Микросервисная и модульная системы — это типы архитектуры IT-решений.
При работе с модулями мы дорабатываем коробочную версию существующего IT-продукта.
Под коробочной версией имеем в виду монолит, готовую систему с ядром, которая поставляется всем заказчикам одинаково, «как есть».
Доработка состоит в создании модулей с недостающим функционалом.
Новые модули получаем путём переиспользования частей монолита (ядра или других модулей).
Бизнес-логика прописывается внутри монолита: для программы (приложения, сайта, портала) есть одна точка входа и одна точка выхода.
При работе с микросервисами мы создаём IT-продукт с нуля, составляя его из «кирпичиков» — атомарных микросервисов, отвечающих за отдельный небольшой процесс (отправить письмо, получить данные по заказу, сменить статус заказа, создать клиента и т. п.).
Набор таких блоков объединяется бизнес-логикой в общую систему (например с помощью BPMS). Несмотря на наличие связей, каждый блок автономен и имеет свои точки входа и выхода.
Большинство IT-продуктов для наших заказчиков начинаются с модульной разработки. Часть из них со временем эволюционируют до микросервисов. Для другой части микросервисы не нужны. В этой статье мы рассмотрим, почему это именно так и какие критерии помогают определиться, нужно ли внедрять микросервисы или стоит придерживаться работы с модулями.
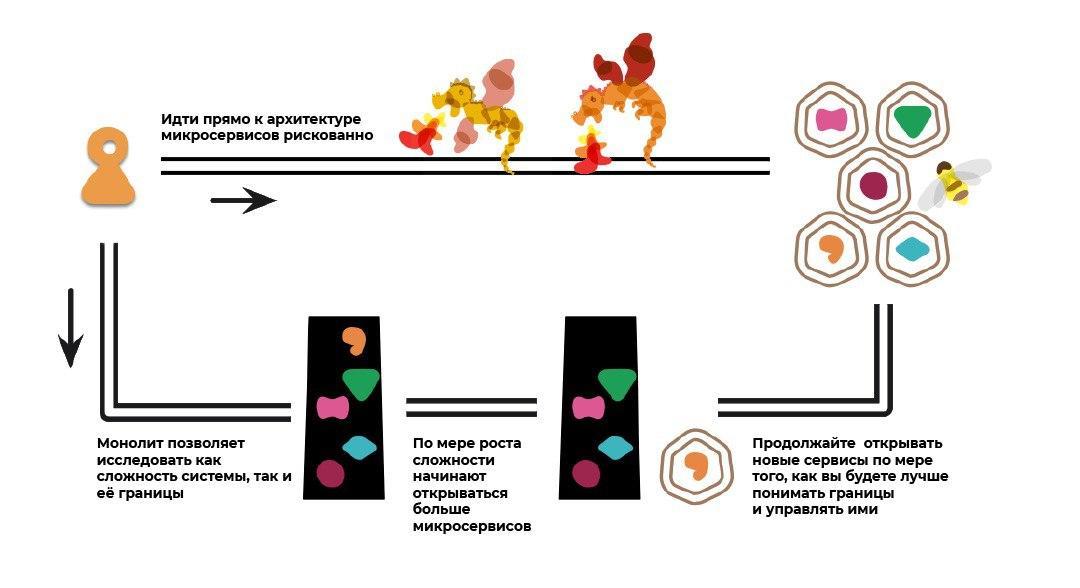
Преимущества модульной архитектуры
Коробочные версии есть у всех систем CMS («Битрикс», Magento, Drupal, Hybris и т. д.), CRM, ERP, WMS и многих других. Они хорошо продаются, и на них есть высокий спрос.
Давайте рассмотрим те объективные причины, по которым заказчики чаще всего выбирают работу с модульной архитектурой и охотно приобретают коробочные решения.
- Высокая скорость внедрения
Установка, настройка и заполнение справочников для такого ПО занимают немного времени. Для компании среднего бизнеса реально приступить к работе с коробкой через три-четыре месяца после старта, иногда даже чуть раньше.
