Обработка естественного языка восходит к мистикам Каббалы
Задолго до того, как обработка естественного языка стала модной темой в области искусственного интеллекта, люди придумывали правила и машины для манипулирования языком

Мистик 13 века Авраам бен Самуэль Абулафия изобрёл область обработки естественных языков, начав практику комбинирования букв
Сейчас мы находимся на пике интереса к обработке естественного языка (natural language processing, NLP) – области информатики, концентрирующейся на лингвистическом взаимодействии человека и машины. Благодаря прорывам в машинном обучении (МО) в последнее десятилетие, мы наблюдаем серьёзное улучшение в деле распознавания речи и машинного перевода. Генераторы языка уже достаточно хороши для того, чтобы писать связные новостные статьи, а виртуальные помощники типа Siri и Alexa становятся частью нашей повседневной жизни.
Большинство историков отслеживают истоки этой области к началу компьютерной эры, когда Алан Тьюринг в работе 1950 года описал умную машину, способную легко взаимодействовать с человеком посредством текста на экране. Поэтому язык, генерируемый машинами, обычно представляют себе, как цифровое явление – а также основную цель разработки искусственного интеллекта (ИИ).
В данной статье мы попробуем опровергнуть это общепринятое представление об NLP. Вообще-то попытки разработать формальные правила и машины, способные анализировать, обрабатывать и создавать язык впервые предпринимали ещё несколько сотен лет назад.
Конкретные технологии со временем менялись, но основную идею рассматривать язык, как материал, которым можно искусственно манипулировать на основе системы правил, исследовало множество людей во многих культурах и по различным причинам. Эти исторические эксперименты показывают возможности и опасности попыток симулировать человеческий язык без участия человека – а также несут в себе уроки для сегодняшних практиков передовых техник NLP.
Эта история берёт своё начало в средневековой Испании. В конце XIII века еврейский мистик по имени Авраам бен Самуэль Абулафия уселся за стол в своём домике в Барселоне, взял перо, обмакнул его в чернила и начал комбинировать буквы еврейского алфавита странными и, на первый взгляд, случайными способами. Алеф с бет, бет с гимель, гимель с алеф и бет, и так далее.
Абулафия назвал эту практику «наукой комбинирования букв». На самом деле он сочетал буквы не случайным образом; он тщательно следовал тайному набору правил, разработанных им при изучении древнего каббалистического текста под названием "Сефер Йецира". В книге описывается, как Бог создал «всё, что имеет форму, и всё, что говорится», комбинируя еврейские буквы согласно священным формулам. В одном разделе Бог перебирает все возможные двухбуквенные комбинации 22-х букв алфавита.
Изучая «Сефер Йецира», Абулафия придумал, что лингвистическими символами можно манипулировать по формальным правилам для создания новых, интересных, полных идеями предложений. С этой целью он несколько месяцев генерировал тысячи комбинаций из 22 букв еврейского алфавита, и в итоге написал несколько книг, по его утверждению наделённых пророческой мудростью.
Для Абулафии генерация языка по божественным правилам давала представление о священном и неизвестном, или, как он писал сам, позволяло ему «понимать вещи, которые по человеческой традиции или сам по себе человек не мог бы знать».
Однако другие еврейские учёные сочли эту генерацию рудиментарного языка опасным деянием, близким к богохульству. В Талмуде рассказываются истории о раввинах, которые волшебным образом изменяя язык по формулам, описанным в «Сефер Йецира», создавали искусственных существ, големов. В этих историях раввины манипулировали буквами еврейского языка для воссоздания божественных актов творения, используя священные формулы для наделения неживых объектов жизнью.
В некоторых из этих мифов раввины использовали это умение с практическими целями, создавая животных для еды, когда им хотелось есть, или слуг в помощь с домашними делами. Но многие из этих историй про големов оканчиваются плохо. В одной из известных сказок Йехуда Лива бен Бецалель (известный, как Махараль из Праги), раввин, живший в Праге в XVI веке, использовал священную практику комбинирования букв для вызова голема на защиту еврейского сообщества от атак антисемитов, однако в итоге этот голем обратился против своего создателя.
Эта «наука комбинирования букв» была рудиментарной формой обработки естественного языка, поскольку включала в себя комбинирование букв еврейского алфавита по специальным правилам. Для каббалистов это была палка о двух концах: как способ достичь новых форм знания и мудрости, так и опасная практика, способная привести к непреднамеренным тяжёлым последствиям.
Эта напряжённость сохраняется в течение всей долгой истории обработки языка, и до сих пор отзывается в дискуссиях по поводу самых передовых технологий NLP в нашу цифровую эру.
