 лет развития проекта. Как по мне — это чётко показывает тенденцию, что проблем дофига, и с годами их становится больше, а не меньше. Что абсолютно неудивительно для проекта такой сложности.
чтобы перетянуть неспециалиста
Мимо — я не верю, что про systemd будут что-то читать "неспециалисты", это слишком узкоспециализированная тема для неспециалистов.
P.S. "свое личное мнение, через призму своего личного искажения реальности" — в целом это, конечно, так и есть. У всех так, я не исключение. Но, обратите внимание — я своё искажение подтвердил кучей ссылок на пруфы, а Вы?
Что касается "проблем с systemd" — их на данную секунду примерно 589 (открытых issues не являющихся фиче-реквестами). На самом деле меньше, конечно, часть из них не звучат как проблемы, но всё-равно их порядка полтыщи… и это спустя 10 лет развития проекта. Как по мне — это чётко показывает тенденцию, что проблем дофига, и с годами их становится больше, а не меньше. Что абсолютно неудивительно для проекта такой сложности.
ну, давайте еще линукс отрицать. Сколько там ишью? Много? Ой, какой линукс плохой. Срочно меняем ядро и мигрируем на более компактные операционные системы. Да, я передергиваю.
Runit и S6 в первую очередь.
я допускаю, что есть применения, куда systemd не очень пихать. Например, у вас какой-нибудь встроенный линукс и тупо нужно экономить память на всем. Но сервера и десктопы? Может все-таки просто признать, что мир изменился, а ты отстал и пора адаптироваться? Иначе это реально похоже на юношеский максимализм. Или донкихотство
Да, сервера и десктопы. У меня именно десктоп на Runit, примерно с 2003. И сервера на Runit, самые обычные, с тех же времён до сегодня (хотя сегодня я чаще беру первую попавшуюся убунту, ставлю на неё докер, включаю автоматическое обновление, и больше про неё почти не вспоминаю… такие времена, disposable stateless сервера, disposable stateless сервисы…).
И я не спорю, что мир изменился. Я там выше в комментариях писал, что у меня на серверах systemd (правда там кроме systemd и докера больше ничего), но ещё, если поискать, у жены Debian на systemd (который по факту администрирую я). Тем не менее, на важных для меня системах (и первая из них это как раз мой десктоп!) этой гадости никогда не будет, там будет либо Runit либо S6 — потому что они простые и надёжные, и с моей точки зрения для компонента отвечающего за загрузку системы и управление всеми сервисами критично только это — простота и надёжность. SysVInit был простым… некоторое время, пока не начали писать портянки в init-скриптах… и никогда не был надёжным. Systemd никогда не был простым и никогда не будет надёжным из-за своей сложности и попытки решить слишком большое количество очень разных проблем.
Так что это не максимализм (как я уже упоминал, в моём окружении попадается systemd и я спокойно к этому отношусь) и не донкихотство (я не один такой "псих", список из 53 дистрибутивов без systemd и жаркие споры о systemd всё время его существования это подтверждают) — просто я чётко понимаю что мне подходит а что нет, и почему именно так.
не донкихотство (я не один такой «псих», список из 53 дистрибутивов без systemd и жаркие споры о systemd всё время его существования это подтверждают)Как раз тот факт, что вы с придыханием упоминаете не количество миллионов людей, которые пользуются Linux, а количеством дистрибутивов — как раз и указывают на то, что это донкихотство.
Я думаю на каждого человека, который пользуется какой-либо другой системой и знает о том, что ей пользуется — приходится не один десяток пользователей systemd (почему знание важно? потому что если вы используете, скажем, Android-телефон и никогда ничего там руками не запускаете — то вам, как бы, пофиг какая там система запуска).
Вы забываете, что любая простота и надёжность runit сразу закончится за его пределами. И где то ту сложность, что вносит systemd, рано или поздно надо будет добавить на другом уровне… А дальше уже кто как любит — размотать ответственность по площади, или сконцентрировать в одном месте.
Где сложность systemd? Он у вас ломался (вообще, постоянно или хотя бы иногда)? Или это нытье в тренде "давайте поноем"?
Т.е. это было на десктопе? Просто на серверах suspend не нужен, кмк
Вы провокатор )
В хорошем смысле.
Вы же понимаете, что Вы огульно обвинили системди в грехе, к которому он мог вообще никакого отношения не имеет? Ну, не знаю — кривая acpi таблица, какой-нибудь криво написанный драйвер и все такое. А виноват почему-то systemd-suspend.
Конечно, я Ваши эмоции прекрасно понимаю. И я бы тоже расстроился и послал систему такую к лешему. Но на тех же серверах и спектр оборудования существенно более узкий, и гарантии надёжности другие. В отличие от десктопа. Поэтому "имеем, что имеем". А если не хочется проблем… на десктопе… То надо сидеть под маком или виндой. Хотя… Там своих нюансов хватает.
Ну, не знаю — кривая acpi таблица, какой-нибудь криво написанный драйвер и все такое.В этом случае, проблема должна была бы воспроизводиться каждый раз, либо только на конкретном ядре.
Поэтому «имеем, что имеем». А если не хочется проблем… на десктопе… То надо сидеть под маком или виндой. Хотя… Там своих нюансов хватает.Там будут свои проблемы, при этом там я их решить точно не смогу.
Мне показалось, или в соседней ветке Вы говорили, что systemd особенно важен на десктопах, потому что там всё сильно сложнее чем на серверах… а теперь что же получается, что на серверах systemd не нужен ибо там всё просто и запустить докер можно и без systemd, а на десктопе systemd нельзя обвинять в проблемах потому что там всё слишком сложно? :-D
Вот если бы человек на одном и том же железе использовал systemd и у него были проблемы, а потом перешёл на runit — и они бы исчезли… тут да, можно было бы говорить о чём-то.
А Вы забываете, что в большинстве случаев нужда в этой сложности может просто не возникнуть. Я на Runit больше 15-ти лет, и за это время такие ситуации возникали один-два раза… и каждый раз решались намного меньшей сложностью, чем приносит с собой systemd.
Будьте последовательны, коллега.
Выкиньте Линукс нафиг. Он же сложный! Я про ядро с драйверами. Сколько там строчек кода? Сколько там уязвимостей? Сколько утечек памяти? А эффективность работы линукса и софта под него с ОЗУ — это притча во всех языцех.
Выкиньте гуй — чем вы там пользуетесь? Gnome? Kde? Да пофиг. Это же тоже страшные вещи, которые нагибают всю остальную систему и заставляют использовать навязанные ими шаблоны!
Ну, так что? Только хардкор — миниядро и оболочка бизибокс. Здесь должен был быть копипаст про Мытищи и старую школу.
/Это стёб, если что/
Вы не поверите… но всё примерно так и есть.
Линукс действительно очень сложный, но, к сожалению, OS Inferno и Plan9 так и не взлетели, хотя они дают примерно тот же функционал но на порядок проще. Так что линукс — только потому, что реальный выбор между ним, маком и виндой, а не потому, что он самый простой и элегантный.
Ядро я собираю самостоятельно, и лишние драйвера и фичи в него не входят.
Насчёт уязвимостей — пока была возможность ядро собиралось с GrSecurity/PaX, это сильно ослабляло проблему безопасности.
Притча про работу с ОЗУ как-то прошла мимо меня — Вы о чём конкретно?
Gnome/KDE у меня действительно нет, у меня Fluxbox и 24 виртуальных десктопа, в каждом из которых по одному full-screen приложению — и это невероятно удобно (почти все друзья посмотрев сделали у себя так же).
Бизибокс штука тоже классная, но не на десктопе, а в контейнерах с Alpine.
/И нет, это не стёб, я абсолютно серьёзен. Если приходится использовать что-то переусложнённое, то вовсе не обязательно к этому привыкать и убеждать себя и окружающих что это — норма. Потому что нет, это не норма. Но иногда это — необходимость./
у меня Fluxbox и 24 виртуальных десктопа, в каждом из которых по одному full-screen приложению — и это невероятно удобно
Так же делаю, только у меня их не 24, а 9 и не fluxbox, а dwm,
При этом использую 4-5 десктопов, так как браузер, а все остальное в терминале с tmux.
Ну вот я вместо tmux просто запустил в большинстве из этих 24-х urxvtc. Переключаться в нужный по Alt+Fx и Alt+Shift+Fx удобно, плюс на неиспользуемые Win-кнопки настроил переключение на следующий/предыдущий и между двумя последними виртуальными десктопами.
Плюс при загрузке машины во всех 24-х сразу запускаются нужные приложения — мессенджеры, браузер, почта, mc, терминалы, подключения по ssh к серверам, просмотр логов, etc.
Если приходится использовать что-то переусложнённое, то вовсе не обязательно к этому привыкать и убеждать себя и окружающих что это — норма. Потому что нет, это не норма.
Странно, я как-то по наивности думал, что это как раз норма. Ведь инструменты усложняются для того, чтобы взять на себя массу работы, которую до того выполнял пользователь, т.е. человек. Делать эту массу работы вручную из одного лишь мотива «так я всё контролирую» — вряд ли это можно назвать нормой. Это всегда было выбором относительно небольшого числа людей. И в случае с systemd, замечу, никто не отбирает у этих людей возможности «контролировать» систему, используя старые инструменты. Берите Gentoo, берите Slackware, да хоть свой дистрибутив собирайте на здоровье.
Никто не предлагает делать вручную то, что могут сделать инструменты. Но это никак не связано с обязательным увеличением сложности этих инструментов — просто бывает один сложный инструмент или десяток простых, но в конечном итоге делают они одно и то же. А ещё бывает так, что отдельному пользователю просто не нужны 100500 фич напиханные в один сложный инструмент, ему нужно всего 6 фич, которые ему могут предоставить 4 простых инструмента.
Л — логика. Количество движений не зависит от количества инструментов.
Нет никакой разницы между тем, чтобы почитать доку на systemd и узнать, как называется необходимый параметр в unit-файле, и тем, чтобы почитать доку на отдельную утилиту, которая делает то же самое, что этот параметр в юнит-файле, и написать запуск этой утилиты в run-файле. Количество читаемой документации и набираемого текста в обоих случаях — в идеальных для systemd условиях — будет одинаковым.
Но условия для systemd далеки от идеальных — вся дока на runit и идущие с ним в комплекте утилиты — это капля по сравнению с морем документации на systemd… и вовсе не потому, что в runit отсутствует важная документация или доку на systemd писал графоман, а потому, что кучка простых инструментов обычно получается намного проще одного сложного, даже при сравнимом функционале. Но сложные инструменты тяготеют к feature bloat, что только увеличивает сложность их использования (включая поиск нужного в документации) в абсолютном большинстве кейсов, в которых эти лишние фичи абсолютно не нужны.
Количество движений не зависит от количества инструментов
Вообще-то зависит. Конкретный пример: чтобы чрутнуться без systemd, нужно ввести целый ряд команд, задействовав минимум 2 утилиты (mount, chroot), чтобы чрутнуться с systemd — достаточно 1 команды (systemd-nspawn)
Количество читаемой документации и набираемого текста в обоих случаях — в идеальных для systemd условиях — будет одинаковым
Чтобы написать юнит, нужно прочитать документацию по юнитам. Чтобы написать скрипт запуска, нужно изучить целый язык программирования — bash. Что сложнее — очевидно.
Очевидно, что Вы передёргиваете:
- Написать юнит мало, его надо ещё положить в правильный каталог и запускать/перезапускать правильными командами. Для этого документации придётся прочитать немного больше.
- bash учить не нужно, к сожалению — его и так все знают, потому что без него жить не получается вне зависимости от наличия или отсутствия systemd. Если бы не этот "маленький" нюанс — то я бы согласился.
Написать юнит мало, его надо ещё положить в правильный каталог и запускать/перезапускать правильными командами. Для этого документации придётся прочитать немного больше.
Серьезно? Это прямо высшая математика? Но вот с "традиционными" системами инита тоже надо знать, куда класть стартовый скрипт сервиса и как его назначать на разные ранлевелы. Баш на баш? Только в случае системди Вы вынуждены это знать, как азбуку. Т.к. это стандарт. Нравится Вам это или нет. А в случае runit — изучать заново.
Написать юнит мало, его надо ещё положить в правильный каталог и запускать/перезапускать правильными командами
Верите, нет, но чтобы найти каталог с юнитами, я не читал документацию, нашёл просто серфингом в менеджере файлов :-)
bash учить не нужно, к сожалению — его и так все знают, потому что без него жить не получается
Вы мне витраете какую-то дичь :-) Подавляющее большинство линуксоидов, с которыми я знаком очно или заочно, баша не знают вовсе.
Верите, нет, но чтобы найти каталог с юнитами, я не читал документацию, нашёл просто серфингом в менеджере файлов
Вот это как раз опасная стратегия, потому что нашли вы, скорее всего, каталог с юнитами из пакетов, которые лучше бы не менять.
Что касается юнитов пакетов, то авторы systemd сделали всё возможное, чтобы их нельзя было найти случайно, т.к. искать конфиги в каталоге /usr/lib линуксоиду в голову не придёт :-)
Отсутствие нормальных массивов и хешей, поэтому во всех скриптах будте любезны эмулировать эти базовые вещи через переменные с подчеркиванием в виде разделителя. Потому что «должно работать везде» и на старых версиях тоже. В последней MacOS например до сих пор bash 3-й версии.
Ну и в придачу моя любимая нерешенная проблема с кавычками, которые просто теряются по дороге вызовов между функциями
$ cat script.sh
#!/bin/bash
echo "\$1="$1
echo "\$2="$2
echo "\$@="$@
$ ./script.sh "aaa bbb"
$1=aaa bbb
$2=
$@=aaa bbb
$ ./script.sh aaa bbb
$1=aaa
$2=bbb
$@=aaa bbb
$1 и $2 корректно отобразились, а вот $@ одинаковый в обеих случаях.
И таких приятных моментов в bash достаточно.
Никто не спорит, что баш — гадость. Речь шла о том, что простой скрипт для запуска сервиса написать может кто угодно, потому что всё равно ведь все работают в консоли, и чтобы написать скрипт не нужно знать ничего особенного сверх того, что и так уже используется в консоли — иными словами что отдельно и целенаправленно "учить баш" для этого не требуется.
Никто не спорит, что баш — гадость
Я спорю. Гадость, не гадость, однако попытки заменить его для интерактивной работы скажем питоном не получаются удобными.
Но жизнь сложнее и поэтому простой скрипт инициализации сети (netifrc) в gentoo занимает 800+ строк, потому что проверяет кучу всего, и загружен ли модуль и разные форматы сетей понимает, но при этом большинство кошмара внутри это кака раз эмуляция массивов, и работа с ними.
