Комментарии 28
Где-то я такие песни уже слышал…
Точно! "больше не нужно будет вводить формулы в компьютер, достаточно будет всего лишь показать формулу на бумаге и компьютер выдаст решение" (с) инженеры 50х.
Backend облаков (кстати, Оракл и МС заявили об облачном альянсе) крутится на том же hadoop + object store, то что hadoop замели веником под красивый и современный облачный ui — ничего не значит.
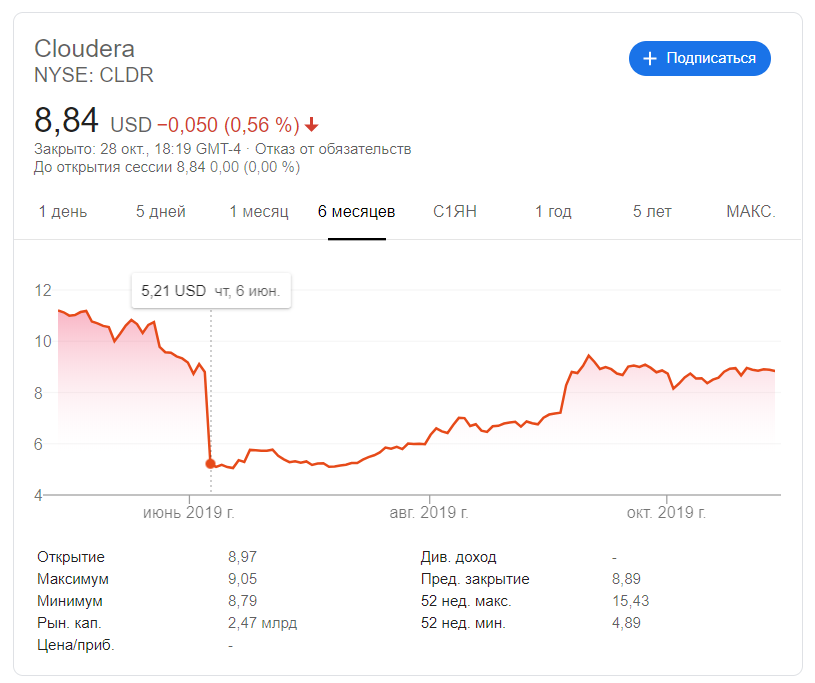
И у вас фактологическая ошибка: обвал акций CLDR — прям обвал — был в конце мая, с $11 до 5, сейчас акции торгуются в районе 9, средняя цена за 52 недели $9.97.
«программа сама позаботится о создании модели данных, связке таблиц и тому подобных задачах» — пусть для начала накошкахреляционных базах потренируется, а то виденные мной ORM до сих пор не предел мечтаний.
PS облачных технологий в стране навалом, в основном — приватные, изредка — гибридные облака. Дикси использовали публичные облака, но после фейла во время охоты на Телеграмм с банхаммером, не уверен, что не сделали облако гибридным.
Точно! "больше не нужно будет вводить формулы в компьютер, достаточно будет всего лишь показать формулу на бумаге и компьютер выдаст решение" (с) инженеры 50х.
Backend облаков (кстати, Оракл и МС заявили об облачном альянсе) крутится на том же hadoop + object store, то что hadoop замели веником под красивый и современный облачный ui — ничего не значит.
И у вас фактологическая ошибка: обвал акций CLDR — прям обвал — был в конце мая, с $11 до 5, сейчас акции торгуются в районе 9, средняя цена за 52 недели $9.97.
«программа сама позаботится о создании модели данных, связке таблиц и тому подобных задачах» — пусть для начала на
PS облачных технологий в стране навалом, в основном — приватные, изредка — гибридные облака. Дикси использовали публичные облака, но после фейла во время охоты на Телеграмм с банхаммером, не уверен, что не сделали облако гибридным.
Не согласен про фактологическую ошибку, на графике очень четко видно обвал:
«hadoop замели веником под красивый и современный облачный ui» — на мой взгляд это большое дело, особенно для понимания как этим пользоваться лицам принимающим решения.

