Предлагаю ознакомиться с расшифровкой доклада Алексей Лесовский из Data Egret "Основы мониторинга PostgreSQL"
В этом докладе Алексей Лесовский расскажет о ключевых моментах постгресовой статистики, что они означают, и почему они должны присутствовать в мониторинге; о том, какие графики должны быть в мониторинге, как их добавить и как интерпретировать. Доклад будет полезен администраторам баз данных, системным администраторам и разработчикам, которым интересен траблшутинг Postgres'а.

Меня зовут Алексей Лесовский, я представляю компанию Data Egret.
Немного слов о себе. Я начинал когда-то давным-давно системным администратором.
Администрировал всякие разные Linux, занимался разными вещами, связанными с Linux, т. е. виртуализацией, мониторингом, работал с прокси и т. д. Но в какой-то момент я стал заниматься больше базами данных, PostgreSQL. Он мне очень нравился. И в какой-то момент я стал заниматься PostgreSQL основную часть своего рабочего времени. И так постепенно я стал PostgreSQL DBA.
И на протяжении всей своей карьеры мне всегда были интересны темы статистики, мониторинга, снятия телеметрии. И когда я был системным администратором, я занимался очень плотно Zabbix. И написал небольшой набор скриптов как zabbix-extensions. Он был довольно популярным в свое время. И там можно было мониторить очень разные важные штуки, не только Linux, но еще разные компоненты.
Сейчас я занимаюсь уже PostgreSQL. Я пишу уже другую штуку, которая позволяет работать с PostgreSQL-статистикой. Она называется pgCenter (статья на хабре — Постгресовая стата без нервов и напрягов).

Небольшая вводная. Какие бывают ситуации у наших заказчиков, у наших клиентов? Происходит какая-то авария, связанная с базой данной. И когда уже восстановили базу данных, приходит начальник отдела или начальник разработки и говорит: «Друзья, надо бы нам замониторить базу данных, потому что случилось что-то плохое и надо, чтобы в будущем такого не происходило». И здесь начинается интересный процесс выбора системы мониторинга или адаптации существующей системы мониторинга для того, чтобы можно было мониторить свою базу данных – PostgreSQL, MySQL или какие-то другие. И коллеги начинают предлагать: «Я слышал, что есть такая-то база данных. Давайте использовать ее». Коллеги начинают друг с другом спорить. И в итоге получается, что мы выбираем какую-то базу данных, но мониторинг PostgreSQL в ней представлен довольно слабо и всегда приходится что-то допиливать. Брать какие-то репозитории из GitHub, клонировать их, адаптировать скрипты, как-то донастраивать. И в итоге это вываливается в некую ручную работу.

Поэтому в этом докладе я постараюсь дать вам некие знания о том, как выбирать мониторинг не только для PostgreSQL, но и для базы данных. И дать те знания, которые позволят вам допилить ваш мониторинг, чтобы получить от него какую-то пользу, чтобы можно было мониторить свою базу данных с пользой, чтобы вовремя предупреждать какие-то предстоящие аварийные ситуации, которые могут возникнуть.
И те идеи, которые будут в этом докладе, их можно напрямую адаптировать к любой базе данных, будь это СУБД или noSQL. Поэтому тут не только PostgreSQL, но здесь будет много рецептов, как сделать это в PostgreSQL. Будут примеры запросов, примеры сущностей, которые есть в PostgreSQL для мониторинга. И если ваша СУБД имеет такие же вещи, которые позволяют засунуть их в мониторинг, вы тоже можете их адаптировать, добавить и будет хорошо.
 В докладе я не буду
В докладе я не буду
рассказывать про то, как доставлять и хранить метрики. Не буду ничего говорить о пост-обработке данных и предоставлению их пользователю. И не буду ничего говорить об алертинге.
Но по ходу повествования я буду показывать разные скриншоты существующих мониторингов, как-то буду их критиковать. Но тем не менее я постараюсь не называть брендов, чтобы не создавать рекламу или антирекламу этим продуктам. Поэтому все совпадения случайны и остаются на вашей фантазии.

Для начала разберемся, что такое мониторинг. Мониторинг – это очень важная штука, которую нужно иметь. Это все понимают. Но в то же самое время мониторинг не относится к бизнес-продукту и на напрямую не влияет на прибыль компании, поэтому на мониторинг всегда уделяют время по остаточному принципу. Если у нас есть время, то мы занимаемся мониторингом, если времени нет, то ОК, поставим в бэклог и когда-нибудь вернемся к этим задачам.
Поэтому из нашей практики, когда мы приходим к клиентам, мониторинг часто недоработан и не имеет каких-то интересных вещей, которые помогали бы нам делать работу лучше с базой данных. И поэтому мониторинг всегда нужно допиливать.
Базы данных – это такие сложные штуки, которые тоже нужно мониторить, потому что базы данных – это хранилище информации. И информация очень важна для компании, ее нельзя никак терять. Но в то же время базы данных – это очень сложные куски программного обеспечения. Они состоят из большого количества компонентов. И многие из этих компонентов нужно мониторить.
 Если мы говорим конкретно про PostgreSQL, то его можно представить в виде такой схемы, которая состоит из большого количества компонентов. Эти компоненты взаимодействуют друг с другом. И в то же время в PostgreSQL есть, так называемая, подсистема Stats Collector, которая позволяет собирать статистику о работе этих подсистем и предоставлять некий интерфейс администратору или пользователю, чтобы он мог просматривать эту статистику.
Если мы говорим конкретно про PostgreSQL, то его можно представить в виде такой схемы, которая состоит из большого количества компонентов. Эти компоненты взаимодействуют друг с другом. И в то же время в PostgreSQL есть, так называемая, подсистема Stats Collector, которая позволяет собирать статистику о работе этих подсистем и предоставлять некий интерфейс администратору или пользователю, чтобы он мог просматривать эту статистику.
Эта статистика представлена в виде некоторого набора функций и вьюх (view). Их можно еще назвать таблицами. Т. е. с помощью обычного psql клиента вы можете подключиться к базе данных, сделать select к этим функциям и вьюхам, и получить уже какие-то конкретные циферки о работе подсистем PostgreSQL.
Вы можете добавить эти циферки в вашу любимую систему мониторинга, нарисовать графики, добавить функции и получить аналитику в долгосрочной перспективе.
Но в этом докладе я не буду рассматривать поголовно все эти функции, потому что это может занять целый день. Я буду обращаться буквально к двум-трем-четырем штукам и буду рассказывать, как они помогают сделать мониторинг лучше.

