Привет, Хабр! Представляю вашему вниманию перевод статьи "Web2Text: Deep Structured Boilerplate Removal" коллектива авторов Thijs Vogels, Octavian-Eugen Ganea и Carsten Eickhof.
Веб-страницы являются ценным источником информации для многих задач обработки естественного языка и поиска информации. Эффективное извлечение основного содержимого из этих документов имеет важное значение для производительности производных приложений. Чтобы решить эту проблему, мы представляем новую модель, которая выполняет классификацию и маркировку текстовых блоков на странице HTML как шаблонных блоков, или блоков содержащих основной контент. Наш метод использует Скрытую Марковскую модель поверх потенциалов, полученных из признаков объектной модели HTML-документа (Document Object Model, DOM) с использованием сверточных нейронных сетей (Convolutional Neural Network, CNN). Предложенный метод качественно повышает производительность для извлечения текстовых данных из веб-страниц.
1. Введение
Современные методы обработки естественного языка и поиска информации сильно зависят от больших коллекций текста. Всемирная паутина — неиссякаемый источник контента для таких приложений. Тем не менее, общая проблема заключается в том, что веб-страницы включают в себя не только основной контент (текст), но также рекламу, списки гиперссылок, навигацию, превью других статей, баннеры и т.д. Этот шаблонный контент часто оказывает негативное влияние на производительность производного приложения [15,24]. Задача отделения основного текста на веб-странице от остального (шаблонного) содержимого в литературе известна как «удаление стандартного шаблона», «сегментация веб-страницы» или «извлечение содержимого». Известные популярные методы для этой проблемы используют алгоритмы на основе правил или машинного обучения. Наиболее успешные подходы сначала выполняют разбиение входной веб-страницы на текстовые блоки, а затем двоичную {1, 0} маркировку каждого блока в качестве основного содержимого или шаблона. В этой статье мы предлагаем Скрытую Марковскую модель поверх нейронных потенциалов для задачи удаления шаблонов. Мы используем способность сверточных нейронных сетей для изучения унарных и парных потенциалов по блокам на основе сложных нелинейных комбинаций признаков на основе DOM. Во время прогнозирования мы находим наиболее вероятную метку блока {1, 0}, максимизируя совместную вероятность последовательности меток с использованием алгоритма Витерби [23]. Эффективность нашего метода продемонстрирована на стандартных наборах сравнительных данных.
Остальная часть этого документа структурирована следующим образом. Раздел 2 дает обзор связанных с тематикой работ различных авторов. Раздел 3 формально определяет проблему извлечения основного контента, описывает процедуру сегментации блоков данных и детализирует нашу модель. Раздел 4 демонстрирует достоинства нашего метода на нескольких эталонных наборах данных для извлечения контента из веб-страниц.
2. Обзор связанных работ
Ранние подходы к удалению шаблонного HTML-кода используют ряд эвристических и основанных на правилах методов [7] под названием Body Text Extractor (BTE). BTE основан на наблюдении, что основной контент содержит более длинные абзацы непрерывного текста, где HTML-теги встречаются реже по сравнению с остальной частью веб-страницы. Рассматривая совокупное распределение тегов в зависимости от позиции в документе, BTE идентифицирует плоскую область в середине этого графика распределения, чтобы предсказать основное содержимое страницы. Несмотря на простоту, этот алгоритм имеет два недостатка: (1) он использует только местоположение тегов HTML, а не их структуру, тем самым теряя потенциально ценную информацию, и (2) он может идентифицировать только один непрерывный участок основного контента, что нереально для значительного процента современных веб-страниц.
Для решения этих проблем было разработано несколько других алгоритмов для работы с деревьями DOM, что позволяет использовать семантику структуры HTML [11,19,6]. Проблема этих ранних методов заключается в том, что они интенсивно используют тот факт, что страницы раньше были разделены на разделы с помощью тегов <table>, что больше не является допустимым предположением.
На следующем этапе работы структура DOM используется для совместной обработки нескольких страниц из одного домена с учетом их структурного сходства. Этот подход был впервые предложен Юи и соавт. [24] и был улучшен различными другими авторами [22]. Эти методы очень подходят для обнаружения содержимого шаблона, присутствующего на всех страницах веб-сайта, но имеют низкую производительность на веб-сайтах, которые состоят только из одной веб-страницы. В этой статье мы сосредоточимся на извлечении одностраничного контента без использования контекста других страниц того же сайта.