Для компаний малого бизнеса этот срок может составлять всего несколько дней. - Доступная цена
Некоторые продукты могут быть вообще бесплатны. Конечно, это не касается высоконагруженных проектов и enterprise-решений со сложной логикой. - Для многих задач достаточно готового функционала
В коробочных версиях часто заложено много готового функционала. В таком случае для неглавных задач бизнеса вполне подойдёт софт из коробки. Например, если вам нужно поставить программу для инвентаризации, но инвентаризация не является приоритетной задачей вашего бизнеса и вы не планируете получать прибыль за счёт этого действия, вам будет достаточно коробочного решения. - Пусть небольшая, но вариативность
Обычно продукт из коробки представлен в двух или более модификациях с разным включённым функционалом. Для разных типов бизнеса, масштабов компании и прочих условий подбираются разные модификации.
Есть и другие, субъективные факторы, которые могут вводить в заблуждение и влиять на решение об использовании коробки и модулей.
1. Гонка производителей
Продавцы ПО горячо убеждают заказчиков, что их решение из коробки самое верное: оно и годами проверенное, и модное, и enterprise, и популярное, и маркетинговое… Любой поставщик: «Битрикс», Magento, SAP, Oracle, OpenCart, Django и все остальные — усердно работает над маркетингом и техникой продаж.
2. Неверное представление о сложности доработок
Заказчики часто полны оптимизма. Они выбирают коробочный софт и думают: «Да, будут нужны доработки. Но это легко: не придётся изобретать что-то новое. У нас — популярная версия, не могут же миллионы пользователей ошибаться и покупать плохой продукт».
В их представлении процесс доработок выглядит так: есть главный (коробочный) функционал. Чтобы в нём что-нибудь «допилить», разработчикам придётся «всего лишь» переопределить модуль или быстренько написать собственный. При этом не нужно использовать повторяющиеся методы, ведь якобы в монолите продумано всё: прописаны единые методы подсчёта налогов, есть чёткие правила по написанию методов доставки и оплаты, понятный workflow заказов и т. п.
В реальной жизни дела обстоят по-другому. И после приятных эмоций от лёгкого старта работы с коробкой заказчики всё же сталкиваются с суровой реальностью. Чаще всего такое случается с компаниями из среднего и крупного бизнеса, в проектах которых есть уникальная бизнес-логика, и доработки в них нужны масштабные.
Если же ваша компания относится к малому бизнесу и программное обеспечение не является вашим главным активом, то, скорее всего, вам подойдёт популярное коробочное (а лучше — облачное) решение.
Давайте рассмотрим, с какими проблемами можно столкнуться в работе с модульной архитектурой и как микросервисы помогают этого избежать.
Проблемы модульных систем
Основная проблема в том, что все модульные системы не предназначены для серьёзного переопределения функционала. У них есть коробка, готовые модули — вот ими лучше и пользоваться.
Чем ближе к уровню enterprise размеры проекта и сложность их кастомизаций, тем больше будет проблем с доработкой модулей. Поговорим об основных из них.
Проблема № 1. Ядро системы становится точкой замедления, а модульность — лишним усложнением
Допустим, ваш проект связан со сложной логикой складов. Если вы выбрали модульную архитектуру, то разработчикам нужно не просто создать функционал для управления этими складами — им нужно переопределить или расширить модуль мультискладов, который, в свою очередь, пользуется методами ядра.
При этом необходимо учесть сложную логику возвратов по складам: зависимость от событий из CRM-системы, перемещение товара между каталогами и т. д. Также стоит учесть и скрытую логику, которая связана с возвратом денежных средств, бонусных баллов и т. д.
