Комментарии 50
А то ж! Завтра в вашем телефоне перестанет работать Сири, а послезавтра Тесла не отличит поворот от кенгуру.
Это цитата из «Лопнул ли пузырь машинного обучения, или начало новой зари», там про это хорошо было )))
А коррекция (ожиданий) для инвесторов крайне нужна, я про это писал по ссылкам внизу статьи.
Пока идет ускоряющееся расширение областей применения нейросетей (как в науке, так и в продуктах), которое активно поддерживают новые акселераторы. Раньше всего как оно работает увидим в телефонах, где нейроакселераторы были опробованы год назад Apple & Huawei (и это было рисковано и чипы часто просто занимали место в телефоне), но оно прошло успешно и сейчас идет расширение линейки (и акселераторов, и продуктов с ними). Т.е. относительно банальный рост)
Статья отличная, спасибо!
Однако Deep Learning слишком долго на пике хайпа на кривой Гартнера (вот, например, 2018 год), и ожидаемо должен был свалиться. Тем более разговоры о том, что Free lunch is over для классических сверточных сетей ведуться достаточно массированно. Вот статья, в которой есть основные тезисы таких разговоров, ее уже упоминали здесь в комментариях.
Если же посмотреть на Гартнера 2019 года, то можно увидить интересный эффект — DL не свалился с пика, а просто исчез… развалившись на составные части — AutoML, GAN сети, Transfer Learning. Но ни в "пропасть разочарования", ни на "плато продуктивности" ни одна из этих частей (пока) не попала.
Что это означает доподлинно судить не берусь, но мне кажется, что DL как цельное понятие с пика хайпа уходит.
Статья отличная, спасибо!Спасибо!)
Однако Deep Learning слишком долго на пике хайпа на кривой ГартнераЯ бы различал подобные взлеты в науке, у стартапов, и у продуктов.
Гартнер — это для стартапов и я с перегретостью темы для них я согласен, о чем писал.
С наукой — сложнее, поскольку там волны возникают либо когда тема расширяется, либо при открытии нового метода, который дает хотя бы локальный прорыв.
Ну и сложнее всего (и интереснее) с продуктами. Я про это писал недавно в большой статье — про экспоненциальный рост рынков. Там были хорошие графики, как выглядит взлет продуктов.
Возвращаясь к нейросетям — на мой взгляд взлет действительно глубоких сетей (100+ слоев) только начинается. И все очень зависит от акселераторов. У них рост точно будет, но если будет прорыв (в 100 раз быстрее GPU хотя бы в узких областях) — это будет мощнейший толчок. Основания для оптимизма есть.
DL не свалился с пика, а просто исчез… развалившись на составные части — AutoML, GAN сети, Transfer LearningДа-да-да! Именно так. Происходит явное расширение темы. При том, что соседние области явно усиливают друг-друга просто за счет использования одних инструментов, одного железа и т.д.
DL как цельное понятие с пика хайпа уходит.Если DL уйдет с пика хайпа для стартапов — это будет большое благо (сейчас масса случаев, когда деньги дали явным проходимцам). Печально будет, если история повторится с завернутыми в другие обертки теми же ушами. Пока, к тому идет.
И все очень зависит от акселераторов. У них рост точно будет, но если будет прорыв (в 100 раз быстрее GPU хотя бы в узких областях) — это будет мощнейший толчок. Основания для оптимизма есть.
