Введение
Для чего может понадобиться знание методики семантического дифференциала?
- Можем узнать наше место относительно конкурентов в подсознании потребителей. Нам может показаться, что клиенты плохо относятся к нашему товару, но что будет, если мы узнаем, что к конкурентам они относятся ещё хуже по наиболее значимым для нас критериям?
- Можем узнать, насколько успешна наша реклама относительно реклам товаров конкурентов из той же категории (Call of Duty или Battlefield?)
- Определим, над чем стоит поработать при позиционировании. Образ компании либо товара воспринимают как «дешевый»? Видимо, при проведении новой рекламной кампании нам предстоит либо оставаться в этом уголке сознания потребителя (и смириться с этим статусом), либо срочно менять вектор развития. Xiaomi позиционируются как более дешевые альтернативы флагманов с тем же железом (условно). У них есть четко выверенная позиция, которая выделяет их на фоне именитых конкурентов, позиционирующих себя как дорогих – Apple, Samsung, etc. Одной из главных проблем в таком случае станет то, что ассоциация (а именно на них и построен весь метод в целом) со словом «дешевый» может привлечь и ассоциацию «плохой», либо «некачественный».
К слову, это работает и при сравнении любых других объектов в выбранной категории — вы можете сравнивать и процессоры, и телефоны, и новостные порталы! По сути, фантазия для применения этого метода не ограничена.
Как определить, по каким именно критериям мне следует сравнивать наши товары?
В принципе, ответить на этот вопрос можно по-разному – вы можете попробовать взять экспертное интервью, полуструктурированное интервью, или же выбрать метод фокус-групп. Некоторые из полученных вами категорий могут встретиться вам на просторах интернета — это не должно вас смущать. Помните, что главное в вашем исследовании — не уникальность полученных данных, а их объективность и достоверность.
Также следует отметить, что не единожды в различных учебных пособиях я встречал подобные фразы: «Плохое, как правило, ассоциируется с холодным, темным, низким; хорошее – с теплым, светлым, высоким». Представьте, если Sprite после очередной рекламы «Избавься от жажды» увидит, что их напиток по-прежнему ассоциируется с теплым?
Именно поэтому стоит обращать внимание на то, с чем именно мы работаем – если для приложения, основной целью которого является релаксация, мы получим в ассоциативном ряду слово «спокойный», то совсем не обязательно, что мы захотим получить такую же характеристику и к шутеру. В некоторой степени, оценка — самая субъективная часть этого метода, но не стоит забывать, что он изначально ориентирован на работу с ассоциативным рядом, который может изменяться от потребителя к потребителю (именно поэтому ещё одним важным фактором станет изучение вашей целевой аудитории, которое чаще проводится с помощью метода анкетного опроса или структурированного интервью).
Методология
Ещё до начала этапа мы обязаны определиться с тем, какие рекламные сообщения (будем разбирать все на данном примере) хотим протестировать. В нашем случае ими станут рекламы следующих телефонов:


Для простоты освоения метода возьмем двух респондентов.
Первый этап – определение категорий для изучения.
Предположим, что с помощью метода фокус-групп мы смогли определить следующие 9 категорий (цифра не взята с потолка – первоначально именно столько критериев, разделенных на 3 равные группы — факторы оценки (Е), фактор силы (Р) и фактор активности (А), предлагал определять автор):
- Возбуждающий 1 2 3 4 5 6 7 Умиротворяющий
- Банальный 1 2 3 4 5 6 7 Уникальный
- Натуральный 1 2 3 4 5 6 7 Искусственный
- Дешевый 1 2 3 4 5 6 7 Дорогой
- Креативный 1 2 3 4 5 6 7 Банальный
- Отталкивающий 1 2 3 4 5 6 7 Притягивающий
- Яркий 1 2 3 4 5 6 7 Тусклый
- Грязный 1 2 3 4 5 6 7 Чистый
- Доминантный 1 2 3 4 5 6 7 Второстепенный
Второй этап – разработка опросника.