Готтрон и соавт. [10] предлагают методы сглаживания кода контента, которые могут идентифицировать несколько областей контента. Эти методы анализируют исходный код HTML как вектор единиц, представляющих фрагменты текста, и нулей, представляющих теги. Затем этот вектор итеративно сглаживается, так что в конечном итоге он находит активные области, где доминирует текст (контент), и неактивные области, где доминируют теги (шаблон). Эта идея сглаживания была распространена также на структуру DOM [4,21]. Чакрабарти и соавт. [3] назначают вероятность содержания для каждого листа дерева DOM, используя изотоническое сглаживание, чтобы объединить вероятности меток соседей с теми же родителями. В аналогичном направлении Сан и соавт. [21] использует как соотношение тегов / текста, так и информацию о дереве DOM для распространения сумм плотности вероятности по дереву.
Методы машинного обучения предлагают удобный способ комбинирования различных показателей «наполненности», автоматически взвешивая созданные вручную признаки в соответствии с их относительной важностью. Система FIASCO от Бауэр и соавт. [2] использует машины опорных векторов (SVM) для классификации HTML-страницы как последовательности блоков, которые генерируются посредством сегментации страницы на основе DOM и представлены лингвистическими, структурными и визуальными признаками. Работы Колшаттер и соавт. [17] также используют SVM для независимой классификации блоков. Споста и соавт. [20] расширяют этот подход, переформулируя проблему классификации как случай маркировки последовательности, где все блоки помечены совместно. Они используют условные случайные поля, чтобы воспользоваться корреляциями между метками соседних блоков контента. Этот метод был самым успешным в конкурсе CleanEval [1].
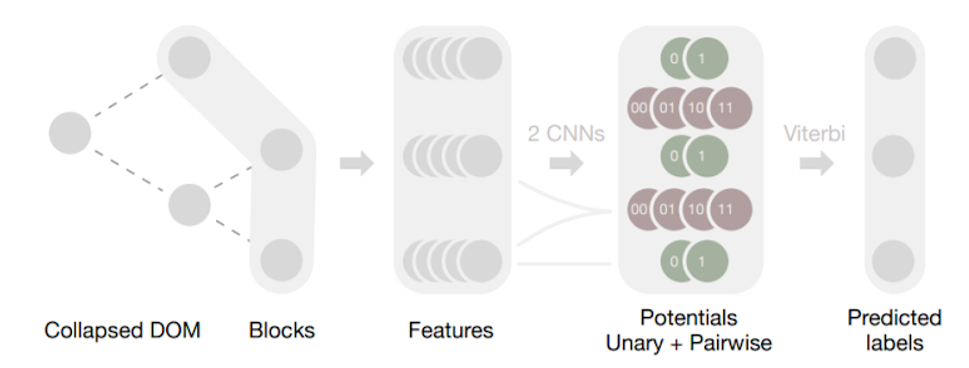
Рис. 1. Конвейер Web2Text. Листья свернутого дерева DOM (Collapsed DOM) веб-страницы образуют упорядоченную последовательность блоков, которые нужно пометить. Для каждого блока мы извлекаем ряд признаков на основе дерева DOM. Две отдельные сверточные сети, работающие на этой последовательности признаков, дают два соответствующих набора потенциалов: унарные потенциалы для каждого блока и парные потенциалы для каждой пары соседних блоков. Они определяют Скрытую Марковскую модель. Используя алгоритм Витерби, мы находим оптимальную маркировку, которая максимизирует общую вероятность последовательности, предсказанную нейронными сетями.
В этой статье мы предлагаем эффективный метод получения признаков, которые собираются от ближайших соседей в дереве DOM. Кроме того, мы используем систему глубокого обучения для автоматического изучения комбинаций нелинейных функций, что дает модели преимущество перед традиционными линейными подходами. Наконец, мы совместно оптимизируем метки для всей веб-страницы в соответствии с локальными потенциалами, предсказанными нейронными сетями.