Ну не согласен, я в консоли уже лет 20 наверное, и это все больно вспоминать, причем *BSD и линуксы были. Раньше тонны скриптов за собой тягал самописных для разных задач + настройки под все что можно консольное + настройки x-server. На сервере такая же жуть была, только там еще разные инит скрипты кастомные.
Тот же OpenRC почти всем устраивал, но перекрытия системных конфигов не было, поэтому вручную перекрывай и смотри чтобы не сломалось при обновлении. Инициализация сети — долго. А если сеть упала — то все можем после ребута не подняться из-за какого-то демона.
systemd — не панацея, те же страдания, только чуть меньше, поэтому и перешел на него. И потому что есть cron с человеческим лицом
Вообще-то зависит. Конкретный пример: чтобы чрутнуться без systemd, нужно ввести целый ряд команд, задействовав минимум 2 утилиты (mount, chroot), чтобы чрутнуться с systemd — достаточно 1 команды (systemd-nspawn)
Вообще-то с коллегой powerman я согласен. Не по форме, но по сути. Сколько я не рассуждал — про логирование, про мониторинг, про управление серверами (scm + оркестрация) — загадочным образом минимальное количество компонентов в минимальной работоспособной связке оказывалось величиной постоянной. Такие вот дела.
у меня Fluxbox и 24 виртуальных десктопаПочему 24? Какие хоткеи назначены?
ответ выше
Вы вызываете у меня честно очень разные эмоции. Потому что "сборка дистрибутива под себя" — это правда очень круто. И очень здорово, когда человек может аргументированно пояснить, почему он взял такое решение, а не другое. С другой стороны, я вижу четкий крен у Вас в сторону докера (да нафиг он нужен на самом деле — меньше деталей — надежнее система, могу аргументировать). А если подумать еще, то вот это:
Ядро я собираю самостоятельно, и лишние драйвера и фичи в него не входят.
отличный способ пострелять себе по ногам. Ну, например, Вы выкинули все драйвера, кроме тех, которые есть на конкретной железке, где запущен Ваш линукс, а потом обновили железо. И чего-то не стартует — сеть, вайфай (самое критичное), потом все остальное, потому что чего-то не хватило.
Вот поэтому я и называю это юношеским максимализмом — это не дает никакого ощутимого бенефита, кроме возможно небольшой капельки опыта (это скорее в плюс) и личного ощущения прекрасного ;), зато времени жрет как не в себя с потенциально сомнительным на практике результатом. Я когда-то думал тоже, что удастся перехитрить индустрию или в чем-то превзойти кумиров. Оказалось, что нет — середнячок-с. Ресурсов нет.
Поэтому я уж лучше какой-нибудь контент качественный (ну, тут уж как получится) попробую запилить. И как-то внезапно мы перескакиваем на филофовские тьху философские темы о смысле жизни и покорении космоса и природы.
Железо обновляется раз в несколько лет (с последним мне особо повезло — уже 8 лет на разогнанном i7-2600K, и только в этом году начал задумывать про апгрейд). И пересборка ядра в этом процессе отнимает самый минимум времени — гораздо больше уходит на то, чтобы сначала почитать обзоры и решить что брать, а потом собрать очередной тихий комп с громадными но тихими кулерами везде.
Но в целом — да, я согласен насчёт отсутствия ощутимых преимуществ, и в последние годы стараюсь собирать ядро близко к стандартному конфигу. Тем не менее, конфиг ядра содержит безумную тьму опций… так что либо в него вообще не надо лезть, либо если уже лезешь, то несложно отключить много такого, чего конкретно на этом компе нет, и никогда не будет — это как минимум уменьшает площадь атаки.
Притча про работу с ОЗУ как-то прошла мимо меня — Вы о чём конкретно?
Насчет ОЗУ пример https://habr.com/ru/company/oleg-bunin/blog/431536/
Это просто типичный пример "линукс дает памяти приложению столько, сколько оно запросит, без реальных гарантий наличия ОЗУ" -> все приложения начинают аллоцировать память как попало -> рано или поздно ОЗУ заканчивается и все заканчивается плачевно.
Я много игрался с overcommit и отсутствием свопа (кстати, последнее — официальный критерий работы кубернетеса). И могу сказать, что все плохо. Но возможно у меня попросту слишком завышенные ожидания от generic-purpose ядра и операционки.
Да, любопытно, спасибо. Я как-то не сталкивался раньше, или сталкивался но не проследил причину. Я много лет работал (на 16, потом на 24 GB RAM) без свопа, но в последнее время начал включать его на десктопах (с vm.swappiness = 1) — лучше когда машина начинает тормозить и по этому факту можно сориентироваться что браузер или телеграм как-то много гиг памяти скушали и пора их перезапустить, чем когда она просто умирает в этот момент. Но на серверах это не очень работает, там лучше о проблеме узнавать не по диким тормозам, а несколько ранее, по алертам от мониторинга. Так что смысл свопа на серверах от меня всё ещё ускользает.
Так что смысл свопа на серверах от меня всё ещё ускользает.
Один из аргументов адептов свопа заключается в том, что часть страниц памяти софта можно скинуть на диск без вреда для дальнейшей его работы. В этом есть определенная логика, т.к. любой софт сначала инициализируется, потом работает. И при переходе из первой во вторую стадию появляются данные, которые не нужны. И можно освободить ОЗУ тупо скинув эти страницы в своп. С другой стороны, есть куча доводов против свопа.
А ночью бекапы еще делаются
бекапы еще можно снимать на уровне снапшота файловой системы или блочного устройства (там свои нюансы, но это может не аффектить саму операционку внутри виртуалки) — надо думать, как лучше сделать (баланс между просто/надежно/быстро/дешево/консистентный бекап).
Так что смысл свопа на серверах от меня всё ещё ускользает.Своп на серверах требуется просто потому, что выключить его полностью в Linux невозможно.
Да, его можно сделать нулевым и, типа, «отключить» — но это всё обман. Странички, загруженные из бинарников или
mmapленные из файлов — можно выкинуть из памяти всегда, им выделенныей своп не нужен. А вот данные, которые просто размещены в памяти — без явно выделенного свопа сбросить на диск нельзя.Это разделение данные на «данные первого сорта» (которые всегда доступны) и данные второго сорта (доступ к которым может быть сильно затруднён) — «кончается слезьми» очень много где… просто потому что код (без которого, как бы, сервер работать не может) — это как раз «данные второго сорта».
Забавно, но вот как раз в гитлабе бинарного кода мало (всего лишь интерпретатор ruby и библиотеки), а основная часть кода на файлы как раз не маппится. Оттого и эффект свопа выходит противоположным.
всего лишь интерпретатор ruby и библиотекиИ вот когда этот интерпретатор выгрузится и начнёт работать с тайкой скоростью, что ответ сервер удет давать не за миллисекунды, а за часы… вот тогда проблемы, собственно, и будут заметны.
Можно, конечно, прибивать такие сервера внешним watchdog'ом — кто ж спорит.
Можно OOM киллер прикрутить.
Но принципиально это проблему не решает.
Что до пользы свопа и его неминуемости — все это я читал. Все эти советы одинаковые для всех ОС — своп неотъемлемая часть виртуальной памяти, всегда его включайте хотя бы небольшой и т.д. и т.п. Только практика показывает, что вреда от него на серверных ОС больше, чем пользы.
Что до пользы свопа и его неминуемости — все это я читал. Все эти советы одинаковые для всех ОС — своп неотъемлемая часть виртуальной памяти, всегда его включайте хотя бы небольшой и т.д. и т.п.
Ну, для Windows 98 это было актуально, для современных систем — нет, они прекрасно живут без свопа.
Все аргументы за включение свопа сводятся к одному и тому же: а вдруг у вас переполнится память? То есть 16 гигов памяти + 16 гигов свопа — ок, а 32 гига память без свопа — почему-то не ок.
Впрочем, отключение свопа действительно отключает некоторый функционал: hibernate, дампы в винды при крэше.
Причем тут винда, если речь про Линукс? Я уж не говорю про то, что оомкиллер (сюрприз! Сюрприз!) может срабатывать и при вполне свободной ОЗУ
Причем тут винда, если речь про Линукс?
Просто перечислил примеры случаев, когда нужен своп.
Так, в линуксе для hibernate своп нужен, в винде — нет (она сбрасывает память в отдельный файл). Зато в винде он нужен при блюскрине.
может срабатывать и при вполне свободной ОЗУ
Исчерпание виртуальной памяти при свободной физической вполне имеет место быть.
Своп необязательно должен быть на диске — в zram, например.
Но это, всё, на самом деле — суррогаты свопа.
Исходная причина — что без свопа странички оказываются поделёнными на странички «первого сорта» и «второго сорта».
Ну вот я читаю про systemd — стоит ли с ним начать разбираться. Вроде часть моих проблем он решает, но в некоторых случаях проблемы создаёт. Например, не получается красиво подружить resolvd dnsmasq и Докер для локальной разработки.
Например, не получается красиво подружить resolvd dnsmasq и Докер для локальной разработки.
эта история в принципе красиво не решаема, в том числе и из-за особенностей доцкера. Т.е. это не проблема системди опять же
Пока в ubuntu был upstart, то нормально dnsmask работал с докер на моих задачах.
Ну, так отключите тогда systemd-resolved, если он мешает. В чем проблема?
Не взлетело простое systemctl disable systemd-resolved && apt install dnsmasq (по памяти) — совсем резолвинг отвалился. Ещё пробовал пару мануалов how to return dnsmasq in ubuntu 18.04 — вроде заработало, но с докером связать не получилось, он стал только на 8.8.8.8 фолбэк резолвить. Пару часов поковырялся и плюнул.
Мой коллега разработчик за вечер разобрался с аналогичной проблемой и предложил несколько решений в разных комбинациях демонов.
Т.е. проблема конечная и решаема.
Коллеги, которые минусали г-на VolCh — Вы бы вместо тихого молчания, попросту помогли коллеге разобраться с проблемой. Ну, ей-Богу. Человек, считай, старожил Хабра, адекватные вещи пишет, ну, не справился с резолвом — бывает.
systemd-resolve же висит на 127.0.0.53:53, нет?
~$ sudo ss -tnlp | grep 53
LISTEN0 32 127.0.0.1:53 0.0.0.0:* users:(("dnsmasq",pid=31694,fd=11))
LISTEN0 128 127.0.0.53%lo:53 0.0.0.0:* users:(("systemd-resolve",pid=31414,fd=13))Докера нет, но использовать оба резольвера — никаких проблем. Более того, dnsmasq может использовать systemd-resolve как бэкенд.
systemctl disable systemd-resolved … — совсем резолвинг отвалилсяСкорее всего, стало просто некому писать в /etc/resolv.conf, откуда приложения берут настройки dns. Сам пакет resolvconf в 18.04 не установлен. Но таки да, это проблема к systemd отношение если и имеет, то весьма опосредованное.
Дальше риторический — а чего по звездочкам не сравнить, не очень выгодно получится?
Если бы речь шла о каком-то другом популярном и сложном продукте — да, конечно, больше популярность, больше фич ⇒ больше issues и багов. Проблема systemd в том, что мне в качестве PID 1 и загрузчика системы в принципе не нужен сложный и фичастый продукт — мне нужно что-то максимально простое и надёжное, потому что это слишком критичный элемент системы. А systemd простым и надёжным не является, отсюда тьма issues и багов.
Перефразируя, количество issues и багов доказывает не то, что systemd плохой или глючный, а то, что он слишком большой и сложный… и по этой причине не подходит для использования в качестве системного загрузчика тем людям, которые считают эти качества недопустимыми для данного элемента системы.
Как по мне — это чётко показывает тенденцию, что проблем дофига, и с годами их становится больше, а не меньше.Вообще это показывает то, то людям это небезразлично. Если копнить — то внушительный процесс этих проблем наблюдаётся и в других системах запуска, просто… там они не считаются проблемами.
Ваш же рассказ про Runit просто изобилирует таким проблемами: так не делать, вот это не использовать, сюда не нажимать… да,
issues для них нету — ну так это скорее недостаток, а не преимущество.У каждой системы и её автора есть свой взгляд на то, как ей надо пользоваться, а как не надо. И если ей пользоваться так, как задумано автором — обычно она работает лучше, и жить проще. systemd здесь ни разу не исключение, Поттеринг тоже крайне нетерпим к тем вариантам использования, с которыми он не согласен — напр. уже упоминавшийся здесь неоднократно journald.
Я лично согласен с тем подходом, который рекомендуется авторами runit и s6, и не согласен с тем, который рекомендуется systemd. Поэтому ограничения runit "сюда не нажимать" меня не беспокоят, я их воспринимаю не как ограничения моей свободы куда-то нажать, а как намёк, что есть более простой способ решения моей задачи — и обычно такой способ действительно есть.
Ну а уж если вы решили использовать BIND, то незабудьте озаботиться написанием собственных генераторов [https://blog.iwakd.de/systemd-fstab-and-bind-mounts-with-options] -> blog.iwakd.de/sites/default/files/bindmount-generator.txt
Вот это разнос! Какой позор!!!
в этом нет реальной необходимости: у меня Gentoo, причем даже
Ваш личный опыт не может быть мерилом глобальных явлений и потребностей.
появился Devuan, который «Debian без systemd». Википедия говорит, что есть 53 дистрибутива без systemd
Почти все они — далеко не в топе популярности, в этом суть.
1200+ issues, из них 89 открытых багов
Для сравнения, у OpenRC 61 issue, из них поиск по слову bug выдаёт 14
Демагогия с подменой понятий. Функциональность openrc — лишь небольшое подмножество функциональности systemd. И да, говорить «ну и зачем тогда нужно было делать жирный комбайн, если есть простой openrc/sysvinit?» — тоже демагогия. Потому что остальная функциональность systemd в случае openrc/sysvinit не пропадает, она так же существует в системе, просто реализуется другими программами, со своими багами и уязвимостями. Вся разница лишь в том, что все эти функции в systemd хорошо взаимоинтегрированы и легкодоступны пользователю благодаря унификации подходов и приёмов работы с ними, а в случае с openrc/sysvinit мы имеем ворох разнородных программ, смотанных изолентой.
Демагогия на демагогии и демагогией погоняет — вот и вся аргументация ненавистников systemd. А ещё ненавистники systemd очень любят говорить за всех, вещая что кому нужно и не нужно :-)
Почти все они — далеко не в топе популярности, в этом суть.Миллионы мух не могут ошибаться, да.
Потому что остальная функциональность systemd в случае openrc/sysvinit не пропадает, она так же существует в системе, просто реализуется другими программами, со своими багами и уязвимостями.У всех них есть фатальный недостаток же! Давайте кроме cron-а добавим Systemd Timer, чтобы сразу две программы выполняли одни и те же функции.
Давайте кроме cron-а добавим Systemd Timer, чтобы сразу две программы выполняли одни и те же функции.
