Комментарии 502
P.S. Привет Electron в Skype…
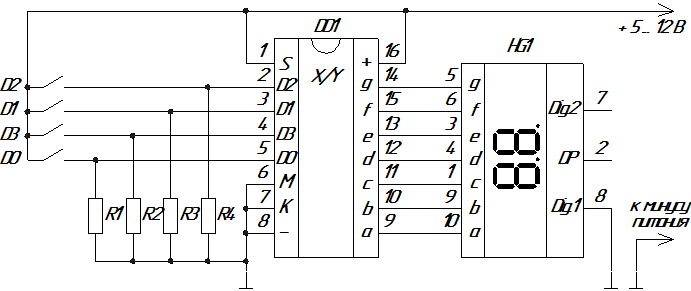
В далеком далеком прошлом ;) нажатие на кнопку формировало картинку на аппаратном уровне. не нашел схемы более низкого уровня ;(
А сейчас цепочка событий распухла до неприличия.
Клавиатуры (блютуз). Буквы в юникоде с модификаторами направления и прочим.
Отрисовка на виртуальном видеоадаптере виртуальной машины. Куча вычислительной
мощности уходит на виртуализацию и отвязку от аппаратного уровня.
Ну уберут лишнии слои абстракции, оптимизируют код по максимум. Но как это поможет запустить ИИ для Go от DeepMind на мобилке или даже обычном компе (как простая модель ИИ)? Для этого нужна интеграция с другим вычислительным устройством.
Но как это поможет запустить ИИ для Go от DeepMind на мобилке или даже обычном компе (как простая модель ИИ)?Для чего это? Вы не можете без этого жить прям?
Да, вот прям я не могу — мечтаю создать бота для другой подобной игры и чтобы его можно было обучать и запускать хотя бы на обычном компе, а не на специализированному оборудовании (TPU) в облаке.
Но речь не обо мне одном. Игру Go привел в качестве примера задачи, в которой существует огромное количество ветвлений и неопределенностей на каждом шагу и с которой современные методы на основе глубинного обучения от DeepMind справляются на отлично. Также можно привести в качестве примеров ботов к Starcraft 2, что даже более приближено к реальной жизни, но они пока не обходят уверенно человека.
На основе этого я предполагаю, что подобные методы могут использоваться уже для реальных задач, упомянутых в моем комменте ниже.
Также можно привести в качестве примеров ботов к Starcraft 2, что даже более приближено к реальной жизни, но они пока не обходят уверенно человека.А кому будет нужна игра, в которой боты уверенно и всегда будут обходить игрока? :)
жизнь без страданий не жизнь
Ну например играть то всё ещё можно против людей, а ботов использовать для тренировки. Ну и кроме того есть куча игр где можно группой людей играть против одного бота(или меньшей группы ботов) и тогда тоже интереснее если боты сильнее. Если совсем начать фантазировать, то на базе таких ботов можно сделать гораздо более интересных мобов/боссов для каких-нибудь ММО. И т.д. и т.п. :)
Если будет "читерить", то есть нарушать какие-то заранее определённые правила, то тогда его надо фиксить. Во всех остальных случаях лично я буду только рад.
У нас с вами по моему какое-то разное понимание того что значит "читерить".
Вот предствьте себе бота, который играет в шахматы. Если он придумал какой-то новый, до этого никому неизвестный, шахматный этюд и использовал его в игре, то это замечательно. Если он "научился" перемещать фигуры по доске в обход шахматных правил, то это "читерство" и это надо фиксить.
Скажем красная зона вместо запрета на кемперство.
Почему вы думаете, что пенальти и разный уровень игры — это разные вещи?
Падальщики легко забиваются двуручным оружием с… классическим управлением: просто стоишь на одном месте и машешь оружием вправо-влево. Проклинаемые многими полевые жуки убиваются полностью аналогично, только одноручным оружием. Любого одиночного бойца с двуручем легко убить с одноручником: блок-боковой удар, повторить до смерти оппонента. AI там на столько туп, что сколько не усиливай противников, их довольно легко убить простым набором движений с тем самым «неудобным» классическим управлением, просто анимация обычного удара зависит от навыка и имеет большую паузу в завершении движения связки, а анимация боковых ударов не зависит и имеет очень короткое окно остаточной анимации, из-за чего легко продолжается блоком или ударов в другую сторону.
Примерно так же, как навык профессиональных игроков прятаться в неочевидных местах и стрелять в полтора пикселя, мелькнувшие на экране разнится от новичка с хаками на автонаведение и показ противников сквозь стены.
А разный уровень игры предполагает разное поведение бота, у него одинаковое количество hp и одинаковый урон на разных уровнях сложности, не значительно отличается меткость, главное отличие в поведении, во взаимодействии с игроком; засады, ловушки, выработка контр тактики… Разница в ощущения от игры с ботами первого и второго типа — колоссальная!
А кому будет нужна игра, в которой боты уверенно и всегда будут обходить игрока? :)
И вот создали они себе бог(т)ов, чтобы было кому молиться… :)
история компьютерного язычества (С)
А кто ж тогда все доски для го раскупил после того, как это произошло?
Военным.
Ну вообще страшненько конечно.
Также можно привести в качестве примеров ботов к Starcraft 2, что даже более приближено к реальной жизни, но они пока не обходят уверенно человека.
Полагаю, основная проблема в том, что качественно обучить можно только играя с людьми, но при этом нельзя запустить сразу много инстансов бота, иначе люди начнут чаще играть с ботами, чем с людьми, а соответственно и поведение игроков будет меняться и тогда обучение еще хуже получится. То есть обучая бота играть как человек(или лучше чем человек), главное не испортить самих игроков, иначе фигня получится.
Я надеялся, что следующая версия ИИ для StarCraft от DeepMind будет обучаться на играх сама с собой. Как было с игрой Go: сначала обучалась на человеческом опыте, потом AlphaZero, которая училась, играя сама с собой.
В командных боях боты это вообще чит. 5 человек со своими характерами и эмоциями должны как-то скооперировавшись играть, а боты, по сути, как один большой бот играют.
Так боты играли в совершенно другую доту с совершенно другим балансом (в котором у людей не было опыта). В этом варианте доты, действительно, возможно, что равное распределение ресурсов и было более эффективно.
Виртуальная машина C# работает совместно с виртуальной машиной JAVA
через абстракции Линукса над конкретной архитектурой железа.
При этом все более длительное нужно делать асинхронно, чтобы не мешать
свистолко-перделкам на экране. Так как пользователи любят красивые эффекты
анимации, что действие началось и требуется подождать. Расчетов на 100-200 мс,
а в основном потоке их делать запрещено. ANR прилетит.
AlphaGO требовала больших мощностей для обучения нейросети, но для запуска в последних играх использовался уже всего один компьютер, а не кластер.
Информация из википедии:
Версия, которая выиграла у Фань Хуэя в октябре 2015 года, работала в кластере из нескольких машин с использованием 176 графических процессоров.
В игре с Ли Седолем в марте 2016 года AlphaGo использовала 48 TPU процессоров.
В матче против Кэ Цзе в мае 2017 года новая версия AlphaGo использовала только один компьютер на Google Cloud c 4 TPU процессорами, то есть примерно в 10 раз меньшую вычислительную мощность, чем была использована в матче с Ли Седолем.
О том и речь, что TPU — это другое вычислительное устройство, не обычный процессор CPU.
Учитывая уплотнение компоновки на чипе и появление 64-ядерных процессоров, думаю в скором времени не составит большого труда сделать процессор, в котором будет штук 20 обычных ядер, штук 20 TPU, штук 20 ARM и еще видеоядро как у топовой видеокарты :-)
Весь вопрос дадут ли вам доступ к самой сети(данным), а не к вычислителю. Обсчитать при наличии доступа к данным можно на чем угодно.
Я вот их тех, кто ненавидит фреймворки и хочет каждый узел оптимизировать пока дым из ушей не пойдёт, обсуждать, планировать систему ДО начала её реализации, учитывать всевозможные нестандартные кейсы её эксплуатации и дальнейшей модернизации, нормализовать данные по максимуму насколько это вообще возможно, обходить стороной сборщики мусора и интерпретируемые языки… но «жизнь такова какова, и никакова больше» (с) поэтому я пишу говнокод на яве и иногда перед сном пустив слезу мечтаю о параллельной вселенной, в которой «всё правильно»
Я вот их тех, кто ненавидит фреймворки и хочет каждый узел оптимизировать пока дым из ушей не пойдёт, обсуждать, планировать систему ДО начала её реализации, учитывать всевозможные нестандартные кейсы её эксплуатации и дальнейшей модернизации, нормализовать данные по максимуму насколько это вообще возможно, обходить стороной сборщики мусора и интерпретируемые языки…
Не волнуйтесь, со временем это пройдёт
В вся эта фигня с раздуванием давно была посчитана, и если кротко… Где мы не гоняем данные\матан, чем больше слоёв и больше «высокого» получим в итоге кучу кала которая будет с трудом работать и тратить кучу времени просто на перемещения данных в памяти
Модный нынче тренд — фреймворки. Важно освоить очередной фреймворк, а что скрывается под ним никого не интересует.
В результате когда все это начинает тормозить, или давать не тот результат, которого ожидали, все списывается на фреймворк — «он так работает, мы с этим ничего не можем поделать».
Количество (в процентном соотношении) разработчиков, способных заглянуть по фреймворк, разобраться с особенностями API той платформы, под которую ведется разработка и использовать их для разработки высокопропроизводительной системы, стремительно падает.