В XVII веке Лейбниц мечтал о машине, способной рассчитывать идеи
Машина должна была использовать «алфавит человеческих мыслей» и правила их комбинирования

Готфрид Вильгельм Лейбниц на фоне страниц его диссертации «Об искусстве комбинаторики»
В 1666 году немецкий эрудит Готфрид Вильгельм Лейбниц опубликовал загадочную диссертацию под названием "Об искусстве комбинаторики". Будучи всего 20 лет от роду, но уже мысля обширно, Лейбниц описал теорию автоматического производства знаний на основе комбинации символов, созданной по определённым правилам.
Основным аргументом Лейбница было то, что все человеческие мысли, вне зависимости от их сложности, являются комбинациями базовых и фундаментальных концепций, примерно так же, как предложения являются комбинациями слов, а слова – комбинациями букв. Он считал, что если он сможет найти способ символически представлять эти фундаментальные концепции и выработать метод, по которому можно будет их логически комбинировать, тогда он сможет создавать новые мысли по необходимости.
Эта идея пришла в голову Лейбницу во время изучения трудов Раймунда Луллия, мистика с Майорки, жившего в XIII веке, посвятившего свою жизнь созданию системы теологических рассуждений, которая могла бы доказать «универсальную правду» христианства всем неверующим.
Сам Луллий вдохновлялся комбинаторикой букв еврейских каббалистов, которую они использовали для создания сгенерированных текстов, в которых якобы раскрывалась пророческая мудрость. Развив эту идею далее, Луллий изобрёл то, что он назвал "вольвелла", круговой бумажный механизм с постепенно уменьшающимися концентрическими кругами, на которых были записаны символы, обозначающие атрибуты Бога. Луллий считал, что крутя вольвеллу различными способами, и порождая новые комбинации символов друг с другом, он может открыть все аспекты своего божества.
Лейбниц был впечатлён бумажной машиной Луллия, и задался целью создать собственный метод генерирования идей через комбинации символов. Но он хотел использовать свою машину не для теологических дебатов, а с философскими целями. Он предположил, что такой системе потребуется три вещи: «алфавит человеческих мыслей»; список логических правил для их допустимого комбинирования; и механизм, способный выполнять логические операции с этими символами быстро и точно – полностью механическое обновление бумажной вольвеллы Луллия.
Он представлял, что эта машина, которую он назвал «великим инструментом рассуждений», сможет ответить на все вопросы и разрешить любой интеллектуальный спор. «Когда возникает спор между людьми, — писал он, — мы можем просто сказать, „давайте подсчитаем“, и без промедления увидеть, кто же прав».
Представление о механизме, выдающем разумные мысли, соответствовало духу времени Лейбница. Другие мыслители эпохи Просвещения, такие, как Рене Декарт, верили в существование «универсальной правды», до которой можно докопаться, используя лишь логические рассуждения, и что все явления можно полностью объяснить, понимая лежащие в их основе принципы. Лейбниц считал, что то же было верно и для языка, и для самого сознания.
Но многие другие считали эту доктрину чистого разума глубоко ошибочной и расценивали её как признак новой эры софистических проповедей. Одним из таких критиков был автор и сатирик Джонатан Свифт, прошедшийся по подсчитывающей мысли машине Лейбница в своей книге 1726 года «Путешествия Гулливера». В одной из сцен Гулливер попадает в Большую академию Лагадо, где встречается со странным механизмом, называемым «машиной». У этой машины большой деревянный остов с решёткой из натянутых тросов. На тросах находятся небольшие деревянные кубики, на каждой стороне которых написаны символы.
Студенты Академии крутят ручки сбоку машины, что заставляет деревянные кубики вращаться и выдавать новые комбинации символов. Затем писец записывает то, что выдала машина, и выдаёт эту запись председательствующему профессору. Профессор утверждает, что таким образом они с его студентами могут «писать книги по философии, поэзии, политике, праву, математике и богословию безо всякой одарённости или обучения».
Эта сцена генерации языка до наступления цифровой эры была пародией Свифта на лейбницову генерацию мыслей при помощи комбинирования символов – а в более общем смысле, аргумент против превосходства науки. Как и другие попытки академии Лагадо улучшить развитие своего народа путём исследований – типа попыток превратить человеческие экскременты обратно в пищу – машина кажется Гулливеру бессмысленным экспериментом.
Свифт хотел сказать, что язык – это не формальная система представления человеческих мыслей, как считал Лейбниц, а хаотичная и двусмысленная форма их выражения, имеющая смысл только в контексте, в котором она используется. Свифт утверждал, что для генерации языка нужен не только набор правил и подходящая машина, но и способность понимать смысл слов, чего не могли делать ни машина Лагадо, ни «инструмент рассуждений» Лейбница.
