 Elasticsearch, вероятно, самая популярная поисковая система на данный момент с развитым сообществом, поддержкой и горой информации в сети. Однако эта информация поступает непоследовательно и дробно.
Elasticsearch, вероятно, самая популярная поисковая система на данный момент с развитым сообществом, поддержкой и горой информации в сети. Однако эта информация поступает непоследовательно и дробно.
Самое первое и главное заблуждение — "нужен поиск, так бери эластик!". Но в действительности, если вам нужен шустрый поиск для небольшого или даже вполне себе крупного проекта, вам стоит разобраться в теме поподробней и вы откажетесь от использования именно этой системы.
Вторая проблема заключается в том, что пытаясь разобраться с начала, получить общую картину окажется непросто. Да инфы навалом, но последовательность в ее изучении выстраивается постфактум. Придется из книг бежать в документацию, а из документации обратно в книги, параллельно разгугливая тонкости, только чтобы понять, что такое Elasticsearch, почему он работает именно так и для чего же его вообще использовать, а где стоит выбрать что-то попроще.
В этой статье я попытался последовательно объяснить то что мне кажется главным в Elasticsearch, то для чего он был придуман и как он устроен.
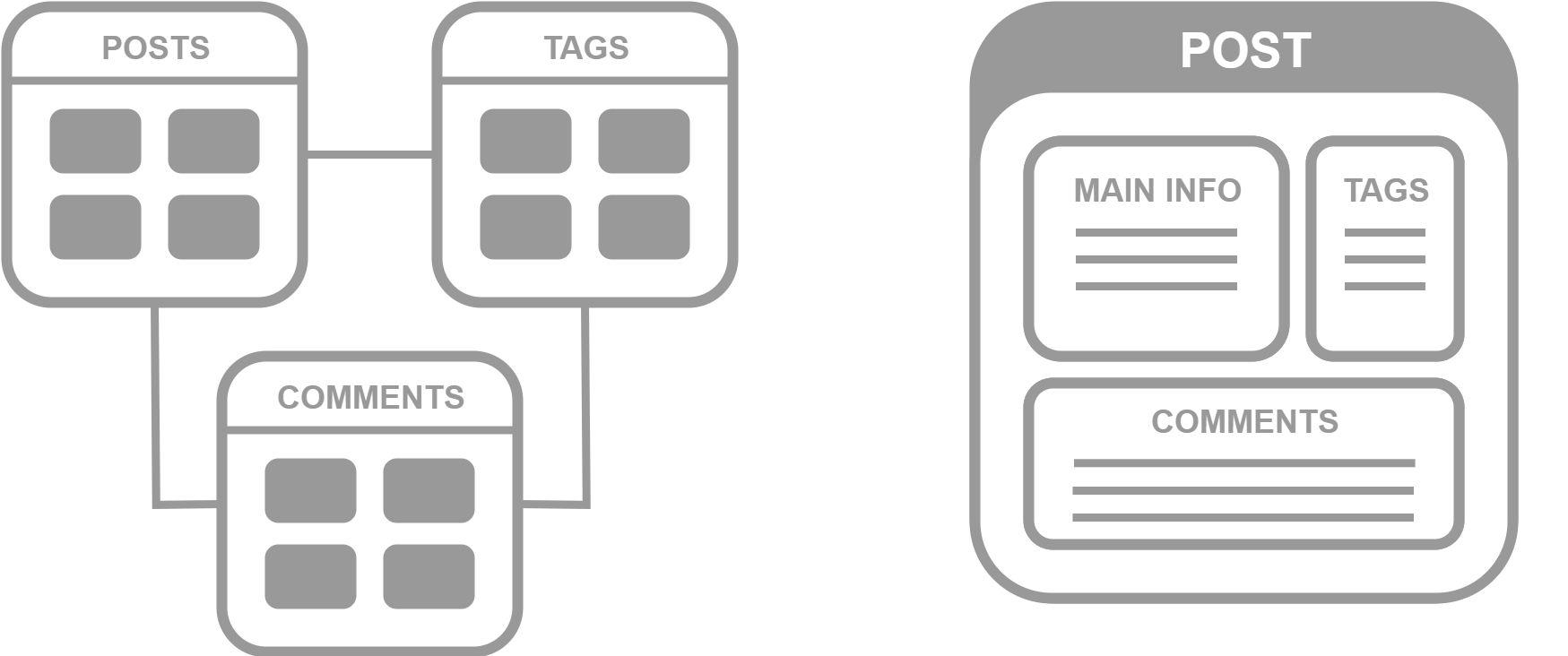
Для наглядности выдумаем себе задачу. Реализация поиска в коллективном блоге по всем материалам и пользователям. Система позволяет создавать теги, сообщества, геометки и все остальные штуки, которые нам помогают категоризировать огромное количество информации.
