Комментарии 86
Последовательно? Но в ssd же таблицы трансляции адресов, которые ОС не контролирует…
У вас есть замеры скорости до и после дефрагментации?
Накопители же используют сразу несколько микросхем в параллель для увеличения скорости чтения/записи, используют достаточно крупный набортный буфер ОЗУ, чтобы скрыть время работы с массивом FLASH между отсутствием обращения к накопителю со стороны системы. Сами NANDы тоже развиваются в плане достижения более высоких скоростей работы, но базовый принцип работы NAND это не отменяет.
Именно поэтому, скорость работы SSD следует оценивать не по линейной скорости а конкретно по IOPS. Причём, не по маркетинговым цифрам а в тестах. Ведь, даже если читать фрагментированный большой файл или папку то приходится делать дополнительные чтения метаданных.
всегда мучал вопрос: если у меня пол диска разбито на разделы и еще половина не разбита. диск использует ту часть для записи или елозит только по разбитой области?
А вообще SSD пишут во всю доступную емкость флэша, и параллельно на все чипы NAND, только данные по блокам не всегда будут симметрично записаны, иногда вне очереди влетает срочная запись от сборщика мусора или flush от драйвера. Так что данные на NAND в принципе почти всегда фрагментированы, вопрос в том, насколько они равномерно замаплены на флэше, чтобы их можно было в параллели читать, или что-то приходится читать в одну нитку с одного чипа (в худшем случае).
накопитель вообще ничего не знает о разделах. для него есть набор секторов, в некоторых из которых есть данные (если вы неиспользуемую область никак не инициализировали, то с точки зрения накопителя все эти сектора пустые).
у накопителя в результате куча свободного места, которое он может использовать для записи не запуская сборщик мусора, это называется over-provisioning, почитать можно, например, тут.
скорее опасна обратная ситуация: 90% диска забито статичными данными (скажем, коллекция фильмов), а в оставшиеся 10% идёт активная запись (ну, например своп, и на машине у вас куча виртуалок, которым не хватает памяти). если вся запись пойдёт только в эти 10% диска, то ресурс этих областей быстро исчерпается, чтобы такого не произошло, накопитель должен периодически перемещать записанные данные. но как это реализовано (и реализовано ли во всех накопителях) — мы не знаем.
Вы протестировали несколько устройств, получили РАЗНЫЕ результаты, в том числе и явно свидетельствующие, что некоторые производители уже решили эту проблемы.
Но вывод у вас «SSD деградируют».
Так давайте все-же честно интерпретировать результаты — некоторые модели некоторых производителей имеют неоптимальные алгоритмы, из-за чего они могут деградировать в таких случаях.
Напоминает:
"Лично я садясь на самолёт на всякий случай окропил его святой водой, перекрестился. Хуже не будет, а покой дорог, однако"
очень правильный вопрос.
в первоначальном обсуждении мы выяснили, что срабатывают эвристики операционной системы на упреждающее чтение.
вот с тестовой машины:
root@debian:/# fio --name=test1 --filename=testfile --bs=4k --iodepth=1 --numjobs=1 --rw=read --timeout=10 |grep IOPS
read: IOPS=425k, BW=1659MiB/s (1740MB/s)(16.0GiB/9874msec)
root@debian:/# fio --name=test1 --filename=testfile --bs=4k --iodepth=1 --numjobs=1 --rw=randread --timeout=10 |grep IOPS
read: IOPS=12.4k, BW=48.6MiB/s (50.0MB/s)(486MiB/10001msec)
root@debian:/# fio --name=test1 --filename=testfile --bs=4k --iodepth=1 --numjobs=1 --rw=read --direct=1 --timeout=10 |grep IOPS
read: IOPS=12.5k, BW=48.7MiB/s (51.0MB/s)(487MiB/10001msec)
root@debian:/# blockdev --setra 0 /dev/nvme0n1p2; fio --name=test1 --filename=testfile --bs=4k --iodepth=1 --numjobs=1 --rw=read --timeout=10 |grep IOPS
read: IOPS=12.5k, BW=48.6MiB/s (51.0MB/s)(487MiB/10001msec)первая попытка: последовательное чтение блоками по 4кб (включается упреждающее чтение операционной системы), имеем >>400к iops.