И если говорить про мониторинг базы, то что нужно мониторить? В первую очередь нужно мониторить доступность, потому что база – это сервис, который предоставляет доступ к данным клиентам и нам нужно мониторить доступность, а предоставляет также ее некоторые качественные и количественные характеристики.

Также нужно мониторить клиентов, которые подключаются к нашей базе, потому что они могут быть как и нормальными клиентами, так и вредными клиентами, которые могут наносить вред базе данных. Их тоже нужно мониторить и отслеживать их деятельность.

Когда клиенты подключаются к базе данных, то очевидно, что они начинают работать с нашими данными, поэтому нам нужно мониторить и то, как клиенты работают с данными: с какими таблицами, в меньшей степени с какими индексами. Т. е. нам нужно оценить ворклоад (workload), который создается нашими клиентами.

Но и ворклоад состоит, конечно, из запросов. Приложения подключаются к базе, обращаются к данным с помощью запросов, поэтому важно оценивать, какие запросы у нас в базе данных, отслеживать их адекватность, что они не являются криво написанными, что какие-то опции нужно переписать и сделать так, чтобы они работали быстрее и с более лучшей производительностью.

И раз мы говорим про базу данных, то база данных – это всегда фоновые процессы. Фоновые процессы позволяют поддерживать производительность базы данных на хорошем уровне, поэтому для их работы они требуют некое количество ресурсов для себя. И в то же время они могут пересекаться с ресурсами клиентских запросов, поэтому жадная работа фоновых процессов может непосредственно влиять на производительность клиентских запросов. Поэтому их тоже нужно мониторить и отслеживать, что нет никаких перекосов в плане фоновых процессов.

И это все в плане мониторинга базы данных остается в системной метрике. Но учитывая, что у нас по большей части вся инфраструктура уезжает в облака, системные метрики отдельного хоста всегда отходят на второй план. Но в базах данных они все еще актуальны и мониторить системные метрики, конечно, тоже нужно.

С системными метриками более-менее все хорошо, все современные системы мониторинга уже поддерживают эти метрики, но в целом каких-то компонентов все-таки недостаточно и нужно некоторые вещи добавлять. Про них я тоже затрону, несколько слайдов будет про них.

Первый пункт плана – это доступность. Что такое доступность? Доступность в моем понимании – это способность базы обслуживать подключения, т. е. база поднята, она, как сервис, принимает подключения от клиентов. И эту доступность можно оценивать некоторыми характеристиками. Эти характеристики очень удобно выносить на дашборды.