Правильно. Юзер за все заплатит (все эти инстансы и автоскейлы учтены в стоимости услуг для потребителя — чудес не бывает)
это актуально если у вас число программистов примерно равно числу пользователей.
Так надо не на разрабов сетовать, а на требования рынка (т.е самих потребителей). А программисту скоько заплатили, столько он и споет.
Звучит, как будто зодчий из 16 века, посмотрел на современные многоэтажки и говорит:"что за ерунда! Это фуфло бетонное и 100 лет не простоит. Вот я замки строил из чистого камня 500 лет назад, так они до сих пор не покосились". И будет прав, только никто все равно не будет покупать жилье на которое надо собирать деньги три поколения.
Осталось лишь заставить себя пользоваться такими вот картинками "аппаратного уровня".
Я понимаю, что кажется, что диод зажечь — схема и не нужна особо, а спека на какой-то sx1509b, внезапно, десятки страниц.
Одно слово ASIC (ПЛИС), имхо за ними будущее, как только производители перестанут жевать сопли и не станут пихать этот функционал в каждый процессор, причем с общим стандартом и открытыми спецификациями, а не так как сейчас, чтобы начать разрабатывать нужно заплатить четырехзначные суммы
Во-вторых, как верно заметил JerleShannara плата за реконфигурируемость ПЛИС — это огромные накладные расходы, выливающиеся в то, что дизайн на ПЛИС имеет скорость и потребление, сравнимые с ASIC на пять-шесть поколений технологии старше (= медленный кипятильник).
Потому что делать на конечных автоматах то, что можно написать на Си — нерационально. Быстрее разработка, легче отладка, меньше ошибок, кушает меньше ресурсов. Потому что у FPGA конечное число логических вентилей и ЛЮБОЙ кусок логики или необходимость помнить что-то (если только не используется внешняя память — а DDR3 на платах с FPGA часто встречается) расходует эти ресурсы. Более того — с приближением к этому лимиту сильно возрастает сложность задачи по разводке схемы, она может даже не развестись с нужными скоростными характеристиками. Дешёвые FPGA стоят совсем недорого, каждый купить может какой-нибудь Microzed, а быстрые стоят тысячи долларов. А для серьёзных задач нужны быстрые. Реализовать процессор на FPGA можно, только вы получите 32-битный медленный аналог CPU 20-летней давности за сумасшедшие деньги. FPGA адекватны только для особого спектра задач, например для высокоскоростной потоковой обработки данных, когда вы пишете несколько конечных автоматов, на выходе будет стоять, скажем IP-ядро контроллер Ethernet MAC-уровня, а если есть несколько тысяч долларов и лишние ресурсы, то можно даже сделать TCP/IP. Но для такой задачи нужно разработать свою печатную плату (а иногда не одну), произвести её (это очень дорого по сравнению с любыми Xeon)
А ещё область разработки для FPGA — это заповедник проприетарщины. Честно, тут нечему завидовать. Тут ситуация как в разработке ПО до появления Open Source — платные «компиляторы» и пр.
И чтобы 2 раза не вставать: нет, квантовые компьютеры никогда не заменят обычные. Они работают по совершенно другому принципу, для них известно всего пара десятков очень узконаправленных алгоритмов и максимум, что их ждёт — роль сопроцессоров для спец. вычислений (криптография, некоторые области математики и пр.). Если удастся создать квантовый компьютер с достаточным числом кубитов (а вероятность этого экспоненциально уменьшается с каждым новым кубитом)
Процы будут покупаться под конкретную ось :) АМД доведёт линух до ума, сделав его полноценным конкурентом Майкам.
Блюпуп-клавиатура это удобство, но в тоже время требует другого интерфейса работы с собой, а это требует абстракции, чтобы в использующей клавиатуру программе не было необходимости делать несколько реализаций ввода. Юникод решил проблему не-латинских символов и «ой, а у меня не та страница кодировки» и теперь я всегда уверен, что буква будет показана верно.
И т.д. и т.п. с одной стороны мы тратим мощности на ненужные на первый взгляд вещи, а с другой решаем много проблем с удобством и надёжностью работы.
Банально на примере вашей схемы. Что будет, если вместо 5 вольт случайно подадут 220? Светодиод сгорит, а чтобы этого не было требуется ставить защиту, которая усложняет схему.
А теперь напридумывали столько удобств. Но чтобы они все работали
нужны мощности как для крутого шутера из 2000х
Раньше это были повозки с двигателем без всяких удобств и какого-либо комфорта и люди тоже использовали то что есть. Сейчас же в автомобиле всё меньше деталей необходимых для выполнения задачи перемещения из точки А в точку Б, а остальное это всякие магнитолы, кондиционеры, массажеры попы и т.д. То есть по сути вещи, которые требуют ресурсов, уменьшают надёжность, стоят денег, но при этом добавляют комфорт водителю и пассажирам.
В результате любители езды по лесам говорят, что это отстой, т.к. ненадёжно, а им нужно ремонтироваться в 100500 километрах от дома и для этого нет ничего лучше козла. Городские же жители с удовольствиям ездят на ненадёжных и неэффективных, но комфортных автомобилях. И давайте будем честными, вы не захотите ездить на старом (это которому лет 50) автомобиле, а вернётесь к новому, т.к. при всех минусах комфорт оказывается дороже.
Так же и с разработкой ПО. Пока мощности растут быстрее наших потребностей мы думаем о комфорте в разработке ПО. Как только упрёмся в предел производительности начнём заниматься оптимизацией.
А то, что человек «подсаживается» на приятное и комфортное было до эры электроники: ожирение и алкоголизм :)
И нет никакой гарантии, что человечество пойдет по пути оптимизиции, может быть количество проблем будет настолько огромным, что проще будет сделать заново. А может быть всё превратится в неразгребаемую помойку.
Ведь технический долг копить так просто и весело, а рвзгребать горы говна не хочется никому.
Ну автомобилю которому 50 лет вряд ли, но вот который был создан 20 лет назад вполне. В комфорте через пару часов возможно уснуть через пару часов, а так, когда ощущаешь пятой точкой все неровности, за 4-6 часов трудновато будет уснуть.
В разработке ПО такой же подход. Свой алгоритм разработки под каждую конкретную задачу. Где-то нужен сервис чтоб с консолькой и мог запускаться во всяких овнах, а где-то красивая картинка нужна или там куча "светофоров"
Современное «авто» это когда мотор крутит уменьшенные колеса (какие то R3 с шинами типа 20\5), колеса крутят ленту, от ленты уже вращаются полуоси, с нормальными R15 185\80.
козла просто можно отремонтировать в лесу, а БМВ нет. поэтому иногда козел.
применительно к ПО — чем проще интерфейс — тем проще пользоваться.
насчет надежности — конечно ручной молоток сложнее сломать чем пневмо, но дураку дай…
одно дело — излишества, другое дело — удобство.
к сожалению — излишеств в ПО щас гигантское количество.
видимо у людей столько бабла, что продается и время программиста, и продажника, и еще кучи народа обслуживающего ПО. + на хороший комп.
И даж параграф есть:
«What surprised me, though, was the similarities between the Shuttle computer and the Soviet clock. I expected the Shuttle computer to use 1980s microprocessors and be a generation ahead of the Soyuz clock, but instead the two systems both use TTL technology, and in many cases chips with almost identical functionality.»
А сейчас цепочка событий распухла до неприличия.
Клавиатуры (блютуз). Буквы в юникоде с модификаторами направления и прочим.
Отрисовка на виртуальном видеоадаптере виртуальной машины. Куча вычислительной
мощности уходит на виртуализацию и отвязку от аппаратного уровня.
Но вы же не хотите лезть с паяльником в видеокарту, когда требуется, например, сменить шрифт? Все эти виртуализации, абстракции, автоматическое подключение попросту удобны.
Никому не нужен дисплей, способный менять отображаемые цифры за наносекунды (как тот на схеме выше), т.к. скорость пользователя ограничена значениями примерно в сотни миллисекунд.
Точки баланса в каждом случае различны. Они в многомерном пространстве с осями "производительность", "безопасность", "стоимость разработки", "сложность поддержки", etc… Плохое с одной точки зрения решение может быть удовлетворительным или даже хорошим с другой точки зрения. Если система конкретно тормозит, возможно, она хороша в чём-то другом (например, в низкой стоимости разработки).
Справедливости ради, фунционал у 2016 и 95 ворда отличается.
Даже размеры интерфейса.
Не в 500 раз, конечно, хотя для, как миниум, UI, цифры близки, как мне кажется.
Никто не мешает хранить ресурсы в векторе (компактно), а потом при необходимости конвертить в растр для ускорения отображения (типа JIT компиляции такой). Действительно — пользователи ОБЫЧНО то же разрешение экрана на своих устройствах не меняют. Поэтому и растры им нужны не в виде коллекции на все случаи жизни, а конкретные
Ну, Майкрософт, допустим, не хочет, но почему тот же LibreOffice не уделал всех?
Так почему никто не переехал?
В андроиде есть возможность графические ресурсы для UI на подмножестве SVG делать (VectorDrawable/VectorDrawableCompat). Иногда используют. А иногда (чаще) проще нарезать картинки (все равно у адекватного дизайнера автоматом режутся)
Возьмите что-то попроще. Ну например простые картинки-скетчи. Логично использовать в них векторную графику, но это дорого, потому почти везде jpg размером в полмегабайта.
Угу, на растеризацию вектора, особенно детального, тратится сильно больше ресурсов, чем на отрисовку битмапа (просто набора цветных пикселей). За универсальность платим.