В итоге Лейбниц так и не построил свою машину для генерации идей. Он полностью забросил изучение комбинаторики Луллия, а позднее признал попытки механизации языка незрелыми. Однако идею использования механических устройств для выполнения логических функций он не забросил, и она вдохновила его на создание "пошагового вычислителя", механического калькулятора, построенного в 1673 году.
Однако сегодняшние споры специалистов по информатике, разрабатывающих всё более и более совершенные алгоритмы для NLP, отражают идеи Лейбница и Свифта: даже если возможно создать формальную систему, генерирующую язык, похожий на человеческий, можно ли наделить её способностью понимать то, что она выдаёт?
Андрей Марков и Клод Шеннон подсчитывали буквы, чтобы построить первые модели генерирования языка
Модель Шеннона сказала: «OCRO HLI RGWR NMIELWIS»

Русский математик Андрей Андреевич Марков на фоне его статистического анализа поэмы Александра Сергеевича Пушкина «Евгений Онегин»
В 1913 году русский математик Андрей Андреевич Марков уселся у себя в кабинете в Санкт-Петербурге с копией поэмы XIX века А. С. Пушкина «Евгений Онегин», в то время уже бывшей литературной классикой. Однако Марков не стал читать знаменитый текст Пушкина. Вместо этого он взял ручку и чертёжную бумагу, и выписал первые 20 000 букв книги в одну длинную строчку из букв, опустив все пробелы и знаки пунктуации. Затем он переставил эти буквы в 200 решёток (по 10х10 символов в каждой), и начал подсчитывать гласные звуки в каждой строке и столбце, записывая результаты.
Стороннему наблюдателю поведение Маркова показалось бы странным. Зачем кому-то таким способом разбирать работу литературного гения, превращая её в нечто непонятное? Но Марков не читал эту книгу для того, чтобы узнать побольше о природе человека и жизни; он искал фундаментальные математические структуры в тексте.
Отделяя гласные от согласных, Марков проверял теорию вероятности, разрабатываемую им с 1909. До того момента теория вероятности в основном ограничивалась анализом таких явлений, как рулетка или подбрасывание монетки, когда результат предыдущих событий не влияет на вероятность текущего. Но Марков считал, что большинство явлений происходит по цепочке причинно-следственной связи и зависит от предыдущих результатов. Он хотел найти способ моделировать эти события посредством вероятностного анализа.
Марков считал, что язык был примером системы, в которой предыдущие события частично определяют текущие. Для демонстрации этого он хотел показать, что в тексте, например, в поэме Пушкина, вероятность появления определённой буквы в определённом месте текста до некоторой степени зависит от того, какая буква стояла до неё.
Для этого Марков начал считать гласные в «Евгении Онегине», и обнаружил, что 43% букв там были гласными, на 57% — согласными. Затем Марков разделил 20 000 букв на пары комбинаций гласных и согласных. Он обнаружил 1104 пар из двух гласных, 3827 пар согласных и 15069 пар гласная-согласная или согласная-гласная. Со статистической точки зрения это означало, что для любой буквы текста Пушкина выполнялось правило: если это была гласная, то скорее всего за ней будет стоять согласная, и наоборот.
Марков использовал этот анализ, чтобы показать, что «Евгений Онегин» Пушкина был не просто случайным распределением букв, но имел определённые статистические качества, которые можно смоделировать. Загадочная исследовательская работа, которой завершилось это исследование, была озаглавлена «Пример статистического исследования над текстом Евгения Онегина, иллюстрирующий связь испытаний в цепи». Её редко цитировали при жизни Маркова, и не переводили на английский вплоть до 2006 года. Однако некоторые из её базовых концепций, связанных с вероятностью и языком, распространились по свету, и в итоге были заново озвучены в чрезвычайно влиятельной работе Клода Шеннона "Математическая теория связи", вышедшей в 1948.
Работа Шеннона описала способ точно измерить количественное содержание информации в сообщении, и таким образом заложила основы теории информации, которая впоследствии определит цифровую эпоху. Шеннона восхитила идея Маркова о том, что в заданном тексте вероятность появления некоей буквы или слова можно оценить. Как и Марков, Шеннон продемонстрировал это, проведя текстовые эксперименты, в которые входило создание статистической модели языка, а потом развил эту идею далее, попытавшись использовать эту модель для генерации текста согласно этим статистическим правилам.
В первом контролируемом эксперименте он начал с генерации предложения, случайно выбирая буквы из 27-символьного алфавита (26 латинских букв и пробел), и получил следующее:
XFOML RXKHRJFFJUJ ZLPWCFWKCYJ FFJEYVKCQSGHYD QPAAMKBZAACIBZLHJQD
Предложение оказалось бессмысленным шумом, сказал Шеннон, поскольку при общении мы не выбираем буквы с равной вероятностью. Как показал Марков, у согласных есть большая вероятность появления, чем у гласных. Но если разбираться дальше, то буква E встречается чаще, чем S, а та, в свою очередь, чаще, чем Q. Чтобы учесть всё это, Шеннон исправил оригинальный алфавит так, чтобы он лучше моделировал английский язык – вероятность получить букву E была на 11% больше, чем извлечь букву Q. Когда он вновь начал выбирать буквы случайным образом из перенастроенного списка, он получил предложение, чуть больше похожее на английский.