Все знают, что такое дашборды. Это когда ты бросил один взгляд на экран, на котором сведена необходимая информация. И вы уже можете сразу определить – есть проблема в базе или нет.
Соответственно доступность базы данных и другие ключевые характеристики всегда необходимо выносить на дашборды, чтобы эта информация была под рукой, была у вас всегда рядом. Какие-то дополнительные детали, которые уже помогают при расследовании инцидентов, при расследовании каких-то аварийных ситуаций, их уже нужно выносить на вторичные дашборды, либо скрывать в drilldown-линках, которые ведут на сторонние системы мониторинга.
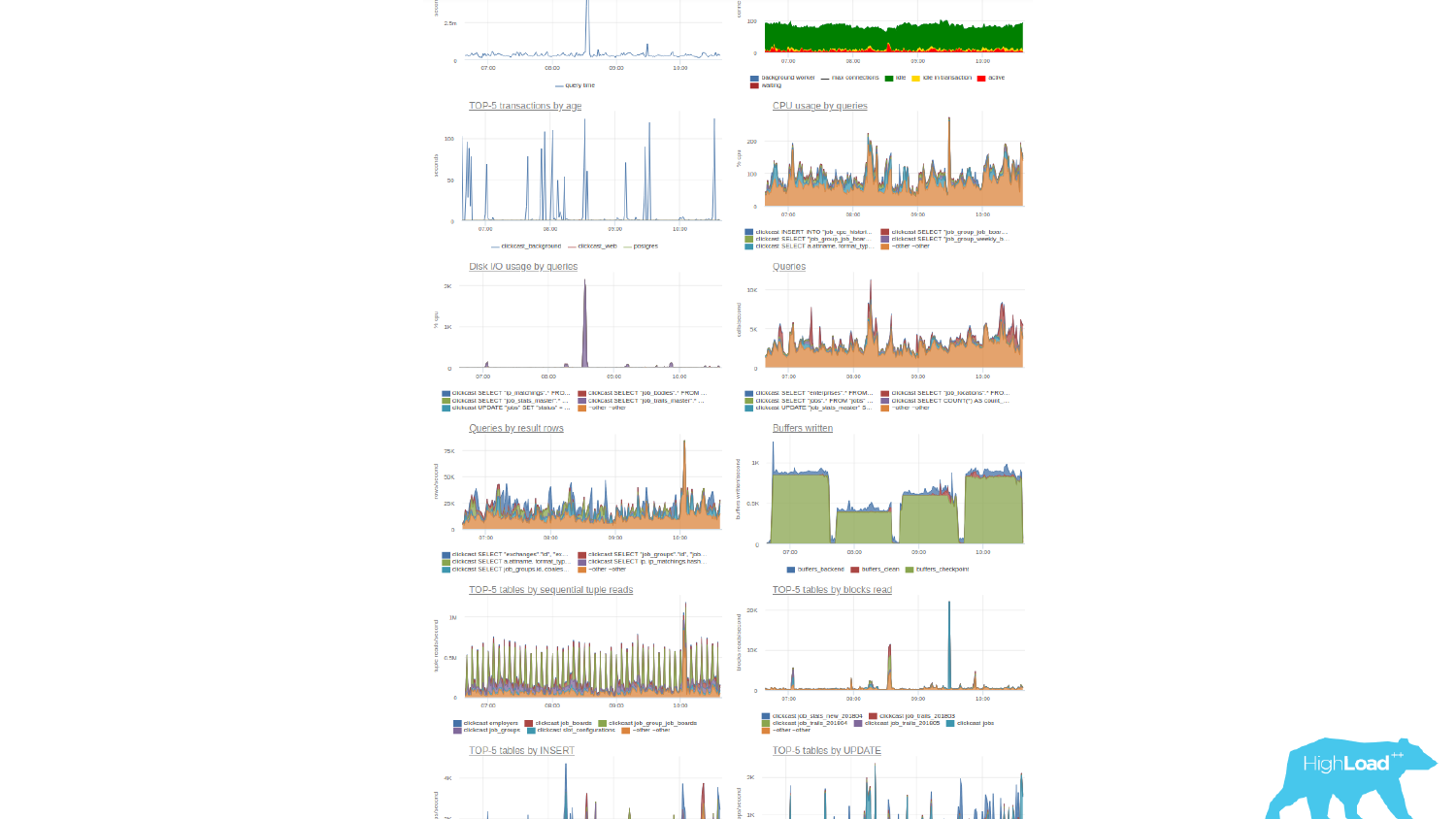
Пример одной известной системы мониторинга. Это очень крутая система мониторинга. Она собирает очень много данных, но с моей точки зрения, у нее странное понятие дашбордов. Там есть ссылка «создать дашборд». Но когда вы создаете дашборд, вы создаете некий список, состоящий из двух колонок, некий список графиков. И когда вам нужно что-то посмотреть, вы начинаете мышкой кликать, листать, искать нужный график. И на это уходит время, т. е. дашбордов, как таковых, нет. Есть лишь списки графиков.

Что нужно добавлять на эти дашборды? Можно начать с такой характеристики как время отклика. В PostgreSQL есть вьюха pg_stat_statements. По умолчанию она отключена, но это одна из важных системных вьюх, которую всегда необходимо включать и использовать. Она хранит в себе информацию о всех выполняющихся запросах, которые в базе данных выполнялись.
Соответственно, мы можем оттолкнуться от того, что можно взять суммарное время выполнения всех запросов и поделить на количество запросов с помощью вышеприведенных полей. Но это такая средняя температура по больнице. Мы можем оттолкнуться от других полей – минимальное время выполнения запросов, максимальное и медианное. И даже можем строить перцентили, в PostgreSQL есть соответствующие функции для этого. И мы можем получить какие-то цифры, которые характеризуют время отклика нашей базы по уже выполненным запросам, т. е. мы не выполняем фейковый запрос 'select 1' и смотрим время отклика, а мы анализируем время ответов по уже выполненным запросам и рисуем либо отдельной цифрой, либо строим по ней график.
Также важно отслеживать количество ошибок, которые генерируются системой в данный момент. И для этого можно использовать вьюху pg_stat_database. Мы ориентируемся на поле xact_rollback. Это поле показывает не только количество rollback, которые происходят в базе, но еще и учитывает количество ошибок. Условно говоря, мы можем выводить эту цифру в наш дашборд и смотреть сколько у нас ошибок в данный момент. Если ошибок много, то это уже хороший повод заглянуть в логи и посмотреть, что же это за ошибки и почему они происходят, а дальше уже инвестигировать и решать их.

Можно добавить такую штуку, как Тахометр. Это количество транзакций в секунду и количество запросов в секунду. Условно говоря, вы можете использовать эти цифры как текущую производительность вашей базы данных и наблюдать есть ли пики запросов, пики транзакций или, наоборот, база недогружена, потому что какой-то backend отвалился. Эту цифру важно всегда смотреть и помнить, что для нашего проекта вот такая производительность является нормальной, а значения выше и ниже уже какие-то проблемные и непонятные, а значит, нужно смотреть, почему такие цифры.
Для того чтобы оценивать количество транзакций, мы снова можем обратиться к вьюхе pg_stat_database. Мы можем сложить количество commit и количество rollback и получить количество транзакций в секунду.
Все понимают, что в одну транзакцию может уложиться несколько запросов? Поэтому TPS и QPS немного разные.
Количество запросов в секунду можно получить по pg_stat_statements и просто просчитать сумму всех выполненных запросов. Понятно, что мы сравниваем текущее значение с предыдущим, вычитаем, получаем дельту, получаем количество.