Я бы привел в пример для сравнения скриптовую сцену в игре и фильм.
en.wikipedia.org/wiki/Haiku_Vector_Icon_Format
разбор формата в HEX-редакторе:
blog.leahhanson.us/post/recursecenter2016/haiku_icons.html
Насколько я помню, SVG это XML-текст, который еще надо долго парсить и т.д., а HVIF это бинарный формат, в котором урезано много того, что не относится к задаче, да еще и есть то, что реально надо — LOD варианты иконок, к примеру. :)
Личная просьба тем, кто это, возможно, когда-то прочитает — если будете пилить какой-то свой пет-проект (еще лучше — на чем-то дохлом, типа ардуины), попробуйте ради веселья использовать этот формат в нем. :) Заодно и на статейку материал будет!
Смена темы оформления одним кликом. Выбор шрифта с демонстрацией этого шрифта без применения.
Насчёт рисования математических выражений не уверен, мне кажется в 97 ворде надо было плагин ставить.
Математические выражения в адекватном виде появились только в 2007 ворде. Но, блин, почему вещи, которыми пользуются процентов этак 10 пользователей (слияние, рецензирование, рассылки, темы, математические выражения), не вынести в плагины или модули и make WinWord small and mighty again? Многим и правда старичка-Лексикона хватало.
Wordpad есть по-умолчанию в каждом дистрибутиве windows. Это сами юзеры кушают кактус используя "Word" для простых документов.
Вордпад таки немного перебор, но если бы в него завезли таблицы и пару мелочей типа выравнивания по ширине, его бы хватало. С удивлением обнаружил, что в него завезли нормально работающие СОМ-объекты.
в макос есть вполне вменяемый TextEdit, в браузере всегда можно открыть Google Docs с поддержкой всех распространенных форматов… Десктопные программы умирают (
Вы пробовали работать в google docs с большим документом со сложным форматированием? Онлайн сервисы хороши когда вам нужно быстро накидать пару страниц текста с типовым форматированием, но если вам работу работать нужно, то они умирают в первые полчаса.
А никто не говорит, что надо гуглодоксом пользоваться для сложных документов. Простые кейсы типа напечать служебку или быстренько посчитать что-то в таблице — покрываются. А для справедливости — со сложным форматированием даже в офисных пакетах от версии к версии могут быть проблемы
Гуглдок даже от такого начинает постоянно и на полную грузить пару ядер процессора, ждет в районе гигабайта памяти на каждую вкладку с подобным файлом и при этом все-равно умудряется постоянно и заметно притормаживать. Если что-то побольше и посложнее — вообще просто повесится может.
Хотя точно такую же табличку даже древний Excel 2000 открывает без проблем за секунду используя всего 10-20 Мб памяти, почти не нагружая процессор и при этом все будет «летать» во время работы.
А никто не говорит, что надо гуглодоксом пользоваться для сложных документов.
Ну в таком случае десктопные программы совсем не умирают. Они просто используются для сложных вещей. Собственно именно с вашим утверждением про смерть десктопного офиса я здесь и спорил на самом деле.
Предпросмотр шрифтов крайне удобная штука, тут спору нет!
Но вот что-то прям такого нового с 97 года они всё равно нифига не добавили :-)
Например у нас в компании ворд (и вообще офисный пакет) изпользуется на всю катушку. Как пример про темы (я уверен, многие снисходительно усмехнулись, когда я про них упомянул) представьте себе процедуру изменения корпоративного стиля в компании, сотрудники которой раскиданы по всему миру. Элементарная замена шрифта и цветов превращается в ад для специалистов соответствующих отделов. В новом ворде я просто выбираю тему и не парюсь. Они её как то там обновляют по необходимости, не вникал.
А обычные текстовые документы практически произвольной сложности легко делаются в LibreOffice Writer.
Не имею ни малейшего понятия, кто и зачем (конкуренция разных команд? или купили разработчиков?) его сделал, и что с ним потом стало…
DOCX такой маленький из-за того, что это на самом деле архив, а не из-за оптимизации формата. Внутри же него до сих пор используются тяжеловесные XML.
Если зазиповать doc, то получится в два раза меньше, чем такой же docx.
Upd. Надо читать все каменты, прежде, чем писать свои :)
Кстати я многие документы в нотпаде держу
С учетом того, что существует Markdown и такие прекрасные визуальные редакторы как Typora, это почти что превращается в базовую версию ворда, но с дополнительными плюсами (простой текстовый формат возможностью простого версионирования).
Все-таки там нет форматирования, это не очень удобно и наглядно.
Зато просто и под рукой
Ну так Markdown — то же самое + подсветка и форматирование как бонус.
Его практически и изучать не нужно — он очень простой, ну и любой текстовый документ уже сам по себе практически Markdown)
И в Word-2025 так же будет.
Потому что большего им просто не требуется.
Но Microsoft это делать не будет, потому что как потом продавать MS Office?
А другие не смогут, потому что пользователи уже привыкли к Word/Excel и менять не захотят.
А вы думали, почему так легко найти и установить пиратскую версию Офиса?
Многие до сих пор верят — это потому, что глупые программисты Microsoft просто не могут сделать нормальную защиту.
А другие не смогут, потому что пользователи уже привыкли к Word/Excel и менять не захотят.
ИМХО захотят если он будет выполнять эти 20% возможностей, а не как OO/LO и иже с ним.
Твои ЛИЧНЫЕ документы вообще никому неинтересны.
А вот как в составе хомячков — ты выполняешь свои роли.
Google все равно, смог он получить в свои загребущие системы личные документы Revertis или нет.
Но ему не все равно, когда счет документов, обрататываемых в Google Docs, исчисляется миллионнами штук. Он получает из них достаточно данных, чтобы строить модели, делать предсказания, и продавать рекламу.
Таким образом, наличие в цепких лапках Гугла одного-единственного Хабраюзера Гугл никак не беспокоит. Гугл беспокоит решение вопроса в виде охвата в миллионы людей.
Тем не менее, считаю, что каждый имеет право решить отдавать свои документы Гуглу или кому-то еще и наслаждаться таргетированной рекламой или нет. Так что вопрос Privacy, так же как и вопрос наличия устойчивого соединия к сети Internet, остается актуальным.
PS если серьёзно — достаточно давно встречаю статьи о новых типах транзисторов с потенциально большими скоростями, новые типы памяти и прочие любопытные штуки, которые всерьёз не финансируются, пока работают (и приносят прибыль) уже освоенные технологии.
Конечно же продолжаем!
PS не говорю, что сейчас исследования в нексген-технологиях не ведутся и/или денег совсем не дают, но по сравнению с переходом на новые техпроцессы…
уходить с него на что-нибудьили уходить с него на что именно? Проблема ровно в том, что несмотря на огромные RnD-расходы, уходить все еще некуда, просто некуда. На графене за пятнадцать лет даже одиночные транзисторы толком не заработали, на нанотрубках все даже хуже, чем на графене, никакой «оптики» просто не существует.
Лучшее, что мы имеем со всех этих «новых технологий» — это силовые транзисторы на нитриде галлия для быстрой зарядки мобильников.
Хотя, возможно, все очерки типа «показан прототип нового транзистора/памяти/etc» — фэйк или белый шум, я ж не настоящий схемотехник.
Как кажется с моего креслаК сожалению, вам кажется. Из моего кресла настоящего схемотехника довольно хорошо видно, что реальной альтернативы кремнию для вычислений общего назначения в ближайшие лет двадцать не будет.
я ж не настоящий схемотехник
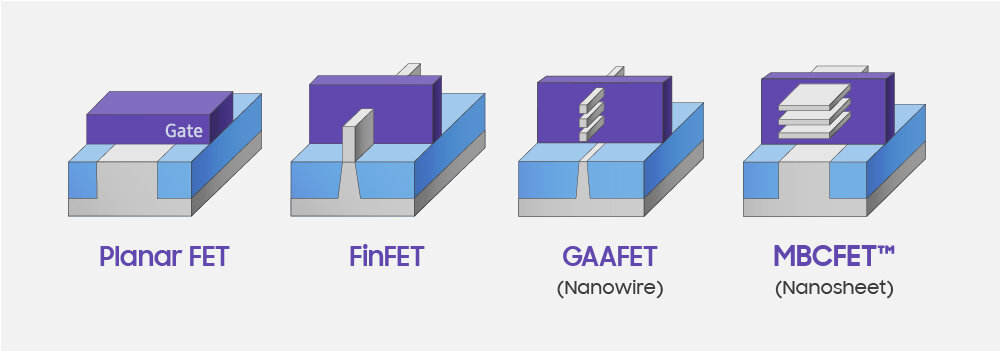
В физический предел уперлись уже очень давно (он, к слову, около 20 нм), с тех пор все «7-5-3 нм» — это упаковка транзисторов сначала вертикально (FinFET), а потом в несколько слоев (nansheet, nanowire и прочие GAAFET).
«показан прототип нового транзистора/памяти/etc» — фэйк или белый шум«Прототип» — это не то же самое, что можно реально серийно производить. У MRAM например были офигительные прототипы, но при попытках довести технологию выяснилось, что когда надо обеспечить больше трех циклов перезаписи, она оказывается не только не быстрее SRAM, но и чуть ли не медленнее флэша, что делает ее просто ненужной. И таких историй море, но о них редко пишут в новостях, ведь британские ученым не отчитываются ими по грантам.
