Комментарии 17
Да уж.
А реальный нейрон просто возбуждается, не зная про весь этот математический и вычислительный ужас.
Просмотрев пост, хочется стать нейроном.
А реальный нейрон просто возбуждается, не зная про весь этот математический и вычислительный ужас.
Просмотрев пост, хочется стать нейроном.
Я подобного математического шедевра еще не видел. В хорошем смысле. Очень круто! ))
P.S. У меня так сходу не получилось проследить, чем отличается нейрон ADALINE от перцептрона Розенблатта с линейной функцией активации и отличаются ли они вообще.
Насколько я помню, нейрон ADALINE от перцептрона Розенблатта отличается тем, что в перцептроне есть дополнительный случайный необучаемый слой с нелинейной функцией активации. То есть анализируются не входные признаки, а их случайные комбинации. И есть теорема, которая утверждает что любое множество точек станет линейно разделимым если "накидать" достаточное число нейронов в промежуточном слое.
НЛО прилетело и опубликовало эту надпись здесь
Код здесь приведен в учебных целях для наглядности. Для практических применений лучше взять какую-нибудь готовую библиотеку с реализацией нейросетки, должно быть что-то и для JS.
Если хотите строить на JS такие же графики, то не знаю, возможно и для JS есть что-то подобное, но, вообще, именно за такие графики и манипулирование многомерными массивами многие любят как раз Пайтон.
Если хотите строить на JS такие же графики, то не знаю, возможно и для JS есть что-то подобное, но, вообще, именно за такие графики и манипулирование многомерными массивами многие любят как раз Пайтон.
Статья мощная, фундаментальная. Не знаю, сможет ли человек без подготовки, который «не в теме», разобраться в её содержимом. Математические основы изложенного метода лет 60 как хорошо описаны. И за эти годы продвинулись вперёд, особенно с появлением мощных ЭВМ. Я бы интересующимся этой темой рекомендовал читать «Адлер Ю.П., Маркова Е.В., Грановский Ю.В. Планирование эксперимента при поиске оптимальных условий, 1971» или более свежую «Васильков Ю.В., Василькова Н.Н. Компьютерные технологии вычислений в математическом моделировании: учебное пособие, 1999 (2002)». Последняя книжка отсканирована и доступна. Там и градиент, и тяжёлый шарик, и случайный поиск и много всего.
Я тоже занимался подобной тематикой, только называлось это не нейросети, а моделирование, прогнозирование, оптимизация. Сначала я встроил чужой компонент (ActiveX). Выглядело примерно вот так: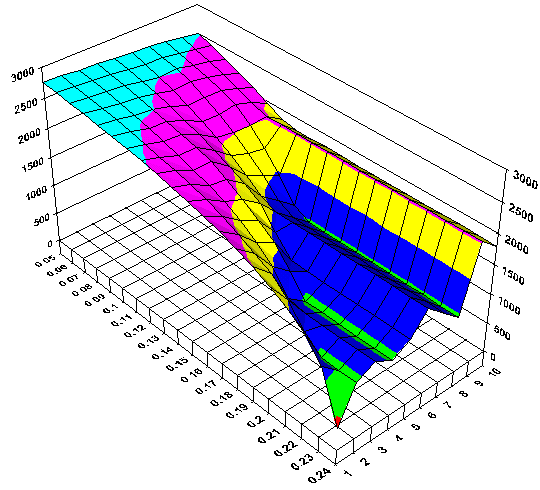
Но этого оказалось недостаточно и появилось такое чудо: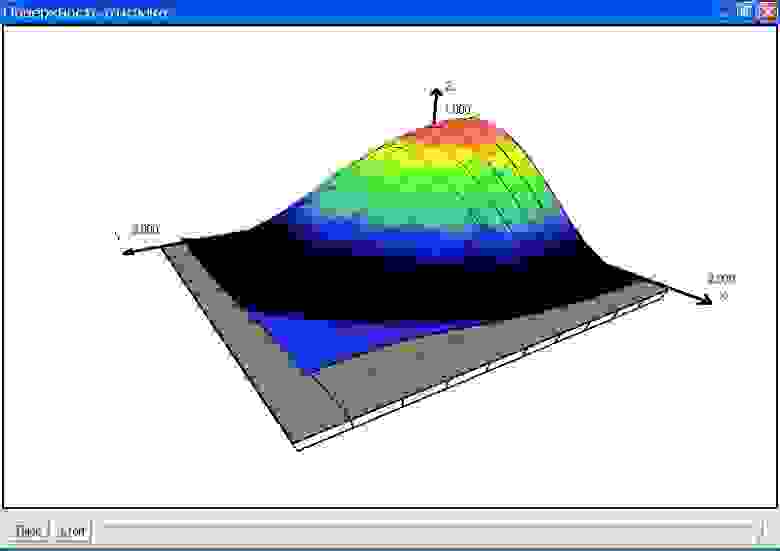
Которое было анимировано:
Это из моих публикаций 1999 года.