Таймеры действительно очень мощный механизм, сильно лучше, чем крон. Фишка крона только в простоте и в том, что ему уже 30 лет в обед и все его проблемы известны. Но крон от этого лучше не становится. Жаль, что многи открывают таймеры для себя только сейчас
Давайте кроме cron-а добавим Systemd Timer, чтобы сразу две программы выполняли одни и те же функции.
«Всё сказанное может быть использовано против вас»
Админы localhost'а, скорее всего, с таким и не сталкивались никогда, но в реальной жизни сплошь и рядом проблема — многократный запуск кроном одного и того же процесса. Потому что во времена, когда «UNIX way ещё не был потерян» такой сценарий просто не встречался.
systemd.timer нам даёт «из коробки» гарантию, что не более 1 копии сервиса будет запущено, ограничение по времени работы, jitter времени запуска (чтобы 1000+ серверов не ломились разом обновлять список пакетов) и плюс, все остальные плюшки, которые systemd даёт. Даже можно сделать так, чтобы до/после сервиса запускался другой автоматически по зависимостям (с другими пермишнами, например).
многократный запуск кроном одного и того же процесса.
в результате — flock, lock и pid файлы и прочие костыли. Которые будут либо в строчке вызова в кроне, либо внутри самого запускаемого сервиса или скрипта. Нет, уж, спасибо — наелся
Как правильно заметили — в systemd такой фигни нет
А самая убер фишка (если мне память не изменяет) — вот предположим крон не отработал запуск скрипта по расписанию. Ну, или крон не был включен, или машина была в дауне. Никаких способов (внятных!) узнать, что скрипт не был запущен — не существует. И что хуже — если крон пропустил запуск, то он его пропустил и не будет при первой возможности скрипт запускать (а иногда это надо!!!). systemd решает эту проблему
Ну тут как раз и возникает ситуация — либо ты собираешь большую коллекцию разнообразных костылей и инструментов (причём для решения одной задачу у тебя будет пяток разных удобных программ, а для какой-то другой — только лишь набор костылей)… либо изучаешь один комплект программ — и с ним работаешь.
Админы localhost'а, скорее всего, с таким и не сталкивались никогда, но в реальной жизни сплошь и рядом проблема — многократный запуск кроном одного и того же процесса.И чем эта проблема вызывается? Один и тот же скрипт дважды вносят?
ограничение по времени работыА в чём здесь заслуга именно systemd? Если нужно ограничить время выполнения, то можно использовать timeout, если ограничить потребление процессора cpulimit и так далее.
Один и тот же скрипт дважды вносят?
Необязательно. Просто время выполнения старой копии пересеклось с запуском новой копии. Или не знаю — перевод на летнее/зимнее время Вы учли?
Повторюсь — в рамках крона и скриптописательства это все решаемо. Но это все выглядит как изобретение велосипеда заново каждый раз.
А в чём здесь заслуга именно systemd? Если нужно ограничить время выполнения, то можно использовать timeout, если ограничить потребление процессора cpulimit и так далее.
Стандартизация механизмов. Отрыв конфигурации (таймауты, лимиты...) от самого кода. Понятный менеджмент.
Стандартизация механизмов. Отрыв конфигурации (таймауты, лимиты...) от самого кода.И в чём выгода вместо того, чтобы дописать что-то в строку запуска писать это как отдельный параметр? В одном случае есть скрипт на баше, в другом юнит файл. Количество строк в данном вопросе тоже отличаться особо не будет.
Ну и плюс дебаг задач cron это просто жесть.
Если пугает оверхед то есть LFS, Gentoo и BSD.
Хотите сделал embedded что-нибудь, куда никакие «чужие» программы не ставятся — творите, что хотите.
А в массовой платформе — должны быть удотволерены потребности 99% пользоателей. Если даже в результате получится так, что каждый из них использует 1% возможностей платформы… но это будет разный 1% для каждого из них.
systemd нужен софту, с которым работает пользователь. А пользователю действительно пофигу, главное, чтобы работало.
systemd в современной GNU/Linux предоставляет набор функций, который никаким другим, кросс-дисстрибутивным, способом — не делаются.
А уж нужны эти функции программе или нет — это разработчику решать. Не вам, не мне и даже не «мейнетерам».
Можно пример, как они решают?
То есть если бы udev не шёл в комплекте с systemd, то вы бы пользовались systemd с удовольствием с eudev?
Если бы udev и всё остальное, не имеющее никакого отношения к PID 1, не шло в комплекте с systemd, им бы все пользовались с удовольствием.
А тем барахлом, что существует в реальности и называется systemd, добровольно пользуются только виндузятники, которым надёжность программ, а также удобство пользователей и разработчиков, дороже, чем принципы.
А тем барахлом, что существует в реальности и называется systemd, добровольно пользуются только виндузятники, которым надёжность программ, а также удобство пользователей и разработчиков, дороже, чем принципы.Ещё им пользуются те, кто уважают философию Unix и, в частности, такой важный пункт как «Пишите программы, которые бы работали вместе».
Напомню, что ни один Unix (настоящий Unix, ведущий родословную от разработки Кена Томпсона и Деннисом Ритчи) не позволяет вам выбирать, скажем, системный логгер.
Он там отдельный процесс да, но он является частью базовой системы и поставляется вместе с ней. Всегда.
Напомню, что ни один Unix (настоящий Unix, ведущий родословную от разработки Кена Томпсона и Деннисом Ритчи) не позволяет вам выбирать, скажем, системный логгер.
Отсюда, очевидно, следует, что в идеале cистемный логгер и должен быть частью системы и поставляться с ней. Всегда.
Вы хотите пользоваться философией Unix, а я хочу пользоваться собственно Unix. Ну или чем-то похожим на Unix. И у меня это было, у меня был GNU/Linux. А потом у меня забрали возможность пользоваться GNU/Linux и подсунули вместо него systemd.
Вы хотите пользоваться философией Unix, а я хочу пользоваться собственно Unix.Что вас останавливает? FreeBSD и DragonFly BSD до сих пор существует.
Ну или чем-то похожим на Unix.Проздравляю! systemd сделал GNU/Linux более похожим на настоящий Unix. Такой как Darwin (с его launchd) или Solaris (с SMF). Ваша мечта исполнена.
Отсюда, очевидно, следует, что в идеале cистемный логгер и должен быть частью системы и поставляться с ней. Всегда.Не в идеале, а «в соотвествии с философией Unix». А идеал — он у всех разный. В этом-то вся и беда: нет никакого одного идеала, который бы устроил всех. А операционки, которые устраивают миллиарды пользователей, тем не менее, есть: Android, Windows, iOS (в этом порядке). systemd же — попытка сделать GNU/Linux ещё одной подобной…
А потом у меня забрали возможность пользоваться GNU/LinuxКакая конкретно часть GNU или Linux у вас пропала?
и подсунули вместо него systemd.Systemd заменил как раз не компоненты GNU и не Linux, а ужасающую многоуровневую коллекцию костылей, подпёртых другими костылями, которая может нравиться, вы уж извините, только мазохистам.
До того как Поттеринг втащил его в systemd.Ещё раз: Поттеринг ну никак не мог этого сделат. Куда-либо втащить udev могли только разработчики udev. А многие из них даже в RedHat не работают. И если они это сделали — то это был их выбор. А не ваш или Поттеринга.
Почему вы так яростно выступаете за вашу свободу и ваш выбор — но лишаете разрабочиков udev этой возможности?
Например пресловутый Поттеринг втащил кодовую базу udev в кодовую базу systemd.О как. Вот прямо так и втащил? А разработчики udev при этом сопротивлялись и плакали? Какой нехорошний Поттеринг, однако.
Я вам секрет скажу: без согласия разработчиков udev он бы ничего никуда втащить не смог.
И только благодаря мейнтейнерам Gentoo я пользую eudev и не имею навязанного Поттерингом хлама в системе.До тех пор, пока вы это делаете молча и не рассказывая баек про то, как злой Поттеринг хлестал разработчиков udev розгами — это ваш выбор.
А вот когда вы начинаете стонать и плакать и требовать, что разработчики софта «входили в положение» и поддерживали Gentoo без
systemd… вот тогда это перестаёт быть вашим личным делом, извините.Миллионы мух не могут ошибаться
У всех них есть фатальный недостаток же! Давайте кроме cron-а добавим Systemd Timer, чтобы сразу две программы выполняли одни и те же функции
Правда, это тут считается нормальной аргументацией, а не детским кривлянием? Походу, Хабр реально заболел :-)
Позвольте поинтересоваться: зачем "кроме cron-а", когда можно (и нужно) "вместо cron-а"?
1200+ issues
это из-за распространенности (популярности) такое кол-во issues. На моих, никому не нужных проектах, 0 issues. Но это не значит, что их там нет)
начиналось как просто PID 1 и стала тем, что я бы назвал middleware современного дистрибутива Linux
И это плохо само по себе. Тем более, что опыт показывает, что в этом нет реальной необходимости: у меня Gentoo, причем даже не на OpenRC а на Runit, и при этом много лет используется udev (точнее eudev) и вот на днях перешёл на logind (точнее на elogind). Как видите, нет большой проблемы выделить полезные и нужные компоненты из systemd — или, говоря иначе, нет и небыло реальной технической (в отличие от политической!) необходимости изначально слеплять их в одно целое.
У меня на одном сервере пару сотен VLAN — так вот все кроме systemd боль и страдания. Все остальные системы инициализируют интерфейсы при загрузке и это занимает очень много времени (порядка 15 мин), с systemd все это за счет отложенной инициализации по необходимости занимает секунды.
Здесь реальная проблема не в том месте. У меня на десктопе под десяток VLAN-ов, каждый инициализируется ровно двумя строчками в /etc/runit/1 при загрузке системы и занимает это примерно нисколько, не смотря на синхронный запуск:
ip link add link enp9s0 name eth.wifi up type vlan id 6
ip addr add 192.168.6.1/24 dev eth.wifiВ целом, Вы правы, конечно. Только вот выводы из этого можно сделать разные — кто-то делает вывод, что нужен большой и сложный инструмент на все случаи жизни, а кто-то, что нужен ещё один мелкий и тупой инструмент конкретно под текущую задачу. Мне ближе последний подход. Но гораздо чаще случается кое-что другое: люди всё переусложняют на пустом месте, и пытаются решить проблему сложным способом не потому, что возможностей инструмента недостаточно, а просто потому, что не видят простое решение.
Надо что-то сложнее чем две строчки — все страдай — пиши логику на баше.
Вы не поверите, но обычно — не надо. Двух строчек хватает.
Надо айпишник получать по DHCP — страдай.
dhclient enp2s0 — одной строки хватает.
Надо интерфейсы собрать в bonding — страдай.
Этого я не делал, но вполне допускаю что тоже пары строку плюс по строке на интерфейс вполне может оказаться достаточно. Либо нужен отдельный простой инструмент, который умеет делать только это.
Такая же проблема с cron — тупым запускальщиком задач.
Не знаю, что конкретно Вы имели ввиду, но тут в обсуждении упоминалась ситуация, когда cron запускает дважды одну задачу из-за того, что она слишком долго работает, и это всё почему-то ломает. На мой взгляд, блокировка параллельного выполнения задачи, которую нельзя запускать параллельно — не задача cron, просто потому, что он далеко не единственный "запускальщик" в системе, и ту же задачу может запустить кто-то ещё (админ ручками, например). Задача должна блокировать себя самостоятельно, не перекладывая это на внешний инструмент — потому что внешний инструмент не может знать, какие задачи и на каких этапах их выполнения могут нуждаться в блокировках.
Количество багов это все-таки так себе метрика. У тех же компиляторов которыми не только все софт собирается, но и ядро багов многие тысячи и у gcc и у clang. Количество багов определяется также популярностью продукта.
… появился Devuan, который «Debian без systemd»Это тот, который потратил два года, чтоюы перейти на Jessie и уже год, как не может версию на Buster выкатить? Оно вам точно надо?
Википедия говорит, что есть 53 дистрибутива без systemd.И у скольки из них есть хотя бы 10 миллионов пользователей?
Я это к тому, что из Вашего описания складывается впечатление, что последние бастионы сопротивления пали на дебиане, и везде воцарился systemd… так вот, это не так.С точки зрения обычного разработчика — это вполне себе так. Баги, вопроизводящиеся только на дистрибутивах без systemd уже вполне можно закрывать как WONTFIX.
Это, собственно, мне кажется главным достижением systemd. Остальное — мелочи.
А факты можно увидеть в базе CVE: 56 записей.А давайте микрофактчекинг. Вот ткнул на одну их этих CVE (примерно посреди экрана): если сервис исполняется из под непривилигированного пользователя, локальный пользователь, имеющий права вышеописанного пользователя может перезаписать PID файл и убедить systemd убить какий-нибудь другой процесс.
Как и когда эта проблема была решена в вашем любимом Runit?
Про Runit сказать сложнее за отсутствием его на гитхабе, но насколько мне известно багов в нём нет.Тем более интересно послушать как решается проблема с PID файлами.
контейнеры из коробки не умеют в зависимости. Это означает, что должна быть либо тяжелая система оркестрации (читай — кубернетес), либо всякие костыли внутри самого приложения, которые проверяют все необходимые для его работы зависимости. Просто надо разделять теплое и мягкое. systemd — это про отдельные единичные сервера. И на них он прекрасно работает. Насчет замены docker — вообще-то у systemd нет такой задачи, но да, для дистрибуции софта docker не особо нужен, если можно использовать systemd+chroot или nspawn.
А UNIX-way изначально был чуть другой, там раньше вообще ядро статически под железо генерили, а потом использовали унифицированное API для запуска сотен взаимодействующих процессов. Сначала RDBMS какой-нибудь, или подобие того, что стало называться LAMP а позже это переросло в SUN-овское «Cеть — это компьютер».
Вот зря systemd полез в управление зависимостями сервисов. Все равно до сети, облаков и кластеров не дорос, а остался в рамках управления рабочей станцией, которая пытается стать «немножко сервером». Если только Поттеринг кубернетис или там hadoop не перепишет :)
Systemd хорош, чтобы сделать «удобненькую» рабочую станцию, где постоянно флешки-камеры-наушники-сканеры отключаются-включаются, несколько мышей-тачей и у которой сеть постоянно переходит с WiFi на GSM-свисток
мне казалось, что это решается каким-нибудь udev'ом. Ну, ок, это не столь важно )
Вот зря systemd полез в управление зависимостями сервисов.
а по мне не зря.
Если только Поттеринг кубернетис или там hadoop не перепишет
предложите ему )))))
Проблема в том, что systemd является плохим локальным резолвером, логгером, ntp-сервером, управлялкой контейнеров и черт его знает чем ещё, в чём постоянно находят дырки и фундаментальные проблемы. А избавиться от этого если «в дистрибутиве решили» бывает ничерта не просто.
