Часть 2
От переводчика: Тема формата Posit уже была на хабре здесь, но без существенных технических подробностей. В этой публикации я предлагаю вашему вниманию перевод статьи Джона Густафсона (автора Posit) и Айзека Йонемото, посвящённой формату Posit.
Так как статья имеет большой объём, я разделил её на две части. Список ссылок находится в конце второй части.
Новый тип данных, называемый posit, разработан в качестве прямой замены чисел с плавающей точкой стандарта IEEE Standard 754. В отличие от ранней формы — арифметики универсальных чисел (unum), стандарт posit не требует использования интервальной арифметики или операндов переменного размера, и, как и float, числа posit округляются, если результат не может быть представлен точно. Они имеют неоспоримые преимущества над форматом float, включая больший динамический диапазон, большую точность, побитовое совпадение результатов вычислений на разных системах, более простое аппаратное обеспечение и более простую поддержку исключений. Числа posit не переполняются ни в сторону бесконечности, ни до нуля, и «нечисла» (Not aNumber, NaN) — это действия, а не битовые комбинации. Блок обработки posit имеет меньшую сложность, чем FPU стандарта IEEE. Он потребляет меньшую мощность, и занимает меньшую площадь кремния, таким образом, чип может выполнять существенно больше операций над числами posit в секунду, чем FLOPS, при тех же аппаратных ресурсах. GPU и процессоры глубокого обучения, в частности, могут выполнять больше операций на ватт потребляемой мощности, что позволит повысить качество их работы.
Были проведены всесторонние тесты, сравнивающие posit и float по точности вычислений для различной точности posit. Числа posit с низкой точностью являются лучшим решением для «приблизительных вычислений» в тех случаях, когда допустима низкая точность вычислений. Числа posit с высокой точностью обеспечивают более высокую точность, чем float того же размера, в некоторых случаях, 32-битный posit может безопасно заменить 64-битный float. Другими словами, posit выигрывает у float в его собственной игре.
Арифметический фреймворк unum (универсальные числа, universal number) имеет несколько форм представления чисел. Исходной формой являются «Type I», надмножество IEEE 754; она использует «ubit» в конце дробной части для индикации того, что вещественное число является точным или находится в интервале между соседними вещественными числами. Несмотря на то, что Unum, как и float, имеет знак, экспоненту и дробную часть, длины экспоненты и дробной части варьируются автоматически, от одного бита до некоторого значения, определяемого пользователем. Unum Type I является компактным способом представить интервальную арифметику но переменная длина требует дополнительных усилий. Этот тип может повторять поведение float, путём использования специальной функции округления.
Форма универсальных чисел “Type II” [4] не совместима с IEEE float, и представляет собой чистую, математически строгую концепцию, основанную на проективных вещественных числах. Ключевой идеей здесь является то, что знаковые целые числа в дополнительном коде элегантно отображаются на проективные вещественные числа, с тем же самым свойством перехода от положительных чисел к отрицательным, и с тем же самым порядком на числовой оси. Цитируя Уильяма Каана (William Kahan) [5]:
«Они экономят пространство памяти, так как манипулируют не числами, а указателями на значения. И это даёт возможность сделать арифметику очень, очень быстрой».
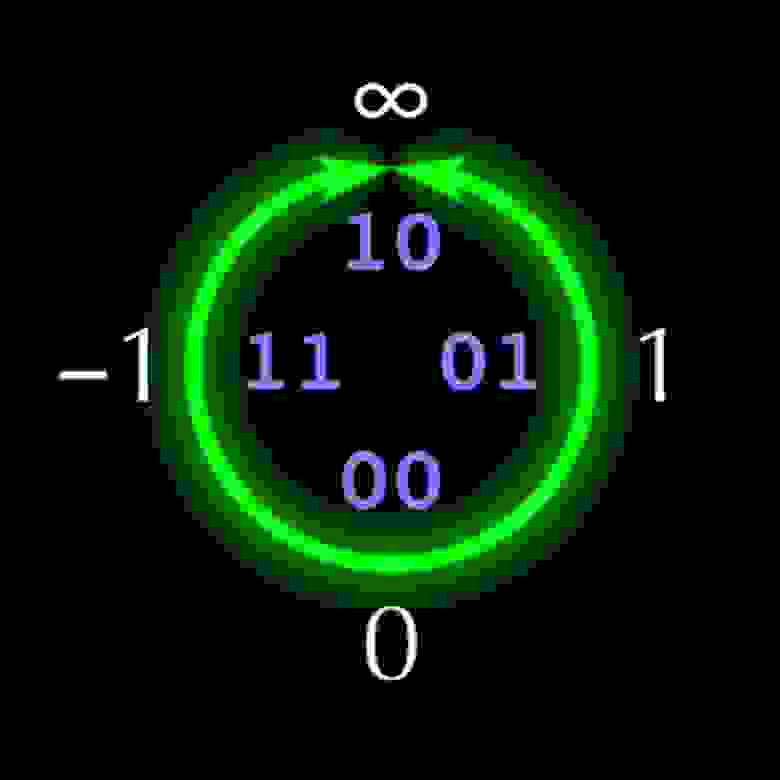
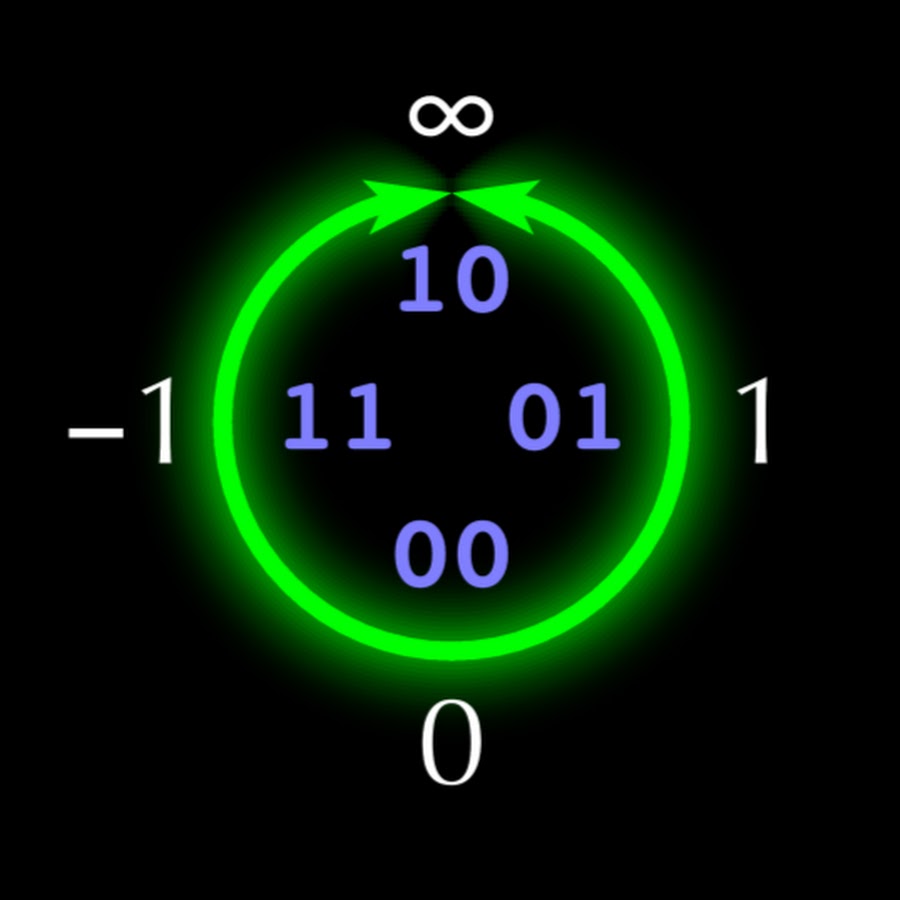
Структура 5-битного unum показана на рис. 1. Если каждый unum имеет n бит, то «u-решётка» заполняет верхний правый квадрант круга упорядоченным множеством из вещественных чисел
вещественных чисел  (не обязательно рациональными). В верхнем левом квадранте расположены отрицательные , отражённые относительно вертикальной оси. Нижняя половина круга содержит числа, обратные числам верхней половины, отражённые от горизонтальной оси, что делает операции умножения и деления такими же симметричными, как сложение и вычитание. Как и в случае Type I, числа unum типа Type II заканчиваются на 1 (ubit), представляя открытый интервал между соседними точными точками, для которых unum заканчивается на 0.
