Цель и задача
Напомню, что в рамках первой статьи мы получили модель с удовлетворяющим нас качеством и пришли к выводу, что не стоит сразу строить нейронные сети, на некорректных данных большой пользы от этого не будет. Чтобы избежать потери времени и своих сил, достаточно проанализировать ошибки на “простых” моделях.
В этой статье мы поговорим о выводе в продуктив рабочей модели.
Первые тесты классификатора. Из Мефодия в Анну
Так вот, после анализа ошибок получили приемлемое качество и решили вывести модель в продуктив. Развернули модель в качестве веб-сервиса, дописали средствами телефонии вызов сервиса во время звонка. И если до этого мы боролись с типовыми сложностями ml-задач (разметка, дисбаланс), методы борьбы с ними известны, то дальше начиналось самое интересное.
Долго не задумываясь, мы решили начать с робота Мефодия, который будет встречать клиентов роботизированным голосом.
Мефодий обслуживал людей так.
Первый тестовый день показал, что людей не устраивает робот.
| Мефодий | |
|---|---|
| Брошенные трубки | 19% |
| Молчуны | 58% |
19% клиентов бросили трубку, 58% промолчали и ничего не ответили Мефодию. Почему-то только после этих цифр мы задумались, что прежде, чем запустить сервис, нужно было продумать, что будет спрашивать робот, каким голосом, будет ли это робот или “оператор”, другими словами, нужно было задуматься об интеграции модели в реальный мир пользователей. Это оказалось самым сложным.
Интеграция. Чек-лист
Нами был составлен чек-лист по интеграции системы с реальным миром. Итак, перед запуском такого рода сервиса в продуктив нужно подумать про:
- Цель диалога
- Фразы бота
- Oбъём текста/речи от бота
- Выявление конца реплики клиента
- Сценарий взаимодействия
Далее поясняю каждый из пунктов.
Первый важный момент — это понять, что мы хотим получить, внедрив робота. Мы сразу ответили: “сформулированный запрос в техподдержку”. Но как спросить так, чтобы пользователю стало понятно, чего от него хотят, это отдельная история. Мы штурмовали каждую фразу, лишь бы количество людей, ответивших боту, выросло. Основные выводы, к которым мы пришли, касательно фраз робота:
- Фразы бота не должны содержать страдательный залог
- Фразы бота должны быть короткими
- В конце каждой фразы должно быть понятно, что делать пользователю. Нужно использовать направляющие вопросы на каждом этапе общения с ботом. На нашем опыте могу сказать, что разница между фразами “Слушаю вас” и “Какой у вас вопрос?” есть!
- Важна заключительная фраза в общении с ботом, чтобы клиент понял, чего ему ждать дальше. В нашем случае в конце общения робот чётко проговаривал: “Я перевожу ваш звонок на специалиста по этому вопросу”, таким образом клиент понимал ценность общения с роботом.
Далее мы решили поэкспериментировать с голосом робота, так у нас появилась девушка Мария.
Аудио
Результат теста с Марией дал нам надежду.
| Мефодий | Мария | |
|---|---|---|
| Брошенные трубки | 19% | 14% |
| Молчуны | 58% | 27% |
Уже больше людей отвечали роботу, молчунов стало 27% вместо 58%, но всё ещё их количество хотелось сократить. Мы отслушали примеры из тестового запуска и выявили интересные случаи, когда люди не успевали договорить или же даже не успевали начать говорить. Выше представлен пример, где Мария перебила клиента, не дождалась конца ответа.
Нашлись люди, которые молчат умышленно, они знают, что это робот и ждут оператора. С ними мы разбирались отдельно. А есть люди, которые не смогли ответить из-за малого количества заложенного времени на ответ. Мы понимали, что перебивать совсем невежливо, так снижается лояльность клиента.
Решили поставить эксперименты по выбору продолжительности записи ответа клиента. Нужно было подобрать оптимальную продолжительность записи, чтобы как можно больше фраз стало информативными, то есть в них содержался осмысленный текст, который можно классифицировать. В таблице представлен процент информативных фраз при разной продолжительности записи ответа клиента.
| Время на ответ | Мефодий | Мария |
|---|---|---|
| 5 секунд | 52.4 | 56.3 |
| 7 секунд | 63.8 | 78.2 |
| 10 секунд | 84.1 | 91.4 |
| 12 секунд | 83.7 | 92.1 |
| 15 секунд | 79.2 | 90.6 |
Эксперименты показали, что 10 секунд достаточно чтобы сформулировать запрос.
Но ограничивать по времени — это лишь один из способов завершения записи ответа клиента, есть и другие. Детекция тишины или определение конца реплики по интонации говорящего — более действенные способы. В мире уже реализована детекция затухания речи, разработчики ориентируются на интонацию. Мы же после нескольких экспериментов с конкретным временем записи ответа, решили детектировать тишину средствами Asteriska, этого уже было достаточно, чтобы получить хорошие результаты.