пока всё и так работает (т.к. добавление лишних прослоек компенсируется ускорением железа) — никто не станет делать более чистый код: это, в большинстве случаев, не выгодно, а когда перестанет работать — останется слишком большое количество людей, который привыкли быстрее хватать стильный-новый фреймворк, обмазывать так-себе-кодом и пушить в прод.
По поводу фрейморков: я тут перешёл на веб разработку с обычной и удивлён важности использования последних технологий — если WinForms вполне нормально, а что там под капотом вообще никого не волнует, то в вебе почему-то использование технологий не первой свежести всех пугает
Ничего удивительного, веб торчит наружу и старое имеет гораздо больше обнаруженных уязвимостей.
ПХП — язык созданный для одной домашней страницы взлетел, тогда как Питон, который уже тогда был круче до сих пор только набирает и отбирает свою долю популярности.
Джумла взлетела, Вордпрес не просто взлетел, уже создает вакансии «разработчик плагинов под вордпрес». Первое было когда-то лютым геморром, второе — движок для блогов, который вдруг ВНИЗАПНА стал движком для всего…
Маджента взлетела, хотя был опенсурсный ОпенКарт…
и таких примеров взлетевших в вебе недоразумений еще вагон, например ТИПО3 (да отсохнет его карбюратор во веки веков)
Ну как действительно упрутся и необходимость будет подпирать, что-то придумают. А сейчас то зачем, и так триллионные стоимости компаний, помогающих эффективно сжигать время и деньги пользователей. Главное эффективно менеджерить да рассовывать опционы-акции по карманам.
А до того GlobalFoundries решили выкинуть в трубу многомиллиардные исследования для 7 нм и остановиться на 14 нм навсегда — потому что не могли довести прототипы до промышленного освоения. Более того, они на этом потеряли не только инвестированные арабскими шейхами деньги, но и контракт с AMD, который принес бы им сейчас золотые горы. А так они накормили своего основного конкурента, окончательно отказавших от притязаний на самые вкусные рынки. То есть речь идёт как раз не об абстрактном прогрессе, а о том, что прямо сегодня инвесторы терпят убытки, а эффективные менеджеры получают вместо опционов пинки под зад (нынешние CEO и CTO и Intel, и GloFo ещё и двух лет не отработали).
У вас есть какие-то разумные объяснения такому поведению в условиях, когда можно было просто придумать что-то принципиально новое? У меня вот без привлечения рептилоидов не получается.
А инвесторы, видимо, устали слушать отчёт об успешных испытаниях нового прототипа
*но это не точно, может и не выйти, как и в прошлый раз.
PS Радует, что хоть где-то эффективные, но несправившиеся менеджеры получают под зад коленом вместо золотого парашюта, как в Boeing.
Поставили не на ту лошадь?Но это не бьется с концепцией «как действительно упрутся и необходимость будет подпирать, что-то придумают». Вот же, уперлись, подпирает еще как. Ничего не придумали. Причем их очень много таких ничего не придумавших и начавших вместо этого упускать колоссальные прибыли. Вот вам прямо список с годами, объясните мне хотя бы его половину.

Вот вам прямо список с годами, объясните мне хотя бы его половину.
MIT в прошлом году опубликовал хорошую статью с анализом по этому вопросу.
И пока все не упрутся в физику до конца — прорывных технологи не будет — то есть реально все, без возможности заказать чипы по следующему поколению техпроцесса у соседей.
К тому же, не всем нужен самый тонкий и свежий техпроцесс, массовые контроллеры/логика спокойно и на старых техпроцессах будут выпускаться и продаваться миллионами.
PS это не попытка отстоять свою точку зрения не смотря на факты, это досужие рассуждения на тему, с целью получить ещё несколько интересных ссылок и идей. Вашу правоту признал несколькими постами выше.
без возможности заказать чипы по следующему поколению техпроцесса у соседейВозможность заказать свои чипы соседям есть у разработчиков чипов, а не у фабрик. GloFo и UMC не могут заказывать производство на TSMC при всем желании. Все, что они могут сделать — придумать что-то прорывное и отобрать долю производственного рынка обратно. Точнее, как мы выяснили, они не могут этого сделать)
массовые контроллеры/логика спокойно и на старых техпроцессах будут выпускаться и продаваться миллионами.А вот это совсем другая история, причем сразу в нескольких измерениях.
Рынок «старых технологий» во-первых, меньше, чем новых, а во-вторых, он гораздо конкурентнее, потому что прибыли меньше, больших клиентов тоже меньше, а игроков на рынке больше. Так что для того, чтобы хорошо себя чувствовать там, фабрике надо быть едва ли не менее изобретательной, чем при работе с передовыми нодами. Причем изобретательной в вещах, котоые с одной стороны, дешевле, а с другой — очень сложно придумать и реализовать что-то такое, что конкуренты не смогут быстро повторить. И что не сможет повторить TSMC со своими практически бесконечными ресурсами на RnD.
Можете пояснить за циклы "тик-так":
- Выпускается старая архитектура на новом техпроцессе или обычно всё-таки новая на новом?
- С точки зрения повышения производительности (на время разработки) выгоднее новый техпроцесс или оптимизация архитектуры для существующего или даже предыдущего?
Я не совсем понимаю, почему так упорно идут от 90/65нм вниз, это маркетинг, инерция сознания или правда технически оправданно?
Тик — старая архитектура на новом процессе.
Так — новая архитектура на старом процессе.
Итого процесс и архитектура обновляются с одинаковой скоростью, но в разное время.
Второй вопрос — отличная тема для докторской диссертации. Он не имеет ответа в общем случае, потому что зависит от того, насколько новый процесс лучше старого, есть ли у архитектуры ресурсы для оптимизации и т.д. и т.п.
Если совсем грубо, то наверное перейти на новый техпроцесс дороже, но проще и быстрее, чем выжимать соки из имеющегося. И это «быстрее» во многих случаях означает сорвать куш с новым продуктом или вылететь в трубу. Спокойно шлифовать архитектуру годами можно только при полном отсутствии конкурентов.
или правда технически оправданноПравда технически и экономически оправдано в большинстве случаев, где это происходит.
А условные копеечные микроконтроллеры клепали и будут еще долго клепать на 180 нм.
Я вот вроде бы знаю кто такие Intel и AMD. Но примерно года три-четыре назад начал все чаще слышать упоминание таких названий как Global Foundry, TSMC и еще какие-то в разговорах о амд и интел. И вот эти ребята мне совершенно непонятны, в частности кто они такие, где живут, чем именно занимаются и, главное, как именно и почему они связаны с AMD и Intel.
TSMC и GlobalFoundries как раз и есть эти сторонние фабрики. Они не продают никакие микросхемы конечным пользователям, но предоставляют услуги производства разработчикам.
Например, GloFo — это бывшие фабрики AMD, выделенные в самостоятельную компанию, TSMC всегда имел бизнес-модель фабрики, а заводы Samsung производят чипы и для своих, и для сторонних заказчиков (которым раньше был например Apple).
Модель сторонних фабрик появилась, потому что производственное оборудование стоит безумно дорого, и почти никто из разработчиков не может себе его позволить.
Забавнее то, что поставщик оборудования для литографии уже давно вообще монопольный.
Даже, в приведённой вами ссылке на Вики, удвоение транзисторов каждый год (а не полтора):
появление новых моделей микросхем наблюдалось спустя примерно год после предшественников, при этом количество транзисторов в них возрастало каждый раз приблизительно вдвое/зануда off/
Так-то это и законом не было. Если я правильно помню историю, то Мур вообще в шутку это сказал на какой-то вечеринке. И формально этот "закон" в общем-то никогда и не выполнялся, удвоение шло за большие промежутки времени. В таком контексте вертеть действительно можно как угодно, это в любом случае просто красивая цитата которая уже давно живет своей жизнью в мире журналистов.
это в любом случае просто красивая цитата которая уже давно живет своей жизнью в мире журналистов.Не обижайте журналистов, эту цитату подхватили на щит и таскали на нем много лет вовсе не они, а маркетологи Intel, торжественно возложившие на свою компанию обязанность сделать «закон Мура» самосбывающимся пророчеством.
Быренько нагуглил среди старых статей:
compress.ru/article.aspx?id=9558
www.ferra.ru/review/techlife/s25856.htm
Ровно сорок лет назад, 19 апреля 1965 года, в журнале Electronics (vol. 39, N8) в рубрике «Эксперты смотрят в будущее» вышла знаменитая теперь статья Гордона Мура «Cramming more components onto integrated circuits», в которой тогдашний директор отдела разработок компании Fairchild Semiconductors и будущий со-основатель корпорации Intel дал прогноз развития микроэлектроники на ближайшие десять лет на основании анализа шестилетнего развития младенческой тогда еще электроники, предсказав, что количество элементов на кристаллах электронных микросхем будет и далее удваиваться каждый год.
Вон, в DropBox несколько лет назад, запилили управление хранилищем на Go. Оно выполняло свои функции, но тормозило из-за GC. Они переписали его на Rust, и производительность возросла намного. Пересказываю по памяти, но эта история была у них в блоге.
А точно был мальчик? Потому что я тоже эту публикацию помню, а потом вроде бы оказалось что там журналистов учёные насиловали как могли, и на самом деле Dropbox переписал на Rust только пару мелких служб в которых у них затык по производительности был, а всё остальное как было на Go так и есть.
Фигасе "мелкие службы". Magic Pocket использующий Rust это по сути центральная компонента их хранилища. Конечно, его не полностью переписали с Go, но всё же. К сожалению, презентации где о переписывании рассказывалось более подробно более не доступны...