Когда происходит так много переопределений, монолит существенно изменяется. Важно помнить, что зависимость между объёмом нового функционала и количеством модулей нелинейная: для добавления одной функции нужно либо внести изменения в несколько модулей, каждый из которых меняет работу другого, либо в новом модуле переопределить большое количество методов других модулей, что сути не меняет.
После всех изменений система так усложняется, что для добавления следующих кастомизаций будет требоваться неприлично большое количество часов.
Проблема № 2. Принцип самодокументирования не поддерживается в модульных системах
Документацию для модульных систем сложно поддерживать в актуальном состоянии. Её много, и она устаревает с каждым изменением. Доработка одного модуля влечёт изменения в нескольких других документах (в пользовательской, технической документации), и все их нужно переписывать.
Как правило, заниматься такими работами некому: тратить время ценных IT-специалистов на это — значит просто сливать бюджет. Даже использование хранения документации в коде (PHPDoc) не гарантирует её достоверности. В конце концов, если документация может отличаться от реализации, она обязательно будет отличаться.
Проблема № 3. Большая связность кода — путь к регрессии: «здесь изменили — там отвалилось»
Классические проблемы модульных систем — в части борьбы с регрессией.
Разработку по TDD сложно использовать для монолитов из-за большой связности разных методов (на пять строчек кода можно запросто потратить 30 строчек тестов, плюс фикстуры).
Поэтому при борьбе с регрессией приходится покрывать функционал интеграционными тестами.
Но ввиду и без того медленной разработки (ведь разрабатывать нужно аккуратно, чтобы предусмотреть много переопределений) заказчики не хотят платить за сложные интеграционные тесты.
Функциональные тесты становятся настолько большими, насколько и бессмысленными. Они выполняются часами даже в параллельном режиме.
Да, современный front вроде PWA можно тестировать API-функционально. Но тесты часто зависят от получения данных из внешнего контура — и поэтому начинают фейлиться, если, например, тестовый SAP отстаёт от продуктового на N месяцев, а тестовый «1С» присылает неверные данные.
Когда же приходится выкладывать небольшую правку по какому-нибудь модулю, разработчики должны выбирать из двух зол: запустить полный прогон CI и потратить кучу времени на деплой или выложить хотфиксом без прогона тестов, рискуя всё-таки что-то сломать. Весьма драматично, когда такие правки прилетают от отдела маркетинга в «чёрную пятницу». Безусловно, рано или поздно регрессия и человеческая ошибка случатся. Знакомо?
В конечном счёте для выполнения бизнес-целей команда переходит в авральный режим работы, умело жонглирует тестами и внимательно смотрит на dashboard’ы из логов — Kibana, Grafana, Zabbix… А что получаем в итоге? Перегорание.
Согласитесь, такая ситуация с регрессией не похожа на «стабильный enterprise», каким он должен быть в мечтах и грёзах заказчика.
Проблема № 4. Связность кода и обновление платформы
Ещё одна проблема связности кода — это сложности при обновлении платформы.
Например, Magento содержит два миллиона строк кода. Куда бы мы не посмотрели — везде много кода (Akeneo, Pimcore, Битрикс). При добавлении функционала в ядро, лучше бы учесть изменения в ваших кастомных модулях.
Приведём живой пример для Magento.
В конце 2018 года вышла новая версия платформы Magento 2.3. В Open Source Edition были добавлены мультисклады и Elasticsearch. Кроме того, в ядре были исправлены тысячи ошибок и добавлены некоторые приятности в OMS.
С чем столкнулись e-Commerce проекты, у которых уже были написаны мультисклады на Magento 2.2? Им было нужно переписывать кучу логики в обработке заказа, чекауте, карточке товара с тем, чтобы использовать коробочный функционал. Ведь «так правильно» — зачем дублировать в модулях функционал коробочной версии? Уменьшить объём кастомного кода в большом проекте всегда полезно — ведь все коробочные методы учитывают именно эти мультисклады, и обновлять коробку без такого рефакторинга может быть бессмысленно (отметём security issues для простоты, тем более их можно накатывать и без обновления).