вторая попытка: случайное чтение, имеем 12.4к iops (операционная система догадывается отключить упреждающее чтение).
третья попытка: последовательное чтение в обход кэша, имеем 12.5к iops (операционная система не может использовать упреждающее чтение).
третья попытка: последовательное чтение с явно отключенным упреждающим чтением, имеем 12.5к iops.
итого: именно упреждающее чтение обеспечивает более высокую скорость линейного чтения на SSD (операционная система сбрасывает на диск несколько операций чтения сразу, что позволяет устройству обрабатывать их параллельно).
почему же при внутренней фрагментации падает скорость линейного чтения — сие пока для меня тайна великая есть.
почему же при внутренней фрагментации падает скорость линейного чтения — сие пока для меня тайна великая есть.
Ответ тут.
На верхней части этой картинки:
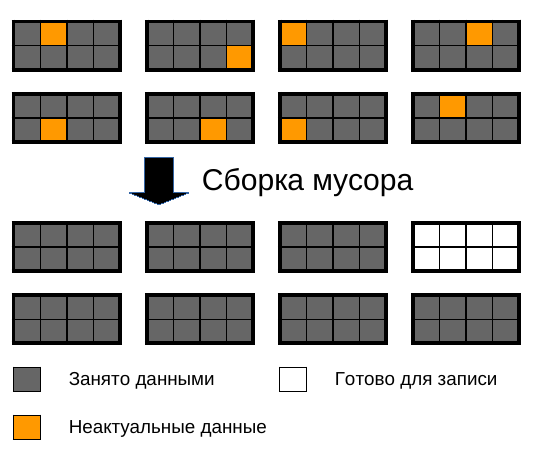
не понимаю.
контроллеру пришли 32 команды "прочитай 4кб сектор", какая ему разница, расположены физически эти сектора подряд, или разбросаны по нескольким страницам с «дырками»?
У многих профессиональных SSD сектор вообще 512 байт. Явно это сделано в угоду совместимости, а не является оптимальным размером для NAND.
Плюс не нужно тратить время на адресацию микросхем, блоков. Скорее всего там многоступенчатая система адресации.
Вот из википедии:
Технология NOR позволяет получить быстрый доступ индивидуально к каждой ячейке, однако площадь ячейки велика. Наоборот, NAND имеют малую площадь ячейки, но относительно длительный доступ сразу к большой группе ячеек.
Из тех что я тыкал, были, условные, команды -«читать не переставая», «читать х последовательно», «читать одну страницу». Притом время на команду была сильно разная, и иногда было выгодней «дефрагментировать» и читать целиком 1МБ, а не по 100 раз обрывая чтение. Разница при этом может быть до ~40% (могу и врать, это было года 3-4 назад)
итого: именно упреждающее чтение обеспечивает более высокую скорость линейного чтения на SSD
извиняюсь, поторопился с выводами.
скорость последовательного чтения с отключенным упреждающим чтением равна скорости случайного чтения не на всех моделях SSD. видимо, некоторые модели делают упреждающее чтение во внутренний буфер (или просто оперируют при чтении блоками размером больше 4Кб)
А почему вы так прицепились к 4КБ? У большинства ссд логический блок вообще 512 байт. Поэтому можно было написать "блоками больше 512 байт".
У большинства ссд логический блок вообще 512 байт
но мы же обычно не обращаемся к блочным устройствам напрямую, а используем файловые системы.
размер блока по умолчанию в ext4 и xfs как раз и есть 4кб. ЕМНИП в ntfs размер кластера по умолчанию тоже 4кб.
В особенности при параллельной нагрузке.
Сейчас при разбитии диска на разделы, современный софт сам правильно начинает новый раздел.