Ах да, ещё он в чруте ничего запустить не может. Потому что оверинжиниринг. Ну и чтобы подебажить, например, systemctl — нужно читать сорцы и искать секретные переменные, как оказалось (впрочем, апстарт ещё хуже дебажился).
И про это поттерингу из каждого утюга и вещали. Просто он не слушал никого.
Проблема в том, что systemd является плохим локальным резолвером, логгером, ntp-сервером, управлялкой контейнеров и черт его знает чем ещё, в чём постоянно находят дырки и фундаментальные проблемы.
это не так. В смысле — всего указанного функционала в systemd может не хватить. Это правда. Но тогда берешь, отключаешь эти компоненты и вместо них устанавливаешь другие, более удобные и подходящие для конкретной задачи.
timesyncd -> chrony, например.
resolved -> меняешь на локальный dnsmasque.
С управлением контейнерами вообще смешно. Потому что docker… ну, без systemd как будто не особо функционален (в результате приходится оборачивать контейнеры в юниты, т.к. из докера супервизор как из говна пуля). Подчеркну, что если тащить оркестратор типа кубернетес — это решение вообще совсем другой задачи (а именно управление набором машин).
Ах да, ещё он в чруте ничего запустить не может
чушь. RootDirectory видели в описании юнитов?
Хммм… А может тайный шаманский смысл init 1 и состоит в том, чтобы он запускал процессы и управлял ими? Ну там перезапускал после падения или ребута, например?
А может быть стоило вместо пиления бесполезных nspawn/machinectl добавить опцию записи STDERR/STDOUT в файл не через 6 лет после того, как она появилась, а хотя бы годика на 3 раньше?
Да не, чушь какая-то.
> чушь. RootDirectory видели в описании юнитов?
А теперь сделайте chroot /somewhere service foobar start
И представьте, что у вас нет желания делать костыли, которые переносили бы unit из чрута в основную систему, добавляя RootDirectory, потому что это делает chroot не портабельным. Ну или вы просто из системы, где systemd нет, чрутитесь в систему с systemd и сервис запустить нужно очень срочно.
Загрузиться по сети, чрутнуться, запустить сервисы в незагружаюшейся системе (кстати, система не загружается до ssh намного чаще именно под systemd) и начать миграцию на живой хост — это ведь вообще никто не делает в этом мире. Все просто выключают сервера и идут пить кофе в таких случаях. Зачем в подобных ситуациях экономить время.
> отключаешь эти компоненты и вместо них устанавливаешь другие, более удобные и подходящие для конкретной задачи.
Только вот чаще всего не отключаешь, а оставляешь — вместе с уязвимостями.
А ещё чаще — нет тебе дела до чтения всего changelog systemd на тему того, что ещё они затащили внутрь себя, чтобы вовремя это выключить.
А самое печальное, что все уязвимости в systemd пошли по второму кругу — dns/ntp amplification уже были, ждём shellshock over dhcp.
Только вот чаще всего не отключаешь, а оставляешь — вместе с уязвимостями.
Вопрос точки зрения. Запустить одновременно timesyncd/ntpd/chrony — надо ещё умудриться. Или Вы говорите о полном выкорчевывании неиспользуемых компонентов из системы вплоть до деинсталляции?
А может быть стоило вместо пиления бесполезных nspawn/machinectl
Для вас бесполезные, а я даже знаю пользователей этих возможностей. Хотя, как по мне, их реализация выглядит сомнительной.
А теперь сделайте chroot /somewhere service foobar start
Зачем? Давайте сойдёмся на том, что мы смотрим на проблему с разных точек? Для меня чрут — это способ изолированного запуска сервисов. Оно реализовано в systemd? Да, вполне. Вы же пытаетесь загрузить какой-то сторонний дистрибутив, чрутнуться и получить рабочую систему. Ну, как минимум, доступную в рекавери режиме. Ну, эээ. Это как бы совсем другая история. Да, это должно быть продумано. Но я не видел никаких проблем с восстановлением работы линукса. IPMI + recovery режима в самой операционной системе было достаточно. ОКей, возможно мне везло и повреждения были не столь большие. Но, черт возьми, не должен же рекавери быть сложнее, чем накатить систему с нуля + налить в нее конфиг или восстановить полностью из бекапа в образе? И причем тут тогда чрут?
Ну почему ж.
udp 0 0 127.0.0.53:53 0.0.0.0:* 813/systemd-resolve
tcp 0 0 127.0.0.53:53 0.0.0.0:* LISTEN 813/systemd-resolve
udp 0 0 127.0.0.1:53 0.0.0.0:* 1121/unbound
tcp 0 0 127.0.0.1:53 0.0.0.0:* LISTEN 1121/unbound Просто apt-get install unbound и поехали.
А с менее сетевыми вещами — вообще фигня вопрос. rsyslog+journald никого не удивляет же.
> Для вас бесполезные, а я даже знаю пользователей этих возможностей.
Повторюсь. Я не против nspawn. Я против того, чтобы он был частью systemd. Потому что systemd должен развиваться как init 1, а не тащить за собой грабли в этой части, потому что ресурсы команды уходят на черт те что и сбоку бантик, вместо тех фич, которые от них ждут, именно как от init-а.
А nspawn должен развиваться как управлялка контейнерами, а не оставаться плохой управлялкой контейнеров в составе systemd.
> Но я не видел никаких проблем с восстановлением работы линукса
И пока вы его восстанавливали — сервис валялся? Удобно =)
(и про розовый мир, в котором всё зарезервировано можете не вспоминать, я там был (впрочем, и есть, тьфу-тьфу-тьфу) — трындят-с).
и про розовый мир, в котором всё зарезервировано можете не вспоминать, я там был
все айти — это про деньги. И если простой сервиса стоит дороже, чем нанять еще одного специалиста, который будет поднимать его, или дороже, чем вторая железка с репликой сервиса и балансировкой, то в общем-то так и сделают. А если денег нет, то о чем вообще речь? Как из говна и палок собрать конфетку? Как правило получается "как обычно".
Добавлю.
udp 0 0 127.0.0.53:53 0.0.0.0: 813/systemd-resolve
tcp 0 0 127.0.0.53:53 0.0.0.0: LISTEN 813/systemd-resolve
udp 0 0 127.0.0.1:53 0.0.0.0: 1121/unbound
tcp 0 0 127.0.0.1:53 0.0.0.0: LISTEN 1121/unbound
Просто apt-get install unbound и поехали.
А с менее сетевыми вещами — вообще фигня вопрос. rsyslog+journald никого не удивляет же.
По поводу рсислог и журнала. Я уже высказывался выше зачем так сделано. Это вполне… Осознанный ход, чтобы админы бородатые из прошлого века не задавали дурацких вопросов "где мои логи". Вот им и дают их в стандартных местах. Конечно, связка journald -> rsyslog создает свои проблемы. Например, жрет х2 места на диске под логи. И проц грузит. Но… Предложите лучше, чтобы удовлетворить всех пользователей.
Касательно unbound +resolved. Не совсем понял, почему наличие двух резолверов проблема. Можете подробно объяснить, без эмоций? Резолвд ведь не светит на весь интернет своим 53м портом. И доступен только локально
связка journald -> rsyslog создает свои проблемы. Например, жрет х2 места на диске под логи
Это где она жрёт? По дефолту jourlnald пишет в /run/systemd/journal (который tmpfs). К тому же он логи ротейтит и сжимает.
А если подумать? Вот вы шлете в логи стандартный поток. journald его перехватывает. rsyslog в убунту 18 берет и бережно эти логи перекладывает в /var/log/syslog Да, это не проблема systemd как такового, а особенностей настройки конкретного дистрибутива, но это факт. Посмотрите, пожалуйста, конфиги. А потом КОГДА-нибудь приходит logrotate и перепячивает файл /var/log/syslog в .1, потом гзипует в .2.gz и так пять копий.
Аргументировал свой тезис?
Забыл добавить про персистенцию логов. Но коллега выше уже ответил. Не берусь утверждать 100%, но на серверных системах как будто логи журналди сохраняются между перезапусками. Меня это устраивает. Но там две не совсем очевидные настройки, которые на это влияют — наличие каталога и флага в conf файле
rsyslog в убунту 18 берет и бережно эти логи перекладывает в /var/log/syslog
Он ничего не перекладывает. rsyslog вообще про journald не знает ничего и ему не нужно знать. Что ему в сокет пишут, то он пишет на диск. А пишет ему journald. Не нравится — systemctl disable --now rsyslog или apt purge rsyslog.
две не совсем очевидные настройки
Очень даже очевидные. Всё в документации подробно расписано.
Что ему в сокет пишут, то он пишет на диск
как это противоречит наблюдаемому поведению? Я уж не говорю о том, что теоретически rsyslog умеет хватать напрямую из imjournal, но там свои нюансы
Не нравится — systemctl disable --now rsyslog или apt purge rsyslog
ну, да. Еще раз повторюсь — описанное не является проблемой, это особенность настройки конкретного дистрибутива.
Очень даже очевидные. Всё в документации подробно расписано.
все так, подтверждаю, что в доке все есть ) Но кто же ее читает, когда надо побыстрее фигак-фигак и в продакшен? И нужно иметь в голове эту модель работы (не просто булевский флаг On/Off).
Ну, и отдельный вопрос, что доку по сустемди могли сделать какой-то более человечной, что ли.
Противоречит в том, что у journald логи всегда сжаты. Не будет там «x2», равно как и ситуации, когда безумный процесс нагенерил 5Гб логов и они в текстовом файле валяются, пока logrotate не запустится.
доку по сустемди могли сделать какой-то более человечной
У systemd отличная дока, всё подробно расписано. Что не нравится? Много чего запоминать надо? Так не надо — man systemd.directives
Противоречит в том, что у journald логи всегда сжаты. Не будет там «x2», равно как и ситуации, когда
Х2 в моем ответе было достаточно вольной оценкой. Можете понимать как хотите. И то, что объем на хранение больше одинарного, и то, что логи в двух местах. Касательно точного математического критерия — смотря что брать за базу. Если рсислог пишет текстовые логи, то они наверняка могут и больше, чем в х2 раздуться. По сравнению с пожатыми бинарными.
безумный процесс нагенерил 5Гб логов и они в текстовом файле валяются, пока logrotate не запустится.
С докером (и драйвером логирование journald) это выглядит вообще-то именно ровно так.
Повторюсь, у нас с Вами опыт не противоречит друг другу, конфигурации разные, поэтому и нюансы.
У systemd отличная дока, всё подробно расписано. Что не нравится? Много чего запоминать надо? Так не надо — man systemd.directives
Думать надо ) много. Например, в systemd.service описаны не все параметры, а часть надо искать в systemd.exec (если я ничего не перепутал). Ну, и по мелочи.
Какой это комментарий по счету в ветке? Третий? И вот вы уже докатились до «ретрограды сраные не дают развивать systemd, как нам хочется, какие-то бородатые админы хотят логи на диски, ишь чего захотели!». И это тоже большая проблема команды разработки systemd и Поттеринга в частности — его мнение не святое и потребителей нужно слушать. Если поверх текстовых логов написано полтора миллиона километров исходников всякой интеграции — то никто не будет всё это переписывать (а особенно в кровавом ынтерпрайзе) только ради того, чтобы потешить ЧСВ Поттеринга, который считает, что бинарные логи лучше.
И я не берусь спорить, что именно лучше. Я вам говорю, что текстовые логи пишут все и писать никто никогда не перестанет — и жить с этим нужно уметь, а не кричать на каждом углу «ретрограды мешают развитию».
А ещё они за каким-то чертом реализовали свой интерфейс для приёма-отправки логов по сети, который (внезапно) никто не бежит роняя кал поддерживать в своих системах.
> Не совсем понял, почему наличие двух резолверов проблема
Потому что уязвимости никуда не деваются. А в resolved том же они были, есть и в том числе достаточно неприятные. Как и в любом другом компоненте systemd.
Не вижу ничего в Вашем ответе, кроме эмоций.
А в resolved том же они были, есть и в том числе достаточно неприятные.
вот, например, вместо того, чтобы обсудить уязвимости.
Соряндекс (развожу руками).
А не нужно всё сваливать на бородатых админов. Главные ретрограды в мире — далеко не они.
> вот, например, вместо того, чтобы обсудить уязвимости.
www.opennet.ru/opennews/art.shtml?num=52340
www.cvedetails.com/cve/CVE-2019-15718
А не нужно всё сваливать на бородатых админов. Главные ретрограды в мире — далеко не они.
а кто сваливает ) просто привел пример возможно субоптимального конфиг-сета.
www.opennet.ru/opennews/art.shtml?num=52340
мы про resolved вроде говорили, не ?
www.cvedetails.com/cve/CVE-2019-15718
аналогично.
p.s. да, по второму внимательнее прочитал — это проблема resolved.
Это решается простой вещью — просто добавляется опция хранения логов journald в файлах (возможно — «и в файлах тоже»).
А вместо этого Поттеринг и Ко бурчат, что все таких плохие, не хотят бинарные логи, реализуя текстовые логи странными способами. «Все плохие, а мы дартаньяны» — их позиция, за 10 лет ничего толком не поменялось. И таких вопросов много, по которым они просто уперлись в позу, вместо того, чтобы сделать то, что от них просят (в том числе и те, кто деньги им в конечном итоге приносит). Я от этого устал, ещё читая оригинальные рассылки, когда debian собирался на systemd переходить, уж извините.
Вот нахожу ответ Поттеринга в ответ на очень похожий баг:
«Friends don't let friends you pam_securetty.so. It's stupid and obsolete. Please ask your distro to remove it from their default PAM fragments.»
А потом что? Иду и меняю дистрибутив, по его мнению? Или иду перекапывать половину дистрибутива, что бы он без pam_securetty.so завелся?
Со snoopy та же история была, те же ответы — «мы пушистые, во всём виноваты разработчики snoopy». Разработчики snoopy поматерились и переписали, а разработчики других подобных продуктов написали в README.md «never will work with systemd, goodbye».
И может быть в каком-то из этих случаев он и прав, но к сороковому случаю уже точно понимаешь, какая черепашка периодически врёт.
Ну судя по поиску проблема была в том что pam_securetty запрещал логиниться root на ненастоящем терминале, а для контейнера не возможно создать терминал подходящий для pam_securetty. Тут либо pam_securetty отключить внутри контейнера или одно из двух. А какая у разработчиков systemd должна быть реакция на эту ситуацию?
Просто реакция? Не называть вещи тупыми никогда и нипочему в публичном багтрекере, который индексируется гуглом. Хотя бы потому, что pam_securetty числится за авторством коллеги Поттеринга — people.redhat.com/sopwith (не знаю, бывшего или настоящего).
Ещё вместо имеющего оскорбительную окраску в данном контексте «obsolete» можно использовать общепринятое «legacy, we can't support this».
