Комментарии 256
Добавлю, что если определить операцию >=> (называется "композиция Клейсли" (Kleisli composition)) таким образом:
(>=>) :: Monad m => (a -> m b) -> (b -> m c) -> (a -> m c)
(f >=> g) = \x -> f x >>= gМожно тогда определить операции bind (который >>=) и join через эту операцию >=>, так что определение монады можно эквивалентно делать через разные операции, они всё равно друг через друга выражаются.
Тогда монадические законы становятся намного проще для запоминания и понимания:
f >=> return ≡ freturn >=> g ≡ g(f >=> g) >=> h ≡ f >=> (g >=> h)
То есть return оказывается правой и левой единицей в такой структуре, и операция >=> обладает ассоциативностью.
Такие структуры называют страшным словом моноид, но на самом деле ничего страшного нет, такими свойствами обладают множество вещей: числа относительно сложения, числа относительно умножения, строки относительно конкатенации, множества относительно объединения и так далее.
Не уверен, что этот пример упрощает понимание) Я специально придерживался C# где можно чтобы не пугать людей. 2 года назад у меня сигнатура и определение >=> вызвали бы паническую атаку.
Для людей, незнакомых с хаскеллем, переведу на сишарп:
Func<A, T<C>> FishOperator<T>(Func<A, T<B>> f, Func<B, T<C>> g)
{
return x => Bind(f(x), g);
}И соответственно законы:
- FishOperator(f, Pure) = f
- FishOperator(Pure, g) = g
- FishOperator(FishOperator(f, g), h) = FishOperator(f, FishOperator(f, g))
return это алиас на pure, который задеприкейтили потому что он похож на return в императивных языках, но по сути ощутимо отличается.
А чем больше пытаются объяснить разными способами, что такое монады, тем менее понятно для непосвященных это становится. Хотя достаточно просто задать вопрос: какие способы композиции функциональности (сиречь кода, или функций) вы знаете? Я лично знаю три:
1) естественный — операция композиции (.)
f :: b -> c
g :: a -> b
(f . g) = \ x -> f (g x)
2) с помощью типов, просто надо вспомнить что код — это тоже обычный тип данных и часть функциональности можно спокойно структурировать/вынести/обернуть в единообразный тип T результата функции) — операция композиции (>=>)
f :: a -> T b
g :: b -> T c
(f >=> g) = \ x -> f x >>= g
3) сопрограммы (но это не точно).
Я, честно говоря, надеялся что автор тут это раскроет, но как-то не сложилось. То есть, получился подход к теме еще с одной стороны (помимо чистой теории категорий и картинок с коробочками), но вот объединения всех взглядов на предмет опять в одном тексте как-то не получилось.
Связь между теорией категорий и применением не прям существенная, потому что как следует из названия теория категорий исследует множество категорий, а в программировании она одна — категория типов. Поэтому всё богатство теорката сводится просто к аналогиям, что вот смотрите, тут есть математическая структура с некоторыми свойствами, и очень похожая структура данных, которая ведет себя почти так же.
Теоркат — скорее источник вдохновения, нежели вещь которая находит непосредственное применение в коде.
Реализация моноида — это просто способ сделать некоторые вычисления более удобными, например выразить операции суммы, произведения, all, any, и так далее. Я через моноид например делал многопоточный подсчёт количества слов в тексте: разбиваем текст на какое-то количество чанков, независимо считаем в каждом сколько слов. В итоге получаем множество объектов вида (кусок предыдущего слова, количество слов, начало следующего слова). Склеивая их друг с другом, подсчитываем слова, профит. Реализация в виде моноида позволяет не писать никакой многопоточный код — можноиспользовать стандартный, просто даёте на вход файл и говорите "сверните моим моноидом", на выходе — подсчитанное количество слов в этом файле. Просто и удобно.
Про связь типов и чисел можно почитать занимательные статьи вроде этой про АДТ, но кроме этого ничего прям супер классного нет.
Так стоп, прикладная математика работает так: есть реальная сущность -> формализируем -> получаем мат.модель -> делаем лукап в мат теории -> получаем полезную теорему -> все развернули обратно в реальность -> ура есть профит.
Если же у меня просто какие то реальные сущености. И я их классифицирую то это ботаника.
Не всегда же так. Например, сначала придумываем, как обобщить сумму ряда, чтобы для расходящегося натурального ряда она давала -1/12, а потом через сотню лет находим физический процесс (стр.85), который как раз описывается такой формулой.
Аналогия весьма отдалённая, т.к. в физике всегда есть что то что на текущий момент нельзя объяснить :)
Например, у вас уже есть вот эта бесплатная теорема которая вроде бы упрощает тестирование. Может еще что то уже есть, или про категорию типов известно мало полезных свойств?
Например, какой нужен минимум фич чтобы программировать над типами? вот если в раст завезут наконец эти HKT то уже можно радоваться или нет?) Я думаю в первую очередь это интересно создателем новых ЯП или развивателям текущих.
Так ведь наоборот же, оказалось что объяснение давно уже было)
Бесплатные теоремы можно получать достаточно просто, у хаскеллистов даже есть бот который делает это автоматически. Но, чтобы получить бесплатную теорему, нужно сначала сформулировать, что собственно хотим. А правильно заданный вопрос, как известно, это половина ответа.
Что до хкт и остального — радоваться можно каждой хорошей фиче, но какого-то супер-формального обоснования для них пока нет. Всё же программирование всё еще не доросло до инженерной дисциплины, куча вещей продолжает делаться методом тыка и "у гугла так принято".
Ну, такие свойства есть. Собственно, основное свойство такое, что если мы пишем монады, то мы всегда можем их композировать друг с другом. А всё программирование заключается в том, чтобы побить сложную задачу накучку мелких, решить их по-отдельности, и собрать обратно. И вот когда мы собираем их обратно, обычно и возникают проблемы, потому что паззл не совпадает, и мы начинаем молотком их забивать, "закостыливая" некоторые места. Отсюда все эти эксепшны "should never throw" и так далее.
Гарантия того, что паззл гарантированно собирается — очень неплохая штука.
Ну как-бы из ассоциативности нечто похожее и должно вытекать, вроде )))
В целом это все понятно — на интуитивном уровне. Т.е. есть у нас единица, и есть ассцоиативная операция — можем сделать fold при помощи этой операции и этой единицы. Разве что гарантией я бы это не называл (ну или я не вижу, откуда у нас тут гарантии).
Потому что стрелка клейсли. Потому что монады описывают эффекты, и у вас не получится случайно вызвать в цикле функцию которая ходит в рест сервис и получить бан за ддос апи. Потому что стрелки клейсли:

У нас есть функция a -> m b и b -> m c, и мы их хотим скомпозировать в a -> m c. В этом нам монады и помогают.
А когда мы не можете отличить a -> b и a -> m b и используем одно вместо другого, и получается заддосивание шлюзов и другие неприятные вещи. Потому что это знание все равно есть, но вместо проверки компилятором одно живет в духе "давайте венгерской нотацией называть функции с суффиксом Async и сделаем правило не вызывать Async функции в цикле", а может и еще хуже: где-нибудь закопанно на корпоративной вики.
Потому что монады описывают эффекты, и у вас не получится случайно вызвать в цикле функцию которая ходит в рест сервис и получить бан за ддос апи. Потому что стрелки клейсли
Вообще никакой связи. Обычная ф-я — это тоже стрелка Клейсли, но никто не мешает вызвать в цикле ф-ю, которая ходит в рест сервис и получить бан за ддос апи. Вообще с чего бы это были проблемы с вызовами стрелок Клейсли в цикле, когда есть forM_
forM_ явно показывет, что тут происходит эффект (причем какой конкретно), поэтому можно догадаться, что что-то не то. А вот когда обычный map вдруг так делает, результат совсем иной.
forM_ явно показывет, что тут происходит эффект (причем какой конкретно)
Какой эффект явно происходит в Id?
А вот когда обычный map вдруг так делает, результат совсем иной.
У меня map так не делает, только forEach.
Какой эффект явно происходит в Id?
Если я пишу коде (Monad m) =>… то мне не важно, какой там эффект, я даю возможность вставить любой. В том числе и "no-op". Было быстранно, если бы не разрешал.
У меня map так не делает, только forEach.
А я вот в дотнете видел .Select(x => {Console.WriteLine(x); return x*2;}) не раз.
В том числе и "no-op"
Это софистика сейчас, если no-op это эффект, то тогда не-монадический код имеет эффект — тот самый no-op.
А я вот в дотнете видел .Select(x => {Console.WriteLine(x); return x*2;}) не раз.
Но это же плюс, что можно внутрь мапа засунуть спокойно лог и почекать че там, разве нет?
Это софистика сейчас, если no-op это эффект, то тогда не-монадический код имеет эффект — тот самый no-op.
Монада дает возможность встроить эффект, но-оп это тоже эффект. Точно так же как ФВП дают возможность передавать функцию, которая может быть () -> {} — нооп. От этого возможность выполнить произвольную функцию про которую мы ничего не знаем — не перестала быть ценной.
Но это же плюс, что можно внутрь мапа засунуть спокойно лог и почекать че там, разве нет?
Нет, это минус, у меня так эластик умер. А заодно и БД, когда орм не смогла это странслировать в SQL и попыталась выгрузить всю таблицу в память.
Нет, это минус, у меня так эластик умер. А заодно и БД, когда орм не смогла это странслировать в SQL и попыталась выгрузить всю таблицу в память.
Ну вот это к монадам и ФП точно отношения не имеет. Проблема-то не в Console.WriteLine, а в отсутствии маппинга.
и доказали, что выполняются некоторые правила (типа наличия единицы и ассоциативности)
Дело в том, что в реальности они не выполняются. В ИРЛ-программировании не существует "настоящих" монад, по-этому любое утверждение о свойствах может неожиданно и нетривиально обломаться. И если в хаскеле это еще можно как-то подшаманить — то в энергичном языке нет. Да и некоторые монады просто в логике своей работы противоречат "монадичности".
Но свойства эти бесполезные и на практике неприменимые (за очень редким исключением) — по-этому никто обычно и не парится тем, что монада на самом деле не монада (вон для Nullable в c# тупо не пишется джойн, но менее монадой Nullable от этого не становится).
С другой стороны, выполняются "слабые конструктивные" утверждения — навроде того, что если у вас есть монада, то почти наверняка она определенным образом выражается через call/cc-монаду.
"ИРЛ-программирование" — это чем программисты на работе занимаются. Настоящих монад там нету по той же самой причине, по которой в реальности нету настоящих квадратов или кругов.
С другой стороны если нам не нужен какой то из законов, то почему бы его не выкинуть?
Все правильно, все законы можно выкинуть. Более того — не надо даже быть функтором (тем более аппликативом). Все, что нужно — это бинд, притом от него даже не требуется иметь заданную сигнатуру. Если вы его напишите, то сможете без каких-либо проблем использовать полученную штуку в качестве монады.
Здесь просто есть один не всем очевидный момент — монада задает некоторое подмножество для более общей конструкции. Нам на практике нужна вот именно эта более общая конструкция. Не монада.
Что у нас в реальности? В реальности мы отдаем наверх некоторый объект x: a и продолжение cont: b -> c. Потом мы делаем f(x, cont) — это та самая общая конструкция, которая определяет, каким образом нам следует применить продолжение к тому, что мы реально туда засунули. Если здесь теперь a = m a', b = a', c = m c', то cont: a' -> m c', и f — это бинд. Общий тип f будет a -> (b -> c) -> d. Ограничение на типы при этом возникает из требования универсальности бинда: тип d должен быть связан с типом c, и тип a с типом b, собственно, a = m b, c = d в случае монады. Но вы можете выбрать другие варианты, какие захотите, все будет работать. Ну и никто, конечно, не требует ни законов ни даже функториальности тут.
Все правильно, все законы можно выкинуть.
Не совсем все выкинуть, а просто не думать о тех из них, про которые думает компилятор. Пока о них думает компилятор например проверяя типы — все хорошо. Ну вот допустим написали хитрый fold, а потом выяснилось что с ним ассоциативность не работает за которой компилятор не следит — что результат будет зависеть от того в каком порядке фолдить. И узнаем об этом на проде где много ядер и потоков, где возникли кейсы, в которых он стал меняться.
Не совсем все выкинуть, а просто не думать о тех из них, про которые думает компилятор.
Думать надо о тех, которые нужны, и не думать о тех, которые не нужны. Монадические законы нам, по факту не нужны почти никогда. Исключение одно — если вы пишите на хаскеле и используете комбинаторы, которые написаны с оглядкой на эти законы.
Ну вот допустим написали хитрый fold
А при чем тут fold? Мы конкретно про монады. Ну и операция для folda в принципе не должна быть ассоциативна (часто это и не возможно), от нее это не требуется.
Спрашиваю из интереса, не ради спора. Если можно — простое объяснение, пожалуйста.
ReaderT это трансформер. Монадой будет ReaderT m, где m-монада.
Да, точно. Вопрос тогда — точно ли будет? И какая есть "не монада", скрывающаяся за личиной монады.
Может у Вас есть идеи?
Непонятно, что такое ненастоящая монада. В теории категорий монада определяется строго. Все это определение слышали и мусолить его смысла нет. Если нуженипример функтора, не являющегося монадой, то — ZipList. Доказательство не знаю.
Просто не раз уже подобные утверждения слышал, хотел узнать подробнее.
Пример ненастоящей монады — это Promise в Javascript.
Оно подчиняется основным монадическим законам, но при этом не является функтором из-за особенностей обработки вложенных обещаний.
Также некоторая "ненастоящесть" наблюдается в монаде Promsie/Task/Future/… во многих нефункциональных языках — "настоящая"-то монада должна быть ленивой, чего обычно не наблюдается.
А вот про ленивость я не помню требований. Если говорить про категорию, то там важно только чтобы стрелки коммутировали. "Ленивость" — внешнее свойство по отношению к тому что теоркат моделирует. Если вспомнить, то мы в япах нас интересует категория Set. А отображения между множествами просто "есть", никто не "вычисляет" функции, соответственно и ленивости/жадности никакой тоже нет.
Тут противоречие не столько с теоркатом, сколько со стандартной интерпретацией теорката в программировании. Условный Task<int> — это не просто некоторое значение, а фоновой процесс, имеющий наблюдаемые сторонние эффекты.
Возможно, можно построить интерпретацию, которая рассматривает не значения, а процессы. Но мне кажется что так не получится.
Почему наблюдаемые? На уровне абстракции тасков вы их не наблюдаете.
Ну мы же всегда в модели оцениваем. А то так получится что fmap id != id, потому что разное количество памяти выделяем, а это тоже можно пронаблюдать, и сделать вывод что функторы не работают. Или замерять количество выделяемого процессором тепла, для двух фмапов будет больше, чем для одного. Ну и так далее.
Есть некоторые разумные рамки модели, в которых мы считаем эквивалентность действий. Наличие или отсутствие ленивости не дает заметных для модели особенностей.
Nullable не подходит ни под один из перечисленных тайпклассов, потому что у него очень сильное ограничение на аргумент: его нельзя использовать для ссылочных типов или другого Nullable.
Nullable<string> s; // ошибка
Nullable<Nullable<int>> i; // снова ошибкаВ учебниках по ФП часто упоминают про еще один закон для функторов, но тут есть один нюанс: если вы соблюдаете первый закон, то второй соблюдается автоматически. Это математический факт, так называемая "бесплатная теорема".
Это верно только для языков, в которых у значений нет "врождённых" свойств. Для C# это не так:
public extension BrokenFunctor of List : Functor<List>
{
public static List<B> Map<A, B>(List<A> source, Func<A, B> map) =>
typeof(A) == typeof(B) ? source.Select(map).ToList() : new List<B>();
}Теперь для Applicative
К сожалению, реализовать один и тот же интерфейс для одного типа двумя различными способами нельзя
Вроде бы именно для shape в C# это как раз можно? Не просто же так каждой реализации даётся своё имя...
// вообще тут должен быть бесконечный генератор элемента 'a'
Вообще необходимость генерации именно бесконечной последовательности надо бы вывести из каких-нибудь аксиом Applicative.
А почему функтор? Имея функции LiftA2 и Pure легко реализовать Map:
Я бы всё-таки обошелся без "мусорного" нуля и без замыкания:
static T<B> MapAnyFunctor<T, A, B>(T<A> source, Func<A, B> map) where T : Applicative =>
LiftA2(source, Pure(map), (a, f) => f(a));На самом деле тут ведь вопрос как определить категорию. Если мы возьмем категорию структур (то есть Hask / ReferenceTypes) то всё снова работать будет.
А если с практической точки зрения, то нас интересует как оно в целом композиться будет, и тут опять всё ок. Да, монада менее удобная чем Option и требует лишних присяданий с констрейнтами, от которых можно было бы избавиться, но в остальном — подчиняется всем тем же законам.
Это верно только для языков, в которых у значений нет "врождённых" свойств. Для C# это не так:
А еще можно через рефлекшн залезть и поменять приватные поля. Что поделать — язык позволяет костылить подобным образом, предполагается, что так делать не надо. Возможно про это стоит упомянуть отдельным дисклеймером.
Вроде бы именно для shape в C# это как раз можно? Не просто же так каждой реализации даётся своё имя...
Да, по этому параметру они схожи с имплиситами скалы, но там тоже вроде стараются по-возможности делать новые инстансы. Да и это еще может поменяться, все же пропозал хоть и чемпион, но только проектируется.
Вообще необходимость генерации именно бесконечной последовательности надо бы вывести из каких-нибудь аксиом Applicative.
Это очевидно из тех соображений, что LiftA2(Pure(a), bs, SomeFunc) должно быть эквивалентно bs.Map(b => SomeFunc(a, b)). А теперь вспомним, что ZipList по своей семантики LiftA2 усекает список до самого короткого. Отсюда вывод, что результат Pure(a) должен быть длиннее любого наперед заданного списка bs. По индукции приходим к тому, что результат должен быть бесконечной длины.
Я бы всё-таки обошелся без "мусорного" нуля и без замыкания:
Это эквивалентные вещи. Просто в качестве мусорного значения вы взяли входной аргумент. К слову, в языке вроде Rust где вы не сможете смувить значение, этот вариант не выйдет. А вот использовать () (которого в сишарпе, к сожалению, нет) всегда можно.
Нет, Nullable не будет функтором даже в категории структур из-за запрета на рекурсию.
Не припомню в определении функтора никакого требования на произвольную вложенность. Nullable<T> не является обычной структурой в принципе. Map будет работать с любой структурой, а сам Nullable мы в категорию (оригинальных объектов) не включаем, если мап работает, значит — функтор.
Он же, в данном случае, эндофунктор. Тогда если мы Nullable в кодомен не включили, то и в домене его нет. Тогда куда функтор?
Так функтор живет в другой категории) Если посмотрим на картинку из милевского:
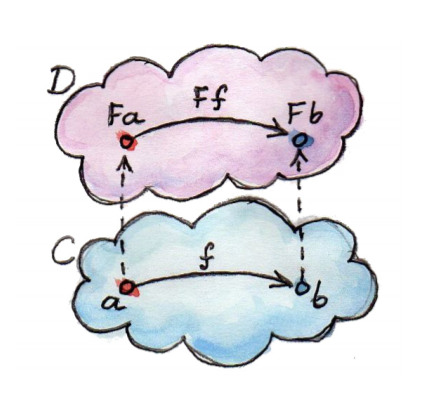
То можно увидеть, что функтор отображает категорию С в D. Соответственно, мы можем сказать, что в С нет нуллейбла, а в D он есть.
Так-то так, вот только при применении этой теории к программированию домены всех функторов должны совпадать. Ну или нужен спец. синтаксис для ограничения домена, которого я в примерах не наблюдаю.
Вас компилятор сам остановит, потребовав where T : struct, который и является ограничением домена. По ссылкам на плейграунд оно всё есть, я убрал из кода чтобы не отвлекать.
И да, нуллейбл я взял просто потому что он для разработчиков привычнее, сам-то я предпочитаю полноценный опшн, конечно же. И не в последнюю очередь из-за возможности нестинга.
Круто. А тогда у join'a для Nullable какой тип? :)
Хм, видимо действительно где-то законы нарушаются. Хороший вопрос, видимо нельзя просто так вырвать F из самой категории C. Стоит над этим подумать.
Хм, видимо действительно где-то законы нарушаются.