Чтение и запись группы секторов были включены еще в ATA-2, раздел 10.6.
Вы пытаетесь бенчмаркать производительность writeback-кеша на SSD. Выключите (hdparm -W0) и посмотрите после этого.
Все SSD поделятся на три класса:
- начнут невообразимо тормозить (400 IOPS — уже круто).
- начнут тормозить за пределами добра и зла (30 IOPS)
- не поменяют производительность.
Наиболее интересные — третьи. Они срали на команду "выключить writeback" и продолжают его делать. Некоторые самсунги этим грешат. Есть кондёр на устройстве — "мы лучше знаем нужен вам writeback или нет".
Вы пытаетесь бенчмаркать производительность writeback-кеша на SSD
тестами скорости чтения?
Есть кондёр на устройстве — "мы лучше знаем нужен вам writeback или нет".
так оно и есть.
без конденсатора "честные" ssd начинают тупить под типичной нагрузкой БД (синхронная запись в лог), для того и нужны DC накопители, чтобы при разумных гарантиях сохранности данных иметь хорошую производительность.
Всё сложнее.
База данных использует flush (что такое flush зависит от шины, но внутри ядра это BIO_FLUSH) для обеспечения write barriers. Интерпретация flush'а зависит от устройства. Например, рейды с батарейкой его игнорируют. Так же поступают DC-grade SSD, у которых есть кондёр на борту для завершения записи в случае фейла.
А есть управление кешом. Например, у серьёзных аппаратных рейдов выключение кеша его выключает. Даже если рейд может быстро и с writeback'ом, если сказал "выключить", значит "выключить". Аналогично должны вести себя и устройства. Если им сказали "выключить кеш", значит кеш надо выключить.
Но бывают товарищи, которые умнее всех и верят, что у них-то фирмваря без багов, и это игнорируют.
Есть большая разница между игнорированием flush'а и игнорированием команды "выключить кеширование на запись".
не представляю ситуации, в которой действительно может потребоваться отключить wb кэш на dc дисках (да и не на dc тоже, надо просто "к месту" вызывать sync aka flush).
это же будет жутко медленно и с огромным write amplification внутри.
хотя, вроде бы, есть некоторые кастомерские ssd, которые работают вовсе без wb. ну и, конечно, есть optane, которому это не нужно.
Например, если диск под рейдом с writeback'ом, то write amplification будет меньше. Хотя всё равно будет, да.
Вкл/выкл я привожу как метод оценить реальную производительность и честность вендора.
Любое применение, где критично считать, что если диск сказал «записано», то оно там реально записано. Например, базы данных.
> это же будет жутко медленно и с огромным write amplification внутри.
Медленно — решается тем, что такое применение ставит много асинхронных параллельных операций одновременно. Не зря в пост-SATA интерфейсах (как тот же NVMe) дают, например, 65536 одновременных операций (пространство тегов — 16 бит).
Усиление записи — да, если к моменту, когда контроллер дойдёт до выполнения операции, не скажут записать соседние блоки — будет большое усиление, а как иначе-то?
> хотя, вроде бы, есть некоторые кастомерские ssd, которые работают вовсе без wb.
Как раз для дома тайный writeback почти безвреден, а для серверной стороны это критично — если диск отрапортует, что записал, а на самом деле нет — получить невосстановимую базу будет банально.
а для серверной стороны это критично — если диск отрапортует, что записал, а на самом деле нет — получить невосстановимую базу будет банально.
ну для всяких log-based структур это не так критично, скорее всего будет откат на прошлое консистентное состояние (я понимаю, что это тоже зачастую неприемлемо)
и да, о каких именно сбоях мы говорим?
как минимум неожиданное отключение питания обрабатывается (для этого ионисторы и стоят).
Если в логе, например, сказано «транзакция 12345 успешно закоммичена», а в файлах таблиц данных нет — никто и не поймёт, что надо откатывать, пока не полезут видимые глюки.