Пример с детекцией тишины
Казалось бы, всё уже хорошо, робот слушает столько, сколько нужно, получил новый голос и имя “Анна”. Но очередной тест с такими улучшениями показал значительное снижение количества лишь брошенных трубок. Количество молчунов тоже снизилось, но хотелось лучше.
| Мефодий | Мария | Анна, v1 | |
|---|---|---|---|
| Брошенные трубки | 19% | 14% | 5% |
| Молчуны | 58% | 27% | 14% |
Недолго думая, решили модифицировать сценарий взаимодействия бота с клиентом. Если клиент не отвечает(молчун) и мы это детектируем в течение трёх секунд, то робот Анна переспрашивает. За счёт детекции тишины, применённой ранее, реализовать такое оказалось несложно. Итоговая схема сценария диалога представлена ниже.
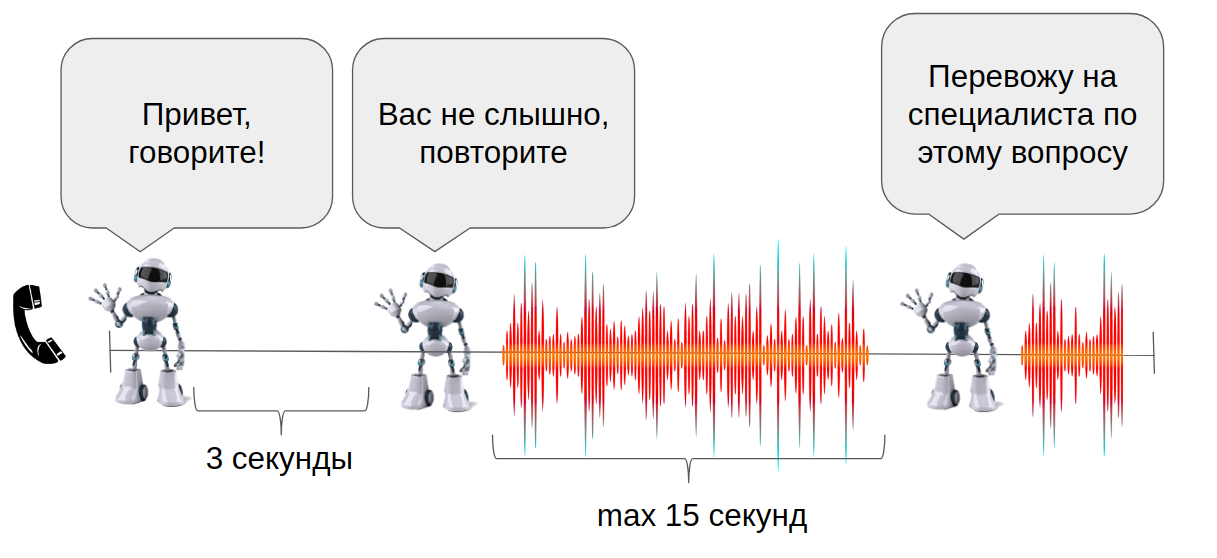
Это было сделано, чтобы оживить разговор и повторить вопрос робота тогда, когда пользователь, возможно, просто не услышал первую фразу от Анны.
Пример с переспросом
| Мефодий | Мария | Анна, v1 | Анна, v2 | |
|---|---|---|---|---|
| Брошенные трубки | 19% | 14% | 5% | 4% |
| Молчуны | 58% | 27% | 14% | 6% |
| Ответов после переспроса | - | - | - | 48% |
В итоге в продуктив и ушла такая реализация, с 4% брошенных трубок и лишь 6% молчунов. Мы шли до этого около 6 месяцев, казалось бы модель готова, классифицирует неплохо, а внедрить было тяжело.
Выводы поста
Готовая модель — это малое, что можно сделать, довести до продуктива получится тогда, когда поймёшь своих пользователей, как и что они говорят, готовы ли общаться с роботом.
Лишь после этого, внедрить модель не составит труда и бизнес-показатели пойдут вверх.
Внедрение Анны. Итоги
Классификация звонков позволила сократить время разговора. Оно сократилось на 15 секунд, а это 350 обработанных звонков в день. Сократилось за счёт того, что операторы сразу отвечали на вопрос, который переходил к ним от робота, и не тратили время на то, чтобы выслушать клиента. Но не это главное.
Классификация звонков позволила операторам принимать звонки на конкретные темы. Что было важно из-за проблем, про которые писала в первой части статьи: многообразие тем не позволяло операторам быстро выйти в линию, сначала требовалось выучить ответы на все вопросы клиентов. После внедрения системы обучение операторов стало занимать 1 неделю вместо 3 месяцев. Оператор, конечно же, продолжает учиться, но уже может принимать звонки на тему, которую изучил в первую неделю.
Увидимся в следующей статье, где расскажу ещё об одном кейсе применения голосовых классификаторов, а именно, как робот Анна сократила количество переводов между техподдержкой и отделом продаж.