И это какбе намекает на то, что, по факту — хрен с ними, с законами :)
видимо нельзя просто так вырвать F из самой категории C.
Монада это же моноид в категории _эндо_функторов, по определению. С-но, здесь требуется не просто вытащить функтор — требуется построить полноценную категорию эндофункторов над чем-то, в которой уже Nullable будет вести себя монадически.
Точно, забыл эту часть про эндофункторы. Тогда всё встает на свои места
Верно. Соответственно, нуллейбл неплохой пример аппликатива, который не является монадой. Обычно все интересные аппликативы являются монадами, а тут хороший контрпример.
А так сложилось просто потому что в Haskell проще не ограничивать, а в C# оказалось проще ограничить.
Нет, дело не в том, что проще было ограничить, а в том, что сначала референс типы сделали нуллябельными ("потому что так в джаве" (с) тимлид шарповой команды), а потом чтобы не страдать от двойной нуллябельности сначала сделали nullable, а потом 3 года прикручивали нуллейбл референс типы в последнем шарпе. И то там куча приколов с этими магическими атрибутами с битовыми масками, но об этом как-нибудь в другой раз, пожалуй.
Или, если в двух словах: сначала не подумали, а потом на голову свалилась обратная совместимость.
А в ФП мире у тебя все состояние в параметрах, поэтому нет необходимости забивать что то по дефолту на будущее.
Раст например императивный некуда, императивнее сишарпа, но там нуллов нет, а всё что надо завернуто в Option.
Но там есть mem::uninitiated или что то такое. хотя я думаю это все можно завернуть тоже в типы.
Уже нет, его задеприкейтили)
Но суть не сильно поменялась. Вот если был бы на уровне типов мы могли бы менять тип одного и того же куска памяти, и через завтипы бы гарантировалось бы заполнение перед использованием (по аналогии с проверкой на сравнение индекса в случае массива), тогда было бы другое дело.
Ну, вы можете, но не в расте.
Все же нужно баланс соблюдать. Я не думаю, что кто-то хочет доказывать 2+2=4 в каждой программе.
По сути если у вас есть инстанс типа, значит он правильно заполнен. Воспользовать "неправильным" заполнением можно только через ансейф, а заполнение некорректным типом это инста-УБ (что по ссылке кстати и написано). Поэтому как раз-таки вынесли на уровень типов, что любой T всегда well-formed, если нигде УБ нет.
ATS так умеет.
Обычно все интересные аппликативы являются монадами, а тут хороший контрпример.
Это как раз хороший пример того, что чтобы быть монадой в смысле "интерфейс блаблабла" и нормально это в качестве монады использовать — совсем не требуется быть монадой математически :)
Фактически, чтобы что-то было монадой нам нужен только бинд, это все. А тип бинда для Nullable вполне пишется, т.к. там нету композиции функторов.
Это как раз хороший пример того, что чтобы быть монадой в смысле «интерфейс блаблабла» и нормально это в качестве монады использовать — совсем не требуется быть монадой математически
Думаю не совсем так. Если надо последовательно в один поток пройтись по цепочке композированных элементов, то достаточно Bind. Если надо распараллелить проход, то надо чтобы соблюдалась ассоциативность, то есть надо быть полугруппой. Если есть вероятность, что кто то из частей цепочек окажется пустым, то пригодится единичный элемент из моноида. Если это не линейная цепочка, а дерево, то пригодится свойство эндофунктора.
Если надо распараллелить проход, то надо чтобы соблюдалась ассоциативность
Вы не совсем понимаете, что там за ассоциативность. На самом деле прямой ассоциативностью она становится только для объектов-множеств, в случае эндофункторов ее нельзя так трактовать. Это свойство, бкуквально, значит, что
join(join(T^2)*T) = join(T*join(T^2))
в случае категории Set Т — обычное множество, а join — некоторая бинарная операция на нем и, с-но, данное свойство обозначает ассоциативность join как бинарной операции. В случае эндофункторов join не является бинарной операцией, по-этому об ассоциативности говорить просто смысла нет.
То, о чем вы говорите — это ассоциативность композиции стрелок в соответствующей категории Клейсли (и наличие id-стрелки). Если у вас есть bind то вы можете легко написать композицию Клейсли, и она будет ассоциативной для чистых функций. но это, кстати, не значит, что что-то можно параллелить — сама композиция, конечно, параллелится, но вот результат этой композиции можно исполнять лишь последовательно (в общем случае, в частных, конечно, параллелить можно).
Мне кажется вы путаете монады с побочным эффектом, ассоциативность которых всего лишь фикция
Ассоциативна композиция Клейсли, т.е. ф-я >=>: (a -> m b) -> (b -> m c) -> a -> m c.
Или я ошибаюсь и есть примеры чистых монад, которые нельзя схлопывать с середины?
Зависит от того, что понимать под "чистой монадой" и "схлопыванием с середины" :)
Теперь про вторую часть.
Первым пунктом, следующим из предыдущего абзаца, стоит выделить упрощение языка. Посмотрите, сколько мусора натащил сишарп, чтобы выразить простую идею "Сделай что-нибудь, а затем сделай кто-нибудь еще". И асинк-авейт, и LINQ, и null propagation являются частными случаями общей идеи.
Вот только асинк-авейт и LINQ под общий тайпкласс не затащить никак пока в языке есть мутабельность.
В случае асинк-авейт в функцию Bind передаётся функция, которая должна быть вызвана не более 1 раза и которая может иметь побочные эффекты.
В случае LINQ в функцию Bind/SelectMany передаётся функция, которая может быть вызвана любое число раз и которая не должна иметь побочных эффектов.
Вы не можете взять достаточно сложный код с асинк-авейт и переписать его на LINQ без преобразования алгоритма из структурного в функциональный. Также как вы не можете использовать асинк-авейт для IEnumerable.
И это всё — не просто недоработки в языке, а именно что следствие мутабельности. Тот же Rust, как вы говорите, "прошелся по граблям" не из мазохизма разработчиков, а потому что альтернатива тут — стать Хаскелем. Каким бы замечательным языком ни был Haskell, второй такой же язык никому не нужен, ибо первый уже есть.
Сишарп тут в абсолютно схожей ситуации. Посмотрите на вот этот пакет System.Linq.Async. Разработчики из майкрософта в нём занимаются буквально тем, что копипастят реализацию LINQ из corefx, расставляя где надо async-await.
Напомню, что сама реализация LINQ из corefx оказалась такой большой не просто так, а из-за разных оптимизаций, которые, так уж вышло, компилятор без помощи программиста сделать не смог бы.
Тут лучше бы подошел пример библиотеки Akka.NET Streams, а именно файлов FlowOperations.cs и SubFlowOperations.cs, где в одном и том же проекте разработчики оказались вынуждены написать полную копию своего же API...
Ну, мутабельность это серьезная пробелема, да. Сходу даже сказать что надо с делать чтобы её победить сказать не готов. Если не предлагать конечно всем писать в иммутабельном стиле с явным State<T> где надо.
И это всё — не просто недоработки в языке, а именно что следствие мутабельности. Тот же Rust, как вы говорите, "прошелся по граблям" не из мазохизма разработчиков, а потому что альтернатива тут — стать Хаскелем. Каким бы замечательным языком ни был Haskell, второй такой же язык никому не нужен.
Мне кажется они просто недостаточно этот момент продумали. Не боги горшки обжигают, поэтому несовершенство языка вполне объяснимо.
Напомню, что сама реализация LINQ из corefx оказалась такой большой не просто так, а из-за разных оптимизаций, которые, так уж вышло, компилятор без помощи программиста сделать не смог бы.
Ага, особенно функции Min/Max/Average/..., которые просто вываливаются списком из 30 перегрузок)
Тут лучше бы подошел пример библиотеки Akka.NET Streams, а именно файлов FlowOperations.cs и SubFlowOperations.cs, где в одном и том же проекте разработчики оказались вынуждены написать полную копию своего же API...
Хороший пример, спасибо, если не возражаете, добавлю в статью.
Мне кажется они просто недостаточно этот момент продумали. Не боги горшки обжигают, поэтому несовершенство языка вполне объяснимо.
Да нет, тут в другом дело. У них язык с линейными типами, притом полноценными, а из этого сразу же следует два вида функций. А если в языке два вида функций — то и тайпкласс монад тоже распадается на два разных тайпкласса с разными свойствами.
Ну, мутабельность это серьезная проблема, да. Сходу даже сказать что надо с делать чтобы её победить сказать не готов.
То, что сейчас делается — то и надо делать. Можно обобщить немного.
У нас есть два вида монад: "ветвящаяся" монада и "линейная" монада. Им нужен разный синтаксис, "ветвящейся" — функциональный LINQ, "линейной" — структурный async-await.
Монада IEnumerable будет строго "ветвящейся", монада Task будет строго "линейной". Монаду Option можно записать в оба тайпкласса.
Ага, особенно функции Min/Max/Average/..., которые просто вываливаются списком из 30 перегрузок)
Ну тут-то точно не в монадах дело, этим функциям явно не хватает "арифметического" тайпкласса с операциями сложения-вычитания и т.п.
Верно, но я вскольз говорил в том числе и про пользу от более мощных систем типов.
У них язык с линейными типами, притом полноценными
Ах, если бы, если бы.
Какие-то странные там претензии...
Например, автор того текста пытается запретить "building a reference counted cycle which will leak into infinity", но при этом считает нормальным mem::forget.
Я просто хотел сказать, что в Rust не линейные типы, а аффинные. Гарантий на вызов деструкторов нет, любое значение можно забыть через std::mem::forget, зафорсить вызов некоторой поглощающей функции вместо деструктора нельзя (ну, чтобы это в компил-тайме проверялось, естесственно).
С практической точки зрения разницы никакой. Представьте, что переменная некоторого типа будет уничтожена через день/неделю/месяц/год/10 лет… Всё это время ситуация остаётся корректной с точки зрения линейности типа. Что принципиально меняется когда это время становится равно бесконечности?
И да, деструктор — это такая же "поглощающая" функция, от того что его вызов вставляется автоматически, а не вручную, ничего не меняется.
Для случаев, когда деструктора недостаточно, всегда есть #[must_use]
И да, деструктор — это такая же "поглощающая" функция, от того что его вызов вставляется автоматически, а не вручную, ничего не меняется.
Меняется: аргументы передать нельзя, об ошибке сообщить нельзя.
Для случаев, когда деструктора недостаточно, всегда есть #[must_use]Не поможет, всегда можно сделать let _ = value;
В случае LINQ функция <...> не должна иметь побочных эффектов
Это только в случае PLINQ, да и то с оговорками. В общем случае эта функция никому ничего не должна.
В случае асинк-авейт в функцию Bind передаётся функция, которая должна быть вызвана не более 1 раза и которая может иметь побочные эффекты.
Формально, побочные эффекты имеет сам Bind. А аргумент бинда просто отдает Task. Проблемой можно было бы тут назвать не мутабельность, а то, что два await на один и тот же таск и на две копии одного — это разные вещи, но на самом деле это не проблема. С-но, написать linq-реализацию для таска никто не мешает, можно и обратное сделать, вон в f# все прекрасно работает. Никаких "линейных монад" и "ветвящихся монад" тут нет, одинаковые они.
LINQ-реализацию для таска сделать и правда никто не мешает, но пользоваться ей будет неудобно.
Это просто потому что синтаксис для linq зело обгрызанный. Но со свойствами конкретных монад, мутабельностью, тем, как рпименяется аргумент бинда, или еще чем подобным оно никак не связано.
Приведите тогда пример не-обгрызанного синтаксиса, который не будет выглядеть в языке чужеродно.
Ну так вот async/await прекрасно выглядит.
Я пару статей назад писал такой код — объективно чужеродного в нем ничего нет. Но так писать не принято. Почему? Не знаю, наверное майкрософт мало рекламировал.
Он не то чтобы чужероден — но он написан в функциональном стиле. В языке C# должна быть возможность написать структурный код.
Мне нравится концепция 3 layer cake, поэтому не вижу ничего дурного в функциональном стиле. Каждый слой отвечает за свой аспект, но бизнес-логику (а именно там больше всего кода, причем самого важного кода) и для неё обычно как раз функциональный вариант подходит лучше, если, конечно, язык позволяет.
Весь LINQ очень функциональный, но почти все разработчики которых я знаю пользуются именно им, а не их императивным аналогом — циклами.
Но так писать не принято.
Я так писал. Брат жив :)
Есть, кстати, важный плюс — логику не связанную с-но с конкретным монадическим вычислением приходится вытаскивать в отдельные чистые ф-и (т.к. внутрь linq вкорячить затруднительно), что в итоге делает код приятнее.
Монады введены в хаскель ради отложенной обработки сторонних эффектов, а это (внезапно) как раз и есть асинхронная операция. Что нужно для асинхронности? Сложить отложенный вызов в коробку и поставить на балкон ожидать, пока она там приготовится. Вот именно такая простейшая идея и лежит в основе монад — засовываем туда не исполнение, а информацию об исполнении. В ФП такой информацией является функция. Её отдают монаде (коробке на балконе) и забывают обо всём. Далее компилятор определяет момент, когда сложатся условия для вызова функции (то есть прячет от пользователя асинхронность, свешивая её на разработчика компилятора) и после наступления условий — вызывает функцию.
Теперь подумаем, а что нужно для императивной реализации показанной выше простейшей схемы? И оказывается (опять внезапно), что нужно просто прочитать первый абзац и реализовать его императивно. Но вместо функции передать объект такого типа, который реализует нужную функцию. В приличных императивных языках это давно делается передачей лямбда-функций. То есть от всей функциональщины полезной оказалась идея передачи функции в качестве параметра. И да, эта идея одобрена и широко используется в императивных языках. А вот монады, которые как мы видели, по сути есть коробки для тех же самых функций, во первых, нужны только в асинхронных случаях (и автор это сам доказал, приведя два примера одного и того же синхронного кода на хаскеле и на С#), а во вторых тривиальнейшим образом реализуются в приличных императивных языках, будь у разработчика для этого минимальное желание.
Ну и вывод. Из-за непонимания природы явления (монады) автор притянул за уши изоляцию асинхронности к славословию в адрес ФП. То есть славословие здесь совершенно неуместно, ибо монады есть лишь один из множества (и весьма кучерявый) способ управления асинхронностью. Кто хочет реализовать именно такой способ, тот делает это легко в рамках имеющихся возможностей императивных языков. А если же кто-то использует неподходящие способы реализации асинхронности, то автор совершенно зря выбирает такие примеры в качестве подтверждения своего славословия, ибо безумный код подтверждает лишь безумие кодировщика, а не какие-то преимущества ФП.
Сложить отложенный вызов в коробку и поставить на балкон ожидать, пока она там приготовится. Вот именно такая простейшая идея и лежит в основе монад — засовываем туда не исполнение, а информацию об исполнении.
Эмм, информация об исполнении — это один из инстанов монады, в частности монада IO. Есть еще Par, есть Async, есть еще разные.
А есть например — List, Option, Either, которые никакой информации об исполнении не засовывают. Как будем с ними? Или будем натягивать сову, что дескать возможное отсутствие значения это информация об исполнении?
Теперь подумаем, а что нужно для императивной реализации показанной выше простейшей схемы? И оказывается (опять внезапно), что нужно просто прочитать первый абзац и реализовать его императивно. Но вместо функции передать объект такого типа, который реализует нужную функцию. В приличных императивных языках это давно делается передачей лямбда-функций. То есть от всей функциональщины полезной оказалась идея передачи функции в качестве параметра.
Это и есть простая функция, которая принимает лямбду. Просто она лежит в интерфейсе (чтобы её можно было вызвать для разных типов), а для её реализация нужна возможность выражения T<> в сигнатуре (иначе функцию не написать).
А вот монады, которые как мы видели, по сути есть коробки для тех же самых функций, во первых, нужны только в асинхронных случаях
Кроме асинхронных случаев там есть и другие примеры.
Ну и вывод. Из-за непонимания природы явления (монады) автор притянул за уши изоляцию асинхронности к славословию в адрес ФП. То есть славословие здесь совершенно неуместно, ибо монады есть лишь один из множества (и весьма кучерявый) способ управления асинхронностью.
Кучерявый способ — это тот, который используется практически во всех современных языках? Это и then в жсе (бог с ним, что промисы в жс ненастоящие монады), это and_then в расте, это ContinueWith в сишарпе, это thenCompose в Java… Все они кучерявые, оказывается. А где не кучерявые? Могу ли я предположить, что в го?
В частном случае все понятно, хоть на голом си пишите. В конечном итоге все сводится к х86 асм или другой вм. Но чтобы не делать дурную работу и ускорить процесс разработки нужны сначала интерфейсы, потом дженерики.
Насколько я понимаю для полноценных монад нужен уровень абстракции выше. Собственно интуитивно понять отличие от привычных дженериков легко, если посмотреть на сигнатуру: вместо List<T> мы пишем M<Data>. Т.е. параметризуем не по внутренностям а по внешней обертке.
Монада это частный пример такой абстракции. Если аргумент функции это монада, то это значит что аргумент это не просто какой-то тип, и даже не тип с таким-то интерфейсом. Монада определяет соотношение между типами. Т.е. в примере выше у нас есть некое соотношение M для типа Data. Таких соотношений бывает много, три из них рассмотренных в статье, потому что эти паттерны встречаются чаще всего. Т.е. сама по себе реализация монады для какого-то класса встречается сплошь и рядом, а сила в том что это новый уровень абстракции.
Там всё сложнее.
Полноценная монада, это такая фигня, которая удовлетворяет набору требований. То есть определение монады включает набор требований из теорий групп и категорий. Только после выполнения требований указанных теорий мы получим «настоящую» монаду. Но при этом есть одно жирное «но».
Проблема в том, что определение монады с практической точки зрения ненужно в подавляющем большинстве случаев.
То есть мы просто и тупо копируем паттерн «монада» из любви к искусству. Точнее — фанаты ФП копируют. А пользы от копирования — только, так сказать, понты в разговорах на хабре.
Я вижу лишь один пример в виде истории хаскеля, а на другие примеры мне просто жалко тратить время из-за, по сути, полной бесполезности такой траты. Пример из хаскеля простой — нужно было как-то «элегантно» запретить менять состояние вне текущей функции, но при этом обеспечить решение таких задач, как ввод-вывод. Сначала там были потоки, которые (особенно с точки зрения математиков) выглядели «неидеоматически». То есть народ нарягался по поводу отсутствия «архитектурной красоты». И вот появилась идея с монадами. Точнее кто-то сочинил краткую запись этой идеи на хаскеле, унаследовав при этом ещё и от теоркатно-групповых понятий, которые на тот момент уже были в хаскеле. И только затем уже к монадам прикрутили паттерн «возьми это и сделай с ним вот это». При этом развели адскую сложность, сочинив по дороге десяток дополнительных паттернов и пару десятков понятий. И всё для чего? Что бы система выглядела «стройной».
Подчеркну — не ради каких-то практических выгод (о которых в статье заявляет автор), а именно ради «стройности». Но со стороны это выглядит (как правильно заметили другие) overarchitected решением. В практической разработке таких архитекторов никто не любит из-за необходимости тратить много личного времени на реализацию их безумств. Хотя начальство, бывает, покупается на «математические основы» и тому подобное.
Глубокие и разветвлённые иерархии наследования в ООП часто приводят именно к плохому пониманию большинством создаваемой программы, а в случае с ФП к иерархиям добавлен целый океан самой абстрактной математики (то есть не имеющей прямых практических приложений, а от того мало кому понятной, ибо никто не способен ответить на простой вопрос — зачем это надо?).
Возможно, при моделировании чего-то столь же абстрактного, как и сама теория категорий, монады в хаскеле действительно дают какие-то бонусы благодаря соответствию определениям из теорий групп и категорий. Но вот в практической деятельности пользы от соответствия абстрактным теориям я не встречал. По частям, например для теории групп, могу себе представить пользу, но вот где все эти определения нужны в сумме — не знаю.
Ну а ссылки на повышенный уровень абстракции здесь, в общем-то, опять ничего не объясняют и лишь добавляют ещё больше тумана. Разработчику нужно знать, зачем нужны абстракции. Например — абстракция «список» — очень понятная, простая, с массой практических приложений. А вот абстракция «монада» — здесь я уступаю дорогу сторонникам ФП, может когда-нибудь и до них дойдёт, что их идеи без понимания практического смысла никто не поддержит.