Схема хранения данных
То, какие действия с данными мы будем производить определит схему их хранения:
- скорее всего поисковая система должна будет быстро производить поиск
- запись и удаление могут не отличаться высокой скоростью, в системах поиска, полагаю, этим можно пренебречь
- структура данных будет интенсивно изменяться и хранилище может заполняться из нескольких независимых источников( различных баз, в том числе внешних для нашей системы )
Представьте еще раз сколько атрибутов может иметь публикация и сколько связанных с ней объектов. Автор, категория, сообщество, геометки, медиафайлы, теги, связанные публикации. Этот список можно продолжать до исчерпания фантазии. Если мы храним это в привычной реляционной базе то имеем миллион связей и миллиард атрибутов. Это прекрасно подходит для структурированного хранения долгие годы, но не очень вяжется с требованиями быстрого поиска.
А что если мы захотим добавить пару интеграций с внешними системами? Придется реализовать дополнительные таблицы или даже базы. Нам всегда будет нужно что-то добавить или изменить в объектах доступных для поиска. Вы понимаете к чему я клоню.
Намного быстрее читать из объектов, содержащих все необходимое здесь и сейчас. И намного проще вносить изменения в неструктурированную схему данных.
{
"title" : "С чего начинается Elasticsearch",
"author" : {
"name": "Roman"
},
"content" : "Elasticsearch, вероятно, самая популярная поисковая система...",
"tags":[
"elasticsearch"
],
"ps": "Да, проще всего представить это как JSON, BSON или XML"
}К тому же такие структуры данных проще делить, разносить по разным физическим хранилищам, распределять, ведь объекты уже содержат все необходимое.
Эти объекты мы можем воспринимать как отдельные страницы, файлы, карточки, все это можно назвать некими документами. Поэтому такая модель хранения данных называется документоориентированной.
Elasticsearch это документоориентированная база данных
Поиск
Теперь необходимо определиться с механизмами поиска. Данные организованы в виде документов. Как мы привыкли осуществлять поиск по документу?
Типичным примером документа будет веб-страница. Если мы попытаемся поискать по всей странице в браузере, поиск будет осуществляться по всему содержащемуся тексту. И это удобно для большинства кейсов.
Примерно так же работают многие поисковые системы, поиск происходит по всему тексту проиндексированных страниц, а не по отдельным полям, тегам или заголовкам. Это называется полнотекстовым поиском.
Искать предстоит по огромному количеству документов и было бы разумно запомнить что в каком документе лежит. В реляционных СУБД мы привыкли оптимизировать подобный поиск индексами.
Что такое индекс на самом деле? Если не вдаваться в детали, индекс это сбалансированное дерево, то есть дерево, в котором длина путей(количество шагов межу узлами) не будет отличаться больше чем на один шаг.

Например если бы мы проиндексировали наш пост, то у нас бы получилось дерево, листьями которого, являлись бы используемые в нем слова. Простыми словами, мы будем знать заранее, какие слова находятся в документе и как их быстро в нем найти. Не смотря на такую удобную структуризацию данных, обход дерева звучит как не самое лучшее решение для максимально быстрого поиска.
А что если сделать все наоборот — собрать список всех используемых слов и узнать, в каких документах они встречаются. Да, индексация займет больше времени, но нас в первую очередь интересует именно скорость поиска, а не индексации.

Такой индекс называется обратным индексом и используется для полнотекстового поиска.
Хороший пример — популярная open-source библиотека полнотекстового поиска, конечно же, с обратным индексом, Apache Lucene.