Теперь представьте: сколько времени уйдёт на такое обновление и как это можно тестировать без интеграционных тестов, писать которые затруднительно?
Неудивительно, что у многих обновление платформы проходит или без рефакторинга, но с увеличением дублирования, или (если команда хочет всё делать по фэншую) с «уходом» надолго в рефакторинг и наведение порядка.
Проблема № 5. Непрозрачность бизнес-процессов
Одна из самых важных проблем в управлении проектами состоит в том, что заказчик не видит всю логику и все бизнес-процессы проекта. Их можно лишь восстановить из кода или из документации (актуальность которой, как мы говорили ранее, проблематично поддерживать в модульных системах).
Да, у «Битрикса» есть BPM-часть, а у Pimcore — визуализация workflow. Но эта попытка управлять модулями с помощью бизнес-процессов всегда вступает в противоречие с наличием ядра. Кроме того, события, сложные таймеры, транзакционные операции — все этого не встречается в BPM монолитов. Повторюсь: это касается средних и крупных компаний. Для небольшой компании возможностей модульных систем хватит. Но если мы говорим про enterprise-сегмент, то в этом решении всё же не хватает единого центра управления, куда можно зайти и посмотреть на схеме любой процесс, любой статус, как именно что-то происходит, какие есть исключения, таймеры, события и кроны. Не хватает возможности изменять бизнес-процессы, а не модули. Процессное управление проектом захлёбывается в скорости изменений и связности логики.
Проблема № 6. Сложность масштабирования системы
Если вы разворачиваете монолит, он будет развёрнут целиком со всеми модулями на каждом app-сервере. Т.е. нельзя отдельно увеличить сервис обработки заказов и бонусов в сезон, отдельно от всего остального кода.
Нужно больше памяти и процессоров, что сильно повышает стоимость кластера.
Как микросервисы избавляют заказчиков от недостатков, типичных для модульной разработки. Оркестрация микросервисов в Camunda и jBPM
Спойлер: решение перечисленных в прошлом пункте проблем возможно с использованием BPMS и оркестрированием микросервисных систем.
BPMS (англ. business process management system) — это программное обеспечение для управления бизнес-процессами в компании. Популярные BPMS, с которыми работаем и мы, — Camunda и jBPM.
Оркестровка описывает то, как сервисы должны взаимодействовать между собой, используя для этого обмен сообщениями, включая бизнес-логику и последовательность действий. Используя BPMS, мы не просто рисуем абстрактные схемы — по нарисованному и будет выполняться наш бизнес-процесс. То, что мы видим на схеме, гарантированно коррелирует с тем, как работает процесс, какие микросервисы используются, какие параметры, по каким таблицам решений происходит выбор той или иной логики.

В качестве примера взят часто встречающийся процесс — отправка заказа в доставку.
По какому-либо сообщению или прямому вызову мы запускаем обработку заказа с процессом выбора метода доставки. Задана логика выбора.
В итоге процессы, сервисы и разработка:
- становятся быстро читаемыми;
- самодокументируемыми (работают именно так, как нарисованы, и нет рассинхрона между документацией и реальной работой кода);
- просто отлаживаемыми (легко посмотреть, как проходит тот или иной процесс, и понять, в чём ошибка).
Познакомимся с принципами, по которым работают системы управления бизнес-процессами.
Принцип BPMS № 1. Разработка становится визуальной и процессной
BPMS позволяет создать бизнес-процесс, в котором команда проекта (разработчик или бизнес-пользователь) определяет последовательность запуска микросервисов, а также условий и веток, по которым он движется. При этом один бизнес-процесс (последовательность действий) может включаться в другой бизнес-процесс.
Всё это наглядно представлено в BPMS: в режиме реального времени можно смотреть эти схемы, править их, выкладывать в продуктив. Здесь принцип самодокументируемой среды выполняется максимально — процесс работает именно так, как это визуализировано.