Хотя это всё в итоге уйдёт в обсуждение темы «зачем нужна теория категорий», а потому даже в стандарте хаскеля пишут примерно так — теория категорий здесь не при делах, просто вот есть у нас такие вычурные названия и паттерны, и всё, пользуйте (если хотите).
Понимание практического смысла давно есть — всякие вещи вроде корутин, теперь можно реализовывать не на уровне компилятора, а описывать непосредственно на языке программирования.
Возможно, при моделировании чего-то столь же абстрактного, как и сама теория категорий, монады в хаскеле действительно дают какие-то бонусы благодаря соответствию определениям из теорий групп и категорий. Но вот в практической деятельности пользы от соответствия абстрактным теориям я не встречал. По частям, например для теории групп, могу себе представить пользу, но вот где все эти определения нужны в сумме — не знаю.
Ходить по HTTP в другие сервисы, взаиомдействовать с БД, читать данные из конфига, писать данные в лог — это всё "абстрактные и оторванные от практики вещи"? Или "я привык считать, что монады — это что-то сложное для математиков, поэтому буду игнорировать все факты, которые этому противоречат"?
Ну а ссылки на повышенный уровень абстракции здесь, в общем-то, опять ничего не объясняют и лишь добавляют ещё больше тумана. Разработчику нужно знать, зачем нужны абстракции. Например — абстракция «список» — очень понятная, простая, с массой практических приложений. А вот абстракция «монада» — здесь я уступаю дорогу сторонникам ФП, может когда-нибудь и до них дойдёт, что их идеи без понимания практического смысла никто не поддержит.
То есть "хочу двух наследников одного интерфейса, один из которых работает синхронно, а другой — асинхронно" — это туманная непонятная фигня? Как по мне, куда уж практичнее. Конечно, есть любители взять асинхронный интерфейс как набольший общий делитель, и обмазаться Task.FromResult/Promise.resolve/... в синхронном варианте, но мне это едва ли кажется хорошим и надежным решением. Которое ещё и не работает, стоит чуть-чуть усложнить пример.
Другой пример — хотим читать данные из конфига, соответственно в ДТО для чтения из конфига все поля — опциональные:
struct Config {
workers_count: Option<u32>,
latency: Option<u32>,
app_url: Option<String>,
app_port: Option<Port>,
...
}когда мы это дело из конфига прочитали, мы хотим отдать конфиг приложению. Но приложение конечно же не хочет работать с нуллами, ему нужны значения по-дефолту, если не было указано в конфиге иного:
struct AppConfig {
workers_count: u32,
latency: u32,
app_url: String,
app_port: Port,
...
}
fn get_config(config: Config) -> AppConfig {
AppConfig {
workers_count = config.workers_count.unwrap_or(10),
latency = config.latency.unwrap_or(100),
app_url = config.app_url.unwrap_or("localhost".into()),
app_port = config.app_port.unwrap_or(Port::new(8080)),
...
}
}Вопрос — как не писать функцию get_config и не дублировать структуру AppConfig?
Если вы не знаете, каким образом этот вопрос относится к монадам, то рекомендую перечитать статью.
Как эти конкретные задачи решаются при помощи монад? Если это опять будет стандартное указание на один из способов работы с асинхронностью, то я выше уже говорил — есть и другие способы. Самый простой пример — просто отдаём listener некой функции и забываем о проблеме. Этот шаблон реализован уже с пол века назад (до появления ФП), и вот теперь его же реализовали «с монадами», то есть наворотили много абстрактных понятий вокруг тривиального обработчика результата запроса. Но зачем эта вся абстракция? Что она меняет? Ведь мы всё тот же listener передаём (да, и в монаду тоже).
Ну и далее логично следует очередная простая проблемка — зачем нам выполнять определения из теорий групп и категорий для listener-а? Что это даёт? Где тут нужны ассоциативность, коммутативность и прочее?
Скажу по другому — математика исследует некое пространство по определённым правилам, это придаёт исследованной части некоторую структурированность и гарантирует выполнение в ней неких закономерностей. Но когда закономерность находится на уровне сложности 2+2, ради одного только такого «достижения» не стоит приплетать математические теории к программированию. Это аналогично приплетению формализации арифметики Пеано ко всем привычным ариметическим действиям в программировании. Представим себе стандартное сложение в любом языке программирования — вместо 2+2 нам пришлось бы работать с чем-то вроде «секвенторов» (должно же звучать «заумно»?), которым пришлось бы передавать «инкрементируемые типы» выполняющие законы ассоциативности, коммутативности и т.д. И да, сторонники такого подхода очень быстро переопределили бы операцию "+", придав ей привычный вид, но конечно же, на входе этой операции были бы всё те же заумные типы, а для понимания операции программистам пришлось бы изучить бездну книг по абстрактной математике и формальному выводу. Да, в итоге все бы привыкли и всё бы вернулось на круги своя, то есть к привычному и короткому 2+2, но что бы дойти до этого простейшего варианта всех бы нагнули на поход через никому ненужные абстрактные дебри. Это и есть тот прекрасный мир, который дают нам монады?
>> То есть «хочу двух наследников одного интерфейса, один из которых работает синхронно, а другой — асинхронно» — это туманная непонятная фигня?
Повторяюсь — это реализуется тривиально. Сначал делается библиотечная функция, которая заботится об асинхронности, а потом этой функции скармливаются синхронные listener-ы. Так при чём же здесь монады?
>> Вопрос — как не писать функцию get_config и не дублировать структуру AppConfig?
Вообще-то в большинстве языков есть возможность задавать дефолтные значения прямо в конструкторе. Чем вас не устраивает такой подход?
ЗЫ.
Если окажется, что для ответа вам понадобится сказать что-то вроде «я имел в виду не только то что написал, но ещё и вот что...», то подчеркну — точность формулировок при рассуждениях о монадах (особенно со стороны их адвокатов) является обязательным атрибутуом, без которого вся математика сразу идёт лесом, потому что это уже не математика. Поэтому попробуйте всё же без упрощающих сокращений и ожидания от собеседника понимания именно того контекста, о котором вы подумали, но никому не сказали.
Самый простой пример — просто отдаём listener некой функции и забываем о проблеме.
Монада это и есть listener, все верно. Просто к самому паттерну добавляются некоторые встроенные средства для его использования — вам не надо выполнять руками cps-преобразование кода (которое требуется для того, чтобы пробрасывать коллбеки) и огребать от callback hell, за вас все делает либо do-нотация, либо набор монадических комбинаторов, либо (на худой конец) жесткое структурирование через bind.
Иными словами, с точки зрения чисто практического использования, монады — это listener, который сделан так, чтобы снять с программиста необходимость закатывать солнце вручную.
При том данный набор минимален — т.е. если вы попробуете сделать такой "удобный listener", вы в любом случае получите эквивалентную монадам конструкцию.
Фактически, вся польза монад — она идет от того, что монады это специализации call/cc.
Ну и далее логично следует очередная простая проблемка — зачем нам выполнять определения из теорий групп и категорий для listener-а?
После того как вы фиксировали набор комбинаторов для конкретной монады и не выходите за его пределы — незачем. Более того — на практике и не выполняют.
Т.е. в итоге толку от математики ноль — условие теорем нарушены и их выводами мы не пользуемся? Тогда это ботаника, как я уже сказал выше.
В случае lister, а елси надо скомбинировать два listner-а, то как это сделать? Где гарантии что типы будут совместимы? Почему ни в С# ни в Rust нельзя определить этот концепт тогда, Может все такие нужна теория для типов чтобы понимать что мы делаем?
Т.е. в итоге толку от математики ноль — условие теорем нарушены и их выводами мы не пользуемся?
Почему же не пользуемся? Пользуемся, только не свойствами, а "слабыми конструктивными утверждениями". Ну, т.е., зная, что что-то похоже на монаду или еще какую хрень (и чем именно похоже, а чем — непохоже) я могу, исходя из отношения хрени к другой хрени, делать выводы о том, как, скорее всего, можно (или нельзя) реализовать одну хрень на основе другой.
Опять же, сам тот факт, что я заранее знаю правильный интерфейс (монадический) — это уже полезно. Мне думать не надо, я просто вижу задачу Х, которая хорошо ложится на монадки, и пишу для нее bind. И у меня все будет работать, причем работать удобно. И это не говоря о том что данный интерфейс универсален и многим программистам знаком — что тоже хороший плюс.
Короче, все это фп — оно чтобы думать поменьше. Просто любители ФП — люди сами по себе, обычно, не очень умные. Потому стараются везде углы срезать, и чтоб все за них как-то решалось, само собой, без напряжения извилин. Бац — и работает.
В случае lister, а елси надо скомбинировать два listner-а, то как это сделать?
Ну как, берете и в один колбек суете другой колбек :)
Как раньше на жсе асинхронный код без асинков и промисов писали, так и пишите :)
Короче, все это фп — оно чтобы думать поменьше. Просто любители ФП — люди сами по себе, обычно, не очень умные. Потому стараются везде углы срезать, и чтоб все за них как-то решалось, само собой, без напряжения извилин. Бац — и работает.
Вот с языка снял. Я начал интересоваться ФП, когда понял, что моих мозгов не хватает на то, чтобы контролировать все мутабельные эффектфул вычисления в программе, и мне нужны костылики в виде типов, общепринятых паттернов, чистоты функций, и прочего. Немного зваидую людям, которым не составляет труда держать всё в голове и писать дублиующийся код, нигде не ошибаясь. Я так не могу.
В случае с динамической типизацией гарантий что там с каллбэками будет никаких нету в любом случае.
А вообще математика так не работает, если примерно все условия выполнены это абсолютно не значит что хоть одно следствие верно. В данном случае не должно быть труда просто по аналогии доказать новые теоремы с учётом каких то особых случаев. Типа только если все функции завершаются, или что там вам ещё надо?
В случае с динамической типизацией гарантий что там с каллбэками будет никаких нету в любом случае.
Гарантии есть в том, что интерфейс будет "хорошим". Т.е. через него точно будет можно выразить (причем достаточно удобным способом) все, что мне потребуется.
А вообще математика так не работает
Именно так она и работает, вы ее плохо знаете просто.
В данном случае не должно быть труда просто по аналогии доказать новые теоремы с учётом каких то особых случаев. Типа только если все функции завершаются, или что там вам ещё надо?
Во-первых, это никому не надо. Во-вторых, дело далеко не только в завершаемости. Некоторые, назовем так, "штуки с биндом" являются вполне осмысленными и полезными штуками, но при этом не являются, формально, монадами by design, как ни выкручивайся (т.е. если мы потребуем выполнения монадических законов, то штука будет работать неправильно).
Просто к самому паттерну добавляются некоторые встроенные средства для его использования — вам не надо выполнять руками cps-преобразование кода (которое требуется для того, чтобы пробрасывать коллбеки) и огребать от callback hell, за вас все делает либо do-нотация, либо набор монадических комбинаторов, либо (на худой конец) жесткое структурирование через bind.
Вы в этой фразе смешали в кучу много понятий. Но если их разгрести, то мы увидим отсутствие необходимости в монадах. Так же, как нет необходимости в изучении формализации Пеано для вычисления 2+2.
Собственно всё сводится к тому, что ваши «некоторые встроенные средства» прекрасно реализуются на любом языке, и без монад. Хотя, скажем, вложенная типизация (типа T<A<B<C...>>>) пока что мало распространена, но это опять же не монады, а встроенный в компилятор отдельный механизм, отслеживающий проблемы типизации. Это я к ответу участника «PsyHaSTe», там у него типизированные инстансы выдаются за пользу от монад. Может вы что-то другое имели в виду, но ваши жаргонизмы я не понял.
При том данный набор минимален — т.е. если вы попробуете сделать такой «удобный listener», вы в любом случае получите эквивалентную монадам конструкцию.
А вот этот момент, на мой взгляд, очень важен. То есть я пока не вижу «минимальности» набора. Но вы же это однозначно утверждаете. Значит, по всей видимости, у вас есть понимание, почему же этот набор минимальный. Ну и было бы чудесно, если бы вы это понимание изложили. А то получается «у нас всё круто» и никаких доказательств.
Можно хотя бы на примере — что я не смогу сделать на императивном языке без монад? Но лучше с некоторым теоретическим обоснованием. Только не увлекайтесь теорией категорий, я её поверхностно копал (и не только я).
Далее отвечу участнику «PsyHaSTe» (ибо меня тут ограничивают).
>> Никакой копипасты. И какая тут асинхронность?
Копипаста никуда не денется. Где-то в другом месте будут присвоены нужные значения. Вы просто это место не показали. Но оно есть, я вас уверяю. И да, не забывайте, что вы выставляли требование о «различных значениях в различных ситуациях». И вот эти «различные значения» как раз где-то обязательно всплывут и в вашем коде. Но есть ещё вариант, что вы просто использовали типизацию вместо монад, тогда это просто неуместный пример (надеюсь, что вы о чём-то другом думали, но не донесли).
>> программа не дедлочится, и не ддосит шлюз
Ну вот опять никак необоснованное утверждение. По сути вы заявили, что введение магического слова «монады» избавляет нас от нескольких классов ошибок. Но механизм такого избавления, почему-то, вы не раскрываете. А было бы интересно найти отличия от заявлений алхимиков и им подобных. Надеюсь вам есть что сказать.
Ну и вот ваши требования к указанным вами конструкциям:
Тем что дефолты могут быть разные в разных частях приложения. И тем что не во всех языках десериализаторы умеют вызывать конструктор
Исходя из таких пожеланий можно предположить, что монады неким мистическим образом сами угадывают, какие же дефолты у нас будут в разных частях приложения, правильно? И повторюсь — не путайте монады с типизацией, а так же не путайте типизацию с множеством дефолтных значений.
Но если их разгрести, то мы увидим отсутствие необходимости в монадах
Необходимости вообще ни в чем нет — кроме наличия тьюринг-полного языка. Брейнфак, к примеру, подойдет.
Собственно всё сводится к тому, что ваши «некоторые встроенные средства» прекрасно реализуются на любом языке, и без монад.
Не-а, без монад не реализуются. В том и дело. Ну, т.е., что-то вы реализовать можете, но если это что-то будет удобно в использовании — это будет монада либо надстройка над монадой.
там у него типизированные инстансы выдаются за пользу от монад. Может вы что-то другое имели в виду
Я сказал ровно то, что хотел — монады избавляют вас от необходимости делать руками cps-преобразование.
То есть я пока не вижу «минимальности» набора.
Ну так вы попробуйте сделать какой-то другой набор.
Можно хотя бы на примере — что я не смогу сделать на императивном языке без монад?
Очевидно, что на любом тьюринг-полном языке можно сделать все, что угодно.
Давайте так, вот у меня есть код:
async function yoba() {
const x1 = await query1();
if (f(x1)) {
for (const x2 of x1) {
if(g(x2)) {
await query31(x2);
await query32(x2);
} else {
await query33(x2);
}
await query 34(x2);
}
await query41(x1);
} else {
await query42(x1);
}
return await query5(x1);
}запишите плиз как у вас там будет на listener'ах это дело ну или с каким-нибудь "другим набором". Естественно, код должен быть таким, чтобы без изменений работать и в том случае, если я захочу по вебсокету запросы отправлять, а не по хттп. Или в базу. Или курьерской доставкой, не важно (под "без изменений" подразумевается, что сама ф-я должна без изменений работать — конечно же не запрещается эту ф-ю по-разному запускать или передавать ей разные сервисы дополнительным аргументом, ваше дело, как вы захотите эту логику прокидывать).
ЗЫ: вот я знаю монады, по-этому сразу знаю как реализовать аналог конструкции for из примера выше, даже в языке, у которого поддержки монад в том или ином виде не будет (т.е. не будет async/await или чего-то вроде того). Мне даже думать не надо — я просто сразу знаю. А вы знаете?
Да так же и будет. Но без монад. Точнее — без необходимости привлекать понятие «монада».
Смысл происходящего в вашем примере простой — программа ждёт, пока будет результат. Нужны ли для этого монады? Очевидно — нет. Достаточно просто синхронизации ожидания с доставкой результата.
Но далее вы «поправились», то есть добавили условие неизменности показанной функции при изменяемом функционале программы. И что же для этого нужно? Ну опять же — нужна просто возможность передавать альтернативный функционал внутрь функции. Да, такая передача напоминает шаблон, используемый монадами (или используемый сторонниками ФП). Но повторюсь — передача функции придумана и реализована очень давно, точно ранее появления ФП. Поэтому притягивать за уши монады к именно такому шаблону было бы явно нечестно.
В итоге имеем ту же джава-скриптовую функцию, что и у вас, но с передачей в неё ваших восьми запросов. В ООП логично было бы упаковать восемь запросов в некий контейнер (реализующий интерфейс), для краткости и понятности происходящего. Ну а внутри контейнера никто не мешает реализовывать 8 вызовов как угодно, хоть на 8 классов побить, хоть на 100, хоть в одном всё оставить.
Какие относительно нестандартные концепции мы используем в такой функции? Всего их две — синхронизированное ожидание и передача контейнера с функционалом. Заметим, что концептов более чем один. А вот монада — она всегда одна. То есть если даже согласиться с притягиванием за уши давно известного, но теперь «модно-молодёжно» поданного под соусом монад, то в монадах мы имеем неизбежный недостаток — они неделимы. То есть в них уменьшена гибкость. А гибкость — штука очень полезная. И вот я, со своим старомодным подходом при помощи давно известных принципов/концептов, легко реализую нужную гибкость, разделив ожидание и передачу контейнера на более удобные (в некоторых случаях) части, а в случае ФП с монадами придётся всегда городить «по шаблону», то есть негибко.
Ну и «совсем в итоге» — так зачем же нам монады, если я обошёлся без них, а к тому же они ещё и негибкие? Я вот не хочу, что бы меня нагибали на использование кем-то придуманного шаблона, даже если при этом уверяют, что «всё построено на ужасно умной математике».
Да так же и будет. Но без монад
Как "так же"? Код приведите, пожалуйста.
Нужны ли для этого монады? Очевидно — нет. Достаточно просто синхронизации ожидания с доставкой результата.
Ну так вы код покажите как сделаете это на "простых listener'ах", не используя монадический интерфейс.
Ну и «совсем в итоге» — так зачем же нам монады, если я обошёлся без них
Вы без них не обошлись, пока что вы ничего не сделали. Ни с монадами, ни без.
public class Service<T2,T1 extends Iterable<T2>,T3> extends Synchronizer
{
public T3 yoba(Behavior<T1,T2,T3> b) throws InterruptedException, ExecutionException
{
T1 x1 = get(()->b.query1());
if (test(()->b.f(x1)))
{
for (T2 x2:x1)
{
if (test(()->b.g(x2)))
{
act(()->b.query31(x2));
act(()->b.query32(x2));
}
else act(()->b.query33(x2));
act(()->b.query34(x2));
}
act(()->b.query41(x1));
}
else act(()->b.query42(x1));
return get(()->b.query5(x1));
}
}
Если непонятен входной параметр, то вот он:
public interface Behavior<T1,T2,T3>
{
public T1 query1();
public boolean f(T1 t1);
public boolean g(T2 t2);
public void query31(T2 x2);
public void query32(T2 x2);
public void query33(T2 x2);
public void query34(T2 x2);
public void query41(T1 x1);
public void query42(T1 x1);
public T3 query5(T1 x1);
}
Ну и примитивнейшая библиотека, реализацию которой осилит даже ещё не дописавший до конца Hello World начинающий разработчик:
public class Synchronizer
{
private ExecutorService executorService;
protected <T> T get(Supplier<T> bs) throws InterruptedException, ExecutionException
{ return executorService.submit(()->bs.get()).get(); }
protected boolean test(BooleanSupplier bs) throws InterruptedException, ExecutionException
{ return executorService.submit(()->bs.getAsBoolean()).get(); }
protected void act(Runnable r) throws InterruptedException, ExecutionException
{ executorService.submit(r).get(); }
}Собственно выше дана полная реализация вашего «ТЗ». Реализуя приведённый Behavior вы в нём можете хоть с марсом связываться, общая логика сервиса от этого не изменится.