Если акселераторы будут в 100 раз быстрее GPU, то их встроят в GPU (как встроили Tensor Cores), и они уже не будут быстрее GPU :)
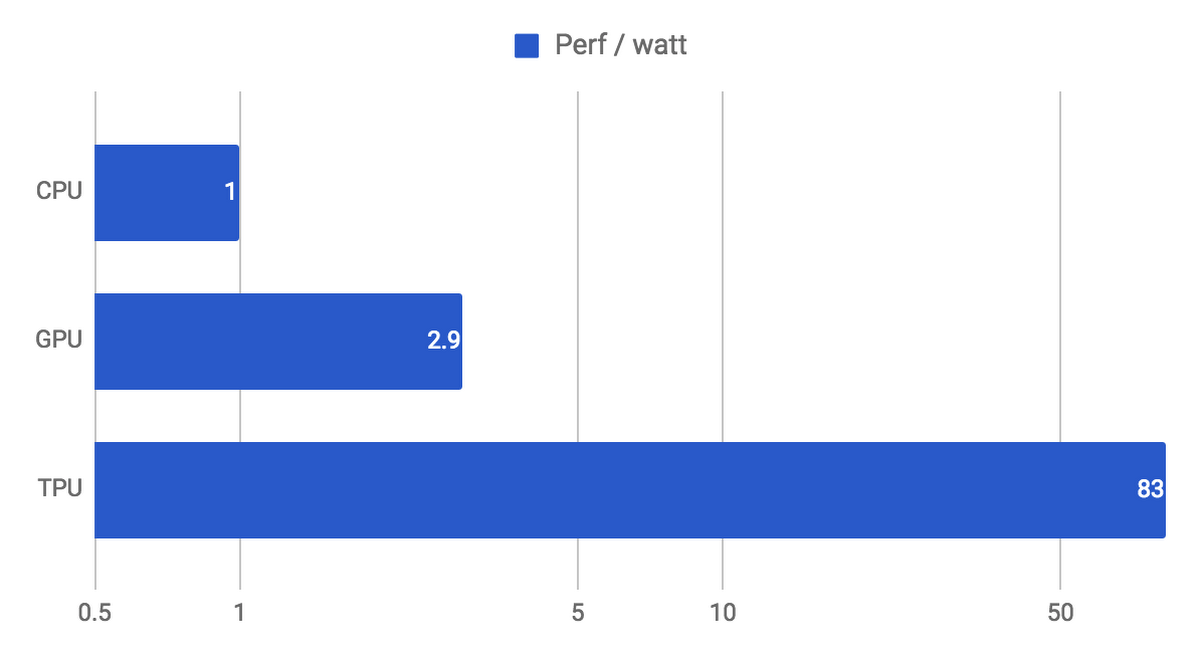
- А во сколько раз по FPS/Watt уже сейчас акселераторы быстрее, чем GPU?
- И какие это акселераторы? Intel Myriad X, Google TPU, Huawei neurochip, ....
- Есть ли какие-то акселераторы, которые значительно ускоряют depthwise-convolutional-layers, а именно модели EfficientNet (EfficientDet), MixNet, GhostNet, MobileNetv3? Потому как BFLOPS у них мало, а FPS на CPU и GPU ниже, чем у старых обычных ResNet при тех же Top1/Top5 accuracy.
- И как считаете, какие оптимизации победят: depthwise-convolutional или binary-convolutional (xnor-net) или какие-то ещё?
Пока что только XNOR-net (используя SVR) удалось ускорить Yolo в 50 раз (FPS/watt) зашив в FPGA: www.researchgate.net/publication/323375650_A_Lightweight_YOLOv2_A_Binarized_CNN_with_A_Parallel_Support_Vector_Regression_for_an_FPGA

Но
1. все таки есть падение точности ~2-4%, требуется обучение используя SVR и есть сложности по использованию новых фишек: mish, weighted-fusion (ASFF, BiFPN, ...),…
2. они сравнили Yolo_v2_float32 (а не bit1) на GPU против Yolo_v2_bit1 на FPGA
3. бинарные операции теперь доступны в Tensor Cores начиная с CC 7.5 — реализация GEMM_BINARY для Yolo-XnorNet на GPU используя Tensor Cores: github.com/AlexeyAB/darknet/blob/dcfeea30f195e0ca1210d580cac8b91b6beaf3f7/src/im2col_kernels.cu#L1224-L1419
Поэтому разрыв будет меньше.
С Новым Годом! :)
Если акселераторы будут в 100 раз быстрее GPU, то их встроят в GPU (как встроили Tensor Cores), и они уже не будут быстрее GPU :)Абсолютно устраивает! Если новые GPU будут в 100 раз быстрее текущим — самое оно! ) (хотя похоже патентные войны там будут еще те + я недавно общался с очень нерядовым сотрудником NVIDIA, он говорит, что руководство несколько забронзовело и тему, похоже, пропускает). До этого общался с одним из людей, занимающимся архитектурой GPU в AMD — тоже пока всерьез не работают. А двигать тему только кто-то крупный сможем. Поэтому ждем.
А во сколько раз по FPS/Watt уже сейчас акселераторы быстрее, чем GPU?К сожалению в FPS/Watt не сравниваются (а жаль!), но в прошлой статье я приводил известный график еще давнего гуглового TPUv1, где он был в 28,6 раз быстрее GPU. Что, в том числе, резко толкнуло тему. Кстати в комментариях там много было как раз про ускорение нейросетей на FPGA.
А так именно про аналоговую акселерацию материалов мало. Думаю, что ближе к продуктам всплеск информации пойдет. Если IBM не перекроет тему патентами.