Все микросервисы становятся кубиками процесса, которые можно добавлять из оснастки бизнес-пользователю. Бизнес управляет процессом, а разработчик ответственен за наличие и корректность работы конкретного микросервиса. При этом все стороны понимают общую логику и назначение процесса.
Принцип BPMS № 2. Каждый сервис имеет понятные входы и выходы
Принцип звучит очень просто, и неопытному разработчику или бизнес-пользователю может показаться, что BPMS никак не улучшает саму стратегию написания микросервисов. Мол, нормальные микросервисы можно писать и без BPMS.
Да, можно, но сложно. Когда разработчик пишет микросервис без BPMS, у него неизбежно возникает желание сэкономить на абстрактности. Микросервисы становятся откровенно большими, а иногда и вовсе начинают переиспользовать другие. Появляется стремление сэкономить на прозрачности передачи результата от одного микросервиса к другому.
BPMS побуждает писать более абстрактно. Разработка ведётся именно процессно, с определением входа и выхода.
Принцип BPMS № 3. Параллелизация обработки очереди
Представьте процесс обработки заказов: нам нужно сходить в некий маркетплейс, забрать все хорошие заказы и начать обрабатывать их.

Посмотрите на схему (часть схемы). Здесь определено, что каждые 10 минут мы проверяем все заказы маркетплейса, затем запускаем параллельно (на что указывает вертикальный «гамбургер» в Process Order) обработку каждого заказа. При успехе передаём все данные в ERP и завершаем обработку.
Если нам вдруг потребуется поднять логи по обработке конкретного заказа, в Camunda, JBoss или любой другой BPMS мы сможем полностью восстановить все данные и увидеть, в какой очереди это было и с какими параметрами входа/выхода.
Принцип BPMS №4. Ошибка и эскалация
Представьте, что в процессе доставки товара произошла ошибка. Например (кстати, это реальный кейс), транспортная компания забрала заказ, а склад после этого сгорел. Другая реальная история: предновогодний аврал, товар сначала задержался, а потом, может быть, и потерялся.
В таком случае в BPMS мышкой накликивают события, например уведомление клиента в случае, если время доставки прошло. Если от транспортной компании внутри получили какую-то ошибку, можно запустить процесс по своей ветке и всё прервать: уведомить, дать скидку на следующий заказ, вернуть деньги.
Все подобные исключения сложно не только программировать вне BPMS (например таймер в таймере), но и понимать в контексте всего процесса.
Принцип BPMS №5. Выбор действий по одному из событий и межпроцессные варианты
Представьте всё тот же заказ в доставке.
Всего у нас три варианта развития событий:
- товар был доставлен в ожидаемые сроки;
- товар не был доставлен в ожидаемые сроки;
- товар был потерян.
Прямо в BPMS мы можем определить процедуру отгрузки товара в транспортную компанию и ожидать по заказу одно из событий:
- успешную доставку (сообщения от процесса доставки товара о том, что всё доставлено);
- или наступление какого-то времени.
Если время не прошло, вам нужно запустить другой сервис: разбор этого конкретного заказа с оператором (нужно поставить ему задачу в системе OMS/CRM, чтобы выяснить, где находится заказ) с дальнейшим уведомлением клиента.
Но если в процессе расследования заказ всё-таки был доставлен, нужно прервать расследование и завершить обработку заказа.
В BPMS все прерывания и исключения — на стороне BPMS. Вы не перегружаете код этой логикой (а само наличие такой логики в коде сделало бы микросервисы большими и плохо переиспользуемыми в других процессах).
Принцип BPMS №6. В вашей Camunda вы увидите все логи
С помощью событий и межпроцессного варианта вы:
- видите всю последовательность событий в одном окне (что с заказом, по какой ветке исключений он прошёл и т. п. — легко посмотреть);
- можете собрать всю аналитику для BI на основании одних только логов BPMS (без необходимости перегружать микросервисы логирующими событиями).
