
Не так давно я писал уже о своем боте для изучения иностранных языков. Точнее — для расширения словарного запаса (aka зубрежки слов). В той же статье я написал, что изучение слов без контекста малопродуктивно и что лучше изучать тексты, чем просто пытаться вбить себе в голову энное количество слов.
Кроме того, мне всегда хотелось быстрее перейти к чему-то более практическому — например, чтению текстов на Quora или Wikipedia, новостей, пусть даже на упрощенном варианте языка. Напомню, я изучаю финский язык в связи с переездом в Финляндию, поэтому весьма актуальной для меня является возможность начать как можно раньше говорить с окружающими меня людьми, среди которых часто попадаются финны:-)
Так появилась новая задача — сделать изучение слов не самоцелью, а инструментом работы с текстами, которые мне интересны. В идеале — инструментом подготовки к говорению на темы, на которые я бы хотел говорить.
План
Что же можно сделать, чтобы приблизиться к поставленной цели?
Во-первых, изучение слов по-прежнему нужно, но оно должно быть доработано с учётом наличия контекста у слов.
Во-вторых, необходимы задания на синтаксис, на строение предложений, так как понимание предложений, в первую очередь — их структуры, очень важно, особенно для языков, в которых возможен свободный порядок слов (например, финский).
В-третьих, нужны задания для работы со всем текстом.
Ну и последнее — если я хочу учиться говорить, то нужны распознавание речи и генерация речи по тексту и задания, использующие эти технологии.
Workflow (aka дидактика)
Как правильно выстроить учебные шаги, чтобы обучение было максимально продуктивным?
Обучение говорению с опорой на текст известно давно и используется повсеместно. Идея простая — сначала читаем текст, разбираем его лексику и грамматику, синтаксис, структуру и смысл самого текста. Дальше переходим от пассивного изучения к активному — например, пишем изложение по тексту, и на основе изложения — пересказ. Таким образом, можно достаточно мягко перейти от чтения к говорению.
Напомню, что основным мотивом создания бота для меня была возможность изучения языка по любому тексту, который я нахожу нужным или интересным. Поэтому никакого статического контента там быть не может — всё только по усмотрению ученика. Таким образом, можно приблизиться к созданию системы автоматизированного изучения языка, совмещающей в себе персонализацию обучения и проверенную на практике методику обучения иностранным языкам.
Что получилось
Получилась новая версия старого бота. В OppiWordsBot (именно так он называется) по-прежнему можно заниматься старой доброй зубрёжкой слов, которые теперь можно добавлять списками по частотности и так называемым «умным списком» на основе word2vec.
Но теперь появилась команда /addtext, которая позволяет вставить в строку ввода любой текст, после чего он будет обработан и из него будут извлечены все предложения, слова, а также словосочетания.
(Здесь и далее все примеры на английском языке)

Из полученных лексических единиц генерируется список, слова и фразы из которого пользователь может добавить для изучения командой /addwords. При добавлении каждого слова можно выбрать варианты определений из Wiktionary, Yandex Dictionary, Google Translate или добавить свой вариант.

По команде /learn предлагается выбрать список слов для обучения и, если пользователь выбирает список, созданный на основе из текста, то собственно с этого момента и начинается процесс изучения лексики текста.

Сначала бот знакомит пользователя с новой лексикой — задача запомнить значение новых слов и фраз.

Затем нужно запомнить, как слово произносится и попытаться произнести его самостоятельно. Система подскажет, где пользователь совершил ошибку при произнесении слова. Тут используются платные сервисы Google, поэтому эти упражнения доступны только по платной подписке (3 евро в месяц).
Дальше пользователь должен произнести слово, опираясь только на значение. Здесь слово дано в контексте предложений, в которых оно встречается в тексте. И снова система подскажет, где была ошибка в речи пользователя. Тут тоже — упражнение только по подписке.

Последнее задание на лексику — написать слово по его значению. И снова — слово в контексте.