Elasticsearch использует индексы Lucene для хранения данных и поиска
Масштабирование
Как бы мы не пытались оптимизировать структуры данных и алгоритмы поиска, когда речь заходит о действительно больших массивах данных и действительно большом количестве запросов, необходимо задуматься о возможности повлиять на производительность системы путем увеличения аппаратного ресурса. Проще говоря, мы хотим иметь возможность накинуть немного памяти, ЦП и дискового пространства, чтобы все ехало быстрее. Мы можем назвать это масштабируемостью.
Самый простой вариант — накинуть железа на сервер. Если представить каждую условную единицу вычислительной мощности как деревянный кубик, то сейчас мы сложим кубики в одно место или один на другой, строя башню вертикально. Такое масштабирование и называется вертикальным.
Второй вариант — разделить наши задачи на группу машин. В этом случае мы тоже увеличиваем аппаратный ресурс, но сейчас кубики мы можем расположить на воображаемом столе как угодно на его плоскости, то есть горизонтально. Угадайте, как называется такое масштабирование?
Первый способ гарантирует нам быстрый результат без боли, но конечно не все так гладко. Как долго мы сможем увеличивать ресурс отдельной машины? Во-первых дешевым способом это будет только в самом начале, дальше оплата одного сервера будет стоить как несколько машин попроще. Во-вторых вы рано или поздно упретесь в потолок — железо, драйверы, пропускная способность и еще куча логических и физических ограничений. А самое главное, критический сбой в одной машине повлечет сбой всей системы, закономерно.
В отличии от первого способа второй не накладывает таких явных ограничений, мы можем добавлять машины сколько угодно, связывая их сетью. Конечно, это повлечет сетевые издержки — низкая скорость передачи в сети(в сравнении с обработкой на одной машине), сетевой оверхед. Но вместе с тем сеть имеет одно очень важное свойство — большую отказоустойчивость.
Распределенный индекс
Ок, для хранения данных и поиска мы будем использовать инстанс Lucene. Но ранее мы решили, что для обеспечения горизонтального масштабирования нам необходимо иметь возможность размещать данные на разных машинах. В действительности, какая разница как данные хранятся физически? Важно чтобы мы имели единое логическое хранилище. Каждый инстанс Lucene должен стать частью одного большого индекса, или осколком(shard) разбитого индекса. Шард будет выполнять непосредственно операции по поиску и записи данных.

Shard в Elasticsearch — это логическая единица хранения данных на уровне базы, которая является отдельным экземпляром Lucene.
Index — это одновременно и распределенная база и механизм управления и организации данных, это именно логическое пространство. Индекс содержит один или более шардов, их совокупность и является хранилищем.
Классическое сравнение индекса с другими базами выглядит примерно так.
Elasticsearch SQL MongoDB Index Database Database Mapping/Type Table Collection Field Column Field Object(JSON) Tuple Object(BSON)
Но существуют отличия в использовании этих абстракций. Рассмотрим еще один классический пример. У пользователя системы может храниться очень много информации, и мы решаем создавать новую базу для каждого пользователя. Это звучит дико! Но на самом деле в Elasticsearch это распространенная и даже хорошая практика. Индекс это довольно легкий механизм и лучше разделять большие данные, тем более, когда это логически оправдано. Системе проще работать с небольшими индексами чем с разросшейся базой для всего. Например, так вы можете создавать отдельный индекс для логов на каждый день и это широко используется.
По умолчанию количество шардов для индекса будет равным 5, но его всегда возможно изменить в настройкахindex.number_of_shards: 1или с помощью запроса шаблонов индекса.
PUT _template/all { "template": "*", "settings": { "number_of_shards": 1 } }
Важно управлять этим значением. Всегда принимайте решения с точки зрения параллельной обработки.
Каждый шард способен хранить примерно 232 или 4294967296 записей, это значит, что скорее всего вы упретесь в лимит вашего диска. Однако стоит понимать, все шарды будут участвовать в поиске и если мы будем искать по сотне пустых, потратим время впустую. Если шарды будут слишком большими мы так же будем тратить лишнее время на поиск, а так же операций перемещения и индексации станут очень тяжелыми.
Забегая вперед. Со временем Elasticsearch двигает и изменяет шарды, объединяя дробные и мелкие в большие. Следите за размером ваших шардов, при достижении 10ГБ производительность значительно падает.
Кластер
Мы определились с базовой концепцией распределенного индекса. Сейчас необходимо решить, как в действительности будет осуществляться управление отдельными базами.