Спасибо за хороший комментарий!
Вполне возможно, что nVidia забронзовело, но ничего явно лучше, чем nVidia GPU до сих пор нет.
Формально nVidia GPU (Tensor_Cores_V100 = 125 TFlops) и Google TPUv3 (90 TFlops) имеют очень высокие TOPS и TOPS/watt.
И нейросеть Google EfficientNet B0 имеет крайне низкий BFLOPS (0.900 = 0.450 FMA) и высокий Top1 (71.3% batch=30 или 76.3% batch=2048).
Только когда запускаешь Google EfficientNet B0 (0.9 BFLOPS = 0.45 FMA) на nVidia GPU RTX 2070 (52 000 GFlops Tensor Cores), то получаем 143 FPS на бенчмарке (batch=1), т.е. как если бы GPU работал со скоростью 128 Gflops, что в 400 раз ниже, чем заявленные 52 000 Gflops. Тоже самое и с TPU, поэтому Google использует для TPU-edge модифицированные EfficientNet у которых BFLOPS гораздо выше, но и (парадокс) FPS тоже выше.
Т.е. для формальных рейтингов они использую одно, а в продакшене используют совсем другое.
Т.е. пока в значительной степени ускорение акселераторов (TPU, Tensor Cores, ...) дутое.
То ли Google нашел способ как кардинально ускорить DW-conv, SE-block,… в будущих TPU, то ли их показатели Top1/BFLOPS заводят их все дальше в тупик (EfficientNet, MixNet, MobileNetv3, GhostNet, ...), в то время пока nVidia ускорило BIT1-conv, но не спешит ускорять DW-conv.
И это ещё пол беды, у многих других SOTA-нейросетей результаты просто не воспроизводятся и отличаются от заявленных в 2 раза и более.
Но все таки такие штуки как Intel Myriad X, Google TPU Edge и их развитие радуют.
Да, та ваша статья тоже интересная: habr.com/ru/post/455353
Любопытно в ней:
- TPUv1 лучше, чем GPU (вероятно K80) в 28 раз по INT8-TOPS/Watt — сравнивает Google.
- TPUv3 (90 TFLOPS16 / 200 Watt = 0.45) в 1.1x раза хуже, чем GPU V100 PCIe (125 TFLOPS16 / 250 Watt = 0.5) по TFlops/watt и в 1.38x раз хуже по абсолютному значению Tflops — сравнивает Huawei
Просто в первом случае:
- сравнение Google vs nVidia делал Google, а не сторонняя фирма
- сравнивал по INT8, потому что TPUv1 умело только INT8 вычисления, а GPU был на тот момент слабо заточен под INT8 (сейчас Tensor Cores поддерживает INT8 с 4х производительностью относительно TC-Float32)
- на INT8 можно делать только Inference, но нельзя обучать с приемлемой точностью (модели INT8 и BIT1 всегда обучаются на FP32/16 и затем квантуются)
А во втором случае сравнение Google vs nVidia делала Huawei, которая сравнила не предвзято Google TPU и nVidia GPU, и предвзято выпятила свой Neurochip.
Поэтому может nVidia и забронзовело, но ничего явно лучше, чем nVidia GPU до сих пор нет.

И это ещё пол беды, у многих других SOTA-нейросетей результаты просто не воспроизводятся и отличаются от заявленных в 2 раза и более.У меня про это тоже отдельная статья, ставшая лучшей в хабах ИИ и МО за год есть). Беда очень большая однозначно.
А во втором случае сравнение Google vs nVidia делала Huawei, которая сравнила не предвзято Google TPU и nVidia GPU, и предвзято выпятила свой Neurochip.Я про это пишу. MLPerf собираются типа проблему порешать. Правда Huawei там до сих пор не появился, что печалит. А так у товарищей амбиции не только проблему честных сравнений порешать, но и создать большие публичные датасеты, которые могут дать эффект сравнимый с ImageNet. Т.е. круче только горы, все серьезно.
В принципе они правы. Сегодня даже компаниям стало сложно большие публичные датасеты создавать, уж больно легко там разные законы нарушить. Именно из-за этого закрыли Netflix Prize, Байду закрыл DeepSpeech (20 тысяч часов размеченной речи!), закрыли Crawled Amazon reviews (50М записей). Я про это как-нибудь напишу, возможно. Если у них получится — будет круто. Начало хорошее.
А по акселераторам — даже если там реально в 10 раз преимущество на реальных задачах (а это так по словам коллег) — уже понятно, откуда миллиардные инвестиции в область. И еще интереснее, если завтра за счет аналоговой арифметики будет 100 раз.