> как минимум неожиданное отключение питания обрабатывается
Ну если на запасе энергии оно сумеет таки записать весь свой кэш — тогда ok. Но ещё во времена наличия только HDD были скандалы про диски, которые для улучшения бенчмарков не давали выключать WB кэш. Там запаса не было.
Но ещё во времена наличия только HDD были скандалы про диски, которые для улучшения бенчмарков не давали выключать WB кэш
ну это совсем другая история.
все встречавшиеся мне enterprise ssd имеют защиту от пропадания питания, подобной защиты на hdd я не помню, слишком много энергии жрёт hdd (потому так популярны были raid-контроллеры с bbwc).
но остаётся вопрос насколько хорошо эта защита реализована.
что будет, если подвиснет проц на ssd? не подвесит ли его некий нестандартный пакет на pci-e шине? используется ли для кэша ecc-память?
не подвесит ли его некий нестандартный пакет на pci-e шине?
Такое возможно? Откуда такому пакету взяться?
Откуда такому пакету взяться?
вот так рассуждают программисты, а потом очередная CVE появляется )))
В яслях для программистов учат наизусть «Не доверяй входным данным».
А в чуть более старшей группе садика для программистов изучают законы Мёрфи и следствия из них, например: "Даже если неприятность не может случиться, она случается" (Обобщение следствий, сделанное Шнэттеpли).
Я пытаюсь вам объяснить, что вопрос задан неверно.
Нужно доказывать не то, что злокозненный пакет может появиться, а то, что он не может появиться. И если не это доказано (а оно не может быть доказано хотя бы в силу разнообразия аппаратных систем) — считать, что на входе у нас может быть что угодно.

Очевидно, что здесь перечислены не все комбинации для 8 бит. Т.е. если у пакета из Reserved будет правильная CRC, это и будет нестандартным пакетом для устройства, не учитывающего возможное появления таких пакетов.
В NAND flash можно писать (точнее стирать) только большими блоками. А операционная система видит SSD как набор 512-байтовых (или 4096-байтовых) секторов, каждый из которых может быть адресован независимо.
Насколько большие блоки? Может выставить соответствующий размер сектора?
Скажу за себя: всегда периодически (раз в месяц, иногда реже) оптимизирую файловую таблицу и дефрагментирую ssd при помощи UltraDefrag (старой, бесплатной, версией).
Ps: а кто у нас сейчас в топе для бэкапа дисков/разделов? Использую актив диск но это немного не то. Акронису иногда крышу сносит от свободного места в конце диска. Гост медленный.
Раз в пару месяцев я бэкаплю системный ssd полностью на второй такой же (не посекторно!) и сразу ставлю его в машину. Одновременно и бэкап, и его проверка, и дефрагментация.
да, это будет решением для дисков вроде упоминавшейся тут тошибы.
впрочем, на домашнем ПК случайной записи должно быть немного, так что и острой проблемы быть не должно.
Ps: а кто у нас сейчас в топе для бэкапа дисков/разделов?
Clonezilla — если на накопителе поддерживаемая файловая система (список велик), то копируются и восстанавливаюся только занятые блоки.
Лично я предпочитаю Parted Magic, который использует всё ту же Clonezilla. Благодаря тому, что дистрибутив идёт под GNU GPL, его совершенно легально можно скачать с торрентов, куда его выкладывают покупатели (на оф.сайте бесплатное скачивание недоступно).
Available Spare: 100%
Available Spare Threshold: 10%
Percentage Used: 181%
Data Units Read: 493,393,022 [252 TB]
Data Units Written: 417,292,043 [213 TB]
Host Read Commands: 61,788,393,431
Host Write Commands: 14,257,962,326
Controller Busy Time: 1,598,454,616
Power Cycles: 11
Power On Hours: 7,918
Результат, без часового ожидания в конце.
preparing...