3. Веб в текст
Удаление шаблонов — это проблема маркировки разделов текста веб-страницы как основного содержимого или шаблонного элемента (чего-либо еще) [1]. Далее мы обсудим различные этапы нашего метода. Полный конвейер также показан на рисунке 1.
3.1. Предварительная обработка
Мы ожидаем, что ввод исходной веб-страницы будет записан в (X) HTML-разметке. Каждый документ анализируется как дерево объектной модели документа (дерево DOM) с помощью Jsoup [12].

Рис. 2. Пример свернутой модели DOM. Слева: исходный код HTML, посередине — соответствующее дерево DOM, справа — соответствующий свернутый DOM.
Мы предварительно обрабатываем это дерево DOM, i) удаляя пустые узлы или узлы, содержащие только пробелы, ii) удаляя узлы, которые не имеют никакого содержимого, которое мы можем извлечь: например, <br>, <checkbox>, <head>, <hr>, <iframe>, <img>, <input>. Мы используем отношения родительского и прародительского дерева DOM. Однако в необработанном DOM-дереве эти отношения не всегда имеют смысл. На рисунке 2 показан типичный фрагмент дерева DOM, в котором два соседних узла имеют общий семантический родительский элемент (<ul>), но не один и тот же родительский DOM. Чтобы улучшить выразительность признаков на основе дерева (например, «количество дочерних элементов родительского узла»), мы рекурсивно объединяем отдельные дочерние родительские узлы с их соответствующими дочерними. Мы называем полученную древовидную структуру Collapsed (свернутый) DOM (CDOM).
3.2. Сегментация блоков
Наш алгоритм извлечения контента основан на маркировке последовательности. Веб-страница рассматривается как последовательность блоков, которые помечены как основной контент, или как шаблон. Существует несколько способов разбить веб-страницу на блоки, наиболее популярными в настоящее время являются: i) строки в файле HTML, ii) листья DOM, iii) листья DOM уровня блока. Мы выбираем наиболее гибкую стратегию листьев DOM, описанную ниже. Разделы на странице, для которых требуются разные метки, обычно разделены хотя бы одним тегом HTML. Следовательно, можно считать DOM-листья (узлы #text) блоками нашей последовательности. Потенциальным недостатком этого подхода является то, что гиперссылка в текстовом абзаце может получить метку, отличную от соседнего текста. Однако согласно этой схеме, эмпирическая оценка Web2Text не показывает случаев, когда части текстового абзаца ошибочно помечаются как шаблонные, а остальные — как основной контент.
3.3. Извлечение признаков
Признаки — это свойства узла, которые могут указывать на то, что это содержимое страницы, или шаблон. Такие признаки могут основываться на тексте узла, структуре CDOM или их комбинации. Мы различаем блочные признаки и граничные признаки.
Блочные признаки захватывают информацию о каждом блоке текста на странице. Они представляют собой статистические данные, собранные на основе узла CDOM, родительского узла, родительского узла и корня дерева CDOM. Всего мы собираем 128 признаков для каждого текстового блока, например, «Узел - это элемент <p>», «средняя длина слова», «относительная позиция в исходном коде», «текст родительского узла содержит адрес электронной почты», «соотношение стоп-слов на всей странице» и т.д. Далее, все не двоичные характеристики преобразуются и стандартизируются, чтобы они были приблизительно гауссовскими с нулевым средним и единичной дисперсией в обучающем наборе.
Граничные признаки захватывают информацию о каждой паре соседних текстовых блоков. Мы собираем 25 признаков для каждой такой пары. Расстояние до двух узлов в дереве определяется как сумма количества уровней от обоих узлов до их первого общего предка. Первыми граничными признаками, которые мы используем, являются бинарные объекты, соответствующие количеству уровней дерева 2, 3, 4 и> 4. Другой признак указывает, есть ли разрыв строки между узлами в не стилизованной HTML-странице, и т.д.