«hadoop замели веником под красивый и современный облачный ui» — на мой взгляд это большое дело, особенно для понимания как этим пользоваться лицам принимающим решения.
Перечитал ещё раз и понял, что потерял контекст: речь об июне же, но при этом используется «В этом месяце», что и сбило меня с толку. Возможно, лучше «в тот месяц»?
Лица, принимающие решения и раньше не видели потрохов систем, для этого есть отделы аналитики, которые перерабатывают датасеты и рисуют графики, уже привычные конечным бизнес-пользователям.
Прототипы автоматизированных bi-систем видел, но не впечатлён: их natural language — английский, а круг решаемых задач весьма примитивный, решения весьма типичных задач «где мы больше всего теряем деньги в этом квартале?» или «а ну-ка, блокируй фрод!» они не дают и смогут дать не раньше появления работающего AI, а без этого вспоминается байка про 1с, за которым бухгалтеры сами пишут лёгкий и понятный код (практически на натуральном языке, ага).
Лица, принимающие решения и раньше не видели потрохов систем, для этого есть отделы аналитики, которые перерабатывают датасеты и рисуют графики, уже привычные конечным бизнес-пользователям.
Прототипы автоматизированных bi-систем видел, но не впечатлён: их natural language — английский, а круг решаемых задач весьма примитивный, решения весьма типичных задач «где мы больше всего теряем деньги в этом квартале?» или «а ну-ка, блокируй фрод!» они не дают и смогут дать не раньше появления работающего AI, а без этого вспоминается байка про 1с, за которым бухгалтеры сами пишут лёгкий и понятный код (практически на натуральном языке, ага).
Ну я как раз и говорю про заявления BI вендоров и видения будущего от Gartner, усилия направлены в эту сторону. Пока, в исполнении есть нюансы, не без этого.
А, эти балаболыконсалтеры…
— согласно одному из прогнозов аналитика Gartner, к 1993 году ожидался вывод из эксплуатации последнего мейнфрейма (Серия IBM Z до сих пор обновляется и продаётся)
— в 2006 году Gartner счёл, что наиболее эффективной стратегией для Apple будет прекращение выпуска аппаратного обеспечения.
IMHO: Крупный бизнес, у которого крупные деньги и крупная бигдата, вряд ли отдаст кластеры в детские дома и немедленно начнёт лить петабайты в облака (в 2 сразу, для отказоустойчивости), мелкому за глаза для анализа хватит и Excel (да и денег у мелкого бизнеса нет на эти игры), среднему проще нанять команду, получить решение и дальше расти.
— согласно одному из прогнозов аналитика Gartner, к 1993 году ожидался вывод из эксплуатации последнего мейнфрейма (Серия IBM Z до сих пор обновляется и продаётся)
— в 2006 году Gartner счёл, что наиболее эффективной стратегией для Apple будет прекращение выпуска аппаратного обеспечения.
IMHO: Крупный бизнес, у которого крупные деньги и крупная бигдата, вряд ли отдаст кластеры в детские дома и немедленно начнёт лить петабайты в облака (в 2 сразу, для отказоустойчивости), мелкому за глаза для анализа хватит и Excel (да и денег у мелкого бизнеса нет на эти игры), среднему проще нанять команду, получить решение и дальше расти.
пока то что я вижу это попытки продать продукт компаниям которые не хотят или не могут нанять дорогой персонал вида дата инжинеров, дата сантистов
а BI который разговаривает с пользователем через Алексу и соотвествено амазон клауд я уже видел и видел растерянные лица СБшников которые не знали как это квалифицировать, когда финансовая инфа компании льется в чужое облако без всяких договоров и НДА
а BI который разговаривает с пользователем через Алексу и соотвествено амазон клауд я уже видел и видел растерянные лица СБшников которые не знали как это квалифицировать, когда финансовая инфа компании льется в чужое облако без всяких договоров и НДА
Все правильно, история в том числе об этом
СБшиники да — встревожены
пока то что я вижу это попытки продать продукт компаниям которые не хотят или не могут нанять дорогой персонал вида дата инжинеров, дата сантистов
СБшиники да — встревожены
да тут много всякого, взять хотя бы 152ФЗ, если залить клиентские данные в облако то это будет нарушение ФЗ.
