При написании приложений на Python, для работы с базами данных часто используются объектно-реляционные мапперы (ORM). Примерами ORM являются SQLALchemy, PonyORM и объектно-реляционный маппер, входящий в состав Django. При выборе ORM довольно важную роль играет её производительность.
На Хабре, да и в интернете в целом, можно найти не один тест производительности. Как пример качественного бенчмарка python ORM можно привести бенчмарк от Tortoise ORM (ссылка на репозиторий). Данный бенчмарк анализирует скорость работы шести ORM для одиннадцати различных видов SQL-запросов.
В целом бенчмарк от tortoise хорошо позволяет оценить скорость выполнения запросов при использовании разных ORM, но у такого подхода к тестированию я вижу одну проблему. ORM зачастую используют в веб приложениях, где одновременно несколько пользователей могут посылать различные запросы, но я не нашел ни одного бенчмарка, оценивающего работу ORM при таких условиях. Вследствие этого я решил написать свой бенчмарк и сравнить с помощью него PonyORM и SQLAlchemy. За основу я взял бенчмарк TPC-C.
Компания TPC с 1988 года разрабатывает тесты, направленные на обработку данных. Они давно стали индустриальным стандартом и используются почти всеми вендорами оборудования на различных образцах аппаратного и программного обеспечения. Главная особенность этих тестов состоит в том, что они нацелены на тестирование при огромной нагрузке в условиях, максимально приближенных к реальным.
TPC-C симулирует работу сети складов. Он включает в себя комбинацию из одновременно выполняемых транзакций пяти различных типов и сложности. База данных состоит из девяти таблиц с большим количеством записей. Производительность в тесте TPC-C измеряется в транзакциях в минуту.
Я решил протестировать два Python ORM (SQLALchemy и PonyORM) с использованием метода тестирования TPC-C, адаптированного под данную задачу. Целью теста является оценка скорости обработки транзакций при обращении к базе одновременно нескольких виртуальных пользователей.
Описание теста
В написанном мной тесте сначала создается и наполняется база данных, которая представляет из себя базу сети складов. Схема БД выглядит так:
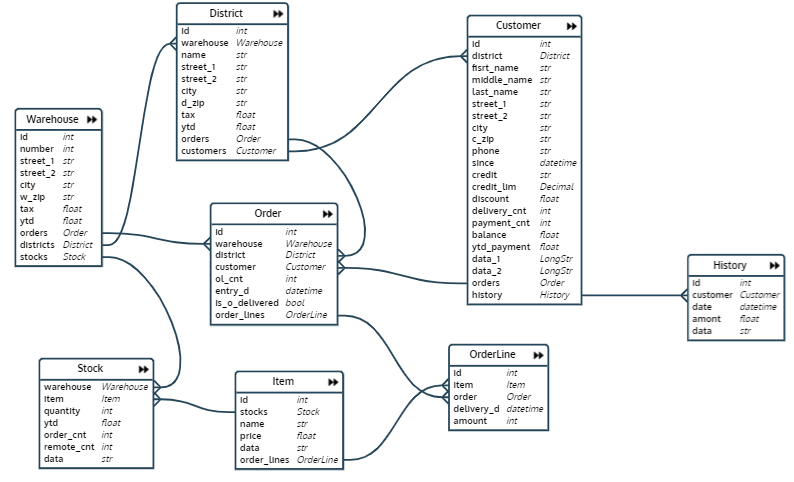
База данных состоит из восьми отношений:
- Warehouse — склад
- District — участок склада
- Ордер — заказ
- OrderLine — строка заказа (позиция заказа)
- Stock — количество определенного товара на определенном складе
- Item — товар
- Customer — клиент
- History — История платежей клиента
В ходе теста обрабатываются транзакции, посылаемыe одновременно от лица нескольких виртуальных пользователей. Каждая транзакция состоит из нескольких запросов. Всего в данном тесте существует пять видов транзакций, которые подаются на обработку с разной процентной вероятностью:
- new_order (создание нового заказа) — 45%
- payment (оплата клиентом заказа) — 43%
- order_status (возвращает состояние последнего заказа клиента) — 4%
- delivery (доставка заказов) — 4%
- stock_level (возвращает остаток на складе заказанных предметов) — 4%
Вероятность появления транзакций такая же, как и в оригинальном тесте TPC-C.