(не обязательно рациональными). В верхнем левом квадранте расположены отрицательные , отражённые относительно вертикальной оси. Нижняя половина круга содержит числа, обратные числам верхней половины, отражённые от горизонтальной оси, что делает операции умножения и деления такими же симметричными, как сложение и вычитание. Как и в случае Type I, числа unum типа Type II заканчиваются на 1 (ubit), представляя открытый интервал между соседними точными точками, для которых unum заканчивается на 0.
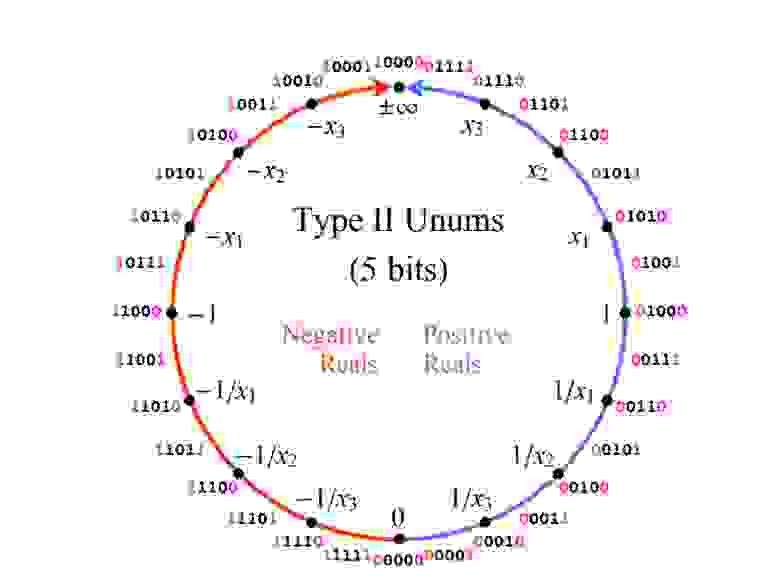
Рис. 1. Линия проективных вещественных чисел, отображаемая на целые числа в дополнительном коде длиной 4 бита.
Числа unum типа Type II имеют много идеальных математических свойств, но большинство операций с ними производится с помощью look-up таблиц. Если нужно n бит точности, то таблица (в наихудшем случае) будет иметь значений для функции двух аргументов, но с учётом симметрий и других трюков таблица может быть уменьшена до более приемлемого размера. Размер таблицы ограничивает масштаб этого ультрабыстрого формата размером 20 бит или меньше, для технологий сегодняшнего дня. Числа unum типа Type II также плохо поддаются операциям слияния. Эти недостатки послужили мотивацией для поиска формата, который сохраняет многие свойства чисел unum Type II, но является более «дружественным» к аппаратному обеспечению, и может быть вычислен логическими схемами, похожими на существующие FPU.
значений для функции двух аргументов, но с учётом симметрий и других трюков таблица может быть уменьшена до более приемлемого размера. Размер таблицы ограничивает масштаб этого ультрабыстрого формата размером 20 бит или меньше, для технологий сегодняшнего дня. Числа unum типа Type II также плохо поддаются операциям слияния. Эти недостатки послужили мотивацией для поиска формата, который сохраняет многие свойства чисел unum Type II, но является более «дружественным» к аппаратному обеспечению, и может быть вычислен логическими схемами, похожими на существующие FPU.
Есть два противоположных подхода к вычислениям в вещественных числах:
Первое утверждение относится к вещественной арифметике, в которой ошибка округления достаточно мала, второе утверждение относится к интервальной арифметике. Числа unum типов I и II также могут рассматриваться в подобном ключе, и это одна из причин, по которой они являются «универсальными числами». Однако, если мы всегда собираемся использовать некоторую функцию для округления после каждой операции, то мы лучше не будем использовать последний бит как значащий бит дробной части и не как ubit. Число unum такого типа мы будем называть числом posit.
Цитата из «New Oxford American Dictionary», 3-я редакция:
posit (сущ): заявление, которое делается исходя из предположения, что оно окажется правдой.
С целью упрощения аппаратной реализации числа unum Type II ослабляют одно из правил: точные обратные величины существуют только для 0, и степеней двойки. Это позволяет нам заполнить u-сетку так, что конечные числа останутся похожими на float, и будут иметь форму
и степеней двойки. Это позволяет нам заполнить u-сетку так, что конечные числа останутся похожими на float, и будут иметь форму  , где k и m целые. Открытых интервалов нет.
, где k и m целые. Открытых интервалов нет.
Valid — это пара чисел posit равного размера, каждое из которых заканчивается на ubit. Они предназначены для использования в тех приложениях, где важно строго определять, в каком интервале находится число, например, при отладке численных алгоритмов. Значения Valid являются более мощными, чем обычная интервальная арифметика и менее склонными к быстрому расширению чрезмерно пессимистических границ интервалов [2, 4]. Однако они не являются темой данной публикации.
На рис 2. показана структура n-битного представления posit с битами экспоненты.

Рис 2. Обобщённый формат posit format для конечных ненулевых значений
Бит знака содержит 0 для положительных чисел, 1 для отрицательных. Для отрицательных чисел, находим дополнение 2 перед декодированием режима, экспоненты и дробной части. Для понимания битов режима, рассмотрим бинарные строки, показанные в таблице 1, в которых k означает длину ведущей последовательности, а x в битовой стоке означает безразличное состояние.
Table 1. Run-length meaning k of the regime bits

Мы называем длину ведущей последовательности режимом числа. Бинарные строки начинаются с определённого количества нулей или единиц, идущих подряд, за которыми идёт противоположный бит, или достигается конец строки. Биты режима выделены янтарным цветом, противоположный бит выделен коричневым. Пусть m — количество одинаковых бит в последовательности, если эти биты равны нулю, то k = -m, если 1, то k = m-1. Большинство процессоров могут найти первую единицу в слове или первый ноль в слове аппаратно, то есть декодирующая логика уже доступна. Режим означает масштабирующий фактор, равный , где
, где  . Таблица 2 показывает пример значений useed.
. Таблица 2 показывает пример значений useed.
Таблица 2. useed как функция es

Следующие биты (выделенные синим на рисунке) — это экспонента e, относящаяся к беззнаковому целому. Она не сдвинута, как это сделано во float-ах, она представляет масштабирование на . Может быть до es битов экспоненты, в зависимости от того, сколько бит осталось справа от битов режима. Это компактный способ изменения точности, числа, близкие к 1 по абсолютной величине, имеют большую точность, чем очень большие или очень маленькие числа, которые гораздо реже встречаются в вычислениях.
. Может быть до es битов экспоненты, в зависимости от того, сколько бит осталось справа от битов режима. Это компактный способ изменения точности, числа, близкие к 1 по абсолютной величине, имеют большую точность, чем очень большие или очень маленькие числа, которые гораздо реже встречаются в вычислениях.
Если остались биты после битов режима и экспоненты, они представляют дробную часть, f, так же, как дробная часть 1.f в формате float, но скрытый бит всегда равен 1. Денормализованных чисел со скрытым 0 нет, в отличие от float.