3.4. Унарные и парные потенциалы сверточной нейронной сети (Convolutional Neural Network, CNN)
Мы назначаем одинарные потенциалы для каждого текстового блока, который должен быть помечен, и попарные потенциалы для каждой пары соседних текстовых блоков. В нашем случае потенциалы являются вероятностями, как объяснено ниже. Унарные потенциалы pi (li = 1), pi (li = 0) представляют собой вероятности того, что метка li текстового блока i является содержимым или шаблоном, соответственно. Два потенциала суммируются в один. Парные потенциалы pi, i + 1 (li = 1, li + 1 = 1), pi, i + 1 (li = 1, li + 1 = 0), pi, i + 1 (li = 0, li + 1 = 1) и pi, i + 1 (li = 0, li + 1 = 0) — вероятности перехода меток пары соседних текстовых блоков. Эти попарные потенциалы также суммируют по одному для каждой пары текстовых блоков.
Два набора потенциалов моделируются с использованием CNN с 5 слоями, нелинейностью ReLU между слоями, размерами фильтров (50, 50, 50, 10, 2) для унарной сети и (50, 50, 50, 10, 4) для парной сети. Все фильтры имеют шаг 1 и размеры ядра (1, 1, 3, 3, 3) соответственно. Унарная CNN принимает последовательность атрибутов блока, соответствующую последовательности текстовых блоков, которые должны быть помечены, и выводит унарные потенциалы для каждого блока. Парная CNN получает последовательность границ текста, соответствующую последовательности границ, которые должны быть помечены, и выводит парные потенциалы для каждого блока. Мы используем заполнение нулями, чтобы каждый слой создавал последовательность того же размера, что и его входная последовательность. Выходы для унарной сети представляют собой последовательности по 2 значения на блок, которые нормализуются с помощью функции softmax. Выходными данными для парной сети являются последовательности из 4 значений на пару блоков, которые нормируются аналогичным образом. Таким образом, выход для блока i косвенно зависит от диапазона блоков вокруг него. Мы используем регуляризацию отсева (dropout) со скоростью обучения 0,2 и L2 регуляризацию со скоростью 10-4.
Для унарных потенциалов мы минимизируем кросс-энтропию:

где l∗i — истинная метка блока i, θunary — параметры унарной сети, а n — индекс последнего текстового блока в последовательности.
Для парной сети мы минимизируем кросс-энтропию:

где θpairwise — параметры попарной сети.
3.5. Вывод
Прогноз наиболее вероятной последовательности меток на входной веб-странице работает следующим образом. Обозначим последовательность текстовых блоков на странице как (b0, b1, ..., bn) и запишем вероятность соответствующей маркировки (l0, l1, ..., ln) ∈ {0, 1}n как:

где λ — коэффициент интерполяции между унарным и попарным членами. Мы используем λ = 0,1 в наших экспериментах. Это выражение описывает Скрытую Марковскую модель и максимизируется с помощью алгоритма Витерби [23], чтобы найти оптимальные метки данных с учетом прогнозируемых потенциалов CNN.
4. Эксперименты
Наши эксперименты сгруппированы в два этапа. Мы начнем с оценки производительности Web2Text при удалении шаблонного массива веб-страниц в тренировочных данных. На втором этапе мы обращаемся к гораздо большей коллекции данных и исследуем, как улучшенное извлечение контента приводит к повышению качества поиска информации. Оба эксперимента подчеркивают преимущества Web2Text по сравнению с современными альтернативами.
4.1. Тренировочные данные
CleanEval 2007 [1] является крупнейшим общедоступным набором данных для этой задачи. В среднем он содержит 188 текстовых блоков на веб-страницу. Он состоит из набора данных для тренировки модели (60 страниц) и набора для тестов (676 страниц). Разделяем первый набор на обучающий набор (55 страниц) и тестовый набор (5 страниц). Поскольку наша модель имеет более 10000 параметров, вполне вероятно, что исходный тренировочный набор слишком мал для нашего метода. Поэтому мы изменили второй раздел CleanEval следующим образом: обучение (531 страница), проверка (58 страниц) и тестирование (148 страниц).
Автоматическая маркировка блоков. Насколько нам известно, существующие наборы данных (в том числе CleanEval) не достаточно удобны для обучения моделей. Эти наборы данных состоят только из пар “веб-страница — очищенный текст” (извлеченный вручную). Как следствие, для увеличения набора обучающих данных необходимо восстановить выравнивание исходного текста из очищенного текста, а также маркировку блоков. Некоторые методы (например, [20]) основаны на дорогих ручных аннотациях блоков. Одним из наших вкладов является следующая процедура автоматического восстановления пар (блок, метка) из исходных пар (веб-страница, чистый текст). Это позволяет нам использовать больше обучающих данных по сравнению с предыдущими методами.