По сравнению с оригинальным тестом TPC-C данный тест несколько упрощен, в связи с техническими ограничениями и тем, что я хочу проверить производительность ORM, а не устойчивость железа к нагрузке. Оригинальный тест проводится на серверах с 64+ ГБ оперативной памяти, большим количеством процессоров и огромным дисковым пространством.
Основные различия:
- Тест запускается с меньшим количеством виртуальных пользователей, чем в оригинальном тесте
- Меньше количество записей в таблицах. Например: количество записей в отношении Stock в оригинальном тесте рассчитывается по формуле 100 000 * W, где W — это количество складов, а в написанном мной тесте: 100 * W
- В оригинальном тесте некоторые из 5 транзакций имеют несколько вариантов запроса данных из базы. Например в транзакции Payment с одной вероятностью клиент будет запрашиваться из базы по ID, с другой по фамилии и имени. На данный момент в моём тесте в подобных ситуациях вызов производится только по ID, в дальнейшем планирую реализовать и второй вариант
- В схеме моего теста отсутствует таблица NewOrder. В оригинальном тесте, когда создается заказ, то он добавляется и в таблицу Order, и в таблицу NewOrder. После доставки заказа, он удаляется из таблицы NewOrder. Это ускорит работу при огромном количестве транзакций в минуту, но так как у меня меньше потоков, обращающихся к базе, то это, на мой взгляд, излишне. Вместо этого в таблице Order я добавил bool атрибут “is_o_delivered”, который будет равен False, до тех пор, пока заказ не доставят
Далее я кратко опишу, что делает каждая транзакция.
New Order
- Транзакции подается два аргумента: id склада и id клиента
- Из базы запрашиваются склад и клиент по переданным id
- Случайным образом берется один из участков склада
- Генерируется случайное число строк(позиций) заказа
- Создается объект заказа
- В цикле создаются объекты для позиций данного заказа. На каждой итерации цикла из базы случайным образом берется товар из отношения Item.
- Для каждого товара в заказе, в базе изменяется его доступное количество на складе.
Payment
- Транзакции подается два аргумента: id склада и id клиента
- Из базы запрашиваются склад и клиент по переданным id
- Случайным образом берется один из участков склада и сумма оплаты
- Баланс склада и отдельного участка увеличивается на сумму оплаты
- Баланс клиента уменьшается на сумму оплаты.
- Счетчик количества оплат у клиента увеличивается на 1
- Суммарная сумма, полученного от данного клиента, увеличивается на сумму оплаты
- Создается объект истории платежей.
Order Status
- Транзакции подается id клиента
- Из базы данных берутся клиент и его последний заказ
- Из заказа берутся его статус (доставлен он или нет) и позиции заказа
Delivery
- Транзакции подается id склада
- Из базы запрашиваются склад по id и все его участки
- Для каждого участка берется самый старый из не доставленных заказов. В каждом из них статус доставки меняется на True
- Из базы берутся пользователи, чьи заказы были доставлены в ходе данной транзакции, и у каждого из них увеличивается счетчик доставок
Stock Level
- Транзакции подается id склада
- Из базы запрашивается склад по id
- Из базы запрашиваются последние 20 заказов этого склада
- Для каждой позиции этих заказов из базы запрашиваются количество остатка товара на складе
Результаты тестирования
В тестировании участвуют два ORM:
- SQLAlchemy. На графиках изображен синей линией
- PonyORM. На графиках изображен желтой линией
Ниже приведены результаты запуска теста на 10 минут с 2 параллельными процессами, обращающимися к базе. Процессы запускаются с помощью модуля multiprocessing.