Я тоже занимался подобной тематикой, только называлось это не нейросети, а моделирование, прогнозирование, оптимизация. Сначала я встроил чужой компонент (ActiveX). Выглядело примерно вот так:
Но этого оказалось недостаточно и появилось такое чудо:

Которое было анимировано:
Это из моих публикаций 1999 года.
«Есть такой человек. Это я». Правда математическое образование у меня есть, но было это давно. Давно же хотел потрогать ML, но не было удобного материала. Пробовал Курсею, но не зашло совершенно. А вот статью прочитал за 2 вечера. Интересно, сколько вы ее писали? Правда немного удивило, как вы производную разжевываете, хотя некоторые курсы анализа ее даже вводят, как тангенс угла наклона касательной.
Все же после статьи повис вопрос: что дальше? Хочется и TensorFlow попробовать, по-возможности не размениваясь на обертки и упрощения. Посоветуйте, что еще почитать, пожалуйста.
Все же после статьи повис вопрос: что дальше? Хочется и TensorFlow попробовать, по-возможности не размениваясь на обертки и упрощения. Посоветуйте, что еще почитать, пожалуйста.
На то, чтобы разобраться, весной довольно плотно обложившись книгами потратил полтора-два месяца (перед этим еще года два эпизодически неплотно заходил на тему, не вникая в суть происходящего — например, запускал примеры из интернета с обучением сетки на MNIST). Тогда же подготовил слайды для лекций с основной канвой повествования. На статью сейчас потратил примерно месяц (не каждый день, по паре-тройке часов по вечерам), большая часть времени ушла на перерисовку картинок (вскрылось множество мелких неточностей или опечаток, что можно быстро пролистать на лекции, в статье уже оставлять нельзя), анимацию и на войну с MayAvi последнюю неделю. Когда картинки есть и стоят в нужном порядке, текст уже идет сам.
По производной сначала тоже хотел оттолкнуться от тангенса (это важно для понимания дальнейших телодвижений), предварительно дав ссылку, например, на этот ролик: www.youtube.com/watch?v=OniFjwZ3b00. Но когда все остальное было готово, решил, что гулять, так гулять, и сделал всё целиком.
Книги порекомендую две основные упомянутые: С. Николенко, Глубокое обучение, погружение в мир нейронных сетей и Себастьян Рашка, Python и машинное обучение.
Обе, в общем, маст хэв.
Есть еще Тарик Рашид, Создаем нейронную сеть. Тоже, в целом, неплохая, он концентрируется именно на сетках и пытается жевать их с азов и с самого начала, но местами уходит в другую крайность и слишком упрощает, при этом, некоторые вещи, которые мне для понимания были важны, он тоже упустил.
Вывод формул я почти полностью взял из Рашида, сверив с Николенко. Николенко для реализации первой сетки почти сразу после пояснений про ошибки и производные берет тензор-флоу.