Сейчас не буду копаться в законах, да и юрист из меня слабоватый. Но, на одной из конференций, был приглашен специалист из правового консалтинга который утверждал, что хранение данных в облаке, даже иностранном не запрещено. Отмечал, что собирать данные нужно на российский сервер, а потом можно передавать в любое облако. Сослаться на законы не хватает квалификации, транслирую, что было мною услышано.
Если лить в облако вместо перс данных только ключ — айдишник а перс данные хранить в Россиюшке то тогда норм, хотя юристы пока с фз 152 не знают что делать и трактуют любое слово в любую сторону, так что под отзыв лицензии или еще какую канитель можно попасть и если ты банк или телеком или еще какой авиа перевозчик то шутить с риском потери лицензии не будешь
Вы этого консалтера продажного наверное на вендорской конференции слушали… Ну так с него взятки гладкий в случае чего. На трансграничку нужно получать разрешение владельца ПДн. Даже при наличии такого согласия от обязанности обеспечить защиту там по российским законам никто не отменял. Как вы будете выкручиваться с криптографией отдельная история…
Хайповое название, а по факту идите в облака. Вот, где Биг Дата.
аффтор путает платформу хадупа с канторами-дистроклепателями. место малоизвестного mapr просто займет майкростофт с его mssql2019. в mssql2019 тот самый hadoop+spark пойдет в комплекте.
а клаудера вероятно тоже загнется с такими закидонами. они для проформы выкладывают в опенсорс свои продукты, а на деле позванивают клиентов и вымагают деньги на супорт. заявляют что хрен вы там бесплатно что-то без нас соберете.
а клаудера вероятно тоже загнется с такими закидонами. они для проформы выкладывают в опенсорс свои продукты, а на деле позванивают клиентов и вымагают деньги на супорт. заявляют что хрен вы там бесплатно что-то без нас соберете.
А не тогда ли Cloudera подняла цены на лицензии?
И, кстати, не отменила ли express edition?
И, кстати, не отменила ли express edition?
за ценами на лицензии не следил и про express не слышал. вроде не было такой редакции. у них еще можно скачать их сборку (полный дистрибутив) бесплатно, но с февраля они это закроют. скачать дистрибутив смогут лишь обладатели подписки. цены что-то около $6k за ноду в год. странновастая стратегия мягко говоря, учитывая рост облаков и возможность в пару кликов поднимать хадуп кластеры в облаках.
— Я вас дважды огорчу(с)
Текущий ценник от $10к/нода в год + доп плата за ядра и место на дисках на 1 ноде выше определённого свежие цены
Бесплатный Express вроде ещё существует, но надолго ли? Типы лицензий, express ещё указан
Есть и другие редакции, но они странны составом, хоть и изрядно дешевле.
К тому же, Cloudera после слияния с Hortonworks и смерти MapR осталась единственным раскрученным поставщиком сборок hadoop.
Текущий ценник от $10к/нода в год + доп плата за ядра и место на дисках на 1 ноде выше определённого свежие цены
Бесплатный Express вроде ещё существует, но надолго ли? Типы лицензий, express ещё указан
Есть и другие редакции, но они странны составом, хоть и изрядно дешевле.
К тому же, Cloudera после слияния с Hortonworks и смерти MapR осталась единственным раскрученным поставщиком сборок hadoop.
Закат эпохи Big Data прям не заголовок а кликбейт
Генерация информации ускоряется но маркетологи анононсировали загат эпохи больших данных
пожалуй куплю попкорн и подожду когда они выкатят новую эпоху, интересно что это будет:
эпоха громадных данных?
эпоха ту фрекен матч данных?