4096+0 records in
4096+0 records out
4294967296 bytes (4.3 GB, 4.0 GiB) copied, 1.22541 s, 3.5 GB/s
4096+0 records in
4096+0 records out
4294967296 bytes (4.3 GB, 4.0 GiB) copied, 2.4611 s, 1.7 GB/s
4096+0 records in
4096+0 records out
4294967296 bytes (4.3 GB, 4.0 GiB) copied, 1.29826 s, 3.3 GB/s
fio: write 50M...
sleep 10
4096+0 records in
4096+0 records out
4294967296 bytes (4.3 GB, 4.0 GiB) copied, 2.51806 s, 1.7 GB/s
sleep 20
4096+0 records in
4096+0 records out
4294967296 bytes (4.3 GB, 4.0 GiB) copied, 2.4617 s, 1.7 GB/s
sleep 30
4096+0 records in
4096+0 records out
4294967296 bytes (4.3 GB, 4.0 GiB) copied, 2.46044 s, 1.7 GB/s
fio: write 200M...
sleep 10
4096+0 records in
4096+0 records out
4294967296 bytes (4.3 GB, 4.0 GiB) copied, 2.51369 s, 1.7 GB/s
sleep 20
4096+0 records in
4096+0 records out
4294967296 bytes (4.3 GB, 4.0 GiB) copied, 2.50427 s, 1.7 GB/s
sleep 30
4096+0 records in
4096+0 records out
4294967296 bytes (4.3 GB, 4.0 GiB) copied, 2.57665 s, 1.7 GB/s
fio: write 800M...
sleep 10
4096+0 records in
4096+0 records out
4294967296 bytes (4.3 GB, 4.0 GiB) copied, 2.44405 s, 1.8 GB/s
sleep 20
4096+0 records in
4096+0 records out
4294967296 bytes (4.3 GB, 4.0 GiB) copied, 2.67699 s, 1.6 GB/s
sleep 30
4096+0 records in
4096+0 records out
4294967296 bytes (4.3 GB, 4.0 GiB) copied, 2.43979 s, 1.8 GB/s
fio: write 4000M...
sleep 10
4096+0 records in
4096+0 records out
4294967296 bytes (4.3 GB, 4.0 GiB) copied, 2.52351 s, 1.7 GB/s
sleep 20
4096+0 records in
4096+0 records out
4294967296 bytes (4.3 GB, 4.0 GiB) copied, 2.75889 s, 1.6 GB/s
sleep 30
4096+0 records in
4096+0 records out
4294967296 bytes (4.3 GB, 4.0 GiB) copied, 2.64889 s, 1.6 GB/s
Время чтения (в секундах) файла размером 4Гб для разных дисков:
Стоит учесть что многие накопители (самсунги в частности) имеют SLC кэш (от 4 до 40+ Gib — обычно есть в спецификации). Я думаю подобное тестирование имеет смысл делать на объемах от 100 GiB.
Просто нет никаких возможностей для управления размещением файлов на SSD из системы.
Всем заведует контроллер.
я не уверен на 100%, что все SSD правильно обрабатывают ситуацию «пишем нули в область, для которой до этого делали TRIM»А зачем их писать? Какой в этом смысл? И главное — практически все ssd на лету сжимают данные, поэтому нули он скорее всего просто не запишет.
По поводу дефрагментации —
Оптимальное расположение файлов на HDD — непрерывно в одном месте диска.
Оптимальное расположение файлов на SSD — файл равномерно размазан по всем микросхемам.
По факту для наибольшего быстродействия файл должен быть очень сильно фрагментирован, если это слово вообще применимо к SSD.
Ну и если не устраивает такая свистопляска — смотрите в сторону Intel Optane на 3dxpoint, там нет всех этих премудростей nand памяти с очисткой ячеек и выравниванием износа — тупо идет запись туда, куда сказали, прям как на HDD.
А зачем их писать? Какой в этом смысл?