Ось Х — время в минутах
Ось У — количество выполненных транзакций
В качестве СУБД используется PostgreSQL
Запуск со всеми транзакциям
Сначала я запустил тест со всеми пятью транзакциями, как и предполагается в тесте TPC-C. В результате данного теста Pony оказался быстрее почти в два раза.

Средняя скорость:
Pony — 2543 тран/мин
SQLAlchemy — 1353.4 тран/мин
После этого я решил отдельно оценить производительность данных ORM на каждой из пяти транзакций по отдельности. Ниже приведены результаты для каждой отдельной транзакции.
Транзакция “New Order”

Средняя скорость:
Pony — 3349.2 тран/мин
SQLAlchemy — 1415.3 тран/мин
Транзакция “Payment”
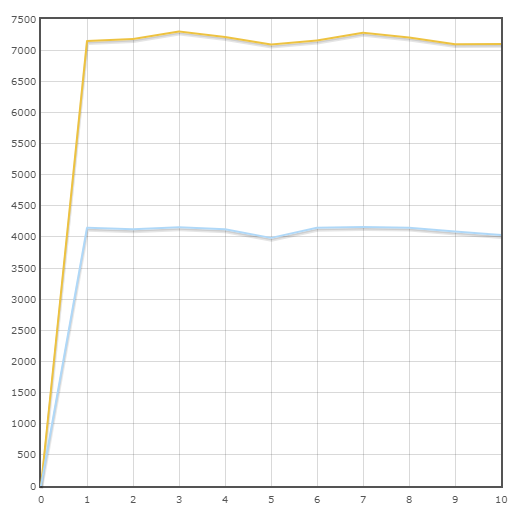
Средняя скорость:
Pony — 7175.3 тран/мин
SQLAlchemy — 4110.6 тран/мин
Транзакция “Order Status”
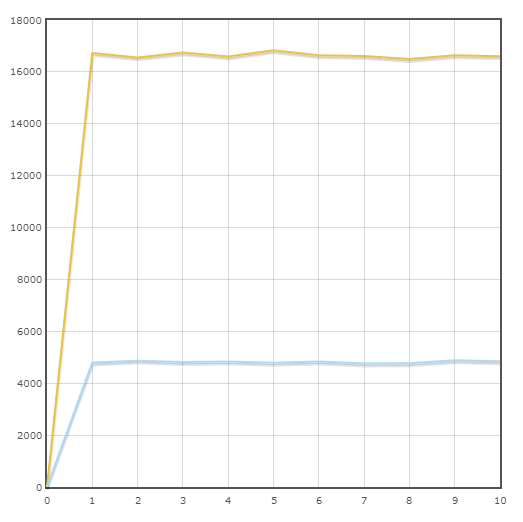
Средняя скорость:
Pony — 16645.6 тран/мин
SQLAlchemy — 4820.8 тран/мин
Транзакция “Delivery”
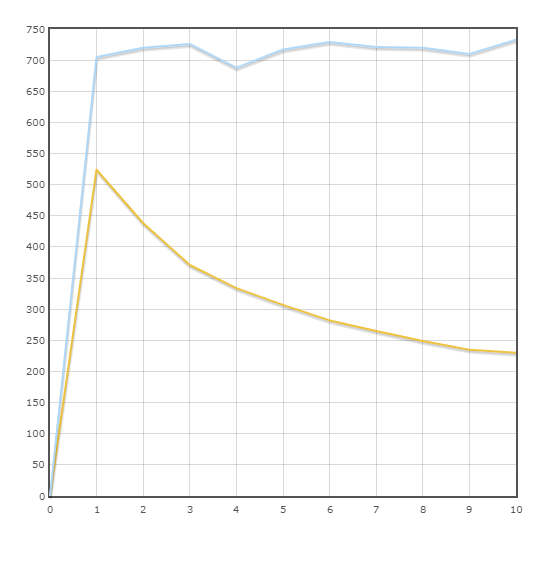
Средняя скорость:
SQLAlchemy — 716.9 тран/мин
Pony — 323.5 тран/мин
Транзакция “Stock Level”
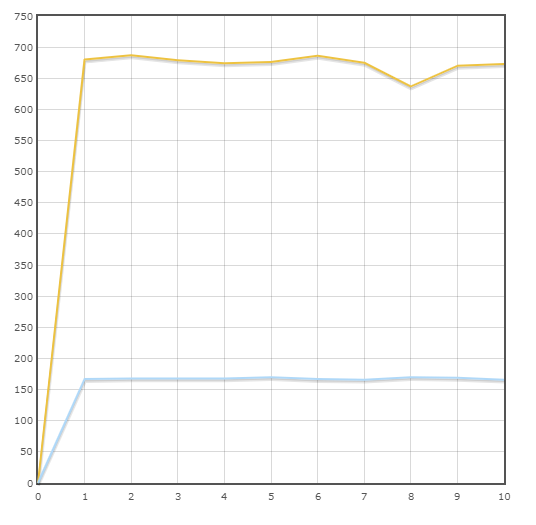
Средняя скорость:
Pony — 677.3 тран/мин
SQLAlchemy — 167.9 тран/мин
Анализ результатов тестирования
После получения результатов я проанализировал, почему в различных ситуациях одна ORM работает быстрее другой и пришел к следующим выводам:
В 4 из 5 транзакций PonyORM оказалась быстрее, так как, при генерации SQL кода PonyORM запоминает результат трансляции выражений Python в язык SQL, и не выполняет трансляцию заново при повторном выполнении запроса, в то время как SQLALchemy вынуждена генерировать текст SQL при каждом выполнении запроса.Пример подобного запроса на PonyORM:
stocks = select(stock for stock in Stock if stock.warehouse == whouse and stock.item in items).order_by(Stock.id).for_update()
