В одном из чатов мне задали вопрос:
— А есть что-то почитать, как правильно упаковывать сервера в стойки?
Я понял, что такого текста не знаю, поэтому написал свой.
Во-первых, этот текст про физические сервера в физических дата центрах (ДЦ). Во-вторых, считаем, что серверов достаточно много: сотни-тысячи, для меньшего количества этот текст не имеет смысла. В-третьих, считаем, что у нас есть три ограничителя: физическое место в стойках, электропитание на стойку, и пусть стойки стоят в рядах, так что мы можем использовать один ToR свитч для подключения серверов в соседних стойках.
Ответ на вопрос сильно зависит от того, какой параметр мы оптимизируем и что мы можем варьировать, чтобы добиться наилучшего результата. Например, нам лишь надо занять минимум места, чтобы больше оставить на дальнейший рост. А может, у нас есть свобода в выборе высоты стоек, мощности на стойку, розеток в PDU, количества стоек в группе свитчей (один свитч на 1, 2 или 3 стойки), длины проводов и работ по протяжке (это критично на концах рядов: при 10-ти стойках ряду и 3-х стойках на свитч придется тянуть провода в другой ряд или недоиспользовать порты в свитче), etc., etc. Отдельные истории: выбор серверов и выбор ДЦ, будем считать, что они выбраны.
Хорошо бы понимать некоторые нюансы и подробности, в частности, среднее/максимальное потребление серверов, и как нам подается электричество. Так, если у нас российское питание 230В и одна фаза на стойку, то 32А автомат может держать ~7кВт. Допустим, мы номинально платим за 6кВт на стойку. Если провайдер меряет наше потребление только по ряду из 10 стоек, а не по каждой стойке, и если автомат стоит на отсечке условно 7кВт, то технически мы можем в отдельно взятой стойке сожрать 6.9кВт, в другой 5.1кВт и все будет ок — ненаказуемо.
Обычно наша основная цель — это минимизация расходов. Лучший критерий для измерения — снижение TCO (total cost of ownership — совокупная стоимость владения). Она состоит из следующих кусков:
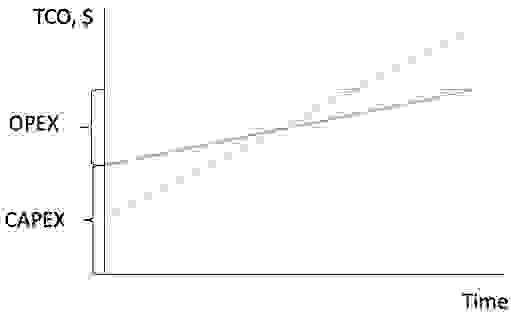
В зависимости от того, как велики отдельные куски в общем пироге, нам надо оптимизировать самое дорогое, а остальное пусть использует все оставшиеся ресурсы как можно более эффективно.
Допустим, у нас есть уже существующий ДЦ, есть высота стойки H юнитов (для примера H=47), электричество на стойку Prack (Prack=6кВт), и мы решили использовать h=2U двухюнитовые сервера. Уберем 2..4 юнита из стойки на свитчи, патч панели и органайзеры. Т.е. физически, у нас в стойке помещается Sh=rounddown((H-2..4)/h) серверов (т.е. Sh = rounddown((47-4)/2)=21 сервер на стойку). Запомним это Sh.
В простом случае все сервера в стойке одинаковые. Итого, если мы забьем стойку серверами, то на каждый сервер мы сможем в среднем потратить мощность Pserv=Prack/Sh (Pserv = 6000Вт/21 = 287Вт). Для простоты мы тут игнорируем потребление свитча.
Сделаем шаг в сторону и определимся, что такое максимальное потребление сервера Pmax. Если очень просто, очень неэффективно и совсем безопасно, то читаем, что написано на блоке питания сервера — это оно.
Если сложнее, более эффективно, то берем TDP (thermal design package) всех компонентов и суммируем (это не очень правда, но можно и так).
Обычно мы TDP компонентов (кроме CPU) не знаем, поэтому берем самый правильный, но и самый сложный подход (нужна лаборатория) — берем экспериментальный сервак нужной конфигурации и нагружаем его, например, Linpack'ом (CPU и память) и fio (диски), меряем потребление. Если подходить серьезно, то надо еще и создать наиболее теплую среду в холодном коридоре во время тестов, потому что это влиет и на потребление вентилятров, и на потребление CPU. Получаем максимальное потребление конкретного сервера с конкретной конфигурацией в этих конкретных условиях под этой конкретной нагрузкой. Просто имеем в виду, что новая прошивка системы, другой версия софта, другие условия могут повлиять на результат.
Итого, возвращаемся к Pserv и как нам его сравнить с Pmax. Это вопрос понимания работы сервисов и того, насколько крепкие нервы у вашего техдира.