В результате вы сможете собрать статистику именно по проблемам обработки, скорости переходов, всех процессов по компании. Появляется унифицированность логирующей информации — легко увязать событие в доставке с действием оператора или событием любой другой информационной системы.
Обратите внимание на разницу с модульной системой: там тоже можно сделать универсальные логи, но при взаимодействии с другими системами нужно будет что-то делать с унификацией логирования и в них, а это возможно далеко не всегда.
Выводы: итоги сравнения микросервисной и модульной архитектуры
Каждый тип построения архитектуры имеет свои преимущества и недостатки. Универсального решения нет.
Мы не пропагандируем массовый переход на микросервисы. Наоборот, для малого бизнеса или при использовании совсем небольшого количества кастомизаций модульный подход будет более подходящим.
Также мы не являемся противниками какого-либо IT-решения (Битрикс, Magento, фреймворки вроде Symfony или Django и т.п.), ведь мы ежемесячно разрабатываем только на этих фреймворках более шести тысяч часов кода, и столько же — front’а и микросервисов. Поэтому мы и убеждены, что важно искать подходящее техническое решение, а не пропагандировать использование конкретной платформы (до чего, увы, скатывается значительная часть продаж в IT).
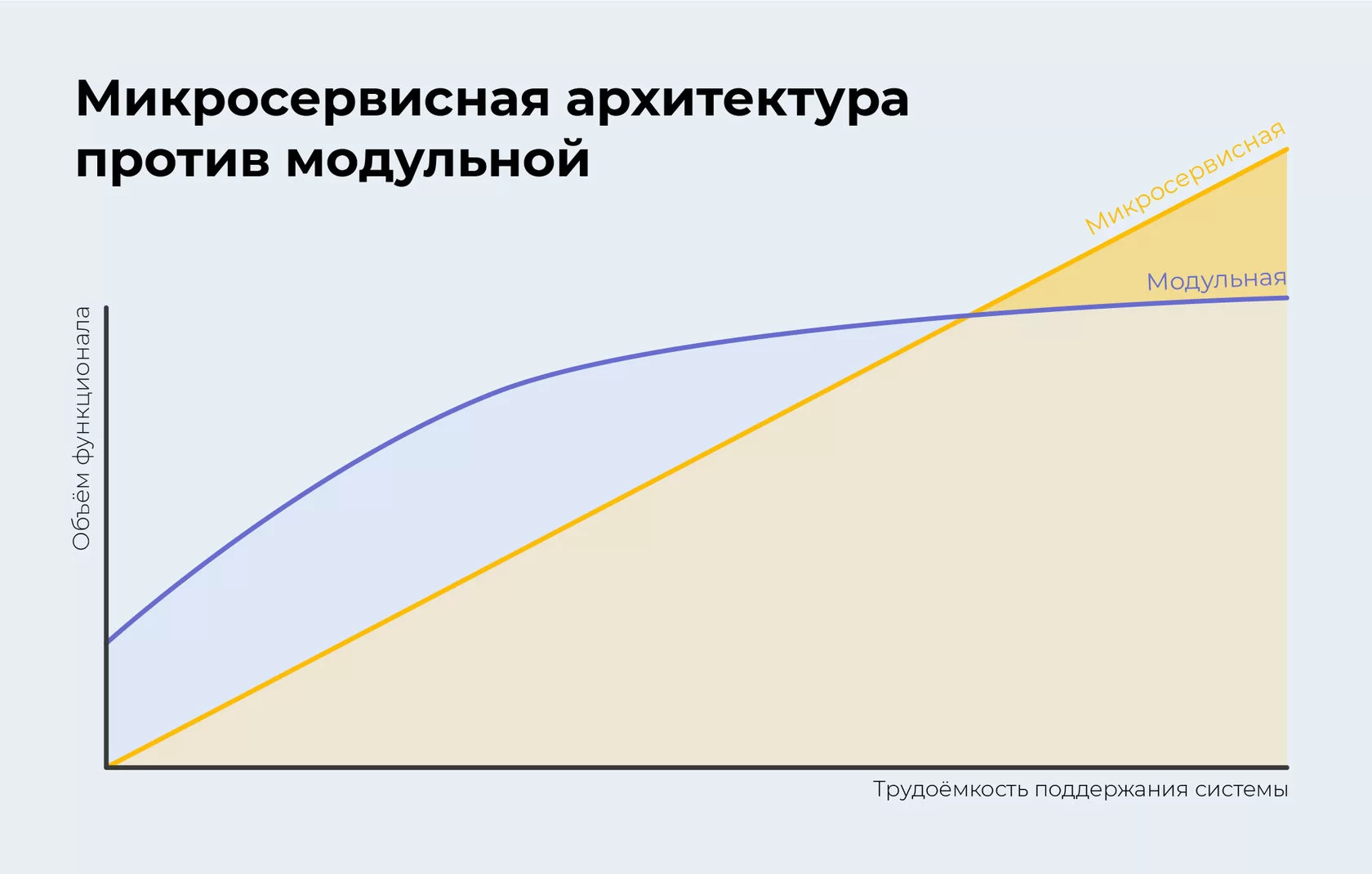