Грань между хамством и называнием вещей своими именами очень тонка. К сожалению, чтобы соответствовать нормам общества приходится тренировать двоемыслие и облекать все мысли в максимально стерильную форму, дабы особо чувствительные натуры, не дай Бог, не оскорбились.
Нет вообще никакой причины использовать слово «stupid», когда ты отвечаешь своим пользователям.
«Вы поставили тупой debian9, а у нас новое железо и теперь у вас не будет работать сетевая карта» — нормальный ответ от саппорта хостера, например? Или «Наше железо не поддерживается в debian 9, поставьте драйвер или обновитесь до десятки» — двоемыслие?
Проблема же не в одном тикете, проблема в том, что это происходит постоянно. Поттеринг называет всех ретроградами, закрывает тикеты с разгромными описаниями, а потом за ним приходят другие сотрудники RH и чинят эти тикеты, потому что они заведены людьми с платной подпиской на RHEL.
«Вы поставили тупой debian9, а у нас новое железо и теперь у вас не будет работать сетевая карта» — нормальный ответ от саппорта хостера, например?Ну если о Debian9 — наверное ненормальный. А вот если RedHat 9 (Shrike), то да, вполне.
а потом за ним приходят другие сотрудники RH и чинят эти тикеты, потому что они заведены людьми с платной подпиской на RHELНепонятно только почему эти люди вообще лезут в upstream. Они уже заплатили за подписку, которая должна давать им право (и даёт, в общем-то) быть ретроградами — зачем они пытаются лезть туда, где поддерживать софт времён Царя Гороха никто не обязан.
Я вот не вижу ничего странного в том, чтобы определённые доработки в софте выполнялись только за деньги. А в тяжёлых случаях и за деньги никто не возьмётся…
Это всё ещё не повод называть RH9 _тупым_. Legacy и не поддерживается — да, вполне логично. Но тупым-то он не стал, просто своё отжил.
> Непонятно только почему эти люди вообще лезут в upstream.
Наверное это как-то связано с тем, что все ключевые разработчики systemd сидят на зарплате у RH и пилят systemd за деньги. Тут я уже подробностей не знаю.
В любом случае, systemd — давно не личный pet-project Поттеринга, чтобы оскорблять всех несогласных, мы все в одной лодке. И это, повторюсь, в публичном трекере, где он является лицом компании RH — что он пишет в рассылках местами цитировать в приличных местах стыдно.
Но тупым-то он не стал, просто своё отжил.Что значит «он своё отжил», если «тупым он не стал»? Тут, извините, что-то одно из двух.
А pam_securetty — это именн что дурацкая вещь: такая же, как ограничение доступа по UID чужого компа (как в ранних версиях NFS сделано).
И это, повторюсь, в публичном трекере, где он является лицом компании RH — что он пишет в рассылках местами цитировать в приличных местах стыдно.А почему, собственно?
Да, Леннарт — чувак жёсткий и сторонник решать проблемы там, где они возникают, а не путём пристраивания 100500 слоёв костылей к уже имеющимся костылям. Собственно потому он и смог сделать systemd… все, кто выражается менее жёстко изобратели всё более «прогрессивные» коллекции
init-скриптов…Нет. Он смог сделать systemd, потому что переложил ответственность за написание костылей на других разработчиков и мейнтейнеров — слишком большой у него был запас доверия. И systemd в дистрибутивах отличных от федоры-центоси-rh всё ещё является «прогрессивной коллекцией init-скриптов», потому что нихрена непонятно, как и на systemd переехать, и требования платных клиентов выполнить, не сломав им весь прод.
А на сдачу — угробил гном во всех дистрибутивах, кроме RH-based. На убунту 20.04 с гномом (особенно flashback) без слёз не взглянешь, всё отваливается.
Нет, это называется токсичный мудак, не более. В 2010-м это прокатывало, в 2020-м люди устали от таких «специалистов». И какие бы проблемы он в действительности не решал — он так им и останется. Люди не хотят взаимодействовать с ним — а это в конечном итоге вредит проекту и разобщает community — никто не хочет лезть в эту клоаку.
Торвальдс не менее категоричен и «жесткий», так же эффективно решает проблемы, но никто его токсичным не считает — потому что его позиция всегда понятна, а не состоит из «stupid notabug».
За сим предлагаю дискуссию закрыть, мы друг друга ни в чём не убедим.
но никто его токсичным не считает
Не то, чтобы я был с Вами не согласен по сути, но чисто правды ради на Линуса тоже вполне себе конкретно пытаются наезжать за стиль общения https://habr.com/ru/post/423607/
Ну или Боинг возьмите — там та же история.
В области IT это не так заметно, так как отрыв (сделанный как раз в 70е-80е «токсичными мудаками») уж очень велик, но если так и будет цениться умение красиво говорить, а не умение что-то делать — результат, со временем, будет тот же.
И против токсиков я ничего в рабочем процессе не имею. И да, вещи можно называть своими именами. Но своими именами, а не голословно оскорблять.
Но вот соблюдать элементарные правила вежливости и уважения к собеседниками и коллегам публично высказываясь как лицо продукта/компании на официальном ресурсе — нужно. Даже если для этого приходится использовать другие обороты в речи. И делать это нужно не потому что я так хочу или «борцы с токсичностью», а потому что если такие Поттеринги станут лицом OSS повсеместно — взрослые воспитанные дяди ни копейки денег таким людям и их компаниям не понесут, а со временем снова начнут относиться ко всей этой движухе, как к играм школьников. Таков мир, ничего уже не поделаешь.
опцию записи STDERR/STDOUT в файл
Так кто мешает самому вписать, зачем 6 лет ждать?
ExecStart=sh -c "exec foo &> /var/log/foo.log"Загрузиться по сети, чрутнуться, запустить сервисы в незагружаюшейся системе
Это каждый день происходит? Сочувствую. А раз в полгода можно глазами .service посмотреть, он редко когда больше 1 экрана размером.
система не загружается до ssh намного чаще именно под systemd
Если вы работаете в серьёзной компании (или пользуетесь нормальным хостером), то коннектимся в iLO/IPMI/IP-KVM и просто с консоли разбираемся. А если так, поиграться — ну, опять же, можно посочувствовать и пожелать удачи в организации хороших условий работы.
чаще всего не отключаешь, а оставляешь
Для этого есть один раз написанный сценарий ansible, чтобы привести хост к нужному состоянию. Да, если он смотрит в интернет — первое, что делаем — закрываем доступ отовсюду.
все уязвимости в systemd пошли по второму кругу — dns/ntp amplification уже были
В systemd нет NTP сервера, только клиент, там не могло никакого amplification быть.
ждём shellshock over dhcp
Не дождётесь. Советую ознакомиться со списком ограниченных пермишнов:
systemctl cat systemd-networkdТак это медленно. Намного быстрее сделать это на уровне запускалки, которая можно подменить дескрипторы STDERR/STDOUT.
Ну и делает Unit, мягко говоря, бракованным — systemd следит за тем, работает ли процесс sh, а не процессом, за которым он должен наблюдать. Возможны ситуации, когда процесс закончился, а шелл остался чего-то ждать.
> Это каждый день происходит? Сочувствую. А раз в полгода можно глазами .service посмотреть, он редко когда больше 1 экрана размером.
> Если вы работаете в серьёзной компании (или пользуетесь нормальным хостером), то коннектимся в iLO/IPMI/IP-KVM и просто с консоли разбираемся. А если так, поиграться — ну, опять же, можно посочувствовать и пожелать удачи в организации хороших условий работы.
Во-первых, не разработчикам systemd и не вам менять реалии того, в каких условиях люди запускают свои сервисы перед тем, как ко мне принесут проблемы. Они не хотят выслушивать, какие они плохие и криворукие, они хотят проблему решить. И быстро, желательно.
Во-вторых, вы не понимаете одной простой истины — сначала подними сервис любым способом, а потом уже чини это так, чтобы не сломалось опять. Unit-ы не запускаются в чрутах. Точка. Это неудобно и это — следствие именно «прекрасных розовых представлений о реальном мире, в котором все преклонят колени перед systemd». И важна там каждая минута.
В третьих, вы сами-то по iKVM что-то делаете? Или просто с точки зрения локалхоста рассуждаете? Намного удобнее recovery-образ по сети загрузить и по ssh уже запустить и разбираться.
> Не дождётесь. Советую ознакомиться со списком ограниченных пермишнов:
Это работает ровно до того момента, пока CVE не будет заключаться в обходе списка пермишнов. Менять список резолверов в системе через CVE-2019-15718 пермишны никак не мешали, например.
В timesyncd уязвимостей меньше, ок, на него я зря наговариваю.
Ну и делает Unit, мягко говоря, бракованным — systemd следит за тем, работает ли процесс sh, а не процессом, за которым он должен наблюдать.
Нет, не делает. Обратите внимание на exec, эта команда там не просто так написана.
Но это всё равно не отменяет вопроса о том, почему неизбежные StandardOutput=/StandardError= появились настолько поздно.
В Android поступили проще: их init просто запускает все процессы передавая им /dev/null в качестве
stdout и stderr… а как, что и как там будет логировать — не его проблемы.Какая-то уж очень наивная надежда, с учетом количества legacy, с которым мы сталкиваемся. У чего-то уже и исходников-то давно нет (вон php5.2 до сих пор из-за старого zend-а востребован, пусть сейчас и меньше).
> В Android поступили проще: их init просто запускает все процессы передавая им
Могу предположить, что так было изначально в платформе? Тогда это хотя бы честно (пусть и неудобно).
systemd следит за тем, работает ли процесс sh, а не процессом, за которым он должен наблюдать
Позорище. Вы знаете, что команда exec делает? Или мне опять мануал процитировать?
Менять список резолверов в системе через CVE-2019-15718
А в суперзащищённой OpenBSD тоже дырочки находит. И что?
пока CVE не будет заключаться в обходе списка пермишнов.
Эти пермишны — ядерные cgroups, capabilities, неймспейсы, syscall фильр. Поэтому если такой CVE появится, то он пойдёт напрямую к разработчикам ядра. При чём тут systemd?
Зачем, если есть minikube, который потом по необходимости скейлится до обычного кубера?
Не пытайтесь теперь все свести к кубернетесу. Ну, нафиг он нужен на отдельно стоящей машине. Может там вообще докер лишний со всеми его приколами.
Но вот зачем ни в machinectl, ни в lxc не сделали network=host — до сих пор не понимаю, мда.
А, прошу прощения тогда )
У меня в загашниках есть аналогичная история, но ровно наоборот ) Разработчик поставляет докерфайл, т.к. ничего другого он не умеет. А целевая платформа без докера и его там никогда не будет. Я придумал решение именно, что с изолированным root-dir, все прекрасно работает и устанавливается через деб пакет. Возможно, стоит рассказать о том, как мы к этому пришли — мало ли кому пригодится.
целевая платформа без докера и его там никогда не будет
Возьмите podman и не мучайтесь.
не мы решаем, если машину предоставляет заказчик.
Теоретически можно написать ТЗ, но тогда могут найти более сговорчивую команду разработки )))
Разработчик поставляет докерфайл, т.к. ничего другого он не умеет
Почитайте, что такое podman и расскажите заказчику. В этой схеме явно многие слышали лишь «напевы Мойши» про docker.
podman — это docker без демона, работающего от рута. В крайнем случае его вообще можно самому скомпилить, положить в /home и использовать. Да, для сборки контейнера — берём buildah.
Наличие докерфайла упрощает жизнь, вот и надо его использовать. Зачем городить какие-то костыли и грабли?
Спасибо, я в курсе что такое podman. И в курсе, что он, к сожалению, пока сыроват. Как и альтернативные способы сборки (мы сейчас активно мигрируем на kaniko)
это docker без демона, работающего от рута
Уже сделали что-то подобное и в докере (если я со ссылкой не ошибся). Но… поздновато.
В крайнем случае его вообще можно самому скомпилить, положить в /home и использовать
да-да-да, знаем мы такое ) в рамках Ынтепрайза кладем любой бинарь в ~/.local/bin и радуемся жизни
Читаем man systemd.nspawn:
[NETWORK] SECTION OPTIONS
…
Private=
Takes a boolean argument, which defaults to off. If enabled, the container will run in its own network namespace and not share network interfaces and
configuration with the host. This setting corresponds to the --private-network command line switch.
Мне бы наоборот хотелось, чтобы контейнер занимал порты основной системы, как это делает, например, обычный chroot. Чтобы потом сверху не было никаких nat/bridge и так далее.
Это сильно увеличивает портабельность контейнеров на практике в будущем — ничего на хосте настраивать не нужно. Максимум — порт внутри контейнера сменить.
Собственно, я так в чрутах лет 10 раскатывал всё всё ещё до того, как докер стал модным.
Собственно, 90% людей, которые хотят «переехать на докер» на моей практике хотят не докер, а обычный статический chroot, чтобы потом его rsync-ом между машинами перевозить можно было и запускать. (понятное дело, что ко мне с вопросами в целом редко приходят люди, которые плохо представляют, что такое докер — они и без меня справились уже, тут речь про тех, кто услышал модное слово и решил внедрять).
По-моему, большой оверхид просто для зависимостей контейнеров тащить кубер на отдельную машину. При том, что она в нём так себе реализована. Инитконтейнеры, которые просто башем ждут пока зависимость, например база, начнёт отвечать — так себе решение. Или что-то появилось удобнее?
Нет, не появилось. Нас активно толкают к написанию своих операторов. На каждый чих и на каждое управляемое кубернетесом приложение. Проблема в том, что нормальных операторов практически и нет. Там гора корнер кейсов, о которых разрабы вообще не думают.
Хотя требования к деплою и прочему это меняет, конечно. Но тут такой вопрос — либо едешь в миникуб с надеждой на то, что потом оно на несколько машин поедет, либо ты не планируешь ехать на несколько машин потом и используешь для инита что-то попроще (portainer или docker-compose из systemd того же) и не заморачиваешься.
А чем он концептуально отличается в двух словах, если не сложно? Всегда воспринимал его как просто обёртку для быстрого разворачивания кубера в режиме однонодового кластера.
Но меньше сервисов, меньше ресурсов, проще запустить на отдельной машине, настраивать почти нечего.
тем что minikube — это отдельная виртуалка. То, на что я дал ссылки, — это по сути полноценные дистрибуции, которые могут использоваться как для разработки, так и для IoT, например, в силу своей легковесности.
minikube поддерживает разные среды исполнения, в том числе нативный — "родной" докер системы, без всяких виртуалок.
minicube первым всегда в голову приходит, у него ноги от тех же разработчиков растут.
Issue заведен? мы все бы проголосовали.
Может, где-то что-то явно зависит от network-online.target?
systemctl list-dependencies network-online.target --all --reverse
systemd — взял и работает из коробки ) под простые кроссплатформенные сервисы на java, вся настройка с зависимостями старта всего 22 понятные строчки (без форматирования).
