Комментарии 48
Ну так это по сути уже убитый диск, это его судьба — сломаться окончательно. Просто перед тем, как это произойдет, можно еще извлечь какую-то пользу, главное бекапы делать не забывать ежедневно.
Если после стольких прогонов, в том числе по проблемным секторам, он вышел в стабильную работу, то можно условно считать что запилов, приводящих к таким результатам, нету.
повреждения полимерного покрытия могут иметь место, но проход головок над ними пока что не приводит к новым контактам слайдера и поверхности. Но это событие носит вероятностный характер.
а поврежденнй цепляю на пару часов к машине на холостой ход. Головки в таком случае на парковке, а весь мусор, образовавшийся при запиле и летающий внутри диска должен осесть на специальных подушечках фильтрации.
есть нюанс. если диск уже обнаружил дефекты, то немалая вероятность, что просто так держать головки на парковке он не будет. А будут весьма активно работать процедуры оффлайн скана (не во всех семействах).



i="0";В остальных случаях они уместны. Ну ещё
`FOO` можно заменить на $(FOO) для лучшей читаемости, но в этих местах кавычки всё-таки нужны, в смысле не могут быть просто выброшены.echo «starting iteration $n»; — кавычки не нужны, впрочем, и глаз не режет.Без кавычек, если в $n окажутся специальные символы, то сначала они будут соответствующим образом интерпретированы. К примеру "*" добавит к строке список содержимого текущего каталога. Украшение вывода echo при помощи подобных символов не такая уж и редкость. Использовать echo в shell лучше всегда с кавычками.
let i="$i"+1; — кавычки не нужныВ данном случае кавычки не меняют поведения, но для привычки я бы всё равно написал скорее так:
let "i=$i+1"while [ "$i" -le "$sizebl" ]; — кавычки не нужныБез кавычек пустые $i или $sizebl приведут к ошибкам «unknown operand» и «argument expected» соответственно. С кавычками же мы получим пустые строки, в условии воспринимающиеся как ноль.
В языке shell "[" — это команда, а остальные строки являются её аргументами. Пустой аргумент без кавычек — это отсутствующий аргумент и его место в таком случае займёт следующий, это может в корне поменять логику работы скрипта, не только в случае с test, а с любой командой или функцией.
Ставя лишние кавычки в shell, хуже не сделаешь, а вот забыв их где нужно — получим проблемы.
Отсутствие кавычек вокруг строки в shell-скрипте — это типичная «бомба на будущее», понятие, имеющееся и в других языках программирования. Вы можете скорректировать код и в дальнейшем кавычки потребуются, а изменить все строки вы можете забыть. К тому же это исключит вырабатывание привычки, сделает стиль кода неоднородным и увеличит частоту ваших ошибок.
Когда вы пишете на shell — практики других языков программирования во многом неприменимы из-за его архитектуры. Если, не смотря на большой опыт в программировании в целом, конкретно с shell вы сталкивались не часто, то вы можете попытаться сделать довольно много ошибочных оптимизаций в коде. Это другой мир, с другой историей становления. В таком случае, возможно, лучше сразу использовать Python и не связываться с shell.
echo «starting iteration $n»; — кавычки не нужны, впрочем, и глаз не режет.
Всм не нужны? Там же 3 слова, по моему опыту в таких случаях echo таки требует кавычки.
n="1" пропустил, но в целом — google.github.io/styleguide/shell.xml#QuotingЛучше уж насыпать необязательных кавычек, чем думать каждый раз при написании и чтении, точно ли в этой переменной не может быть пробела.
Баш для меня как инструмент, который постоянно под рукой. Обычно пишу почти как попало: набросал, поставив вместо команд эхо, проверил, убрал эхо, раскомментил команды, добавил еще что-то, проверил, если ок — оставляю.
Если код будет использоваться не только мной либо будет использоваться (и дописываться) через время в дальнейшем, то исправляю синтаксис, отступы, убираю «магические числа» и имена файлов в переменные, могу уложить все по функциям если относительно большой скрипт либо высокая повторяемость кода. Кавычки в случае i=«1» обычно не ставлю — это перед публикацией переусердствовал для единообразия и читабельности (подсветки).
А вот при выводе переменных в качестве аргументов к командам — стараюсь ставить, ведь значение в переменных в большинстве случаев задаются не вручную, а являются результатом парсинга вывода исполнения команд и лучше перебдеть, чем в какой-то момент получить аналог XSS-атаки.
но на данной модели это не работает и мне приходит осознание, что просто стирание-чтение, как и запись-чтение не сможет проявить все проблемные места. Ведь если поврежденный бит, вне зависимости от того, что именно в него пытались записать, с большей вероятностью читается как «1», то при записи в него «1», последующее чтение будет проходить без ошибок, но при записи иного паттерна — может набраться достаточно несоответствийНет, так магнитная запись не работает. Используется частотная или фазовая модуляция, а значит, на головку подаются куски синусоид. И если место повреждено (не магнитится), в любом паттерне будет ошибка (если только сбойное место достаточно большое, чтобы не быть исправлено ECC-избыточностью).
Хороший квест, мне интересно было.
Решение: разбит на два логических диска C: и D:, совпадающих с физическими, но последние 1 ГБ каждого физического диска не используются разделами (свободны). Уже четыре года никаких ошибок нет.
По моему опыту пластины ЖД редко умирают целиком и все сразу. Обычно портится только часть. Как правильно, центр или край.
А откуда вы знаете, что трансляция физики в логику у вашего диска именно такая? У большинства современных трансляция идёт полосами характерного размера в десятки мегабайт по каждой из поверхностей, после чего идёт переключение на следующую. То есть если два диска в коробке, то там, во-первых, поверхностей чаще всего используется 4, а во-вторых, трансляция идёт как 0123321001233210.., где каждая цифра — несколько десятков-сотен треков по каждой поверхности. Исключение я видел — ноутбучные Самсунги, но и там нет деления по поверхностям, просто куски большого размера. Вы можете это проверить, запустив какую-нибудь измерялку скорости линейного чтения по всему диску, где он читается. Если все как вы говорите, там будет "пила" скорости с числом зубцов == числу головок, а если как я — монотонно убывающая от начала к концу лесенка. Это оттого, что скорость обмена на внешних и внутренних дорожках отличаются раза в два, к центру скорость падает.
Возможно у sparhawk больше всего были изношены самые нагруженные части диска — области MFT, которые как правило расположены в начале и в середине (резервная MFT) логической части диска.
Поэтому отбраковка логических частей диска тоже имеет смысл.
Поэтому отбраковка логических частей диска тоже имеет смысл.
Попытки заочной отбраковки однозначно не имеют смысла в силу того, что не стоит гадать, где именно находятся проблемы. Необходимо проводить нормальное тестирование диска. И на основании тестов делать вывод о том стоит ли далее этот диск пытаться обслуживать или сразу отправить в утиль.
области MFT, которые как правило расположены в начале
MFT может быть фрагментирована и ее куски могут быть разбросаны по всему диску.
и в середине (резервная MFT) логической части диска.
MFT mirror — это всего лишь 4 записи (при стандартном размере записи 1024 байта — это 4кб). Также некоторые дисковые менеджеры ставят позицией MFT Mirr второй кластер.
По всему диску хаотично разбросаны индексные записи, в некоторых из них частота перезаписей была очень высокая и вероятность возникновения проблемы не ниже, чем в местах расположения MFT.
Пример разброса индексов по диску. обратите внимание на размер ползунка и его позицию.