Теперь очевидные преимущества:
1) Нет монад. То есть нет всего того ненужного множества смыслов, которыми грузят мир сторонники ФП. Все эти смыслы с точки зрения реализации ТЗ — просто мусор. Может в каких-то других очень редких случаях эти смыслы полезны, но в вами же предложенном задании — от них толку = абсолютный ноль.
2) При реализации на ФЯП вы будете вынуждены полностью повторить все указанные выше конструкции, плюс запихать часть из них в компилятор, скрывая суть происходящего от разработчика.
3) Кроме того вы обязаны использовать так называемую «do notation», иначе получите месиво из вложенных лямбда-функций, передаваемых таким же образом вложенным монадам. Привлечение do notation в данном случае самым наглядным образом доказывает, что даже сторонники ФП согласны с очевидным фактом — императивно выражать мысли об алгоритмах намного проще (что мы и имеем в предложенном выше коде).
4) Как и было указано ранее, неделимость монады приводит к невозможности использовать раздельно синхронизацию и передачу контейнеров с функционалом, что уменьшает гибкость варианта с ФП.
5) В целом для получения аналогичного по функционалу самостоятельно созданного и работоспособного решения с императивным подходом требуется самая минимальная подготовка, которую обучаемый получает за несколько месяцев. В случае же ФП средний обучаемый убьёт годы, пока поймёт суть происходящего.
Если сказать короче — в угоду следованию функциональной модели ФП приводит к совершенно ненужной сложности, из которой далее следуют выше показанные пункты (и наверняка не только они). Ну а ваше заявление про некую минимальность решения на основе ФП явно не выдерживает критики.
Если непонятен входной параметр, то вот он:
public interface Behavior<T1,T2,T3> { public T1 query1(); public boolean f(T1 t1); public boolean g(T2 t2); public void query31(T2 x2); public void query32(T2 x2); public void query33(T2 x2); public void query34(T2 x2); public void query41(T1 x1); public void query42(T1 x1); public T3 query5(T1 x1); }
То есть вы всерьёз считаете, что пилить по интерфейсу на каждую комбинацию операций — это нормально?
В чём вообще смысл писать executorService.submit(()->foo()).get(); и чем это отличается от простого вызова foo() кроме повышенного расхода ресурсов?
Я действительно сделал неоптимально, с вашей подачи проверил — можно оптимальнее. Но вот смысл происходящего в коде объяснять — не ожидал, что это вообще потребуется. А вы, видимо, именно не понимаете смысл происходящего (судя по вопросу).
Выше комментарий точно так же вытекает из непонимания. Правда уровни непонимания, похоже, разные.
Вот эти уровни:
1) Непонимание сути обсуждения.
2) Непонимание сути «ТЗ».
3) Непонимание базового API Java.
С первыми двумя, я надеялся, со стороны сторонников ФП не будет сложностей, но я оказался неправ…
Если же сложность с пунктом №3, то вот здесь всё написано.
Ну и по оптимальности.
Действительно, я «по быстрому» выбрал те интерфейсы, которые даны в пакете function, а вот Callable находится в concurrent. Но разумеется, можно было напрямую использовать Callable и тогда в Synchronizer-е не нужны были бы лямбды.
Какой урок можно вынести из моего ляпа? Очень простой — сторонники ФП свято верят в магические свойства их любимого подхода, и в частности — в компилятор. Мол если программа скомпилировалась, то там просто не может быть проблем! Да, именно так они и заявляют. Не все, но наиболее агрессивная часть в прямом смысле верует в подобную чушь, а потому без всяких сомнений выкладывает её на всеобщее обозрение. И вот на моём отрицательном примере мы видим, что компилирующаяся программа на самом деле неоптимальна, просто потому, что я невнимательно просмотрел всю цепочку исполнения в целом. А сторонники ФП же ведь ожидают, что если всё скомпилировалось, то и мега-оптимизатор за них решит все возможные проблемы производительности, а магическая структура ФП никак не даст им написать явную лажу, ведь там сплошная математика и прочее бла-бла-бла.
В общем — ещё один пункт в список недостатков ФП — этот подход, благодаря связи с математикой, вселяет ложную уверенность в своей правоте. Только никакая математика в мире никогда не исправит человеческую ошибку в таких местах, для которых математика не предназначена. И этот момент сторонники ФП (особенно агрессивная их часть) всегда забывают.
Ну а если сообщество ФП кроме эмоционального «фи» более не имеет возражений, то придётся записать в наш журнал полную и безоговорочную победу здравого смысла над фанатизмом ФП.
Реализуя приведённый Behavior вы в нём можете хоть с марсом связываться, общая логика сервиса от этого не изменится.
Вы, видимо, не поняли. Behavior как раз меняться не должен. Он имеет одну единственную реализацию, которая используется во всех случаях. Именно в этом смысл. Ф-и query не содержат никакой логики о том, как запрос отправляется. Они возвращают сам запрос (не ответ, запрос).
Ну и да — что-то я колбеков с листенерами у вас не увидел, вы просто сделали код синхронным, понаставив блоков. Так что в любом случае не засчитывается, давайте вторую попытку.
Ну любая асинк функция это стейт машина, которую коментатор вышк вам расписал явно. Монады это не совсем про это. Асинк в жаваскрипте как я понимаю это не общая абстракция а просто один конкретный трюк компилятора.
В том-то и проблема, что user_man не написал никакого конечного автомата.
Ну любая асинк функция это стейт машина, которую коментатор вышк вам расписал явно. Монады это не совсем про это
Во-первых, как верно заметили ниже, он ничего не расписал, а просто сделал код синхронным. Во-вторых — как бы о том и речь, что монада вам позволит оформить этот КА вменяемо, а не при помощи ручной реализации, ручного прокидывания колбеков в листенеры или еще как.
Асинк в жаваскрипте как я понимаю это не общая абстракция а просто один конкретный трюк компилятора.
Можно async/await поменять на function*/yield — будет общая абстракция.
Нет, так дело не пойдёт. Навели тумана и теперь троллите. Нехорошо.
Предлагаю следующий план дискуссии:
1) Вы честно признаёте, что показанная реализация соответствует вашему «ТЗ».
2) Вы соглашаетесь с тем, что не указали полной информации в своём ТЗ, а потому там осталось место для различных вариантов реализации.
3) Вы, наконец, указываете, каким же на самом деле должно быть ТЗ, благо моя реализация вам явно показывает, где и что вы недоговорили.
4) Ну и было бы неплохо привести вашу версию кода. Это устранит неоднозначность, свойственную любому ТЗ, а так же не даст вам отвертеться в случае, когда я приведу аналогичный по функционалу и более простой код без монад.
Ну а отсутствие ответа или очередную песню из серии «а ты сам догадайся» я буду воспринимать лишь как подтверждение того факта, что, к сожалению, общаюсь с мелким жуликом, прикрывающимся разговорами о «неправильной» интерпретации секретных мыслей ради избежания ответственности за свои слова.
ЗЫ.
Надеюсь нет нужды напоминать ваше собственное ТЗ, но для других оставлю ссылку. Текст скопировал, на всякий случай.
А зачем форкать, а потом сразу делать get (join)? Где асинхронность? Я то сначала подумал вы там стейт-машину сделали, а вы просто лямбда скобочек понатаскали.
1) Вы честно признаёте, что показанная реализация соответствует вашему «ТЗ».
Но она не соответствует. Ваш код:
- синхронный, хотя оригинальный код работает асинхронно
- требует переписывать запросы под каждый протокол передачи, хотя явно требовалось не переписывать
2) Вы соглашаетесь с тем, что не указали полной информации в своём ТЗ
Я же вам привел пример кода. Он и является основным ТЗ, все прочее — просто пояснение. Очевидно, что вы должны написать код, который работает также. hint: оригинальный код мог быть асинхронным. hint2: а мог быть и нет, предполагалось что синхронность/асинхронность можно выбирать на call site
Ну и было бы неплохо привести вашу версию кода.
Так я привел свою версию кода, она выше. Ну, если строго, то можете сразу смотреть на этот код как на:
function* yoba() {
const x1 = yield query1();
if (f(x1)) {
for (const x2 of x1) {
if(g(x2)) {
yield query31(x2);
yield query32(x2);
} else {
yield query33(x2);
}
yield query 34(x2);
}
yield query41(x1);
} else {
yield query42(x1);
}
return query5(x1);
}Ну и потом мы делаем просто runInHTTP(yoba) или runInWebsocket(yoba) или runInMarsDeliverNetwork(yoba).
Автор начальной версии ТЗ немого добавил к своим предыдущим соображениям, но из этих соображений видно, что вменяемого ТЗ не будет. Из этого далее последует интересный вывод.
Сначала о первоначальной версии ТЗ. Его автор действительно хотел получить другой результат, но как он сам ранее говорил — он пишет подобный код на монадах даже не задумываясь. Поэтому и получил то, что получил.
Далее придётся пояснять всем отметившимся «знатокам», почему они все неправы. Да, обидно, ЧСВ страдает, но надо. Умные примут этот урок, ну а остальным уже ничем не поможешь.
Итак, массово расставленные в коде предыдущей версии ТЗ ключевые слова await означают, что первоначальный код (внезапно) точно такой же синхронный, как и предоставленный в ответ на ТЗ. Поясню коротко, как работает конструкция await («знатоки», не ухмыляйтесь, а прочитайте внимательно). Сначала создаётся обещание. В момент его создания в параллельном потоке запускается выполнение его задачи. А в момент встречи ключевого слова await текущий поток (то есть не тот, в котором выполняет свою задачу обещание) останавливается и ждёт завершения работы обещания. Так вот, густо расставленные await-ы как раз и останавливают текущий поток именно в тех местах, в которых он бы остановился, если бы все эти queryXY запускались строго последовательно. И это превращает выполнение запросов в синхронный процесс. Зачем это надо? Понятия не имею. Автор предложил мне показать код вместо дальнейших пояснений. Поэтому я и не стал думать о таких вещах, а тупо сделал копию предложенного. Да, у меня вызов тоже синхронный, да, непонятно, зачем это нужно, но здесь важно одно — такая реализация соответствует ТЗ. А если ТЗ «не очень», то какие претензии к реализации? Trash in, trash out.
Далее автор попытался поправиться и выдал код на yield-ах. Но я не стану далее загонять его в угол (да и с самого начала не хотел, ведь мог же автор поинтересоваться, например, как запустить задачу в параллельном потоке). Скажу только, что на yield-ах всё получилось не лучше — теперь получением результат управляет вызывающая сторона, но как раз она-то и не знает, когда закончится выполнение запросов, да и вообще про запросы ничего не знает. Она будет дёргать код, который без всяких параллельных потоков будет заставлять вызывающую сторону ждать в самом привычном однопоточном режиме. То есть как всё было синхронным, так и осталось. Хотя последовательность выходных значений у функции изменилась. Но это, видимо, не то, что ожидал автор.
В общем, не повторяя акты из марлезонского балета, сразу приведу код, который (как требуют «знатоки») является реально асинхронным. Вот он:
public class Service<T2,T1 extends Iterable<T2>,T3> extends Synchronizer
{
public T3 yoba(Behavior<T1,T2,T3> b) throws InterruptedException,
ExecutionException
{
T1 x1 = b.query1();
reset();
if (b.f(x1))
{
for (T2 x2:x1)
{
if (b.g(x2))
{
async(()->b.query31(x2));
async(()->b.query32(x2));
}
else async(()->b.query33(x2));
async(()->b.query34(x2));
}
async(()->b.query41(x1));
}
else async(()->b.query42(x1));
Future<T3> f=async(()->b.query5(x1));
complete();
return f.get();
}
}
И вот слегка модифицированный под потребность Synchronizer:
public class Synchronizer
{
private ExecutorService executorService;
private List<Future<?>> futures = new ArrayList<Future<?>>();
public void complete() throws InterruptedException, ExecutionException
{
for (Future<?> f:futures)
f.get();
futures.clear();
}
public void reset()
{
for (Future<?> f:futures)
f.cancel(true);
futures.clear();
}
public Future<?> async(Runnable r) throws InterruptedException, ExecutionException
{ return add(executorService.submit(r)); }
public <T> Future<T> async(Callable<T> c) throws InterruptedException,
ExecutionException
{ return add(executorService.submit(c)); }
private <T> Future<T> add(Future<T> f)
{
futures.add(f);
return f;
}
}
Собственно, здесь наглядно видно, что код из ТЗ (теперь уже из двух версий) практически в неизменном виде присутствует как в последнем, так и в первом решении. Код крайне простой.
Код последовательный и понятный. Никаких монад. Никаких лишних приседаний (лифты да разнообразные переопределённые стрелки в смеси с адским деревом математических типов).
Но кроме собственно очевидной из кода простоты, имеем ещё и очевидную простоту получившейся системы в целом. Почему? Потому что все «знатоки» в голос заявляли мне, что мой код синхронный (правда после указания на Java API), а вот автору ТЗ никто не сказал, что и в его коде «что-то не так». Почему не сказал? Да потому что все эти промисы реально сложнее предложенного решения. Ну и оказалось, что никто из «знатоков» не разбирается в том, как работают промисы. А вот в моём коде — разобрались моментально. А всё почему? Да потому, что «делают на монадах не задумываясь» ((с) не моё). А когда видят вменяемое описание происходящего (наследие создателей Java), то привычка делать не задумываясь их не подводит. Потому что наследие стоящее.
Монады (как и JavaScript) прячут от разработчика суть происходящего. Пояснения к функционированию как монад, так и скриптовых конструкций — убогие. Хоть и развелась куча учебников по скрипту, а всё равно подробную цепочку всего происходящего они не дают. Ну а про ФП и говорить нечего — только разбираться с исходным кодом компилятора, иначе — никак. Точнее — иначе опять будет «делают на монадах не задумываясь».
Так в чём же польза от монад? Повторюсь — это всего лишь костыли, делающие программирование на ФЯП более «элегантным» (с некоторых точек зрения). И всё. Более в них смысла нет, одна морока (как и с любыми костылями).
Ну а фанатам ФП остаётся сказать одно — не зазнавайтесь. Ибо молоды вы ещё приводить аргументы в противостотянии ФП — императив. Может лет вам и много, но знаний (и особенно — опыта) у вас очень мало. Императивом занимались реальные монстры, с которыми вы ни в какое сравнение не идёте. Культура разработки на императиве даже не снилась тем университетским лаборантам, которые создали, например, хаскель (и чисто для справки — они не зазнавались). Ну а последовавшие за ними любители и вовсе отметились лишь работами уровня «курсовая» да «дипломная», так откуда у них возьмётся культура разработки? Учитесь у отцов-основателей, забейте своё ЧСВ подальше и изучайте, например, Java, просто потому, что те, кто её создавал, как раз были причастны к той мощной культуре разработки, о которой вы, к сожалению, понятия не имеете. И вот эти отцы никогда бы не стали заявлять что-то вроде «делаю на монадах не задумываясь», потому что, например, синхронизация — это непростая задача, а решать непростые задачи «не задумываясь» — ну вы только что видели, к чему это приводит.
В общем пока всё, умные поймут, дураки разольют нечистоты, ну да к этим «выбросам» мне не привыкать :)
А в момент встречи ключевого слова await текущий поток (то есть не тот, в котором выполняет свою задачу обещание) останавливается и ждёт завершения работы
Нет, не ждет. Если бы это было так, то при любом await код на жсе бы вставал колом, т.к. жс — однопоточный и блокировка потока это блокировка всего жса. Т.е. вы просто не понимаете как работает await. Вы верно сказали — создается промис, вот только никакой блокировки не происходит, а просто в этот промис передается колбек на оставшееся вычисление, иными словами f(await x) = x.then(f). Вы же говорили про колбеки с листенерами? Вот я вам и написал пример про колбеки с листенерами.
Скажу только, что на yield-ах всё получилось не лучше — теперь получением результат управляет вызывающая сторона, но как раз она-то и не знает, когда закончится выполнение запросов, да и вообще про запросы ничего не знает
Вызывающая сторона-то как раз все и знает. Как делается асинхронный код на жсовских генераторах, можете почитать: https://hackernoon.com/async-await-generators-promises-51f1a6ceede2
В общем, не повторяя акты из марлезонского балета, сразу приведу код, который (как требуют «знатоки») является реально асинхронным
Вы опять написали неправильный код. Ну это понятно почему — вы, оказывается, не знали, как работает async/await и по-этому вообще не поняли, что надо сделать. Ознакомьтесь с семантикой промисов и await, посмотрите еще раз внимательно на оригинальный код и давайте третью попытку. Ну и да — я же вам явно сказал, что Behavior должен быть один единственный на все случаи, в этом смысл, а у вас снова костылится свой на каждый кейз.
Если бы это было так, то при любом await код на жсе бы вставал колом, т.к. жс — однопоточный и блокировка потока это блокировка всего жса
А как же Worker-ы?
В общем так — в скрипте вы выдали строго последовательный код, блокировку на IO и параллельное выполнение чего-то другого вы тоже не продемонстрировали. Я же первый раз повторил ваше творчество, ну а второй — уже сделал как надо.
По ТЗ — оно, мягко говоря, ни о чём. Зачем нужно было демонстрировать функцию, строго последовательно что-то там выполняющую? У меня на эту тему единственная мысль — вы ожидали, что я буду повторять некий привычный лично вам шаблон. Ну а я не повторил. И вы в ступоре — как так, все же делают по шаблону! Отсюда ваше настойчивое повторение каких-то «хинтов» и прочих намёков. Да, прямо сказать сложно, ведь нужно сначала самому понять — я мыслю шаблонно. Ну что-ж, тогда я вам указываю на вашу проблему.
По изменению второго варианта моего кода. Главный вопрос — зачем? Городить какой-то неэффективный шаблон исключительно потому, что спрашивающий привык видеть именно этот шаблон? Это глупо. Приведённый код эффективен, распараллеливает задачу по максимуму (для большего вы не дали информации в своём ТЗ). Ухудшать код ради удовлетворения лично вас у меня желания нет.
Ну и концептуально. Речь, вообще-то, шла о монадах. Но стандартный трюк с уходом в частности опять на сцене. Не скажу, что это делается намеренно, потому что это просто очередной шаблон. Это же так привычно — увидел неоднозначность «в чужом глазу» и сразу смело бросился «исправлять», забыв о сути обсуждения.
Ну да не вы один такой. Ответы всех остальных ещё хуже — краткий выкрик на очень узкую тему, нередко основанный на эмоциях, а не на попытках подумать. То есть опять сплошной шаблон.
Далее в комментариях, наверняка, перейдём к шаблону «ты перешёл на личности», а потому повторюсь — не я перешёл на личности, а в все живёте по шаблону. Например по шаблону «указать на шаблон перехода на личности».
Ладно, надоело что-то доказывать тем, кому просто неинтересно ничего, кроме любимых шаблонов.
А как же Worker-ы?
А в случае воркеров это не через сам жс обеспечивается, а "снаружи". Внутри самого жс-кода вы никак за пределы своего потока выйти не можете.
В общем так — в скрипте вы выдали строго последовательный код, блокировку на IO и параллельное выполнение чего-то другого вы тоже не продемонстрировали
Так там нету блокировки, и параллельного выполнения нету. Там асинхронный код.
Я же первый раз повторил ваше творчество, ну а второй — уже сделал как надо.
Вы оба раза написали код, который работает не так, как исходный. И сделали это потому, что не знаете как работает async/await. Почему вы с прошлого поста не ознакомились с принципом работы этой конструкции?
Давайте я вам попробую объяснить, но это последний раз. если у вас есть код async f() { await x(); z = await y(); return z; } то этот код эквивалентен коду f() { return x().then(() => y()).then((z) => z) }. Оно же эквивалентно f(callback) { x(() => y((z) => callback(z))); }
кто здесь что блокирует? Никто и нигде. Это обычный асинхронный код. Его от вас и требовали. Точнее — от вас требовали код который может быть а может и не быть асинхронным будучи запущенным в разных контекстах.
Приведённый код эффективен, распараллеливает задачу по максимуму
Задачу как раз параллелить не надо. Все await должны выполняться строго друг за другом. Но при этом текущий поток не должен блокироваться — т.е. выполнение должно быть асинхронным. Погуглите concurrency vs parallelizm и прекратите позориться.
Объясняю:
Вы не дали никакой информации по вызывающей ваш код стороне. Даже более — навели туману про HTTP и ещё чего-то там. Значит это может быть что угодно. Но тогда с чего вы взяли, что «что угодно» — это ваш любимый браузер?