Сначала мы линейно сканируем очищенный текст веб-страницы, используя окна из 10 последовательных символов. Каждый такой фрагмент проверяется на уникальность на исходной веб-странице (после обрезки пробелов). Если такое уникальное совпадение найдено, то его можно использовать для разделения очищенного текста и исходной веб-страницы на две части, к которым один и тот же метод сопоставления может быть применен рекурсивно в режиме «разделяй и властвуй». После обработки всех уникальных фрагментов мы используем динамическое программирование для выравнивания оставшихся разделенных частей чистого текста с соответствующими разделенными частями исходных блоков веб-страниц. В конце, в редком случае, когда содержимое блока только частично соответствует очищенному тексту, мы помечаем его как содержимое, если только 2/3 его текста соответствует целевому тексту.
4.2. Детали обучения
Унарные и парные сети с предсказанием потенциала обучаются отдельно с помощью оптимизатора Адама [14] и скорости обучения 10–3 для 5000 итераций. Каждая итерация обрабатывает мини-батч из 128 фрагментов веб-страницы длиной 9 блоков. Мы выполняем прерывание обучения, не наблюдая никаких улучшений после этого количества шагов. Затем мы выбираем модель, соответствующую наименьшей ошибке в проверочном наборе данных.
4.3. Исходные условия
Мы сравниваем Web2Text с рядом методов, описанных в литературе или используемых в популярных библиотеках. BTE [7] и Unfluff [8] являются эвристическими методами. [17,16] — это популярная система машинного обучения, которая предлагает различные настройки извлечения контента, которые мы использовали в наших экспериментах (см. Таблицу 1). CRF [20] достигает одного из лучших результатов на CleanEval. Эта модель машинного обучения тренирует условное случайное поле (Conditional Random Field, CRF) поверх признаков блока, чтобы выполнить классификацию блоков. Однако, как объяснено в Разделе 4.1, CRF использует другое разбиение блоков веб-страниц и дорогостоящие ручные аннотации блоков. Как следствие, мы не смогли переобучить его и, таким образом, использовали только их готовую модель, предварительно обученную на оригинальном разделении CleanEval. Для справедливого сравнения мы также тренируемся на оригинальном разделении CleanEval, но ниже отметим, что наша нейронная сеть имеет гораздо больше параметров и будет страдать от недостатка обучающих данных.
Размеры модели. Модель CRF [20] содержит 9 705 параметров. Для сравнения, наша унарная сеть CNN содержит 17 960 параметров, в то время как парная CNN содержит 12 870 параметров. Общее количество параметров для объединенной структурированной модели составляет 30 830. Это объясняет, почему оригинальный набор обучающих данных слишком мал для нашей модели.
4.4. Результаты извлечения контента
В таблице 1 приведены результаты этого эксперимента. Все метрики основаны на блоках, где все блоки имеют одинаковый вес. Мы отмечаем, что Web2Text получает самые лучшие оценки точности (Accuracy), Recall и F1 по сравнению с популярными базовыми показателями, включая предыдущих победителей CleanEval. Обратите внимание, что эти числа получены путем оценки каждого метода с использованием одной и той же процедуры сегментации блока, а именно стратегии, описанной в разделе 3.2. Кроме того, отметим, что по сравнению с использованием Web2Text только с унарной CNN, выгоды от скрытой модели Маркова в этом эксперименте незначительны.

Таблица 1. Результаты глубокого структурированного извлечения содержимого веб-страницы в наборе данных CleanEval. Мы используем два разных разделения этого набора данных: исходное разделение (55 — обучение, 5 — валидация, 676 — тестирование) и наше разделение (531 — обучение, 58 — валидация, 148 — тестирование). Подтверждено, что наш метод выигрывает от увеличения обучающего набора данных.
Время работы. Web2Text занимает в среднем 54 мс на веб-страницу; 35 мс для анализа DOM и извлечения признаков, и 19 мс для прямого прохода нейронной сети и алгоритма Витерби. Эти измерения были выполнены на Macbook с процессором Intel Core i5 с частотой 2,8 ГГц.