Запись нулей на SSD — это "TRIM для бедных", потому что не все контроллеры поддерживали TRIM, а некоторые нехорошие RAID контроллеры (на удивление, очень многие и даже high-end) не пропускают TRIM к SSD (и не используют его). И нет, далеко не все SSD используют компрессию. В любом случае проще обнаруживать запись нулей и отмечать блок как "неиспользованный", потому что в этом случае можно просто отдавать нули обратно при чтении неиспользованных блоков. Правда, не все контроллеры это распознают (распознавали).
Оптимальное расположение файлов на SSD — файл равномерно размазан по всем микросхемам.
Только если эта "размазанность" не во вред производительности. Так или иначе существует максимальный (и минимальный) размер блока (страницы) который можно читать/писать, размазанность частей этого блока "по микросхемам" может ускорять процессы (striping), но когда мы оперируем на уровне размеров блоков, фрагментация уже может стать проблемой (о чём и говорят тесты выше), в зависимости от физической реализации.
preparing...
4096+0 записей получено
4096+0 записей отправлено
4294967296 байт (4,3 GB, 4,0 GiB) скопирован, 5,17868 s, 829 MB/s
4096+0 записей получено
4096+0 записей отправлено
4294967296 байт (4,3 GB, 4,0 GiB) скопирован, 5,19728 s, 826 MB/s
4096+0 записей получено
4096+0 записей отправлено
4294967296 байт (4,3 GB, 4,0 GiB) скопирован, 5,24497 s, 819 MB/s
fio: write 50M...
./1.sh: строка 11: fio: команда не найдена
sleep 10
4096+0 записей получено
4096+0 записей отправлено
4294967296 байт (4,3 GB, 4,0 GiB) скопирован, 5,29743 s, 811 MB/s
sleep 20
4096+0 записей получено
4096+0 записей отправлено
4294967296 байт (4,3 GB, 4,0 GiB) скопирован, 5,13125 s, 837 MB/s
sleep 30
4096+0 записей получено
4096+0 записей отправлено
4294967296 байт (4,3 GB, 4,0 GiB) скопирован, 5,32871 s, 806 MB/s
fio: write 200M...
./1.sh: строка 11: fio: команда не найдена
sleep 10
4096+0 записей получено
4096+0 записей отправлено
4294967296 байт (4,3 GB, 4,0 GiB) скопирован, 5,32313 s, 807 MB/s
sleep 20
4096+0 записей получено
4096+0 записей отправлено
4294967296 байт (4,3 GB, 4,0 GiB) скопирован, 5,40436 s, 795 MB/s
sleep 30
4096+0 записей получено
4096+0 записей отправлено
4294967296 байт (4,3 GB, 4,0 GiB) скопирован, 5,32842 s, 806 MB/s
fio: write 800M...
./1.sh: строка 11: fio: команда не найдена
sleep 10
4096+0 записей получено
4096+0 записей отправлено
4294967296 байт (4,3 GB, 4,0 GiB) скопирован, 5,19135 s, 827 MB/s
sleep 20
4096+0 записей получено
4096+0 записей отправлено
4294967296 байт (4,3 GB, 4,0 GiB) скопирован, 5,28124 s, 813 MB/s
sleep 30
4096+0 записей получено
4096+0 записей отправлено
4294967296 байт (4,3 GB, 4,0 GiB) скопирован, 5,39725 s, 796 MB/s
fio: write 4000M...
./1.sh: строка 11: fio: команда не найдена
sleep 10
4096+0 записей получено
4096+0 записей отправлено
4294967296 байт (4,3 GB, 4,0 GiB) скопирован, 5,19901 s, 826 MB/s
sleep 20
4096+0 записей получено
4096+0 записей отправлено
4294967296 байт (4,3 GB, 4,0 GiB) скопирован, 5,32232 s, 807 MB/s
sleep 30
4096+0 записей получено
4096+0 записей отправлено
4294967296 байт (4,3 GB, 4,0 GiB) скопирован, 5,28964 s, 812 MB/s
sleep 3600
800Мб/с — ну очень мало. и у вас fio не стоит, без него нет смысла запускать скрипт.
p.s — удивила странная работа перенаправления в файл, никогда такого не видел. Результаты остались в терминале, а в файл записались только паузы и fio.