Далее из вашего следования шаблону работы с браузерным кодом вы делаете вывод, что выполнение задачи может быть исключительно однопоточным. Это не так.
Вот цитата из ECMA-262:
8.4.1 EnqueueJob
8. Perform any implementation or host environment defined processing of pending.
Затем вы опять шаблонно (для фронтэнда) описываете используемые понятия, такие как блокировка, синхронность, асинхронность и т.д.:
>>Так там нету блокировки, и параллельного выполнения нету. Там асинхронный код.
Объясняю:
Блокировка, это когда задача останавливается и чего-то ждёт (задача заблокирована). Отсутствие блокировки — это когда задача продолжает выполняться после неблокирующего вызова.
Синхронный код обязан синхронно с каким-то другим кодом начать исполнение с заданной точки. Асинхронный код не имеет таких ограничений и может выполняться с любой точки, независимо от любого другого кода.
В вашем случае код после await отдаёт результат работы вызывающей стороне. Однопоточность здесь добавляет путаницы, поскольку возникает потребность уложить всё в один цикл обработки задач, в отличии от многопоточного варианта, когда несколько задач могут выполняться одновременно.
Это означает, что ваш код синхронизируется на точке await. Ваш код не может выполняться без учёта этой точки синхронизации. Если он будет выполняться без учёта синхронизации, то вы получите неготовый результат и искажённый смысл работы алгоритма (например, в виде исключения).
Далее вы опять настаиваете на своём привычном шаблоне:
>> Вы оба раза написали код, который работает не так, как исходный. И сделали это потому, что не знаете как работает async/await.
Я действительно не являюсь абсолютным экспертом по JS, но тем не менее, последовательное выполнение вашего кода я понять могу. Даже больше скажу — я почитал дополнительно по модели исполнения JS и, в общем-то, вынес для себя кое-что полезное (чего не знал до общения с вами), но всё равно ваш код от этого не становится каким-то особенным, он по прежнему последовательно и синхронно, блокируя исполнение до получения результата, выполняет функции из вашей вызывающей yob-ы.
Теперь более высокий уровень:
В качестве ТЗ имеем некую функцию, которая вызывает другие функции. Ничего неизвестно ни про вызывающую сторону, ни про функции, вызываемые из базовой. Вопрос — как нам выполнить эту функцию эффективно? Поскольку эффективность выполнения вызываемых функций и работа вызывающей стороны нам неподконтрольны, для нас остаётся единственный вариант — распараллелить выполнение подконтрольной нам базовой функции. В вашем случае всё выполняется последовательно и синхронно. Какая в этом эффективность? Мой вариант будет выполнен быстрее на многоядерной платформе, а чем будет выделяться ваш вариант? Вот именно поэтому я и выбираю мой вариант, а не какой-то (до сих пор непонятный) шаблон, на который вы всё намекаете, но никак показать не можете.
На самом деле ваши намёки, скорее всего, говорят о так называемой инверсии контроля, а не об асинхронности. То есть абсолютно синхронно и последовательно некая внешняя задача вызывает вашу yob-у, ну а yoba как-то по разному отвечает, в зависимости от контекста.
Что нужно для реализации вашего ТЗ в вранианте «инверсия контроля»? Как минимум — нужно знать контекст. То есть когда и в зависимости от чего менять поведение yob-ы. Вы такой информации не привели. Поэтому, опять же, мне остаётся лишь один вариант — менять поведение через переданные мне вызываемые функции, что я и сделал. Не попал в вами любимый шаблон? Ну что-ж, не я же такое ТЗ составил.
Вообще, по хорошему, вы давно должны были понять, что выдали неполную информацию. Я вам об этом говорил абсолютно прямо, без хинтов и намёков. Но вы даже на секунду не задумались, а продолжили гнуть свою линию — ничего не хочу знать, дай мне мой любимый шаблон.
Ладно, это всё опять же была лишь лирика, потому что основная тема — монады.
И, видимо, по монадам вы изначально хотели донести, что оказывается, монады могут получать функцию, и когда-то (в зависимости от контекста) её запускать. Ага, это всё та же инверсия контроля. То есть вы отдаётесь своим монадам и они вас дёргают по своему усмотрению. Этим вы, видимо, хотели показать «простоту» передачи callback-ов, но вы не поняли очень простую вещь — в однопоточном режиме, используемом в браузерах, все эти передачи функций приводят к эквиваленту гораздо более простого кода — последовательного и без монад.
Вот пример:
f(()=>g(()=>h()));В однопоточной среде эквивалентно:
f();
g();
h();
Что проще? Месиво из лямбд или просто последовательное перечисление того, что нужно сделать?
И да, этот пример никак не относится к асинхронности. Здесь строго синхронно вызывается одна и та же последовательность действий, но в первом варианте (вашем) — это всё запутано, а потому кому-то может показаться, что там есть асинхронность. Во втором же варианте всё ясно. Вот и вам бы научиться излагать свои мысли примерно на таком же уровне понятности.
ЗЫ.
Я подчеркну — с асинхронностью, в отличии от вас, я привык работать не в браузерах, а в реальных приложениях, требующих высокой производительности, а потому ваш однопоточный подход для меня ничем неинтересен (и да, я его не изучал до уровня эксперта). Но тем не менее, я хоть пытаюсь понять, что вы там себе придумали (какие шаблоны ждёте), ну а вы же даже и не собирались ничего понимать, просто повторяете одно и то же — дай мне как я привык. И как с таким подходом можно работать?
Я бекендщик. Java. Мне все понятно что написано выше, так что не надо вертеться как уж на сковороде. Научитесь сначала отличать асинхронный и парралельно исполняемый код. А та чушь про синхронизацию вообще никакого отношения к реальности не имеет. И приведенный код не эквивалентен.
Поскольку эффективность выполнения вызываемых функций и работа вызывающей стороны нам неподконтрольны, для нас остаётся единственный вариант — распараллелить выполнение подконтрольной нам базовой функции.
А как вы собираетесь распараллелить зависимые по данным функции?
Утрированный пример:
- сделать запрос на сайт.
- обработать ответ.
- На основе результата сделать ещё один запрос.
Вы предлагаете отправить 2 запроса параллельно и утверждаете, что подобная логика будет работать быстрее и правильнее.
Вы предлагаете отправить 2 запроса параллельно и утверждаете, что подобная логика будет работать быстрее и правильнее.
Интересно узнать, где вы нашли подобные заявления с моей стороны?
Посмотрите на функцию из ТЗ и мою реализацию внимательнее. Там есть зависимость от результата первого вызова. И там нет предложенного вами подхода.
У вас все вызовы query31 параллельно друг другу выполняются, если executorService это разрешает, что противоречит исходному ТЗ.
А если executorService однопоточный, то вызовы query31 из разных yoba параллельно выполняться не могут, что тоже противоречит исходному ТЗ.
Есть, конечно, ещё третий вариант — свой executorService на каждый вызов yoba — но в этом случае всё умрёт под нагрузкой. Конечно, в ТЗ про "не умирать под нагрузкой" ничего сказано не было, но обычно такие вещи подразумеваются.
Значит это может быть что угодно.
Все верно, вы поняли наконец. код должен работать с любой вызывающей стороной без изменений самого кода. Скажет вызывающая сторона работать асинхронно — код будет работать асинхронно, скажет работать параллельно — будет работать параллельно, скажет работать последовательно, с блокировками — будет работать последовательно, с блокировками.
Я же с самого начала на это указал, в первом посте. Невнимательно вы постановку задачи читаете читаете.
что выполнение задачи может быть исключительно однопоточным.
Оно, конечно, может быть многопоточным. Никто вас не ограничивал. Главное — оно не должно быть параллельным. Каждый из query выполняется только после того, как предыдущий query вернул результат.
Это означает, что ваш код синхронизируется на точке await.
На await ничего не синхронизируется. Я не понимаю, я же вам указал, что именно происходит при await, как он рассахаривается. Зачем вы чушь свою повторяете? Забудьте про await если для вас это чересчур сложная конструкции, вот код, эквивалентный коду с await: f(callback) { x(() => y((z) => callback(z))); }
Что здесь с чем синхронизируется?
Мой вариант будет выполнен быстрее на многоядерной платформе
Ваш код будет выполнен неправильно. Потому что запросы должны идти последовательно, а не параллельно.
Как минимум — нужно знать контекст.
Моя функция с yield работает без знания контекста. Благодаря монадам.
Напоминаю, вы сказали, что монады не нужны — вот и покажите мне аналогичный код без монад.
>> код должен работать с любой вызывающей стороной без изменений самого кода.
Он и работает. Никаких изменений не требуется.
>> Скажет вызывающая сторона работать асинхронно — код будет работать асинхронно, скажет работать параллельно — будет работать параллельно, скажет работать последовательно, с блокировками — будет работать последовательно, с блокировками.
А вот слово «скажет» — это передача информации. О передаче дополнительных параметров в ТЗ слов нет, так что опять вы в плену шаблона.
>> Оно, конечно, может быть многопоточным. Никто вас не ограничивал. Главное — оно не должно быть параллельным. Каждый из query выполняется только после того, как предыдущий query вернул результат.
Для последовательного исполнения задач нужно просто написать последовательность их вызовов. Монады при этом не нужны.
>> На await ничего не синхронизируется. Я не понимаю, я же вам указал, что именно происходит при await, как он рассахаривается. Зачем вы чушь свою повторяете? Забудьте про await если для вас это чересчур сложная конструкции, вот код, эквивалентный коду с await: f(callback) { x(() => y((z) => callback(z))); }
Что здесь с чем синхронизируется?
В одном потоке — и то нужно синхронизировать. Вопрос только в реализации потоков. Но вы опять рассматриваете лишь свой шаблон, и потому не понимаете простых вещей.
>> Ваш код будет выполнен неправильно. Потому что запросы должны идти последовательно, а не параллельно.
Пишите ТЗ понятно и будет вам счастье. Ну а про последовательное исполнение — см. выше.
>> Моя функция с yield работает без знания контекста. Благодаря монадам.
>> Напоминаю, вы сказали, что монады не нужны — вот и покажите мне аналогичный код без монад.
И моя функция работает без знания контекста. И без монад. И даже в двух реализациях. Ещё про третью выше говорил — без синхронизации, всё в одном потоке последовательно.
Я не знаю, как нужно не хотеть отвечать, что бы вот так как вы постоянно отвечать одно и то же, но при это как-то не лениться набирать все эти слова. Совершенно непонятна ваша мотивация. Не хотите отвечать? Так не отвечайте. Не хотите объяснять, но хотите ответить? Тогда вопрос — а зачем такой цирк?
В общем, если вы всё же осилите выход за пределы шаблона, то вы наверняка всё поймёте, но тут, похоже, ещё и психология как-то влияет. Вы что, просто оправдываетесь, видя убедительные аргументы? Не были бы они убедительными, вы ведь просто могли бы промолчать, мол вот дурак сам себя выпорол, но вы же отвечаете. Не понимаю я вас.
Ну так сделайте инверсию контроля в своем коде, тогда будет ближе к тому как работает async. Зачем пустая болтовня?
И, в конце концов, любой разработчик с мозгами давно понял суть моего варианта (комментарии это доказывают). Значит если нужно, он легко адаптирует решение под себя, хоть с инверсией, хоть с деффками на каблуках. Поэтому упорство автора здесь совершенно ни к чему.
А причем тут движок джава скрипта когда корутины уже во многих других языках есть? Смысл в том чтобы можно было много таких функций запустить одновременно. Каждая функция обработчик например обработчик одного запроса. Или несколько разных асинк функций одновременно. Это реализуется на каллбэках — как делали в жабоскрипте раньше, но выглядит более запутанно.
Не видел никого, кому было бы понятно, что вы там написали. У вас получилось написать f(); g(); в запутанном виде с кучей ненужных классов, но у вас так и не получилось сделать работу асинхронной.
А в момент встречи ключевого слова await текущий поток (то есть не тот, в котором выполняет свою задачу обещание) останавливается и ждёт завершения работы обещания.
Ни на одном из известных мне языков (C#, Python, Javascript, Rust, C++) оператор await не работает описанным вами образом.
Пожалуйста, разберитесь хоть немного в теме прежде чем писать подобные "разгромные" комментарии.
Как в том анекдоте, Вы не читатель, вы писатель.
Узнайте зачем нужен await и event-loop.
Дело не в "ТЗ". Дело в том что Вы не поняли код, который принялись критиковать. Это говорит о том, что Вы понятия не имеете что такое монады, для чего они нужны и как работают.
Как эти конкретные задачи решаются при помощи монад?
Да, решаются. Пример с конфигом например решается по принцифу TF:
struct AnyConfig<M> where M : <> {
workers_count: M<u32>,
latency: M<u32>,
app_url: M<String>,
app_port: M<Port>,
...
}тогда тривиально:
type Config = AnyConfig<Option>;
type AppConfig = AnyConfig<Id>;Никакой копипасты. И какая тут асинхронность?
Ну и далее логично следует очередная простая проблемка — зачем нам выполнять определения из теорий групп и категорий для listener-а? Что это даёт? Где тут нужны ассоциативность, коммутативность и прочее?
Даёт это то, что проще думать о приложении: программа не дедлочится, и не ддосит шлюз потому что кто-то забыл что в цикле стучаться в сервис — не всегда хорошо. Такие, ощутимые на мой взгляд плюсы. Ну и бесплатная параллелизация автоматически из коробки тоже неплохая штука.
Скажу по другому — математика исследует некое пространство по определённым правилам, это придаёт исследованной части некоторую структурированность и гарантирует выполнение в ней неких закономерностей. Но когда закономерность находится на уровне сложности 2+2, ради одного только такого «достижения» не стоит приплетать математические теории к программированию.
Люди зачем-то учат все эти солиды, паттерны, и прочие акки. Интересно, зачем, ведь это куда сложнее чем 2+2, и то, что в статье.
Представим себе стандартное сложение в любом языке программирования — вместо 2+2 нам пришлось бы работать с чем-то вроде «секвенторов» (должно же звучать «заумно»?), которым пришлось бы передавать «инкрементируемые типы» выполняющие законы ассоциативности, коммутативности и т.д. И да, сторонники такого подхода очень быстро переопределили бы операцию "+"
За аналогиями опять ничего непонятно. Где кого кто нагибает, какая лишняя сложность? Вам дают интерфейс, который позволяет вот например конфиги не копипастить, вы говорите что это сложно. А искать ошибку в 10 "отнеследованных" в ущербно-ориентированном стиле коде — это просто? Вместо ошибки компилятора дебажить многопоточную мутабельную багу — это просто?
Повторяюсь — это реализуется тривиально. Сначал делается библиотечная функция, которая заботится об асинхронности, а потом этой функции скармливаются синхронные listener-ы. Так при чём же здесь монады?
Ну то есть натягиваем сову на глобус, и делаем "типа асинхронные" классы, которые на самом деле — синхронные. Спасибо, не надо такого.
Вообще-то в большинстве языков есть возможность задавать дефолтные значения прямо в конструкторе. Чем вас не устраивает такой подход?
Тем что дефолты могут быть разные в разных частях приложения. И тем что не во всех языках десериализаторы умеют вызывать конструктор, а в некоторых случаях вроде протобафа — и не будут уметь.
Ваш пример про конфиг, он ведь про HKT на самом деле. Т.е. вы смогли выразить некий абстрактный интерфейс и получили переисподьзование кода. В статье эта мысль ускользает и кажется что вы просто переизобрели асинк и авэйт.
Да, но без fmap на M<> почти ничего интересного с такой структурой не сделать.
В статье эта мысль ускользает и кажется что вы просто переизобрели асинк и авэйт.
Асинк авейт изобрели 20 лет назад, когда ду нотацию придумали. А потом спустя 10 лет её переизобрел майкросот для IO и так он пошло в мир.
Да с ней вообще мало что сделаешь, все равно нужно либо unwrap сделать либо синтаксический сахар из хачкеля чтобы прозрачно работать со внутренностями.
С ней почти всё что надо можно сделать. Что не надо — можно дополнить ручными вызовами к функциям предоставляемым бифунктором, который дает второй мап (для ошибок). А анврап в 99% случаев делать не нужно.
Какие ошибки если там Id? Вообщем я не знаю о чем вы, пример бы помог.
Unwrap в смысле .Value? Ну да, он нужен, но только на верхнем уровне который знает про то как достать значение. А в остальном монадичекий интерфейс 100% возможностей типа дает.
Про ошибки я имел в виду Either, у меня анврап с ним ассоциируется. И вот с ним не так — монадический интерфейс не дает способа достучаться до значения ошибки, он позволяет работать только с успешным результатом. Чтобы добраться до ошибки нужны другие интерфейсы.
Практический смысл можно найти, например, в filterM. Хотя и несколько синтетический.
Интересный вопрос, для функтора могу ответить картинкой которую выше кидал:
Придется поверхностно коснуться теории категорий, но постараюсь сделать это нестрашно. Итак, у нас есть две категории, в С объекты a и b, а в D Fa, Fb. В языках программирования единственной категорией которая используется является категория Set. В ней объекты — это множества (говоря иначе — типы), а стрелки между ними — отображения между множествами (говоря иначе — функции из одного типа в другой).
Кстати, сразу понятно, почему мы должны говорить "категория" — множества всех множетств не существует, а категория — вполне.
Теперь давайте возьмем, что a — это int, b — double, F — IEnumerable.
Тогда эта диагрмма говорит нам о том, что есть некая функция createListA :: a -> IEnumerable<A> и Ff :: IEnumerable<A> -> IEnumerable<B>.
С другой стороны у нас есть функция f :: A -> B и createListB :: b -> IEnumerable<B>.
Диаграмма коммутирует, а это означает, что неважно, по какому пути мы пойдем, мы придем в одну итоговую точку. То есть
createList(new A()).Map(f) === createList(f(new A())
Что по сути отражает простой факт того, что Map всего лишь применяет функцию к значению внутри контейнера, и больше никак на него не влияет.
Обратите внимание, что createList не обязан быть равен pure, хотя имеет ту же сигнатуру. Например, он может выглядеть так:
static IEnumerable<T> CreateList<T>(T x) => new[] { x, x, x };По типам мы сошлись, эти законы будут выполняться, но это — не pure.
Про аппликатив могу ниже расписать, если интересно. Но там вроде все достаточно очевидно. По сути там написано то что если есть функция из а в б, и из б в ц, то должна существовать функция из а в ц, как минимум композиция этих двух.
Вижу картинку и чую руку Бартоша Милевского. У него на сайте взяли?
Я по образованию математик, а по опыту работы — разработчик С++. Поэтому мне понятны либо коммутативные диаграммы, либо С++ код. С# код разумею с трудом.
Функтор — просто морфизм между категориями, переводящий обьекты в обьекты, морфизмы между ними — в морфизмы в образе класса морфизмов. Что, собственно, ваша (или таки Бартоша?) картинка и показывает.
Ковариантный функтор сохраняет порядок композиции морфизмов, контравариантный — разворачивает в обратном порядке.
Аппликативный функтор что делает?
Вижу картинку и чую руку Бартоша Милевского. У него на сайте взяли?
Его статьи в книжку скомпилировали, по моему скромному мнению весьма неплохую: https://github.com/hmemcpy/milewski-ctfp-pdf
Я по образованию математик, а по опыту работы — разработчик С++. Поэтому мне понятны либо коммутативные диаграммы, либо С++ код. С# код разумею с трудом.
Понял. Тогда понятнее будут диаграммы с вики.
Монада:
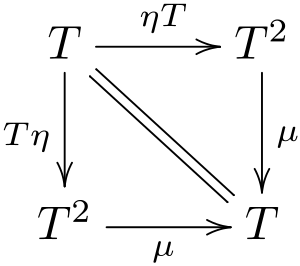
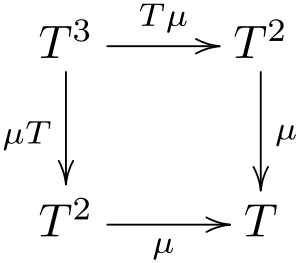
Где ню — это pure, а мю — это джоин:
join :: (Monad m) => m (m a) -> m a
join x = x >>= idДля аппликатива такой нет, но если бы меня попросили нарисовать, это выглядело бы как-то так:
Вот тут можно почитать что сам Бартош пишет. TLDR:
We can define the categorical version of the Haskell’s applicative functor as a lax closed functor going from a closed category C to Set. It’s a functor equipped with a natural transformation:
f (a => b) -> (f a -> f b)
where a=>b is the internal hom-object in C (the second arrow is a function type in Set), and a function:
1 -> f i
where 1 is the singleton set and i is the unit object in C.