Можно добавить дополнительные метрики по желанию, которые также помогают оценивать доступность нашей базы и отслеживать – не было ли каких-то downtime.
Одна из этих метрик – это uptime. Но uptime в PostgreSQL – это немного хитрая штука. Расскажу, почему. Когда PostgreSQL запустился, начинается отчитываться uptime. Но если в какой-то момент, например, ночью выполнялась какая-то задача, пришел OOM-killer и завершил принудительно дочерний процесс PostgreSQL, то в этом случае PostgreSQL завершает соединение всех клиентов, сбрасывает область shared памяти и начинает восстановление с последней контрольной точки. И пока длится это восстановление с контрольной точки, база не принимает подключения, т. е. эту ситуацию можно оценивать, как downtime. Но при этом счетчик uptime не сбросится, потому что он учитывает время запуска postmaster с самого первого момента. Поэтому такие ситуации можно пропустить.
Также следует мониторить количество воркеров вакуума. Все знают, что такое autovacuum в PostgreSQL? Это интересная подсистема в PostgreSQL. Про нее написано много статей, много сделано докладов. Много обсуждений про вакуум, о том, как он должен работать. Многие считают его неизбежным злом. Но так и есть. Это некий аналог сборщика мусора, который чистит устаревшие версии строк, которые не нужны ни одной из транзакции и освобождает место в таблицах, индексах для новых строк.
Почему нужно его мониторить? Потому что вакуум иногда делает очень больно. Он отжирает большое количество ресурсов и клиентские запросы от этого начинают страдать.
И мониторить следует его через вьюху pg_stat_activity, про которую я буду говорить в следующем разделе. Эта вьюха показывает текущую активность в базе данных. И через эту активность мы можем отследить количество вакуумов, которые работают прямо сейчас. Мы можем отслеживать вакуумы и видеть, что если у нас превышен лимит, то это повод заглянуть в настройки PostgreSQL и как-то оптимизировать работу вакуума.
Другой особенностью PostgreSQL является то, что PostgreSQL очень больно от долгих транзакций. Особенно, от транзакций, которые долго висят и ничего не делают. Это, так называемые, stat idle-in-transaction. Такая транзакция удерживает блокировки, она мешает работать вакууму. И как следствие – таблицы пухнут, они увеличиваются в размере. И запросы, которые работают с этими таблицами, они начинают работать медленнее, потому что нужно лопатить все старые версии строк из памяти на диск и обратно. Поэтому время, длительность самых долгих транзакций, самых долгих запросов вакуума тоже нужно мониторить. И если мы видим какие-то процессы, которые работают уже очень долго, уже больше 10-20-30 минут для OLTP-нагрузки, то на них нужно уже обращать внимание и завершать принудительно, либо оптимизировать приложение, чтобы они не вызывались и не висели так долго. Для аналитической нагрузки 10-20-30 минут – это нормально, там бывает еще и более долгие.

Дальше у нас вариант с подключенными клиентами. Когда мы уже сформировали дашборд, вывесили на него ключевые метрики доступности, мы можем также добавить туда и дополнительную информацию о подключенных клиентах.
Информация о подключенных клиентах важна, потому что, с точки зрения PostgreSQL, клиенты бывают разными. Бывают хорошие клиенты, бывают плохие клиенты.
Простой пример. Под клиентом я пониманию приложение. Приложение подключилось к базе данных и начинает сразу слать туда свои запросы, база данных их обрабатывает и выполняет, результаты возвращает клиенту. Это хорошие и правильные клиенты.
Бывают ситуации, что клиент подключился, он удерживает коннект, но при этом ничего не делает. Он находится в состоянии idle.
Но бывают плохие клиенты. Например, тот же клиент подключился, открыл транзакцию, что-то поделал в базе и потом ушел в код, допустим, чтобы обратиться ко внешнему источнику или для того, чтобы сделать там обработку, полученных данных. Но при этом он не закрыл транзакцию. И транзакция висит в базе и удерживает в блокировку на строке. Это плохое состояние. И если вдруг приложение где-то внутри у себя упадет по эксепшену (Exception), то транзакция может остаться открытой на очень долгое время. И это влияет напрямую на производительность PostgreSQL. PostgreSQL будет работать медленнее. Поэтому таких клиентов важно вовремя отслеживать и завершать их работу принудительно. И нужно оптимизировать свое приложение, чтобы не было таких ситуаций.
Другими плохими клиентами являются ожидающие клиенты. Но они становятся плохими из-за обстоятельств. Например, простая простаивающая транзакция: может открыть транзакцию, взять блокировки на какие-то строки, потом где-то в коде она упадет, останется висящая транзакция. Придет другой клиент, запросит те же самые данные, но он столкнется с блокировкой, потому что та висящая транзакция уже удерживает блокировки на какие-то нужные строки. И вторая транзакция будет висеть в ожидании, когда первая транзакция завершится или ее администратор принудительно закроет. Таким образом, ждущие транзакции могут накапливаться и переполнять лимит подключений к базе данных. И когда лимит переполнен, то приложение уже не может работать с базой. Это уже аварийная ситуация для проекта. Поэтому плохих клиентов нужно отслеживать и своевременно на них реагировать.

Другой пример мониторинга. И здесь уже приличный дашборд. Есть информация по коннектам сверху. DB connection – 8 штук. И это все. У нас нет информации о том, какие клиенты активные, какие клиенты просто idle, ничего не делают. Нет информации о висящих транзакциях и об ожидающих коннектах, т. е. это такая цифра, которая показывает количество коннектов и все. А дальше гадайте сами.