Такими темпами к 2025 году мы и сильный ИИ увидим.
Что касается СИИ, здесь ключевую роль сыграет «генеральная идея», которая объединит существующие методы ML/DL вокруг новой архитектуры.
На фоне этого понимания очень странно слышать прогнозы о «новой зиме ИИ»…Негативные новости просто лучше кликаются.) Всегда! Это вечная тема, примерно как статьи о крахе доллара)
Что касается СИИ, здесь ключевую роль сыграет «генеральная идея», которая объединит существующие методы ML/DL вокруг новой архитектуры.Возможно. По крайней мере нет ощущения, что с архитектурами все резервы выбраны, скорее наоборот. В любом случае плавное развитие благодаря ускорению обучения заведомо будет происходить.
Главное что в текущем прогрессе смущает — что почти нет кардинально новых идей. По сути все новые алгоритмы/идей/результаты — это обсасывание идей и подходов 4-5 летней давности. Те же GAN — это 14 год.
С другой стороны наука так и должна работать. Нужно сначала сформулировать почему то что получилось не является ИИ. А когда задача будет сформулирована и понятна — тогда уже можно будет попробовать её решить.
Пока что-то всё упирается в «нужно больше хороших датасетов»/«как нам организовать разметку»:)
Главное что в текущем прогрессе смущает — что почти нет кардинально новых идей.
Идей много. Мало идей, которые получается заставить работать. Скажем, model-based reinforcement learning заставили работать лучше других подходов совсем недавно в MuZero. А древнюю идею объединения коннекционизма с манипуляциями символами пока заставить работать не получается. И когда/если получится, то это тоже не будет новой идеей.
Вторая крутая статья за две недели! Как у вас сил хватает!:)Антон, спасибо! Очень приятно! Писал урывками 2 месяца, положил разом просто) Хотелось до конца года успеть.
Главное что в текущем прогрессе смущает — что почти нет кардинально новых идей. По сути все новые алгоритмы/идей/результаты — это обсасывание идей и подходов 4-5 летней давности. Те же GAN — это 14 год.В каком-то смысле это так кажется. Я как раз пытался донести мысль, что сейчас есть разные интересные идеи, но пока они так же уродливы, как и GAN в 2014, поэтому их крутизну мало кто заметил. И это нормально. С остальными идеями было то же самое, как правило, условное «признание» и «известность» приходили к ним через год-два после публикации. В худшем случае — через 20 лет. Это нормально! ) И хорошо видно по графикам.
Ну и в целом — исходя из того же Томаса Куна — после прорыва (в том числе микропрорыва типа GAN) — идет плато и оно тоже крайне для этого развития важно. У тех же GAN плато иллюстрируется великолепно. И это тоже очень важно.
Пока что-то всё упирается в «нужно больше хороших датасетов»/«как нам организовать разметку»:)Это правда. Идет революция. Новое поколение алгоритмов работает на данных и текущих данных
Новое поколение алгоритмов работает на данных и текущих данных категорически катастрофически не хватает.
Ну, собственно, 50 лет назад у нейросетей была та же самая проблема :)
Данные появились — в результате задачи, поставленные для сетей 70-х годов, мы теперь решать худо-бедно умеем. Ждем еще 50 лет.
И это не только Пентагон. Например, анализ движений глаз. Вы себе не представляете, как много можно оттуда извлечь данных о человеке. Характер, привычки, склонности, падкость на рекламу и т.п. Больше, чем человек о себе знает. С условными Google Glass 3.0 люди не представляют, сколько информации о себе сольют. Куда там броузерам. И все будет добровольно, как со смартфонами, только на новом уровне.
Ассемблер/С/С++ — это всё же код. Это всякие if-else. Я могу взять другой код и разобраться в нём. Да, с позиций двух десятилеток 21 века это сложно, т.к. конечный код это порой нагромождение фреймворков и библиотек. Но я могу провести аудит кода. Могу точно объяснить почему код себя ведёт так, а не иначе и как это исправить так.
А нейросети? Как мне проводить аудит безопасности кода для шифрования данных? Если зафиксирован сбой программы, то насколько успешно я это исправлю? И таких вопросов — уйма. Сейчас-то ПО страшновато использовать, а что будет в будущем? )
Есть интуитивное неприятие того, что мы вступаем в эру «нечёткого» программирования.Более того. Это неприятие еще толком не началось, поскольку ML/DL программирование еще в стадии начального становления. В стеках разработки оно нигде толком не прокинуто, существует на своих фреймворках, которые также еще пока стремительно меняются. Дальше будет интереснее)
Сейчас-то ПО страшновато использовать, а что будет в будущем? )Жизнь станет еще лучше и еще интереснее, без вариантов))) Роль интуиции в отладке точно вырастет ))) Как минимум!