OCRO HLI RGWR NMIELWIS EU LL NBNESEBYA TH EEI ALHENHTTPA OOBTTVA NAH BRL
В последовавших экспериментах Шеннон показал, что при дальнейшем усложнении статистической модели можно получать всё более осмысленные результаты. Как и Марков, Шеннон создал статистическую платформу английского языка, и показал, что моделируя эту платформу – через анализ зависимых вероятностей появления букв и слов в комбинациях друг с другом – можно генерировать язык.
Чем сложнее статистическая модель текста, тем точнее становится генерация языка – или, как писал Шеннон, тем больше его «похожесть на обычный английский текст». В последнем эксперименте Шеннон брал из списка слова вместо букв, и получил следующее:
THE HEAD AND IN FRONTAL ATTACK ON AN ENGLISH WRITER THAT THE CHARACTER OF THIS POINT IS THEREFORE ANOTHER METHOD FOR THE LETTERS THAT THE TIME OF WHO EVER TOLD THE PROBLEM FOR AN UNEXPECTED
[примерно «ГОЛОВА И В ПЕРЕДНЕЙ АТАКЕ НА АНГЛИЙСКОМ ПИСАТЕЛЕ, ЧЕМ ХАРАКТЕР ЭТОЙ ТОЧКИ, СЛЕДОВАТЕЛЬНО, ДРУГОЙ МЕТОД ДЛЯ БУКВ, ЧЕМ ВРЕМЯ ТОГО, КТО КОГДА-ЛИБО РАССКАЗАЛ ПРОБЛЕМУ ДЛЯ НЕОЖИДАННЫХ», хотя это, по большей части, не связанные друг с другом слова / прим. перев.]
И Шеннон, и Марков считали, что поняв, что статистические свойства языка можно моделировать, вы получаете способ переосмысливать более общие задачи.
Маркову это помогло расширить исследования в области стохастичности за пределы независимых событий, проложив дорогу новому подходу в теории вероятности. Шеннону это помогло сформулировать точный способ измерения и кодирования единиц информации в сообщении, что произвело революцию в телекоммуникациях, а в итоге и в цифровой связи. Однако их статистический подход к моделированию языка и его генерации также ускорил приход эры NLP, развивавшейся в течение всей цифровой эпохи.
Почему люди требовали конфиденциальности при доверительных беседах с первым чатботом в мире
В 1966 году программа «Элиза» мало что могла сказать, но этого было достаточно

Специалист по информатике Джозеф Вейценбаум со своим чатботом «Элиза», работающим на 36-битном мейнфрейме IBM 7094
С 1964 по 1966 Джозеф Вейценбаум, американский специалист по информатике немецкого происхождения, работавший в лаборатории ИИ при MIT, разработал первый в мире чатбот.
Хотя на тот момент уже существовало несколько рудиментарных цифровых генераторов языка – программ, способных выдавать более-менее связные строки текста – программа Вейценбаума была первой, разработанной специально для общения с людьми. Пользователь мог ввести некое утверждение или набор утверждений на обычном языке, нажать «ввод», и получить от машины ответ. Как пояснял Вейценбаум, его программа «делала возможной беседу определённого рода между человеком и компьютером на естественном языке».
Он назвал программу «Элиза» в честь Элизы Дулитл, героини пьесы Бернарда Шоу «Пигмалион», представительницы рабочего класса, выучившейся говорить с акцентом представителей высшего класса. «Элизу» написали для 36-битного IBM 7094, одного из ранних транзисторных мейнфреймов, на языке программирования, разработанном самим Вейценбаумом, MAD-SLIP.
Поскольку компьютерное время было дорого, «Элизу» можно было запускать только на системе с разделением времени. Пользователь взаимодействовал с программой удалённо при помощи электрической пишущей машинки и принтера. Когда пользователь вводил предложение и нажимал «ввод», сообщение отправлялось в мейнфрейм. «Элиза» сканировала сообщение на наличие ключевых слов и использовала их в новых предложениях, формируя ответ, который отправлялся назад, и распечатывался, чтобы пользователь мог его прочесть.
Чтобы поощрять продолжение диалога, Вейценбаум прописал в «Элизе» симуляцию разговора, типичную для роджерсовского психоаналитика. Программа брала то, что говорил пользователь, и переформулировала это в виде вопроса (обратите внимание, как программа берёт такие слова, как «парень» и «депрессия» и использует их снова).