Если совсем не рисковать, то считаем, что все сервера могут одномоментно начать потреблять свой максимум. В этот же момент может сложиться один ввод в ДЦ. Инфра и в этих условиях должна предоставлять сервис, поэтому Pserv ≡ Pmax. Это подход, где абсослютно важна надежность.
Если же техдир думает не только об идеальной безопасности, но и о деньгах компании и достаточно смелый, то можно решить, что
Тут очень полезно не просто гадать, а мониторить потребление и знать, как реально в обычных и пиковых условиях сервера потребляют электричество. Поэтому после некоторого анализа техдир сжимает всё, что у него есть, и говорит: «мы волевым решением принимаем, что максимально достижимое среднее от максимумов потребления серверов на стойку на **столько-то** ниже максимального потребления», условно Pserv=0.8*Pmax.
И тогда в стойку на 6кВт влезает уже не 16 серверов с Pmax = 375Вт, а 20 серверов с Pserv = 375Вт \* 0.8 = 300Вт. Т.е. на 25% больше серверов. Это очень большая экономия — ведь и стоек нам сразу надо на 25% меньше (а там еще и на PDU, свитчах да кабелях сэкономим). Серьезный минус такого решения — надо постоянно мониторить, что наши предположения все еще верны. Что новая версия прошивки не меняет существенным образом работу вентиляторов и потребления, что разработка вдруг с новым релизом не начала использовать сервера гораздо эффективней (читай добились большей загрузки и большего потребления на сервер). Ведь тогда и наши первоначальные предположения, и выводы сразу становятся неверными. Это риск, который надо ответственно принимать (или избегать и тогда платить за очевидно недогруженные стойки).
Важное замечание — стоит пытаться распределять сервера из разных сервисов по стойкам горизонтально, если это возможно. Это надо, чтобы не случались истории, когда одна партия серверов для одного сервиса приходит, стойки вертикально забиваются ею для повышения «плотности» (потому что так проще). В реальности же получается, что одна стойка забита одинаковыми низконагруженными серверами одного сервиса, а другая — одинаково высоконагруженными. Вероятность падения второй существенно выше, т.к. профиль нагрузки одинаков, и все сервера вместе в этой стойке начинают потреблять одинаково много в результате повышения нагрузки.
Вернемся к распределению серверов в стойках. Мы рассмотрели физические ограничения по месту в стойке и ограничения по электропитанию, теперь взглянем и на сеть. Можно использовать свитчи на 24/32/48 портов N (для примера у нас 48-портовые ToR свитчи). Вариантов, к счастью, не так много, если не задумываться о break-out кабелях. Рассматриваем сценарии, когда у нас есть один свитч на стойку, один свитч на две или три стойки в группе Rnet. Мне кажется, что больше трех стоек в группе — уже перебор, т.к. проблема кабелирования между стойками становится сильно больше.
Итак, для каждого сетевого сценария (1, 2 или 3 стойки в группе) распределяем сервера по стойкам:
Srack = min(Sh, rounddown(Prack/Pserv), rounddown(N/Rnet))
Таким образом, для варианта с 2 стойками в группе:
Srack2 = min(21, rounddown(6000/300), rounddown(48/2)) = min(21, 20, 24) = 20 серверов на стойку.
Аналогично считаем остальные варианты:
Srack1 = 20
Srack3 = 16
И мы практически у цели. Считаем количество стоек для распределения всех наших серверов S (пусть будет 1000):
R = roundup(S / (Srack * Rnet)) * Rnet
R1 = roundup(1000 / (20 * 1)) * 1 = 50 * 1 = 50 стоек
R2 = roundup(1000 / (20 * 2)) * 2 = 25 * 2 = 50 стоек
R3 = roundup(1000 / (16 * 3)) * 3 = 21 * 3 = 63 стойки
Дальше считаем TCO для каждого варианта на основании количества стоек, необходимого количества свитчей, кабелирования, etc. Выбираем тот вариант, где TCO меньше. Profit!
Заметим, что хотя необходимое количество стоек для вариантов 1 и 2 одинаково, их цена будет разной, т.к. количество свитчей для второго варианта вдвое меньше, а длина необходимых кабелей больше.
P.S. Если есть возможность поиграть мощностью на стойку и высотой стойки, вариативность увеличивается. Но процесс можно свести к вышеописанному, просто перебирая варианты. Да, комбинаций будет побольше, но все-таки весьма ограниченное количество — питание на стойку для расчета можно увеличивать с шагом по 1 кВт, типовые стойки бывают ограниченного количества типоразмеров: 42U, 45U, 47U, 48U, 52U. И тут для расчета может помочь Excel'евский What-If analysis в режиме Data Table. Смотрим на полученные таблички и выбираем минимум.
— А есть что-то почитать, как правильно упаковывать сервера в стойки?