После освоения лексики и ввода команды /learn, бот предложит разобраться с грамматикой. Правда, пока только с синтаксисом и пока только при помощи одного упражнения — расставить слова в правильном порядке.

После того, как все предложения освоены, бот предложит поработать с текстом, если снова набрать /learn. Для начала предстоит сделать краткое изложение каждого абзаца. Если абзац не содержит важной для всего текста информации, можно его пропустить, введя любой символ (один).
Полученное краткое изложение текста бот предложит прочитать или воспроизвести по памяти. Текст будет распознан, и бот покажет отличия вашего текста от ожидаемого. Это тоже доступно только по подписке.
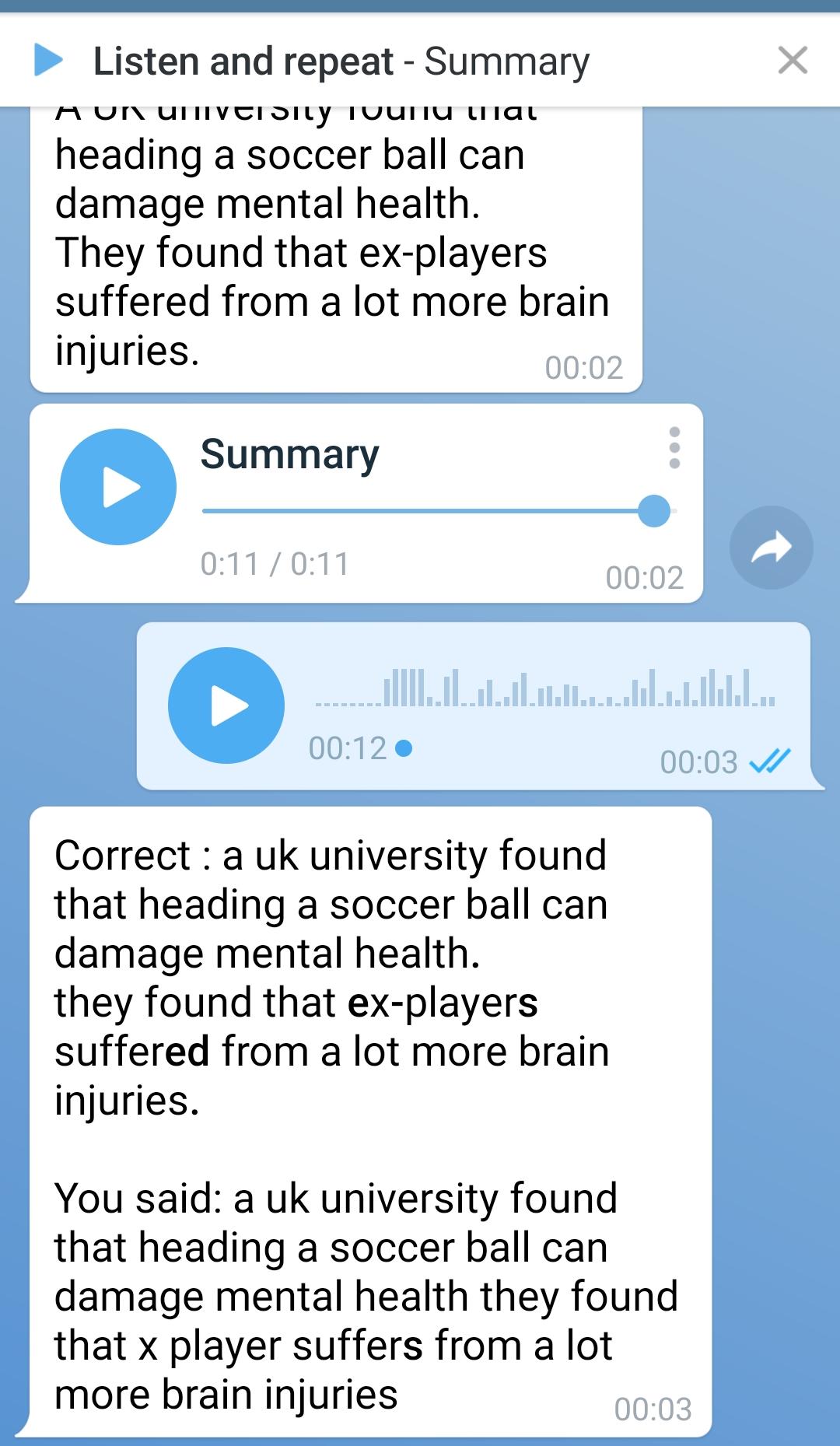
Таким образом, бот ведёт пользователя от простого заучивания лексики к первым шагам в говорении на тему выбранного пользователем текста и с опорой на него.
Как этим пользоваться
Главное правило — не ждать чуда)
Не стоит надеяться, что, если с начальным уровнем языка загрузить большой и сложный текст в бот, то неким магическим образом можно выучить весь язык и начать свободно читать, понимать и говорить. Всё, что может сделать бот — помочь запомнить лексику и в определённой мере синтаксис текста и подвести вас к говорению с опорой на этот текст. Это уже немало, но до чудес тут, естественно, далеко.
Чтобы максимально эффективно пользоваться ботом, нужно выбирать не очень сложные тексты. В противном случае вы окажетесь погребены под горой заданий на новую лексику, что в итоге может свести вашу мотивацию на нет.
Я стараюсь выбирать небольшие тексты (три — пять абзацев), не очень сложные (лучше адаптированные) на интересующую меня тематику. Обычно это либо новости в адаптированном изложении, либо учебные тексты. Можно попробовать создать свой текст при помощи Google Translate и изучать его, но стоит учитывать, что автоматический перевод может дать неидеальный текст и есть риск выучить не совсем тот язык, который вы хотели бы выучить.