Там вроде только OSD переписали — то есть собственно демон который висит над диском и шурудит секторами, по одному демону на диск, а остальное осталось как есть; да и Magic Pocket там важная, но не самая объёмная часть инфраструктуры. То есть да, в целом дело хорошее и вселяет надежду (я уже джва году жду не дождусь возможности попробовать Rust в embedded продакшне), но я не уверен, что это большая веха для Rust. Скорее просто ещё одно напоминание о том что такие вещи вообще не стоит писать на garbage collected языках.
И как он ускорит код написанный на C++?
Чтобы писать более производительный код, нужны не новые программисты, а новые менеджеры. Оттестированный и профилированный код на плюсах пишется сильно дольше, чем вжух-поделки под электрон.
А почему не условная компиляция? А при скачивании отдавать юзеру аналог cpuZ, чтобы поставить собранную точно под его устрйоство версию?
Ну, имхо, она существует, правда, во мне и Tkinter глубокого эстетического протеста не вызывает. Но даже если их нет, то в чём невозможность использовать по библиотеке на платформу, сведя их интерфейсы к единому? Трудоёмко, да, часть специфичных фич осыплется, но в принципе вполне реально.
Вот для Rust'а многие пытаются это сделать
Дадите ссылки? Интересно
А потом поиском по гитхабу :)
качественную кроссплатформенную библиотеку GUI
Qt уже давно есть
Я конечно не автор, но Qt не нативен. Вот прямо сейчас я не могу настроить compose в телеграме и курсор выглядит в брузере и в тележке не так как в системе. Это баги которым уже лет больше чем я пользуюсь линуксом. В винде-же отрисовка даже кнопок отличается, и программу на Qt видно сразу.
Нормальная библиотека должна использовать стандартные функции ОС, а не городить тонну абстракций. Она должна рисовать все элементы не так как хотят ее создатели, а так как принято в системе, через системные вызовы (хотя я прекрасно знаю что это за ужас — работа в чистом gtk или winapi по сравнению с Qt). Пока такого не произошло — будут недовольные, как я.
В этом и проблема и преимущество линукса одновременно — зоопарк DE, зоопарк фреймворков и подходов к API. Получаем ситуацию как у меня сегодня после обновления elementary os — все приложения gtk младше 3.ХХ стали выглядеть как win98, другие нормально, третьи по Qt'шному. Меня, как UI перфекциониста который зачитывался Apple HIG в свое время, это очень расстраивает. Еще больше меня расстраивает когда я вижу как мелкая программа (brasero вроде) тянет 140 метров зависимостей и свякие Qt-шные либы.
Я прекрасно понимаю что elementary os с pantheon на gtk тянет к себе qt-шные либы потому что в ней их нет.
Я говорю про то что сейчас у меня в системе 2 библиотеки отрисовки интерфейса, как минимум, и каждая из них отличается по UX и UI друг от друга. И каждая из них требует своих танцев с бубном чтоб с ней было удобно работать мне, как пользователю.
Понимаете маразм? У меня курсор становится другим при движении над Qt приложением, возвращаясь обратно в стандартный вид над рабочим столом.
btw с виндой не сравнить — мои приложения под bcb из 98 винды работают под десяткой и даже выглядят нативно без подтягиваний зависимостей, тогда как gtk2 в gtk3 уже выглядит как родом из 90-х.
Кроссплатформенный гуй пытаются сделать с конца 90х, а воз и ныне там. Три основных подхода
- оборачивать существующие платформенные библиотеки (Java SWT, React Native, Java AWT, Xamarin Forms, WxWidgets)
- рисовать все самим (Swing, Flutter, QT)
- использовать HTML (Electron)
Все имеют фатальные недостатки. В итоге одна компания пиарит подход 1 (React Native), через 3 года видно что это хрень и уже другая компания начинает пиарить подход 2 (Flutter) только для того, чтобы через 3 года все увидели, что это тоже хрень и кто-то начал пиарить подход 1.
Пользуюсь многим софтом на трех платформах (мак, вин, лин) — Firefox, Thunderbird, Chrome и куча по мелочи. qBittorent всякие которые на Qt.
Качеством доволен вполне. Понятно что неидеально, но не раздражает.
Какой там кроссплатформенный гуй, в высоком разрешении шрифты рисовать по-нормальному не научились. Все три рендерилки плохи по-своему и плохо рисуют на ретинах.
В пятой версии Qt уже не сама рисует, перешли к подходу 1 :)
Проблема только в том, что если захочешь кому-то предложить на Дельфи написать, сразу обосрут. Что в компании на работе, что в опенсорсном сообществе.
freepascal.ru
с радостью возьмется за предложенную и оплаченную работу :)
А то все хочу да хочу в свои стеки программирования еще ios добавить, но останавливает необходимость иметь их телефон и что-то на стол.
При разработке под iOS живой мак вроде как обязателен, т.к. он осуществляет подпись приложения. Без этого программу не выложить в AppStore. На Хабре как-то писались несколько статей об этом.
В остальном сборка под iOS почти ничем не отличается от сборки под мак.
Таким образом весь основном функционал отлаживается сначала под виндой. Это очень комфортно, потому что компилятор Delphi крайне быстрый. А потом уже интерфейсные части отлаживаются под конкретную платформу. Тут процесс дольше идёт, т.к. сборка, например, под Android небольшого проекта занимает около 30-40 сек.
Насчет Android:
Android вот х64 завезли наконец-то. Правда App Bundle пока не завезли :( В комплекте есть Android SDK но старый(!) — лучше использовать «родной» от Google — хотя Embarcadero и не рекомендует — однако у меня проблем не возникло.
ПС: Есть «косяк» на данный момент. Если вы выложите Android x64 APK — оно не заработает на arm v7 :) Delphi по-умолчанию не пакует в x64 APK 32-х битный бинарник. Нужно «ручками» добавить в deploy конфигурацию.
Насчет Linux:
Да, завезли, но официально — пока только консоль, без GUI (кажется х64 only). История с SDK такая же. Нужна ОС с которой Delphi вытянет SDK (Да, и снова можно «виртуалку»). Однако FMX GUI для линукса есть на просторах интернета. Вроде бы как у них разраб ушел который его пилил, там прям скандал какой-то был. Но оно есть и работает исправно. Правда денег стоит www.fmxlinux.com/order.html (ну или… вы знаете где искать)
PPS: Очень круто что отладчик работает и в iOS, и в MacOS, и в Windows/Linux/Android… Но учтите что отладчик для Android только х32 например. Если мне не изменяет память то для MacOS тоже. А значит отладка на «Каталине» невозможна. (Собирать х64 MacOS Delphi при этом умеет само собой)
Вы просто компилируете одно и то же приложение на разные платформы?
Как решаете вопрос с отсутствием "курсора" на мобильных платформах?
«Курсор» как бы в таких приложения не нужен. Здесь же всё решается экранными элементами и жестами. На дельфи любой жест запрограммировать можно. Экранные элементы с полями ввода автоматически вызывают системную клавиатуру. Можно задавать её тип (полная, цифровая, для набора номера и т.п.).
Вообще по этой теме можно было бы целую статейку написать.
Вопрос — нужен ли весь код на плюсах или вполне достаточно будет условного Kotlin Native, а то и просто в JVM с тонкой прослойкой HAL на С?
Пока, по ощущениям, в некоторых областях RnD дело идёт именно к этому.
Выгода налицо.
Выгода-то налицо, но несколько грустно, что скорость выполнения и потребление ресурсов не являются значимыми критериями при разработке.
Раньше вы нанимали команду под IOS,Android,Win,Web. А теперь нанимаете только веб-прогеров и они пилят вам все это на одном (практически) стеке.
А теперь можно нанять одну команду Delphi и она соберет один код под IOS,Android,Win,Mac,Linux (FMX) и Web (UniGUI). Мы именно так и делаем.
Либо мы приструним свои амбиции, либо мы вернёмся к написанию более экономного и эффективного кода. Иначе говоря, назад в будущее.
Во-первых, какой бы экономный и эффективный код не был, это не поможет в долговременной перспективе. Во-вторых, также есть Закон Обстинга, который гласит о том, мощь компиляторов удваивается каждые 18 лет, так что с неэффективным кодом не все так плохо. В третьих, есть другие архитектуры, которые могут кардинально увеличивать производительность определенных вычислений (нейросети): Аппаратное ускорение глубоких нейросетей: GPU, FPGA, ASIC, TPU, VPU, IPU, DPU, NPU, RPU, NNP и другие буквы.
Незачем. Но мессенджером все хотелки не ограничиваются, надо стремиться к какой-то форме ИИ, который можно запускать на мобильных телефонах.
Но его будут пихать в каждый мессенджер, причём у каждого свой, маркетинг, повышение юзабилити, все дела. Мне больше нравится unix-way с композицией маленьких однозадачных программ.
надо стремиться к какой-то форме ИИА кто сказал, что это надо? Кому? Зачем?
Какую проблему мы собираемся решать этим ИИ?
Когда только появился ПК, люди тоже не понимали, зачем он им нужен. Теперь же жизнь без него представить сложно.
Для чего надо: всяческие автопилоты, роботы-уборщики. Если говорить про мобилки — консультанты, помощники (не такие, как Siri). И куча других приложений на самом деле, в которых идет активное взаимодействие с окружающей средой и в которых существует большое количество неопределенностей.
Для эффективной обработки информации из окружающего мира текущая архитектура процессоров не подходит ни по производительности (для нейросетей нужно больше считать, но не обязательно точно), ни по энергосбережению.