В предыдущих фрагментах статьи вы познакомились с недостатками и преимуществами модульной архитектуры. Надеемся, это уже помогло оценить, подошла бы вам больше доработка коробочной версии или же создание микросервисов с нуля. Если же определиться не удалось, давайте посмотрим, как меняются разные типы архитектуры в зависимости от срока жизни проекта.
На старте проекта:
- с микросервисами — у вас нулевой функционал, и весь его нужно написать, чтобы приступить к работе;
- с модульной системой — из коробочной версии вам сразу же доступен большой объём функционала, и вы можете начинать пользоваться продуктом в ближайшее время после покупки.
После первых 3–4 месяцев разработки (это средний срок выпуска первого MVP) и далее:
- с микросервисами — объём функционала постепенно выравнивается по сравнению с коробочной версией. Для среднего бизнеса микросервисная архитектура догонит модульную достаточно быстро, а для крупного — вообще мгновенно. И в дальнейшем поддержание и развитие модульной системы в пересчёте на единицу функционала будет увеличиваться;
- с модульной системой — скорость развития функционала будет значительно ниже, чем в микросервисах.

В заключение давайте рассмотрим, как выглядит оркестрация микросервисов на конкретных примерах.
Примеры визуализации оркестрации сервисов
Рассмотрим оркестрацию сервисов с использованием Camunda. По следующим изображениям вы сможете оценить, как удобно управлять микросервисами с помощью BPMS с оркестратором. Все процессы наглядны, логика очевидна.