Ранее мы решили, что за операции поиска и индексации отвечает отдельный инстанс Lucene(шард). Для того, чтобы обращаться к распределенной системе шардов, нам необходимо иметь некий координирующий узел, именно он будет принимать запросы и давать задания на запись или получение данных. То есть помимо хранения данных мы выделяем еще один вариант поведения программы — координирование.
Таким образом мы изначально ориентируемся на два вида узлов — CRUD-узлы и координирующие узлы. Назовем их data node и coordinating node. У нас есть куча машин объединенных в сеть и все это очень напоминает кластер.

Каждый запущенный экземпляр Elasticsearch является отдельным узлом(node). Cluster — это совокупность определенных нод. Когда вы запускаете один экземпляр ваш кластер будет состоять из одной ноды.
Для того чтобы объединить узлы в кластер они должны соответствовать ряду требований:
- Ноды должны иметь одинаковую версию
- Имя кластера
cluster.nameв конфигурации должно быть одинаковым
Конфигурация читается из файла elasticsearch.yml и переменных среды. Здесь мы можете настроить почти все, что касается неизменных в рантайме свойств ноды.
Вы можете поднимать несколько узлов на одной машине, для этого необходимо запускать инстансы из разных директорий файловой системы и в конфигурации указать разные портыhttp.port, по умолчанию порт 9200 для внешнего доступа и 9300 для внутрикластерного соединения. Это может понадобиться для тестирования и проектирования кластера, однако в проде подразумевается использование отдельных машин.
Каждый тип ответственности узлов налагает определенные системные требования. Очевидно, что data-ноды будут часто обращаться к диску и использовать значительные объемы памяти в процессе работы.
Мы так же можем утверждать, что не все данные будут запрашиваться одинаково часто. Данные постепенно "остывают" по мере снижения запросов. Мы можем назвать это жизненным циклом хранения данных. Хорошей идеей было бы держать хайповые публикации там, откуда их можно быстро достать, а забытые мемы 2007 можно положить подальше.
Начиная с версии 6.7 Elasticsearch предлагает механизм управления жизненным циклом. Для этого доступны три типа нод — hot, warm и cold.
Существует рекомендация по выбору аппаратных конфигураций для каждого из типов. Например hot-ноды должны иметь быстрые SSD, для warm и cold достаточно HDD-диска. Оптимальные соотношения память/диск будут следующими:
- hot — 1:30
- warm — 1:100
- cold — 1:500
Для того чтобы определить тип ноды как data node необходимо установить значение в конфигурацииnode.data: true, при этом рекомендуется выделять ноду под один конкретный тип, для повышения стабильности и производительности кластера.
Важнейшим аспектом в использовании распределенных систем является параллельное выполнение задач. Существует популярная модель распределенных вычислений, которая имеет лаконичное название MapReduce. И заключается она разделении выполнения задачи на два больших шага:
- Map — предварительная обработка данных, формулировка задачи и последующая ее передача выполняющим узлам
- Reduce — свертка множества результатов worker-нод в один финальный ответ

Именно такой механизм поможет нам выполнять операции с шардами. Координирующий узел получит запрос, предварительно переформулирует его для внутрикластерного взаимодействия и выполнит запросы к нашим worker-нодам(в данном случае к data-нодам).
Следовательно, coordinating-ноды должны иметь достаточный ресурс памяти, ЦП и быструю сеть, но при этом могут иметь скромный диск, ведь не осуществляют хранения данных.
Однако при большой частоте запросов, такие ноды могут стать узким местом системы. Мы можем пойти привычным путем и превратить точку внешнего доступа в плоскость. Пусть координирующих нод будет множество.
Такой подход позволит нам применять балансировку запросов, это можно сделать прямо в клиентском коде либо использовать любые существующие балансировщики.
В Elasticsearch все узлы неявно являются координирующими. Однако, стоит выделять отдельные coordinating-ноды, не выполняющие других операций. Забегая вперед, такие ноды можно определить, установив значения всех типов в false.Управление кластером
На данном этапе мы имеем возможность доступа к данным из множества точек — coordinating-нод. В этом нет проблем, если мы говорим о простых операциях чтения/записи в существующий индекс. Но если говорить о выделении новых шардов или их перемещении, может начаться путаница.