С ИИ на мобилке человек может быть уже не нужен
Да и в общем облачный биллинг с оплатной за выполнение делает прозрачность стоимость кривого кода
Придёт 5G с миллисекундными задержками — и все вычисления переедут в облака с процессорами в жидком гелии, а телефоны и компьютеры будут просто терминалами удалённого доступа по типу блумберга.
5G не придёт. Как не пришли 4G, 3G и в общем-то 2G. И оптика в каждый дом не пришла. Так что нормальный процессор, несколько гиг памяти и терабайтный винт под медиа на домашнем компьютере останутся нормой ещё очень долго, скорее навсегда.
Сейчас и Чукотку тащат оптику, так постепенно дотянут везде где живет несколько сотен тысяч людей. Тонкие клиенты не будут сносно работать много где, хотя бы из-за пингов. А размещать дата центры станут в первую очередь там где большая концентрация потребителей.
Так что частично в этом направлении все и двигается. Я уже сейчас свой лэптоп использую фактически как тонкий клиент для разработки, т.к. задачи зачастую требуют вычислительных мощностей несколько другого порядка.
Единственная проблема — головная станция дорого стоит (150-300 тыс руб, примерно пара тысяч на абонента), но думаю что цены упадут со временем, как обычно они падают на любое железо.
Но с другой стороны это мало принципиально, положит он улицу в поселке под Сызранью или подъезд в 16-этажке в МСК, ведь та упомянутая «оптика», которую тянут в квартиры все равно GPON, вряд ли вообще кому-то тянут классический SFP в квартиры.
Вообще провайдер обычно терминал GPON свой предоставляет и паролей не дает, возможно потому что собирает SMNP с него или пингует, помимо управления. И если какой-то терминал погас, а через время лег весь порт — то стоит начинать проверку оттуда.
Понятно что неявно и неоднозначно, но все достаточно решаемо, в крайнем случае сходит монтажник и порежет/поварит, за 5-6 итераций можно найти злоумышленника, все равно в ветке не больше 32 абонентов.
С другой стороны менять свичи после прошедшей грозы — не менее увлекательно, езернет тоже имеет свои недостатки (лимит длины кабеля, пробой статикой, воруют провод на медь) и остаться без связи по какой-то причине можно точно также.
Тут просто нюанс в том что GPON можно запросто по деревне растянуть, а с другими технологиями это уже проблема с пропускной способностью, деньгами и/или надежностью.
Я вообще не оголтелый сторонник GPON, но населенным пунктам с малой плотностью населения он дает ту возможность, которой раньше не было. Ну и кроме того эта технология уже распространяется, можно ее любить или не любить, это мало что меняет.
1) Оператор ставит мне какую-то коробку, свою я поставить не могу (долго искал SFP-GPON модули, даже нашел, а потом поиском по всяким наг.ру нашел и то, что даже если я это извращение куплю и поставлю — работать оно не будет, в лучшем случае оно заработает после оплаты оператору, который купит чертову лицензию, которая позволит одной сторонней железке работать с головным устройством).
2) Попутно решая пункт (1) наткнулся на упоминание про умников с «ну тутже LC, яж его могу в свой SFP засунуть» и результативным матом техподдержки и монтажников, который этого умника искали.
3) Скорость дана «по-маркетолуховски» (гигабит — ага, угу, пока на этом волокне висит один абонент, как только будут висеть больше — не выйдет уже).
Про GPON в сельской местности я с вами полностью согласен, именно там он и должен рулить и бибикать, прочие варианты там дают реальный гемор.
3) Скорость дана «по-маркетолуховски» (гигабит — ага, угу, пока на этом волокне висит один абонент, как только будут висеть больше — не выйдет уже).Собственно, все домашние провайдеры выдают «маркетолуховскую» скорость в своих тарифах. Пользователю в квартире за 500 рублей в месяц никто не будет резервировать канал, не для него эта роза цвела. Лично я плачу 1500 рублей в месяц за «гигабитный интернет», при том, что чисто физически в подъезд попадает линк на полтора. И тем не менее по ночам я регулярно ловлю скорости за 70 мегабайт в секунду, днем — 10-50.
Просто не надо удивляться, что везде стоит «до», оплачивая ежемесячно смешные суммы. Где резервация — там тысячи, если не десятки тысяч рублей в месяц. Это не эксклюзивно для GPON.
2) «Умники» конечно могут положить сеть с SFP, но оно ведь работать не будет, как попробуют — так и перестанут, врядли это сложится в систему, они ведь подключились чтоб интернет иметь, а не любоваться на свой SFP. Кроме того есть шанс огрести люлей от провайдера если укладывать сеть постоянно.
3) Скорость она все равно везде по-маркетолуховски дана, если в 24портовый езернет-свич в подъезде приходит гигабит от провайдера — то это все равно гигабит на всех на свиче, а не каждому гарантированные 100мбит/с (и даже если соседи по свичу не качают то это все равно не гарантирует 100мбит до интернета, тк тут еще зависит все от общей загрузки канала провайдера, в час пик оно может и просесть тк канал зашарен всем абонентам и обычно он шарится 1/10, т.е. в среднем каждые 100мбит/с гарантированного канала шарится на 10 человек с 100мбит/с подключением, но в силу большой абонентской базы и разным потреблением у каждого в каждый момент — нагрузка не упирается в полку ).
На GPON наоборот есть шанс поиметь что-то больше 100мбит если подключено мало народа на линии или кто-то не качает.(у меня например тариф 150мбит/с, из которых я только 100 утилизирую, тк надо свой микротик поменять на что-то с гигабитными портами).
Гарантированная скорость на канале стоит других денег всегда, это удел бизнеса, а не домашнего подключения.
Даже в США и Европе (особенно в районах со старой застройкой) c проводным высокоскоростным Интернетом всё грустно: или дорого по российским меркам, или тупо нету. Безлимитный Интернет на телефоне? Почти всегда или дорого, или с урезанной скоростью, или с мелким шрифтом в договоре. Так даже говорить, что "там, где деньги, там и связь хорошая", не правильно.
В 10 км за МКАД 3G обычно есть, значительно реже 2G, но временами в районах с неплотной застройкой вышки соединены не шнурком, а радиорелейкой, то есть десяток 4G смартов могут съесть канал на весь населённый пункт.
Так даже говорить, что «там, где деньги, там и связь хорошая», не правильно.
В бедных странах выше плотность населения, т.ч. оказывается выгодно проводить быструю новую сеть. В богатых странах — ноборот, низкая плотность населения. Богатый человек может сесть на машину и решить свои вопросы по доступу к чему-либо.
Даже если принять за истину спорный тезис "В бедных странах выше плотность населения. В богатых странах — ноборот, низкая плотность населения", то необходимость ехать на машине за хорошей связью точно не тот триумф телекома, который позволит запускать все хоть сколько-то тяжёлые задачи на удалённой машине и принимать только картинку.
Это в России то высокая плотность населения?
Возможно это и не совсем честный 4G, однако с сильным недостатком мобильного трафика я еще не сталкивался.
У меня yota с 540 рублей за безлимитный интернет. Дорого ли это для ITшника? я бы сказал что нет.
По поводу оптики — ростелеком ведет в квартиру оптику, это вроде GPON технология у них. Ну и роутер соответствующий.
Так что у меня и с проводным и беспроводным интернетом все шустренько, причем нахожусь я далеко от Москвы.
Ну а США насколько знаю относительно отсталый по этим меркам потому что у них куча legacy инфраструктуры. В РФ и онлайн банкинг весьма продвинутый по мировым меркам насколько я понимаю.
А 4G есть по всему городу? И на всех окраинах? И во всех помещениях?
А gpon — это такая достаточно ограниченная технология, в том числе и с возможными проблемами при отказах. Но дешёвая при внедрении.
Оптика прямо по квартире?
На остальные вопросы с радостью отвечу через час.
Но мне сложно судить, о чем именно спрашивал Viceroyalty
Думаю, что местоположение вашего роутера его не интересовало, но могу ошибаться.
Актуальная статья бы не помешала.
Только современней компиляторы низкоуровневых языков в целом генерируют более оптимальный код по сравнению с написанным вручную :)
Интересно, может уже создадут компиляторы с ai под капотом, которые смогут, имея какое-то говно типа электрона на входе заменить его эквивалентным кодом на с? Типа, написал прототип, оттестировал на 56 ядерном маке, а потом пару суток компиляции, и на выходе артефакт, делающий все тоже самое, но раз в 100 быстрее?
И для тех, кто хочет упороться именно этим, существует LLVM.
Просто выигрыш по оптимизации с ним не такой уж прям сильный.
Но в каком-нибудь вебе или в бизнес-приложениях, вещах которые сами по себе являются высокоуровневыми, т.е. надстройками над надстройками, ассемблер конечно неуместен.
Это вы захотели решить задачу останова. Которая не разрешима.
Н.Вирт «Долой жирные программы»
Стало правилом: всякий раз, когда выпускается новая версия программного продукта, существенно — порой на много мегабайт — подскакивают его требования к размерам памяти.
Совершенно верно! Более того, мы даже не знаем, какие именно функции оно выполняет, пока снаружи оно похоже на фонарик. Взаимодействие с двумя десятками рекламных и собирающих вашу активность сетей, да мало ли ещё полезного, нужного и важного (для своих авторов) может делать фонарик. Я вот ещё думал раньше, что программа шагомера должна просто шаги считать :)
Путают bloatware (когда в программу для прожига cd-дисков добавляют видеоредактор и почтовый клиент) и распухание стека.