Система, которую мы описали, это естественное следствие заполнения u-сетки. Начнём с простого 3-битного posit, для ясности, на рис. 3 показана только правая половина проективных вещественных чисел. Итак, числа на рис. 3. подчиняются правилам Type II. Есть только два особых значения: 0 (все биты 0) и ±∞ ( единица, за которой следуют все нули), их битовая последовательность не следует позиционной нотации. Для других значений posit на рис.3., биты раскрашены, как было описано выше. Отметим, что все положительные значения на рис.3 являются точными значениями useed в степени k, представленной битами режима.
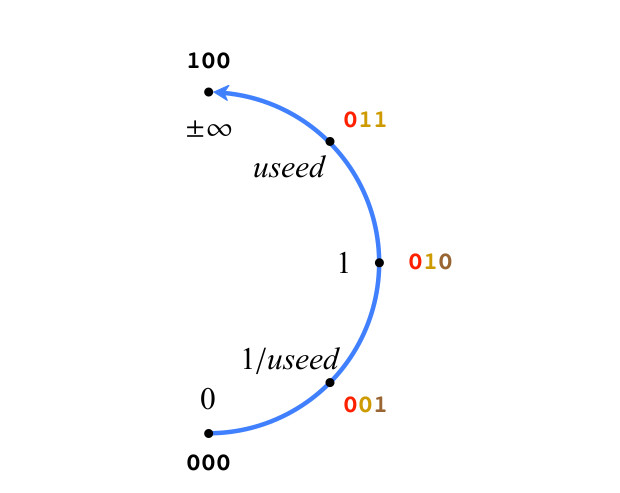
Рис.3. Положительные значения 3-битного posit
Точность чисел Posit увеличивается по мере добавления бит, и значения остаются там, где они есть на круге, когда добавляется бит 0. Когда добавляется 1, создаётся новое значение между двумя значениями posit на круге. Какое числовое значение мы должны им присвоить? Пусть maxpos будет наибольшим положительным значением, а minpos — наименьшим положительным значением на круге, определяемыми битовой строкой. На рис.3., maxpos — это useed, а minpos — это 1/useed. Правила интерполяции следующие:
Между maxpos и ±∞, новое значение — это maxpos × useed; между 0 и minpos, новое значение — это minpos / useed (с новым битом режима)
Между существующими значениями и
и  , где m и n отличаются больше, чем на 1, новое значение будет их геометрическим средним,
, где m и n отличаются больше, чем на 1, новое значение будет их геометрическим средним,  (с новым битом экспоненты).
(с новым битом экспоненты).
В других случаях, новое значение расположено посередине между существующими x и y, то есть является арифметическим средним, (с новым битом дробной части)
(с новым битом дробной части)
Как пример, рис. 4 показывает построение чисел posit от 2 до 5 бит с es=2, и, таким образом, useed=16.
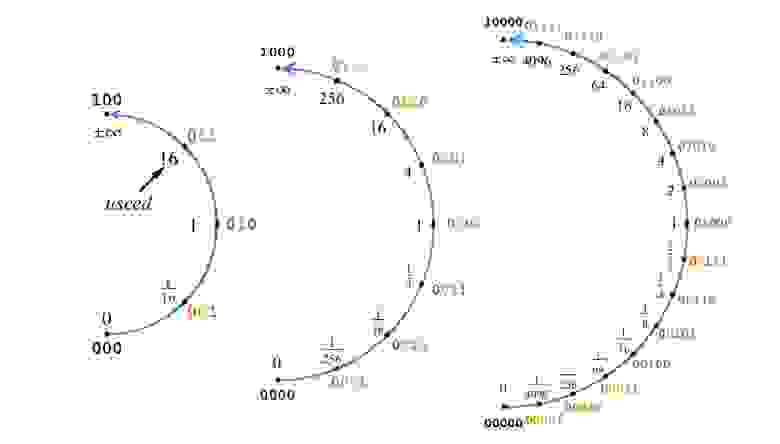
Рис. 4. Построение Posit с двумя битами экспоненты,
Если на рис. 4 добавить ещё один бит, чтобы получить 6-битные posit, к числам posit, представляющим диапазоны значений между 1/16 и 16, будет добавлен бит дробной части, а не бит экспоненты. Рассмотрим строку бит, представляющую число posit p как знаковое целое, в диапазоне от до
до  . Пусть k будет целым числом, представляющим биты режима, e — беззнаковым числом, представляющим биты экспоненты, если они присутствуют. Если набор бит дробной части
. Пусть k будет целым числом, представляющим биты режима, e — беззнаковым числом, представляющим биты экспоненты, если они присутствуют. Если набор бит дробной части  , возможно, пустой, то пусть f будет значением, представляющим число
, возможно, пустой, то пусть f будет значением, представляющим число  . Тогда p представляет
. Тогда p представляет
Биты режима и es выполняют ту же функцию, что и биты экспоненты в стандартном float, вместе они определяют масштабирующий коэффициент, равный степени двух, и каждый инкремент useed означает сдвиг бит. Число maxpos равно
бит. Число maxpos равно  и minpos равно
и minpos равно  . Пример декодирования числа posit показан на рис.5 (с «нестандартным» значением для es, для упрощения).
. Пример декодирования числа posit показан на рис.5 (с «нестандартным» значением для es, для упрощения).
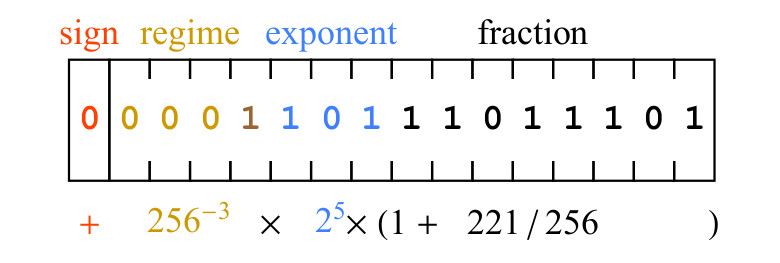
Рис. 5. Пример битовой строки posit и её математический смысл
Бит знака 0 означает, что значение положительное. Биты режима 0001 имеют последовательность из трёх нулей, что означает, что k=-3, следовательно, масштабирующий коэффициент, вносимый битами режима, равен . Биты экспоненты,101, представляют 5 как беззнаковое двоичное целое, и вносимый масштабирующий коэффициент равен
. Биты экспоненты,101, представляют 5 как беззнаковое двоичное целое, и вносимый масштабирующий коэффициент равен  . Наконец, биты дробной части 11011101 представляют число 221, то есть дробная часть равна 1+221/256. Выражение, записанное под битовым полем на рис.5. приводит нас к результату
. Наконец, биты дробной части 11011101 представляют число 221, то есть дробная часть равна 1+221/256. Выражение, записанное под битовым полем на рис.5. приводит нас к результату 
Несмотря на то, что стандарт IEEE не определяет 8-битные float, числа posit разметом 8 бит с es=0 доказали свою полезность для некоторых целей, они очень полезны для построения нейросетей [3, 8]. В настоящее время для этих целей часто используются числа IEEE с половинной точностью (16-bit), но 8-битные числа posit потенциально могут обрабатываться в 2-4 раза быстрее. Важной функцией в нейросетях является сигмоида, имеющая асимптоту 0 при и 1 при
и 1 при  . Общий вид сигмоидной функции
. Общий вид сигмоидной функции  , и она является дорогой для вычислений, и легко может потребовать более сотни циклов процессора на вызов функции exp(x) из библиотеки, и из-за деления. С числами posit, можно просто инвертировать первый бит числа posit, представляющего x, сдвинуть число на 2 бита вправо, заполняя биты слева нулями, и результирующая функция posit, показанная на рис.6. фиолетовым цветом, близка к сигмоиде (показанной зелёным), и даже имеет тот же наклон при пересечении оси y.