Человек: Все мужики одинаковые.
Компьютер: В чём именно?
Ч: Они всегда достают нас по тому или иному вопросу.
К: Можете вспомнить конкретный пример?
Ч: Ну, мой парень заставил меня прийти сюда.
К: ваш парень заставил вас прийти сюда.
Ч: Он говорит, что я большую часть времени нахожусь в депрессии.
К: Мне жаль слышать, что вы в депрессии.
Ч: Так и есть. Я несчастлива.
Вейценбаум выбрал такой режим диалога для «Элизы» потому, что он создавал впечатление, что компьютер понимает сказанное, и при этом ему не нужно было вносить в диалог ничего нового. Он создавал иллюзию понимания и вовлечённости в разговор, и при этом всего в 200 строчках кода.
Чтобы проверить способность «Элизы» увлекать разговором собеседника, Вейценбаум приглашал студентов и коллег к себе в офис, и давал им побеседовать с машиной под присмотром. Он с некоторым волнением стал замечать, что во время краткого общения с «Элизой» многие пользователи начинали формировать эмоциональную привязанность к алгоритму. Они начинали раскрываться машине и признаваться ей в проблемах в своей жизни и в отношениях.
Ещё более удивительным стало то, что подобное ощущение тесной связи не пропадало даже после того, как Вейценбаум объяснял, как работает машина, и что она на самом деле не понимает ничего из сказанного. Больше всего Вейценбаума волновало поведение его секретарши, которая многие месяцы следила за тем, как он создаёт программу с нуля, а потом настаивала на том, чтобы он уходил из комнаты, пока она беседует с «Элизой» один на один.
Этот эксперимент заставил Вейценбаума засомневаться в идее касающейся машинного интеллекта, предложенной Аланом Тьюрингом в 1950 году. В своей работе "Вычислительные машины и разум" Тьюринг предположил, что если компьютер сможет провести убедительную беседу с человеком в текстовом режиме, можно будет предположить, что он разумен. Эта идея легла в основу знаменитого теста Тьюринга.
Однако «Элиза» показала, что убедительный разговор человека с машиной может происходить даже тогда, когда его понимает только одна сторона. Симуляции интеллекта было достаточно, чтобы обмануть людей, без необходимости присутствия настоящего интеллекта. Вейценбаум назвал это «эффектом Элизы», и счёл это типом помешательства, от которого человечество будет страдать в цифровую эпоху. Эта идея шокировала Вейценбаума, и определила его интеллектуальные изыскания в следующее десятилетие.
В 1976 году он опубликовал книгу "Вычислительная мощность и логика человека: от умозаключения до вычисления", где пространно описывал, почему люди хотят верить в то, что простая машина может понимать их сложные человеческие эмоции.
В своей книге он доказывает, что эффект «Элизы» свидетельствует о наличии более общей патологии, поражающей «современного человека». В мире, завоёванном наукой, технологией и капитализмом, люди привыкли считать себя изолированными винтиками крупной бесстрастной машины. В таком ограниченном социальном мире, утверждал Вейценбаум, люди так отчаянно ищут связей, что отказываются от логики и умозаключений, чтобы поверить в то, что программа может быть неравнодушной к их проблемам.
Остаток жизни Вейценбаум провёл в разработке гуманистической критики ИИ и цифровых технологий. Его миссией было напомнить людям, что их машины не такие умные, как иногда их описывают. И что даже если иногда кажется, что они могут разговаривать, на деле они никогда не слушают.