Я встречал описание такого реально используемого подхода: тренируется сетка, на её основе делается PID(?) контроллер с доказуемыми свойствами.
По-моему, в идеале должно быть такое: нейросетка на основе описания задачи интуичит какие известные алгоритмические решения к каким частям задачи можно применить, дообучается работать с частями, для которых ещё нет явного решения, пытается дистиллировать дообученную часть в набор явных правил и добавляет эти правила к известным способам решения.
Цепи обратной связи с «железно-алгоритмическими» решениями концепции ПИД — это хорошо, но не везде же это применимо. Это АСУТП всякие, в эту степь. Сдаётся мне в «обычном» программировании никого так сильно это не озаботит.
Виджет погоды за 4 года распух с 400кБ до 12МБ)У бесплатного виджета погоды нужно смотреть, чем он реально занят. А то как в анекдоте: «приложению „Фонарик“ требуется доступ к вашим контактам, звонкам и диску»)))
Работодателей заботит. Такая система, накапливая готовые решения и строя интуицию, где их стоит применять, может дорасти до уровня кодера. Результатом дистилляции может быть не только контроллер, но и алгоритм (не обязательно оптимальный).
Впрочем, это — дальняя перспектива.
Если вводить запрет, любой, то слушаться этого запрета будут только законопослушные люди. А незаконопослушным на запрет наплевать. Это как бы очевидно.
Поэтому когда кто-то продвигает что-то вроде «давайте запретим оружие», я слышу «давайте запретим оружие нормальным людям. А у преступников пусть остаётся»
Когда сотрудники Гугла продавили отказ от сотрудничества с Пентагоном, это же не означало, что никто больше в мире не будет разрабатывать никакого военного ИИ. По сути, они заявили «пусть у Штатов не будет военного ИИ, а у остальных пусть будет».
Так что, с точки зрения противников США, они молодцы и герои, а с точки зрения американцев они то ли придурки, то ли предатели.
Когда сотрудники Гугла продавили отказ от сотрудничества с Пентагоном, это же не означало, что никто больше в мире не будет разрабатывать никакого военного ИИ. По сути, они заявили «пусть у Штатов не будет военного ИИ, а у остальных пусть будет».Это не так, увы. 10 миллиардный тендер Пентагона 100% выиграла американская компания.
Как бы 2 человека это верно, ровно столько из миллионов детей сейчас хотят стать космонавтами… еслиб это было году этак в 1961 или, хотя бы 1970гг, а сейчас все больше моделями или певцами или банкирами…
А за статью огромное спасибо
Так традиционным программистам надо бояться или нет?
Про нейросети в медицине не упомянулиПро это в прошлой статье хорошо было.
Так традиционным программистам надо бояться или нет?Ага! Страдающим неофобией уже можно начинать бояться! ) Остальным — можно начинать учиться! Как-то так)
настораживает такая любовь и пропаганда неточных вычислений,Ну у вас и терминология)
Это не любовь и не пропаганда, а констатация факта, что для акселерации нейросетей уже сегодня наиболее распространенный прием — это перевод весов в целые числа и их квантование. И потенциально используя это свойство нейросетей можно еще довольно значительно ускорить вычисления.
А точные чипы разрушатся от старости и мы потеряем вообще возможность хоть что-то посчитать и смоделировать с таких областях. Очень страшная перспектива.))) «С приходом GPU 25 лет назад все CPU разрушились от старости и мы вообще потеряли возможность что-то выполнить не параллельно»))). К счастью NPU и TPU не отменяют CPU и даже GPU. Можно с облегчением выдохнуть!
(i) объяснимые результаты (exlainable results) — в некоторых областях регуляторы уже это требуют, и даже в объявлениях на прием на работу стало попадатся
(ii) системы устойчивые к adversarial samples ( не знаю как этот термин по-русски ), т.е системы которые нельзя заставить ошибатся подсунув специально сгенерированные данные. На эту тему был большой tutorial на прошлом NeurIPS ( videoken.com/embed/fQyT5wkFxGI, adversarial-ml-tutorial.org )
7 лет хайпа нейросетей в графиках и вдохновляющие перспективы Deep Learning 2020-х