Но, блин, ни по одной из книг я не мог до конца врубиться в то, что происходит хотя бы и с одним нейроном, пока сам все не сделал по шагам. Например, чел, выводит несколько страниц формул, все последовательно и логично, а потом бац — все объяснение градиентного спуска — плоская парабола со стрелочками (откуда она там взялась — не очень понятно, только что была куча формул, а к этой параболе нифига нет), и потом сразу цветки ирисов на плоскости, разделенные прямой (я пока не построил графики активации, не мог понять из текста, что там в этот промежуточный волшебный момент происходит, и что это прямая — никакая не прямая, а на самом деле плоскость в 3д).
В качестве продолжения рекомендую еще полистать мои слайды
Нейрон с сигмоидой (планирую конвертировать в такую же статью):
speakerdeck.com/sadr0b0t/bol-shiie-dannyie-liektsiia11-loghistichieskaia-rieghriessiia-ghradiientnyi-spusk-s-sighmoidoi
И, наконец, попытка объединить нейроны в сеть и обучить ее в таком же ручном режиме:
speakerdeck.com/sadr0b0t/bol-shiie-dannyie-liektsiia12-mnoghosloinyi-piertsieptron-mnoghomiernyi-ghradiient-obratnoie-rasprostranieniie
Последнее пока не получилось, там, похоже, включаются какие-то граничные условия, но зато стало понятно, почему у нейронов должна быть нелинейная активация и почему с линейной ничего не выдет.
По производной сначала тоже хотел оттолкнуться от тангенса (это важно для понимания дальнейших телодвижений), предварительно дав ссылку, например, на этот ролик: www.youtube.com/watch?v=OniFjwZ3b00. Но когда все остальное было готово, решил, что гулять, так гулять, и сделал всё целиком.
Книги порекомендую две основные упомянутые: С. Николенко, Глубокое обучение, погружение в мир нейронных сетей и Себастьян Рашка, Python и машинное обучение.
Обе, в общем, маст хэв.
Есть еще Тарик Рашид, Создаем нейронную сеть. Тоже, в целом, неплохая, он концентрируется именно на сетках и пытается жевать их с азов и с самого начала, но местами уходит в другую крайность и слишком упрощает, при этом, некоторые вещи, которые мне для понимания были важны, он тоже упустил.
Вывод формул я почти полностью взял из Рашида, сверив с Николенко. Николенко для реализации первой сетки почти сразу после пояснений про ошибки и производные берет тензор-флоу.
Но, блин, ни по одной из книг я не мог до конца врубиться в то, что происходит хотя бы и с одним нейроном, пока сам все не сделал по шагам. Например, чел, выводит несколько страниц формул, все последовательно и логично, а потом бац — все объяснение градиентного спуска — плоская парабола со стрелочками (откуда она там взялась — не очень понятно, только что была куча формул, а к этой параболе нифига нет), и потом сразу цветки ирисов на плоскости, разделенные прямой (я пока не построил графики активации, не мог понять из текста, что там в этот промежуточный волшебный момент происходит, и что это прямая — никакая не прямая, а на самом деле плоскость в 3д).
В качестве продолжения рекомендую еще полистать мои слайды
Нейрон с сигмоидой (планирую конвертировать в такую же статью):
speakerdeck.com/sadr0b0t/bol-shiie-dannyie-liektsiia11-loghistichieskaia-rieghriessiia-ghradiientnyi-spusk-s-sighmoidoi
И, наконец, попытка объединить нейроны в сеть и обучить ее в таком же ручном режиме:
speakerdeck.com/sadr0b0t/bol-shiie-dannyie-liektsiia12-mnoghosloinyi-piertsieptron-mnoghomiernyi-ghradiient-obratnoie-rasprostranieniie
Последнее пока не получилось, там, похоже, включаются какие-то граничные условия, но зато стало понятно, почему у нейронов должна быть нелинейная активация и почему с линейной ничего не выдет.