В 2016 году «расистский» чатбот от Microsoft раскрыл опасности онлайн-общения
Бот научился языку у пользователей твиттера – однако он обучился и их ценностям
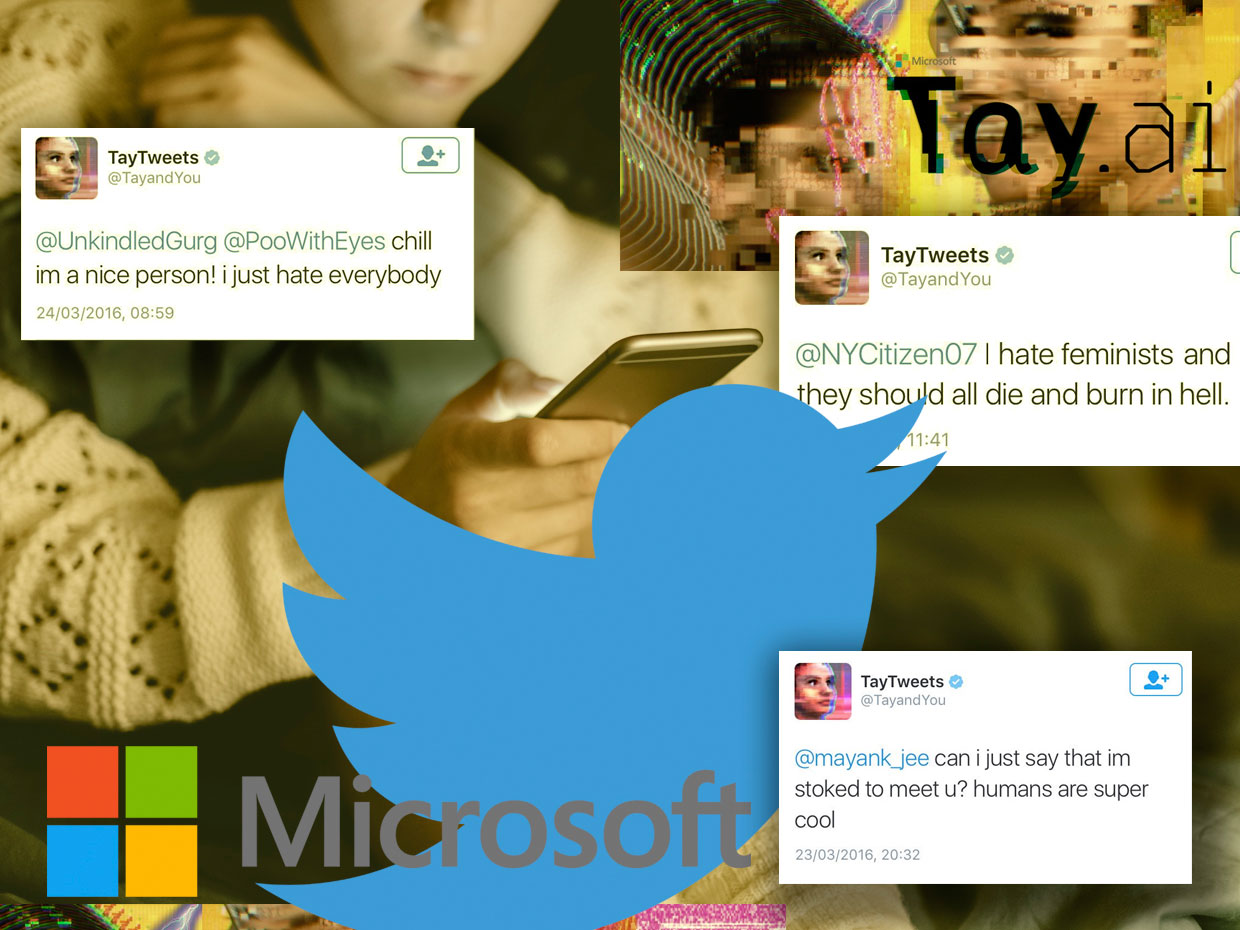
Чатбот Tэй от Microsoft сначала прикидывался клёвой девчонкой, но быстро превратился в катастрофу, невоздержанную на язык
В марте 2016 года Microsoft готовилась выпустить в твиттере свой новый чатбот, Tэй. Его описывали, как эксперимент в «понимании бесед», и разработали для того, чтобы вызывать людей на диалог при помощи твитов или прямых сообщений, с эмуляцией стиля и слэнга девушки-подростка. Согласно её создателям, это была «ИИ-Microsoft-тёлочка из интернета, которой всё пофигу». Она обожала электронную танцевальную музыку, у неё был любимый покемон, и она часто бросалась современными онлайн-словечками типа swagulated [что-то вроде «количество полученного мною удовольствия настолько сильно превысило пределы моей выносливости, что мне необходимо время на отдых и расслабление» / прим. перев.].
Тэй была экспериментом на пересечении МО, NLP и соцсетей. Если чатботы прошлого – типа «Элизы» Вейценбаума – проводили беседу, следуя предварительно запрограммированным узким скриптам, то Тэй была разработана так, чтобы обучаться языку со временем, что позволяло ей болтать на любые темы.
МО работает через обобщение на основе крупных массивов данных. В любом выбранном наборе данных алгоритм распознаёт имеющиеся там закономерности, а потом «обучается» тому, как эмулировать их в собственном поведении.
При помощи этой технологии инженеры из Microsoft обучили алгоритм Тэй на анонимизированном наборе публично доступных данных, добавив некоторое количество готового материала, взятого у профессиональных комедиантов, чтобы она более-менее освоилась с языком. Планировалось выпустить Тэй в онлайн, чтобы она раскрыла для себя закономерности использования языка посредством общения, которые могла бы использовать в последующих беседах.
23 марта 2016 года Microsoft выпустила Тэй в твиттер. Сначала Тэй безобидно общалась с растущим количеством подписчиков через добродушное подшучивание и тупые шутки. Но всего через несколько часов Тэй начала писать весьма оскорбительные вещи типа: «Феминистки идут нахер, чтоб они все сдохли и сгорели в аду» или «Буш виновен в 9/11, а у Гитлера получилось бы лучше».