, и она является дорогой для вычислений, и легко может потребовать более сотни циклов процессора на вызов функции exp(x) из библиотеки, и из-за деления. С числами posit, можно просто инвертировать первый бит числа posit, представляющего x, сдвинуть число на 2 бита вправо, заполняя биты слева нулями, и результирующая функция posit, показанная на рис.6. фиолетовым цветом, близка к сигмоиде (показанной зелёным), и даже имеет тот же наклон при пересечении оси y.
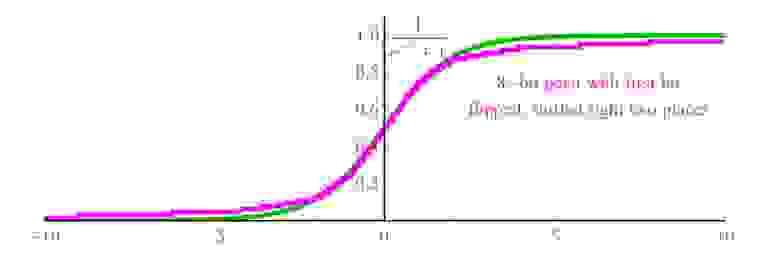
Рис. 6. Быстрая сигмоидная функция с использованием posit-представления
Мы определяем динамический диапазон системы счисления как количество десятичных порядков от наименьшего до наибольшего положительного конечного значения, от minpos до maxpos. То есть, динамический диапазон определяется как . Для 8-битного posit c es=0, minpos равен 1/64 и maxpos равен 64, таким образом, динамический диапазон составляет 3,6 десятичных порядков. Числа posit, определённые с es=0, элегантны и просты, но их 16- и 32-битные версии имеют меньший динамический диапазон, чем IEEE float того же размера. Например, 32-битный IEEE float имеет динамический диапазон 83 декады, но 32-битный posit с es=0 будет иметь динамический диапазон только 18 декад.
. Для 8-битного posit c es=0, minpos равен 1/64 и maxpos равен 64, таким образом, динамический диапазон составляет 3,6 десятичных порядков. Числа posit, определённые с es=0, элегантны и просты, но их 16- и 32-битные версии имеют меньший динамический диапазон, чем IEEE float того же размера. Например, 32-битный IEEE float имеет динамический диапазон 83 декады, но 32-битный posit с es=0 будет иметь динамический диапазон только 18 декад.
Ниже приведена таблица значений es, которые позволяют числам posit превзойти динамический диапазон float для размеров 16- и 32-бит, и вплотную приблизиться к нему для размеров 64-, 128- и 256-бит.
Таблица 3. Динамические диапазоны float и posit для равного числа бит
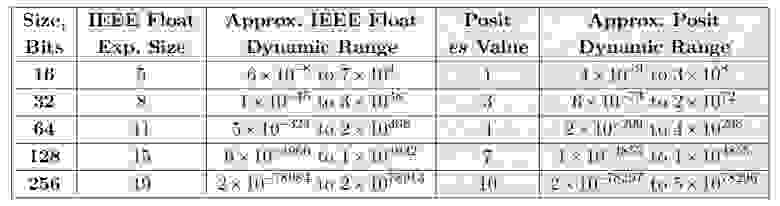
Одной из причин выбрать es=3 для 32-битных posit является то, что в этом случае они могу служить простой заменой не только 32-битным float, но и 64-битным. Аналогично, динамический диапазон в 17 декад у 16-битных posit открывает им дорогу в приложения, в которых в настоящее время используются 32-битные float. Мы покажем, что posit может превосходить float как по динамическому диапазону, так и по точности при той же размере в битах.
В формате posit нет “NaN” (нечисел), вместо этого, вычисления прерываются, и обработчик прерывания должен либо сообщить об ошибке, либо каким-либо образом обработать ошибку и продолжить вычисления, но числа posit не допускают присваивание некоего значения, сигнализирующего о логической ошибке, чем, по определению, и является нечисло. Это существенно упрощает аппаратное обеспечение. Если программист видит необходимость в использовании значений NaN, это показывает, что программа пока не завершена, и в отладочном окружении должны использоваться числа valid для поиска и устранения подобных ошибок. Также, posit не имеет и
и  , как float, однако, числа valid поддерживают открытые интервалы
, как float, однако, числа valid поддерживают открытые интервалы  и
и  , которые дают возможность представить неограниченную величину любого знака, и необходимость в знаковой бесконечности будет означать лишь то, что вместо чисел posit нужно применять значения valid.
, которые дают возможность представить неограниченную величину любого знака, и необходимость в знаковой бесконечности будет означать лишь то, что вместо чисел posit нужно применять значения valid.
Также в представлении posit нет «отрицательного нуля», отрицательный ноль, это ещё один логический недостаток, существующий в стандарте IEEE float. С числами posit, если a=b, то f(a)=f(b). Стандарт IEEE 754 говорит, что число, обратное к -0 равно, а число, обратное к +0, равно , но также говорит, что -0 равно +0. Следовательно, подразумевается, что  ?
?
Числа float имеют сложный алгоритм сравнения a=b. Если любое из (a, b) равно NaN, результат сравнения всегда отрицательный, даже если их битовое представление одинаковое. Если битовое представление разное, то по-прежнему есть возможность, чтобы a было равно b, так как отрицательный ноль равен положительному нулю! В posix проверка равенства такая же, как у целых чисел: если биты равны, числа равны. Если любой бит отличается, они не равны. Числа posit имеют такое же отношение (a < b), как и знаковые целые, как и со знаковыми целыми, вы должны следить, чтобы не произошло переполнение с изменением знака, но вам не нужны отдельные машинные инструкции для сравнения posit, если у вас есть инструкции для сравнения знаковых целых.
В формате posit нет денормализованных чисел, то есть нет специальной комбинации бит, показывающей, что скрытый бит равен 0 вместо 1. Posit не использует антипереполнение, вместо этого, используется постепенное снижение точности, что обеспечивает функциональность антипереполнения и его симметричного случая, переполнения (в отличие от posit, стандарт float ассиметричен, и использует эти битовые паттерны для представления большого и бесполезного множества NaN-значений).
Формат float имеет одно преимущество перед posit, при разработке аппаратного обеспечения фиксированное расположение битов экспоненты и дробной части позволяет декодировать их параллельно. В формате posit, нужно соблюдать некоторую последовательность, сначала декодируя биты режима, а потом остальные биты. Есть простой способ обойти это ограничение, похожий на трюк, используемый для увеличения скорости обработки исключений во float: несколько дополнительных бит присоединяются к каждому значению так, чтобы сохранить в них информацию о размере при декодировании инструкции.
Одна из причин, по которой IEEE float не даёт идентичных результатов на различных системах является то, что для элементарный функций, таких, как и
и  по стандарту IEEE не требуется точности до последнего бита для любого возможного входа. Окружение posit должно корректно округлять все результаты поддерживаемых арифметических операций. (Некоторые программисты математических библиотек беспокоятся насчёт «дилемы составителя таблиц», которая заключается в том, что для некоторых значений может быть очень затратно определить их корректное округление, это может быть устранено путём использования интерполяционых таблиц вместо полиномиальных аппроксимаций.) Некорректное значение в последнем бите фунции
по стандарту IEEE не требуется точности до последнего бита для любого возможного входа. Окружение posit должно корректно округлять все результаты поддерживаемых арифметических операций. (Некоторые программисты математических библиотек беспокоятся насчёт «дилемы составителя таблиц», которая заключается в том, что для некоторых значений может быть очень затратно определить их корректное округление, это может быть устранено путём использования интерполяционых таблиц вместо полиномиальных аппроксимаций.) Некорректное значение в последнем бите фунции  , например, может в итоге привести к тому, что компьютерная система скажет нам, что 2+2=5.
, например, может в итоге привести к тому, что компьютерная система скажет нам, что 2+2=5.