Генерация информации ускоряется но маркетологи анононсировали загат эпохи больших данных
пожалуй куплю попкорн и подожду когда они выкатят новую эпоху, интересно что это будет:
эпоха громадных данных?
эпоха ту фрекен матч данных?
Тут скорее о закате Hadoop в его классическом понимании. Данные растут, спору нет.
А куда лить, если не в Hadoop?
Ceph? Glusterfs? А специалистов по ним где брать и за чей счёт переезд?
Spark over ceph есть, но со скоростью, судя по тестам ребят из Red Hat, там проблемы.
В общем, я не против, но слишком много вопросов и слишком мало профита.
PS чистый hadoop никому давно не нужен, по крайней мере, MapR(YARN не нужен, GUI тоже), продвигавшая его, таки загнулась.
Ceph? Glusterfs? А специалистов по ним где брать и за чей счёт переезд?
Spark over ceph есть, но со скоростью, судя по тестам ребят из Red Hat, там проблемы.
В общем, я не против, но слишком много вопросов и слишком мало профита.
PS чистый hadoop никому давно не нужен, по крайней мере, MapR(YARN не нужен, GUI тоже), продвигавшая его, таки загнулась.
вот кстати интересный вопрос куда лить то что сейчас льют в дата лэйк?
возможно MPP базы и всякие клик хаусы хорошы но ведь они под определенные сценарии использования
возможно MPP базы и всякие клик хаусы хорошы но ведь они под определенные сценарии использования
Многие вендоры сделали коннекторы для своих MPP под spark.
Только в ценнике и стоимости владения по сравнению с hadoop совсем не уверен,
а если добавить переобучение админов и переезд…
Hadoop получился штукой с открытой архитектурой: можно начать стартовым комплектом из 3 дешёвых серверов (или виртуалок), и добавляя более скоростные ноды вместе с выводом старых, понемногу расширить и ускорить кластер практически до любого уровня за недорого, при этом, достаточно детально описанной и избавленой от детских болячек.
Альтернатив не вижу — или стартовый комплект с ценой крыла самолёта, или сыроватый для прода, или специалистов на весь мир 4.5 человека и 3 из них говорят на хинди.
Только в ценнике и стоимости владения по сравнению с hadoop совсем не уверен,
а если добавить переобучение админов и переезд…
Hadoop получился штукой с открытой архитектурой: можно начать стартовым комплектом из 3 дешёвых серверов (или виртуалок), и добавляя более скоростные ноды вместе с выводом старых, понемногу расширить и ускорить кластер практически до любого уровня за недорого, при этом, достаточно детально описанной и избавленой от детских болячек.
Альтернатив не вижу — или стартовый комплект с ценой крыла самолёта, или сыроватый для прода, или специалистов на весь мир 4.5 человека и 3 из них говорят на хинди.
Со скоростью там все не так уж и плохо, если мы не говорим про erasure coding, а про 3х репликацию. Но при этом есть posix-совместимость и возможность доступа к объектному хранилищу без завязки на конкретные версии компонент экосистемы. Например, можете взять любой версии Spark/Hive/Impala, лишь бы коннектор к S3 не подвел. Мне кажется — это выход для тех компаний, у которых по несколько кластеров для разных команд. mesos + ceph + все, с чем вы привыкли работать с данными в привычном для вас CDH/HDP/Vanilla.
Простите, «там» — это где? S3? Ceph?
И, встречали, киньте ссылью с тестами (английский, максимум — испанский), мне интересна эта тема.
И, встречали, киньте ссылью с тестами (английский, максимум — испанский), мне интересна эта тема.
«Там» — это в объектном хранилище Ceph. Spark/Hive/Impala использует коннекторы S3 для подключения к нему в той статье, на которую вы дали ссылку, тесты там тоже есть. И там видно, что бОьшая часть ворклоадов сравнивалась с Ceph с erasure coding, в то время как в HDFS использовалась обычная 3х репликации. В тех тестах, где в Ceph включали 3х репликацию, разница в производительности с HDFS не была значительной, я бы сказал что производительность была сопоставима.
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
Закат эпохи Big Data