Распухание стека — интегральная часть процесса разработки. Если у вас программе есть хоть одна строковая переменная, знайте, ваша программа — жирный неповоротливый убюдок для идиотов. Потому что настоящая хардкорная программа работает только с числами. Желательно, в троичной системе, чтобы получать более высокую точность.
И сравнивать какой нибудь лексикон и современный microsoft word с аргументами «он делает тоже самое но жрет в тысячи раз меньше», очень глупо.
Так же закончил читать сегодня статейку про dart vm у которой с компиляцией так же не все просто. Есть куча режимов, в т.ч. тоже и jit и aot, и выглядит это все как вполне неплохой задел на будущее для оптимизации высокоуровнего кода на дарте в достаточно оптимизированные машинные инструкции. Про v8 что там к чему я не знаю, не люблю js, но часто вижу заголовки все больше рапортующие об ускорении движка.
Что касается раздутого кода, следует учитывать, что сложность решаемых проблем (или как минимум контекст и запросы) растёт, и неизбежным следствием попыток обуздать эту сложность становится увеличение уровней абстракций. Но я согласен, это не повод не думать над тем, что пишешь, просто не всё так плохо.
преодоление memory bottleneck за счет размещения оперативной памяти в корпусе с вычислителем и организации взаимодействия между ними по широким шинам (всё те же ILV)
При этом оперативная память будет такой же съемной, как и сейчас, либо сразу полностью интегрированной в процессор?
У меня лично другой вопрос возникает:
А как они этот бутерброд охлаждать будут? Я слышал, что сегодня и так уже есть определенные проблемы с охлаждением всего того, что живет под крышкой CPU.
А как они этот бутерброд охлаждать будут?
Хороший вопрос. Xilinx пишут, что использовали корпус без крышки (lidless, bare die).
А уж когда они его в смартфон поставят…
Либо вообще продавать материнские платы с интегрированным процессором и возможно даже охлаждением. В 2020, я думаю, купят и не поморщатся.
Выше же речь шла об наслоении процессоров/памяти друг на друга. И тут проблема с охлаждением обязательно вылезет.
Говоря, что лимит однопоточной производительности исчерпан, ориентируются на Интел,
но у них весь конвейер разработки встал из-за проблем с техпроцессом. Sunny Cove даже с незначительными отличиями от Skylake показывает неплохой прирост.
за счет размещения оперативной памяти в корпусе с вычислителем и организации взаимодействия между ними по широким шинам
Это помогает только если код оптимизированный. Собственно такие процессоры для HPC уже выпускают — Fujitsu A64FX.
Резервов повышения производительности ещё на много лет хватит.
С чего Вы это взяли, особенно с учетом проблем с теплоотводом от всего этого кипятильника?
www.techpowerup.com/259653/intel-sunny-cove-successor-significantly-bigger-jim-keller?cp=2
We have a roadmap to 50x more transistors and huge steps to make on each piece of the stack.
Новые техпроцессы позволяют радикально увеличивать количество транзисторов на кристалле.
Современные мобильные чипы содержат до 10 миллиардов транзисторов при бюджете в несколько ватт.
Новые техпроцессы позволяют радикально увеличивать количество транзисторов на кристаллеЕсть только один нюанс: стоимость каждого отдельного транзистора раньше с уменьшением проектных норм уменьшалась, а теперь растет.
Спроектировать и произвести тестовый чип по 180 нм по силам и средствам не только любому стартапу, на него даже многие хоббисты-одиночки могут на завтраках наэкономить. По современным технологиям разговор о прототипировании начинается с миллионов долларов, а серийное производство окупается только при миллионных тиражах, что, ы свою очередь, сильно сокращает возможности развития для отрасли куда-то в сторону от многоядерных процессоров для мобильных телефонов.
сложность решаемых проблем (или как минимум контекст и запросы) растёт
Забавно, что параллельно с подходом "процы мощные, памяти много, 20 слоев абстракции ниочем" благодаря облакам набирает силу ещё более ублюдочный подход "стейтлесс, скейлабилити и микросервисы с первой строчки кода", что рождает решения, которые тратят 90% ресурсов рантайма на работу с джейсонами. Особенно забавно, когда таких уродцев с очередями, кубернетесом и десятком сервисов собирают под задачи с нагрузкой 300 сообщений в день
Тут важна ваша роль в проекте. Если вы заказчик/пм/продакт овнер (менеджер), то да, неприятно. За ваш счёт себе резюме фармят. Если же дев, то одни плюсы) Можно разогнать свою рыночную стоимость в разы, и ни разу не наврав в резюме и на собесе, найти себе интересную работу с реальным хайлоадом, где такой стек обоснован здравым смыслом.
Про деплой вообще не понял. А как вообще по другому можно?
Всё-таки эра экономии наступит чуть быстрей, но в мобильном варианте.Там сказывается два факторами -потребление и тепловыделение и уже подходит к приделу архитектура, таскать чемодан батареек мало кто захочет.Да и обычные процессоры опять же скоро упруться в тепловой барьер, пихать то транзисторы то можно, а одновременно работать все сгорит из за тепла, итак в серверных процессорах уже 300 ватт теплоотдачи..
таскать чемодан батареек мало кто захочет
Я хочу! Можно мне телефон с ёмким аккумулятором, можно толщиной 20-25мм.
Правда, реального смысла в закруглённых бортах телефона как не видел, так и не вижу.
Разве что скользит лучше и быстрее скорость набирает /irony
Xkcdphone? А если серьёзно, я бы так и делал, если бы изолента не перекрывала экран, а usbовый хвостик не торчал и не мешал.
Xkcdphone?
Про него даже не слышал, а вот с изолентой много чего лепил, правда в последнее время перешел на серый «божественный скотч» из строймага, он лучше той изоленты, что у нас продается.
Мы таков в(на?) офисный телефон с подключенным безлимитом, которым пользовалось много народу и соответственно быстро садился аккумулятор ставили. На тот момент это было ЕМНИП 4500 мАч вместо штатного на 1400 мАч.
Единственное неудобство штатная зарядка занимала больше 3-4 часов, т.к. телефон был совсем не в курсе что у него емкость батареи каким-то образом в 3 раза увеличилась.
Не знаю правда выпускают ли сейчас такие под современные модели.
таскать чемодан батареек мало кто захочет
уже таскают, пока маленькие, но прогресс не остановить — павербанк называется.
Когда вышел TRS-80 пацаненку было 22 годика. Статья — перевод американской гали.ру?
Мы же только до контейнеров дошли, а там внутри еще должны быть паллеты, на них ящики, в ящиках коробки, в коробках пакеты, и т.д.
К сожалению, совсем не все задачи можно раскидать на много ядер.
Не видел еще программ которые бы не любили быстрых ядер. Особенно это видно в играх которые как бы любят многопоток, а на самом деле скорость одного ядра решает как и раньше.
Само-собой, не надо бросаться в крайности и делать 100 ядер, не дотягивающих до 1ГГц, но и 2 ядра уже мало где покажут хорошую производительность, даже на 5ГГц. Исключения с той стороны есть — САПР, ЕМНИП, работает на одном ядре.
Но я бы предпочел, чтобы софт по возможности раскладывали на ядра. Их количество нарастить проще, чем частоту и IPC.
К примеру, когда Билл Гейтс
Позабавили реверансы в сторону Билл Гейтс. Вот так и рождаются мифы.
Однако их там минимум четверо (команда) писало этот вариант интерпретатора.
Один момент я помню, когда веб летал: когда диал-ап начал уходить в прошлое, пришёл ADSL, но ещё не появилось свистелок-перделок по 20 мб рождённых вебпаком и написанных на каком-то Реакте в не самом лучшем стиле.
Зачем Фейсбук загружает 13.7 мб кода на Javascript и 1.7 мб CSS на индексе, что они там делают? Раньше 13 мб занимали целые дистрибутивы приложений.
Легендарный Warcraft 2 весил 29 мб (без видео и музыки).
Ладно Фейсбук, зачем Хабр, созданный программистами для программистов загружает 4 мб Javascript кода. Неужели тут где-то есть реально сложный функционал, о котором я не знаю?
Радует только то, что людям которые это понимают всегда найдётся работа.
Ладно Фейсбук, зачем Хабр, созданный программистами для программистов загружает 4 мб Javascript кода.
Насчет этого я бы усомнился, судя по редактору постов и парсеру Markdown.
Может кто-то помнит рекламный ролик хрома — вроде бы картошку рубили на части и она в замедленном показе падала в чашку, а параллельно на экране открывалась страница с гуглом и успевала загрузиться раньше.
Вот ровно так же было на АДСЛ с теми самыми старыми сайтами в нулевых еще версиях того же хрома — все открывалось мгновенно, даже приходилось привыкать, что кнопку отмены загрузки (Х) вообще не успеваешь рассмотреть, она дергается и тут же снова становится круглой стрелкой рефреша страницы. :)
Хабр, созданный программистами
Крючков не умеет «прогать».
100% должны. Это дикость что делает Photos на win 10. Библиотека на 50к фото индексировалась больше 5 часов с максимальной загрузкой всех 8 ядер. После индексации ленте фотографии все равно показываются с ощутимой задержкой. Если быстро скроллить то загружаются 8 ядер процессора после чего начинаются фризы. Приложение занимает 0,5гб в оперативной памяти.
Разработчики его по всей видимости родственники разработчиков скайпа.
Которые перестанут поощрять, нанимать, обучать и продвигать программистов (и систему), создающих описанную проблему.