Журнал для просмотра состояния, включая живой вывод и ошибок — отлично заходит, конечно, в дополнение к файлам/записям лога.
Есть простая мысль современности: чем проще и легче целиком выполняется задача, тем чаще будут пользоваться, т.к. будут меньше тратить мозготоплива для трогания этой части.
Пользователи уже давно требует одну кнопку на интерфейсе с расшифровкой «сделать хорошо» )
а адище из опций unit'ов — тут конечно чёрный пояс не нужен, ага.
Это дискуссионный вопрос, что лучше — адище из init скриптов или адище из unit'ов. Мне лучше заходит второе.
А если у пользователя возникнет 100501-й вариант, то пользователь должен что?
примеры? Не знаю ни одной задачи, которую в принципе невозможно решить через системди.
Но, то как он делается, ИМХО, порождает другие проблемы:
— Рождается огромный монстр.
— Не очень сложные проблемы не решаются годами.
Например у меня время от времени systemd-udevd начинает жрать процессор на ровном месте. Помогает только рестарт systemd-udevd. Проблема известная. И этой проблеме уже не меньше 3-х лет.
Проблема известная. И этой проблеме уже не меньше 3-х лет.
А чем вы занимались 3 года? PR на гитхаб кто делать будет? Добрый дядя? Или может она всё же не такая известная?
Если что — относительно недавно мой PR в системд приняли без вопросов. Даже страшный Поттеринг не пришёл, хотя я уже готовился.
PR на гитхаб кто делать будет?
Я думаю, что реально высококлассных спецов, которые могут что-то грамотно пофиксить и при этом не сломать что-то еще — не так много. Но даже если так, то можно хотя бы собрать фактуру и озвучить наличие проблемы, а не отсиживаться в уголке — с этим я полностью согласен.
А насчёт Поттеринга… Предлагаю переименовать его в Бармалея, чтоб страшнее было )))
Там нет никакого рокет сайенса. Обычный C. Если отбросить страхи — можно спокойно заняться. Тем более, 1227 открытых тикетов — сколько можно пользы комьюнити принести и уважения получить.
А извините, можно провокационный вопрос? Вам кто-то что-то должен? Как бы это опен-сурс. Я понимаю, если б деньги были уплочены. Но обычно те, кто используют Линукс на десктопах — ни копейки сообществу не дали. Только потребляют. И все. Это не хорошо, и не плохо. Просто данность. Но в этой позиции, когда что-то у кого-то не работает — сорян. Никто не виноват.
А вот эта позиция мне как-то не очень. Давайте заставим всех перейти на наш софт, в котором нет «фатальных недостатков», и который гораздо сложнее, но ошибки мы исправлять будем когда-нибудь, если захотим.
Извините, я действительно резковат, потому что накипело. Я прекрасно понимаю, что в мире коммерческого софта все точно так же плохо и, такое ощущение, что вся индустрия катиться куда-то в сторону дна — т.к. никто ни за что не отвечает. Крупные гиганты чхать хотели на свои же SLA — все равно деваться клиенту некуда. Весь софт поставляется AS IS и если Вы несете финансовые потери… то это никого не волнует. Опен-сурс действительно (в каком-то смысле) воскрешает надежду на лучший мир. Но когда начинаешь копать — все оказывается сложнее (из серии — ты действительно шлешь красивый, правильный PR, а его заруливают по политическим соображениям, например, потому что он реализует то, что в платной версии продукта, или не сходишься точками зрений с ведущими инженерами проекта).
И в Вашем случае — первым шагом было бы озвучить проблему, чтобы ее можно было нагуглить. Вдруг действительно есть еще 100500 людей, которые от этого испытывают неудобство. Как и рекомендует коллега выше. А дальше уже будет видно.
Тоесть у него там что-то не запустилося(сеть «не так» или днс нету или какойто драйвер не проинициализировался) — и вот он просто не запускает юнит.
На одном из серверов есть три одинаковых на вид файлика запускающие три разных сервиса. Все три на питоне, в одном venv. Второй — не запускается при старте. Ну вот просто так.
В SysVinit таких проблем — не было.
Но, когда глубже начал копать, пришел к выводу, что даже при наличии проблем systemd на голову выше предыдущих систем, удобен и не так страшен. Возможно я бы некоторые части спроектировал по другому (journald кажется самой проблемной частью), но я его уже принял и, можно сказать, «подружился».
Я получил огромное удовольствие от статьи, спасибо автору огромное.
Где-то 3-4 года работал с systemd плотно, так что для меня это дом родной.
Хорош он или нет — не скажу, но мне со временем стало все понятно и удобно.
gnome не работает без logind, logind не работает без cgroups, в итоге клиентская софтинка требует наличия в системе не портабельного управления правами.
1. Дикая фрагментация (невозможно вообще никак создать десктопное приложение «для GNU/Lunux», нужны десятки сборок под кучу дистрибутивов).
2. Отказ от использования новых технологий (любой софт пишется так, как будто все будут запускать его на AIX, HP-UX и Solaris… если и возникает соблазн использовать что-то большее, то это делается как прикрученный сбоку аддон).
Сейчас, слава богу, от этого отошли: systemd, по большей части, решает первую, Wayland с сотоварищи — вторую.
1. Дикая фрагментация (невозможно вообще никак создать десктопное приложение «для GNU/Lunux», нужны десятки сборок под кучу дистрибутивов).Так эта проблема никуда не делась. Либо будет реализована поддержка разных библиотек, либо нужны будут неофициальные патчи под местный дистрибутив, либо она будет прибита гвоздями к убунте насквозь, как тот же самый самый unity, либо её засунут в контейнер.
Сейчас, слава богу, от этого отошли: systemd, по большей части, решает первую, Wayland с сотоварищи — вторую.Вобще-то wayland создаёт первую проблему. Сейчас есть несколько композиторов с разными наворотами и багами.
Сейчас есть несколько композиторов с разными наворотами и багами.Для них реально нужно писать разные программы? Плохо, если так.
Либо будет реализована поддержка разных библиотек, либо нужны будут неофициальные патчи под местный дистрибутив, либо она будет прибита гвоздями к убунте насквозь, как тот же самый самый unity, либо её засунут в контейнер.Контейнеры на десктопе плохо работают. Нужно, чтобы кто-то (неважно кто: IBM, Google, да хоть Microsoft) построил над
systemd что-то стабильное.Условного говоря та или иная программистская экосистема может поддерживать только лишь определённый «объём разнообразия».
Если огрублять: имея некое количество рабочих рук вы можете выпустить либо 100 программ под 100 дистрибутивов, либо 10000 программ под 1.
На самом деле не совсем так и, возможно, вместо 100 программ под 100 дистрибутивов удастся выпустить «всего» 1000 программ — но идея в этом. 1000 программ под 100 дистрибутивов вы явно не выпустите. Нужно не уменьшение не разнообразия в принципе, а уменьшение его «ненужного объёма».
Windows является такой вот «узловой точкой»: все программы пишутся под неё, а не под конкретную железку и, наоборот, железка выпускатся под Windows, а не под конкретную программу. Да, там есть некоторые ньансы с шейдрами, всё такое… но в целом — с точки зрения разработчика таки есть Windows, а не отдельно 100500 видеокарт, 100500 сетевых карт и так далее…
iOS и MacOS — тоже.
У Android получается чуть хуже… но они всё равно к этому стремятся.
А вот GNU/Linux… полный кошмар. Да, есть одно ядро, да, есть GlibC, теперь вот сервисы
systemd тоже подпричесали… А вот всё что выше… сплошной CADT…Для них реально нужно писать разные программы? Плохо, если так.Сейчас у меня установлен одновременно и sway и gnome-shell. В sway для создания скриншотов я использую grim. В gnome-shell он падает с ошибкой.
wl_registry@2: error 0: invalid version for global wl_output (4): have 2, wanted 3
compositor doesn't support wlr-screencopy-unstable-v1
Контейнеры на десктопе плохо работают.То-то каноникал всё в snap засовывает, и тот же chromium в 20.04 неявное его ставит
Нужно, чтобы кто-то (неважно кто: IBM, Google, да хоть Microsoft) построил над systemd что-то стабильное.А systemd тут при чём? Для десктопного приложения понадобится ещё и графика(xorg, wayland), звук(alsa, pulseaudio, PipeWare) и куча всего остального.
Если огрублять: имея некое количество рабочих рук вы можете выпустить либо 100 программ под 100 дистрибутивов, либо 10000 программ под 1.Под дистрибутив собирают мейнетеры, которые порой добавляют какие-то свои собственные патчи. В любом случае, если гвоздями не прибивать программу к каким-то патченым библиотекам, то найдётся умелец, который пересоберёт её под другой дистрибутив. От разработчика максимум что потребуется, так это принять какой-то патч.
А вот GNU/Linux… полный кошмар.Одно дело, если программа зависит от ядра, например какой-то планировщик или файрвол. А вот остальное должно запускаться на любом ядре, хоть на hurd, хоть на bsd.
да, есть GlibCЕсть ещё musl а на нём void(опционально), alpine.
Каноникал всё засовывает, потому что в видит в этом решение проблемы. Это не значит что вот оно всё, в результате, начало, вдруг, хорошо работать.Контейнеры на десктопе плохо работают.То-то каноникал всё в snap засовывает, и тот же chromium в 20.04 неявное его ставит
Может и допилят. Со временем. Если не забросят и не начнут очередную новую и красивую игрушку пилить.
Кстати ваша же ссылка объясняет — почему они так поступили. Вот именно потому что другого способа дать людям поставить-таки свою программу — они не видят.
Нужно, чтобы кто-то (неважно кто: IBM, Google, да хоть Microsoft) построил над systemd что-то стабильное.
А systemd тут при чём?
Systemd это базис, основа. Возможность создавать «фоновые процессы и прочее».Для десктопного приложения понадобится ещё и графика(xorg, wayland), звук(alsa, pulseaudio, PipeWare) и куча всего остального.Совершенно верно. И пока вот это вот всё не будет приведено к какому-то кросс-платформенному стандарту… «кина не будет».
Но в эпоху до
systemd было сложно даже простенькую консольную утилиту с фоновым демоном сотворить, так что нельзя сказать, что то, что сделал systemd (унификацию хотя бы вот этих базовых вещей) было сделано зря…Под дистрибутив собирают мейнетеры, которые порой добавляют какие-то свои собственные патчи.К терапевту. Платформа должна, внезапно, быть платформой. Позволять разработчикам ПО поставлять его пользователям. И всё.
Пока этого нет — у вас не платформа, а полуфабрикат для автоматизированного рабочего места, в лучшем случае. Обычные пользователи с этим работать не смогут.
Что, собственно, и показало фиско нетбуков. Помните? Когда они появились — они шли, очень часто, с Линуксами разных версий. Но начались возвраты, так как пользователи не хотят жить в мире, где «под дистрибутив собирают мейнетеры» и им нужно ждать пока эти самые «мейнетеры» соблаговолят что-то собрать. Они хотят зайти, скажем, на сайт Discord или Slac (ну, во времена нетбуков — ICQ, конечно, но не принципиально), скачать программу и пользоваться. И всё.
Можно даже не на сайт Discord (пользователи iOS всё качают с AppStore и не плачут), но ситуация, когда бинарник собирается не разработчиком один раз, а кем-то ещё для массовой платформы не работает.
Подавляющее большинство приложений и в AppStore и в Google Play не обновляются никогда. Да, вы их в Top100 не увидите, они где-то с Top100000 начинаются… но по количеству — это подавляющее большинство. Всякие банк-клиенты и разные примочки от ISP… а без них, повторяю, «кина не будет».
В любом случае, если гвоздями не прибивать программу к каким-то патченым библиотекам, то найдётся умелец, который пересоберёт её под другой дистрибутив.Это — вообще к психиатру. Подавляющее большинство разработчиков не готовы не то, что поставлять кому-то исходники, они даже не будут никогда новую версию собирать! Они что-то собрали, выложили на свой web-сайт или в стор… и всё.
Многие программы вообще — «поделки на коленке», сделанные кем-нибудь под заказ на фрилансере. Там не то, что патчи принять некому, там вообще разработика, которого интересовала судьба программы, которую он один раз сделал, нету.
Слава богу он достаточно редок для того, чтобы всерьёз о его существовании не задумываться.да, есть GlibC
Есть ещё musl а на нём void(опционально), alpine.
В этом то и смысл, что можно взять популярный дистрибутив типа ubuntu или mint, где за пользователя уже всё решили и настроили, или можно выбрать/собрать что-то своё. Крупные компании создают какое-то стабильное решение, вроде стима или тех же контейнеров вроде snap/flatpak, в котором решены требуемые для разработчиков проблемы, а мейнетры потом могут портировать это под свой дистрибутив. Взять тот же стим, он работает практически везде. Если зайти на snapcraft.io, то он для каждой программы будет показывать с какого дистрибутива её ставят чаще всего. При этом список дистрибутивов внушителен.
Вот попробуй на винду поставь маковское или наоборот.А оно мне нужно? Банк-клиент на Линукс не завести, зачастую ни виндовый, ни маковский. А без него говорить о том, чтобы вот этом вот вашим Линуксом начала пользоваться бухгалтерия — можно даже не начинать.
В этом то и смысл, что можно взять популярный дистрибутив типа ubuntu или mint, где за пользователя уже всё решили и настроили, или можно выбрать/собрать что-то своё.Вот только даже популярные дистрибутивы не продоставляют того же сервиса для разработчиков программ, что MacOS или Windows.
Чтобы программу один раз сделать — и 5-10 (а то и 20, если речь про Windows) лет использовать.
Взять тот же стим, он работает практически везде.За счёт того, что он системой, фактически, не взаимодействует. Только с железом.
Это хорошо подходит для игрушек — но плохо, для десктопных программ. Которым нужно уметь как-то работать с нотификациями, запускать каких-то демонов и прочее.
Да и даже чтобы «подхватить системную тему», как тут жалуются, банально.
За счёт того, что он системой, фактически, не взаимодействует. Только с железом.А какое взаимодействие банковского клиента с системой? Демон запустить? А демону какая разница, кто его запускает? Насколько мне известно, то в случае с .net, первым или вторым, существуют проблемы с запуском на современной винде, и сисадминам приходится их как-то обходить. Ну перепишет админ скрипты запуска, в чём проблема?
Да и даже чтобы «подхватить системную тему», как тут жалуются, банально.Это зависит от того какие переменные окружения и какая часть файловой системе доступны изнутри контейнера.
Чтобы программу один раз сделать — и 5-10 (а то и 20, если речь про Windows) лет использовать.Я понимаю, когда программу пишет одиночка, или это какая-то игрушка. Но что, неужели у серьёзных контор, типа банков, программы пишут студенты, какие не оставляют после себя ничего кроме бинарника? Возьмём centos, там срок поддержки 10 лет, бери и пользуйся одним и тем же. Вышел следующий релиз, опять же поправили немного кода и всё по прежнему.