Более фундаментальная причина того, что IEEE float не даёт повторяющихся результатов на разных системах, заключается в том, что стандарт разрешает использование завуалированных методов для избегания переполнения/антипереполнения, и для повышения точности операций, такие, как внутреннее сохранение дополнительного бита переноса для экспоненциальной и дробной части. Арифметика posit запрещает такие скрытые трюки.
Последняя (2008 год) версия стандарта IEEE 754 [7] включает в требования комбинированную операцию умножения-сложения. Это было противоречивое изменение, не одобренное многими членами комитета. Комбинированные операции приводят к отсрочке операции округления до момента завершения последней операции в вычислении, включающем в себя более чем одну операцию, после выполнения всех операций, включая точные целочисленные операции. Комбинирование операций — это не то же самое, что арифметические операции с расширяемой точностью, которые могут увеличивать разрядность целых чисел до переполнения памяти компьютера.
Окружение posit требует обязательного присутствия следующих комбинированных операций:
Комбинированное умножение-сложение
Комбинированное сложение-умножение
Комбинированное умножение-умножение-вычитание
Комбинированное суммирование
Комбинированное скалярное умножение
Отметим, что все операции из приведённого списка являются подмножеством комбинированного скалярного умножения [6] в терминах требований к аппаратному обеспечению процессора. Наименьшее по абсолютному значению ненулевое число, которое может быть получено с помощью скалярного умножения — это . Любое произведение, это целое число, умноженное на . Если мы хотим получить скалярное произведение векторов
. Любое произведение, это целое число, умноженное на . Если мы хотим получить скалярное произведение векторов  и как точную операцию в scratch-зоне, нам нужно целое, достаточно большое, чтобы хранить
и как точную операцию в scratch-зоне, нам нужно целое, достаточно большое, чтобы хранить  . Вспомним, что
. Вспомним, что  и
и  . Таким образом,
. Таким образом,  . С учётом битов переноса и округления вверх до степени двойки, получим рекомендованные значения, приведённые в табл.4.
. С учётом битов переноса и округления вверх до степени двойки, получим рекомендованные значения, приведённые в табл.4.
Таблица 4. Точные размеры аккумулятора для каждого размера posit

В некоторых случаях размер аккумулятора сопоставим с размером регистра, в других случаях, требуется scratch-зона, эквивалентная кэшу L1 или L2. Комбинированные операции могут выполняться программно или аппаратно, но должны быть доступны для выполнения в posit-среде.
От переводчика: Тема формата Posit уже была на хабре здесь, но без существенных технических подробностей. В этой публикации я предлагаю вашему вниманию перевод статьи Джона Густафсона (автора Posit) и Айзека Йонемото, посвящённой формату Posit.
Так как статья имеет большой объём, я разделил её на две части. Список ссылок находится в конце второй части.
Новый тип данных, называемый posit, разработан в качестве прямой замены чисел с плавающей точкой стандарта IEEE Standard 754. В отличие от ранней формы — арифметики универсальных чисел (unum), стандарт posit не требует использования интервальной арифметики или операндов переменного размера, и, как и float, числа posit округляются, если результат не может быть представлен точно. Они имеют неоспоримые преимущества над форматом float, включая больший динамический диапазон, большую точность, побитовое совпадение результатов вычислений на разных системах, более простое аппаратное обеспечение и более простую поддержку исключений. Числа posit не переполняются ни в сторону бесконечности, ни до нуля, и «нечисла» (Not aNumber, NaN) — это действия, а не битовые комбинации. Блок обработки posit имеет меньшую сложность, чем FPU стандарта IEEE. Он потребляет меньшую мощность, и занимает меньшую площадь кремния, таким образом, чип может выполнять существенно больше операций над числами posit в секунду, чем FLOPS, при тех же аппаратных ресурсах. GPU и процессоры глубокого обучения, в частности, могут выполнять больше операций на ватт потребляемой мощности, что позволит повысить качество их работы.
Были проведены всесторонние тесты, сравнивающие posit и float по точности вычислений для различной точности posit. Числа posit с низкой точностью являются лучшим решением для «приблизительных вычислений» в тех случаях, когда допустима низкая точность вычислений. Числа posit с высокой точностью обеспечивают более высокую точность, чем float того же размера, в некоторых случаях, 32-битный posit может безопасно заменить 64-битный float. Другими словами, posit выигрывает у float в его собственной игре.
Основы: Числа Unums: Type I и Type II
Арифметический фреймворк unum (универсальные числа, universal number) имеет несколько форм представления чисел. Исходной формой являются «Type I», надмножество IEEE 754; она использует «ubit» в конце дробной части для индикации того, что вещественное число является точным или находится в интервале между соседними вещественными числами. Несмотря на то, что Unum, как и float, имеет знак, экспоненту и дробную часть, длины экспоненты и дробной части варьируются автоматически, от одного бита до некоторого значения, определяемого пользователем. Unum Type I является компактным способом представить интервальную арифметику но переменная длина требует дополнительных усилий. Этот тип может повторять поведение float, путём использования специальной функции округления.
Форма универсальных чисел “Type II” [4] не совместима с IEEE float, и представляет собой чистую, математически строгую концепцию, основанную на проективных вещественных числах. Ключевой идеей здесь является то, что знаковые целые числа в дополнительном коде элегантно отображаются на проективные вещественные числа, с тем же самым свойством перехода от положительных чисел к отрицательным, и с тем же самым порядком на числовой оси. Цитируя Уильяма Каана (William Kahan) [5]:
«Они экономят пространство памяти, так как манипулируют не числами, а указателями на значения. И это даёт возможность сделать арифметику очень, очень быстрой».
Структура 5-битного unum показана на рис. 1. Если каждый unum имеет n бит, то «u-решётка» заполняет верхний правый квадрант круга упорядоченным множеством из
вещественных чисел (не обязательно рациональными). В верхнем левом квадранте расположены отрицательные , отражённые относительно вертикальной оси. Нижняя половина круга содержит числа, обратные числам верхней половины, отражённые от горизонтальной оси, что делает операции умножения и деления такими же симметричными, как сложение и вычитание. Как и в случае Type I, числа unum типа Type II заканчиваются на 1 (ubit), представляя открытый интервал между соседними точными точками, для которых unum заканчивается на 0.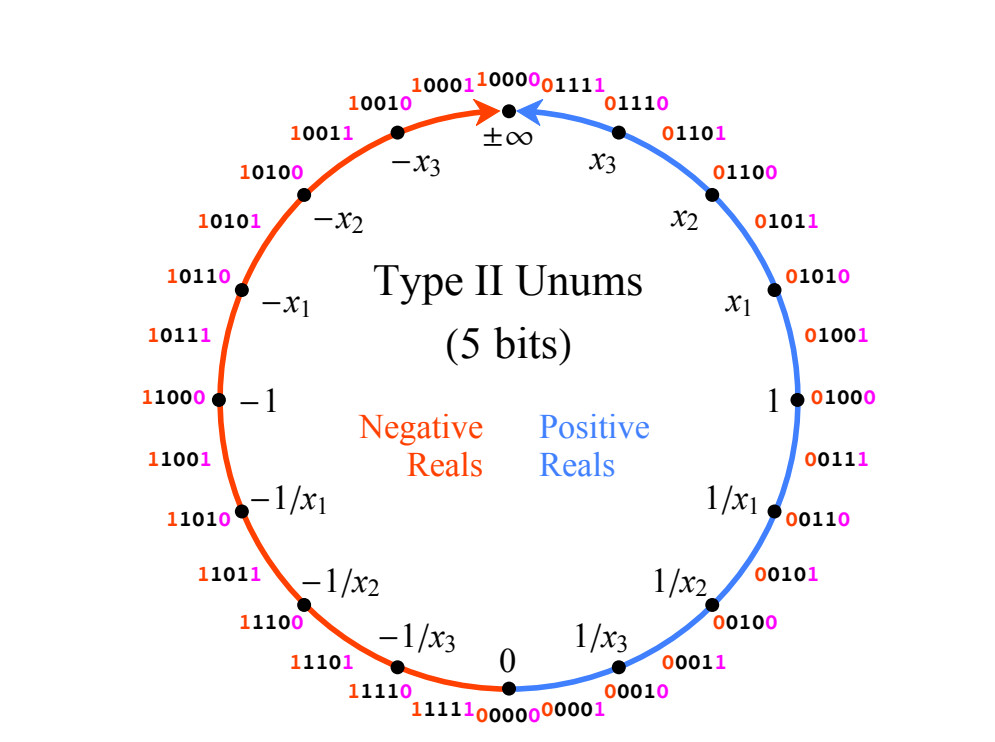
Рис. 1. Линия проективных вещественных чисел, отображаемая на целые числа в дополнительном коде длиной 4 бита.