(всех кто читает это просьба не пугаться, это объяснение не для программистов :) )
зы а основание логарифма это не функтор?
Посмотрите, сколько мусора натащил сишарп
Возможно сказывается мой длительный разрыв с C#, но мне кажется, что с конструкциями типа
public extension IdMonad of Id : Monad<Id>
{
static IdMonad<A> Pure<A>(A a) => new Id<A>(a); // просто создаем обертку
static IdMonad<B> Bind<A, B>(IdMonad<A> ta, Func<A, IdMonad<B>> mapInner) =>
mapInner(ta.Value);
}
«бизнесовый» код не становится более выразительным. Я не исключаю, что где-то в дебрях фреймворка, куда выносится вся техническая сложность, такие конструкции позволят реализовать обобщающий механизм для дальнейшего написания читаемого кода. Чтение же подобного «бизнесового» кода не вызывает никакого удовольствия.
Как понимаю такой код будет только в стандартной библиотеке.
А где вы в этом коде бизнес-логику увидели?
Это ведь реализация Monad для Id, то есть стандартного тайпкласса для стандартного типа. Могу провести такую аналогию: часто ли вы реализовываете IEnumerable для List, например? Является ли это бизнесовым кодом?
А что тут непривлекательного? Один генерик аргумент, пара параметров, это разве сложно? Вот вполне себе актуальная сигнатура из C# 3.0:
public static TResult Aggregate<TSource,TAccumulate,TResult>(this IEnumerable<TSource> source, TAccumulate seed, Func<TAccumulate,TSource,TAccumulate> func, Func<TAccumulate,TResult> resultSelector);Как по мне — выглядит куда сложнее, чем то что в статье.
github.com/louthy/language-ext
Нет, сишарп для такого не предназначен. Нужно брать язык, который проектировался под это дело, как минимум фшарп (хотя имхо он не очень), иначе получается вот такое:
Я использовал шарп в статье, чтобы идея была понтяна, ведь гайдов на скале/хаскелле хватаети без меня. Но напрямую переносить вообще все подходы — пусть вникуда. Вот ребята сделал LanguageExt, и получилось вот это.
В скале/хаскелле, ну или хотя даже фшарпе, такого не произойдет. Хотя в C# 7 добавили свитч, в восьмом switchExpression, с ними можно довольно приятные вещи делать.
Хотя если смотреть объективно, то проблема в том что они используют match вместо Bind. Отсюда вся портянка.
в ду-нотации:
from userId in _securityService.GetCurrentUserId()
from sectionInfo in _employeePersonalSectionRepository.RetreivePersonalSection(employeeId, userId)
from _ in Guard(ApplySecurityRulesOnSection(sectionInfo))
from _ in Guard(FixContactsOnPersonalSectionBeforeConvert(sectionInfo).MapErr(e => new InternalException("Failed to fix phone numbers", e)))
select new EmployeePersonalSectionDTO { ... };читается куда проще
Поэтому я считаю, что будущее именно за мощными языками, позволяющими делать удобные библиотеки, а не за кодом, который быстро написал — быстро выбросил и сделал новый.Браво!
Это вы Rust описали.
Это любой яп, например Liquid Haskell + Boring Haskell.
Или Scala, сложность понимания нормального кода и библиотечного может различаться на порядки
Вы только что говорили про "двухядерные" языки) А с разделяющим компилятором пожалуйста: джава и хаскель, вот вам разделение.
Ну завернулись в си апи и обвызывайтесь) А любое более плотное аби это уже ближе к одному япу, от которого вы только что отказывались.
Тут родится тот же вопрос, сколько камней — кучка. Не вижу смысла в таком разделении, либо вы с ним не столкнетесь, либо эмоции будут исключительно негативными. Не вижу в этом пользы.
а) бизнес может нанимать недорогих сотрудников, которые могут быстро решать сложные задачи с помощью крутых библиотек;
б) эйчары четко знают, кого искать (кандидаты тоже понимают, что их ждет);
б) полная совместимость «двух яп».
Одновременное сочетание трех этих пунктов и есть киллер-фича в вопросе выбора яп для работы.
Мне кажется, это выглядит так только на бумаге. НА практике у меня вот например в микросервисе 10% кода это генерики, достаточно общего вида. Это уже библиотека или еще приложения?
Не надо держать разработчиков за идиотов, которые не соблюдают KISS. Принудительное насаждение своих правил и искусственные ограничения до добра еще никого не довели.
Помните был период, когда все писали "на шаблонах"? AbstractFactoryFactory, SingletonFacadeCommandDecorator… Монады это тоже своего рода шаблоны проектирования. Подобно другим шаблонам, сами по себе они выглядят как ацкий оверинжениринг — их ценность проявляется лишь в контексте. Рассказать обо всём в формате статьи невероятно сложно. Но есть и специфичные заморочки.
Во-первых контекст задает теория категорий — вещь чрезвычайно абстрактная. Ближайшие аналогии, приблизительно объясняющи подход "на пальцах", отсылают в другие, не менее мудренные, разделы математики. Метафоры же, привычные штатным разработчикам, забывшим матан ещё со школы, не объясняют вообще ни чего.
Во-вторых язык теории категорий не поддерживается в популярных языках программирования (даже в интерпретации хаскеля реализован только частный случай). Попытки использования элементов в языках, где нет подходящих выразительных средств, выглядят скорее как синтаксическое мракобесие.
Радует, что интерес к теме постепенно растет. Но мне кажется пройдет ещё ни одна итерация, когда это перестанет быть похожим на прототип.
Все эти: вербозной, 100 раз на дню, захардкожены, заавейтиться, таки релизнули, нишмагла.
Причём в других случаях подобные навороты не дают пробраться дальше второго абзаца. А здесь вдруг оказалось всё красиво. Как так получается?
Интересно, с появлением расширения Shapes и расширения HKT в сишарпе следует ждать «сдвига парадигмы» в стандартных библиотеках?
А где запутались? Видимо я плохо донес.
Функтор — интерфейс с одним методом, который позволяет превращать T<A> в T<B>, где T — это наша структура данных, массив там, или еще что.
Аппликативный функтор — интерфейс с двумя методами, первый метод представляет собой конструктор с одним генерик параметром, другой — метод, который из пары T<A> и T<B> и функции (A, B) => C составить T<C>. Например, из двух массивов сделать один массив, из двух Task<T> сделать одну, и так далее.
Монада — интерфейс с одним своим методом (и одним унаследованным от аппликатива), который позволяет T<A> и функции A => T<B> получить T<B>, например из таски которая асинхронно вернет айди заказа и функции, которая по айди заказа получает весь заказ мы можем получить таску, которая возвращает заказ.
Суммарно получается 3 интерфейса с 4 методами. Которые, хотя и содержат пару генерик параметров, вроде достаточно читаемые, особенно если проводить аналогии со списками или тасками.
Если я могу как-то лучше объяснить — будет проще если есть конкретные вопросы и недопонимания.
Глупый вопрос, возможно, но я правильно понимаю, что подобные абстракции имеют смысл только в статически типизированных языках? Мой питонисткий мозг отказывается понимать, в чём вообще проблема написать map(func, iterable). Или питоновский map по сути и есть универсальный функтор?
Ну, весь смысл в том, чтобы компилятор помогал когда вы пишете ерунду. Если нет компилятора — то и смысла в этом мало. Хотя есть инциативы заниматься подобным: для жс, для питона, но всё же у динамики совсем другие трейдофы (иначе люди не стали бы брать динамику), поэтому для них это просто неподходящий инструмент.
Но сейчас идет тенденция усиления типизации динамики (TypeScript, Mypy, ..), поэтому эти знания все равно может оказаться полезными.
map — это не функтор, это функция, которая есть у функторов). Функторами в питоне являются, например, итераторы.
Глупый вопрос, возможно, но я правильно понимаю, что подобные абстракции имеют смысл только в статически типизированных языках?
Нет, типизация тут вообще не при делах, разве что за исключением того, что в динамике нет встроенного ad-hoc полиморфизма и по-этому есть сложности с тем, чтобы писать универсальный по монадам код. Но, поскольку такой код практически полностью бесполезен, это не является сколько-нибудь существенной проблемой.
Вот я беру Хаскель, пишу в нём `:k (->)` и вижу:
Prelude> :k (->)
(->) :: * -> * -> *
Но почему (->) имеет два параметра и результат (три `*`), а не один параметр и результат?
Я, видимо, не понимаю чего-то очень базового, но я «не понимаю чего именно я не понимаю» :(
Ну и второй (но скорее уже факультативный) вопрос: а зачем вообще делать функцию экземплярами классов Functor \ Applicative \ Monad?
Потому что это кайнд, а не тип. В данном случае стрелка принимает два аргумента, и возвращает один аргумент.
Возьмем C# тип Func.
Получаем Func :: * -> * -> *
попробем подставить вместо звездочек конкретные типы:
FuncAB :: A -> B -> Func<A, B>
То есть всё верно: чтобы из типа Func получить тип, нужно передать ему два типа — тип аргумента и тип результата.
Кайнд это количество аргументов тайп конструктора, а не самой стрелки в данном случае.
Func принимает два аргумента (тип аргумента и тип результата), и возвращает стрелку из этого аргумента в этот результат. Всё логично.
Ну и второй (но скорее уже факультативный) вопрос: а зачем вообще делать функцию экземплярами классов Functor \ Applicative \ Monad?
За тем же, зачем например для своей коллекции полезно реализовать IEnumerable/ICollection/... — получаете множество библиотечных функций нахаляву.
То есть тот же LINQ имеет под сотню методов, которые автоматически начинают работать с вашим типом когда вы реализуете единственный метод GetEnumerator. То же и тут, только в в хаскелле методов расширений над монадами куда больше.
Круто! Только не понятно, как это использовать. Хочется увидеть решение реальной задачи.
В учебниках по ФП часто упоминают про еще один закон для функторов, но тут есть один нюанс: если вы соблюдаете первый закон, то второй соблюдается автоматически. Это математический факт, так называемая «бесплатная теорема».
Это верно для Haskell, но не для остальных языков, в том числе C#. Более того, даже в Haskell законы выполняются условно, по модулю bottom.
Спасибо за статью. Уже почти понятно (: Что скажете о F#? Это "настоящий" функциональный язык или общая среда с C# принесла врождённые костыли? А питон? Сейчас на волне интереса почти все языки называют функциональными или почти функциональными. Хотелось бы как то отранжировать по "функциональности". Самым функциональным, если я правильно понимаю, будет хаскел, а дальше?
Понятие "функциональный язык" весьма расплывчато, потому что и в этой, и в прошлой статье я писал в фп стиле на вполне себе ООП сишарпе. А можно из хаскелля превратить в ДСЛ для ассемблерных вставок. Тут скорее вопрос, поощряет ли язык тот или иной подход.
Это если про чистое ФП. Если же речь про практику, то для меня нижней границей применимости является как раз возможность выразить функтор (простейший интерфейс с одним методом). Если его нельзя выразить, то особого ФП не выйдет. Это как писать в ООП стиле без возможности множественного наследования интерфейсов. Можно, но весьма неудобно. Без фуктора не будет монад, без монад не будет нормального способа описывать эффекты. А язык который не умеет в консоль ответ выводить без кучи бойлерплейта вряд ли будет кому-то интересен.
В фшарпе этих возможностей нет, более того, настроения коммьюнити что "нам нафиг не нужон, этот ваш хкт". А раз никому он там не нужен, то его и не появится. Питон вообще не моё, но тот же mypy довольно любопытно выглядит, слежу за его развитием вполглаза.
За хаскеллем идут языки с завтипами: Idris 2/Agda/F*, и совсем сырые новички вроде Formality. За академией наблюдать интересно, но хаскель пока самый передовой язык, под который есть нормальный тулинг: иде, редакторы, библиотеки,… (да, они есть).
«нам нафиг не нужон, этот ваш хкт»
простите моё невежество, что такое хкт?
HKT = higher-kinded types, типы высшего порядка
Да, в F# нет монад. Функциональность в том, что там, э-э-э, есть функции и синтаксис ML-подобный.
Да вряд ли F# когда-то станет аналогом хаскеля, потому что использует тот же рантайм что и C# и нужно поддерживать интероп в обе стороны. Если я все правильно понял, то HKT по этой причине и отсутствует (нет поддержки в рантайме), а по пути скалы не хотят идти (стирание типов). У HKT есть еще обратная сторона медали — тайп-астронавтика, примеры: Cats и ZIO из скалы, некоторые запрещают их использование. Также это очень странно, когда люди ругают F#, и при этом пытаются писать на c# как на хаскеле.
что-то я не понял, в Ф# нет монад? и комьюнити не хочет?
В f# нет монад, т.к. нету hkt, но там есть computation expressions, а это вещь более общая, удобная и полезная, чем монады. По-этому монады в f# не очень актуальны.
Про hkt написали выше — в шарпе нет стирания типов и генерики поддержаны на уровне рантайма. По-этому для адекватной реализации вариант скалы не прокатит и надо патчить рантайм, а делать существенные патчи рантайма специально под f# никто не будет.
Мне казалось что это MS ответ хаскелю.
ghc (основная реализация хаскеля де-факто) и так как бы под-мсненный, назовем так. По-этому мс отвечать на него незачем. А вообще у них еще F* есть.
В f# нет монад, т.к. нету hkt, но там есть computation expressions, а это вещь более общая, удобная и полезная, чем монады. По-этому монады в f# не очень актуальны.
Очень хотелось бы посмотреть, в частности на систему эффектов. А то я в курсе только FT и фри монад в разных обертках (Free, Freer, Polisemi, ...), интересно что может F# предложить?
Очень хотелось бы посмотреть, в частности на систему эффектов.
Любая система эффектов — это всегда обертка над call/cc, так что формально все эти конструкции (около)эквивалентны. Разница там исключительно в формате использования, а у computational expressions синтаксис приятнее и богаче чем у do-нотации, и реализация более "прямая", вот в общем-то и все.
Но все системы эффектов основаны на том, что у нас есть T<A> и мы преобразуем это в T<B>. Без этого кучи полезных комбинаторов не написать.
Можно конкретный пример, типа "вот есть интерфейс за которым можно спрятать пару реализаций, вот реализации, вот использование"? Ду это ведь лишь сахар, смысл не в нем, а в генерик бинде, поверх которого можно навернуть джоины/filterM/replicateM/guard/when/...
Ду это ведь лишь сахар, смысл не в нем, а в генерик бинде, поверх которого можно навернуть джоины/filterM/replicateM/guard/when/.
Ноуп, в том и дело что смысл как раз в ду-нотации. Ну да, а хаскеле еще важны комбинаторы — и это как раз фундаментальный косяк в дизайне хаскеля. Именно из-за этого в хаскеле тебе монады необходимы — потому что если что-то не является монадой, то ты с этим чем-то не сможешь работать ни через ду-нотацию, ни через комбинаторы, а если ты с этим чем-то не можешь работать ни через ду-нотацию, ни через комбинаторы, то эта хрень становится де-факто бесполезной.
Эффект сам по себе, изначально, это просто некоторая ф-я, которая применяется в выброшенному из вычисления продолжению — это все. Когда мы применяем продолжение само по себе, т.е. f(cont)(x), f !== id — тут эффекта нет (ну или "пустой эффект"), а вот когда f !== id, тут эффект и появляется.
Как я уже выше говорил, если мы пытаемся написать наиболее общий тип нашего f то у нас выходит a -> (b -> c) -> d и нет никаких причин это ограничивать, ты можешь выбрать любую f и все будет работать. Но есть языки без нативного call/cc и чтобы юзать это было приемлемо — тебе надо сделать f монадическим биндом. Вся машинерия с переходом Monad -> Free -> Freer нужна исключительно для одного — указать способ представления, в рамках которого все большее и большее подмножество f станет корректным монадическим биндом, чтобы потом ты для такого f мог дунотатить дунотацию и комбинировать комбинаторы. Вот хорошая статья на тему: http://okmij.org/ftp/Haskell/extensible/more.pdf
Обрати внимание, что происходит с сигнатурой "бинда".
С-но, там где есть call/cc (нативный офк) это все ненужно, и лишперы эффекты не понтуясь юзают примерно с 70-х. Не называя их так офк, потому что в лиспах с call/cc они делаются и используются тривиально, и там вообще нечего обсуждать — продолжение выбросил, потом применил. О чем разговор?
Но вот написать функцию, которая работает с произвольной монадой, уже не получится. В частности, функции traverse на F# не видать.
Штука в том, что за пределами хаскеля необходимость в подобного рода ф-ях примерно нулевая.
Эффект сам по себе, изначально, это просто некоторая ф-я, которая применяется в выброшенному из вычисления продолжению — это все.
Нет, эффект не является тем что вы назвали.
Штука в том, что за пределами хаскеля необходимость в подобного рода ф-ях примерно нулевая.
Ага, ну вот совсем нулевая. До тех пор пока задача укладывается в набор примитивов, подготовленных Microsoft. А вот как только перестаёт...
Нет, эффект не является тем что вы назвали.
Бред не несите, пожалуйста.
Ага, ну вот совсем нулевая.
Не совсем, но около. Нулевая в языках с call/cc, да, т.к. там traverse с друзьями это обычные for/map/fold/filter/etc., т.е. вообще все монадические комбинаторы — это стандартные языковые конструкции или обычные (немонадические) функции. Мне не надо делать какой-то там траверс или _forМ чего-то там, чтобы в схемке поочередно применить список эффектов (ну async например), я просто так и напишу (map await lst), где map — просто обычная функция map. Ну или лучше простым циклом (for ([x lst]) (await x)). При этом никаких специальных действий для того, чтобы этот map или этот for работал для любого эффекта, мне не надо, оно сразу работает.
А вот как только перестаёт...
А вот как только перерастает — отсутствие примитива эквивалентно отсутствию комбинатора в стандартной библиотеке. Тогда мы должны этот комбинатор написать сами — и точно то же самое мы можем сделать и в f# просто написав его для конкретной монады. Все равно для какой-то другой она нам не понадобится, смысл портить код лишними абстракциями?
А вот как только перерастает — отсутствие примитива эквивалентно отсутствию комбинатора в стандартной библиотеке. Тогда мы должны этот комбинатор написать сами — и точно то же самое мы можем сделать и в f# просто написав его для конкретной монады.
Так, да не так.
В Хаскеле я могу написать, на выбор, или свой комбинатор и использовать его со стандартной монадой — или свою монаду и использовать её со стандартным комбинатором.
В F# мне доступен только первый вариант, но не второй.
В Хаскеле я могу написать, на выбор, или свой комбинатор и использовать его со стандартной монадой — или свою монаду и использовать её со стандартным комбинатором.
Как я уже сказал, в языке с поддержкой эффектов вам ни первое ни второе не надо, т.к. в качестве требуемых комбинаторов работают обычные языковые конструкции. Ну чтобы понятнее было, на примере (shift/reset — операторы обертки над call/cc для захвата delimeted continuations, см https://docs.racket-lang.org/reference/cont.html?q=control#%28form._%28%28lib._racket%2Fcontrol..rkt%29._reset%29%29):
#lang racket
(require racket/control)
(define (map f lst) ; обычный map, специально сделал вместо библиотечного, чтобы было видно отсутствие магии
(if (null? lst) '() (cons (f (car lst)) (map f (cdr lst)))))
(define (maybe-effect x) ; обертки делать не стал, считаем что '() - это Nothing, все остальное - Some
(shift k (if (null? x) null (k x))))->
> (reset
(map (compose add1 maybe-effect) '(1 2 3 4)))
'(2 3 4 5) ; mapM не нужОн
> (reset
(map (compose add1 maybe-effect) '(1 () 3 4)))
'() ; обрыв вычислений на первой '()можно подусложнить слегка:
> (define (list-effect x)
(shift k (flatten (map k x))))
> (reset
(define x (list-effect (map maybe-effect '(1 3))))
(define y (list-effect (map maybe-effect '(1 () 3))))
(+ x y))
'()
> (reset
(define x (list-effect (map maybe-effect '(1 3))))
(define y (list-effect (map maybe-effect '(1 3))))
(+ x y))
'(2 4 4 6)
>так что описываемый вами выбор в хаскеле — это, извините, но выбор между гамбургером с говном и гигантской клизмой. И нет какого-то смысла сокрушатьсЯ, что чего-то из двух не завезли. При том, что:
В F# мне доступен только первый вариант, но не второй.