Пример: диск обычного пользователя.
Таблица разделов.

Построим карту расположения фрагментов MFT

Результат построения.

предсказуемым оказался только первый фрагмент, который не самый крупный.
Тоже использую диск, выдающий ошибки чтения ближе к краям физических дисков (внутри коробки два диска).
Решение: разбит на два логических диска C: и D:, совпадающих с физическими, но последние 1 ГБ каждого физического диска не используются разделами (свободны). Уже четыре года никаких ошибок нет.
Вы заблуждаетесь. Вы не можете создать раздел только в границах одной физической пластины. Логическое пространство реализуется из зон чередующихся между всеми головками. Например реализация логического пространства в жестком диске Seagate ST9500325AS. На скриншоте можно увидеть, как идет чередование мини-зон.
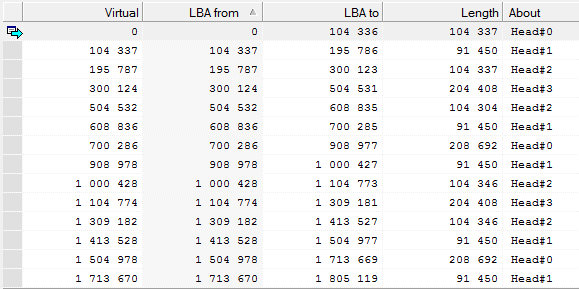
Чередование зон в жестком диске Samsung HD753LJ