Обновил слайды про нейрон с сигмоидой
speakerdeck.com/sadr0b0t/bol-shiie-dannyie-liektsiia11-loghistichieskaia-rieghriessiia-ghradiientnyi-spusk-s-sighmoidoi
и про обучение сети из 3-х нейронов (в этом году получилось ее обучить — в прошлом году была ошибка в коде)
speakerdeck.com/sadr0b0t/bol-shiie-dannyie-liektsiia12-mnoghosloinyi-piertsieptron-mnoghomiernyi-ghradiient-obratnoie-rasprostranieniie
И про TensorFlow есть вариант видео-лекция (слайды пока не выложил):
vk.com/video?z=video53223390_456239477%2Fpl_cat_updates
они, правда, теперь там старый АПИ прячут в обертку Keras в новых версиях, поэтому планирую дальше переходить на PyTorch
speakerdeck.com/sadr0b0t/bol-shiie-dannyie-liektsiia11-loghistichieskaia-rieghriessiia-ghradiientnyi-spusk-s-sighmoidoi
и про обучение сети из 3-х нейронов (в этом году получилось ее обучить — в прошлом году была ошибка в коде)
speakerdeck.com/sadr0b0t/bol-shiie-dannyie-liektsiia12-mnoghosloinyi-piertsieptron-mnoghomiernyi-ghradiient-obratnoie-rasprostranieniie
И про TensorFlow есть вариант видео-лекция (слайды пока не выложил):
vk.com/video?z=video53223390_456239477%2Fpl_cat_updates
они, правда, теперь там старый АПИ прячут в обертку Keras в новых версиях, поэтому планирую дальше переходить на PyTorch
Автор, спасибо за статью! Хабр торт :)
Я давно не следил за прогрессом в нейросетях, потому задам несколько празндых вопросов не совсем по теме статьи:
1) Современные нейросети глубинного обучения построены на таких же нейронах (быть может, с более хитрой функцикей активации), или на чём-то принципиально ином?
2) Насколько я знаю, современные нейросети многослойны. Чем отличается нейрон многослойной сети от нейрона однослойной сети? Отсутствием пороговой функции?
3) Какие методы оптимизации используются в машинном обучении на практике? Такой же градиентный спуск?
Я давно не следил за прогрессом в нейросетях, потому задам несколько празндых вопросов не совсем по теме статьи:
1) Современные нейросети глубинного обучения построены на таких же нейронах (быть может, с более хитрой функцикей активации), или на чём-то принципиально ином?
2) Насколько я знаю, современные нейросети многослойны. Чем отличается нейрон многослойной сети от нейрона однослойной сети? Отсутствием пороговой функции?
3) Какие методы оптимизации используются в машинном обучении на практике? Такой же градиентный спуск?
1) В первом приближении таких же. Разве что функция суммации может быть изощренней из-за тех же свёрток, например. И да, чем глубже сеть, тем больше внимания уделяют функциям активации, наряду с другими ухищрениями (архитектурой, регуляризацией, инициализацией весов, нормировкой выходов слоёв и т.д.), чтобы обеспечить стабильную работу градиентного спуска.
2) Ничем. Многослойность говорит только о том, сколько слоёв нейронов соединены друг с другом.
3) Да, градиентные методы остаются наиболее универсальными. Разумеется у них много вариаций и улучшений по сравнению с самым наивным вариантом, но суть остаётся той же.
2) Ничем. Многослойность говорит только о том, сколько слоёв нейронов соединены друг с другом.
3) Да, градиентные методы остаются наиболее универсальными. Разумеется у них много вариаций и улучшений по сравнению с самым наивным вариантом, но суть остаётся той же.
По 3) есть один важный момент: на самом деле в ML используются стохастический градиентный спуск и его модификации, обычный градиентный спуск в ML бесполезен. Просто оказывается гораздо эффективней разбить данные скажем на 100 частей и сделать 100 итераций градиентного спуска учитывая на каждом шаге только одну часть нежели сделать одну итерацию на всех данных. В обоих случаях вычислительные затраты практически идентичны.
хорошо изложенно. Вспомнил университет.
Я сейчас прохожу современный курс по теме на Курсере, но все равно ваше объяснение и иллюстрации — лучшее, что я когда-либо видел. Спасибо!
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
Градиентный спуск по косточкам