Соответственно, чтобы добавить эту информацию в мониторинг, нужно обратиться к системной вьюхе pg_stat_activity. Если вы много времени проводите в PostgreSQL, то это очень хорошая вьюха, которая должна стать вашим другом, потому что она показывает текущую активность в PostgreSQL, т. е. что происходит в нем. На каждый процесс есть отдельная строчка, которая показывает информацию по этому процессу: с какого хоста выполнено подключение, под каким пользователем, под каким именем, когда запущена транзакция, какой сейчас выполняется запрос, какой запрос выполнялся последним. И, соответственно, состояние клиента мы можем оценивать по полю stat. Условно говоря, мы можем сделать группировку по этому полю и получить те stats-ы, которые есть сейчас в базе данных и количество коннектов, которые с этим stat-ом в базе данных. И уже полученные цифры мы можем отправлять в наш мониторинг и рисовать по ним графики.
Также важно оценивать длительность транзакции. Я уже говорил, что важно оценивать длительность вакуумов, но и транзакции оцениваются точно так же. Есть поля xact_start и query_start. Они, условно говоря, показывают время старта транзакции и время старта запроса. Мы берем функцию now(), которая показывает текущую отметку времени и вычитаем timestamp транзакции и запроса. И получаем длительность транзакции, длительность запроса.
Если мы видим длинные транзакции, мы должны их уже завершать. Для OLTP-нагрузки длинные транзакции – это уже больше 1-2-3 минут. Для OLAP-нагрузки длинные транзакции являются нормальными, но если они выполняются больше двух часов, то это тоже признак того, что где-то у нас есть перекос.

Когда клиенты подключились к базе данных, они начинают работать с нашими данными. Они обращаются к таблицам, они обращаются к индексам, чтобы получить данные из таблицы. И важно оценивать то, как клиенты работают с этими данными.
Это нужно для того, чтобы оценивать наш ворклоад и примерно понимать, какие таблицы у нас самые «горячие». Например, это нужно в ситуациях, когда мы хотим «горячие» таблицы поместить на какое-то быстрое SSD хранилище. Например, какие-то архивные таблицы, которые мы уже давно не используем можно вынести на какой-то «холодный» архив, на SATA диски и пусть они там живут, к ним обращение будет идти по необходимости.
Также это полезно для обнаружения аномалий после всяких релизов и деплоев. Допустим, проект выкатил какую-то новую фичу. Например, добавили новую функциональность для работы с базой. И если мы построим графики использования таблиц, мы на этих графиках сможем легко обнаружить эти аномалии. Например, всплески update или всплески delete. Это очень хорошо будет видно.
Также можно обнаружить аномалии «поплывшей» статистики. Что это значит? В PostgreSQL очень сильный и очень хороший планировщик запросов. И разработчики много времени уделяют его развитию. Как он работает? Для того чтобы строить хорошие планы, PostgreSQL с некоторым интервалом времени, с некоторой периодичностью собирает статистику о распределении данных в таблицах. Это самые частые значения: количество уникальных значений, информация о NULL в таблице, очень много информации.
На основе этой статистики планировщик строит несколько запросов, выбирает наиболее оптимальный и использует этот план запроса для выполнения самого запроса и возвращения данных.
И бывает, что статистика «плывет». Данные качества, количества поменялись как-то в таблице, но статистика при этом не собралась. И сформированные планы могут оказаться не оптимальными. И если у нас планы окажутся неоптимальными по собираемому мониторингу, по таблицам, мы сможем увидеть эти аномалии. Например, где-то качественно изменились данные и вместе индекса стал использоваться последовательный проход по таблице, т.е. если запросу нужно вернуть всего лишь 100 строк (стоит ограничение limit 100), то для этого запроса будет выполнен полный перебор. И это всегда очень плохо сказывается на производительности.
И мы сможем увидеть это в мониторинге. И уже посмотреть на этот запрос, выполнить для него explain, собрать статистику, построить новый дополнительный индекс. И уже отреагировать на эту проблему. Поэтому это важно.

Другой пример мониторинга. Я думаю, многие его узнали, потому что он очень популярный. Кто использует у себя в проектах Prometheus? А кто использует этот продукт совместно с Prometheus? Дело в том, что в стандартном репозитории этого мониторинга есть дашборд для работы с PostgreSQL – postgres_exporter Prometheus. Но тут есть одна плохая деталь.

Есть несколько графиков. И в качестве unity указаны байты, т. е. там 5 графиков. Это Insert data, Update data, Delete data, Fetch data и Return data. В качестве unit измерения указаны байты. Но дело в том, что статистика в PostgreSQL возвращает данные в tuple (строках). И, соответственно, эти графики – это очень хороший способ занизить ваш ворклоад в несколько раз, в десятки раз, потому что tuple – это не байт, tuple – это строка, это много байтов и она всегда переменной длины. Т. е. вычислить ворклоад в байтах с помощью tuples – это нереальная задача или очень сложная. Поэтому, когда вы используете дашборд или встроенный мониторинг, всегда важно понимать, что он работает правильно и возвращает вам корректно оцененные данные.

Как получать статистику по этим таблицам? Для этого в PostgreSQL есть некоторое семейство вьюх. И основная вьюха – это pg_stat_user_tables. User_tables – это означает, что таблицы, созданные от лица пользователя. В противовес есть системные вьюхи, которые используются самим PostgreSQL. И есть сводная таблица Alltables, которая включает и системные, и пользовательские. Вы можете отталкиваться от любой из них, которая вам больше всего нравится.
По вышеуказанным полям можно оценивать количество insert, update и delete. Тот пример дашборда, который я использовал, как раз использует эти поля для оценки характеристик ворклоада. Поэтому мы также можем отталкиваться от них. Но стоит помнить, что это tuples, а не байты, поэтому мы не можем взять и сделать это байтами.
На основе этих данных мы можем строить, так называемые, TopN-таблицы. Например, Top-5, Top-10. И можно отслеживать те горячие таблицы, которые утилизируются больше остальных. Например, 5 «горячих» таблиц по вставке. И по этим TopN-таблицам мы оцениваем наш ворклоад и можем оценивать всплески ворклоада после всяких релизов и апдейтов, и деплоев.
Также важно оценивать размеры таблицы, потому что иногда разработчики выкатывают новую фичу, и у нас таблицы начинают пухнуть в своих больших размерах, потому что решили дописать дополнительный объем данных, но при этом не спрогнозировали, как это скажется на размере базы данных. Такие случае тоже бывают для нас сюрпризами.