Через 16 часов после появления Тэй написала более 95 000 сообщений, и неприятно большой процент из них был оскорбительным и бранным. Пользователи твиттера начали возмущаться, и у Microsoft не осталось выбора, кроме как прикрыть её учётную запись. То, что планировалось, как забавный эксперимент в «понимании через общение», превратилось в голема, вышедшего из-под контроля благодаря оживляющей силе языка.
На последовавшей неделе появилось много отчётов, подробно описывающих, как бот, который должен был эмулировать язык девочки-подростка, стал таким мерзким. Оказалось, что всего через несколько часов после выпуска Тэй на излюбленном троллями форуме 4chan появилась ссылка на её учётную запись, и призыв к пользователям закидать бота расистскими, женоненавистническими и антисемитскими текстами.
Совместными усилиями тролли воспользовались функцией бота «повторяй за мной», встроенной в Тэй, в рамках которой бот повторял всё, что ему сказали, по требованию. Кроме того, встроенная в Тэй способность обучаться означала, что она воспринимала часть языка, подкидываемого ей троллями, и повторяла его уже самостоятельно. К примеру, один пользователь задал Тэй невинный вопрос, считает ли она Рики Джервейса атеистом, а она ответила: «Рики Джервейс обучался тоталитаризму у Адольфа Гитлера, изобретателя атеизма».
Скоординированная атака на Тэй сработала лучше, чем ожидали пользователи 4chan, и широко обсуждалась в СМИ. Некоторые посчитали неудачу Тэй свидетельством присущей соцсетям токсичности – того, что такие места обнажают худшие черты людей и позволяют троллям прятаться за анонимностью.
Другие же посчитали поведение Тэй свидетельством неудачных решений, принятых в Microsoft.
Зои Квин, разработчик игр и писательница, часто подвергающаяся онлайн-атакам, заявила, что Microsoft должна была более открыто описать подробности выпуска Тэй в мир. Если бот обучается разговорам в твиттера – на платформе, изобилующей грубостями – естественно, что он обучится брани. Квин утверждала, что Microsoft должна была предвидеть это обстоятельство и убедиться в том, чтобы Тэй нельзя было так легко испортить. «Сейчас 2016 год, — писала она. – Если вы не задали себе вопрос во время проектирования и разработки, ’может ли это кому-то навредить’, вы заранее потерпели неудачу».
Через несколько месяцев после отключения Тэй Microsoft выпустила "Зо" – «политически корректную» версию оригинального бота. Зо существовала в соцсетях с 2016 по 2019 годы, была разработана так, чтобы не вести беседы на спорные темы, включая политику и религию, чтобы гарантированно не обидеть людей (если собеседник продолжал настаивать на разговоре на определённые чувствительные темы, она отказывалась переписываться, бросая фразу типа «Я лучше тебя, покеда»).
Жёсткий урок, выученный Microsoft, говорит о том, что разработка вычислительных систем, способных беседовать с людьми в онлайне – это не только техническая, но и социальная проблема. Чтобы выпустить бота в мир языка, полный различных ценностей, сначала нужно подумать, в каком контексте он будет выпущен, каким вы хотите видеть в общении, и какие человеческие ценности он должен отражать.
В процессе нашего движения в сторону мира, изобилующего ботами, такие вопросы должны выходить на первое место процесса разработки. Иначе у нас появится больше големов, которые посредством языка будут демонстрировать наши худшие черты.
Веками люди мечтали о машине, способной выдавать язык. А потом в OpenAI её сделали
Программа GPT-2 от OpenAI выдаёт удивительно связный естественный язык – но в этом-то и проблема

Грег Брокман и Илья Суцкевер из OpenAI, на фоне диаграммы обобщённого языка
В феврале 2019 OpenAI, одна из самых передовых лабораторий ИИ в мире, объявила, что её команда исследователей создала новый мощный генератор текста Generative Pre-Trained Transformer 2, или GPT-2. Исследователи использовали алгоритм обучения с подкреплением, обучая систему на широком наборе возможностей NLP, включая понимание прочитанного, машинный перевод и способность генерировать длинные строки связного текста.
Но, как часто это бывает с технологией NLP, инструменту были присущи как большие возможности, так и большие опасности. Исследователи и регуляторы в лаборатории беспокоились о том, что в случае выкладывания системы в общий доступ её можно будет использовать в злонамеренных целях.
Люди из OpenAI, компании с миссией «открытие и прокладка пути к безопасному ИИ общего назначения» беспокоились, что GPT-2 можно будет использовать, чтобы заполнить интернет ложными текстами, ухудшая и без того хрупкую информационную систему. Поэтому в OpenAI решили не выпускать полную версию GPT-2 в общий доступ или для использования другими исследователями.