А какое взаимодействие банковского клиента с системой?Как-то умудриться найти 1C-бухгалтерию нужно, однако.
Ну перепишет админ скрипты запуска, в чём проблема?Как только вы произнесли слово «админ» — вы потеряли десктоп. Весь, практически. Так как в 90% случаев никакого админа, способного что-то сделать со скриптами запуска у персоналки нету.
Это зависит от того какие переменные окружения и какая часть файловой системе доступны изнутри контейнера.Нет. В первую очередь это зависи от того — существует ли стандартный протокол, которым система и приложение могут воспользоваться для этих целей.
А если вы каждые пару лет меняете принципы, на которых «движок», заведующий системной темой, работет — то как программы смогут к этому приспособиться? Никак, конечно.
А наличие/отсутствие контейнера — это уже следующий этап.
Но что, неужели у серьёзных контор, типа банков, программы пишут студенты, какие не оставляют после себя ничего кроме бинарника?Нет, конечно. У банков другая беда: там, чтобы что-то изменить в исходнике нужно оформить 100500 бумажек и получить 100500 разрешений и согласований.
Но… причины разные, а результат один: никто «мейнетерам» ничего собирать не даст.
Возьмём centos, там срок поддержки 10 лет, бери и пользуйся одним и тем же.У CentOS нет никакой поддержки, строго говоря. Поддержка есть у RHEL, но там цена уже как у Windows и, соотвественно, распространение — вообще никакое.
Но да, очень много коммерческого софта только RHEL (и, неофициально, CentOS) и поддерживают…
Однако, к сожалению или к счастью, маркетинговая машина RedHat на десктоп пытается продвигать совершенно туда не годящуюся Fedora, а CentOS оказывается мало кому нужен.
Как-то умудриться найти 1C-бухгалтерию нужно, однако.Что значит как-то найти? Либо бухгалтерия открывает какой-то сокет, и все его ищут в одном и том же месте, либо есть какой-то конфиг, в котором этот адрес прописывается.
Как только вы произнесли слово «админ» — вы потеряли десктоп.Скажите, а какой софт, нужный именно персоналкам нуждается во всём этом? И потом, вы так говорите, словно сразу же после того, как программа сдана заказчику программист тут же увольняется, и его больше никто не видит. И ни нового программиста найти, ни даже сисадмина возможным не представляется.
Если речь идёт о чём-то сложном, то драйвера для принтера могут ставиться на висту, но на семёрку уже нет. Просто семёрки на момент продажи не было, вот и всё.
Нет. В первую очередь это зависи от того — существует ли стандартный протокол, которым система и приложение могут воспользоваться для этих целей.Текущая тема лежит где-то на диске, вне доступа контейнера, даже на чтение. Как по вашему он о ней узнать должен?
А если вы каждые пару лет меняете принципы, на которых «движок», заведующий системной темой, работет — то как программы смогут к этому приспособиться?Во-первых где такое происходило, а во-вторых как этому поможет systemd? Если речь идёт о gtk3, то мимо, так как там проблема была из-за переписывания движка, а не из-за того, что кто-то в контейнере запустил. Оно и без контейнера не работало бы.
У CentOS нет никакой поддержки, строго говоря.Репозитории поддерживаются в актуальном состоянии.
Либо бухгалтерия открывает какой-то сокет, и все его ищут в одном и том же месте, либо есть какой-то конфиг, в котором этот адрес прописывается.Где этот сокет лежит, как называется конфиг, с каких версий Debian/RedHat/Ubuntu/etc всё это поддерживается?
Скажите, а какой софт, нужный именно персоналкам нуждается во всём этом?Почти любой. Игры, пожалуй, единственное очевидное исключение. Долгое время даже самая банальная операция «добавить кнопку в меню запуска так, чтобы пользователь вашу программу смог, чёрт побери, найти и запустить» не имела удовлетворительного решения (не знаю, кстати, сейчас с этим уже всё хорошо или даже эта проблема соталось неразрешимой).
И потом, вы так говорите, словно сразу же после того, как программа сдана заказчику программист тут же увольняется, и его больше никто не видит.Зачем увольняться? Подавляющее большинство софта написано фрилансерами. И неважно — это кто-то, найденный на Upwork или студент, которому пообещали сколько-то денег за то, что он напишет программу, помогающую печатать билеты (одна из моих первых программ, за которую мне заплатили — когда я ещё в университете учился).
И ни нового программиста найти, ни даже сисадмина возможным не представляется.Вопрос в цене. Если вам нужно найти того студента лет через пять (меня, кстати, нашли и я там что-то потом ещё дописывал) — это один ценник, если нужно каждые полгода, при выходе новой версии операционки, кому-то платить — другой.
Если речь идёт о чём-то сложном, то драйвера для принтера могут ставиться на висту, но на семёрку уже нет. Просто семёрки на момент продажи не было, вот и всё.Да, Microsoft это осознал. И потому уже пять лет прошло с момента выхода Windows 10 — а следующей за ней версии Windows нет… и не планируется.
Текущая тема лежит где-то на диске, вне доступа контейнера, даже на чтение. Как по вашему он о ней узнать должен?Откуда я знаю? Я, что ли, продвигаю контейнеры в качестве решения отсуствия стабильного ABI в системе?
Во-первых где такое происходило, а во-вторых как этому поможет systemd?Systemd, действительно, решает «не ту сторону задачи»: запуск фоновых процессов — это скорее что-то, что нужно на сервере, чем на десктопе.
Впрочем всякие СБИС этим тоже занимаются (документы отправлять/принимать и всё такое), так что нельзя сказать, что это уж совсем всё на десктопе не нужно.
Но да — это малая часть решения, с этим согласен.
Оно и без контейнера не работало бы.Именно! Контейнер нужен чтобы решить следующую задачу: как ограничить приложение, которое, вообще говоря, может хотеть воровать вашу информацию. Android/iOS/macOS/Windows этим озаботились в последнее время, так что и Linux придётся подтягиваться… но проблему отсуствия стабильно ABI и SDK в принципе — это не решает.
Это да — но этого недостаточно. В современном мире — нужно не только делать хорошую вещь, но и хорошо её рекламировать. А CentOS нужен RedHat единственное для того, чтобы кто-то другой такую же вещь не стал делать — потому там речь идёт скорее об антирекламе.У CentOS нет никакой поддержки, строго говоря.
Репозитории поддерживаются в актуальном состоянии.
В каком-то альтернативном мире, где RedHat активно продвигает CentOS как «настоящую OS для desktop»… всё может выглядеть иначе — но в нашем мире этого быть не может, так как RedHat, всё-таки, зарабатывает деньги на RHEL и ему совершенно неинтересно, чтобы продажи RHEL упали…
Где этот сокет лежит, как называется конфиг, с каких версий Debian/RedHat/Ubuntu/etc всё это поддерживается?Мы говорим с принципиально разных точек зрения.
Я говорю про то, что если есть условная бухгалтерия, то она запускается как демон, и этот же демон создаёт сокет, и его уже читает. Вот например wayland создаёт по такому пути /run/user/$UID/wayland-0, и всё равно в какой системе происходит дело, можно так хоть ubuntu и void соеденить, при том, что во второй runit. И клиенту wayland достаточно просто подключиться к этому адресу.
Где конфиг будет лежать говорится в документации к приложению, либо в каком-нибудь стандартном пути.
Долгое время даже самая банальная операция «добавить кнопку в меню запуска так, чтобы пользователь вашу программу смог, чёрт побери, найти и запустить» не имела удовлетворительного решения (не знаю, кстати, сейчас с этим уже всё хорошо или даже эта проблема соталось неразрешимой).Я не знаю, о каких дремучих временах идёт речь, но сейчас для этого на хосте нужно создать два файла, иконки и описания, и эти файлы будут работать везде.
Если вам нужно найти того студента лет через пять (меня, кстати, нашли и я там что-то потом ещё дописывал) — это один ценник, если нужно каждые полгода, при выходе новой версии операционки, кому-то платить — другой.Я всё жду, что мне приведут пример того, что каждые полгода ломается, но видимо напрасно жду. Даже если и брать какой-то дистрибутив типа федоры, то и там меняться будут разные компоненты, типа звука, видео, планировщика задач… Программы на go статически линкуются, так что их вообще можно как в винде носить на флешке и запускать на первом попавшемся линуксе. Ну может с небольшими исключениями, если там будет PA или что-то такое, но необходимости что-то постоянно менять нет.
Да, Microsoft это осознал. И потому уже пять лет прошло с момента выхода Windows 10 — а следующей за ней версии Windows нет… и не планируется.Это вам так кажется. Сейчас винда — плавающий релиз и подобна условному arch. То есть, если что-то в 10 винде работало в 2015, то это не значит, что оно будет работать в 2020. Просто в винде больше внимания уделяется обратной совместимости.
Я, что ли, продвигаю контейнеры в качестве решения отсуствия стабильного ABI в системе?А ABI тут при чём? Достаточно сохранять совместимость внутри мажорной версии, а файлы темы далеко не бинарники.
Android/iOS/macOS/Windows этим озаботились в последнее время, так что и Linux придётся подтягиваться…Там не решение проблемы, а костыли. Вот хочу я на андроиде поиграть, а игра просит доступ к диску. Если я откажусь, то она упадёт, если соглашусь, то она залезет куда угодно. Вот как мне например запретить чтение фотографий, а музыки разрешить?
но проблему отсуствия стабильно ABIНе для системных программ это решается тем, что программа носит с собой нужные ей версии системных библиотек, либо тем, что эти библиотеки храняться в репозитории. В том же самом Альте до сих пор есть gtk1, а последний его выпуск в 1999 году был. Конкретно в этом вопросе совместимость не хуже чем у винды будет.
Можно вообще в сторону nix глянуть, там вообще можно одновременно держать разные версии одной и той же библиотеки, прямо как в винде. Конечно nix довольно молодой проект, по сравнению с видной, но там совместимость будет огромная.
В каком-то альтернативном мире, где RedHat активно продвигает CentOS как «настоящую OS для desktop»… всё может выглядеть иначеВ CentOS ядро старое, для офиса пойдёт, там всё равно железо подбирают, а вот дома покупать железо семилетней давности не хочется.
И клиенту wayland достаточно просто подключиться к этому адресу.Клиент-то ладно. А сервер кто и как запустит?
Я говорю про то, что если есть условная бухгалтерия, то она запускается как демон, и этот же демон создаёт сокет, и его уже читает.Допустим. Но вот как это сделать в системе с systemd — я понимаю: systemd.socket регистрируется (в
/etc/systemd/user или $HOME/.config/systemd/user), в нужный момент systemd поднимет бухгалтерию, клиент с ней общается.Как вы это предлагаете делать в системе без
systemd?можно так хоть ubuntu и void соеденить, при том, что во второй runit.то есть ruint тоже будет сканировать
/etc/systemd/user? Или как?Я не знаю, о каких дремучих временах идёт речь, но сейчас для этого на хосте нужно создать два файла, иконки и описания, и эти файлы будут работать везде.Везде они работать не будут. Их нужно в правильный каталог для этого положить. Вроде бы в
$HOME/.local/share/applications. Но на 100% я даже в этом не уверен.Я всё жду, что мне приведут пример того, что каждые полгода ломается, но видимо напрасно жду.Да всё ломается. Тогда же, студентом, я написал какую-то приблуду для Linux (там какой-то учёт пользователей, всё такое). Через год, после обновления, она сломалась, так как была слинкована с libstdc++.so.5, а тут как раз вышел GCC 3.4, libstdc++ обновилась…
И это была простая консольная утилита! А если бы вдруг, внезапно, бипнуть захотел и слинковался бы с какой-нибудь библиотекой, которая это позволяла бы?
Да и про боль от «ломастеров» Gtk+ вы же вспомнили — не я.
Программы на go статически линкуются, так что их вообще можно как в винде носить на флешке и запускать на первом попавшемся линуксе.Программы на Go, к сожалению, очень ограничены в плане поддерживаемого GUI.
Просто в винде больше внимания уделяется обратной совместимости.И вот это вот «просто» и отделяет систему у которой есть шансы на desktop от системы, у которой шансов нет.
Сейчас винда — плавающий релиз и подобна условному arch.Только очень издалека, если не всматриваться.
Что происходит, если Arch меняет /usr/bin/python с Python2 на нифига несовместимый Python3? Сотни пакетов перестают работать и ух мейнтенеров появляется очередна забота.
Что происходит если в Windows несовместимым образом меняется какая-та библиотека? Ответственный за неё получает люлей, обновление отзывается и через некоторое время — выходит по новой. В Windows Store по этому поводу не происходит ничего.
А ABI тут при чём? Достаточно сохранять совместимость внутри мажорной версии, а файлы темы далеко не бинарники.Ну вот Ubuntu так решает проблему изменений в ABI.
Там не решение проблемы, а костыли.Костыли — лучше, чем отсутствие решения в принципе.
Вот как мне например запретить чтение фотографий, а музыки разрешить?Пока что никак. Но если приложение не кладёт свои файлы куда ни попадя, то другое приложение доступ к ним не получит.
В том же самом Альте до сих пор есть gtk1, а последний его выпуск в 1999 году был. Конкретно в этом вопросе совместимость не хуже чем у винды будет.Не знаю, конкретно с альтом не работал. Но Windows-программы 10-15 летней давности у меня, скорее работают (причём, что смешно, даже в Linux), а вот Linux-программам подобной же давности — всё время чего-то не хватает. Но да, может быть в Debian и Fedora всё не так, а вот в ALT — там всё круто… непонятно почему под него программ не особо много. Какой-нибудь TeamViewer есть под Debian и Fedora (хотя после установки нифига не запускается и требует, как обычно, возни с недостающими библиотеками… но это ж Linux, я привык), а вот под ALT… нету.
Конечно nix довольно молодой проект, по сравнению с видной, но там совместимость будет огромная.Нет там «огромной совместимости». Потому для desktop'а это не работает. Это на сервере более-менее как-то работает.
А на desktop я хочу, с одной стороны, ставить всякое дерьмо с разных сайтов (какие-нибудь дурацкие банк-клиенты и программы для заполнения налоговых деклараций), а с другой — иметь возможность нажать кнопочку в программе редактирования фоточек и расшарить эту фотографию в Discord или WhatsApp.
Для того, чтобы всё это работало — система должна быть определённым образом спроектирована. А то, что вы можете редактор фоточек запустить с libwhatsapp.so.20, а сам WhatsApp — с libwhatsapp.so.30 и они отлично запустятся, но не смогут взаимодействовать — никому особо не нужно.
А сервер кто и как запустит?Кто угодно.
Как вы это предлагаете делать в системе без systemd?Вот wayland-у всё равно, есть systemd или его нет. Иксам аналогично, сокет будет создан в том же самом месте, и systemd в его пути фигурировать не будет.