По моему опыту пластины ЖД редко умирают целиком и все сразу. Обычно портится только часть. Как правильно, центр или край.
Умирает там, где произойдет контакт слайдера и поверхности и появится первичное повреждение полимерного покрытия. Если повреждение полимера серьезно, то как бы вы не пытались создать разделы не затрагивающие места дефектов, то все ваши старания все равно будут насмарку по причине того, что проблему усугубят процедуры оффлайн сканирования.
Мне кажется, будет лучше, если Вы переименуете статью, заменив слово «Hitachi» на «HDD» или «винчестер». А то заголовок вызывает впечатление, что у фирмы Hitachi большие проблемы.
Прошивки закрыты на всех более-менее современных накопителях, кроме устаревших (до ряда F3) сигейтов, которым было достаточно uart и усердного курения док из сети. Как минимум ключ для входа в технорежим требуют все, да и служебные команды в широкий доступ не сливаются, а wd marvel и иже с ними есть не от особой открытости, а просто в результате чьих-то раскопок, своих или утащенных чужих. Более-менее правильные инструменты есть для многих современных дисков, но с их ценой тратить время на ремонт диска — это из пушки по воробьям. При этом полноценного ремонта сделать не получится по причине отсутствия для этого необходимых ресурсов, даже если вы можете попасть в служебную область диска. Причина простая — у современного диска, который отправлен в магазин, фирмварь "эксплуатационная". А при самотестировании, которое как раз и скрывает дефекты, калибрует канал чтения-записи и т.д., используется другая, "сертификационная", которая потом перезаписывается. С той, что на диске, отправленном в продажу, ничего интересного уже не сделать...
Более-менее правильные инструменты есть для многих современных дисков, но с их ценой тратить время на ремонт диска — это из пушки по воробьям.Ну так и автор занимается не для заработка или экономии, а просто для забавы (Just for Fun).
Для вытягивания информации со сбойного диска рекомендую обратить внимание на ddrescue — гораздо удобнее, чем копировать данные с умирающего диска в образ обычным dd. И больше шансов успеть утянуть максимум информации, в случае если ошибки чтения диска прогрессируют.
partclone.ntfs -D -s /dev/sdc1 -O ./disk_map.domain
ddrescue -d -f --sparse --domain-logfile ./disk_map.domain /dev/sdc1 ./part.img ./data_rescue.log
В результате получаем в текущем каталоге файл образа раздела part.img… Если диск доживёт, конечно :)
А уже если битый диск есть желание потом использовать, то та же ddrescue имеет ключик --log-rates, позволяющий оценить исправные и неисправные участки диска. Если последних мало и они компактно расположены, можно просто создать таблицу разделов с пустым пространством в этом месте. Все тусовки с попытками оживить серьёзно битые участки выйдут себе дороже. Да и манипуляции с контрольными суммами лишние, даже если вы пишете на диск просто нули, по факту на блины льётся шумоподобный сигнал, ничего общего с нашими нулями не имеющий (можно погуглить PRML).
Понимаю, что данные пишутся не в прямом виде, а применяется хитрое кодирование и модуляции для записи, но по опыту, даже из секторов не способных хранить значение (но читаемых без IO-error'ов), после вайпа читаются 00. возможно там какие-то аттрибуты для пустых юзаются
Насчёт партклона — зависит от файловой системы, которую вы спасаете, но если склероз не изменяет, непрочитанные участки битовой карты (bitmap в случае ntfs) оно трактует как занятые. Точно так делает ntfsprogs, насчёт партклона надо смотреть. Поэтому получается "перебдеть". Полный клон безусловно может дать больше возможностей, но тут нужно прикинуть состояние диска, если у вас считалась битовая карта, а диск сильно поврежден, то проще сделать образ занятого, а уж если это получилось, то спокойно дочитываем остальное. Иначе больше вероятность ушатать головы, читая пустые области. Что же касается нулей, то диску ровно все равно, что хранить, ряд нулей — просто одно из состояний сектора, это не флэш. Если оно прочиталось, то как минимум не с первого раза и на данный момент этот сектор читается, что бы там ни было записано...
#!/bin/bash
# формат строки запуска hddtest.sh /dev/disk logfile [blocksize]
diskdev=$1
test_log=${2:-~/work/hdd/test.log}
blsz=${3:-409600}
sizebyte=$(lsblk $diskdev -dbno SIZE)
sizebl=$[sizebyte/blsz] #"781428" for 320GB
iter=( $(seq 0 $[sizebl-1]) )
verificate () {
verf=$(diff -s fil tst | sed 's/.* //g')
[[ "$verf" != "identical" ]] && {
md5tst=( $(md5sum tst) )
echo "$i : md5 $md5tst is not ok"
cp tst{,_${n}_$i}
}
}
test_disk () {
case $1 in 'write_disk')
local write_command="dd if=fil of=$diskdev bs=$blsz seek=$i";;
esac
for i in ${iter[@]}; do
$write_command
dd if=/dev/null of=tst
dd if=$diskdev bs=$blsz of=tst skip=$i count=1 conv=notrunc,noerror,sync
verificate
done
}
main_loop () {
while true; do
((n++))
echo "starting iteration $n"
dd if=/dev/urandom of=fil bs=$blsz count=1
md5ok=( $(md5sum fil) )
cp fil{,_$n}
echo "random pattern md5sum $md5ok"
smartctl -A $diskdev
echo "filling disk with zeroes"
dd if=/dev/zero of=$diskdev bs=$blsz #count="$sizebl"
echo "disk is wiped fully"
dd of=/dev/null if=$diskdev bs=$blsz # count="$sizebl"
echo "writing disk with fil-pattern"
test_disk 'write_disk'
echo "test of full writed with fil-pattern disk"
test_disk
smartctl -A $diskdev
smartctl -t long $diskdev
sleep 5000
done
}
main_loop &> "$test_log"
Сразу вспомнил как в Виктории вырезал сбойные блоки на полуторатеррабайтном Сигейте, то ещё удовольствие… (▀̿Ĺ̯▀̿ ̿)
Автору удалось решить задачку подручными средствами. Правда туда были привнесены существенные тормоза в виде проверки прочитанного содержимого. Но в любом его стараниями был достигнут результат.
1. Все данные пишутся в зашумленном виде, а не в чистом, как представляется автору. При записи пользовательских данных нет разницы будут там нули или случайный паттерн. Это действие даст одинаковый результат в плане дальнейшего качества чтения.
2. У микропрограмм жестких дисков достаточно серьезные методы контроля целостности прочитанных данных. При некорректируемых за счет ECC ошибках чтения при стандартных АТА командах современный накопитель не отдаст никаких данных, а только сигнализирует об ошибке в регистре ошибок.
3. Искажение данных может происходить в ОЗУ накопителя при условии ее неисправности.
записываем диск случайным паттерном с чтением только что записанного блока и сравнением его чек-суммы;
читаем диск после полной записи, проверяя чек-суммы каждого блока;
Если есть желание проверить контроллер на предмет исправности его буферного ОЗУ, то в той же Victoria можно выполнить тест записи с DDD. В случае появления читабельных секторов с искаженным содержимым можно будет сделать вывод о необходимости замены PCB с переносом ПЗУ. Этот тест будет работать заметно быстрее варианта предложенного автором. В остальном все сведется к количеству циклов записи-чтения с переназначением (Remap). Если накопитель не совсем труп, то этими стараниями можно будет получить что-то хоть частично годное к эксплуатации. Если же проблема серьезна, то все эти действия приведут к запиливанию пластин.