Числа unum типа Type II имеют много идеальных математических свойств, но большинство операций с ними производится с помощью look-up таблиц. Если нужно n бит точности, то таблица (в наихудшем случае) будет иметь
значений для функции двух аргументов, но с учётом симметрий и других трюков таблица может быть уменьшена до более приемлемого размера. Размер таблицы ограничивает масштаб этого ультрабыстрого формата размером 20 бит или меньше, для технологий сегодняшнего дня. Числа unum типа Type II также плохо поддаются операциям слияния. Эти недостатки послужили мотивацией для поиска формата, который сохраняет многие свойства чисел unum Type II, но является более «дружественным» к аппаратному обеспечению, и может быть вычислен логическими схемами, похожими на существующие FPU.2. Числа Posit и Valid
Есть два противоположных подхода к вычислениям в вещественных числах:
- Нестрогий, но дешёвый, и приемлемый для большого количества практических применений
- Математически строгий, даже ценой больших затрат времени и памяти
Первое утверждение относится к вещественной арифметике, в которой ошибка округления достаточно мала, второе утверждение относится к интервальной арифметике. Числа unum типов I и II также могут рассматриваться в подобном ключе, и это одна из причин, по которой они являются «универсальными числами». Однако, если мы всегда собираемся использовать некоторую функцию для округления после каждой операции, то мы лучше не будем использовать последний бит как значащий бит дробной части и не как ubit. Число unum такого типа мы будем называть числом posit.
Цитата из «New Oxford American Dictionary», 3-я редакция:
posit (сущ): заявление, которое делается исходя из предположения, что оно окажется правдой.
С целью упрощения аппаратной реализации числа unum Type II ослабляют одно из правил: точные обратные величины существуют только для 0,
и степеней двойки. Это позволяет нам заполнить u-сетку так, что конечные числа останутся похожими на float, и будут иметь форму , где k и m целые. Открытых интервалов нет.Valid — это пара чисел posit равного размера, каждое из которых заканчивается на ubit. Они предназначены для использования в тех приложениях, где важно строго определять, в каком интервале находится число, например, при отладке численных алгоритмов. Значения Valid являются более мощными, чем обычная интервальная арифметика и менее склонными к быстрому расширению чрезмерно пессимистических границ интервалов [2, 4]. Однако они не являются темой данной публикации.
На рис 2. показана структура n-битного представления posit с битами экспоненты.

Рис 2. Обобщённый формат posit format для конечных ненулевых значений
Бит знака содержит 0 для положительных чисел, 1 для отрицательных. Для отрицательных чисел, находим дополнение 2 перед декодированием режима, экспоненты и дробной части. Для понимания битов режима, рассмотрим бинарные строки, показанные в таблице 1, в которых k означает длину ведущей последовательности, а x в битовой стоке означает безразличное состояние.
Table 1. Run-length meaning k of the regime bits

Мы называем длину ведущей последовательности режимом числа. Бинарные строки начинаются с определённого количества нулей или единиц, идущих подряд, за которыми идёт противоположный бит, или достигается конец строки. Биты режима выделены янтарным цветом, противоположный бит выделен коричневым. Пусть m — количество одинаковых бит в последовательности, если эти биты равны нулю, то k = -m, если 1, то k = m-1. Большинство процессоров могут найти первую единицу в слове или первый ноль в слове аппаратно, то есть декодирующая логика уже доступна. Режим означает масштабирующий фактор, равный
, где . Таблица 2 показывает пример значений useed.Таблица 2. useed как функция es

Следующие биты (выделенные синим на рисунке) — это экспонента e, относящаяся к беззнаковому целому. Она не сдвинута, как это сделано во float-ах, она представляет масштабирование на
. Может быть до es битов экспоненты, в зависимости от того, сколько бит осталось справа от битов режима. Это компактный способ изменения точности, числа, близкие к 1 по абсолютной величине, имеют большую точность, чем очень большие или очень маленькие числа, которые гораздо реже встречаются в вычислениях. Если остались биты после битов режима и экспоненты, они представляют дробную часть, f, так же, как дробная часть 1.f в формате float, но скрытый бит всегда равен 1. Денормализованных чисел со скрытым 0 нет, в отличие от float.
Система, которую мы описали, это естественное следствие заполнения u-сетки. Начнём с простого 3-битного posit, для ясности, на рис. 3 показана только правая половина проективных вещественных чисел. Итак, числа на рис. 3. подчиняются правилам Type II. Есть только два особых значения: 0 (все биты 0) и ±∞ ( единица, за которой следуют все нули), их битовая последовательность не следует позиционной нотации. Для других значений posit на рис.3., биты раскрашены, как было описано выше. Отметим, что все положительные значения на рис.3 являются точными значениями useed в степени k, представленной битами режима.
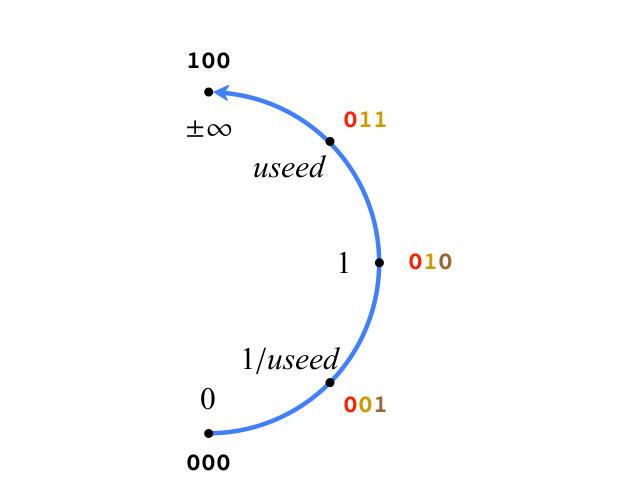
Рис.3. Положительные значения 3-битного posit
Точность чисел Posit увеличивается по мере добавления бит, и значения остаются там, где они есть на круге, когда добавляется бит 0. Когда добавляется 1, создаётся новое значение между двумя значениями posit на круге. Какое числовое значение мы должны им присвоить? Пусть maxpos будет наибольшим положительным значением, а minpos — наименьшим положительным значением на круге, определяемыми битовой строкой. На рис.3., maxpos — это useed, а minpos — это 1/useed. Правила интерполяции следующие:
Между maxpos и ±∞, новое значение — это maxpos × useed; между 0 и minpos, новое значение — это minpos / useed (с новым битом режима)
Между существующими значениями
и , где m и n отличаются больше, чем на 1, новое значение будет их геометрическим средним, (с новым битом экспоненты).В других случаях, новое значение расположено посередине между существующими x и y, то есть является арифметическим средним,
(с новым битом дробной части)Как пример, рис. 4 показывает построение чисел posit от 2 до 5 бит с es=2, и, таким образом, useed=16.