Методологически правильный опросник для двух респондентов по двум рекламам будет иметь следующий вид:

Как вы можете заметить, наименьшая и наибольшая величина меняется в зависимости от строчки. По мнению создателя данного метода – Чарльза Осгуда, такой способ помогает проверить внимательность респондента, а также степень его вовлеченности в процесс (заметил и уточнил – супер!). Впрочем, некоторые исследователи (особенно недобросовестные) могут не чередовать шкалы, чтобы затем их не инвертировать. Таким образом, они пропускают четвертый пункт в нашем списке.
Третий этап – сбор данных, занесение их в нашу шкалу.
С этого момента вы можете как начать забивать данные в Excel (как сделал я для большего удобства), так и продолжать все делать вручную – в зависимости от того, какое количество человек вы решили опросить (Как по мне, Excel сподручнее, но при малом количестве респондентов быстрее выйдет посчитать вручную).

Четвертый этап – восстановление шкал.
Если вы решили следовать «правильному» методу, то теперь вы обнаружите, что вам следует привести шкалы к единому значению. В данном случае я решил, что максимальным значением у меня будет «7», а минимальным – «1». Следовательно, четные столбцы остаются нетронутыми. Остальные значения мы «восстанавливаем» (отражаем значения — 1<=>7, 2<=>6, 3<=>5, 4=4).
Теперь наши данные будут представлены в следующем виде:
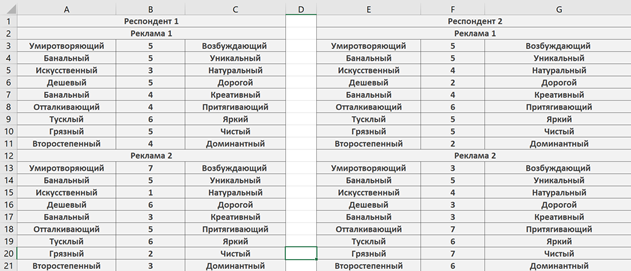
Пятый этап – вычисление средних и общих показателей.
Самые популярные показатели – «победитель» по каждой шкале («наилучший») и «проигравший» по каждой шкале («наихудший»).
Получаем путем стандартного суммирования и деления на количество респондентов всех отметок у каждого бренда по выбранной характеристике и их последующего сравнения.
Средние показатели по каждой рекламе в восстановленном виде:
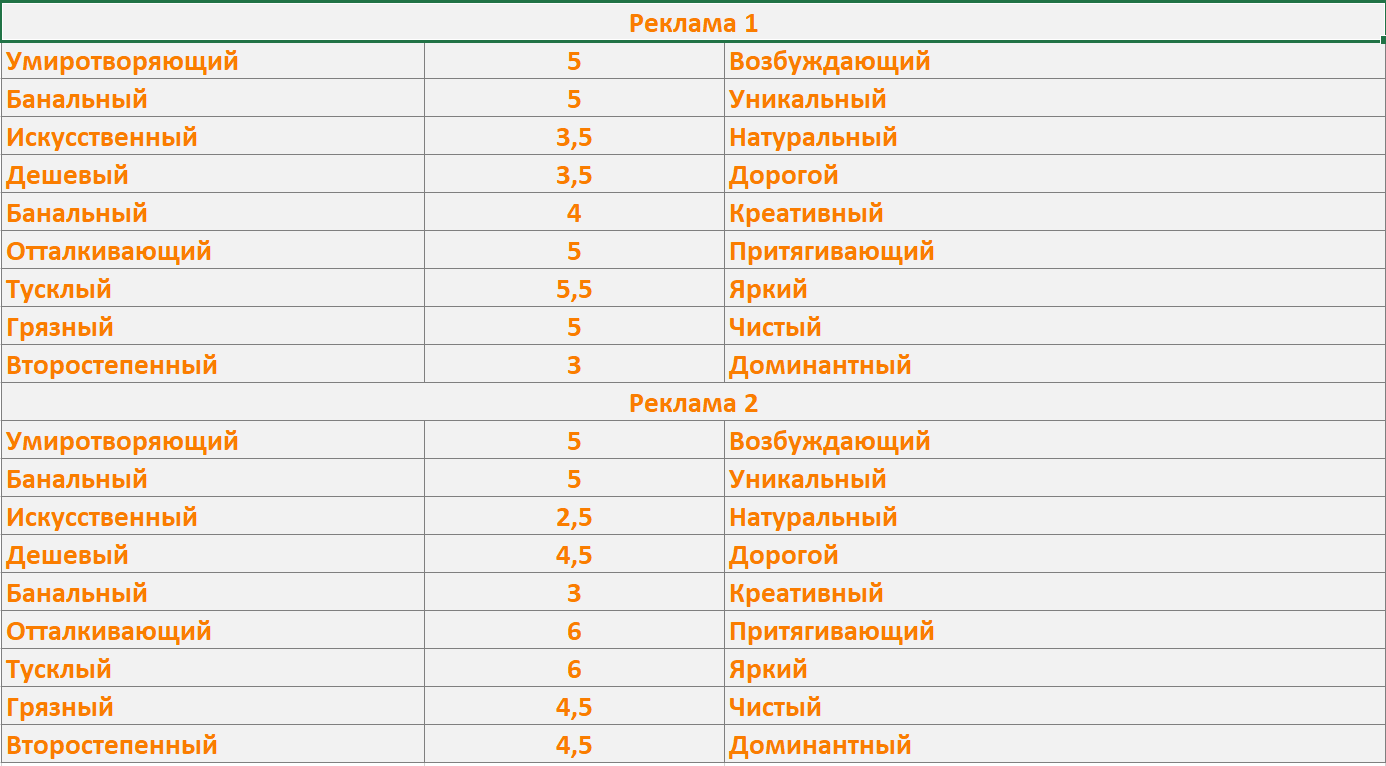
- Возбуждающий и умиротворяющий – одинаковые показатели (5).
- Банальный и уникальный – одинаковые показатели (5).