то есть ruint тоже будет сканировать /etc/systemd/user? Или как?Если вы обратили внимение, то это абсолютный путь. Я просто пробрасываю /run/user/$UID, в void, и wayland клиенты сами разбираются. Ни runit, ни systemd в этом процессе вообще не участвуют. Максимум, что от них требуется, так это запустить sway или gnome-shell, на этом их работа заканчивается. С тем же самым успехом, я могу запускать их из консоли руками, это никому не важно. За сокетами следит прикладной софт, в данном случае wayland клиенты.
Везде они работать не будут. Их нужно в правильный каталог для этого положить.Под «везде» я подразумеваю, что и в убунте и в воиде, и в кедах и в гноме. Правильный каталог нужен, как и в винде.
А если бы вдруг, внезапно, бипнуть захотел и слинковался бы с какой-нибудь библиотекой, которая это позволяла бы?Вот вам и нужно линковаться статически, если хотите жить десятилетиями. Либо носить библиотеки с собой. Тот же огнелис в виде бинарника можно скачать с сайта мозиллы, и он будет работать на самых разных линуксах.
Что происходит если в Windows несовместимым образом меняется какая-та библиотека? Ответственный за неё получает люлей, обновление отзывается и через некоторое время — выходит по новой. В Windows Store по этому поводу не происходит ничего.Там либо по тихому говорят, что какой-то софт/железо не заработает, либо обновляют систему и у людей это отваливается. В обсуждении какой-то очередной новости читал об этом в комментариях, если вспомню, приведу ссылку.
Ну вот Ubuntu так решает проблему изменений в ABI.Космонавт решает свои собственные проблемы, а именно независимость от дебиана, и перекладывает необходимость собирать программы на разработчиков.
Костыли — лучше, чем отсутствие решения в принципе.Это не решение. Решение, это либо firejail, либо какой-то другой контейнер.
Нет там «огромной совместимости». Потому для desktop'а это не работает. Это на сервере более-менее как-то работает.Там есть возможность прописать конкретную версию библиотеки, плюс возможность иметь несколько библиотек в одной системе.
А то, что вы можете редактор фоточек запустить с libwhatsapp.so.20, а сам WhatsApp — с libwhatsapp.so.30 и они отлично запустятся, но не смогут взаимодействовать — никому особо не нужно.У вас есть реальный опыт, или это пример из головы? Если первое, то расскажите в каком месте возникает проблема.
Ало, ребята. Если я условный разработчик условной 1С-бухгалтерии — то что и куда мне в инсталлятор-то пихать, чтобы этот «кто угодно» возбудился и меня, в случае надобности, запустил? А?А сервер кто и как запустит?Кто угодно.
Wayland'у всё равно, так как это просто протокол. И HTTP всё равно. И FTP. А вот Mutter'у — нифига не всё равно. KWin'у не всё равно. NGINX'у не всё равно. Apache не всё равно.Как вы это предлагаете делать в системе без systemd?
Вот wayland-у всё равно, есть systemd или его нет.
А с одном протоколом, но без реализующего его сервера… «кина не будет».
Я просто пробрасываю /run/user/$UID, в void, и wayland клиенты сами разбираются.Алё, гараж! Вы это бухгалтеру предлагает «пробрасывать в /run/user/$UID, в void»? Или автослесарю? Вы вообще в своём уме? Они вообще ни
$UID, ни /run/user не знают и знать не хотят.И они в свём праве: вы вот много знаете про правила оформления отчёности по возрату налога на природные ресурсы? Нет? А с какого перепугу они тогда должны выяснять как /run/user/$UID, в void в пробрасывать?
За сокетами следит прикладной софт, в данном случае wayland клиенты.Вот только создать оные сокеты, в системе без
systemd — тупо некому. «Кто угодно» — это, извините, не ответ.Правильный каталог нужен, как и в винде.Ну… уже хорошо. Плохо то, что в винде этот «правильный каталог» появился где-то в прошлом веке, а в Linux — уже в этом. Но лучше поздно, чем никогда. Ещё бы все клиенты SVG начали понимать (или программы перестали бы его класть) — совсем хорошо стало бы.
Вот вам и нужно линковаться статически, если хотите жить десятилетиями.Вот толко работать так — не получится. Помню я эти развлечения, когда Adobe Reader захватывал /dev/dsp и от флеша нельзя было добиться ни звука. Отлично помню. Да, в конце-концов эту проблему решили. Но обратите внимание на дату. А сюда взгляните… Десять лет, Карл. Десять! Не было никакой возможности получить нормальный звук от программ, которые следовали вашему совету.
Тот же огнелис в виде бинарника можно скачать с сайта мозиллы, и он будет работать на самых разных линуксах.Вот только ни иконки в стартовом меню ни звука на дистрибутивах, что постарше — вы не получите. Как и аппаратного ускорения декодирования видео на тех, что поновее.
Там либо по тихому говорят, что какой-то софт/железо не заработает, либо обновляют систему и у людей это отваливается.Вопрос, как всегда: какой процент пользователей это затрагивает. Молчание Flash при запущенном Adobe Reader — затронуло изрядное количество людей. Собственно всех, кто пользовался ими обоими лет 10-12 назад. Что важно, потому что как раз в то время Linux получил шанс — и благополучно просрал его, потому что нифига ж не работало!
перекладывает необходимость собирать программы на разработчиков.Да не «перекладывает он ответственность». Возможность собрать программу и её поставить заказчику — это то, что разработчики программ всегда хотели получить от GNU/Linux и им эту возможность под разными предлогами, никогда не давали.
Даже разработчики свободного софта этого хотят — прорываться через «ментейнеров» чтобы багфикс пользователи могли увидить — им ну вот ни разу не упало.
А уж проприетарный (а его, напоминаю, большинство — если включить сюда все поделки типа той моей программы для печати билетов) — так и подавно.
У вас есть реальный опыт, или это пример из головы? Если первое, то расскажите в каком месте возникает проблема.Ну libwhatsapp.so.20, как несложно догадаться — из головы. Реальный опыт тоже был, пока не начали для всего на свете Web-морды делать.
Что, впрочем, не решило проблемы, так как Web-морды работают, как несложно догадаться, и в Linux и в Windows, а Windows-программы — только в Windows, так что «нормальному пользователю» было всегда несколько бессмысленно даже пытаться в Linux влазить.
Вроде бы в последние лет 10, постепенно, начали что-то похожее на платформу в Linux делать — но, опять-таки, их теперь две: Flatpak и Snap. И снова, блин, несовместимые. Ну вот зачем так делать-то?
Хотя вроде в этот раз уже совсем маразмом заниматься не стали и вроде и то и другое поддерживается в обоих дистрибутивах.
Так что, возможно, CADT период в Linux, наконец-то, кончился и, возможно, под Linux даже начнут появляться программы… поживём, увидим.
Конечно nix довольно молодой проект, по сравнению с видной, но там совместимость будет огромная
ржу в полный голос!
Ну вот Ubuntu так решает проблему изменений в ABI.
Все хуже. Дело в том, что все эти магазины приложений заточены только под актуальную версию ОС и под последнюю версию приложения. Действительно, поддержка совместимости вверх и вниз — это очень дорогое удовольствие. Я уж не говорю про то, что приложение ВДРУГ может из магазина исчезнуть — забудьте, Вы платите деньги, но Вы уже не владеете ничем, кроме эфемерным правом использования ПО. Тем более в случае SaaS прилаг. Последняя боль у меня случилась после покупки Wunderlist'а Microsoft'ом. Был отличный органайзер, а стал пшик. Не говоря уже о том, что данные они смигрировать таки не смогли (появился слепок от 2015, а самые свежие заметки были потеряны).
Программы на go статически линкуются, так что их вообще можно как в винде носить на флешке и запускать на первом попавшемся линуксе. Ну может с небольшими исключениями, если там будет PA или что-то такое, но необходимости что-то постоянно менять нет.
к сожалению, это ложь. Т.е. в целом — да, при соблюдении архитектуры и каких-то параметров версии операционной системы — вероятность успешного запуска и работы произвольного взятого go бинарника выше, чем помоечного с++ проекта с кучей динамических зависимостей… Но я почему-то все время напарываюсь на какие-то граничные случаи. Ну, и бинари по 80МБ — это как бы не совсем круто.
То-то каноникал всё в snap засовывает
То-то хромиум теперь не подхватывает системную тему и выдаёт ошибку доступа при попытке закачать локальный файл :\
https://github.com/elogind/elogind решает эту проблему.
без logind, logind не работает без cgroups
cgroups — это функционал ядра вообще-то, а systemd это лишь интерфейс. История такова, что в ядре последние годы появилось много фич, которые на user-level никто не мог использовать. Поэтому systemd это лишь следствие. Предложение породило спрос.
Точно так же — LXC, Docker это следствие предложения.
Не было бы Поттеринга, кто-то другой что-то подобное придумал бы. Выглядело бы как-то иначе, возможно, но недовольных, может, было бы ещё больше.
не портабельного управления правами
А куда вам его портировать?
А куда вам его портировать?
OS X, Windows, OpenBSD, AIX например.
Предложение породило спрос.Ну… не совсем так. Предложение-то не с чистого листа взялось. CGroups изначально запилил Google — для нужд датацентров. Чтобы как-то ограничивать процессы без виртуалок.
А потом уже, когда они были достаточно развиты, Поттеринга посетило озарение: да блинский же фиг — у нас есть отличный инструмент для контроля демонов, а мы за ними охотимся через
.pid-файлы и ps | grep. Почему бы не сделать управление демонами «как у больших»?Ну и сделал.
Но изначально, конечно, у Гугла всё было: и патчи в ядро и софт для своих контейноров… просто он сильно завязан на специфику Гугла, потому
systemd с нуля пришлось писать…Не было бы Поттеринга, кто-то другой что-то подобное придумал бы. Выглядело бы как-то иначе, возможно, но недовольных, может, было бы ещё больше.Однозначно. Когда у вас уже есть половина решения… идея дописать-таки вторую половину, что называется, «носится в воздухе».
Бывает хуже — применяют "большие" решения там, где оверхед от них превышает пользу. Но "стандарт индустрии де-факто".
Это нормальная, по-моему, ситуация. Совсем хуже, когда такое внезапно переходит из стадии поддержки в стадию активного развития.
Я про ситуации, когда от старого, которое "просто работает" начинают требовать новые, непредусмотренные на этапе его создания, функции без полного его переписывания.
Задача выросла из платформы — меняю платформу, а не устраиваю колхоз. Сидел я на FreeBSD и все было норм. Задачи выросли jail просто перестал устраивать, docker просто удобнее и функциональнее стал. Перешел на Gentoo — какое-то время тоже все было норм, жил с OpenRC. Задачи выросли перешел на Debian и systemd. Задачи дальше продолжают расти — не будет хватать перейду в облака.
Да я в идеале хочу сеть как во FreeBSD, унификацию управления сетью как в OpenBSD (все настраивается через ifconfig), из Gentoo хотелось бы vhosts (просто супер для разных веб приложений). Но так не будет, поэтому и приходиться менять платформу каждый раз при росте.
Предложение-то не с чистого листа взялось.
Разумеется, весь функционал появлялся зачем-то. Я к тому, что примерно в 2010 году (когда systemd появился) CGroups были, но никто их толком не мог использовать.
Некоторым кажется, что Поттеринг придумал огромный комбайн, хотя сам systemd (с PID=1), в основном, лишь дёргает ручки ядра в нужном порядке. А фичи-то в ядре.
управление демонами «как у больших»?
У кого «больших»? Если не ошибаюсь, убегание fork'нутых демонов от контроля ни в одном UNIX'е не решено. Да и сам fork+exec появился как грязный хак, чтобы как-то фоновые процессы работали. В SysV немного пошли в эту сторону ("respawn=" в inittab), но такого же функционала, как cgroups, не было.
У кого «больших»? Если не ошибаюсь, убегание fork'нутых демонов от контроля ни в одном UNIX'е не решено. Да и сам fork+exec появился как грязный хак, чтобы как-то фоновые процессы работали. В SysV немного пошли в эту сторону («respawn=» в inittab), но такого же функционала, как cgroups, не было.
Я не совсем понимаю что имеет в виду khim. Мне кажется, что в конечном итоге хотят из systemd сделать систему «оркестрации» процессов, и что рано или поздно выкатят подобие изолированных сред или каждой группе процессов своя песочница. Наплодилось куча зомби, среда перезапустилась из-за того что количество процессов внутри больше настройки MaxProcInSlice/MaxProcInGroup.
Да и на самом деле для всего кроме сервером зомби процессы не создают проблем, так как эти устройства достаточно часто перезагружаются (и из-за обновлений тоже).
Вообще khim все правильно говорит. systemd решает кучу проблем. Причем зомби — не самая основная.
Самое простое — умеет ли SysV нормально перезапускать зависимые сервисы? Там без приседаний с бубном это не сделать. Потом. Мониторинг работы процессов. Раньше надо было писать pid-файлы. Вспоминаете весь ужас с ними связанный? Начиная от того, что их нужно правильно создавать, чтобы, например, после перезапуска сервера они очищались. Плюс потенциальные race condition, если сервис умер, но кто-то успел занять этот pid. Сюда же проблема убегания процессов (вот тот пассаж про fork+exec). В systemd тупо объявляешь юнит как forking и он сам дальше следит — кто там от кого форкнулся. Далее. В рамках SysV в принципе невозможно сделать честное распределение ресурсов — а тут це-группы, халява. Дели как хочешь. И все ограничения будут гарантированно работать.
выкатят подобие изолированных сред или каждой группе процессов своя песочница
Что systemd, что LXC, что докер используют один и тот же функционал ядра (cgroups, неймспейсы, syscall filter ит.п.), но в разном объёме.
Возможность изолировать процессы — это хорошо.
Наплодилось куча зомби
Если появляются зомби — значит софт кривой. В нормальной ситуации их не возникает.
зомби процессы не создают проблем
Зомби это не процесс, а запись в списке процессов.
В 2013-м году я был одним из хейтеров, писавшим на всех бордах, какая systemd бяка, потом сидел на "маргинальных" дистрибутивах: Slackware и Ubuntu, в тот период моё профессиональное развитие фактически стояло. Главным доводом для мены было то, что в системах с sysVinit прослеживается принцип 1 сервис = 1 скрипт, в systemd такого принципа нет, юнитов много и это создаёт путаницу. Но на самом деле, если ты что-то не осилил с первого раза, это не повод начинать этого бояться. Вот сейчас я работаю в хостинговой компании, работаю с серверами на CentOS 7, на рабочем компе стоит Fedora, на домашнем — то же, я активно использую возможности systemd, такие как systemd-journald, я развиваюсь профессионально, развиваться нужно вместе с продуктами. а иначе — застой и деградация.
systemd десять лет спустя. Историческая и техническая ретроспектива