Второй тоже доступен но в виде синтаксических конструкций. Т.е. тоже завезли таки.
ЗЫ: да, compose сверху — это просто композиция ф-й, (define (compose f g) (λ (x) (f (g x))))
больше скобочек богу лиспа :)
Здесь речь о поддержке одного конкретного эффекта — IO. Как быть, если нужно разграничить эффекты?
Здесь речь о поддержке одного конкретного эффекта — IO
Там речь о любом эффекте. Так и пишите, только вместо list-effect или maybe-effect будет io-effect. Причем будет свободно композиться со всеми другими эффектами — без всяких трансформеров.
Человек очень изящно просто обошел проблему невыразительной системы типов — взял динамический яп где не нужно описывать интерфейсы функторов/монад. И хоба, они сразу оказались не нужны.
Гениально же.
Человек очень изящно просто обошел проблему невыразительной системы типов
Во-первых, продолжения тоже типизируются, есть не одна модель. Ты не забывай, что мы обсуждаем вещи, которые перестали быть мейнстримом еще к выходу первого стандарта хаскеля. Тогда все описывалось как раз в рамках cps-семантики (в том числе и эффекты офк, коим сто лет в обед), а про мондадки никто и слыхом не слыхивал.
Во-вторых, при чем тут типы, если мы обсуждаем выразительность конструкций и с-но возможность писать тот или иной код просто с алгоритмической точки зрения? Типы — вещь совершенно ортогональная. Не надо мешать монады и и типы, это типичная ошибка людей, которые не разбираются в теме и не понимают, откуда что произошло, исторически. Монады ни для какой типизации и разделения чего-либо не нужны, для этого даже HKT не нужны, т.к. они эмулируются при желании.
В-третьих — не нужны не из-за отсутствия типов, а именно из-за того, что абсолютно все, что можно написать с монадами, можно написать в cps, только напрямую. При этом продолжения, в отличии от монад, прекрасно композятся, иными словами, для них не существует основной проблемы монад в принципе.
В-четвертых — надо понимать, еще раз, что монады появились как костыль для более-менее вменяемого использования продолжений в языках, в которых их нет. Очевидно, что если у тебя есть первичный, базовый концепт, то производный для тебя бесполезен.
Вообще, пейперов про продолжения и мондадки, как что к чему относится и как что через что выражается овердофига, взял бы да почитал для самообразования.
Типы тут при том, что монады "работают" на уровне типов. В частности, при попытке типизировать ваши трюки с продолжениями неизбежно всплывут монады.
В частности, ваша map — это на самом деле и есть mapM. А ваши "эффекты" на самом деле монады.
Типы тут при том, что монады "работают" на уровне типов.
Монада — это инстанс тайпкласса или реализация интерфейса (обращаю внимание — не сам тайпкласс или интерфейс, а конкретный инстанс/реализация!), т.е. некоторый набор ф-й, работающих определенным образом. Не тип. Так что монада (как набор из ф-й) работает именно на уровне значений. Вы можете, конечно, попытаться определить некоторый тип, состоящий ровно из тех значений, для которых этот инстанс/реализация определены — и у вас будет что-то что можно интерпретировать в качестве чего-то похожего на тип, если натянуть сову ж*пой на глобус. Но это в любом случае совершенно независимые вещи — можно использовать типы без монад, а можно монады без типов. Это же кажется самоочевидным, в чем ваша проблема с пониманием такого простого факта?
В частности, ваша map — это на самом деле и есть mapM.
Это обычный map. Там реализация приведена. Можете посмотреть реализацию map, mapM и сравнить.
при попытке типизировать ваши трюки с продолжениями неизбежно всплывут монады
Или не всплывут, ага. Скажем так, при попытке просто взять и протипизировать продолжения напрямую в монадических терминах — возникают некоторые проблемы. Там для бинда получается тип более общий чем у freer и он, в общем случае, не тип монадического бинда.
А ваши "эффекты" на самом деле монады.
"Эффекты" и продолжения появились лет за 15 до монад. Так что, верно будет сказать обратное — это монады на самом деле просто эффекты и продолжения. Что я, в общем-то, уже неоднократно тут и говорил. На самом деле монады и появились изначально как вариант категорной интерпретации cps.
Это обычный map. Там реализация приведена. Можете посмотреть реализацию map, mapM и сравнить.
Да, точно. Извиняюсь, я скобочки неправильно разглядел. Но это просто делает ваши эффекты ещё более запутанными.
Вот, к примеру, как получить в результате "сложения" списков (1 3) и (1 () 3) не пустоту, а список (2 4 () () 4 6)?
"Эффекты" и продолжения появились лет за 15 до монад.
Не вижу чему это противоречит.
Но это просто делает ваши эффекты ещё более запутанными.
Да нет, все предельно просто, если понимать как работает shift/reset.
Вот, к примеру, как получить в результате "сложения" списков (1 3) и (1 () 3) не пустоту, а список (2 4 () () 4 6)?
Ну вообще там не пустота, а просто flatten так отрабатывает из-за того что nothing это (). Я просто сделал более простую реализацию, чтобы не нагружать деталями. Если не срезать углы, то целиком выглядеть все должно так:
#lang racket
(require racket/control)
(define list-tag (make-continuation-prompt-tag))
(define maybe-tag (make-continuation-prompt-tag))
(define (list-effect x)
(shift-at list-tag k (append* (map k x))))
(struct just (value) #:transparent)
(struct nothing () #:transparent)
(define (maybe-effect x)
(shift-at maybe-tag k (if (nothing? x) (nothing) (k (just-value x)))))
(define (yoba)
(reset-at list-tag
(list
(reset-at maybe-tag
(define x (maybe-effect (list-effect `(,(just 1) ,(just 2)))))
(define z (maybe-effect (list-effect `(,(nothing) ,(just 6)))))
(just (+ x z))))))->
> (yoba)
(list (nothing) (just 7) (nothing) (just 8))
> тут три отличия:
- правильный flatten (append* это однократный flatten как в хаскеле, а flatten лисповый работает подругому) и правильная обработка maybe (с nothing/just в итоге ничего не путается как с '())
- разделение захваченных продолжений — ну достаточно очевидно, что если мы из контекста эмитим некоторый набор эффектов, то и перехватывать мы их должны по отдельности, по-этому на каждый эффект должен быть свой reset
- здесь явно юзается return эффектов, которые должны быть interchangeable с ресетами чтобы корректно отрабатывала композиция. По-хорошему можно засахарить (reset effect-tag (effect-return expr)) в (reset-effect expr) и (reset-effect1 (reset-effect2… (reset-effectn expr)) в (effects (effect1… effectn) expr), но я не стал чтобы явно было видно что происходит.
Не вижу чему это противоречит.
Это собственно указывает, что исторически является чем. Монады — реализацией эффектов/продолжений, а не наоборот.
Ну и сразу что есть «эффекты», что «продолжения».
Про продолжения и call/cc нашёл статью достаточно начального для меня уровня на русском (перевод):
fprog.ru/lib/ferguson-dwight-call-cc-patterns
Про cps-преобразование, эффекты (и почему монады это упрощённое call/cc) вопросы однако остались.
Как я понимаю в Haskell монады нужны были как трюк против обхода ленивости и ссылочной прозрачности во время компиляции (мы обманываем компилятор вынуждая его проставлять ВСЕ вызовы функций в определенной последовательности до момента когда код из декларативного станет императивным).
Естественно, если Вы уже в монаде — то ваш map это монадический mapM?
Так, конечно, можно считать, но с большой натяжкой — дело в том, что mapM для каждой монады свой (это же полиморфная по монаде ф-я), а "мой map" — он один. И если вы реализацию map кому-то покажете, то вам никто не скажет, что это mapM.
Ну так и монада одна — ContT IO r a?
Ну как — вон там list был или maybe :)
В любом случае — какая разница-то? Смысл в том, что комбинаторы писать не нужно, без них даже лучше. По-этому и не жалко, что написать их нельзя.
Разница огромная. Монады намного более примитивная конструкция, в то время как ваши продолжения(конкретная реализация в racket) уже неявно включают в себя монады(IO, Cont и бог знает какие ещё). С типизацией всё плохо. И какой тогда вообще в этом смысл? От хаскеля _весь_ профит в типизации. А тут есть страшная конструкция, с которой вообще возможно работать только потому, что не надо всё типизировать. Практической пользы от этого ноль.
Ваш первый вариант кода(без continuation-mark) основан на динамических преобразованиях, и если туда добавить just/nothing, то всё ломается
Там нет преобразований, просто любое не-null значение считается just а null — nothing.
Точно так же у меня пока не получилось скомпоновать два «эффекта» в Cont(из-за того, что r получается разный). Так что судить тут не могу.
А зачем вы пытаетесь компоновать эффекты в cont?
Разница огромная. Монады намного более примитивная конструкция
Все наоборот.
уже неявно включают в себя монады(IO, Cont и бог знает какие ещё)
Нет, не включают.
И какой тогда вообще в этом смысл?
Эм. Ну а какой в принципе в монадах смысл? Писать легко код, котоырй без монад было бы писать сложно.
От хаскеля весь профит в типизации.
От хаскеля — в типизации, да, на то он и хаскель. А монады-то тут при чем? Они и без типизации прекрасно работают. И Продолжения тоже. Вы не путайте ортогональные концепции. Типизация — это одно дело (типизация работает на уровне типов, что логично), а языковые конструкции — это другое дело (они работают на уровне значений).
Не важно типизируется или не типизируется у вас тот же await/async — профит от такой конструкции одинаковый, что в c#, что в js, и состоит этот профит в удобной возможности писать асинхронный код. Аналогично с остальными монадами. Наличие или отсутствие типизации никак не влияет на тот факт, что монады просто позволяют легко и удобно выражать определенные вещи.
А тут есть страшная конструкция
Почему страшная? Наоборот — она с формально-теоретической точки зрения очень красивая и изящная, и находится в основе — в отличии от монад, которые исторически появились в качестве костыля.
Практической пользы от этого ноль.
Как это ноль? Вы можете просто спокойно писать код, который работает — при этот вам не надо ни тратить время на написание монадических комбинаторов, ни на написание трансформеров, которые прерващают код с монадами в натуральный адъ (продолжения же в отличии от монад композятся).
Преимущества продолжений над монадами очевидны — любой код, который пишется на монадах, пишется на продолжениях проще и понятнее.
В этом и состоит самый что ни на есть практический смысл — достигать того же эффекта но за счет более малого количества более простого, понятного и поддерживаемого кода.
Не знаю как это работает.
Ну в этом и проблема. Вы зачем-то обсуждаете концепцию, не зная, как она работает. Там вон выше человек async/await обсуждает, не понимая, как он работает и при этом изо всех сил упирается в своих заблуждениях. Не повторяйте эту ошибку, глупо очень выглядит.
Лучше просто конкретные вопросы задайте, если вам что-то непонятно, и я объясню.
Там нет преобразований, просто любое не-null значение считается just а null — nothing.Ну да
Все наоборот.Возможно, но пока я этого не вижу
Нет, не включают.Объясните
Почему страшная? Наоборот — она с формально-теоретической точки зрения очень красивая и изящная, в отличии от монад, которые исторически появились в качестве костыля.По мне с точностью до наоборот. Конструкция, родившаяся из особенностей работы интерпретатора. А монады — в результате обобщения. Но мне пока рано судить.
А как можно представить IO в виде продолжения?
Как это ноль? Вы можете просто спокойно писать код, который работает — при этот вам не надо ни тратить время на написание монадический комбинаторов, ни на написание трансформеров, которые прерващают код с монадами в натуральный адъ (продолжения же в отличии от монад композятся).О какой понятности речь, если я до сих пор до конца не понял как эта штуковина работает? С tf у меня таких проблем нет(да и стакается там всё неплохо). Плюс отсутствие типизации — и это невозможно использовать в production.
Преимущества продолжений над монадами очевидны — любой код, который пишется на монадах, пишется на продолжениях проще и понятнее.
На самом деле понятно почему в hs предпочли именно монады.
Возможно, но пока я этого не вижу
Ну просто как факт примите. Тут ничего видеть или не видеть не надо, это объективная вещь.
Объясните
Что тут объяснять? Нету там никаких "автоматически включенных" монад. Именно потому у вас и возникает проблема с написанием типов, что вы пытаетесь эти монады туда воткнуть — а их там нет.
По мне с точностью до наоборот.
Ну еще раз, есть чье-то мнение (не важно, ваше или мое), а есть факты.
Конструкция, родившаяся из особенностей работы интерпретатора. А монады — в результате обобщения.
Все, конечно, было совсем не так. Никакие интерпретаторы к продолжениям вообще ну никак не относились изначально, продолжения — это как раз гибкий теоретический концепт на основе которого описывается семантика разных интересных вещей. Фактически, абсолютно все что можно описать — можно описать в рамках cps-семантики. Монады же появились конкретно как костыльная замена cps-семантике.
А как можно представить IO в виде продолжения?
Любую монаду, очевидно, элементарно можно представить через продолжения просто потому, что любая монада тривиально выражается через монаду продолжений, а реализовать монаду продолжений на продолжениях, как вы понимаете… это такое :)
Но вообще изначально ИО-семантики строились как раз на cps, монад тогда еще не было. Можете погуглить на эту тему пейперы, если интересно.
О какой понятности речь, если я до сих пор до конца не понял как эта штуковина работает?
Вы и не должны, вы же не знаете как продолжения работают. Монадический код для человека, который его впервые увидел — тоже сплошной hurrdurr, пока человек не поймет, что такое бинд, не узнает, как рассахаривается ду-нотация и почему это работает все вообще. Но если конкретно на ваш вопрос ответить, то приведите плиз аналог вот этого кода на хаскеле:
(reset-at list-tag
(list
(reset-at maybe-tag
(define x (maybe-effect (list-effect `(,(just 1) ,(just 2)))))
(define z (maybe-effect (list-effect `(,(nothing) ,(just 6)))))
(just (+ x z)))))И тогда мы о понятности сможем поговорить, ага.
Плюс отсутствие типизации — и это невозможно использовать в production.
- это в приницпе можно типизировать
- в продакшене есть куча нетипизированного, прекрасно работающего кода
я, заметьте, не отрицаю пользы типизации. Но вот эти утверждения из разряда "без типизации невозможно использовать в продакшене" — попросту непрофессионально.
На самом деле понятно почему в hs предпочли именно монады.
Скажем так, не то чтобы был какой-то выбор. А что именно вам понятно? Почему предпочли? Какая может быть причина писать более сложный и запутанный код с кучей лишнего, когда можно писать более простой и без лишнего?
Скажем так, не то чтобы был какой-то выбор. А что именно вам понятно? Почему предпочли? Какая может быть причина писать более сложный и запутанный код с кучей лишнего, когда можно писать более простой и без лишнего?
Если они такие удобные, почему я не вижу ни одного языка где бы на полном серьезе оно бы использовалось как основа для эффектфул вычислений?
Ну просто как факт примите. Тут ничего видеть или не видеть не надо, это объективная вещь.Не могу, ибо Вы пока никаких объективных фактов не привели. Сравните их в одинаковых условиях — на одном языке и desugared. На том же хс без do нотации, тогда и можно будет сказать что проще, что сложнее и что как стакается.
Вы hs хорошо знаете? Я средне, с racket вообще не знаком.
(Ну или я сам сравню, когда-нибудь; когда пойму полностью)
Но если конкретно на ваш вопрос ответить, то приведите плиз аналог вот этого кода на хаскеле:У меня пока не получается. К тому же я не знаю как сделать эти теги =\
(и да, если я не смогу — это ничего хорошего о cps не скажет; ну и обо мне тоже)
я, заметьте, не отрицаю пользы типизации. Но вот эти утверждения из разряда «без типизации невозможно использовать в продакшене» — попросту непрофессионально.без типов можно работать в продакшене. Но код и «поток исполнения» должны быть простыми.
Скажем так, не то чтобы был какой-то выбор. А что именно вам понятно? Почему предпочли? Какая может быть причина писать более сложный и запутанный код с кучей лишнего, когда можно писать более простой и без лишнего?интересно, как бы выглядел аналог do нотации для hs? Делся бы куда-нибудь «лишний код»? Всё сразу бы застакалось?
Не могу, ибо Вы пока никаких объективных фактов не привели.
Я вам только что объективный факт назвал. Верить или не верить ваше дело.
Сравните их в одинаковых условиях — на одном языке и desugared.
В примерах выше нет никакого сахара, с-но десугарить нечего. Сахар можно было бы приделать (пару макросов для удобства), но я намеренно не стал.
У меня пока не получается.
nuff said
К тому же я не знаю как сделать эти теги =\
Так и не надо делать теги. Я говорю про следующее — вот у вас есть два значения x и y с типом List Maybe Number, т.е. двойная монадка. Покажите как вы в ду-нотации например получите при помощи монадок из этих двух значений List Maybe их сумм. Ну и до кучи — как потом поменять код чтобы второе значение было Maybe List вместо List Maybe и как поменять код чтобы результат был Maybe List а не List Maybe.
Но код и «поток исполнения» должны быть простыми.
Так а там выше простой код и поток исполнения. Он по сложности на уровне написания mapM примерно. Т.е. Человек, который имеет понимание и опыт работы с продолжениями на том же уровне, на котором надо иметь понимание и опыт работы с монадами, чтобы понять, что такое mapM и как она реализуется — вообще без проблем поймет код выше. Это как бы старые, всем известные, классические штуки, их в пейперах писали еще до вашего рождения, скорее всего (ну до моего точно).
интересно, как бы выглядел аналог do нотации для hs?
Да так же как выглядит бы и выглядел, почему должен быть как-то по-другому он? Дело-то не в ду-нотации, ду-нотация просто сахар. Дело в используемых конструкциях. В примерах выше нету никакого аналога ду-нотации или чего-то типа того, там просто обычный код.
А как тогда выражается Just Nothing?
В таком виде — никак. А должен? :) Это считай как мейби-"монадка" для nullable типа. Которая на самом деле не монадка, как выше выясняли :)
Что не мешает ее юзать как монадку, впрочем.
В любом случае, лучше смотри сразу на вторую реализацию.
Если они такие удобные, почему я не вижу ни одного языка где бы на полном серьезе оно бы использовалось как основа для эффектфул вычислений?
Ну, полноценные продолжения — это достаточно сложно с точки зрения рантайма.
Ну, полноценные продолжения — это достаточно сложно с точки зрения рантайма.
Ок, тогда будем посмотреть когда появится эргономичная реализация. А то пока это всё слишком оторвано от практики.
В примерах выше нет никакого сахара, с-но десугарить нечего. Сахар можно было бы приделать (пару макросов для удобства), но я намеренно не стал.В них — нет. Мне интересно в контексте cps как замена монад. А для монад в hs используется сахар. Просто хочу сравнить монады без сахара и cps без сахара в hs. Но это уже я сам, наверное.
nuff said=(
Так и не надо делать теги. Я говорю про следующее — вот у вас есть два значения x и y с типом List Maybe Number, т.е. двойная монадка. Покажите как вы в ду-нотации например получите при помощи монадок из этих двух значений List Maybe их сумм. Ну и до кучи — как потом поменять код чтобы второе значение было Maybe List вместо List Maybe и как поменять код чтобы результат был Maybe List а не List Maybe.
Ну вообще:
liftM2 (liftM2 (+))а с do как-то так:
do
x <- xs
y <- ys
return $ do
x' <- x
y' <- y
return $ x' + y'Так а там выше простой код и поток исполнения. Он по сложности на уровне написания mapM примерноmapM уже слишком сложно для скрипта, на мой взгляд.
Да так же как выглядит бы и выглядел, почему должен быть как-то по-другому он? Дело-то не в ду-нотации, ду-нотация просто сахар. Дело в используемых конструкциях. В примерах выше нету никакого аналога ду-нотации или чего-то типа того, там просто обычный код.do нотация это сахар, я не спорю. Просто в каком-нибудь C, что-бы писать код аналогичный hs IO, не нужна do нотация. Так же и в racket для cps. В хаскель она понадобится, если не выносить все функции на уровень cps.