Пример аналогичного запроса на SQLAlchemy:
stocks = session.query(Stock).filter( Stock.warehouse == whouse, Stock.item.in_(items)).order_by(text("id")).with_for_update()
По всей видимости SQLAlchemy выполняет транзакции типа Delivery быстрее потому, что умеет объединять несколько операций UPDATE, применяемых к разным объектам, в единую команду.
Вот пример такого запроса, как он записан в логах SQLAlchemy:
INFO:sqlalchemy.engine.base.Engine:UPDATE order_line SET delivery_d=%(delivery_d)s WHERE order_line.id = %(order_line_id)s
INFO:sqlalchemy.engine.base.Engine:(
{'delivery_d': datetime.datetime(2020, 4, 6, 14, 33, 6, 922281), 'order_line_id': 316},
{'delivery_d': datetime.datetime(2020, 4, 6, 14, 33, 6, 922272), 'order_line_id': 317},
{'delivery_d': datetime.datetime(2020, 4, 6, 14, 33, 6, 922261))Pony же в подобных ситуациях будет отправлять отдельный запрос для каждого Update:
SELECT "id", "delivery_d", "item", "amount", "order"
FROM "orderline"
WHERE "order" = %(p1)s
{'p1':911}
UPDATE "orderline"
SET "delivery_d" = %(p1)s
WHERE "id" = %(p2)s
AND "order" = %(p3)s
{'p1':datetime.datetime(2020, 4, 7, 17, 48, 58, 585932), 'p2':5047, 'p3':911}
UPDATE "orderline"
SET "delivery_d" = %(p1)s
WHERE "id" = %(p2)s
AND "order" = %(p3)s
{'p1':datetime.datetime(2020, 4, 7, 17, 48, 58, 585990), 'p2':5048, 'p3':911}Вывод
По итогу данного тестирования, могу сказать, что Pony работает гораздо быстрее при выборке из базы данных, а SQLAlchemy в некоторых случаях может с заметно большей скоростью производить запросы типа Update.
В дальнейшем я планирую протестировать таким способом и другие ORM (Peewee, Django).
Ссылки
Код теста: ссылка на репозиторий
SQLAlchemy: документация, комьюнити
Pony: документация, комьюнити