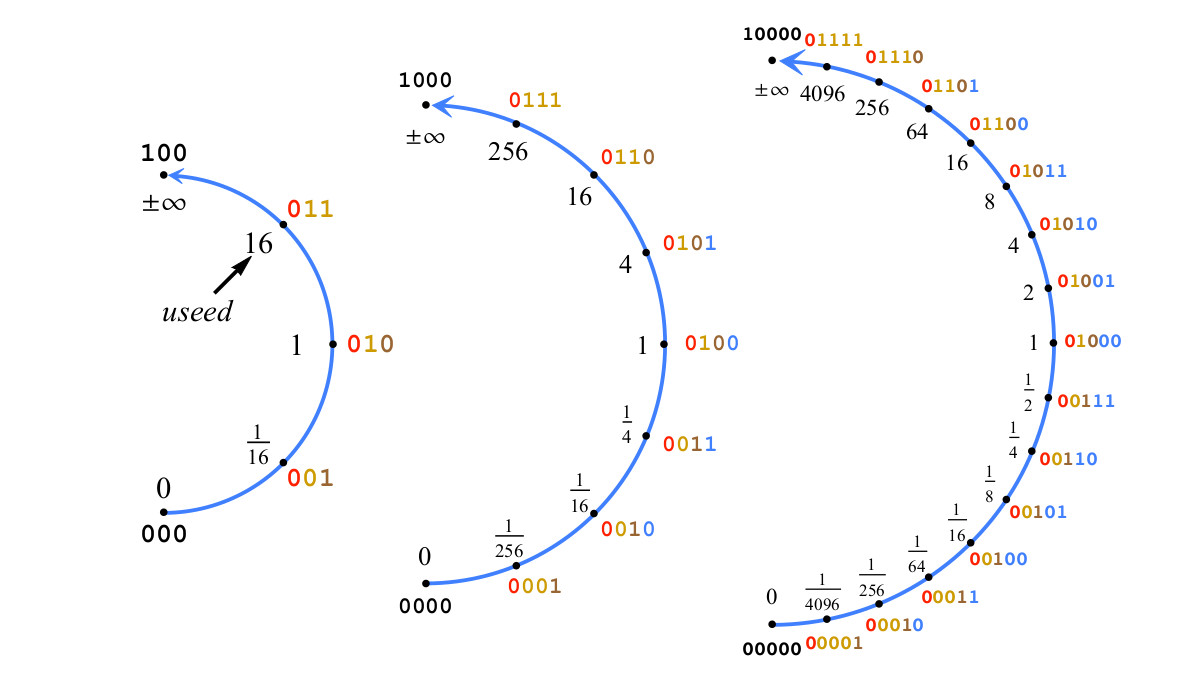
Рис. 4. Построение Posit с двумя битами экспоненты,
Если на рис. 4 добавить ещё один бит, чтобы получить 6-битные posit, к числам posit, представляющим диапазоны значений между 1/16 и 16, будет добавлен бит дробной части, а не бит экспоненты. Рассмотрим строку бит, представляющую число posit p как знаковое целое, в диапазоне от
до . Пусть k будет целым числом, представляющим биты режима, e — беззнаковым числом, представляющим биты экспоненты, если они присутствуют. Если набор бит дробной части , возможно, пустой, то пусть f будет значением, представляющим число . Тогда p представляет
Биты режима и es выполняют ту же функцию, что и биты экспоненты в стандартном float, вместе они определяют масштабирующий коэффициент, равный степени двух, и каждый инкремент useed означает сдвиг
бит. Число maxpos равно и minpos равно . Пример декодирования числа posit показан на рис.5 (с «нестандартным» значением для es, для упрощения).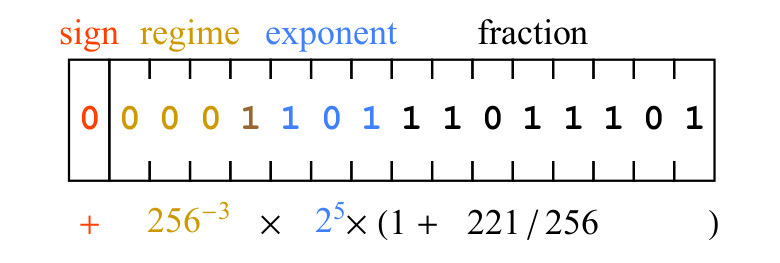
Рис. 5. Пример битовой строки posit и её математический смысл
Бит знака 0 означает, что значение положительное. Биты режима 0001 имеют последовательность из трёх нулей, что означает, что k=-3, следовательно, масштабирующий коэффициент, вносимый битами режима, равен
. Биты экспоненты,101, представляют 5 как беззнаковое двоичное целое, и вносимый масштабирующий коэффициент равен . Наконец, биты дробной части 11011101 представляют число 221, то есть дробная часть равна 1+221/256. Выражение, записанное под битовым полем на рис.5. приводит нас к результату 2.2. 8-битные posit и обучение нейронной сети
Несмотря на то, что стандарт IEEE не определяет 8-битные float, числа posit разметом 8 бит с es=0 доказали свою полезность для некоторых целей, они очень полезны для построения нейросетей [3, 8]. В настоящее время для этих целей часто используются числа IEEE с половинной точностью (16-bit), но 8-битные числа posit потенциально могут обрабатываться в 2-4 раза быстрее. Важной функцией в нейросетях является сигмоида, имеющая асимптоту 0 при
и 1 при . Общий вид сигмоидной функции , и она является дорогой для вычислений, и легко может потребовать более сотни циклов процессора на вызов функции exp(x) из библиотеки, и из-за деления. С числами posit, можно просто инвертировать первый бит числа posit, представляющего x, сдвинуть число на 2 бита вправо, заполняя биты слева нулями, и результирующая функция posit, показанная на рис.6. фиолетовым цветом, близка к сигмоиде (показанной зелёным), и даже имеет тот же наклон при пересечении оси y.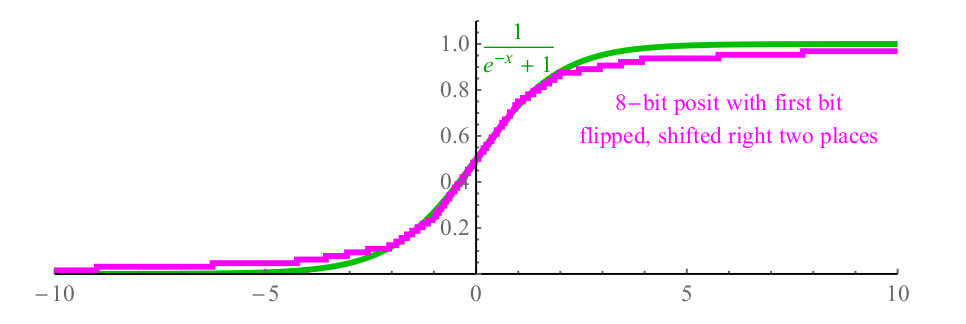
Рис. 6. Быстрая сигмоидная функция с использованием posit-представления
2.3. Использование Useed для того, чтобы достичь и превзойти динамический диапазон float
Мы определяем динамический диапазон системы счисления как количество десятичных порядков от наименьшего до наибольшего положительного конечного значения, от minpos до maxpos. То есть, динамический диапазон определяется как
. Для 8-битного posit c es=0, minpos равен 1/64 и maxpos равен 64, таким образом, динамический диапазон составляет 3,6 десятичных порядков. Числа posit, определённые с es=0, элегантны и просты, но их 16- и 32-битные версии имеют меньший динамический диапазон, чем IEEE float того же размера. Например, 32-битный IEEE float имеет динамический диапазон 83 декады, но 32-битный posit с es=0 будет иметь динамический диапазон только 18 декад.Ниже приведена таблица значений es, которые позволяют числам posit превзойти динамический диапазон float для размеров 16- и 32-бит, и вплотную приблизиться к нему для размеров 64-, 128- и 256-бит.