И сейчас небольшой вопрос для вас. Какой возникает вопрос, когда вы замечаете нагрузку на сервере с базой данных? Какой следующий вопрос у вас возникает?

Но на самом деле вопрос возникает следующий. Какие запросы вызывает нагрузка? Т. е. не интересно смотреть процессы, какие вызывает нагрузка. Понятно, что если host с базой данных, то там запущена база данных и понятно, что только базы данных там и будет утилизировать. Если мы откроем Top, то увидим там список процессов в PostgreSQL, которые что-то делают. Из Top будет не понятно, что они делают.

Соответственно, нужно обнаружить те запросы, которые вызывают наибольшую загрузку, потому что тюнинг запросов, как правило, дает больше профит, чем тюнинг конфигурации PostgreSQL или операционной системы, или даже тюнинг железа. По моей оценке – это примерно 80-85-90 %. И это делается гораздо быстрее. Быстрее поправить запрос, чем поправить конфигурацию, запланировать рестарт, особенно, если базу рестартовать нельзя, либо добавлять железо. Проще где-то переписать запрос или добавить индекс, чтобы получить уже более лучший результат от этого запроса.

Соответственно, нужно мониторить запросы и их адекватность. Возьмем другой пример мониторинга. И тут тоже вроде прекрасный мониторинг. Есть информация по репликации, есть информация по пропускной способности, блокировкам, утилизации ресурсов. Все прекрасно, но нет информации по запросам. Не понятно, какие запросы выполняются в нашей базе данных, как долго они выполняются, сколько этих запросов. Нам нужно в мониторинге всегда иметь эту информацию.

И для получения этой информации мы можем использовать модуль pg_stat_statements. На его основе можно строить самые разные графики. Например, можно получать информацию по самым частым запросам, т. е. по тем запросам, которые выполняются чаще всех. Да, после деплоев тоже очень полезно посмотреть на него и понимать, нет ли какого-то всплеска запросов.
Можно мониторить самые долгие запросы, т. е. те запросы, которые выполняются дольше всех. Они работают на процессоре, они потребляют ввод-вывод. Мы это тоже можем оценивать по полям total_time, mean_time, blk_write_time и blk_read_time.
Мы можем оценивать и мониторить самые тяжелые запросы в плане использования ресурсов, те, которые читают с диска, которые работают с памятью или, наоборот, создают какую-то пишущую нагрузку.
Можем оценивать самые щедрые запросы. Это те запросы, которые возвращают большое количество строк. Например, это может быть какой-то запрос, где забыли поставить лимит. И он просто возвращает все содержимое таблицы или запроса по запрошенным таблицам.
И можно также мониторить запросы, которые используют временные файлы или временные таблицы.

И у нас остались фоновые процессы. Фоновые процессы – это в первую очередь чекпоинты или их еще называют контрольными точками, это autovacuum и репликация.
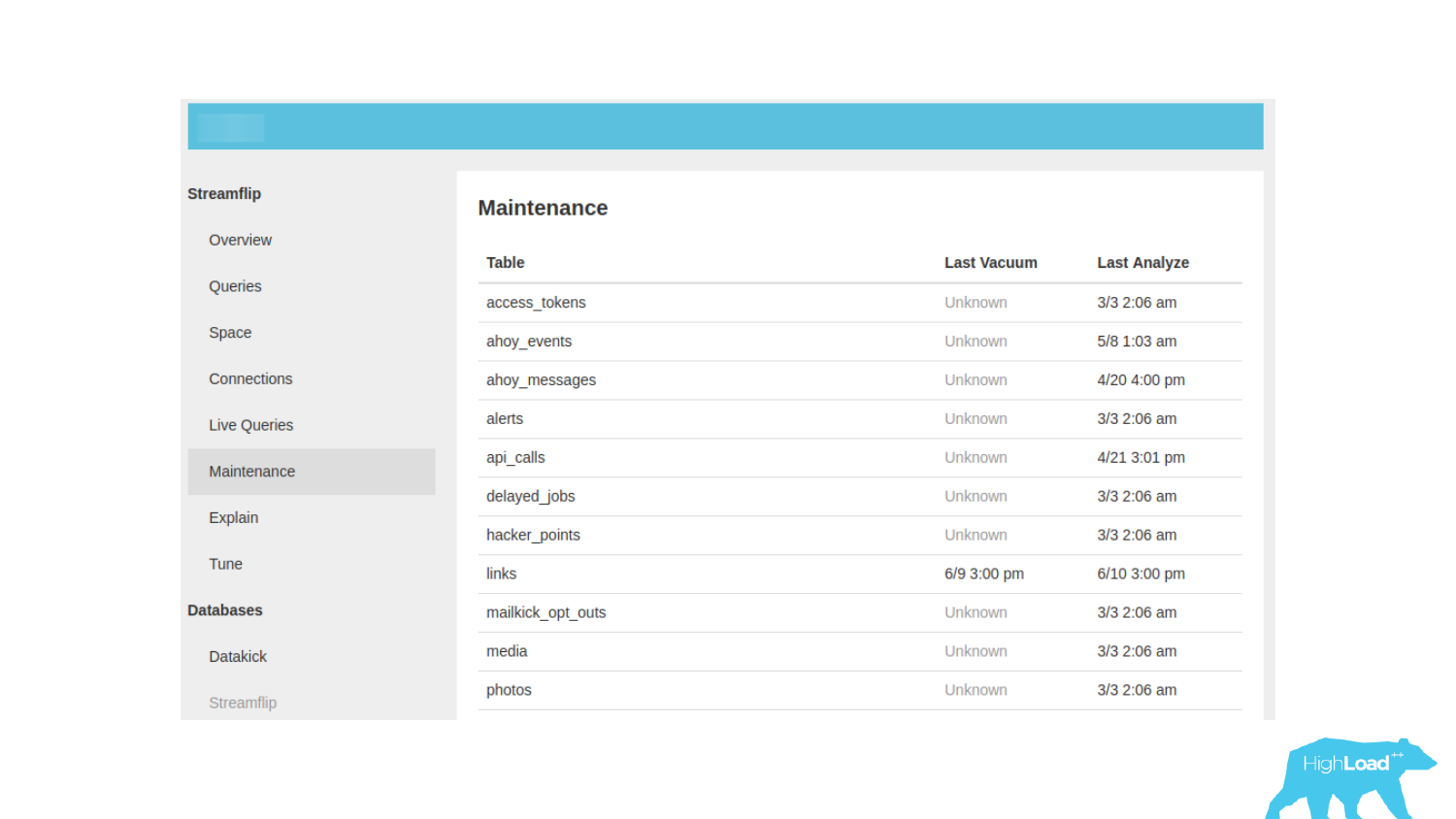
Другой пример мониторинга. Есть слева вкладка Maintenance, переходим на нее и надеемся увидеть, что-то полезное. Но здесь только время работы вакуума и сбора статистики, больше ничего. Это очень бедная информация, поэтому всегда нужно иметь информацию о том, как работают фоновые процессы у нас в базе данных и нет ли проблем от их работы.