Предположим, возможность coordinating-нодам управления состоянием кластера. Один узел примет решение о перемещении шарда на одну data-ноду, а второй о перемещении того же на другую. Список возможных общекластерных действий может быть довольно широким, а список возможных конфликтов еще шире.
Очевидно такие важные решения должен принимать один центральный узел. Мы определили, что для каждого типа действий необходимо выделять отдельную роль, чтобы избежать потерь производительности на ноде. И "главный в кластере" звучит как отдельная ответственность.
Назовем такие ноды master-node. Активный мастер всегда должен быть один, он будет управлять топологией кластера: создавать новый индекс, выделять и распределять шарды, перемещать их и объединять в случае необходимости. Мастер всегда знает все о состоянии кластера.
В кластере Elasticsearch обязательно должен быть как минимум один узел отвечающий требованиям master node. Для этого в конфигурации ноды необходимо установить значениеnode.master: true.
Master-ноды отвечают за важные, но довольно легкие общекластерные действия. Это означает, что они требуют большого ресурса и высокой стабильности от физической ноды. В кластерах от 10 нод необходимо всегда выделять отдельные only-master узлы.
Репликация данных
Сейчас каждая запись в нашем индексе существует только в одном месте, и потеря хранящего ее узла приведет к потере данных на неопределенный срок. Для того, чтобы этого избежать существует механизм репликации. Важно не путать понятия реплики и бэкапа, если бэкап позволяет восстановить данные в случае утери, то реплика является полной копией базы.
Если мы потеряем одну из data-нод, то всегда сможем продолжить работу с репликами шардов в другом узле и тем временем вернуть потерянный.
То есть для каждого шарда должна быть как минимум одна копия на другой ноде. Можно конечно выделять по отдельной машине для каждой реплики, но это очень расточительно. Нужно разместить копии данных на разных узлах, но это не значит, что эти узлы должны хранить только шарды реплик.

Чтобы жестко установить количество реплик индекса используется параметрnumber_of_replicas. Так же мы можем изменить это значение в рантайме выполнив запрос:
PUT / _settings { "index": { "number_of_replicas": someVal } }
Таким образом мы всегда имеем реплики всех шардов и не поднимаем неэффективно простаивающие ноды.
Основной шард назовем первичным или primary shard, а любую из его копий реплицирующим шардом или replica shard, первичный шард и его реплики это группа репликации.
С учетом реплик запись данных будет происходить в два этапа, в первом запись затронет только первичный шард и только после того, как произойдет операция flush слияния изменений и операция commit фиксации в индексе Lucene, будет отправлен внутренний запрос на изменение всех реплик.

Для мониторинга состояния кластера в Elasticsearch существует cluster health status. Статус может иметь три значения:
green— все окyellow— есть утраченные шарды, кластер полностью работоспособен, но едет на репликахred— есть утраченные шарды, кластер неработоспособен или часть данных недоступна
Для максимальной стабильности кластера необходимо, чтобы количество дата-нод было больше или равно количества реплик.
Отказоустойчивость
Сейчас данные будут доступны даже в случае сбоя одного из хранящих узлов. Но что если кластер потеряет мастера? Потеря единственного мастера равноценна потере кластера.
Тут все по привычной схеме — поднимаем несколько мастеров.
Но если у нас есть, например, два управляющих узла, как понять, какой из них в данный момент должен управлять кластером? Как они смогут договориться о своих решениях? Очевидно, что в каждый момент времени должен быть только один управляющий кластером узел.
То есть при потере мастера его место должен занять один из кандидатов.
В Elasticsearch настройкаnode.master: trueне будет означать, что данный узел является мастером, это всего лишь скажет о том, что он может быть выбран в качестве главного узла. По умолчанию настройки будут установлены следующим образом:
node.master: truenode.data: true
Представим. Главный управляющий узел стал недоступен для кластера, кластер берет первого кандидата и устанавливает его на вакантное место. Спустя определенное время первый мастер возвращается в кластер и ничего не знает о том, что его место уже занято. Мастер-ноды являются своего рода его мозгом, и теперь мозг кластера становится разделен. Это классическая проблема распределенных систем и она так и называется split-brain problem.