Я понял, что такого текста не знаю, поэтому написал свой.
Во-первых, этот текст про физические сервера в физических дата центрах (ДЦ). Во-вторых, считаем, что серверов достаточно много: сотни-тысячи, для меньшего количества этот текст не имеет смысла. В-третьих, считаем, что у нас есть три ограничителя: физическое место в стойках, электропитание на стойку, и пусть стойки стоят в рядах, так что мы можем использовать один ToR свитч для подключения серверов в соседних стойках.
Ответ на вопрос сильно зависит от того, какой параметр мы оптимизируем и что мы можем варьировать, чтобы добиться наилучшего результата. Например, нам лишь надо занять минимум места, чтобы больше оставить на дальнейший рост. А может, у нас есть свобода в выборе высоты стоек, мощности на стойку, розеток в PDU, количества стоек в группе свитчей (один свитч на 1, 2 или 3 стойки), длины проводов и работ по протяжке (это критично на концах рядов: при 10-ти стойках ряду и 3-х стойках на свитч придется тянуть провода в другой ряд или недоиспользовать порты в свитче), etc., etc. Отдельные истории: выбор серверов и выбор ДЦ, будем считать, что они выбраны.
Хорошо бы понимать некоторые нюансы и подробности, в частности, среднее/максимальное потребление серверов, и как нам подается электричество. Так, если у нас российское питание 230В и одна фаза на стойку, то 32А автомат может держать ~7кВт. Допустим, мы номинально платим за 6кВт на стойку. Если провайдер меряет наше потребление только по ряду из 10 стоек, а не по каждой стойке, и если автомат стоит на отсечке условно 7кВт, то технически мы можем в отдельно взятой стойке сожрать 6.9кВт, в другой 5.1кВт и все будет ок — ненаказуемо.
Обычно наша основная цель — это минимизация расходов. Лучший критерий для измерения — снижение TCO (total cost of ownership — совокупная стоимость владения). Она состоит из следующих кусков:
- CAPEX: закупка инфраструктуры ДЦ, серверов, сетевых железок и кабелирование
- OPEX: аренда ДЦ, потребляемое электричество, обслуживание. OPEX зависит от срока службы. Разумно предположить его равным 3 годам.

В зависимости от того, как велики отдельные куски в общем пироге, нам надо оптимизировать самое дорогое, а остальное пусть использует все оставшиеся ресурсы как можно более эффективно.
Допустим, у нас есть уже существующий ДЦ, есть высота стойки H юнитов (для примера H=47), электричество на стойку Prack (Prack=6кВт), и мы решили использовать h=2U двухюнитовые сервера. Уберем 2..4 юнита из стойки на свитчи, патч панели и органайзеры. Т.е. физически, у нас в стойке помещается Sh=rounddown((H-2..4)/h) серверов (т.е. Sh = rounddown((47-4)/2)=21 сервер на стойку). Запомним это Sh.
В простом случае все сервера в стойке одинаковые. Итого, если мы забьем стойку серверами, то на каждый сервер мы сможем в среднем потратить мощность Pserv=Prack/Sh (Pserv = 6000Вт/21 = 287Вт). Для простоты мы тут игнорируем потребление свитча.
Сделаем шаг в сторону и определимся, что такое максимальное потребление сервера Pmax. Если очень просто, очень неэффективно и совсем безопасно, то читаем, что написано на блоке питания сервера — это оно.
Если сложнее, более эффективно, то берем TDP (thermal design package) всех компонентов и суммируем (это не очень правда, но можно и так).
Обычно мы TDP компонентов (кроме CPU) не знаем, поэтому берем самый правильный, но и самый сложный подход (нужна лаборатория) — берем экспериментальный сервак нужной конфигурации и нагружаем его, например, Linpack'ом (CPU и память) и fio (диски), меряем потребление. Если подходить серьезно, то надо еще и создать наиболее теплую среду в холодном коридоре во время тестов, потому что это влиет и на потребление вентилятров, и на потребление CPU. Получаем максимальное потребление конкретного сервера с конкретной конфигурацией в этих конкретных условиях под этой конкретной нагрузкой. Просто имеем в виду, что новая прошивка системы, другой версия софта, другие условия могут повлиять на результат.
Итого, возвращаемся к Pserv и как нам его сравнить с Pmax. Это вопрос понимания работы сервисов и того, насколько крепкие нервы у вашего техдира.
Если совсем не рисковать, то считаем, что все сервера могут одномоментно начать потреблять свой максимум. В этот же момент может сложиться один ввод в ДЦ. Инфра и в этих условиях должна предоставлять сервис, поэтому Pserv ≡ Pmax. Это подход, где абсослютно важна надежность.