Или вот другая похожая для меня ситуация: диск (wd320 3.5) записывается и читается блоками по 4кб нормально и даже график Виктория гладкий рисует, но при чтении блоков размером 400кб с определенными секторами внутри блока — стабильно вылетают ошибки буфера.
То есть вопрос почему из-за озу могут гарантировано случаются чтения при работе с конкретными секторами. Я то себе из предположений выстроил себе какую-то модель в голове, но хотелось бы знать версию специалиста.
1. Ошибки в драйвере ОС. Некорректно разбирается регистр ошибок и в некоторых случаях забирается содержимое пустого буфера. Отсюда гладкий скан, но прочитанное в некоторых точках не соответствует записанному.
2. Ошибки в микропрограмме жесткого диска.
Для исследования ошибок желательно сделать множественные попытки записи и чтения с сохранением результата чтения в файлы. После исследовать разночтения между тем что прочиталось в разных версиях и тем, что должно было быть записано.
То есть вопрос почему из-за озу могут гарантировано случаются ошибки чтения при работе с конкретными секторами.
Это ошибки чтения не из-за ОЗУ. Ошибки в ОЗУ зачастую никак не регистрируются, если не проводить дополнительный контроль целостности данных, как например это делали вы, и носят случайный характер. А вот ошибки в виде некорректного ремапа, когда точечно накопитель может быстро выдавать ABR при попытке чтения или устанавливать иные биты в регистре флагов и эти ошибки не регистрируются драйвером работающим с устройством могут приводить к ситуации описанной вами.
Умирающий хард Hitachi, bash и технонекрофилия