В обществе подобные проблемы зачастую решаются путем голосования. Подобный механизм используется и в распределенных системах. Как только кластер теряет управляющий узел, должен быть запущен процесс голосования.
Важно определить какой из кандидатов больше всего подходит на роль главного узла. Такой кандидат должен обладать самой актуально информацией о кластере. Для краткого описания актуальности информации о кластере может использоваться версионирование. При каждом изменении кластера главный узел будет обновлять некую служебную информацию и повышать номер версии, далее то же самое будет параллельно происходить в нодах-кандидатах.
Сравнив номера версий мы можем определить наиболее подходящих кандидатов на роль мастера. Теперь если отпавшая мастер-нода вернется в кластер, то процесс голосования запустится снова и будет выбран единственный управляющий узел.

Теперь важно понять когда можно считать, что голосование прошло успешно? Если проголосовали все участники? Или половина? Или другое любое другое магическое количество?
Решение этой проблемы заключается в определении кворума. Это умное название для контрольного количества голосующих.
Очевидно, что такое важное решение как выбор мастера должно приниматься на основе большинства, то есть 50%+один голос. Справедливо, надежно. Это значение и станет кворумом.
Таким образом, количество кандидатов на мастера должно быть нечетным и не меньше трех. Рекомендуется использовать простую формулу для расчета оптимально количества таких нод:
КОЛИЧЕСТВО_КАНДИДАТОВ = ОБЩЕЕ_КОЛИЧЕСТВО_НОД/2 + 1
Решения для любых общекластерных действий принимаются путем голосования, и вся необходимая для голосования информация содержится в конфигурации голосования. Право голоса определяет еще одну роль, ведь право голоса не означает, что узел может быть кандидатом.
В Elasticsearch узлы, которые могут участвовать в голосовании можно определить в конфигурации:node.voting_only: true.
Elasticsearch автоматически изменяет конфигурацию голосования при изменении кластера. Поэтому нельзя одновременно отключать половину или более голосующих нод. Например, если в вашей конфигурации в данный момент 7 голосующих нод и вы отключили сразу 4, кластер станет недоступным, потому что останется 3 ноды, а в конфигурации голосования кворумом является значение 4.
Теперь, если кластер разделится на две части, узлы меньшей, пропинговав доступные в ней узлы и сравнив их количество со значением кворума, будут знать, что именно они отпали от кластера и не могут участвовать в принятии решений.
Транспорт
Пришло время поговорить о том, как общаться с кластером из внешних систем, и как будут общаться узлы внутри кластера. Есть ряд плюсов и минусов использования и традиционных, и специальных протоколов. Для краткого сравнения существует таблица.
| Протокол | Достоинства | Недостатки |
|---|---|---|
| HTTP | Низкий порог вхождения, в сравнении с нативным протоколом. Для использования нужен только HTTP клиент и погнали. HTTP API никогда не ломает совместимость, при обновлении версии ES, ваше приложение продолжит работать так же. Возможно проксировать и использовать балансировщики нагрузки. JSON. | Клиент не знает топологию кластера, поэтому может потребовать большее количество запросов для получения данных. Оверхед. |
| ES Native | Лучший выбор для ОЧЕНЬ больших данных. Если необходимо выполнить большое количество операций с индексом, нативный протокол значительно ускорит. | Используется под JVM. Использование влечет жесткую связность с ES. Обновления требуют перекомпиляции и повторного развертывания пользовательских клиентов. Возможны обновления ломающие совместимость. |
Для внутренней коммуникации в кластере Elsaticsearch использует нативный протокол.
Заключение
Хочется верить, что прочитав эту статью вы поняли основы распределенных поисковых систем. Возможности масштабирования и отказоустойчивости — это то для чего был создан Elasticsearch и то, почему он приобрел популярность.
Я постарался кратко и последовательно рассказать о том, как и почему именно так это устроено. В этой статье я намеренно не стал упоминать об экосистеме Elastic, плагинах, запросах, токенизации, маппинге и остальном. Так же я не сказал об Ingest и machine learning нодах, на мой взгляд, они дают дополнительные возможности и не являются базовыми.
Дополнительные материалы
Elastic Stack and Product Documentation
Книга Elasticsearch 5.x Cookbook, Third Edition