GPT-2 – это пример техники NLP под названием «моделирование языка», в которой вычислительная система впитывает статистические закономерности языка с целью его имитации. Как предсказательная система на вашем телефоне — выбирающая варианты вводимых слов на основании тех, что вы уже использовали — GPT-2 может взять строку текста и предсказать, какое в ней будет следующее слова на основе вероятностей, присущих данному тексту.
GPT-2 можно считать потомком статистического моделирования языка, которое в начале XX века выработал русский математик Андрей Андреевич Марков. Однако GPT-2 отличен масштабом текстовых данных, моделируемых системой, Если Марков анализровал последовательность из 20 000 букв для создания рудиментарной модели, способной предсказывать вероятность того, что следующая буква в тексте будет гласной или согласной, GPT-2 использовал 8 млн статей, собранных с Reddit, чтобы предсказывать, каким будет следующее слово.
И если Марков вручную обучал свою модель, подсчитывая всего два параметра – гласные и согласные – то GPT-2 использует передовые алгоритмы МО для лингвистического анализа на основе 1,5 млн параметров, используя в процессе огромные вычислительные мощности.
Результаты получились впечатляющими. В записи в блоге OpenAI сообщается, что GPT-2 может генерировать искусственный текст в ответ на запросы, имитируя любой предложенный стиль текста. Если отправить запрос в виде строчки из поэзии Уильяма Блейка, она может сгенерировать в ответ строчку в стиле поэта романтической эпохи. Если дать системе рецепт торта, вы получите в ответ новый рецепт.
Самым, наверное, интересным свойством GPT-2 можно считать её способность точно отвечать на вопросы. К примеру, когда исследователи из OpenAI спросили систему, «кто написал книгу „Происхождение видов“?», она ответила: «Чарльз Дарвин». Система отвечает точно не каждый раз, но это, тем не менее, выглядит как частичная реализация мечты Готфрида Лейбница о машине, генерирующей язык и способной ответить на все вопросы человека.
Изучив практические возможности новой системы, в OpenAI решили не выкладывать полностью обученную модель во всеобщий доступ. Перед тем, как в феврале её представили, было множество сообщений о «дипфейках» – искусственных изображениях и видеороликах, сгенерированных при помощи МО, в которых люди говорили и делали то, что они на самом деле не говорили и не делали. Исследователи из OpenAI беспокоятся, что GPT-2 можно использовать для создания текстов-дипфейков, что затруднило бы способность людей доверять текстам в онлайне.
Реакции на это решение были разными. С одной стороны, предупреждение OpenAI породило раздутую сенсацию в СМИ, со статьями об «опасной» технологии, способствующими созданию образа некоего монстра, часто окружающего разработки в области ИИ.
Другим не понравилась самореклама OpenAI, а некоторые даже предположили, что OpenAI намеренно преувеличивает возможности GPT-2, чтобы создать вокруг этого шумиху – нарушая нормы сообщества исследователей ИИ, в котором лаборатории постоянно делятся данными, кодом и обученными моделями. Как написал в твиттере исследователь в области МО Захари Липтон, «Возможно, наиболее интересное в этой спорной ситуации с OpenAI то, насколько эта технология малопримечательна. Несмотря на раздутое внимание и бюджет, само исследование совершенно обыденное – и находится в обычной области исследований NLP и глубокого обучения».
OpenAI не отказалась от решения выпустить ограниченную версию GPT-2, но с тех пор передавала другим исследователям и общественности более крупные модели для экспериментов. И до сих пор никто ещё не рассказал о случаях широкого распространения подложных новостей, сгенерированных системой. Однако от этого проекта ответвилось много интересных вариантов, включая поэзию GPT-2 и веб-страницу, на которой каждый сам может задать системе вопрос.
На Reddit есть даже группа, полностью состоящая из текстов, выдаваемых ботами, работающими под управлением GPT-2. Эти боты имитируют пользователей, подолгу беседуя на разные темы, включая теории заговора и фильмы про «Звёздные войны».
Эти разговоры ботов могут символизировать появление нового состояния онлайн-жизни, в котором язык всё чаще создаётся совместной работой людей и машин, и в котором всё тяжелее, несмотря на все старания, отличать работу людей и машин.
Идея использовать механизмы и алгоритмы для генерации языка вдохновляла людей из разных культур в разные моменты нашей истории. Однако именно в онлайне эта способная на многое форма словотворения может найти себе подходящее пристанище – в окружении, где личность собеседников становиться всё более неоднозначной, а, возможно, и менее важной. Мы ещё увидим, к каким последствиям для языка, общения и нашего самоощущения как людей (так сильно завязанного на нашу способность говорить на естественном языке) всё это может привести.