Если же техдир думает не только об идеальной безопасности, но и о деньгах компании и достаточно смелый, то можно решить, что
- мы начинаем менеджить наших вендоров, в частности, запрещаем проводить плановое обслуживание в моменты планируемой пиковой нагрузки для минимизации падения одного ввода;
- и/или наша архитектура позволяет потерять стойку/ряд/ДЦ, а сервисы продолжают работать;
- и/или мы хорошо размазываем нагрузку горизонтально по стойкам, поэтому наши сервисы никогда не прыгнут к максимальному потреблению в одной стойке все вместе.
Тут очень полезно не просто гадать, а мониторить потребление и знать, как реально в обычных и пиковых условиях сервера потребляют электричество. Поэтому после некоторого анализа техдир сжимает всё, что у него есть, и говорит: «мы волевым решением принимаем, что максимально достижимое среднее от максимумов потребления серверов на стойку на **столько-то** ниже максимального потребления», условно Pserv=0.8*Pmax.
И тогда в стойку на 6кВт влезает уже не 16 серверов с Pmax = 375Вт, а 20 серверов с Pserv = 375Вт \* 0.8 = 300Вт. Т.е. на 25% больше серверов. Это очень большая экономия — ведь и стоек нам сразу надо на 25% меньше (а там еще и на PDU, свитчах да кабелях сэкономим). Серьезный минус такого решения — надо постоянно мониторить, что наши предположения все еще верны. Что новая версия прошивки не меняет существенным образом работу вентиляторов и потребления, что разработка вдруг с новым релизом не начала использовать сервера гораздо эффективней (читай добились большей загрузки и большего потребления на сервер). Ведь тогда и наши первоначальные предположения, и выводы сразу становятся неверными. Это риск, который надо ответственно принимать (или избегать и тогда платить за очевидно недогруженные стойки).
Важное замечание — стоит пытаться распределять сервера из разных сервисов по стойкам горизонтально, если это возможно. Это надо, чтобы не случались истории, когда одна партия серверов для одного сервиса приходит, стойки вертикально забиваются ею для повышения «плотности» (потому что так проще). В реальности же получается, что одна стойка забита одинаковыми низконагруженными серверами одного сервиса, а другая — одинаково высоконагруженными. Вероятность падения второй существенно выше, т.к. профиль нагрузки одинаков, и все сервера вместе в этой стойке начинают потреблять одинаково много в результате повышения нагрузки.
Вернемся к распределению серверов в стойках. Мы рассмотрели физические ограничения по месту в стойке и ограничения по электропитанию, теперь взглянем и на сеть. Можно использовать свитчи на 24/32/48 портов N (для примера у нас 48-портовые ToR свитчи). Вариантов, к счастью, не так много, если не задумываться о break-out кабелях. Рассматриваем сценарии, когда у нас есть один свитч на стойку, один свитч на две или три стойки в группе Rnet. Мне кажется, что больше трех стоек в группе — уже перебор, т.к. проблема кабелирования между стойками становится сильно больше.
Итак, для каждого сетевого сценария (1, 2 или 3 стойки в группе) распределяем сервера по стойкам:
Srack = min(Sh, rounddown(Prack/Pserv), rounddown(N/Rnet))
Таким образом, для варианта с 2 стойками в группе:
Srack2 = min(21, rounddown(6000/300), rounddown(48/2)) = min(21, 20, 24) = 20 серверов на стойку.
Аналогично считаем остальные варианты:
Srack1 = 20
Srack3 = 16
И мы практически у цели. Считаем количество стоек для распределения всех наших серверов S (пусть будет 1000):
R = roundup(S / (Srack * Rnet)) * Rnet
R1 = roundup(1000 / (20 * 1)) * 1 = 50 * 1 = 50 стоек
R2 = roundup(1000 / (20 * 2)) * 2 = 25 * 2 = 50 стоек
R3 = roundup(1000 / (16 * 3)) * 3 = 21 * 3 = 63 стойки
Дальше считаем TCO для каждого варианта на основании количества стоек, необходимого количества свитчей, кабелирования, etc. Выбираем тот вариант, где TCO меньше. Profit!
Заметим, что хотя необходимое количество стоек для вариантов 1 и 2 одинаково, их цена будет разной, т.к. количество свитчей для второго варианта вдвое меньше, а длина необходимых кабелей больше.
P.S. Если есть возможность поиграть мощностью на стойку и высотой стойки, вариативность увеличивается. Но процесс можно свести к вышеописанному, просто перебирая варианты. Да, комбинаций будет побольше, но все-таки весьма ограниченное количество — питание на стойку для расчета можно увеличивать с шагом по 1 кВт, типовые стойки бывают ограниченного количества типоразмеров: 42U, 45U, 47U, 48U, 52U. И тут для расчета может помочь Excel'евский What-If analysis в режиме Data Table. Смотрим на полученные таблички и выбираем минимум.