- Самый натуральный – реклама 1.
- Самый дорогой – реклама 2.
- Самый креативный – реклама 1.
- Самый притягивающий – реклама 2.
- Самый яркий – реклама 2.
- Самый чистый – реклама 1.
- Самый доминантный – реклама 2.
Теперь перейдем к обобщенным показателям. В данном случае нам предстоит просуммировать каждый бренд по всем его оценкам, полученным от всех респондентов по всем характеристикам (тут пригодятся наши средние). Так мы определим «абсолютного лидера» (их может быть 2, а то и 3).
Общая сумма баллов – Реклама 1 (39,5 баллов). Реклама 2 (41 баллов).
Победитель – Реклама 2.
Главное, чтобы вы четко осознавали, что победитель без большого отрыва – легкая добыча.
Шестой этап – построение карт восприятия.
Одним из наиболее приемлемых и приятных зрелищ для глаз ещё с момента введения в науку Анхерсоном и Кроме стали графики и таблицы. При отчете гораздо нагляднее выглядят именно они, в связи с чем Чарльз и позаимствовал у более точных наук и психологии в придачу карты восприятия. Они помогают наглядно отразить вам, где именно находится ваш бренд/реклама/товар. Строятся они через присвоение обеим осям двух значений – например, ось X станет обозначением для критерия «грязный-чистый», а ось Y «тусклый-яркий».
Строим карту:
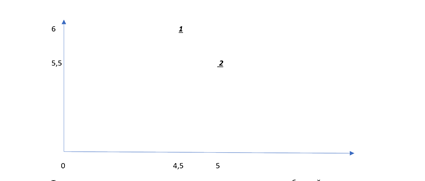
Теперь мы можем наглядно увидеть, как именно в сознании потребителей стоят два товара-представителя известных компаний.
Главным достоинством карт восприятия является их удобство. По ним достаточно легко анализировать потребительские предпочтения и имиджи различных марок. А это, в свою очередь, имеет большое значение для создания эффективных рекламных сообщений. шкалой, используемой для оценки товара по какому-либо признаку.
Итоги
Как вы видите, метод в сокращенном виде не является сложным для понимания, применять его могут не только специалисты в области методологии социальных и маркетинговых исследований, но и обычные пользователи.