4096+0 записей получено
4096+0 записей отправлено
4294967296 байт (4,3 GB, 4,0 GiB) скопирован, 5,32284 s, 807 MB/s
4096+0 записей получено
4096+0 записей отправлено
4294967296 байт (4,3 GB, 4,0 GiB) скопирован, 5,26583 s, 816 MB/s
4096+0 записей получено
4096+0 записей отправлено
4294967296 байт (4,3 GB, 4,0 GiB) скопирован, 5,34693 s, 803 MB/s
4096+0 записей получено
4096+0 записей отправлено
4294967296 байт (4,3 GB, 4,0 GiB) скопирован, 5,39388 s, 796 MB/s
4096+0 записей получено
4096+0 записей отправлено
4294967296 байт (4,3 GB, 4,0 GiB) скопирован, 5,27483 s, 814 MB/s
4096+0 записей получено
4096+0 записей отправлено
4294967296 байт (4,3 GB, 4,0 GiB) скопирован, 5,67319 s, 757 MB/s
4096+0 записей получено
4096+0 записей отправлено
4294967296 байт (4,3 GB, 4,0 GiB) скопирован, 6,05745 s, 709 MB/s
4096+0 записей получено
4096+0 записей отправлено
4294967296 байт (4,3 GB, 4,0 GiB) скопирован, 5,89485 s, 729 MB/s
4096+0 записей получено
4096+0 записей отправлено
4294967296 байт (4,3 GB, 4,0 GiB) скопирован, 5,72409 s, 750 MB/s
4096+0 записей получено
4096+0 записей отправлено
4294967296 байт (4,3 GB, 4,0 GiB) скопирован, 6,59454 s, 651 MB/s
4096+0 записей получено
4096+0 записей отправлено
4294967296 байт (4,3 GB, 4,0 GiB) скопирован, 6,61636 s, 649 MB/s
4096+0 записей получено
4096+0 записей отправлено
4294967296 байт (4,3 GB, 4,0 GiB) скопирован, 6,6462 s, 646 MB/s
4096+0 записей получено
4096+0 записей отправлено
4294967296 байт (4,3 GB, 4,0 GiB) скопирован, 7,58384 s, 566 MB/s
4096+0 записей получено
4096+0 записей отправлено
4294967296 байт (4,3 GB, 4,0 GiB) скопирован, 7,49087 s, 573 MB/s
4096+0 записей получено
4096+0 записей отправлено
4294967296 байт (4,3 GB, 4,0 GiB) скопирован, 7,4826 s, 574 MB/s
4096+0 записей получено
4096+0 записей отправлено
4294967296 байт (4,3 GB, 4,0 GiB) скопирован, 7,87835 s, 545 MB/s
fio: write 50M…
sleep 10
sleep 20
sleep 30
fio: write 200M…
sleep 10
sleep 20
sleep 30
fio: write 800M…
sleep 10
sleep 20
sleep 30
fio: write 4000M…
sleep 10
sleep 20
sleep 30
sleep 3600
Скорость, конечно…
Скорость, конечно…
а просто dd if=/dev/nvme0n1 of=/dev/null bs=1M iflag=direct status=progress что показывает?
Вот тогда контроллер практически не сможет проводить свою тайную дефрагментацию и будет колоссальное падение производительности.
Поэтому ваш скрипт и не смог выявить проблему на всех SSD, что не забивал всё свободное место. Пока есть свободное место хороший контроллер будет писать только на свободные страницы, да ещё и в фоне дефрагментацию делать.
На профессиональных SSD (Samsung PM1725, Oracle F640) очень большой объём скрытой области и очень мощный процессор, и поэтому там влияние будет меньше, даже при заполнении всего диска.
делайте выводы…
Ещё один взгляд на вопрос «нужна ли дефрагментация для SSD»