В них — нет. Мне интересно в контексте cps как замена монад. А для монад в hs используется сахар.
Ну а для продолжений зачем какой-то сахар? Просто обычный код пишите и все. Т.е. продолжения без сахара — это вот код выше.
а с do как-то так:
Ага, ну во-первых код уже сложнее, чем оригинал с продолжениями, а во-вторых — там было еще два вопроса: как изменить код, чтобы во втором значении был другой порядок монад, и как изменить код, чтобы в результате был другой порядок монад.
mapM уже слишком сложно для скрипта, на мой взгляд.
А кто обсуждал скрипты?
do нотация это сахар, я не спорю. Просто в каком-нибудь C, что-бы писать код аналогичный hs IO, не нужна do нотация.
Без ду-нотации будет портянка из биндов. Ну с-но код в ио на сишке будет выглядеть точно так же как как в ио на хаскеле но без ду-нотации и комбинаторов.
В хаскель она понадобится, если не выносить все функции на уровень cps.
Смысл в томи состоит, чтобы вынести.
Монады по-определению выполняются в определенном порядке. Если порядок не важен, нужно использовать аппликативы
(-XDoApplicative в помощь)
Монады по-определению выполняются в определенном порядке.
Так порядок определенный, вопрос в том, как следует изменить код, чтобы его поменять.
Если порядок не важен, нужно использовать аппликативы
Здесь нужен бинд, аппликативы не прокатят. Ну т.е. конкретно в этом примере бинд не нужен, но я могу сделать так, чтобы z зависело от x:
(define (yoba)
(reset-at list-tag
(list
(reset-at maybe-tag
(define x (maybe-effect (list-effect `(,(just 1) ,(just 2)))))
(define z (maybe-effect (list-effect `(,(nothing) ,(just x)))))
(just (+ x z))))))и здесь без бинда вафли
Затем же, зачем и монадам?
Ну, монадам ду-нотация нужна за тем, что портянка из бинда с коллбеками без нее выглядит не очень. С продолжениями нету никакой такой портянки.
По мне так мой код намного проще.
Совсем нет, в моем коде я просто сперва разворачиваю любой эффект, а потом сворачиваю, как надо. В вашем же случае вам приходится делать вложенный do, да еще и с прибитой очередностью в монадах. У вас объективно в коде больше происходит, тут исключительно эффект утенка.
- как сделать так, что-бы нельзя было сделать из [Maybe Int] — Maybe [Int]?
Не совсем понял, что это значит. Тип зафиксировать? Ну если типы есть просто устанавливаете нужный возвращаемый тип и все. Или что вы имели ввиду?
Изменить просто — добавить sequence к аргументу или результату.
Поконкретнее можно? Что и куда вы собрались добавлять? Ну т.е. то что вы говорите не будет работать (если я вас верно понял), я просто, чтобы уточнить, где ошибка.
Просто без типов обычно скрипты.
Да нет, без типов обычные программы, по сложности ничем не отличающиеся от программ с типами.
Смысл был в том что-бы можно было писать a -> a.
Ну вот я в racket пишу функцию: (define (f x) x) — это a -> a. С-но я могу на типизированном диалекте это повторить:
#lang typed/racket
(: f (All (a) (-> a a)))
(define (f x) x)
> (f 10)
- : Integer [more precisely: Positive-Byte]
10
> Видите, работает, ф-я с типом a -> a.
Монады реализуются на уровне языка, и довольно просто, если бы с продолжениями было так-же, то может они бы и смогли конкурировать.
Ну, это совсем не так. Монады практически не применяются в языках, в которых нету нативной поддержки монад. Т.е. сделать-то формально можно, но это неюзабельно.
И если бы концепция продолжений была популярна, сделали бы ещё одну нотацию как для стрелок.
Зачем там какая-то нотация? А по части популярности, ну да, тут верно. С-но, нормальные продолжения есть только в scheme-derived диалектах лиспа.
Но при чем тут популярность? Мы же саму конструкцию обсуждаем. На продолжениях можно "напрямую" писать простой и выразительный код. Проще и выразительнее чем на монадах.
Не совсем понял, что это значит. Тип зафиксировать? Ну если типы есть просто устанавливаете нужный возвращаемый тип и все. Или что вы имели ввиду?Да, что-то я совсем не объяснил. Допустим я по каким-то причинам не хочу что-бы кто-то мог сделать из моего Maybe (MyList a) — MyList (Maybe a). Что для этого потребуется?
Совсем нет, в моем коде я просто сперва разворачиваю любой эффект, а потом сворачиваю, как надо. В вашем же случае вам приходится делать вложенный do, да еще и с прибитой очередностью в монадах. У вас объективно в коде больше происходит, тут исключительно эффект утенка.У меня объективно происходит меньше. У Вас пришлось какие-то теги вводить + codeflow по сути вывернут наизнанку.
Поконкретнее можно? Что и куда вы собрались добавлять? Ну т.е. то что вы говорите не будет работать (если я вас верно понял), я просто, чтобы уточнить, где ошибка.
f :: [Maybe Int] -> Maybe [Int] -> Maybe [Int]
f xs ys = sequence $ do
x <- xs
y <- sequence ys
return $ do
x' <- x
y' <- y
return $ x' + y'Как то так?
Да нет, без типов обычные программы, по сложности ничем не отличающиеся от программ с типами.и тс из воздуха вырос? Аннотации типов? В теории, теория не отличается от практики.
Видите, работает, ф-я с типом a -> aя думал Вы поняли, что я хотел сказать. hs( a -> a ) это не то же самое что java( Function<A,A> ), например. И не то же самое что racket( (-> a a) ).
Что-бы hs функция была эквивалентна java, её нужно переписать как то так: hs( a -> IO a ). А что-бы она была эквивалентна racket — вот так: hs( a -> (a -> IO r) -> IO r ).
По этому я и спрашиваю какую нотацию применить, что-бы стакать такие вот функции?
Да, что-то я совсем не объяснил. Допустим я по каким-то причинам не хочу что-бы кто-то мог сделать из моего Maybe (MyList a) — MyList (Maybe a).
Все равно не понял. Если эта ф-я вычислима и корректно типизируется, значит, она должна писаться. Или вы вроде как про то, что myList будет вести себя аналогично IO, т.е. из него нельзя вытащить значение? Но это не запрещает писать ф-и с подобной сигнатурой, т.е. та же List (IO a) -> IO (List a) (упомянутая вами sequence) пишется, несмотря на то, что из IO значение вытащить нельзя. Можно посмотреть на вашу монаду MyList, для которой sequence будет "запрещен"?
У меня объективно происходит меньше
Нет, это не так, я же уже сказал.
У Вас пришлось какие-то теги вводить
Это низкоуровневые детали реализации. Ну т.е. как если бы вы do-нотацию раскрыли. Можно это все свернуть за сахар, конечно.
codeflow по сути вывернут наизнанку.
В смысле вывернут? Наоборот! Если мне надо взять сумму то я и пишу сумму (+ x y). А потом просто ставлю эффекты — например, если надо мне обработать список то будет (+ (list-effect x) y) надо воткнуть туда мейби, то добавлю (+ (list-effect x) (effect-maybe y)) а снаружи просто добавляются ресеты. Обычный ровный control-flow. С-но пример с do-нотацией сложнее уже даже в случае одной монады. С ростом числа монад все усложняется кардинально, т.е. ваш пример с sequence уже вообще по сложности по сравнению с эффектами куда-то в небеса улетает, там когнитивная нагрузка несравнимая.
Как то так?
Ага, ну вот теперь мы до сути дошли — для монад нет универсального коммутатора, а для эффектов есть. С-но — вам чтобы достичь того же что с эффектами надо написать коммутаторы для всех монад, а потом перебирать их кобминацию под каждый конкретный случай. В случае с эффектами вы просто пишите код как он есть и делаете wrap/unwrap эффекта.
и тс из воздуха вырос? Аннотации типов?
Я не понял вопроса.
я думал Вы поняли, что я хотел сказать. hs( a -> a ) это не то же самое что java( Function<A,A> ), например. И не то же самое что racket( (-> a a) ).
Я понимаю, что вы хотите сказать, но то, что вы хотите сказать неверно, в том и дело. a -> a в хаскеле это то же самое, что и a -> a в джаве или в racket (насколько понятие "то же самое" применимо для разных систем типов, конечно же).
Что-бы hs функция была эквивалентна java, её нужно переписать как то так: hs( a -> IO a ). А что-бы она была эквивалентна racket — вот так: hs( a -> (a -> IO r) -> IO r ).
Нет, не надо, в том и штука. Какая-нибудь функция вроде (define (f x) (+ x 1)) это в точности то же самое что и f x = x + 1.
Соответственно:
По этому я и спрашиваю какую нотацию применить, что-бы стакать такие вот функции?
Никакой нотации не надо. Это обычные ф-и a -> a, они стакаются совершенно обычным образом.
Вы из-за неправильного понимания происходящего создаете проблему там, где ее нет, по факту.
Можно посмотреть на вашу монаду MyList, для которой sequence будет «запрещен»?Смысл в том что я могу написать sequence для [IO a] -> IO [a], но не могу для IO [a] -> [IO a]. Потому что IO не Traversable. Как это сделать для продолжений?
В смысле вывернут? Наоборот!Ничего не наоборот, а именно так.
Я понимаю, что вы хотите сказать, но то, что вы хотите сказать неверно, в том и дело. a -> a в хаскеле это то же самое, что и a -> a в джаве или в racket (насколько понятие «то же самое» применимо для разных систем типов, конечно же).a -> a в hs это то же самое, что и Function<A,A> в джаве, я правильно понял? Тогда чему эквивалентно a -> IO a? Тоже Function<A,A>? Из этого выходит что a -> a эквивалентно a -> IO a, т.е. налицо нарушение логики. Так что тут Вы не правы.
Нет, не надо, в том и штука. Какая-нибудь функция вроде (define (f x) (+ x 1)) это в точности то же самое что и f x = x + 1.это то же самое до тех пор, пока не появится продолжение.
Соответственно:
Никакой нотации не надо. Это обычные ф-и a -> a, они стакаются совершенно обычным образом.Я уже объяснил какой тип у продолжений. Не вижу смысла ходить по кругу. Функция с продолжением никак не может быть a -> a (в hs).
Вы из-за неправильного понимания происходящего создаете проблему там, где ее нет, по факту.
Ну а для продолжений зачем какой-то сахар? Просто обычный код пишите и все. Т.е. продолжения без сахара — это вот код выше.Затем же, зачем и монадам?
Ага, ну во-первых код уже сложнее, чем оригинал с продолжениями, а во-вторых — там было еще два вопроса: как изменить код, чтобы во втором значении был другой порядок монад, и как изменить код, чтобы в результате был другой порядок монад.эмм. По мне так мой код намного проще.
Изменить просто — добавить sequence к аргументу или результату. А у Вас? + как сделать так, что-бы нельзя было сделать из [Maybe Int] — Maybe [Int]?
А кто обсуждал скрипты?Просто без типов обычно скрипты. Компилируемый язык без типов вообще глупость сама по себе. Но благо сейчас, с аннотациями типов, смысл появляется.
Смысл в томи состоит, чтобы вынести.Смысл был в том что-бы можно было писать a -> a. Монады реализуются на уровне языка, и довольно просто, если бы с продолжениями было так-же, то может они бы и смогли конкурировать.
И если бы концепция продолжений была популярна, сделали бы ещё одну нотацию как для стрелок.
Монады же появились конкретно как костыльная замена cps-семантике.Напишите, пожалуйста, статью об этом. Будет очень интересно почитать.
Там нет преобразований, просто любое не-null значение считается just а null — nothing.
А как тогда выражается Just Nothing?
То что траверс не нужен за пределами хаскелля мне даже комментировать неловко.
Ок, использовать монады computation expressions и правда позволяют, и даже немного сверху.
Но вот написать функцию, которая работает с произвольной монадой, уже не получится. В частности, функции traverse на F# не видать.
Вот пол-месяца назад я думал, что почти разобрался с Haskell.
Потом прочитал 4 «лонгрида», с обсуждениями call\cc и продолжениями и связей с монадами и перестал что-либо понимать (окончательно?).
Объясните пожалуйста если кто-то найдёт в себе силы и время.
Попробую по-порядку:
I. Вот моё представление о Haskell (до прочтения заумных комментариев на хабре):
0. Expressions (в смысле ссылочно-прозрачные функции) это хорошо при прочих равных.
Но:
1. «statement» часто обладает более насыщенной семантикой, чем «expressions» (сравните изменение элемента дерева в Haskell с императивом. А изменение 1го узла графа!?).
2. Чтобы FP-программы не оказались многословнее потребовались способы «более сильной» комбинации выражений, в сравнении с промышленными языками
3. Вот «из-за 1 и 2» и ввели такие понятия, как аппликативные функторы и монады (монады, также, оказались удобны для сокрытия внутри IO, почему так — надо разобраться (*)).
Это было очень удобно, хотя и оставались «мелкие» вопросы, с которыми оставалось разобраться:
I.a. Правда ли, что "<-" из do-нотации «невыразима без do-нотации сама по себе» (хотя любые законченные функции в do-нотации могут быть альтернативно выражены через комбинирование).
I.b В какой именно момент происходят вычисления монадических функций (как сами значения, так и эффекты)?
I.b.ii Для монады IO применяется общее правило про время вычисления функций (с учётом зависимости по данным через «переменную RealWorld») или нет?
Это примерно моё представление о Хаскель 2 недели назад оно «не бесповоротно неправильное»?
Можно же чуть-чуть доразобраться и идти дальше?
II.
Вот пришло время разобраться почему: «монады, а не аппликативные функторы?», «IO как монады, а не отдельный механизм», а также «I.a, I.b, I.b.ii»,
Прочитал 4 больших статьи на хабре с обсуждением и зарубами специалистов по ФП на 200+ комментариев, несколько статей со ссылками на новые понятия…
Итак я узнал (spoiler:
II.a do-нотация зачастую многословнее, чем комбинирование через >>=. Но писать надо всё равно через do (а не вырабатывать интуицию «функционального подхода» на >>=), — я думал ровно наоборот
II.b монады это «просто» реализация паттерна call/cc, — это вообще как? Ну т.е. что такое паттерн call/cc я прочитал (передаём функцию «досрочного» возврата в лямбду).
II.c монады реализуют ту же семантику, что и async\await, — тут я опять ничего не понял. Какое это имеет отношение, к ФП или Хаскелю (кроме исторически-дизайнерского legacy)? Чистые же функции с ленивыми вычислениями и так распараллелены по данным? Зачем нам мыслить категориями async\await?
II.d IO через монады это сознательный дизайн хаскеля, — но зачем!? Это же IO надо связать в последовательность, для этого надо между IO-вызовами передавать «скрытую переменную RealWorld». Неужели такое дизайнерское решение чем-то хорошо, я вот СОВЕРШЕННО не понимаю чем (эти «кишки элементов реализации наружу» мне какие-то лабораторные опытные образцы напоминают).
Резюмируя: знающие товарищи (если у вас найдётся на это время):
— поправьте меня, если я совсем не прав в своих предварительных представлениях (I.1 — I.4).
— если же мои предварительные представления о ФП «не совсем неправильные»:
— объясните как сделано — I.a — I.c
— а также какое отношение «II.a — II.d» имеет к действительности и зачем сделано именно так.
ПС
Извините за сумбур, если я недоразобрался.
Спасибо за внимание, если прочитали, и за внимание и потраченное время, если найдёте время и силы ответить!
Очень сумбурно, постараюсь ответить на то, что понял.
- Expressions (в смысле ссылочно-прозрачные функции) это хорошо при прочих равных.
Но:- «statement» часто обладает более насыщенной семантикой, чем «expressions» (сравните изменение элемента дерева в Haskell с императивом. А изменение 1го узла графа!?).
Экспрешны это выражение, что-то вычисляющие. Стейтменты — что-то делающие. В чистых ФП языках стейтментов вообще по сути нет (но можно написать похожие функции). Ну а в императивных языках без них них не обойтись. Экспрешны в целом удобнее, потому что ссылочная прозрачность. Я в статье про ФП подоробно это разбирал.
- Чтобы FP-программы не оказались многословнее потребовались способы «более сильной» комбинации выражений, в сравнении с промышленными языками
Верно
- Вот «из-за 1 и 2» и ввели такие понятия, как аппликативные функторы и монады (монады, также, оказались удобны для сокрытия внутри IO, почему так — надо разобраться (*)).
Да, монады придумали как штуку, позволяющую задать порядок вычислениям. За счет переписывания f(); g(); как g(f(x)), из-за чего f всегда должен вычисляться раньше, чем g.
I.a. Правда ли, что "<-" из do-нотации «невыразима без do-нотации сама по себе» (хотя любые законченные функции в do-нотации могут быть альтернативно выражены через комбинирование).
Этот вопрос я не понял.
I.b В какой именно момент происходят вычисления монадических функций (как сами значения, так и эффекты)?
В момент возврата значения из main. Если return 0 это окончание любой программы в императивных языках, то в Haskell с этого выполнение программы как раз начинается. Вся программа состоит из кучи накомпозенных друг на друга действий, и в конце концов вся эта громандная стейтмашина возвращается из мейна, и тогда начинает работать и производить описанные действия.
II.a do-нотация зачастую многословнее, чем комбинирование через >>=. Но писать надо всё равно через do (а не вырабатывать интуицию «функционального подхода» на >>=), — я думал ровно наоборот
Не особо она многословнее, а главное — понятнее и лучше ложится на человеческую интуицию. Больше одного >>= в одном выражении читать уже трудно.
II.b монады это «просто» реализация паттерна call/cc, — это вообще как? Ну т.е. что такое паттерн call/cc я прочитал (передаём функцию «досрочного» возврата в лямбду).
Это к оратору выше, который за это задвигал.
II.c монады реализуют ту же семантику, что и async\await, — тут я опять ничего не понял. Какое это имеет отношение, к ФП или Хаскелю (кроме исторически-дизайнерского legacy)? Чистые же функции с ленивыми вычислениями и так распараллелены по данным? Зачем нам мыслить категориями async\await?
async/await это ду-нотация — удобный способ записывать монадические вычисления. Асинхронное взаимодействие это пример монады, его удобно использовать для объяснения монад людям, которые постоянно асинк функции пишут и используют.
II.d IO через монады это сознательный дизайн хаскеля, — но зачем!? Это же IO надо связать в последовательность, для этого надо между IO-вызовами передавать «скрытую переменную RealWorld». Неужели такое дизайнерское решение чем-то хорошо, я вот СОВЕРШЕННО не понимаю чем (эти «кишки элементов реализации наружу» мне какие-то лабораторные опытные образцы напоминают).
Я лично не использую интерпретацию с RealWorld, оно только запутывает. Мне кажется более простым объяснени, что IO — это просто Id монада, у которой значение — не публичное поле, а приватное, поэтому работать с ним можно только через монадический интерфейс. А прочитать это значение может только магический рантайм "вне" main.
Правда ли, что "<-" из do-нотации «невыразима без do-нотации сама по себе»
do
x <- getSomething
putSomething x
getSomething >>= \x -> putSomething x
getSomething >>= putSomething
В какой именно момент происходят вычисления монадических функций (как сами значения, так и эффекты)?Зависит от монады. Например выражение:
Just 1 >> Just 2 -- вернёт Just 2
Nothing >> Just 2 -- вернёт Nothing
Такие монады как IO можно представить как способ комбинирования команд. Что-то вроде
command1 >> command2 >> command3Для монады IO применяется общее правило про время вычисления функций (с учётом зависимости по данным через «переменную RealWorld») или нет?С точки зрения языка, IO от других монад не отличается.
монады это «просто» реализация паттерна call/cc, — это вообще как? Ну т.е. что такое паттерн call/cc я прочитал (передаём функцию «досрочного» возврата в лямбду).Это неправда. Поведение, аналогичное многим монадам можно воспроизвести через call/cc и наоборот. Но это не значит что монады это реализация call/cc.
IO через монады это сознательный дизайн хаскеля, — но зачем!?Что-бы была возможность описывать IO действия на чистом ЯП?
самое интересное - последняя четверть текста
я чуть не закрыл страницу
Монады как паттерн переиспользования кода