4.5. Влияние на эффективность поиска
Помимо ранее представленной внутренней оценки точности извлечения текста, нас интересует прирост производительности, который испытывают производные приложения при работе с выходом различных систем удаления шаблонных блоков, например такие как поисковые системы. Данные системы индексируют вывод систем извлечения текста и должны лучше отвечать на заданный пользователем запрос при работе с очищенным текстом в сравнении с необработанным HTML, или примитивно очищенным контентом.
Наши эксперименты основаны на хорошо известной коллекции веб-страниц ClueWeb12. Она организована в виде двух четко определенных наборов документов. Полного набора CW12-A из 733M веб-документов (27,3 ТБ несжатого текста) и меньшего набора CW12-B со случайной выборкой 52M документов (1,95 ТБ несжатого текста). Коллекция индексируется с использованием поисковой системы Indri. Наши 50 тестовых запросов наряду с их оценками релевантности взяты из издания TREC Web Track 2013 года [5].

Таблица 2. Показатели извлечения текста. Звездочка (*) указывает на значительную разницу в производительности между необработанным и очищенным контентом HTML. Кинжал (†) указывает, что модель значительно превосходит все другие методы извлечения текста.
В таблице 2 показано качество каждой комбинации модели поиска при индексации как необработанного, так и очищенного веб-содержимого. Внутри каждой комбинации статистическая значимость различий в производительности между необработанным и очищенным контентом HTML обозначается звездочкой. Модели, которые значительно превосходят все остальные методы извлечения текста, обозначены †. Можно отметить, что в целом поисковые системы, индексирующие CW12-A, дают более сильные результаты, чем те, которые работают только на подмножестве CW12-B. Из-за процесса случайной выборки многие потенциально важные документы отсутствуют в этой небольшой коллекции. Аналогично, при всех сопоставимых настройках модель вероятности запроса (QL) работает значительно лучше, чем модель релевантности (RM). Как предполагалось ранее, извлечение текста может повлиять на качество последующего извлечения документа. Мы отмечаем, что методы низкого количества вызовов (BTE, article-ext, large-ext, Unfluff) приводят к потерям в производительности поиска, поскольку соответствующие фрагменты контента неправильно удаляются в качестве шаблонного. В то же время самые точные модели (CRF, Web2Text) смогли внести улучшения по всем показателям. В частности, Web2Text превзошел все базовые показатели на уровне значимости 0,05. Мы отмечаем, что для этого эксперимента Web2Text был обучен на нашем разделении CleanEval, как описано в Разделе 4.1.
5. Выводы
В этой статье представлен новый алгоритм Web2Text для извлечения основного контента из веб-страниц. Этот метод сочетает в себе преимущества популярных подходов к маркировке последовательностей, таких как CRF [9], с методами глубокого обучения, которые используют структуру DOM в качестве источника информации. Наша экспериментальная оценка данных сравнительного анализа CleanEval показывает значительный прирост производительности по всем современным методам. Во второй серии экспериментов мы демонстрируем, как высокоточное удаление шаблонных данных может значительно повысить производительность производных систем, например, поисковых систем.
6. Авторы
Тийс Фогельс, Октавиан-Ойген Ганеа и Карстен Эйкхоф.
Кафедра компьютерных наук, Швейцарская высшая техническая школа Цюриха.
- Marco Baroni, Francis Chantree, Adam Kilgarriff, and Serge Sharoff. CleanEval: a competition for cleaning web pages. In LREC, 2008.
- Daniel Bauer, Judith Degen, Xiaoye Deng, Priska Herger, Jan Gasthaus, Eugenie Giesbrecht, Lina Jansen, Christin Kalina, Thorben Kräger, Robert Märtin, Martin Schmidt, Simon Scholler, Johannes Steger, Egon Stemle, and Stefan Evert. FIASCO: Filtering the internet by automatic subtree classification, osnabruck. In Building and Exploring Web Corpora: Proceedings of the 3rd Web as Corpus Workshop, incorporating CleanEval, volume 4, pages 111–121, 2007.