Так как пока интерфейс бота полностью на английском языке, некоторое его знание требуется для изучения любого языка при помощи бота. Локализация планируется, но пока на это нет ни сил, ни времени.
Что дальше
Так как большинство пользователей бота изучают английский язык, я планирую добавить упражнения на видовременные формы (Present Simple, Past Perfect и пр.). Они также будут автоматически генерироваться из текстов пользователя и обрабатываться алгоритмом интервального повторения (именно грамматические явления, а не их лексическая репрезентация).
Сейчас я также работаю над оптимизацией упражнений — некоторые из них вполне возможно дублируют друг друга и их можно было бы сократить, чтобы ускорить процесс обучения. Будут добавлены и новые упражнения на лексику (семантика и морфология) и грамматику (исправление ошибок, например).
Есть планы и по развитию заданий на говорение, но об этом пока рано говорить.
Если хотите обсудить бот, что-то предложить или задать вопрос, можете сделать это в Телеграм-группе OppiWordsBotGroup.
Код выложен на гитхаб https://github.com/tezer/OppiWordsBot.
UPDATE для тех, у кого английский на базовом уровне и англоязычный интерфейс вызывает проблемы.
Проще всего начать работу так:
/start — запускаете бота
/settings — устанавливаете свой язык (например, русский — russian), потом выбираете словари, которые будут для вас использоваться. Лучше выбрать только YandexDictionary и GoogleTranslate, потому что они будут переводить определения на ваш язык.
Не забудьте указать, какой язык изучаете командой /setlanguage (язык указывать только на английском языке, то есть для английского написать English, а, например, для немецкого — German, но не Deutsch)
После этого можете либо добавлять слова по одному при помощи команды /addwords, либо можете добавить списком самые частотные слова изучаемого языка: /wordlist, потом первая кнопка (Top frequency words), потом ввести, например, 0:20, чтобы получить 20 самых частотных слов.
Можно также добавить учебный текст при помощи /addtext, потом /addwords, чтобы добавить слова из этого текста. Главное, чтобы текст был простым.