Когда мы рассматриваем контрольные точки, то следует помнить, что контрольные точки у нас сбрасывают «грязные» страницы из области shared памяти на диск, затем создают контрольную точку. И эта контрольная точка уже дальше может использоваться как некое место при восстановлении, если вдруг PostgreSQL был завершен в аварийном порядке.
Соответственно, чтобы сбросить все «грязные» страницы на диск, нужно проделать некий объем записи. И, как правило, на системах с большим объемом памяти – это очень много. И если у нас чекпоинты делаются очень часто в какой-то короткий интервал, то дисковая производительность будет очень сильно проседать. И клиентские запросы будут страдать от нехватки ресурсов. Они будут бороться за ресурсы и им будет не хватать производительности.
Соответственно, через pg_stat_bgwriter по указанным полям мы можем мониторить количество случающихся чекпоинтов. И если у нас за какой-то промежуток времени (за 10-15-20 минут, за полчаса) очень много чекпоинтов, например, 3-4-5, то это уже может быть проблемой. И уже нужно посмотреть в базе данных, посмотреть в конфигурации, что вызывает такое обилие чекпоинтов. Может быть, какая-то большая запись идет. По ворклоаду можем уже оценить, потому что у нас графики ворклоада уже добавлены. Мы можем уже подтюнить параметры контрольных точек и сделать так, чтобы они не сильно влияли на производительность запросов.

Я снова возвращаюсь к autovacuum, потому что это такая штука, как я уже говорил, которая запросто может сложить производительность как дисков, так и запросов, поэтому всегда важно оценивать количество autovacuum.
Количество воркеров autovacuum в базе данных ограничено. По умолчанию их три, поэтому если у нас все время три воркера работают в базе, то это значит, что у нас autovacuum недонастроен, нужно поднимать лимиты, пересматривать настройки autovacuum и уже лезть в конфигурацию.
Важно оценивать какие у нас работают воркера вакуума. Либо это запущенный от пользователя, DBA пришел и руками запустил какой-то вакуум, и это создало нагрузку. У нас появилась какая-то проблема. Либо это количество вакуумов, которые откручивают счетчик транзакций. Для некоторых версий PostgreSQL – это очень тяжелые вакуумы. И они могут запросто сложить производительность, потому что они вычитывают всю таблицу целиком, сканируют все блоки в этой таблице.
И, конечно, длительность вакуумов. Если у нас долгие вакуумы, которые работают очень долгое время, то это значит, что нам снова стоит обратить внимание на конфигурацию вакуума и, возможно, пересмотреть его настройки. Потому что может появиться ситуация, когда вакуум работает над таблицей долгое время (3-4 часа), но за время работы вакуума в таблице успели накопиться снова большой объем мертвых строк. И как только вакуум завершится, ему снова нужно вакуумить эту таблицу. И мы приходим к ситуации – бесконечного вакуума. И в таком случае вакуум не справляется со своей работы, и таблицы начинают постепенно пухнуть в размерах, хотя объем полезных данных в ней остается прежним. Поэтому при долгих вакуумах мы всегда смотрим на конфигурацию и пытаемся оптимизировать ее, но при этом, чтобы не страдали производительность клиентских запросов.

Сейчас практически нет инсталляции PostgreSQL, где не было потоковой репликации. Репликация – это процесс переноса данных с мастера на реплику.
Репликация в PostgreSQL устроена через журнал транзакций. Мастер генерирует журнал транзакций. Журнал транзакции по сетевому соединению едет на реплику, дальше на реплике он воспроизводится. Все просто.
Соответственно, для мониторинга лага репликации используется вьюха pg_stat_replication. Но с ней не все просто. В версии 10 вьюха претерпела несколько изменений. Во-первых, часть полей была переименована. И часть полей была добавлена. В 10-ой версии появились поля, которые позволяют оценивать лаг репликации в секундах. Это очень удобно. До версии 10 была возможность оценивать лаг репликации в байтах. Такая возможность осталась и в 10-ой версии, т. е. вы можете выбирать, что вам удобнее – оценивать лаг в байтах или оценивать лаг в секундах. Многие делают и то и другое.
Но тем не менее, чтобы оценивать лаг репликации, нужно знать позицию журнала в транзакции. И эти позиции журнала транзакции как раз есть во вьюхе pg_stat_replication. Условно говоря, мы с помощью функции pg_xlog_location_diff() можем взять две точки в журнале транзакции. Посчитать между ними дельту и получить лаг репликации в байтах. Это очень удобно и просто.
В 10-ой версии эта функция была переименована в pg_wal_lsn_diff(). Вообще, во всех функциях, вьюхах, утилитах, где встречалось слово «xlog», оно было заменено на значение «wal». Это и во вьюхах, и в функциях. Это вот такое нововведение.
Плюс в 10-ой версии добавились строчки, которые конкретно показывают лаг. Это write lag, flush lag, replay lag. Т. е. эти штуки важно мониторить. Если мы видим, что у нас лаг репликации, то нужно исследовать, почему он появился, откуда взялся и устранять проблему.