Таблица 3. Динамические диапазоны float и posit для равного числа бит
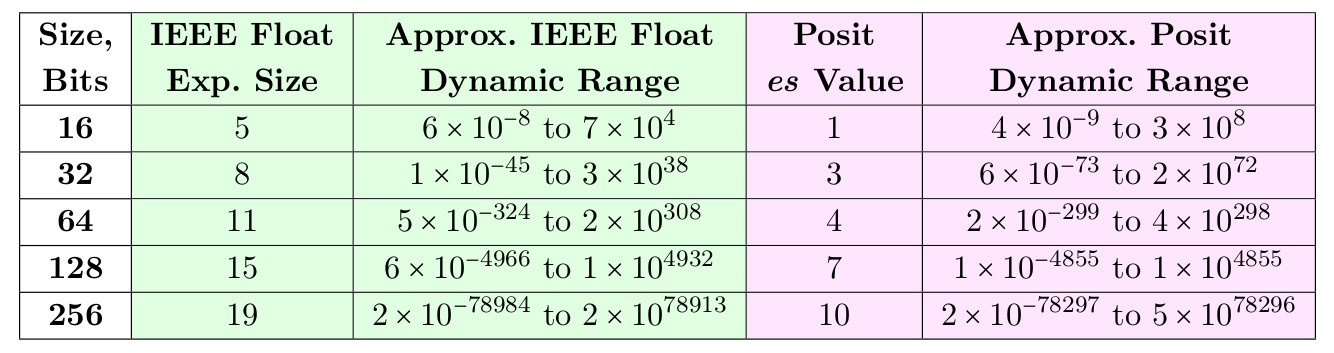
Одной из причин выбрать es=3 для 32-битных posit является то, что в этом случае они могу служить простой заменой не только 32-битным float, но и 64-битным. Аналогично, динамический диапазон в 17 декад у 16-битных posit открывает им дорогу в приложения, в которых в настоящее время используются 32-битные float. Мы покажем, что posit может превосходить float как по динамическому диапазону, так и по точности при той же размере в битах.
2.4. Качественное сравнение форматов Float и Posit
В формате posit нет “NaN” (нечисел), вместо этого, вычисления прерываются, и обработчик прерывания должен либо сообщить об ошибке, либо каким-либо образом обработать ошибку и продолжить вычисления, но числа posit не допускают присваивание некоего значения, сигнализирующего о логической ошибке, чем, по определению, и является нечисло. Это существенно упрощает аппаратное обеспечение. Если программист видит необходимость в использовании значений NaN, это показывает, что программа пока не завершена, и в отладочном окружении должны использоваться числа valid для поиска и устранения подобных ошибок. Также, posit не имеет
и , как float, однако, числа valid поддерживают открытые интервалы и , которые дают возможность представить неограниченную величину любого знака, и необходимость в знаковой бесконечности будет означать лишь то, что вместо чисел posit нужно применять значения valid.Также в представлении posit нет «отрицательного нуля», отрицательный ноль, это ещё один логический недостаток, существующий в стандарте IEEE float. С числами posit, если a=b, то f(a)=f(b). Стандарт IEEE 754 говорит, что число, обратное к -0 равно
, а число, обратное к +0, равно , но также говорит, что -0 равно +0. Следовательно, подразумевается, что ?Числа float имеют сложный алгоритм сравнения a=b. Если любое из (a, b) равно NaN, результат сравнения всегда отрицательный, даже если их битовое представление одинаковое. Если битовое представление разное, то по-прежнему есть возможность, чтобы a было равно b, так как отрицательный ноль равен положительному нулю! В posix проверка равенства такая же, как у целых чисел: если биты равны, числа равны. Если любой бит отличается, они не равны. Числа posit имеют такое же отношение (a < b), как и знаковые целые, как и со знаковыми целыми, вы должны следить, чтобы не произошло переполнение с изменением знака, но вам не нужны отдельные машинные инструкции для сравнения posit, если у вас есть инструкции для сравнения знаковых целых.
В формате posit нет денормализованных чисел, то есть нет специальной комбинации бит, показывающей, что скрытый бит равен 0 вместо 1. Posit не использует антипереполнение, вместо этого, используется постепенное снижение точности, что обеспечивает функциональность антипереполнения и его симметричного случая, переполнения (в отличие от posit, стандарт float ассиметричен, и использует эти битовые паттерны для представления большого и бесполезного множества NaN-значений).
Формат float имеет одно преимущество перед posit, при разработке аппаратного обеспечения фиксированное расположение битов экспоненты и дробной части позволяет декодировать их параллельно. В формате posit, нужно соблюдать некоторую последовательность, сначала декодируя биты режима, а потом остальные биты. Есть простой способ обойти это ограничение, похожий на трюк, используемый для увеличения скорости обработки исключений во float: несколько дополнительных бит присоединяются к каждому значению так, чтобы сохранить в них информацию о размере при декодировании инструкции.
3. Побитовая совместимость и комбинированные операции
Одна из причин, по которой IEEE float не даёт идентичных результатов на различных системах является то, что для элементарный функций, таких, как
и по стандарту IEEE не требуется точности до последнего бита для любого возможного входа. Окружение posit должно корректно округлять все результаты поддерживаемых арифметических операций. (Некоторые программисты математических библиотек беспокоятся насчёт «дилемы составителя таблиц», которая заключается в том, что для некоторых значений может быть очень затратно определить их корректное округление, это может быть устранено путём использования интерполяционых таблиц вместо полиномиальных аппроксимаций.) Некорректное значение в последнем бите фунции , например, может в итоге привести к тому, что компьютерная система скажет нам, что 2+2=5.Более фундаментальная причина того, что IEEE float не даёт повторяющихся результатов на разных системах, заключается в том, что стандарт разрешает использование завуалированных методов для избегания переполнения/антипереполнения, и для повышения точности операций, такие, как внутреннее сохранение дополнительного бита переноса для экспоненциальной и дробной части. Арифметика posit запрещает такие скрытые трюки.
Последняя (2008 год) версия стандарта IEEE 754 [7] включает в требования комбинированную операцию умножения-сложения. Это было противоречивое изменение, не одобренное многими членами комитета. Комбинированные операции приводят к отсрочке операции округления до момента завершения последней операции в вычислении, включающем в себя более чем одну операцию, после выполнения всех операций, включая точные целочисленные операции. Комбинирование операций — это не то же самое, что арифметические операции с расширяемой точностью, которые могут увеличивать разрядность целых чисел до переполнения памяти компьютера.
Окружение posit требует обязательного присутствия следующих комбинированных операций:
Комбинированное умножение-сложение
Комбинированное сложение-умножение
Комбинированное умножение-умножение-вычитание
Комбинированное суммирование
Комбинированное скалярное умножение
Отметим, что все операции из приведённого списка являются подмножеством комбинированного скалярного умножения [6] в терминах требований к аппаратному обеспечению процессора. Наименьшее по абсолютному значению ненулевое число, которое может быть получено с помощью скалярного умножения — это
. Любое произведение, это целое число, умноженное на . Если мы хотим получить скалярное произведение векторов и как точную операцию в scratch-зоне, нам нужно целое, достаточно большое, чтобы хранить . Вспомним, что и . Таким образом, . С учётом битов переноса и округления вверх до степени двойки, получим рекомендованные значения, приведённые в табл.4.Таблица 4. Точные размеры аккумулятора для каждого размера posit

В некоторых случаях размер аккумулятора сопоставим с размером регистра, в других случаях, требуется scratch-зона, эквивалентная кэшу L1 или L2. Комбинированные операции могут выполняться программно или аппаратно, но должны быть доступны для выполнения в posit-среде.