Бизнес-процессы выглядят так:
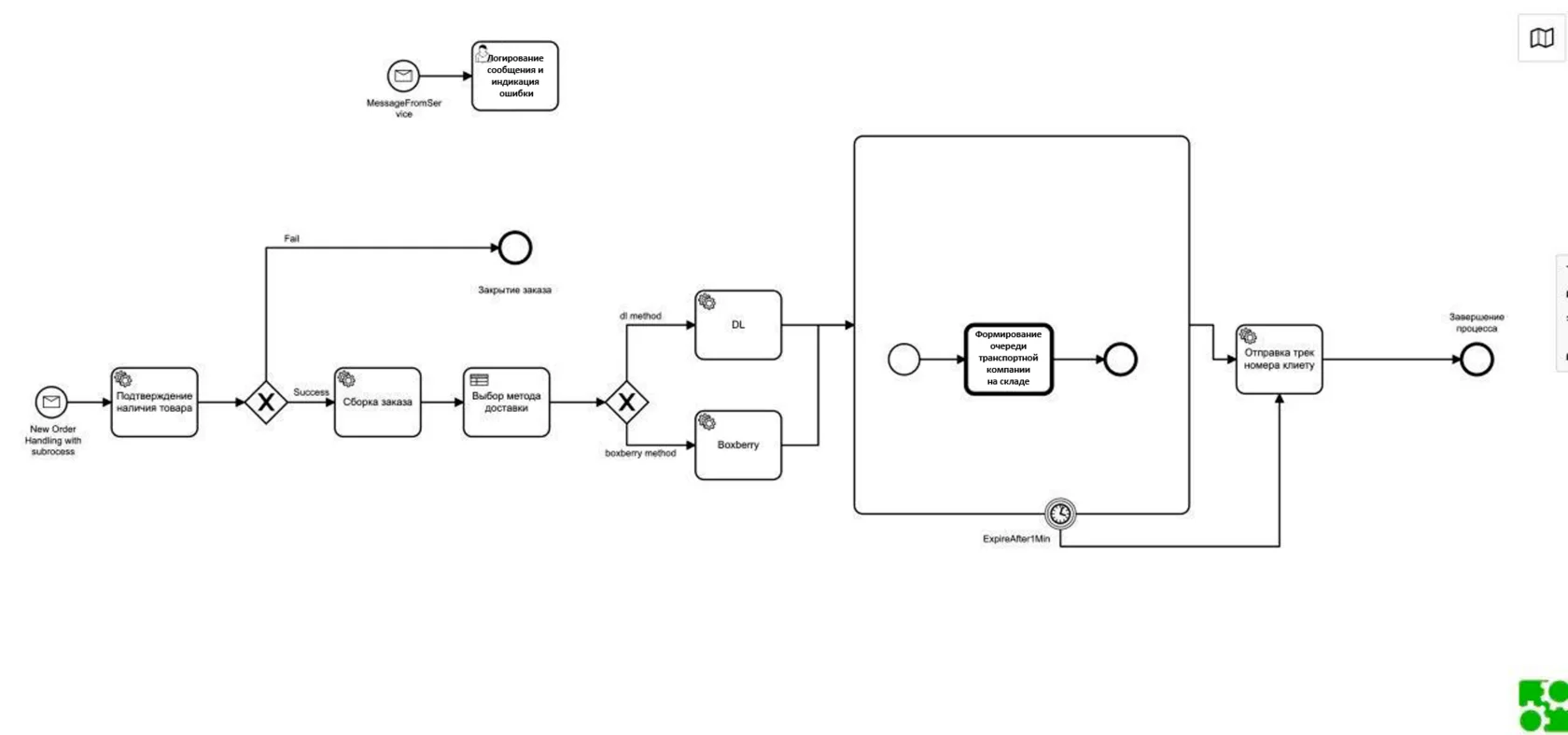
Пример (заказ, сервис наличия):

Видно, что в этом заказе была ветка «Нет товара».
Другой экземпляр заказа (ушёл на сборку):

Заказ пошёл дальше и по таблице решений (DMN) ушёл в ветку обработки определённым оператором службы доставки (Boxberry):

Уход на вложенный процесс:

Вложенный процесс отработал:
История прохождения бизнес-процессов:

Свойства такой визуализации:
- бизнес-процессы легко читаются даже неподготовленным пользователем;
- они исполняемы, т. е. работают именно так, как нарисованы, нет рассинхрона между «документацией» и реальной работой кода;
- процессы прозрачны: легко посмотреть, как проходил тот или иной импорт, заказ, обработка, легко понять, где была допущена ошибка.
Напомним, мы в kt.team применяем и модульную, и микросервисную разработку, подбирая подходящий вариант персонально для каждого продукта. Но если выбор уже сделан в пользу микросервисной архитектуры, то тут мы твёрдо убеждены, что без BPM-систем вроде Camunda или jBPM обойтись невозможно.
Смотрите также: видео на тему «Микросервисная или монолитная архитектура: что выбрать?»