Надо просто тестировать своё ПО на слабых машинах, с ограничением по памяти, с урезанным интернетом.
100% солидарен!
Если-бы в 2000 году кто-то сказал, что браузер когда-то станет занимать 4гб памяти то над ним бы только поржали.
У меня как-то хром освоил 22Гб и не особо останавливался.
Всякие кэши обычно (т.е. практически всегда) занимают некоторую долю от доступного объёма памяти, а не столько, сколько им минимально нужно. Как бы это плюс — если пользователь потратился на память, она не должна простаивать. Если свободной памяти будет меньше — программы ужмутся, влезут хоть в 1ГБ, а то и в 512МБ.
Я иногда слышу высказывания типа "винда/хром/jvm сожрала N ГБ памяти, куда ей столько" (это на системе с 32/64/128ГБ памяти-то!). Так говорить можно только при совершенном непонимании принципа кэширования и неспособности даже допустить мысль о том, что в другой конфигурации системы программа может жрать меньше, потому что она жрёт не столько, сколько ей нужно, а столько, сколько может себе позволить.
1. браузер кеширует сайты для скорости — он молодец.
2. сайтоделы пишут сайт с бесконечной прокруткой и не заморачиваются, что он съест пару гб оперативки — во-первых, у пользователя больше, во-вторых, работать одновременно с несколькими сайтами — не самый частый случай. Тоже в обще-то правы. Ещё и бизнес не даёт пару недель на оптимизации, бизнесу фичи и time to market важнее.
3. Антивирус жрёт и процессор, и память — никуда не деться.
4. Утилиты, JVM, VM, системные процессы и кэши — рабочие инструменты.
А в итоге — никто не виноват, но свободной памяти нет. Нехорошо как-то.
Очень похоже на ощущение как при попытке поработать на Windows 95 c 4 МБ памяти и с отключенным дисковым кэшем.
Подумаешь, всего-то памяти в 1000 раз больше стало, но «передайте ильичу — нам и 10 000 по плечу»
В сегодняшних условиях, когда производительность условного «core i3» более не растёт со сменой поколений просматривается аж несколько подходов к возможности и дальше писать всё более и более «привлекательный» для пользователя (т.е. красивый и функциональный) код.
При этом, конечно, каким будет конечное решение: какой-то «чистый» подход, смешанный подход либо решение придёт «со стороны» сегодня не понятно:
— многопоточное программирование — тот же серверный ARM в терафлопсах уже свою производительность меряет (да мерялка не идеальна). Проблем у этого подхода много: отсутствие устоявшихся и боле-менее универсальных подходов и инструментов, проблемы при написании «монолитных» приложений, плохое распараллеливание (зависимость по данным или real-time требования, или ещё что-то) для части приложений, возрастание простоев (lock-free и wait-free алгоритмы всё равно не бесплатны) с увеличением числа потоков, необходимость достаточно производительного потока для пользовательского интерфейса и т.д.
— специальные ускорители — тут мобильные устройства, в массовом сегменте, пионеры. Графика (даже 2Д)? Звук? Кодаки? Шифрование — пожалуйста воспользуйтесь спец. устройством и ни в чём себе не отказывайте.
ИМХО комбинирование этих двух подходов (для «прожорливых» задач выделенное устройство, всё остальное хорошо распараллелено) на приличное время компенсирует отсутствие роста производительности «условного core i3»
— переход с «условной Java[Script]» на «условный Rust» — ну поскольку прирёрло (или скоро припрёт) и мощности реально почти не растут, то придётся пересаживаться. Переход на С \ С++ выглядит нереальным.
— обучение массового программиста писать алгоритмически производительный код — да мне видится, что заявленный в статье метод решения проблемы «процессоры больше не становятся быстрее» стоит где-то здесь, после многопоточности, спец-вычислителей, перехода на rust…
Ну а совсем фантастичных сценариев, типа выполнения всего в облаках через G5 — выше уже накидали, но, по ряду причин, слабо верится ;)
Если UASM с моим проектом управляется за 0.5-0.6 сек, то ассемблер мелкософта целых 17 сек.
Наверно компиляторы M$VSС++ тоже такие тормознутые, и если переписать код, то вероятно раз 20-30 можно ускорится.
Проект XRayExtensions
github.com/NanoBot-AMK/XRayExtensions
Точней
github.com/NanoBot-AMK/XRayExtensions/tree/master/shoc_10006_xrgame
С 14 ревизии использую UASM
Лучше бы вместо новых телефонов, продавали пвсевдоапгредый. Купил себе немного ускорения на телефон и годик (или пол года) ходишь и у тебя всё летает.))
Все «затормаживание» — это добавление костылей для поддержки совместимости старого железа с новыми фичами ОС.
Например в 4й версии айфона не было функции прозрачности у графического процессора, а в пятом она уже есть и новая ОС уже конечно пишется с рюшечками прозрачности (плавно появляющееся меню). А как теперь в 4м быть? Пишутся софтверные костыли-библиотека совместимости, которые прозрачность рисуют силами CPU, вот и привет тормоза (не кидайте помидорами, не помню когда прозрачность в GPU появилась, это для примера).
И так везде, в т.ч. и на андроидах и на компах.
Наверно когда-нибудь мы упремся в какое-то соотношение производительности, размеров и энергопотребления и тогда срок жизни устройств увеличится. Может наоборот — каналы связи станут толще и у нас на руках будут только терминалы — тогда тоже не потребуется ежегодный апгрейд.
1. Выкинуть всё старое и не нужное.
2. Упорядочить то что осталось на столько, что бы выполнение задачи не заняло сверхчеловеческих ресурсов.
Любой ввод-вывод, любая работа с периферией, вывод на экран — везде разные, для того и городят всякие абстракции чтобы не разгребать проблемы на каждом новом железе.
Скажем, как пример — скрипт на Python или простой веб-сервис на Ruby легко может одинаково запускаться на Win/Mac/Lin, причем даже вне зависимости от архитектуры процессора (x86/x64/arm). С++ такое и не снилось
С точки зрения какой-нибудь вЕнды или Линукса — да, наверное, можно скомпилировать несколько разных версий программы под разные платформы, а потом упаковать в единый исполняемый файл (если вообще форматы ELF и PE это позволяют). Но проще все равно таскать отдельные исполняемые файлы под каждую платформу со своим циклом и пайплайном сборки и тестирования
весьма условно ) как и все остальное )
Go вполне удобно кросс-компилируется под поддерживаемые платформы, например.
До сих пор повторить не можем, нужно больше программистов…
Когда не «игра ААА класса типа мувики красивости и всё такое», но о жрательных и некоторых других важных для юзера и ИТ характеристиках ничего из этой аббревиатуры не следует, — а типа как с техникой бытовой, только не холодильник, а например фреймворк React 7 B (BBAA) класса — значит терпеть можно, хоть не дно типа D-- (DD--CD-) (или как оно там), но хотя бы.
Производительность — Потребление памяти — Удобство программиста — Удобство пользователя
Упрощенная оценка одной буквой — по минимальному из параметров.
Дальнейшее — детали. Например в оценку за производительность вкладывать параметры работоспособности без лагов на процах low-20% юзеров, типичная загрузка 1 ядра, coreX8 систем, типичная загрузка GPU каких-то соотв. сегментов юзеров, типичное энергопотребление Ватт с метриками для мобил, ноутов и десктопов… В оценках по памяти из главных метрик типичное потребление оперативки, дружелюбность к кэшам процессора L1-L3, метрики по видеопамяти и метрики по I/O. И т.д.
Этого давно не хватает индустрии.
Тем более, производительность приложений в пределах 20-30 процентов я и сам могу менять, разгоном и драйверами ( если не прикладывать моск — то -30% достигается не менее легко)
Идея интересная, но труднореализуемая и с некоторыми недостатками.
Кажется, то, о чём вы говорите, называется "нефункциональные требования"… А на практике есть минимальные и рекомендуемые требования к железу.
Проблема вашего подхода в том, что ПО, требующее много ресурсов, как раз таки оптимизируется с целью использования всех доступных ресурсов, сколько ему ни дай, — это повышает скорость. Так, любой кэш пытается отъесть всю доступную ему память, от этого он работает быстрее. И более того, размер того же кэша иногда настраивается, что делает вашу оценку качества не вполне корректной.
Но для оценки всяких жрущих как на в себя мессенджеров, наверное, это зашло бы.
В оценках по памяти из главных метрик типичное потребление оперативки, дружелюбность к кэшам процессора L1-L3
В теории всё красиво, а на практике…
Потребление 500Мб ОЗУ для калькулятора это много или мало? А для видеомонтажа в 4К?
А если это 3D рендер, где просчитывается не просто красный кубик, а сложнейшая сцена?
В итоге приходим к ситуации, что даже в одном классе задач нельзя сделать формальные метрики, т.к. всегда будет десяток разных НО.
— качество стирки (да, на это есть свое стандарты)
— качество отжима/сушки
— расход электроэнергии на 1 стирку
— расходы воды на 1 стирку
И все по стандартной буквенной шкале «А» «B», «C» и «D» означающие диапазоны значений соответствующих характеристик.
Потом конечно, гигабайты и на жестком, и на оперативке вылились как из рога изобилия. Чтобы оправдать раздутость кода, кажется, даже появилась философия экстремального программирования (XP), которая оправдывает подход «лишь бы работало здесь и сейчас». Я уже не очень практикую кодинг, но даже на меня проекты из 150-200-300 экземпляров Form наводят ужас.
Мы приближаемся к пределу вычислительных мощностей – нам нужны новые программисты