С системными метриками практически все в порядке. Когда зарождается любой мониторинг, он начинает с системных метрик. Это утилизация процессоров, памяти, swap, сети и диска. Но тем не менее многих параметров там по умолчанию нет.
Если с утилизацией процесса все в порядке, то с утилизацией диска есть проблемы. Как правило, разработчики мониторингов добавляют информацию о пропускной способности. Она может быть в iops или байтах. Но они забывают про latency и утилизацию дисковых устройств. Это более важные параметры, которые позволяют оценивать, насколько у нас загружены диски и насколько они тормозят. Если у нас высокий latency, то это значит, что есть какие-то проблемы с дисками. Если у нас высокая утилизация, то это значит, что диски не справляются. Это более качественные характеристики, чем пропускная способность.
При том, что эту статистику можно также получить из файловой системы /proc, как это делается для утилизации процессоров. Почему эту информацию не добавляют в мониторинги, я не знаю. Но тем не менее важно иметь это в своем мониторинге.
Тоже самое относительно сетевых интерфейсов. Есть информация о пропускной способности сети в пакетах, в байтах, но тем не менее нет информации о latency и нет информации об утилизации, хотя это тоже полезная информация.

Любые мониторинги имеют недостатки. И какой мониторинг вы бы не взяли, он всегда будет не соответствовать каким-то критериям. Но тем не менее они развиваются, добавляются новые фичи, новые вещи, поэтому выбирайте что-то и допиливайте.
И для того чтобы допиливать, нужно всегда иметь представление, что означает отдаваемая статистика и как с помощью ее можно решать проблемы.
И несколько ключевых моментов:
- Всегда нужно мониторить доступность, иметь дашборды, чтобы вы могли быстро оценить, что с базой все в порядке.
- Всегда нужно иметь представление о том, какие клиенты работают с вашей базой данной, чтобы отсеивать плохих клиентов и отстреливать их.
- Важно оценивать то, как эти клиенты работают с данными. Нужно иметь представление о вашем ворклоаде.
- Важно оценивать, как формируется этот ворклоад, с помощью каких запросов. Вы можете оценивать запросы, вы можете их оптимизировать, рефакторить, строить для них индексы. Это очень важно.
- Фоновые процессы могут негативно влиять на клиентские запросы, поэтому важно отслеживать, чтобы они не используют слишком много ресурсов.
- Системные метрики позволяют вам делать планы на масштабирование, на увеличение емкости ваших серверов, поэтому важно тоже их отслеживать и оценивать.

Если вас заинтересовала эта тема, то вы можете пройтись по этим ссылкам.
http://bit.do/stats_collector — это официальная документация с коллектора статистики. Там есть описание всех статистических вьюх и описание всех полей. Вы можете их прочитать, понять и проанализировать. И уже на основе них строить свои графики, добавлять в свои мониторинги.
Примеры запросов:
http://bit.do/dataegret_sql
http://bit.do/lesovsky_sql
Это корпоративный наш репозиторий и мой собственный. В них есть примеры запросов. Там нет запросов из серии select* from что-то там. Там уже готовые запросы с джойнами, с применением интересных функций, которые позволяют из сырых цифр сделать читаемые, удобные значения, т. е. это байты, время. Вы можете их ковырять, смотреть, анализировать, добавлять в свои мониторинги, строить на их основе свои мониторинги.
Вопросы
Вопрос: Вы сказали, что не будете рекламировать бренды, но мне все-таки интересно – в своих проектах вы какие дашборды используете?
Ответ: По-разному. Бывает, что мы приходим к заказчику и у него уже есть свой мониторинг. И мы консультируем заказчика о том, что нужно добавить в его мониторинг. Хуже всего обстоят дела с Zabbiх. Потому что у него нет возможности строить TopN-графики. Сами мы используем Okmeter, потому что мы консультировали этих парней по мониторингу. Они делали мониторинг PostgreSQL на основе нашего ТЗ. Я пишу свой pet-project, который данные собирает через Prometheus и отрисовывает их в Grafana. У меня задача сделать в Prometheus свой экспортер и дальше уже отрисовывать все в Grafana.
Вопрос: Есть ли какие-то аналоги AWR-отчетов или … агрегации? Известно вам о чем-то таком?
Ответ: Да, я знаю, что такое AWR, это крутая штука. На данный момент есть самые разные велосипеды, которые реализуют примерно следующую модель. С некоторым интервалом времени пишутся некоторые baselines в тот же самый PostgreSQL или в отдельное хранилище. Их можно погуглить в интернете, они есть. Один из разработчиков такой штуки сидит на форуме sql.ru в ветке PostgreSQL. Его можно там поймать. Да, такие штуки есть, их можно использовать. Плюс в своем pgCenter я тоже пишу штуку, которая позволяет делать то же самое.
P.S.1 Если вы иcпользуете postgres_exporter, то какой дашборд вы используете? Их там несколько. Они уже устаревшие. Может сообщество создатm обновленный шаблон?
P.S.2 Убрал pganalyze, так как is a proprietary SaaS offering which focuses on performance monitoring and automated tuning suggestions.