- Deepayan Chakrabarti, Ravi Kumar, and Kunal Punera. Page-level template detection via isotonic smoothing. In Proceedings of the 16th international conference on World Wide Web, pages 61–70. ACM, 2007.
- Deepayan Chakrabarti, Ravi Kumar, and Kunal Punera. A graph-theoretic approach to webpage segmentation. In Proceedings of the 17th international conference on World Wide Web, pages 377–386. ACM, 2008.
- Kevyn Collins-Thompson, Paul Bennett, Fernando Diaz, Charlie Clarke, and Ellen Voorhees. Overview of the TREC 2013 web track. In Proceedings of the 22nd Text Retrieval Conference (TREC’13), 2013.
- Sandip Debnath, Prasenjit Mitra, Nirmal Pal, and C Lee Giles. Automatic identification of informative sections of web pages. IEEE transactions on knowledge and data engineering, 17(9):1233–1246, 2005.
- Aidan Finn, Nicholas Kushmerick, and Barry Smyth. Fact or fiction: Content classification for digital libraries. Unrefereed, 2001.
- Adam Geitgey. Unfluff – an automatic web page content extractor for node.js!, 2014.
- John Gibson, Ben Wellner, and Susan Lubar. Adaptive web-page content identification. In Proceedings of the 9th annual ACM international workshop on Web information and data management, pages 105–112. ACM, 2007.
- Thomas Gottron. Content code blurring: A new approach to content extraction. In Database and Expert Systems Application, 2008. DEXA’08. 19th International Workshop on, pages 29–33. IEEE, 2008.
- Suhit Gupta, Gail Kaiser, David Neistadt, and Peter Grimm. DOM-based content extraction of HTML documents. In Proceedings of the 12th international conference on World Wide Web, pages 207–214. ACM, 2003.
- Jonathan Hedley. Jsoup HTML parser, 2009.
- Rong Jin, Alex G Hauptmann, and ChengXiang Zhai. Language model for information retrieval. In Proceedings of the 25th annual international ACM SIGIR conference on Research and development in information retrieval, pages 42–48. ACM, 2002.
- Diederik Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
- Christian Kohlschütter. A densitometric analysis of web template content. In Proceedings of the 18th international conference on World wide web, pages 1165– 1166. ACM, 2009.
- Christian Kohlschütter et al. Boilerpipe – boilerplate removal and fulltext extraction from HTML pages. Google Code, 2010.
- Christian Kohlschütter, Peter Fankhauser, and Wolfgang Nejdl. Boilerplate detection using shallow text features. In Proceedings of the third ACM international conference on Web search and data mining, pages 441–450. ACM, 2010.
- Victor Lavrenko and W Bruce Croft. Relevance based language models. In Proceedings of the 24th annual international ACM SIGIR conference on Research and development in information retrieval, pages 120–127. ACM, 2001.
- Shian-Hua Lin and Jan-Ming Ho. Discovering informative content blocks from web documents. In Proceedings of the eighth ACM SIGKDD international conference on Knowledge discovery and data mining, pages 588–593. ACM, 2002.
- Miroslav Spousta, Michal Marek, and Pavel Pecina. Victor: the web-page cleaning tool. In 4th Web as Corpus Workshop (WAC4)-Can we beat Google, pages 12–17, 2008.
- Fei Sun, Dandan Song, and Lejian Liao. Dom based content extraction via text density. In Proceedings of the 34th international ACM SIGIR conference on Research and development in Information Retrieval, pages 245–254. ACM, 2011.
- Karane Vieira, Altigran S Da Silva, Nick Pinto, Edleno S De Moura, Joao Cavalcanti, and Juliana Freire. A fast and robust method for web page template detection and removal. In Proceedings of the 15th ACM international conference on Information and knowledge management, pages 258–267. ACM, 2006.
- Andrew J Viterbi. Error bounds for convolutional codes and an asymptotically optimum decoding algorithm. In The Foundations Of The Digital Wireless World: Selected Works of AJ Viterbi, pages 41–50. World Scientific, 2010.
- Lan Yi, Bing Liu, and Xiaoli Li. Eliminating noisy information in web pages for data mining. In Proceedings of the ninth ACM SIGKDD international conference on Knowledge discovery and data mining, pages 296–305. ACM, 2003.








